

FILO: Automated FIx-LOcus Identification for Android Framework Compatibility Issues



Abstract
1. Introduction
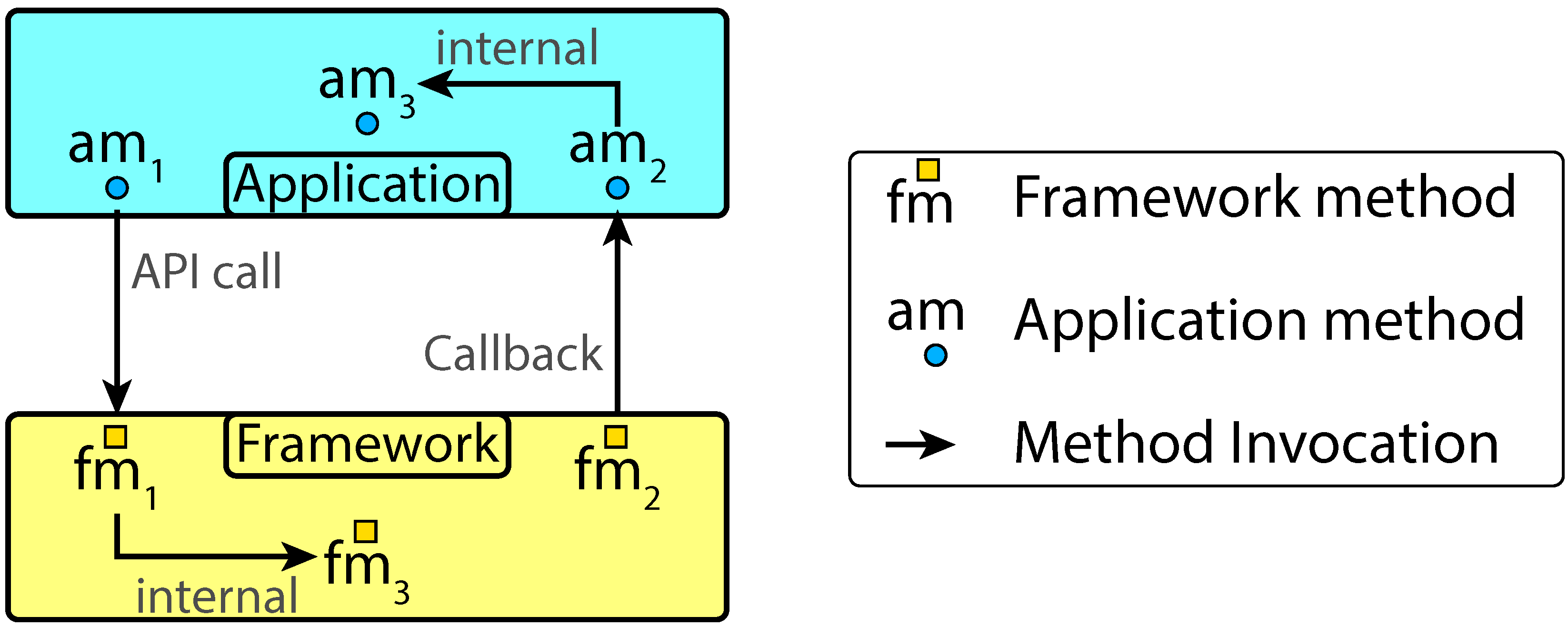
- The interactions between the framework and the app must contain evidence of the failure: Since the incompatibility is between an app and its API framework, the problem must be intuitively visible by observing their interactions (i.e., calls from the app to the framework, and vice versa). The comparison of the interactions observed when the app interacts with the compatible and the incompatible versions of the framework can be used to identify the suspicious interactions that are in turn useful to identify the code regions that originated them, and are thus likely responsible for the failure.
- The method that must be fixed is likely responsible for a large and coherent set of suspicious interactions: Since the faulty code in the app must be the source of the incorrect interactions between the app and the framework, the method to be fixed must be a method internal to the app that controls the execution of a significantly large and coherent set of suspicious interactions. Based on this intuition, FILO generates a ranked list of methods that the developers can exploit to ease fix location. Each method is also associated with the suspicious interactions under its influence to provide insights about the rationale of the selection.
- FILO, a technique that addresses the incompatibilities between an app and an updated framework by producing a ranked list of suspicious methods, associated with supporting evidence about their selection, from a single GUI test case;
- The empirical evidence that FILO can operate efficiently and effectively;
- A freely available implementation of our tool and a replication package (https://gitlab.com/learnERC/filo accessed on 10 June 2024) that can be used to replicate the results reported in the paper.
2. Running Example
| Listing 1. The Fix for the GoodWeather app. |
 |
3. FIx-LOcus
- The Test Execution phase executes the GUI test case on the two Android APIs to collect the interactions between the app and the two Android frameworks. These interactions are collected as execution traces.
- The Anomaly Detection phase identifies the blocks (i.e., the contiguous sequences) of suspicious interactions by comparing the two execution traces.
- The Fix Locus Candidates Identification phase processes the suspicious interactions to return a list of likely faulty methods of the app, with the methods being associated with the corresponding suspicious blocks as supporting evidence of the suspicious interactions that motivate the selection.
3.1. Test Execution
| Listing 2. Excerpt of the GoodWeather baseline trace. |
 |
| Algorithm 1: Test Execution |
 |
3.2. Anomaly Detection
| Listing 3. Excerpt of a Suspicious Invocation Block. |
 |
| Algorithm 2: Anomaly Detection |
 |
3.3. Fix-Locus Candidates Identification
3.3.1. Construction of the Failure Call Tree
| Algorithm 3: Failure Call Tree Generation |
 |
3.3.2. Ranking
4. Prototype
Analyzer
5. Empirical Evaluation
- RQ1: What is the sensitivity of FILO to the choice of the parameters? This RQ investigates how the choice of a configuration impacts the performance of FILO. To answer this RQ, we performed an exhaustive exploration of the configuration space and studied how the results changed with changing configurations.
- RQ2: What is the quality of the ranking produced by FILO? This RQ investigates how well the ranking returned by FILO identifies the method that should be modified to implement the fix. To answer this RQ, we obtained the rankings for a number of different apps with different characteristics and checked whether FILO is able to place the methods that should be modified to produce the fix at the top positions of the ranking, specifically within the first 10 positions or, ideally, within the first five positions as recommended by Kochhar et al. [15].
- RQ3: What is the effectiveness of FILO compared to both Naive Trace Analysis and SBFL techniques? This RQ compares the performances of FILO to two competing approaches. Naive Trace Analysis (NTA) represents the strategy of simply comparing the baseline trace with the failure one. This comparison is designed to demonstrate that the only comparison of the traces is not enough to localize the faulty method. We also compared FILO to Ochiai [1], which is an extensively used fault localization technique. This comparison is defined to demonstrate that a strategy specifically designed to localize problems introduced by framework changes is more effective than general-purpose fault localization. It is also noteworthy that FILO has weaker assumptions than Ochiai, since it does not require a full test suite with several passing tests to be applied, but it can be applied from a single failing test case.
- RQ4: What is the relevance of the information that FILO associates with the methods in the ranking? This RQ investigates if the SIBs produced by FILO are really representative of the symptoms of the failures, and thus they can be used to obtain a better understanding of the failure root causes. To answer this RQ, we compared the content of the SIBs to the actual set of methods related to the incompatibility between the framework and the app.
- RQ5: Is FILO actually useful to developers when fixing app issues? This RQ determines the perceived usefulness of FILO by developers. To answer this RQ we performed a human study with 24 developers, comparing the effort needed to debug apps with and without using FILO.
5.1. Subject Apps
5.2. RQ1: What Is the Sensitivity of FILO to the Choice of the Parameters?
- A1F0: it records the level 1 interactions (direct method invocations) from the app to the framework, while it does not record any interaction from the framework to the app.
- A0F1: it records the level 1 interactions (direct method invocations) from the framework to the app, while it does not record any interaction from the app to the framework.
- A1F1: it records the level 1 interactions (direct method invocations) from the framework to the app and vice versa.
- A2F0: it records the level 2 interactions (direct method invocations and indirect method invocations of depth 1) from the app to the framework, while it does not record any interaction from the framework to the app.
- A0F2: it records the level 2 interactions (direct method invocations and indirect method invocations of depth 1) from the framework to the app, while it does not record any interaction from the app to the framework.
- A1F2: it records the level 1 interactions (direct method invocations) from the app to the framework, and the level 2 interactions (direct method invocations and indirect method invocations of depth 1) from the framework to the app.
- A2F1: it records the level 1 interactions (direct method invocations) from the framework to the app, and the level 2 interactions (direct method invocations and indirect method invocations of depth 1) from the app to the framework.
- A2F2: it records the level 2 interactions (direct method invocations and indirect method invocations of depth 1) from the framework to the app and vice versa.
5.3. RQ2: What Is the Quality of the Ranking Produced by FILO?
5.4. RQ3: How Does FILO Compare to Both Naive Trace Analysis and SBFL Techniques?
5.5. RQ4: What Is the Relevance of the Information Captured in the SIBs Obtained by Comparing the Execution Traces?
5.6. RQ5: Is FILO Actually Useful to Developers When Fixing App Issues?
5.7. Threats to Validity
5.8. Limitations
6. Related Work
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McDonnell, T.; Ray, B.; Kim, M. An empirical study of API stability and adoption in the android ecosystem. In Proceedings of the IEEE International Conference on Software Maintenance, Eindhoven, The Netherlands, 22–28 September 2013; pp. 70–79. [Google Scholar]
- Mahmud, T.; Che, M.; Yang, G. Android api field evolution and its induced compatibility issues. In Proceedings of the 16th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Helsinki, Finland, 19–23 September 2022; pp. 34–44. [Google Scholar]
- Wei, L.; Liu, Y.; Cheung, S.-C. Taming Android fragmentation: Characterizing and detecting compatibility issues for Android apps. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 226–237. [Google Scholar]
- Mostafa, S.; Rodriguez, R.; Wang, X. Experience Paper: A Study on Behavioral Backward Incompatibilities of Java Software Libraries. In Proceedings of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis, Santa Barbara, CA, USA, 10–14 July 2017; pp. 215–225. [Google Scholar]
- Abreu, R.; Zoeteweij, P.; van Gemund, A.J.C. On the accuracy of spectrum-based fault localization. In Proceedings of the Testing: Academic and Industrial Conference Practice and Research Techniques—MUTATION (TAICPART-MUTATION 2007), Windsor, UK, 10–14 September 2007; pp. 89–98. [Google Scholar]
- Jones, J.A.; Harrold, M.J. Empirical evaluation of the Tarantula automatic fault-localization technique. In Proceedings of the 20th IEEE/ACM International Conference on Automated Software Engineering, Long Beach, CA, USA, 7 November 2005; pp. 273–282. [Google Scholar]
- Mobilio, M.; Riganelli, O.; Micucci, D.; Mariani, L. FILO: FIx-LOcus Recommendation for Problems Caused by Android Framework Upgrade. In Proceedings of the 2019 IEEE 30th International Symposium on Software Reliability Engineering (ISSRE), Berlin, Germany, 28–31 October 2019; pp. 358–368. [Google Scholar]
- Teclib. GLPI Android Inventory Agent. Available online: https://github.com/glpi-project/android-inventory-agent (accessed on 10 June 2024).
- Michael Kerrisk, Diff(1)? Linux Manual Page. Available online: http://man7.org/linux/man-pages/man1/diff.1.html (accessed on 10 June 2024).
- Foundation, J. Appium. Available online: http://appium.io/ (accessed on 10 June 2024).
- Android Studio. Available online: https://developer.android.com/studio (accessed on 10 June 2024).
- The Android Profiler. Available online: https://developer.android.com/studio/profile/android-profiler (accessed on 10 June 2024).
- XDA Developers, Xposed. Available online: https://forum.xda-developers.com/f/xposed-general.3094/ (accessed on 10 June 2024).
- Mobilio, M.; Riganelli, O.; Micucci, D.; Mariani, L. Filo: Fix-locus localization for backward incompatibilities caused by android framework upgrades. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering Virtual Event, Melbourne, Australia, 21 September 2020; pp. 1292–1296. [Google Scholar]
- Kochhar, P.S.; Xia, X.; Lo, D.; Li, S. Practitioners’ expectations on automated fault localization. In Proceedings of the 25th International Symposium on Software Testing and Analysis, Saarbrucken, Germany, 18–20 July 2016; pp. 165–176. [Google Scholar]
- GitHub, Inc. GitHub. Available online: https://github.com (accessed on 10 June 2024).
- Cunningham, J. Activities. Available online: https://github.com/cunnj/Activities (accessed on 10 June 2024).
- AriaLyy, Boss Transfer. Available online: https://github.com/shijunjzr/BlogDemo/ (accessed on 10 June 2024).
- xiangtailiang, FakeGPS. Available online: https://github.com/xiangtailiang/FakeGPS (accessed on 10 June 2024).
- Paul, T. FilePicker. Available online: https://github.com/DeveloperPaul123/FilePickerLibrary (accessed on 10 June 2024).
- Mozilla, FirefoxLite. Available online: https://github.com/mozilla-mobile/FirefoxLite (accessed on 10 June 2024).
- FOSS Browser. Available online: https://f-droid.org/packages/de.baumann.browser/ (accessed on 10 June 2024).
- Dieter Adriaenssens, GetBack_GPS. Available online: https://github.com/ruleant/getback_gps (accessed on 10 June 2024).
- Eugene Kislyakov, GoodWeather. Available online: https://github.com/qqq3/good-weather (accessed on 10 June 2024).
- KanjiFix. Available online: https://github.com/ascendedguard/android-kanji-fix (accessed on 10 June 2024).
- MapDemo. Available online: https://github.com/MiniPlaneterKUET/MapDemo (accessed on 10 June 2024).
- Swanberg, J. PoGoIV. Available online: https://github.com/farkam135/GoIV (accessed on 10 June 2024).
- OpenTraining. Available online: https://github.com/chaosbastler/opentraining (accessed on 10 June 2024).
- PrivacyPolice. Available online: https://github.com/BramBonne/privacypolice (accessed on 10 June 2024).
- Stanley Idesis, QuotoGraph. Available online: https://github.com/stanidesis/quotograph (accessed on 10 June 2024).
- Martin Lapiš, SearchView. Available online: https://github.com/lapism/SearchBar-SearchView (accessed on 10 June 2024).
- Network 47, ToneDef. Available online: https://github.com/Fortyseven/ToneDef (accessed on 10 June 2024).
- TrebleShot. Available online: https://github.com/trebleshot/android (accessed on 10 June 2024).
- Kishida, K. Property of Average Precision and Its Generalization: An Examination of Evaluation Indicator for Information Retrieval Experiments; National Institute of Informatics: Tokyo, Japan, 2005. Available online: https://www.nii.ac.jp/TechReports/public_html/05-014E.pdf (accessed on 10 June 2024).
- Wong, W.E.; Gao, R.; Li, Y.; Abreu, R.; Wotawa, F. A survey on software fault localization. IEEE Trans. Softw. Eng. 2016, 42, 8. [Google Scholar] [CrossRef]
- Google, Monkey. Available online: https://developer.android.com/studio/test/monkey (accessed on 10 June 2024).
- Choudhary, S.R.; Gorla, A.; Orso, A. Automated Test Input Generation for Android: Are We There Yet? In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NE, USA, 9–13 November 2015; pp. 429–440. [Google Scholar]
- Android Framework Classes and Services. Available online: https://android.googlesource.com/platform/frameworks/base.git (accessed on 10 June 2024).
- Linares-Vásquez, M.; Bavota, G.; Penta, M.D.; Oliveto, R.; Poshyvanyk, D. How Do API Changes Trigger Stack Overflow Discussions? A Study on the Android SDK. In Proceedings of the 22nd International Conference on Program Comprehension, Hyderabad, India, 2–3 June 2014; pp. 83–94. [Google Scholar]
- Li, L.; Gao, J.; Bissyandé, T.F.; Ma, L.; Xia, X.; Klein, J. Characterising Deprecated Android APIs. In Proceedings of the 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE), Gothenburg, Sweden, 14 May 2018; pp. 254–264. [Google Scholar]
- Gong, L.; Lin, H.; Liu, D.; Yang, L.; Wang, H.; Qiu, J.; Li, Z.; Qian, F. Who Should We Blame for Android App Crashes? An In-Depth Study at Scale and Practical Resolutions. ACM Trans. Sens. Networks 2024, 20, 1–24. [Google Scholar] [CrossRef]
- Xia, H.; Zhang, Y.; Zhou, Y.; Chen, X.; Wang, Y.; Zhang, X.; Cui, S.; Hong, G.; Zhang, X.; Yang, M.; et al. How Android developers handle evolution-induced API compatibility issues: A large-scale study. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, Seoul, Republic of Korea, 27 June–19 July 2020; pp. 886–898. [Google Scholar]
- Cai, H.; Zhang, Z.; Li, L.; Fu, X. A large-scale study of application incompatibilities in Android. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, Beijing, China, 15–19 July 2019; pp. 216–227. [Google Scholar]
- Li, L.; Bissyandé, T.F.; Wang, H.; Klein, J. CiD: Automating the Detection of API-Related Compatibility Issues in Android Apps. In Proceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis, Amsterdam, The Netherlands, 16–21 July 2018; pp. 153–163. [Google Scholar]
- Huang, H.; Wei, L.; Liu, Y.; Cheung, S.-C. Understanding and detecting callback compatibility issues for android applications. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 532–542. [Google Scholar]
- Mahmud, T.; Che, M.; Yang, G. Android compatibility issue detection using api differences. In Proceedings of the 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER), Honolulu, HI, USA, 9–12 March 2021; pp. 480–490. [Google Scholar]
- Mora, F.; Li, Y.; Rubin, J.; Chechik, M. Client-specific equivalence checking. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 441–451. [Google Scholar]
- Fazzini, M.; Orso, A. Automated cross-platform inconsistency detection for mobile apps. In Proceedings of the 2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Urbana, IL, USA, 30 October 2017; pp. 308–318. [Google Scholar]
- Riboira, A.; Abreu, R. The GZoltar project: A graphical debugger interface. In Proceedings of the International Academic and Industrial Conference on Practice and Research Techniques, Windsor, UK, 4–6 September 2010; pp. 215–218. [Google Scholar]
- Steimann, F.; Frenkel, M.; Abreu, R. Threats to the validity and value of empirical assessments of the accuracy of coverage-based fault locators. In Proceedings of the 2013 International Symposium on Software Testing and Analysis, Lugano, Switzerland, 15–20 July 2013; pp. 314–324. [Google Scholar]
- Parnin, C.; Orso, A. Are automated debugging techniques actually helping programmers? In Proceedings of the 2011 International Symposium on Software Testing and Analysis, Toronto, ON, Canada, 17–21 July 2011; pp. 199–209. [Google Scholar]
- Pradel, M.; Gross, T.R. Leveraging test generation and specification mining for automated bug detection without false positives. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 288–298. [Google Scholar]
- Dig, D.; Negara, S.; Mohindra, V.; Johnson, R. ReBA: A Tool for Generating Binary Adapters for Evolving Java Libraries. In Proceedings of the Companion of the 30th International Conference on Software Engineering, Leipzig, Germany, 10–18 May 2008; pp. 963–964. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2016, 41, 15. [Google Scholar] [CrossRef]
- Mariani, L.; Pastore, F.; Pezzè, M. Dynamic analysis for diagnosing integration faults. IEEE Trans. Softw. Eng. 2011, 37, 4. [Google Scholar] [CrossRef]
- Pastore, F.; Mariani, L.; Goffi, A.; Oriol, M.; Wahler, M. Dynamic analysis of upgrades in C/C++ software. In Proceedings of the 2012 IEEE 23rd International Symposium on Software Reliability Engineering, Dallas, TX, USA, 27–30 November 2012; pp. 91–100. [Google Scholar]
- Zuddas, D.; Jin, W.; Pastore, F.; Mariani, L.; Orso, A. MIMIC: Locating and understanding bugs by analyzing mimicked executions. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering, Vasteras, Sweden, 15–19 September 2014; pp. 815–826. [Google Scholar]
- Gazzola, L.; Micucci, D.; Mariani, L. Automatic software repair: A survey. IEEE Trans. Softw. Eng. 2019, 45, 34–67. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MethodName | Susp |
|---|---|
| org.asdtm.goodweather.MainActivity.onOptionsItemSelected | 0.48 |
| org.asdtm.goodweather.MainActivity.gpsRequestLocation | 0.47 |
| org.asdtm.goodweather.MainActivity$1.onLocationChanged | 0.05 |
| App | Locs | Inc. API | Failure | Fault |
|---|---|---|---|---|
| Activities | 1.1 K | 26 | Crash on startup | Missing Oreo adaptive icon support |
| BossTransfer | 2.6 K | 23 | Crash when opening the details about items in a list | Wrong permission logic |
| FakeGPS | 2.4 K | 23 | Crash when opening the view to set the fake position | Missing permission logic |
| FilePicker | 2.9 K | 23 | Folders erroneously shown as empty | Faulty support to the new api |
| FirefoxLite | 102 K | 22 | Back button doesn’t work when tracker popup window appears | Popup in background has to be explicit |
| FOSSBrowser | 18 K | 25 | Crash on startup | Faulty support to the previous api |
| GetBack GPS | 9.0 K | 23 | Unable to retrieve current position | Missing permission logic |
| GoodWeather | 6.3 K | 23 | Hang when refreshing meteo forecast | Missing permission logic |
| InventoryAgent | 10.0 K | 23 | App stuck when loading inventory | Missing permission logic |
| KanjiFix | 1.3 K | 21 | Unable to fix Japanese glyph rendering | Fonts require a new procedure to be loaded |
| MapDemo | 0.6 K | 23 | Crash when retrieving the current position | Missing permission logic |
| OpenTraining | 60.8 K | 26 | Notification does not show up | New library for notification |
| PoGoIV | 14.3 K | 24 | Unable to perform the auto update | New api requires the use of FileProvider |
| PrivacyPolice | 1.3 K | 23 | Unable to connect to wifi networks | Api methods with changed semantics |
| QuotoGraph | 11.5 K | 24 | Crash on startup | Api methods with changed semantics |
| SearchView | 3.9 K | 21 | Crash on startup | Api methods with changed semantics |
| ToneDef | 3.4 K | 23 | Error message when dialling from the phone contacts list | Missing permission logic |
| TrebleShot | 40.6 K | 22 | External storage cannot be written | Minimum version was erroneously setted |
| MAP Distribution | Best MAP | MAP | MAP | MAP | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Average | # | % | # | % | # | % | # | % | |
| A0F1 | 0.3991 | 0.6134 | 0.4750 | 230 | 4.47% | 679 | 13.18% | 1418 | 27.53% | 3733 | 72.47% |
| A0F2 | 0.3527 | 0.5407 | 0.4361 | 8 | 0.16% | 680 | 13.20% | 2951 | 57.29% | 2200 | 42.71% |
| A1F0 | 0.1250 | 0.1667 | 0.1388 | 660 | 12.81% | 5151 | 100.00% | 5151 | 100.00% | 0 | 0.00% |
| A1F1 | 0.3483 | 0.5755 | 0.4443 | 1 | 0.02% | 996 | 19.34% | 2054 | 39.88% | 3097 | 60.12% |
| A1F2 | 0.3120 | 0.5019 | 0.3849 | 5 | 0.10% | 568 | 11.03% | 5091 | 98.84% | 60 | 1.16% |
| A2F0 | 0.1528 | 0.2222 | 0.1918 | 660 | 12.81% | 4675 | 90.76% | 5151 | 100.00% | 0 | 0.00% |
| A2F1 | 0.3761 | 0.5755 | 0.4579 | 1 | 0.02% | 835 | 16.21% | 2054 | 39.88% | 3097 | 60.12% |
| A2F2 | 0.3119 | 0.5111 | 0.3885 | 5 | 0.10% | 550 | 10.68% | 4511 | 87.58% | 640 | 12.42% |
| A0F1 | A0F2 | A1F0 | A1F1 | A1F2 | A2F0 | A2F1 | A2F2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Application | #SIB | Rank | #SIB | Rank | #SIB | Rank | #SIB | Rank | #SIB | Rank | #SIB | Rank | #SIB | Rank | #SIB | Rank |
| Activities | 18 | 1, 8 | 18 | 2, 6 | 2 | - | 17 | 2, 8 | 17 | 2, 6 | 2 | - | 17 | 2, 8 | 17 | 2, 6 |
| BossTransfer | 33 | 1 | 37 | 1 | 18 | - | 36 | 1 | 40 | 2 | 18 | - | 36 | 1 | 40 | 2 |
| FakeGPS | 43 | 1 | 71 | 2 | 4 | - | 45 | 1 | 73 | 1 | 4 | - | 45 | 1 | 73 | 1 |
| FilePicker | 45 | 1 | 63 | 1 | 91 | 1 | 135 | 1 | 152 | 1 | 91 | 1 | 135 | 1 | 152 | 1 |
| FirefoxLite | 2170 | 1 | 2822 | 1 | 66 | - | 2630 | 1 | 3016 | 1 | 83 | - | 2649 | 1 | 3036 | 1 |
| FOSSBrowser | 131 | 6 | 218 | - | 2 | - | 131 | - | 218 | - | 3 | - | 132 | - | 219 | - |
| GetBackGPS | 35 | 3 | 41 | 3 | 7 | - | 40 | 1 | 48 | 3 | 9 | - | 43 | 1 | 49 | 2 |
| GoodWeather | 49 | 2, 3 | 61 | 2, 3 | 1 | - | 49 | 1, 2 | 61 | 2, 3 | 1 | - | 49 | 1, 2 | 61 | 2, 3 |
| InventoryAgent | 2456 | 6, 12 | 3134 | 2, 7 | 266 | - | 3010 | 7, 16 | 3149 | 2, 9 | 482 | - | 3486 | 6, 14 | 3842 | 2, 8 |
| KanjiFix | 1 | 1 | 1 | - | 1 | 1 | 1 | 1 | 1 | - | 1 | 1 | 1 | 1 | 1 | - |
| MapDemo | 5 | 2 | 257 | 1 | 0 | - | 5 | 1 | 262 | 5 | 0 | - | 5 | 1 | 262 | 5 |
| OpenTraining | 301 | 1 | 461 | 1 | 90 | - | 400 | 5 | 601 | 1 | 90 | - | 400 | 5 | 601 | 1 |
| PoGoIV | 72 | 3 | 105 | 5 | 24 | - | 90 | 5 | 155 | 6 | 24 | - | 90 | 5 | 155 | 6 |
| PrivacyPolice | 44 | 1 | 45 | 1 | 2 | 1 | 44 | 3 | 45 | 1 | 2 | 1 | 44 | 3 | 45 | 1 |
| QuotoGraph | 1 | 1 | 1 | 1 | 1 | - | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| SearchView | 1 | - | 1 | - | 1 | - | 1 | - | 1 | - | 1 | - | 1 | - | 1 | - |
| ToneDef | 178 | - | 182 | 5, 3 | 1 | - | 178 | - | 182 | 6, 3 | 1 | - | 178 | - | 182 | 6, 3 |
| TrebleShot | 41 | 2 | 91 | 3 | 4 | - | 47 | 4 | 100 | 2 | 10 | - | 52 | 4 | 110 | 2 |
| Application | BestMAP A0F1 | BestMAP A2F1 | MAP A0F1 | MAP A2F1 | NTA A2F1 | NTA A0F1 | Ochiai (Method) | Ochiai (Statement) |
|---|---|---|---|---|---|---|---|---|
| Activities | 1, 8 | 2, 8 | 2, 2 | 2, 2 | -, - | -, - | - | - |
| BossTransfer | 1 | 1 | 1 | 2 | - | - | 4 | 32 |
| FakeGPS | 1 | 1 | 1 | 1 | 612 | - | 13 | 65 |
| FilePicker | 1 | 1 | 1 | 1 | 347 | - | 81 | - |
| FirefoxLite | 1 | 1 | 1 | 1 | - | - | 88 | 279 |
| FOSSBrowser | 6 | - | 6 | - | - | - | - | - |
| GetBack GPS | 3 | 1 | 3 | 3 | - | - | - | - |
| GoodWeather | 2, 3 | 1, 2 | 2, 3 | 1, 2 | -, - | -, - | 1, 32 | 5, 5 |
| InventoryAgent | 6, 12 | 6, 14 | 6, 11 | 8, 17 | -, - | -, - | 5, 52 | 17, 199 |
| KanjiFix | 1 | 1 | 1 | 1 | 2 | - | 19 | 23 |
| MapDemo | 2 | 1 | 2 | 2 | - | - | 1 | 1 |
| OpenTraining | 1 | 5 | 3 | 6 | - | - | 195 | 1008 |
| PoGoIV | 3 | 5 | 3 | 3 | - | - | 48 | 283 |
| PrivacyPolice | 1 | 3 | 1 | 1 | 41 | - | 21 | 130 |
| QuotoGraph | 1 | 1 | 1 | 1 | - | - | - | - |
| SearchView | - | - | - | - | 311 | - | - | - |
| ToneDef | - | - | - | - | - | - | 24 | 13 |
| TrebleShot | 2 | 4 | 2 | 4 | - | - | 15 | 635 |
| Top-1 | 9 | 9 | 7 | 7 | 0 | 0 | 2 | 1 |
| Top-5 | 15 | 15 | 15 | 14 | 1 | 0 | 4 | 3 |
| Top-10 | 18 | 17 | 18 | 17 | 1 | 0 | 4 | 3 |
| Not in the ranking | 2 | 3 | 2 | 3 | 17 | 22 | 5 | 6 |
| Application | Soundness | Completeness |
|---|---|---|
| Activities | 100.00% | 99.79% |
| BossTransfer | 95.79% | 97.78% |
| FakeGPS | 100.00% | 74.72% |
| FilePicker | 91.56% | 65.41% |
| FirefoxLite | 88.37% | 91.20% |
| FOSSBrowser | 81.03% | 27.32% |
| GetBack GPS | 63.65% | 49.82% |
| GoodWeather | 87.50% | 84.11% |
| InventoryAgent | 98.29% | 99.45% |
| KanjiFix | 75.00% | 75.00% |
| MapDemo | 100.00% | 49.71% |
| OpenTraining | 94.18% | 85.52% |
| PoGoIV | 80.46% | 55.57% |
| PrivacyPolice | 100.00% | 79,78% |
| QuotoGraph | 100.00% | 81.14% |
| SearchView | 100.00% | 69.57% |
| ToneDef | 95.31% | 34.54% |
| TrebleShot | 37.58% | 18.17% |
| Average | 88.09% | 68.57% |
| Group | Ranking for GoodWeather | Ranking for TrebleShot | #Subjects |
|---|---|---|---|
| 1 | Yes | No | 12 |
| 2 | No | Yes | 12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mobilio, M.; Riganelli, O.; Micucci, D.; Mariani, L. FILO: Automated FIx-LOcus Identification for Android Framework Compatibility Issues. Information 2024, 15, 423. https://doi.org/10.3390/info15080423
Mobilio M, Riganelli O, Micucci D, Mariani L. FILO: Automated FIx-LOcus Identification for Android Framework Compatibility Issues. Information. 2024; 15(8):423. https://doi.org/10.3390/info15080423
Chicago/Turabian StyleMobilio, Marco, Oliviero Riganelli, Daniela Micucci, and Leonardo Mariani. 2024. "FILO: Automated FIx-LOcus Identification for Android Framework Compatibility Issues" Information 15, no. 8: 423. https://doi.org/10.3390/info15080423
APA StyleMobilio, M., Riganelli, O., Micucci, D., & Mariani, L. (2024). FILO: Automated FIx-LOcus Identification for Android Framework Compatibility Issues. Information, 15(8), 423. https://doi.org/10.3390/info15080423