

Toward Ensuring Data Quality in Multi-Site Cancer Imaging Repositories

 , , , and
, , , and 
Abstract
:1. Introduction
2. Materials and Methods
- The first step is to create the Data Quality Conceptual Model which consists of the set of data quality metrics that will be assessed by this methodology.
- The second step is to create a well-defined data-collection protocol, which is the product of a data integration procedure. This protocol constitutes a set of requirements that data should follow to be properly integrated into a multi-center repository and is designed to ensure data homogeneity among multiple-source data. The procedure is briefly described in previous work [20], but this article is extended to describe the steps in detail, as well as all the resulting requirements and data quality rules that ensure that the data are compliant with the metrics set through the conceptual model.
- The third step is the quality assessment of the data provided through a Data Integration Quality Check Tool (DIQCT), which, based on the rules provided by step 2, checks if the quality requirements are met. The tool informs the user of corrective actions that need to be taken prior to the data provision to ensure that the data provided is of high quality. The tool was described in a previous publication [21], but in this article, an extended version is presented along with the evaluation results of 3 rounds of user experience assessment.
2.1. Data
2.2. Data Quality Conceptual Model
2.3. Data Quality Requirements and Rules Definition Procedure
2.3.1. Clinical Metadata and Structure
- Identification: As a first step, an initial template was created for each cancer type—breast, colorectal, lung, prostate—incorporating domain knowledge from medical experts and the related literature. This first template included the methodology for separating collected data in different time points, as well as associating related imaging, laboratory, and histopathological examinations with each time point.
- Review: These initial templates were circulated to the medical experts and reviewed. The medical experts shared their comments on the proposed protocol and an asynchronous discussion took place to debate on controversial topics. In this step, fields were added, removed, or modified to fit the needs of the specific study.
- Merge: After the review and the received comments, a consensus on each template was extracted and discussed thoroughly in a meeting with the medical experts to resolve homogenization issues.
- Redefine: The data providers were asked to provide an example case for each cancer type. These example cases were reviewed for consistency between the entries deriving from different sites. Based on the inputs received, the allowable value sets were defined. The pre-final version of the templates was extracted in a homogenized way.
- Standardize: At this point, the standardization of the fields’ content took place. Each one of the value sets was standardized to follow categorical values or medical standards. In applicable cases, terminologies based on medical standards, such as ICD-11 and ATC, were adopted.
- Review and Refine: The templates were circulated again for verification.
2.3.2. Imaging Data
2.4. Data Integration Quality Check Tool
- Version 1: In this version, the tool was implemented in two ways: (i) as an executable file (.exe): the pipeline along with all the dependencies was built as a directly executable file (ii) as Docker Image: the pipeline along with all the dependencies was built in a docker container publicly available to all members of the consortium.
- Version 2: To improve the usability of DIQCT, in the second version, a web application was implemented using R programming language and R Studio Shiny server, allowing the interactive execution of specific scripts through HTML pages. This application includes 5 components, and the execution of each of them is controlled by the user.
- Version 3: The third release contains four additional components and some improvements in terms of efficiency and visualization.
2.5. Evaluation Methodology for the Quality Tool
3. Results—The INCISIVE Case
3.1. Data
3.2. Data Quality Ruleset
3.3. The DIQCT
- Clinical metadata Integrity
- Structure and codification: In this component, errors related to the template structure and patient codification are reported. Specifically, this component checks and reports (i) The structure of the provided template. The provided template structure, in terms of tabs and columns, is compared to the one initially defined and circulated for use, and alterations are reported to the user for correction. This check is related to the second dimension, Accuracy. (ii) The patient’s ids. The inserted patient unique identification numbers are checked to ensure they follow the proper encoding and for duplicate entries in the template. The user must correct the reported errors and continue. This check is related to both Accuracy and Uniqueness and Rules 1 and 3.
- Content Validity: In this component, errors related to the template content are reported. Specifically, this component checks if the standards and terminologies proposed for the allowable values of all fields of the templates are followed. It reports, for each patient separately in a different row, the fields of each tab that do not comply with the proposed value range. This component also checks if the time points provided are within the boundaries proposed in the collection protocol definition and if all time points provided are in the correct chronological order. The user must review erroneous entries. This check is related to Validity and Accuracy quality dimensions and Rules 2 and 4.
- Case Completeness: This component presents an overview of the data provided. It depicts a summary for each patient in terms of what modalities are available at each time point, as well as the percentage of mandatory fields that are present for each patient and a list of the absent fields so the user can review the missing values and provide more information if possible. This report is related to Completeness and Rule 5.The components of the second category are:
- Template-image Consistency: This component has a dual role: (i) For each patient, the imaging modalities provided are inserted in the template to a corresponding time point. This component checks for each entry the agreement between the template and the images provided. (ii) If the provided images are compliant with the template, it performs a proper renaming of the studies’ folders to a predefined naming convention so they can be stored in a unified way. In case of inconsistency between the template and the folders, a message appears for the specific patient. The user must correct the reported errors and continue. This component is related to Integrity and Rules 1 and 3.The components of the third category are:
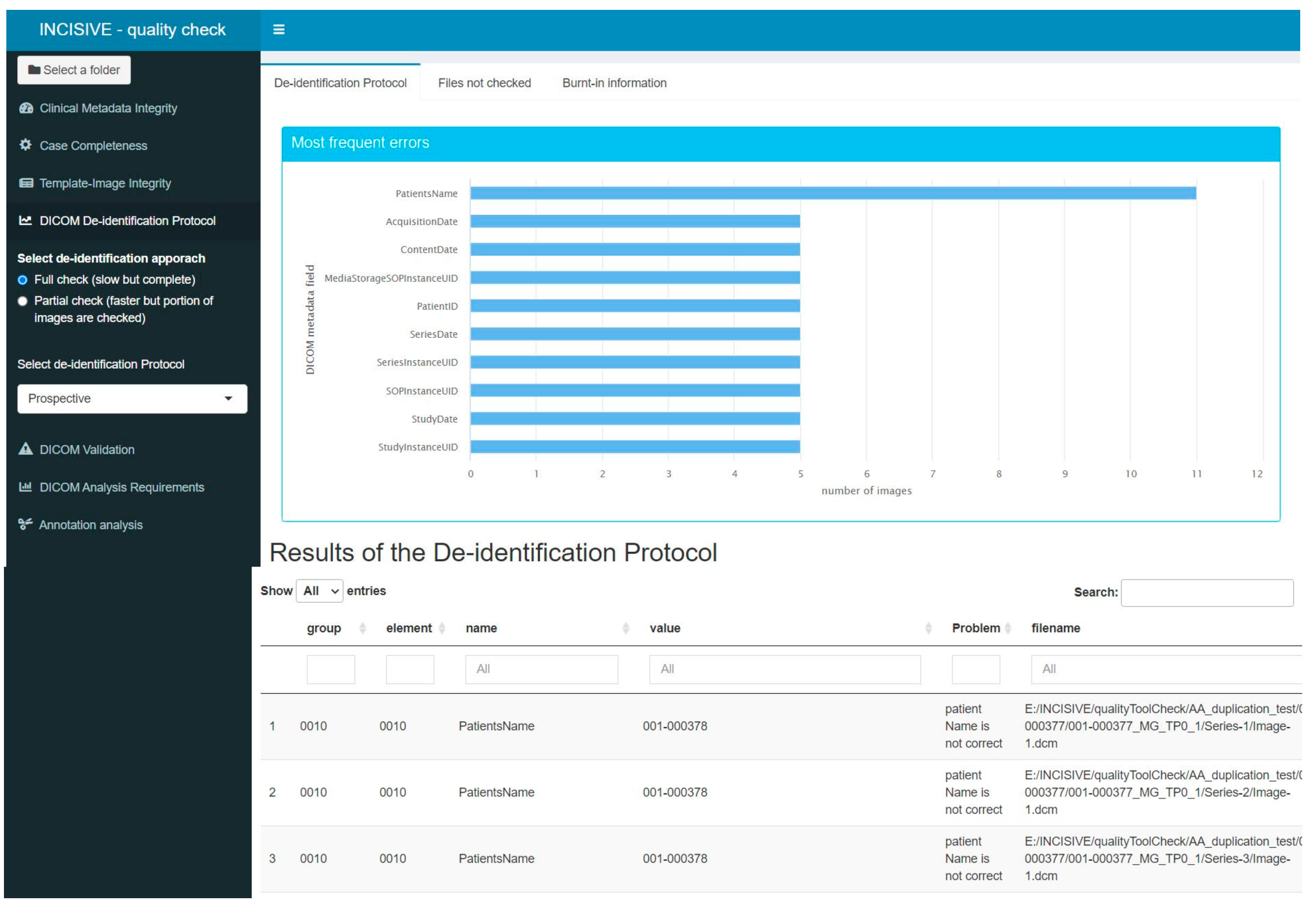
- DICOM De-identification Protocol: DICOM files contain not only imaging information, such as intensity for each pixel, but also several valuable metadata crucial for the proper interpretation of the images. These metadata are stored in specific DICOM tags, each characterized by a group of two hexadecimal values. The de-identification protocol is defined by a list of tags and their respective actions, which could involve removing the value or replacing it with a new one. The main goal of this component is to verify whether a specific de-identification protocol has been correctly applied to the imaging data. To achieve this, the tool checks the metadata in all the DICOM files and suggests appropriate actions to ensure compliance with the protocol. Users can interact with the tool and choose among different protocols, making it highly versatile. The tool generates an output in a tabular format, listing the metadata that does not comply with the protocol, along with the path to the corresponding image and the corrective action that needs to be applied. Additionally, the tool provides a graphical representation of the most common errors using a bar chart. It is important to note that this component does not assess whether personal data are overlaid in the image as burned-in information. Its primary focus is on the proper handling of DICOM metadata to maintain data consistency and privacy. It is related to Consistency and Rule 7.
- DICOM Validation: As mentioned earlier, DICOM metadata contains valuable information related to the acquisition protocol. The cornerstone of this component is the dciodvfy tool (https://dclunie.com/dicom3tools/dciodvfy.html, accessed on 27 August 2024), which provides comprehensive functionality by performing various checks on DICOM files. First, it verifies attributes against the requirements of Information Object Definitions (IODs) and Modules as defined in DICOM PS 3.3 Information Object Definition. Second, it ensures that the encoding of data elements and values aligns with the encoding rules specified in DICOM PS 3.5 Data Structures and Encoding. Third, the tool validates data element value representations and multiplicity using the data dictionary from DICOM PS 3.6 Data Dictionary. Lastly, it checks the consistency of attributes across multiple files that are expected to be identical for the same entity in all instances. Through these checks, the tool ensures the integrity and conformity of the DICOM data, promoting accurate and standardized medical image management. However, it is important to note that the DICOM Standard Committee does not provide any official tool to ensure complete DICOM compliance. As a result, this tool does not guarantee that the DICOM file is entirely compliant with DICOM, even if no errors are found during the validation process. Nevertheless, the tool does report major errors, such as missing mandatory attributes, the presence of invalid values in DICOM tags, encoding issues, or errors in the unique identifiers. Similar to the de-identification component, the outcome of the validation component is provided both in a tabular format listing the errors found for each DICOM file and in a graphical format where the most common issues in all the DICOM files are visualized as bar charts. This user-friendly presentation aids in identifying and addressing potential problems in the DICOM data, contributing to enhanced data quality and reliability. This component integrates rule 6 and Validity.
- DICOM Analysis Requirements: DICOM Analysis Requirements: This component aims to assess whether the DICOM files can be used for analysis purposes. In this regard, AI developers need to define specific requirements that a file must meet to be suitable for analysis. Three types of requirements can be distinguished:
- Image Requirements: These are related to the data quality used for analysis and training of the algorithms. Quality factors may include pixel size, slice thickness, field of view, etc. The analysis of DICOM files ensures that the data have similar quality. The component produces an outcome table listing the images that do not fulfill each requirement. This component relates to Rule 9 and Consistency.
- Required imaging modalities: These requirements are related to the imaging modalities expected for each cancer type. AI developers collaborate with clinical experts to define these modalities, which are specific to each type of cancer. The component checks whether at least one of the imaging modalities defined for each cancer type is provided. For instance, if data from lung cancer patients are provided, the AI developers expect to access CT images or X-rays, as the implemented models rely on these types of images. This component incorporates rule 8 and Completeness.
- Annotations: This requirement relates to the availability of annotation files in the correct series folder. Some AI tools may need segmentation files, so this component checks whether an annotation file of a specified format, such as a NIFTI file, is present in a folder. Additionally, the tool verifies whether the annotation file has the same number of pixels across the X and Y planes as the DICOM files located in the same folder. It also checks whether the number of slices in the annotation file coincides with the number of DICOM images in the folder. If more than one annotation file is found in the same folder or if the annotation file is not in the series folder, an appropriate message is provided. The tool generates an outcome table listing all the annotation files found, along with any issues that may have been identified and relate to Rule 10 and Consistency.
- DICOM Overall Patient Evaluation: This component summarizes the findings from the previous component and presents a table containing all the patients and the extent to which the quality requirements are met. Additionally, this component checks for any duplicate images that may exist for each patient and across the whole repository. Each requirement is included in a separate column of the table. If a requirement is fully met for a patient, the respective cell is colored green. In cases where a requirement is only partially covered, for example, not all the expected imaging modalities are provided, the cell is colored in beige. However, if the requirement is not met at all, the cell is colored red. This component relates to Uniqueness and Completeness.
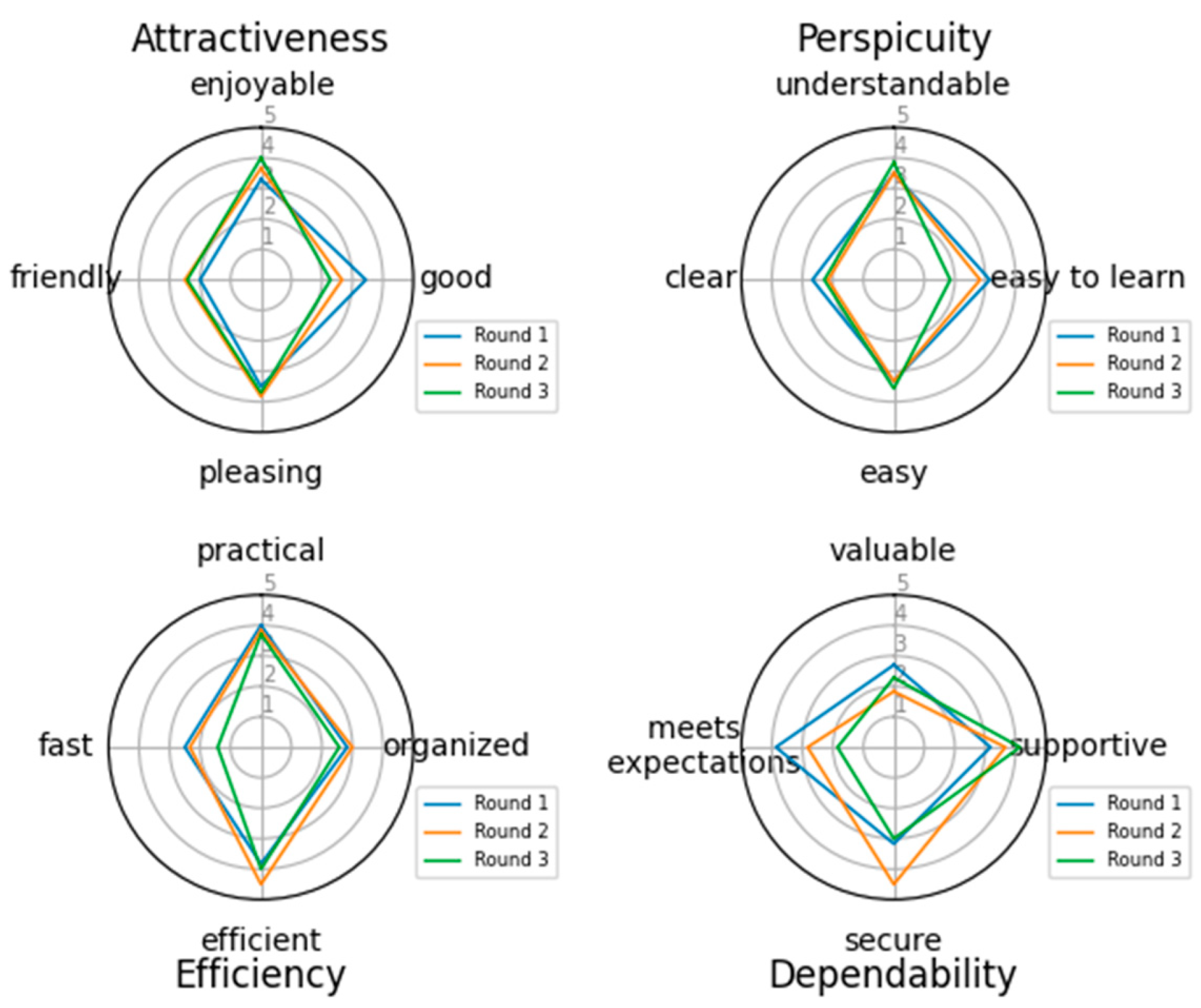
3.4. Evaluation of the Tool
4. Discussion
5. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kocarnik, J.M.; Compton, K.; Dean, F.E.; Fu, W.; Gaw, B.L.; Harvey, J.D.; Henrikson, H.J.; Lu, D.; Pennini, A.; Xu, R.; et al. Cancer Incidence, Mortality, Years of Life Lost, Years Lived with Disability, and Disability-Adjusted Life Years for 29 Cancer Groups From 2010 to 2019 A Systematic Analysis for the Global Burden of Disease Study 2019. JAMA Oncol. 2022, 8, 420–444. [Google Scholar] [CrossRef]
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Parkin, D.M.; Piñeros, M.; Znaor, A.; Bray, F. Cancer statistics for the year 2020: An overview. Int. J. Cancer 2021, 149, 778–789. [Google Scholar] [CrossRef] [PubMed]
- Saslow, D.; Boetes, C.; Burke, W.; Harms, S.; Leach, M.O.; Lehman, C.D.; Morris, E.; Pisano, E.; Schnall, M.; Sener, S.; et al. American Cancer Society Guidelines for Breast Screening with MRI as an Adjunct to Mammography. CA Cancer J. Clin. 2007, 57, 75–89. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Lu, B.; He, M.; Wang, Y.; Wang, Z.; Du, L. Prostate Cancer Incidence and Mortality: Global Status and Temporal Trends in 89 Countries From 2000 to 2019. Front. Public Health 2022, 10, 811044. [Google Scholar] [CrossRef] [PubMed]
- Siegel, R.L.; Miller, K.D.; Sauer, A.G.; Fedewa, S.A.; Butterly, L.F.; Anderson, J.C.; Cercek, A.; Smith, R.A.; Jemal, A. Colorectal cancer statistics, 2020. CA Cancer J. Clin. 2020, 70, 145–164. [Google Scholar] [CrossRef] [PubMed]
- Aberle, D.R.; Black, W.C.; Chiles, C.; Church, T.R.; Gareen, I.F.; Gierada, D.S.; Mahon, I.; Miller, E.A.; Pinsky, P.F.; Sicks, J.D. Lung Cancer Incidence and Mortality with Extended Follow-up in the National Lung Screening Trial. J. Thorac. Oncol. 2019, 14, 1732–1742. [Google Scholar] [CrossRef]
- Bhinder, B.; Gilvary, C.; Madhukar, N.S.; Elemento, O. Artifi Cial intelligence in cancer research and precision medicine. Cancer Discov. 2021, 11, 900–915. [Google Scholar] [CrossRef]
- Bizzo, B.C.; Almeida, R.R.; Michalski, M.H.; Alkasab, T.K. Artificial Intelligence and Clinical Decision Support for Radiologists and Referring Providers. J. Am. Coll. Radiol. 2019, 16, 1351–1356. [Google Scholar] [CrossRef]
- Yin, J.; Ngiam, K.Y.; Teo, H.H. Role of Artificial Intelligence Applications in Real-Life Clinical Practice: Systematic Review. J. Med. Internet Res. 2021, 23, e25759. [Google Scholar] [CrossRef]
- Martinez-Millana, A.; Saez-Saez, A.; Tornero-Costa, R.; Azzopardi-Muscat, N.; Traver, V.; Novillo-Ortiz, D. Artificial intelligence and its impact on the domains of universal health coverage, health emergencies and health promotion: An overview of systematic reviews. Int. J. Med. Inform. 2022, 166, 104855. [Google Scholar] [CrossRef]
- Gillies, R.J.; Schabath, M.B. Radiomics improves cancer screening and early detection. Cancer Epidemiol. Biomark. Prev. 2020, 29, 2556–2567. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.H.; Lin, L.; Wu, C.F.; Li, C.F.; Xu, R.H.; Sun, Y. Artificial intelligence for assisting cancer diagnosis and treatment in the era of precision medicine. Cancer Commun. 2021, 41, 1100–1115. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Wu, J.; Wang, N.; Zhang, X.; Bai, Y.; Guo, J.; Zhang, L.; Liu, S.; Tao, K. The value of artificial intelligence in the diagnosis of lung cancer: A systematic review and meta-analysis. PLoS ONE 2023, 18, e0273445. [Google Scholar] [CrossRef] [PubMed]
- Spadaccini, M.; Troya, J.; Khalaf, K.; Facciorusso, A.; Maselli, R.; Hann, A.; Repici, A. Artificial Intelligence-assisted colonoscopy and colorectal cancer screening: Where are we going? Dig. Liver Dis. 2024, 56, 1148–1155. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Hu, Z.; Mahal, B.A.; Zhao, S.D.; Kensler, K.H.; Pi, J.; Hu, X.; Zhang, Y.; Wang, Y.; Jiang, J.; et al. Integrated Analysis of Genetic Ancestry and Genomic Alterations across Cancers. Cancer Cell. 2018, 34, 549–560.e9. [Google Scholar] [CrossRef]
- Carle, F.; Di Minco, L.; Skrami, E.; Gesuita, R.; Palmieri, L.; Giampaoli, S.; Corrao, G. Quality assessment of healthcare databases. Epidemiol. Biostat. Public Health 2017, 14, 1–11. [Google Scholar] [CrossRef]
- Kahn, M.G.; Callahan, T.J.; Barnard, J.; Bauck, A.E.; Brown, J.; Davidson, B.N.; Estiri, H.; Goerg, C.; Holve, E.; Johnson, S.G.; et al. A Harmonized Data Quality Assessment Terminology and Framework for the Secondary Use of Electronic Health Record Data. eGEMs 2016, 4, 18. [Google Scholar] [CrossRef]
- Kim, K.-H.; Choi, W.; Ko, S.-J.; Chang, D.-J.; Chung, Y.-W.; Chang, S.-H.; Kim, J.-K.; Kim, D.-J.; Choi, I.-Y. Multi-center healthcare data quality measurement model and assessment using omop cdm. Appl. Sci. 2021, 11, 9188. [Google Scholar] [CrossRef]
- Huser, V.; DeFalco, F.J.; Schuemie, M.; Ryan, P.B.; Shang, N.; Velez, M.; Park, R.W.; Boyce, R.D.; Duke, J.; Khare, R.; et al. Multisite Evaluation of a Data Quality Tool for Patient-Level Clinical Datasets. eGEMs 2016, 4, 24. [Google Scholar] [CrossRef]
- Kosvyra, A.; Filos, D.; Fotopoulos, D.; Tsave, T.; Chouvarda, I. Towards Data Integration for AI in Cancer Research. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Mexico, 1–5 November 2021; pp. 2054–2057. [Google Scholar] [CrossRef]
- Kosvyra, A.; Filos, D.; Fotopoulos, D.; Tsave, O.; Chouvarda, I. Data Quality Check in Cancer Imaging Research: Deploying and Evaluating the DIQCT Tool. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBC, Scotland, UK, 11–15 July 2022; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2022; pp. 1053–1057. [Google Scholar] [CrossRef]
- Laugwitz, B.; Held, T.; Schrepp, M. LNCS 5298—Construction and Evaluation of a User Experience Questionnaire; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5298. [Google Scholar]
- Pezoulas, V.C.; Kourou, K.D.; Kalatzis, F.; Exarchos, T.P.; Venetsanopoulou, A.; Zampeli, E.; Gandolfo, S.; Skopouli, F.; De Vita, S.; Tzioufas, A.G.; et al. Medical data quality assessment: On the development of an automated framework for medical data curation. Comput. Biol. Med. 2019, 107, 270–283. [Google Scholar] [CrossRef]
- Wada, S.; Tsuda, S.; Abe, M.; Nakazawa, T.; Urushihara, H. A quality management system aiming to ensure regulatory-grade data quality in a glaucoma registry. PLoS ONE 2023, 18, e0286669. [Google Scholar] [CrossRef] [PubMed]
- Zaridis, D.I.; Mylona, E.; Tachos, N.; Pezoulas, V.C.; Grigoriadis, G.; Tsiknakis, N.; Marias, K.; Tsiknakis, M.; Fotiadis, D.I. Region-adaptive magnetic resonance image enhancement for improving CNN-based segmentation of the prostate and prostatic zones. Sci. Rep. 2023, 13, 714. [Google Scholar] [CrossRef] [PubMed]
- Dovrou, A.; Nikiforaki, K.; Zaridis, D.; Manikis, G.C.; Mylona, E.; Tachos, N.; Tsiknakis, M.; Fotiadis, D.I.; Marias, K. A segmentation-based method improving the performance of N4 bias field correction on T2weighted MR imaging data of the prostate. Magn. Reson. Imaging 2023, 101, 1–12. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rule | Name | Brief Description |
|---|---|---|
| 1 | Naming Conventions | (a) PatientId: XXX-YYYYYY (b) Imaging Examinations: PatientId_Modality_timepoint |
| 2 | Timepoints | Definition of 4 Time points: Baseline, After 1st Treatment, 1st and 2nd Follow-Up and their period |
| 3 | Structure | (a) Clinical Metadata—Template, (b) Folder Structure |
| 4 | Value Ranges | (a)Allowable Type, (b) Actual Value Range |
| 5 | Mandatory fields | Definition of the minimum fields that should be present in the template |
| 6 | DICOM Validation | Attributes Verification, Encoding Validation, Value Representation and Multiplicity Check, Attributes Consistency |
| 7 | De-identification protocol | Definition of the de-identification profile |
| 8 | Expected imaging modalities | Definition of the list of imaging modalities per cancer type |
| 9 | Analysis requirements | Definition of the expected values that each imaging modality should have to be used for analysis |
| 10 | Annotation mismatch | (a) the number of DICOM images is the same as the number of slices in the annotation file, (b) The number of rows and the number of columns for both the annotation file and the images are identical |
| No of Participants | Clinical Experts | Technical Experts | Windows | Linux | Mac | |
|---|---|---|---|---|---|---|
| Round 1 | 9 | 3 | 6 | 7 | 1 | 1 |
| Round 2 | 6 | 4 | 2 | 5 | - | 1 |
| Round 3 | 7 | 4 | 3 | 5 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kosvyra, A.; Filos, D.T.; Fotopoulos, D.T.; Tsave, O.; Chouvarda, I. Toward Ensuring Data Quality in Multi-Site Cancer Imaging Repositories. Information 2024, 15, 533. https://doi.org/10.3390/info15090533
Kosvyra A, Filos DT, Fotopoulos DT, Tsave O, Chouvarda I. Toward Ensuring Data Quality in Multi-Site Cancer Imaging Repositories. Information. 2024; 15(9):533. https://doi.org/10.3390/info15090533
Chicago/Turabian StyleKosvyra, Alexandra, Dimitrios T. Filos, Dimitris Th. Fotopoulos, Olga Tsave, and Ioanna Chouvarda. 2024. "Toward Ensuring Data Quality in Multi-Site Cancer Imaging Repositories" Information 15, no. 9: 533. https://doi.org/10.3390/info15090533