
Beyond Supervised: The Rise of Self-Supervised Learning in Autonomous Systems


Abstract
1. Introduction
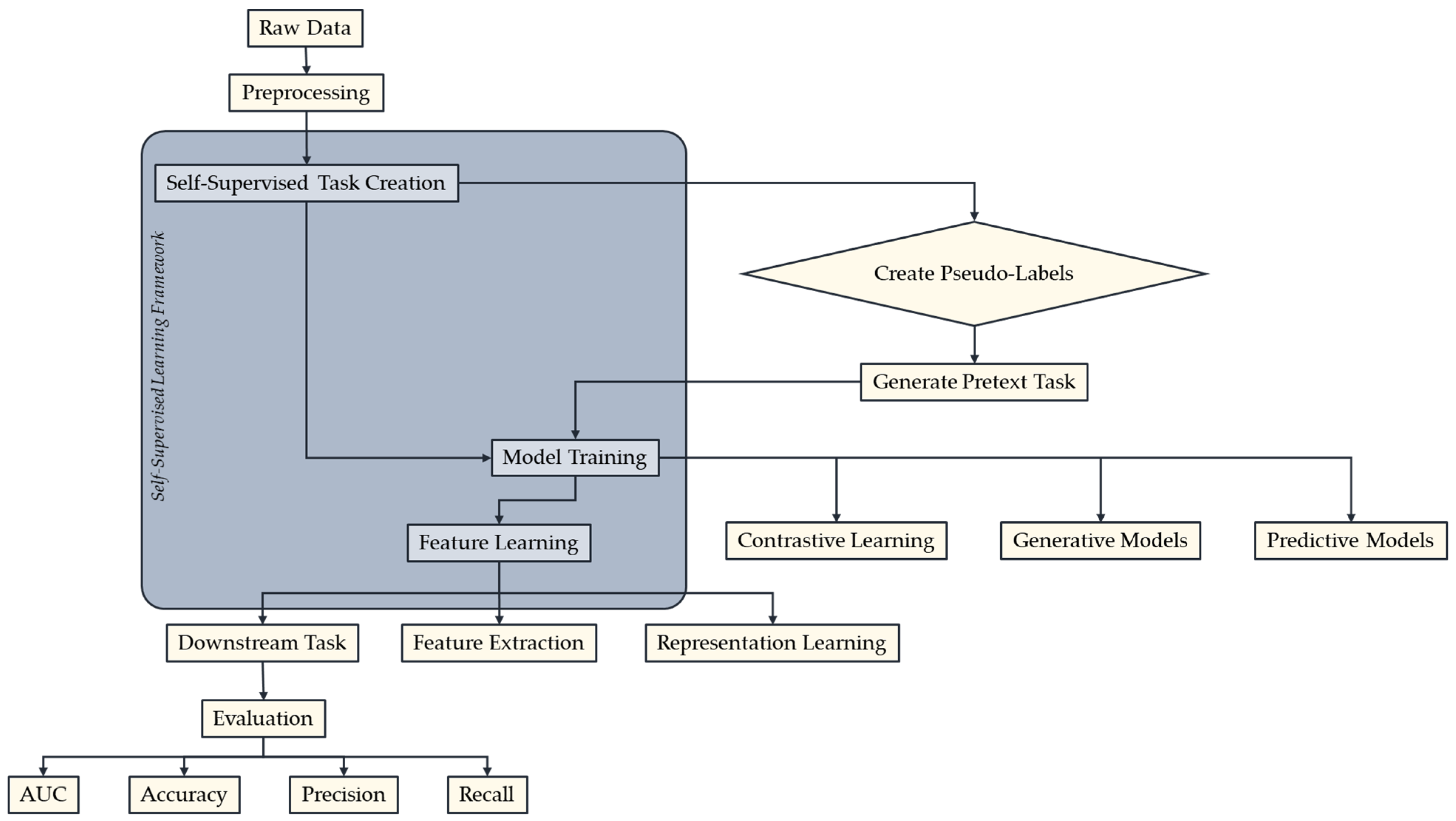
2. Concept and Techniques of Self-Supervised Learning
3. Transformative Applications of Self-Supervised Learning
3.1. Image Recognition
3.2. Natural Language Processing (NLP)
3.3. Robotics
3.4. Autonomous Vehicles
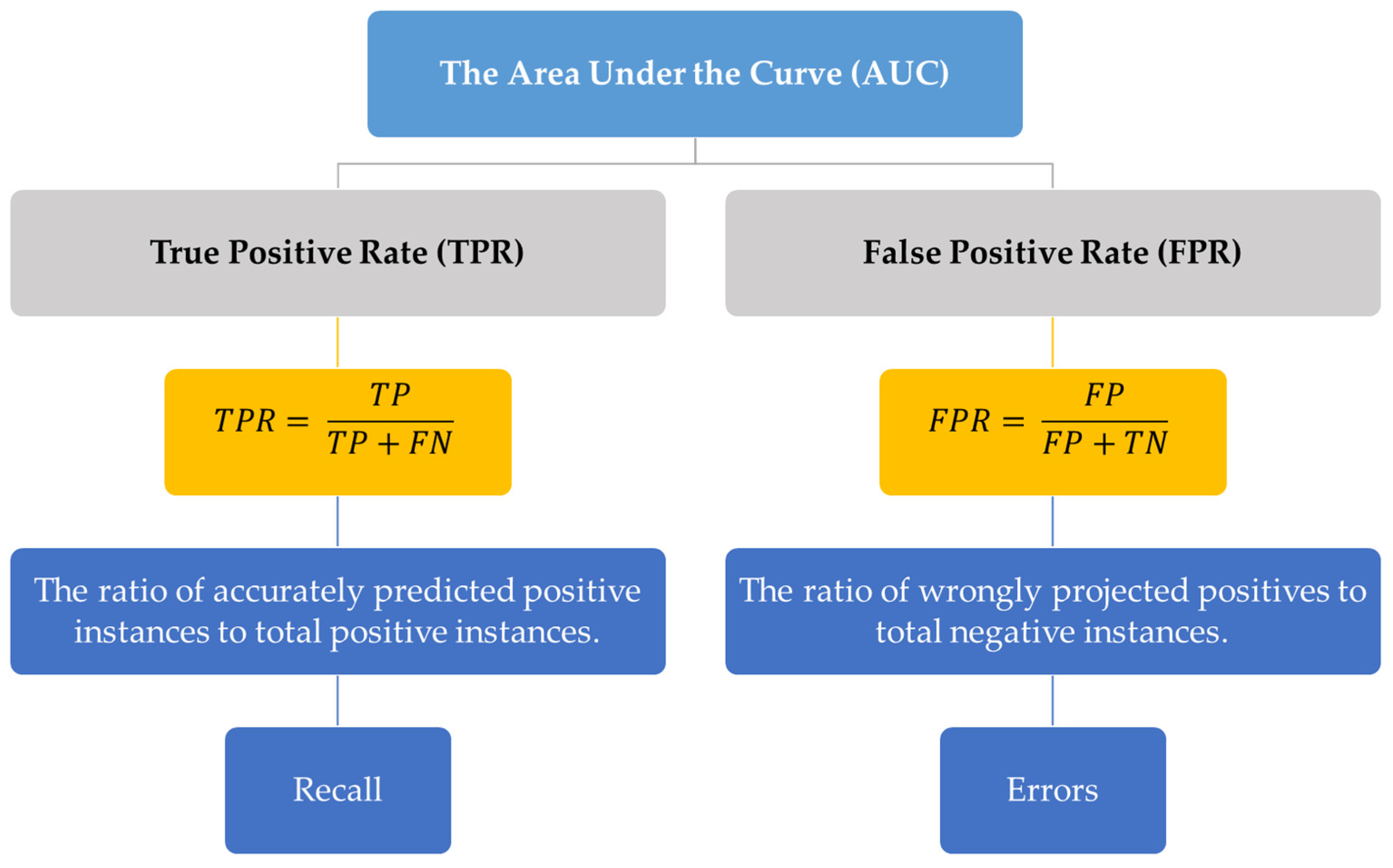
4. Importance of Area under the Curve in Machine Learning
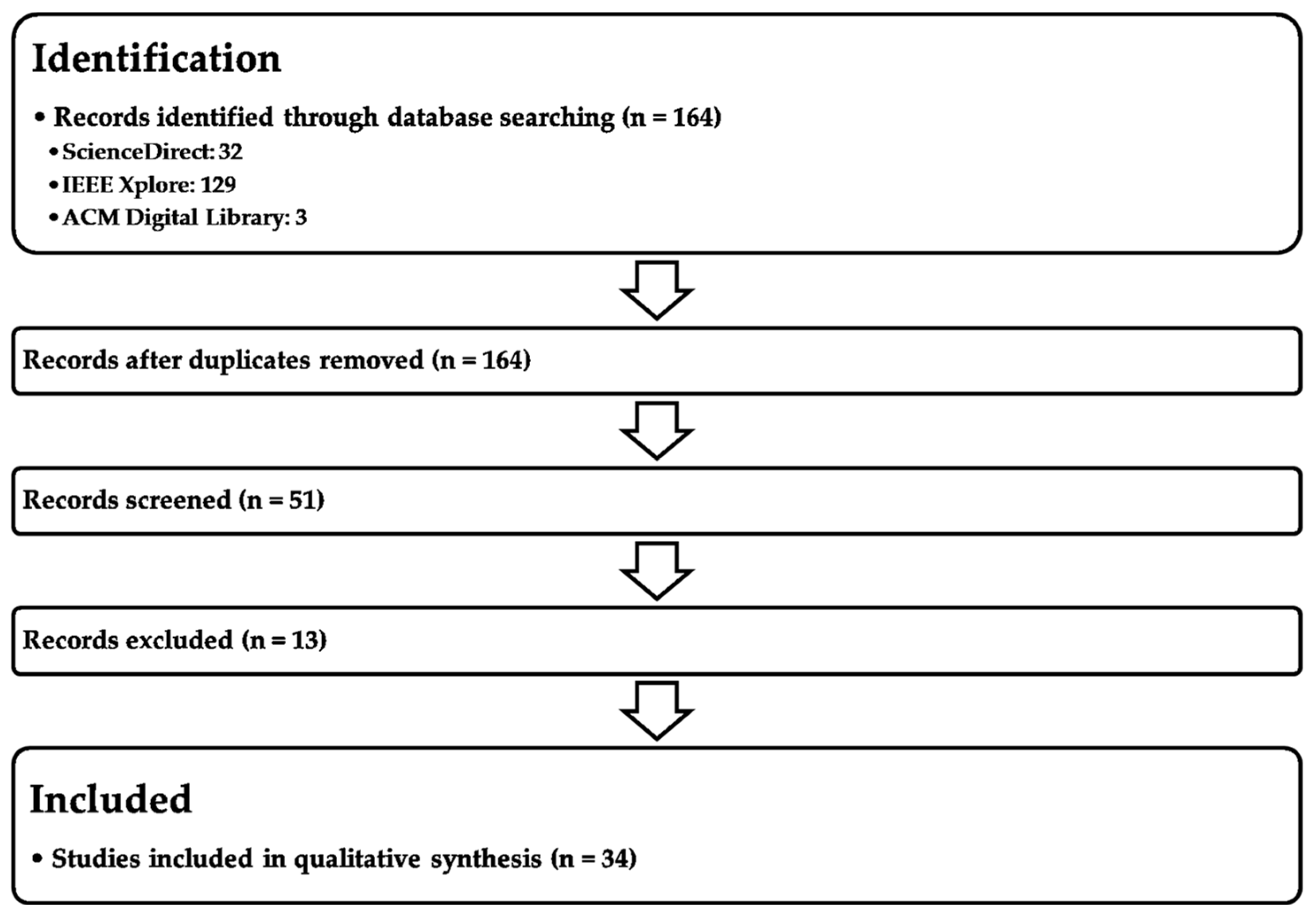
5. Methodology
Keyword Query:(“self-supervised learning” OR “self-supervised model” OR “self-supervision” OR “SSL”) AND (“supervised learning” OR “unsupervised learning” OR “supervised model” OR “unsupervised model”) AND (“Area Under the Curve” OR “AUC”).
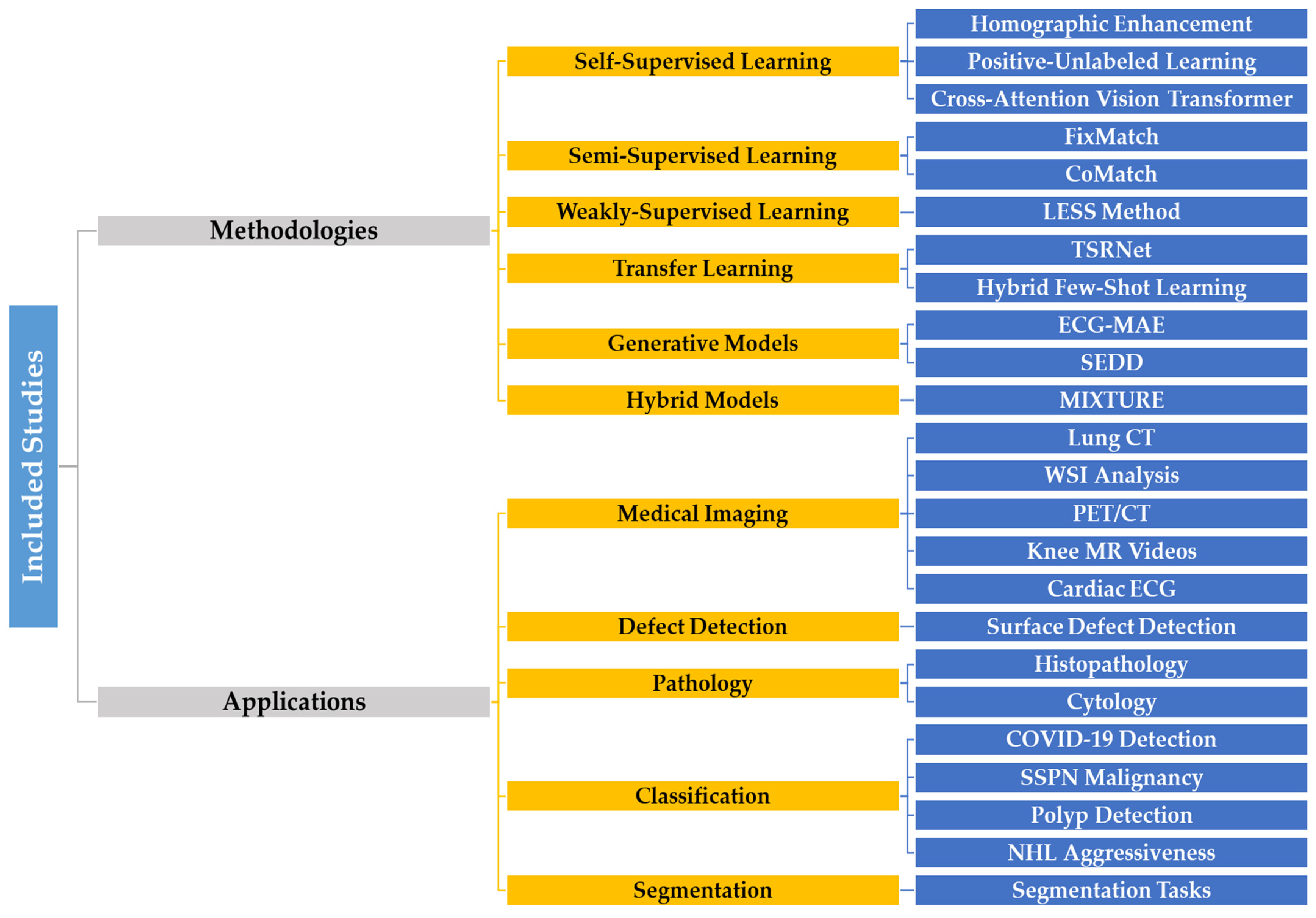
6. Critical Review of Self-Supervised Learning Models Using AUC
6.1. Diagnostic Imaging Classification
6.2. Defect Detection and Segmentation
6.3. Self-Supervised Learning in Pathology
7. AUC Evaluation
8. Challenges and Future Directions
- The AUC, a widely used metric in SSL model evaluation, may only sometimes accurately reflect the performance, particularly in datasets with imbalances. Meaningful evaluation requires metrics like the AUC to appropriately assess model performance.
- Precise and consistent annotations are vital to ensure SSL models’ accuracy in medical imaging datasets. Poorly annotated data can significantly skew model predictions, highlighting the importance of high-quality labeled data.
- Medical imaging datasets often lack labeled data, especially for rare diseases, hindering SSL model training. Addressing the data scarcity and imbalances is crucial for SSL techniques to learn minority class representations effectively.
- SSL approaches based on deep learning often feature complex architectures, necessitating significant computational resources for training and inference. Simplifying the model structures or adopting more efficient techniques can mitigate the computational complexity and improve the accessibility.
- Clinicians must trust and comprehend SSL models for widespread clinical use. Transparent model creation, validation, and interpretable predictions are essential in facilitating clinical adoption.
9. Conclusions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Tufail, S.; Riggs, H.; Tariq, M.; Sarwat, A.I. Advancements and Challenges in Machine Learning: A Comprehensive Review of Models, Libraries, Applications, and Algorithms. Electronics 2023, 12, 1789. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Taherdoost, H. Machine learning algorithms: Features and applications. In Encyclopedia of Data Science and Machine Learning; IGI Global: Hershey, PA, USA, 2023; pp. 938–960. [Google Scholar]
- Fink, O.; Wang, Q.; Svensen, M.; Dersin, P.; Lee, W.-J.; Ducoffe, M. Potential, challenges and future directions for deep learning in prognostics and health management applications. Eng. Appl. Artif. Intell. 2020, 92, 103678. [Google Scholar] [CrossRef]
- Liu, B. Supervised Learning. In Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data; Liu, B., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 63–132. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.; Cubuk, E.; Goodfellow, I. Realistic evaluation of semi-supervised learning algortihms. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–15. [Google Scholar]
- Ferrara, E. Fairness and bias in artificial intelligence: A brief survey of sources, impacts, and mitigation strategies. Sci 2023, 6, 3. [Google Scholar] [CrossRef]
- Gianfrancesco, M.A.; Tamang, S.; Yazdany, J.; Schmajuk, G. Potential biases in machine learning algorithms using electronic health record data. JAMA Intern. Med. 2018, 178, 1544–1547. [Google Scholar] [CrossRef]
- Pagano, T.P.; Loureiro, R.B.; Lisboa, F.V.; Peixoto, R.M.; Guimarães, G.A.; Cruz, G.O.; Araujo, M.M.; Santos, L.L.; Cruz, M.A.; Oliveira, E.L. Bias and unfairness in machine learning models: A systematic review on datasets, tools, fairness metrics, and identification and mitigation methods. Big Data Cogn. Comput. 2023, 7, 15. [Google Scholar] [CrossRef]
- Van Giffen, B.; Herhausen, D.; Fahse, T. Overcoming the pitfalls and perils of algorithms: A classification of machine learning biases and mitigation methods. J. Bus. Res. 2022, 144, 93–106. [Google Scholar] [CrossRef]
- Zhang, P.; He, Q.; Ai, X.; Ma, F. Uncovering Self-Supervised Learning: From Current Applications to Future Trends. In Proceedings of the 2023 International Conference on Power, Communication, Computing and Networking Technologies, Wuhan, China, 24–25 September 2023; pp. 1–8. [Google Scholar]
- Rani, V.; Nabi, S.T.; Kumar, M.; Mittal, A.; Kumar, K. Self-supervised learning: A succinct review. Arch. Comput. Methods Eng. 2023, 30, 2761–2775. [Google Scholar] [CrossRef]
- Zhao, Z.; Alzubaidi, L.; Zhang, J.; Duan, Y.; Gu, Y. A comparison review of transfer learning and self-supervised learning: Definitions, applications, advantages and limitations. Expert Syst. Appl. 2023, 242, 122807. [Google Scholar] [CrossRef]
- Albelwi, S. Survey on self-supervised learning: Auxiliary pretext tasks and contrastive learning methods in imaging. Entropy 2022, 24, 551. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.-C.; Pareek, A.; Jensen, M.; Lungren, M.P.; Yeung, S.; Chaudhari, A.S. Self-supervised learning for medical image classification: A systematic review and implementation guidelines. NPJ Digit. Med. 2023, 6, 74. [Google Scholar] [CrossRef] [PubMed]
- Purushwalkam, S.; Morgado, P.; Gupta, A. The challenges of continuous self-supervised learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 702–721. [Google Scholar]
- Taherdoost, H. Blockchain and machine learning: A critical review on security. Information 2023, 14, 295. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Nahm, F.S. Receiver operating characteristic curve: Overview and practical use for clinicians. Korean J. Anesthesiol. 2022, 75, 25. [Google Scholar] [CrossRef] [PubMed]
- de Hond, A.A.; Steyerberg, E.W.; van Calster, B. Interpreting area under the receiver operating characteristic curve. Lancet Digit. Health 2022, 4, e853–e855. [Google Scholar] [CrossRef]
- Polo, T.C.F.; Miot, H.A. Use of ROC curves in clinical and experimental studies. J. Vasc. Bras. 2020, 19, e20200186. [Google Scholar] [CrossRef] [PubMed]
- Hajian-Tilaki, K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Casp. J. Intern. Med. 2013, 4, 627. [Google Scholar]
- Kwegyir-Aggrey, K.; Gerchick, M.; Mohan, M.; Horowitz, A.; Venkatasubramanian, S. The Misuse of AUC: What High Impact Risk Assessment Gets Wrong. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 1570–1583. [Google Scholar]
- Mandrekar, J.N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chiaroni, F.; Rahal, M.-C.; Hueber, N.; Dufaux, F. Self-supervised learning for autonomous vehicles perception: A conciliation between analytical and learning methods. IEEE Signal Process. Mag. 2020, 38, 31–41. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Kong, D.; Zhao, L.; Huang, X.; Huang, W.; Ding, J.; Yao, Y.; Xu, L.; Yang, P.; Yang, G. Self-supervised knowledge mining from unlabeled data for bearing fault diagnosis under limited annotations. Measurement 2023, 220, 113387. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Balestriero, R.; Kawaguchi, K.; Rudner, T.G.; LeCun, Y. An information-theoretic perspective on variance-invariance-covariance regularization. arXiv 2023, arXiv:2303.00633. [Google Scholar]
- Misra, I.; Maaten, L.v.d. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6707–6717. [Google Scholar]
- Arora, S.; Khandeparkar, H.; Khodak, M.; Plevrakis, O.; Saunshi, N. A theoretical analysis of contrastive unsupervised representation learning. arXiv 2019, arXiv:1902.09229. [Google Scholar]
- Shurrab, S.; Duwairi, R. Self-supervised learning methods and applications in medical imaging analysis: A survey. PeerJ Comput. Sci. 2022, 8, e1045. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Latif, S.; Rana, R.; Qadir, J.; Epps, J. Variational autoencoders for learning latent representations of speech emotion: A preliminary study. arXiv 2017, arXiv:1712.08708. [Google Scholar]
- Saxena, D.; Cao, J. Generative adversarial networks (GANs) challenges, solutions, and future directions. ACM Comput. Surv. (CSUR) 2021, 54, 1–42. [Google Scholar] [CrossRef]
- Abdulrazzaq, M.M.; Ramaha, N.T.; Hameed, A.A.; Salman, M.; Yon, D.K.; Fitriyani, N.L.; Syafrudin, M.; Lee, S.W. Consequential Advancements of Self-Supervised Learning (SSL) in Deep Learning Contexts. Mathematics 2024, 12, 758. [Google Scholar] [CrossRef]
- Ren, X.; Wei, W.; Xia, L.; Huang, C. A comprehensive survey on self-supervised learning for recommendation. arXiv 2024, arXiv:2404.03354. [Google Scholar]
- Ramírez, J.G.C. Advancements in Self-Supervised Learning for Remote Sensing Scene Classification: Present Innovations and Future Outlooks. J. Artif. Intell. Gen. Sci. (JAIGS) 2024, 4, 45–56. [Google Scholar]
- Khan, M.R. Advancements in Deep Learning Architectures: A Comprehensive Review of Current Trends. J. Artif. Intell. Gen. Sci. (JAIGS) 2024, 1. [Google Scholar] [CrossRef]
- Radak, M.; Lafta, H.Y.; Fallahi, H. Machine learning and deep learning techniques for breast cancer diagnosis and classification: A comprehensive review of medical imaging studies. J. Cancer Res. Clin. Oncol. 2023, 149, 10473–10491. [Google Scholar] [CrossRef]
- Nielsen, M.; Wenderoth, L.; Sentker, T.; Werner, R. Self-supervision for medical image classification: State-of-the-art performance with~ 100 labeled training samples per class. Bioengineering 2023, 10, 895. [Google Scholar] [CrossRef]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar]
- Azizi, S.; Culp, L.; Freyberg, J.; Mustafa, B.; Baur, S.; Kornblith, S.; Chen, T.; Tomasev, N.; Mitrović, J.; Strachan, P. Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging. Nat. Biomed. Eng. 2023, 7, 756–779. [Google Scholar] [CrossRef] [PubMed]
- Di Liello, L. Structural Self-Supervised Objectives for Transformers. arXiv 2023, arXiv:2309.08272. [Google Scholar]
- Zhou, M.; Li, Z.; Xie, P. Self-supervised regularization for text classification. Trans. Assoc. Comput. Linguist. 2021, 9, 641–656. [Google Scholar] [CrossRef]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8968–8975. [Google Scholar]
- Karnan, H.; Yang, E.; Farkash, D.; Warnell, G.; Biswas, J.; Stone, P. STERLING: Self-Supervised Terrain Representation Learning from Unconstrained Robot Experience. In Proceedings of the 7th Annual Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Abbate, G.; Giusti, A.; Schmuck, V.; Celiktutan, O.; Paolillo, A. Self-supervised prediction of the intention to interact with a service robot. Robot. Auton. Syst. 2024, 171, 104568. [Google Scholar] [CrossRef]
- Sermanet, P.; Lynch, C.; Chebotar, Y.; Hsu, J.; Jang, E.; Schaal, S.; Levine, S.; Brain, G. Time-contrastive networks: Self-supervised learning from video. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1134–1141. [Google Scholar]
- Lang, C.; Braun, A.; Schillingmann, L.; Valada, A. Self-supervised multi-object tracking for autonomous driving from consistency across timescales. IEEE Robot. Autom. Lett. 2023, 8, 7711–7718. [Google Scholar] [CrossRef]
- Luo, C.; Yang, X.; Yuille, A. Self-supervised pillar motion learning for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3183–3192. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Bachute, M.R.; Subhedar, J.M. Autonomous driving architectures: Insights of machine learning and deep learning algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Namdar, K.; Haider, M.A.; Khalvati, F. A modified AUC for training convolutional neural networks: Taking confidence into account. Front. Artif. Intell. 2021, 4, 582928. [Google Scholar] [CrossRef]
- Kim, Y.; Toh, K.-A.; Teoh, A.B.J.; Eng, H.-L.; Yau, W.-Y. An online AUC formulation for binary classification. Pattern Recognit. 2012, 45, 2266–2279. [Google Scholar] [CrossRef]
- Leevy, J.L.; Hancock, J.; Khoshgoftaar, T.M.; Abdollah Zadeh, A. Investigating the effectiveness of one-class and binary classification for fraud detection. J. Big Data 2023, 10, 157. [Google Scholar] [CrossRef]
- Baumann, C.; Singmann, H.; Gershman, S.J.; von Helversen, B. A linear threshold model for optimal stopping behavior. Proc. Natl. Acad. Sci. USA 2020, 117, 12750–12755. [Google Scholar]
- Djulbegovic, B.; Hozo, I.; Mayrhofer, T.; van den Ende, J.; Guyatt, G. The threshold model revisited. J. Eval. Clin. Pract. 2019, 25, 186–195. [Google Scholar] [CrossRef]
- Kopsinis, Y.; Thompson, J.S.; Mulgrew, B. System-independent threshold and BER estimation in optical communications using the extended generalized gamma distribution. Opt. Fiber Technol. 2007, 13, 39–45. [Google Scholar]
- Vanderlooy, S.; Hüllermeier, E. A critical analysis of variants of the AUC. Mach. Learn. 2008, 72, 247–262. [Google Scholar] [CrossRef]
- Ferri, C.; Hernández-Orallo, J.; Flach, P.A. A coherent interpretation of AUC as a measure of aggregated classification performance. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 657–664. [Google Scholar]
- Yang, Z.; Xu, Q.; Bao, S.; He, Y.; Cao, X.; Huang, Q. Optimizing two-way partial auc with an end-to-end framework. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 10228–10246. [Google Scholar]
- Bhat, S.; Mansoor, A.; Georgescu, B.; Panambur, A.B.; Ghesu, F.C.; Islam, S.; Packhäuser, K.; Rodríguez-Salas, D.; Grbic, S.; Maier, A. AUCReshaping: Improved sensitivity at high-specificity. Sci. Rep. 2023, 13, 21097. [Google Scholar] [CrossRef] [PubMed]
- Sharma, R.; Ji, K.; Chen, C. AUC-CL: A Batchsize-Robust Framework for Self-Supervised Contrastive Representation Learning. In Proceedings of the The Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2023. [Google Scholar]
- Wang, S.; Li, D.; Petrick, N.; Sahiner, B.; Linguraru, M.G.; Summers, R.M. Optimizing area under the ROC curve using semi-supervised learning. Pattern Recognit. 2015, 48, 276–287. [Google Scholar] [CrossRef] [PubMed]
- Brown, J. Classifiers and their metrics quantified. Mol. Inform. 2018, 37, 1700127. [Google Scholar] [CrossRef] [PubMed]
- Halimu, C.; Kasem, A.; Newaz, S.S. Empirical comparison of area under ROC curve (AUC) and Mathew correlation coefficient (MCC) for evaluating machine learning algorithms on imbalanced datasets for binary classification. In Proceedings of the 3rd International Conference on Machine Learning and Soft Computing, Da Lat, Vietnam, 25–28 January 2019; pp. 1–6. [Google Scholar]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A better measure than accuracy in comparing learning algorithms. In Proceedings of the Advances in Artificial Intelligence: 16th Conference of the Canadian Society for Computational Studies of Intelligence, AI 2003, Halifax, NS, Canada, 11–13 June 2003; Proceedings 16, 2003. pp. 329–341. [Google Scholar]
- Yuan, Z.; Yan, Y.; Sonka, M.; Yang, T. Large-scale robust deep auc maximization: A new surrogate loss and empirical studies on medical image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3040–3049. [Google Scholar]
- Dong, Y.; Pachade, S.; Liang, X.; Sheth, S.A.; Giancardo, L. A self-supervised learning approach for registration agnostic imaging models with 3D brain CTA. iScience 2024, 27, 109004. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Chen, J.; Zhou, L. Spatiotemporal self-supervised representation learning from multi-lead ECG signals. Biomed. Signal Process. Control 2023, 84, 104772. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, C.; Liu, X.; Qian, R.; Song, R.; Chen, X. Patient-Specific Seizure Prediction via Adder Network and Supervised Contrastive Learning. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 1536–1547. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Dai, Q. A self-supervised COVID-19 CT recognition system with multiple regularizations. Comput. Biol. Med. 2022, 150, 106149. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Pi, P.; Tang, C.; Wang, S.-H.; Zhang, Y.-D. TSRNet: Diagnosis of COVID-19 based on self-supervised learning and hybrid ensemble model. Comput. Biol. Med. 2022, 146, 105531. [Google Scholar] [CrossRef]
- Pascual, G.; Laiz, P.; García, A.; Wenzek, H.; Vitrià, J.; Seguí, S. Time-based self-supervised learning for Wireless Capsule Endoscopy. Comput. Biol. Med. 2022, 146, 105631. [Google Scholar] [CrossRef]
- Wongchaisuwat, N.; Thamphithak, R.; Watunyuta, P.; Wongchaisuwat, P. Automated classification of polypoidal choroidal vasculopathy and wet age-related macular degeneration by spectral domain optical coherence tomography using self-supervised learning. Procedia Comput. Sci. 2023, 220, 1003–1008. [Google Scholar] [CrossRef]
- Liu, J.; Qi, L.; Xu, Q.; Chen, J.; Cui, S.; Li, F.; Wang, Y.; Cheng, S.; Tan, W.; Zhou, Z.; et al. A Self-supervised Learning-Based Fine-Grained Classification Model for Distinguishing Malignant From Benign Subcentimeter Solid Pulmonary Nodules. Acad. Radiol. 2024, in press. [CrossRef]
- Xu, C.; Feng, J.; Yue, Y.; Cheng, W.; He, D.; Qi, S.; Zhang, G. A hybrid few-shot multiple-instance learning model predicting the aggressiveness of lymphoma in PET/CT images. Comput. Methods Programs Biomed. 2024, 243, 107872. [Google Scholar] [CrossRef]
- Perumal, M.; Srinivas, M. DenSplitnet: Classifier-invariant neural network method to detect COVID-19 in chest CT data. J. Vis. Commun. Image Represent. 2023, 97, 103949. [Google Scholar] [CrossRef]
- Manna, S.; Bhattacharya, S.; Pal, U. Self-supervised representation learning for detection of ACL tear injury in knee MR videos. Pattern Recognit. Lett. 2022, 154, 37–43. [Google Scholar] [CrossRef]
- Xu, R.; Hao, R.; Huang, B. Efficient surface defect detection using self-supervised learning strategy and segmentation network. Adv. Eng. Inform. 2022, 52, 101566. [Google Scholar] [CrossRef]
- Zhou, S.; Tian, S.; Yu, L.; Wu, W.; Zhang, D.; Peng, Z.; Zhou, Z. Growth threshold for pseudo labeling and pseudo label dropout for semi-supervised medical image classification. Eng. Appl. Artif. Intell. 2024, 130, 107777. [Google Scholar] [CrossRef]
- Zhou, S.; Tian, S.; Yu, L.; Wu, W.; Zhang, D.; Peng, Z.; Zhou, Z.; Wang, J. FixMatch-LS: Semi-supervised skin lesion classification with label smoothing. Biomed. Signal Process. Control 2023, 84, 104709. [Google Scholar] [CrossRef]
- Uegami, W.; Bychkov, A.; Ozasa, M.; Uehara, K.; Kataoka, K.; Johkoh, T.; Kondoh, Y.; Sakanashi, H.; Fukuoka, J. MIXTURE of human expertise and deep learning—Developing an explainable model for predicting pathological diagnosis and survival in patients with interstitial lung disease. Mod. Pathol. 2022, 35, 1083–1091. [Google Scholar] [CrossRef]
- Zhao, B.; Deng, W.; Li, Z.H.; Zhou, C.; Gao, Z.; Wang, G.; Li, X. LESS: Label-efficient multi-scale learning for cytological whole slide image screening. Med. Image Anal. 2024, 94, 103109. [Google Scholar] [CrossRef]
- Orlandic, L.; Teijeiro, T.; Atienza, D. A semi-supervised algorithm for improving the consistency of crowdsourced datasets: The COVID-19 case study on respiratory disorder classification. Comput. Methods Programs Biomed. 2023, 241, 107743. [Google Scholar] [CrossRef]
- Chakravarty, A.; Emre, T.; Leingang, O.; Riedl, S.; Mai, J.; Scholl, H.P.N.; Sivaprasad, S.; Rueckert, D.; Lotery, A.; Schmidt-Erfurth, U.; et al. Morph-SSL: Self-Supervision with Longitudinal Morphing for Forecasting AMD Progression from OCT Volumes. IEEE Trans. Med. Imaging 2024. [Google Scholar] [CrossRef]
- Zhang, P.; Hu, X.; Li, G.; Deng, L. AntiViralDL: Computational Antiviral Drug Repurposing Using Graph Neural Network and Self-Supervised Learning. IEEE J. Biomed. Health Inform. 2024, 28, 548–556. [Google Scholar] [CrossRef]
- Li, T.; Guo, Y.; Zhao, Z.; Chen, M.; Lin, Q.; Hu, X.; Yao, Z.; Hu, B. Automated Diagnosis of Major Depressive Disorder With Multi-Modal MRIs Based on Contrastive Learning: A Few-Shot Study. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 1566–1576. [Google Scholar] [CrossRef]
- Huang, C.; Xu, Q.; Wang, Y.; Wang, Y.; Zhang, Y. Self-Supervised Masking for Unsupervised Anomaly Detection and Localization. IEEE Trans. Multimed. 2023, 25, 4426–4438. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, K.; Dou, W.; Ma, Y. Cross-Attention Based Multi-Resolution Feature Fusion Model for Self-Supervised Cervical OCT Image Classification. IEEE/ACM Trans. Comput. Biol. Bioinform. 2023, 20, 2541–2554. [Google Scholar] [CrossRef]
- Yang, Z.; Liang, J.; Xu, Y.; Zhang, X.Y.; He, R. Masked Relation Learning for DeepFake Detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1696–1708. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, J.; Zhao, Y.P.; Lu, M.; Shi, J. Contrastive Multi-View Composite Graph Convolutional Networks Based on Contribution Learning for Autism Spectrum Disorder Classification. IEEE Trans. Biomed. Eng. 2023, 70, 1943–1954. [Google Scholar] [CrossRef]
- Yu, J.G.; Wu, Z.; Ming, Y.; Deng, S.; Wu, Q.; Xiong, Z.; Yu, T.; Xia, G.S.; Jiang, Q.; Li, Y. Bayesian Collaborative Learning for Whole-Slide Image Classification. IEEE Trans. Med. Imaging 2023, 42, 1809–1821. [Google Scholar] [CrossRef]
- Kragh, M.F.; Rimestad, J.; Lassen, J.T.; Berntsen, J.; Karstoft, H. Predicting Embryo Viability Based on Self-Supervised Alignment of Time-Lapse Videos. IEEE Trans. Med. Imaging 2022, 41, 465–475. [Google Scholar] [CrossRef]
- Luo, J.; Lin, J.; Yang, Z.; Liu, H. SMD Anomaly Detection: A Self-Supervised Texture–Structure Anomaly Detection Framework. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Huang, H.; Wu, R.; Li, Y.; Peng, C. Self-Supervised Transfer Learning Based on Domain Adaptation for Benign-Malignant Lung Nodule Classification on Thoracic CT. IEEE J. Biomed. Health Inform. 2022, 26, 3860–3871. [Google Scholar] [CrossRef]
- Schmidt, A.; Silva-Rodríguez, J.; Molina, R.; Naranjo, V. Efficient Cancer Classification by Coupling Semi Supervised and Multiple Instance Learning. IEEE Access 2022, 10, 9763–9773. [Google Scholar] [CrossRef]
- Kim, K.S.; Oh, S.J.; Cho, H.B.; Chung, M.J. One-Class Classifier for Chest X-Ray Anomaly Detection via Contrastive Patch-Based Percentile. IEEE Access 2021, 9, 168496–168510. [Google Scholar] [CrossRef]
- Tardy, M.; Mateus, D. Looking for Abnormalities in Mammograms With Self- and Weakly Supervised Reconstruction. IEEE Trans. Med. Imaging 2021, 40, 2711–2722. [Google Scholar] [CrossRef]
- Godson, L.; Alemi, N.; Nsengimana, J.; Cook, G.P.; Clarke, E.L.; Treanor, D.; Bishop, D.T.; Newton-Bishop, J.; Gooya, A.; Magee, D. Immune subtyping of melanoma whole slide images using multiple instance learning. Med. Image Anal. 2024, 93, 103097. [Google Scholar] [CrossRef]
- Bai, Y.; Li, W.; An, J.; Xia, L.; Chen, H.; Zhao, G.; Gao, Z. Masked autoencoders with handcrafted feature predictions: Transformer for weakly supervised esophageal cancer classification. Comput. Methods Programs Biomed. 2024, 244, 107936. [Google Scholar] [CrossRef]
- Ali, M.K.; Amin, B.; Maud, A.R.; Bhatti, F.A.; Sukhia, K.N.; Khurshid, K. Hyperspectral target detection using self-supervised background learning. Adv. Space Res. 2024, 74, 628–646. [Google Scholar] [CrossRef]
- Bastos, M. Human-Centered Design of a Semantic Annotation Tool for Breast Cancer Diagnosis. Available online: https://www.researchgate.net/profile/Francisco-Maria-Calisto/publication/379311291_Human-Centered_Design_of_a_Semantic_Annotation_Tool_for_Breast_Cancer_Diagnosis/links/66041361390c214cfd14da37/Human-Centered-Design-of-a-Semantic-Annotation-Tool-for-Breast-Cancer-Diagnosis.pdf (accessed on 13 July 2024).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description | Examples | Sources |
|---|---|---|---|
| Contrastive Learning | Methods that train models to distinguish between related and unrelated data samples. | SimCLR: A simple framework for the acquisition of contrastive visual representations | [11,27,28,36] |
| MoCo: Contrastive momentum for unsupervised learning of visual representations | |||
| Generative Models | Methods that train models to generate or reconstruct the input data, capturing the underlying data distribution. | Variational autoencoders (VAEs): Generative models that learn a latent representation of the data | [35,36,37,38] |
| Generative adversarial networks (GANs): Adversarial training of a generator to produce realistic samples | |||
| Predictive Models | Tasks that involve predicting some aspect of the input data require the model to understand and capture relevant features. | Predicting relative positions of image patches | [35] |
| Solving jigsaw puzzles formed from image patches | |||
| Predicting rotations applied to images |
| Selection Criteria | Details |
|---|---|
| Inclusion Criteria |
|
| Exclusion Criteria |
|
| Method | Application | AUC | Comparison Results | Reference |
|---|---|---|---|---|
| General-purpose contrastive SSL | LVO detection in CTA data | 0.88 | Competitive performance compared to the teacher model | [74] |
| ECG-MAE: Generative self-supervised pre-training | Multi-label ECG classification | 0.9474 (macro-averaged AUC) | Exceeded prior studies in downstream performance | [75] |
| AddNet-SCL | Clinical diagnosis using EEG signals | 94.2% | Competitive results compared to state-of-the-art methods | [76] |
| COVID-19 recognition system based on CT images | COVID-19 diagnosis | 0.989 | Achieved high recognition accuracy with limited training data | [77] |
| TS | COVID-19 classification from lung CT images | 1 | Highest accuracy achieved compared to existing models | [78] |
| Pre-training method based on transfer learning with SSL | Polyp detection in wireless endoscopy videos | 95.00 ± 2.09% | Achieved state-of-the-art results in polyp detection | [79] |
| SSL technique for OCT image classification | Differentiation between PCV and wet AMD from OCT images | 0.71 | Desirable performance with a small proportion of labeled data | [80] |
| Self-supervision pre-training-based fine-grained network | Differentiating malignant and benign SSPNs | 0.964 (internal testing set), 0.945 (external test set) | Robust performance in predicting SSPN malignancy | [81] |
| Hybrid few-shot multiple-instance learning model with SSL | Diffuse large B-cell lymphoma (DLBCL) versus follicular lymphoma (FL) classification in PET/CT images | 0.795 ± 0.009 | Outperformed typical counterparts in NHL aggressiveness prediction | [82] |
| DenSplitnet: Dense blocks with SSL | COVID-19 classification from chest CT scans | 0.95 | Outperformed other methods in COVID-19 diagnosis | [83] |
| SSL approach for MR video classification | Classification of anterior cruciate ligament tear injury from knee MR videos | 0.848 | Achieved reliable and explainable performance | [84] |
| SEND | Surface defect detection | 98.40% (average) | Achieved competitive performance with minimal computational consumption | [85] |
| GTPL and PLD | Semi-supervised skin lesion diagnosis | 89.19–94.76% | Improved semi-supervised classification performance | [86] |
| FixMatch-LS and FixMatch-LS-v2 | Medical image classification (skin lesion) | 91.63–95.44% | Improved performance with label smoothing and consistency constraints | [87] |
| MIXTURE: Human-in-the-loop explainable AI | Usual interstitial pneumonia diagnosis from pathology images | 0.90 (validation set), 0.86 (test set) | Achieved high accuracy with an explainable AI approach | [88] |
| LESS | Cytological WSI analysis | 96.86% | Outperformed state-of-the-art MIL methods on pathology WSIs | [89] |
| Semi-supervised learning for cough sound classification | COVID-19 versus healthy cough sound classification | 0.797 | Increased labeling consistency and improved classification performance | [90] |
| Morph-SSL | Longitudinal OCT scans for prediction of nAMD conversion | 0.779 | Outperformed end-to-end and pre-trained models | [91] |
| AntiViralDL | Predicting virus–drug associations | 0.8450 | Outperformed four benchmarked models | [92] |
| Multi-modal MRI based on contrastive learning | Diagnosis of major depressive disorder (MDD) | 0.7309 | Achieved 73.09% AUC | [93] |
| SSM | Anomaly detection and localization | 0.983 (Retinal-OCT), 0.939 (MVTec AD) | Outperformed several state-of-the-art methods | [94] |
| Self-supervised ViT-based model | Cervical OCT image classification | 0.9963 ± 0.0069 | Outperformed Transformers and CNNs | [95] |
| Masked relation learning | DeepFake detection | +2% AUC improvement | Outperformed state-of-the-art methods | [96] |
| Contrastive multi-view composite graph convolutional networks (CMV-CGCN) | Autism spectrum disorder (ASD) classification | 0.7338 | Outperformed state-of-the-art methods | [97] |
| Bayesian collaborative learning (BCL) | WSI classification | 95.6% (CAMELYON16), 96.0% (TCGA-NSCLC), 97.5% (TCGA-RCC) | Outperformed all compared methods | [98] |
| Temporal cycle consistency (TCC) | Predicting pregnancy likelihood from developing embryo videos | 0.64 | Outperformed time alignment measurement (TAM) | [99] |
| Multiscale two-branch feature fusion | Self-supervised image anomaly detection | 98.82% | Outperformed existing anomaly detection methods | [100] |
| Self-supervised transfer learning based on domain adaptation (SSTL-DA) | Benign–malignant lung nodule classification | 95.84% | Achieved competitive classification performance | [101] |
| Coupling SSL and MIL for WSI classification | WSI classification | 0.801 (Cohen’s kappa with 450 patch labels) | Achieved competitive performance with SSL and MIL baselines | [102] |
| CSIP | Automatic detection of diseased lung shadowing | 0.96 (average AUC) | Improved diagnostic performance compared to existing methods | [103] |
| Mixed self- and weakly supervised learning framework | Abnormality detection in medical imaging | Up to 0.86 (image-wise AUC) | Competitive results versus multiple state-of-the-art methods | [104] |
| Pathology-specific self-supervised models | Classification of gigapixel pathology slides | 0.80 (mean AUC) | Achieved competitive performance in immune subtype classification | [105] |
| MIL-based framework with self-supervised pre-training | Cancer classification from whole-slide images | 93.07% (accuracy), 95.31% | Outperformed existing methods | [106] |
| Automated differentiation between PCV and wet AMD | Optical coherence tomography (OCT) image analysis | 0.71 | Desirable performance compared to traditional supervised learning models | [107] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taherdoost, H. Beyond Supervised: The Rise of Self-Supervised Learning in Autonomous Systems. Information 2024, 15, 491. https://doi.org/10.3390/info15080491
Taherdoost H. Beyond Supervised: The Rise of Self-Supervised Learning in Autonomous Systems. Information. 2024; 15(8):491. https://doi.org/10.3390/info15080491
Chicago/Turabian StyleTaherdoost, Hamed. 2024. "Beyond Supervised: The Rise of Self-Supervised Learning in Autonomous Systems" Information 15, no. 8: 491. https://doi.org/10.3390/info15080491
APA StyleTaherdoost, H. (2024). Beyond Supervised: The Rise of Self-Supervised Learning in Autonomous Systems. Information, 15(8), 491. https://doi.org/10.3390/info15080491