


AI-Driven QoS-Aware Scheduling for Serverless Video Analytics at the Edge

Abstract
:1. Introduction
- (i)
- We characterize a serverless video analytics workflow by demonstrating the impact of interference and heterogeneity on its performance. This characterization involves analyzing how resource interference and the presence of heterogeneous hardware configurations affect the latency of serverless video analytics tasks.
- (ii)
- We have designed a DRL agent capable of addressing different QoS requirements under varying levels of resource interference on a distributed, multi-tenant, heterogeneous cluster of virtual machines (VMs). The DRL agent dynamically adjusts the placement, migration, and scaling of serverless functions to regulate the workflow’s end-to-end latency, keeping it as close as possible to the user-defined QoS targets. By doing so, the agent minimizes resource waste, ensuring efficient utilization of computational resources while maintaining the desired performance levels.
- (iii)
- We have integrated the designed DRL agent into four distinct scheduler implementations to assess the efficacy of different levels of dependence on the DRL model. These implementations include varying degrees of reliance on the DRL agent’s decisions, from full control over function placement and migration to partial integration with existing scheduling mechanisms like Kubernetes and OpenFaaS. This comparative analysis helps in understanding the benefits and tradeoffs of using a DRL-based approach vs. traditional scheduling methods.
- (iv)
- Through extensive experimental evaluation, we demonstrate that Darly significantly improves the management of serverless video analytics workloads. Specifically, Darly achieves up to 11 times fewer QoS violations compared to the Kubernetes scheduler.
2. Related Work
- (i)
- The criticality of enhancing the performance of serverless workflows has been discussed in various research works [29,30,31,32,33,34], which succeed in addressing the user-defined latency requirements for a specific workload by decreasing the function’s intercommunication; this accounts for a major performance bottleneck for naturally stateless serverless functions [35]. Faastlane [29] executes functions of a workflow instance on separate threads of a process to minimize function interaction latency. However, heterogeneity or resource interference that may cause unpredictable performance variability is not considered. Respectively, in Sonic [30], it is thoroughly studied in which ways inter-function data exchange could be implemented in terms of storage technologies to save execution time and costs. Also, Pocket [32] focuses on efficient data sharing, but it does not significantly consider the application’s computational profile, a factor that can introduce stochasticity and performance variability.
- (ii)
- Much research has been conducted regarding the placement of applications [16,17,26,36,37]. In [17,36], the authors design an interference-aware scheduler, focusing on batch workloads. Paragon [16] uses collaborative filtering to classify and co-locate applications targeting interference minimization. Cometes [26] targets energy consumption reduction on Edge devices, following a static approach that does not consider the dynamicity of the runtime state. Cirrus [37] improves the performance of ML training serverless workflows (time-to-accuracy) by employing several techniques to extend AWS Lambda offerings at infrastructure-level, i.e., data-prefetching, data-streaming, as well as in application-level, i.e., training algorithms redesign. Therefore, while it achieves significant performance improvement, both developer effort (for custom algorithm design) and domain-specific tuning knobs make it difficult to be generalized for serverless workflows.
- (iii)
- In [23], reinforcement learning (RL) is employed for defining the concurrency level, i.e., the per-function concurrent request allowance before auto-scaling out. The paper focuses on homogeneous cloud servers and targets single-function applications, considering only horizontal scaling as a viable action. Additionally, it neglects interference due to co-location. Also, in [24], a reinforcement learning solution is introduced to address the cold start problem with function auto-scaling. However, their work neither considers dynamically changing QoS requirements, nor accounts for resource heterogeneity and interference. DVFaaS [38] and SequenceClock [39] employ proportional–derivative–integral (PID) control for dynamic resource allocation. DVFaaS utilizes dynamic voltage and frequency scaling (DVFS), focusing on power minimization [40], while SequenceClock employs CPU quota scaling. However, neither of these works considers function migration, nor hardware resource heterogeneity.
3. Target Serverless Infrastructure and Video Analytics Pipeline Characterization
3.1. Target Serverless Infrastructure
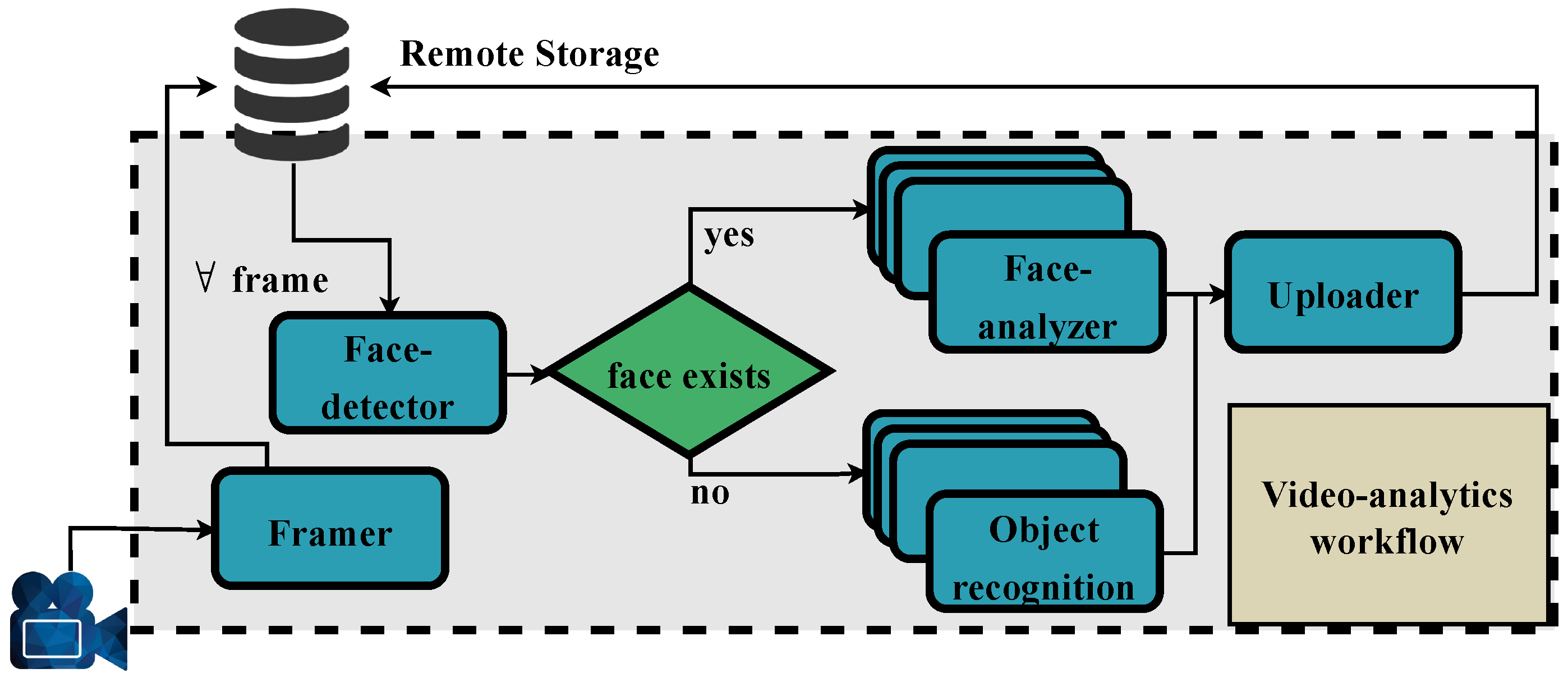
3.2. Target Video Analytics Pipeline
- Framer: The Framer parses the input mp4 video file and extracts a user-defined number of frames (n). All frames are sequentially extracted from the video; thus, this function does not support horizontal scaling. After the extraction of the last frame, all collected frames are saved to MinIO remote storage [50].
- Face-detector: The Face-detector uses Haar feature-based cascade classifier [51] to perform an object-detection task in the extracted frames, i.e., examine if a frame contains a human face. If yes, it forwards the frame to the Face-analyzer, otherwise, it forwards it to the Object-recognition function.
- Face-analyzer: The Face-analyzer utilizes a pre-trained ResNet50 DNN model [52] and performs emotion recognition on the faces identified by the Face-detector.
- Uploader: Last, the Uploader aggregates the inference results of (3) and (4) and uploads them to remote storage.
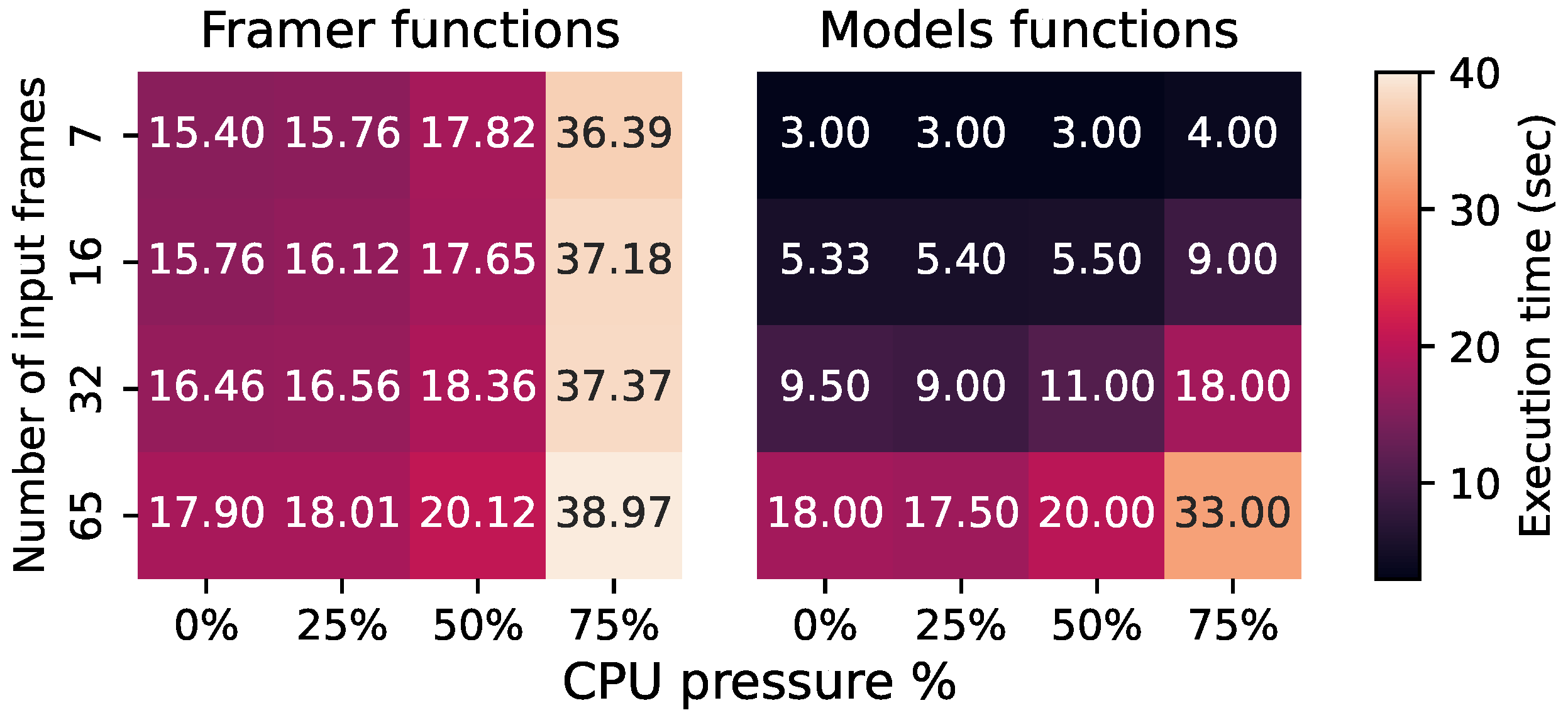
3.3. Performance Characterization of Video Analytics Pipeline
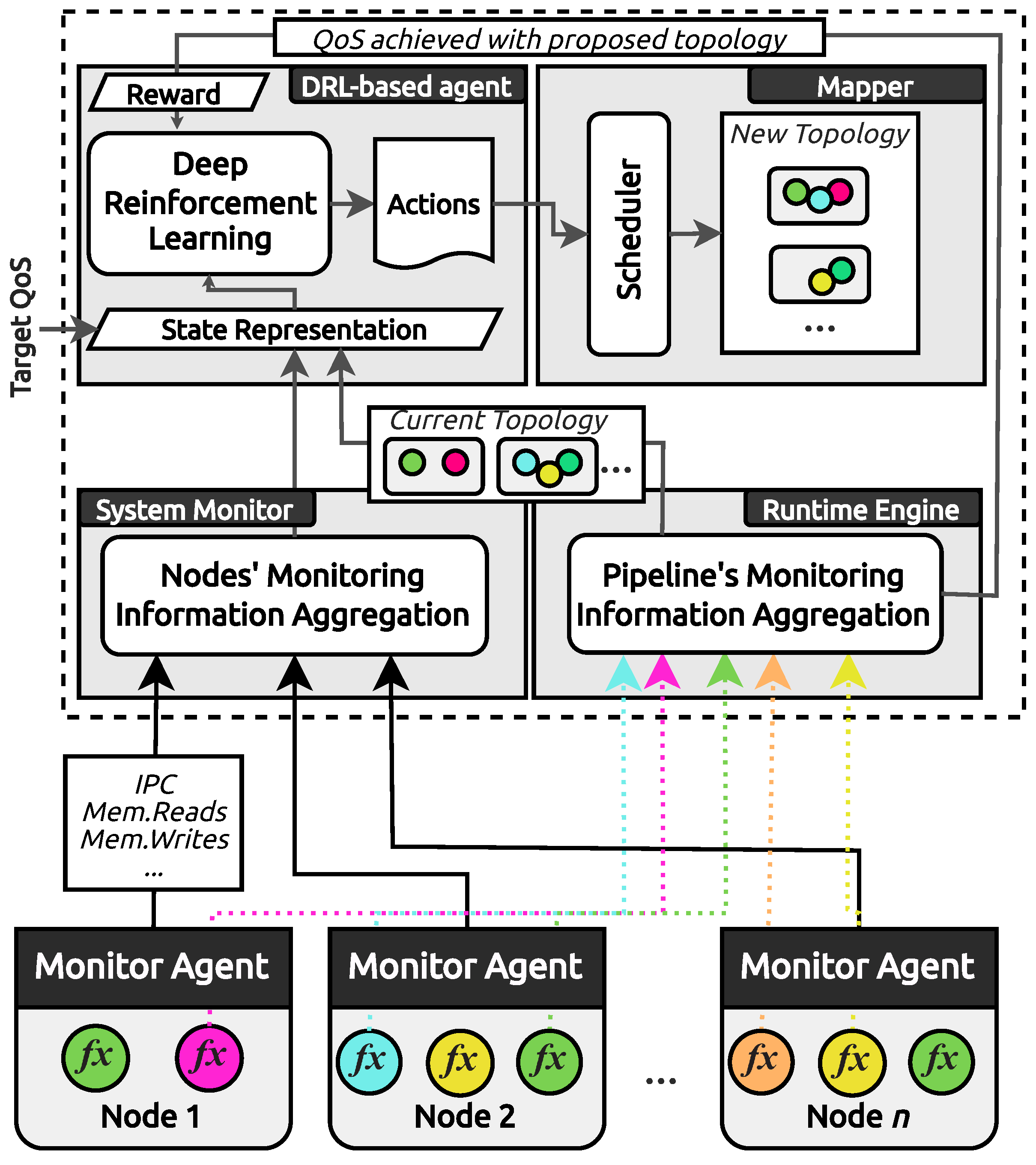
4. Darly: A Dynamic DRL-Based Scheduler
4.1. System Monitor
4.2. Runtime Engine
4.3. DRL-Based Agent
4.3.1. Policy Optimization
4.3.2. State Encoding
4.3.3. Action Set
4.3.4. Rewarding Strategy
4.4. Mapper
4.5. Technical Implementation
| Algorithm 1 Darly Algorithm |
|
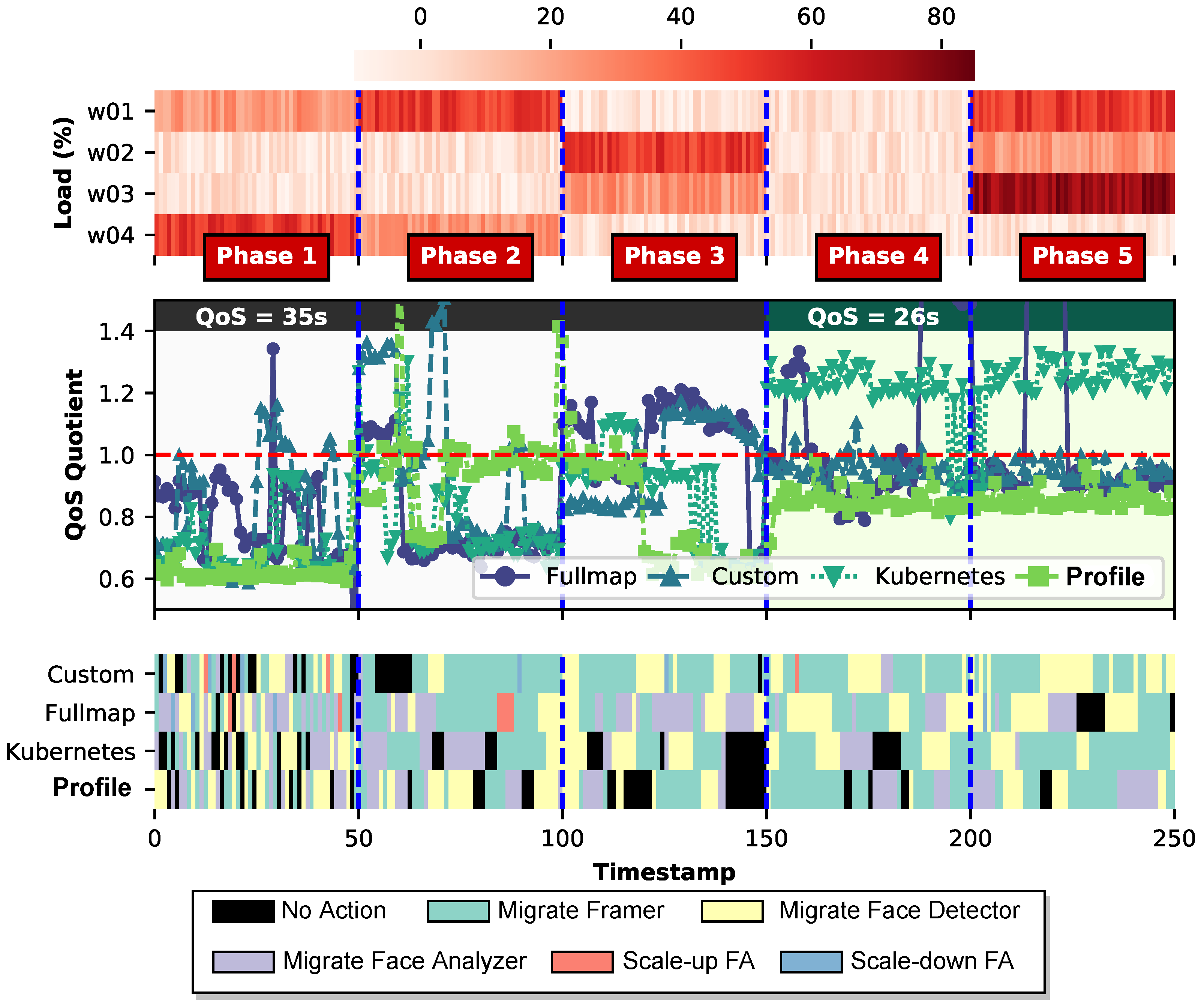
5. Results
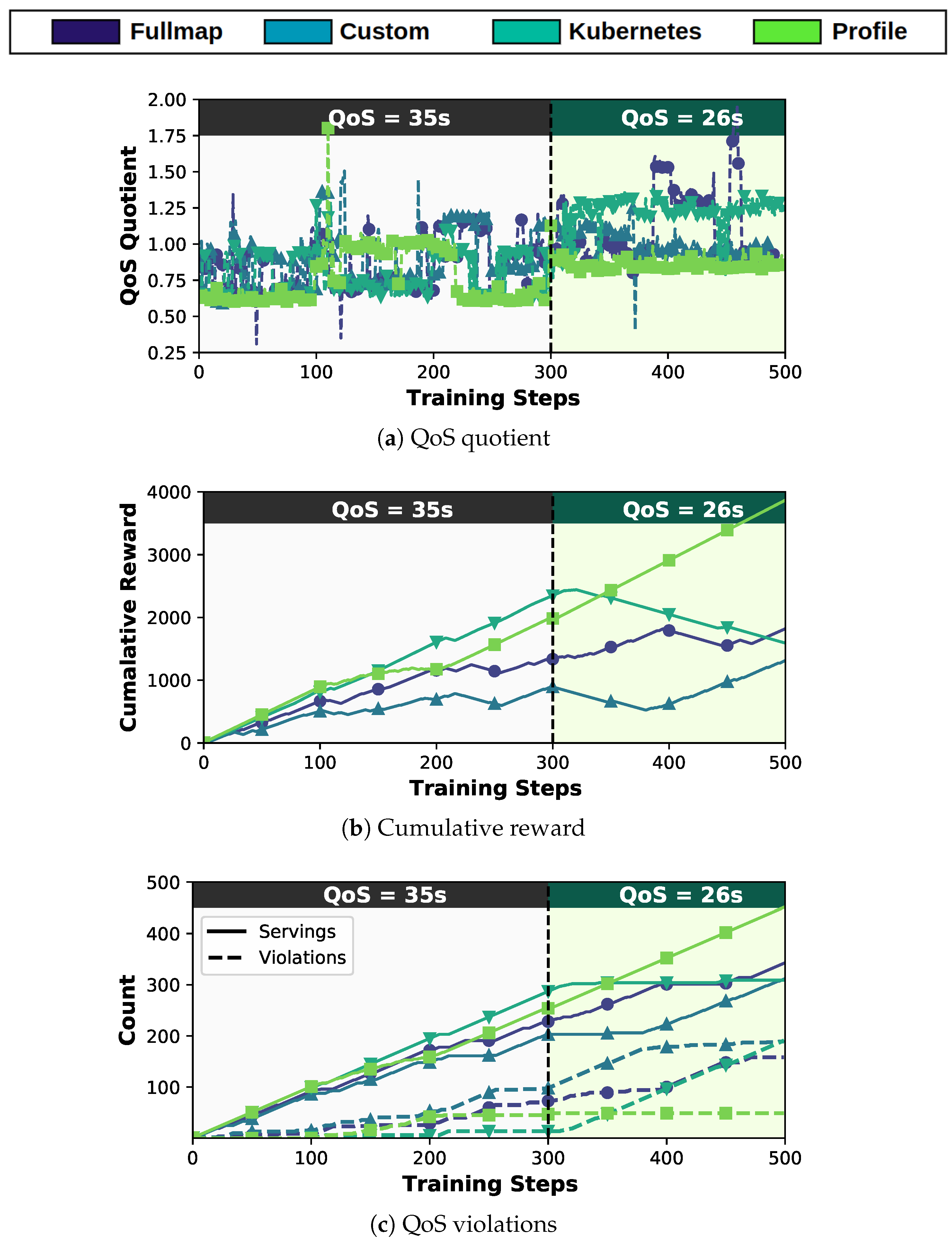
- Fullmap-based: Decides both the migration and the destination of a function (i.e., move from to ), while having the freedom to relocate any function to any node.
- Custom-based: Decides both the migration and the destination of the Framer and Face-detector functions, but only the migration (if chosen to be performed) for the Face-analyzer and Object-recognition functions since their destination node will always be the least loaded node. In this way, we investigate whether giving the agent partial or full freedom upon the landing node makes any difference to convergence speed and quality.
- Kubernetes-based: While Kubernetes does not support migration, we consider a Kubernetes -based policy that decides the migration of a function (i.e., move ) and afterward, the native Kubernetes scheduler is employed for determining the migrating node based on its own scheduling policy. In this way, we examine the functionality enhancement of the kube-scheduler that, by default, is unaware of the individual performance characteristics of functions.
- Profile-based: Again, decides just the migration of a function but the destination node is chosen by leveraging knowledge extracted from offline profiling that was performed in Section 3.3, where each function’s performance is analyzed under various circumstances; therefore, we can make an accurate enough estimation of its latency before deciding the landing node.
5.1. Comparative Evaluation of Schedulers during Training
5.2. Decision-Making Analysis of the DRL Agent
5.3. DRL-Based vs. Native Kubernetes Scheduling
5.4. Darly’s Performance Overhead
6. Benefits and Challenges of Integrating Darly into IoT/MEC Infrastructures
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Asim, M.; Wang, Y.; Wang, K.; Huang, P.Q. A review on computational intelligence techniques in cloud and edge computing. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 742–763. [Google Scholar] [CrossRef]
- Lu, Y.; Chowdhery, A.; Kandula, S. Optasia: A relational platform for efficient large-scale video analytics. In Proceedings of the 7th ACM Symposium on Cloud Computing, Santa Clara, CA, USA, 5–7 October 2016; pp. 57–70. [Google Scholar]
- Musalem, A.; Olivares, M.; Schilkrut, A. Retail in high definition: Monitoring customer assistance through video analytics. Manuf. Serv. Oper. Manag. 2021, 23, 1025–1042. [Google Scholar] [CrossRef]
- Baresi, L.; Filgueira Mendonça, D.; Garriga, M. Empowering low-latency applications through a serverless edge computing architecture. In Proceedings of the Service-Oriented and Cloud Computing: 6th IFIP WG 2.14 European Conference, ESOCC 2017, Oslo, Norway, 27–29 September 2017; Proceedings 6. Springer: Berlin/Heidelberg, Germany, 2017; pp. 196–210. [Google Scholar]
- Lyu, X.; Cherkasova, L.; Aitken, R.; Parmer, G.; Wood, T. Towards efficient processing of latency-sensitive serverless dags at the edge. In Proceedings of the 5th International Workshop on Edge Systems, Analytics and Networking, Rennes, France, 5–8 April 2022; pp. 49–54. [Google Scholar]
- Jonas, E.; Schleier-Smith, J.; Sreekanti, V.; Tsai, C.C.; Khandelwal, A.; Pu, Q.; Shankar, V.; Carreira, J.; Krauth, K.; Yadwadkar, N.; et al. Cloud programming simplified: A berkeley view on serverless computing. arXiv 2019, arXiv:1902.03383. [Google Scholar]
- Fouladi, S.; Wahby, R.S.; Shacklett, B.; Balasubramaniam, K.V.; Zeng, W.; Bhalerao, R.; Sivaraman, A.; Porter, G.; Winstein, K. Encoding, Fast and Slow:{Low-Latency} Video Processing Using Thousands of Tiny Threads. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 363–376. [Google Scholar]
- Romero, F.; Zhao, M.; Yadwadkar, N.J.; Kozyrakis, C. Llama: A heterogeneous & serverless framework for auto-tuning video analytics pipelines. In Proceedings of the ACM Symposium on Cloud Computing, Seattle, WA, USA, 1–4 November 2021; pp. 1–17. [Google Scholar]
- AWS Lambda @ Edge. Available online: https://aws.amazon.com/lambda/edge/ (accessed on 10 May 2024).
- Tzenetopoulos, A.E.A. FaaS and Curious: Performance Implications of Serverless Functions on Edge Computing Platforms. In Proceedings of the International Conference on High Performance Computing, Virtual Event, 24 June–2 July 2021; pp. 428–438. [Google Scholar]
- Rausch, T.; Hummer, W.; Muthusamy, V.; Rashed, A.; Dustdar, S. Towards a serverless platform for edge {AI}. In Proceedings of the 2nd USENIX Workshop on Hot Topics in Edge Computing (HotEdge 19), Renton, WA, USA, 10–12 July 2019. [Google Scholar]
- Pfandzelter, T.; Bermbach, D. tinyfaas: A lightweight faas platform for edge environments. In Proceedings of the 2020 IEEE International Conference on Fog Computing (ICFC), Sydney, Australia, 21–24 April 2020; pp. 17–24. [Google Scholar]
- Russo, G.R.; Cardellini, V.; Presti, F.L. A framework for offloading and migration of serverless functions in the Edge–Cloud Continuum. Pervasive Mob. Comput. 2024, 100, 101915. [Google Scholar] [CrossRef]
- Patterson, L.; Pigorovsky, D.; Dempsey, B.; Lazarev, N.; Shah, A.; Steinhoff, C.; Bruno, A.; Hu, J.; Delimitrou, C. HiveMind: A hardware-software system stack for serverless edge swarms. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; pp. 800–816. [Google Scholar]
- Ginzburg, S.; Freedman, M.J. Serverless isn’t server-less: Measuring and exploiting resource variability on cloud faas platforms. In Proceedings of the 2020 Sixth International Workshop on Serverless Computing, Delft, The Netherlands, 7–11 December 2020; pp. 43–48. [Google Scholar]
- Delimitrou, C.; Kozyrakis, C. Paragon: QoS-aware scheduling for heterogeneous datacenters. ACM SIGPLAN Not. 2013, 48, 77–88. [Google Scholar] [CrossRef]
- Tzenetopoulos, A.; Masouros, D.; Xydis, S.; Soudris, D. Orchestration Extensions for Interference-and Heterogeneity-Aware Placement for Data-Analytics. Int. J. Parallel Program. 2024, 52, 298–323. [Google Scholar] [CrossRef]
- OpenFaas. Available online: https://www.openfaas.com/ (accessed on 10 May 2024).
- Baldini, I.; Castro, P.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Suter, P. Cloud-native, event-based programming for mobile applications. In Proceedings of the International Conference on Mobile Software Engineering and Systems, Austin, TX, USA, 16–17 May 2016; pp. 287–288. [Google Scholar]
- Kubernetes. Available online: https://kubernetes.io/ (accessed on 1 February 2024).
- AWS Lambda. Available online: https://aws.amazon.com/lambda/ (accessed on 22 January 2024).
- Song, B.; Paolieri, M.; Golubchik, L. Performance and Revenue Analysis of Hybrid Cloud Federations with QoS Requirements. In Proceedings of the 2022 IEEE 15th International Conference on Cloud Computing (CLOUD), Barcelona, Spain, 10–16 July 2022; pp. 321–330. [Google Scholar] [CrossRef]
- Schuler, L.; Jamil, S.; Kühl, N. AI-based resource allocation: Reinforcement learning for adaptive auto-scaling in serverless environments. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 804–811. [Google Scholar]
- Agarwal, S.; Rodriguez, M.A.; Buyya, R. A Reinforcement Learning Approach to Reduce Serverless Function Cold Start Frequency. In Proceedings of the 2021 IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing (CCGrid), Melbourne, Australia, 10–13 May 2021; pp. 797–803. [Google Scholar] [CrossRef]
- Wang, B.; Ali-Eldin, A.; Shenoy, P. Lass: Running latency sensitive serverless computations at the edge. In Proceedings of the 30th International Symposium on High-Performance Parallel and Distributed Computing, Stockholm, Sweden, 21–25 June 2021; pp. 239–251. [Google Scholar]
- Marantos, C.; Tzenetopoulos, A.; Xydis, S.; Soudris, D. Cometes: Cross-device mapping for energy and time aware deployment on edge infrastructures. IEEE Embed. Syst. Lett. 2023, 16, 98–101. [Google Scholar] [CrossRef]
- Wu, N.; Xie, Y. A survey of machine learning for computer architecture and systems. ACM Comput. Surv. (CSUR) 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Giagkos, D.; Tzenetopoulos, A.; Masouros, D.; Soudris, D.; Xydis, S. Darly: Deep Reinforcement Learning for QoS-aware scheduling under resource heterogeneity Optimizing serverless video analytics. In Proceedings of the 2023 IEEE 16th International Conference on Cloud Computing (CLOUD), Chicago, IL, USA, 2–8 July 2023; pp. 1–3. [Google Scholar]
- Kotni, S.; Nayak, A.; Ganapathy, V.; Basu, A. Faastlane: Accelerating {Function-as-a-Service} Workflows. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 21), Online, 14–16 July 2021; pp. 805–820. [Google Scholar]
- Mahgoub, A.; Wang, L.; Shankar, K.; Zhang, Y.; Tian, H.; Mitra, S.; Peng, Y.; Wang, H.; Klimovic, A.; Yang, H.; et al. {SONIC}: Application-aware data passing for chained serverless applications. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 21), Online, 14–16 July 2021; pp. 285–301. [Google Scholar]
- Sreekanti, V.; Wu, C.; Lin, X.C.; Schleier-Smith, J.; Faleiro, J.M.; Gonzalez, J.E.; Hellerstein, J.M.; Tumanov, A. Cloudburst: Stateful functions-as-a-service. arXiv 2020, arXiv:2001.04592. [Google Scholar] [CrossRef]
- Zhang, T.; Xie, D.; Li, F.; Stutsman, R. Narrowing the gap between serverless and its state with storage functions. In Proceedings of the ACM Symposium on Cloud Computing, Santa Cruz, CA, USA, 20–23 November 2019; pp. 1–12. [Google Scholar]
- Shillaker, S.; Pietzuch, P. Faasm: Lightweight isolation for efficient stateful serverless computing. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20), Online, 15–17 July 2020; pp. 419–433. [Google Scholar]
- Klimovic, A.; Wang, Y.; Stuedi, P.; Trivedi, A.; Pfefferle, J.; Kozyrakis, C. Pocket: Elastic ephemeral storage for serverless analytics. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), Carlsbad, CA, USA, 8–10 October 2018; pp. 427–444. [Google Scholar]
- Klimovic, A.; Wang, Y.; Kozyrakis, C.; Stuedi, P.; Pfefferle, J.; Trivedi, A. Understanding ephemeral storage for serverless analytics. In Proceedings of the 2018 USENIX annual technical conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 789–794. [Google Scholar]
- Tzenetopoulos, A.; Masouros, D.; Xydis, S.; Soudris, D. Interference-aware orchestration in kubernetes. In Proceedings of the International Conference on High Performance Computing, Frankfurt/Main, Germany, 22–25 June 2020; pp. 321–330. [Google Scholar]
- Carreira, J.; Fonseca, P.; Tumanov, A.; Zhang, A.; Katz, R. Cirrus: A serverless framework for end-to-end ml workflows. In Proceedings of the ACM Symposium on Cloud Computing, Santa Cruz, CA, USA, 20–23 November 2019; pp. 13–24. [Google Scholar]
- Tzenetopoulos, A.; Masouros, D.; Soudris, D.; Xydis, S. DVFaaS: Leveraging DVFS for FaaS Workflows. IEEE Comput. Archit. Lett. 2023, 22, 85–88. [Google Scholar] [CrossRef]
- Fakinos, I.; Tzenetopoulos, A.; Masouros, D.; Xydis, S.; Soudris, D. Sequence Clock: A Dynamic Resource Orchestrator for Serverless Architectures. In Proceedings of the 2022 IEEE 15th International Conference on Cloud Computing (CLOUD), Barcelona, Spain, 10–16 July 2022; pp. 81–90. [Google Scholar]
- Tzenetopoulos, A.; Masouros, D.; Xydis, S.; Soudris, D. Leveraging Core and Uncore Frequency Scaling for Power-Efficient Serverless Workflows. arXiv 2024, arXiv:2407.18386. [Google Scholar]
- Wang, L.; Li, M.; Zhang, Y.; Ristenpart, T.; Swift, M. Peeking behind the curtains of serverless platforms. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 133–146. [Google Scholar]
- Tzenetopoulos, A.; Lentaris, G.; Leftheriotis, A.; Chrysomeris, P.; Palomares, J.; Coronado, E.; Kazhamiakin, R.; Soudris, D. Seamless HW-accelerated AI serving in heterogeneous MEC Systems with AI@EDGE. In Proceedings of the 33rd International ACM Symposium on High-Performance Parallel and Distributed Computing (HPDC 2024), Pisa, Italy, 3–7 July 2024; Forthcoming. [Google Scholar]
- Intel® Performance Counter Monitor—A Better Way to Measure CPU Utilization. 2012. Available online: https://www.intel.com/content/www/us/en/developer/articles/tool/performance-counter-monitor.html (accessed on 10 March 2024).
- Ananthanarayanan, G.; Bahl, P.; Bodík, P.; Chintalapudi, K.; Philipose, M.; Ravindranath, L.; Sinha, S. Real-time video analytics: The killer app for edge computing. Computer 2017, 50, 58–67. [Google Scholar] [CrossRef]
- Ao, L.; Izhikevich, L.; Voelker, G.M.; Porter, G. Sprocket: A serverless video processing framework. In Proceedings of the ACM Symposium on Cloud Computing, Carlsbad, CA, USA, 11–13 October 2018; pp. 263–274. [Google Scholar]
- Netflix and AWS Lambda Case Study. Available online: https://aws.amazon.com/solutions/case-studies/netflix-and-aws-lambda/ (accessed on 15 December 2023).
- Zhang, M.; Wang, F.; Zhu, Y.; Liu, J.; Wang, Z. Towards cloud-edge collaborative online video analytics with fine-grained serverless pipelines. In Proceedings of the 12th ACM Multimedia Systems Conference, Istanbul, Turkey, 28 September–1 October 2021; pp. 80–93. [Google Scholar]
- Zhang, H.; Shen, M.; Huang, Y.; Wen, Y.; Luo, Y.; Gao, G.; Guan, K. A serverless cloud-fog platform for dnn-based video analytics with incremental learning. arXiv 2021, arXiv:2102.03012. [Google Scholar]
- Rohan, M.; Ahmed, S.; Kaleem, M.; Nazir, S. Serverless Video Analysis Pipeline for Autonomous Remote Monitoring System. In Proceedings of the 2022 International Conference on Emerging Technologies in Electronics, Computing and Communication (ICETECC), Jamshoro, Pakistan, 7–9 December 2022; pp. 1–6. [Google Scholar]
- MinIO. Available online: https://min.io/ (accessed on 18 November 2023).
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Delimitrou, C.; Kozyrakis, C. ibench: Quantifying interference for datacenter applications. In Proceedings of the 2013 IEEE International Symposium on Workload Characterization (IISWC), Portland, OR, USA, 22–24 September 2013; pp. 23–33. [Google Scholar]
- InfluxDB. Available online: https://www.influxdata.com/ (accessed on 10 March 2024).
- Masouros, D.; Xydis, S.; Soudris, D. Rusty: Runtime interference-aware predictive monitoring for modern multi-tenant systems. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 184–198. [Google Scholar] [CrossRef]
- Queue-Worker. Available online: https://docs.openfaas.com/reference/async/ (accessed on 10 May 2023).
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Kim, M.; Kim, J.S.; Choi, M.S.; Park, J.H. Adaptive discount factor for deep reinforcement learning in continuing tasks with uncertainty. Sensors 2022, 22, 7266. [Google Scholar] [CrossRef]
- Shahrad, M.; Fonseca, R.; Goiri, Í.; Chaudhry, G.; Batum, P.; Cooke, J.; Laureano, E.; Tresness, C.; Russinovich, M.; Bianchini, R. Serverless in the wild: Characterizing and optimizing the serverless workload at a large cloud provider. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20), Online, 15–17 July 2020; pp. 205–218. [Google Scholar]
- AWS Lambda Pricing. Available online: https://aws.amazon.com/lambda/pricing/ (accessed on 10 June 2024).
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-baselines3: Reliable reinforcement learning implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VM | vCPUs | Memory | Underlying CPU (Intel® Xeon®) | L3(MB) |
|---|---|---|---|---|
| worker-01 (w01) | 8 | 15.6 GB | Gold 5218R @ 2.10 GHz | 28 |
| worker-02 (w02) | 8 | 15.6 GB | Gold 6138 @ 2.00 GHz | 28 |
| worker-03 (w03) | 16 | 31.4 GB | Silver 4210 @ 2.00 GHz | 14 |
| worker-04 (w04) | 4 | 15.6 GB | E5-2658A @ 2.20 GHz | 30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giagkos, D.; Tzenetopoulos, A.; Masouros, D.; Xydis, S.; Catthoor, F.; Soudris, D. AI-Driven QoS-Aware Scheduling for Serverless Video Analytics at the Edge. Information 2024, 15, 480. https://doi.org/10.3390/info15080480
Giagkos D, Tzenetopoulos A, Masouros D, Xydis S, Catthoor F, Soudris D. AI-Driven QoS-Aware Scheduling for Serverless Video Analytics at the Edge. Information. 2024; 15(8):480. https://doi.org/10.3390/info15080480
Chicago/Turabian StyleGiagkos, Dimitrios, Achilleas Tzenetopoulos, Dimosthenis Masouros, Sotirios Xydis, Francky Catthoor, and Dimitrios Soudris. 2024. "AI-Driven QoS-Aware Scheduling for Serverless Video Analytics at the Edge" Information 15, no. 8: 480. https://doi.org/10.3390/info15080480