
Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning



Abstract
1. Introduction
1.1. Background
1.2. Aims
- Analyzing the present situation regarding digital payment fraud and the effects it has on customers, businesses, and financial institutions;
- Investigating cases involving unauthorized account takeover, ID theft, phishing, and malware assaults, which are only some of the kinds of online payment fraud that may be identified and categorized;
- Assessing how reliable, efficient, and flexible current methods are for detecting fraudulent online payments;
- Examining the use of AI, and big data analytics as part of Industry 4.0 and the IoT to improve digital payment fraud detection.
1.3. Objectives
- Conducting a comprehensive literature review that examines the present status of digital payment fraud, its different kinds, trends, and impact on stakeholders and examining the potential of AI, big data analytics, and the IoT to improve digital payment fraud detection as part of Industry 4.0;
- Analyzing how well machine learning, predictive analytics, and anomaly detection work together to identify and stop online fraud along with the effectiveness, efficiency, scalability, and responsiveness of current methods for detecting fraud;
- Investigating the cases of fraudulent transactions and suitable methods for analyzing them correctly and appropriately, along with recommending changes to current fraud detection systems and suggesting novel ways to make use of the features offered by Industry 4.0 software;
- Analyzing how alternative fraud detection measures affect user happiness, customer loyalty, and the likelihood that they will switch to digital payment systems. To successfully prevent digital payment fraud in Industry 4.0, organizations and stakeholders need access to actionable information and best practices.
1.4. Research Questions
- What methods are effective in detecting fraudulent transactions and double checking their validity?
- How do we differentiate between true and false positives in fraudulent transactions and balance differences between accuracy, recall, and F1 score if true fraudulent transactions are small in number?
- What are the security and privacy risks and benefits of using Industry 4.0 technologies like AI to improve digital payment fraud detection?
2. Related Work
2.1. Advanced Technologies in Fraud Detection
2.2. Data Analytics and Big Data
2.3. Challenges and Research Gaps
- It is essential for fraudulent acts to be uncovered as soon as possible to limit monetary losses. While much progress has been made toward real-time detection capabilities, many current fraud detection systems continue to face obstacles. There are technological hurdles that must be overcome in order to process massive quantities of transactional data in real time and use sophisticated analytics approaches under tight time restrictions.
- Fraudsters’ methods of avoiding being caught are also constantly developing and changing. These ever-changing fraud patterns might be difficult to identify using conventional approaches. The authors of [3] argue that further work is required to develop detection technologies that can swiftly identify and react to new types of fraud.
- There are privacy issues since detecting fraud sometimes requires analyzing private client information. Finding a happy medium between detecting fraud efficiently and keeping customers’ personal information secure is difficult. More work is needed to develop privacy-protecting fraud detection algorithms that can successfully identify fraudulent activity without compromising data security.
- Combining many cutting-edge methods, including artificial intelligence, machine learning, data analytics, and blockchain, has the potential to improve fraud detection efforts significantly. However, there is still work to be done to integrate these technologies successfully. Integrating various technologies into complete fraud detection systems requires further studies to establish frameworks and approaches [17].
- Effective fraud detection often requires cooperation between financial institutions, payment processors, and regulatory organizations. By working together, businesses and law enforcement agencies may pool their resources to better identify and prevent fraud. However, issues regarding data sharing, data governance, and legal concerns must be resolved to promote cooperation and information exchange.
- As approaches for detecting fraud become more sophisticated, there will be a greater need for models that can be easily explained and interpreted. It is critical to establish confidence and provide transparency in the fraud detection process by understanding the reasoning behind fraud detection results and evaluating the judgments made by the models employed. Further study is required to allow advanced fraud detection systems to produce interpretable models and offer reasons for their conclusions.
2.4. Future Directions
- -
- Artificial intelligence (AI), machine learning (ML), data analytics, and blockchain need to be investigated further with respect to how they may work together. More effective and reliable fraud detection systems may be developed via novel ways that combine the benefits of various technologies. For instance, combining blockchain technology with AI and ML algorithms may improve security, transparency, and the ability to identify fraud in real time [19].
- -
- The objective of technological progress should be to make it possible to identify and prevent fraud in real time. Scalable and efficient algorithms that can handle massive quantities of data in real time, enabling fast detection of and reaction to fraudulent activity, should be the focus of future research. Financial losses and the effects of fraud may be reduced significantly if they can be uncovered in real-time.
- -
- Research into consumer behavior patterns and the creation of behavior-based fraud detection algorithms is a promising avenue for the study of fraud. Customers’ browser histories, transaction records, and interactions with online payment gateways may all be analyzed for discrepancies that might point to fraudulent actions [20]. The accuracy of fraud detection may be greatly improved by creating models that use behavior analytics and machine learning.
- -
- In order to successfully address digital payment fraud, it is essential for industry players such as financial institutions, payment processors, and regulatory agencies to work together and share relevant data [21]. For businesses to pool their data and insights to develop more thorough fraud detection models, more efforts have to be made toward building frameworks and methods for safe and ethical data sharing. When businesses work together, best practices, fraud information, and lessons learned may all be shared more easily.
- -
- The safety and reliability of electronic payment systems depend on the establishment of comprehensive regulatory frameworks and standards. There is a need for more investigation into regulatory factors and the development of guidelines and standards for fraud detection. Data privacy, client permission, data exchange, and conformity with current financial rules are all concerns that need to be addressed by these frameworks.
- -
- Researchers and professionals in the industry may improve the efficacy, efficiency, and safety of fraud detection in digital payment systems by exploring these future paths. Businesses and customers alike will benefit from a more secure and reliable digital payment ecosystem if participants in this ecosystem adopt new technologies, cooperate, and adhere to regulatory frameworks.
3. Research Methodology
3.1. Study Dataset
3.2. Experimental Execution
3.3. Performance Evaluation Measures
4. Experimental Results
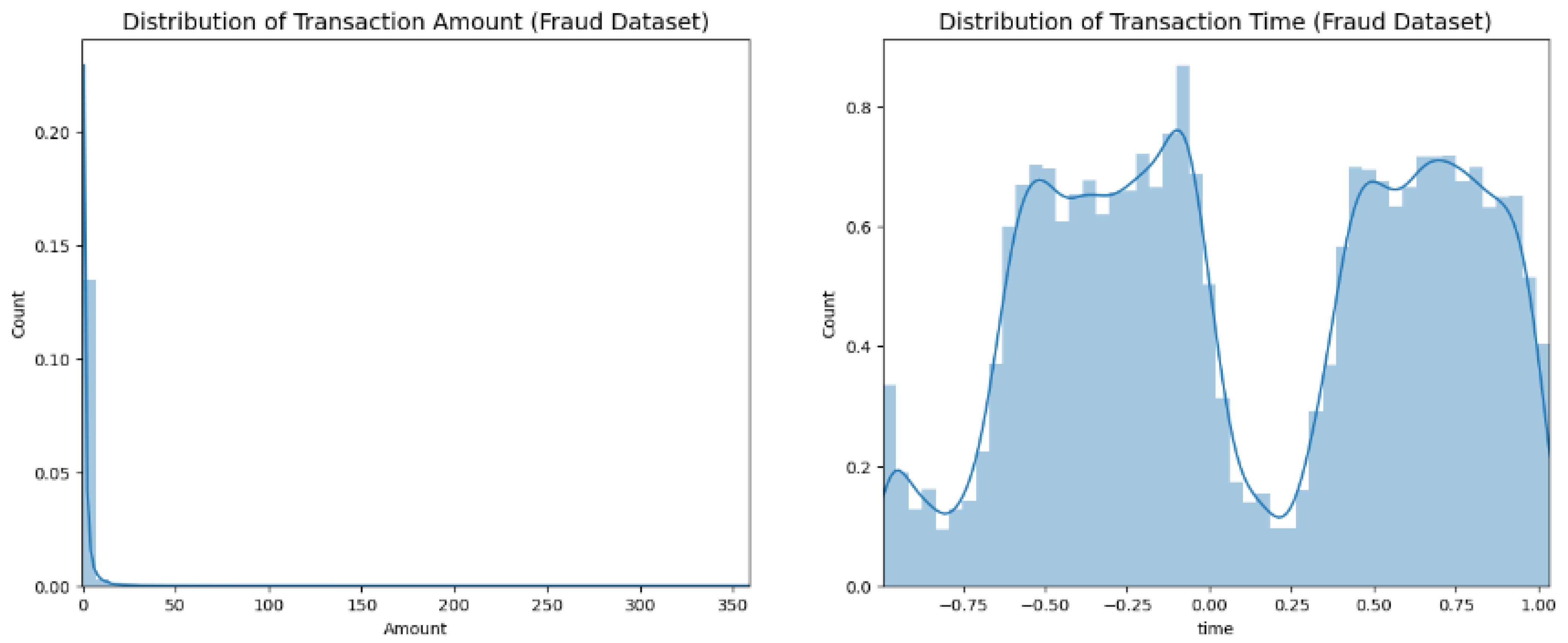
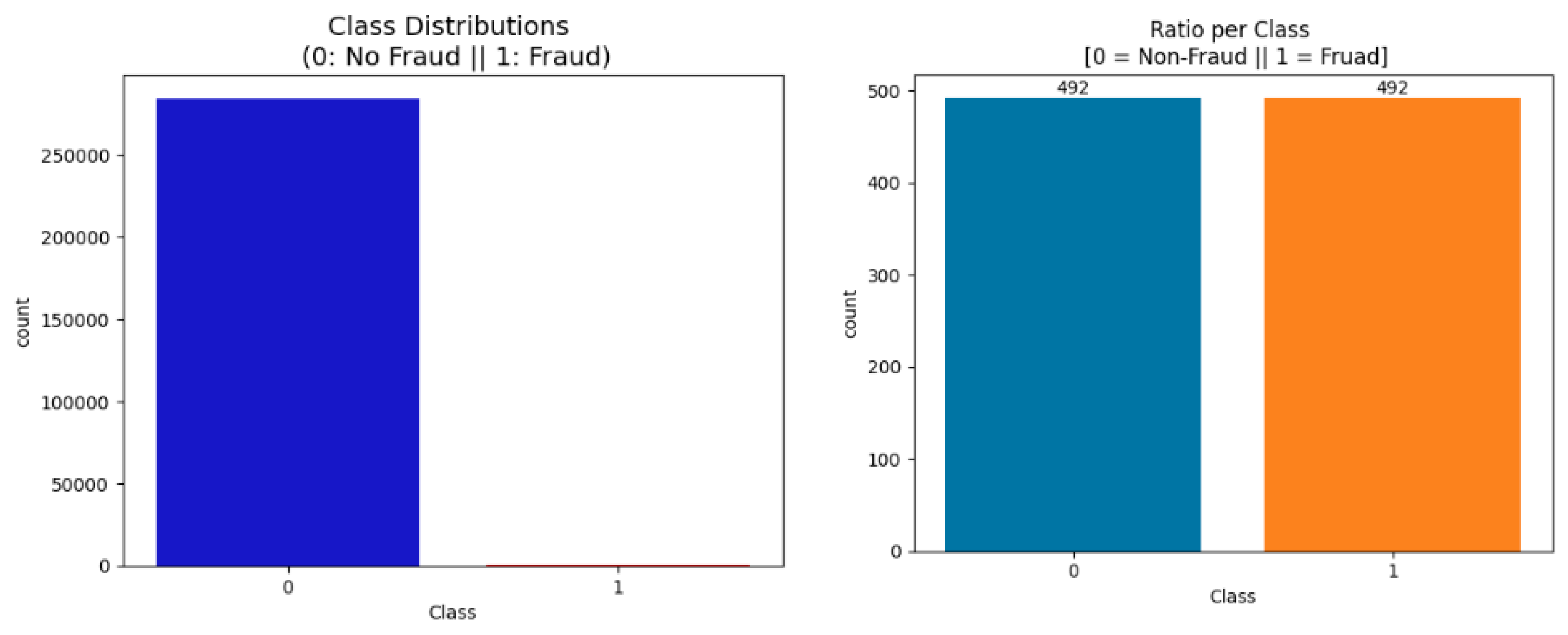
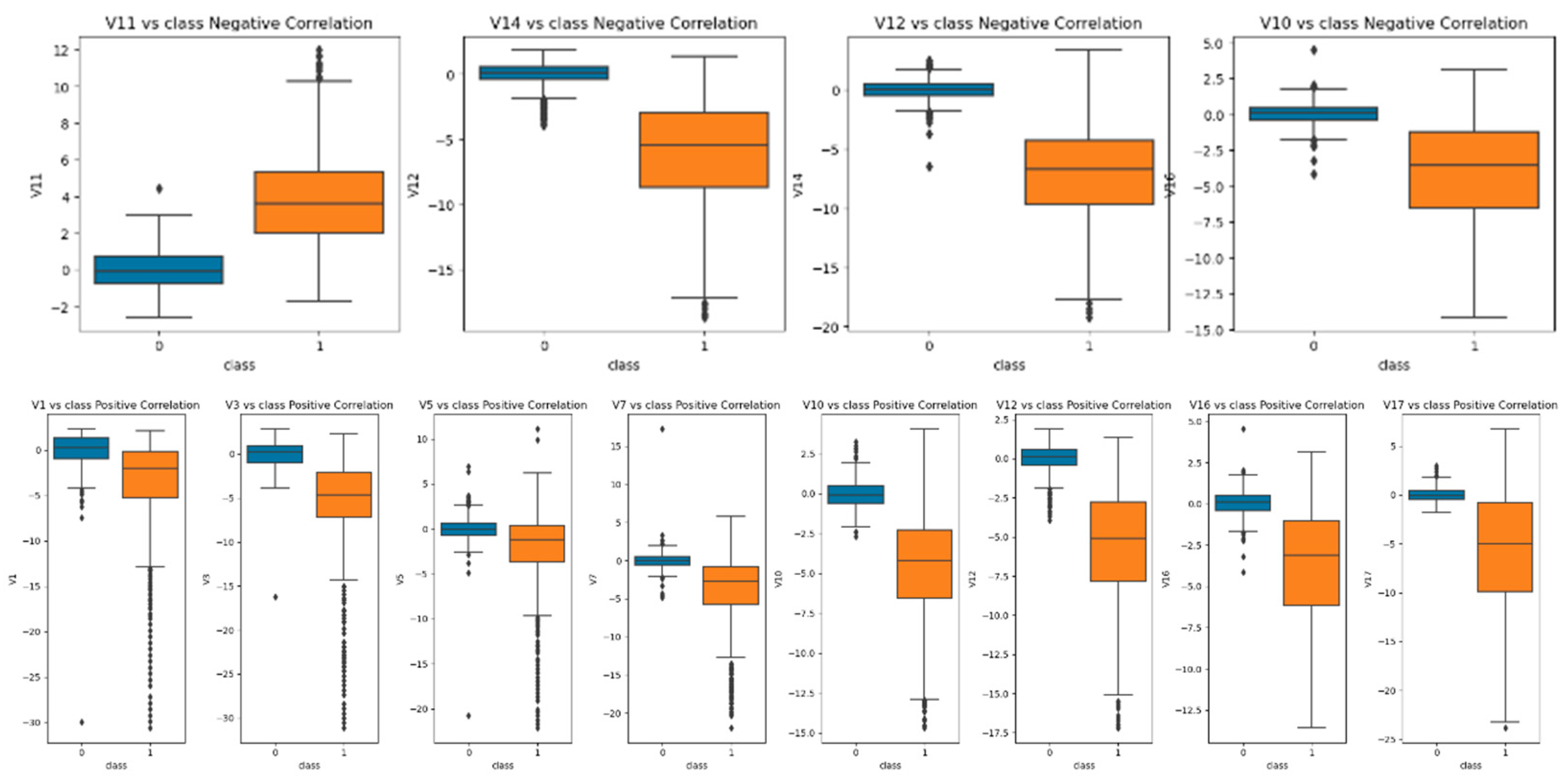
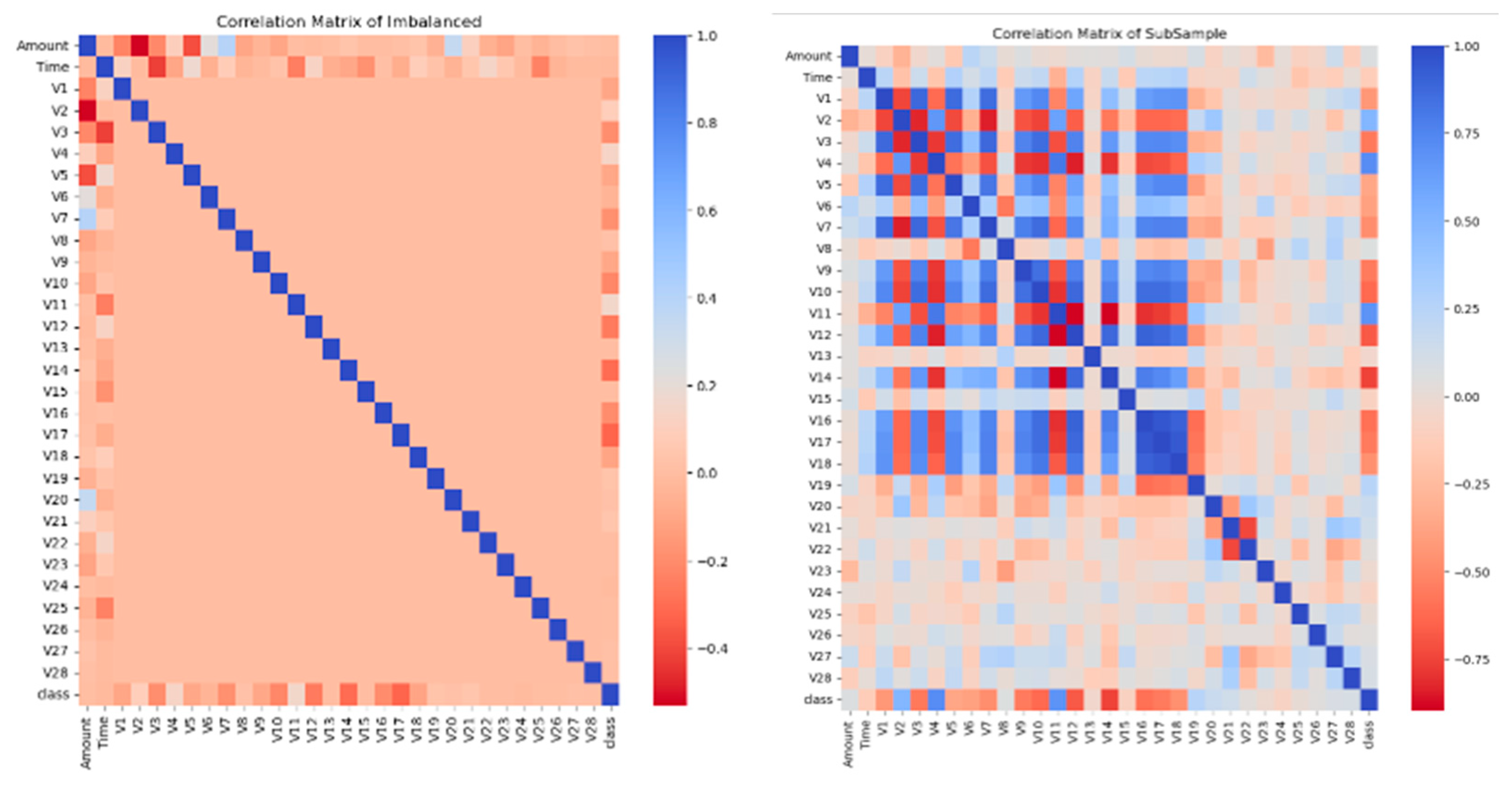
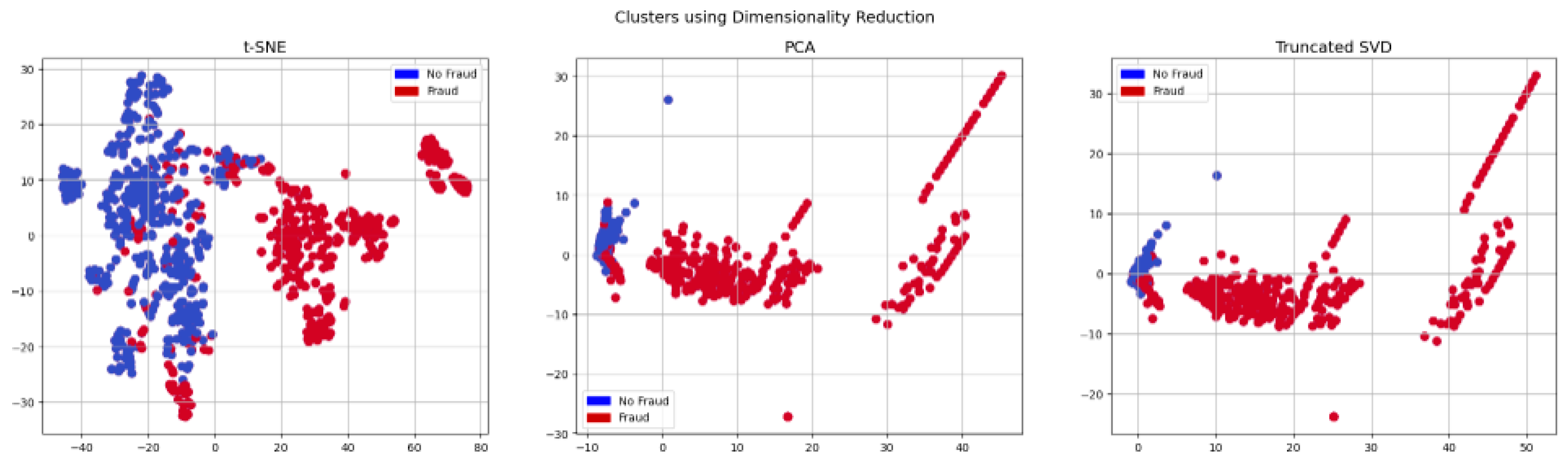
4.1. Detecting and Mitigating Data Anomalies in Relation to the Target
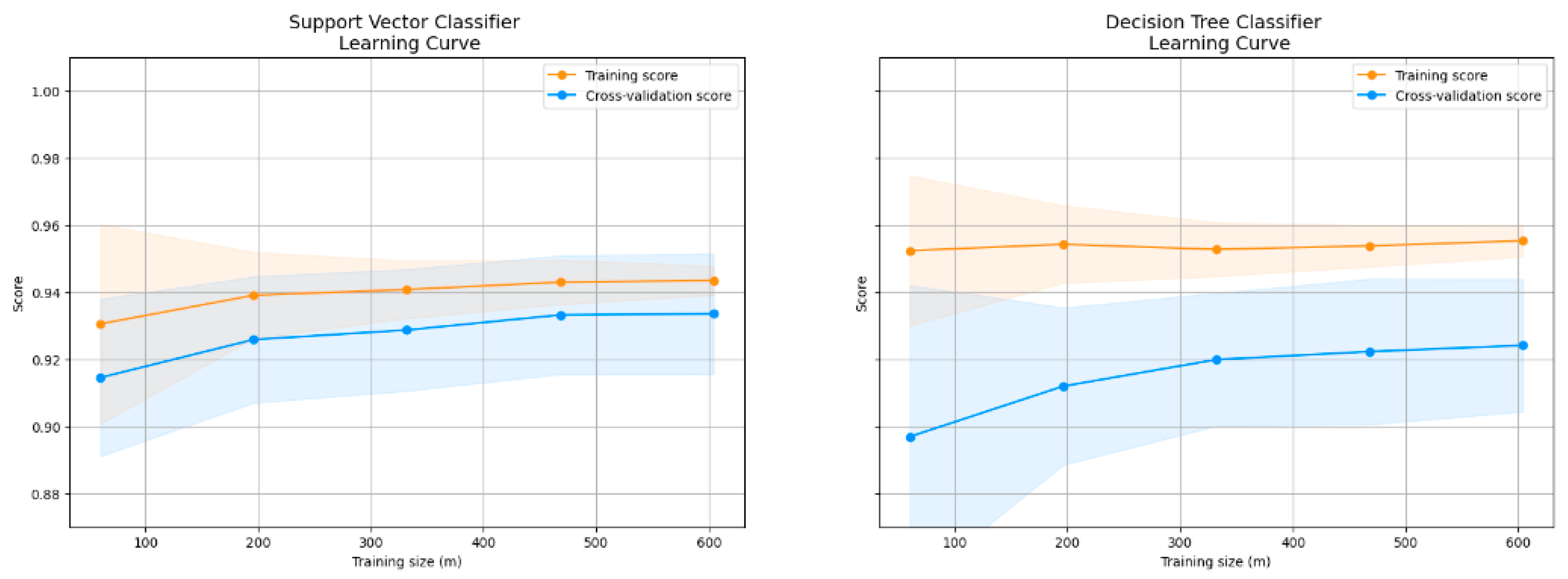
4.2. Model Performance Results and Discussion
4.3. Classification Reports for Each Model
- Precision: Precision, sometimes called positive predictive value, is a metric used for assessing a classifier’s accuracy by looking at the proportion of instances it properly identifies as positive (true positives) relative to the total number of instances it predicts as positive (true positives plus false positives). Accuracy in fraud detection refers to how many “Fraud” instances were correctly identified.
- 2.
- Recall: A classifier’s recall is the percentage of positive cases it properly identifies (true positives) relative to the total number of positive instances (true positives + false negatives). In the context of detecting fraud, recall is the rate at which the classifier correctly identifies true “Fraud” situations.
- 3.
- F1-Score: The F1-score is the optimal compromise between accuracy and recall. The trade-off between accuracy and recall is reflected in a single statistic. It is helpful when there is an imbalance between classes, like in fraud detection, where the “Fraud” class is often in the minority.
4.4. Comparison
5. Discussion
6. Conclusions and Recommendations
Research Contributions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chang, V.; Doan, L.M.T.; Di Stefano, A.; Sun, Z.; Fortino, G. Digital payment fraud detection methods in digital ages and Industry 4.0. Comput. Electr. Eng. 2022, 100, 107734. [Google Scholar] [CrossRef]
- Li, A.; Pandey, B.; Hooi, C.F.; Pileggi, L. Dynamic Graph-Based Anomaly Detection in the Electrical Grid. IEEE Trans. Power Syst. 2022, 37, 3408–3422. [Google Scholar] [CrossRef]
- Ali, A.; Razak, S.A.; Othman, S.H.; Eisa, T.A.E.; AI-Dhaqm, A.; Nasser, M.; Elhassan, T.; Elshafie, H.; Saif, A. Financial Fraud Detection Based on Machine Learning: A Systematic Literature Review. Appl. Sci. 2022, 12, 9637. [Google Scholar] [CrossRef]
- Khando, K.; Islam, M.S.; Gao, S. The Emerging Technologies of Digital Payments and Associated Challenges: A Systematic Literature Review. Future Internet 2022, 15, 21. [Google Scholar] [CrossRef]
- Alsenaani, K. Fraud Detection in Financial Services using Machine Learning. Master’s Thesis, RIT 1 Lomb Memorial Dr, Rochester, NY, USA, 2022. [Google Scholar]
- Gupta, S.; Varshney, T.; Verma, A.; Goel, L.; Yadav, A.K.; Singh, A. A Hybrid Machine Learning Approach for Credit Card Fraud Detection. Int. J. Inf. Technol. Proj. Manag. 2022, 13, 1–13. [Google Scholar] [CrossRef]
- Xu, C.; Zhang, J. Collusive Opinion Fraud Detection in Online Reviews. ACM Trans. Web 2017, 11, 1–28. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P.; Khan, S.; Suman, R. Blockchain technology applications for Industry 4.0: A literature-based review. Blockchain Res. Appl. 2021, 2, 100027. [Google Scholar] [CrossRef]
- Sadgali, I.; Sael, N.; Benabbou, F. Performance of machine learning techniques in the detection of financial frauds. Procedia Comput. Sci. 2019, 148, 45–54. [Google Scholar] [CrossRef]
- Ahmadi, S. Open AI and its Impact on Fraud Detection in Financial Industry. J. Knowl. Learn. Sci. Technol. 2023, 2, 263–281. [Google Scholar]
- Piccarozzi, M.; Aquilani, B.; Gatti, C. Industry 4.0 in Management Studies: A Systematic Literature Review. Sustainability 2018, 10, 3821. [Google Scholar] [CrossRef]
- Berhane, T.; Walelign, T.M.A.; Seid, A.M. A Hybrid Convolutional Neural Network and Support Vector Machine-Based Credit Card Fraud Detection Model. Math. Probl. Eng. 2023, 2023, 34627. [Google Scholar] [CrossRef]
- Sarno, R.; Sinaga, F.; Sungkono, K.R. Anomaly detection in business processes using process mining and fuzzy association rule learning. J. Big Data 2020, 7, 5. [Google Scholar] [CrossRef]
- Ahmed, M.; Ansar, K.; Muckley, C.; Khan, A.; Anjum, A.; Talha, M. A semantic rule based digital fraud detection. PeerJ Comput. Sci. 2021, 7, e649. [Google Scholar] [CrossRef]
- Mhlanga, D. Block chain technology for digital financial inclusion in the industry 4.0, towards sustainable development? Front. Blockchain 2023, 6, 1035405. [Google Scholar] [CrossRef]
- Al-Hashedi, K.G.; Magalingam, P. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Kumari, A.; Devi, N.C. The Impact of FinTech and Blockchain Technologies on Banking and Financial Services. Technol. Innov. Manag. Rev. 2022, 12. [Google Scholar] [CrossRef]
- Chatterjee, P.; Das, D.; Rawat, D.B. Digital twin for credit card fraud detection: Opportunities, challenges, and fraud detection advancements. Future Gener. Comput. Syst. 2024, 158, 410–426. [Google Scholar] [CrossRef]
- Alzahrani, R.A.; Aljabri, M. AI-based Techniques for Ad Click Fraud Detection and Prevention: Review and Research Directions. J. Sens. Actuator Netw. 2022, 12, 4. [Google Scholar] [CrossRef]
- Jemai, J.; Zarrad, A.; Daud, A. Identifying Fraudulent Credit Card Transactions Using Ensemble Learning. IEEE Access 2024, 12, 54893–54900. [Google Scholar] [CrossRef]
- Dai, S. Research on Detecting Credit Card Fraud Through Machine Learning Methods. In Proceedings of the 2022 2nd International Conference on Business Administration and Data Science (BADS 2022), Kashgar, China, 28–30 October 2022; pp. 1030–1037. [Google Scholar]
- Ahmad, H.; Kasasbeh, B.; Aldabaybah, B.; Rawashdeh, E. Class balancing framework for credit card fraud detection based on clustering and similarity-based selection (SBS). Int. J. Inf. Technol. 2023, 15, 325–333. [Google Scholar] [CrossRef]
- Btoush, E.A.L.M.; Zhou, X.; Gururajan, R.; Chan, K.C.; Genrich, R.; Sankaran, P. A systematic review of literature on credit card cyber fraud detection using machine and deep learning. PeerJ Comput. Sci. 2023, 9, e1278. [Google Scholar] [CrossRef] [PubMed]
- Vanini, P.; Rossi, S.; Zvizdic, E.; Domenig, T. Online payment fraud: From anomaly detection to risk management. Financ. Innov. 2023, 9, 66. [Google Scholar] [CrossRef]
- Thudumu, S.; Branch, P.; Jin, J.; Singh, J. A comprehensive survey of anomaly detection techniques for high dimensional big data. J. Big Data 2020, 7, 1–30. [Google Scholar] [CrossRef]
- Cao, W.; Ming, Z.; Xu, Z.; Zhang, J.; Wang, Q. Online Sequential Extreme Learning Machine with Dynamic Forgetting Factor. IEEE Access 2019, 7, 179746–179757. [Google Scholar] [CrossRef]
- Khedmati, M.; Erfini, M.; GhasemiGol, M. Applying support vector data description for fraud detection. arXiv 2020, arXiv:2006.00618. [Google Scholar]
- Ileberi, E.; Sun, Y.; Wang, Z. Performance Evaluation of Machine Learning Methods for Credit Card Fraud Detection Using SMOTE and AdaBoost. IEEE Access 2021, 9, 165286–165294. [Google Scholar] [CrossRef]
- Rtayli, N.; Enneya, N. Enhanced credit card fraud detection based on SVM-recursive feature elimination and hyper-parameters optimization. J. Inf. Secur. Appl. 2020, 55, 102596. [Google Scholar] [CrossRef]
- Osman, H. Cost-sensitive learning using logical analysis of data. Knowl. Inf. Syst. 2024, 66, 3571–3606. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy (No Fraud) | Precision (No Fraud) | Recall (No Fraud) | F1 Score (No Fraud) | Accuracy (Fraud) | Precision (Fraud) | Recall (Fraud) | F1 Score (Fraud) |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | 0.99 | 0.92 | 0.99 | 0.95 | 0.99 | 0.99 | 0.90 | 0.94 |
| KNN | 0.98 | 0.89 | 0.98 | 0.93 | 0.97 | 0.97 | 0.87 | 0.92 |
| SVC | 0.99 | 0.89 | 0.99 | 0.94 | 0.99 | 0.99 | 0.87 | 0.92 |
| Decision Tree | 0.94 | 0.87 | 0.94 | 0.90 | 0.93 | 0.93 | 0.84 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, V.; Ali, B.; Golightly, L.; Ganatra, M.A.; Mohamed, M. Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning. Information 2024, 15, 478. https://doi.org/10.3390/info15080478
Chang V, Ali B, Golightly L, Ganatra MA, Mohamed M. Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning. Information. 2024; 15(8):478. https://doi.org/10.3390/info15080478
Chicago/Turabian StyleChang, Victor, Basit Ali, Lewis Golightly, Meghana Ashok Ganatra, and Muhidin Mohamed. 2024. "Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning" Information 15, no. 8: 478. https://doi.org/10.3390/info15080478
APA StyleChang, V., Ali, B., Golightly, L., Ganatra, M. A., & Mohamed, M. (2024). Investigating Credit Card Payment Fraud with Detection Methods Using Advanced Machine Learning. Information, 15(8), 478. https://doi.org/10.3390/info15080478