
Measuring and Understanding Crowdturfing in the App Store

Abstract
:1. Introduction
- We analyze the features of crowdturfing accounts, reviews, and behaviors, then compare them with genuine users to discover differences, giving us new insights into crowdturfing in the App Store. Our disclosure of them will help take further actions and seek more effective detection methods.
- Our research on the delivery time of the crowdsourcing platform that provides reviews informs the size of the sliding window. We divide the process of constructing graphs into smaller tasks along the time dimension, which can reduce overhead and increase efficiency.
- We compare six commonly used machine learning algorithms to reveal which algorithms and features are effective for the detection of crowdturfing reviews. Based on these features, our classifier models achieve the highest accuracy of 98% in detection.
2. Background
2.1. Review System in the App Store
2.2. Metadata Definition
3. Related Work
4. Research Method
4.1. Overview
4.2. Dataset Description
4.2.1. Data Collection
4.2.2. Data Preprocessing
- If the reviews are posted before 31 December 2017, we filter them.
- Filter reviews whose body length is below the predefined threshold.
4.3. Problem Definition
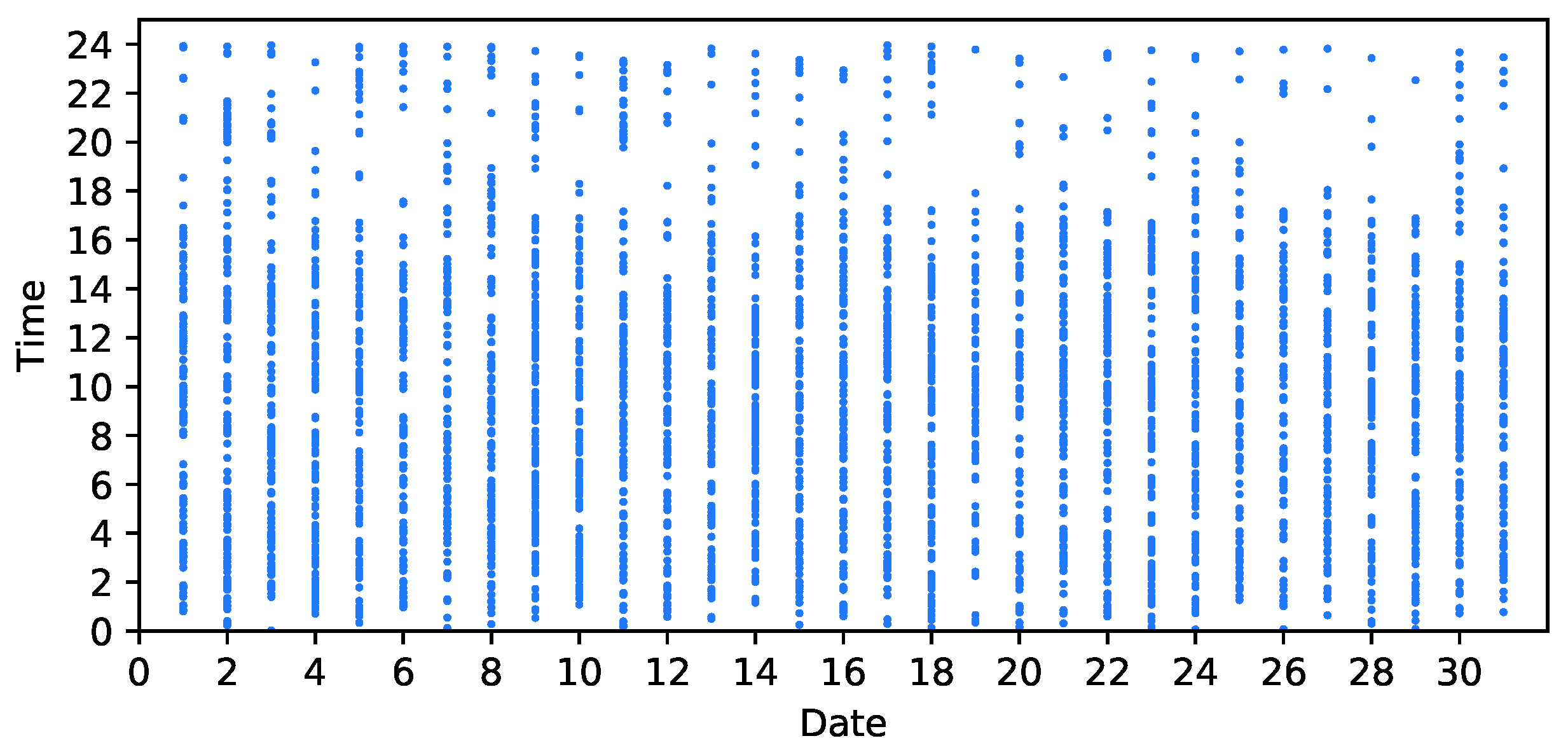
4.4. Sliding Window
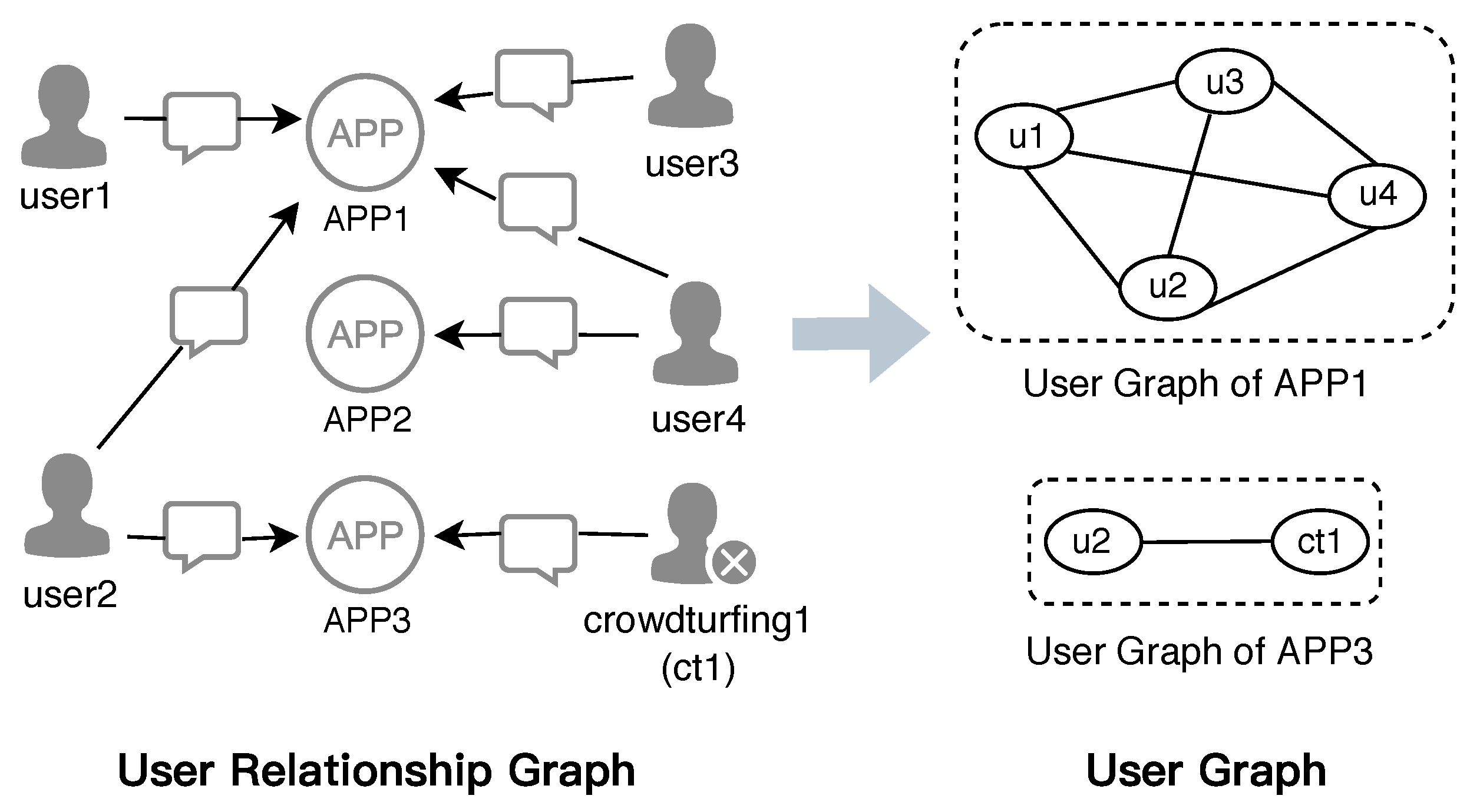
- Window W starts from the date , and the current date range is . There exists a user who posts a review in and another user who posts a review in . Since both comment on , an edge is created between the two vertices. User Graph G currently has 1 edge.
- The window slides back one day with a step width of 1, and the current date range is . There are two new users who post reviews on the new date . Thus, edges are generated between new vertices and between old vertices that exist in the current range, i.e., excluding the vertex corresponding to that is no longer in the current window date range. User Graph G currently has 4 edges.
- The window slides to and the current date range is . New vertices in are connected with vertices in . User Graph G currently has 6 edges.
| Algorithm 1: Framework of sliding window and constructing graph |
 |
4.5. Detecting Communities
5. Measurement
5.1. Ground-Truth Data
5.2. Genuine vs. Crowdturfing Analysis
5.2.1. Star Ratings
5.2.2. Ratio of Positive Reviews
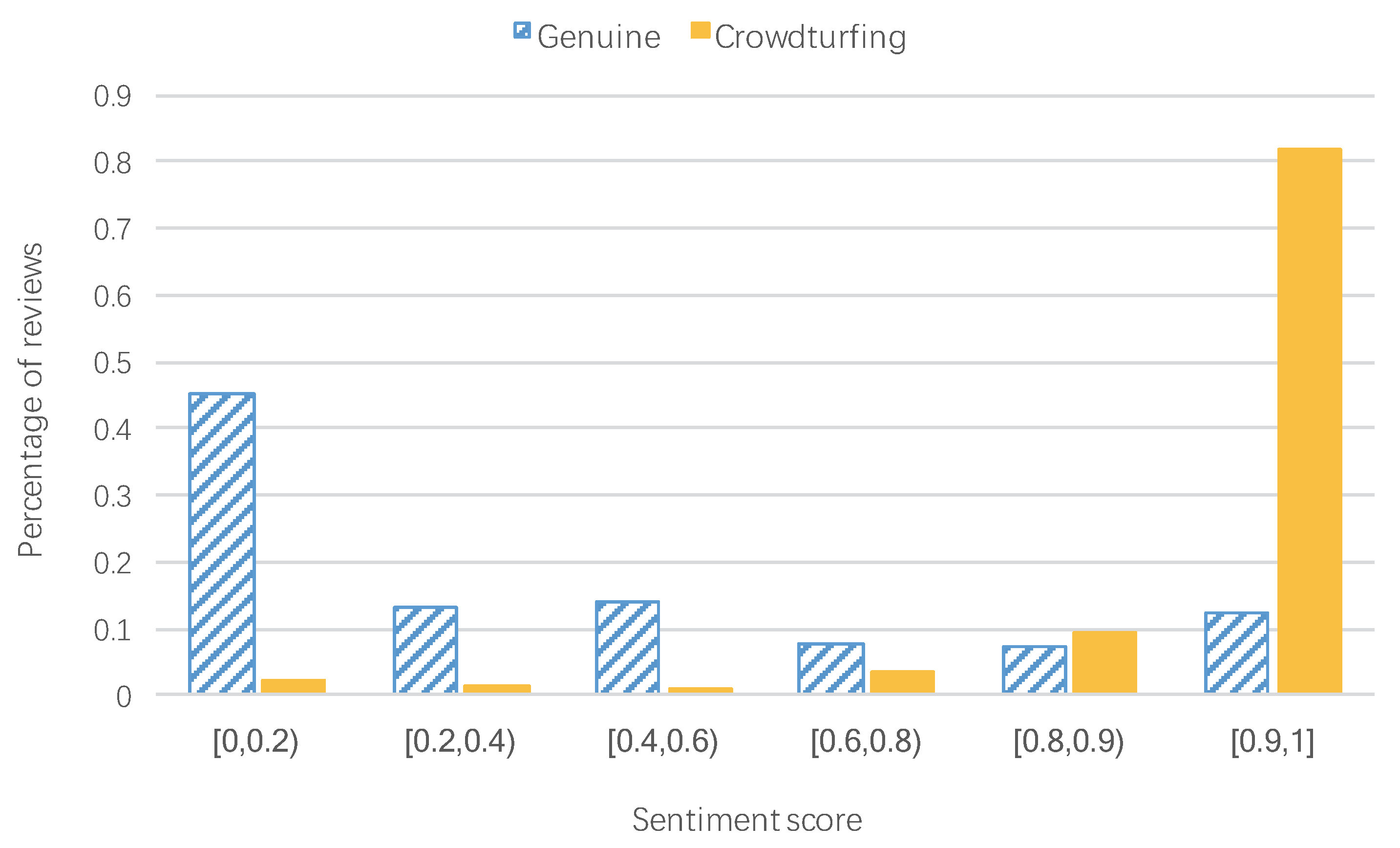
5.2.3. Sentiment Analysis of Review Data
5.3. Crowdturfing Characteristics Analysis
5.3.1. Categories of Apps
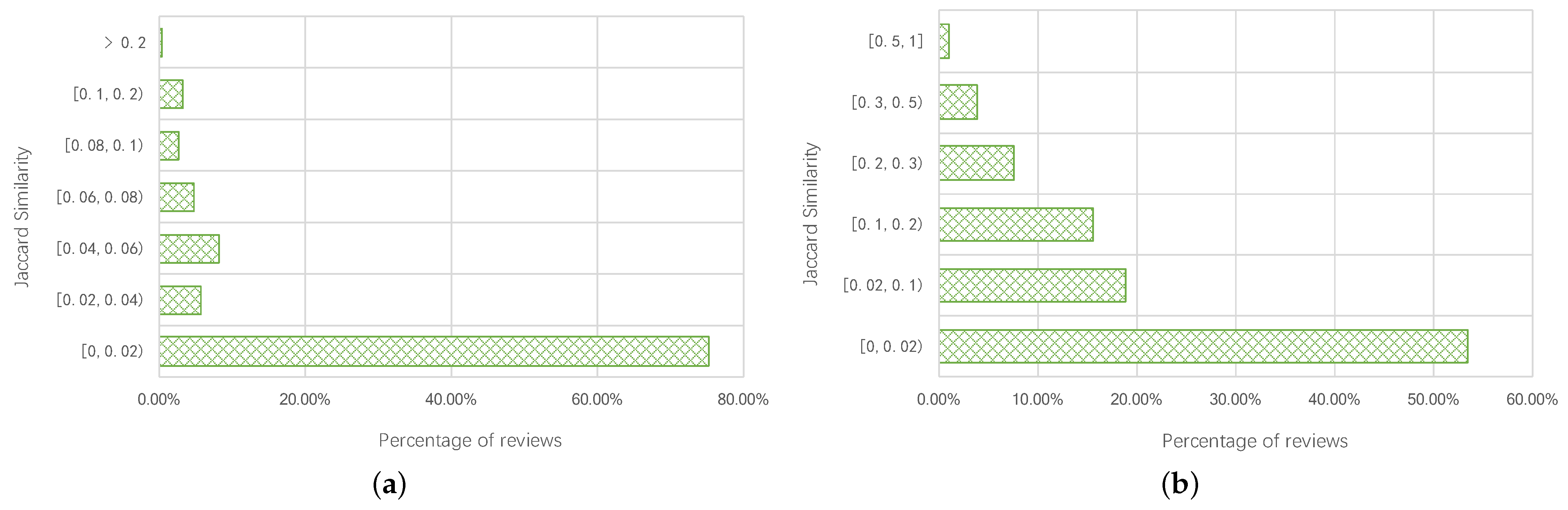
5.3.2. Similarity of Reviews
5.3.3. Common Words
5.3.4. Number of Reviews Provided
5.4. Relations between the Ratio of Crowdturfing Reviews and App Rankings
6. Crowdturfing Detection
6.1. Features Selection
6.2. Evaluation Metrics
6.3. Performance of Classifiers
6.4. Experiments on the Unlabeled Data
6.5. Feature Importance
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, J.; Lee, S.; Kim, J. Crowdtarget: Target-based detection of crowdturfing in online social networks. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 12–16 October 2015; pp. 793–804. [Google Scholar]
- Lee, Y.; Wang, X.; Lee, K.; Liao, X.; Wang, X.; Li, T.; Mi, X. Understanding iOS-based Crowdturfing Through Hidden {UI} Analysis. In Proceedings of the 28th {USENIX} Security Symposium ({USENIX} Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 765–781. [Google Scholar]
- Local Consumer Review Survey. 2023. Available online: https://www.brightlocal.com/research/local-consumer-review-survey/ (accessed on 20 February 2023).
- Shihab, M.R.; Putri, A.P. Negative online reviews of popular products: Understanding the effects of review proportion and quality on consumers’ attitude and intention to buy. Electron. Commer. Res. 2019, 19, 159–187. [Google Scholar] [CrossRef]
- App Store Review Guidelines: Developer Code of Conduct. 2022. Available online: https://developer.apple.com/app-store/review/guidelines/#code-of-conduct (accessed on 7 March 2023).
- Yao, Y.; Viswanath, B.; Cryan, J.; Zheng, H.; Zhao, B.Y. Automated crowdturfing attacks and defenses in online review systems. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 30 October–3 November 2017; pp. 1143–1158. [Google Scholar]
- Su, N.; Liu, Y.; Li, Z.; Liu, Y.; Zhang, M.; Ma, S. Detecting Crowdturfing “Add to Favorites” Activities in Online Shopping. In Proceedings of the 2018 World Wide Web Conference, Republic and Canton of Geneva, CHE, Lyon, France, 23–27 April 2018; pp. 1673–1682. [Google Scholar]
- Feng, Q.; Zhang, Y.; Kuang, L. Crowdturfing Detection in Online Review System: A Graph-Based Modeling. In Proceedings of the Collaborative Computing: Networking, Applications and Worksharing: 17th EAI International Conference, CollaborateCom 2021, Virtual Event, 16–18 October 2021; pp. 352–369. [Google Scholar]
- Liu, B.; Sun, X.; Ni, Z.; Cao, J.; Luo, J.; Liu, B.; Fu, X. Co-Detection of crowdturfing microblogs and spammers in online social networks. World Wide Web 2020, 23, 573–607. [Google Scholar] [CrossRef]
- App Store—Apple. Available online: https://www.apple.com/app-store/ (accessed on 1 January 2023).
- Xie, Z.; Zhu, S. AppWatcher: Unveiling the underground market of trading mobile app reviews. In Proceedings of the 8th ACM Conference on Security & Privacy in Wireless and Mobile Networks, New York, NY, USA, 22–26 June 2015; pp. 1–11. [Google Scholar]
- New “Report a Problem” Link on Product Pages. Available online: https://developer.apple.com/news/?id=j5uyprul (accessed on 20 February 2023).
- App Store Review Guidelines: Business. Available online: https://developer.apple.com/app-store/review/guidelines/#business (accessed on 1 October 2021).
- How to Report a Concern in Google Play and App Store. Available online: https://appfollow.io/blog/how-to-report-a-concern-in-google-play-and-app-store (accessed on 20 February 2023).
- How Do I Report Scam Apps. Available online: https://discussions.apple.com/thread/3801852 (accessed on 20 February 2023).
- Reporting an Apple Store App That Is a SCAM. Available online: https://discussions.apple.com/thread/253565159?answerId=256677556022#256677556022 (accessed on 20 February 2023).
- Enterprise Partner Feed Relational. Available online: https://performance-partners.apple.com/epf (accessed on 1 May 2023).
- Wang, G.; Wilson, C.; Zhao, X.; Zhu, Y.; Mohanlal, M.; Zheng, H.; Zhao, B.Y. Serf and turf: Crowdturfing for fun and profit. In Proceedings of the 21st international Conference on World Wide Web, New York, NY, USA, 16–20 April 2012; pp. 679–688. [Google Scholar]
- Lee, K.; Webb, S.; Ge, H. Characterizing and automatically detecting crowdturfing in Fiverr and Twitter. Soc. Netw. Anal. Min. 2015, 5, 1–16. [Google Scholar] [CrossRef]
- Voronin, G.; Baumann, A.; Lessmann, S. Crowdturfing on Instagram-The Influence of Profile Characteristics on The Engagement of Others. In Proceedings of the Twenty-Sixth European Conference on Information Systems 2016, Portsmouth, UK, 23–28 June 2018. [Google Scholar]
- Kaghazgaran, P.; Caverlee, J.; Squicciarini, A. Combating crowdsourced review manipulators: A neighborhood-based approach. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, New York, NY, USA, 5–9 February 2018; pp. 306–314. [Google Scholar]
- Corradini, E.; Nocera, A.; Ursino, D.; Virgili, L. Investigating negative reviews and detecting negative influencers in Yelp through a multi-dimensional social network based model. Int. J. Inf. Manag. 2021, 60, 102377. [Google Scholar] [CrossRef]
- Corradini, E.; Nocera, A.; Ursino, D.; Virgili, L. Defining and detecting k-bridges in a social network: The yelp case, and more. Knowl.-Based Syst. 2020, 195, 105721. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Corradini, E.; Terracina, G.; Ursino, D.; Virgili, L. Extraction and analysis of text patterns from NSFW adult content in Reddit. Data Knowl. Eng. 2022, 138, 101979. [Google Scholar] [CrossRef]
- Li, S.; Caverlee, J.; Niu, W.; Kaghazgaran, P. Crowdsourced app review manipulation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 7–11 August 2017; pp. 1137–1140. [Google Scholar]
- Saab, F.; Elhajj, I.; Chehab, A.; Kayssi, A. CrowdApp: Crowdsourcing for application rating. In Proceedings of the 2014 IEEE/ACS 11th International Conference on Computer Systems and Applications (AICCSA), Doha, Qatar, 10–13 November 2014; pp. 551–556. [Google Scholar]
- Guo, Z.; Tang, L.; Guo, T.; Yu, K.; Alazab, M.; Shalaginov, A. Deep graph neural network-based spammer detection under the perspective of heterogeneous cyberspace. Future Gener. Comput. Syst. 2021, 117, 205–218. [Google Scholar] [CrossRef]
- Dou, Y.; Li, W.; Liu, Z.; Dong, Z.; Luo, J.; Yu, P.S. Uncovering download fraud activities in mobile app markets. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 671–678. [Google Scholar]
- Hu, Y.; Wang, H.; Ji, T.; Xiao, X.; Luo, X.; Gao, P.; Guo, Y. CHAMP: Characterizing Undesired App Behaviors from User Comments based on Market Policies. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), Virtual, 25–28 May 2021; pp. 933–945. [Google Scholar]
- Joshi, K.; Kumar, S.; Rawat, J.; Kumari, A.; Gupta, A.; Sharma, N. Fraud App Detection of Google Play Store Apps Using Decision Tree. In Proceedings of the 2022 2nd International Conference on Innovative Practices in Technology and Management (ICIPTM), Pradesh, India, 23–25 February 2022; Volume 2, pp. 243–246. [Google Scholar]
- Rathore, P.; Soni, J.; Prabakar, N.; Palaniswami, M.; Santi, P. Identifying groups of fake reviewers using a semisupervised approach. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1369–1378. [Google Scholar] [CrossRef]
- Xu, Z.; Sun, Q.; Hu, S.; Qiu, J.; Lin, C.; Li, H. Multi-view Heterogeneous Temporal Graph Neural Network for “Click Farming” Detection. In Proceedings of the PRICAI 2022: Trends in Artificial Intelligence: 19th Pacific Rim International Conference on Artificial Intelligence, PRICAI 2022, Shanghai, China, 10–13 November 2022; pp. 148–160. [Google Scholar]
- Li, N.; Du, S.; Zheng, H.; Xue, M.; Zhu, H. Fake reviews tell no tales? dissecting click farming in content-generated social networks. China Commun. 2018, 15, 98–109. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef] [Green Version]
- Tang, Z.; Tang, K.; Xue, M.; Tian, Y.; Chen, S.; Ikram, M.; Wang, T.; Zhu, H. iOS, Your {OS}, Everybody’s {OS}: Vetting and Analyzing Network Services of iOS Applications. In Proceedings of the 29th {USENIX} Security Symposium ({USENIX} Security 20), Boston, MA, USA, 12–14 August 2020; pp. 2415–2432. [Google Scholar]
- Beutel, A.; Xu, W.; Guruswami, V.; Palow, C.; Faloutsos, C. Copycatch: Stopping group attacks by spotting lockstep behavior in social networks. In Proceedings of the 22nd International Conference on World Wide Web, New York, NY, USA, 13–17 May 2013; pp. 119–130. [Google Scholar]
- Wang, Z.; Hou, T.; Song, D.; Li, Z.; Kong, T. Detecting review spammer groups via bipartite graph projection. Comput. J. 2016, 59, 861–874. [Google Scholar] [CrossRef]
- Compare Categories. Available online: https://developer.apple.com/app-store/categories/ (accessed on 30 March 2023).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|
| # of reviews | 9,250,284 | 12,189,435 | 8,091,701 | 8,979,512 | 7,135,120 |
| # of users | 7,038,175 | 8,445,133 | 5,821,240 | 6,350,432 | 5,218,392 |
| Category | Feature | Type | Example |
|---|---|---|---|
| User behavior (UB) | # reviews (total) | Int | 11 |
| % positive reviews (4–5 stars) | Float | 0.5 | |
| Review (RE) | Review text | String | Nice. |
| Sentiment score | Float | 0.6163 | |
| Character length | Int | 26 | |
| Rating | Int | 5 |
| Classifier | Features | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| SVM | UB | 0.9394 | 0.9403 | 0.9355 | 0.9403 |
| RE | 0.8952 | 0.8806 | 0.8411 | 0.8806 | |
| UB+RE | 0.9091 | 0.9067 | 0.8887 | 0.9067 | |
| RF | UB | 0.9628 | 0.9627 | 0.9608 | 0.9627 |
| RE | 0.9701 | 0.9701 | 0.9691 | 0.9701 | |
| UB+RE | 0.9775 | 0.9776 | 0.9771 | 0.9776 | |
| MLP | UB | 0.9435 | 0.9440 | 0.9437 | 0.9440 |
| RE | 0.9665 | 0.9664 | 0.9650 | 0.9664 | |
| UB+RE | 0.9668 | 0.9664 | 0.9666 | 0.9664 | |
| DT | UB | 0.9242 | 0.9254 | 0.9247 | 0.9254 |
| RE | 0.9616 | 0.9590 | 0.9598 | 0.9590 | |
| UB+RE | 0.9560 | 0.9515 | 0.9528 | 0.9515 | |
| LR | UB | 0.9624 | 0.9627 | 0.9617 | 0.9627 |
| RE | 0.9550 | 0.9552 | 0.9535 | 0.9552 | |
| UB+RE | 0.9813 | 0.9813 | 0.9811 | 0.9813 | |
| KNN | UB | 0.9560 | 0.9552 | 0.9531 | 0.9552 |
| RE | 0.9296 | 0.9291 | 0.9235 | 0.9291 | |
| UB+RE | 0.9332 | 0.9328 | 0.9280 | 0.9328 |
| Classifier | Features | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| SVM | UB | 0.8702 | 0.8400 | 0.8244 | 0.8400 |
| RE | 0.7918 | 0.6954 | 0.6017 | 0.6954 | |
| UB+RE | 0.8319 | 0.7839 | 0.7506 | 0.7839 | |
| RF | UB | 0.8776 | 0.8627 | 0.8539 | 0.8627 |
| RE | 0.8959 | 0.8814 | 0.8746 | 0.8814 | |
| UB+RE | 0.9083 | 0.8944 | 0.8888 | 0.8944 | |
| MLP | UB | 0.8456 | 0.8473 | 0.8441 | 0.8473 |
| RE | 0.8763 | 0.8733 | 0.8689 | 0.8733 | |
| UB+RE | 0.8829 | 0.8838 | 0.8825 | 0.8838 | |
| DT | UB | 0.8317 | 0.8343 | 0.8317 | 0.8343 |
| RE | 0.8425 | 0.8383 | 0.8299 | 0.8383 | |
| UB+RE | 0.8961 | 0.8944 | 0.8916 | 0.8944 | |
| LR | UB | 0.8888 | 0.8773 | 0.8705 | 0.8773 |
| RE | 0.8853 | 0.8684 | 0.8594 | 0.8684 | |
| UB+RE | 0.8978 | 0.8879 | 0.8824 | 0.8879 | |
| KNN | UB | 0.8672 | 0.8513 | 0.8405 | 0.8513 |
| RE | 0.8703 | 0.8587 | 0.8499 | 0.8587 | |
| UB+RE | 0.8591 | 0.8538 | 0.8466 | 0.8538 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Q.; Zhang, X.; Li, F.; Tang, Z.; Wang, S. Measuring and Understanding Crowdturfing in the App Store. Information 2023, 14, 393. https://doi.org/10.3390/info14070393
Hu Q, Zhang X, Li F, Tang Z, Wang S. Measuring and Understanding Crowdturfing in the App Store. Information. 2023; 14(7):393. https://doi.org/10.3390/info14070393
Chicago/Turabian StyleHu, Qinyu, Xiaomei Zhang, Fangqi Li, Zhushou Tang, and Shilin Wang. 2023. "Measuring and Understanding Crowdturfing in the App Store" Information 14, no. 7: 393. https://doi.org/10.3390/info14070393
APA StyleHu, Q., Zhang, X., Li, F., Tang, Z., & Wang, S. (2023). Measuring and Understanding Crowdturfing in the App Store. Information, 14(7), 393. https://doi.org/10.3390/info14070393