

AI-Enhanced Decision-Making for Course Modality Preferences in Higher Engineering Education during the Post-COVID-19 Era

 , , , and
, , , and
Abstract
1. Introduction
2. Literature Review
2.1. Machine Learning in Education
2.1.1. Machine Learning Methods
2.1.2. Variable Selection in Machine Learning
2.2. Related Works
2.3. Theory-Driven ML in Educational Research
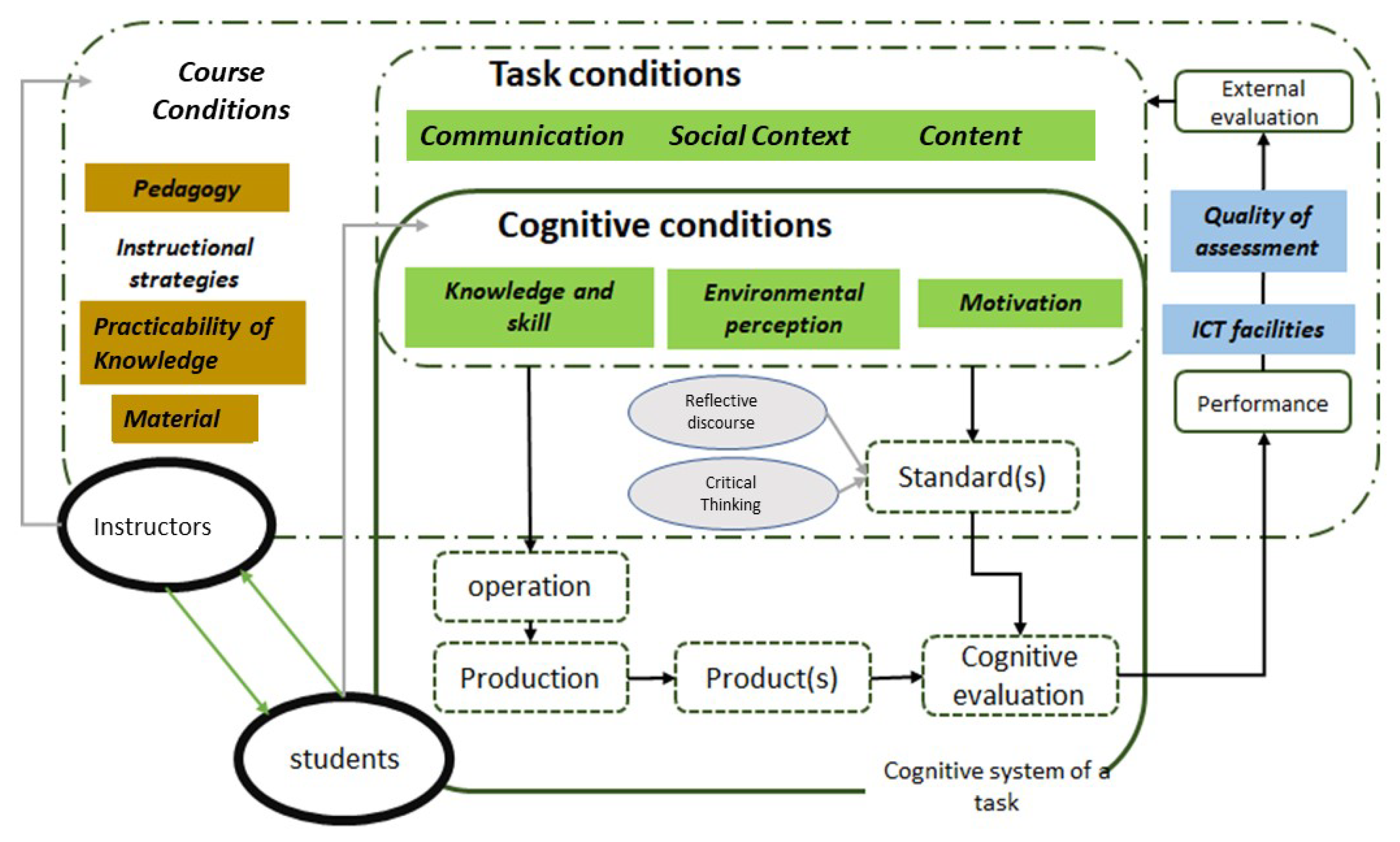
3. Theoretical Framework
3.1. Self-Regulated Learning (SRL)
3.2. Course Modality as a Part of Technology-Enhanced Learning
3.3. E-Learning Systems
4. Research Design
4.1. Participants
4.2. Validity and Reliability Analysis
5. Methodology
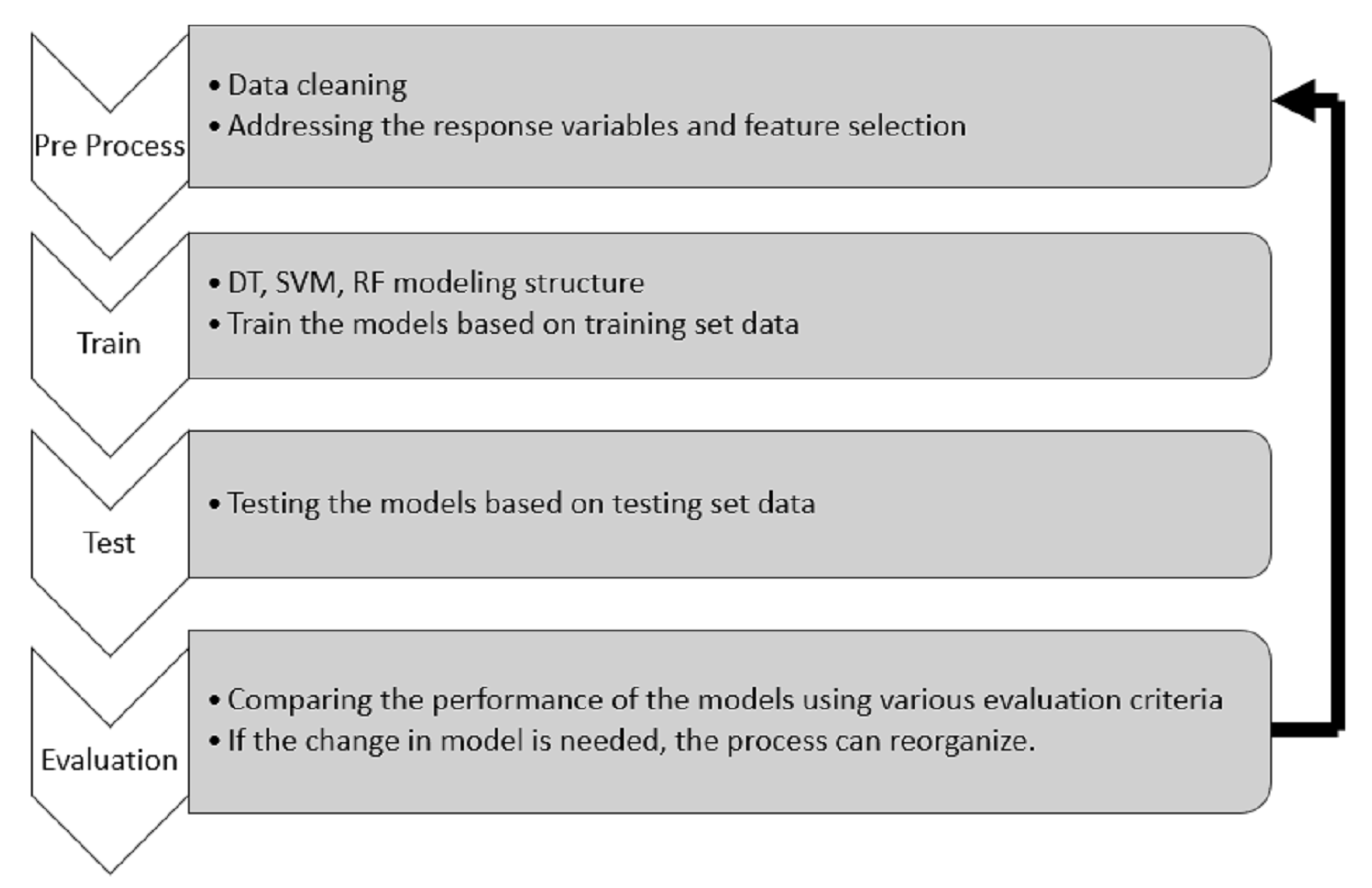
5.1. Machine Learning Process
5.2. Machine Learning Models
5.3. Accuracy of ML Models
6. Results
6.1. Prediction Using Classification Techniques
6.2. Subscales’ Ranking and Framework
7. Discussion
8. Conclusions
9. Future Research Directions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rauseo, S.; Rathnayake, D.; Marinciu, R. Decision-making under uncertainty: How university students navigate the academic implications of the COVID-19 pandemic challenges. In Agile Learning Environments amid Disruption: Evaluating Academic Innovations in Higher Education during COVID-19; Springer: Berlin/Heidelberg, Germany, 2022; pp. 655–674. [Google Scholar]
- Lekishvili, T.; Kikutadze, V. Decision-Making process transformation in post-COVID-19 world in higher educational Institutions. In Digital Management in COVID-19 Pandemic and Post-Pandemic Times: Proceedings of the International Scientific-Practical Conference (ISPC 2021), Moscow, Russia, 2–4 November 2021; Springer: Cham, Switzerland, 2023; pp. 169–177. [Google Scholar]
- Krismanto, W.; Tahmidaten, L. Self-Regulated Learning in online-based teacher education and training programs. Aksara J. Ilmu Pendidik. Nonform. 2022, 8, 413. [Google Scholar] [CrossRef]
- Skar, G.B.U.; Graham, S.; Huebner, A. Learning loss during the COVID-19 pandemic and the impact of emergency remote instruction on first grade students’ writing: A natural experiment. J. Educ. Psychol. 2022, 114, 1553. [Google Scholar] [CrossRef]
- Pekrul, S.; Levin, B. Building Student Voice for School Improvement. In International Handbook of Student Experience in Elementary and Secondary School; Thiessen, D., Cook-Sather, A., Eds.; Springer: Dordrecht, The Netherlands, 2007; Chapter 27; pp. 711–726. [Google Scholar] [CrossRef]
- Winne, P.H. Cognition and Metacognition within Self-Regulated Learning. In Handbook of Self-Regulation of Learning and Performance, 2nd ed.; Shunk, D.S., Greene, J.A., Eds.; Taylor and Francis: Abingdon, UK, 2017; pp. 36–48. [Google Scholar] [CrossRef]
- Lima, R.M.; Villas-Boas, V.; Soares, F.; Carneiro, O.S.; Ribeiro, P.; Mesquita, D. Mapping the implementation of active learning approaches in a school of engineering–the positive effect of teacher training. Eur. J. Eng. Educ. 2024, 1–20. [Google Scholar] [CrossRef]
- Alpaydin, E. Machine Learning: The New AI; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Macarini, L.A.B.; Cechinel, C.; Machado, M.F.B.; Ramos, V.F.C.; Munoz, R. Predicting students success in blended learning—evaluating different interactions inside learning management systems. Appl. Sci. 2019, 9, 5523. [Google Scholar] [CrossRef]
- Johri, A.; Katz, A.S.; Qadir, J.; Hingle, A. Generative artificial intelligence and engineering education. J. Eng. Educ. 2023, 112, 572–577. [Google Scholar] [CrossRef]
- Hilbert, S.; Coors, S.; Kraus, E.; Bischl, B.; Lindl, A.; Frei, M.; Wild, J.; Krauss, S.; Goretzko, D.; Stachl, C. Machine learning for the educational sciences. Rev. Educ. 2021, 9, e3310. [Google Scholar] [CrossRef]
- Singh, J.; Steele, K.; Singh, L. Combining the Best of Online and Face-to-Face Learning: Hybrid and Blended Learning Approach for COVID-19, Post Vaccine, & Post-Pandemic World. J. Educ. Technol. Syst. 2021, 50, 140–171. [Google Scholar] [CrossRef]
- Singh, J.; Perera, V.; Magana, A.J.; Newell, B.; Wei-Kocsis, J.; Seah, Y.Y.; Strimel, G.J.; Xie, C. Using machine learning to predict engineering technology students’ success with computer-aided design. Comput. Appl. Eng. Educ. 2022, 30, 852–862. [Google Scholar] [CrossRef]
- Koretsky, M.D.; Nolen, S.B.; Galisky, J.; Auby, H.; Grundy, L.S. Progression from the mean: Cultivating instructors’ unique trajectories of practice using educational technology. J. Eng. Educ. 2024, 113, 330–359. [Google Scholar] [CrossRef]
- Zimmerman, B.J.; Campillo, M. Motivating Self-Regulated Problem Solvers. In The Psychology of Problem Solving; Cambridge University Press: Cambridge, MA, USA, 2003; pp. 233–262. [Google Scholar] [CrossRef]
- Talib, N.I.M.; Majid, N.A.A.; Sahran, S. Identification of Student Behavioral Patterns in Higher Education Using K-Means Clustering and Support Vector Machine. Appl. Sci. 2023, 13, 3267. [Google Scholar] [CrossRef]
- Martin, F.; Wang, C.; Sadaf, A. Student perception of helpfulness of facilitation strategies that enhance instructor presence, connectedness, engagement and learning in online courses. Internet High. Educ. 2018, 37, 52–65. [Google Scholar] [CrossRef]
- Psyridou, M.; Koponen, T.; Tolvanen, A.; Aunola, K.; Lerkkanen, M.K.; Poikkeus, A.M.; Torppa, M. Early prediction of math difficulties with the use of a neural networks model. J. Educ. Psychol. 2023, 116, 212–232. [Google Scholar] [CrossRef]
- Inusah, F.; Missah, Y.M.; Najim, U.; Twum, F. Data mining and visualisation of basic educational resources for quality education. Int. J. Eng. Trends Technol. 2022, 70, 296–307. [Google Scholar] [CrossRef]
- Safaei, M.; Sundararajan, E.A.; Driss, M.; Boulila, W.; Shapi’i, A. A systematic literature review on obesity: Understanding the causes & consequences of obesity and reviewing various machine learning approaches used to predict obesity. Comput. Biol. Med. 2021, 136, 104754. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Bayirli, E.G.; Kaygun, A.; Öz, E. An analysis of PISA 2018 mathematics assessment for Asia-Pacific countries using educational data mining. Mathematics 2023, 11, 1318. [Google Scholar] [CrossRef]
- Mehrabi, A.; Morphew, J. Board 73: AI Skills-based Assessment Tool for Identifying Partial and Full-Mastery within Large Engineering Classrooms. In Proceedings of the ASEE Annual Conference & Exposition, Portland, OR, USA, 23–26 June 2024; ASEE: Washington, DC, USA, 2024. [Google Scholar] [CrossRef]
- Alghamdi, M.I. Assessing Factors Affecting Intention to Adopt AI and ML: The Case of the Jordanian Retail Industry. MENDEL 2020, 26, 39–44. [Google Scholar] [CrossRef]
- Li, F.Q.; Wang, S.L.; Liew, A.W.C.; Ding, W.; Liu, G.S. Large-Scale Malicious Software Classification With Fuzzified Features and Boosted Fuzzy Random Forest. IEEE Trans. Fuzzy Syst. 2021, 29, 3205–3218. [Google Scholar] [CrossRef]
- Liu-Yi, W.; Li-Gu, Z.H.U. Research and application of credit risk of small and medium-sized enterprises based on random forest model. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 371–374. [Google Scholar] [CrossRef]
- Park, C.G. Implementing alternative estimation methods to test the construct validity of Likert-scale instruments. Korean J. Women Health Nurs. 2023, 29, 85–90. [Google Scholar] [CrossRef]
- Abdelmagid, A.S.; Qahmash, A.I.M. Utilizing the Educational Data Mining Techniques ‘Orange Technology’ for Detecting Patterns and Predicting Academic Performance of University Students. Inf. Sci. Lett. 2023, 12, 1415–1431. [Google Scholar] [CrossRef]
- Ahmad, I.; Basheri, M.; Iqbal, M.J.; Rahim, A. Performance comparison of support vector machine, random forest, and extreme learning machine for intrusion detection. IEEE Access 2018, 6, 33789–33795. [Google Scholar] [CrossRef]
- Sengupta, S. Towards Finding a Minimal Set of Features for Predicting Students’ Performance Using Educational Data Mining. Int. J. Mod. Educ. Comput. Sci. 2023, 15, 44–54. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.K.R.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 130. [Google Scholar] [CrossRef]
- Yin, Y.; Jang-Jaccard, J.; Xu, W.; Singh, A.; Zhu, J.; Sabrina, F.; Kwak, J. IGRF-RFE: A hybrid feature selection method for MLP-based network intrusion detection on UNSW-NB15 dataset. J. Big Data 2023, 10, 15. [Google Scholar] [CrossRef]
- Saeed, A.; Zaffar, M.; Abbas, M.A.; Quraishi, K.S.; Shahrose, A.; Irfan, M.; Huneif, M.A.; Abdulwahab, A.; Alduraibi, S.K.; Alshehri, F.; et al. A Turf-Based Feature Selection Technique for Predicting Factors Affecting Human Health during Pandemic. Life 2022, 12, 1367. [Google Scholar] [CrossRef]
- Zaffar, M.; Hashmani, M.A.; Savita, K.; Rizvi, S.S.H.; Rehman, M. Role of FCBF Feature Selection in Educational Data Mining. Mehran Univ. Res. J. Eng. Technol. 2020, 39, 772–779. [Google Scholar] [CrossRef]
- Tadist, K.; Najah, S.; Nikolov, N.S.; Mrabti, F.; Zahi, A. Feature selection methods and genomicbig data: A systematic review. J. Big Data 2019, 6, 79. [Google Scholar] [CrossRef]
- Vommi, A.M.; Battula, T.K. A hybrid filter-wrapper feature selection using Fuzzy KNN based on Bonferroni mean for medical datasets classification: A COVID-19 case study. Expert Syst. Appl. 2023, 218, 119612. [Google Scholar] [CrossRef]
- Zhou, X.; Li, Y.; Song, X.; Jin, L.; Wang, X. Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method. Energies 2023, 16, 1638. [Google Scholar] [CrossRef]
- Singh, J.; Evans, E.; Reed, A.; Karch, L.; Qualey, K.; Singh, L.; Wiersma, H. Online, Hybrid, and Face-to-Face Learning Through the Eyes of Faculty, Students, Administrators, and Instructional Designers: Lessons Learned and Directions for the Post-Vaccine and Post-Pandemic/COVID-19 World. J. Educ. Technol. Syst. 2022, 50, 301–326. [Google Scholar] [CrossRef]
- Carmona, C.; Castillo, G.; Millán, E. Discovering Student Preferences in E-Learning. In Proceedings of the International Workshop on Applying Data Mining in E-Learning, Crete, Greece, 17–20 September 2007; pp. 33–42. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Assessing Supervised Machine Learning Techniques for Predicting Student Learning Preferences. In Proceedings of the 3rd Congress on Information and Communication Technologies in Education, London, UK, 27–28 February 2018; Dimitracopoulou, A., Ed.; University of Aegean: Rhodes, Greece, 2019. [Google Scholar] [CrossRef]
- Hew, K.F.; Hu, X.; Qiao, C.; Tang, Y. What predicts student satisfaction with MOOCs: A gradient boosting trees supervised machine learning and sentiment analysis approach. Comput. Educ. 2020, 145, 103724. [Google Scholar] [CrossRef]
- Hebbecker, K.; Förster, N.; Forthmann, B.; Souvignier, E. Data-based decision-making in schools: Examining the process and effects of teacher support. J. Educ. Psychol. 2022, 114, 1695. [Google Scholar] [CrossRef]
- Turgut, Y.; Bozdag, C.E. A framework proposal for machine learning-driven agent-based models through a case study analysis. Simul. Model. Pract. Theory 2023, 123, 102707. [Google Scholar] [CrossRef]
- Ouyang, F.; Wu, M.; Zheng, L.; Zhang, L.; Jiao, P. Integration of artificial intelligence performance prediction and learning analytics to improve student learning in online engineering course. Int. J. Educ. Technol. High. Educ. 2023, 20, 1–23. [Google Scholar] [CrossRef]
- Mehrabi, A.; Morphew, J. Investigating and predicting the Cognitive Fatigue Threshold as a Factor of Performance Reduction in Assessment. In Proceedings of the ASEE Annual Conference & Exposition, Portland, OR, USA, 23–26 June 2024; ASEE: Washington, DC, USA, 2024. [Google Scholar] [CrossRef]
- Muis, K.R.; Chevrier, M.; Singh, C.A. The Role of Epistemic Emotions in Personal Epistemology and Self-Regulated Learning. Educ. Psychol. 2018, 53, 165–184. [Google Scholar] [CrossRef]
- Kumar, R.; Sexena, A.; Gehlot, A. Artificial Intelligence in Smart Education and Futuristic Challenges. In Proceedings of the 2023 International Conference on Disruptive Technologies (ICDT), Greater Noida, India, 11–12 May 2023; pp. 432–435. [Google Scholar]
- Aparicio, M.; Bacao, F.; Oliveira, T. An e-Learning Theoretical Framework | Enhanced Reader. Educ. Technol. Soc. 2016, 19, 293–307. [Google Scholar]
- Schrumpf, J. On the Effectiveness of an AI-Driven Educational Resource Recommendation System for Higher Education. Int. Assoc. Dev. Inf. Soc. 2022, 1, 883–901. [Google Scholar]
- Whiteside, A.L.; Dikkers, A.G.; Lewis, S. More Confident Going into College’: Lessons Learned from Multiple Stakeholders in a New Blended Learning Initiative. Online Learn. 2016, 20, 136–156. [Google Scholar] [CrossRef]
- Sitzmann, T.; Ely, K. A Meta-Analysis of Self-Regulated Learning in Work-Related Training and Educational Attainment: What We Know and Where We Need to Go. Psychol. Bull. 2011, 137, 421–442. [Google Scholar] [CrossRef]
- Balid, W.; Alrouh, I.; Hussian, A.; Abdulwahed, M. Systems engineering design of engineering education: A case of an embedded systems course. In Proceedings of the IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE) 2012, Hong Kong, China, 20–23 August 2012; p. W1D-7. [Google Scholar]
- Passey, D. Technology-enhanced learning: Rethinking the term, the concept and its theoretical background. Br. J. Educ. Technol. 2019, 50, 972–986. [Google Scholar] [CrossRef]
- Duval, E.; Sharples, M.; Sutherland, R. Research themes in technology enhanced learning. In Technology Enhanced Learning: Research Themes; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Jackson, C.K. The full measure of a teacher: Using value-added to assess effects on student behavior. Educ. Next 2019, 19, 62–69. Available online: https://go.gale.com/ps/i.do?p=AONE&sw=w&issn=15399664&v=2.1&it=r&id=GALE%7CA566264029&sid=googleScholar&linkaccess=fulltext (accessed on 10 August 2023).
- Gunawardena, M.; Dhanapala, K.V. Barriers to Removing Barriers of Online Learning. Commun. Assoc. Inf. Syst. 2023, 52, 264–280. [Google Scholar] [CrossRef]
- Rabbi, J.; Fuad, M.T.H.; Awal, M.A. Human Activity Analysis and Recognition from Smartphones using Machine Learning Techniques. arXiv 2021. [Google Scholar] [CrossRef]
- Sánchez-Ruiz, L.; López-Alfonso, S.; Moll-López, S.; Moraño-Fernández, J.; Vega-Fleitas, E. Educational Digital Escape Rooms Footprint on Students’ Feelings: A Case Study within Aerospace Engineering. Information 2022, 13, 478. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D.G. Statistics notes: Cronbach’s alpha. BMJ 1997, 314, 572. [Google Scholar] [CrossRef]
- Afthanorhan, A.; Ghazali, P.L.; Rashid, N. Discriminant Validity: A Comparison of CBSEM and Consistent PLS using Fornell & Larcker and HTMT Approaches. J. Phys. Conf. Ser. 2021, 1874, 012085. [Google Scholar] [CrossRef]
- Henseler, J.; Ringle, C.M.; Sarstedt, M. A new criterion for assessing discriminant validity in variance-based structural equation modeling. J. Acad. Mark. Sci. 2015, 43, 115–135. [Google Scholar] [CrossRef]
- Yusoff, A.S.M.; Peng, F.S.; Abd Razak, F.Z.; Mustafa, W.A. Discriminant validity assessment of religious teacher acceptance: The use of HTMT criterion. J. Phys. Conf. Ser. 2020, 1529, 042045. [Google Scholar] [CrossRef]
- Ab Hamid, M.R.; Sami, W.; Sidek, M.M. Discriminant Validity Assessment: Use of Fornell & Larcker criterion versus HTMT Criterion. J. Phys. Conf. Ser. 2017, 890, 012163. [Google Scholar] [CrossRef]
- Rempel, J.K.; Holmes, J.G.; Zanna, M.P. Trust in close relationships. J. Personal. Soc. Psychol. 1985, 49, 95–112. [Google Scholar] [CrossRef]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef] [PubMed]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef]
- Chopade, S.; Chopade, S.; Gawade, S. Multimedia teaching learning methodology and result prediction system using machine learning. J. Eng. Educ. Transform. 2022, 35, 135–142. [Google Scholar] [CrossRef]
- Campbell, I. Chi-squared and Fisher–Irwin tests of two-by-two tables with small sample recommendations. Stat. Med. 2007, 26, 3661–3675. [Google Scholar] [CrossRef] [PubMed]
- Borrego, M.; Froyd, J.E.; Hall, T.S. Diffusion of engineering education innovations: A survey of awareness and adoption rates in US engineering departments. J. Eng. Educ. 2010, 99, 185–207. [Google Scholar] [CrossRef]
- Masood, H. Breast cancer detection using machine learning algorithm. Int. Res. J. Eng. Technol. (IRJET) 2021, 8, 1–5. [Google Scholar]
- Rachburee, N.; Punlumjeak, W. A comparison of feature selection approach between greedy, IG-ratio, Chi-square, and mRMR in educational mining. In Proceedings of the 2015 7th International Conference on Information Technology and Electrical Engineering (ICITEE), Chiang Mai, Thailand, 29–30 October 2015; pp. 420–424. [Google Scholar]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Jia, W.; Sun, M.; Lian, J.; Hou, S. Feature dimensionality reduction: A review. Complex Intell. Syst. 2022, 8, 2663–2693. [Google Scholar] [CrossRef]
- Kursa, M.B.; Jankowski, A.; Rudnicki, W.R. Boruta—A System for Feature Selection. Fundam. Inform. 2010, 101, 271–285. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Appl. Sci. 2021, 3, 1–12. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sens. Actuators B Chem. 2015, 212, 353–363. [Google Scholar] [CrossRef]
- Alotaibi, B.; Alotaibi, M. Consensus and majority vote feature selection methods and a detection technique for web phishing. J. Ambient Intell. Humaniz. Comput. 2021, 12, 717–727. [Google Scholar] [CrossRef]
- Borandag, E.; Ozcift, A.; Kilinc, D.; Yucalar, F. Majority vote feature selection algorithm in software fault prediction. Comput. Sci. Inf. Syst. 2019, 16, 515–539. [Google Scholar] [CrossRef]
- Jindal, A.; Dua, A.; Kaur, K.; Singh, M.; Kumar, N.; Mishra, S. Decision Tree and SVM-Based Data Analytics for Theft Detection in Smart Grid. IEEE Trans. Ind. Inform. 2016, 12, 1005–1016. [Google Scholar] [CrossRef]
- Teo, S.G.; Han, S.; Lee, V.C.S. Privacy Preserving Support Vector Machine Using Non-linear Kernels on Hadoop Mahout. In Proceedings of the 2013 IEEE 16th International Conference on Computational Science and Engineering, Sydney, Australia, 3–5 December 2013; pp. 941–948. [Google Scholar] [CrossRef]
- Sikder, J.; Datta, N.; Tripura, S.; Das, U.K. Emotion, Age and Gender Recognition using SURF, BRISK, M-SVM and Modified CNN. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20–22 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Kuo, K.M.; Talley, P.C.; Chang, C.S. The accuracy of machine learning approaches using non-image data for the prediction of COVID-19: A meta-analysis. Int. J. Med Inform. 2022, 164, 104791. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning From Imbalanced Data: Open Challenges and Future Directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Lunardon, N.; Menardi, G.; Torelli, N. ROSE: A Package for Binary Imbalanced Learning. R J. 2014, 6, 79–89. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A Systematic Study of the Class Imbalance Problem in Convolutional Neural Networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Sharma, A.; Verbeke, W. Improving Diagnosis of Depression With XGBOOST Machine Learning Model and a Large Biomarkers Dutch Dataset (N = 11,081). Front. Big Data 2020, 3, 15. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.Y. An Empirical Study of Boosting Methods on Severely Imbalanced Data. Appl. Mech. Mater. 2014, 513–517, 2510–2513. [Google Scholar] [CrossRef]
- Beuthner, C.; Friedrich, M.; Herbes, C.; Ramme, I. Examining survey response styles in cross-cultural marketing research: A comparison between Mexican and South Korean respondents. Int. J. Mark. Res. 2018, 60, 257–267. [Google Scholar] [CrossRef]
- Vora, D.R.; Iyer, K.R. Deep Learning in Engineering Education: Implementing a Deep Learning Approach for the Performance Prediction in Educational Information Systems. In Deep Learning Applications and Intelligent Decision Making in Engineering; IGI Global: Hershey, PA, USA, 2021; pp. 222–255. [Google Scholar]
- Vora, D.R.; Iyer, K.R. Deep Learning in Engineering Education: Performance Prediction Using Cuckoo-Based Hybrid Classification. In Machine Learning and Deep Learning in Real-Time Applications; IGI Global: Hershey, PA, USA, 2020; pp. 187–218. [Google Scholar]
- Saputra, N.A.; Hamidah, I.; Setiawan, A. A bibliometric analysis of deep learning for education research. J. Eng. Sci. Technol. 2023, 18, 1258–1276. [Google Scholar]
- Davis, L.; Sun, Q.; Lone, T.; Levi, A.; Xu, P. In the Storm of COVID-19: College Students’ Perceived Challenges with Virtual Learning. J. High. Educ. Theory Pract. 2022, 22, 66–82. [Google Scholar]
- Li, H. The Influence of Online Learning Behavior on Learning Performance. Appl. Sci. Innov. Res. 2023, 7, 69. [Google Scholar] [CrossRef]
- Kanetaki, Z.; Stergiou, C.; Bekas, G.; Troussas, C.; Sgouropoulou, C. A hybrid machine learning model for grade prediction in online engineering education. Int. J. Eng. Pedagog 2022, 12, 4–23. [Google Scholar] [CrossRef]
- Onan, A. Mining opinions from instructor evaluation reviews: A deep learning approach. Comput. Appl. Eng. Educ. 2020, 28, 117–138. [Google Scholar] [CrossRef]
- Yogeshwaran, S.; Kaur, M.J.; Maheshwari, P. Project based learning: Predicting bitcoin prices using deep learning. In Proceedings of the 2019 IEEE global engineering education conference (EDUCON), Dubai, United Arab Emirates, 8–11 April 2019; pp. 1449–1454. [Google Scholar]
- Lameras, P.; Arnab, S. Power to the Teachers: An Exploratory Review on Artificial Intelligence in Education. Information 2022, 13, 14. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Models | Students | Instructors | ||||
|---|---|---|---|---|---|---|
| I2 Theoretical | I4 Practical | I6 Theoretical–Practical | H2 Theoretical | H4 Practical | H6 Theoretical–Practical | |
| SVM | 0.45 | 0.43 | 0.56 | 0.48 | 0.53 | 0.42 |
| DT | 0.39 | 0.40 | 0.45 | 0.41 | 0.53 | 0.35 |
| RF | 0.45 | 0.43 | 0.58 | 0.49 | 0.62 | 0.37 |
| Models | Students | Instructors | ||||
|---|---|---|---|---|---|---|
| I2 Theoretical | I4 Practical | I6 Theoretical–Practical | H2 Theoretical | H4 Practical | H6 Theoretical–Practical | |
| SVM | 0.44 | 0.66 | 0.47 | 0.64 | 0.46 | 0.54 |
| DT | 0.38 | 0.62 | 0.41 | 0.61 | 0.21 | 0.32 |
| RF | 0.47 | 0.74 | 0.58 | 0.64 | 0.36 | 0.43 |
| Models | Students | Instructors | ||||
|---|---|---|---|---|---|---|
| I2 Theoretical | I4 Practical | I6 Theoretical–Practical | H2 Theoretical | H4 Practical | H6 Theoretical–Practical | |
| SVM | 0.70 | 0.75 | 0.80 | 0.50 | 0.65 | 0.55 |
| DT | 0.71 | 0.72 | 0.71 | 0.53 | 0.65 | 0.48 |
| RF | 0.78 | 0.81 | 0.94 | 0.69 | 0.72 | 0.79 |
| Groups | ||||||
|---|---|---|---|---|---|---|
| Students | Instructors | |||||
| I2 Theo. | I4 Prac. | I6 T-P | H2 Theo. | H4 Prac. | H6 T-P | |
| Likert type (5-scale) | ||||||
| 1 | Ped. | Ped. | Ped. | Ped. | Ped. | Work-life Ori. |
| 2 | Motiv. | Motiv. | Work-life Ori. | Motiv. | Motiv. | Ped. |
| 3 | Qual. of Assess. & ICT | Know., Ins. & Skill | Motiv. | Work-life Ori. | Work-life Ori. | Motiv. |
| 4 | Know., Ins. & Skill | Theory & Pract. | Qual. of Assess. & ICT | Qual. of Assess. & ICT | Qual. of Assess. & ICT | Theory & Pract. |
| 5 | Work-life Ori. | Work-life Ori. | Know., Ins. & Skill | Know., Ins. & Skill | Theory & Pract. | Qual. of Assess. & ICT |
| 6 | Theory & Pract. | Qual. of Assess. & ICT | Theory & Pract. | Theory & Pract. | Know., Ins. & Skill | Know., Ins. & Skill |
| Likert type (3-scale) | ||||||
| 1 | Ped. | Ped. | Ped. | Ped. | Ped. | Motiv. |
| 2 | Motiv. | Motiv. | Motiv. | Motiv. | Motiv. | Ped. |
| 3 | Qual. of Assess. & ICT | Know., Ins. & Skill | Qual. of Assess. & ICT | Know., Ins. & Skill | Work-life Ori. | Work-life Ori. |
| 4 | Know., Ins. & Skill | Theory & Pract. | Know., Ins. & Skill | Work-life Ori. | Qual. of Assess. & ICT | Theory & Pract. |
| 5 | Work-life Ori. | Work-life Ori. | Work-life Ori. | Theory & Pract. | Theory & Pract. | Qual. of Assess. & ICT |
| 6 | Theory & Pract. | Qual. of Assess. & ICT | Theory & Pract. | Qual. of Assess. & ICT | Know., Ins. & Skill | Know., Ins. & Skill |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehrabi, A.; Morphew, J.W.; Araabi, B.N.; Memarian, N.; Memarian, H. AI-Enhanced Decision-Making for Course Modality Preferences in Higher Engineering Education during the Post-COVID-19 Era. Information 2024, 15, 590. https://doi.org/10.3390/info15100590
Mehrabi A, Morphew JW, Araabi BN, Memarian N, Memarian H. AI-Enhanced Decision-Making for Course Modality Preferences in Higher Engineering Education during the Post-COVID-19 Era. Information. 2024; 15(10):590. https://doi.org/10.3390/info15100590
Chicago/Turabian StyleMehrabi, Amirreza, Jason Wade Morphew, Babak Nadjar Araabi, Negar Memarian, and Hossein Memarian. 2024. "AI-Enhanced Decision-Making for Course Modality Preferences in Higher Engineering Education during the Post-COVID-19 Era" Information 15, no. 10: 590. https://doi.org/10.3390/info15100590
APA StyleMehrabi, A., Morphew, J. W., Araabi, B. N., Memarian, N., & Memarian, H. (2024). AI-Enhanced Decision-Making for Course Modality Preferences in Higher Engineering Education during the Post-COVID-19 Era. Information, 15(10), 590. https://doi.org/10.3390/info15100590