
Extreme Learning Machine-Enabled Coding Unit Partitioning Algorithm for Versatile Video Coding


Abstract
:1. Introduction
- (1)
- In this work, we propose a distinctive approach by modeling the CU size decision as a classification problem and employing the extreme learning machine model for predicting the CU partitioning mode. The uniqueness lies in the utilization of the ELM model, which offers the advantage of predicting the CU partitioning mode without necessitating image feature extraction. This stands in contrast to traditional machine learning algorithms and enhances efficiency.
- (2)
- Additionally, to further elevate the predictive accuracy, we incorporate an online learning method. By continuously adapting to the evolving dataset, this technique improves the prediction accuracy of our proposed approach.
2. Technical Background
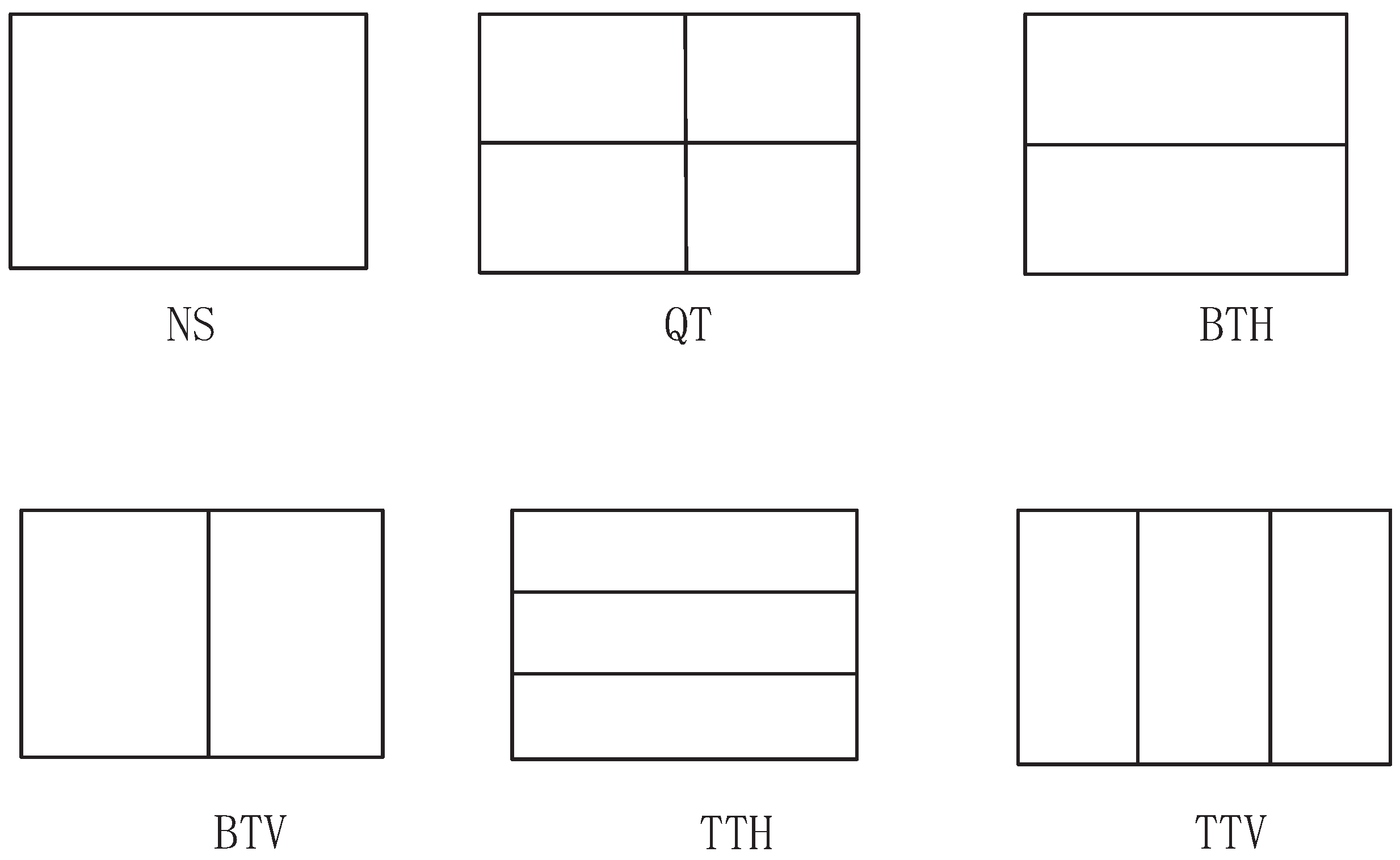
2.1. VVC/H.266
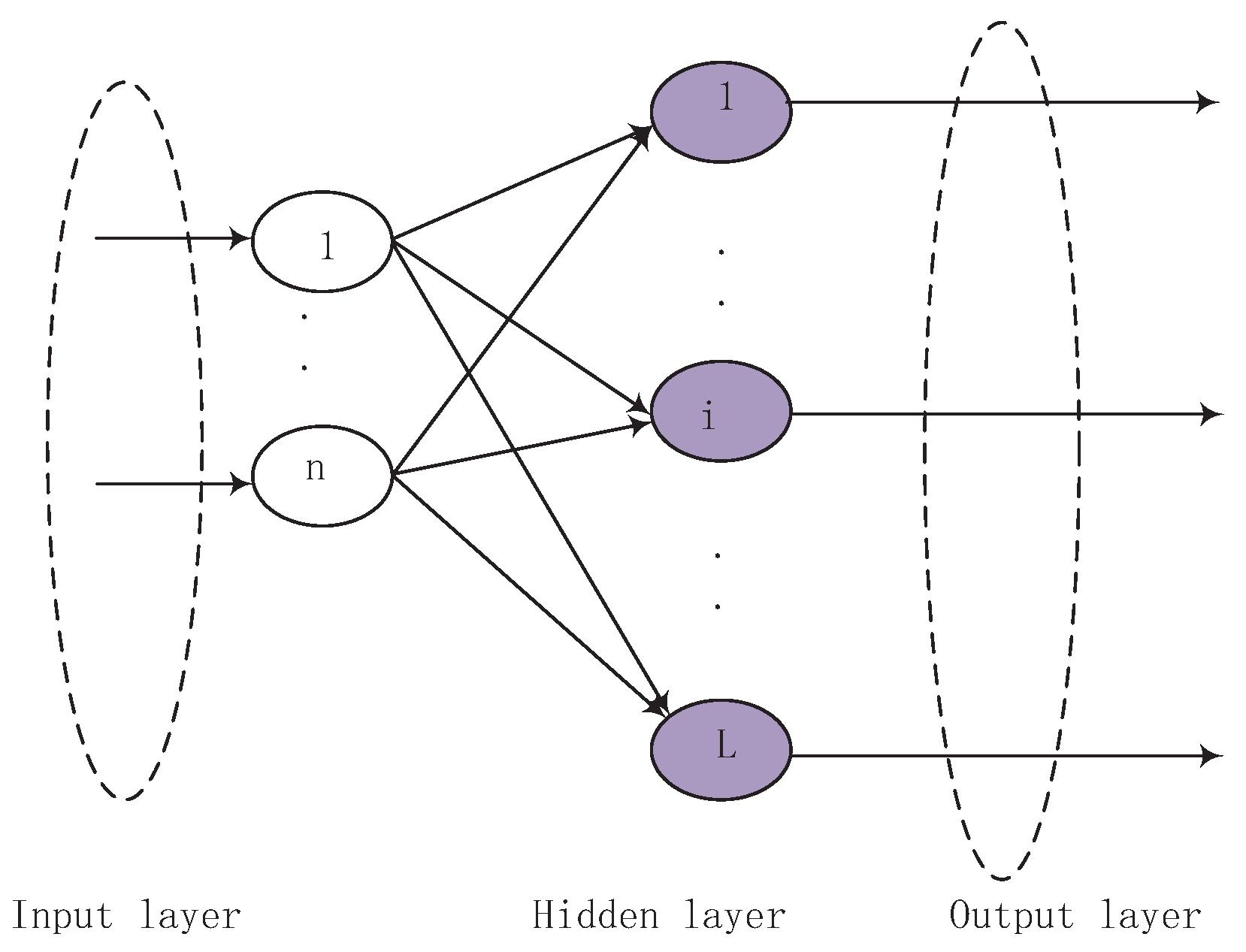
2.2. Extreme Learning Machine
3. The Proposed Extreme Learning Machine-Enabled Coding Unit Partitioning Algorithm
3.1. Algorithm Model
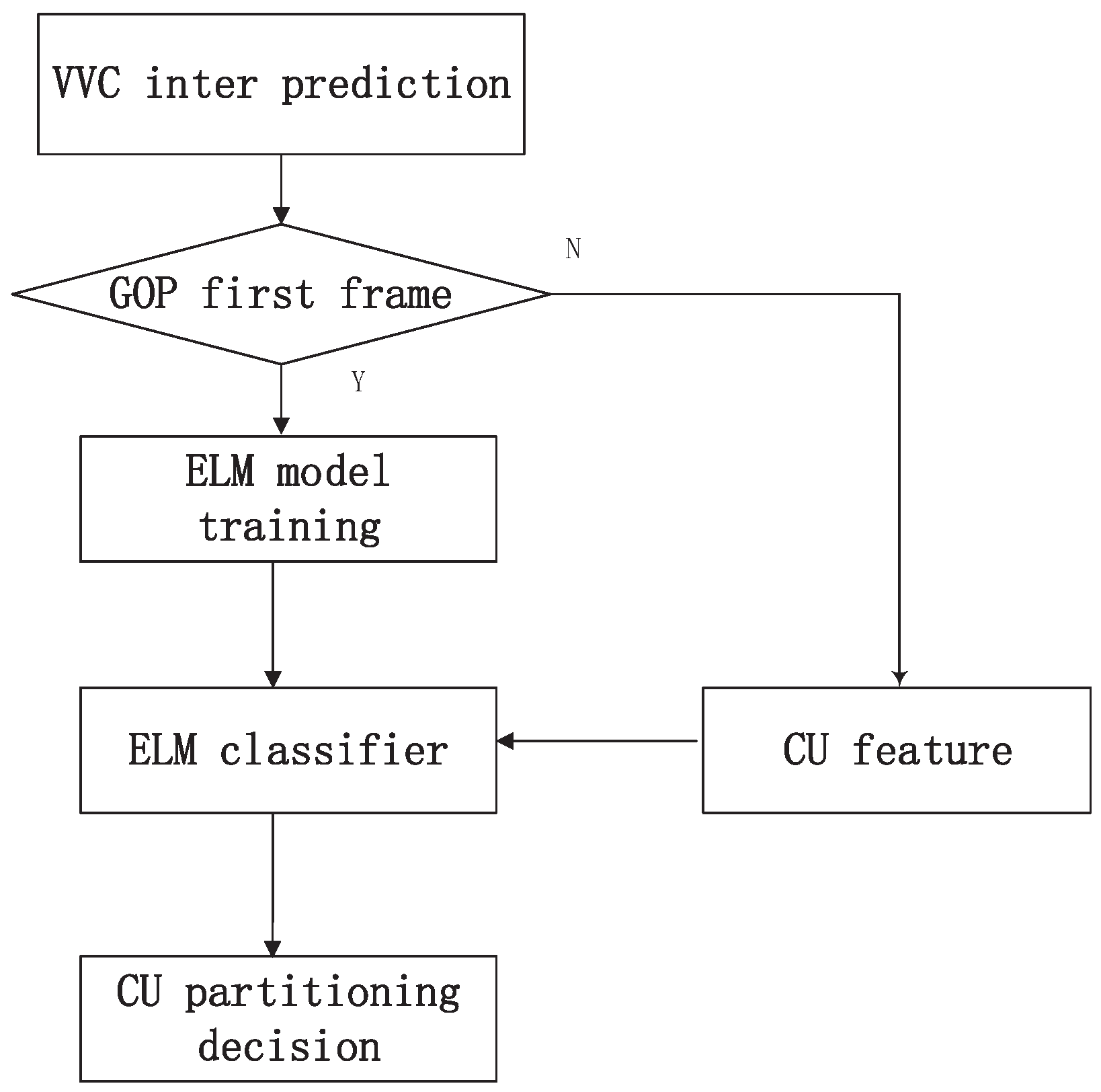
3.2. The Overall Framework
- (1)
- Feature extraction and parameter learning: As shown in Figure 4, in the CU partitioning process, the first frame of each group of pictures (GOPs) is designated as the parameter learning frame. For each coding unit (CU), an effective feature vector is extracted, which forms a training set. During this step, the number of hidden layer nodes and the activation function are configured.
- (2)
- ELM network initialization and training: The ELM network is initialized by generating random weights (w) and biases (b). The hidden layer output matrix (H) is computed, and using this matrix, the weight matrix of the output layer is calculated. This leads to the establishment of the output function of the ELM network.
- (3)
- CU mode partitioning using ELM classifier: Building upon the ELM classifier’s output function, CU mode partitioning is conducted on the remaining frames of the GOPs. This process results in the determination of the final CU partitioning mode, thereby enabling an efficient encoding strategy for subsequent frames.
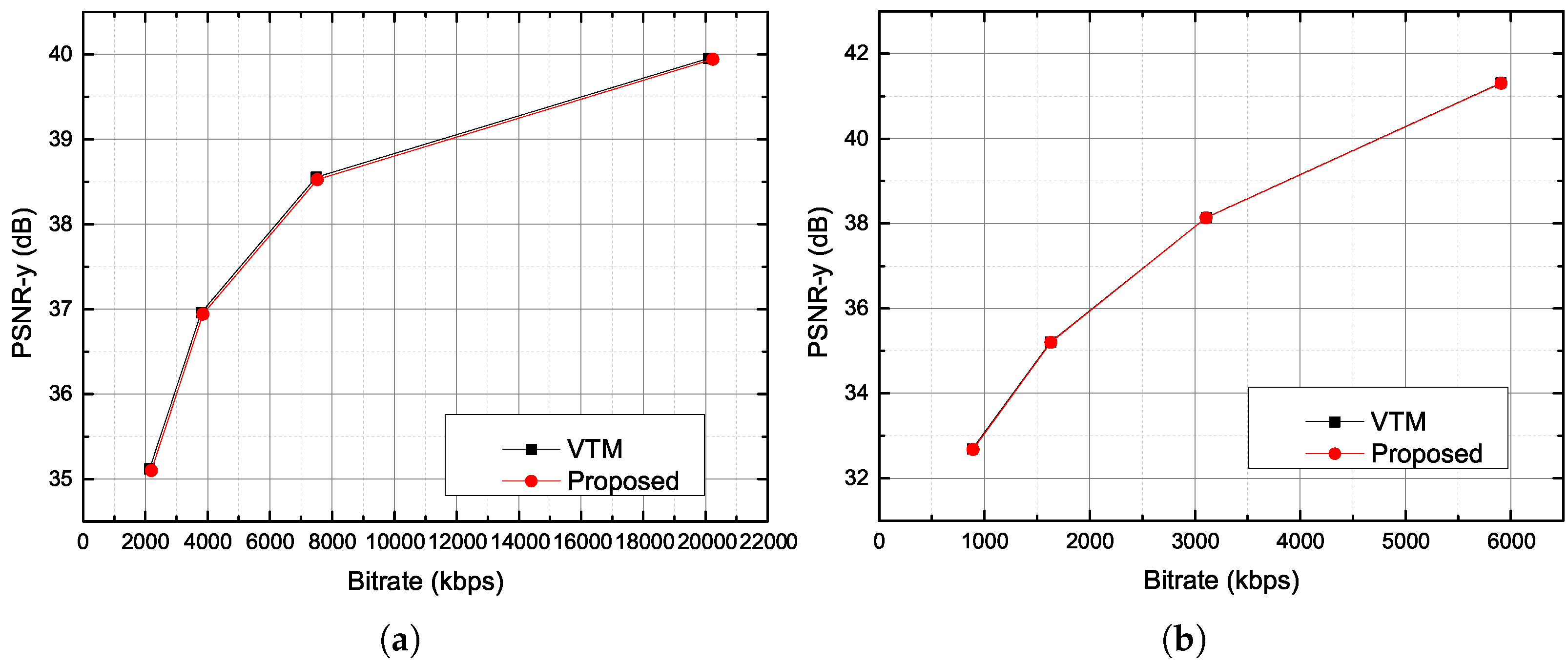
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Polak, L.; Kufa, J.; Kratochvil, T. On the Compression Performance of HEVC, VP9 and AV1 Encoders for Virtual Reality Videos. In Proceedings of the IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Paris, France, 27–29 October 2020; pp. 1–5. [Google Scholar]
- Kufa, J.; Polak, L.; Simka, M.; Stech, A. Software and Hardware Encoding of Omnidirectional 8 K Video: A Performance Study. In Proceedings of the 33rd International Conference Radioelektronika, Pardubice, Czech Republic, 19–20 April 2023; pp. 1–5. [Google Scholar]
- Li, W.; Jiang, X.; Jin, J.; Song, T.; Yu, F.R. Saliency-Enabled Coding Unit Partitioning and Quantization Control for Versatile Video Coding. Information 2022, 13, 394. [Google Scholar] [CrossRef]
- Min, B.; Ray, C.C. A fast CU size decision algorithm for the HEVC intra encoder. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 892–896. [Google Scholar]
- Jimenez-Moreno, A.; Martínez-Enríquez, E.; Díaz-de-María, F. Bayesian adaptive algorithm for fast coding unit decision in the High Efficiency Video Coding (HEVC) standard. Signal Process. Image Commun. 2017, 56, 1–11. [Google Scholar] [CrossRef]
- Sun, X.; Chen, X.; Xu, Y.; Xiao, Y.; Wang, Y.; Yu, D. Fast CU size and prediction mode decision algorithm for HEVC based on direction variance. J. Real-Time Image Process. 2019, 16, 1731–1744. [Google Scholar] [CrossRef]
- Fan, Y.; Chen, J.; Sun, H.; Katto, J.; Jing, M. A fast QTMT partition decision strategy for VVC intra prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, Y.; Huang, L.; Jiang, B.; Wang, X. Fast CU partition decision for H.266/VVC based on the improved DAG-SVM classifier model. Multimed. Syst. 2021, 27, 1–14. [Google Scholar] [CrossRef]
- Chen, F.; Ren, Y.; Peng, Z.; Jiang, G.; Cui, X. A fast CU size decision algorithm for VVC intra prediction based on support vector machine. Multimed. Tools Appl. 2020, 79, 27923–27939. [Google Scholar] [CrossRef]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. Adaptive CU split decision with pooling-variable CNN for VVC intra encoding. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), Sydney, NSW, Australia, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Fu, T.; Zhang, H.; Mu, F.; Chen, H. Fast CU partitioning algorithm for H.266/VVC intra-frame coding. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 55–60. [Google Scholar]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-complexity CTU partition structure decision and fast intra mode decision for versatile video coding. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1668–1682. [Google Scholar] [CrossRef]
- Shang, X.; Li, G.; Zhao, X.; Zuo, Y. Low complexity inter coding scheme for Versatile Video Coding (VVC). J. Vis. Commun. Image Represent. 2023, 90, 103683. [Google Scholar] [CrossRef]
- Li, H.; Zhang, P.; Jin, B.; Zhang, Q. Fast CU Decision Algorithm Based on Texture Complexity and CNN for VVC. IEEE Access 2023, 11, 35808–35817. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Zhao, J.; Zhang, Q. Fast CU Partitioning Algorithm for VVC Based on Multi-Stage Framework and Binary Subnets. IEEE Access 2023, 11, 56812–56821. [Google Scholar] [CrossRef]
- Tissier, A.; Hamidouche, W.; Mdalsi, S.B.D.; Vanne, J.; Galpin, F.; Menard, D. Machine Learning Based Efficient QT-MTT Partitioning Scheme for VVC Intra Encoders. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4279–4293. [Google Scholar] [CrossRef]
- Shang, X.; Li, G.; Zhao, X.; Han, H.; Zuo, Y. Fast CU size decision algorithm for VVC intra coding. Multimed. Tools Appl. 2023, 82, 28301–28322. [Google Scholar] [CrossRef]
- Zhang, M.; Hou, Y.; Liu, Z. An early CU partition mode decision algorithm in VVC based on variogram for virtual reality 360 degree videos. EURASIP J. Image Video Process. 2023, 1, 9. [Google Scholar] [CrossRef]
- Saldanha, M.; Sanchez, G.; Marcon, C.; Agostini, L. Configurable Fast Block Partitioning for VVC Intra Coding Using Light Gradient Boosting Machine. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3947–3960. [Google Scholar] [CrossRef]
- Jin, D.; Lei, J.; Peng, B.; Li, W.; Ling, N.; Huang, Q. Deep Affine Motion Compensation Network for Inter Prediction in VVC. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 3923–3933. [Google Scholar] [CrossRef]
- Huang, Y.W.; An, J.; Huang, H.; Li, X.; Hsiang, S.T.; Zhang, K.; Gao, H.; Ma, J.; Chubach, O. Block Partitioning Structure in the VVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3818–3833. [Google Scholar] [CrossRef]
- Gaspar, A.; Oliva, D.; Hinojosa, S.; Aranguren, I.; Zaldivar, D. An optimized Kernel Extreme Learning Machine for the classification of the autism spectrum disorder by using gaze tracking images. Appl. Soft Comput. 2022, 120, 108654. [Google Scholar] [CrossRef]
- Ganesan, A.; Santhanam, S.M. A novel feature descriptor based coral image classification using extreme learning machine with ameliorated chimp optimization algorithm. Ecol. Inform. 2022, 68, 101527. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November2003; pp. 1398–1402. [Google Scholar]
- Yeo, W.H.; Kim, B.G. CNN-based fast split mode decision algorithm for versatile video coding (VVC) inter prediction. J. Multimed. Inf. Syst. 2021, 8, 147–158. [Google Scholar] [CrossRef]
- Amestoy, T.; Mercat, A.; Hamidouche, W.; Menard, D.; Bergeron, C. Tunable VVC frame partitioning based on lightweight machine learning. IEEE Trans. Image Process. 2019, 29, 1313–1328. [Google Scholar] [CrossRef] [PubMed]
- Pan, Z.; Zhang, P.; Peng, B.; Ling, N.; Lei, J. A CNN-based fast inter coding method for VVC. IEEE Signal Process. Lett. 2021, 28, 1260–1264. [Google Scholar] [CrossRef]
- Tissier, A.; Hamidouche, W.; Vanne, J.; Menard, D. Machine Learning Based Efficient Qt-Mtt Partitioning for VVC Inter Coding. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1401–1405. [Google Scholar]
- Tang, N.; Cao, J.; Liang, F.; Wang, J.; Liu, H.; Wang, X.; Du, X. Fast CTU partition decision algorithm for VVC intra and inter coding. In Proceedings of the IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; pp. 361–364. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Description |
|---|---|
| Software | VTM12.0 |
| Video size | , , , |
| Configurations | Random access (RA), low delay (LD) |
| QP | 22, 27, 32, 37 |
| Maximum CTU size |
| RA | LD | ||||
|---|---|---|---|---|---|
| Size | Sequence | BDBR (%) | TS (%) | BDBR (%) | TS (%) |
| BasketballDrive | 2.17 | 46.29 | 1.59 | 41.69 | |
| BQTerrace | 0.33 | 52.03 | 0.22 | 50.01 | |
| Cactus | 0.69 | 51.66 | 0.64 | 57.64 | |
| Kimono | 1.51 | 50.14 | 1.03 | 53.81 | |
| ParkScene | 0.62 | 55.47 | 0.46 | 52.56 | |
| BasketballDrill | 0.22 | 52.06 | 0.20 | 54.79 | |
| BQMall | 0.40 | 54.25 | 0.49 | 54.20 | |
| PartyScene | 0.27 | 46.86 | 0.16 | 45.75 | |
| RaceHorsesC | 1.51 | 41.88 | 0.86 | 43.97 | |
| BlowingBubbles | 0.66 | 41.49 | 0.72 | 41.22 | |
| BQSquare | 0.35 | 43.19 | 0.10 | 46.82 | |
| RaceHorses | 1.71 | 40.96 | 1.04 | 44.24 | |
| FourPeople | 0.27 | 61.57 | 0.32 | 58.59 | |
| KristenAndSara | 0.65 | 63.27 | 0.70 | 57.35 | |
| Average | 0.76 | 50.04 | 0.59 | 50.19 | |
| Method | (BDBR, TS) | |
|---|---|---|
| RA | Proposed | (0.76, 50.04) |
| Yeo’s [25] | (1.10, 13.10) | |
| Amestoy’s [26] | (0.61, 30.10) | |
| Shang’s [13] | (1.56, 40.08) | |
| Tissier’s [28] | (1.65, 31.3) | |
| LD | Proposed | (0.59, 50.19) |
| Pan’s [27] | (2.52, 24.83) | |
| Li’s [14] | (1.29, 47.90) | |
| Tang’s [29] | (1.34, 31.43) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Xiang, M.; Jin, J.; Song, T. Extreme Learning Machine-Enabled Coding Unit Partitioning Algorithm for Versatile Video Coding. Information 2023, 14, 494. https://doi.org/10.3390/info14090494
Jiang X, Xiang M, Jin J, Song T. Extreme Learning Machine-Enabled Coding Unit Partitioning Algorithm for Versatile Video Coding. Information. 2023; 14(9):494. https://doi.org/10.3390/info14090494
Chicago/Turabian StyleJiang, Xiantao, Mo Xiang, Jiayuan Jin, and Tian Song. 2023. "Extreme Learning Machine-Enabled Coding Unit Partitioning Algorithm for Versatile Video Coding" Information 14, no. 9: 494. https://doi.org/10.3390/info14090494
APA StyleJiang, X., Xiang, M., Jin, J., & Song, T. (2023). Extreme Learning Machine-Enabled Coding Unit Partitioning Algorithm for Versatile Video Coding. Information, 14(9), 494. https://doi.org/10.3390/info14090494