



Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning

Abstract
1. Introduction
- We proposed and developed an Uncertainty-Aware Dynamic Early Stopping (UA-DES) technique to optimize the training process of Deep Belief Networks (DBNs).
- We integrated the UA-DES into a DBN-based ransomware detection model to prevent both underfitting and overfitting, for more accurate detection to test our theory.
- We evaluated the performance of the proposed technique against existing solutions.
2. Related Studies
- Batch size has an impact on both the speed and stability of the learning process.
- L2 regularization is a technique employed to mitigate overfitting by imposing a penalty on the size of the model’s parameters.
- Momentum is a parameter that aids in the acceleration of gradients in the appropriate direction, thereby facilitating the smoothing of updates during training.
- Dropout is a regularization technique that involves randomly excluding certain neurons during the training process. This helps to mitigate overfitting by reducing the model’s reliance on the precise weights of individual neurons.
- The learning rate is a crucial factor during the iterative process of moving towards the minimum of a loss function. Learning rate determines the size of the step taken at each iteration and plays a key role toward efficiently converging to the best, so-called “best” solution.
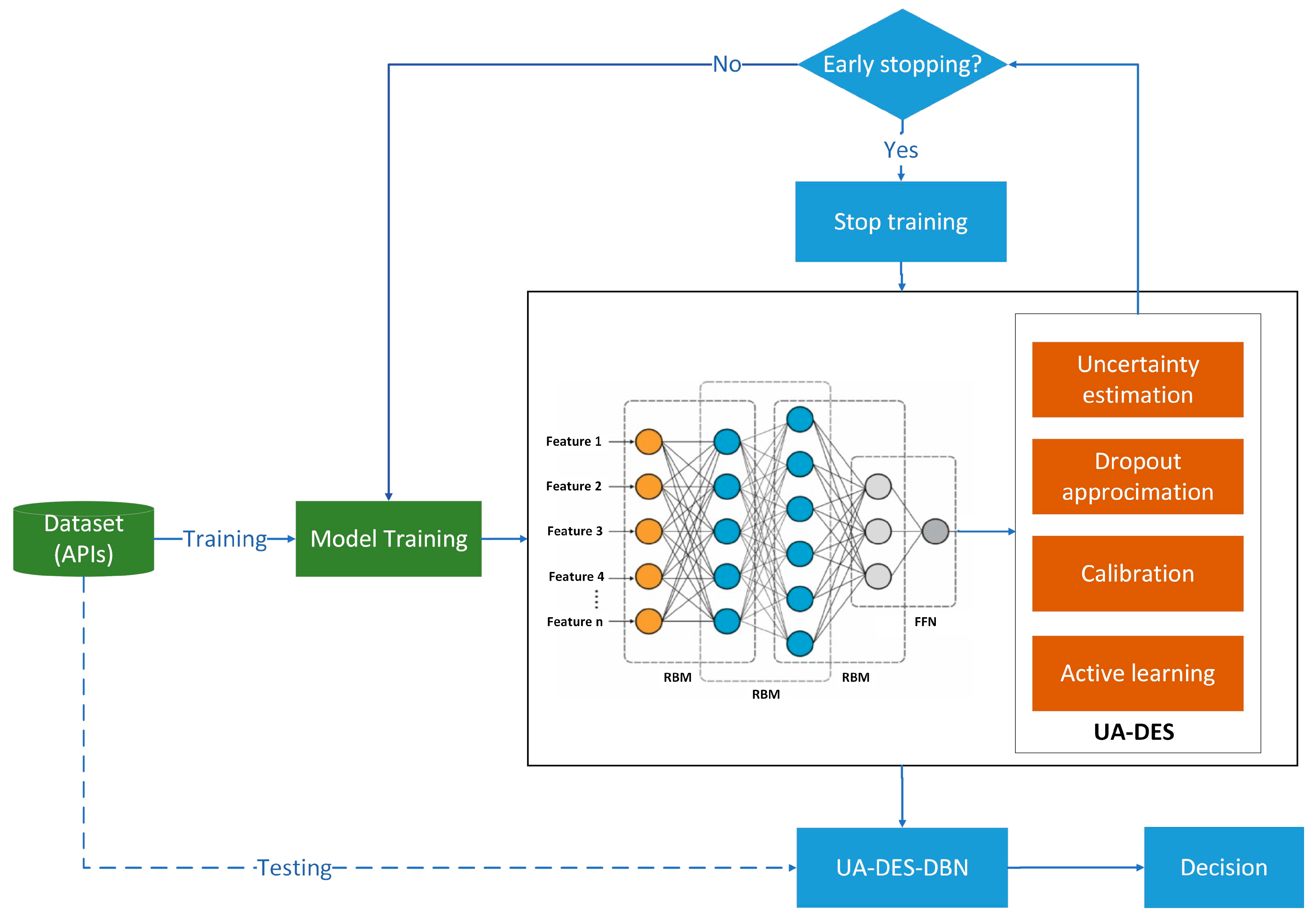
3. The Methodology
3.1. Uncertainty-Aware Dynamic Early Stopping (UA-DES)
- Step 1: Bayesian Performance Modeling
- Posterior Distribution of Performance Metrics:
- 2.
- Uncertainty Estimation:
- Step 2: Dropout as a Bayesian Approximation
- Step 3: Calibration Techniques for Reliable Probability Estimates
- Step 4: Active Learning Framework
- Step 5: Dynamic Stopping Criteria
| Algorithm 1 Pseudocode describing the proposed UA-DES and integration with the DBN model |
| Initialize DBN model |
| Initialize training parameters (epochs, learning rate, etc.) |
| Initialize early stopping parameters (threshold for performance improvement, uncertainty threshold, calibration quality threshold) |
| 1: For each epoch in training: |
| 2: Train DBN on training dataset |
| 3: Evaluate DBN on validation dataset |
| 4: Calculate performance metric (e.g., accuracy, F1 score) |
| 5: # Dropout as Bayesian approximation for uncertainty estimation |
| 6: Perform dropout simulations on validation dataset |
| 7: Calculate mean and standard deviation of performance metric across simulations |
| 8: # Calibration of probability estimates |
| 9: Calibrate model outputs on validation dataset |
| 10: Calculate calibration quality (e.g., Expected Calibration Error) |
| 11: # Active learning for data efficiency |
| 12: If epoch % active_learning_interval == 0: |
| 13: Identify and prioritize uncertain samples in training dataset |
| 14: Retrain DBN model including prioritized samples |
| 15: # Dynamic stopping criterion VALIDATION based on performance improvement, uncertainty, and calibration |
| 16: If (performance improvement < performance improvement threshold) and |
| 17: (standard deviation of performance metric < uncertainty threshold) and\ |
| 18: (calibration quality > calibration quality threshold): |
| 19: stop the training |
3.2. The Development of Improved UA-DES DBN for Ransomware Detection
3.3. Experimental Environment and Setup
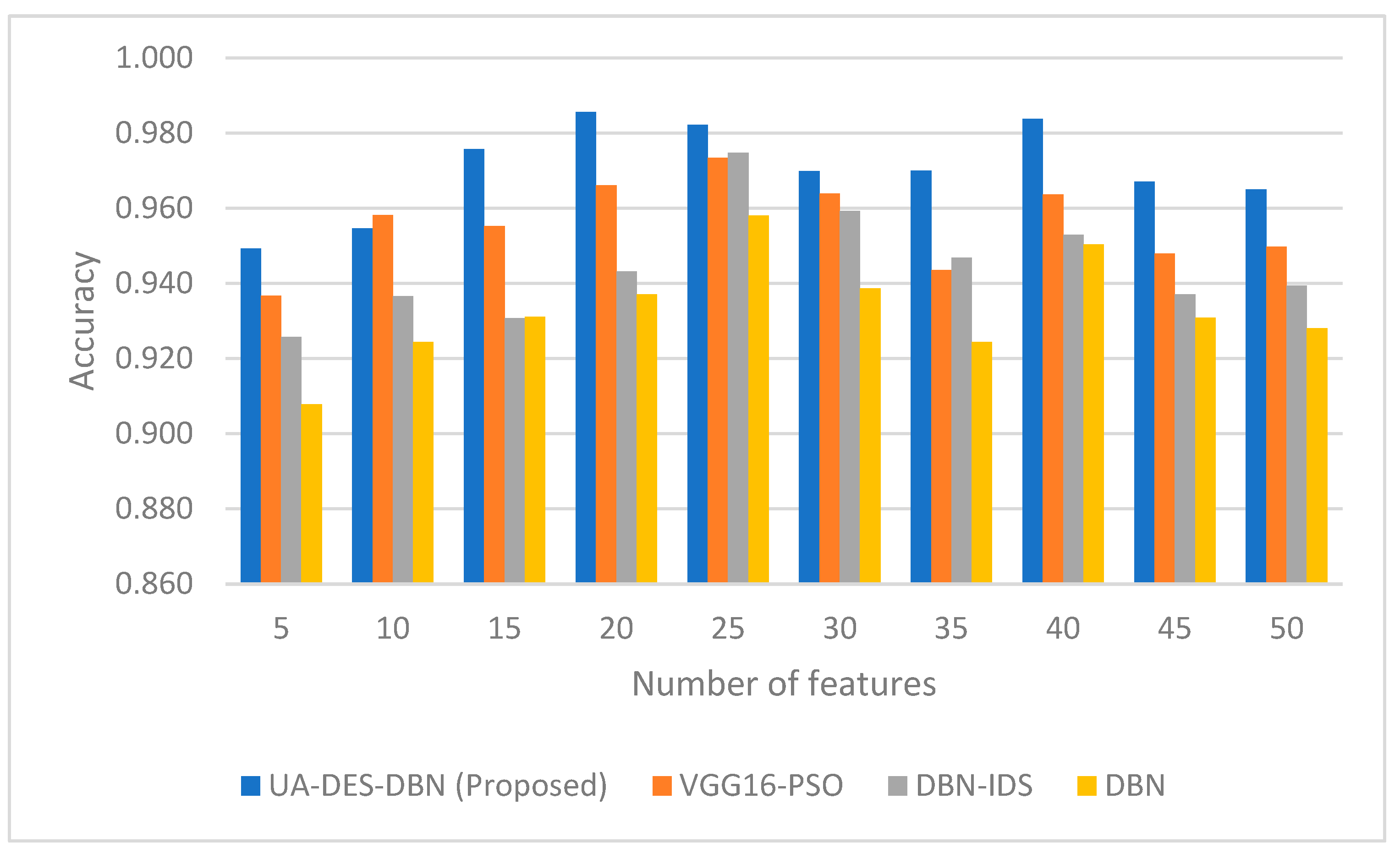
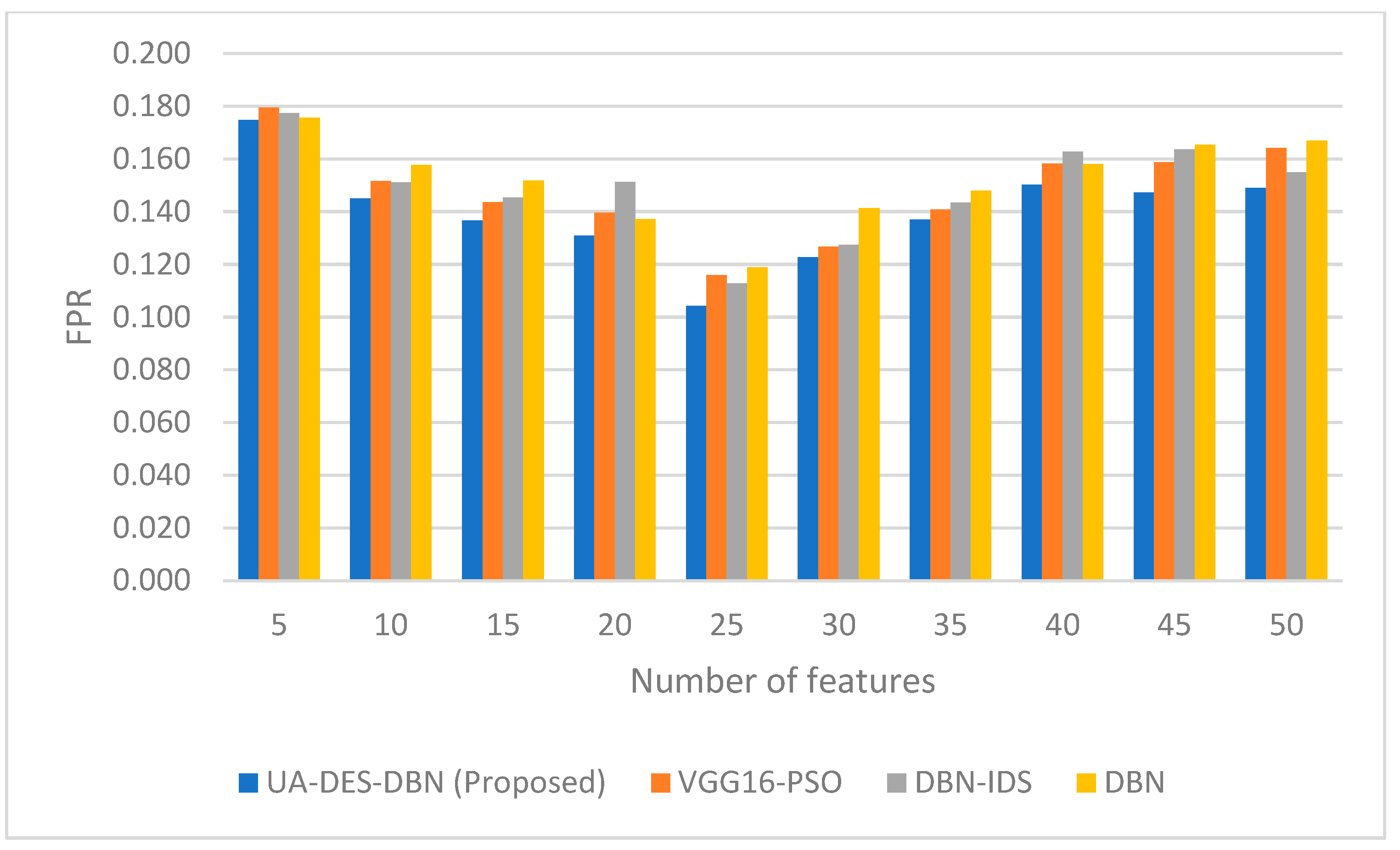
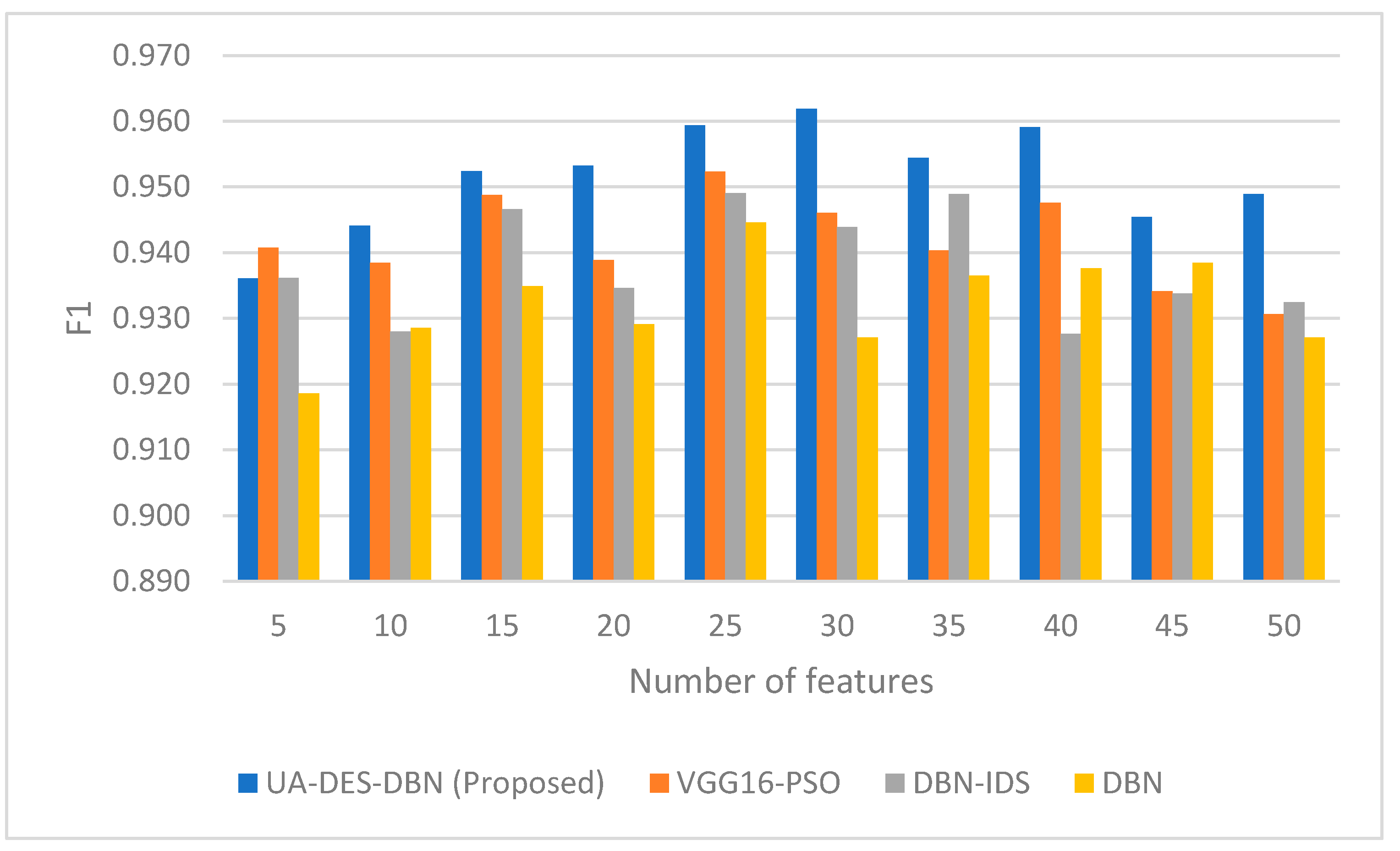
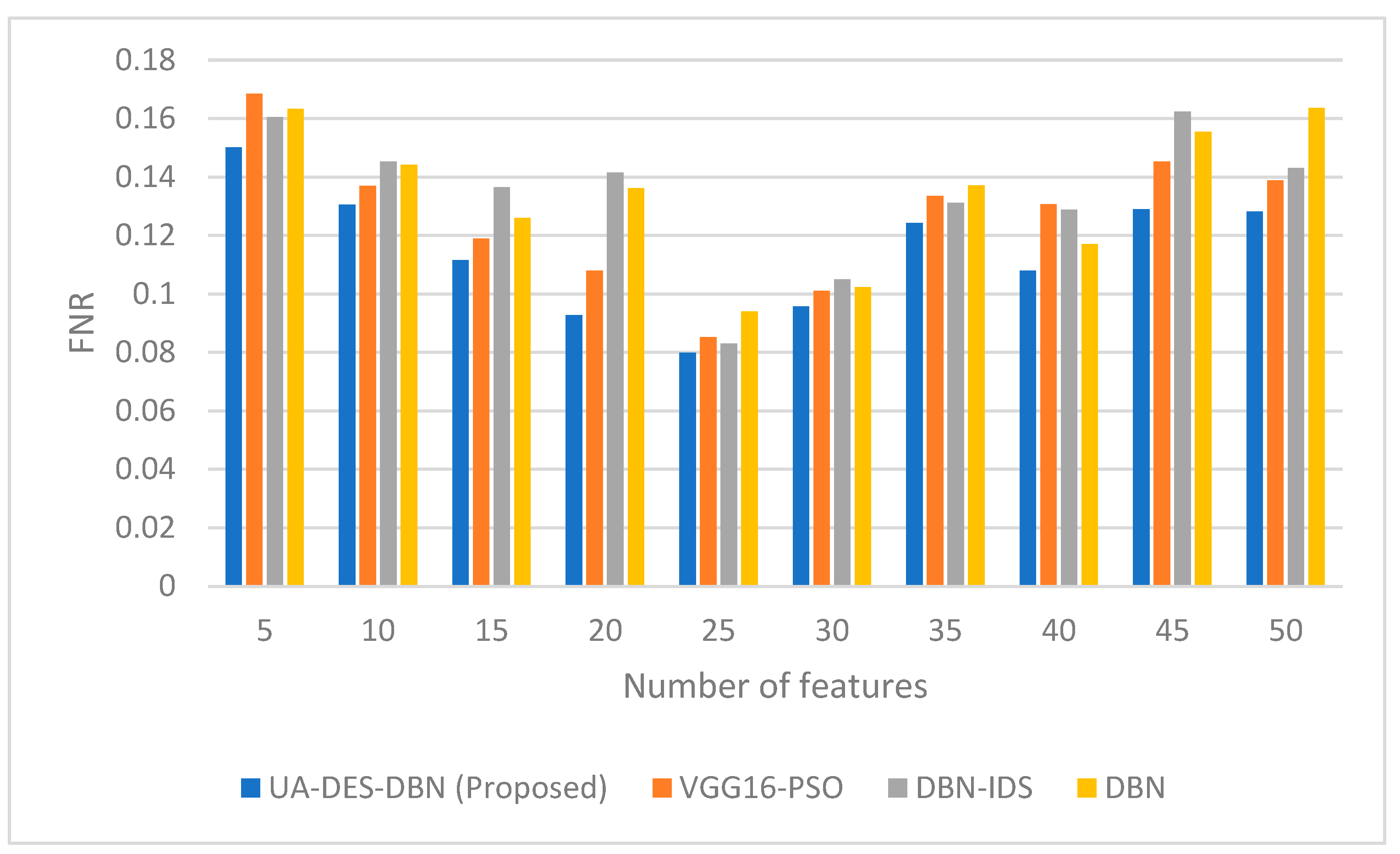
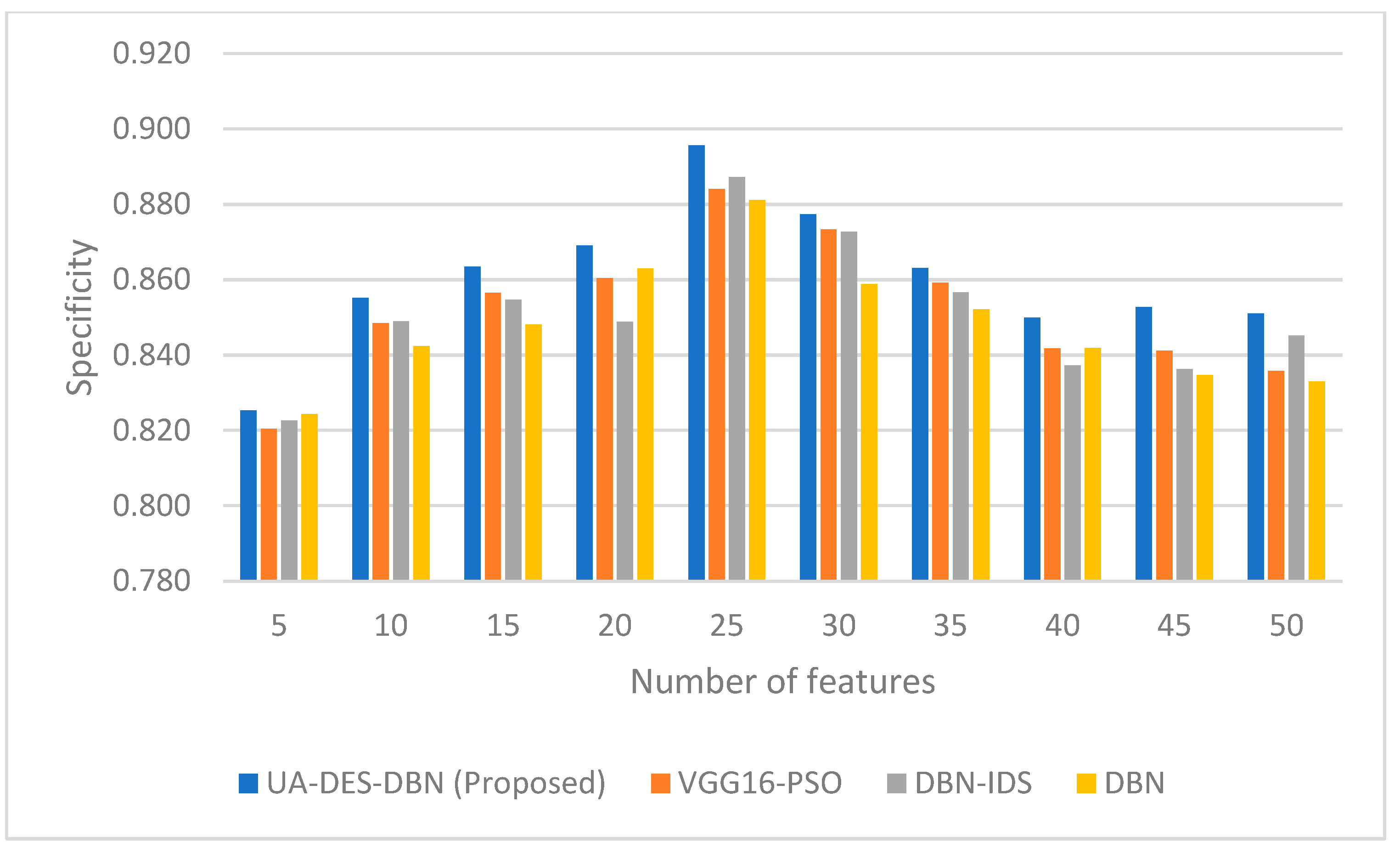
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jillepalli, A.A.; Sheldon, F.T.; de Leon, D.C.; Haney, M.; Abercrombie, R.K. Security Management of Cyber Physical Control Systems Using NIST SP 800-82r2. In Proceedings of the 2017 13th International Wireless Communications and Mobile Computing Conference (IWCMC), Valencia, Spain, 26–30 June 2017; pp. 1864–1870. [Google Scholar]
- Alqahtani, A.; Sheldon, F.T. Temporal Data Correlation Providing Enhanced Dynamic Crypto-Ransomware Pre-Encryption Boundary Delineation. Sensors 2023, 23, 4355. [Google Scholar] [CrossRef] [PubMed]
- Alqahtani, A.; Gazzan, M.; Sheldon, F.T. A proposed crypto-ransomware early detection (CRED) model using an integrated deep learning and vector space model approach. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 275–279. [Google Scholar]
- Gazzan, M.; Sheldon, F.T. An enhanced minimax loss function technique in generative adversarial network for ransomware behavior prediction. Future Internet 2023, 15, 318. [Google Scholar] [CrossRef]
- Gazzan, M.; Alqahtani, A.; Sheldon, F.T. Key factors influencing the rise of current ransomware attacks on industrial control systems. In Proceedings of the 2021 IEEE 11th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 27–30 January 2021; pp. 1417–1422. [Google Scholar]
- Zakaria, W.Z.A.; Alta, N.M.K.M.; Abdollah, M.F.; Abdollah, O.; Yassin, S.W.M.S. Early Detection of Windows Cryptographic Ransomware Based on Pre-Attack API Calls Features and Machine Learning. J. Adv. Res. Appl. Sci. Eng. Technol. 2024, 39, 110–131. [Google Scholar]
- Alqahtani, A.; Sheldon, F.T. e MIFS: A Normalized Hyperbolic Ransomware Deterrence Model Yielding Greater Accuracy and Overall Performance. Sensors 2024, 24, 1728. [Google Scholar] [CrossRef] [PubMed]
- Gazzan, M.; Sheldon, F.T. Opportunities for early detection and prediction of ransomware attacks against industrial control systems. Future Internet 2023, 15, 144. [Google Scholar] [CrossRef]
- Kapoor, A.; Gupta, A.; Gupta, R.; Tanwar, S.; Detection, I.E.D.R. Avoidance, and Mitigation Scheme: A Review and Future Directions. Sustainability 2021, 14, 8. [Google Scholar] [CrossRef]
- Urooj, U.; Al-Rimy, B.A.S.; Zainal, A.B.; Saeed, F.; Abdelmaboud, A.; Nagmeldin, W. Addressing Behavioral Drift in Ransomware Early Detection Through Weighted Generative Adversarial Networks. IEEE Access 2023, 12, 3910–3925. [Google Scholar] [CrossRef]
- Lee, K.; Lee, S.-Y.; Yim, K. Machine Learning Based File Entropy Analysis for Ransomware Detection in Backup Systems. IEEE Access 2019, 7, 110205–110215. [Google Scholar] [CrossRef]
- Bold, R.; Al-Khateeb, H.; Ersotelos, N. Reducing False Negatives in Ransomware Detection: A Critical Evaluation of Machine Learning Algorithms. Appl. Sci. 2022, 12, 12941. [Google Scholar] [CrossRef]
- Al-Garadi, M.A.; Mohamed, A.; Al-Ali, A.; Du, X.; Ali, I.; Guizani, M. A Survey of Machine and Deep Learning Methods for Internet of Things (IoT) Security. IEEE Commun. Surv. Tutor. 2020, 22, 1646–1685. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance Comparison and Current Challenges of Using Machine Learning Techniques in Cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Liu, Y.; Tantithamthavorn, C.; Li, L.; Liu, Y. Deep Learning for Android Malware Defenses: A Systematic Literature Review. Acm Comput. Surv. 2022, 55, 1–36. [Google Scholar] [CrossRef]
- Uysal, D.T.; Yoo, P.D.; Taha, K. Data-Driven Malware Detection for 6G Networks: A Survey From the Perspective of Continuous Learning and Explainability via Visualisation. IEEE Open J. Veh. Technol. 2023, 4, 61–71. [Google Scholar] [CrossRef]
- Urooj, U.; Al-rimy, B.A.S.; Zainal, A.; Ghaleb, F.A.; Rassam, M.A. Ransomware Detection Using the Dynamic Analysis and Machine Learning: A Survey and Research Directions. Appl. Sci. 2021, 12, 172. [Google Scholar] [CrossRef]
- Shemitha, P.A.; Dhas, J.P.M. Crow Search With Adaptive Awareness Probability-Based Deep Belief Network for Detecting Ransomware. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2251010. [Google Scholar] [CrossRef]
- Lansky, J.; Ali, S.; Mohammadi, M.; Majeed, M.K.; Karim, S.H.T.; Rashidi, S.; Hosseinzadeh, M.; Rahmani, A.M. Deep Learning-Based Intrusion Detection Systems: A Systematic Review. IEEE Access 2021, 9, 101574–101599. [Google Scholar] [CrossRef]
- Radoglou-Grammatikis, P.; Sarigiannidis, P.; Diamantoulakis, P.; Lagkas, T.; Saoulidis, T.; Fountoukidis, E.; Karagiannidis, G. Strategic Honeypot Deployment in Ultra-Dense Beyond 5G Networks: A Reinforcement Learning Approach. IEEE Trans. Emerg. Top. Comput. 2024, 1–12. [Google Scholar] [CrossRef]
- Banaamah, A.M.; Ahmad, I. Intrusion Detection in IoT Using Deep Learning. Sensors 2022, 22, 8417. [Google Scholar] [CrossRef] [PubMed]
- Cao, F. Intrusion Anomaly Detection Based on Pseudo-Count Exploration. Res. Sq. 2023. [Google Scholar] [CrossRef]
- Vembu, D.; Ramasamy, G. Optimized Deep Learning-based Intrusion Detection for Wireless Sensor Networks. Int. J. Commun. Syst. 2022, 36, e5254. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Janicke, H.; Smith, R. Deep Learning Techniques for Cyber Security Intrusion Detection: A Detailed Analysis. In Proceedings of the 6th International Symposium for ICS & SCADA Cyber Security Research 2019 (ICS-CSR), Athens, Greece, 10–12 September 2019. [Google Scholar] [CrossRef]
- Cho, H.; Kim, Y.-J.; Lee, E.; Choi, D.; Lee, Y.J.; Rhee, W. Basic Enhancement Strategies When Using Bayesian Optimization for Hyperparameter Tuning of Deep Neural Networks. IEEE Access 2020, 8, 52588–52608. [Google Scholar] [CrossRef]
- Dorka, N.; Boedecker, J.; Burgard, W. Adaptively Calibrated Critic Estimates for Deep Reinforcement Learning. Ieee Robot. Autom. Lett. 2023, 8, 624–631. [Google Scholar] [CrossRef]
- Rezaeezade, L.; Batina, A. Regularizers to the Rescue: Fighting Overfitting in DeepLearning-based Side-Channel Analysis. J. Cryptogr. Eng. 2022; under review. [Google Scholar] [CrossRef]
- Moodley, C.; Sephton, B.; Rodríguez-Fajardo, V.; Forbes, A. Deep Learning Early Stopping for Non-Degenerate Ghost Imaging. Sci. Rep. 2021, 11, 8561. [Google Scholar] [CrossRef] [PubMed]
- Kaandorp, M.P.T.; Zijlstra, F.; Federau, C.; While, P.T. Deep Learning Intravoxel Incoherent Motion Modeling: Exploring the Impact of Training Features and Learning Strategies. Magn. Reson. Med. 2023, 90, 312–328. [Google Scholar] [CrossRef]
- Dossa, R.F.J.; Huang, S.Y.; Ontañón, S.; Matsubara, T. An Empirical Investigation of Early Stopping Optimizations in Proximal Policy Optimization. IEEE Access 2021, 9, 117981–117992. [Google Scholar] [CrossRef]
- Choi, H.; Lee, H. Exploiting All Samples in Low-Resource Sentence Classification: Early Stopping and Initialization Parameters. arXiv 2021, arXiv:2111.06971. [Google Scholar] [CrossRef]
- Wang, H.; Li, T.H.; Zhang, Z.; Chen, T.; Liang, H.; Sun, J. Early Stopping for Deep Image Prior. arXiv 2021, arXiv:2112.06074. [Google Scholar] [CrossRef]
- Li, T.H.; Zhuang, Z.; Liang, H.; Peng, L.; Wang, H.; Sun, J. Self-Validation: Early Stopping for Single-Instance Deep Generative Priors. arXiv 2021, arXiv:2110.12271. [Google Scholar] [CrossRef]
- Dai, T.; Feng, Y.; Wu, D.; Chen, B.; Lu, J.; Jiang, Y.; Xia, S.T. DIPDefend: Deep Image Prior Driven Defense against Adversarial Examples. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1404–1412. [Google Scholar] [CrossRef]
- Almomani, I.; Qaddoura, R.; Habib, M.; Alsoghyer, S.; Al Khayer, A.; Aljarah, I.; Faris, H. Android Ransomware Detection Based on a Hybrid Evolutionary Approach in the Context of Highly Imbalanced Data. IEEE Access 2021, 9, 57674–57691. [Google Scholar] [CrossRef]
- Sharmeen, S.; Ahmed, Y.A.; Huda, S.; Koçer, B.Ş.; Hassan, M.M. Avoiding Future Digital Extortion Through Robust Protection Against Ransomware Threats Using Deep Learning Based Adaptive Approaches. IEEE Access 2020, 8, 24522–24534. [Google Scholar] [CrossRef]
- Fernando, D.W.; Komninos, N. A Study on the Evolution of Ransomware Detection Using Machine Learning and Deep Learning Techniques. IoT 2020, 1, 551–604. [Google Scholar] [CrossRef]
- Kim, T.; Kang, B.; Rho, M.; Sezer, S.; Im, E.G. A Multimodal Deep Learning Method for Android Malware Detection Using Various Features. IEEE Trans. Inf. Forensics Secur. 2019, 14, 773–788. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaševičius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef] [PubMed]
- Du, C.; Tong, Y.; Chen, X.; Liu, Y.; Ding, Z.; Xu, H.; Ran, Q.; Zhang, Y.; Meng, L.; Cui, L.; et al. Toward Detecting Malware Based on Process-Aware Behaviors. Secur. Commun. Netw. 2023, 2023, 6447655. [Google Scholar] [CrossRef]
- Fallah, S.; Bidgoly, A.J. Android Malware Detection Using Network Traffic Based on Sequential Deep Learning Models. Softw. Pract. Exp. 2022, 52, 1987–2004. [Google Scholar] [CrossRef]
- Duhayyim, M.A.; Mohamed, H.G.; Alrowais, F.; Al-Wesabi, F.N.; Hilal, A.M.; Motwakel, A. Artificial Algae Optimization With Deep Belief Network Enabled Ransomware Detection in IoT Environment. Comput. Syst. Sci. Eng. 2023, 46, 1293–1310. [Google Scholar] [CrossRef]
- Bharati, S.; Podder, P. Machine and Deep Learning for IoT Security and Privacy: Applications, Challenges, and Future Directions. Secur. Commun. Netw. 2022, 2022, 8951961. [Google Scholar] [CrossRef]
- Ko, E.; Kim, J.-S.; Ban, Y.; Cho, H.; Yi, J.H. ACAMA: Deep Learning-Based Detection and Classification of Android Malware Using API-Based Features. Secur. Commun. Netw. 2021, 2021, 6330828. [Google Scholar] [CrossRef]
- Lu, T.; Du, Y.; Ouyang, L.; Chen, Q.; Wang, X. Android Malware Detection Based on a Hybrid Deep Learning Model. Secur. Commun. Netw. 2020, 2020, 8863617. [Google Scholar] [CrossRef]
- Alghamdi, M.I. Survey on Applications of Deep Learning and Machine Learning Techniques for Cyber Security. Int. J. Interact. Mob. Technol. 2020, 14, 210–224. [Google Scholar] [CrossRef]
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S.; Xiang, Y. A Survey of Android Malware Detection with Deep Neural Models. ACM Comput. Surv. 2020, 53, 126. [Google Scholar] [CrossRef]
- El-Ghamry, A.; Darwish, A.; Hassanien, A.E. An optimized CNN-based intrusion detection system for reducing risks in smart farming. Internet Things 2023, 22, 100709. [Google Scholar] [CrossRef]
- Jothi, B.; Pushpalatha, M. WILS-TRS—A novel optimized deep learning based intrusion detection framework for IoT networks. Pers. Ubiquitous Comput. 2023, 27, 1285–1301. [Google Scholar] [CrossRef]
- Sharma, A.; Gupta, B.B.; Singh, A.K.; Saraswat, V. A novel approach for detection of APT malware using multi-dimensional hybrid Bayesian belief network. Int. J. Inf. Secur. 2023, 22, 119–135. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Features |
|---|---|
| Crypto APIs | CryptEncrypt CryptGenKey CryptDestroyKey BCryptGenRandom |
| File access APIs | CreateFile FindFirstFileEXA FindNextFileA DeleteFile |
| Network APIs | WinHttpConnect WinHttpOpenRequest |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gazzan, M.; Sheldon, F.T. Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning. Information 2024, 15, 262. https://doi.org/10.3390/info15050262
Gazzan M, Sheldon FT. Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning. Information. 2024; 15(5):262. https://doi.org/10.3390/info15050262
Chicago/Turabian StyleGazzan, Mazen, and Frederick T. Sheldon. 2024. "Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning" Information 15, no. 5: 262. https://doi.org/10.3390/info15050262
APA StyleGazzan, M., & Sheldon, F. T. (2024). Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning. Information, 15(5), 262. https://doi.org/10.3390/info15050262