

Deep Reinforcement Learning for Autonomous Driving in Amazon Web Services DeepRacer

Abstract
:1. Introduction
2. State of the Art Review
3. Materials and Methods
3.1. Policy Network
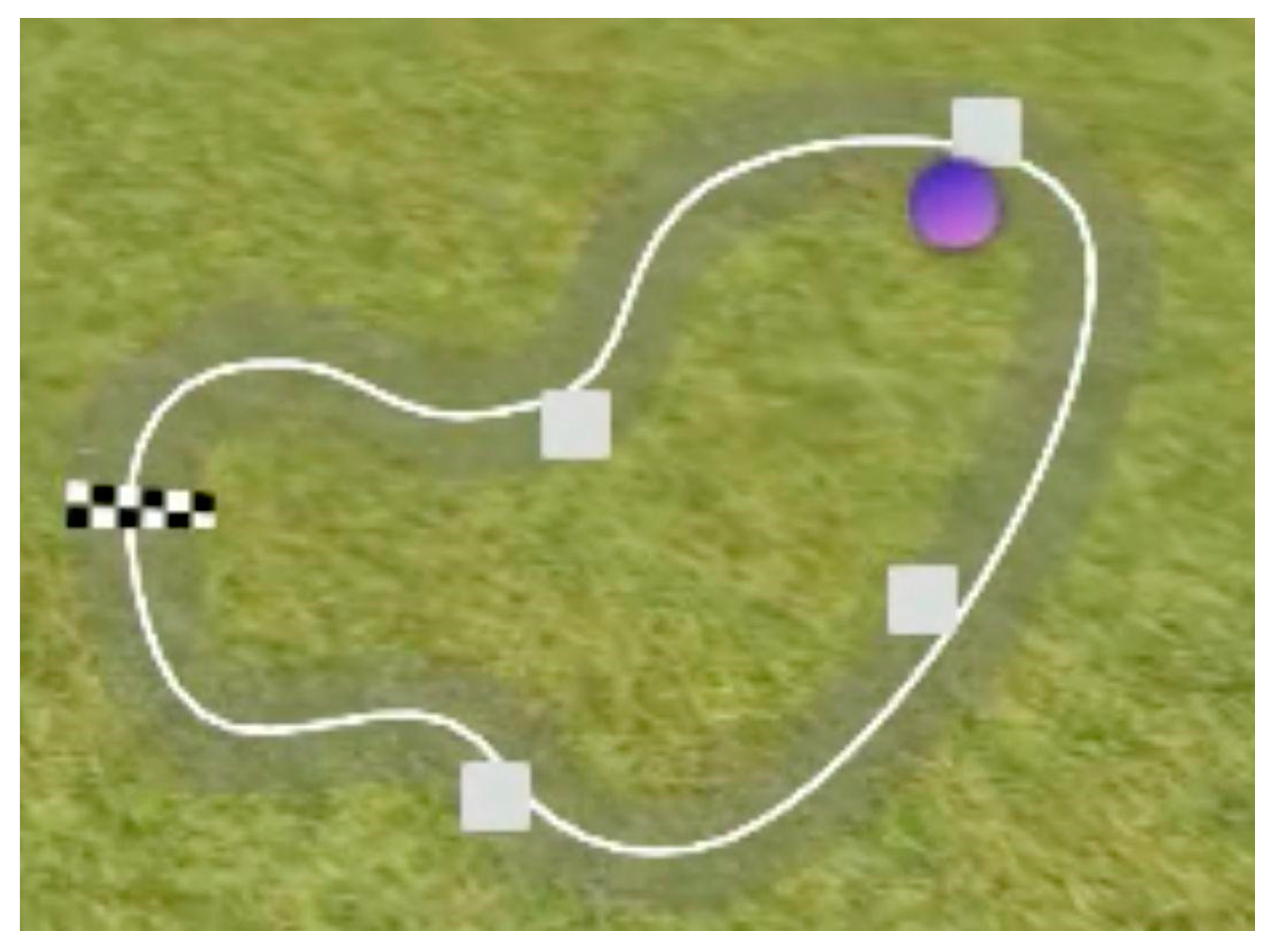
3.2. Hardware and Sensors
3.3. Policy Optimization Algorithms
3.3.1. Proximal Policy Optimisation Algorithm
3.3.2. Soft Actor Critic Algorithm
3.4. Reward Functions
3.4.1. Baseline Reward Function
| Algorithm 1: Baseline reward function | |
| 1: | Input: reward function parameters |
| 2: | Result: reward |
| 3: | Initialize: reward = 1 × 10−3 reward lane = 1 reward avoid = 1 |
| 4: | if car distance to the edge of the road < 0.05 m |
| 5: | reward lane = 1 |
| 6: | else |
| 7: | reward lane = 1 × 10−3 |
| 8: | end if |
| 9: | if obstacle on the same lane as car |
| 10: | if 0.5 ≤ distance to obstacle < 0.8 |
| 11: | reward avoid × = 0.5 |
| 12: | else if 0.3 ≤ distance to obstacle < 0.5 |
| 13: | reward avoid × = 0.2 |
| 14: | else if distance to obstacle < 0.3 |
| 15: | reward avoid = 1 × 10−3 |
| 16: | end if |
| 17: | end if |
| 18: | reward = reward lane × 1 + reward avoid × 4 |
3.4.2. Extended Baseline Reward Function
| Algorithm 2: Extended baseline reward function | |
| 1: | Input: reward function parameters |
| 2: | Result: reward |
| 3: | Initialize: reward = 1 × 10−3 reward lane = 1 reward avoid = 1 |
| 4: | if car distance to the edge of the road < 0.05 m |
| 5: | reward lane = 1 |
| 6: | else |
| 7: | reward lane = 1 × 10−3 |
| 8: | end if |
| 9: | if obstacle on the same lane as car |
| 10: | if 0.5 ≤ distance to obstacle < 0.8 |
| 11: | reward avoid × = 0.5 |
| 12: | else if 0.3 ≤ distance to obstacle < 0.5 |
| 13: | reward avoid × = 0.2 |
| 14: | else if distance to obstacle < 0.3 |
| 15: | reward avoid = 1 × 10−3 |
| 16: | end if |
| 17: | else |
| 18: | if 0.4 ≤ distance to obstacle < 0.5 |
| 19: | reward avoid × = 0.5 |
| 20: | else if distance to obstacle < 0.4 |
| 21: | reward avoid = 1 × 10−3 |
| 22: | end if |
| 23: | end if |
| 24: | reward = reward lane × 1 + reward avoid × 4 |
3.4.3. Continuous Reward Function
| Algorithm 3: Continuous reward function | |
| 1: | Input: reward function parameters |
| 2: | Result: reward |
| 3: | Initialize: reward = 1 × 10−3 reward lane = 1 reward avoid = 1 |
| 4: | if distance from center is <0.35 × track width |
| 5: | reward lane = 1 |
| 6: | else if distance from center is <0.5 × track width |
| 7: | reward lane = 3.33 × track width − 6.66 × track width × distance from center |
| 8: | else |
| 9: | reward lane = 1 × 10−3 |
| 10: | end if |
| 11: | if distance to closest obstacle < 0.25 |
| 12: | reward avoid = 1 × 10−3 |
| 13: | else if 0.25 ≤ distance to obstacle < 0.5 |
| 14: | reward avoid = (distance to obstacle − 0.25) × 4 + 1 × 10−3 |
| 15: | else |
| 16: | reward avoid = 1 |
| 17: | end if |
| 18: | reward = reward lane × 1 + reward avoid × 2 |
4. Results
4.1. Experimentation Settings
4.2. Baseline Model
4.3. Baseline Model with Soft Actor Critic
4.4. Extended Baseline Model
4.5. Extended Baseline with Light Detection and Ranging (LiDAR) Model
4.6. Continuous Reward Function
4.7. Continuous Reward Function with Light Detection and Ranging (LiDAR)
4.8. Continuous Reward Function with Reduced Action Space
5. Discussion and Future Research
5.1. Evaluation of Findings
- The reward function: Using a continuous reward function that outputs smoothly varying reward values that are directly proportional to the agent’s distance from the obstacle and the edge of the track, rather than one that rewards discrete values based on the agent’s proximity to obstacles, provided a more effective guidance to the model. As a result, the agent could make much more precise adjustments to its driving behaviour and react quickly to the environment.
- The RL algorithm: SAC and PPO are both model-free reinforcement learning algorithms commonly used in DeepRacer to train agents to complete tasks. SAC is a model-free algorithm that can learn from past experiences generated by any policy, while PPO is also a model-free algorithm but is more sample-efficient, meaning that it can learn a good policy with fewer training examples. Judging from the reward graph (Figure 5), the trained SAC model was unstable, exhibiting extreme values in both training and evaluation. This instability led to the agent not completing the race in the allotted time. This could be explained by the fact that SAC uses a continuous action space, which requires more data to accurately represent the agent’s actions. In contrast, PPO uses a discrete action space, making it less susceptible to overfitting and allowing for faster convergence. It is possible that training SAC for a longer time would have yielded better results in this particular case, but it is not guaranteed. The reason for the instability of the SAC model is likely due to the large number of parameters and the complex nature of the DeepRacer environment. Additionally, the continuous action space requires a large amount of data to learn a good policy. Increasing the training time would give SAC more opportunities to explore the environment and try different actions. This could lead to the discovery of better policies and a reduction in instability. However, it is also possible that longer training would simply reinforce the existing instability.
5.2. Possible Applications
5.3. Future Research
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey. 2015. Available online: https://trid.trb.org/view.aspx?id=1346216&source=post_page (accessed on 2 January 2024).
- Montgomery, W.D.; Mudge, R.; Groshen, E.L.; Helper, S.; MacDuffie, J.P.; Carson, C. America’s Workforce and the Self-Driving Future: Realizing Productivity Gains and Spurring Economic Growth. 2018. Available online: https://trid.trb.org/view/1516782 (accessed on 2 January 2024).
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- OpenAI; Andrychowicz, M.; Baker, B.; Chociej, M.; Jozefowicz, R.; McGrew, B.; Pachocki, J.; Petron, A.; Plappert, M.; Powell, G.; et al. Learning dexterous in-hand manipulation. Int. J. Robot. Res. 2020, 39, 3–20. [Google Scholar] [CrossRef]
- Tan, J.; Zhang, T.; Coumans, E.; Iscen, A.; Yunfei Bai, Y.; Danijar Hafner, D.; Steven Bohez, S.; Vincent Vanhoucke, V. Sim-to-real: Learning agile locomotion for quadruped robots. arXiv 2018, arXiv:1804.10332. [Google Scholar]
- Peng, X.B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-real transfer of robotic control with dynamics randomization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Muratore, F.; Treede; Gienger, M.; Peters, J. Domain randomization for simulation-based policy optimization with transferability assessment. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 700–713. [Google Scholar]
- Mandlekar, A.; Zhu, Y.; Garg, A.; Fei-Fei, L.; Savarese, S. Adversarially robust policy learning: Active construction of physicallyplausible perturbations. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3932–3939. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Higgins, I.; Pal, A.; Rusu, A.; Matthey, L.; Burgess, C.; Pritzel, A.; Botvinick, M.; Blundell, C.; Lerchner, A. Darla: Improving zeroshot transfer in reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11August 2017; Volume 70, pp. 1480–1490. [Google Scholar]
- Kaur, P.; Taghavi, S.; Tian, Z.; Shi, W. A Survey on Simulators for Testing Self-Driving Cars. In Proceedings of the 2021 Fourth International Conference on Connected and Autonomous Driving (MetroCAD), Detroit, MI, USA, 28–29 April 2021. [Google Scholar] [CrossRef]
- Li, Y.; Yuan, W.; Yan, W.; Shen, Q.; Wang, C.; Yang, M. Choose Your Simulator Wisely: A Review on Open-source Simulators for Autonomous Driving. arXiv 2023, arXiv:2311.11056. [Google Scholar]
- Juliani, A.; Berges, V.P.; Teng, E.; Cohen, A.; Harper, J.; Elion, C.; Goy, C.; Gao, Y.; Henry, H.; Mattar, M.; et al. Unity: A General Platform for Intelligent Agents. arXiv 2018. Available online: https://arxiv.org/abs/1809.02627 (accessed on 6 November 2023).
- Balaji, B.; Mallya, S.; Genc, S.; Gupta, S.; Dirac, L.; Khare, V.; Roy, G.; Sun, T.; Tao, Y.; Townsend, B.; et al. DeepRacer: Autonomous Racing Platform for Experimentation with Sim2Real Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; ISBN 9781728173955. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, G.Y. Mobile robot navigation based on lidar. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; ISBN 9781538612446. [Google Scholar] [CrossRef]
- Khaksar, W.; Vivekananthen, S.; Sahari, K.; Yousefi, M.; Alnaimi, F. A review on mobile robots motion path planning in unknown environments. In Proceedings of the 2015 IEEE International Symposium on Robotics and Intelligent Sensors (IRIS), Langkawi, Malaysia, 18–20 October 2015; ISBN 9781467371247. [Google Scholar] [CrossRef]
- Lei, X.; Zhang, Z.; Dong, P. Dynamic Path Planning of Unknown Environment Based on Deep Reinforcement Learning. J. Robot. 2018, 2018, 5781591. [Google Scholar] [CrossRef]
- Hui, H.; Yuge, W.; Wenjie, T.; Jiao, Z.; Yulei, G. Path Planning for Autonomous Vehicles in Unknown Dynamic Environment Based on Deep Reinforcement Learning. Appl. Sci. 2023, 13, 10056. [Google Scholar] [CrossRef]
- Hausknecht, M.; Stone, P. Deep Recurrent Q-Learning for Partially Observable MDPs. arXiv 2015, arXiv:1507.06527. [Google Scholar]
- Güçkiran, K.; Bolat, B. Autonomous Car Racing in Simulation Environment Using Deep Reinforcement Learning. In Proceedings of the 2019 Innovations in Intelligent Systems and Applications Conference (ASYU), Izmir, Turkey, 31 October 2019–2 November 2019; ISBN 9781728128689. [Google Scholar] [CrossRef]
- Cai, P.; Wang, H.; Huang, H.; Liu, Y.; Liu, M. Vision-Based Autonomous Car Racing Using Deep Imitative Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 6, 7262–7269. [Google Scholar] [CrossRef]
- Rezaee, K.; Yadmellat, P.; Chamorro, S. Motion Planning for Autonomous Vehicles in the Presence of Uncertainty Using Reinforcement Learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; ISBN 9781467388511. [Google Scholar] [CrossRef]
- Gao, M.; Chang, D.E. Autonomous Driving Based on Modified SAC Algorithm through Imitation Learning Pretraining. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021. [Google Scholar] [CrossRef]
- Hien, P.X.; Kim, G.-W. Goal-Oriented Navigation with Avoiding Obstacle based on Deep Reinforcement Learning in Continuous Action Space. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021. [Google Scholar] [CrossRef]
- Song, Q.; Liu, Y.; Lu, M.; Zhang, J.; Qi, H.; Wang, Z.; Liu, Z. Autonomous Driving Decision Control Based on Improved Proximal Policy Optimization Algorithm. Appl. Sci. 2023, 13, 6400. [Google Scholar] [CrossRef]
- Muzahid, A.J.M.; Kamarulzaman, S.F.; Rahman, M.A. Comparison of PPO and SAC Algorithms towards Decision Making Strategies for Collision Avoidance Among Multiple Autonomous Vehicles. In Proceedings of the 2021 International Conference on Software Engineering & Computer Systems and 4th International Conference on Computational Science and Information Management (ICSECS-ICOCSIM), Pekan, Malaysia, 24–26 August 2021. [Google Scholar] [CrossRef]
- Fu, M.; Zhang, T.; Song, W.; Yang, Y.; Wang, M. Trajectory Prediction-Based Local Spatio-Temporal Navigation Map for Autonomous Driving in Dynamic Highway Environments. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6418–6429. [Google Scholar] [CrossRef]
- Mavrogiannis, A.; Chandra, R.; Manocha, D. B-GAP: Behavior-Rich Simulation and Navigation for Autonomous Driving. IEEE Robot. Autom. Lett. 2022, 7, 4718–4725. [Google Scholar] [CrossRef]
- Mohammadhasani, A.; Mehrivash, H.; Lynch, A.F.; Shu, Z. Reinforcement Learning Based Safe Decision Making for Highway Autonomous Driving. arXiv 2021, arXiv:2105.06517. [Google Scholar]
- Liu, M.; Zhao, F.; Niu, J.; Liu, Y. ReinforcementDriving: Exploring Trajectories and Navigation for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 22, 808–820. [Google Scholar] [CrossRef]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep Reinforcement Learning framework for Autonomous Driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef]
- Liu, M.; Zhao, F.; Yin, J.; Niu, J.; Liu, Y. Reinforcement-Tracking: An Effective Trajectory Tracking and Navigation Method for Autonomous Urban Driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6991–7007. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, L.; Yu, H.; Zhang, W.; Mei, Y.; Xiong, H. Hierarchical Reinforcement Learning for Dynamic Autonomous Vehicle Navigation at Intelligent Intersections. In KDD ‘23M Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; ACM: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Tremblay, M.; Halder, S.S.; de Charette, R.; Lalonde, J.-F. Rain Rendering for Evaluating and Improving Robustness to Bad Weather. Int. J. Comput. Vis. 2021, 129, 341–360. [Google Scholar] [CrossRef]
- Chen, G.; Huang, V. Ensemble Reinforcement Learning in Continuous Spaces—A Hierarchical Multi-Step Approach for Policy Training. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence {IJCAI-23}; International Joint Conferences on Artificial Intelligence Organization: San Francisco, CA, USA, 2023. [Google Scholar] [CrossRef]
- Zhai, P.; Luo, J.; Dong, Z.; Zhang, L.; Wang, S.; Yang, D. Robust Adversarial Reinforcement Learning with Dissipation Inequation Constraint. Proc. AAAI Conf. Artif. Intell. 2022, 36, 5431–5439. [Google Scholar] [CrossRef]
- Tiboni, G.; Arndt, K.; Kyrki, V. DROPO: Sim-to-real transfer with offline domain randomization. Robot. Auton. Syst. 2023, 166, 104432. [Google Scholar] [CrossRef]
- Jaekyeom, K.; Seohong, P.; Gunhee, K. Constrained GPI for Zero-Shot Transfer in Reinforcement Learning. NeurIPS Proceedings. Available online: https://proceedings.neurips.cc/paper_files/paper/2022/hash/1d8dc55c1f6cf124af840ce1d92d1896-Abstract-Conference.html (accessed on 8 November 2023).
- Truong, J.; Chernova, S.; Batra, D. Bi-Directional Domain Adaptation for Sim2Real Transfer of Embodied Navigation Agents. IEEE Robot. Autom. Lett. 2021, 6, 2634–2641. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning. Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Field and Service Robotics; Springer International Publishing: Cham, Switzerland, 2017; pp. 621–635. ISBN 9783319673608. [Google Scholar] [CrossRef]
- Espié, E.; Guionneau, C.; Wymann, B.; Dimitrakakis, C.; Coulom, R.; Sumner, A. TORCS, The Open Racing Car Simulator; EPFL: Lausanne, Switzerland, 2015. [Google Scholar]
- Krajzewicz, D.; Hertkorn, G.; Feld, C.; Wagner, P. SUMO (Simulation of Urban MObility); An open-source traffic simulation. In Proceedings of the 4th Middle East Symposium on Simulation and Modelling, Sharjah, United Arab Emirates, 28–30 October 2002; ISBN 90-77039-09-0. [Google Scholar]
- Terapaptommakol, W.; Phaoharuhansa, D.; Koowattanasuchat, P.; Rajruangrabin, J. Design of Obstacle Avoidance for Autonomous Vehicle Using Deep Q-Network and CARLA Simulator. World Electr. Veh. J. 2022, 13, 239. [Google Scholar] [CrossRef]
- Zhang, E.; Zhou, H.; Ding, Y.; Zhao, J.; Ye, C. Learning How to Avoiding Obstacles for End-to-End Driving with Conditional Imitation Learning. In SPML ’19, Proceedings of the 2019 2nd International Conference on Signal Processing and Machine Learning, Hangzhou, China, 27–29 November 2019; ACM: New York, NY, USA, 2019; ISBN 9781450372213. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, S.; Yu, S.; Yu, J.J.Q.; Wen, M. Collision Avoidance Predictive Motion Planning Based on Integrated Perception and V2V Communication. IEEE Trans. Intell. Transp. Syst. 2022, 22, 9640–9653. [Google Scholar] [CrossRef]
- Liang, X.; Liu, Y.; Chen, T.; Liu, M.; Yang, Q. Federated Transfer Reinforcement Learning for Autonomous Driving. In Federated and Transfer Learning; Springer International Publishing: Cham, Switzerland, 2022; pp. 357–371. ISBN 9783031117473. [Google Scholar] [CrossRef]
- Spryn, M.; Sharma, A.; Parkar, D.; Shrima, M. Distributed deep reinforcement learning on the cloud for autonomous driving. In ICSE ’18, Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 28 May 2018; ACM: New York, NY, USA, 2018; ISBN 9781450357395. [Google Scholar] [CrossRef]
- Capo, E.; Loiacono, D. Short-Term Trajectory Planning in TORCS using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; ISBN 9781728125473. [Google Scholar] [CrossRef]
- Wang Sen Jia, D.; Weng, X. Deep Reinforcement Learning for Autonomous Driving. arXiv 2019, arXiv:1811.11329. [Google Scholar]
- Spatharis, C.; Blekas, K. Multiagent reinforcement learning for autonomous driving in traffic zones with unsignalized intersections. J. Intell. Transp. Syst. 2024, 28, 103–119. [Google Scholar] [CrossRef]
- Garza-Coello, L.A.; Zubler, M.M.; Montiel, A.N.; Vazquez-Hurtado, C. AWS DeepRacer: A Way to Understand and Apply the Reinforcement Learning Methods. In Proceedings of the 2023 IEEE Global Engineering Education Conference (EDUCON), Salmiya, Kuwait, 1–4 May 2023. [Google Scholar] [CrossRef]
- Zhu, W.; Du, H.; Zhu, M.; Liu, Y.; Lin, C.; Wang, S.; Sun, W.; Yan, H. Application of Reinforcement Learning in the Autonomous Driving Platform of the DeepRacer. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022. [Google Scholar] [CrossRef]
- Du, H. A Dynamic Collaborative Planning Method for Multi-vehicles in the Autonomous Driving Platform of the DeepRacer. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Hefei, China, 25–27 July 2022. [Google Scholar] [CrossRef]
- Tian, A.; John, E.G.; Yang, K. Poster: Unraveling Reward Functions for Head-to-Head Autonomous Racing in AWS DeepRacer. In MobiHoc ’23, Proceedings of the Twenty-Fourth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, Washington, DC, USA, 23–26 October 2023; ACM: New York, NY, USA, 2023. [Google Scholar] [CrossRef]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; ISBN 0780384636. [Google Scholar] [CrossRef]
- Li, J.; Abusharkh, M.; Xu, Y. DeepRacer Model Training for autonomous vehicles on AWS EC2. In Proceedings of the 2022 International Telecommunications Conference (ITC-Egypt), Alexandria, Egypt, 26–28 July 2022. [Google Scholar] [CrossRef]
- Mccalip, J.; Pradhan, M.; Yang, K. Reinforcement Learning Approaches for Racing and Object Avoidance on AWS DeepRacer. In Proceedings of the 2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC), Torino, Italy, 26–30 June 2023. [Google Scholar] [CrossRef]
- AWS DeepRacer Concepts and Terminology. AWS DeepRacer. Available online: https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-basic-concept.html (accessed on 26 December 2023).
- AWS DeepRacer Evo Is Coming Soon. Amazon Web Services. Available online: https://aws.amazon.com/blogs/machine-learning/aws-deepracer-evo-is-coming-soon-enabling-developers-to-race-their-object-avoidance-and-head-to-head-models-in-exciting-new-racing-formats/ (accessed on 26 December 2023).
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. arXiv 2015, arXiv:1502.05477. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- AWS DeepRacer Reward Function Examples. AWS DeepRacer. Available online: https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-reward-function-examples.html#deepracer-reward-function-example-3 (accessed on 26 December 2023).
- Understanding Racing Types and Enabling Sensors Supported by AWS DeepRacer. AWS DeepRacer. Available online: https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-choose-race-type.html#deepracer-get-started-training-object-avoidance (accessed on 2 January 2024).
- Kovalský, K.; Palamas, G. Neuroevolution vs Reinforcement Learning for Training Non Player Characters in Games: The Case of a Self Driving Car. In Social Informatics and Telecommunications Engineering; Lecture Notes of the Institute for Computer Sciences; Springer International Publishing: Cham, Switzerland, 2021; pp. 191–206. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment No. | Reward Function | Sensors | Algorithm |
|---|---|---|---|
| 1 | Baseline | Stereo camera | PPO |
| 2 | Baseline | Stereo camera | SAC |
| 3 | Extended baseline | Stereo camera | PPO |
| 4 | Extended baseline | Single camera, LiDAR | PPO |
| 5 | Continuous reward function | Stereo camera | PPO |
| 6 | Continuous reward function | Single camera, LiDAR | PPO |
| 7 | Continuous reward function | Single camera, LiDAR | PPO, Reduced Action Space |
| Action No. | Steering Angle (°) | Speed (m/s) |
|---|---|---|
| 1 | −30.0 | 0.50 |
| 2 | −30.0 | 1.00 |
| 3 | −15.0 | 0.50 |
| 4 | −15.0 | 1.00 |
| 5 | 0.0 | 0.50 |
| 6 | 0.0 | 1.00 |
| 7 | 15.0 | 0.50 |
| 8 | 15.0 | 1.00 |
| 9 | 30.0 | 0.50 |
| 10 | 30.0 | 1.00 |
| Hyperparameter | Value |
|---|---|
| Gradient descent batch size | 64 |
| Entropy | 0.01 |
| Discount factor | 0.999 |
| Loss type | Huber |
| Learning rate | 0.0003 |
| Number of experience episodes between each policy-updating iteration | 20 |
| Number of epochs | 10 |
| Trial | Time (MM:SS.mmm) | Trial Results | Off-Track | Off-Track Penalty | Crashes | Crash Penalty |
|---|---|---|---|---|---|---|
| 1 | 03:17.583 | 100% | 0 | -- | 26 | 130 s |
| 2 | 02:09.535 | 100% | 0 | -- | 16 | 80 s |
| 3 | 01:04.011 | 100% | 0 | -- | 6 | 30 s |
| Hyperparameter | Value |
|---|---|
| Gradient descent batch size | 64 |
| Learning rate | 0.0003 |
| SAC alpha (α) value | 0.2 |
| Discount factor | 0.999 |
| Loss type | Mean squared error |
| Number of experience episodes between each policy-updating iteration | 1 |
| Trial | Time (MM:SS.mmm) | Trial Results | Off-Track | Off-Track Penalty | Crashes | Crash Penalty |
|---|---|---|---|---|---|---|
| 1 | 00:46.98 | 100% | 0 | -- | 4 | 20 s |
| 2 | 01:02.74 | 100% | 1 | 2 s | 6 | 30 s |
| 3 | 00:52.74 | 100% | 0 | -- | 5 | 25 s |
| Trial | Time (MM:SS.mmm) | Trial Results | Off-Track | Off-Track Penalty | Crashes | Crash Penalty |
|---|---|---|---|---|---|---|
| 1 | 00:51.988 | 100% | 0 | -- | 4 | 20 s |
| 2 | 00:29.824 | 100% | 0 | -- | 1 | 5 s |
| 3 | 01:04.653 | 100% | 1 | 2 s | 5 | 25 s |
| Trial | Time (MM:SS.mmm) | Trial Results | Off-Track | Off-Track Penalty | Crashes | Crash Penalty |
|---|---|---|---|---|---|---|
| 1 | 01:12.190 | 100% | 0 | -- | 8 | 40 s |
| 2 | 00:46.606 | 100% | 0 | -- | 4 | 20 s |
| 3 | 00:47.126 | 100% | 1 | 2 s | 4 | 20 s |
| Trial | Time (MM:SS.mmm) | Trial Results | Off-Track | Off-Track Penalty | Crashes | Crash Penalty |
|---|---|---|---|---|---|---|
| 1 | 00:22.857 | 100% | 0 | -- | 0 | -- |
| 2 | 00:29.673 | 100% | 0 | -- | 1 | 5 s |
| 3 | 00:30.285 | 100% | 0 | -- | 1 | 5 s |
| Trial | Time (MM:SS.mmm) | Trial Results | Off-Track | Off-Track Penalty | Crashes | Crash Penalty |
|---|---|---|---|---|---|---|
| 1 | 00:53.292 | 100% | 1 | 2 s | 3 | 15 s |
| 2 | 00:27.494 | 100% | 2 | 4 s | 0 | -- |
| 3 | 00:39.144 | 100% | 2 | 4 s | 0 | -- |
| Action No. | Steering Angle (°) | Speed (m/s) |
|---|---|---|
| 1 | −30.0 | 0.75 |
| 2 | −15.0 | 0.75 |
| 3 | 0.0 | 0.75 |
| 4 | 15.0 | 0.75 |
| 5 | 30.0 | 0.75 |
| Experiment Name | Total Crashes | Total Off-Track | Total Race Time | Laps without Crashes |
|---|---|---|---|---|
| Baseline | 48 | 0 | 06:31.129 | 0 |
| SAC baseline | N/A * | N/A * | N/A * | N/A * |
| Extended baseline | 15 | 1 | 02:40.256 | 0 |
| Extended baseline with LiDAR | 10 | 1 | 02:26.465 | 0 |
| Continuous reward | 16 | 1 | 02:45.922 | 0 |
| Continuous reward with LiDAR | 2 | 0 | 01:22.815 | 1 |
| Continuous reward with LiDAR, unknown environment | 3 | 5 | 01:59.930 | 2 |
| Continuous reward, reduced space | N/A * | N/A * | N/A * | N/A * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petryshyn, B.; Postupaiev, S.; Ben Bari, S.; Ostreika, A. Deep Reinforcement Learning for Autonomous Driving in Amazon Web Services DeepRacer. Information 2024, 15, 113. https://doi.org/10.3390/info15020113
Petryshyn B, Postupaiev S, Ben Bari S, Ostreika A. Deep Reinforcement Learning for Autonomous Driving in Amazon Web Services DeepRacer. Information. 2024; 15(2):113. https://doi.org/10.3390/info15020113
Chicago/Turabian StylePetryshyn, Bohdan, Serhii Postupaiev, Soufiane Ben Bari, and Armantas Ostreika. 2024. "Deep Reinforcement Learning for Autonomous Driving in Amazon Web Services DeepRacer" Information 15, no. 2: 113. https://doi.org/10.3390/info15020113
APA StylePetryshyn, B., Postupaiev, S., Ben Bari, S., & Ostreika, A. (2024). Deep Reinforcement Learning for Autonomous Driving in Amazon Web Services DeepRacer. Information, 15(2), 113. https://doi.org/10.3390/info15020113