Abstract
We adapt previous literature on search tasks for developing a domain-specific search engine that supports the search tasks of policy workers. To characterise the search tasks we conducted two rounds of interviews with policy workers at the municipality of Utrecht, and found that they face different challenges depending on the complexity of the task. During simple tasks, policy workers face information overload and time pressures, especially during web-based searches. For complex tasks, users prefer finding domain experts within their organisation to obtain the necessary information, which requires a different type of search functionality. To support simple tasks, we developed a web search engine that indexes web pages from authoritative sources only. We tested the hypothesis that users prefer expert search over web search for complex tasks and found that supporting complex tasks requires integrating functionality that enables finding internal experts within the broader web search engine. We constructed representative tasks to evaluate the proposed system’s effectiveness and efficiency, and found that it improved user performance. The search functionality developed could be standardised for use by policy workers in different municipalities within the Netherlands.
1. Introduction
We investigate how to apply the theoretical understanding of (search) tasks and information seeking on the practical development of search engines. A growing body of scientific work is investigating how a user’s search tasks affect their information seeking (e.g., [1,2,3]). Simultaneously, a growing number of professional search applications are being developed for specific domains, such as patent search [4] and real estate search [5], as such search engines allow for higher search satisfaction [6,7]. Less investigated is how to connect these two worlds: how to develop a domain-specific search engine based on a task analysis. In previous work, a task analysis was proposed to facilitate the design of a search engine for council members [8]. The current work extends and refines this approach while using it to design a search engine for policy workers at a municipality.
The municipality of Utrecht is one of the largest and oldest in the Netherlands, with over 4000 employees. Policy workers (PWs) are responsible for translating the city council’s vision into concrete policies (see Figure 1), which involves a large amount of information seeking [9]. Ineffective search systems cost PWs time and lead to incomplete search results, which can negatively impact the quality of their work. As our initial research question, we investigate the challenges during PW search by investigating their goals and the tools they have available to achieve them.
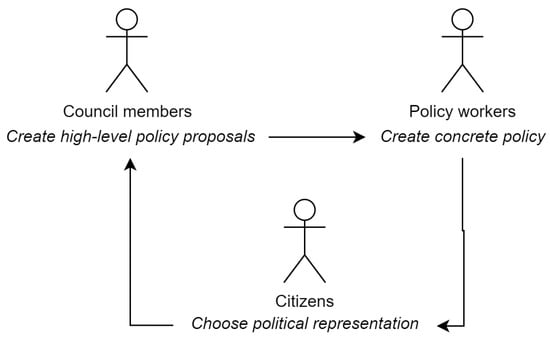
Figure 1.
The role of policy workers and other important groups.
RQ1: What work and search tasks do PWs at the municipality of Utrecht perform?
The findings enable us to design support for those tasks during the second research question, focusing on web-based tasks, as we find that these present the biggest challenges.
RQ2: How can we design functionality for the more effective and efficient completion of the web-based search tasks of PWs?
The paper is structured in two parts that each discuss one of these questions. To answer the first question, we performed semi-structured interviews to characterise the information seeking of policy workers, and identified the tasks that are not well supported. The method of interviewing and the results are described in Section 3 and Section 4, and the search tasks are compared to the available functionality. Based on the findings, two hypotheses are formulated on how to improve the search experience. The first hypothesis (H1) is that a search engine that only includes authoritative web sources would be more effective than how PWs at Utrecht currently search. The second hypothesis (H2) is that PWs prefer to address complex web-based search tasks by finding a domain expert within the organisation. This suggests that supporting complex web-based tasks may be achieved through integrating expert search into the web search engine. These findings contribute to our understanding of information seeking in this domain, which might generalise to other knowledge organisations. Additionally, the approach to designing a search engine helps bring the theoretical understanding of search tasks closer to the practical development of search engines (through the modelling of information, the ranking and the interface).
In the second part of the paper, we develop a system to better support PW tasks, based on hypotheses H1 and H2. To test H1, a web search engine is developed that only indexes authoritative web domains in Section 5. We then test whether this system is more useful for simulated web-based search tasks than existing search tools (H1) in an experiment described in Section 6. We then investigate when policy workers would turn to seeking an expert colleague in their organisation (H2), instead of completing the task themselves. The results are presented in Section 7. Finally, we discuss the value of a task-based approach to designing search systems for target user groups.
2. Related Work
Our first research question regards identifying and characterising the search tasks of policy workers (PWs). We discuss how existing task models are typically generic by design, and how they can be extended to describe domain-specific tasks. Finally, we examine previous literature on the search tasks of PWs specifically.
2.1. Generic Task Models
An influential conceptual model to understand work tasks and search tasks is the conceptual model proposed by Byström and Hansen [10]. This model describes information needs in three levels of increasing context. The first level is a topical description and query. The second level is a situational description, which is the context of the specific task at hand. The third level is a description of broader contextual factors that affect how tasks are performed, such as characteristics of the individual. There are task models that describe tasks at each of these levels.
The first level is the topical description and query. Broder proposed a taxonomy of web-based search intentions that characterise queries into three types: informational, navigational, and transactional [11]. Later, Rose and Levinson extended this taxonomy, replacing the transactional category with a broader “resource” category, where users intend to access or interact with a resource on a page [12]. They also subcategorised the informational and resource categories. Search intents can be classified based on queries [13], which allows developing support for specific types of tasks (e.g., procedural tasks [14]).
The faceted task framework is the most comprehensive model for the second level of the situational context [2]. This framework characterises tasks based on several independent facets that affect the user’s information behaviour and subsequent sub-tasks.
The third level consists of contextual factors. Notable works to model these are the cognitive framework of information seeking and search [15] and the workplace information environment descriptions [16]. The former focuses on the perspective of a single cognitive actor and explores how individuals interact with information. The latter focuses on the practices of groups of actors and is more relevant when describing the needs of a specific user group.
A more extensive overview of how search can be contextualised within the users’ tasks is provided by Shah et al. [17]. For the purpose of supporting user tasks, the situational context is most important (as opposed to the generic characteristics of the user or the overly specifics of a momentary search intent). Hence, we focus on the situational context of PWs.
2.2. Applying Task Models to a Domain
While the previous task models are generalisable and domain independent, they are less suitable for expressing domain-specific information needs. When designing a search system, it is preferable to use a model that is concrete enough to link user tasks to specific subsets of the information in the domain (e.g., linking tasks to specific document genres).
The faceted task model is domain independent and does not include a facet for the task topic aspect, as the list of potential topics is unlimited in the absence of such context [2]. In a specific domain, such as the PW domain, more specific tasks can be identified, which allows for more context to be added to user goals. A more specific domain also enables a more specific information model that can link user tasks to subsets of information in this model.
The current work uses a domain-specific task model made by analysing council member tasks. The faceted task model was extended with domain-specific facets. This was used to identify search requirements and develop a search system [8] as shown in Figure 2. The faceted task model was expanded with domain-specific facets based on how council members described their own tasks. This allowed for a more comprehensive representation of the situational context. The task model describes tasks using several facets, and was developed by coding interview data. An inventory of tasks was created based on the interview data and an observational study. The authors found that the task model provides insight for (1) how to model information, (2) how to present information in the interface in context, (3) and how to allow users to interact with the information. In contrast to previous technology-centred projects at the municipality, which were temporary fixes, their user-centred approach addresses specific underlying problems that hinder the completion of certain search tasks.
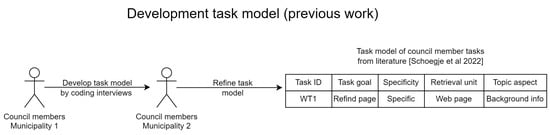
Figure 2.
Development of the task model based on how council members describe their tasks [8].
Although the present study builds upon work from some years ago, it should be noted that the development of domain-specific search engines is an active research topic. More recent works investigated the tasks in domains such as mobile web search [18], music retrieval [19], question answering [20] and intelligent assistants [21]. Other studies investigated more generic domains, such as professional search [3], tasks that occur during teamwork [22] or extracting task context from activities [23]. Notably, the DoSSIER project has 15 PhD students working on topics such as characterising the tasks coming from knowledge work [24].
2.3. Tasks of Policy Workers
Although no task model has been applied to PWs, there is prior work describing PW tasks. These findings help inform the task model we develop in the present work. The information-use environment of American legislators was described in terms of its people, problems, setting, and problem resolutions [25]. Within this context, legislative aides, such as PWs in the municipality, help filter information and play a role as decision formulators who present options, alternatives, and recommendations [26]. PWs work with ill-structured problems, shifting goals, time stress, and action–feedback loops. It is also unclear to them when they have found all useful information [27]. PWs are experts with less search literacy than expected of professional searchers [8,28,29], and their thoroughness can be limited due to time pressures [27]. When characterised based on their types of knowledge, PWs are considered experts with high declarative (what is it) and procedural (how to do it) domain knowledge, moderate declarative search knowledge (where to find it), and various levels of procedural search knowledge (successful ways to find it) [8,15].
Although previous work identified these challenges, previous systems for PWs were typically not designed for their tasks. Instead, these focused on, for example, the structure of information [30,31] or technology-driven innovations.
3. Method to Identifying Policy Worker Tasks
To identify the tasks of policy workers, we applied a task analysis method that was previously developed with council members. The approach is shown in Figure 3. An overview of the tasks was obtained through interviews with policy workers, as search tasks can be an abstract concept for users, and an open format allows the researcher to ask clarifying questions. Additionally, users might report the goals they focus on during work and forget to report sub-tasks necessary to achieve that goal.
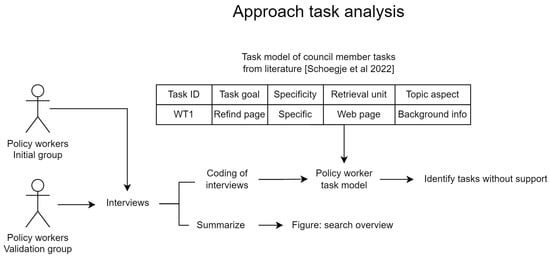
Figure 3.
The tasks of policy workers were analysed as shown, by applying the task model that was previously developed with council members [8].
Two rounds of interviews were conducted to identify the tasks. In the first round, the work tasks and search tasks of policy workers were identified. A second round of interviews was performed to validate the findings from the first round and ask questions about how PWs approach search in general (independent of their current task).
Tasks were identified and characterised (RQ1) by performing a task analysis. The task analysis was performed by coding speech segments from the interviews, starting with a codebook developed in a study with council members [8]. The codes in this codebook are the task facets that were previously identified with council members. Another code was added for web search intention, which we introduced in the related work [12], because it is a specific descriptor of the task goal for the domain of web search.
3.1. Round 1 Interviews
3.1.1. Participants
Participants were recruited by inviting employees who work on municipal policy. Additional participants with other roles were recruited through a convenience sample. All participants had between 1.5 and 2.5 years of experience working at the municipality.
Six one-hour interviews and two half-hour interviews were conducted with eight public servants (five female, three male), including five PWs, two managers and a coordinator for municipal activities in a neighbourhood. The participants had over a year of experience in their current roles, and consisted of six early-career professionals and two late-career professionals.
3.1.2. Semi-Structured Interviews
The majority of interviews consisted of identifying the participants’ different work tasks and then the search tasks these involve (while eliciting information sources and frequent difficulties). The interviewer used the task facets from the task model as a structure to characterise each task. At the end of the interview, the broader topic of finding data on the web was discussed. The interviews concluded by asking the participants what would help them in a new search system. The task perspective during this first round of interviews gave an overview of user goals and how they achieve them.
3.1.3. Codebook
The interview data were analysed by the first author by applying the codebook with the task known facets to the speech fragments. It was checked whether the codebook was stable (saturated) for describing PW tasks, or whether further unexplained themes were present in the data.
3.2. Round 2 Interviews
A second round of interviews was performed to see if the findings from round 1 were consistent and to determine whether the codebook needed to be extended.
3.2.1. Participants
Five other PWs from the municipality were recruited as participants (three female, two male) working in diverse domains of expertise were approached for the second round of interviews. These users had between 0.5 and 1.5 years of experience.
3.2.2. Interviews
The second round of interviews was conducted in a similar manner to the first round, but an additional list of topics was prepared to investigate.
4. Task Analysis Results
The work and search tasks of PWs are presented based on the interviews conducted. An overview of the PW information seeking process is also presented. Finally, consideration is given to how to better support PW tasks.
4.1. Work Tasks
The work tasks of PWs were characterised by their facets in Table 1 (the facets corresponded to the codes from the codebook). During the second round of interviews, evidence for all work tasks was found, except for WT3 (answering council member questions) and WT6 (performing internal services). No additional work tasks were found, indicating that the most relevant work tasks had been identified. The results are discussed in Table 1 per facet.

Table 1.
Descriptions of work tasks that involve web search tasks.
We now discuss the results for each column. The task IDs are shown in the first column, and an informal task description is provided in the second column. The topic aspect facet encompasses various types of declarative domain knowledge in this area, which is the third column. Our findings suggest that tasks mainly focus on the detailed substance of a topic and the current policy related to it.
Information sources for each task are listed in the fourth column. Multiple tasks identified webpages as an important information source. The main webpages mentioned were those belonging to government entities (local, provincial, and national) and webpages containing public sector research, such as those from national statistics bureaus. The specific set of important webpages differed between PWs, possibly due to their different domains of work, and may even vary between individuals.
There were insufficient data to investigate if there exists a finite and authoritative list of important webpages for each domain. However, it was observed that the web domains owned by the municipality are the most authoritative sources of information, as these are maintained by the colleagues of the users.
A large diversity of retrieval units was found as shown in the fifth column. Information is sought in various forms, such as facts, documents, contact information, or datasets. This diversity is likely a consequence of the study not focusing on specific domains but rather on all PWs. This broad scope means that the results have aggregated tasks from different domains, resulting in some loss of detail on specific tasks.
The estimated task complexity is in the final column, which was validated by a PW in a clarification session. The authors found task complexity and frequency useful during system development to prioritise what features should be developed first and to decide when it is worth investing in specialised search functionality.
4.2. Search Tasks
Supporting PW tasks first requires an understanding of the search tasks that occur. A high-level overview of the search tasks we found is shown in Table 2, and described with more facets in Table 3. During the second round of interviews, we found more evidence for all search tasks except for ST3 (exploring colleagues’ tasks), and found no additional tasks.
Table 2.
High-level descriptions of search tasks.
Table 3.
Descriptions of (web) search tasks using a faceted task classification. The dash line separates which tasks involve searching for people, and involve searching for documents.
The mapping between the work and search tasks is not obvious, unlike the findings of a similar study that was performed with council members [8]. The work tasks of PWs are more domain-dependent than those of council members. Aggregating the tasks from multiple domains mandates adopting a more abstract and generic view level than in the previous work. Because of this, we cannot use the user goals in the work tasks to add context to why a search task is performed. Instead, we add a search task motivation facet to describe the context. It paraphrases the broader purpose that users state for a given search task. We find no mapping between tasks, but note that more complex work tasks seem to include more search tasks as was also found previously [32].
The results in Table 2 are discussed per column. It starts with the facets of task ID, task objective and task motivation. The web search intention [12] is in the fourth column. We find a substantial number of references to navigational tasks, such as ‘(re)finding the most current version of a policy document’. Informational tasks also occur, for which users often report asking for help from a colleague. Most complex tasks are informational tasks. Only users who are the expert on a given topic seem to be willing to invest the time and effort to thoroughly search for information, rather than finding an appropriate internal expert and asking them.
There is a difference between the tasks that were mentioned by PWs and the tasks mentioned by users with other functions as shown in the final columns. Which tasks users perform depends on (at least) their role in the organisation and their experience [33]. PWs have more tasks related to finding data and facts online, whereas others have more tasks that involve finding experts (such as PWs). This reflects the role of PWs as the domain experts that eventually answer specialised questions.
The rest of the task facets is used to characterise the same search tasks in more depth in Table 3. The table starts with the task ID and an informal description of the task objective. The information channels used to complete the task are shown in the third column. The primary channels for finding experts are either networking through colleagues or consulting the Who-Is-Who (WIW) system. This is an internal social media system that presents HR data along with the user’s self-described expertise. There is a large vocabulary gap between colleagues, however (even within the same domain), and not all users enter exhaustive information. It is frequently used to find pictures of colleagues that users are about to meet, but the system does not represent the users’ tasks and responsibilities in a findable way.
Other PW search tasks are primarily performed using search on the web or in personal information systems (usually in email or on the Desktop). The iBabs system is used to archive policy information, although this information is also frequently accessed by users through a web search engine.
The topic aspect reflects what type of declarative domain knowledge is applicable to the task and is recorded in the fourth column. PWs may be interested in different aspects of the same topic, and when they are interested in a particular topic aspect, this changes what they understand as the relevant context. The topic aspect of interest indicates which document genres are relevant (e.g., the document subset containing background information vs. the document subset containing political discussions) and how to present search results in the interface (e.g., using speech fragments as the retrieval unit as opposed to whole documents).
Two types of expertise were found as two different topic aspects: the need for a person with declarative knowledge and the need for a person with procedural knowledge. The knowledge type being sought seems to affect what expert is relevant, although further study is required to understand how this works.
The retrieval unit facet indicates the structure of the information a user is looking for in the sixth column. For policy documents, it is typically the most recent version of a given document. For expertise tasks, this typically includes the person with contact information, and possibly a picture if a face-to-face meeting is likely. Tasks involving datasets benefit from additional context, such as who created it and when, and when it was last updated. We note that some of the retrieval units in search tasks did not appear as retrieval units for work tasks, suggesting the work task in question does not determine the retrieval unit of search tasks. The same goes for the topic aspects.
A large proportion of search tasks have specific rather than amorphous goals as seen in the final column. We observe that the Who-Is-Who system on its own is not able to satisfy specific expert search tasks, which seems to lead to users to falling back to networking with colleagues. There is no adequate representation of declarative or procedural domain knowledge of colleagues, making it challenging to search for these effectively.
A categorisation of the PWs themselves based on their knowledge types [15] reveals that PWs demonstrated expertise with high levels of declarative (what is it) and procedural (how to do it) domain knowledge. They possessed significant declarative search knowledge (where to find it) for tasks within their domain and varied levels of procedural search knowledge (how to find it).
4.3. Overview Information Seeking
In Figure 4, we show a simplified overview of where and how policy workers search. The two main findings are that (1) half of the web search tasks involve finding human sources rather than other sources, and that (2) users face an overload of information when they perform search by themselves. We discuss these points in turn.
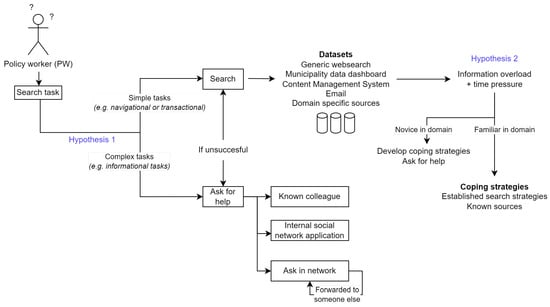
Figure 4.
A simplified overview of information seeking behaviour of policy workers is presented, along with two hypotheses to improve support for their tasks. These were derived from the task analysis.
4.3.1. Role of Expert Search
To contextualise why half of the web search tasks involve finding human sources rather than other sources (see Table 2) we turn to the interviews. Although human sources are known to be important in organisations (e.g., [9,34,35,36]), the municipality was surprised to learn that we found more tasks involving human sources than tasks involving non-human sources. Interviewees noted that this is not only an easier way to search but also yields better results for these tasks. An example of this is found in the role of data coaches. Although these know how to connect users to the correct dataset (ST4), they do not have domain expertise. Because of this, most people-finding tasks look directly for domain experts instead. The following reasons were mentioned on why PWs approach experts:
- The expert knows where relevant data are located, both inside and outside the organisation;
- The expert can give context to the data, e.g., what is trustworthy and worthwhile;
- The expert can give advice on the work task;
- The expert can help avoid performing redundant work;
- The time spent actively searching is reduced.
The reasons above help explain why finding domain experts can be more useful than searching by oneself. The decision to search for an expert has various factors, such as their perceived approachability [9] and individual preferences. We find that experts are primarily approached during complex work tasks (WT2, WT4 and WT5), whereas users do not approach them during simpler work tasks or when they themselves are the expert. We therefore hypothesise that the most important factor for policy workers is whether they perceive a task as complex. Two important aspects of task complexity are the number of subtasks [2] and the task determinability [1] (the level of uncertainty in the task processes and outcomes). If the preferable way to solve complex tasks is to search for experts, then supporting complex tasks would imply integrating expert search functionality. We note that this preference for expert advice appears more relevant in this professional context than in personal search contexts, as previous studies found that users prefer impersonal information sources (e.g., search engines) over interpersonal ones (e.g., experts) during their personal search tasks [37].
4.3.2. Information Overload
Another challenge is that users face an information overload once they search by themselves (PW2: “You don’t know where to search”). This information overload is not unique to policy workers [38]. It exists because there are many information sources and because those sources often include a lot of information that is irrelevant to the PW search tasks. The best example of this is web search: although there are many relevant web resources, this is only a fragment of the whole dataset. Participants indicated the importance of authoritative sources (PW3: “What is the official version [of this document]?”.
Novice PWs noted that the information overload is challenging, which is unsurprising because not only does it take a while to learn effective search strategies in a new domain [39] but it is also more difficult for novices to identify which search results are relevant [40]. Experienced PWs have developed search strategies and know the most pertinent sources to their domain (PW2: “These days I know my way around”). Over time, these coping strategies become part of the information culture of the organisation (e.g., [16] chapter 3, citeDBLP:conf/chi/JonesCDTPDH15) and are taught to novices. Even so, their information seeking still includes uncertainty, and it usually involves high time pressures [27]. For both novice users and experienced users, the combination of information overload and time pressures can be challenging. To deal with information overload, we can develop an information channel that presents users with smaller datasets that contain a larger proportion of useful documents [38].
4.4. Conclusions: How to Better Support PW Web Search Tasks
In the first part of this paper, we characterised the tasks of PWs (RQ1), in order to find how we might better support them (RQ2). The codebook remained unchanged throughout both rounds of the analysis, indicating stability for all task-related themes. This suggests that there are no task facets missing in the task model and that the same model can be used to describe the tasks for both council members and policy workers.
Based on this analysis, we found that PWs use web search as a channel for simple (e.g., navigational/resource) tasks, and they ask colleagues for help for more complex (e.g., informational) tasks. Existing search engines are of limited use for simple search tasks because results from useful and authoritative sources are drowned out by other sources. This problem is largest when searching web sources. To better support simple tasks, we develop a web search engine containing only authoritative sources. The results also suggest that complex tasks would be best supported by integrating expert search functionality. This leads to two hypotheses on how to improve the search experience (RQ2):
H1.
For specific (navigational/resource) tasks during PW web search, a search engine with a focused crawl will be a more usable channel than a generic web search engine.
H2.
For complex web search tasks (in a domain they are not familiar with), PWs will abort searching by themselves to find a colleague/expert on the topic.
The first part of the paper identifies challenges and opportunities in the information-seeking process, resulting in these two hypotheses. Because policy workers at other municipalities have the same tasks, we expect our findings (tasks and hypotheses to support them) to be generalisable. The second part of the paper presents the development of a new search system, which is used to test these hypotheses using simulated tasks.
5. Search System Development
The web-based tasks of PWs were identified. Now, the development of a search engine that better supports these tasks is described. Designing a system is not an exact science, but we found that characterising the users’ tasks is more useful than having the generic user stories that were typically available when designing search engines at the municipality. The approach is shown in Figure 5, where the different facets in the task model informed different aspects of the system design.
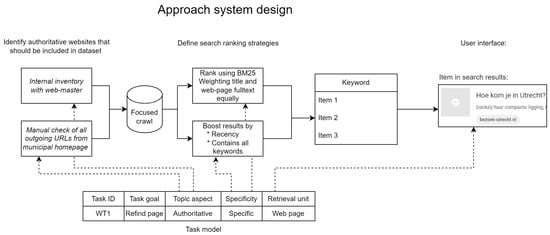
Figure 5.
Development of the proposed search system was informed by the tasks previously identified. Different task facets informed different aspects of the system design.
The UI elements and ranking functions are informed by the task descriptions. The paper describes only the system elements that are relevant for testing the hypotheses.
5.1. Focused Crawl
A total of 40 domains were identified to be included in the focused crawl, consisting of 17 domains from an internal inventory and 23 additional domains found by manually inspecting all 6553 outgoing links from the municipality’s homepage. Organisations that catalogue their web resources can bypass this inventory process.
5.2. UI Elements
A minimal interface was developed to search the authoritative sources, where the search results display the title of the webpage, its domain, and a brief description as shown in Figure 6. The descriptions of the search results are based on the meta-data description of the webpage, which outlines its contents. In cases where this description is unavailable, the interface provides data-driven snippets, which include the first sentence on a page containing a query term.
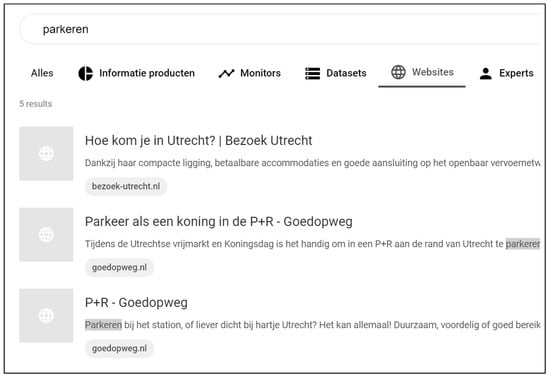
Figure 6.
The document search vertical for searching in authoritative information sources on the web.
5.3. Ranking Functions
Authoritative sources were selected for the focused crawl. A basic BM25F ranking function was constructed based on experimentation, which weights the webpage title, keywords (if available) and fulltext content equally. Whenever the substring “municipality utrecht” was present in the query, we filtered it out (users tended to add it unnecessarily due to their prior experience with web search). To boost the score of documents based on their recency, we used a linear function. The most recent documents in the set had their score multiplied by 1.5, while the oldest documents were multiplied by 1.0.
6. Method
The best search engine is the one that best supports the tasks it is used for [41]. This concerns more variables than just, for example, ranking, and hence we measure the overall usability of the system for the tasks that were identified [42]. Usability consists of effectiveness, efficiency and user satisfaction [43]. These are metrics of both the task process and the task outcome as necessary for a complete task-based evaluation [44]. Additionally, basic search behaviour statistics were tracked. This methodology is similar to that of previous studies, such as the work of Arguello et al. [45]. However, unlike Arguello et al., our evaluation measured task effectiveness based on task outcomes instead of relying on self-reported measures.
Effectiveness, efficiency and search behaviour were measured by (simulated) task performance, and an anonymous post-experiment questionnaire was used to measure user satisfaction.
The effectiveness of a search engine using only authoritative sources (web domains owned by the municipality) was investigated in this study, with the potential for expanding the list of authoritative sources in the future. A challenge in this approach is the variety of systems and search methods utilised by PWs, including preference for different search engines (e.g., Google or Bing) and methods of search (e.g., web search or direct navigation to known webpages). The proposed search engine was intended to supplement the current information eco-system of the municipality and was compared to current search strategies used by PWs, such as generic web search engines, searching the municipality’s homepage, or direct navigation to known pages.
6.1. Task Construction
Because simulated tasks should be realistic and engaging [46,47], the tasks were adapted from real tasks that PWs have performed.
6.1.1. Simple Tasks
Eight simulated tasks were generated by asking PWs to recall and perform simple search tasks they had recently completed. Each task consisted of a sentence providing context for the work task (i.e., what the user wants to do with the information) followed by a sentence describing the search task (i.e., what information the user needs to find). For example, one task was to find a page on the municipality website with a link to the latest version of a policy document titled “Wijkaanpak Overvecht”.
6.1.2. Complex Tasks
Four complex tasks were adapted from information-seeking requests in the mailboxes of policy workers. At least one sentence of the work task context and at least one sentence of the search task context were included in each of the four tasks. These tasks were considered more complex than the simple tasks identified earlier, as they have lower a priori determinability [1,48] and more subtasks [32]. An example of such a task is ‘Suppose a new playground is planned for neighbourhood x. What is the estimated number of households and children in this area?’.
6.2. Task Design
Out of twelve possible tasks, six tasks were assigned to each participant. They completed half of them using the proposed system, and half using any other existing methods. These two conditions are referred to as ‘Proposed system’ and ‘Other’. In each condition, participants completed two simple tasks and one complex task. Half the participants started with one condition, and half with the other. For every two participants, a random selection of tasks was made, where every second participant completed the ones the previous participant did not. These tasks were presented in a random order.
In the study, each task was designed to last until an answer that the participant finds satisfactory is found, a 5 min time limit is reached, or the participant gives up on searching. If the participant stops searching early, they are asked how they would proceed if they needed the information for their work.
6.3. Participants
Fifty people who work with policy information were invited to participate, and 16 respondents (8 female) ended up taking part in the study. Age was not recorded, but the post-experiment questionnaire showed that the participants had an average of 8.5 years of experience working on policy, with only one third of them having fewer than 6 years of experience. After the experiment, 11 of the participants completed an anonymous post-interview questionnaire.
6.4. Data Preparation
Results from one task were dropped due to an interruption affecting the measurements. Additionally, three further tasks were lost due to a corrupted file. The analysis presented below is based on the remaining 92 tasks ().
6.5. Metrics
Search task completion was investigated using effectiveness, efficiency and search satisfaction. Independent tests were conducted for each of these metrics, as they have been found to have little correlation [49,50]. Basic search behaviour was also analysed independently.
Effectiveness was measured as the proportions of tasks that were completed correctly, incorrectly (when inaccurate results were accepted by participants), and incompletely (when participants ran out of time or stopped). In cases where a task was incomplete, participants were asked how they would proceed if they required the information for their work. Efficiency was measured as the time taken to complete a task (in seconds), with a maximum time limit of 300 s.
The system usability scale (SUS) questionnaire was used to measure user satisfaction [51]. While it does not directly measure satisfaction, it is a commonly used usability metric for test-level satisfaction, which measures usability for the entire test session rather than measuring it for each individual task [52].
Basic search behaviour was recorded, including the number of queries, clicks, and direct URL navigations. Additionally, the number of search engines used was recorded (e.g., a search result might have its own local search).
Significant effects on efficiency (in time) and satisfaction (SUS score) were tested using an analysis of variance (ANOVA). For measuring significant effects on task effectiveness, a multinomial logistic regression was used instead, as it can handle the categorical dependent variable. The independent variables in these tests were the task complexity (simple or complex) and the system used (proposed/other).
7. Results
Hypothesis H1, regarding whether search results are obfuscated in generic web search engines, is tested by reporting on the effectiveness and efficiency of task completion. Hypothesis H2, regarding whether users solve complex information tasks by asking colleagues for help, is investigated by asking users open questions when they give up on searching or run out of time.
7.1. Effectiveness
Participant effectiveness using the search engines is shown in Table 4. In some cases, users completed tasks by providing incorrect answers or approximately correct answers. An incorrect answer is defined as one where the user ended the search task, but it would not satisfy the work task upon closer inspection. For instance, users were required to identify the name of the alderman for secondary education, whereas some users found the name of the alderman for primary education instead. An approximately correct answer is when a participant used a known dataset to approximate the correct answer. Another example is when a participant found a summary of the target document rather than that document itself.
Table 4.
Results from comparing the proposed system to existing search methods. Task completion was defined as when the search ends with a correct, approximately correct or incorrect result. Additionally, tasks could also end when the user decided to ask for advice or reached the time limit. Time spent searching was reported for multiple outcomes, such as task completion and stopping search to ask an expert instead. The number of search engines and search actions were reported per task.
It was found that participants were less effective at completing complex tasks, which was as expected. Participants who did not complete a task were asked about their next steps to obtain the information needed for their work. All participants responded that they would ask their colleagues for help, although some considered searching for a while longer before doing so. The reasons for stopping search have been investigated in previous studies, with factors such as deadlines and the feedback of colleagues [27]. These findings are consistent with the idea that users may choose to seek assistance from colleagues to complete sub-tasks within a search.
Multinomial logistic regression was performed to compare the effectiveness of the proposed and other approaches. The results showed that both the task complexity (p = 0.00374, odds ratio = 0.077) and the search engine effects (p = 0.0416, odds ratio = 10.7) were significant factors when comparing the correctly completed tasks to the incorrectly completed tasks. When comparing the correctly completed tasks to the incomplete tasks, only the task complexity had a significant effect (p « 0.001, odds ratio = 0.0093), while the search engine did not (p = 0.59, odds ratio = 1.52). These findings suggest that the choice of search engine did not affect the likelihood of finding a correct result but that using the proposed system was better for avoiding incorrect results. Additionally, the odds ratios indicated that the search engine had a stronger impact on correct task completion than the task complexity.
7.2. Efficiency
The efficiency of tasks performed in the proposed system was compared to those using other search engines to determine whether the proposed system was more efficient in supporting the tasks. Table 4 displays the results, which indicate that in the proposed system, searching was faster and required fewer actions than the other strategies. In general, complex tasks took significantly longer than simple tasks.
A factorial ANOVA was performed to determine whether tasks were performed more efficiently depending on the choice of search engine. The dependent variable was time (in seconds), and the independent variables were task complexity (simple or complex) and search engine (proposed or other). The results showed that both the task complexity () and search engine ( ) had significant effects, while the interaction effect was not significant (, not significant). These results indicate that using the proposed system was more efficient and that simple tasks were completed more quickly. The effect sizes suggest that changes in task complexity had a much larger impact on efficiency than the choice of search engine.
As time went on, users were increasingly likely to stop searching and instead ask colleagues for advice (see Figure 7 and Figure 8), in what seems to be a linear relationship. If a task was not completed, participants were asked how they would proceed if they needed the information for their work. All said that they would find or approach an expert. It may therefore make sense to integrate expert search functionality in the web search engine, especially if a search session has been going on for some minutes. Previous studies found that participants spend longer searching during web search (a median of 10 min) [53], which may be because professional search has a lower barrier to asking for help.

Figure 7.
How much time was spent before users gave up searching by themselves and instead approached an expert.

Figure 8.
How many actions were performed before users gave up searching by themselves and instead approached an expert.
7.3. User Satisfaction
Based on the participants’ responses to the questionnaires, we found that the user satisfaction with the proposed system was average. The score on the system usability scale (SUS) was 69.25, which is an average usability score. Participants also reported an average ‘overall affect’ of the proposed system of 3.7 out of 5, and an ‘average desire to use the system’ of 3.4 out of 5.
7.4. Search Behaviour
The usage of basic search actions in successful search strategies was measured to consider if the system affected search behaviour. As presented in Table 4, it was found that overall fewer search actions were required when using the proposed system compared to the participants’ existing methods. In general, complex tasks required twice as many actions as simple tasks, and as the tasks became more complex, there was an increase in the proportion of navigational actions on each search result.
When not using the proposed search engine, the participants used generic web search engines and/or the one on the municipality’s homepage. In addition, site-scoped search engines on the webpages discovered through the SERP were used. A distinction between successful search strategies using a shallow’/query-based search and a more deep’/navigational search is suggested by these results. In the former, participants rely solely on the search engine and consider only the pages on the SERP as viable results. In contrast, in the latter, participants engage more with each page by directly navigating to it or clicking links.
A factorial ANOVA was performed to test whether the search became more navigational depending on task complexity and search engine used. The dependent variable was the proportion of search actions that were navigational actions (normalised to 0–1), and the independent variables were task complexity and search engines used. The results indicated that task complexity was a significant factor (), whereas the search engine used was not significant (, not significant). This suggests that more complex tasks required more navigational search behaviour to complete correctly, but the search engine used did not affect this behaviour.
A significant interaction effect was found between the task complexity and the search engine, with a (. In the proposed system, a navigational strategy was a significant factor for success in completing complex tasks. It is suggested that this may be due to the limited scope of webpages available in the proposed system, which may have forced users to engage more deeply with the pages available.
8. Discussion
Although low sample sizes were used in both studies, the findings were consistent between two different groups of policy workers, suggesting both that findings are consistent and that we identified the most important tasks. A study conducted with council members found that tasks of a user group with the same function were consistent across municipalities [8]. If the tasks identified in this study are generalisable to other municipalities, then the quantitative findings are also expected to hold true. Additional municipalities can be supported by the search engine by including the authoritative sources relevant to those municipalities.
Overall, the findings of this study are consistent with previous literature on PW information seeking. More specific details were found about the tasks that they perform and on how to support them. It was suggested that knowledge workers, such as policy workers, would greatly benefit if their organisations improved the tools for (internal) expert search.
9. Conclusions
Although previous work presented both generic task models and domain-specific search engines, it is less clear how to combine these two. This paper presents how to combine the two by adapting the generic model for the purpose of developing specific applications. The search tasks of policy workers (PWs) were characterised, and a search engine was developed to improve the support provided for these tasks. In the first part of the paper, an explorative task analysis was conducted to identify and characterise work tasks and search tasks using a faceted task model (RQ1). PWs have different challenges during simple tasks and complex tasks, and these challenges are the largest when performing web search. Existing web search engines are not effective in supporting simple tasks, as authoritative sources are drowned out by less authoritative sources. For complex informational tasks, PWs typically seek assistance from colleagues instead of attempting to search on their own. Complex tasks can be supported by integrating expert search functionality. Two hypotheses were formulated by comparing these findings to existing information systems, with the goal of improving support for PW tasks.
In the second part, a search system was developed to better support PWs, and two hypotheses were tested (RQ2). The first hypothesis proposed that simple tasks could be better supported by a search engine containing only authoritative sources. The second hypothesis states that users would abandon search during complex tasks in favour of seeking advice from colleagues. In an experiment based on real tasks, PWs performed simulated tasks to test these hypotheses.
The hypothesis for simple (navigational/resource) tasks was confirmed, as we found that the search engine with a focused crawl was overall more useful than a generic search engine. The search engine that was used did not affect the chance of obtaining a correct result, but the search engine with only authoritative sources reduced the chance of users accepting incorrect/incomplete information. Furthermore, the proposed system resulted in lower task completion times and generally received positive user satisfaction.
The hypothesis for complex tasks was confirmed, as we found that people tend to abort searching by themselves and instead seek advice from experts. This was attributed to the added value that domain experts provide to the information found, as well as the potential time savings. Therefore, integrating expert search functionality provides valuable support for complex tasks. The municipality was surprised to find that human information sources are more important than non-human sources. All participants gave up on searching by themselves after a few minutes, and instead wanted to approach a colleague for help. The data suggests a linear relationship between the time spent searching and the likelihood of seeking help from a colleague.
As web tasks became more complex, less ‘shallow’ search behaviour was exhibited by users, and more ‘navigational’ behaviour was observed. In the former behaviour, participants mainly interacted by querying and investigating search results. In the latter, they interacted more with each page they visited, by clicking links or searching on the website of a search result.
A limitation of the work is that the qualitative studies were conducted with small sample sizes. Additionally, the search engine only addresses the web-search tasks of policy workers (because at this organisation, other search engines proved sufficient for the other tasks). There is a limit on how well the findings of this study generalise to other users and organisations because we focused on a single user at a single organisation. Future work could quantify how often people in other roles and at other organisations choose to abandon or skip using a search engine in favour of asking colleagues for help. If similar behaviours are found, it would emphasise the importance of properly integrating people as search results within (web) search results. An example could be to perform expert search (see, for example, [54]) and integrate the resulting experts within the (web) search results during long search tasks.
In conclusion, by conducting a task analysis of PWs, we identified tasks that lacked adequate support. A search engine was developed to better support simple (navigational/resource) tasks of PWs, and it was found that complex (informational) tasks can be better supported by integrating expert search functionality. Search functionality for web-based search tasks can be standardised for (at least Dutch) municipalities, given that PWs at different municipalities perform similar tasks.
Author Contributions
T.S. was responsible for the conceptualisation, design and conduction of the studies, as well as writing the first draft of the paper. This was performed under the supervision of T.P. The visualisations were created by T.S. and T.P. All authors contributed to the review and editing of this paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the municipality of Utrecht (no grant number).
Institutional Review Board Statement
The study was conducted in accordance with the policies of the municipality of Utrecht. For further adherence to the Declaration of Helsinki, the protocol is currently under review for the Ethics Committee of the Geoscience Faculty of the Utrecht University.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the studies.
Data Availability Statement
The data presented in this study are not publicly available due to ethical and privacy considerations. We obtained this data and the informed consent on the condition of anonimising the data by analysing it at group level.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Capra, R.; Arguello, J.; O’Brien, H.; Li, Y.; Choi, B. The Effects of Manipulating Task Determinability on Search Behaviors and Outcomes. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR 2018, Ann Arbor, MI, USA, 8–12 July 2018; Collins-Thompson, K., Mei, Q., Davison, B.D., Liu, Y., Yilmaz, E., Eds.; Association for Computing Machinery: Ann Arbor, MI, USA; New York, NY, USA, 2018; pp. 445–454. [Google Scholar] [CrossRef]
- Li, Y.; Belkin, N.J. A faceted approach to conceptualizing tasks in information seeking. Inf. Process. Manag. 2008, 44, 1822–1837. [Google Scholar] [CrossRef]
- Verberne, S.; He, J.; Wiggers, G.; Russell-Rose, T.; Kruschwitz, U.; de Vries, A.P. Information search in a professional context-exploring a collection of professional search tasks. arXiv 2019, arXiv:1905.04577. [Google Scholar]
- Walter, L.; Denter, N.M.; Kebel, J. A review on digitalization trends in patent information databases and interrogation tools. World Pat. Inf. 2022, 69, 102107. [Google Scholar] [CrossRef]
- Heidari, M.; Zad, S.; Berlin, B.; Rafatirad, S. Ontology creation model based on attention mechanism for a specific business domain. In Proceedings of the 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 21–24 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Findwise. Enterprise Search and Findability Survey 2015. 2015. Available online: https://findwise.com/en/enterprise-search-and-findability-survey-2015 (accessed on 27 October 2019).
- Network, T.S. Search Insights 2018. 2018. Available online: https://searchexplained.com/shop/books/book-search-insights-2018/ (accessed on 27 June 2023).
- Schoegje, T.; de Vries, A.P.; Pieters, T. Adapting a Faceted Search Task Model for the Development of a Domain-Specific Council Information Search Engine. In Proceedings of the Electronic Government—21st IFIP WG 8.5 International Conference, EGOV 2022, Linköping, Sweden, 6–8 September 2022; Janssen, M., Csáki, C., Lindgren, I., Loukis, E.N., Melin, U., Pereira, G.V., Bolívar, M.P.R., Tambouris, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13391, pp. 402–418. [Google Scholar] [CrossRef]
- Saastamoinen, M.; Kumpulainen, S. Expected and materialised information source use by municipal officials: Intertwining with task complexity. Inf. Res. 2014, 19, 646. [Google Scholar]
- Byström, K.; Hansen, P. Conceptual framework for tasks in information studies. J. Am. Soc. Inf. Sci. Technol. 2005, 56, 1050–1061. [Google Scholar] [CrossRef]
- Broder, A.Z. A taxonomy of web search. SIGIR Forum 2002, 36, 3–10. [Google Scholar] [CrossRef]
- Rose, D.E.; Levinson, D. Understanding user goals in web search. In Proceedings of the Proceedings of the 13th international conference on World Wide Web WWW, New York, NY, USA, 17–20 May 2004; Feldman, S.I., Uretsky, M., Najork, M., Wills, C.E., Eds.; Association for Computing Machinery: New York, NY, USA, 2004; pp. 13–19. [Google Scholar] [CrossRef]
- Alexander, D.; Kusa, W.; de Vries, A.P. ORCAS-I: Queries Annotated with Intent using Weak Supervision. arXiv 2022, arXiv:2205.00926. [Google Scholar]
- Choi, B.; Arguello, J.; Capra, R. Understanding Procedural Search Tasks “in the Wild”. In Proceedings of the 2023 Conference on Human Information Interaction and Retrieval, CHIIR 2023, Austin, TX, USA, 19–23 March 2023; Gwizdka, J., Rieh, S.Y., Eds.; Association for Computing Machinery: New York, NY, USA, 2023; pp. 24–33. [Google Scholar] [CrossRef]
- Ingwersen, P.; Järvelin, K. The Turn-Integration of Information Seeking and Retrieval in Context; The Kluwer International Series on Information Retrieval; Springer: Dordrecht, The Netherlands, 2005; Volume 18. [Google Scholar] [CrossRef]
- Byström, K.; Heinström, J.; Ruthven, I. Information at Work: Information Management in the Workplace; Facet Publishing: London, UK, 2019. [Google Scholar]
- Shah, C.; White, R.; Thomas, P.; Mitra, B.; Sarkar, S.; Belkin, N.J. Taking Search to Task. In Proceedings of the 2023 Conference on Human Information Interaction and Retrieval, CHIIR 2023, Austin, TX, USA, 19–23 March 2023; Gwizdka, J., Rieh, S.Y., Eds.; ACM: New York, NY, USA, 2023; pp. 1–13. [Google Scholar] [CrossRef]
- Aliannejadi, M.; Harvey, M.; Costa, L.; Pointon, M.; Crestani, F. Understanding Mobile Search Task Relevance and User Behaviour in Context. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, CHIIR 2019, Glasgow, UK, 10–14 March 2019; pp. 143–151. [Google Scholar] [CrossRef]
- Yang, Y.; Capra, R. Nested Contexts of Music Information Retrieval: A Framework of Contextual Factors. In Proceedings of the 2023 Conference on Human Information Interaction and Retrieval, CHIIR 2023, Austin, TX, USA, 19–23 March 2023; Gwizdka, J., Rieh, S.Y., Eds.; ACM: New York, NY, USA, 2023; pp. 368–372. [Google Scholar] [CrossRef]
- Cambazoglu, B.B.; Tavakoli, L.; Scholer, F.; Sanderson, M.; Croft, W.B. An Intent Taxonomy for Questions Asked in Web Search. In Proceedings of the CHIIR ’21: ACM SIGIR Conference on Human Information Interaction and Retrieval, Canberra, ACT, Australia, 14–19 March 2021; Scholer, F., Thomas, P., Elsweiler, D., Joho, H., Kando, N., Smith, C., Eds.; ACM: New York, NY, USA, 2021; pp. 85–94. [Google Scholar] [CrossRef]
- Trippas, J.R.; Spina, D.; Scholer, F.; Awadallah, A.H.; Bailey, P.; Bennett, P.N.; White, R.W.; Liono, J.; Ren, Y.; Salim, F.D.; et al. Learning About Work Tasks to Inform Intelligent Assistant Design. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, CHIIR 2019, Glasgow, UK, 10–14 March 2019; Azzopardi, L., Halvey, M., Ruthven, I., Joho, H., Murdock, V., Qvarfordt, P., Eds.; ACM: New York, NY, USA, 2019; pp. 5–14. [Google Scholar] [CrossRef]
- Wildman, J.L.; Thayer, A.L.; Rosen, M.A.; Salas, E.; Mathieu, J.E.; Rayne, S.R. Task types and team-level attributes: Synthesis of team classification literature. Hum. Resour. Dev. Rev. 2012, 11, 97–129. [Google Scholar] [CrossRef]
- Benetka, J.R.; Krumm, J.; Bennett, P.N. Understanding Context for Tasks and Activities. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, CHIIR 2019, Glasgow, Scotland, UK, 10–14 March 2019; Azzopardi, L., Halvey, M., Ruthven, I., Joho, H., Murdock, V., Qvarfordt, P., Eds.; ACM: New York, NY, USA, 2019; pp. 133–142. [Google Scholar] [CrossRef]
- Segura-Rodas, S.C. What tasks emerge from Knowledge Work? In Proceedings of the 2023 Conference on Human Information Interaction and Retrieval, CHIIR 2023, Austin, TX, USA, 19–23 March 2023; Gwizdka, J., Rieh, S.Y., Eds.; ACM: New York, NY, USA, 2023; pp. 495–498. [Google Scholar] [CrossRef]
- Taylor, R.S. Information use environments. Prog. Commun. Sci. 1991, 10, 55. [Google Scholar]
- Taylor, R.S.; Taylor, R.S. Value-Added Processes in Information Systems; Greenwood Publishing Group: Norwood, NJ, USA, 1986. [Google Scholar]
- Berryman, J.M. What defines ’enough’ information? How policy workers make judgements and decisions during information seeking: Preliminary results from an exploratory study. Inf. Res. 2006, 11, 4. [Google Scholar]
- Crawford, J.; Irving, C. Information literacy in the workplace: A qualitative exploratory study. JOLIS 2009, 41, 29–38. [Google Scholar] [CrossRef]
- van Deursen, A.; van Dijk, J. Civil Servants’ Internet Skills: Are They Ready for E-Government? In Proceedings of the Electronic Government, 9th IFIP WG 8.5 International Conference, EGOV 2010, Lausanne, Switzerland, 29 August–2 September 2010; Wimmer, M.A., Chappelet, J., Janssen, M., Scholl, H.J., Eds.; Springer: Berlin, Germany; Lausanne, Switzerland, 2010; Volume 6228, pp. 132–143. [Google Scholar] [CrossRef]
- Kaptein, R.; Marx, M. Focused retrieval and result aggregation with political data. Inf. Retr. 2010, 13, 412–433. [Google Scholar] [CrossRef]
- Erjavec, T.; Ogrodniczuk, M.; Osenova, P.; Ljubešić, N.; Simov, K.; Pančur, A.; Rudolf, M.; Kopp, M.; Barkarson, S.; Steingrímsson, S.; et al. The ParlaMint corpora of parliamentary proceedings. Lang. Resour. Eval. 2022, 56, 1–34. [Google Scholar] [CrossRef] [PubMed]
- Li, Y. Exploring the relationships between work task and search task in information search. JASIST 2009, 60, 275–291. [Google Scholar] [CrossRef]
- Hackos, J.T.; Redish, J. User and Task Analysis for Interface Design; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Lykke, M.; Bygholm, A.; Søndergaard, L.B.; Byström, K. The role of historical and contextual knowledge in enterprise search. J. Doc. 2021, 78, 1053–1074. [Google Scholar] [CrossRef]
- Morris, M.R.; Teevan, J.; Panovich, K. What do people ask their social networks, and why?: A survey study of status message q&a behavior. In Proceedings of the 28th International Conference on Human Factors in Computing Systems, CHI 2010, Atlanta, GA, USA, 10–15 April 2010; Mynatt, E.D., Schoner, D., Fitzpatrick, G., Hudson, S.E., Edwards, W.K., Rodden, T., Eds.; Association for Computing Machinery: Atlanta, GA, USA; New York, NY, USA, 2010; pp. 1739–1748. [Google Scholar] [CrossRef]
- Oeldorf-Hirsch, A.; Hecht, B.J.; Morris, M.R.; Teevan, J.; Gergle, D. To search or to ask: The routing of information needs between traditional search engines and social networks. In Proceedings of the Computer Supported Cooperative Work, CSCW ’14, Baltimore, MD, USA, 15–19 February 2014; Fussell, S.R., Lutters, W.G., Morris, M.R., Reddy, M., Eds.; Association for Computing Machinery: Baltimore, MD, USA; New York, NY, USA, 2014; pp. 16–27. [Google Scholar] [CrossRef]
- Wang, Y.; Sarkar, S.; Shah, C. Juggling with Information Sources, Task Type, and Information Quality. In Proceedings of the 2018 Conference on Human Information Interaction and Retrieval, CHIIR 2018, New Brunswick, NJ, USA, 11–15 March 2018; Shah, C., Belkin, N.J., Byström, K., Huang, J., Scholer, F., Eds.; ACM: New York, NY, USA, 2018; pp. 82–91. [Google Scholar] [CrossRef]
- Freund, L.; Toms, E.G.; Waterhouse, J. Modeling the information behaviour of software engineers using a work-task framework. In Proceedings of the Sparking Synergies: Bringing Research and Practice Together-Proceedings of the 68th ASIS&T Annual Meeting, ASIST 2005, Charlotte, NC, USA, 28 October–2 November 2005; Volume 42. [Google Scholar] [CrossRef]
- Russell-Rose, T.; Chamberlain, J. Expert search strategies: The information retrieval practices of healthcare information professionals. JMIR Med. Inform. 2017, 5, e7680. [Google Scholar] [CrossRef]
- Saracevic, T. Relevance: A review of the literature and a framework for thinking on the notion in information science. Part II: Nature and manifestations of relevance. J. Assoc. Inf. Sci. Technol. 2007, 58, 1915–1933. [Google Scholar] [CrossRef]
- Liu, C.; Liu, Y.; Liu, J.; Bierig, R. Search Interface Design and Evaluation. Found. Trends Inf. Retr. 2021, 15, 243–416. [Google Scholar] [CrossRef]
- Joho, H. Diane Kelly: Methods for evaluating interactive information retrieval systems with users—Foundation and Trends in Information Retrieval, vol 3, nos 1-2, pp 1-224, 2009, ISBN: 978-1-60198-224-7. Inf. Retr. 2011, 14, 204–207. [Google Scholar] [CrossRef]
- 9241-11; Ergonomic Requirements for Office Work with Visual Display Terminals (VDTs). The International Organization for Standardization: Geneva, Switzerland, 1998; Volume 45.
- Shah, C.; White, R.W. Task Intelligence for Search and Recommendation; Synthesis Lectures on Information Concepts, Retrieval, and Services, Morgan & Claypool Publishers: San Rafael, CA, USA, 2021. [Google Scholar] [CrossRef]
- Arguello, J.; Wu, W.; Kelly, D.; Edwards, A. Task complexity, vertical display and user interaction in aggregated search. In Proceedings of the 35th International ACM SIGIR conference on research and development in Information Retrieval, SIGIR ’12, Portland, OR, USA, 12–16 August 2012; Hersh, W.R., Callan, J., Maarek, Y., Sanderson, M., Eds.; Association for Computing Machinery: Portland, OR, USA; New York, NY, USA, 2012; pp. 435–444. [Google Scholar] [CrossRef]
- Hienert, D.; Mitsui, M.; Mayr, P.; Shah, C.; Belkin, N.J. The Role of the Task Topic in Web Search of Different Task Types. In Proceedings of the 2018 Conference on Human Information Interaction and Retrieval, CHIIR 2018, New Brunswick, NJ, USA, 11–15 March 2018; Shah, C., Belkin, N.J., Byström, K., Huang, J., Scholer, F., Eds.; Association for Computing Machinery: New Brunswick, NJ, USA; New York, NY, USA, 2018; pp. 72–81. [Google Scholar] [CrossRef]
- Kelly, D.; Arguello, J.; Edwards, A.; Wu, W. Development and Evaluation of Search Tasks for IIR Experiments using a Cognitive Complexity Framework. In Proceedings of the 2015 International Conference on The Theory of Information Retrieval, ICTIR 2015, Northampton, MA, USA, 27–30 September 2015; Allan, J., Croft, W.B., de Vries, A.P., Zhai, C., Eds.; Association for Computing Machinery: Northampton, MA, USA; New York, NY, USA, 2015; pp. 101–110. [Google Scholar] [CrossRef]
- Byström, K.; Järvelin, K. Task Complexity Affects Information Seeking and Use. Inf. Process. Manag. 1995, 31, 191–213. [Google Scholar] [CrossRef]
- Frøkjær, E.; Hertzum, M.; Hornbæk, K. Measuring usability: Are effectiveness, efficiency, and satisfaction really correlated? In Proceedings of the CHI 2000 Conference on Human Factors in Computing Systems, The Hague, The Netherlands, 1–6 April 2000; Turner, T., Szwillus, G., Eds.; Association for Computing Machinery: The Hague, The Netherlands; New York, NY, USA, 2000; pp. 345–352. [Google Scholar] [CrossRef]
- Hornbæk, K.; Law, E.L. Meta-analysis of correlations among usability measures. In Proceedings of the 2007 Conference on Human Factors in Computing Systems, CHI 2007, San Jose, CA, USA, 28 April–3 May 2007; Rosson, M.B., Gilmore, D.J., Eds.; Association for Computing Machinery: San Jose, CA, USA; New York, NY, USA, 2007; pp. 617–626. [Google Scholar] [CrossRef]
- Brooke, J. SUS-A quick and dirty usability scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
- Lewis, J.R. The System Usability Scale: Past, Present, and Future. Int. J. Hum. Comput. Interact. 2018, 34, 577–590. [Google Scholar] [CrossRef]
- Teevan, J.; Collins-Thompson, K.; White, R.W.; Dumais, S.T.; Kim, Y. Slow Search: Information Retrieval without Time Constraints. In Proceedings of the Symposium on Human-Computer Interaction and Information Retrieval, HCIR ’13, Vancouver, BC, Canada, 3–4 October 2013; pp. 1–10. [Google Scholar] [CrossRef]
- Balog, K.; Fang, Y.; de Rijke, M.; Serdyukov, P.; Si, L. Expertise Retrieval. Found. Trends Inf. Retr. 2012, 6, 127–256. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).