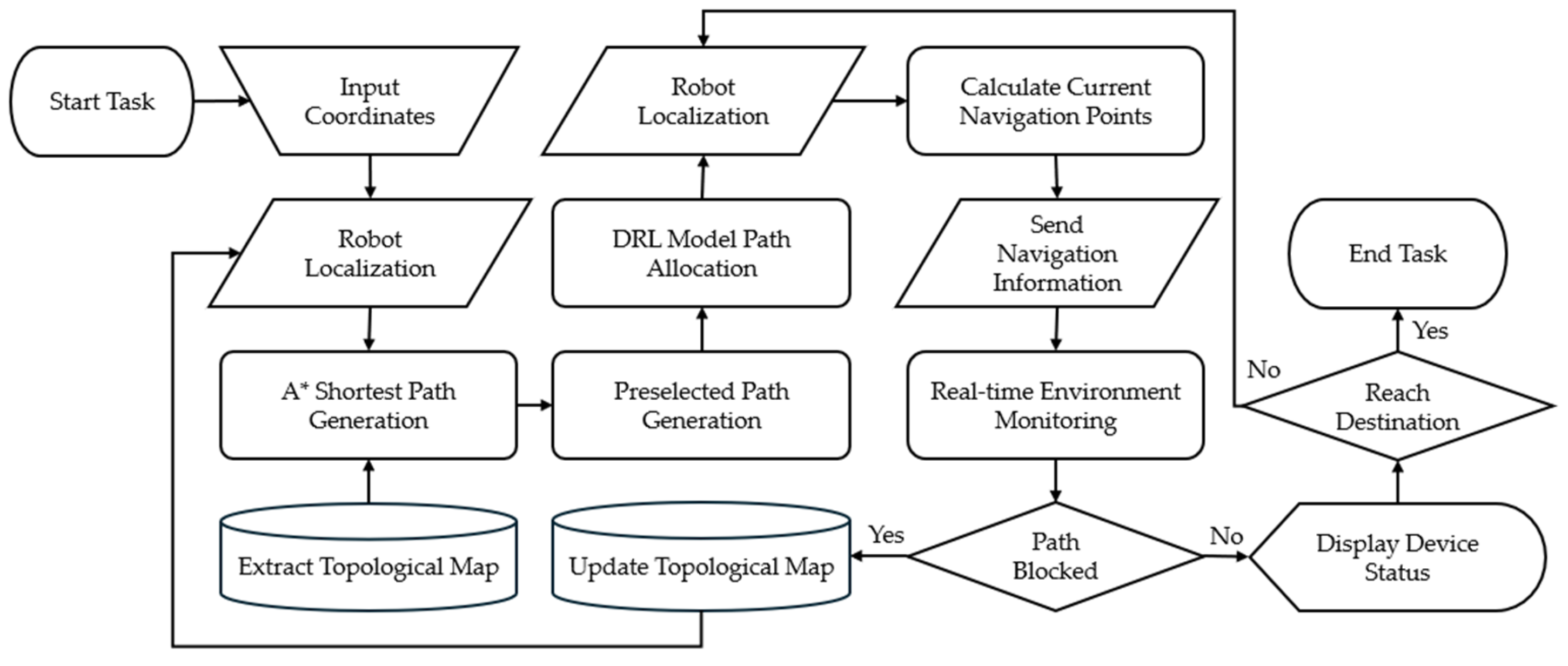
In the proposed multi-robot navigation system, there are four parts: (i) system architecture and process, (ii) environmental map representation, (iii) preselected path generation, and (iv) deep reinforcement learning model. They are described as follows.
3.3. Preselected Path Generation
In this study, the preselected path generation aims to plan three preference paths for each robot from the start point to the end point, one of which is generated by the A* algorithm, while the other two are simpler to use the preferred longitudinal path or preferred horizontal path, and this planning strategy is simple and effective to provide three flexible preference paths. The A* algorithm is a heuristic search algorithm, and the core of the algorithm is to find the minimum cost path by considering the known distance of the path and the estimated remaining distance at the same time during searching. The core of the algorithm is to find the minimum cost path by considering both the known distance and the estimated remaining distance of the path during the search process. Firstly, the start point
and end point
of the robot are defined and the start point
is put into an open list
, which is used to store the nodes to be evaluated, as expressed by
and another closed list
is used to store the evaluated nodes, as expressed by
In the search phase, new nodes around will be continuously added to the open list
, their total cost
will be calculated, and the node with the lowest cost will be further placed in the closed list
. The selection process is represented as
In calculating the total cost
, the first step is to determine whether the node is not included in the closed list
. If it is not included, then the calculation of the total cost f (n) is carried out, and the total cost consists of the actual cost from the starting point to the current node, which is expressed by
and the estimated cost from the current node to the end point, which is expressed by
In this study, we use Manhattan distance as the trigger function
, which is expressed by
Therefore, in the actual cost
,
represents the cumulative cost from the starting point to the current node, and the cost from the current node to the new node is calculated using the initiating function
. The estimated cost
is directly calculated from the current node to the end point using the heuristic function
. Finally, the actual cost and the estimated cost form the total cost
, which is denoted as
After calculating the total cost, the node with the lowest cost will be moved to the closed list
, and further checked whether it reaches the end point to determine whether to end the search or not, and if it does not reach the end point, then keep updating the open list and calculating the cost. Among them, this study does not use the weights mentioned in
Section 3.1 in the path planning stage and treats the scattering of nodes in the map as uniform, so
can be directly regarded as one.
For the other two preselected paths, this study uses a simpler way to plan the paths, and each of them follows the priority of traveling in the vertical or horizontal direction, and the actual cost of
when traveling in the vertical axis only takes the moving distance in the y-axis direction into account, which is expressed by
The actual cost
when traveling in the horizontal direction only considers the moving distance in the x-axis direction, which is expressed by
The sum of the two is the total cost
, denoted as
Therefore, the length of the paths planned by the A* algorithm and the preferred walking strategies on the vertical and horizontal axes are the same, and because of this, the length of the paths is the same for all cases when the deep reinforcement learning model is allowed to choose the paths in
Section 3.4. One example of three preselected paths is shown in
Figure 7. The paths selected by the A* algorithm, the vertical axis priority strategy, and the horizontal axis priority strategy are shown in
Figure 7a–c, respectively.
3.4. Deep Reinforcement Learning Model
In this study, the deep reinforcement learning model is the key component for selecting one path for each robot from each of the three preselected paths planned for each robot in
Section 3.3. There are two parts: (i) environment modeling and (ii) algorithm and model architecture. They are described as follows.
In environment modeling, this study introduces how to model the path selection problem, including the inputs, outputs, and learning objectives of the deep reinforcement learning model; in other words, this subsection introduces the observation space, action, and reward of deep reinforcement l1earning.
First, the environment will continue the topological map content in
Section 2.2, set as shown in
Table 4, a 7 × 3 size node map with 10 robots. In this environment, the state S consists of the state
of each robot, denoted as
and the state
of each robot contains three preselected paths
to
of each robot, denoted as
To ensure a consistent state size, each path is standardized to contain 12 nodes. In the case that the number of nodes is insufficient, it will be filled to a fixed length of 12 by zero padding; thus, it is expressed by
where
and
denotes the actual number of nodes in the
th preselected path of the
i-th robot. Thus, the actual state dimensions will be ten robots and three preselected paths, and the length of the preselected paths is twelve, which describe the location of each robot and its preselected paths and provide the model with the complete information needed for decision making.
In this setting, action A describes the model as the path chosen by each robot; specifically, the dimension of action A is fixed to ten (the number of robots), which selects a path for each robot from the three preselected paths that is the best path for the whole, denoted as
where
The integer values 0, 1, and 2 are used to represent the first, second, and third preselected path, respectively. Thus, the action describes the path selection of the i-th robot.
The purpose of the reward
design is to guide the model to select the optimal path combinations to minimize the number of intersection conflicts between robots. Specifically, in this study, the design of the reward function in the deep reinforcement learning model is very simple, and the reward R is expressed as
It only takes into account the difference between the total number of standard actions of all the robots,
, and the total number of current actions,
, which is a more direct response to the advantages and disadvantages of the current path combinations. In the calculation of the total number of conflicts, this study considers the current position of the robot at each time point, such as at the same time point at the same node where there are n sets of robots located in the same node, and the number is greater than 1; then, it is regarded as n times of conflict. First, each path needs to be developed to obtain the time point when the robot passes through each node, where the weight set by the topology is considered, which is used as the basis for calculating the node and time pair
that will be obtained, including the position information and time information, expressed as
Furthermore, the set of all robots
located at node
at each time point
is counted and is denoted as
and, finally, obtains the total number of collisions
in
In this study, we use proximal policy optimization (PPO) [
30] as the algorithm for deep reinforcement learning. It is based on the actor-critic architecture, which consists of two main components: the actor and the critic. The actor is responsible for determining the actions to be taken in each state by learning a policy function. The critic is responsible for evaluating the quality of these actions by learning a value function that estimates the expected returns following the current policy in the given state. PPO replaces the traditional policy gradient objective with a clipped surrogate objective function. This objective function considers the ratio between the current policy gradient and the old policy gradient and clips the ratio when it exceeds a certain range. This approach limits the magnitude of policy updates, avoiding instability caused by excessive policy changes and thereby improving training stability and effectiveness. Concurrently, the actor updates the policy by maximizing the clipped objective function, while the critic updates the value function by minimizing the mean squared error between predicted and actual returns. This process helps evaluate the performance of the current policy and provides the actor with the basis for policy updates, which is expressed by
where
is the ratio between the probability of the old and new strategies,
is the advantage function, and ε is the hyperparameter that controls the cropping range. By limiting the magnitude of strategy updating, this approach avoids the instability that may be caused by too large a strategy change, thus improving the stability and effectiveness of training. Meanwhile, PPO is designed based on the actor-critic architecture, where the actor is responsible for inputting the action strategy and updating the target function by maximizing the pruned strategy target function, while the critic is based on the state-value function and updating it by minimizing the mean squared error, which is useful for evaluating the performance of the current strategy. The main purpose is to help evaluate the performance of the current strategy and to provide an updated strategy for the actors.
In the model architecture, this study adopts the Multi-Layer Perceptron (MLP) architecture, in which the neurons in each layer are fully connected with all the neurons in the previous layer so that the MLP can efficiently simulate high-dimensional and non-linear function relationships. In the experiments, the number of neurons in the input layer is 360, with a total of 21 nodes, 10 robots, and a default maximum path of 12. In this case, we simply design two hidden layers with sixty-four neurons each and use the Rectified Linear Unit (ReLU) as the activation function of the neurons. Finally, the model has a total of 10 outputs to select paths for 10 robots.












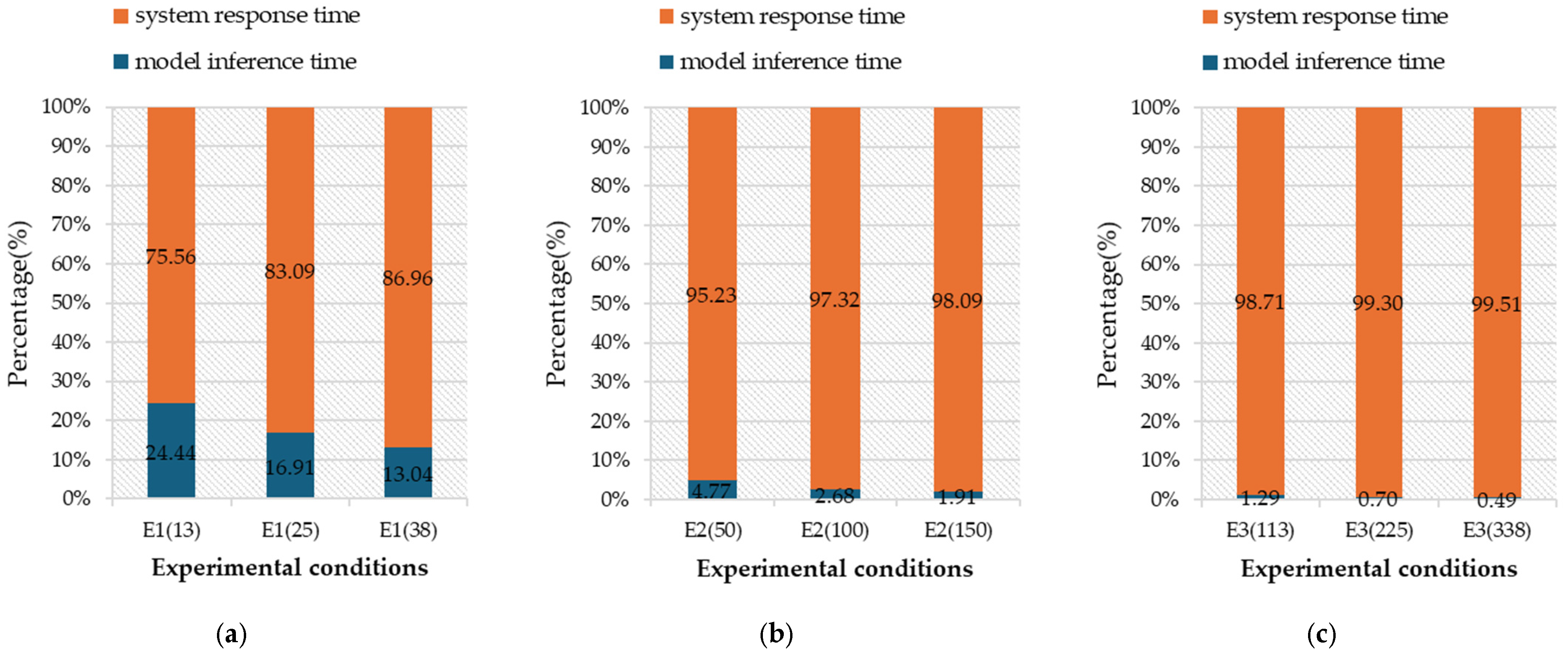



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}