
Intelligent Risk Evaluation for Investment Banking IPO Business Based on Text Analysis

Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. Construction of Text Quality Analysis System Based on Prospectus
3.1.1. Chinese Characters Level
3.1.2. Vocabulary Level
3.1.3. Sentence Level
3.1.4. Chapter Level
3.2. Construction of Company Quality Analysis System Based on Prospectus
3.2.1. Compliance Status
3.2.2. Industry Status
3.2.3. Technology Status
3.2.4. Management Status
3.2.5. Financial Status
3.3. Construction of Risk Intelligent Evaluation System for Investment Banking IPO Business
3.3.1. Feature Selection Based on a Random Forest Model
3.3.2. Risk Prediction Based on Deep Neural Network
3.3.3. Performance Metrics of Machine Learning
4. Application of Risk Intelligent Evaluation System for Investment Banking IPO Business
4.1. Data
4.2. Statistical Features of Risk Evaluation Indicators for Investment Banking IPO Business
4.3. Feature Selection of Risk Evaluation Indicators for Investment Banking IPO Business
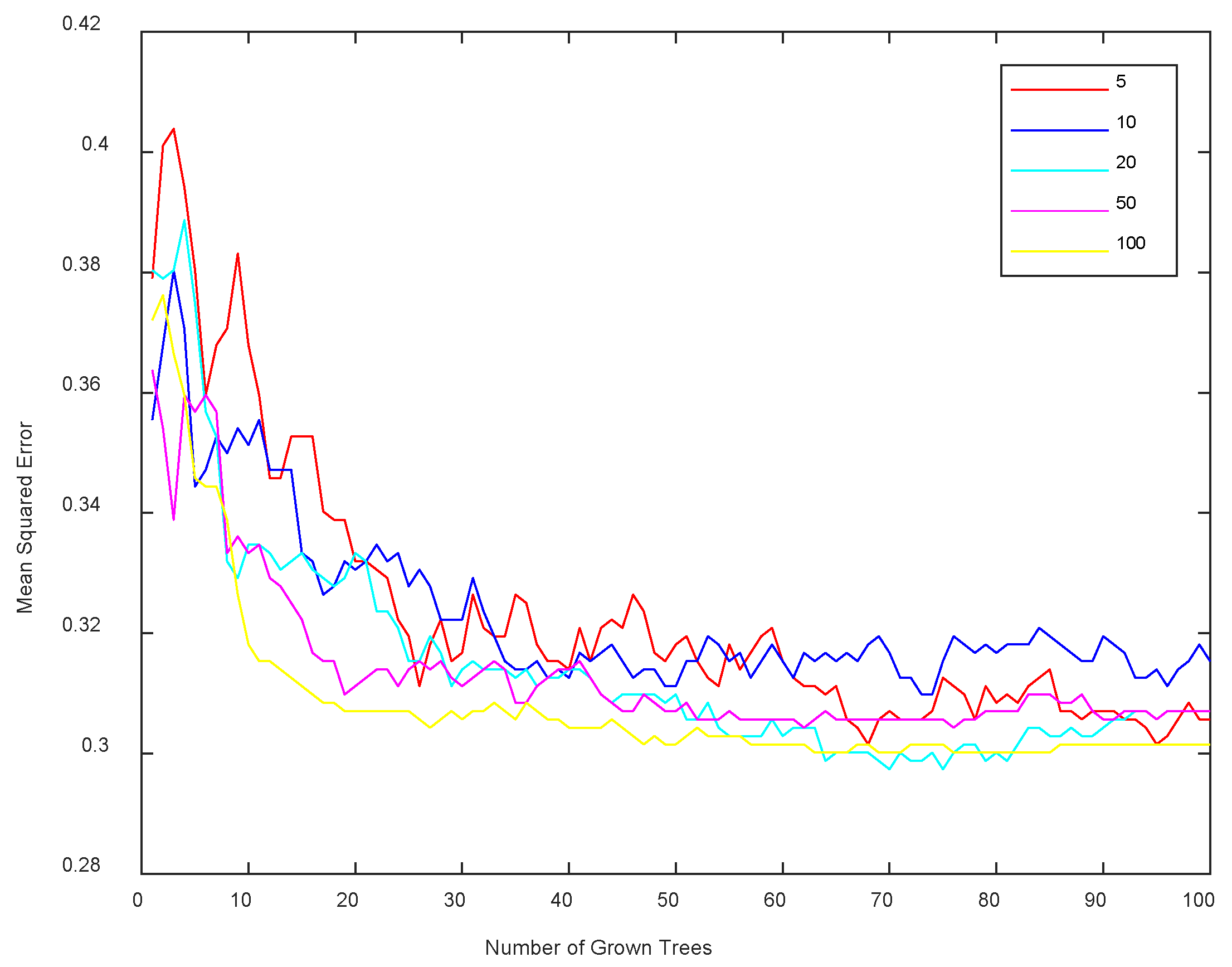
4.4. Risk Prediction for Investment Banking IPO Business Based on Random Forest
4.5. Risk Prediction for Investment Banking IPO Business Based on Deep Neural Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guay, W.; Samuels, D.; Taylor, D. Guiding through the fog: Financial statement complexity and voluntary disclosure. J. Account. Econ. 2016, 62, 234–269. [Google Scholar] [CrossRef]
- Bushee, B.J.; Gow, I.D.; Taylor, D.J. Linguistic complexity in firm disclosures: Obfuscation or information? J. Account. Res. 2018, 56, 85–121. [Google Scholar] [CrossRef]
- Lang, M.; Stice-Lawrence, L. Textual analysis and international financial reporting: Large sample evidence. J. Account. Econ. 2015, 60, 110–135. [Google Scholar] [CrossRef]
- Kelly, B.; Papanikolaou, D.; Seru, A.; Taddy, M. Measuring technological innovation over the long run. Am. Econ. Rev. Insights 2021, 3, 303–320. [Google Scholar] [CrossRef]
- Jiang, F.; Lee, J.; Martin, X.; Zhou, G. Manager sentiment and stock returns. J. Financ. Econ. 2019, 132, 126–149. [Google Scholar] [CrossRef]
- Bochkay, K.; Hales, J.; Chava, S. Hyperbole or reality? Investor response to extreme language in earnings conference calls. Account. Rev. 2020, 95, 31–60. [Google Scholar] [CrossRef]
- Bochkay, K.; Chychyla, R.; Nanda, D. Dynamics of CEO disclosure style. Account. Rev. 2019, 94, 103–140. [Google Scholar] [CrossRef]
- Hanley, K.W.; Hoberg, G. Dynamic interpretation of emerging risks in the financial sector. Rev. Financ. Stud. 2019, 32, 4543–4603. [Google Scholar] [CrossRef]
- Loughran, T.; McDonald, B. Textual analysis in accounting and finance: A survey. J. Account. Res. 2016, 54, 1187–1230. [Google Scholar] [CrossRef]
- Guo, L.; Shi, F.; Tu, J. Textual analysis and machine leaning: Crack unstructured data in finance and accounting. J. Financ. Data Sci. 2016, 2, 153–170. [Google Scholar] [CrossRef]
- Gentzkow, M.; Kelly, B.; Taddy, M. Text as data. J. Econ. Lit. 2019, 57, 535–574. [Google Scholar] [CrossRef]
- Chi, S.S.; Shanthikumar, D.M. Local bias in Google search and the market response around earnings announcements. Account. Rev. 2017, 92, 115–143. [Google Scholar] [CrossRef]
- Jung, M.J.; Naughton, J.P.; Tahoun, A.; Wang, C. Do firms strategically disseminate? Evidence from corporate use of social media. Account. Rev. 2018, 93, 225–252. [Google Scholar] [CrossRef]
- Baloria, V.P.; Heese, J. The effects of media slant on firm behavior. J. Financ. Econ. 2018, 129, 184–202. [Google Scholar] [CrossRef]
- Bonaime, A.; Gulen, H.; Ion, M. Does policy uncertainty affect mergers and acquisitions? J. Financ. Econ. 2018, 129, 531–558. [Google Scholar] [CrossRef]
- Cookson, J.A.; Niessner, M. Why don’t we agree? Evidence from a social network of investors. J. Financ. 2020, 75, 173–228. [Google Scholar] [CrossRef]
- Broeders, D.; Prenio, J. Innovative Technology in Financial Supervision (Suptech): The Experience of Early Users; Financial Stability Institute/Bank for International Settlements: Basel, Switzerland, 2018; Available online: https://www.bis.org/fsi/publ/insights9.pdf (accessed on 20 July 2024).
- Cerchiello, P.; Giudici, P. Big data analysis for financial risk management. J. Big Data 2016, 3, 1–12. [Google Scholar] [CrossRef]
- Nyman, R.; Kapadia, S.; Tuckett, D. News and narratives in financial systems: Exploiting big data for systemic risk assessment. J. Econ. Dyn. Control 2021, 127, 104119. [Google Scholar] [CrossRef]
- Hale, G.; Lopez, J.A. Monitoring banking system connectedness with big data. J. Econom. 2019, 212, 203–220. [Google Scholar] [CrossRef]
- Gandy, A.; Veraart, L.A. A Bayesian methodology for systemic risk assessment in financial networks. Manag. Sci. 2017, 63, 4428–4446. [Google Scholar] [CrossRef]
- Iturriaga, F.J.L.; Sanz, I.P. Bankruptcy visualization and prediction using neural networks: A study of US commercial banks. Expert. Syst. Appl. 2015, 42, 2857–2869. [Google Scholar] [CrossRef]
- Chatzis, S.P.; Siakoulis, V.; Petropoulos, A.; Stavroulakis, E.; Vlachogiannakis, N. Forecasting stock market crisis events using deep and statistical machine learning techniques. Expert. Syst. Appl. 2018, 112, 353–371. [Google Scholar] [CrossRef]
- Gong, C.; Liu, T.; Yang, J.; Tao, D. Large-margin label-calibrated support vector machines for positive and unlabeled learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3471–3483. [Google Scholar] [CrossRef]
- Döpke, J.; Fritsche, U.; Pierdzioch, C. Predicting recessions with boosted regression trees. Int. J. Forecast. 2017, 33, 745–759. [Google Scholar] [CrossRef]
- Hsieh, J.P.A.; Rai, A.; Xu, S.X. Extracting business value from IT: A sensemaking perspective of post-adoptive use. Manag. Sci. 2011, 57, 2018–2039. [Google Scholar] [CrossRef]
- Derakhshan, A.; Beigy, H. Sentiment analysis on stock social media for stock price movement prediction. Eng. Appl. Artif. Intell. 2019, 85, 569–578. [Google Scholar] [CrossRef]
- Affuso, E.; Lahtinen, K.D. Social media sentiment and market behavior. Empir. Econ. 2019, 57, 105–127. [Google Scholar] [CrossRef]
- Ouyang, Z.; Chen, S.; Lai, Y.; Yang, X. The correlations among COVID-19, the effect of public opinion; the systemic risks of China’s financial industries. Phys. A Stat. Mech. Its Appl. 2022, 600, 127518. [Google Scholar] [CrossRef]
- Miller, B.P. The effects of reporting complexity on small and large investor trading. Account. Rev. 2010, 85, 2107–2143. [Google Scholar] [CrossRef]
- Peng, Y.; Albuquerque, P.H.; Kimura, H.; Saavedra, C.A. Feature selection and deep neural networks for stock price direction forecasting using technical analysis indicators. Mach. Learn. Appl. 2021, 5, 100060. [Google Scholar] [CrossRef]
- Sahu, S.K.; Mokhade, A.; Bokde, N.D. An overview of machine learning, deep learning, and reinforcement learning-based techniques in quantitative finance: Recent progress and challenges. Appl. Sci. 2023, 13, 1956. [Google Scholar] [CrossRef]
- Nazareth, N.; Reddy, Y.V.R. Financial applications of machine learning: A literature review. Expert. Syst. Appl. 2023, 219, 119640. [Google Scholar] [CrossRef]
- Dessain, J. Machine learning models predicting returns: Why most popular performance metrics are misleading and proposal for an efficient metric. Expert. Syst. Appl. 2022, 199, 116970. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Lever | Feature | Indicator |
|---|---|---|
| Chinese character | validity of Chinese characters | the number of valid characters |
| commonality of Chinese characters | the number of common characters | |
| the number of sub-common characters | ||
| Vocabulary | commonality of vocabulary | the number of common vocabularies |
| part of speech complexity | the proportion of adverbs | |
| vocabulary semantic difficulty | the proportion of financial vocabulary | |
| Sentence | syntactic complexity | the proportion of adverbs |
| the proportion of common vocabulary | ||
| the proportion of financial vocabulary | ||
| the proportion of valid characters | ||
| the proportion of common characters | ||
| the proportion of sub-common characters | ||
| sentence length | the average number of characters in the sentence | |
| the average number of vocabularies in the sentence | ||
| Chapter | chapter length | the number of characters |
| the number of vocabularies | ||
| the number of sentences |
| Level | Prospectus Section | Indicator |
|---|---|---|
| Compliance status | corporate governance and independence | the number of secondary titles |
| the number of tertiary titles | ||
| the number of quaternary titles | ||
| the number of characters | ||
| Industry status | business and technology: company’s main business, main products, or services; the basic situation of the industry in which the company operates | the number of tertiary titles |
| the number of quaternary titles | ||
| the number of characters | ||
| market share | ||
| sunrise industry or not | ||
| Technology status | business and technology: company’s core technology and research and development; core technologies of the company’s main products | the number of tertiary titles |
| the number of quaternary titles | ||
| the number of characters | ||
| attributes of science and innovation | ||
| Management status | company basic situation: directors, supervisors, senior managers, and core technical personnel | the number of tertiary titles |
| the number of quaternary titles | ||
| the number of characters | ||
| the disclosure of close relatives | ||
| the number of directors | ||
| the number of supervisors | ||
| the number of senior managers | ||
| the number of core technical personnel | ||
| the average age of directors | ||
| the average age of supervisors | ||
| the average age of senior managers | ||
| the average age of core technical personnel | ||
| Financial status | financial and accounting information and management analysis: major financial indicators for the reporting period | the current ratio |
| the asset–liability ratio | ||
| accounts receivable turnover | ||
| inventory turnover | ||
| increase the rate of the main business revenue |
| Passing Rate | Passing Time | Review Inquiries | Audit Replies | Legal Replies | Number of Samples | |
|---|---|---|---|---|---|---|
| Information technology | 66.98 | 254.72 | 5.51 | 4.64 | 3.06 | 318 |
| High-end equipment | 76.92 | 219.31 | 5.85 | 4.77 | 3.54 | 13 |
| New materials | 82.05 | 241.18 | 5.54 | 4.26 | 3.6 | 39 |
| New energy | 70.33 | 257.55 | 5.77 | 4.35 | 3.15 | 91 |
| Energy saving and environmental protection | 70 | 251.80 | 5.53 | 4.59 | 3.21 | 120 |
| Biomedicine | 62.71 | 258.22 | 5.99 | 4.81 | 3.62 | 177 |
| Others | 41.78 | 254.25 | 5.03 | 4.36 | 3.03 | 146 |
| Total | 63.61 | 253.99 | 5.60 | 4.59 | 3.24 | 904 |
| Accuracy Rate | Precision Rate | Recall Rate | |
|---|---|---|---|
| Feature selection | 0.6835 | 0.9730 | 0.8030 |
| All features | 0.6859 | 0.9640 | 0.8015 |
| Review Inquiries | Audit Inquiries | Legal Inquiries | Passing Time | |
|---|---|---|---|---|
| Training results | 0.3748 | 0.3744 | 0.4089 | 0.4126 |
| Fitting results | 0.0831 | 0.2118 | 0.2067 | 0.0218 |
| MAE | 515.8704 | 361.8981 | 248.3763 | 8.26 × 103 |
| MSE | 2.50 × 103 | 1.15 × 103 | 536.2318 | 1.15 × 106 |
| RMSE | 50.0357 | 33.8409 | 23.1567 | 1.07 × 103 |
| Description of Risk | Main Feature |
|---|---|
| Review inquiries | Compliance status: secondary titles, tertiary titles, quaternary titles, the number of characters; the number of sub-common characters; the number of sentences; the attributes of science and innovation; the asset–liability ratio |
| Audit inquiries | Compliance status: secondary titles, tertiary titles, quaternary titles, the number of characters; technology status: the number of characters; the proportion of financial vocabulary; the proportion of sub-common characters; the number of sub-common characters |
| Legal inquiries | Compliance status: secondary titles, tertiary titles, quaternary titles, the number of characters; the proportion of common vocabulary; the proportion of financial vocabulary; the proportion of sub-common characters; the number of financial vocabularies |
| Review time | The number of vocabularies; the number of adverbs; the number of common vocabularies; similarity; the proportion of adverbs; the proportion of sub-common characters; compliance status: tertiary titles, the number of sentences |
| Accuracy Rate | Precision Rate | Recall Rate | |
|---|---|---|---|
| Dimension reduction variables | 0.6816 | 0.9333 | 0.8053 |
| All variables | 0.7273 | 0.9839 | 0.8175 |
| Review Inquiries | Audit Inquiries | Legal Inquiries | Passing Time | Initial Underpricing | |
|---|---|---|---|---|---|
| Fitting results | 0.1489 | 0.2007 | 0.1990 | 0.0157 | 0.0193 |
| MAE | 2.9979 | 1.8473 | 1.4740 | 45.8540 | 0.0651 |
| MSE | 13.7366 | 5.5815 | 3.0562 | 7786.5685 | 0.0133 |
| RMSE | 3.7063 | 2.3625 | 1.7482 | 88.2415 | 0.1154 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wang, C.; Liu, X. Intelligent Risk Evaluation for Investment Banking IPO Business Based on Text Analysis. Information 2024, 15, 498. https://doi.org/10.3390/info15080498
Zhang L, Wang C, Liu X. Intelligent Risk Evaluation for Investment Banking IPO Business Based on Text Analysis. Information. 2024; 15(8):498. https://doi.org/10.3390/info15080498
Chicago/Turabian StyleZhang, Lei, Chao Wang, and Xiaoxing Liu. 2024. "Intelligent Risk Evaluation for Investment Banking IPO Business Based on Text Analysis" Information 15, no. 8: 498. https://doi.org/10.3390/info15080498