1. Introduction
Decentralized Autonomous Organization (DAO) has emerged as a popular blockchain-based application, characterized by organizations built on smart contracts capable of autonomous execution [
1]. With over 10,000 DAOs established worldwide since their introduction in April 2016, the funds deposited in these DAOs have grown significantly, surpassing USD 23B recently [
2]. A distinguishing feature of DAOs is their lack of central control, as their rules are encoded in blockchain-based smart contracts, enabling autonomous and automated operations on a distributed peer-to-peer network. This decentralized mechanism enhances visibility, traceability, accountability, and transparency within the organization, mitigating the costs associated with human mistrust and unfulfilled promises, and improving decision-making efficiency and transparency.
Despite the failure of the initial DAO, The DAO, in April 2016, resulting from a security breach caused by a vulnerability in its smart contract, subsequent DAO projects have continued to emerge and flourish. Various entities, including original blockchain initiatives such as NFTs and DeFi as well as traditional organizations such as corporations, venture capital firms, and political parties, have embraced DAOs as a novel approach to constructing and operating organizations, attracting members, and managing funds. However, despite the growing interest in DAOs and their potential for mass adoption, limited data-driven research exists to comprehend the overall trends and future possibilities associated with DAOs.
Previous studies have primarily focused on case analyses, particularly examining The DAO as the first DAO established on the Ethereum platform [
3,
4,
5]. Additionally, they have explored the historical understanding, use cases, and societal implications of DAOs [
6,
7,
8], as well as the adoption of DAOs and their implications for existing governance systems and businesses [
9,
10,
11,
12,
13,
14,
15]. The existing studies have investigated the underlying technology of DAOs, including their advantages, limitations, and potential solutions [
16].
These endeavors have all been made in order to understand and utilize the emerging technology and tools represented by DAOs. In recent times, an increasing number of studies have contributed to the academic discourse on DAOs. For instance, Lu Liu et al. [
8] comprehensively classified the latest research that combines blockchain and DAO, presenting related studies in various domains, evaluating recent advancements, and predicting future development directions such as corporate governance, blockchain government, and social DAOs for crowdfunding.
By examining the trends and limitations of previous studies, this paper aims to address this research gap by employing data-driven analysis using text-mining technology to investigate the current state of DAOs and propose future research directions and practical applications. While Twitter has been widely utilized as a source of information for blockchain and cryptocurrency research, with a predominant focus on cryptocurrency prices [
17,
18,
19,
20], this study extends beyond price-related investigations by analyzing Twitter data specifically pertaining to DAOs. Furthermore, this research capitalizes on another valuable data source, Reddit, which is acknowledged for its ability to provide insights into general trends within rapidly growing industries [
21].
This research identifies key topics, keywords, and trends associated with DAOs, such as NFTs, finance, gaming, and fundraising. The recurring presence of the term “community” will also be explored to understand its significance in the context of DAOs. The contributions of this study extend to academia, industry, and institutional stakeholders, providing insights that facilitate informed discussions and contribute to future research and practical applications across diverse domains in the field of DAOs.
Furthermore, the implications of this study extend to legal and ethical considerations surrounding DAOs, shedding light on the need for robust frameworks and regulations that address potential challenges and ensure responsible and transparent operations. By addressing these key aspects, this research contributes to the development of a sustainable and inclusive ecosystem for DAOs, unlocking their full potential for the benefit of stakeholders and society as a whole.
2. Methods
2.1. Research Design
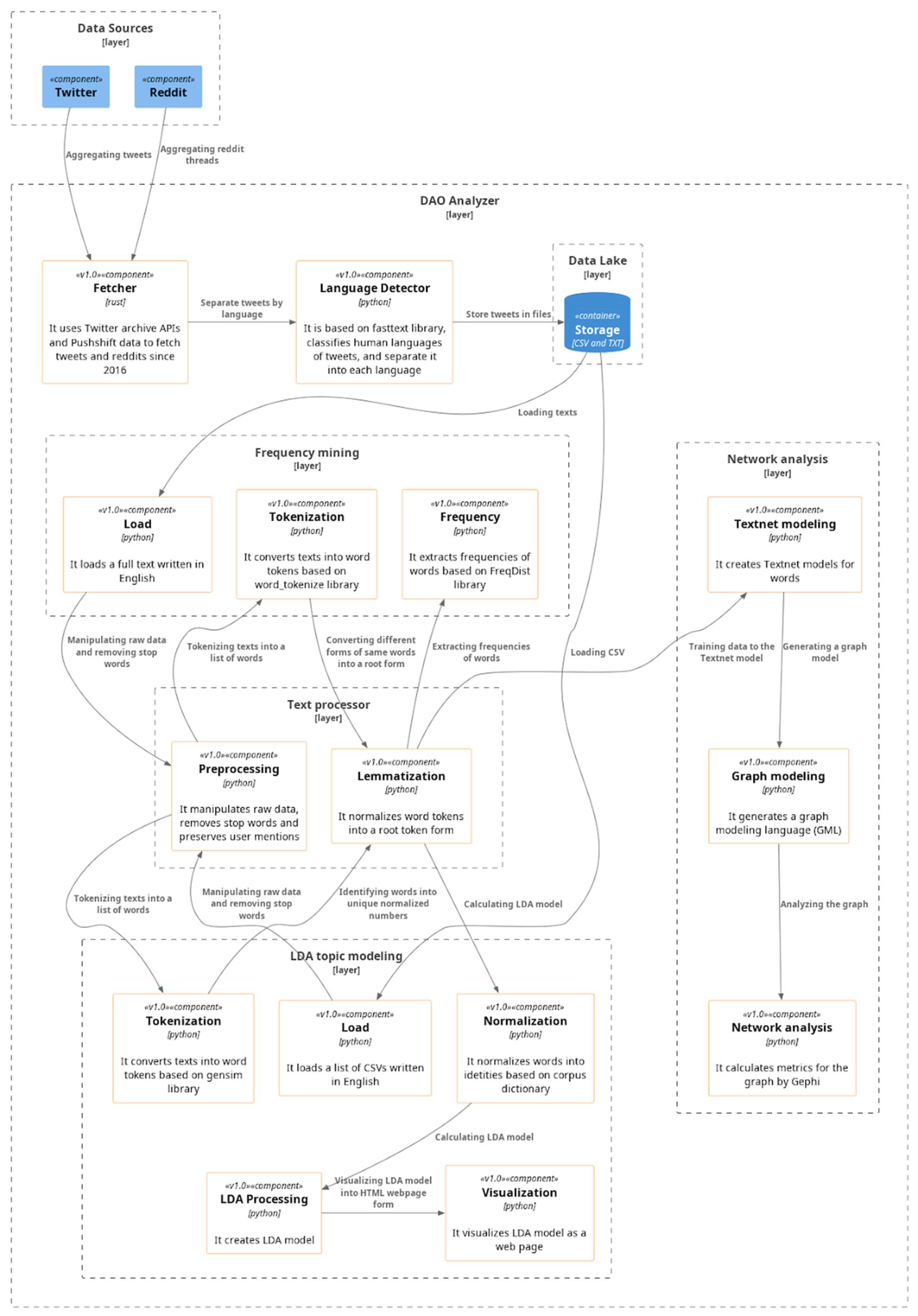
This research presents a data-driven methodology utilizing text mining techniques, as illustrated in
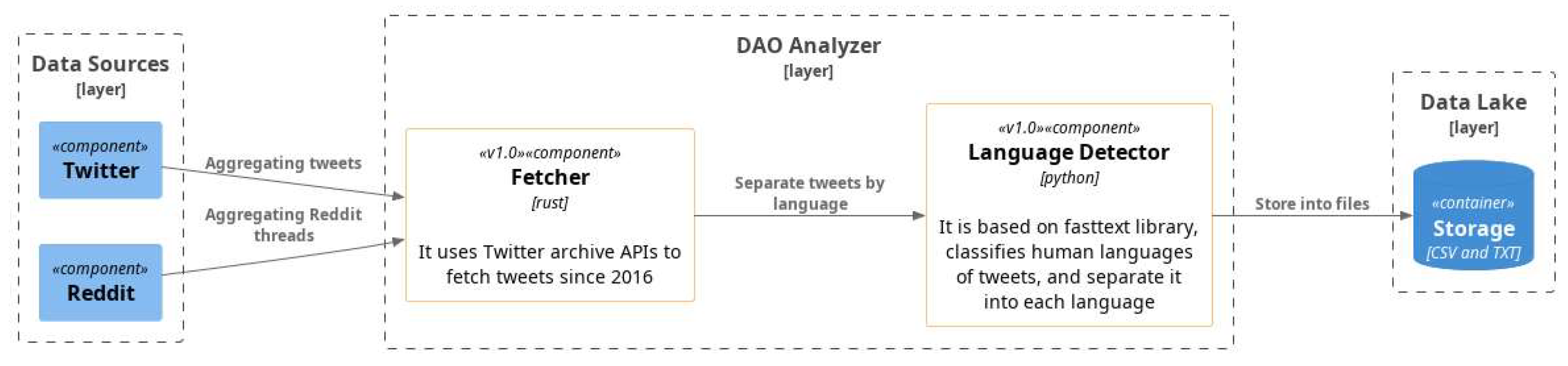
Figure 1. The methodology comprises three core steps: Data selection and aggregation, Data pre-processing, and Data analysis. The data aggregation process involves two phases: data fetching and language detection. In the data fetching phase, the Rust-based fetcher searched for all tweets containing the hashtag “#DAO” since the inception of DAOs in April 2016. To identify the trend and main topics surrounding DAO, this study aggregated all the English-language tweets containing the hashtag “ #DAO“, as hashtags are used on Twitter to express the main topic or the most important word of a short message.
By aggregating tweets with this specific hashtag, we were able to focus our analysis on relevant tweets that were specifically related to DAO and avoid including irrelevant tweets where the term “DAO” was used for a different purpose or meaning. The use of the hashtag ‘#DAO’ ensured that our analysis was focused on the specific topic of interest and provided a clearer picture of the trend and main topics being discussed. Through this selection, it generated 3,885,266 tweets in total. Given the inherent characteristics of DAOs and Web3, where users frequently possess experience, knowledge, influence, and ownership simultaneously, this research considered all texts that deliberately referenced DAOs through the use of hashtags, including user mentions (see
Figure 2).
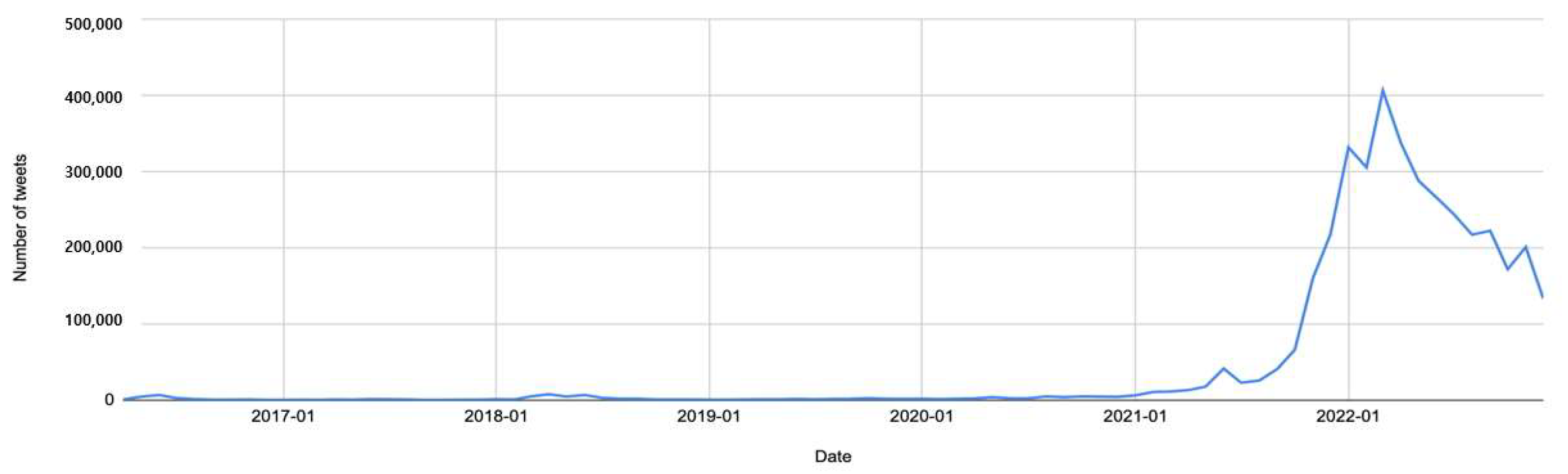
Notably, the number of tweets related to DAOs in 2022 was four times higher than the total number of tweets from 2016 to 2021 (see
Figure 3,
Table 1). However, we did not incorporate the time factor into our research analysis. Additionally, because the fetcher aggregates tweets in over 20 languages, the tweets should be classified into their respective languages in the following phase.
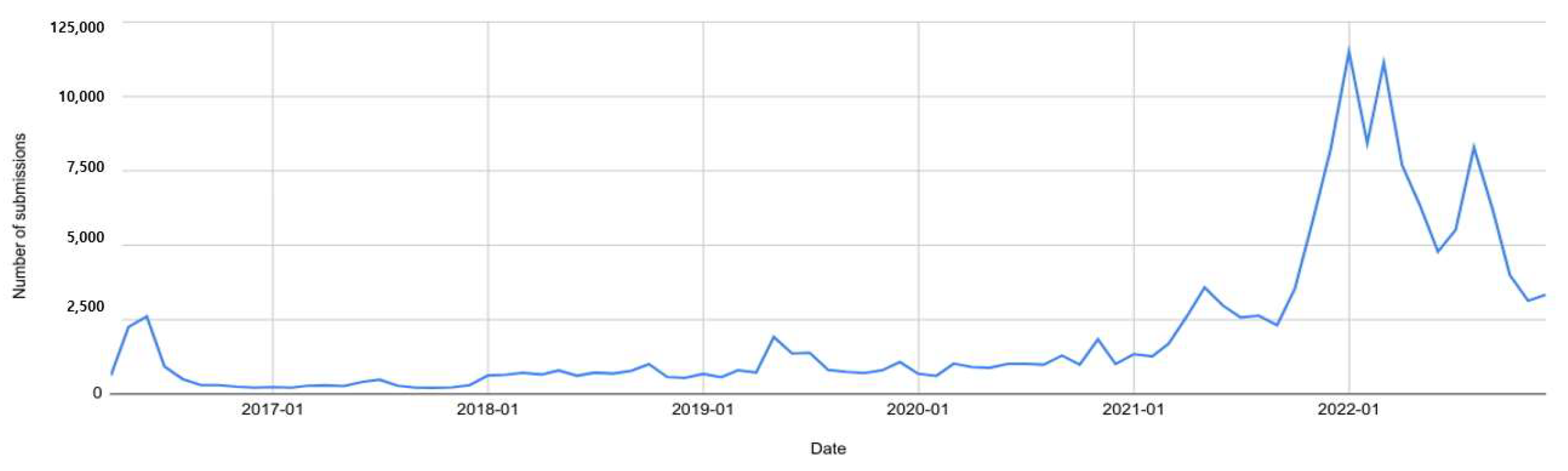
For Reddit, we initially retrieved all submissions from the Pushshift archiving directory. (
https://files.pushshift.io/reddit/submissions/) (accessed on 12 March 2023). Similar to Twitter’s hashtag, Reddit uses the term subreddit. Although a subreddit for DAO exists, it has a limited number of submissions. Therefore, we aggregated all submissions from the DAO subreddit and those that contained ‘DAO’ in their title (see
Figure 4,
Table 2).
In the language detection phase, the fasttext library in Python was used to detect the human language of each data. The tweets and Reddit submissions were recorded as a CSV file containing their creation time, which was grouped by month. The data were then accumulated monthly and written in a separate TXT file for each month. The data aggregation process generated monthly CSV and TXT files, where each CSV file contained the specific dates and content of tweets and submissions, and each TXT file contained only the contents of them, which were used for analysis. This process provided a consistent and structured dataset for the subsequent analysis.
The purpose of pre-processing in this study was to prepare the aggregated texts for word frequency analysis, network analysis, and LDA topic modeling. The pre-processing procedure consisted of two stages: removing unnecessary letters and symbols, and eliminating stop words. In the first stage, the text was cleaned by removing phrases indicating URLs and symbols other than alphabetic and numeric characters. The next step involved removing stop words in English using the NLTK library in Python. The NLTK library contains approximately 40 English prepositions, and other words such as “DAO” and “DAOs” were added for analysis.
Typically, text mining would include WordNet lemmatization, but it was omitted from the proposed approach. Instead, the lemmatization integrated various forms of blockchain terminologies into a single form. For instance, coin symbols such as ETH, and BTC were integrated into the platform names Ethereum and Bitcoin, respectively (
Table 3).
Additionally, several terms in the blockchain industry were standardized into a single form. The reason for omitting WordNet lemmatization is two-fold. Firstly, it has a minimal impact since the research focuses on technical keywords rather than verbs or common nouns to analyze trends. The results were almost identical with or without WordNet lemmatization applied as pre-processing. Secondly, technically significant expressions such as “web3” may be compromised in converting different word expressions into root expressions via WordNet lemmatization. As a result, WordNet lemmatization was not implemented in this study.
The extended stop words, which we defined to filter out irrelevant words, are presented in
Table 4 below. These stop words primarily consist of prepositions and adjectives. Notably, the predefined keywords “amp” and “rt” were also included in the list of stop words. Additionally, we removed the terms “dao” and “daos” from the list of stop words. This exclusion was because these words represent conceptual keywords, which we aimed to analyze, rather than terms for analysis. In the first stage of experimentation, we eliminated these stop words to improve the accuracy of our analysis.
2.2. Data Analysis
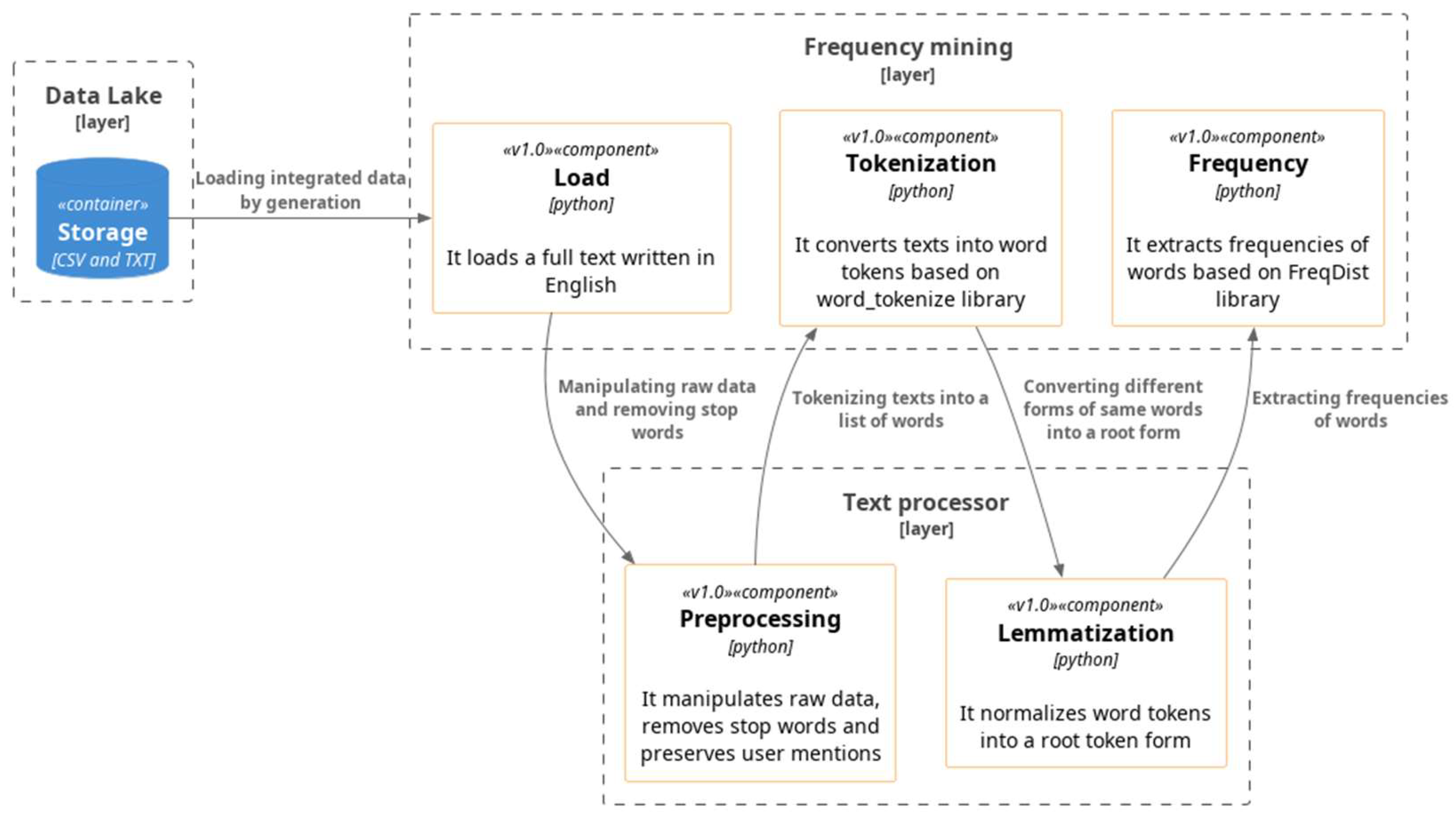
Word frequency analysis is a crucial technique that explored the frequency of words appearing in tweets with ‘#DAO’ or Reddit submissions containing ‘DAO’ in their title from April 2016 to December 2022. This method focuses on analyzing contents without considering their creation date. The frequency analysis process is composed of five distinct steps, which are data loading, data pre-processing, data tokenization, lemmatization, and frequency analysis (see
Figure 5).
The data loading phase starts by reading all the TXT files and loading their contents as a single text into memory. At this stage, the data loading phase was limited to English-language tweets, as the focus of this study was specifically on analyzing English-language content. This text was then subjected to the pre-processing phase, as described in
Section 2.2, where the text is cleansed of unnecessary information such as URLs and symbols. The next step, tokenization, involves converting the text into a list of word tokens. This is carried out by treating all space-separated letters as individual tokens. For example, the sentence “This research focuses on trend analysis of DAO” would be tokenized into “This”, “research”, “focuses”, “on”, “trend”, “analysis”, “of”, “DAO”.
The lemmatization phase involves removing stop words and converting technical keywords into a root form. First, the stop words are defined using the NLTK library, which contains approximately 40 English prepositions, along with other extended stop words defined by us. The extended stop words include “amp”, “dao”, “daos”, “rt”, “us”, “one”, “via”, “great”, “good”, “back”, “get”, “best”, “based”, “today”, “like”, “theres”, “dont”, “anywhere”, “done”, “time”, “hello”, “im”, and “retweet”.
The second step of lemmatization involves converting technical keywords into a root form, as discussed in
Section 2.2. The final phase involves calculating the frequency of occurrences of words in the token list and identifying the 100 most frequent words. In conclusion, word frequency analysis provides a valuable insight into the frequency of words appearing in contents and is an essential step in text analysis. The five-step process of data loading, pre-processing, tokenization, lemmatization, and frequency analysis ensures that the results are accurate and relevant.
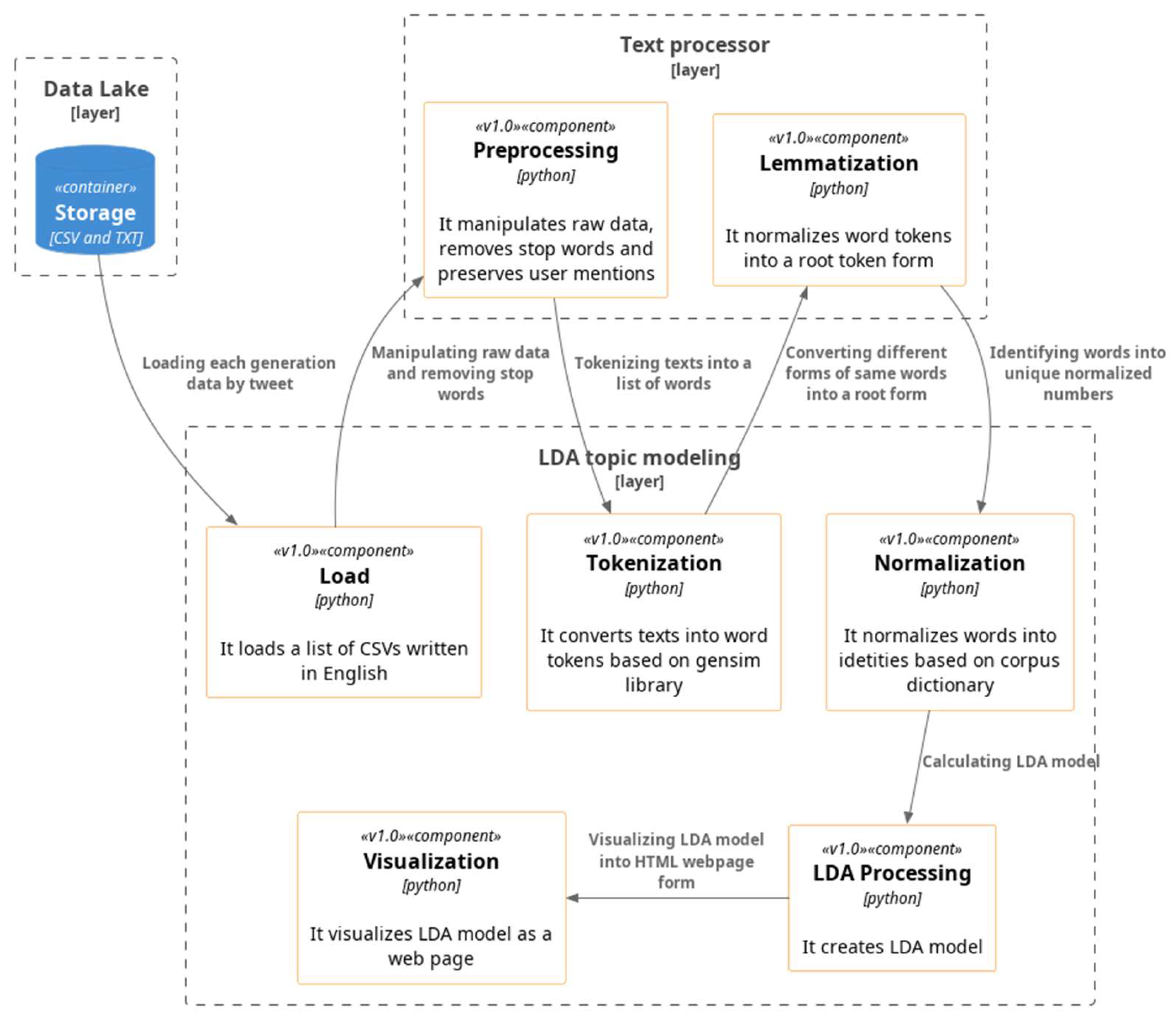
This section details the seven-step LDA topic modeling-based analysis process, which includes data loading, pre-processing, tokenization, lemmatization, normalization, LDA processing, and visualization. During the data storage process, every tweet and Reddit thread was saved as an individual cell in the data lake in the form of a CSV or TXT file. Specifically, each tweet and Reddit thread was saved as a separate line in the TXT file. In the data loading phase, tweets and Reddit threads were loaded from the CSV file and the list of tweets and threads were loaded into memory. The subsequent pre-processing, tokenization and lemmatization phases were the same as those described for frequency analysis (see
Figure 6).
The normalization phase involved converting the tokenized words into normalized IDs based on the Corpora dictionary of the Gensim library in Python. This normalization process converts the word tokens formed as strings into numerical forms that unify their meanings. The LDA processing phase generates an LDA model using the Gensim library, and the resulting model is visualized in a webpage format using the pyLDAvis library. This visualization allows for more accessible analysis of the results of the LDA analysis.
Latent Dirichlet Allocation (LDA) is founded on the concept that documents comprise a set of prospective topics, and each document is composed of words assigned with probability values that indicate their relevance to a certain number of topics, k [
22]. To determine the optimal number of topics for each platform, a range of 5 to 20 topics was generated and their coherence was evaluated using the C_V measure. The C_V score provides a measure of topic coherence, with values closer to 1 indicating higher coherence. However, it is important to acknowledge that the selection of the number of topics is not solely determined by the C_V score, but also considers the researchers’ domain knowledge and expertise. In this study, the number of topics was determined by focusing on the most salient and meaningful topics among the highest C_V scores. Based on this consideration, 12 topics were chosen for Twitter while 8 topics were selected for Reddit (see
Table 5).
Network analysis is a technique that utilizes text mining to identify the relationship between extracted keywords, thereby enabling the identification of the structure within a network [
23]. Centrality analysis is another approach that involves extracting sentence-level text from a document, by dividing it into keywords and analyzing the connections between the extracted keywords to understand the meaning and structure [
24]. By using keywords as actors and connections between actors as nodes, it becomes possible to analyze current situations and trends. Centrality analysis includes degree centrality, closeness centrality, betweenness centrality, and eigenvector centrality [
25].
Degree centrality, for instance, refers to the actor with the most connections to other actors. The higher the betweenness centrality, the better the actor’s position in the network and the easier it is to access resources in the network without relying on other actors. Closeness centrality, on the other hand, measures the proximity of an actor to other actors and represents the distance between an actor and all other actors in the entire network, taking into account the tangentially connected relationships within the network. While degree centrality emphasizes direct connections, closeness centrality emphasizes the length of paths connecting actors. Betweenness centrality acts as an intermediary to control relationships between actors that are not directly connected by computing over the entire network.
Finally, eigenvector centrality is an extension of connection centrality that focuses on the degree of connectedness between connected actors, indicating how important the connected actors are. In other words, actors can be given a weighted centrality to determine which actors have the strongest influence. Overall, the application of network analysis, along with centrality analysis, can provide a more detailed understanding of the structure and relationships within a network, enabling researchers to identify key actors and their influence within the network.
This study utilized the Textnet library to produce a graph modeling language implemented in Python, which yielded a GML file that portrayed the relationships between the trained words. Notably, to minimize the complexity of the analysis process, only the most frequently used 100 words were trained. Subsequently, we employed Gephi, a graphical user interface tool designed for graph analysis, to examine various metrics such as degree centrality. To concentrate on the crucial actors and their influence, we limited our focus to the top 20 words for each centrality analysis criterion.
3. Results
3.3. Network Analysis
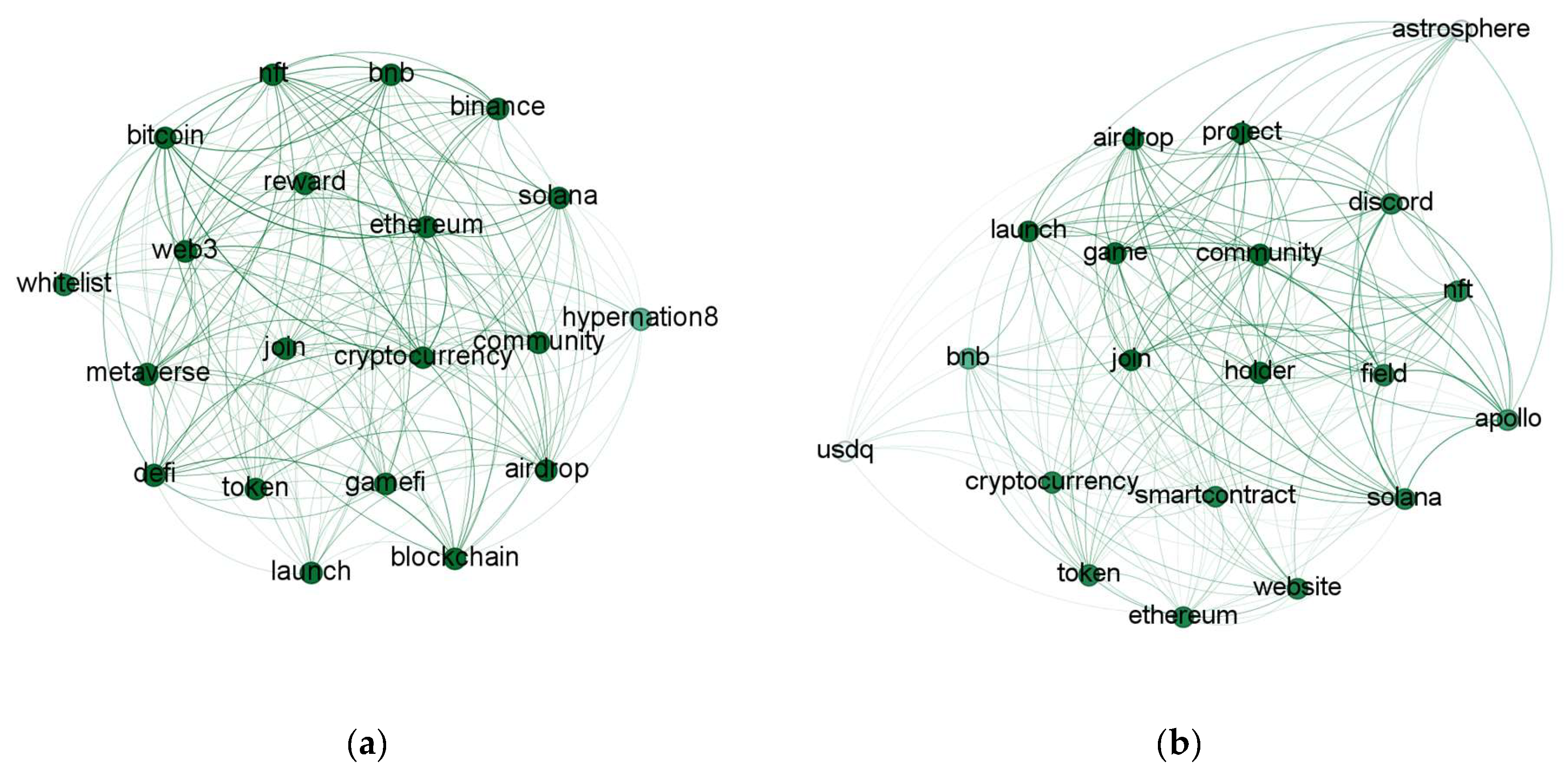
Figure 7 presents a visual representation of the interrelationships of the top 20 keywords within the set of the 100 most frequently occurring keywords. The figure provides a graphical representation that offers insights into the connections and associations between these key terms, allowing for a better understanding of their interplay and significance within the context of the study. Furthermore, we conducted a comprehensive analysis by calculating several centrality measures, namely degree centrality, eigenvector centrality, betweenness centrality, and closeness centrality, for the top 100 keywords.
Centrality measures play a crucial role in analyzing networks. For example, degree centrality assesses the importance of a node based on the number of links it possesses. It helps identify highly connected individuals, popular figures, or those likely to possess a significant amount of information, enabling them to quickly connect with the broader network. Similarly, eigenvector centrality evaluates a node’s influence by considering both its number of connections and the quality of those connections.
It considers the well-connectedness of the node’s connections and extends this analysis throughout the network. On the other hand, betweenness centrality quantifies the frequency with which a node lies on the shortest paths between other nodes. Lastly, closeness centrality assigns scores to nodes based on their proximity to all other nodes in the network. By employing closeness centrality, we can identify individuals who hold strategic positions to exert influence over the entire network more efficiently.
The resulting centrality scores allowed us to identify the keywords that occupied prominent positions within the network. Specifically,
Table 10 and
Table 11 present the top 20 keywords with the highest centrality scores, showcasing their significance in the context of the study.
In the case of Twitter, the results of the frequency analysis revealed that several words, such as nft, airdrop, cryptocurrency, defi, ethereum, community, web3, blockchain, and bnb, ranked high in the network analysis, as well. This indicates that these words are central to the network, based on various criteria. Interestingly, czbinance, which was positioned as the 100th most frequent word in the analysis, emerged as the 6th most central word based on eigenvector centrality, betweenness centrality, and closeness centrality measures. Similarly, elonmusk, despite being ranked 64th in frequency analysis, placed within the top 20 in all centrality measures except degree centrality. These findings illustrate the significant influence of individuals such as Binance founder Changpeng Bellavitis and Elon Musk, even though they are not relatively frequently mentioned.
In contrast to Twitter, the analysis of Reddit (
Table 11) revealed that the top-ranking words in degree centrality displayed divergent results in the other three centrality measures. This discrepancy may stem from the nature of Reddit as a more self-contained platform, where users are able to compose lengthier posts compared to Twitter. Consequently, certain words with relatively lower impact or significance may garner higher frequency and connectivity within the network.
4. Discussion
This study has produced several noteworthy findings. Firstly, the analysis of the top 100 keywords identified prominent mainnet coins, namely bitcoin, ethereum, bnb, solana, avax, and polygon. While existing research on DAOs and blockchain technology often emphasizes the security and scalability aspects of blockchains [
26,
27,
28,
29], the selection of a mainnet for establishing and operating a DAO is crucial. Each mainnet possesses distinct features that can influence the characteristics of an organization, warranting further investigation to determine the most suitable mainnet for specific DAOs. For instance, different mainnets may impose varying time and financial requirements for proposals and voting processes, which can serve as vital variables impacting the functioning of a DAO and the involvement of its members.
The second significant finding pertains to the identification of key themes that reflect the sectors and types of organizations displaying the most interest in DAOs. This study has revealed a notable level of enthusiasm and utilization of DAOs in domains such as NFTs, gaming, and finance. While previous discussions on the application of blockchain technology in organizations have primarily revolved around government and corporate governance studies [
30,
31,
32,
33], the present research highlights the growing adoption of DAOs within specific sector-specific projects, particularly in gaming and finance.
This observation aligns with the statistics provided by Deepdao, which provides the real-time statistics on DAOs worldwide, where the leading treasury projects predominantly consist of financial organizations, with the exception of layers 1 and 2. Such a phenomenon can be attributed to one of the distinguishing characteristics of DAOs, which grants ownership to all project members and allows direct participation in crucial decision-making processes, including operational procedures and compensation policies.
Consequently, it is only natural for projects and organizations operating in sectors such as gaming and finance, where organizational policies directly impact the economic interests of their members, to exhibit a strong interest in embracing DAOs. The study also revealed that the most common words in the blockchain industry, such as nft, airdrop, cryptocurrency, defi, ethereum, community, web3, blockchain, and bnb, are highly central and influential. However, it is interesting to note that individuals such as ‘elonmusk’ and ‘czbinance’ wield significant influence, despite their relatively low frequency of occurrence in the text. The prominence of influential figures in discussions and narratives surrounding DAOs can be attributed to the nascent stage and relatively small size of the DAO market.
During these early stages of market formation, the stories and actions of key individuals have a higher likelihood of being widely discussed and circulated, and of ultimately exerting influence on the market. As the DAO ecosystem continues to evolve and mature, it is anticipated that a broader range of factors and dynamics will shape the market landscape, thereby diversifying the narratives and sources of influence within the industry.
5. Conclusions
This study is expected to stimulate further research and discussions on the utility and challenges of DAOs across various academic, industrial, and institutional domains. Based on the study’s findings, a few research directions emerge for further exploration. First, investigating the evolving landscape of DAOs and their impact on various industries and sectors can provide valuable insights into their long-term potential and challenges. Understanding how DAOs can reshape governance, participation, and economic models across different domains is crucial for informed decision-making and strategic planning. Second, examining the scalability and security aspects of blockchain technology, specifically within the context of DAOs, is essential. As DAOs continue to gain prominence, ensuring the scalability, efficiency, and robustness of underlying blockchain infrastructures becomes paramount.
Research focusing on addressing technical barriers and exploring innovative solutions to enhance the scalability and security of DAOs can pave the way for their widespread adoption. Additionally, it is essential to address the legal and ethical issues associated with DAOs. The decentralized nature of DAOs raises questions about regulatory frameworks, accountability, and dispute resolution mechanisms.
Future research should explore the legal implications of DAO operations, including governance structures, member responsibilities, and compliance with existing laws and regulations. Additionally, ethical considerations regarding DAO decision-making, transparency, and inclusivity should be examined to ensure the responsible and sustainable development of DAOs.
Finally, exploring the social and economic implications of DAOs is crucial. This entails investigating the impact of DAOs on traditional organizational structures, employment patterns, and economic systems. Understanding the potential benefits, challenges, and unintended consequences of DAOs can guide policymakers, industry leaders, and stakeholders in harnessing the full potential of this transformative technology.
It is important to acknowledge the limitations of this study. One significant limitation is the lack of temporal consideration. Given that the majority of data collection from Twitter and Reddit occurred in 2022, it is plausible that the prominence of specific keywords and topics during that period may have exerted an influence on the overall findings. Consequently, it is imperative that future research endeavors encompass a temporal dimension to gain a more comprehensive understanding of the dynamic nature of DAOs and their associated subjects.
Additionally, the methodology employed in analyzing the data, including centrality metrics and keyword frequency analysis, provides a quantitative perspective on the topic. While these approaches offer valuable insights, they may overlook nuanced qualitative aspects of DAOs, such as individual experiences, motivations, and cultural factors that shape the adoption and utilization of DAOs. Incorporating qualitative research methods, such as interviews and case studies, could provide a more comprehensive understanding of the complexities surrounding DAOs.
Furthermore, the study’s focus on the English language limits the generalizability of the findings to a global context. DAOs are a global phenomenon, and their adoption and discussions extend beyond English-speaking communities. Including data from multiple languages and cultural contexts would enhance the study’s breadth and capture a more diverse range of perspectives and trends.
The unique characteristics of these two platforms resulted in variations in the results. However, this study did not delve deeply into analyzing these differences on an individual basis. Therefore, future qualitative research, such as case studies, would be valuable in complementing the findings of this study and providing a more comprehensive understanding of the nuanced variations observed between Twitter and Reddit in relation to DAOs.
Lastly, this study was a basic trend analysis study based on social data, which limited the in-depth discussion of data analysis techniques. Therefore, in future research, it is necessary to develop algorithms or conduct more advanced research considering various data analysis techniques based on DAO-related company big data collection.


_김_(김).png)









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}