

Lightweight Implicit Blur Kernel Estimation Network for Blind Image Super-Resolution


Abstract
1. Introduction
- We introduce a Blind-SR approach that estimates the blur kernel k and the SR image () simultaneously. The blur kernel is implicitly estimated, hence not requiring the supervision of a ground truth kernel;
- Our proposed network compares favorably with respect to state-of-the-art approaches that have a similar number of learnable parameters;
- We provide an end-to-end architecture for the proposed algorithm and extensively analyze its performance via quantitative and qualitative evaluation on benchmark datasets.
2. Related Work
2.1. Non-Blind SR
2.2. Blind-SR
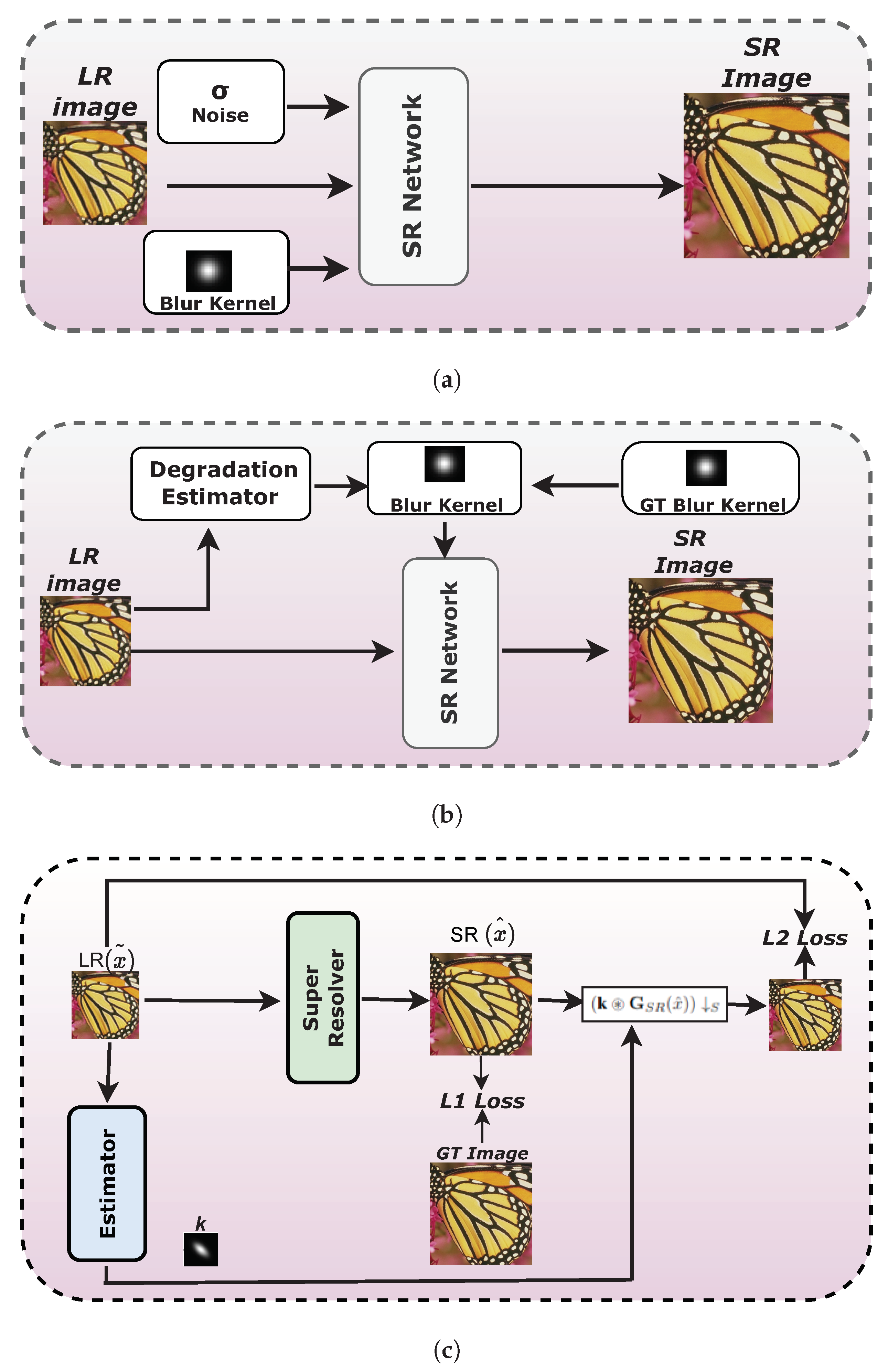
3. Method
3.1. Problem Formulation
3.2. Kernel Estimation
3.3. Super Resolver
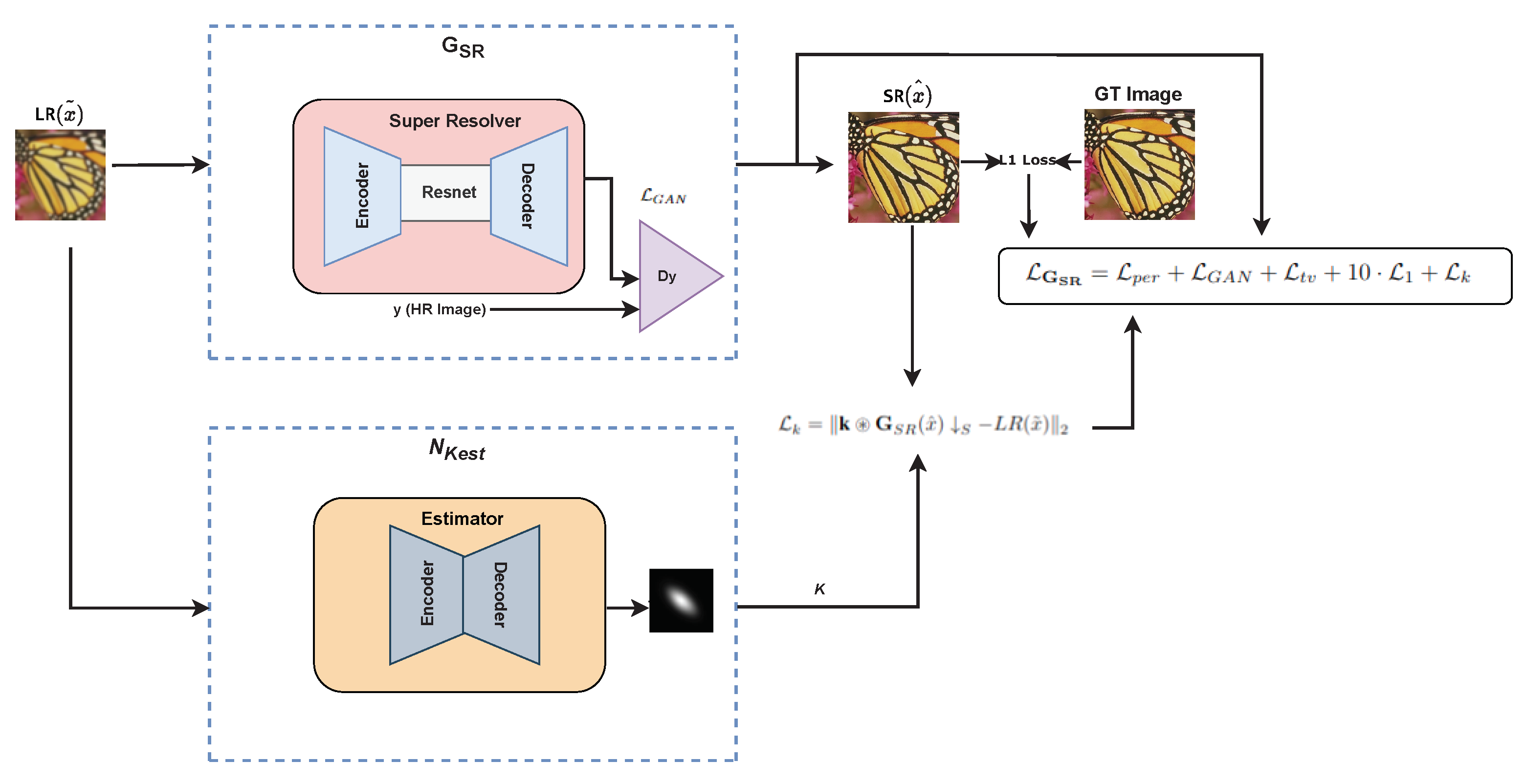
3.4. Network Architectures
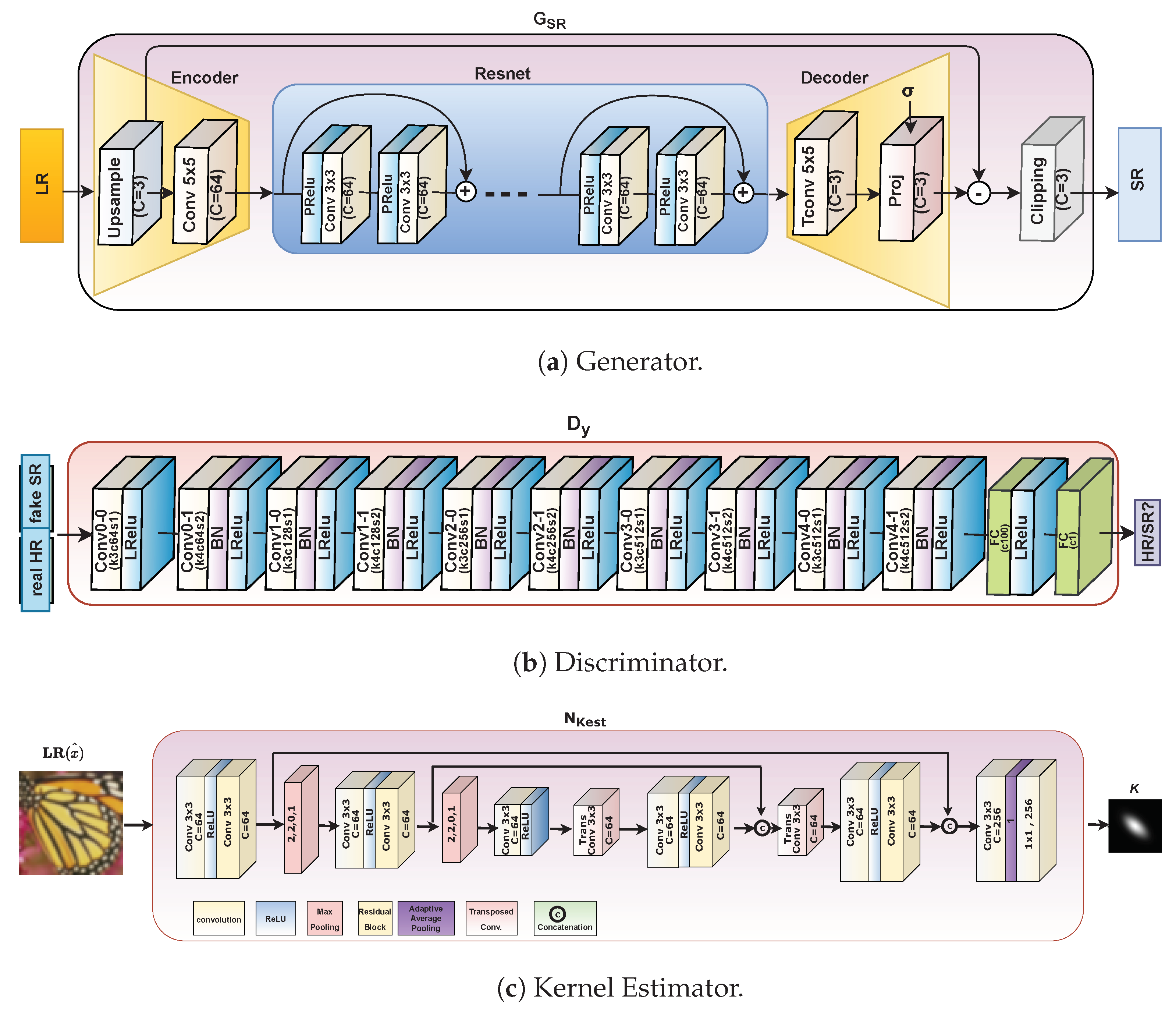
3.4.1. Generator Network ():
3.4.2. Discriminator Network ():
3.4.3. Estimator Network ():
3.5. Loss Calculation
3.5.1. Texture Loss ():
3.5.2. Perceptual Loss ():
3.5.3. TV (Total-Variation) Loss ():
3.5.4. Content Loss ()
3.5.5. Estimator Loss(:
4. Experiments
4.1. Datasets
4.1.1. Setting 1
4.1.2. Setting 2
4.2. Model Optimization
4.3. Technical Details
4.4. Evaluation Metrics
4.5. Experimental Results
4.5.1. Setting 1
4.5.2. Setting 2
4.6. Computational Cost
4.7. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dunnhofer, M.; Martinel, N.; Micheloni, C. Improving MRI-based Knee Disorder Diagnosis with Pyramidal Feature Details. In Proceedings of Machine Learning Research, Proceedings of the Fourth Conference on Medical Imaging with Deep Learning, Lubeck, Germany, 7–9 July 2021; Heinrich, M., Dou, Q., de Bruijne, M., Lellmann, J., Schläfer, A., Ernst, F., Eds.; PMLR: New York, NY, USA, 2021; Volume 143, pp. 131–147. [Google Scholar]
- Huang, S.; Teo, R.; Leong, W.; Martinel, N.; Foresti, G.L.; Micheloni, C. Coverage Control of Multiple Unmanned Aerial Vehicles: A Short Review. Unmanned Syst. 2018, 6, 131–144. [Google Scholar] [CrossRef]
- Leong, W.L.; Martinel, N.; Huang, S.; Micheloni, C.; Foresti, G.L.; Teo, R.S.H. An Intelligent Auto-Organizing Aerial Robotic Sensor Network System for Urban Surveillance. J. Intell. Robot. Syst. 2021, 102, 33. [Google Scholar] [CrossRef]
- Martinel, N.; Micheloni, C.; Foresti, G.L. A pool of multiple person re-identification experts. Pattern Recognit. Lett. 2016, 71, 23–30. [Google Scholar] [CrossRef]
- Martinel, N.; Foresti, G.L.; Micheloni, C. Deep Pyramidal Pooling With Attention for Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 7306–7316. [Google Scholar] [CrossRef]
- Martinel, N.; Dunnhofer, M.; Pucci, R.; Foresti, G.L.; Micheloni, C. Lord of the Rings: Hanoi Pooling and Self-Knowledge Distillation for Fast and Accurate Vehicle Reidentification. IEEE Trans. Ind. Inf. 2022, 18, 87–96. [Google Scholar] [CrossRef]
- Bansal, V.; Foresti, G.L.; Martinel, N. Cloth-Changing Person Re-Identification With Self-Attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, Waikoloa, HI, USA, 4–8 January 2022; pp. 602–610. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Xia, B.; Hang, Y.; Tian, Y.; Yang, W.; Liao, Q.; Zhou, J. Efficient Non-Local Contrastive Attention for Image Super-Resolution. arXiv 2022, arXiv:2201.03794. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the ECCVW, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1575–1584. [Google Scholar]
- Bhat, G.; Danelljan, M.; Timofte, R.; Akita, K.; Cho, W.; Fan, H.; Jia, L.; Kim, D.; Lecouat, B.; Li, Y.; et al. NTIRE 2021 challenge on burst super-resolution: Methods and results. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 613–626. [Google Scholar] [CrossRef]
- Wei, P.; Lu, H.; Timofte, R.; Lin, L.; Zuo, W.; Pan, Z.; Li, B.; Xi, T.; Fan, Y.; Zhang, G.; et al. AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results; Springer: Cham, Switzerland, 2020; Volume 12537 LNCS, pp. 392–422. [Google Scholar] [CrossRef]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF CVPR, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Michaeli, T.; Irani, M. Nonparametric blind super-resolution. In Proceedings of the IEEE ICCV, Sydney, Australia, 1–8 December 2013; pp. 945–952. [Google Scholar]
- Bell-Kligler, S.; Shocher, A.; Irani, M. Blind super-resolution kernel estimation using an internal-gan. NeurIPS 2019, 32. [Google Scholar] [CrossRef]
- Gu, J.; Lu, H.; Zuo, W.; Dong, C. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE/CVF CVPR, Long Beach, CA, USA, 15–20 June 2019; pp. 1604–1613. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Shocher, A.; Cohen, N.; Irani, M. “zero-shot” super-resolution using deep internal learning. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3118–3126. [Google Scholar]
- Liang, J.; Zhang, K.; Gu, S.; Van Gool, L.; Timofte, R. Flow-based kernel prior with application to blind super-resolution. In Proceedings of the IEEE/CVF CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 10601–10610. [Google Scholar]
- Wang, L.; Wang, Y.; Dong, X.; Xu, Q.; Yang, J.; An, W.; Guo, Y. Unsupervised degradation representation learning for blind super-resolution. In Proceedings of the IEEE/CVF CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 10581–10590. [Google Scholar]
- Kim, S.Y.; Sim, H.; Kim, M. Koalanet: Blind super-resolution using kernel-oriented adaptive local adjustment. In Proceedings of the IEEE/CVF CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 10611–10620. [Google Scholar]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the ICCV 2009, Kyoto, Japan, 27 September–4 October 2009; pp. 349–356. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution as sparse representation of raw image patches. In Proceedings of the IEEE CVPR 2008, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the ACCV, Santiago, Chile, 7–13 December 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–126. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Pan, J.; Liu, Y.; Sun, D.; Ren, J.; Cheng, M.M.; Yang, J.; Tang, J. Image formation model guided deep image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11807–11814. [Google Scholar]
- Yang, C.Y.; Ma, C.; Yang, M.H. Single-image super-resolution: A benchmark. In Proceedings of the ECCV, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 372–386. [Google Scholar]
- Efrat, N.; Glasner, D.; Apartsin, A.; Nadler, B.; Levin, A. Accurate blur models vs. image priors in single image super-resolution. In Proceedings of the IEEE ICCV, Sydney, Australia, 1–8 December 2013; pp. 2832–2839. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Understanding and evaluating blind deconvolution algorithms. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1964–1971. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Efficient marginal likelihood optimization in blind deconvolution. In Proceedings of the CVPR, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2657–2664. [Google Scholar]
- Wang, Q.; Tang, X.; Shum, H. Patch based blind image super resolution. In Proceedings of the IEEE (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 709–716. [Google Scholar]
- Umer, R.M.; Foresti, G.L.; Micheloni, C. Deep generative adversarial residual convolutional networks for real-world super-resolution. In Proceedings of the IEEE/CVF CVPRW, Seattle, WA, USA, 14–19 June 2020; pp. 438–439. [Google Scholar]
- Umer, R.M.; Foresti, G.L.; Micheloni, C. Deep Iterative Residual Convolutional Network for Single Image Super-Resolution. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1852–1858. [Google Scholar] [CrossRef]
- Muhammad Umer, R.; Micheloni, C. Deep Cyclic Generative Adversarial Residual Convolutional Networks for Real Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Umer, R.M.; Micheloni, C. RBSRICNN: Raw Burst Super-Resolution through Iterative Convolutional Neural Network. arXiv 2021, arXiv:2110.13217. [Google Scholar]
- Luo, Z.; Huang, Y.; Li, S.; Wang, L.; Tan, T. Unfolding the Alternating Optimization for Blind Super Resolution. Adv. Neural Inf. Process. Syst. (NeurIPS) 2020, 33, 5632–5643. [Google Scholar]
- Bertero, M.; Boccacci, P. Introduction to Inverse Problems in Imaging; CRC Press: Boca Raton, FL, USA, 1998. [Google Scholar]
- Figueiredo, M.; Bioucas-Dias, J.M.; Nowak, R.D. Majorization–minimization algorithms for wavelet-based image restoration. IEEE Trans. Image Process. 2007, 16, 2980–2991. [Google Scholar] [CrossRef] [PubMed]
- Lefkimmiatis, S. Universal denoising networks: A novel CNN architecture for image denoising. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3204–3213. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE CVPRW, Honolulu, HI, USA, 21–26 June 2017; pp. 126–135. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE CVPRW, Honolulu, HI, USA, 21–26 June 2017; pp. 114–125. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Oslo, Norway, 28 June–3 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE CVPR, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liu, X.; Tanaka, M.; Okutomi, M. Single-image noise level estimation for blind denoising. IEEE TIP 2013, 22, 5226–5237. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Deblurring images via dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2315–2328. [Google Scholar] [CrossRef] [PubMed]
- Soh, J.W.; Cho, S.; Cho, N.I. Meta-transfer learning for zero-shot super-resolution. In Proceedings of the IEEE/CVF CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 3516–3525. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Scale | Set5 PSNR/SSIM | Set14 PSNR/SSIM | B100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM | #Params (M) |
|---|---|---|---|---|---|---|---|
| Bicubic | 28.65/0.84 | 26.70/0.77 | 26.26/0.73 | 23.61/0.74 | 25.73/0.84 | / | |
| RCAN * [11] | 29.73/0.86 | 27.65/0.79 | 27.07/0.77 | 24.74/0.78 | 27.64/0.87 | 15.59 | |
| ZSSR * [24] | 29.74/0.86 | 27.57/0.79 | 26.96/0.76 | 24.34/0.77 | 27.10/0.87 | 0.22 | |
| MZSR * [63] | 29.88/0.86 | 27.32/0.79 | 26.96/0.77 | 24.12/0.77 | 27.24/0.87 | 0.22 | |
| CARN * [17] | ×2 | 30.99/0.87 | 28.10/0.78 | 26.78/0.72 | 25.77/0.76 | 26.86/0.86 | 1.592 |
| Pan et al. [62] + CARN [17] | 24.20/0.74 | 21.12/0.61 | 22.69/0.64 | 18.59/0.58 | 21.54/0.74 | / | |
| CARN [17] + Pan et al. [62] | 31.27/0.89 | 29.03/0.82 | 28.72/0.80 | 25.62/0.79 | 29.58/0.91 | / | |
| KernelGAN [21] + ZSSR [24] | 26.02/0.77 | 20.19/0.58 | 21.42/0.60 | 19.55/0.61 | 24.22/0.78 | 0.52 | |
| KernelGAN [21] + MZSR [63] | 29.39/0.88 | 23.94/0.72 | 24.42/0.73 | 23.39/0.77 | 28.38/0.89 | 0.52 | |
| IKC [22] | 33.62/0.91 | 29.14/0.85 | 28.46/0.82 | 26.59/0.84 | 30.51/0.91 | 9.05 | |
| DAN [47] | 34.55/0.92 | 29.92/0.86 | 29.66/0.85 | 27.96/0.87 | 33.82/0.95 | 4.33 | |
| Ours | 31.02/0.89 | 27.87/0.80 | 27.67/0.79 | 25.11/0.80 | 28.44/0.89 | 0.38 | |
| Bicubic | 24.49/0.69 | 23.01/0.59 | 23.64/0.59 | 20.58/0.57 | 21.97/0.70 | / | |
| RCAN * [11] | 24.95/0.71 | 23.33/0.61 | 23.65/0.62 | 20.73/0.61 | 23.30/0.76 | 15.59 | |
| ZSSR * [24] | 24.77/0.70 | 23.32/0.60 | 23.72/0.61 | 20.74/0.59 | 22.75/0.74 | 0.22 | |
| MZSR * [63] | 24.99/0.70 | 23.45/0.61 | 23.83/0.61 | 20.92/0.61 | 23.25/0.76 | 0.22 | |
| CARN * [17] | ×4 | 26.57/0.74 | 24.62/0.62 | 24.79/0.59 | 22.17/0.58 | 21.85/0.68 | 1.592 |
| Pan et al. [62]+ CARN [17] | 18.10/0.48 | 16.59/0.39 | 18.46/0.44 | 15.47/0.38 | 16.78/0.53 | / | |
| CARN [17]+Pan et al. [62] | 28.69/0.80 | 26.40/0.69 | 26.10/0.65 | 23.46/0.65 | 25.84/0.80 | / | |
| KernelGAN [21] + ZSSR [24] | 17.59/0.42 | 19.20/0.49 | 17.14/0.40 | 16.95/0.47 | 19.40/0.61 | 0.52 | |
| KernelGAN [21] + MZSR [63] | 23.08/0.66 | 22.24/0.61 | 21.51/0.56 | 19.37/0.58 | 22.05/0.70 | 0.52 | |
| IKC [22] | 27.84/0.80 | 25.02/0.67 | 24.76/0.65 | 22.41/0.67 | 25.37/0.81 | 9.05 | |
| DAN [47] | 27.64/0.80 | 25.46/0.69 | 25.35/0.67 | 23.21/0.71 | 27.04/0.85 | 4.33 | |
| Ours | 25.94/0.73 | 23.83/0.62 | 24.12/0.60 | 21.15/0.59 | 22.15/0.71 | 0.38 |
| Scale | Bicubic | RCAN* [11] | ZSSR* [24] | KernelGAN [21] + ZSSR [24] | IKC [22] | DAN [47] | KOALAnet [27] | Ours |
|---|---|---|---|---|---|---|---|---|
| ×2 | 27.00/0.77 | 27.52/0.79 | 27.47/0.79 | 27.62/0.79 | 29.24/0.84 | 31.09/0.88 | 30.48/0.86 | 27.53/0.79 |
| ×4 | 23.89/0.64 | 24.16/0.65 | 24.11/0.65 | 24.50/0.66 | 25.26/0.70 | 26.42/0.73 | 26.23/0.72 | 24.67/0.66 |
| Methods | w/o () | Ours |
|---|---|---|
| PSNR/SSIM | 25.63/0.69 | 25.80/0.71 |
| Kernel Width | 1.0 | 2.5 | 3.0 | 3.5 | 4.0 |
|---|---|---|---|---|---|
| Bicubic | 25.20/0.72 | 24.38/0.69 | 23.70/0.66 | 23.18/0.63 | 22.80/0.62 |
| ZSSR [24] | 26.30/0.76 | 25.06/0.72 | 24.11/0.68 | 23.44/0.65 | 22.95/0.62 |
| IKC [22] | 28.12/0.82 | 28.32/0.82 | 28.29/0.81 | 27.90/0.80 | 24.26/0.69 |
| Ours | 26.31/0.76 | 26.05/0.73 | 25.09/0.70 | 24.17/0.66 | 23.38/0.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.H.; Micheloni, C.; Martinel, N. Lightweight Implicit Blur Kernel Estimation Network for Blind Image Super-Resolution. Information 2023, 14, 296. https://doi.org/10.3390/info14050296
Khan AH, Micheloni C, Martinel N. Lightweight Implicit Blur Kernel Estimation Network for Blind Image Super-Resolution. Information. 2023; 14(5):296. https://doi.org/10.3390/info14050296
Chicago/Turabian StyleKhan, Asif Hussain, Christian Micheloni, and Niki Martinel. 2023. "Lightweight Implicit Blur Kernel Estimation Network for Blind Image Super-Resolution" Information 14, no. 5: 296. https://doi.org/10.3390/info14050296
APA StyleKhan, A. H., Micheloni, C., & Martinel, N. (2023). Lightweight Implicit Blur Kernel Estimation Network for Blind Image Super-Resolution. Information, 14(5), 296. https://doi.org/10.3390/info14050296