
How Could Consumers’ Online Review Help Improve Product Design Strategy?






Abstract
:1. Introduction
2. Literature Review
2.1. Development and Academic Application of LDA
- Unsupervised learning: Latent Dirichlet Allocation (LDA) is an unsupervised learning algorithm, which means that it does not require labeled data for training. Instead, it can automatically discover topics and generate topic models from unlabeled text corpora. The goal of LDA is to assign documents to latent topics by analyzing the distribution patterns of words in the text;
- Topic Identification and Distribution: The LDA model is highly useful in the realm of topic identification and distribution. It can be applied to large-scale collections of text to help identify hidden topics within documents and provide information on the distribution of each topic within the document. Through LDA, it is possible to obtain the relevance between each document and topic, as well as the association between each topic and word. This information is crucial for text mining and information retrieval as it aids in understanding the structure and content of a text dataset;
- Scalability: The LDA model exhibits excellent scalability and can handle large-scale text datasets. Traditional LDA algorithms can be accelerated through parallel computing, and they can also be trained in distributed computing environments, leveraging the computational resources of multiple machines for efficient model training. This scalability provides LDA with a significant advantage in handling large volumes of text data and enables it to tackle real-world, large-scale text mining tasks;
- Probabilistic Topic Modeling: LDA is a probabilistic topic modeling algorithm. It assumes that each document is composed of multiple topics, and each topic is composed of multiple words. LDA introduces probability distributions to describe the relationships between topics and words. By modeling the text data, LDA can calculate the probability distributions of each topic and each word, thereby determining the relative importance of topics. This probabilistic modeling approach enables LDA to provide a deeper understanding of the topic structure, helping us uncover the latent semantic associations within the text data.
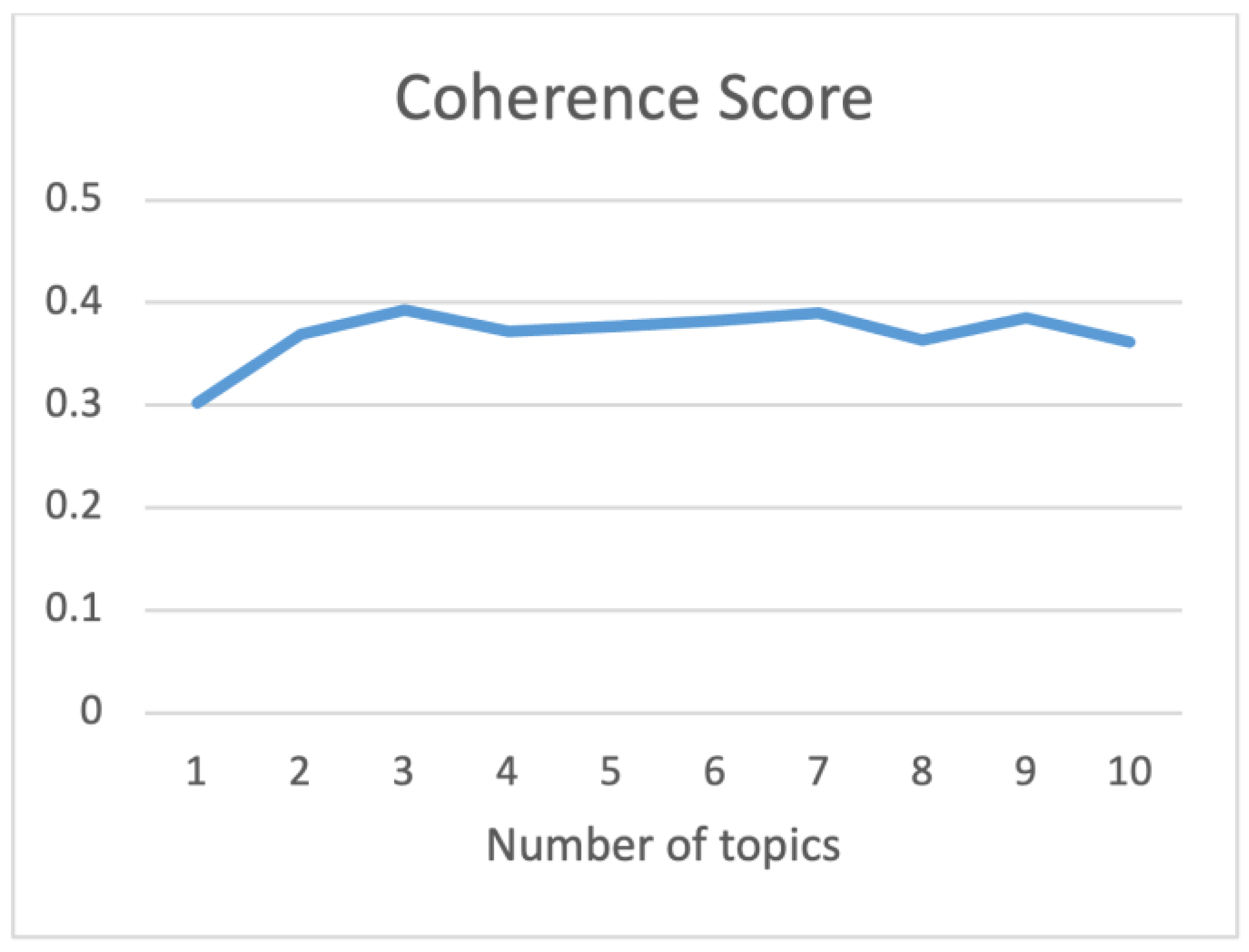
2.2. Judgement of Topic Numbers
2.3. Online Consumer Reviews
3. Methodology
3.1. Data Source and Collection
3.2. Data Processing
4. Results and Discussion
4.1. Topic Modeling and Visualization of User Comments
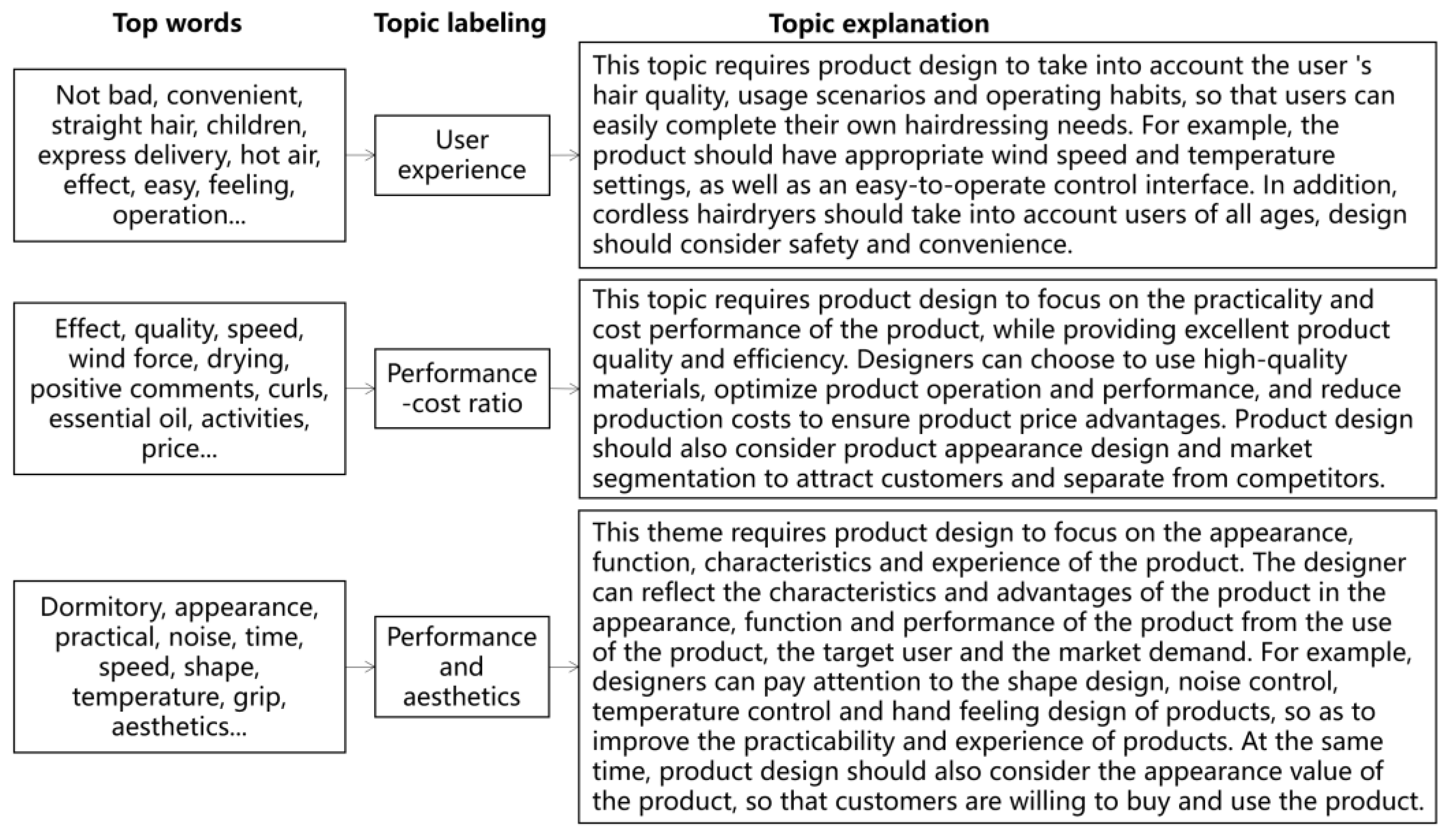
4.2. Topic Model and Labeling
4.3. Development of Cordless Hairdryer Design Index System Based on User Needs
4.4. Cordless Hairdryer Design Index System Verification
5. Conclusions and Limitations
5.1. Theoretical Implications
5.2. Practical Implications
5.3. Limitations and Future Studies
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

| Dimensions | Items | Source |
|---|---|---|
| User satisfaction | I’m very satisfied with this cordless hairdryer. | [60] |
| The quality of this cordless hairdryer is very good. | ||
| This cordless hairdryer meets my expectations. | ||
| Purchase intention | It is likely for me to purchase this cordless hairdryer. | [61] |
| I am capable of purchasing this cordless hairdryer. | ||
| It is possible for me to purchase this cordless hairdryer. | ||
| Usage habits | I would like to stop using my current cordless hairdryer and use this one. | [62] |
| My family would like to stop using my current cordless hairdryer and use this one. | ||
| My friends would like to stop using my current cordless hairdryer and use this one. | ||
| Intention to continue using | I would like to continue my usage of this cordless hairdryer. | [63] |
| I would like to continue my usage of this cordless hairdryer rather than stop. | ||
| My intentions are to continue using this cordless hairdryer rather than use any alternative means. |
Appendix B
| Word | Occurrence | Reviews | TF | TF-IDF |
|---|---|---|---|---|
| Hair | 598 | 534 | 0.036299624 | 0.015262768 |
| Very | 301 | 278 | 0.018271215 | 0.012865541 |
| Straight hair | 308 | 296 | 0.018696127 | 0.012657098 |
| Not bad | 317 | 330 | 0.019242443 | 0.012103162 |
| Convenient | 365 | 415 | 0.022156125 | 0.011744016 |
| Fast | 253 | 283 | 0.015357533 | 0.010692069 |
| Effect | 221 | 260 | 0.013415078 | 0.009834679 |
| Use | 180 | 187 | 0.010926308 | 0.009574172 |
| Very good | 187 | 206 | 0.01135122 | 0.00946438 |
| Special | 161 | 161 | 0.009772976 | 0.009188862 |
| TRUE | 167 | 183 | 0.010137186 | 0.008974109 |
| Useful | 153 | 164 | 0.009287362 | 0.008668753 |
| Heat | 153 | 177 | 0.009287362 | 0.008365343 |
| Appearance | 137 | 155 | 0.008316135 | 0.007965335 |
| Seems | 137 | 159 | 0.008316135 | 0.007876882 |
| Quality | 133 | 156 | 0.008073328 | 0.007703913 |
| Comb | 112 | 115 | 0.006798592 | 0.007385717 |
| Very useful | 125 | 151 | 0.007587714 | 0.007350373 |
| Operation | 118 | 145 | 0.007162802 | 0.007073438 |
| Recommendation | 113 | 132 | 0.006859293 | 0.007049743 |
| Receive | 110 | 129 | 0.006677188 | 0.006919443 |
| Children | 102 | 107 | 0.006191575 | 0.006911798 |
| Like | 108 | 124 | 0.006555785 | 0.006908687 |
| Speed | 110 | 131 | 0.006677188 | 0.006890873 |
| Jingdong | 106 | 123 | 0.006434381 | 0.006809706 |
| Will not | 102 | 115 | 0.006191575 | 0.006726278 |
| Express delivery | 104 | 131 | 0.006312978 | 0.006515007 |
| Comparison | 98 | 114 | 0.005948768 | 0.006491369 |
| Easy | 99 | 122 | 0.006009469 | 0.006387337 |
| Feeling | 98 | 120 | 0.005948768 | 0.006350158 |
| Temperature | 94 | 109 | 0.005705961 | 0.006340369 |
| Packaging | 91 | 106 | 0.005523856 | 0.006195138 |
| Did not | 89 | 102 | 0.005402452 | 0.006145356 |
| Time | 88 | 101 | 0.005341751 | 0.006105489 |
| Curls | 88 | 102 | 0.005341751 | 0.006076307 |
| Natural | 86 | 100 | 0.005220347 | 0.005995609 |
| Exactly | 75 | 84 | 0.004552628 | 0.005559025 |
| Hair curler | 74 | 83 | 0.004491927 | 0.005514689 |
| Things | 73 | 82 | 0.004431225 | 0.005470003 |
| Satisfaction | 72 | 84 | 0.004370523 | 0.005336664 |
| No need | 71 | 88 | 0.004309822 | 0.005179342 |
| Purchase | 67 | 75 | 0.004067015 | 0.005164093 |
| Product | 66 | 74 | 0.004006313 | 0.00511676 |
| Price | 69 | 84 | 0.004188418 | 0.005114303 |
| Inward curls | 68 | 82 | 0.004127716 | 0.005095345 |
| Hot wind | 67 | 81 | 0.004067015 | 0.00504823 |
| Hair style | 67 | 83 | 0.004067015 | 0.004993029 |
| Frizzy | 68 | 87 | 0.004127716 | 0.004986667 |
| White | 66 | 86 | 0.004006313 | 0.004865777 |
| Hot to touch | 62 | 74 | 0.003763506 | 0.004806654 |
| After washing | 63 | 78 | 0.003824208 | 0.004800423 |
| Straighten | 63 | 78 | 0.003824208 | 0.004800423 |
| Essential oil | 62 | 77 | 0.003763506 | 0.004751242 |
| Friend | 61 | 74 | 0.003702804 | 0.004729127 |
| School | 60 | 72 | 0.003642103 | 0.004707106 |
| Dormitory | 59 | 72 | 0.003581401 | 0.004628654 |
| Hairdryer | 56 | 63 | 0.003399296 | 0.00459043 |
| Suitable | 54 | 65 | 0.003277892 | 0.004369536 |
| Design | 53 | 64 | 0.003217191 | 0.004316287 |
| Activity | 51 | 58 | 0.003095787 | 0.004295064 |
References
- Brockhoff, K. Customers’ perspectives of involvement in new product development. Int. J. Technol. Manag. 2003, 26, 464–481. [Google Scholar] [CrossRef]
- Groves, R.M. Nonresponse rates and nonresponse bias in household surveys. Public Opin. Q. 2006, 70, 646–675. [Google Scholar] [CrossRef]
- Hendra, R.; Hill, A. Rethinking response rates: New evidence of little relationship between survey response rates and nonresponse bias. Eval. Rev. 2019, 43, 307–330. [Google Scholar] [CrossRef] [PubMed]
- Qi, J.; Zhang, Z.; Jeon, S.; Zhou, Y. Mining customer requirements from online reviews: A product improvement perspective. Inf. Manag. 2016, 53, 951–963. [Google Scholar] [CrossRef]
- Iwasaki, K.; Kuriyama, Y.; Kondoh, S.; Shirayori, A. Structuring engineers’ implicit knowledge of forming process design by using a graph model. Procedia Cirp. 2018, 67, 563–568. [Google Scholar] [CrossRef]
- Barbado, R.; Araque, O.; Iglesias, C.A. A framework for fake review detection in online consumer electronics retailers. Inf. Process. Manag. 2019, 56, 1234–1244. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, V.; Kalro, A.D. Enhancing the helpfulness of online consumer reviews: The role of latent (content) factors. J. Interact. Mark. 2019, 48, 33–50. [Google Scholar] [CrossRef]
- Li, Y.; Xiong, Y.; Mariuzzo, F.; Xia, S. The underexplored impacts of online consumer reviews: Pricing and new product design strategies in the O2O supply chain. Int. J. Prod. Econ. 2021, 237, 108148. [Google Scholar]
- Lucini, F.R.; Tonetto, L.M.; Fogliatto, F.S.; Anzanello, M.J. Text mining approach to explore dimensions of airline customer satisfaction using online customer reviews. J. Air Transp. Manag. 2020, 83, 101760. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, N.; Liu, B. Lifelong learning for sentiment classification. arXiv 2018, arXiv:1801.02808. [Google Scholar]
- Ahmad, S.N.; Laroche, M. Analyzing electronic word of mouth: A social commerce construct. Int. J. Inf. Manag. 2017, 37, 202–213. [Google Scholar] [CrossRef]
- Nguyen, B.; Nguyen, V.-H.; Ho, T. Sentiment analysis of customer feedbacks in online food ordering services. Bus. Syst. Res. Int. J. Soc. Adv. Innov. Res. Econ. 2021, 12, 46–59. [Google Scholar] [CrossRef]
- He, W. Improving user experience with case-based reasoning systems using text mining and Web 2.0. Expert Syst. Appl. 2013, 40, 500–507. [Google Scholar] [CrossRef]
- Schuff, D.; Mudambi, S. What makes a helpful online review? A study of customer reviews on Amazon.com. Soc. Sci. Electron. Publ. 2012, 34, 185–200. [Google Scholar]
- Yin, D.; Bond, S.D.; Zhang, H. Anxious or angry? Effects of discrete emotions on the perceived helpfulness of online reviews. MIS Q. 2014, 38, 539–560. [Google Scholar] [CrossRef] [Green Version]
- Cao, Q.; Duan, W.; Gan, Q. Exploring determinants of voting for the “helpfulness” of online user reviews: A text mining approach. Decis. Support Syst. 2011, 50, 511–521. [Google Scholar] [CrossRef]
- Chen, P.-Y.; Dhanasobhon, S.; Smith, M.D. All reviews are not created equal: The disaggregate impact of reviews and reviewers at amazon.com. Com 2008. [Google Scholar] [CrossRef] [Green Version]
- Kleinberg, J. Bursty and hierarchical structure in streams. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2002; pp. 91–101. [Google Scholar]
- Pejić Bach, M.; Ivec, A.; Hrman, D. Industrial Informatics: Emerging Trends and Applications in the Era of Big Data and AI. Electronics 2023, 12, 2238. [Google Scholar] [CrossRef]
- Li, T.; Wang, X.; Yu, Y.; Yu, G.; Tong, X. Exploring the Dynamic Characteristics of Public Risk Perception and Emotional Expression during the COVID-19 Pandemic on Sina Weibo. Systems 2023, 11, 45. [Google Scholar] [CrossRef]
- Chung, J.E. A Smoking Cessation Campaign on Twitter: Understanding the Use of Twitter and Identifying Major Players in a Health Campaign. J. Health Commun. 2016, 21, 517–526. [Google Scholar] [CrossRef]
- Zhao, W.; Jin, G.; Huang, C.; Zhang, J. Attention and Sentiment of the Chinese Public toward a 3D Greening System Based on Sina Weibo. Int. J. Environ. Res. Public Health 2023, 20, 3972. [Google Scholar] [CrossRef]
- Chen, W.-K.; Riantama, D.; Chen, L.-S. Using a Text Mining Approach to Hear Voices of Customers from Social Media toward the Fast-Food Restaurant Industry. Sustainability 2021, 13, 268. [Google Scholar] [CrossRef]
- Almatar, M.G.; Alazmi, H.S.; Li, L.; Fox, E.A. Applying GIS and Text Mining Methods to Twitter Data to Explore the Spatiotemporal Patterns of Topics of Interest in Kuwait. ISPRS Int. J. Geo-Inf. 2020, 9, 702. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed]
- Wallace, M.L.; Gingras, Y.; Duhon, R. A new approach for detecting scientific specialties from raw cocitation networks. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 240–246. [Google Scholar] [CrossRef] [Green Version]
- White, H.D. Pathfinder networks and author cocitation analysis: A remapping of paradigmatic information scientists. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 423–434. [Google Scholar] [CrossRef]
- Hu, Z.; Lin, A.; Willett, P. Identification of research communities in cited and uncited publications using a co-authorship network. Scientometrics 2019, 118, 1–19. [Google Scholar] [CrossRef]
- Giuliani, F.; De Petris, M.; Nico, G. Assessing scientific collaboration through coauthorship and content sharing. Scientometrics 2010, 85, 13–28. [Google Scholar] [CrossRef]
- Blei, D.; Ng, A.Y.; Jordan, M.I.; Lafferty, J. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Montes-Escobar, K.; De la Hoz, M.J.; Barreiro-Linzán, M.D.; Fonseca-Restrepo, C.; Lapo-Palacios, M.Á.; Verduga-Alcívar, D.A.; Salas-Macias, C.A. Trends in Agroforestry Research from 1993 to 2022: A Topic Model Using Latent Dirichlet Allocation and HJ-Biplot. Mathematics 2023, 11, 2250. [Google Scholar] [CrossRef]
- Bonetti, A.; Martínez-Sober, M.; Torres, J.C.; Vega, J.M.; Pellerin, S.; Vila-Francés, J. Comparison between Machine Learning and Deep Learning Approaches for the Detection of Toxic Comments on Social Networks. Appl. Sci. 2023, 13, 6038. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 113–120. [Google Scholar]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization techniques for assessing textual topic models. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21–25 May 2012; pp. 74–77. [Google Scholar]
- Wang, Y.; Luo, J.; Niemi, R.; Li, Y.; Hu, T. Catching fire via” likes”: Inferring topic preferences of trump followers on twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Cologne, Germany, 17–20 May 2016; pp. 719–722. [Google Scholar]
- Huang, J.; Tao, Y.; Shi, M.; Wu, J. Empirical Study on Design Trend of Taiwan (1960s–2020): The Evolution of Theme, Diversity and Sustainability. Sustainability 2022, 14, 12578. [Google Scholar] [CrossRef]
- Hao, J.; Gao, X.; Liu, Y.; Han, Z. Acquisition Method of User Requirements for Complex Products Based on Data Mining. Sustainability 2023, 15, 7566. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. A correlated topic model of science. Ann. Appl. Stat. 2007, 1, 17–35. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Viswanath, V.; Chen, P. Extended topic model for word dependency. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 506–510. [Google Scholar]
- Zhao, W.; Chen, J.J.; Perkins, R.; Liu, Z.; Ge, W.; Ding, Y.; Zou, W. A heuristic approach to determine an appropriate number of topics in topic modeling. BMC Bioinform. 2015, 16, S8. [Google Scholar] [CrossRef] [Green Version]
- Gan, J.; Qi, Y. Selection of the optimal number of topics for LDA topic model—Taking patent policy analysis as an example. Entropy 2021, 23, 1301. [Google Scholar] [CrossRef]
- Lau, J.H.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 399–408. [Google Scholar]
- Bouma, G. Normalized (pointwise) mutual information in collocation extraction. Proc. GSCL 2009, 30, 31–40. [Google Scholar]
- Aletras, N.; Stevenson, M. Evaluating topic coherence using distributional semantics. In Proceedings of the 10th International Conference on Computational Semantics (IWCS 2013)–Long Papers, Podsdam, Germany, 19–22 March 2013; pp. 13–22. [Google Scholar]
- Mimno, D.; Wallach, H.; Talley, E.; Leenders, M.; McCallum, A. Optimizing semantic coherence in topic models. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 262–272. [Google Scholar]
- Newman, D.; Lau, J.H.; Grieser, K.; Baldwin, T. Automatic evaluation of topic coherence. In Proceedings of the Human language technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Los Angeles, CA, USA, 2–4 June 2010; pp. 100–108. [Google Scholar]
- Sievert, C.; Shirley, K. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MA, USA, 27 June 2014; pp. 63–70. [Google Scholar]
- Filieri, R.; Hofacker, C.F.; Alguezaui, S. What makes information in online consumer reviews diagnostic over time? The role of review relevancy, factuality, currency, source credibility and ranking score. Comput. Hum. Behav. 2018, 80, 122–131. [Google Scholar] [CrossRef] [Green Version]
- Sparks, B.A.; Perkins, H.E.; Buckley, R. Online travel reviews as persuasive communication: The effects of content type, source, and certification logos on consumer behavior. Tour. Manag. 2013, 39, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Mo, Z.; Li, Y.-F.; Fan, P. Effect of online reviews on consumer purchase behavior. J. Serv. Sci. Manag. 2015, 8, 419. [Google Scholar] [CrossRef] [Green Version]
- Cheng, F.; Yu, S.; Qin, S.; Chu, J.; Chen, J. User experience evaluation method based on online product reviews. J. Intell. Fuzzy Syst. 2021, 41, 1791–1805. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, C.; Hu, Y.; Xu, Z.; Liu, H. Modelling consumer satisfaction based on online reviews using the improved Kano model from the perspective of risk attitude and aspiration. Technol. Econ. Dev. Econ. 2021, 27, 550–582. [Google Scholar] [CrossRef]
- Lutfi, A.A.; Permanasari, A.E.; Fauziati, S. Sentiment analysis in the sales review of Indonesian marketplace by utilizing Support Vector Machine. J. Inf. Syst. Eng. Bus. Intell. 2018, 4, 57–64. [Google Scholar] [CrossRef] [Green Version]
- Fauzi, M.A. Word2Vec model for sentiment analysis of product reviews in Indonesian language. Int. J. Electr. Comput. Eng. 2019, 9, 525. [Google Scholar] [CrossRef] [Green Version]
- Mee, A.; Homapour, E.; Chiclana, F.; Engel, O. Sentiment analysis using TF–IDF weighting of UK MPs’ tweets on Brexit. Knowl.-Based Syst. 2021, 228, 107238. [Google Scholar] [CrossRef]
- Linstone, H.A.; Turoff, M. The Delphi Method; Addison-Wesley: Reading, MA, USA, 1975. [Google Scholar]
- Hwang, Y.; Kim, H.J.; Choi, H.J.; Lee, J. Exploring abnormal behavior patterns of online users with emotional eating behavior: Topic modeling study. J. Med. Internet Res. 2020, 22, e15700. [Google Scholar] [CrossRef]
- Aranda, A.M.; Sele, K.; Etchanchu, H.; Guyt, J.Y.; Vaara, E. From big data to rich theory: Integrating critical discourse analysis with structural topic modeling. Eur. Manag. Rev. 2021, 18, 197–214. [Google Scholar] [CrossRef]
- Wang, Y.-Y.; Wang, Y.-S.; Lin, H.-H.; Tsai, T.-H. Developing and validating a model for assessing paid mobile learning app success. Interact. Learn. Environ. 2019, 27, 458–477. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.-C. Effects of branded e-stickers on purchase intentions: The perspective of social capital theory. Telemat. Inform. 2017, 34, 397–411. [Google Scholar] [CrossRef]
- Chiu, C.-Y.; Chen, C.-L.; Chen, S. Broadband Mobile Applications’ Adoption by SMEs in Taiwan—A Multi-Perspective Study of Determinants. Appl. Sci. 2022, 12, 7002. [Google Scholar] [CrossRef]
- Hung, M.-C.; Chang, I.-C.; Hwang, H.-G. Exploring academic teachers’ continuance toward the web-based learning system: The role of causal attributions. Comput. Educ. 2011, 57, 1530–1543. [Google Scholar] [CrossRef]
- Gu, C.; Huang, T.; Wei, W.; Yang, C.; Chen, J.; Miao, W.; Lin, S.; Sun, H.; Sun, J. The Effect of Using Augmented Reality Technology in Takeaway Food Packaging to Improve Young Consumers’ Negative Evaluations. Agriculture 2023, 13, 335. [Google Scholar] [CrossRef]
- Xu, L.; Hu, H.; Zhang, X.; Li, L.; Cao, C.; Li, Y.; Xu, Y.; Sun, K.; Yu, D.; Yu, C. CLUE: A Chinese language understanding evaluation benchmark. arXiv 2020, arXiv:2004.05986. [Google Scholar]
- Song, J.; Liu, F.; Ding, K.; Du, K.; Zhang, X. Semantic comprehension of questions in Q&A system for Chinese Language based on semantic element combination. IEEE Access 2020, 8, 102971–102981. [Google Scholar]
- Liu, Y.; Jiang, C.; Zhao, H. Assessing product competitive advantages from the perspective of customers by mining user-generated content on social media. Decis. Support Syst. 2019, 123, 113079. [Google Scholar] [CrossRef]
- Rubin, T.N.; Chambers, A.; Smyth, P.; Steyvers, M. Statistical topic models for multi-label document classification. Mach. Learn. 2012, 88, 157–208. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

| Total Documents | Proportion of Documents Supported | Top 10 High-Frequency Words |
|---|---|---|
| 1405 | 46% | Not bad, convenient, straight hair, children, express delivery, hot air, effect, easy, feeling, operation |
| 27.5% | Effect, quality, speed, wind force, drying, positive comments, curls, essential oil, activities, price | |
| 26.4% | Dormitory, appearance, practical, noise, time, speed, shape, temperature, tactile, aesthetics |
| No. | Specialty | Age | Position | Length of Employment |
|---|---|---|---|---|
| 1 | Design engineering | 38 | Project Manager | 10 |
| 2 | Industrial design | 39 | Project Manager | 10 |
| 3 | Industrial design | 43 | Professor | 14 |
| 4 | Industrial design | 46 | Professor | 16 |
| 5 | Design engineering | 55 | Senior Researcher | 27 |
| Topic | Indexes | Explanation |
|---|---|---|
| User experience | Adaptability | The product should be adaptable to the needs of users with different hair types, such as providing different temperature and wind speed settings. |
| Usage scenarios | To design a product that meets user needs, considering the scenarios in which users will use the product, such as travel or home use, is essential. | |
| Ease of use | Product design should consider a user-friendly control interface that facilitates ease of use for the users. | |
| Safety | Considering the needs of children using the product, the design should prioritize both safety and convenience. | |
| Performance-cost ratio | Practicality | The practicality and performance of the product should receive attention, including factors such as speed and power. |
| Product quality | Using high-quality materials is essential to ensure product quality and performance. | |
| Price advantage | To ensure price advantage, it is important to reduce product costs while considering the product’s appearance and target market segment to attract customers. | |
| User reputation | Considering user reviews and feedback is crucial to understand how the product is performing in the market. | |
| Performance and aesthetics | Appearance design | Emphasizing the exterior design of the product to align with fashion and aesthetic standards is important. |
| Noise control | Adopting advanced technology to reduce noise and provide a better user experience is essential. | |
| Temperature control | Providing adjustable temperature control is essential to meet the diverse needs of different users. | |
| Tactile feel design | Considering the tactile design of the product is crucial to ensure user comfort. |
| Sample | Details |
|---|---|
 Sample 1 | Advantages: The product basically meets the needs of cordless hairdryer in terms of adaptability, operation convenience and practicability. Disadvantages: The evaluation of product characteristics is low, especially in appearance design and hand feeling design. In addition, the security design is relatively simple, and the user reputation is general. |
 Sample 2 | Advantages: The product has been recognized by experts in all aspects of the evaluation subject. Disadvantages: The power of the product is relatively small, which is a common technical difficulty in cordless hairdryers. |
| Category | Count | Ratio (%) | |
|---|---|---|---|
| Gender | Male | 119 | 48.77 |
| Female | 125 | 51.23 | |
| Age | 20 or younger | 13 | 5.33 |
| 21–29 | 88 | 36.07 | |
| 30–39 | 113 | 46.31 | |
| 40–49 | 20 | 8.20 | |
| 50–59 | 9 | 3.69 | |
| 60 or older | 1 | 0.41 | |
| Education | Junior high school or below | 2 | 0.82 |
| High school or secondary school | 9 | 3.69 | |
| Undergraduate or college | 194 | 79.51 | |
| Postgraduate or higher | 39 | 15.98 | |
| Marriage Status | Unmarried | 90 | 36.89 |
| Married | 154 | 63.11 | |
| Monthly Income | 3000 or less | 46 | 18.85 |
| 3001–5000 | 30 | 12.30 | |
| 5001–8000 | 57 | 23.36 | |
| 8001–12,000 | 67 | 27.46 | |
| 12,001 or more | 44 | 18.03 | |
| Occupation | Professionals (such as teachers/doctors/lawyers, etc.) | 32 | 13.11 |
| Service workers (catering waiter/driver/salesperson, etc.) | 3 | 1.23 | |
| Freelancers (such as writers/artists/photographers/tour guides, etc.) | 2 | 0.82 | |
| Workers (such as factory workers/construction workers/urban sanitation workers, etc.) | 1 | 0.41 | |
| Staff | 133 | 54.51 | |
| Public institutions/civil servants/government workers | 16 | 6.56 | |
| Student | 51 | 20.90 | |
| Other | 6 | 2.46 | |
| Area | North China: Beijing, Tianjin, Hebei, Shanxi, Inner Mongolia | 38 | 15.57 |
| Northeast China: Liaoning, Jilin, Heilongjiang | 17 | 6.97 | |
| East China: Shanghai, Jiangsu, Zhejiang, Anhui, Fujian, Jiangxi, Shandong | 105 | 43.03 | |
| Central China: Henan, Hubei, Hunan | 23 | 9.43 | |
| South China: Guangdong, Guangxi, Hainan | 43 | 17.62 | |
| Southwest China: Chongqing, Sichuan, Guizhou, Yunnan, Tibet | 14 | 5.74 | |
| Northwest China: Shaanxi, Gansu, Qinghai, Ningxia, Xinjiang | 1 | 0.41 | |
| Hong Kong, Macao, Taiwan | 3 | 1.23 |
| Dimension | Category | Mean | Standard Deviation | t | Significance (2-Tailed) |
|---|---|---|---|---|---|
| SA | Sample 1 | 3.62842 | 0.870380 | −7.102 | 0.000 |
| Sample 2 | 4.13525 | 0.696464 | |||
| PI | Sample 1 | 3.54372 | 1.119067 | −5.985 | 0.000 |
| Sample 2 | 4.05874 | 0.744872 | |||
| UH | Sample 1 | 3.26913 | 1.091168 | −4.951 | 0.000 |
| Sample 2 | 3.71175 | 0.871365 | |||
| CUI | Sample 1 | 3.38388 | 1.051354 | −4.978 | 0.000 |
| Sample 2 | 3.81831 | 0.867675 |
| Dimension | Gender | Mean | Standard Deviation | t | Significance (2-Tailed) |
|---|---|---|---|---|---|
| SA | Male | 3.87535 | 0.850173 | −0.169 | 0.866 |
| Female | 3.88800 | 0.806537 | |||
| PI | Male | 3.80952 | 0.967422 | −0.182 | 0.856 |
| Female | 3.79333 | 1.001316 | |||
| UH | Male | 3.50280 | 1.003856 | −0.263 | 0.792 |
| Female | 3.47867 | 1.019549 | |||
| CUI | Male | 3.58403 | 0.976127 | −0.372 | 0.710 |
| Female | 3.61733 | 0.999224 |
| Source | Dependent Variable | Type III Sum of Squares | Mean Square | F | Significance (2-Tailed) |
|---|---|---|---|---|---|
| Category × Gender | SA | 0.439 | 0.439 | 0.704 | 0.402 |
| PI | 0.519 | 0.519 | 0.573 | 0.450 | |
| UH | 0.767 | 0.767 | 0.785 | 0.376 | |
| CUI | 0.938 | 0.938 | 1.008 | 0.316 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, W.; Lin, K.-C.; Wu, C.-F.; Sun, J.; Sun, W.; Wei, W.; Gu, C. How Could Consumers’ Online Review Help Improve Product Design Strategy? Information 2023, 14, 434. https://doi.org/10.3390/info14080434
Miao W, Lin K-C, Wu C-F, Sun J, Sun W, Wei W, Gu C. How Could Consumers’ Online Review Help Improve Product Design Strategy? Information. 2023; 14(8):434. https://doi.org/10.3390/info14080434
Chicago/Turabian StyleMiao, Wei, Kai-Chieh Lin, Chih-Fu Wu, Jie Sun, Weibo Sun, Wei Wei, and Chao Gu. 2023. "How Could Consumers’ Online Review Help Improve Product Design Strategy?" Information 14, no. 8: 434. https://doi.org/10.3390/info14080434
APA StyleMiao, W., Lin, K.-C., Wu, C.-F., Sun, J., Sun, W., Wei, W., & Gu, C. (2023). How Could Consumers’ Online Review Help Improve Product Design Strategy? Information, 14(8), 434. https://doi.org/10.3390/info14080434