
Simulated Autonomous Driving Using Reinforcement Learning: A Comparative Study on Unity’s ML-Agents Framework



Abstract
:1. Introduction
2. State of the Art Review
3. Materials and Methods
3.1. Reinforcement Learning for Autonomous Cart Racing
3.2. Test Environment
3.3. Algorithms
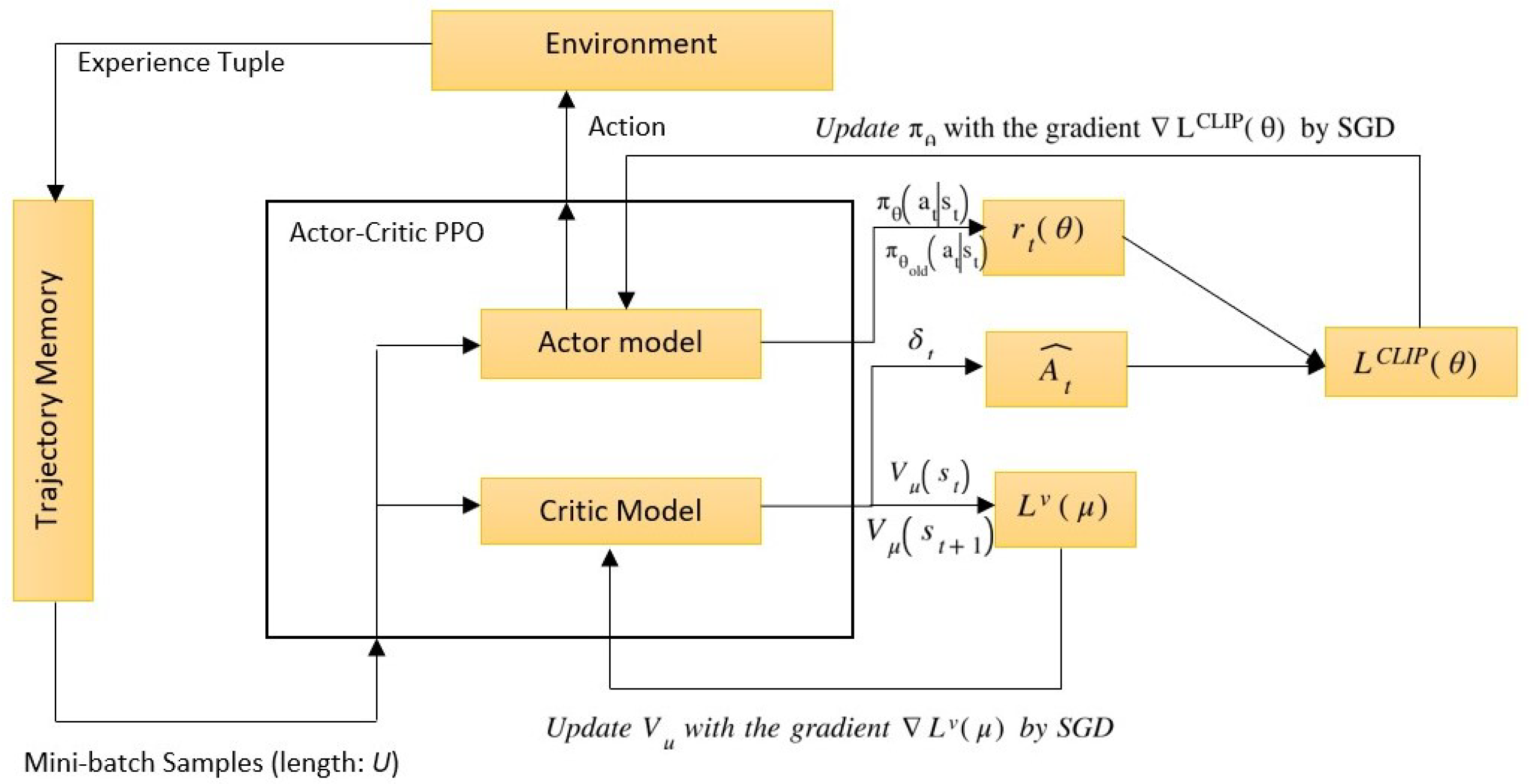
3.3.1. MA-PPO Algorithm
| Algorithm 1 MA-PPO algorithm |
|
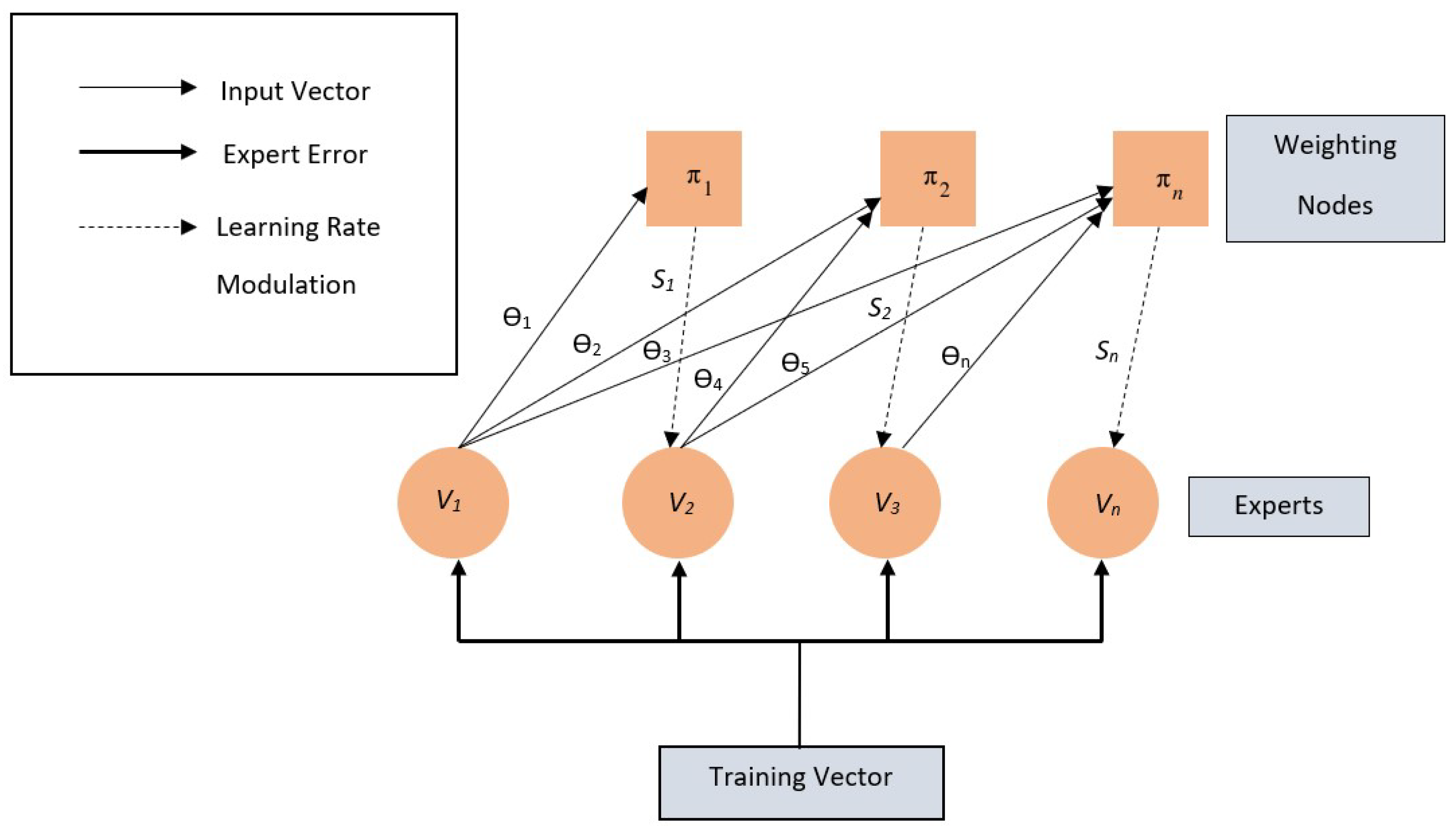
3.3.2. POCA Algorithm
| Algorithm 2 POCA |
|
3.4. Reward Structure of the Implementation
- Agents begin at the starting position where the ML-agents’ ‘brain’ starts listening to input and provides actions for agents to perform.
- Whenever an agent passes through a checkpoint, a reward is added to the agent’s total that equals the , n here being the total number of checkpoints.
- If the time to reach the next checkpoint exceeds 30 s, the episode ends, the agent receives a punishment of −1 and the agent respawns at the start of the track.
- Whenever the agent reaches the final checkpoint, a reward of 0.5 is given, the episode ends and the agent respawns at the starting position.
- To incentivize speed, agents are given a small −0.001 reward (punishment).
- In the case of the added obstacles version of the environment, a negative reward of −0.1 is given every time a collision occurs between the agent and any of the obstacles.
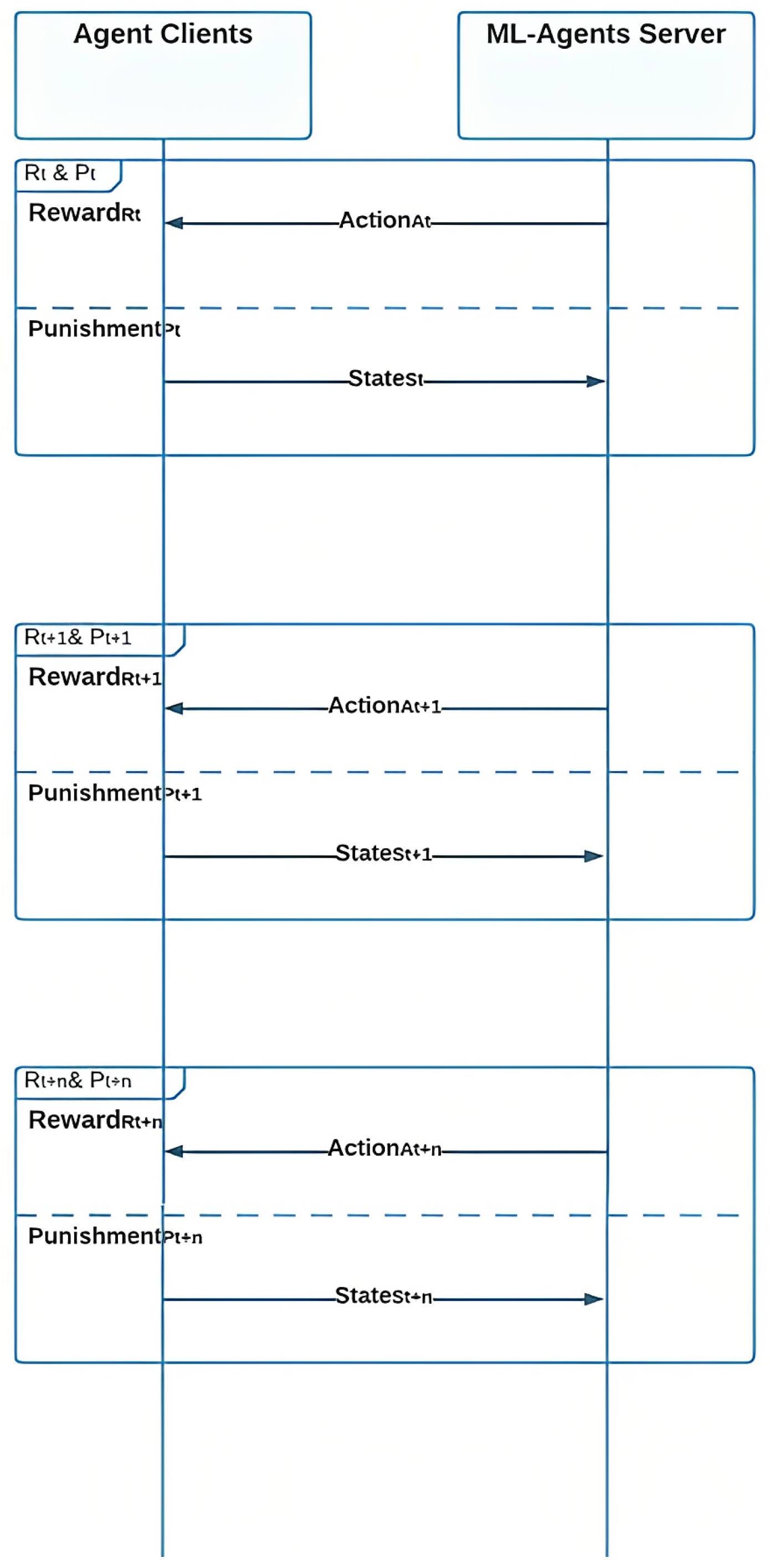
3.5. Agents Sequence Diagram
| Algorithm 3 Reward structure |
|
4. Experimental Evaluation and Results
4.1. Settings
- Environment without obstacles.
- -
- Default models.
- *
- Default PPO algorithm configurations.
- *
- Default POCA algorithm configurations.
- *
- ML-agents default, which also uses the PPO algorithm.
- *
- Adding RNN to the best model from the default models.
- Environment with obstacles.
- -
- Default PPO algorithm.
- -
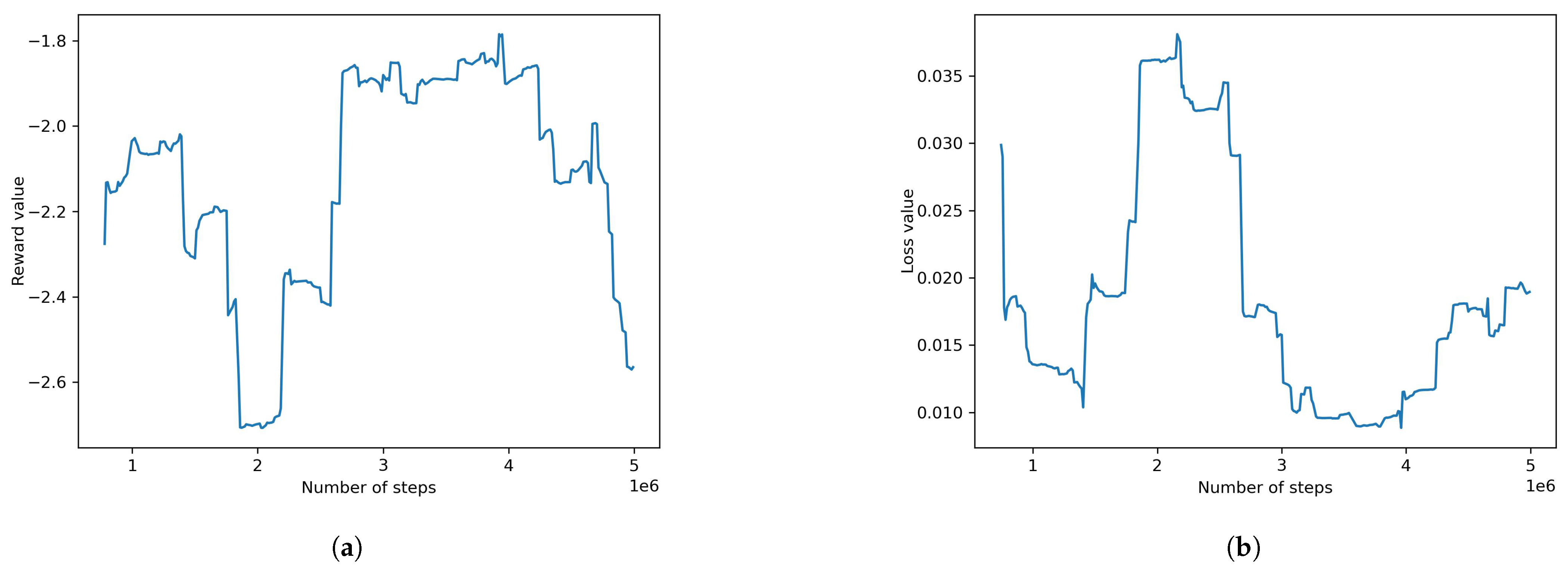
- Adding behavioral cloning as a pre-training condition with the default PPO algorithm
4.2. Results
4.2.1. Environment without Obstacles
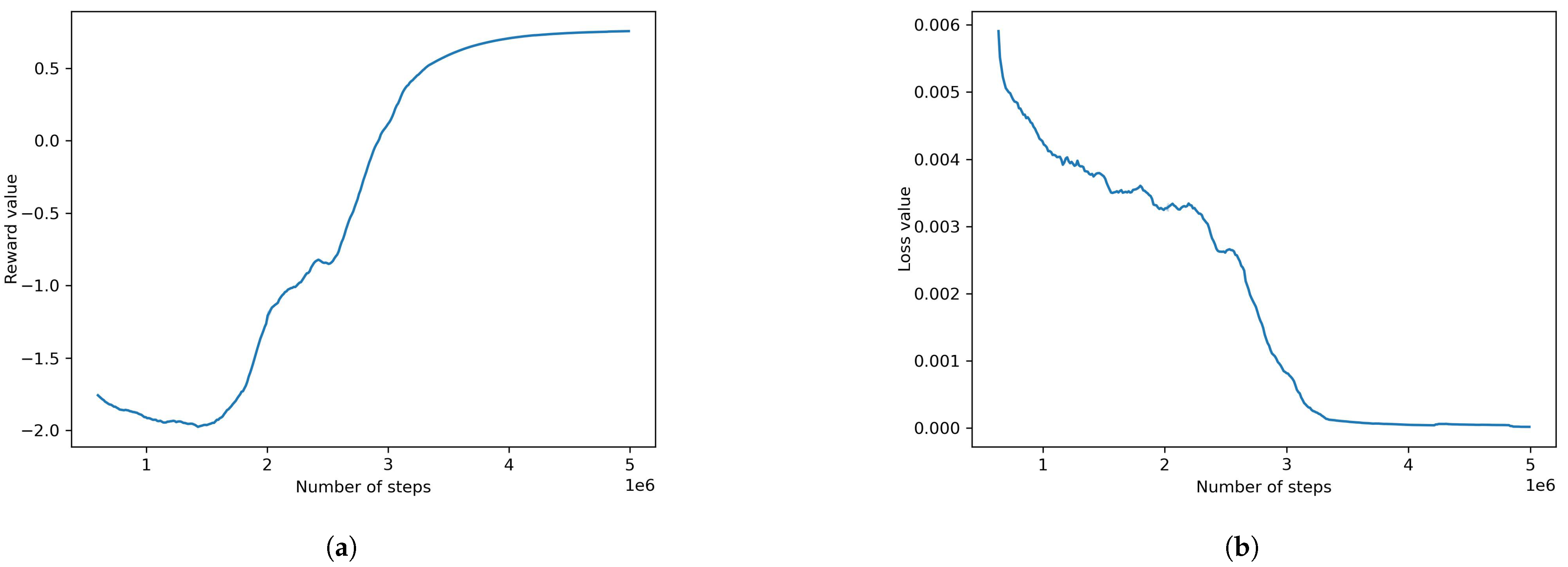
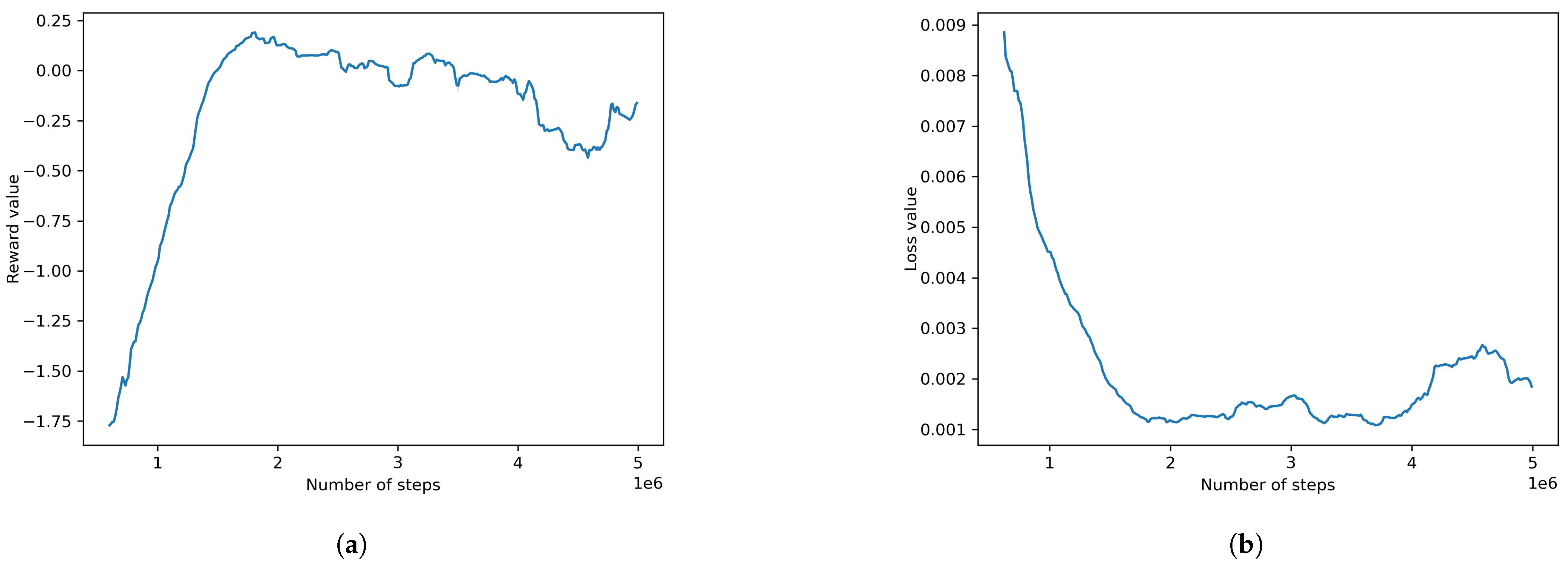
4.2.2. Default PPO Model (Also Environment’s Default)
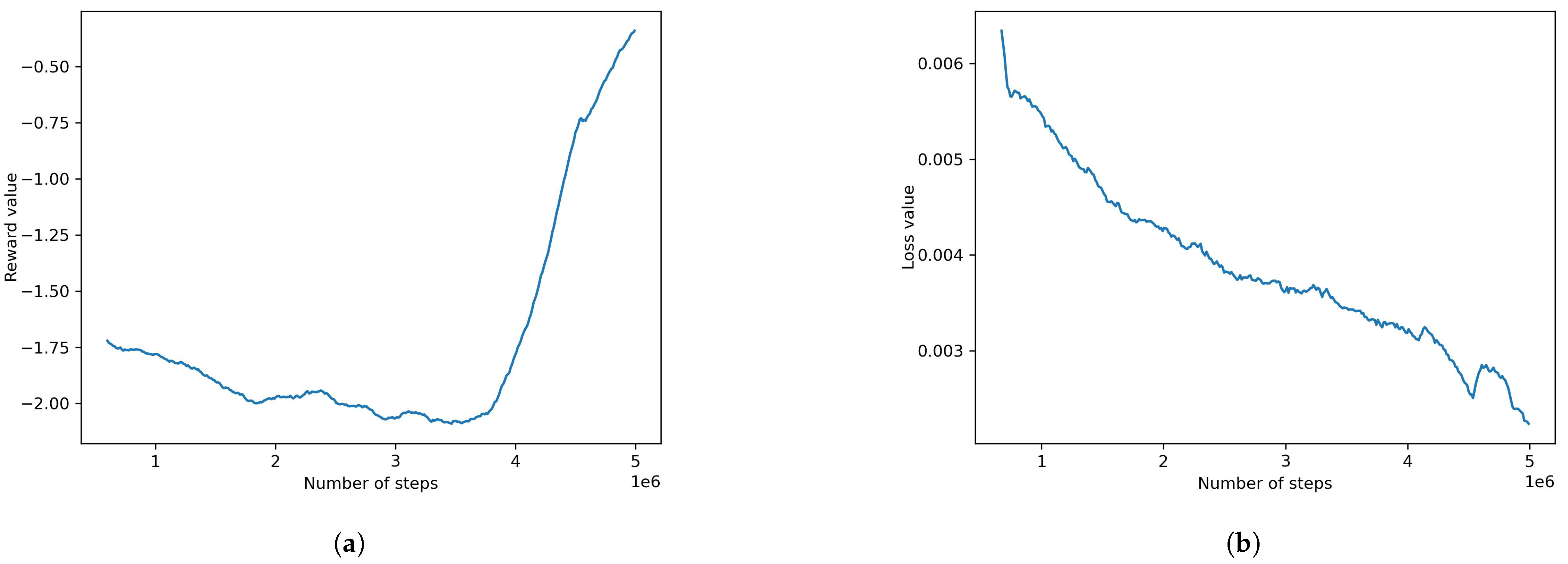
4.2.3. Default POCA Model
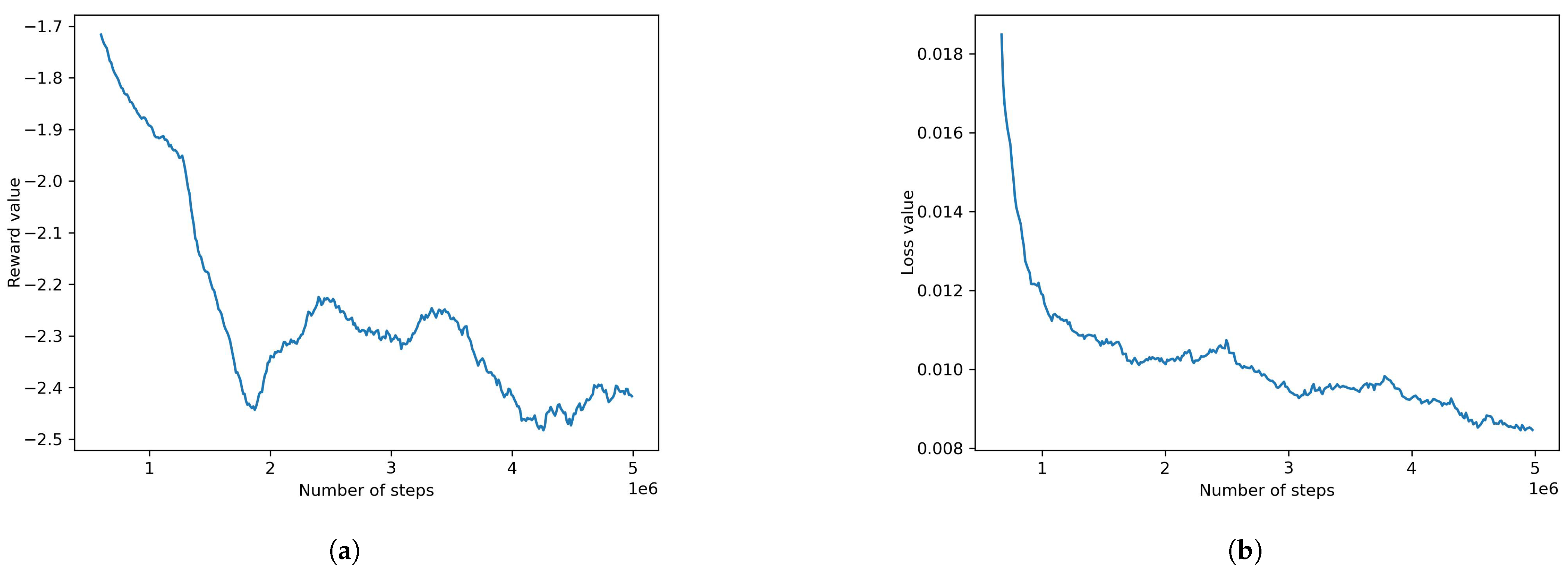
4.2.4. Default PPO Model
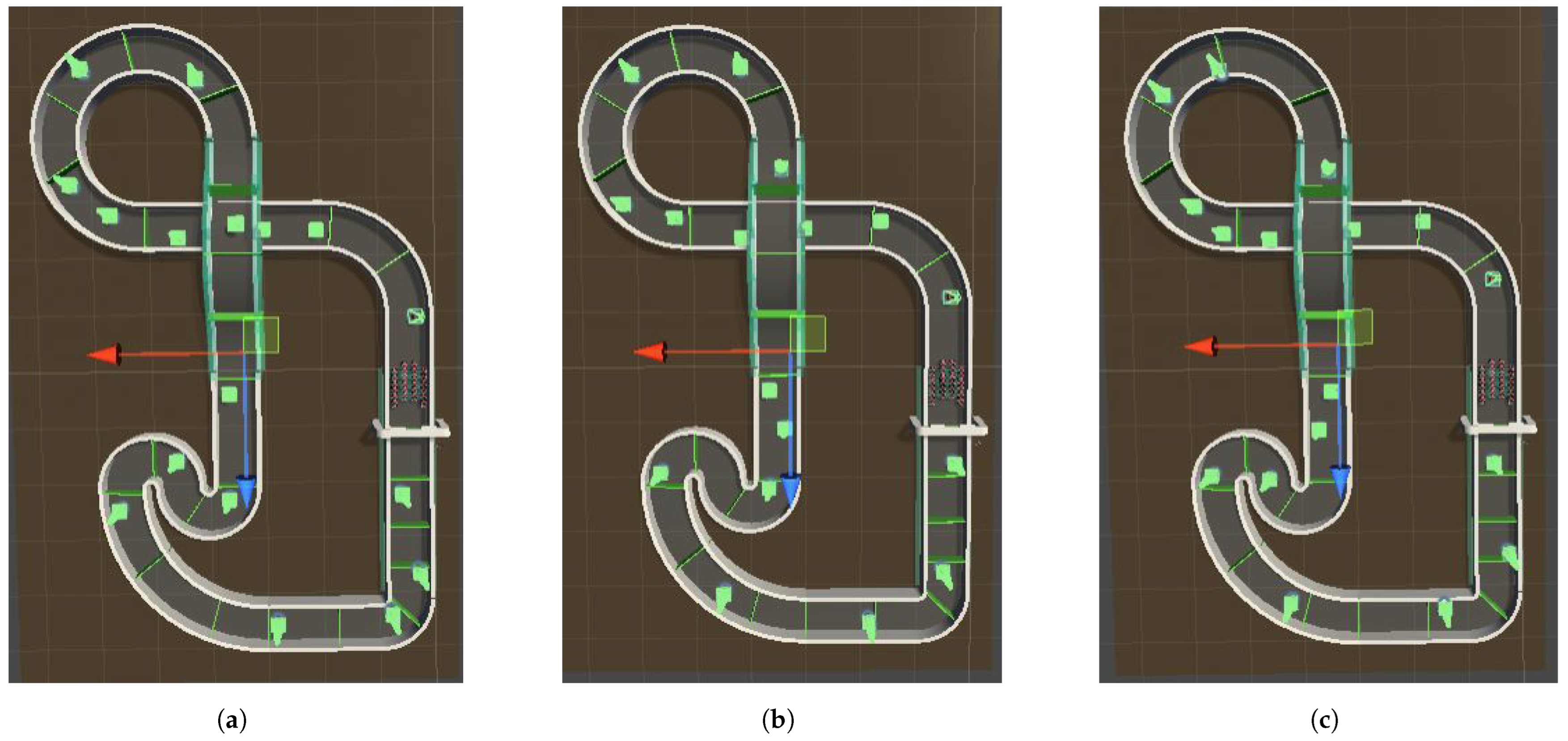
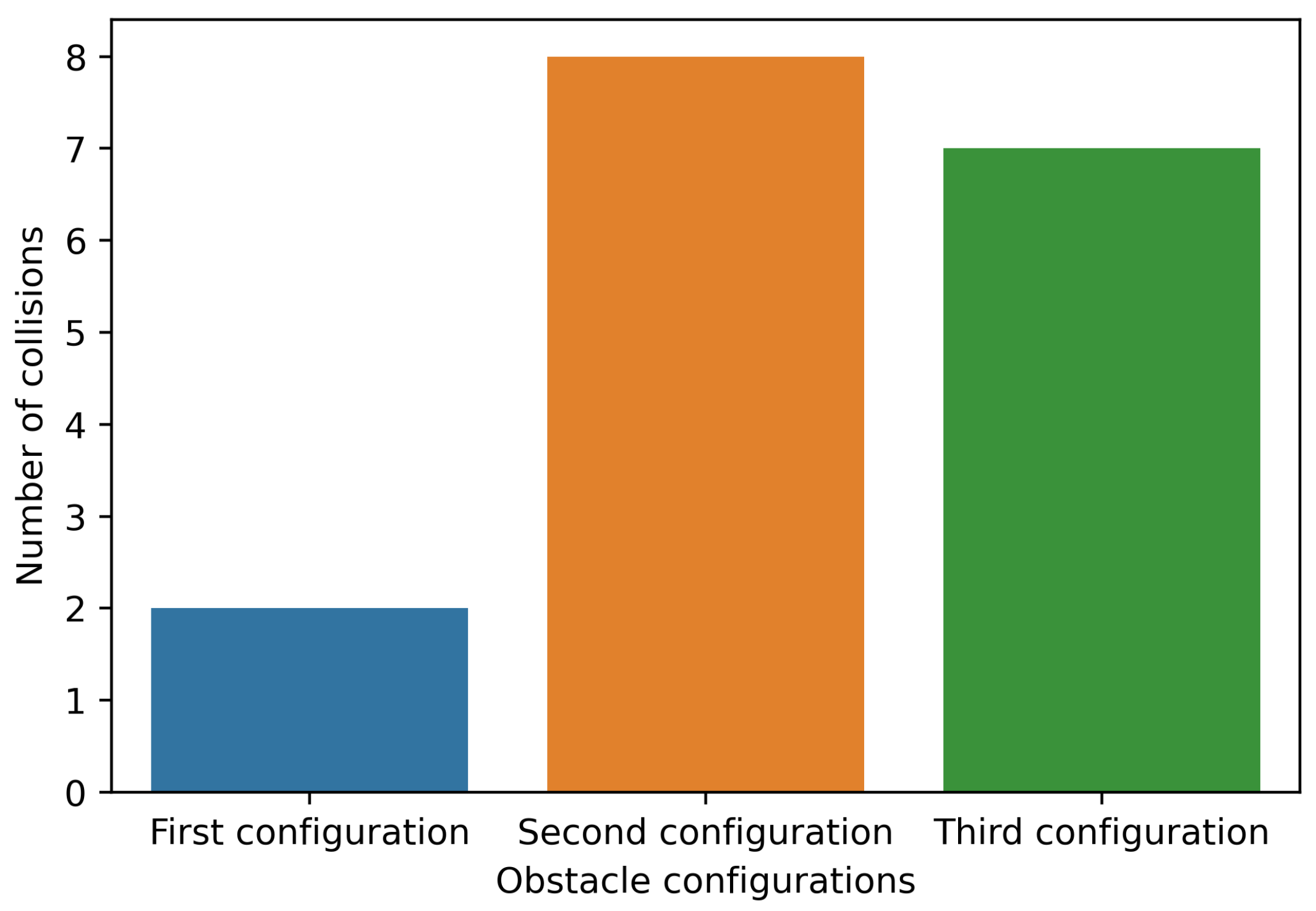
4.2.5. Comparing the Final Model on Different Obstacle Positions
- First configuration: the figure shows the configuration that the model was trained with Figure 14a.
- Second configuration: a configuration in which obstacles were placed in different random positions, as can be seen in Figure 14b.
- Third configuration: another configuration in which obstacles were placed again in different random positions and this can be seen in Figure 14c.
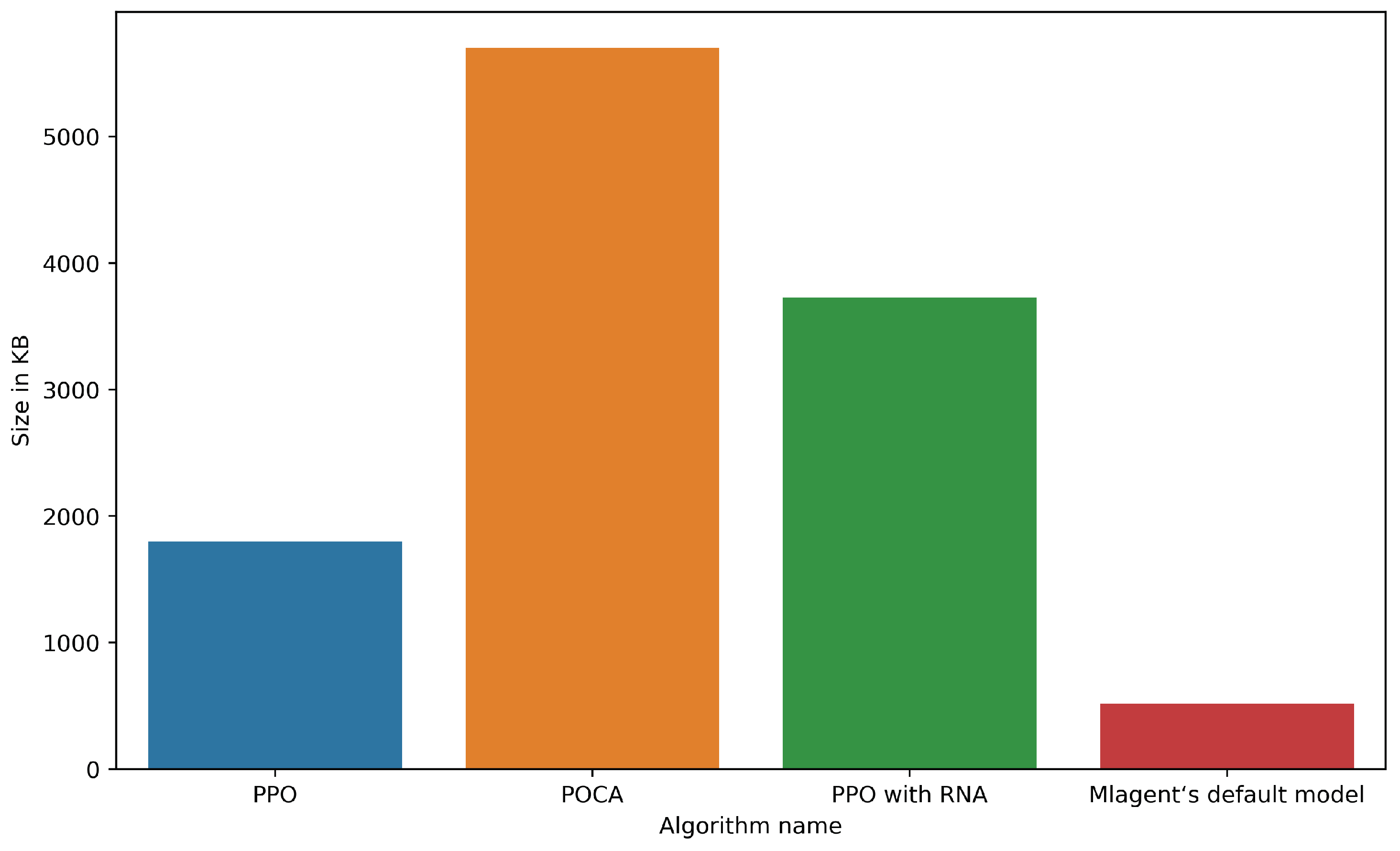
4.2.6. Comparing Model Sizes
5. Discussion and Future Research
5.1. Evaluation of Findings
- First, pre-training with behavioral cloning can help to initialize the agent’s policy network with a set of good initial weights. This can help to improve the convergence speed of the RL algorithm during training, allowing the agent to learn faster and achieve better performance.
- Secondly, behavioral cloning can help to improve the agent’s ability to generalize to new situations such as different obstacle configurations. By training the agent on a dataset of expert demonstrations that includes a variety of different scenarios and obstacle configurations (see Figure 15), the agent can learn to recognize and respond appropriately to different situations it may encounter during the racing task. This can help to improve the agent’s overall performance and reduce the likelihood of it getting stuck in local optima during training.
- Finally, adding behavioral cloning as a pre-training condition with the default PPO algorithm can improve the stability and robustness of the agent’s policy network. By training the agent to mimic the behavior of an expert, the agent can learn to avoid certain mistakes or suboptimal behaviors that may arise during the RL training process. This can help to improve the overall quality of the agent’s policy network and make it more resistant to noise and other sources of variability in the environment.
5.2. Network Simplification Using Pruning Techniques
5.3. Possible Applications
5.4. Future Research
- Expansion of the algorithms used and hyperparameters experimented with. As mentioned above, ML-agents only provide a small subset of algorithms to choose from. It does simplify experimentation and makes it more convenient for any researcher while being very user-friendly with great documentation and a large community. However, it does not explore the large number of algorithms available. It is a great tool/framework, but does have limitations.
- Environment augmentation. There is little research in this particular area. Laskin et al. [55] proposed the enhancement of input data that agents receive, but do not exactly go into the enhancement of the environment. A proposed methodology would include either different random changes to the environment which would prevent the agents from overfitting into the environment they are trained in (this could even be totally different environments trained on). Agents find optimal paths to complete the tasks, making it harder to generalize to different environments or setups. Augmentation of this kind can help generalize the model so that different tracks are completed under different conditions. Examples of such an augmentation are given below:
- -
- Different escape positions for agents during training. Instead of respawning in the same area, agents can respawn and restart episodes in random positions in random orientations. This could prevent overfitting.
- -
- Changing the positions of the obstacles during training. As can be seen in the results, different positions of obstacles (or a larger number of such obstacles) than what it has been trained on make it more difficult for the agents to avoid the said obstacles. This would also decrease overfitting and help generalize to any position of an obstacle.
- -
- Using completely different environments during training. This would be the most challenging task, as this would require much more robust and much larger models. This, however, would almost certainly prevent any overfitting to any one environment.
6. Conclusions
- Different models were trained and the results were recorded. The best model turned out to be the default environment, which uses the PPO algorithm. The model produces a loss value of 0.0013 and a cumulative reward of 0.761 for the final step.
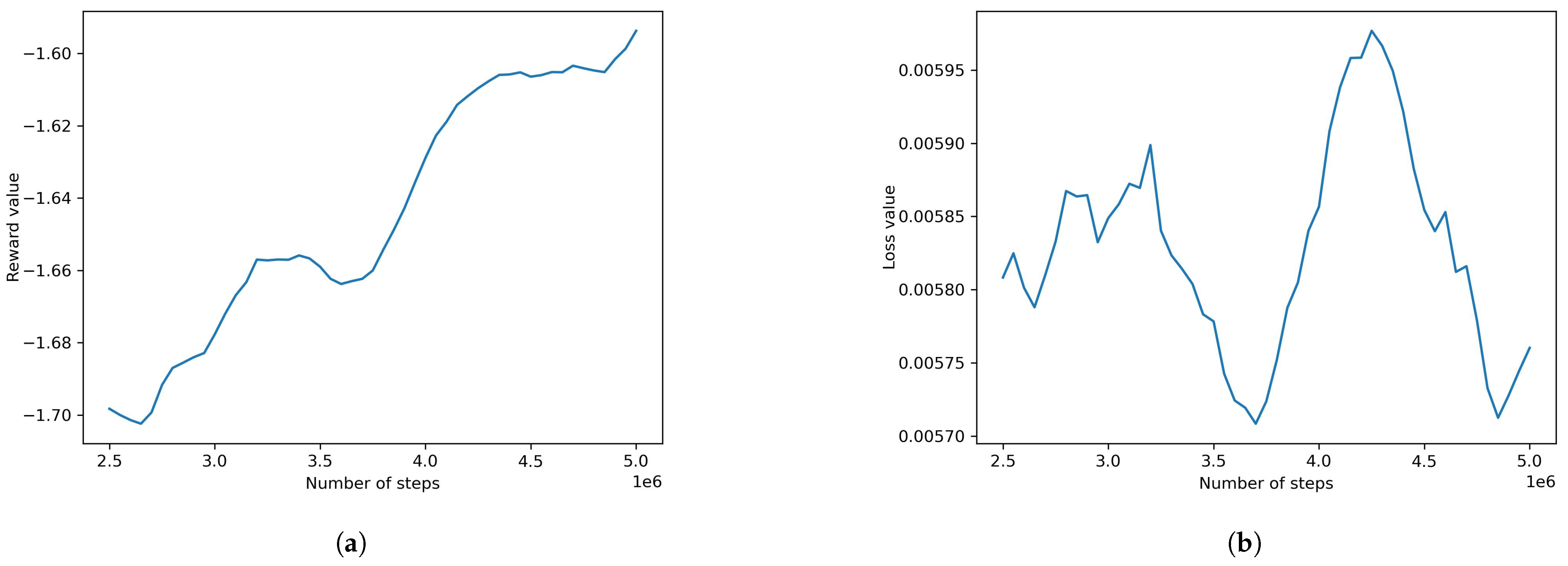
- Adding obstacles and retraining using the best algorithm found did not produce satisfactory results. AI agents were unable to find a policy that results in decent rewards. The reward and loss at the final step of this model were found to be −1.720 and 0.0153, respectively. To assist the model in learning the required behavior, behavioral cloning was used as a pre-training condition. A recording of the desired behavior was made using physical input from the authors. Using behavioral cloning, the model was able to achieve satisfactory results where the agents were able to avoid obstacles and complete the track. The reward and loss for these were 0.0681 and 0.0011, respectively.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Elguea-Aguinaco, Í.; Serrano-Muñoz, A.; Chrysostomou, D.; Inziarte-Hidalgo, I.; Bøgh, S.; Arana-Arexolaleiba, N. A review on reinforcement learning for contact-rich robotic manipulation tasks. Robot. Comput.-Integr. Manuf. 2023, 81, 102517. [Google Scholar] [CrossRef]
- Malleret, T.; Schwab, K. Great Narrative (The Great Reset Book 2); World Economic Forum: Colonie, Switzerland, 2021. [Google Scholar]
- Crespo, J.; Wichert, A. Reinforcement learning applied to games. SN Appl. Sci. 2020, 2, 824. [Google Scholar] [CrossRef]
- Liu, H.; Kiumarsi, B.; Kartal, Y.; Taha Koru, A.; Modares, H.; Lewis, F.L. Reinforcement Learning Applications in Unmanned Vehicle Control: A Comprehensive Overview. Unmanned Syst. 2022, 11, 17–26. [Google Scholar] [CrossRef]
- Jagannath, D.J.; Dolly, R.J.; Let, G.S.; Peter, J.D. An IoT enabled smart healthcare system using deep reinforcement learning. Concurr. Comput. Pract. Exp. 2022, 34, e7403. [Google Scholar] [CrossRef]
- Shuvo, S.S.; Symum, H.; Ahmed, M.R.; Yilmaz, Y.; Zayas-Castro, J.L. Multi-Objective Reinforcement Learning Based Healthcare Expansion Planning Considering Pandemic Events. IEEE J. Biomed. Health Inform. 2022, 1–11. [Google Scholar] [CrossRef]
- Faria, R.D.R.; Capron, B.D.O.; Secchi, A.R.; de Souza, M.B. Where Reinforcement Learning Meets Process Control: Review and Guidelines. Processes 2022, 10, 2311. [Google Scholar] [CrossRef]
- Nian, R.; Liu, J.; Huang, B. A review On reinforcement learning: Introduction and applications in industrial process control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Shaqour, A.; Hagishima, A. Systematic Review on Deep Reinforcement Learning-Based Energy Management for Different Building Types. Energies 2022, 15, 8663. [Google Scholar] [CrossRef]
- Liu, H.; Cai, K.; Li, P.; Qian, C.; Zhao, P.; Wu, X. REDRL: A review-enhanced Deep Reinforcement Learning model for interactive recommendation. Expert Syst. Appl. 2022, 213, 118926. [Google Scholar] [CrossRef]
- Sewak, M.; Sahay, S.K.; Rathore, H. Deep Reinforcement Learning in the Advanced Cybersecurity Threat Detection and Protection. Inf. Syst. Front. 2022, 25, 589–611. [Google Scholar] [CrossRef]
- Cai, P.; Wang, H.; Huang, H.; Liu, Y.; Liu, M. Vision-Based Autonomous Car Racing Using Deep Imitative Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 6, 7262–7269. [Google Scholar] [CrossRef]
- Suresh Babu, V.; Behl, M. Threading the Needle—Overtaking Framework for Multi-agent Autonomous Racing. SAE Int. J. Connect. Autom. Veh. 2022, 5, 33–43. [Google Scholar] [CrossRef]
- Amini, A.; Gilitschenski, I.; Phillips, J.; Moseyko, J.; Banerjee, R.; Karaman, S.; Rus, D. Learning Robust Control Policies for End-to-End Autonomous Driving from Data-Driven Simulation. IEEE Robot. Autom. Lett. 2020, 5, 1143–1150. [Google Scholar] [CrossRef]
- Walker, V.; Vanegas, F.; Gonzalez, F. NanoMap: A GPU-Accelerated OpenVDB-Based Mapping and Simulation Package for Robotic Agents. Remote Sens. 2022, 14, 5463. [Google Scholar] [CrossRef]
- Woźniak, M.; Zielonka, A.; Sikora, A. Driving support by type-2 fuzzy logic control model. Expert Syst. Appl. 2022, 207, 117798. [Google Scholar] [CrossRef]
- Wei, W.; Gao, F.; Scherer, R.; Damasevicius, R.; Połap, D. Design and implementation of autonomous path planning for intelligent vehicle. J. Internet Technol. 2021, 22, 957–965. [Google Scholar] [CrossRef]
- Zagradjanin, N.; Rodic, A.; Pamucar, D.; Pavkovic, B. Cloud-based multi-robot path planning in complex and crowded environment using fuzzy logic and online learning. Inf. Technol. Control 2021, 50, 357–374. [Google Scholar] [CrossRef]
- Mehmood, A.; Shaikh, I.U.H.; Ali, A. Application of deep reinforcement learning tracking control of 3wd omnidirectional mobile robot. Inf. Technol. Control 2021, 50, 507–521. [Google Scholar] [CrossRef]
- Xuhui, B.; Rui, H.; Yanling, Y.; Wei, Y.; Jiahao, G.; Xinghe, M. Distributed iterative learning formation control for nonholonomic multiple wheeled mobile robots with channel noise. Inf. Technol. Control 2021, 50, 588–600. [Google Scholar]
- Bathla, G.; Bhadane, K.; Singh, R.K.; Kumar, R.; Aluvalu, R.; Krishnamurthi, R.; Kumar, A.; Thakur, R.N.; Basheer, S. Autonomous Vehicles and Intelligent Automation: Applications, Challenges and Opportunities. Mob. Inf. Syst. 2022, 2022, 7632892. [Google Scholar] [CrossRef]
- Wang, J.; Xu, Z.; Zheng, X.; Liu, Z. A Fuzzy Logic Path Planning Algorithm Based on Geometric Landmarks and Kinetic Constraints. Inf. Technol. Control 2022, 51, 499–514. [Google Scholar] [CrossRef]
- Luneckas, M.; Luneckas, T.; Udris, D.; Plonis, D.; Maskeliunas, R.; Damasevicius, R. Energy-efficient walking over irregular terrain: A case of hexapod robot. Metrol. Meas. Syst. 2019, 26, 645–660. [Google Scholar]
- Luneckas, M.; Luneckas, T.; Udris, D.; Plonis, D.; Maskeliūnas, R.; Damaševičius, R. A hybrid tactile sensor-based obstacle overcoming method for hexapod walking robots. Intell. Serv. Robot. 2021, 14, 9–24. [Google Scholar] [CrossRef]
- Ayawli, B.B.K.; Mei, X.; Shen, M.; Appiah, A.Y.; Kyeremeh, F. Optimized RRT-A* path planning method for mobile robots in partially known environment. Inf. Technol. Control 2019, 48, 179–194. [Google Scholar] [CrossRef]
- Palacios, F.M.; Quesada, E.S.E.; Sanahuja, G.; Salazar, S.; Salazar, O.G.; Carrillo, L.R.G. Test bed for applications of heterogeneous unmanned vehicles. Int. J. Adv. Robot. Syst. 2017, 14, 172988141668711. [Google Scholar] [CrossRef]
- Herman, J.; Francis, J.; Ganju, S.; Chen, B.; Koul, A.; Gupta, A.; Skabelkin, A.; Zhukov, I.; Kumskoy, M.; Nyberg, E. Learn-to-Race: A Multimodal Control Environment for Autonomous Racing. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Almón-Manzano, L.; Pastor-Vargas, R.; Troncoso, J.M.C. Deep Reinforcement Learning in Agents’ Training: Unity ML-Agents; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2022; Volume 13259 LNCS, pp. 391–400. [Google Scholar]
- Yasufuku, K.; Katou, G.; Shoman, S. Game engine (Unity, Unreal Engine). Kyokai Joho Imeji Zasshi/J. Inst. Image Inf. Telev. Eng. 2017, 71, 353–357. [Google Scholar] [CrossRef]
- Şerban, G. A New Programming Interface for Reinforcement Learning Simulations. In Advances in Soft Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 481–485. [Google Scholar] [CrossRef]
- Ramezani Dooraki, A.; Lee, D.J. An end-to-end deep reinforcement learning-based intelligent agent capable of autonomous exploration in unknown environments. Sensors 2018, 18, 3575. [Google Scholar] [CrossRef]
- Urrea, C.; Garrido, F.; Kern, J. Design and implementation of intelligent agent training systems for virtual vehicles. Sensors 2021, 21, 492. [Google Scholar] [CrossRef]
- Juliani, A.; Berges, V.P.; Teng, E.; Cohen, A.; Harper, J.; Elion, C.; Goy, C.; Gao, Y.; Henry, H.; Mattar, M.; et al. Unity: A general platform for intelligent agents. arXiv 2018, arXiv:1809.02627. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume NIPS’17, pp. 6382–6393. [Google Scholar]
- Guckiran, K.; Bolat, B. Autonomous Car Racing in Simulation Environment Using Deep Reinforcement Learning. In Proceedings of the 2019 Innovations in Intelligent Systems and Applications Conference (ASYU), Izmir, Turkey, 31 October–2 November 2019. [Google Scholar] [CrossRef]
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Trans. Syst. Man Cybern. 1983, SMC-13, 834–846. [Google Scholar] [CrossRef]
- Bhattacharyya, R.P.; Phillips, D.J.; Wulfe, B.; Morton, J.; Kuefler, A.; Kochenderfer, M.J. Multi-Agent Imitation Learning for Driving Simulation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar] [CrossRef]
- Palanisamy, P. Multi-Agent Connected Autonomous Driving using Deep Reinforcement Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Chen, S.; Leng, Y.; Labi, S. A deep learning algorithm for simulating autonomous driving considering prior knowledge and temporal information. Comput.-Aided Civ. Infrastruct. Eng. 2019, 35, 305–321. [Google Scholar] [CrossRef]
- Almasi, P.; Moni, R.; Gyires-Toth, B. Robust Reinforcement Learning-based Autonomous Driving Agent for Simulation and Real World. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Ma, G.; Wang, Z.; Yuan, X.; Zhou, F. Improving Model-Based Deep Reinforcement Learning with Learning Degree Networks and Its Application in Robot Control. J. Robot. 2022, 2022, 7169594. [Google Scholar] [CrossRef]
- Onishi, T.; Motoyoshi, T.; Suga, Y.; Mori, H.; Ogata, T. End-to-end Learning Method for Self-Driving Cars with Trajectory Recovery Using a Path-following Function. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Cohen, A.; Teng, E.; Berges, V.P.; Dong, R.P.; Henry, H.; Mattar, M.; Zook, A.; Ganguly, S. On the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning. arXiv 2021, arXiv:2111.05992. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Gao, J.; Wang, Y.; Bayen, A.; Wu, Y. The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games. arXiv 2021, arXiv:2103.01955. [Google Scholar]
- Reichler, J.A.; Harris, H.D.; Savchenko, M.A. Online Parallel Boosting. In Proceedings of the 19th National Conference on Artifical Intelligence, San Jose, CA, USA, 25–29 July 2004; AAAI Press: Menlo Park, CA, USA, 2004; Volume AAAI’04, pp. 366–371. [Google Scholar]
- Tang, Z.; Luo, L.; Xie, B.; Zhu, Y.; Zhao, R.; Bi, L.; Lu, C. Automatic Sparse Connectivity Learning for Neural Networks. arXiv 2022, arXiv:2201.05020. [Google Scholar] [CrossRef]
- Zhu, M.; Gupta, S. To prune or not to prune: Exploring the efficacy of pruning for model compression. arXiv 2017, arXiv:1710.01878. [Google Scholar]
- Hu, W.; Che, Z.; Liu, N.; Li, M.; Tang, J.; Zhang, C.; Wang, J. CATRO: Channel Pruning via Class-Aware Trace Ratio Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Palacios, E.; Peláez, E. Towards training swarms for game AI. In Proceedings of the 22nd International Conference on Intelligent Games and Simulation, GAME-ON 2021, Aveiro, Portugal, 22–24 September 2021; pp. 27–34. [Google Scholar]
- Kovalský, K.; Palamas, G. Neuroevolution vs. Reinforcement Learning for Training Non Player Characters in Games: The Case of a Self Driving Car; Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering; Springer: Berlin/Heidelberg, Germany, 2021; Volume 377, pp. 191–206. [Google Scholar]
- Laskin, M.; Lee, K.; Stooke, A.; Pinto, L.; Abbeel, P.; Srinivas, A. Reinforcement Learning with Augmented Data. arXiv 2020, arXiv:2004.14990. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Application Domain | RL Algorithm | Performance Metrics |
|---|---|---|---|
| [33] | virtual vehicle simulation | PPO and BC | torque, steering, acceleration, rapidity, revolutions per minute (RPM) and gear number |
| [35] | game playing | deep Q-learning with experience replay | win rate |
| [36] | autonomous driving | - | autonomy |
| [37] | robotics | MADDPG | communication success |
| [38] | autonomous driving | soft actor–critic and rainbow DQN | angle, track position, speed, wheel speeds, RPM |
| [39] | pole balancing | associative search element (ASE) and adaptive critic element (ACE) | score |
| [40] | autonomous driving | Parameter Sharing Generative Adversarial Imitation Learning (GAIL) | RMSE |
| [41] | autonomous driving | DQN | successful intersection crossings |
| [42] | autonomous driving | DQN | driving decisions |
| [43] | robotics | DQN | distance run |
| [44] | robotics | A3C (Asynchronous Advantage Actor–Critic), PPO | OpenAI Gym benchmark metrics |
| [45] | autonomous driving | - | distance travelled |
| Hardware | GPU | Pipelines | Video Memory | Memory Type | |
|---|---|---|---|---|---|
| Nvidia 1650 ti | 1024 | 4 GB | GDDR6 | ||
| Software | Unity Editor Version | ML-Agents Package Version | Pytorch Version | CUDA Version | Python Version |
| 2020.3.39f1 | 0.29.0 | 1.8.0 + cu111 | 11.4 | 3.8.0 |
| Parameter | Value |
|---|---|
| batch_size | 1024 |
| buffer_size | 10,240 |
| learning_rate | 0.0003 |
| beta | 0.005 |
| epsilon | 0.2 |
| lambda | 0.95 |
| num_epoch | 30 |
| learning_rate_schedule | linear |
| Parameter | Value |
|---|---|
| batch_size | 120 |
| buffer_size | 12,000 |
| learning_rate | 0.0003 |
| beta | 0.001 |
| epsilon | 0.2 |
| lambda | 0.95 |
| num_epoch | 30 |
| learning_rate_schedule | linear |
| Parameter | Value |
|---|---|
| batch_size | 1024 |
| buffer_size | 10,240 |
| learning_rate | 0.0003 |
| beta | 0.005 |
| epsilon | 0.2 |
| lambda | 0.95 |
| num_epoch | 30 |
| learning_rate_schedule | linear |
| memory_size | 128 |
| sequence_length | 64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Savid, Y.; Mahmoudi, R.; Maskeliūnas, R.; Damaševičius, R. Simulated Autonomous Driving Using Reinforcement Learning: A Comparative Study on Unity’s ML-Agents Framework. Information 2023, 14, 290. https://doi.org/10.3390/info14050290
Savid Y, Mahmoudi R, Maskeliūnas R, Damaševičius R. Simulated Autonomous Driving Using Reinforcement Learning: A Comparative Study on Unity’s ML-Agents Framework. Information. 2023; 14(5):290. https://doi.org/10.3390/info14050290
Chicago/Turabian StyleSavid, Yusef, Reza Mahmoudi, Rytis Maskeliūnas, and Robertas Damaševičius. 2023. "Simulated Autonomous Driving Using Reinforcement Learning: A Comparative Study on Unity’s ML-Agents Framework" Information 14, no. 5: 290. https://doi.org/10.3390/info14050290
APA StyleSavid, Y., Mahmoudi, R., Maskeliūnas, R., & Damaševičius, R. (2023). Simulated Autonomous Driving Using Reinforcement Learning: A Comparative Study on Unity’s ML-Agents Framework. Information, 14(5), 290. https://doi.org/10.3390/info14050290