

Mining Spatial-Temporal Frequent Patterns of Natural Disasters in China Based on Textual Records

Abstract
1. Introduction
2. Literature Review
2.1. Research Status of Relationships between Natural Disasters
2.2. Research Status of Spatial-Temporal Frequent Pattern Mining
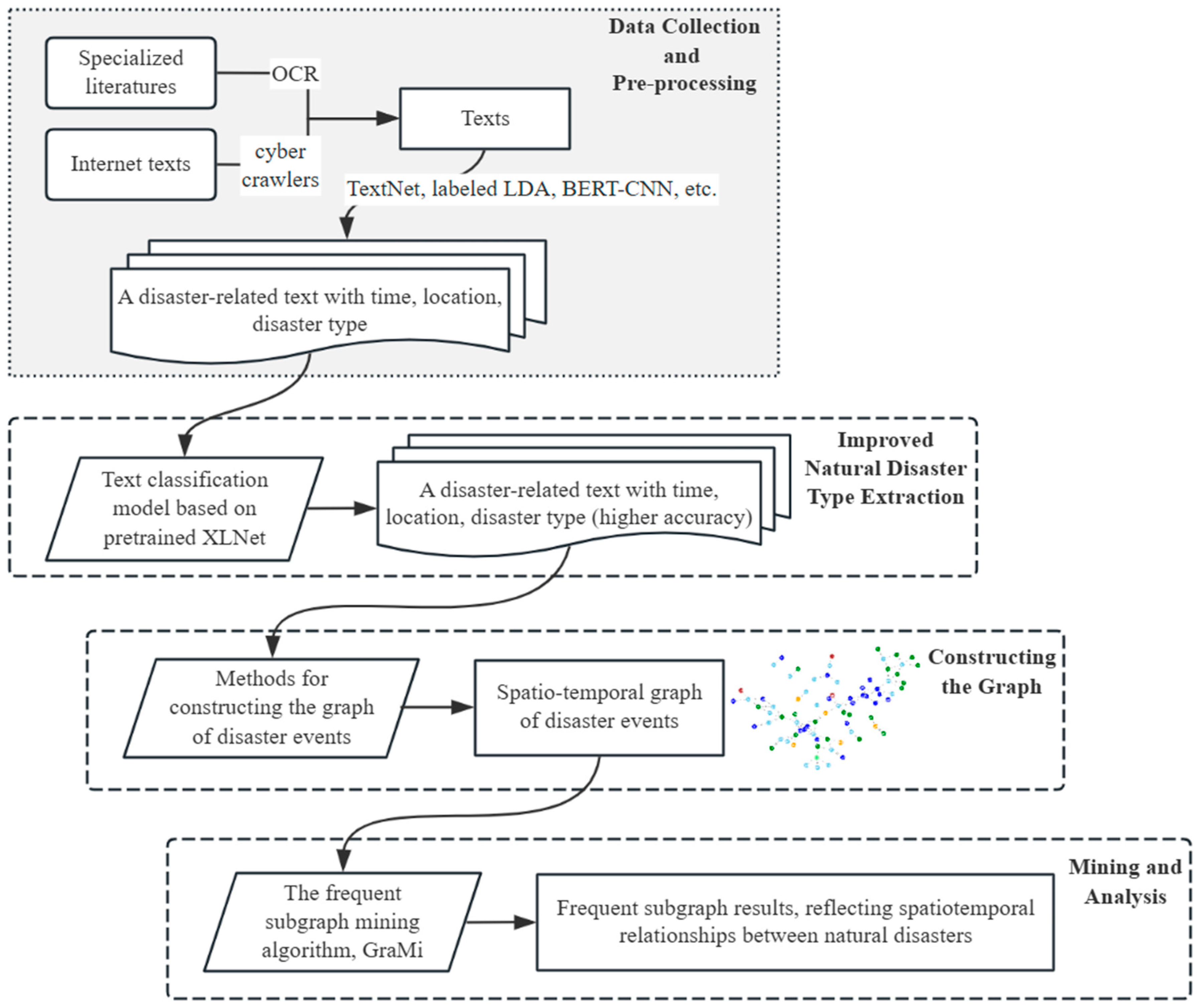
3. Data and Methods
3.1. Data Source and Pre-Processing
3.2. Natural Disaster Type Extraction
3.3. Methods for Constructing the Spatial-Temporal Graph of Disaster Events
3.3.1. Construction of the Nodes in the Graph
3.3.2. Design of the Edge Labels in the Graph
3.3.3. Rules for Creating Edges between Nodes
3.4. The Frequent Subgraph Mining Algorithm
4. Results
4.1. Performance of the Natural Disaster Type Extraction
4.2. The Spatial-Temporal Graph of Disaster Events
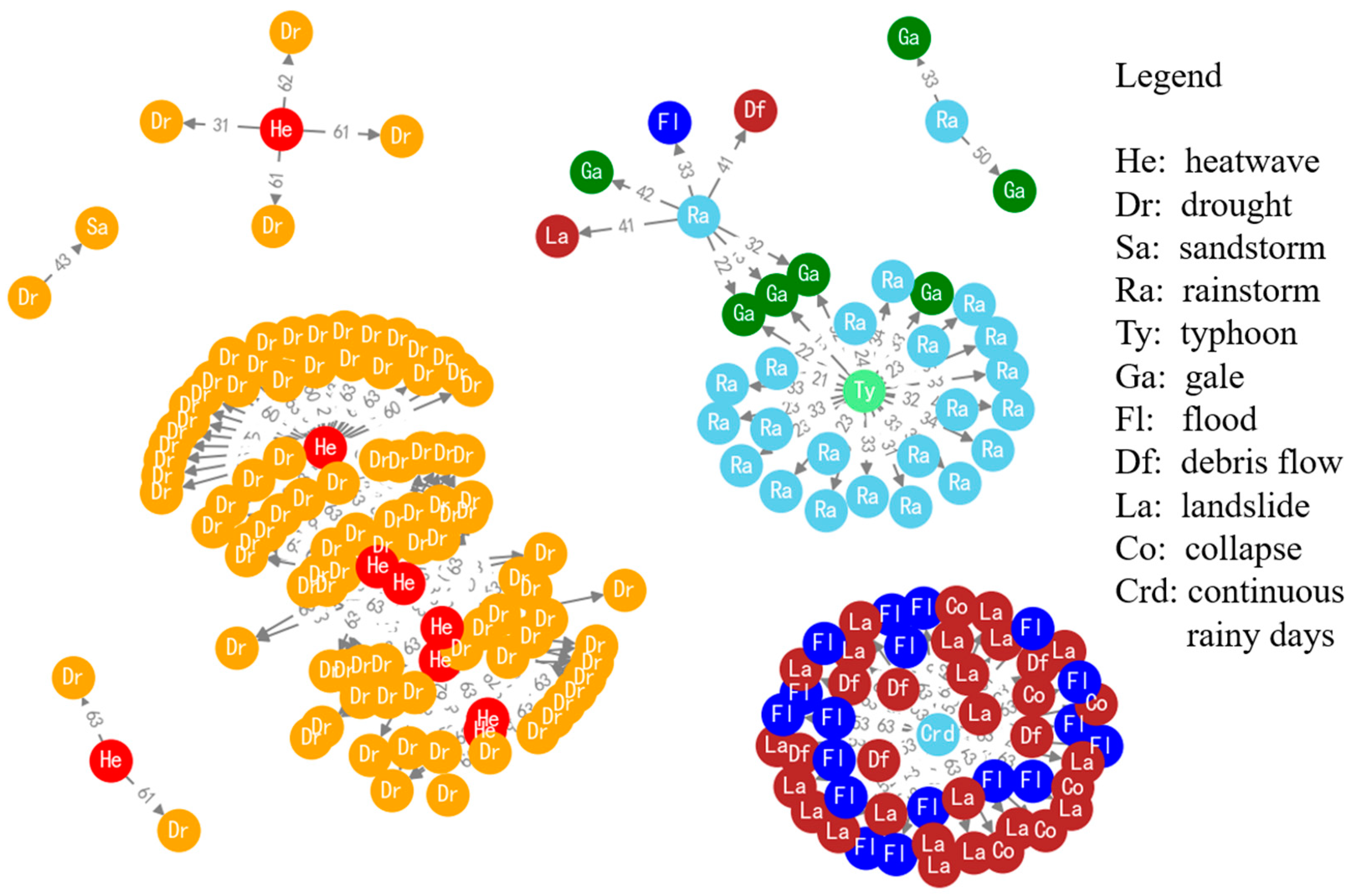
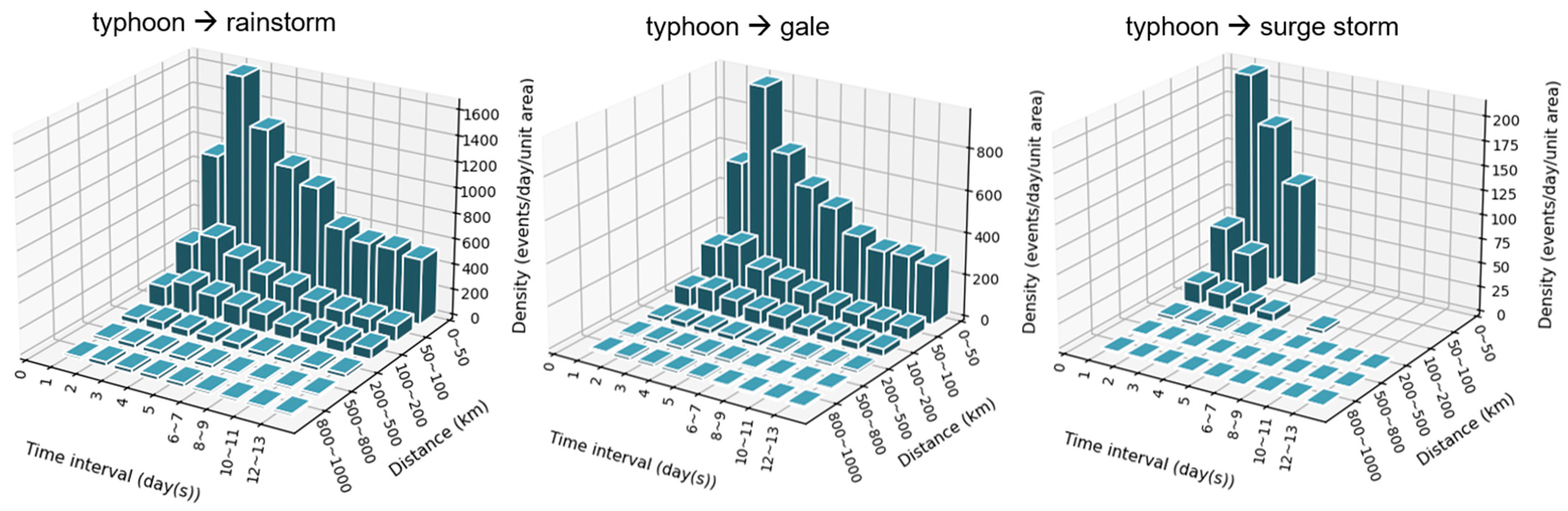
4.3. Results of Frequent Subgraph Mining
4.3.1. Frequent Subgraphs with One Edge
- (1)
- typhoon → rainstorm/gale/storm surge
- (2)
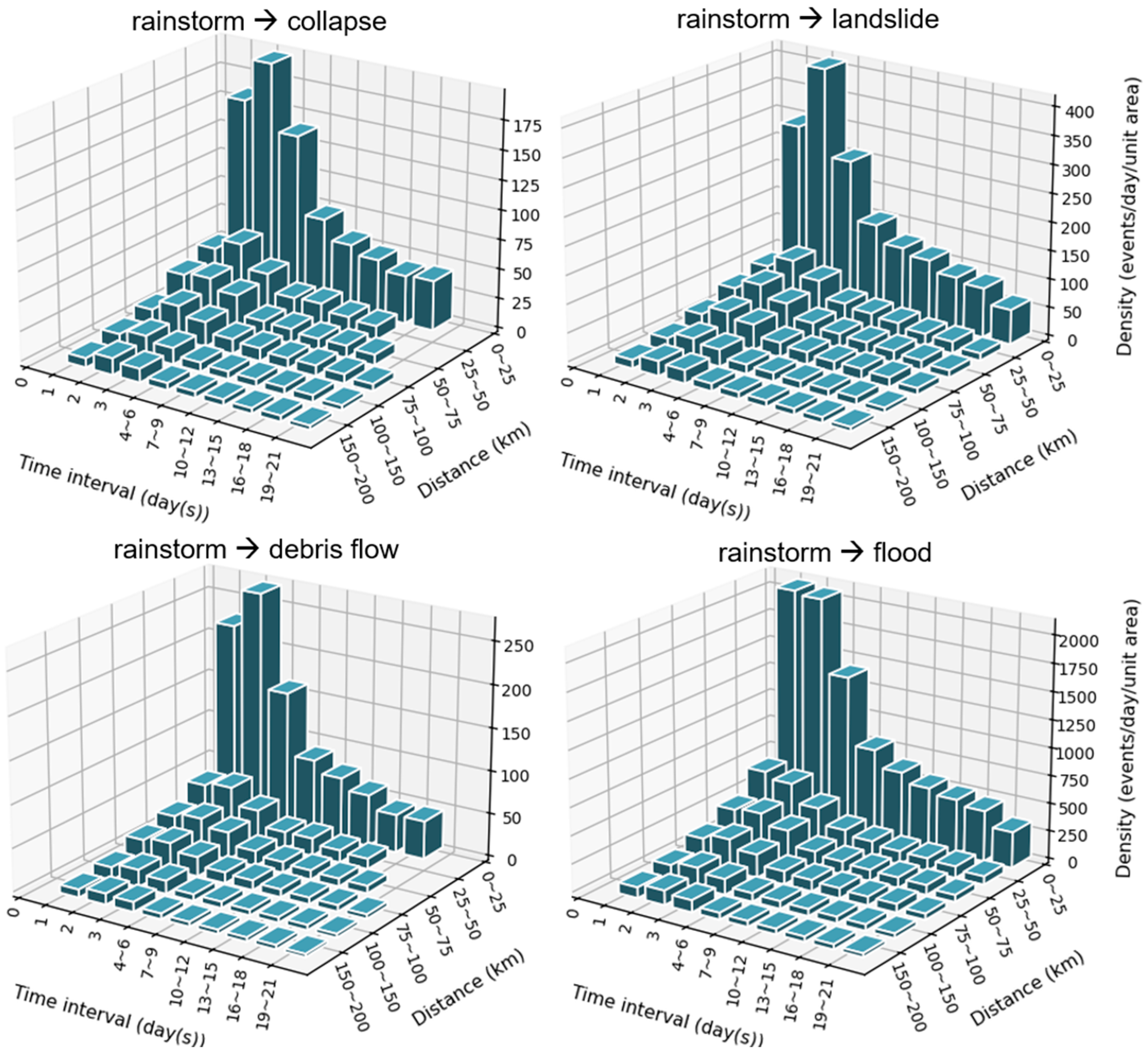
- rainstorm → collapse/landslide/debris flow/flood/tornado
- (3)
- heatwave → drought, drought → heatwave/sandstorm
- (4)
- cold wave → hail/freezing damage/glaze ice/gale/frost/snow disaster/fog disaster
- (5)
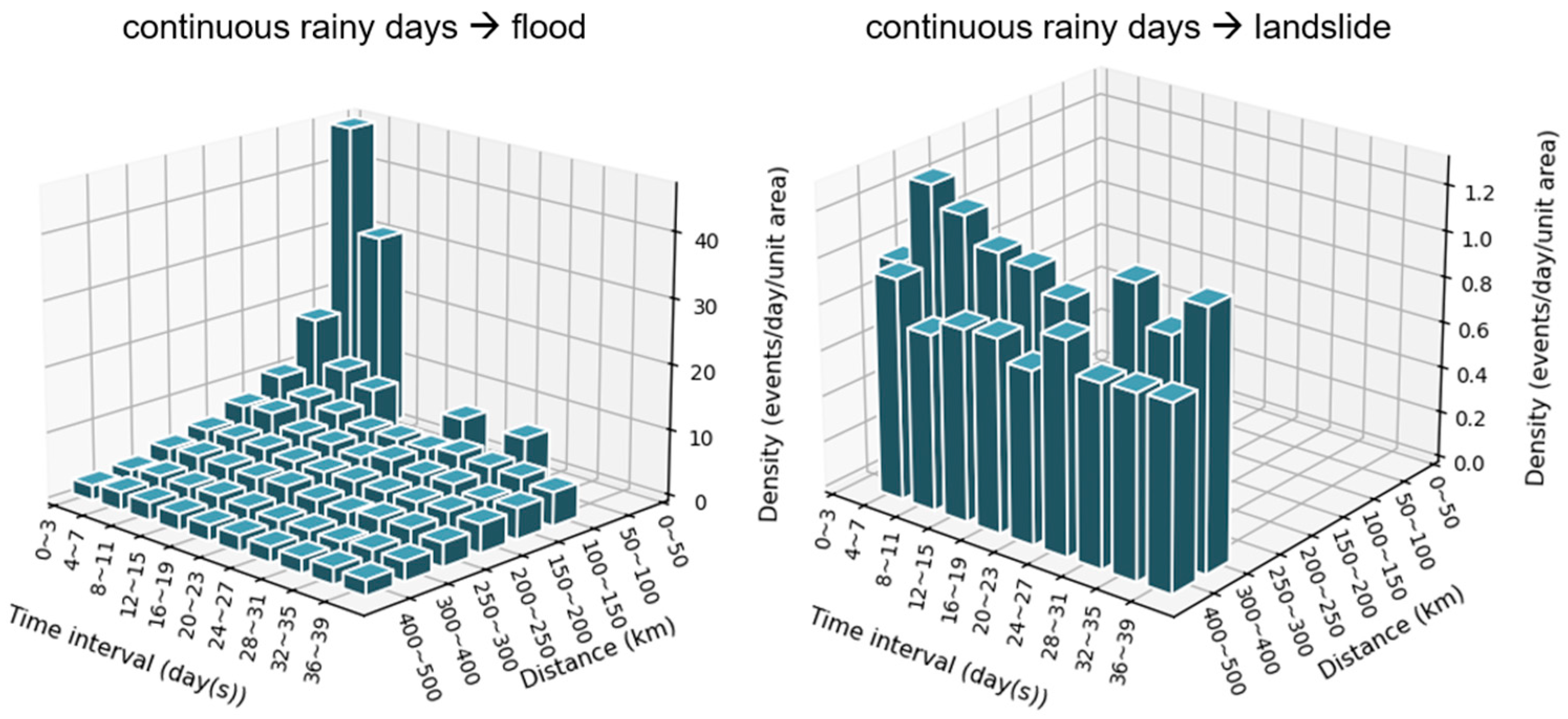
- continuous rainy days → flood/landslide
- (6)
- storm surge → flood
- (7)
- gale → sandstorm
4.3.2. Frequent Subgraphs with Multiple Edges
5. Discussion
- (1)
- When constructing the spatiotemporal graph of disaster events, the constraints on the edge connection may lead to the omission of some frequent patterns. Future research will try not to set the constraints and complete the subgraph mining through high-efficiency methods such as concurrent computation.
- (2)
- The information of occurrence time extracted from textual records may be biased due to disaster warnings issued before the actual occurrence or statistical reports after the event. Future studies will consider eliminating the deviations.
6. Conclusions
- (1)
- After typhoons, rainstorms, and cold waves, the frequencies of various secondary disasters are high. Additionally, the occurrence of heatwaves after droughts is also very common.
- (2)
- The pattern of “gale → sandstorm” is mainly concentrated within 50 km and rarely happens at farther spatial distances, and the most common temporal interval is 1 day.
- (3)
- The occurrence density of most patterns obeys the rule of decreasing with increasing temporal interval and spatial distance, but there are some exceptional patterns not obeying this rule: “heatwave → drought”, “drought → sandstorm”, “cold wave → hail/freezing damage/glaze ice”, and “continuous rainy days → landslide”.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A






References
- China Climate Bulletin 2021. Available online: https://www.cma.gov.cn/zfxxgk/gknr/qxbg/202203/t20220308_4568477.html (accessed on 14 March 2024).
- AghaKouchak, A.; Huning, L.S.; Chiang, F.; Sadegh, M.; Vahedifard, F.; Mazdiyasni, O.; Moftakhari, H.; Mallakpour, I. How do natural hazards cascade to cause disasters? Nature 2018, 561, 458–460. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.J.; Wu, Y.P.; Wang, F.; Li, Y.N. Landslide disaster genesis pattern in Enshi area, Hubei. Chin. J. Geol. Hazard Control 2017, 28, 1–9. (In Chinese) [Google Scholar] [CrossRef]
- Xu, J.; Bai, D.; He, H.; Luo, J.; Lu, G. Disaster Precursor Identification and Early Warning of the Lishanyuan Landslide Based on Association Rule Mining. Appl. Sci. 2022, 12, 12836. [Google Scholar] [CrossRef]
- Fu, P.F.; Sun, H.Q.; Su, Z.C.; Yang, X.J. Research on global drought disaster chain analysis based on EM-DAT data. J. China Inst. Water Resour. Hydropower Res. 2023, 21, 287–294+306. (In Chinese) [Google Scholar] [CrossRef]
- Liu, X.; Guo, H.; Lin, Y.; Li, Y.; Hou, J. Analyzing Spatial-Temporal Distribution of Natural Hazards in China by Mining News Sources. Nat. Hazards Rev. 2018, 19, 04018006. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, H.; Li, X.; He, Z.; Li, J. Analysis of Spatial and Temporal Characteristics of Major Natural Disasters in China from 2008 to 2021 Based on Mining News Database. Nat. Hazards 2023, 118, 1881–1916. [Google Scholar] [CrossRef]
- Liu, B.; Siu, Y.L.; Mitchell, G. Hazard Interaction Analysis for Multi-Hazard Risk Assessment: A Systematic Classification Based on Hazard-Forming Environment. Nat. Hazards Earth Syst. Sci. 2016, 16, 629–642. [Google Scholar] [CrossRef]
- Wang, J.; He, Z.; Weng, W. A Review of the Research into the Relations between Hazards in Multi-Hazard Risk Analysis. Nat. Hazards 2020, 104, 2003–2026. [Google Scholar] [CrossRef]
- Han, J.; Wu, S.; Wang, H. Preliminary Study on Geological Hazard Chains. Earth Sci. Front. 2007, 14, 11–20. [Google Scholar] [CrossRef]
- van Westen, C.; Kappes, M.S.; Luna, B.Q.; Frigerio, S.; Glade, T.; Malet, J.-P. Medium-Scale Multi-Hazard Risk Assessment of Gravitational Processes. In Mountain Risks: From Prediction to Management and Governance; Van Asch, T., Corominas, J., Greiving, S., Malet, J.-P., Sterlacchini, S., Eds.; Springer: Dordrecht, The Netherlands, 2014; pp. 201–231. ISBN 978-94-007-6769-0. [Google Scholar]
- Cui, Y.; Hu, J.; Xu, C.; Zheng, J.; Wei, J. A Catastrophic Natural Disaster Chain of Typhoon-Rainstorm-Landslide-Barrier Lake-Flooding in Zhejiang Province, China. J. Mt. Sci. 2021, 18, 2108–2119. [Google Scholar] [CrossRef]
- Marengo, J.A.; Alcantara, E.; Cunha, A.P.; Seluchi, M.; Nobre, C.A.; Dolif, G.; Goncalves, D.; Assis Dias, M.; Cuartas, L.A.; Bender, F.; et al. Flash Floods and Landslides in the City of Recife, Northeast Brazil after Heavy Rain on May 25–28, 2022: Causes, Impacts, and Disaster Preparedness. Weather Clim. Extrem. 2023, 39, 100545. [Google Scholar] [CrossRef]
- Papagiannaki, K.; Lagouvardos, K.; Kotroni, V.; Bezes, A. Flash Flood Occurrence and Relation to the Rainfall Hazard in a Highly Urbanized Area. Nat. Hazards Earth Syst. Sci. 2015, 15, 1859–1871. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Y.; Zhu, Y.; Ma, Q.; Philippe, G.; Qu, Y.; Yin, H. Probabilistic Analysis on the Influences of Heatwaves during the Onset of Flash Droughts over China. Hydrol. Res. 2023, 54, 869–884. [Google Scholar] [CrossRef]
- Bustio-Martínez, L.; Cumplido, R.; Letras, M.; Hernández-León, R.; Feregrino-Uribe, C.; Hernández-Palancar, J. FPGA/GPU-Based Acceleration for Frequent Itemsets Mining: A Comprehensive Review. ACM Comput. Surv. 2022, 54, 1–35. [Google Scholar] [CrossRef]
- Agrawal, R.; Ramakrishnan, S. Fast algorithms for mining association rules in large databases. In Proceedings of the 20th International Conference on Very Large Data Bases (VLDB’94), Santiago de Chile, Chile, 12–15 September 1994; Morgan Kaufmann: San Francisco, CA, USA, 1994. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining Frequent Patterns without Candidate Generation. SIGMOD Rec. (ACM Spec. Interes. Gr. Manag. Data) 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, W. Composite spatio-temporal co-occurrence pattern mining. In Proceedings of the Wireless Algorithms, Systems, and Applications, Dallas, TX, USA, 26–28 October 2008. [Google Scholar] [CrossRef]
- Alatrista Salas, H.; Bringay, S.; Flouvat, F.; Selmaoui-Folcher, N.; Teisseire, M. The Pattern Next Door: Towards Spatio-Sequential Pattern Discovery. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Kuala Lumpur, Malaysia, 29 May 2012. [Google Scholar] [CrossRef]
- Atluri, G.; Karpatne, A.; Kumar, V. Spatio-Temporal Data Mining: A Survey of Problems and Methods. ACM Comput. Surv. 2018, 51, 1–41. [Google Scholar] [CrossRef]
- Shekhar, S.; Jiang, Z.; Ali, R.Y.; Eftelioglu, E.; Tang, X.; Gunturi, V.M.V.; Zhou, X. Spatiotemporal Data Mining: A Computational Perspective. ISPRS Int. J. Geo-Inf. 2015, 4, 2306–2338. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Wang, L.; Wang, S.; Ding, L. TCPMS-FCP: A Traffic Congestion Pattern Mining System Based on Spatio-Temporal Fuzzy Co-Location Patterns. In Proceedings of the Web Information Systems Engineering—WISE 2022, Biarritz, France, 1–3 November 2022. [Google Scholar] [CrossRef]
- Xia, D.; Lu, X.; Li, H.; Wang, W.; Li, Y.; Zhang, Z. A MapReduce-Based Parallel Frequent Pattern Growth Algorithm for Spatiotemporal Association Analysis of Mobile Trajectory Big Data. Complexity 2018, 2018, 2818251. [Google Scholar] [CrossRef]
- Ghosh, S.; Ghosh, S.K.; Buyya, R. MARIO: A Spatio-Temporal Data Mining Framework on Google Cloud to Explore Mobility Dynamics from Taxi Trajectories. J. Netw. Comput. Appl. 2020, 164, 102692. [Google Scholar] [CrossRef]
- Celik, M. Partial Spatio-Temporal Co-Occurrence Pattern Mining. Knowl. Inf. Syst. 2015, 44, 27–49. [Google Scholar] [CrossRef]
- He, Z.; Tao, L.; Xie, Z.; Xu, C. Discovering Spatial Interaction Patterns of near Repeat Crime by Spatial Association Rules Mining. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef]
- Aydin, B.; Angryk, R. Spatiotemporal Frequent Pattern Mining on Solar Data: Current Algorithms and Future Directions. In Proceedings of the 15th IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 575–581. [Google Scholar] [CrossRef]
- Vega-Oliveros, D.A.; Cotacallapa, M.; Ferreira, L.N.; Quiles, M.G.; Zhao, L.; Macau, E.E.N.; Cardoso, M.F. From Spatio-Temporal Data to Chronological Networks: An Application to Wildfire Analysis. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Ferreira, L.N.; Vega-Oliveros, D.A.; Cotacallapa, M.; Cardoso, M.F.; Quiles, M.G.; Zhao, L.; Macau, E.E.N. Spatiotemporal Data Analysis with Chronological Networks. Nat. Commun. 2020, 11, 1–11. [Google Scholar] [CrossRef]
- Oberoi, K.S.; del Mondo, G. Graph-Based Pattern Detection in Spatio-Temporal Phenomena. In Proceedings of the 16th Spatial Analysis and Geomatics Conference (SAGEO 2021), La Rochelle, France, 5–7 May 2021. [Google Scholar]
- Deng, Z.; Weng, D.; Chen, J.; Liu, R.; Wang, Z.; Bao, J.; Zheng, Y.; Wu, Y. AirVis: Visual Analytics of Air Pollution Propagation. IEEE Trans. Vis. Comput. Graph. 2020, 26, 800–810. [Google Scholar] [CrossRef] [PubMed]
- Petelin, B.; Kononenko, I.; Malačič, V.; Kukar, M. Frequent Subgraph Mining in Oceanographic Multi-Level Directed Graphs. Int. J. Geogr. Inf. Sci. 2019, 33, 1936–1959. [Google Scholar] [CrossRef]
- Park, S.; Yuan, Y.; Choe, Y. Application of Graph Theory to Mining the Similarity of Travel Trajectories. Tour. Manag. 2021, 87, 104391. [Google Scholar] [CrossRef]
- Wang, S.; Niu, X.; Fournier-Viger, P.; Zhou, D.; Min, F. A Graph Based Approach for Mining Significant Places in Trajectory Data. Inf. Sci. 2022, 609, 172–194. [Google Scholar] [CrossRef]
- Ayadi, Z.; Boulila, W.; Farah, I.R. Modeling Complex Object Changes in Satellite Image Time-Series: Approach Based on CSP and Spatiotemporal Graphs. Procedia Comput. Sci. 2023, 225, 2467–2476. [Google Scholar] [CrossRef]
- Hu, D.M.; Yuan, W.; Niu, F.Q.; Yuan, W.; Han, A.A. Multi-model fusion extraction method for chinese text implicative meteorological disasters event information. J. Geoinfo. Sci. 2022, 24, 2342–2355. (In Chinese) [Google Scholar] [CrossRef]
- School of Computer Science and Technology, BIT, Yuan Wu. Available online: https://cs.bit.edu.cn/szdw/jsml/fjs/yw/index.htm (accessed on 28 May 2024).
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Wang, S.; Hu, G. Revisiting Pre-Trained Models for Chinese Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, Online, 16–20 November 2020; Association for Computational Linguistics: Sydney, Australia, 2020; pp. 657–668. [Google Scholar] [CrossRef]
- Gill, J.C.; Malamud, B.D. Reviewing and visualizing the interactions of natural hazards. Rev. Geophys. 2014, 52, 680–722. [Google Scholar] [CrossRef]
- Mohamed, M.J.; Karim, I.R.; Fattah, M.Y.; Al-Ansari, N. Modelling Flood Wave Propagation as a Result of Dam Piping Failure Using 2D-HEC-RAS. Civ. Eng. J. 2023, 9, 2503–2515. [Google Scholar] [CrossRef]
- Edwards, R. Tropical Cyclone Tornadoes: A Review of Knowledge in Research and Prediction. E-J. Sev. Storms Meteorol. 2021, 7, 1–61. [Google Scholar] [CrossRef]
- Salvador, C.; Nieto, R.; Vicente-Serrano, S.M.; García-Herrera, R.; Gimeno, L.; Vicedo-Cabrera, A.M. Public Health Implications of Drought in a Climate Change Context: A Critical Review. Annu. Rev. Public Health 2023, 44, 213–232. [Google Scholar] [CrossRef] [PubMed]
- Darvishi Boloorani, A.; Soleimani, M.; Papi, R.; Neysani Samany, N.; Teymouri, P.; Soleimani, Z. Sources, Drivers, and Impacts of Sand and Dust Storms: A Global View. In Dust and Health: Challenges and Solutions; Al-Dousari, A., Hashmi, M.Z., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 31–49. ISBN 978-3-031-21209-3. [Google Scholar]
- Spencer, T.; Brooks, S.M.; Evans, B.R.; Tempest, J.A.; Möller, I. Southern North Sea Storm Surge Event of 5 December 2013: Water Levels, Waves and Coastal Impacts. Earth-Sci. Rev. 2015, 146, 120–145. [Google Scholar] [CrossRef]
- Elseidy, M.; Abdelhamid, E.; Skiadopoulos, S.; Kalnis, P. GRAMI: Frequent Subgraph and Pattern Mining in a Single Large Graph. Proc. VLDB Endow. 2014, 7, 517–528. [Google Scholar] [CrossRef]
- Godbole, S.; Sarawagi, S. Discriminative Methods for Multi-Labeled Classification. Adv. Knowl. Discov. Data Mining. 2004, 3056, 22–30. [Google Scholar] [CrossRef]
- Guan, Y.; Zheng, F.; Zhang, P.; Qin, C. Spatial and Temporal Changes of Meteorological Disasters in China during 1950–2013. Nat. Hazards 2015, 75, 2607–2623. [Google Scholar] [CrossRef]
- Xu, X.; Tang, Q. Meteorological Disaster Frequency at Prefecture-Level City Scale and Induced Losses in Mainland China during 2011–2019. Nat. Hazards 2021, 109, 827–844. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, G.; Zhai, J.; Liu, Q.; Song, L. Evolution Characteristics of the Rainstorm Disaster Chains in the Guangdong–Hong Kong–Macao Greater Bay Area, China. Nat. Hazards 2023, 119, 2011–2032. [Google Scholar] [CrossRef]
- Shi, J.; Cui, L. Spatial and Temporal Characteristics of Four Main Types of Meteorological Disasters in East China. Atmosfera 2020, 33, 233–247. [Google Scholar] [CrossRef]
- Dhakal, A.S.; Sidle, R.C. Distributed Simulations of Landslides for Different Rainfall Conditions. Hydrol. Process. 2004, 18, 757–776. [Google Scholar] [CrossRef]
- Li, B.; Gao, Y.; Yin, Y.; Wan, J.; He, K.; Wu, W.; Zhang, H. Rainstorm-Induced Large-Scale Landslides in Northeastern Chongqing, China, August 31 to September 2, 2014. Bull. Eng. Geol. Environ. 2022, 81, 271. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spatial Distance | Temporal Interval | ||
|---|---|---|---|
| Levels | Range of Values (km) | Levels | Range of Values (day(s)) |
| 1 | [0, 50) | 0 | 0 |
| 2 | [50, 100) | 1 | 1 |
| 3 | [100, 200) | 2 | 2 |
| 4 | [200, 500) | 3 | 3 |
| 5 | [500, 800) | 4 | 4~6 |
| 6 | [800, 1000) | 5 | 7~9 |
| 6 | 10~12 | ||
| 7 | 13~15 | ||
| 8 | 16~18 | ||
| 9 | 19~21 | ||
| Causal Disaster Category | Consequential Disaster Category | Time Intervals (day) | Spatial Distance (km) |
|---|---|---|---|
| Rainstorms | Floods, Collapses, Landslides, Debris flows, Tornados | 21 | 200 |
| Heatwaves | Droughts | 35 | 200 |
| Droughts | Sandstorms, Heatwaves | 60 | 1000 |
| Snow disaster | Freezing damage | 7 | 100 |
| Cold waves | Freezing damage, Glaze ice, Fog disaster, Gales, Snow disasters, Storm surges, Frosts, Hails | 14 | 1000 |
| Continuous rainy days | Floods, Debris flows, Landslides, Freezing damage, Collapses | 40 | 500 |
| Typhoons | Rainstorms, Gales, Thunder and lightning, Storm surges, Tornados | 14 | 1000 |
| Gales | Sandstorms | 7 | 500 |
| Storm surges | Floods | 7 | 1000 |
| Number of Frequent Subgraphs | |
|---|---|
| All | 103 |
| Contain rainstorm | 103 |
| Contain flood | 103 |
| Contain gale | 84 |
| Contain typhoon | 79 |
| Contain drought | 2 |
| Contain continuous rainy days | 1 |
| Contain debris flow | 1 |
| Contain landslide | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, A.; Yuan, W.; Yuan, W.; Zhou, J.; Jian, X.; Wang, R.; Gao, X. Mining Spatial-Temporal Frequent Patterns of Natural Disasters in China Based on Textual Records. Information 2024, 15, 372. https://doi.org/10.3390/info15070372
Han A, Yuan W, Yuan W, Zhou J, Jian X, Wang R, Gao X. Mining Spatial-Temporal Frequent Patterns of Natural Disasters in China Based on Textual Records. Information. 2024; 15(7):372. https://doi.org/10.3390/info15070372
Chicago/Turabian StyleHan, Aiai, Wen Yuan, Wu Yuan, Jianwen Zhou, Xueyan Jian, Rong Wang, and Xinqi Gao. 2024. "Mining Spatial-Temporal Frequent Patterns of Natural Disasters in China Based on Textual Records" Information 15, no. 7: 372. https://doi.org/10.3390/info15070372
APA StyleHan, A., Yuan, W., Yuan, W., Zhou, J., Jian, X., Wang, R., & Gao, X. (2024). Mining Spatial-Temporal Frequent Patterns of Natural Disasters in China Based on Textual Records. Information, 15(7), 372. https://doi.org/10.3390/info15070372