
Intelligent Text Mining for Ontological Knowledge Graph Refinement and Patent Portfolio Analysis—Case Study of Net-Zero Data Center Innovation Management



Abstract
1. Introduction
2. Literature Review
2.1. Ontological Knowledge Graph (OKG)
2.2. Keyword Extraction
2.3. Clustering Method
2.4. Topic Modeling
2.5. Technology Maturity Analysis
3. Methodology
3.1. DC Net-Zero Technologies’ OKG Construction
3.2. Patent Data Retrieval Strategy Design
3.3. Major Patenting Trend Analysis
3.4. Clustering and Topic Modeling for Enhancing Domain OKG
- Combination of K-means Clustering and KeyBERT Keyword Extraction
- CorEx Topic Modeling
3.5. Critical Patent Portfolio Analysis Based on Refined OKG
- KeyBERT-based Technology Function Matrix (KeyBERT-based eTFM)
- Technology Maturity Analysis
4. Discover Enhanced OKG and Patent Analysis—Case of Net-Zero DC Innovations
4.1. Major Patenting Trend Analysis
4.2. Clustering and Topic Modeling for Enhancing Domain OKG
4.3. Critical Patent Portfolio Analysis Based on Refined OKG
- KeyBERT-based eTFM Analysis
- Technology Maturity Analysis (s-curve)
5. Conclusions, Limitations and Future Works
- (a)
- Data sources and scope: This study utilized data from international journal literature search systems, including IEEE, Google Scholar, and Innovation Q+, as well as the patent search system Derwent Innovation. The data scope may still be limited by the coverage and indexing of these databases. Future research can expand the search to include additional literature databases (e.g., Scopus, WoS, etc.)
- (b)
- Limitations in predictive analysis: The S-curve model for technology maturity is based on historical data and current trends, making it inherently uncertain. It may not account for unexpected breakthroughs, market shifts, regulatory changes, or geopolitical influences. Such factors could rapidly alter technology development trends. Complementing patent analyses with qualitative analysis of these issues is essential for a more comprehensive understanding.
- (c)
- Subjectivity in OKG construction: The initial construction of the OKG was influenced by the subjective interpretations of the researchers during the literature review. Despite subsequent efforts using text mining and NLP models to enhance objectivity, the initial bias may still affect the overall findings and interpretations. To mitigate this, we propose specific future research directions outlined in the following paragraph.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Paulheim, H. Knowledge graph refinement: A survey of approaches and evaluation methods. Semant. Web 2017, 8, 489–508. [Google Scholar] [CrossRef]
- Staab, S.; Studer, R. “What Is an Ontology?”, Handbook on Ontologies; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; pp. 1–17. [Google Scholar]
- Mizoguchi, R.; Ikeda, M. Towards ontology engineering. J.-Jpn. Soc. Artif. Intell. 1998, 13, 9–10. [Google Scholar]
- Arregoces, M.; Portolani, M. Data Center Fundamentals; Cisco Press: Indianapolis, IN, USA, 2003. [Google Scholar]
- IEA. Available online: https://iea.blob.core.windows.net/assets/6b2fd954-2017-408e-bf08-952fdd62118a/Electricity2024-Analysisandforecastto2026.pdf (accessed on 20 March 2023).
- Datacenter Dynamic. Available online: https://www.datacenterdynamics.com/en/news/european-energy-efficiency-directive-published-with-mandatory-data-center-reporting/ (accessed on 20 March 2023).
- Fankhauser, S.; Smith, S.M.; Allen, M.; Axelsson, K.; Hale, T.; Hepburn, C.; Kendall, J.M.; Khosla, R.; Lezaun, J.; Mitchell-Larson, E.; et al. The meaning of net-zero and how to get it right. Nat. Clim. Change 2022, 12, 15–21. [Google Scholar] [CrossRef]
- Strandburg, K.J. Users as innovators: Implications for patent doctrine. Univ. Colo. Law Rev. 2008, 79, 467. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Trappey, A.J.; Lin, G.B.; Chen, H.K.; Chen, M.C. A comprehensive analysis of global patent landscape for recent R&D in agricultural drone technologies. World Pat. Inf. 2023, 74, 102216. [Google Scholar]
- Trappey, A.J.; Wei, A.Y.; Chen, N.K.; Li, K.A.; Hung, L.P.; Trappey, C.V. Patent landscape and key technology interaction roadmap using graph convolutional network–Case of mobile communication technologies beyond 5G. J. Inf. 2023, 17, 101354. [Google Scholar] [CrossRef]
- Trappey, A.J.; Pa, R.J.; Chen, N.K.; Huang, A.Z.; Li, K.A.; Hung, L.P. Digital transformation of technological IP portfolio analysis for complex domain of satellite communication innovations. Adv. Eng. Inform. 2023, 55, 101879. [Google Scholar] [CrossRef]
- Trappey, C.V.; Wu, H.Y.; Taghaboni-Dutta, F.; Trappey, A.J. Using patent data for technology forecasting: China RFID patent analysis. Adv. Eng. Inform. 2011, 25, 53–64. [Google Scholar] [CrossRef]
- Arcan, M.; Manjunath, S.; Robin, C.; Verma, G.; Pillai, D.; Sarkar, S.; Dutta, S.; Assem, H.; McCrae, J.P.; Buitelaar, P. Intent Classification by the Use of Automatically Generated Knowledge Graphs. Information 2023, 14, 288. [Google Scholar] [CrossRef]
- Zafeiropoulos, N.; Bitilis, P.; Tsekouras, G.E.; Kotis, K. Evaluating Ontology-Based PD Monitoring and Alerting in Personal Health Knowledge Graphs and Graph Neural Networks. Information 2024, 15, 100. [Google Scholar] [CrossRef]
- Trappey, A.J.; Trappey, C.V.; Chang, A.C. Intelligent extraction of a knowledge ontology from global patents: The case of smart retailing technology mining. Int. J. Semantic Web Inf. Syst. 2020, 16, 61–80. [Google Scholar] [CrossRef]
- Trappey, A.J.; Liang, C.P.; Lin, H.J. Using machine learning language models to generate innovation knowledge graphs for patent mining. Appl. Sci. 2022, 12, 9818. [Google Scholar] [CrossRef]
- Trappey, A.J.; Chen, P.P.; Trappey, C.V.; Ma, L. A machine learning approach for solar power technology review and patent evolution analysis. Appl. Sci. 2019, 9, 1478. [Google Scholar] [CrossRef]
- Trappey, A.J.; Trappey, C.V.; Liang, C.P.; Lin, H.J. IP Analytics and Machine Learning Applied to Create Process Visualization Graphs for Chemical Utility Patents. Processes 2021, 9, 1342. [Google Scholar] [CrossRef]
- Bharti, S.K.; Babu, K.S. Automatic keyword extraction for text summarization: A survey. arXiv 2017, arXiv:1704.03242. [Google Scholar]
- Khan, M.Q.; Shahid, A.; Uddin, M.I.; Roman, M.; Alharbi, A.; Alosaimi, W.; Almalki, J.; Alshahrani, S.M. Impact analysis of keyword extraction using contextual word embedding. PeerJ 2022, 8, e967. [Google Scholar] [CrossRef] [PubMed]
- Trappey, C.V.; Trappey, A.J.; Lin, H.J.; Chang, A.C. Comparative Analysis of Food Related Sustainable Development Goals in the North Asia Pacific Region. Food Ethics 2023, 8, 21. [Google Scholar] [CrossRef]
- Petrus, J. Soft and Hard Clustering for Abstract Scientific Paper in Indonesian. In Proceedings of the 2019 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS), Jakarta, Indonesia, 24–25 October 2019; IEEE: New York, NY, USA, 2019; pp. 131–136. [Google Scholar]
- Bock, H.H. Clustering methods: A history of k-means algorithms. In Selected Contributions in Data Analysis and Classification; Springer: Berlin/Heidelberg, Germany, 2007; pp. 161–172. [Google Scholar]
- Trappey, A.J.; Chang, A.C.; Trappey, C.V.; Chien, J.Y.C. Intelligent RFQ summarization using natural language processing, text mining, and machine learning techniques. J. Glob. Inf. Manag. 2022, 30, 1–26. [Google Scholar] [CrossRef]
- Blei, D.; Lafferty, J. Correlated topic models. Adv. Neural Inf. Process. Syst. 2006, 18, 147. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Trappey, A.J.; Trappey, C.V.; Govindarajan, U.H.; Jhuang, A.C. Construction and validation of an ontology-based technology function matrix: Technology mining of cyber physical system patent portfolios. World Pat. Inf. 2018, 55, 19–24. [Google Scholar] [CrossRef]
- Gallagher, R.J.; Reing, K.; Kale, D.; Ver Steeg, G. Anchored correlation explanation: Topic modeling with minimal domain knowledge. Trans. Assoc. Comput. Linguistics 2017, 5, 529–542. [Google Scholar] [CrossRef]
- Ounacer, S.; Mhamdi, D.; Ardchir, S.; Daif, A.; Azzouazi, M. Customer Sentiment Analysis in Hotel Reviews Through Natural Language Processing Techniques. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 569–579. [Google Scholar] [CrossRef]
- Adamuthe, A.C.; Thampi, G.T. Forecasting Technology Maturity Curve of Cloud Computing with its Enabler Technologies. J. Sci. Res. 2020, 64, 239–246. [Google Scholar] [CrossRef]
- Kotler, P. Marketing Management, 11th ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Coccia, M.; Roshani, S. Technological Phases of Quantum Technologies Driving Long-Term Development. 2023. Available online: https://www.researchsquare.com/article/rs-2942054/v1 (accessed on 14 January 2024).
- Ampah, J.D.; Jin, C.; Fattah, I.M.R.; Appiah-Otoo, I.; Afrane, S.; Geng, Z.; Yusuf, A.A.; Li, T.; Mahlia, T.I.; Liu, H. Investigating the evolutionary trends and key enablers of hydrogen production technologies: A patent-life cycle and econometric analysis. Int. J. Hydrogen Energy 2023, 48, 37674–37707. [Google Scholar] [CrossRef]
- Huang, Y.; Li, R.; Zou, F.; Jiang, L.; Porter, A.L.; Zhang, L. Technology life cycle analysis: From the dynamic perspective of patent citation networks. Technol. Forecast. Soc. Chang. 2022, 181, 121760. [Google Scholar] [CrossRef]
- Hoosain, M.S.; Paul, B.S.; Kass, S.; Ramakrishna, S. Tools towards the sustainability and circularity of data centers. Circ. Econ. Sustain. 2023, 3, 173–197. [Google Scholar] [CrossRef]
- Jin, X.; Zhang, F.; Vasilakos, A.V.; Liu, Z. Green data centers: A survey, perspectives, and future directions. arXiv 2016, arXiv:1608.00687. [Google Scholar]
- Cao, Z.; Zhou, X.; Wu, X.; Zhu, Z.; Liu, T.; Neng, J.; Wen, Y. Data Center Sustainability: Revisits and Outlooks. IEEE Trans. Sustain. Comput. 2024, 9, 236–248. [Google Scholar] [CrossRef]
- Kuncoro, I.W.; Pambudi, N.A.; Biddinika, M.K.; Widiastuti, I.; Hijriawan, M.; Wibowo, K.M. Immersion Cooling as the Next Technology for Data Center Cooling: A Review. J. Phys. Conf. Ser. 2019, 1402, 044057. [Google Scholar] [CrossRef]
- Cutler, B.; Fowers, S.; Kramer, J.; Peterson, E. Dunking the data center. IEEE Spectr. 2017, 54, 26–31. [Google Scholar] [CrossRef]
- Kanbur, B.B.; Wu, C.; Fan, S.; Duan, F. System-level experimental investigations of the direct immersion cooling data center units with thermodynamic and thermoeconomic assessments. Energy 2017, 217, 119373. [Google Scholar] [CrossRef]
- Gözcü, O.; Özada, B.; Carfi, M.U.; Erden, H.S. Worldwide Energy Analysis of Major Free Cooling Methods for Data Centers. In Proceedings of the 2017 16th IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Orlando, FL, USA, 30 May–2 June 2017; pp. 968–976. [Google Scholar]
- Milad, M.; Darwish, M. UPS System: How Can Future Technology and Topology Improve the Energy Efficiency in Data Centers? In Proceedings of the 2014 49th International Universities Power Engineering Conference (UPEC), Cluj-Napoca, Romania, 2–5 September 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Krein, P.T. Data center challenges and their power electronics. CPSS Trans. Power Electron. Appl. 2017, 2, 39–46. [Google Scholar] [CrossRef]
- Pelley, S.; Meisner, D.; Zandevakili, P.; Wenisch, T.F.; Underwood, J. Power routing: Dynamic power provisioning in the data center. ACM SIGPLAN Not. 2017, 38, 231–242. [Google Scholar]
- Shoukourian, H.; Wilde, T.; Auweter, A.; Bode, A. Monitoring power data: A first step towards a unified energy efficiency evaluation toolset for HPC data centers. Environ. Model. Softw. 2014, 56, 13–26. [Google Scholar] [CrossRef]
- Mytton, D. Data centre water consumption. Clean Water 2014, 4, 11. [Google Scholar] [CrossRef]
- Liang, J.; Xie, J.; Zhang, X.; Wang, X. Study on the Construction of Big Data and Valorization Services of Intelligent Water. In Proceedings of the 2021 IEEE 11th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 18–20 June 2021; pp. 145–149. [Google Scholar]
- Ebrahimi, K.; Jones, G.F.; Fleischer, A.S. A review of data center cooling technology, operating conditions and the corresponding low-grade waste heat recovery opportunities. Renew. Sustain. Energy Rev. 2014, 31, 622–638. [Google Scholar] [CrossRef]
- Sharma, R.K.; Bash, C.E.; Patel, C.D.; Friedrich, R.J.; Chase, J.S. Balance of power: Dynamic thermal management for internet data centers. IEEE Internet Comput. 2005, 9, 42–49. [Google Scholar] [CrossRef]
- Zhang, Y.; Shan, K.; Li, X.; Li, H.; Wang, S. Research and Technologies for next-generation high-temperature data centers–State-of-the-arts and future perspectives. Renew. Sustain. Energy Rev. 2023, 171, 112991. [Google Scholar] [CrossRef]
- Ran, Y.; Hu, H.; Zhou, X.; Wen, Y. Deepee: Joint Optimization of Job Scheduling and Cooling Control for Data Center Energy Efficiency Using Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 645–655. [Google Scholar]
- Bose, R.; Roy, S.; Mondal, H.; Chowdhury, D.R.; Chakraborty, S. Energy-efficient approach to lower the carbon emissions of data centers. Computing 2021, 103, 1703–1721. [Google Scholar] [CrossRef]
- Lykou, G.; Mentzelioti, D.; Gritzalis, D. A new methodology toward effectively assessing data center sustainability. Comput. Secur. 2018, 76, 327–340. [Google Scholar] [CrossRef]
- Ren, S.; He, Y. COCA: Online Distributed Resource Management for Cost Minimization and Carbon Neutrality in Data Centers. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 7–22 November 2013; pp. 1–12. [Google Scholar]
- Cao, Z.; Zhou, X.; Hu, H.; Wang, Z.; Wen, Y. Toward a Systematic Survey for Carbon Neutral Data Centers. IEEE Commun. Surv. Tutor. 2022, 24, 895–936. [Google Scholar] [CrossRef]
- Shaw, R.; Howley, E.; Barrett, E. Applying reinforcement learning towards automating energy efficient virtual machine consolidation in cloud data centers. Inf. Syst. 2022, 107, 101722. [Google Scholar] [CrossRef]
- Yao, W.; Shen, Y.; Wang, D. A weighted pagerank-based algorithm for virtual machine placement in cloud computing. IEEE Access 2019, 7, 176369–176381. [Google Scholar] [CrossRef]
- Scioscia, F.; Bilenchi, I.; Ruta, M.; Gramegna, F.; Loconte, D. A multiplatform energy-aware OWL reasoner benchmarking framework. J. Web Semant. 2022, 72, 100694. [Google Scholar] [CrossRef]
- Reddy, K.H.K.; Luhach, A.K.; Kumar, V.V.; Pratihar, S.; Kumar, D.; Roy, D.S. Towards energy efficient Smart city services: A software defined resource management scheme for data centers. Sustain. Comput. Informatics Syst. 2022, 35, 100776. [Google Scholar] [CrossRef]
- Imamura, S.; Yoshida, E.; Oe, K. Reducing CPU Power Consumption with Device Utilization-Aware DVFS for Low-Latency SSDs. IEICE Trans. Inf. Syst. 2019, 102, 1740–1749. [Google Scholar] [CrossRef]
- Chou, J.C.Y.; Lai, T.H.; Kim, J.; Rotem, D. Exploiting replication for energy-aware scheduling in disk storage systems. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 2734–2749. [Google Scholar] [CrossRef]
- Jhuang, A.C.; Sun, J.J.; Trappey, A.J.; Trappey, C.V.; Govindarajan, U.H. Computer Supported Technology Function Matrix Construction for Patent Data Analytics. In Proceedings of the 2017 IEEE 21st International Conference on Computer Supported Cooperative Work in Design (CSCWD), Wellington, New Zealand, 26–28 April 2017; pp. 457–462. [Google Scholar]
- Urbina-Suarez, N.A.; Angel-Ospina, A.C.; Lopez-Barrera, G.L.; Barajas-Solano, A.F.; Machuca-Martínez, F. S-curve and landscape maps for the analysis of trends on industrial textile wastewater treatment. Environ. Adv. 2024, 15, 100491. [Google Scholar] [CrossRef]
- Zahoor, A.; Kun, R.; Mao, G.; Farkas, F.; Sápi, A.; Kónya, Z. Urgent Needs for Second Life Using and Recycling Design of Wasted E-car Lithium-ion Battery: A Scientometric Analysis. Environ. Sci. Pollut. Res. Int. 2024; ahead of print. [Google Scholar] [CrossRef]
- Zhang, H.; Qi, Y.; Zhang, G. Comparative analysis of intelligent connected vehicle industry in China, United States and European Union from technology lifecycle perspective. Kybernetes, 2023; ahead of print. [Google Scholar] [CrossRef]
- Huang, L.; Hou, Z.; Fang, Y.; Liu, J.; Shi, T. Evolution of CCUS Technologies Using LDA Topic Model and Derwent Patent Data. Energies 2023, 16, 2556. [Google Scholar] [CrossRef]
- Sossa, J.W.Z.; Marro, F.P.; Alzate, B.A.; Salazar, F.M.V.; Patiño, A.F.A. S-Curve analysis and technology life cycle. Application in series of data of articles and patents. Espacios 2016, 37, 19. [Google Scholar]
- Clement, S.; Burdett, K.; Rteil, N.; Wynne, A.; Kenny, R. Is Hot IT a False Economy? An Analysis of Server and Data Center Energy Efficiency as Temperatures Rise. IEEE Trans. Sustain. Comput. 2024, 9, 482–493. [Google Scholar] [CrossRef]
- Zakarya, M.; Khan, A.A.; Qazani, M.R.C.; Ali, H.; Al-Bahri, M.; Khan, A.U.R.; Ali, A.; Khan, R. Sustainable computing across datacenters: A review of enabling models and techniques. Comput. Sci. Rev. 2024, 52, 100620. [Google Scholar] [CrossRef]
- Jihad, N.J.; Abd Almuhsan, M.A. Future trends in optical wireless communications systems. Tech. Rom. J. Appl. Sci. Technol. 2023, 13, 53–67. [Google Scholar] [CrossRef]
- Xu, J.; Fortes, J.A. Multi-objective Virtual Machine Placement in Virtualized Data Center Environments. In Proceedings of the 2010 IEEE/ACM Int’l Conference on Green Computing and Communications & Int’l Conference on Cyber, Physical and Social Computing, Washington, DC, USA, 18–20 December 2010; pp. 179–188. [Google Scholar]
- Dutreilh, X.; Moreau, A.; Malenfant, J.; Rivierre, N.; Truck, I. From Data Center Resource Allocation to Control Theory and Back. In Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing, Miami, FL, USA, 5–10 July 2010; pp. 410–417. [Google Scholar]
- Youssef, A.E. Exploring cloud computing services and applications. J. Emerg. Trends Comp. Inf. Sci. 2012, 3, 838–847. [Google Scholar]
- Ye, K.; Huang, D.; Jiang, X.; Chen, H.; Wu, S. Virtual Machine-based Energy-efficient Data Center Architecture for Cloud Computing: A Performance Perspective. In Proceedings of the 2010 IEEE/ACM Int’l Conference on Green Computing and Communications & Int’l Conference on Cyber, Physical and Social Computing, Washington, DC, USA, 18–20 December 2010; pp. 171–178. [Google Scholar]
- Bitar, N.; Gringeri, S.; Xia, T.J. Technologies and protocols for data center and cloud networking. IEEE Commun. Mag. 2023, 51, 24–31. [Google Scholar] [CrossRef]
- Bari, M.F.; Boutaba, R.; Esteves, R.; Granville, L.Z.; Podlesny, M.; Rabbani, M.G.; Zhang, Q.; Zhani, M.F. Data center network virtualization: A survey. IEEE Commun. Surv. Tutor. 2012, 15, 909–928. [Google Scholar] [CrossRef]
- Lam, C.F.; Liu, H.; Koley, B.; Zhao, X.; Kamalov, V.; Gill, V. Fiber optic communication technologies: What’s needed for datacenter network operations. IEEE Commun. Mag. 2010, 48, 32–39. [Google Scholar] [CrossRef]
- Sato, K.I.; Matsuura, H.; Konoike, R.; Suzuki, K.; Ikeda, K.; Namiki, S. Prospects and challenges of optical switching technologies for intra data center networks. J. Opt. Commun. Netw. 2022, 14, 903–915. [Google Scholar] [CrossRef]
- Cheng, T.Y. A new method of creating technology/function matrix for systematic innovation without expert. J. Technol. Manag. 2012, 7, 118–127. [Google Scholar] [CrossRef]
- Skyquest. Available online: https://www.skyquestt.com/sample-request/data-center-cooling-market (accessed on 25 March 2023).
- Marketsandmarkets. Available online: https://www.marketsandmarkets.com/Market-Reports/data-center-cooling (accessed on 20 March 2023).
- GMI. Available online: https://www.gminsights.com/industry-analysis/data-center-cooling-market (accessed on 25 March 2023).
- Newswire. Available online: https://www.prnewswire.com/news-releases/data-center-rack-market-size-to-grow-by-usd-1628-53-million-belden-inc-black-box-corp-chatsworth-products-inc-and-more-among-the-key-companies-in-the-market-technavio-302090327.html (accessed on 25 March 2023).
- Technavio. Available online: https://www.technavio.com/report/data-center-it-equipment-market-analysis (accessed on 25 March 2023).

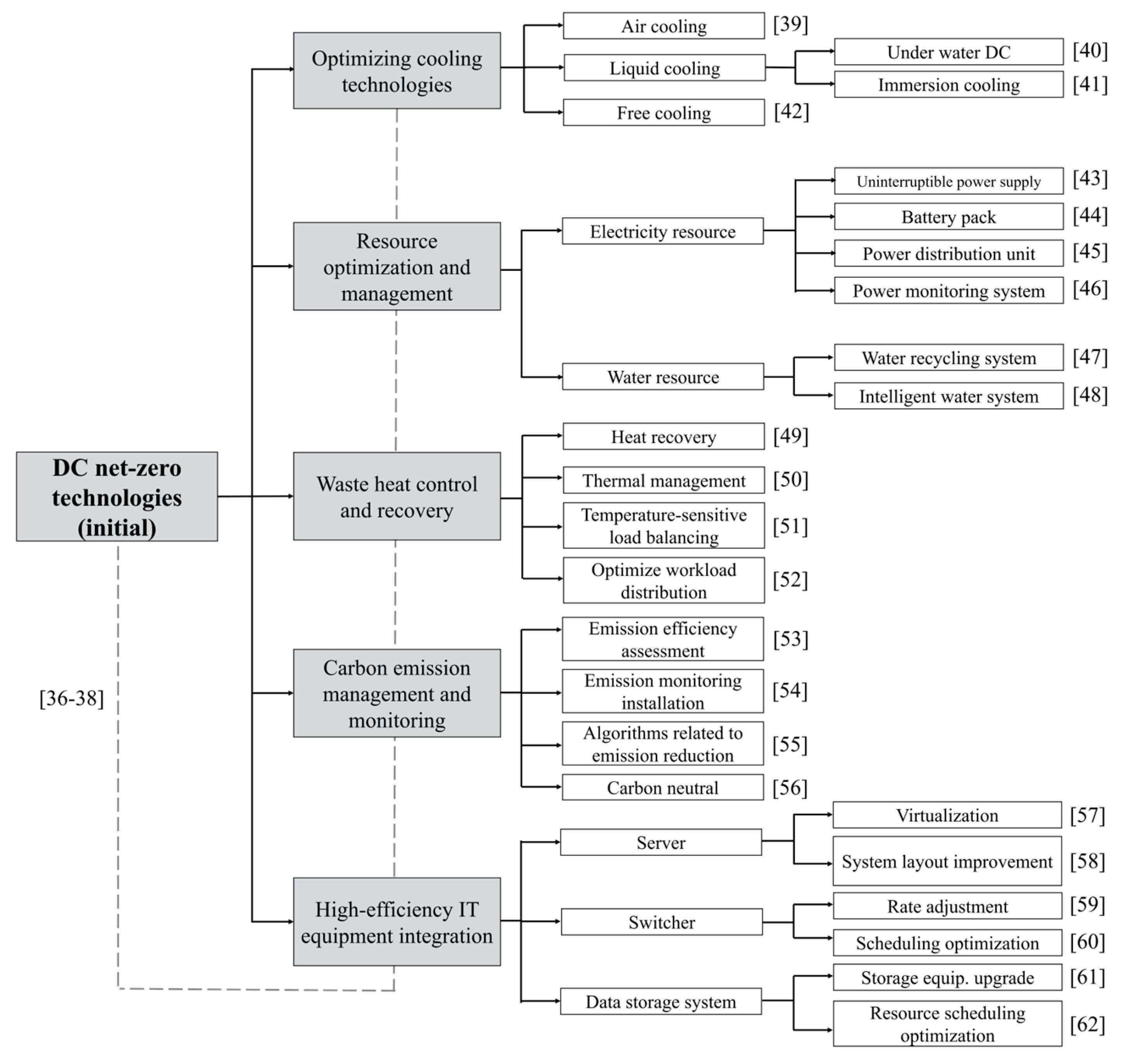
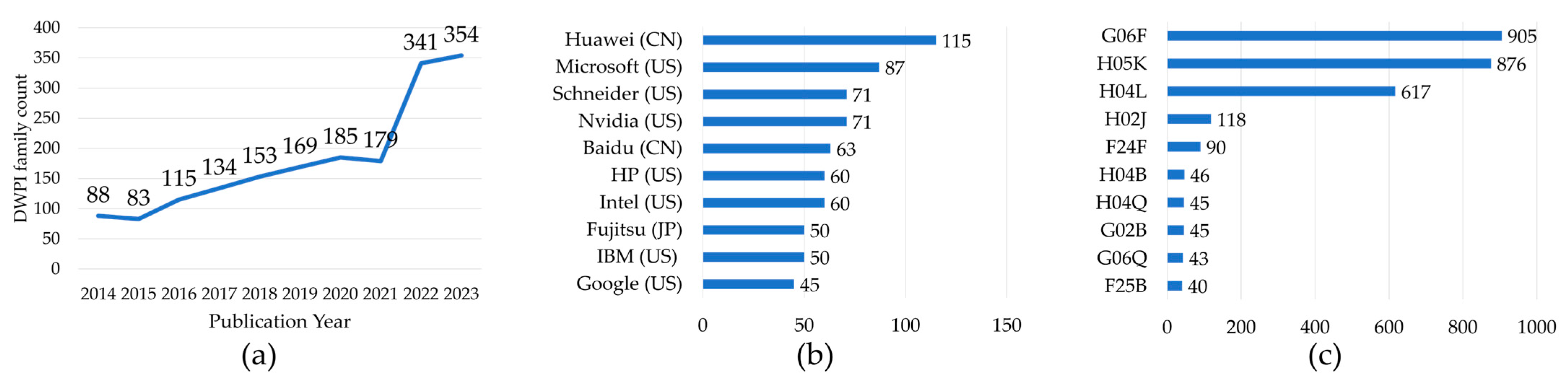

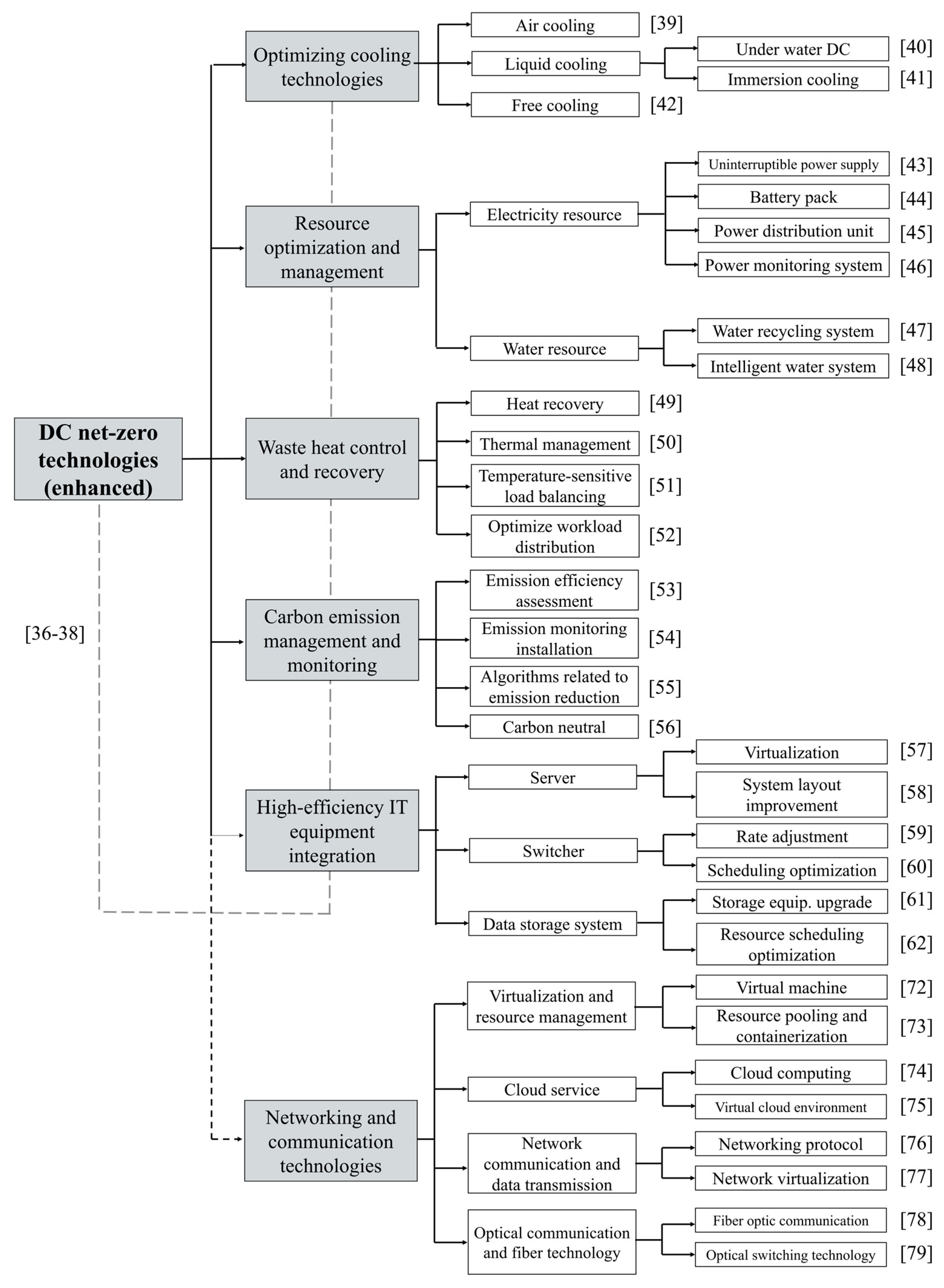
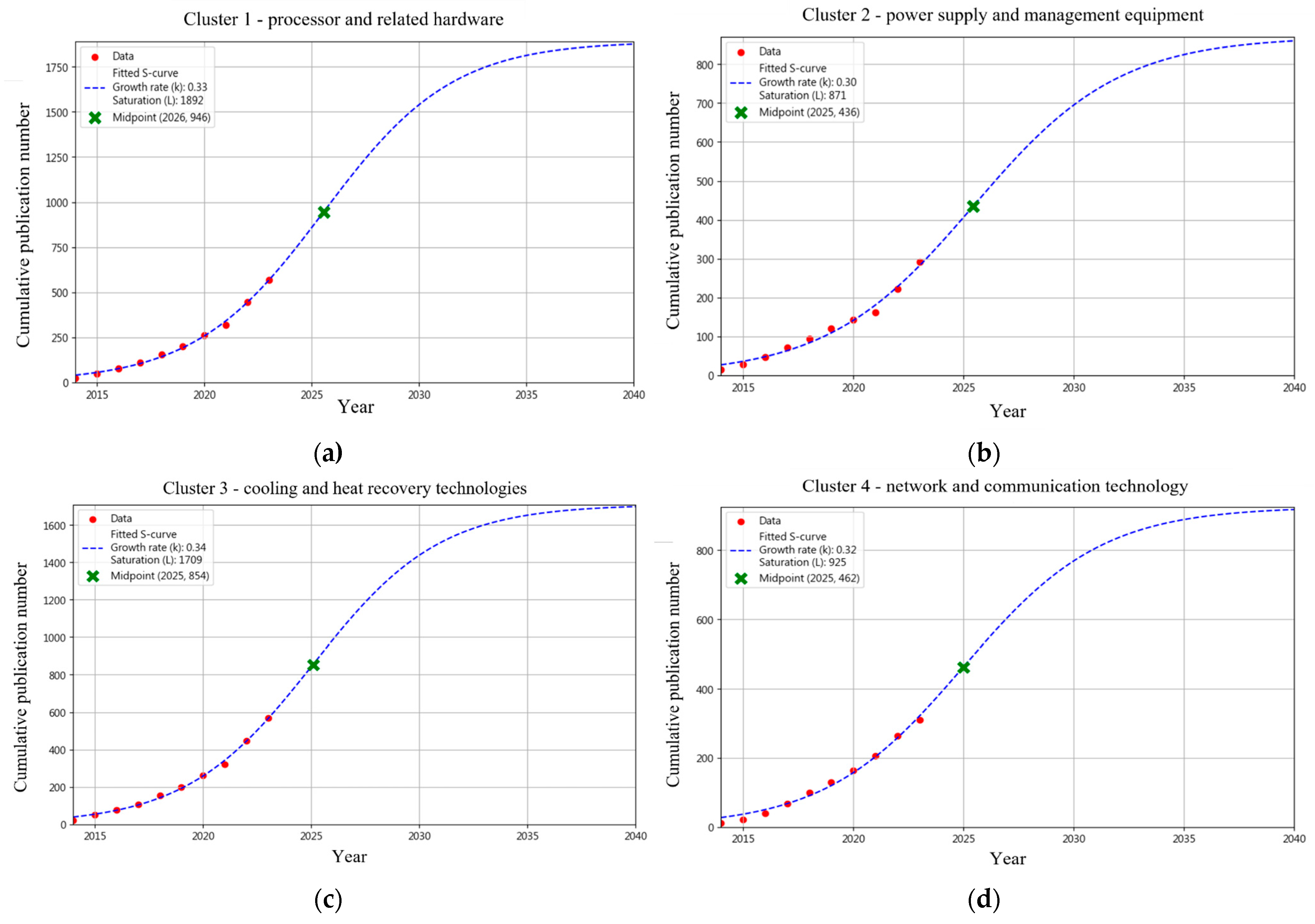

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keyword Extraction Methods | Description | Example |
|---|---|---|
| Simple statistical methods | In the absence of considering linguistic features of the text, attention is focused on extracting statistical data from the text, including word position, word frequency, and inverse document frequency, to generate a list of keywords. | N-gram TF–IDF 1 PAT-tree 2 |
| Linguistic methods | Requires a thorough understanding of grammar and semantic structures between words. It involves techniques such as syntactic role identification, parsing, and morphological analysis to determine keyword relationships. | WordNet EDR 3 Tree Tagger |
| Machine learning methods | Using machine learning algorithms, keywords are identified based on training data, can better handle context and semantics, and typically yield higher accuracy. | SVM 4 NB 5 Bagging KeyBERT |
| Cluster | Cluster Meaning (Number of Patents for Each Cluster) | Keyword Extraction Results |
|---|---|---|
| 1 | Processor and related hardware (631) | CPU, board, processor, server |
| 2 | Power supply and management equipment (291) | transformers, power supplies, capacitors, grids, power equipment |
| 3 | Cooling technology and heat recovery (570) 1 | coolants, cool, cooling racks, refrigeration, fluidical 2 |
| thermoelectric, ventilator, refrigerate, HVAC, heating 3 | ||
| 4 | Network and communication technologies (309) | ethernet, cloud, protocol, transport, IP |
| Topic | Meaning of Topic | Keywords |
|---|---|---|
| 1 | Heat recovery | heat, liquid, heat exchanger, refrigeration, evaporator, coolant |
| 2 | Cooling technology | cool, air, cold, fluid, temperature, cooling, cool air, flow, air flow |
| 3 | Virtualization, resource management and performance optimization | virtual, resource management, performance optimization, virtual machine, resource allocation |
| 4 | Cloud services and resource allocation | virtual, execute, cloud, virtual machine, host, computing, virtualize, workload, instance, program, cloud computing |
| 5 | Power supply and distribution | power, power distribution, power supply, power device, power comprise |
| 6 | Rack and equipment installation | rack, assembly, frame, cabinet, housing, enclosure, electronic rack |
| 7 | Network communication and data transfer | network, network switch, network involve, network traffic, optical |
| 8 | Optical communications and fiber technology | optical, fiber, cable, connector, optical signal |
| 9 | Energy efficiency and conservation measures | reduce, efficiency, energy, energy consumption, energy saving |
| 10 | Storage technology, inspection and measurement technology | drawing, detect, diagram, schematic, drawing schematic |
| F1 Energy Efficiency | F2 Environmental and Sustainability | F3 Energy Efficient Operations | F4 Reliability | Sum | ||
|---|---|---|---|---|---|---|
| T1 | Cooling and heat recovery | 343 | 71 | 241 | 31 | 686 |
| T2 | Energy saving technology | 301 | 70 | 230 | 36 | 637 |
| T3 | Computing systems and HPC | 280 | 41 | 186 | 28 | 535 |
| T4 | Cloud and virtualization | 286 | 40 | 195 | 29 | 550 |
| Sum | 1210 | 222 | 852 | 124 | 2408 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trappey, A.J.C.; Lin, G.-B.; Hung, L.-P. Intelligent Text Mining for Ontological Knowledge Graph Refinement and Patent Portfolio Analysis—Case Study of Net-Zero Data Center Innovation Management. Information 2024, 15, 374. https://doi.org/10.3390/info15070374
Trappey AJC, Lin G-B, Hung L-P. Intelligent Text Mining for Ontological Knowledge Graph Refinement and Patent Portfolio Analysis—Case Study of Net-Zero Data Center Innovation Management. Information. 2024; 15(7):374. https://doi.org/10.3390/info15070374
Chicago/Turabian StyleTrappey, Amy J. C., Ging-Bin Lin, and Li-Ping Hung. 2024. "Intelligent Text Mining for Ontological Knowledge Graph Refinement and Patent Portfolio Analysis—Case Study of Net-Zero Data Center Innovation Management" Information 15, no. 7: 374. https://doi.org/10.3390/info15070374
APA StyleTrappey, A. J. C., Lin, G.-B., & Hung, L.-P. (2024). Intelligent Text Mining for Ontological Knowledge Graph Refinement and Patent Portfolio Analysis—Case Study of Net-Zero Data Center Innovation Management. Information, 15(7), 374. https://doi.org/10.3390/info15070374