
Recognizing Digital Ink Chinese Characters Written by International Students Using a Residual Network with 1-Dimensional Dilated Convolution

Abstract
:1. Introduction
- (1)
- The paper proposes more expressive ten-dimensional feature representation that includes spatial, temporal, and writing direction information for each point from the raw data sampled, significantly improving classification accuracy.
- (2)
- The paper first uses one-dimensional dilated convolutional networks for DICCR, a novel approach in this domain. The proposed 1-D ResNetDC effectively captures multi-scale contextual information in DICCs, encompassing both short-distance and long-distance sequence correlations.
- (3)
- The model is compact and has a reduced number of parameters along with excellent scalability.
2. Related Work
2.1. Digital Ink Chinese Characters Recognition
2.1.1. RNN Approaches
2.1.2. Graph Neural Network Approaches
2.1.3. Convolution Neural Network Approaches
2.2. Digital Ink Trajectory Representation
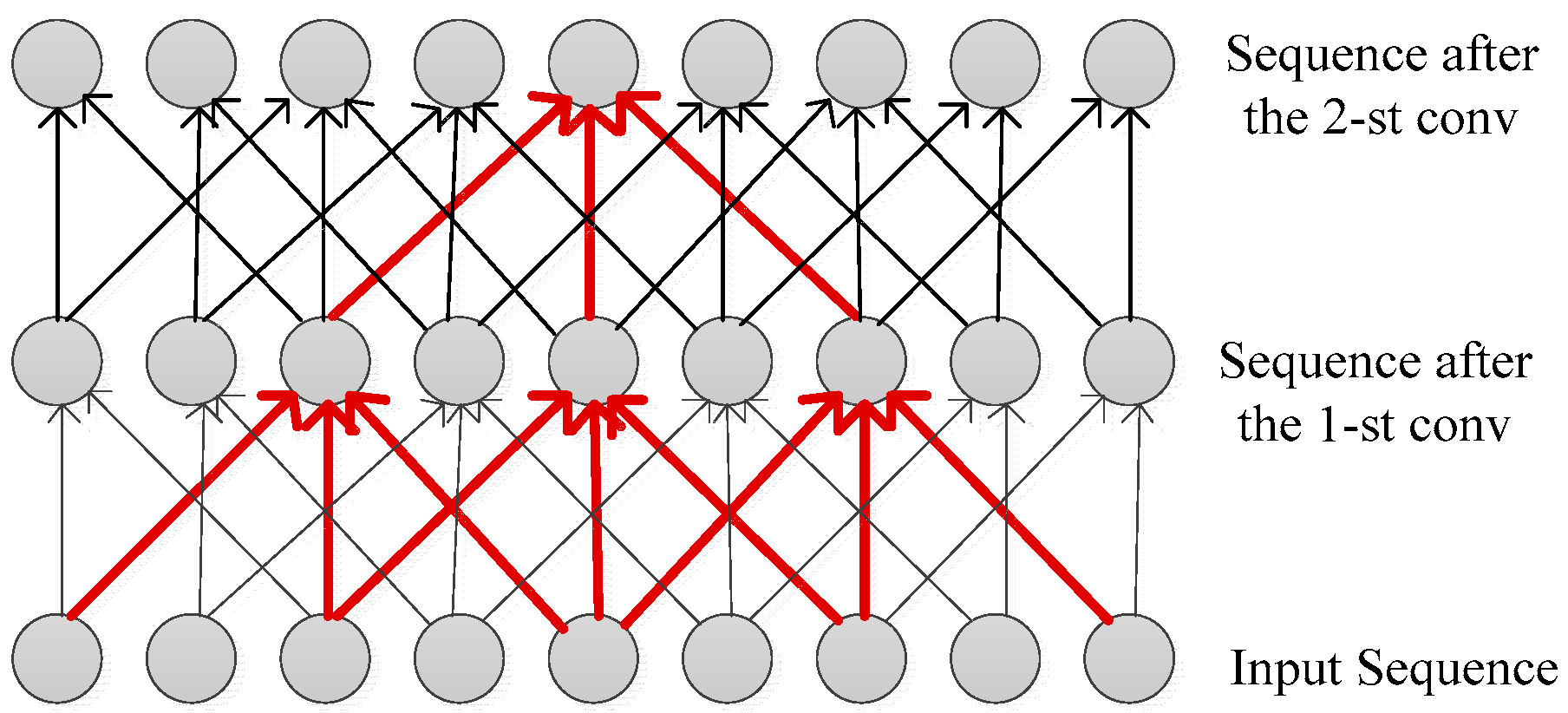
2.3. Dilated Convolution
3. Preprocessing of DICCs for International Students
3.1. Trajectory Normalization
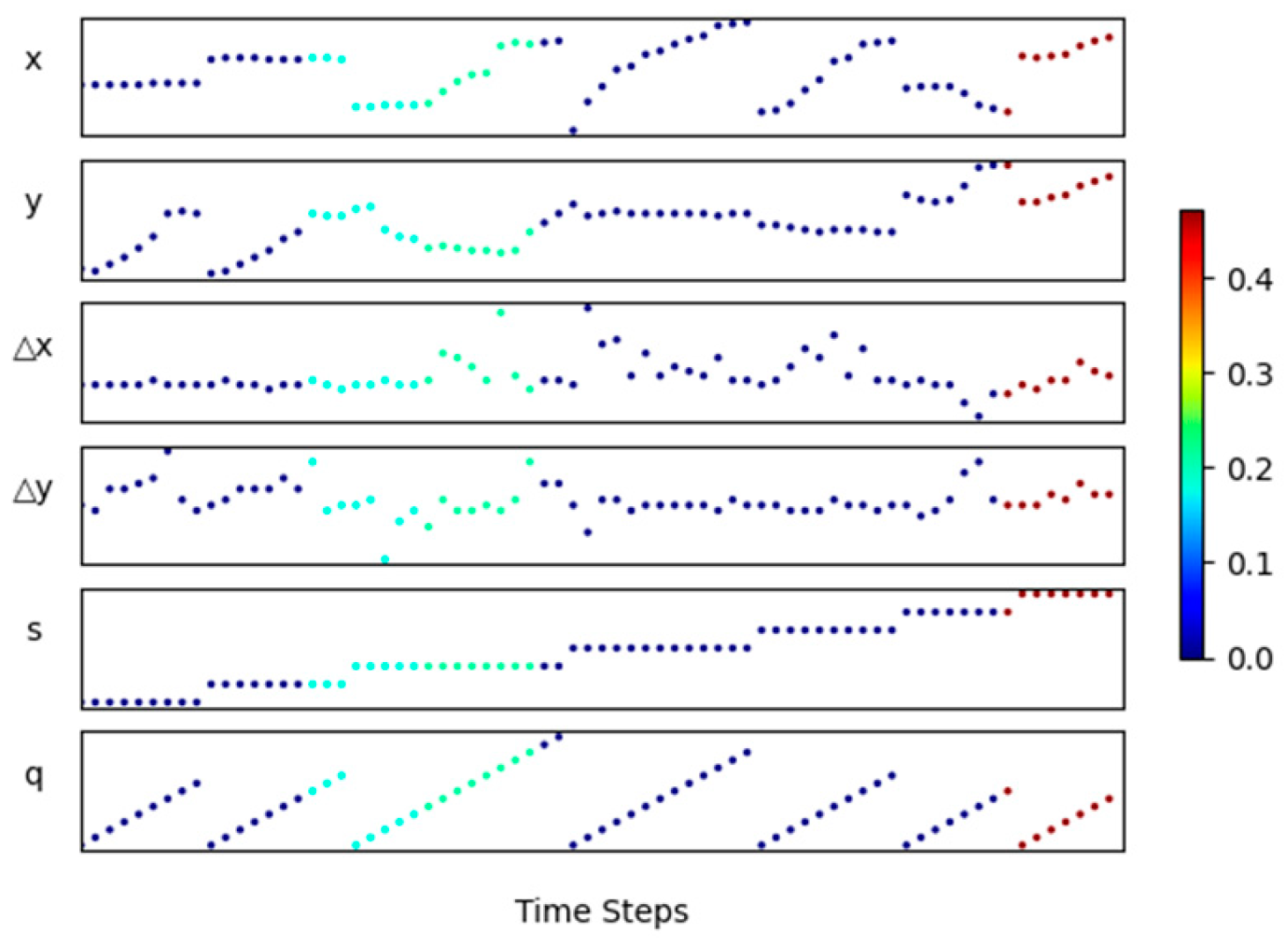
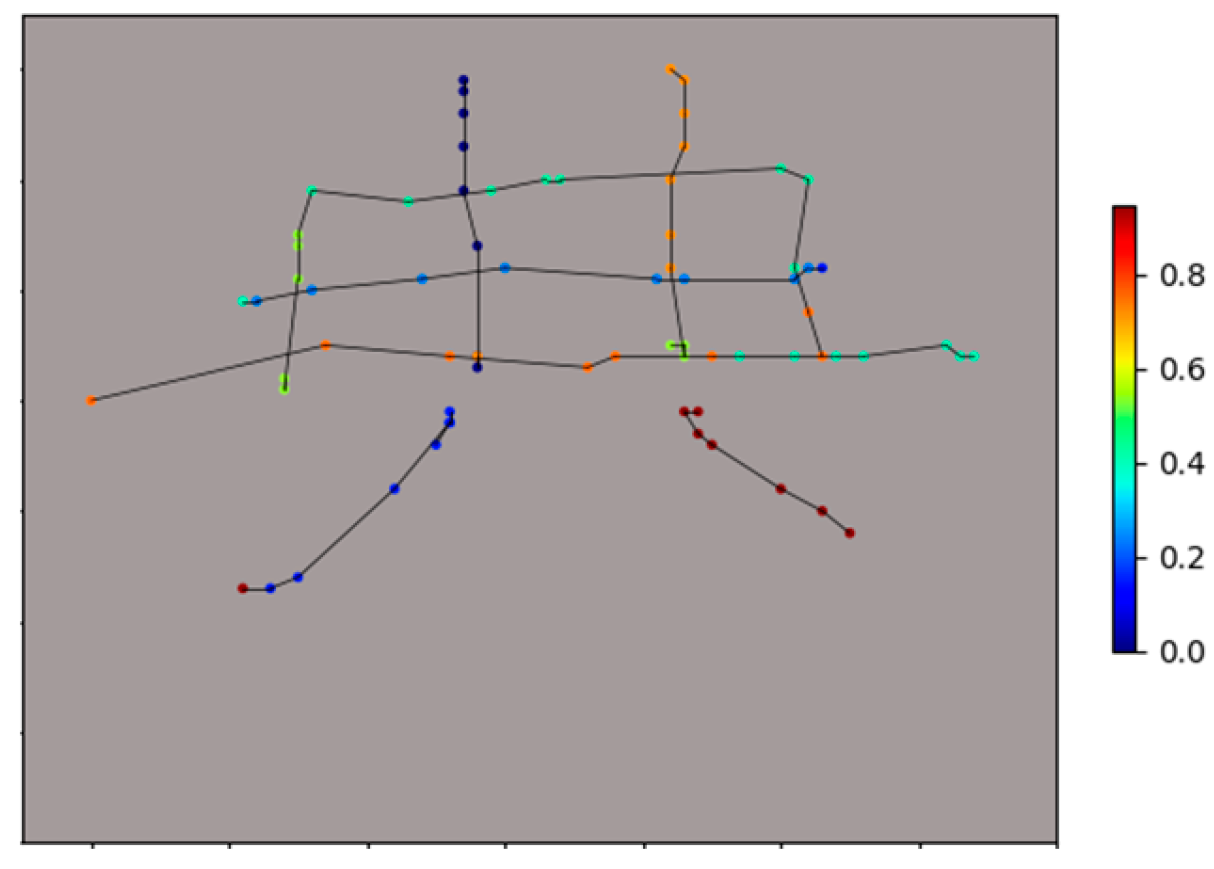
3.2. Trajectory Representation
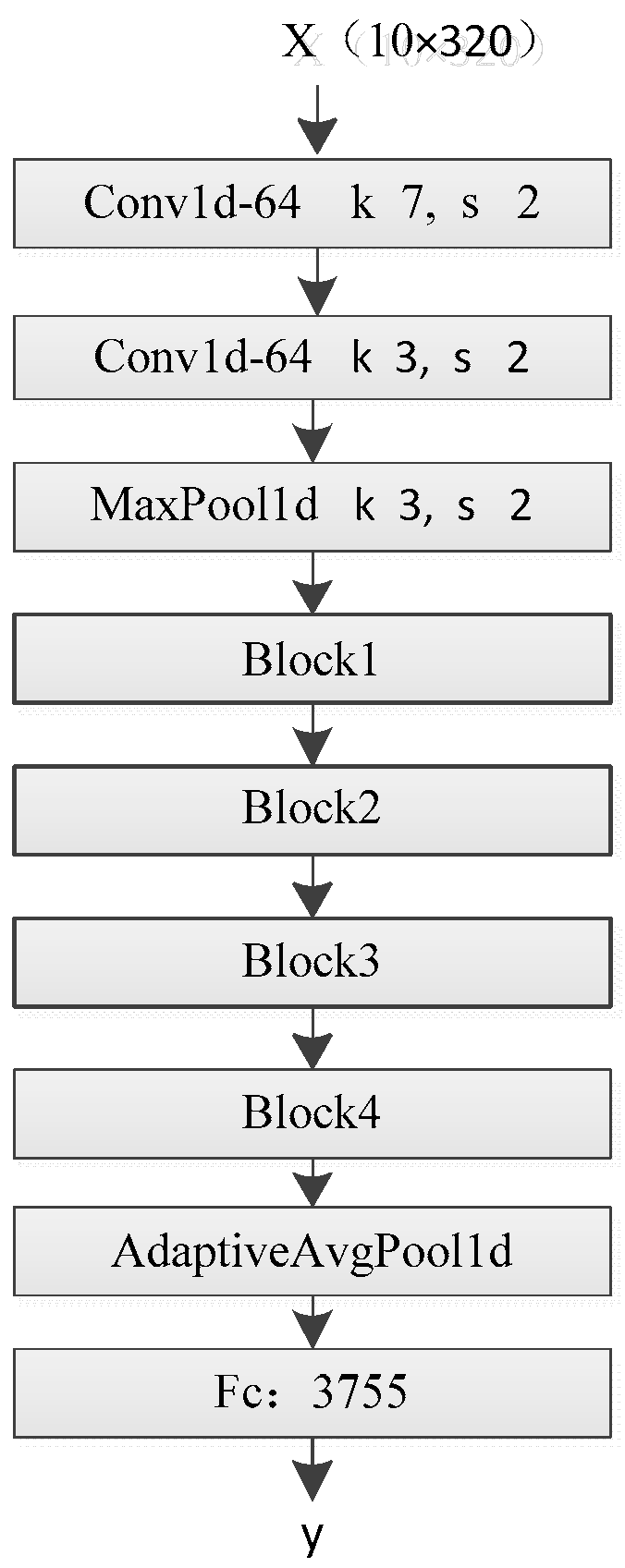
4. One-Dimensional Residual Networks with Dilation Convolution
4.1. Deep Structure
4.2. Residual Modules
4.3. Multi-Scale Dilated Convolution
4.4. Multi-Scale Convolution Kernels
5. Recognizing DICCs Based on the Pre-Trained Model
6. Experiments
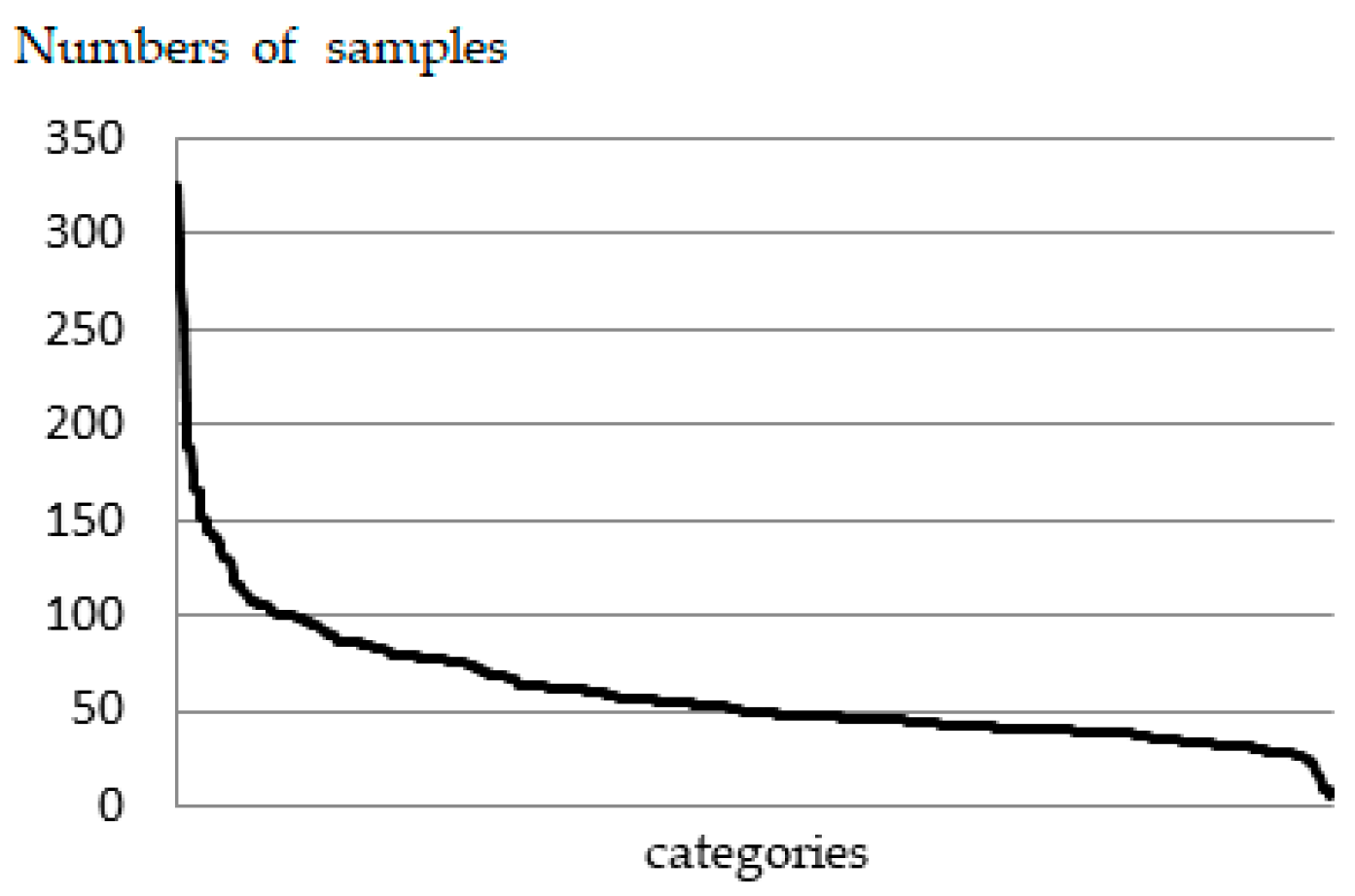
6.1. Datasets
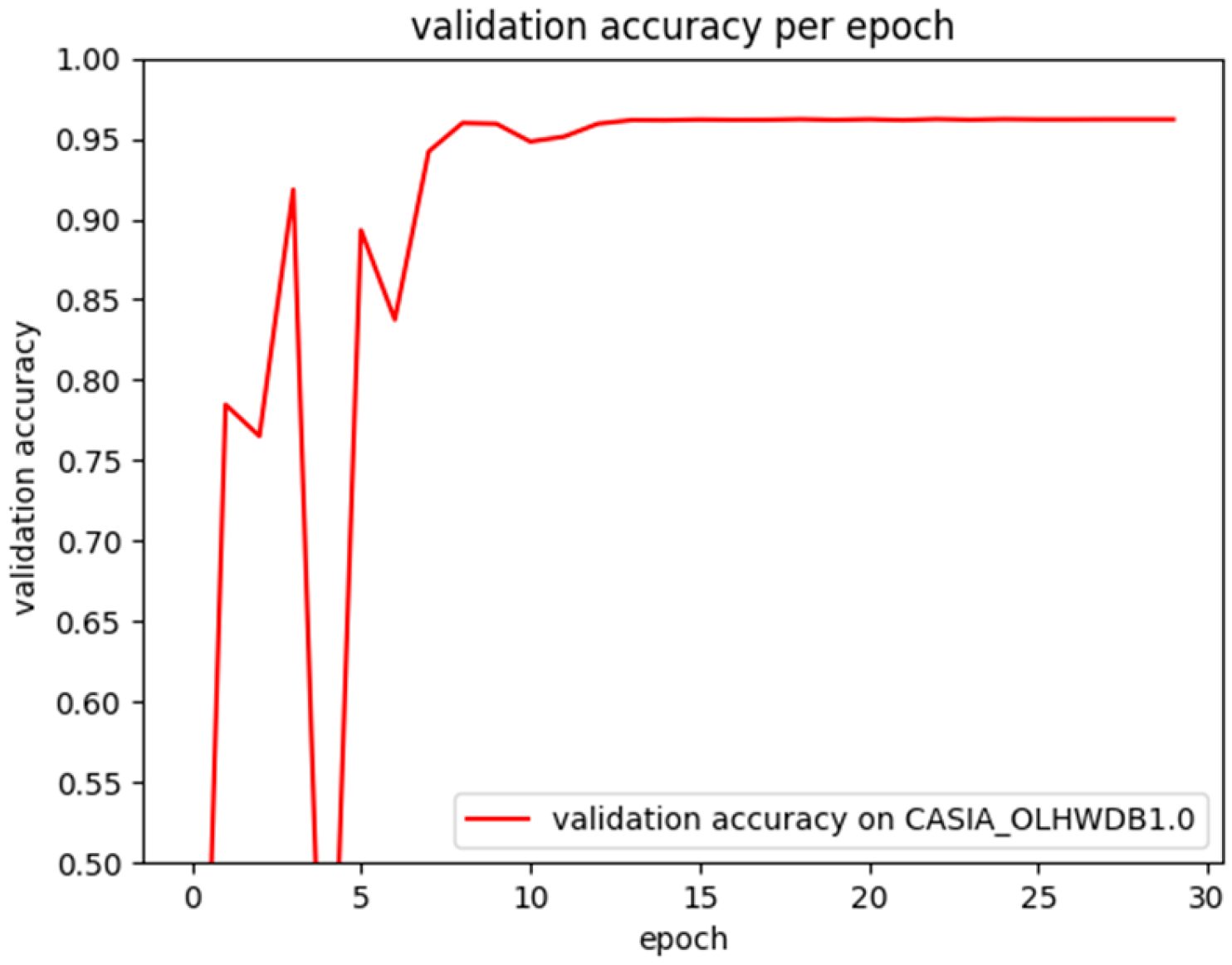
6.2. Model Training
6.3. Influence of Different Trajectory Representation on Classification Accuracy
6.4. Ablation Experiment
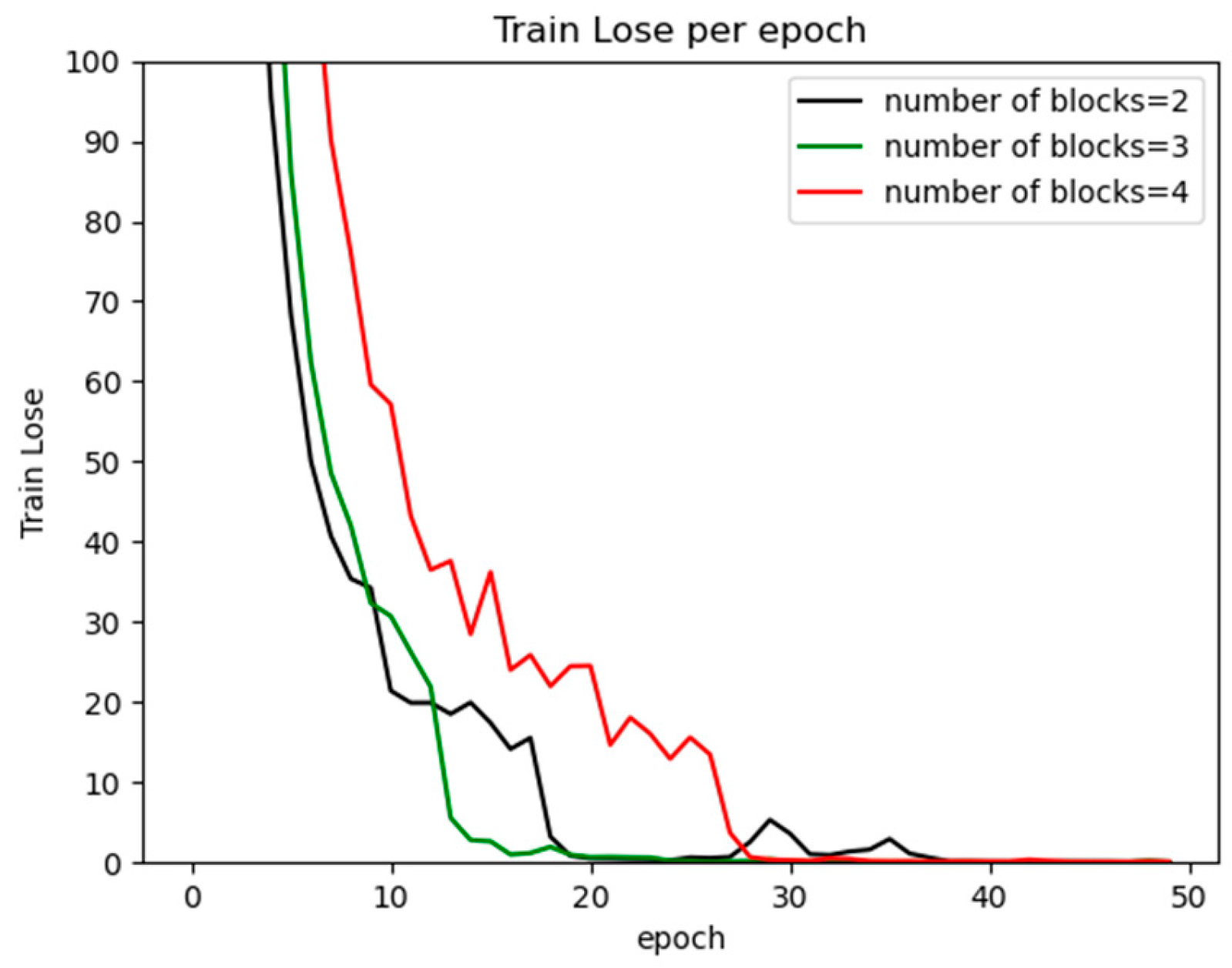
6.4.1. Varying Numbers of Block Modules
6.4.2. Varying Dilation Rates
6.4.3. Scalability of Feature Representation
6.5. Result Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jin, L.W.; Zhong, Z.Y.; Yang, Z.; Xie, Z.; Sun, J. Applications of deep learning for handwritten Chinese character recognition: A review. Acta Autom. Sin. 2016, 42, 1125–1141. [Google Scholar] [CrossRef]
- Sun, S.J.; Zhang, X.W. The evolution and development trend of computer-aided Chinese character writing teaching technology for international learners of Chinese. TCSOL Stud. 2022, 3, 68–76. [Google Scholar] [CrossRef]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3642–3649. [Google Scholar] [CrossRef]
- Graham, B. Sparse arrays of signatures for online character recognition. arXiv 2013, arXiv:1308.0371. [Google Scholar]
- Zhang, X.-Y.; Bengio, Y.; Liu, C.-L. Online and offline handwritten Chinese character recognition: A comprehensive study and new benchmark. Pattern Recognit. 2017, 61, 348–360. [Google Scholar] [CrossRef]
- Zhong, Z.; Jin, L.; Xie, Z. High performance offline handwritten Chinese character recognition using GoogLeNet and directional feature maps. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 846–850. [Google Scholar] [CrossRef]
- Gan, J.; Wang, W.; Lu, K. A new perspective: Recognizing online handwritten Chinese characters via 1-dimensional CNN. Inf. Sci. 2019, 478, 375–390. [Google Scholar] [CrossRef]
- Zhang, X.-Y.; Yin, F.; Zhang, Y.-M.; Liu, C.-L.; Bengio, Y. Drawing and Recognizing Chinese Characters with Recurrent Neural Network. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 849–862. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Du, J.; Dai, L. Trajectory-based Radical Analysis Network for Online Handwritten Chinese Character Recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018. [Google Scholar]
- Bai, H.; Zhang, X. Recognizing Chinese characters in digital ink from non-native language writers using hierarchical models. In Proceedings of the Second International Workshop on Pattern Recognition, Singapore, 19 June 2017; Jiang, X., Arai, M., Chen, G., Eds.; SPIE: Paris, France, 2017; p. 104430A. [Google Scholar] [CrossRef]
- Bai, H.; Zhang, X.-W. Improved hierarchical models for non-native Chinese handwriting recognition using hidden conditional random fields. In Proceedings of the Fifth International Workshop on Pattern Recognition, Chengdu, China, 24 June 2020; Jiang, X., Zhang, C., Song, Y., Eds.; SPIE: Paris, France, 2020; p. 9. [Google Scholar] [CrossRef]
- Liu, C.-L.; Marukawa, K. Pseudo two-dimensional shape normalization methods for handwritten Chinese character recognition. Pattern Recognit. 2005, 38, 2242–2255. [Google Scholar] [CrossRef]
- Ding, K.; Deng, G.; Jin, L. An Investigation of Imaginary Stroke Techinique for Cursive Online Handwriting Chinese Character Recognition. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 531–535. [Google Scholar] [CrossRef]
- Okamoto, M.; Yamamoto, K. On-line handwriting character recognition using direction-change features that consider imaginary strokes. Pattern Recognit. 1999, 32, 1115–1128. [Google Scholar] [CrossRef]
- Bai, Z.-L.; Huo, Q. A study on the use of 8-directional features for online handwritten Chinese character recognition. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Republic of Korea, 31 August–1 September 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 262–266. [Google Scholar] [CrossRef]
- Long, T.; Jin, L. Building compact MQDF classifier for large character set recognition by subspace distribution sharing. Pattern Recognit. 2008, 41, 2916–2925. [Google Scholar] [CrossRef]
- Kimura, F.; Takashina, K.; Tsuruoka, S.; Miyake, Y. Modified quadratic discriminant functions and the application to chinese character recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 149–153. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, K.H.; Kim, S.K.; Lee, J.K. On-line recognition of handwritten chinese characters based on hidden markov models. Pattern Recognit. 1997, 30, 1489–1500. [Google Scholar] [CrossRef]
- Gan, J.; Wang, W.; Lu, K. Characters as Graphs: Recognizing Online Handwritten Chinese Characters via Spatial Graph Convolutional Network. arXiv 2020, arXiv:2004.09412. [Google Scholar]
- Gan, J.; Chen, Y.; Hu, B.; Leng, J.; Wang, W.; Gao, X. Characters as graphs: Interpretable handwritten Chinese character recognition via Pyramid Graph Transformer. Pattern Recognit. 2023, 137, 109317. [Google Scholar] [CrossRef]
- Gan, J.; Wang, W.; Lu, K. A Unified CNN-RNN Approach for in-Air Handwritten English Word Recognition. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Zhuang, C.; Lu, Z.; Wang, Y.; Xiao, J.; Wang, Y. ACDNet: Adaptively Combined Dilated Convolution for Monocular Panorama Depth Estimation. arXiv 2022, arXiv:2112.14440. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. arXiv 2018, arXiv:1702.08502. [Google Scholar]
- Ding, X.; Zhang, X.; Zhou, Y.; Han, J.; Ding, G.; Sun, J. Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs. arXiv 2022, arXiv:2203.06717. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Liu, C.; Yin, F.; Wang, D.; Wang, Q. Online and offline handwritten Chinese character recognition: Benchmarking on new databases. Pattern Recognit. 2013, 46, 155–162. [Google Scholar] [CrossRef]
- Yang, W.; Jin, L.; Tao, D.; Xie, Z.; Feng, Z. DropSample: A new training method to enhance deep convolutional neural networks for large-scale unconstrained handwritten Chinese character recognition. Pattern Recognit. 2016, 58, 190–203. [Google Scholar] [CrossRef]
- Bai, H.; Zhang, X.W.; Fu, Y.G. Adaptive visualization of extracted digital ink characters in Chinese. Comput. Eng. Appl. 2012, 48, 153–158. [Google Scholar]
- Liu, C.-L.; Yin, F.; Wang, D.-H.; Wang, Q.-F. CASIA Online and Offline Chinese Handwriting Databases. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 37–41. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Data Type | Computing Mechanism | Storage Cost | Data Type Conversion |
|---|---|---|---|---|
| 1-D CNN [7] | Sequence | Parallel | Low | Not need |
| 2-D CNN [3,4,5,6] | Image | Parallel | High | Sequences to (feature) images |
| RNN [8,9] | Sequence | Serial | Low | Not need |
| GNN [20,21] | Graph | Parallel | Middle | Sequences to graphs |
| Steps | Aims |
|---|---|
| Removing redundant points | Reduce the size of input data and the amount of computation |
| Flipping horizontally | Adjust the display of Chinese characters |
| Coordinate normalization | Normalize the x- and y-coordinates into a standard interval |
| Layer | Block 1 | Block 2 | Block 3 | Block 4 |
|---|---|---|---|---|
| 1st layer | 64 | 128 | 256 | 512 |
| 2nd layer | 64 | 128 | 256 | 512 |
| 3rd layer | 64 | 128 | 256 | 512 |
| 4th layer | 64 | 128 | 256 | 512 |
| 5th layer | 256 | 512 | 1024 | 2048 |
| Shortcut | 256 | 512 | 1024 | 2048 |
| Layer | Convolution Kernel Size | Dilation Rate | Dilated Kernel Size | Receptive Field |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 |
| 2 | 3 | 1 | 3 | 3 |
| 3 | 3 | 2 | 5 | 7 |
| 4 | 3 | 3 | 7 | 13 |
| 5 | 1 | 1 | 1 | 13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Zhang, X. Recognizing Digital Ink Chinese Characters Written by International Students Using a Residual Network with 1-Dimensional Dilated Convolution. Information 2024, 15, 531. https://doi.org/10.3390/info15090531
Xu H, Zhang X. Recognizing Digital Ink Chinese Characters Written by International Students Using a Residual Network with 1-Dimensional Dilated Convolution. Information. 2024; 15(9):531. https://doi.org/10.3390/info15090531
Chicago/Turabian StyleXu, Huafen, and Xiwen Zhang. 2024. "Recognizing Digital Ink Chinese Characters Written by International Students Using a Residual Network with 1-Dimensional Dilated Convolution" Information 15, no. 9: 531. https://doi.org/10.3390/info15090531
APA StyleXu, H., & Zhang, X. (2024). Recognizing Digital Ink Chinese Characters Written by International Students Using a Residual Network with 1-Dimensional Dilated Convolution. Information, 15(9), 531. https://doi.org/10.3390/info15090531