
Identifying Malware Packers through Multilayer Feature Engineering in Static Analysis




Abstract
1. Introduction
- We meticulously constructed datasets for benign and malware packers through a multistage process, ensuring well-organized samples for training our classifier.
- Our proposed packer classifier incorporates a multilayer feature engineering approach, selecting engineered features based on their prevalence and performance.
- The classifier achieves a high level of accuracy while maintaining exceptional efficiency, surpassing classical signature-based methods.
- Notably, our classifier excels in detecting both family-based packers and unknown packers in real-world scenarios.
2. Related Works
2.1. Packers Identification Approaches
2.1.1. Dynamic Analysis
2.1.2. Static Analysis
3. Background
3.1. Packers
3.2. The Functioning of Packing
- Initialization: as the packed executable is launched, the stub code is loaded into memory.
- Decryption and extraction: containing directives for decrypting and extracting the authentic payload of the packed file, the stub code addresses the typical encryption and obfuscation employed to elude detection.
- Execution: upon successful decryption and unpacking of the content, control is seamlessly handed over from the stub code to the unpacked code, allowing its execution.
- Countermeasures against analysis: certain stubs might incorporate countermeasures designed to complicate the efforts of security researchers attempting to comprehend and scrutinize the concealed content.
3.3. Packer Identification and Unpacking
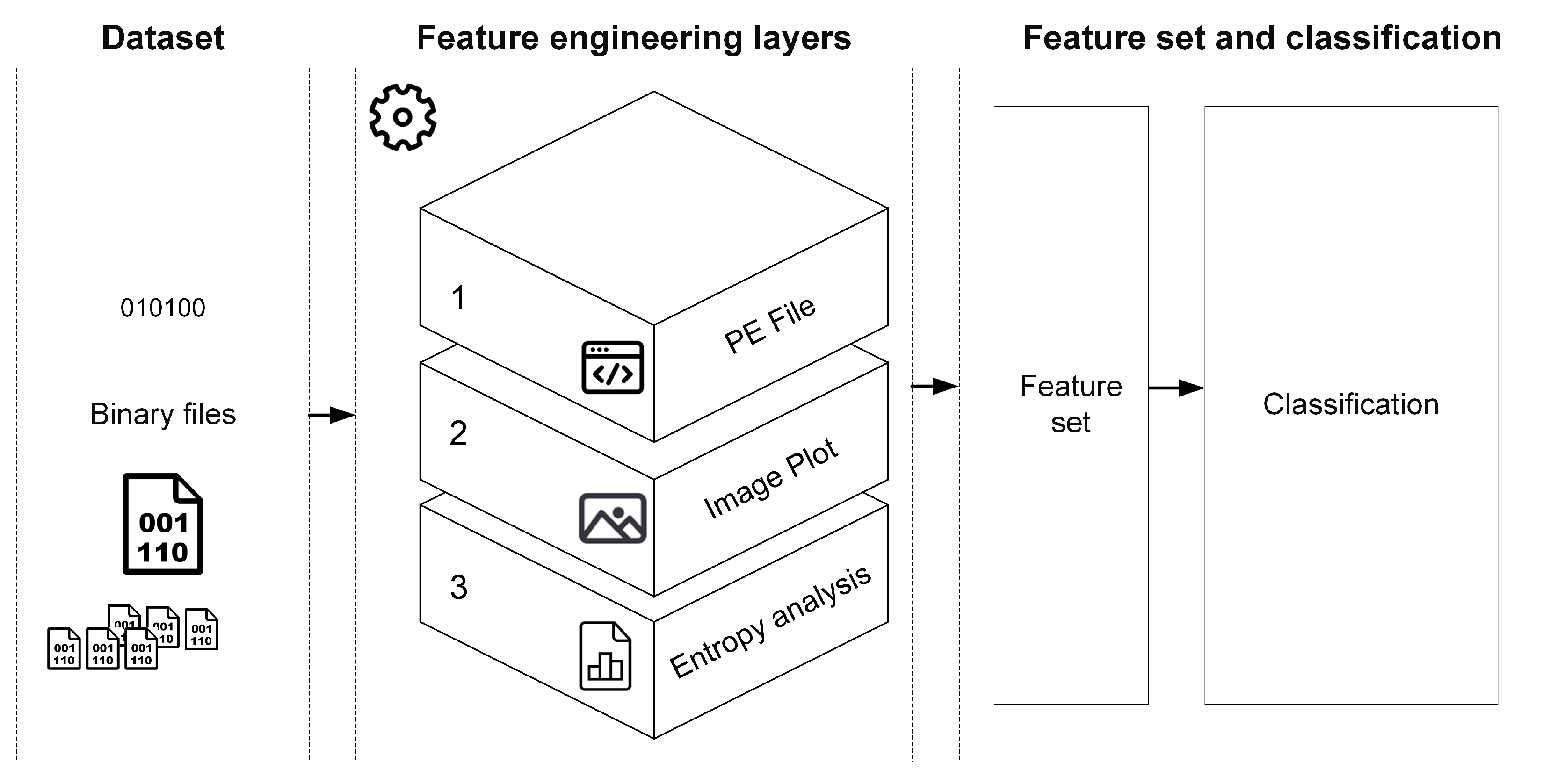
4. Approach
4.1. Feature Engineering
- Engineering or preparing the input data into features that can be comprehended by the machine learning algorithm, thereby meeting its requirements.
- Engineering or transforming variables into features that enhance the performance of machine learning algorithms in terms of predictive accuracy, interoperability, or both.
4.1.1. The PE File Format
4.1.2. Image Plot
| Algorithm 1 Image plot feature set | |
| ▹ Images. ▹ Feature sets ▹ images for packer families; c is # of families ▹l number of the input images ▹ Find difference of and ▹ Features ▹ Gabor jets between and ▹ Features |
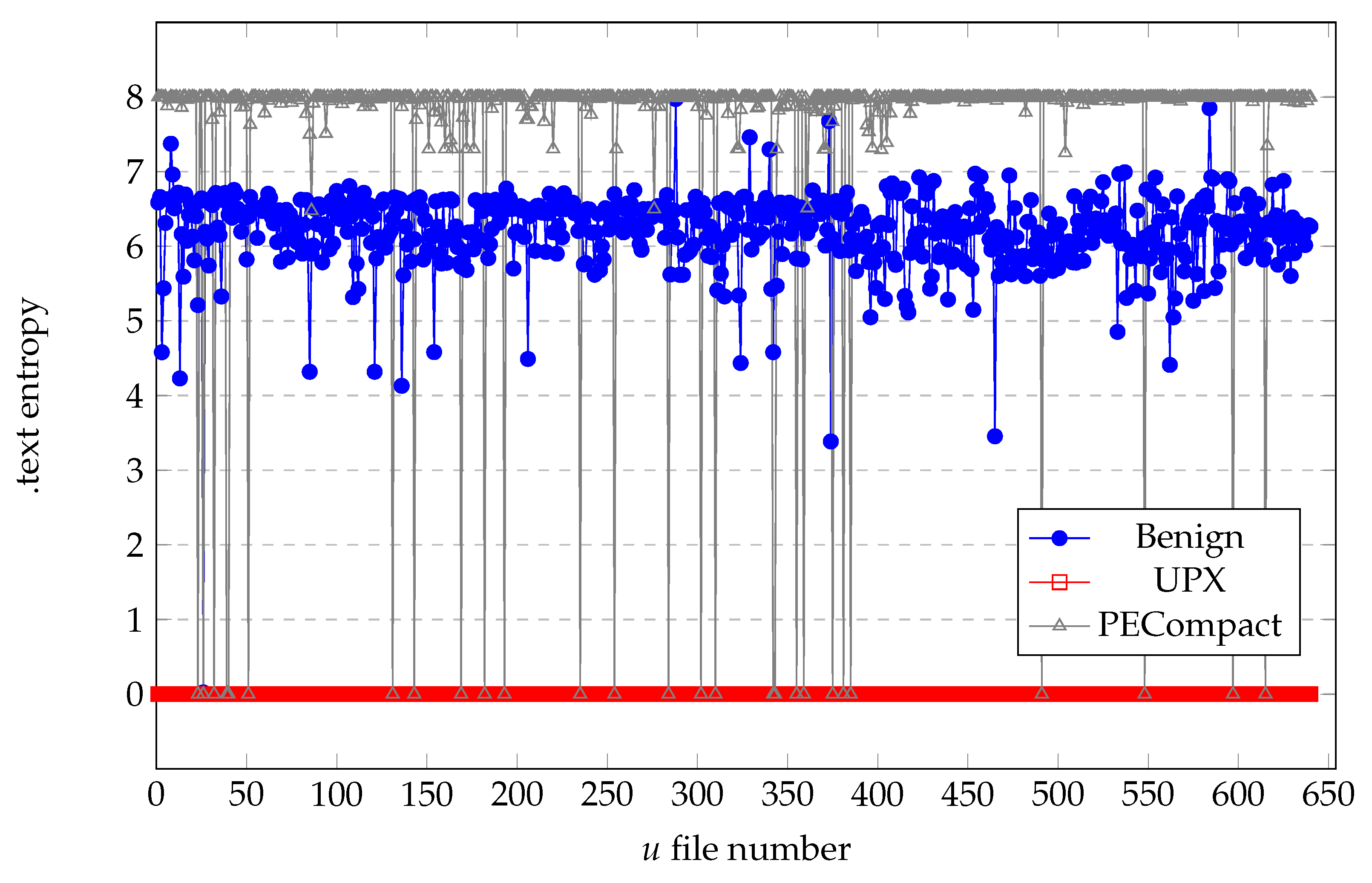
4.1.3. Entropy Analysis
4.2. Feature Set
4.3. Packers Classification
5. Experiments
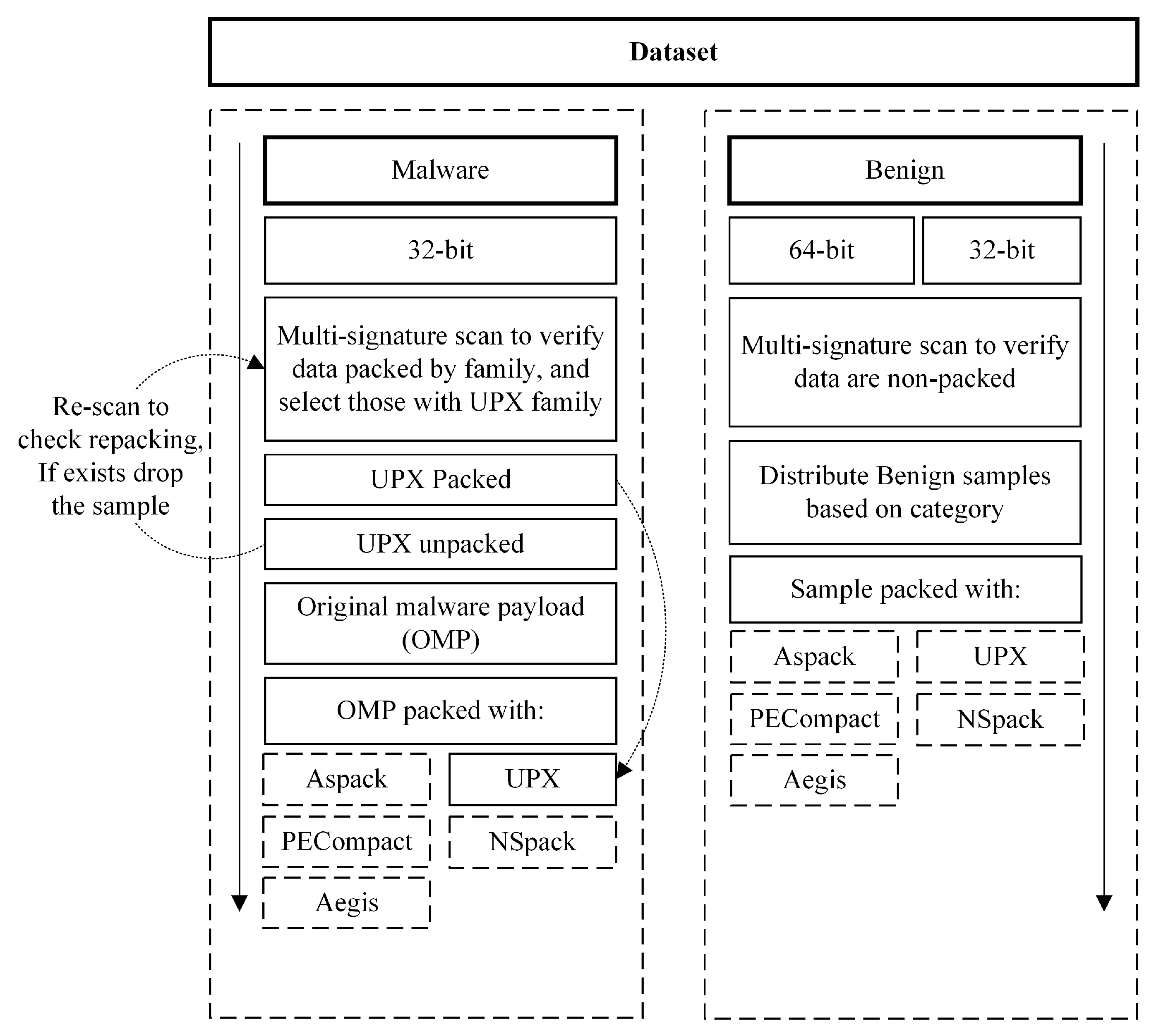
5.1. Dataset Preparation
5.1.1. Benign Samples
5.1.2. Malware Samples
5.2. Evaluation Metrics
- Accuracy: this metric quantifies the percentage of correct predictions for the test data.
- Precision: precision signifies the fraction of relevant examples (true positives) among all the examples that our model predicted to belong to a specific class.
- Recall: recall measures the proportion of examples that our model correctly predicted as belonging to a class, in relation to all the examples that truly belong to that class.
- F1-score: the F1-score is the harmonic mean of precision and recall, offering a balanced assessment of a classifier’s performance in multiclass scenarios.
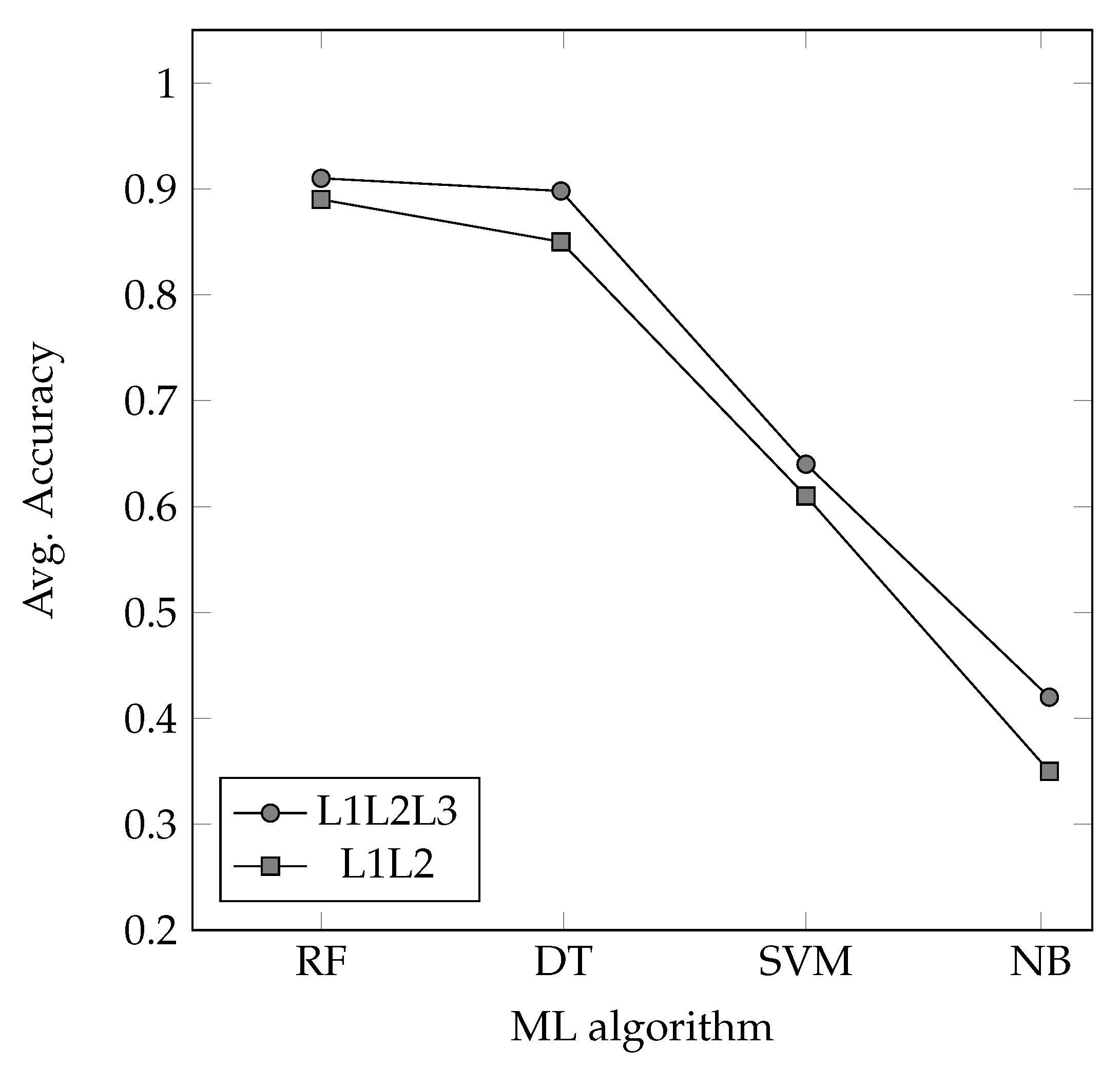
5.3. Experimental Results
5.4. Comparing with PEid
5.5. Unknown Packers
5.6. Comparing with Previous Works
6. Discussion
7. Conclusions
8. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AV | Antivirus |
| CFG | Control flow graph |
| PE | Portable Executable |
| API | Application programming interface |
| VX | Virus eXchange |
| GUI | Graphical user interface |
| SVM | Support vector machine |
| FCG | Function call graph |
| ASM | Assembly |
| LD | Levenshtein distance |
| UPX | Ultimate Packer for eXecutables |
| ATR | Automatic target recognition |
| RAT | Remote access trojan |
References
- Jajodia, S.; Shakarian, P.; Subrahmanian, V.; Swarup, V.; Wang, C. Cyber Warfare: Building the Scientific Foundation; Springer: Berlin/Heidelberg, Germany, 2015; Volume 56. [Google Scholar]
- Herrmann, D. Cyber Espionage and Cyber Defence. In Information Technology for Peace and Security: IT Applications and Infrastructures in Conflicts, Crises, War, and Peace; Reuter, C., Ed.; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2019; pp. 83–106. [Google Scholar] [CrossRef]
- Liţă, C.V.; Cosovan, D.; Gavriluţ, D. Anti-emulation trends in modern packers: A survey on the evolution of anti-emulation techniques in UPA packers. J. Comput. Virol. Hacking Tech. 2018, 14, 107–126. [Google Scholar] [CrossRef]
- McAfee. The Good, the Bad, and the Unknown. 2017. Available online: http://www.techdata.com/mcafee/files/MCAFEE_wp_appcontrol-good-bad-unknown.pdf (accessed on 12 January 2021).
- Ugarte-Pedrero, X.; Balzarotti, D.; Santos, I.; Bringas, P.G. SoK: Deep packer inspection: A longitudinal study of the complexity of run-time packers. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 659–673. [Google Scholar]
- Hai, N.M.; Ogawa, M.; Tho, Q.T. Packer identification based on metadata signature. In Proceedings of the 7th Software Security, Protection, and Reverse Engineering/Software Security and Protection Workshop, Orlando, FL, USA, 5–6 December 2017; pp. 1–11. [Google Scholar]
- Alkhateeb, E.M.; Stamp, M. United Arab Emirates A Dynamic Heuristic Method for Detecting Packed Malware Using Naive Bayes. In Proceedings of the 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 19–21 November 2019; pp. 1–6. [Google Scholar]
- Menéndez, H.D.; Llorente, J.L. Mimicking anti-viruses with machine learning and entropy profiles. Entropy 2019, 21, 513. [Google Scholar] [CrossRef] [PubMed]
- Bat-Erdene, M.; Park, H.; Li, H.; Lee, H.; Choi, M.S. Entropy analysis to classify unknown packing algorithms for malware detection. Int. J. Inf. Secur. 2017, 16, 227–248. [Google Scholar] [CrossRef]
- Bat-Erdene, M.; Kim, T.; Park, H.; Lee, H. Packer detection for multi-layer executables using entropy analysis. Entropy 2017, 19, 125. [Google Scholar] [CrossRef]
- Lim, C.; Ramli, K.; Kotualubun, Y.S.; Syailendra, Y. Mal-flux: Rendering hidden code of packed binary executable. Digit. Investig. 2019, 28, 83–95. [Google Scholar] [CrossRef]
- Ugarte-Pedrero, X.; Santos, I.; Bringas, P.G.; Gastesi, M.; Esparza, J.M. Semi-supervised learning for packed executable detection. In Proceedings of the 2011 5th International Conference on Network and System Security, Milan, Italy, 6–8 September 2011; pp. 342–346. [Google Scholar]
- Perdisci, R.; Lanzi, A.; Lee, W. Classification of packed executables for accurate computer virus detection. Pattern Recognit. Lett. 2008, 29, 1941–1946. [Google Scholar] [CrossRef]
- Dini, P.; Elhanashi, A.; Begni, A.; Saponara, S.; Zheng, Q.; Gasmi, K. Overview on Intrusion Detection Systems Design Exploiting Machine Learning for Networking Cybersecurity. Appl. Sci. 2023, 13, 7507. [Google Scholar] [CrossRef]
- Santos, I.; Ugarte-Pedrero, X.; Sanz, B.; Laorden, C.; Bringas, P.G. Collective classification for packed executable identification. In Proceedings of the 8th Annual Collaboration, Electronic messaging, Anti-Abuse and Spam Conference, Perth, Australia, 1–2 September 2011; pp. 23–30. [Google Scholar]
- Ugarte-Pedrero, X.; Santos, I.; García-Ferreira, I.; Huerta, S.; Sanz, B.; Bringas, P.G. On the adoption of anomaly detection for packed executable filtering. Comput. Secur. 2014, 43, 126–144. [Google Scholar] [CrossRef]
- Naval, S.; Laxmi, V.; Gaur, M.S.; P, V. An efficient block-discriminant identification of packed malware. Sadhana 2015, 40, 1435–1456. [Google Scholar] [CrossRef]
- Naval, S.; Laxmi, V.; Gaur, M.S.; Vinod, P. ESCAPE: Entropy score analysis of packed executable. In Proceedings of the Fifth International Conference on Security of Information and Networks, Jaipur, India, 25–27 October 2012; pp. 197–200. [Google Scholar]
- Laxmi, V.; Gaur, M.S.; Faruki, P.; Naval, S. PEAL—Packed executable analysis. In Proceedings of the International Conference on Advanced Computing, Networking and Security, Surathkal, India, 16–18 December 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 237–243. [Google Scholar]
- Mimura, M.; Ito, R. Applying NLP techniques to malware detection in a practical environment. Int. J. Inf. Secur. 2022, 21, 279–291. [Google Scholar] [CrossRef]
- Jin, Q.; Duan, J.; Vasudevan, S.; Bailey, M. Packer classifier based on PE header information. In Proceedings of the 2015 Symposium and Bootcamp on the Science of Security, Urbana IL, USA, 21–22 April 2015; pp. 1–2. [Google Scholar]
- Choi, Y.S.; Kim, I.K.; Oh, J.T.; Ryou, J.C. Pe file header analysis-based packed pe file detection technique (phad). In Proceedings of the International Symposium on Computer Science and its Applications, Hobart, TAS, Australia, 13–15 October 2008; pp. 28–31. [Google Scholar]
- Saleh, M.; Ratazzi, E.P.; Xu, S. A control flow graph-based signature for packer identification. In Proceedings of the MILCOM 2017—2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 683–688. [Google Scholar]
- Li, X.; Shan, Z.; Liu, F.; Chen, Y.; Hou, Y. A consistently-executing graph-based approach for malware packer identification. IEEE Access 2019, 7, 51620–51629. [Google Scholar] [CrossRef]
- Liu, H.; Guo, C.; Cui, Y.; Shen, G.; Ping, Y. 2-SPIFF: A 2-stage packer identification method based on function call graph and file attributes. Appl. Intell. 2021, 51, 9038–9053. [Google Scholar] [CrossRef]
- Kancherla, K.; Donahue, J.; Mukkamala, S. Packer identification using Byte plot and Markov plot. J. Comput. Virol. Hacking Tech. 2016, 12, 101–111. [Google Scholar] [CrossRef]
- Jung, B.; Bae, S.I.; Choi, C.; Im, E.G. Packer identification method based on byte sequences. Concurr. Comput. Pract. Exp. 2020, 32, e5082. [Google Scholar] [CrossRef]
- Dam, K.H.T.; Given-Wilson, T.; Legay, A.; Veroneze, R. Packer classification based on association rule mining. Appl. Soft Comput. 2022, 127, 109373. [Google Scholar] [CrossRef]
- Biondi, F.; Enescu, M.A.; Given-Wilson, T.; Legay, A.; Noureddine, L.; Verma, V. Effective, efficient, and robust packing detection and classification. Comput. Secur. 2019, 85, 436–451. [Google Scholar] [CrossRef]
- Bergenholtz, E.; Casalicchio, E.; Ilie, D.; Moss, A. Detection of metamorphic malware packers using multilayered LSTM networks. In Proceedings of the International Conference on Information and Communications Security; Springer: Berlin/Heidelberg, Germany, 2020; pp. 36–53. [Google Scholar]
- Damaševičius, R.; Venčkauskas, A.; Toldinas, J.; Grigaliūnas, Š. Ensemble-based classification using neural networks and machine learning models for windows pe malware detection. Electronics 2021, 10, 485. [Google Scholar] [CrossRef]
- Noureddine, L.; Heuser, A.; Puodzius, C.; Zendra, O. SE-PAC: A Self-Evolving PAcker Classifier against rapid packers evolution. In Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual Event, USA, 26–28 April 2021; pp. 281–292. [Google Scholar]
- Cheng, B.; Leal, E.A.; Zhang, H.; Ming, J. On the feasibility of malware unpacking via hardware-assisted loop profiling. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 7481–7498. [Google Scholar]
- D’alessio, S.; Mariani, S. PinDemonium: A DBI-based generic unpacker for Windows executables. In Proceedings of the Black Hat 2016, Las Vegas, NV, USA, July 2016; Available online: https://www.politesi.polimi.it/handle/10589/120861 (accessed on 12 June 2021).
- Carrera, E. PEFile. 2023. Available online: https://github.com/erocarrera/pefile (accessed on 12 June 2021).
- Rezaei, T.; Hamze, A. An efficient approach for malware detection using PE header specifications. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 234–239. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Ristad, E.S.; Yianilos, P.N. Learning string-edit distance. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 522–532. [Google Scholar] [CrossRef]
- Wellman, M.; Nasrabadi, N. Gabor Jets for Clutter Rejection in Infrared Imagery. Defense Technical Information Center. 2004. Available online: https://apps.dtic.mil/sti/pdfs/ADA487612.pdf (accessed on 12 June 2021).
- Wiskott, L.; Krüger, N.; Kuiger, N.; Von Der Malsburg, C. Face recognition by elastic bunch graph matching. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 775–779. [Google Scholar] [CrossRef]
- Günther, M.; Haufe, D.; Würtz, R.P. Face recognition with disparity corrected Gabor phase differences. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 11–14 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 411–418. [Google Scholar]
- Biryukov, A.; Nakahara, J., Jr.; Yıldırım, H.M. Differential entropy analysis of the IDEA block cipher. J. Comput. Appl. Math. 2014, 259, 561–570. [Google Scholar] [CrossRef]
- Donabelle, B.; Richard, M.L.; Mark, S. Structural entropy and metamorphic malware. J. Comput. Virol. Hacking Tech. 2013, 9, 79–192. [Google Scholar]
- Cozzi, E.; Graziano, M.; Fratantonio, Y.; Balzarotti, D. Understanding linux malware. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 161–175. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Alkhateeb, E.; Ghorbani, A.; Habibi Lashkari, A. A survey on run-time packers and mitigation techniques. Int. J. Inf. Secur. 2023, 1–27. [Google Scholar] [CrossRef]
- Kazoleas, I.; Karampelas, P. A novel malicious remote administration tool using stealth and self-defense techniques. Int. J. Inf. Secur. 2022, 21, 357–378. [Google Scholar] [CrossRef]
- Park, L.H.; Yu, J.; Kang, H.K.; Lee, T.; Kwon, T. Birds of a Feature: Intrafamily Clustering for Version Identification of Packed Malware. IEEE Syst. J. 2020, 14, 4545–4556. [Google Scholar] [CrossRef]
- Gao, X.; Hu, C.; Shan, C.; Han, W. MaliCage: A packed malware family classification framework based on DNN and GAN. J. Inf. Secur. Appl. 2022, 68, 103267. [Google Scholar] [CrossRef]
- Thantharate, P.; Anurag, T. CYBRIA-Pioneering Federated Learning for Privacy-Aware Cybersecurity with Brilliance. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 56–61. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AddressOfEP BaseOfCode BaseOfData CheckSum DllCharacteristics e_cblp e_cp e_cparhdr e_crlc e_cs e_csum e_ip e_lfanew e_lfarlc e_minalloc e_oemid e_oeminfo e_sp e_ss ImageBase LoaderFlags Magic MajorLinkerVersion MajorSubsystemVersion MinorLinkerVersion MinorSubsystemVersion Reserved1 sec_Num secaddress SectionAlignment SizeOfCode SizeOfHeapCommit SizeOfHeapReserve SizeOfImageSizeOfIniData SizeOfStackReserve Subsystem entSize e_magic e_maxalloc e_ovno FileAlignment MajorImageVersion MajorOperatingSystemVersion MinorImageVersion MinorOperatingSystemVersion NumberOfRvaAndSizes SizeOfHeaders SizeOfStackCommit SizeOfUninitData Tag |
| UPX0 → Packed.UPX |
| UPX1 → Packed.UPX |
| UPX2 → Packed.UPX |
| UPX! → Packed.UPX |
| .UPX0 → Packed.UPX |
| .UPX1 → Packed.UPX |
| Bookmark managers | 22 | Browsers | 43 |
| Camera | 13 | Clipboard | 23 |
| Screen capture | 11 | Misc | 29 |
| System information | 20 | Tweaks | 25 |
| IP scanners | 19 | Desktop enhancement | 21 |
| Internet remote utilities | 19 | Graphic | 90 |
| Audio and video | 91 | Total | 426 |
| Packer Name | Type | Source | Successfully Packed Samples |
|---|---|---|---|
| UPX | Protector | Online/benign | 392 |
| PECompact | Protector | Online/benign | 384 |
| NSPack | Protector | Online/benign | 328 |
| Aegis | Hostile | Online/benign | 410 |
| Aspack | Protector | Online/benign | 398 |
| Total | 1912 |
| Packer Name | Type | Source | Packed Samples |
|---|---|---|---|
| UPX | Protector | VirusTotal/malware | 870 |
| Aegis | Hostile | VirusTotal/malware | 870 |
| PECompact | Protector | VirusTotal/malware | 863 |
| NSPacker | Protector | VirusTotal/malware | 869 |
| Aspack | Protector | VirusTotal/malware | 856 |
| Total | 4327 |
| Feature Set | Classifier | Family | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| L1L2L3 | RF | UPX | 1.00 | 1.00 | 1.00 |
| PECompact | 1.00 | 0.99 | 0.99 | ||
| NSPacker | 1.00 | 1.00 | 1.00 | ||
| Aegis | 1.00 | 1.00 | 1.00 | ||
| ASPack | 1.00 | 0.99 | 0.99 | ||
| Benign | 0.96 | 0.99 | 0.98 | ||
| J48 | UPX | 0.99 | 1.00 | 1.00 | |
| PECompact | 0.99 | 0.98 | 0.98 | ||
| NSPacker | 1.00 | 1.00 | 1.00 | ||
| Aegis | 1.00 | 1.00 | 1.00 | ||
| ASPack | 0.98 | 0.99 | 0.99 | ||
| Benign | 0.95 | 0.92 | 0.93 | ||
| SVM | UPX | 0.93 | 0.92 | 0.92 | |
| PECompact | 0.68 | 0.91 | 0.78 | ||
| NSPack | 0.95 | 0.77 | 0.85 | ||
| Aegis | 0.98 | 1.00 | 0.99 | ||
| ASPack | 0.99 | 1.00 | 1.00 | ||
| Benign | 0.56 | 0.22 | 0.31 | ||
| NB | UPX | 0.99 | 0.45 | 0.62 | |
| PECompact | 0.52 | 0.80 | 0.63 | ||
| NSPack | 0.81 | 0.63 | 0.71 | ||
| Aegis | 1.00 | 1.00 | 1.00 | ||
| ASPack | 1.00 | 1.00 | 1.00 | ||
| Benign | 0.37 | 0.55 | 0.44 |
| Feature Set | Classifier | Family | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| L1L2 | RF | UPX | 0.98 | 1.00 | 0.99 |
| PECompact | 0.99 | 0.99 | 0.99 | ||
| NSPacker | 0.99 | 1.00 | 0.99 | ||
| Aegis | 1.00 | 1.00 | 1.00 | ||
| ASPack | 1.00 | 0.98 | 0.99 | ||
| Benign | 0.95 | 0.94 | 0.94 | ||
| J48 | UPX | 0.98 | 0.97 | 0.97 | |
| PECompact | 0.98 | 0.97 | 0.98 | ||
| NSPacker | 0.99 | 0.99 | 0.99 | ||
| Aegis | 1.00 | 1.00 | 1.00 | ||
| ASPack | 0.98 | 0.98 | 0.98 | ||
| Benign | 0.96 | 0.95 | 0.95 | ||
| SVM | UPX | 0.93 | 0.98 | 0.95 | |
| PECompact | 0.68 | 0.93 | 0.78 | ||
| NSPack | 0.95 | 0.79 | 0.86 | ||
| Aegis | 0.97 | 1.00 | 0.98 | ||
| ASPack | 1.00 | 0.99 | 0.99 | ||
| Benign | 0.74 | 0.17 | 0.28 | ||
| NB | UPX | 0.96 | 0.35 | 0.51 | |
| PECompact | 0.54 | 0.20 | 0.29 | ||
| NSPack | 0.77 | 0.63 | 0.70 | ||
| Aegis | 1.00 | 1.00 | 1.00 | ||
| ASPack | 1.00 | 0.99 | 1.00 | ||
| Benign | 0.20 | 0.95 | 0.33 |
| Packer Name | Type | Source | Samples |
|---|---|---|---|
| MPRESS | Protector | VirusTotal/malware | 204 |
| DarkComet | Hostile | VirusTotal/malware | 789 |
| N/A | Benign | Online/benign | 250 |
| Total | 1243 |
| Works | Approach | Dataset | Accuracy | Unknown Packers | Dataset Integrity |
|---|---|---|---|---|---|
| Kancherla et al. [26] | Img | OffensiveCompu | 81.34% | ✗ | ✗ |
| Alkhateeb et al. [7] | PE | VirusTotal | 88.50% | ✗ | ✗ |
| Park et al. [48] | PE | VXHeavens | 99.49% | ✗ | ✗ |
| Gao et al. [49] | PE | VirusShare | 97.80% | ✗ | ✗ |
| Proposed work | PE/Img | VirusTotal | 99.60% | ✓ | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkhateeb, E.; Ghorbani, A.; Habibi Lashkari, A. Identifying Malware Packers through Multilayer Feature Engineering in Static Analysis. Information 2024, 15, 102. https://doi.org/10.3390/info15020102
Alkhateeb E, Ghorbani A, Habibi Lashkari A. Identifying Malware Packers through Multilayer Feature Engineering in Static Analysis. Information. 2024; 15(2):102. https://doi.org/10.3390/info15020102
Chicago/Turabian StyleAlkhateeb, Ehab, Ali Ghorbani, and Arash Habibi Lashkari. 2024. "Identifying Malware Packers through Multilayer Feature Engineering in Static Analysis" Information 15, no. 2: 102. https://doi.org/10.3390/info15020102
APA StyleAlkhateeb, E., Ghorbani, A., & Habibi Lashkari, A. (2024). Identifying Malware Packers through Multilayer Feature Engineering in Static Analysis. Information, 15(2), 102. https://doi.org/10.3390/info15020102