
Modeling Chronic Pain Experiences from Online Reports Using the Reddit Reports of Chronic Pain Dataset



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Data Demographics
2.3. Data Preprocessing
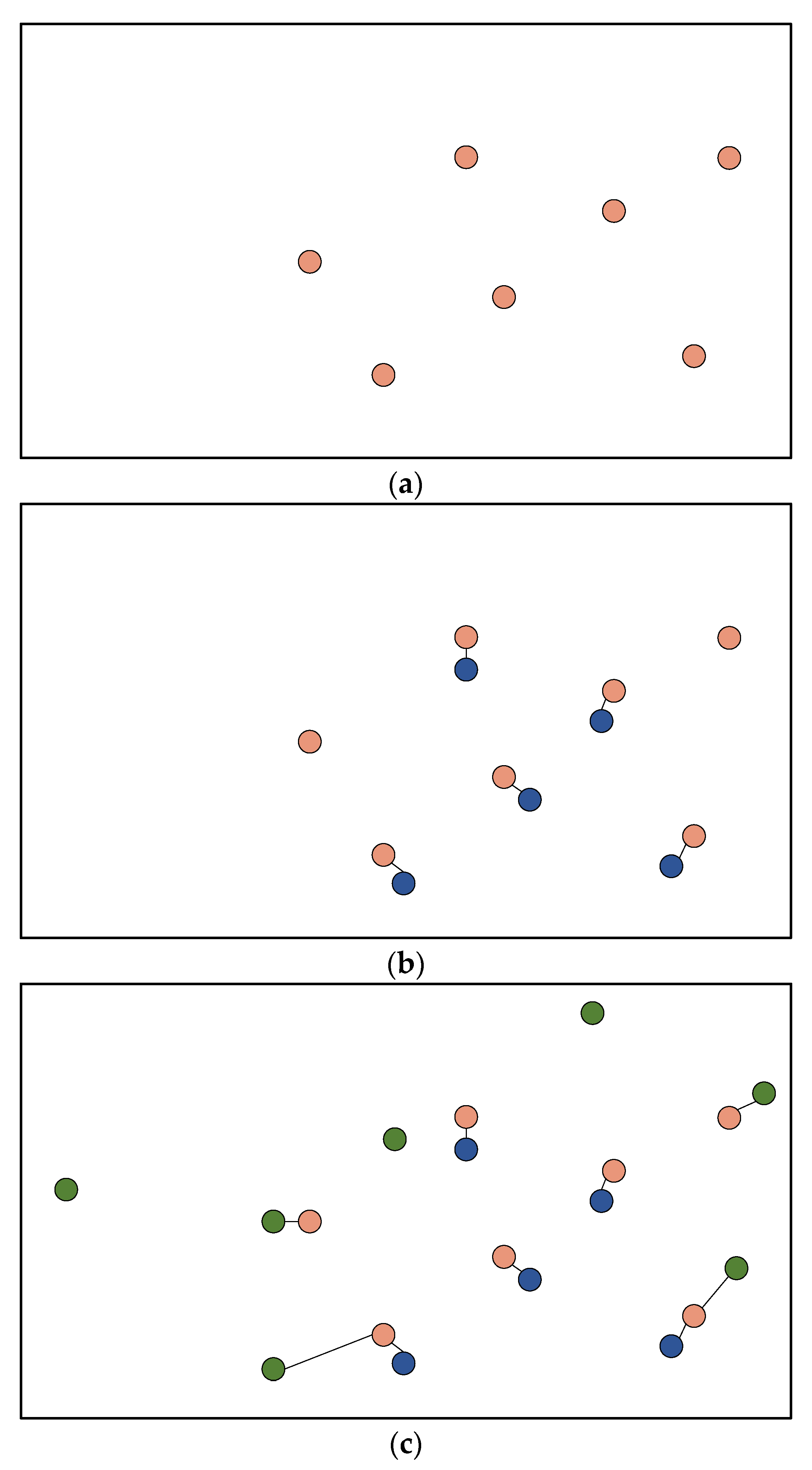
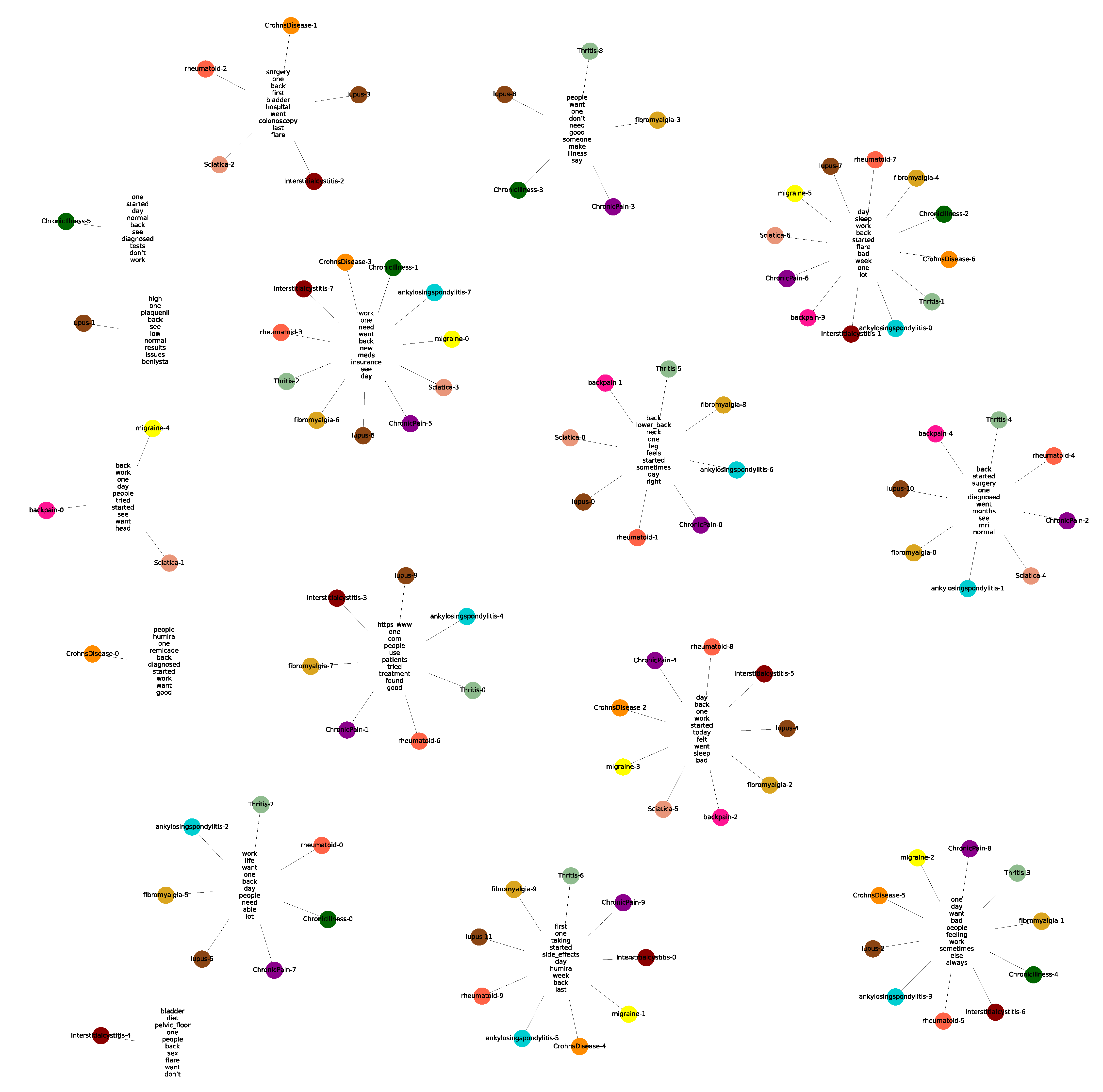
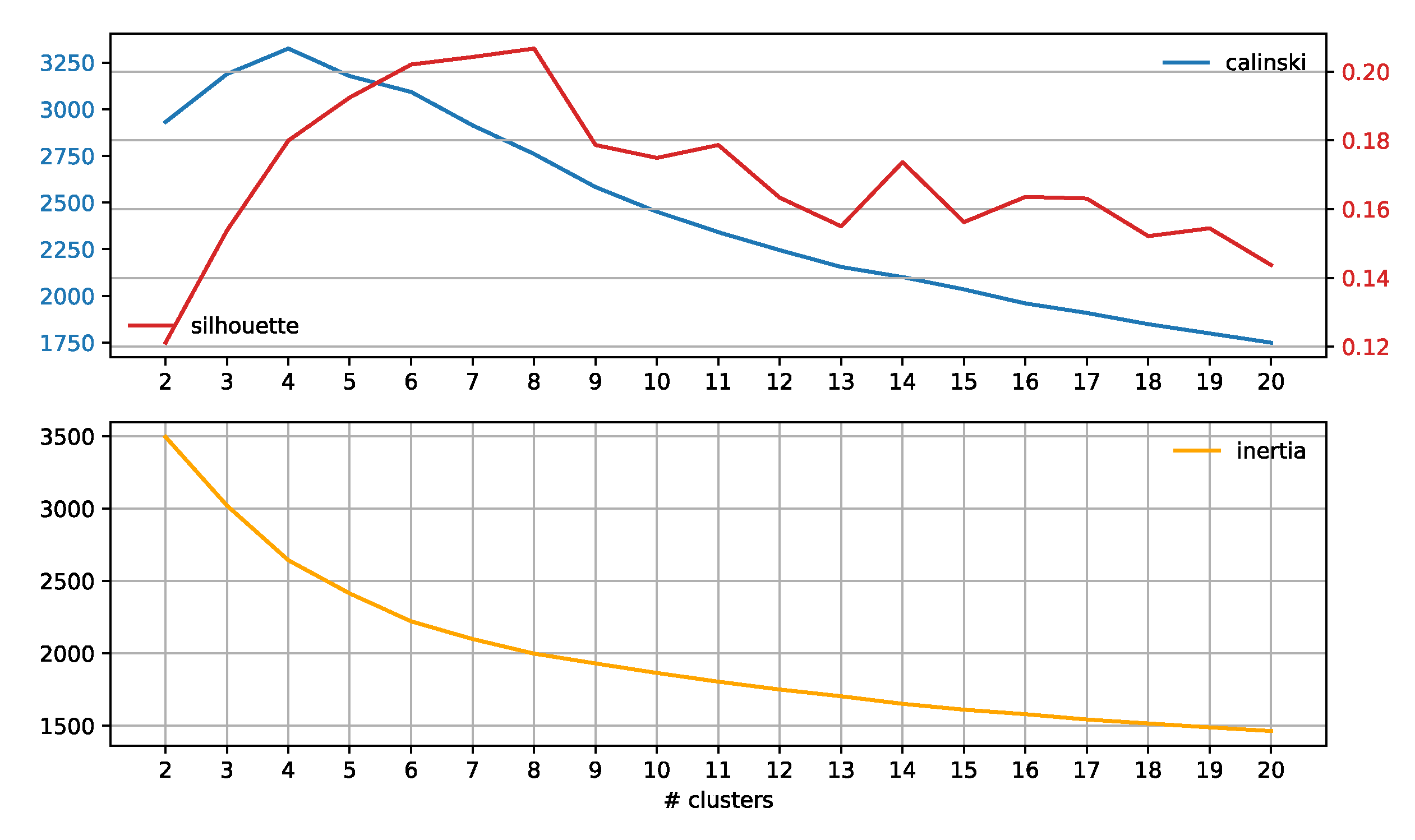
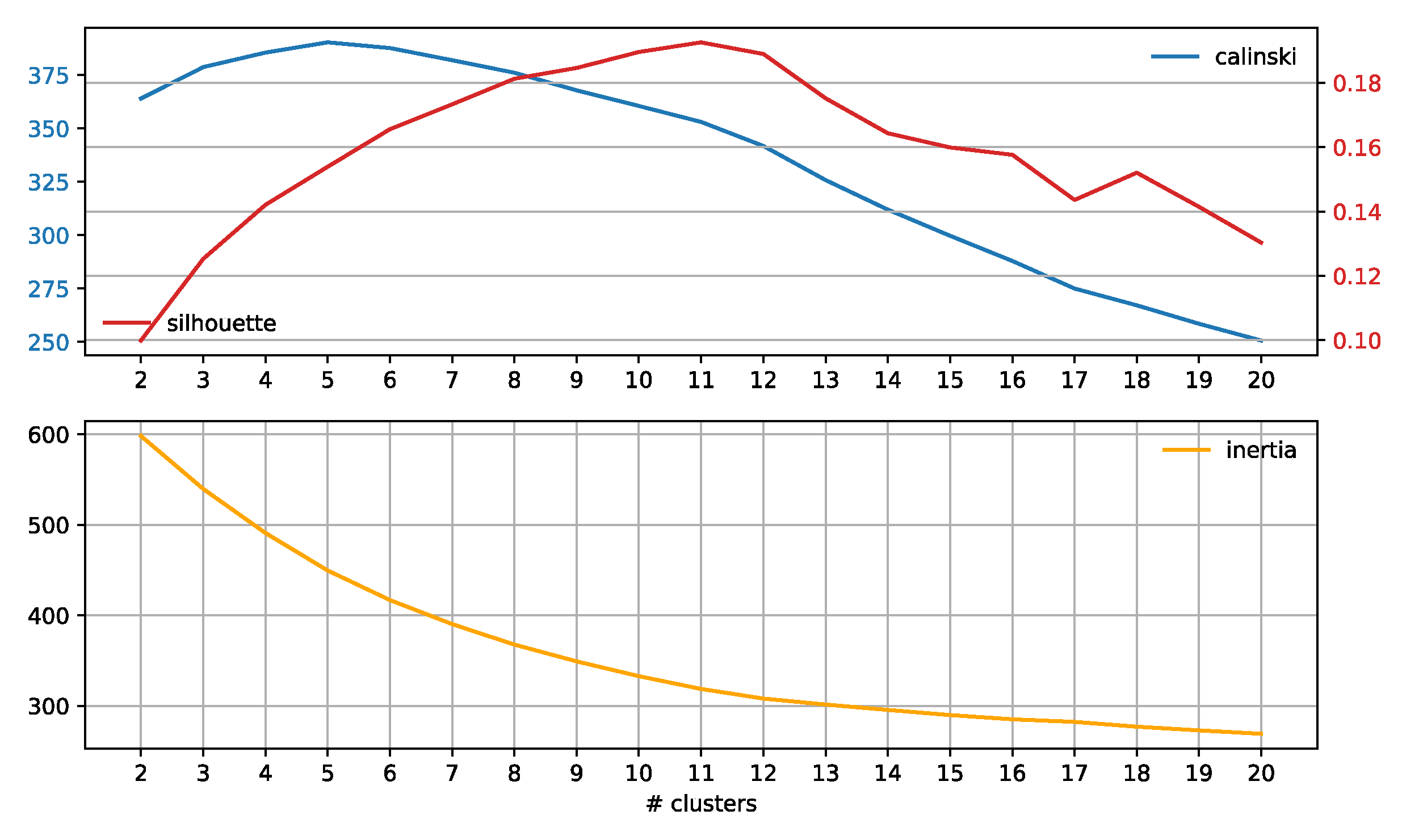
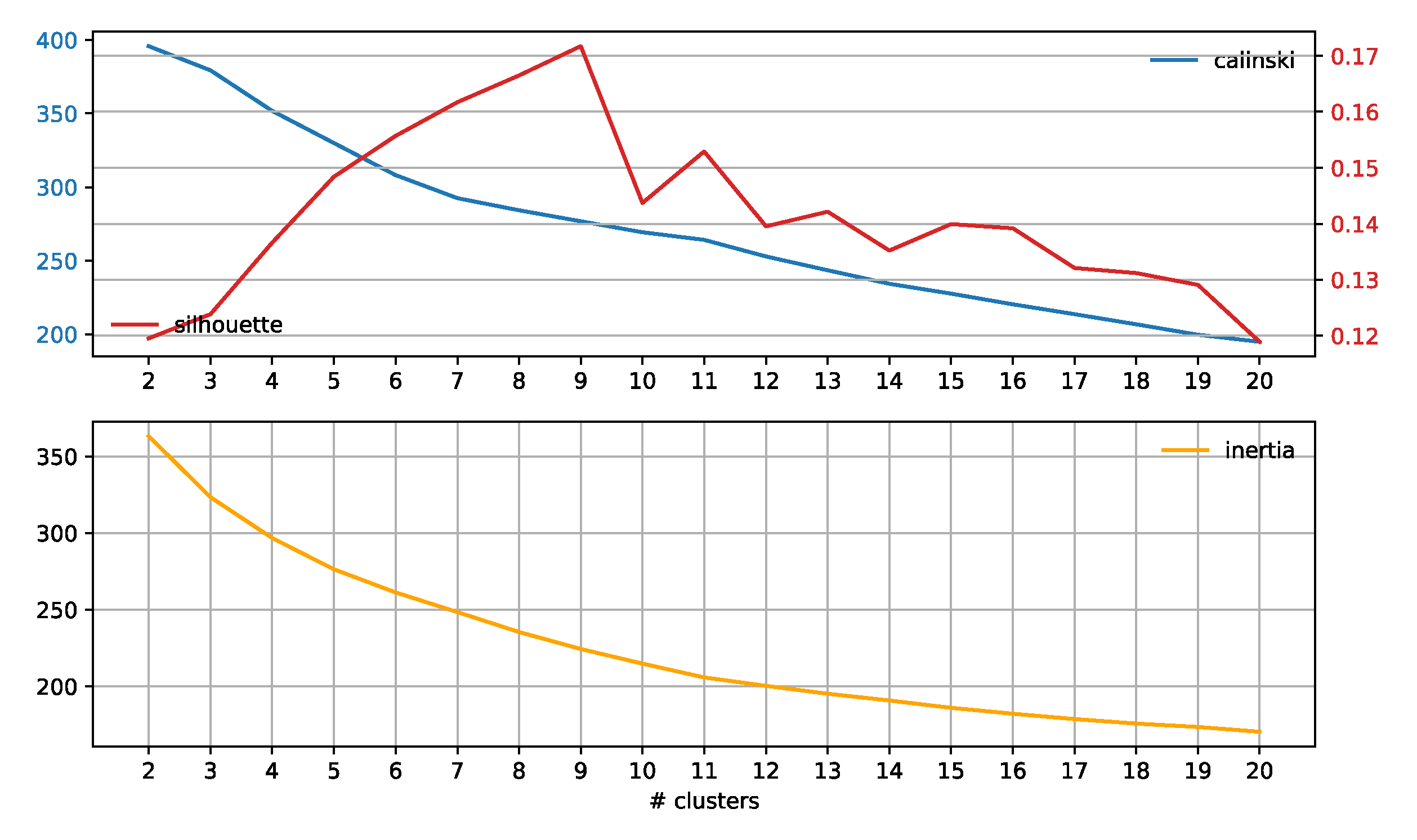
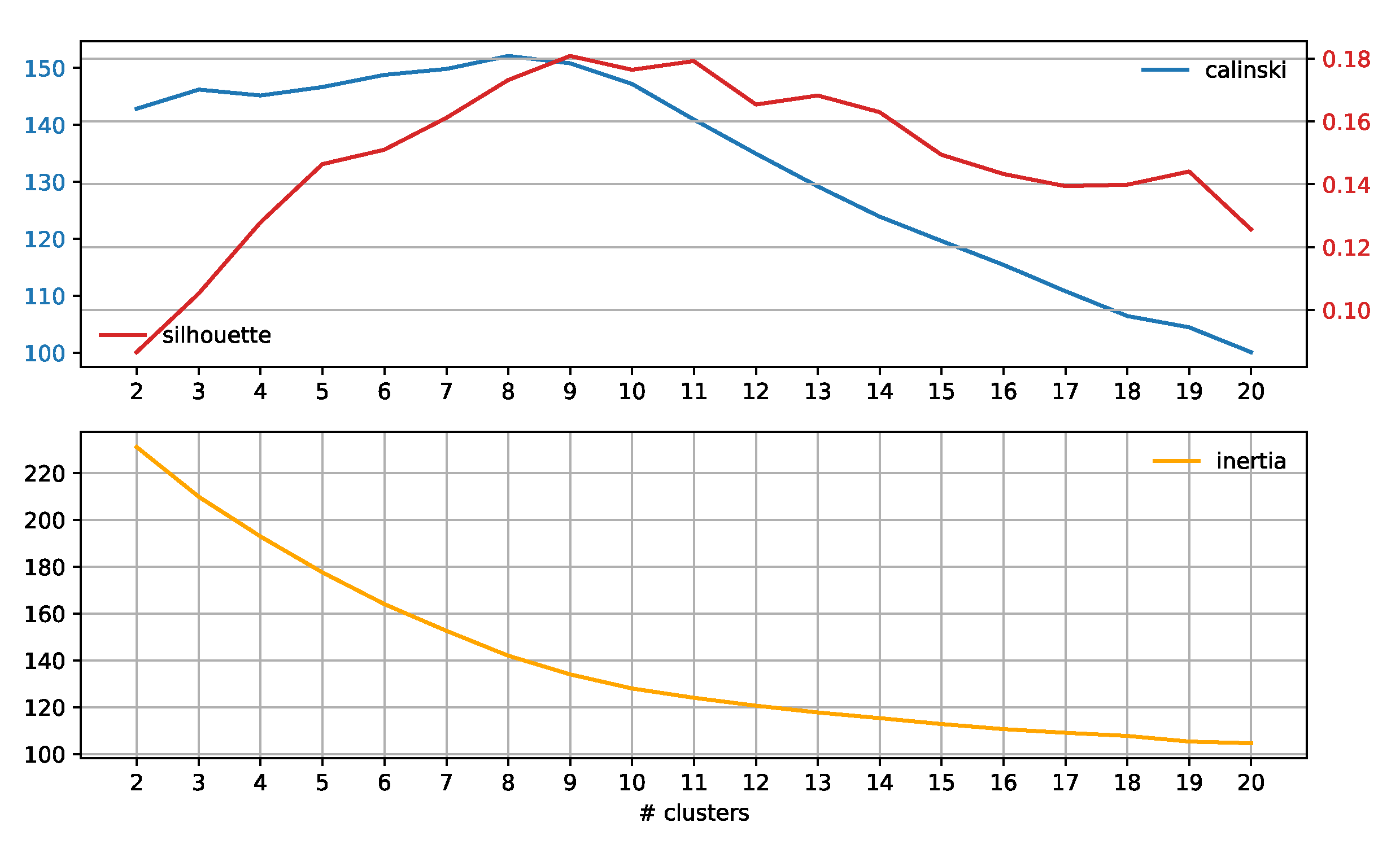
2.4. Subreddit Core Concerns: Semantic Span Similarities
3. Results
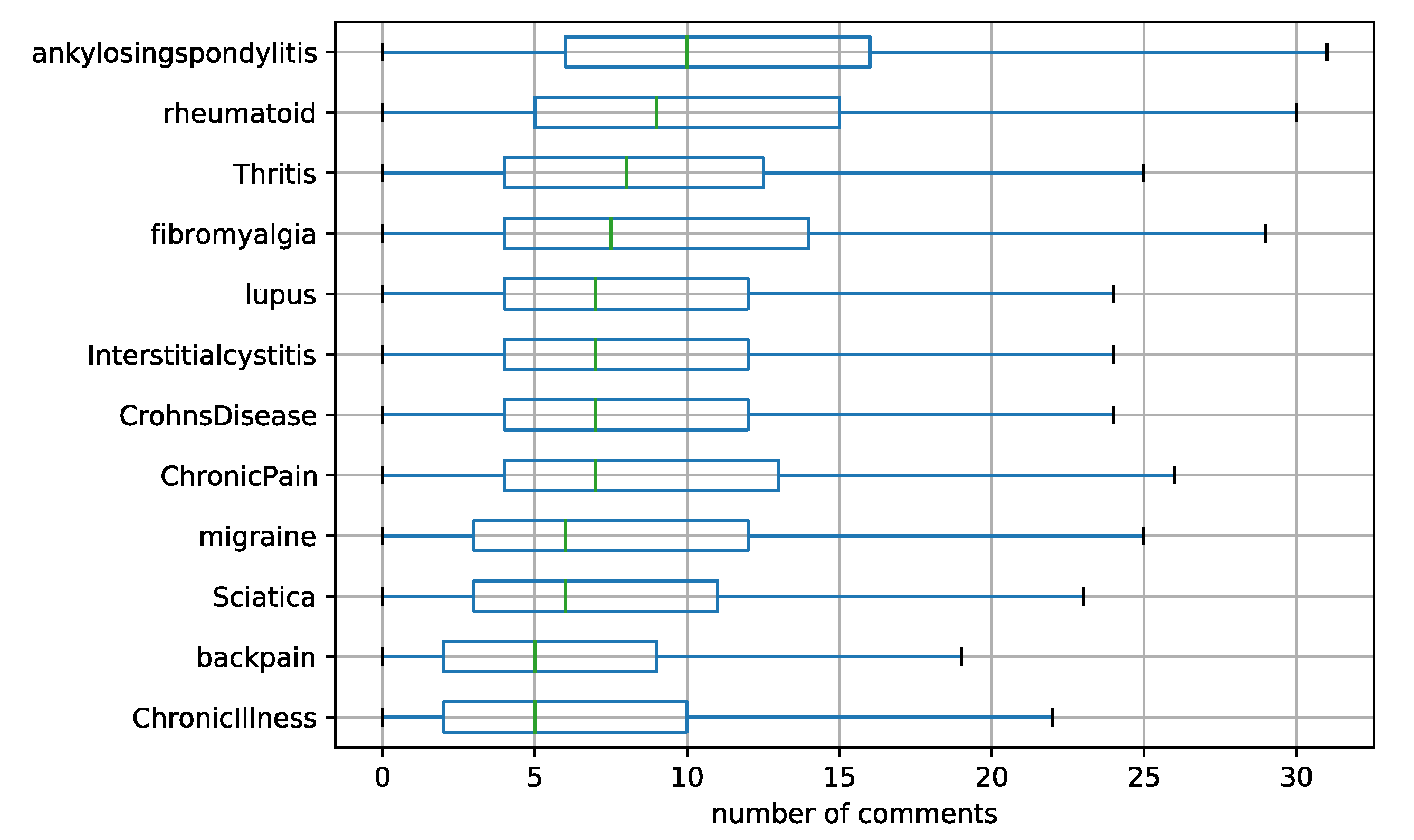
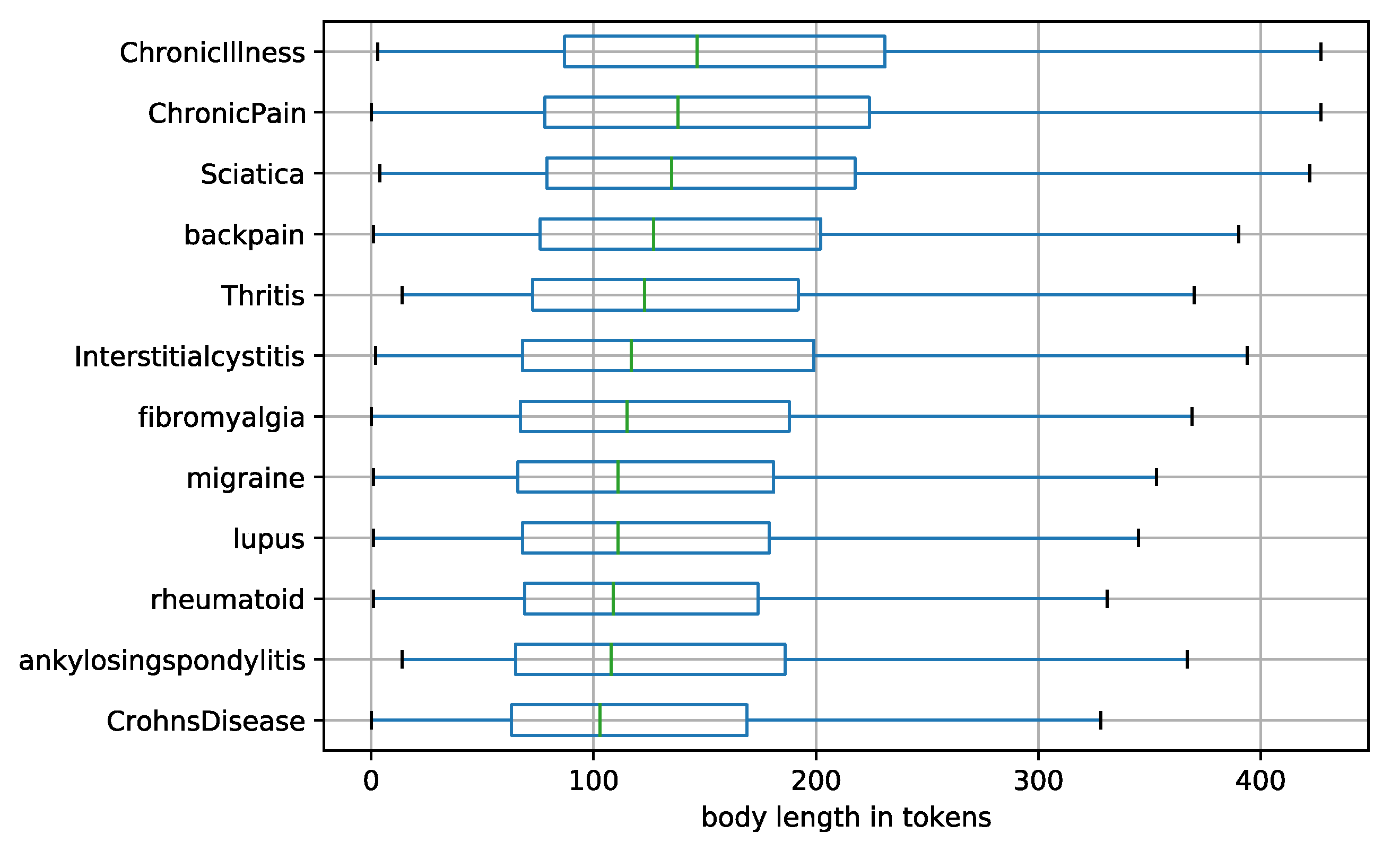
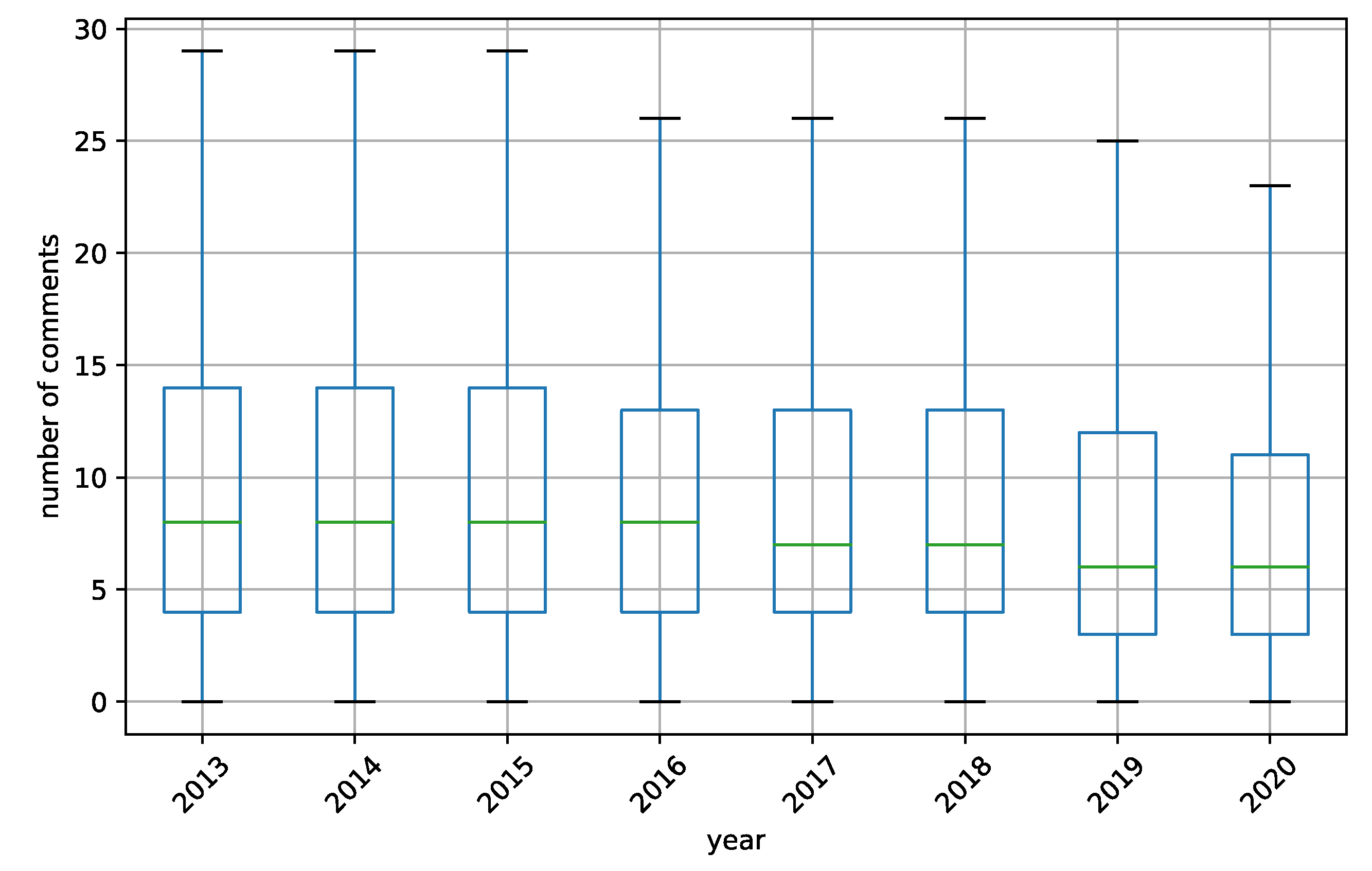
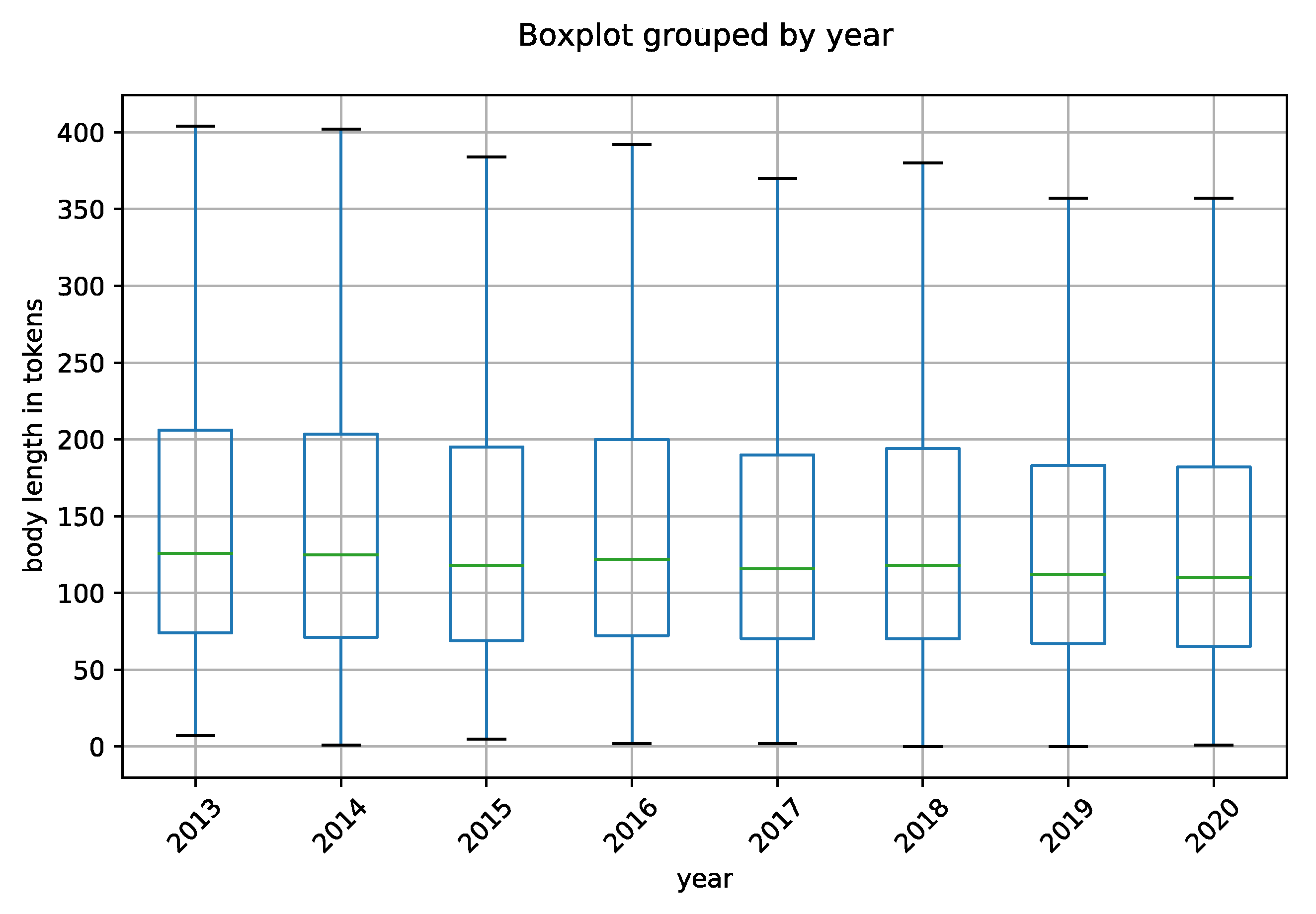
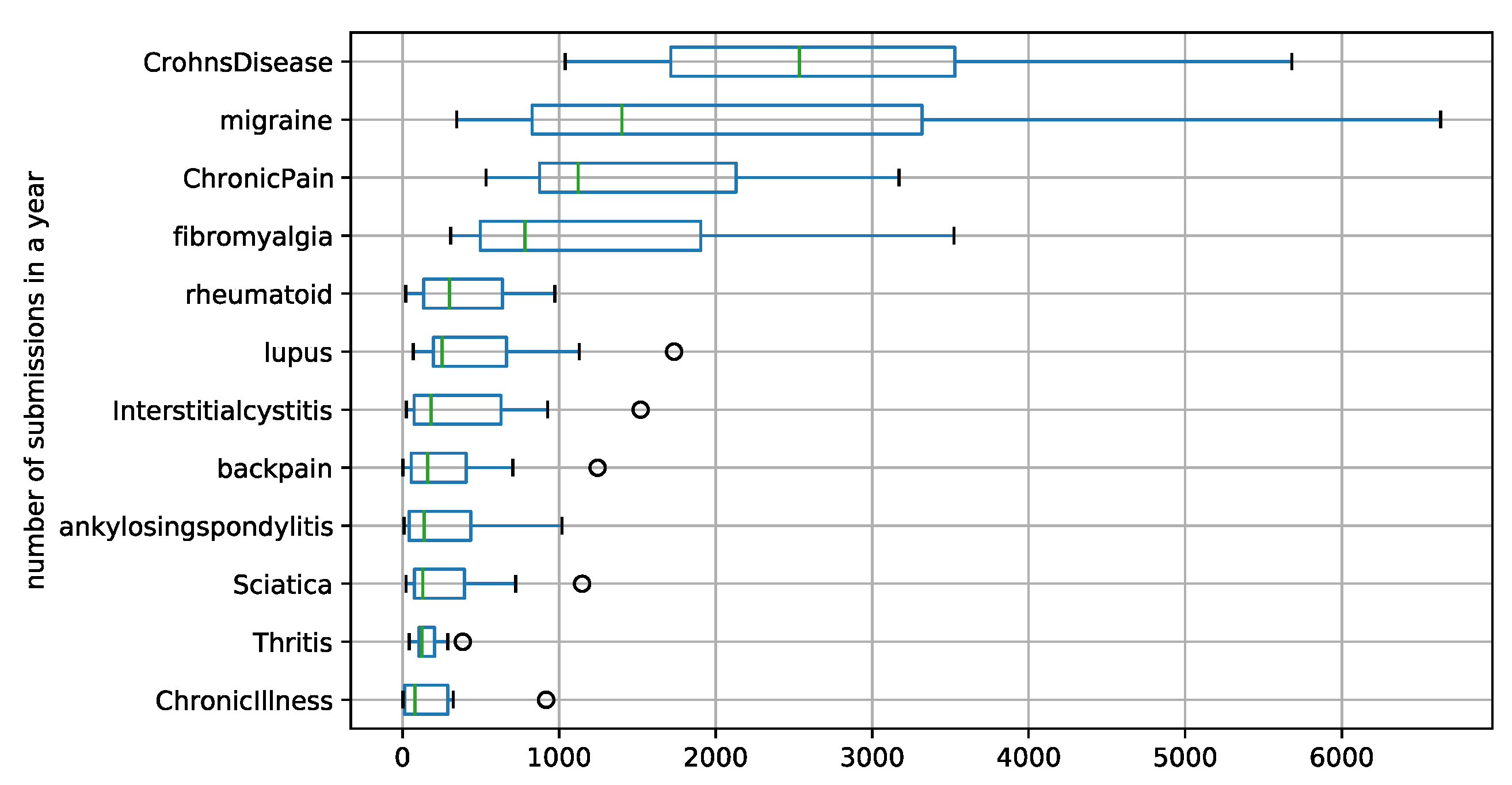
3.1. Data Description
3.2. Data Demographics
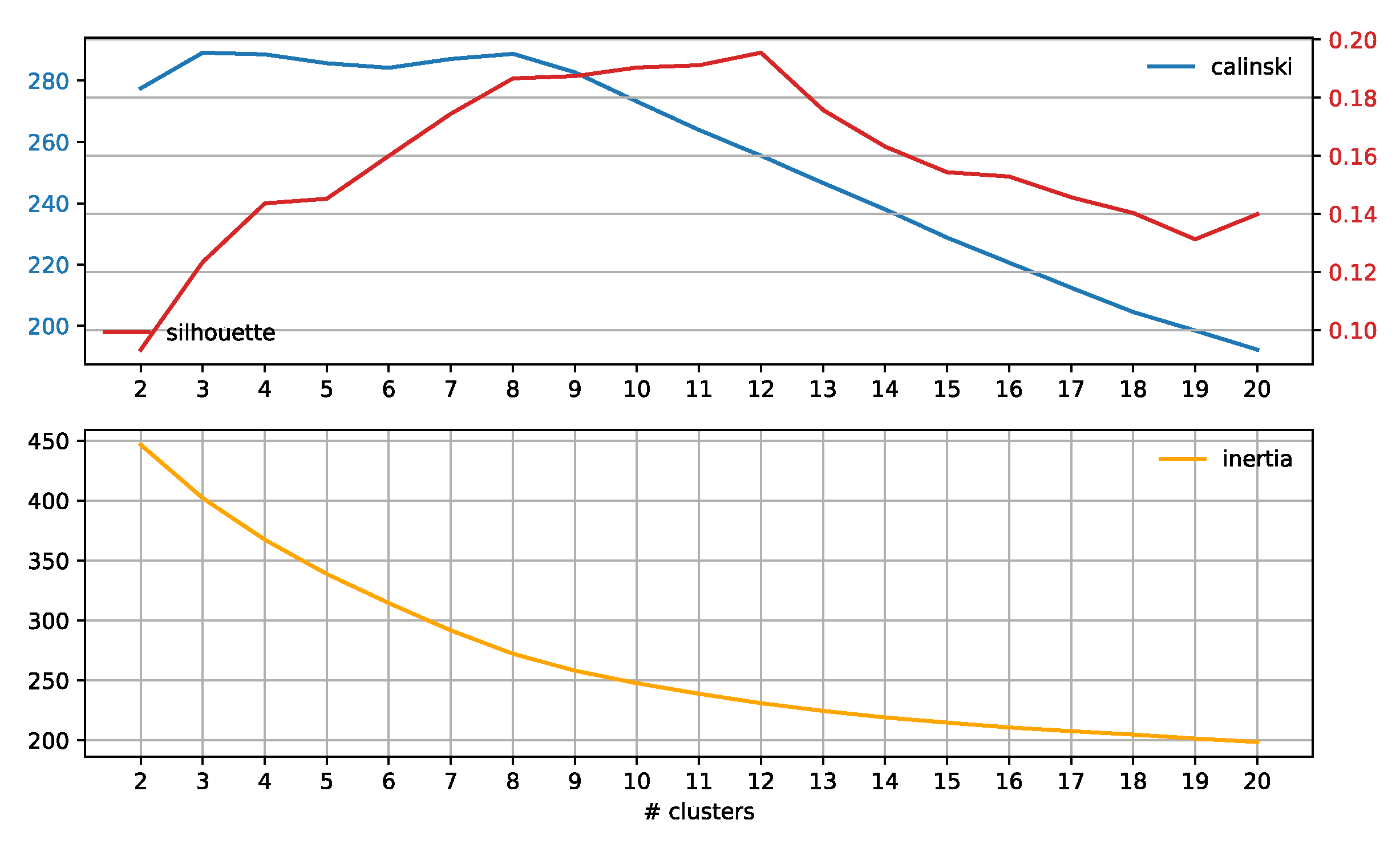
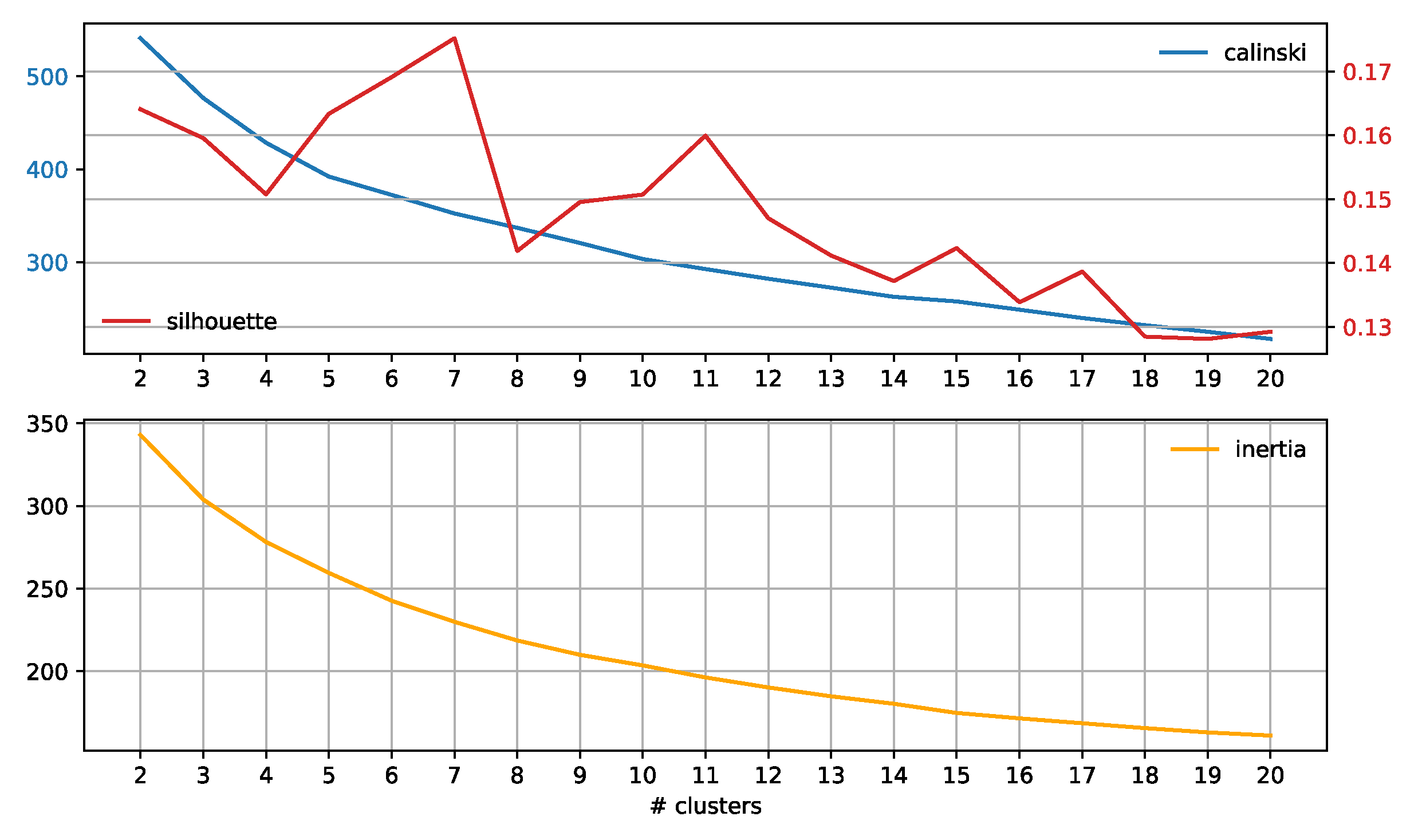
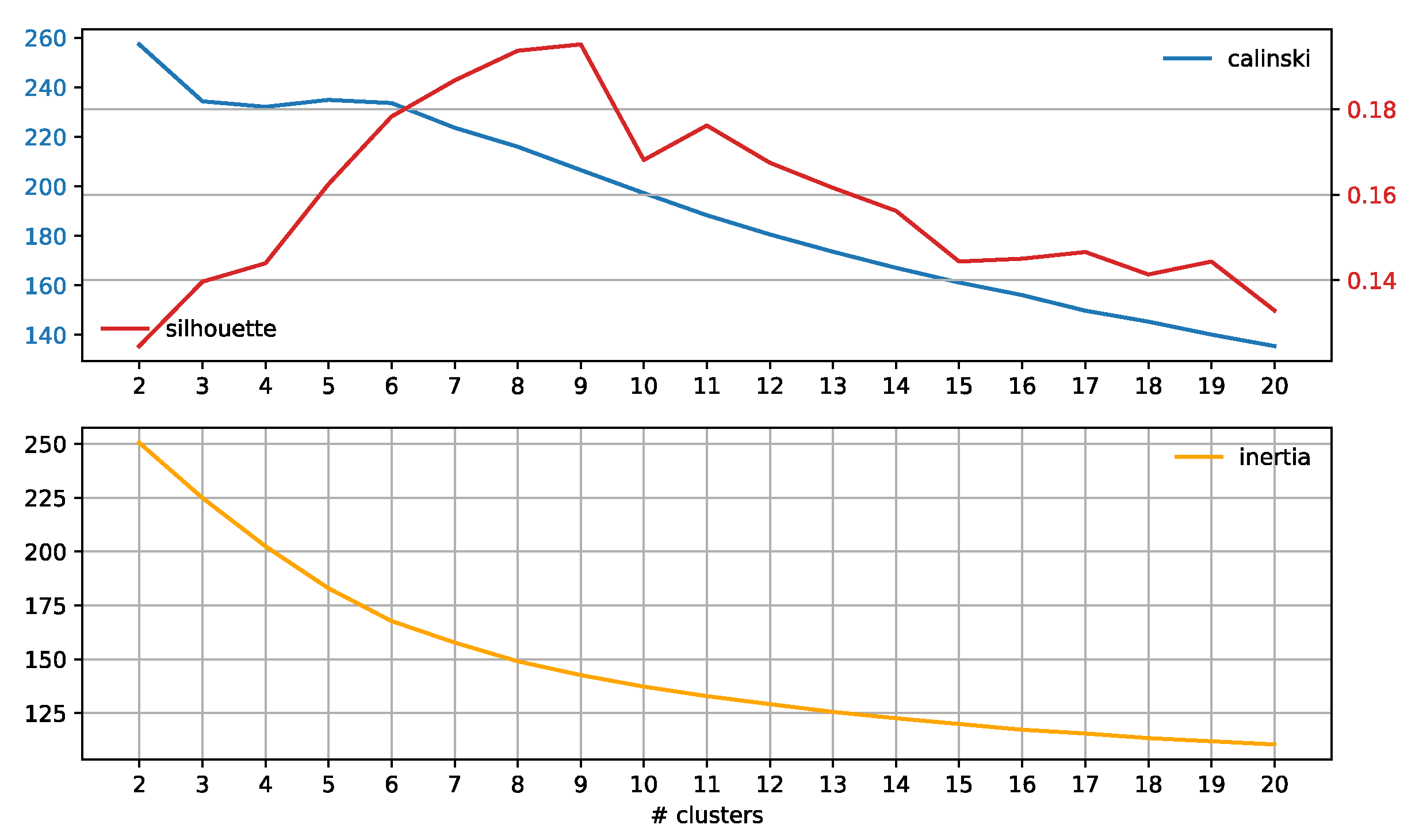
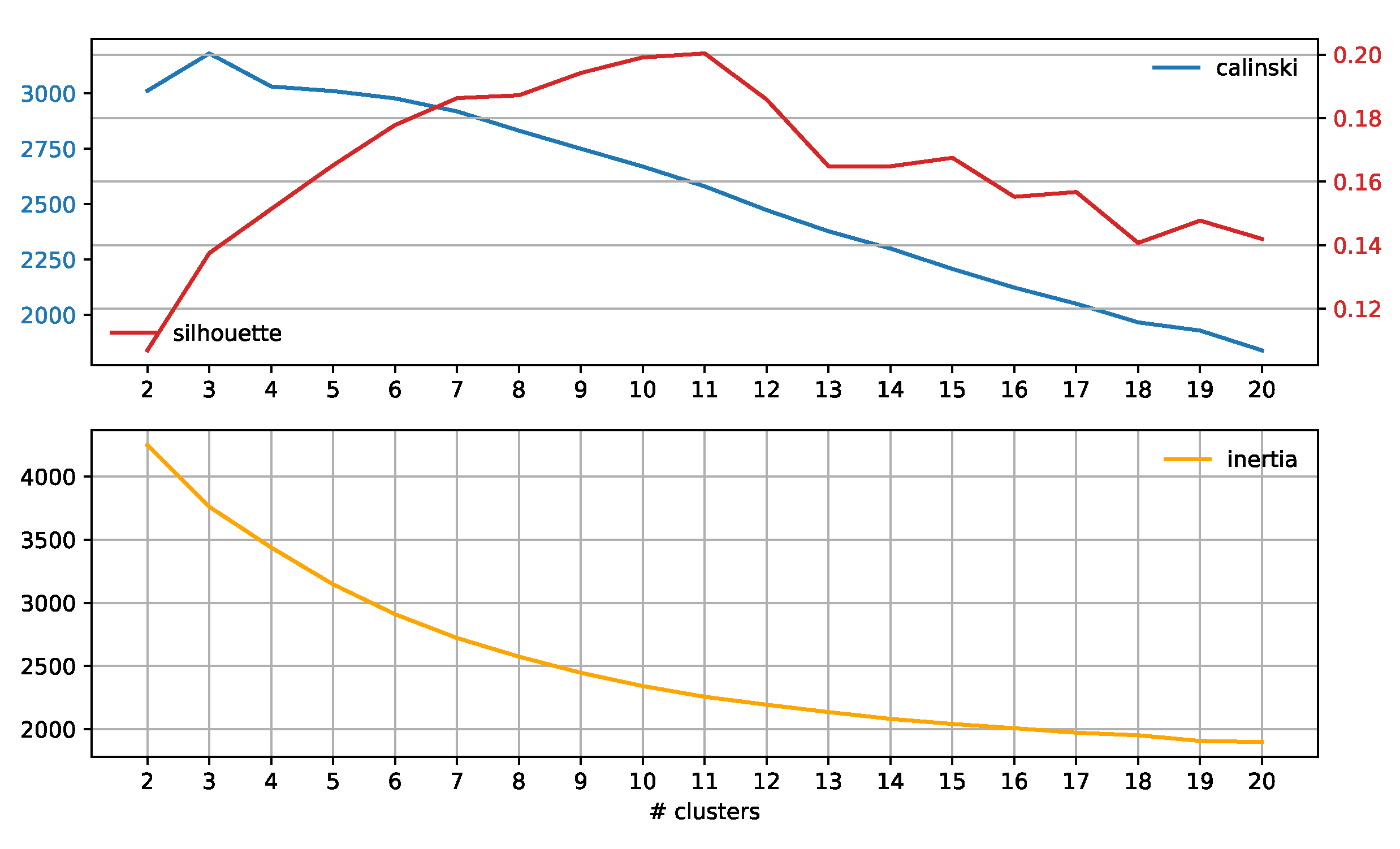
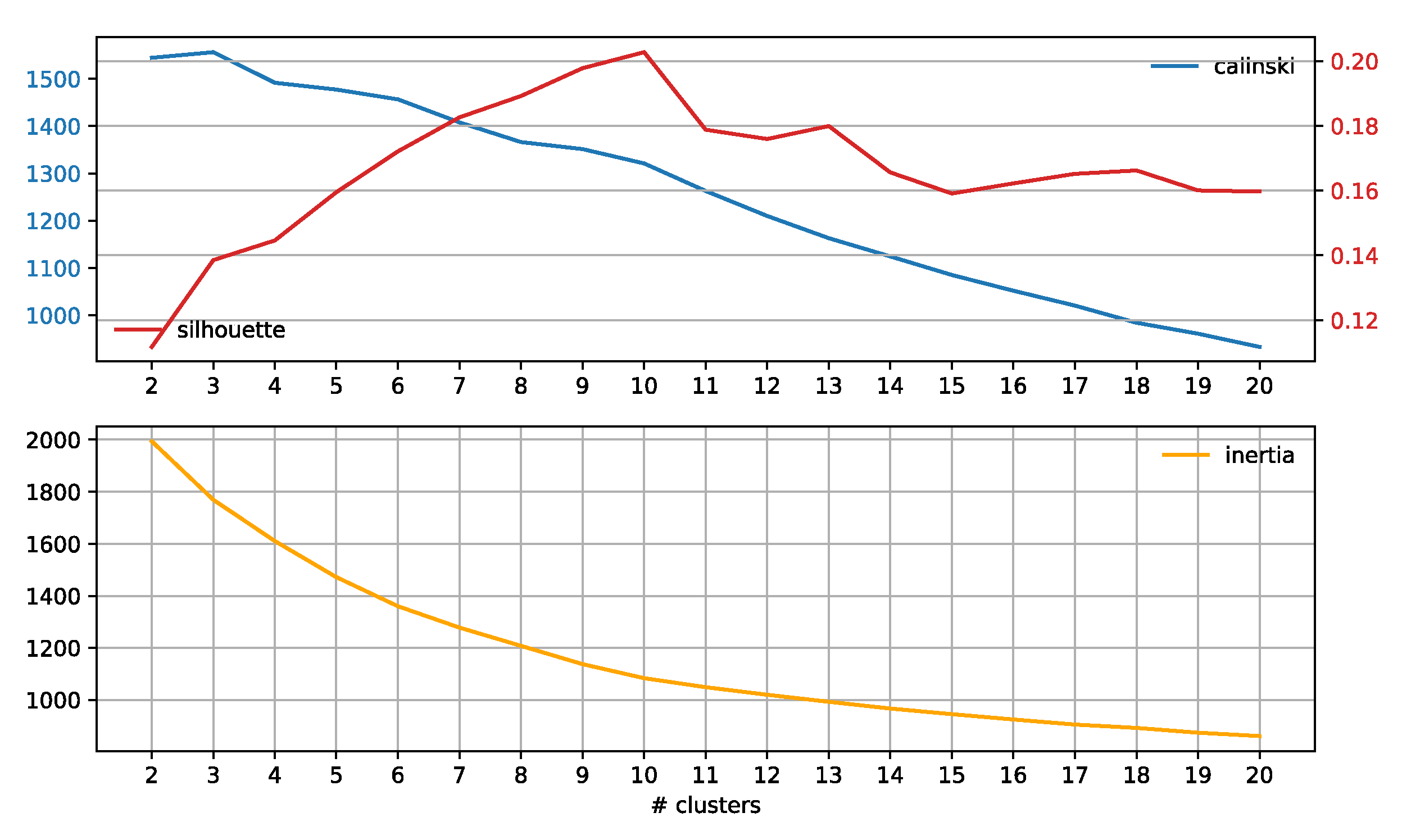
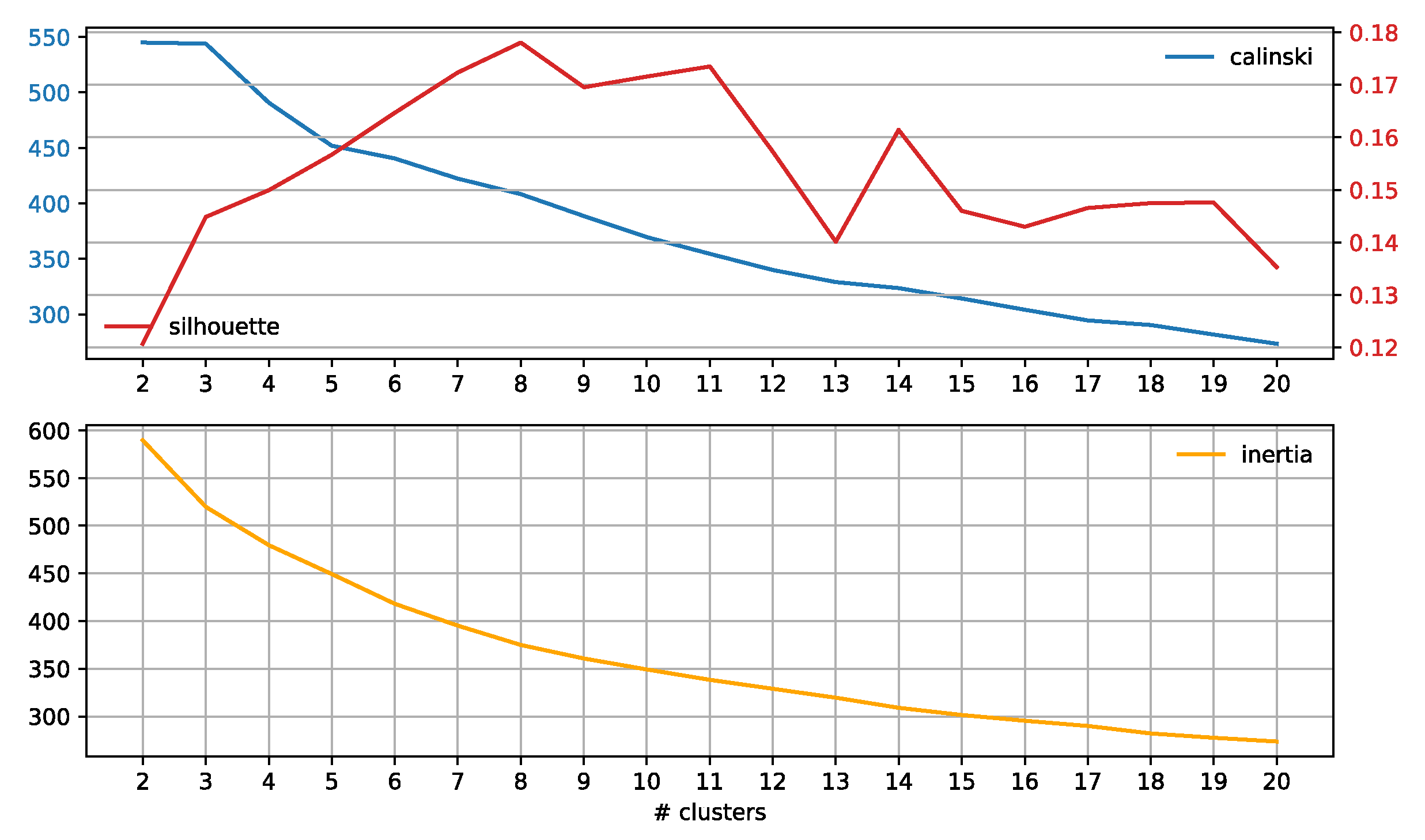
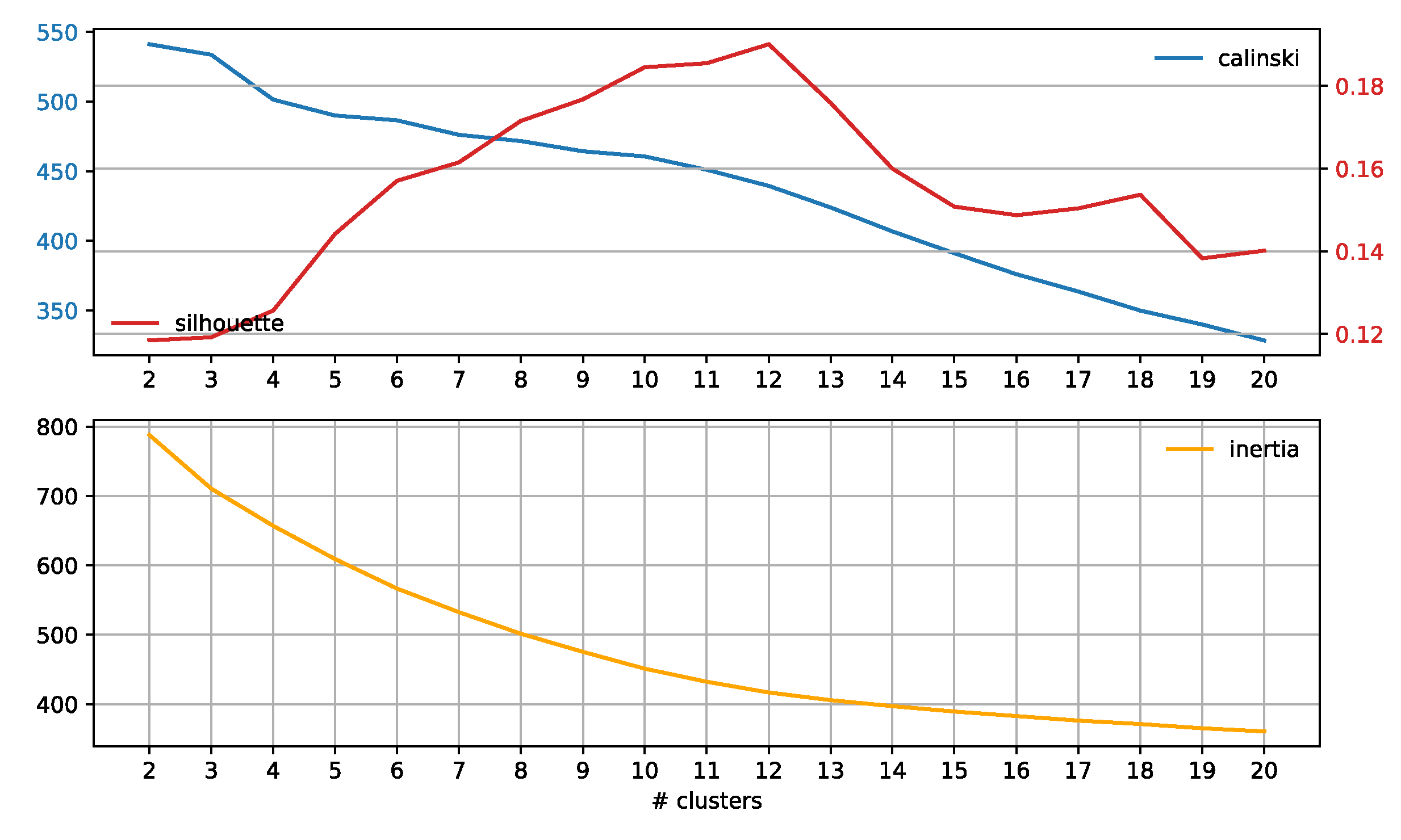
3.3. Subreddit Core Concerns: Semantic Span Similarities
4. Discussion
4.1. Data Demographics
4.2. Subreddit Core Concerns: Semantic Span Similarities
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
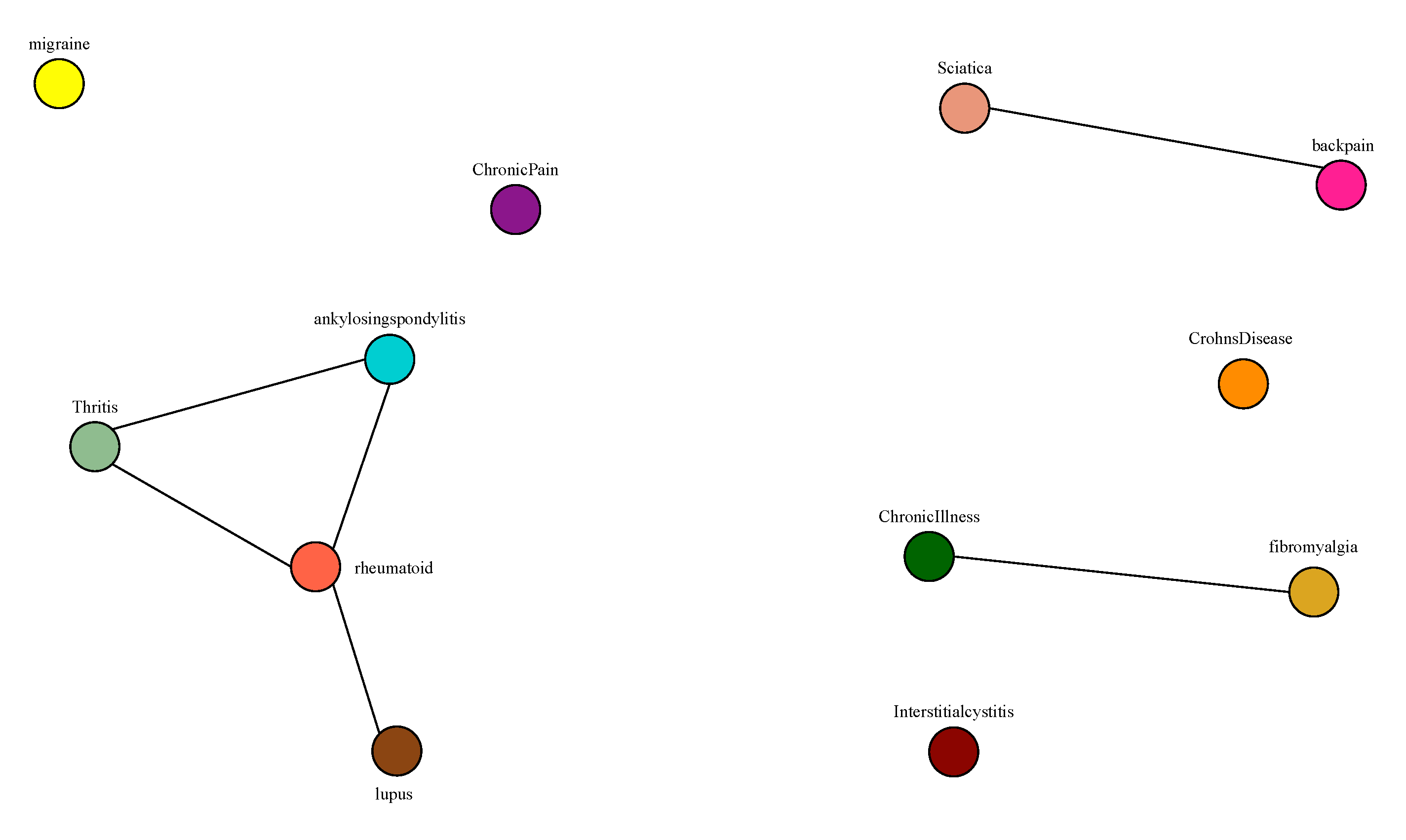
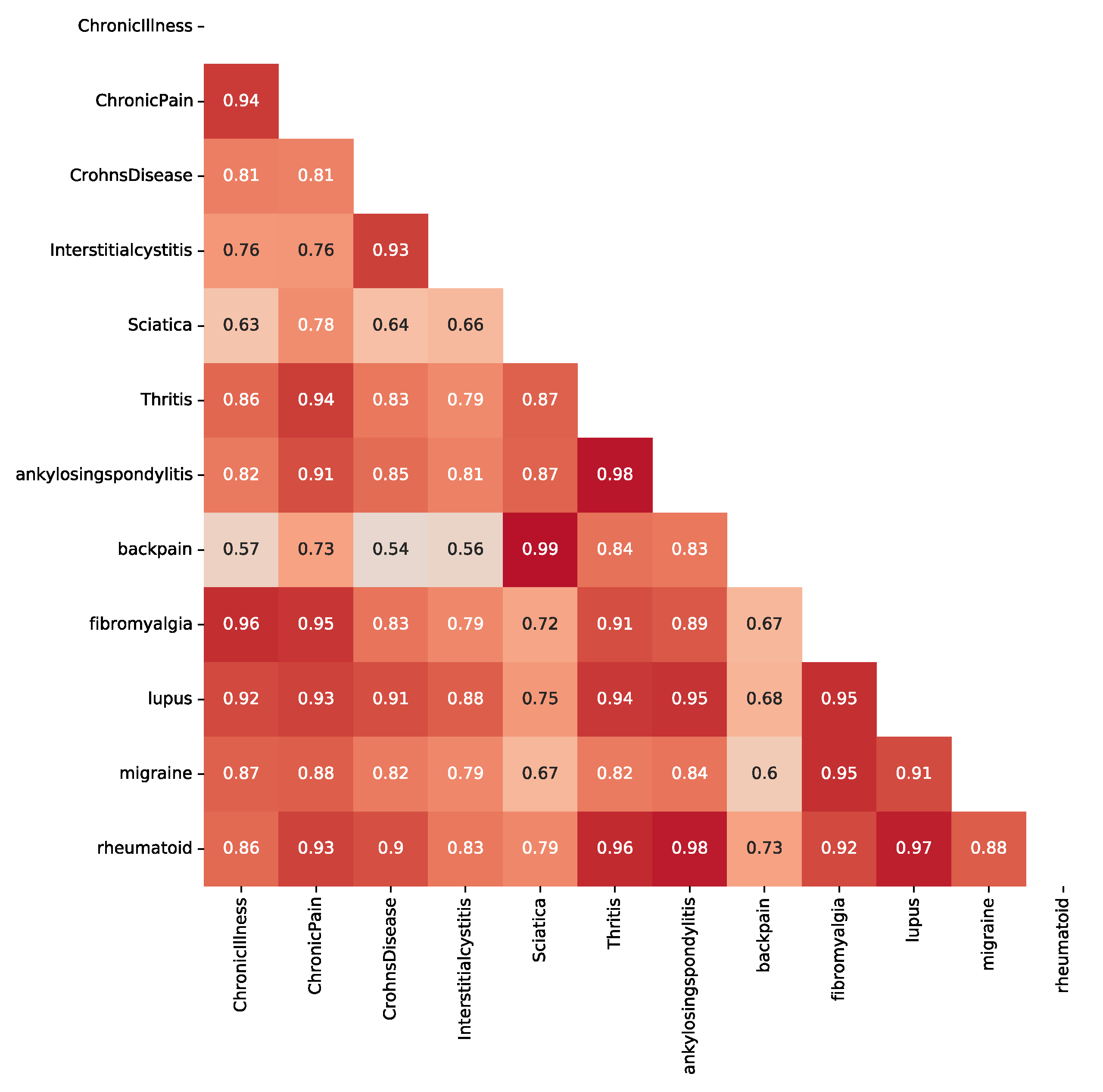
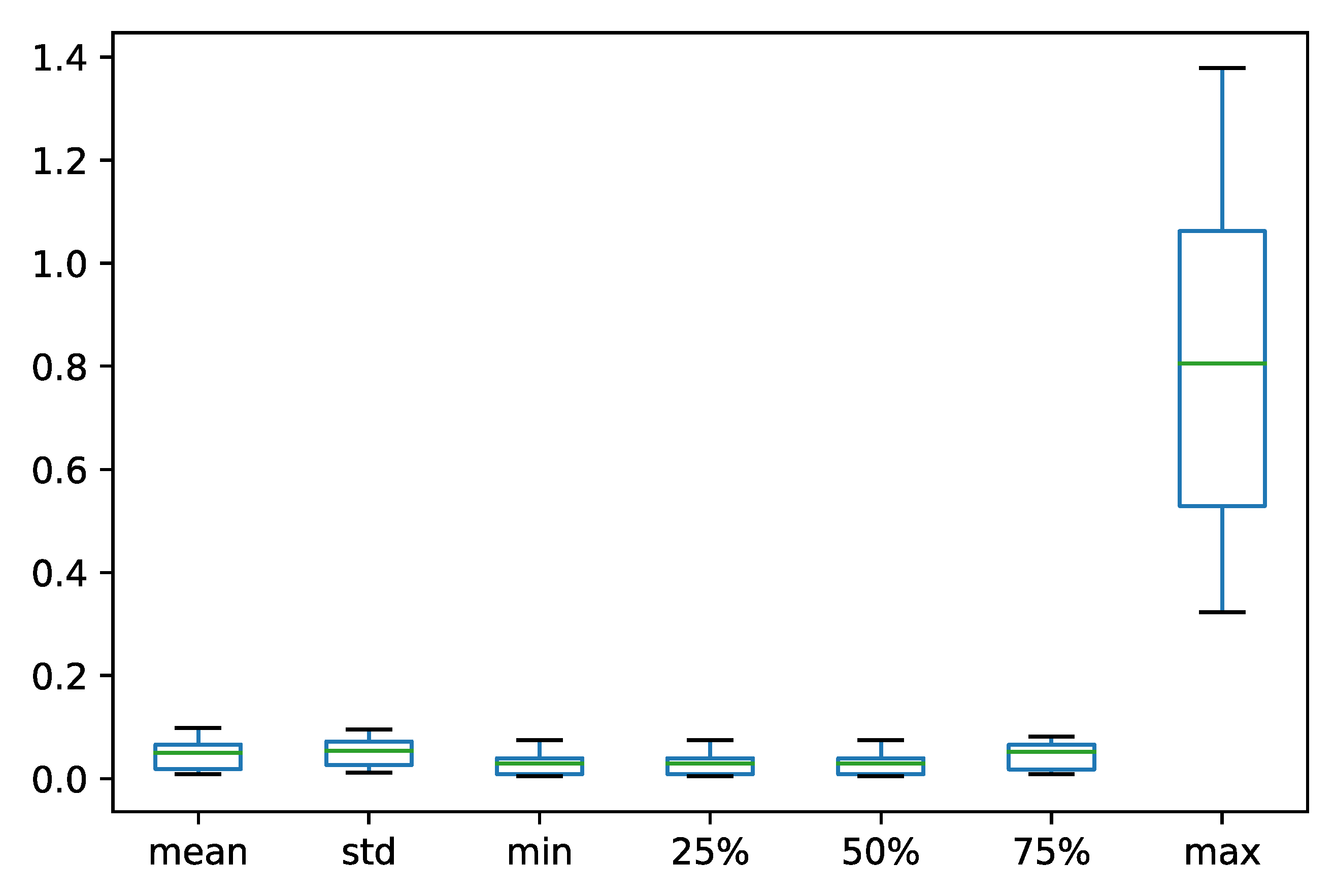
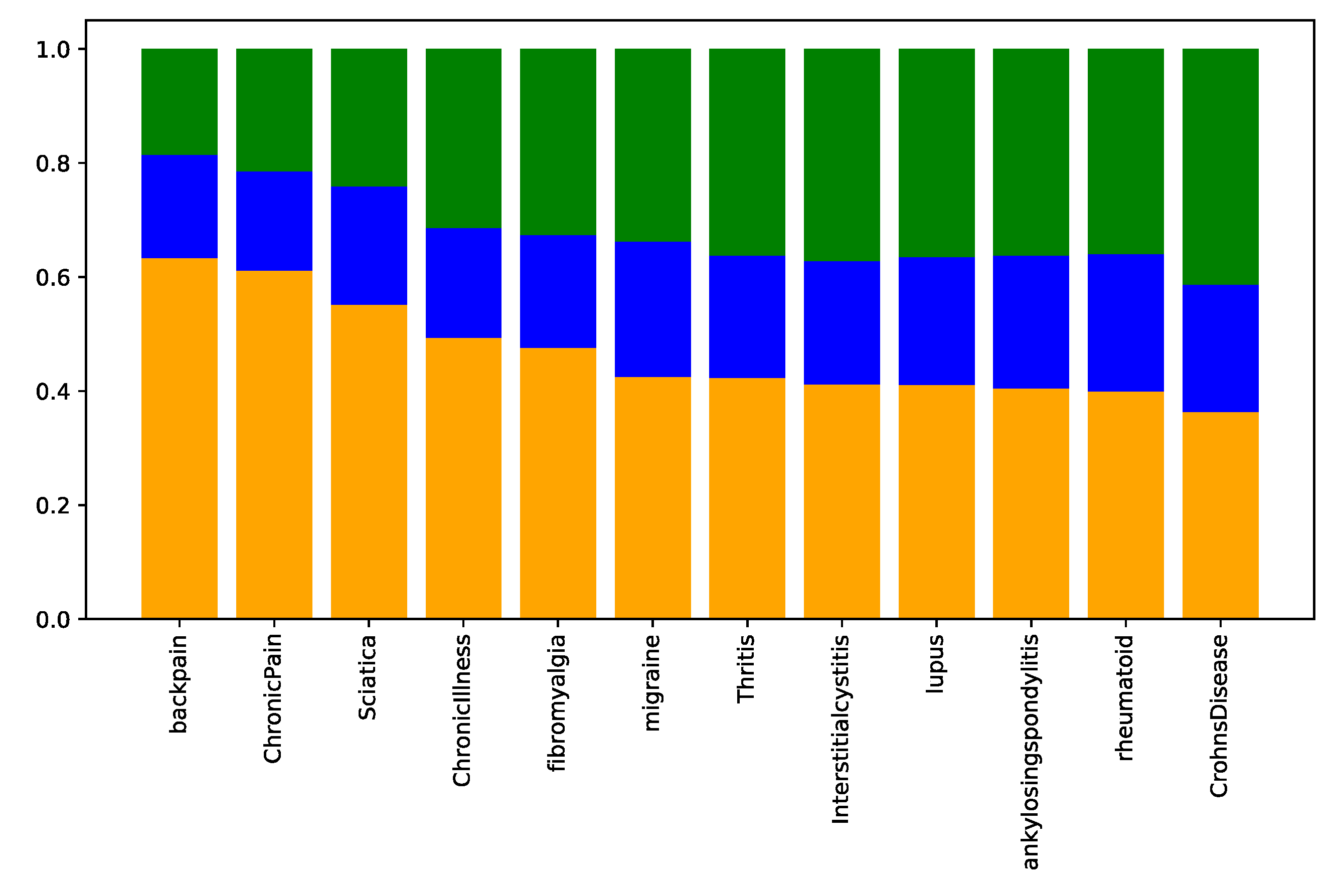
Appendix A.1. Baseline Analysis of Subreddit Similarity
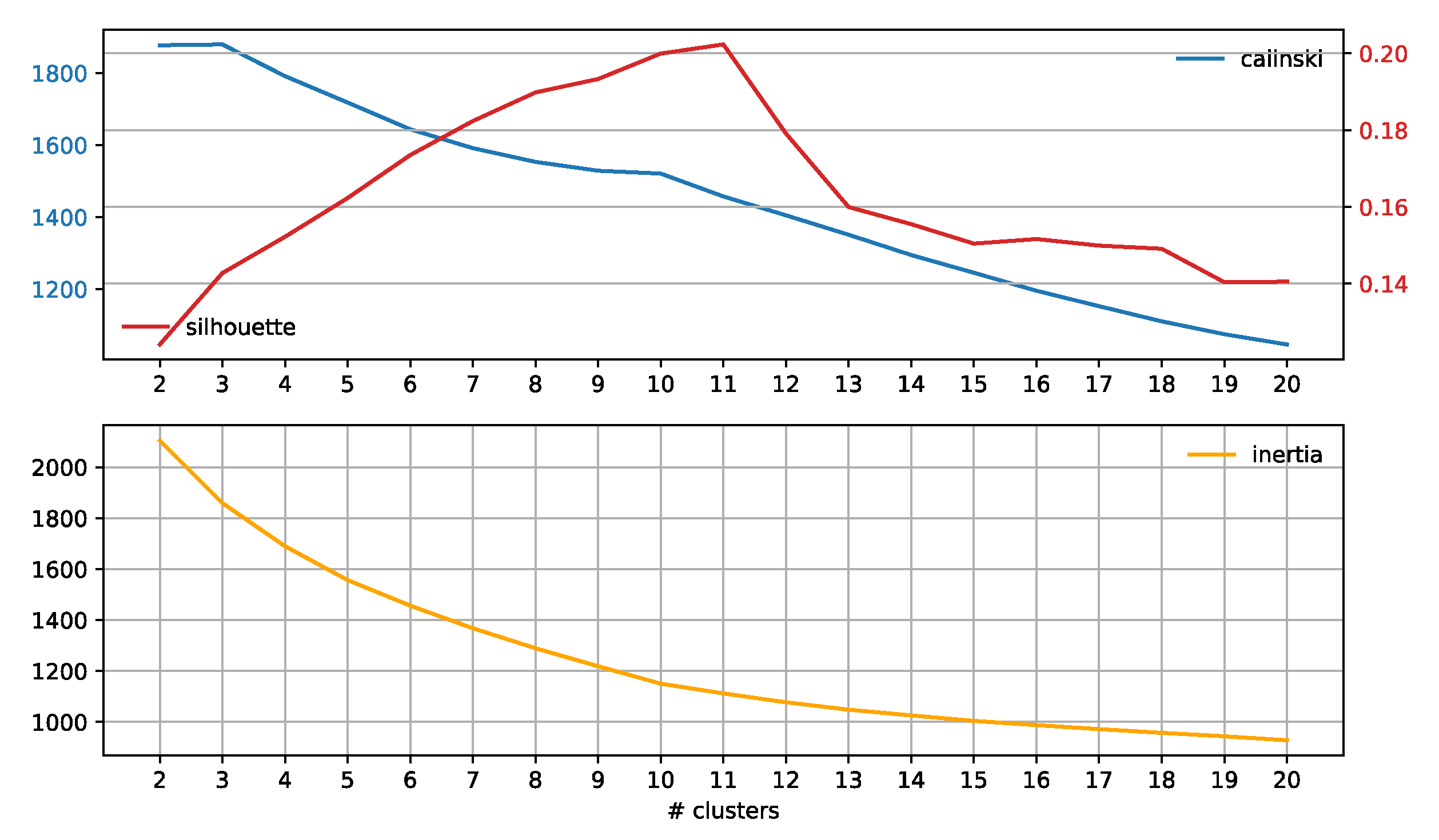
Appendix A.2. Results


Appendix A.3. Discussion
Appendix B
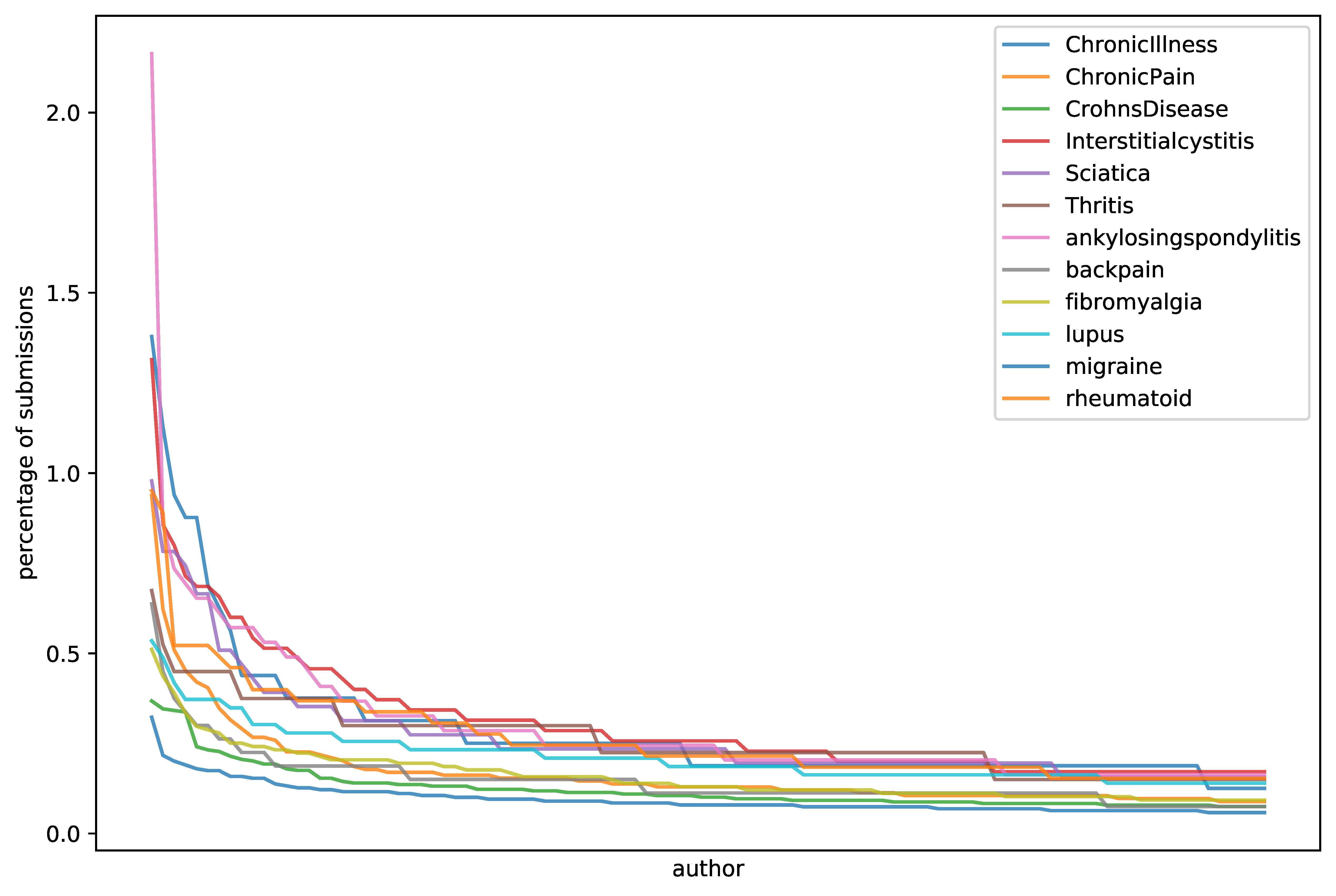
Appendix B.1. Subreddit Activity





Appendix B.2. Author Contribution

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subreddit | Authors | Submissions |
|---|---|---|
| migraine | 10,741 (24.0) | 18,911 (21.6) |
| CrohnsDisease | 9409 (21.0) | 22,836 (26.4) |
| ChronicPain | 6423 (14.3) | 12,365 (14.3) |
| fibromyalgia | 5148 (11.5) | 10,764 (12.4) |
| lupus | 2367 (5.3) | 4300 (5.0) |
| backpain | 2217 (4.9) | 2667 (3.1) |
| rheumatoid | 1823 (4.1) | 3258 (3.8) |
| Interstitialcystitis | 1658 (3.7) | 3500 (4.0) |
| Sciatica | 1572 (3.5) | 2555 (3.0) |
| ankylosingspondylitis | 1340 (3.0) | 2450 (2.8) |
| ChronicIllness | 1105 (2.5) | 1596 (1.8) |
| Thritis | 1012 (2.3) | 1335 (1.5) |


Appendix B.3. Submission Sentiment

Appendix B.4. Vocabulary
| Unigrams | Bigrams |
|---|---|
| back (21.1) | side effects (4.1) |
| day (18.1) | every day (2.9) |
| work (16.5) | lower back (2.8) |
| bad (14.3) | months ago (2.5) |
| started (14.1) | last week (2.4) |
| first (14.1) | last year (2.4) |
| want (14.0) | last night (2.1) |
| else (13.3) | two weeks (2.1) |
| see (12.8) | came back (1.9) |
| last (12.5) | weeks ago (1.8) |
| Subreddit | Unique Vocabulary (%) | Top-3 Most Frequent Unigrams | Top-3 Most Frequent Bigrams |
|---|---|---|---|
| CrohnsDisease | 11.9 | back, day, first | side effects, last week, last year |
| migraine | 9.6 | day, work, started | side effects, every day, last night |
| ChronicPain | 8.8 | back, day, work | lower back, physical therapy, every day |
| fibromyalgia | 5.6 | work, day, back | brain fog, side effects, every day |
| lupus | 2.4 | back, diagnosed, day | came back, blood work, side effects |
| Interstitialcystitis | 2.0 | bladder, flare, uti | pelvic floor, flare-ups, came back |
| backpain | 1.6 | back, work, day | lower back, upper back, right side |
| rheumatoid | 1.5 | started, day, diagnosed | side effects, months ago, blood work |
| ankylosingspondylitis | 1.4 | back, diagnosed, humira | lower back, ankylosing spondylitis, side effects |
| Sciatica | 1.3 | back, surgery, leg | lower back, herniated disc, left leg |
| ChronicIllness | 1.1 | people, illness, work | chronically ill, brain fog, mental health |
| Thritis | 0.8 | back, bad, work | side effects, months ago, lower back |
Appendix C
| Topic Number | Top-10 Most Weighted Words |
|---|---|
| 0 | taking, side effects, tried, medication, meds, started, day, methotrexate, daily, try |
| 1 | don’t, high, Topamax, experience, brain fog, wondering, low, see, use, blood pressure |
| 2 | eat, food, eating, drink, water, trigger, day, drinking, triggers, stomach |
| 3 | sensitivity, triggered, bent, tolerate, benlysta, next appointment, long periods, bar, drain, cream |
| 4 | people, life, want, lot, diagnosed, don’t, advice, always, way, love |
| 5 | neck, don’t, back, cold, won’t, idk, caffeine, head, coffee, right side |
| 6 | diet, exercise, weight, diagnosed, lot, trying, months, tried, good, study |
| 7 | head, sometimes, one, else, usually, feeling, always, feels, almost, weird |
| 8 | hair, skin, red, hot, wear, heat, products, use, shower, sun |
| 9 | work, need, appointment, patients, see, office, one, insurance, called, new |
| 10 | diagnosed, test, normal, diagnosis, fatigue, pregnancy, pregnant, stomach, inflammation, crohn’s |
| 11 | botox, Enbrel, rheum, glasses, pcp, wouldn’t, right eye, ear, ears, hair loss |
| 12 | started, first, last, week, flare, months, weeks, went, back, prednisone |
| 13 | looking, one, find, use, good, people, found, recommendations, helpful, wondering |
| 14 | dizziness, biologics, biologic, wondering, experience, sex, liver, curious, tips, advice |
| 15 | surgery, back, done, recovery, one, mri, long, good, procedure, surgeon |
| 16 | new, month, insurance, treatment, work, one, months, medication, humira, meds |
| 17 | work, day, one, today, bad, want, don’t, need, home, sleep |
| 18 | https www, com, https, watch, video, link, articles, gets better, patients, everyone |
| 19 | back, started, joints, hurt, went, joint, lower back, one, day, right |












References
- Dahlhamer, J.; Lucas, J.; Zelaya, C.; Nahin, R.; Mackey, S.; DeBar, L.; Kerns, R.; von Korff, M.; Porter, L.; Helmick, C. Prevalence of Chronic Pain and High-Impact Chronic Pain Among Adults—United States, 2016. MMWR. Morb. Mortal. Wkly. Rep. 2018, 67, 1001–1006. [Google Scholar] [CrossRef] [PubMed]
- Phillips, C.J. Economic burden of chronic pain. Expert Rev. Pharm. Outcomes Res. 2006, 6, 591–601. [Google Scholar] [CrossRef] [PubMed]
- Wilson, D. Language and the pain experience. Physiother. Res. Int. 2009, 14, 56–65. [Google Scholar] [CrossRef] [PubMed]
- Melzack, R. Torgerson WS: On the Language of Pain. Anesthesiology 1971, 34, 50–59. [Google Scholar] [CrossRef]
- Halliday, M.A.K. On the grammar of pain. Funct. Lang. 1998, 5, 1–32. [Google Scholar] [CrossRef]
- Melzack, R. The McGill Pain Questionnaire: Major Properties and Scoring Methods. Pain 1975, 1, 277–299. [Google Scholar] [CrossRef]
- Katz, J.; Melzack, R. Measurement of Pain. Surg. Clin. N. Am. 1999, 79, 231–252. [Google Scholar] [CrossRef]
- Sullivan, M.D. Pain in language: From sentience to sapience. Pain Forum. 1995, 4, 3–14. [Google Scholar] [CrossRef]
- Yates, A.; Cohan, A.; Goharian, N. Depression and Self-Harm Risk Assessment in Online Forums. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2968–2978. [Google Scholar]
- Yao, H.; Rashidian, S.; Dong, X.; Duanmu, H.; Rosenthal, R.N.; Wang, F. Detection of Suicidality Among Opioid Users on Reddit: Machine Learning–Based Approach. J. Med. Internet Res. 2020, 22, e15293. [Google Scholar] [CrossRef]
- Cohan, A.; Desmet, B.; Yates, A.; Soldaini, L.; Macavaney, S.; Goharian, N. SMHD: A Large-Scale Resource for Exploring Online Language Usage for Multiple Mental Health Conditions. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018. [Google Scholar]
- Foufi, V.; Timakum, T.; Gaudet-Blavignac, C.; Lovis, C.; Song, M. Mining of textual health information from Reddit: Analysis of chronic diseases with extracted entities and their relations. J. Med. Internet Res. 2019, 21, e12876. [Google Scholar] [CrossRef]
- Rohde, J.A.; Sibley, A.L.; Noar, S.M. Topics Analysis of Reddit and Twitter Posts Discussing Inflammatory Bowel Disease and Distress from 2017 to 2019. Crohn’s Colitis 360 2021, 3, otab044. [Google Scholar] [CrossRef] [PubMed]
- Chew, C.; Rebić, N.; Baldwin, C.; Amiri, N.; Proulx, L.; de Vera, M.A. “r/Thritis”, Pregnancy, and Parenting: A Qualitative Descriptive Study of Reddit Forums to Explore Information Needs and Concerns of Women with Rheumatoid Arthritis. ACR Open Rheumatol. 2019, 1, 485–492. [Google Scholar] [CrossRef] [PubMed]
- Goudman, L.; de Smedt, A.; Moens, M. Social Media and Chronic Pain: What Do Patients Discuss? J. Pers. Med. 2022, 12, 797. [Google Scholar] [CrossRef] [PubMed]
- Proferes, N.; Jones, N.; Gilbert, S.; Fiesler, C.; Zimmer, M. Studying Reddit: A Systematic Overview of Disciplines, Approaches, Methods, and Ethics. Soc. Media Soc. 2021, 7. [Google Scholar] [CrossRef]
- Jagfeld, G.; Lobban, F.; Rayson, P.; Jones, S.H. Understanding who uses Reddit: Profiling individuals with a self-reported bipolar disorder diagnosis. In Proceedings of the Seventh Workshop on Computational Linguistics and Clinical Psychology: Improving Access, Online, Mexico, 11 June 2021. [Google Scholar]
- Honnibal, M.; Montani, I.; van Landeghem, S.; Boyd, A. spaCy: Industrial-strength Natural Language Processing in Python. 2020. Available online: https://github.com/explosion/spaCy (accessed on 29 April 2021).
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010. [Google Scholar]
- Vinutha, H.P.; Poornima, B.; Sagar, B.M. Detection of outliers using interquartile range technique from intrusion dataset. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2018; pp. 511–518. [Google Scholar] [CrossRef]
- Roda, G.; Chien Ng, S.; Kotze, P.G.; Argollo, M.; Panaccione, R.; Spinelli, A.; Kaser, A.; Peyrin-Biroulet, L.; Danese, S. Crohn’s disease. Nat. Rev. Dis. Primers. 2020, 6, 22. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Edu, J.B. Latent Dirichlet Allocation Michael I. Jordan. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Lloyd, S.P. Least Squares Quantization in PCM. IEEE Trans. Inf. Theory. 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Caliñski, T.; Harabasz, J. A Dendrite Method Foe Cluster Analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Amin, S.; Uddin, M.I.; Hassan, S.; Khan, A.; Nasser, N.; Alharbi, A.; Alyami, H. Recurrent Neural Networks with TF-IDF Embedding Technique for Detection and Classification in Tweets of Dengue Disease. IEEE Access. 2020, 8, 131522–131533. [Google Scholar] [CrossRef]
- Kang, H.; Yu, Z.; Gong, Y. Initializing and Growing a Database of Health Information Technology (HIT) Events by Using TF-IDF and Biterm Topic Modeling. Annu. Symp. Proc. 2017, 2017, 1024–1033. [Google Scholar]
- Mullins, P.M.; Yong, R.J.; Bhattacharyya, N. Impact of demographic factors on chronic pain among adults in the United States. PAIN Rep. 2022, 7, e1009. [Google Scholar] [CrossRef]
- Nzali, M.D.T.; Bringay, S.; Lavergne, C.; Mollevi, C.; Opitz, T. What patients can tell us: Topic analysis for social media on breast cancer. JMIR Med. Inform. 2017, 5, e23. [Google Scholar] [CrossRef] [PubMed]
- Brody, S.; Elhadad, N. Detecting Salient Aspects in Online Reviews of Health Providers. In Proceedings of the AMIA Annual Symposium Proceedings, Washington, DC, USA, 13–17 November 2010; pp. 202–206. [Google Scholar]
- Gokul, P.P.; Akhil, B.K.; Shiva, K.K.M. Sentence similarity detection in Malayalam language using cosine similarity. In Proceedings of the RTEICT 2017—2nd IEEE International Conference on Recent Trends in Electronics, Information and Communication Technology, Bangalore, India, 19–20 May 2017; pp. 221–225. [Google Scholar] [CrossRef]
- Rakholia, R.M.; Saini, J.R. Information retrieval for Gujarati language using cosine similarity based vector space model. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Al-Anzi, F.S.; AbuZeina, D. Toward an enhanced Arabic text classification using cosine similarity and Latent Semantic Indexing. J. King Saud Univ. Comput. Inf. Sci. 2017, 29, 189–195. [Google Scholar] [CrossRef]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, Georgia, USA, 6–9 June 2022; pp. 216–225. [Google Scholar] [CrossRef]


| Subreddit | Mean Submissions Per Year | Total Number of Submissions | Mean Tokens Per Submission | Total Tokens | Number of Registered Users (Thousands) |
|---|---|---|---|---|---|
| CrohnsDisease | 2854.5 (1569.7) | 22,836 | 127.6 (85.9) | 2,913,623 | 35 |
| migraine | 2363.9 (2238.4) | 18,911 | 134.4 (88.5) | 2,542,288 | 73.9 |
| ChronicPain | 1545.6 (989.6) | 12,365 | 159.7 (99.7) | 1,974,368 | 54.1 |
| fibromyalgia | 1345.5 (1220.4) | 10,764 | 138.6 (90.6) | 1,492,326 | 34.1 |
| lupus | 537.5 (589.2) | 4300 | 135.0 (89.2) | 580,571 | 12 |
| Interstitialcystitis | 437.5 (535.0) | 3500 | 144.5 (96.2) | 505,836 | 9.2 |
| rheumatoid | 407.2 (353.8) | 3258 | 131.7 (84.0) | 429,151 | 12.5 |
| backpain | 333.4 (433.4) | 2667 | 148.0 (92.1) | 394,617 | 15.6 |
| Sciatica | 319.4 (404.9) | 2555 | 156.3 (95.0) | 399,278 | 10.1 |
| ankylosingspondylitis | 306.2 (373.3) | 2450 | 134.5 (90.2) | 329,443 | 8.4 |
| ChronicIllness | 228.0 (329.7) | 1596 | 164.6 (98.1) | 262,716 | 25.5 |
| Thritis | 166.9 (114.4) | 1335 | 142.3 (88.8) | 189,979 | 7.8 |
| Subreddit | Female (%) | Male (%) | Authors with Stated Gender (%) |
|---|---|---|---|
| CrohnsDisease | 40.85 | 59.15 | 20.92 |
| migraine | 63.34 | 36.66 | 24.25 |
| ChronicPain | 54.78 | 45.22 | 28.48 |
| fibromyalgia | 68.24 | 31.76 | 24.71 |
| lupus | 69.35 | 30.65 | 19.43 |
| Interstitialcystitis | 73.26 | 26.74 | 21.65 |
| rheumatoid | 58.58 | 41.42 | 20.13 |
| backpain | 30.04 | 69.96 | 24.18 |
| Sciatica | 32.75 | 67.25 | 21.95 |
| ankylosingspondylitis | 45.45 | 54.55 | 18.06 |
| ChronicIllness | 73.23 | 26.77 | 24.34 |
| Thritis | 51.70 | 48.30 | 29.05 |
| Subreddit | 13–17 (%) | 18–34 (%) | 35–44 (%) | >45 (%) | Authors with Stated Age (%) |
|---|---|---|---|---|---|
| CrohnsDisease | 7.17 | 68.93 | 11.95 | 11.95 | 5.78 |
| migraine | 5.59 | 69.57 | 12.67 | 12.17 | 7.49 |
| ChronicPain | 7.16 | 64.41 | 13.37 | 15.07 | 8.27 |
| fibromyalgia | 3.51 | 68.37 | 18.21 | 9.90 | 6.08 |
| lupus | 6.90 | 68.97 | 9.66 | 14.48 | 6.13 |
| Interstitialcystitis | 2.56 | 74.36 | 14.53 | 8.55 | 7.06 |
| rheumatoid | 8.49 | 60.38 | 16.98 | 14.15 | 5.81 |
| backpain | 7.81 | 65.10 | 14.58 | 12.50 | 8.66 |
| Sciatica | 8.99 | 67.42 | 12.36 | 11.24 | 5.66 |
| ankylosingspondylitis | 5.97 | 70.15 | 13.43 | 10.45 | 5.00 |
| ChronicIllness | 3.80 | 77.22 | 12.66 | 6.33 | 7.15 |
| Thritis | 9.52 | 58.33 | 13.10 | 19.05 | 8.30 |
| Subreddit | North America (%) | Europe (%) | Asia (%) | Oceania (%) | Africa (%) | South America (%) | Authors with Stated Location (%) |
|---|---|---|---|---|---|---|---|
| CrohnsDisease | 71.39 | 13.30 | 5.76 | 4.84 | 2.99 | 1.73 | 18.46 |
| migraine | 70.24 | 13.11 | 6.69 | 4.33 | 3.23 | 2.40 | 21.30 |
| ChronicPain | 72.71 | 9.56 | 5.11 | 6.57 | 3.78 | 2.26 | 23.45 |
| fibromyalgia | 69.61 | 11.15 | 5.48 | 7.16 | 3.62 | 2.97 | 20.90 |
| lupus | 75.93 | 9.85 | 5.69 | 3.28 | 2.19 | 3.06 | 19.31 |
| Interstitialcystitis | 68.36 | 11.64 | 8.73 | 4.00 | 5.09 | 2.18 | 16.59 |
| rheumatoid | 74.71 | 12.50 | 3.78 | 3.20 | 2.33 | 3.49 | 18.87 |
| backpain | 71.14 | 12.08 | 7.61 | 4.25 | 3.13 | 1.79 | 20.16 |
| Sciatica | 74.68 | 8.44 | 8.44 | 2.92 | 2.60 | 2.92 | 19.59 |
| ankylosingspondylitis | 68.35 | 12.24 | 11.39 | 5.91 | 1.69 | 0.42 | 17.69 |
| ChronicIllness | 67.88 | 11.92 | 7.77 | 4.15 | 6.22 | 2.07 | 17.47 |
| Thritis | 70.29 | 10.46 | 5.86 | 8.37 | 3.35 | 1.67 | 23.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nunes, D.A.P.; Ferreira-Gomes, J.; Neto, F.; Martins de Matos, D. Modeling Chronic Pain Experiences from Online Reports Using the Reddit Reports of Chronic Pain Dataset. Information 2023, 14, 237. https://doi.org/10.3390/info14040237
Nunes DAP, Ferreira-Gomes J, Neto F, Martins de Matos D. Modeling Chronic Pain Experiences from Online Reports Using the Reddit Reports of Chronic Pain Dataset. Information. 2023; 14(4):237. https://doi.org/10.3390/info14040237
Chicago/Turabian StyleNunes, Diogo A. P., Joana Ferreira-Gomes, Fani Neto, and David Martins de Matos. 2023. "Modeling Chronic Pain Experiences from Online Reports Using the Reddit Reports of Chronic Pain Dataset" Information 14, no. 4: 237. https://doi.org/10.3390/info14040237
APA StyleNunes, D. A. P., Ferreira-Gomes, J., Neto, F., & Martins de Matos, D. (2023). Modeling Chronic Pain Experiences from Online Reports Using the Reddit Reports of Chronic Pain Dataset. Information, 14(4), 237. https://doi.org/10.3390/info14040237