
From GPT-3.5 to GPT-4.o: A Leap in AI’s Medical Exam Performance


Rostock University Medical Center, Institute of Anatomy, 18057 Rostock, Germany
Information 2024, 15(9), 543; https://doi.org/10.3390/info15090543
Submission received: 29 July 2024
/
Revised: 2 September 2024
/
Accepted: 3 September 2024
/
Published: 5 September 2024
(This article belongs to the Special Issue Real-World Applications of Machine Learning Techniques)
Abstract
:ChatGPT is a large language model trained on increasingly large datasets to perform diverse language-based tasks. It is capable of answering multiple-choice questions, such as those posed by diverse medical examinations. ChatGPT has been generating considerable attention in both academic and non-academic domains in recent months. In this study, we aimed to assess GPT’s performance on anatomical multiple-choice questions retrieved from medical licensing examinations in Germany. Two different versions were compared. GPT-3.5 demonstrated moderate accuracy, correctly answering 60–64% of questions from the autumn 2022 and spring 2021 exams. In contrast, GPT-4.o showed significant improvement, achieving 93% accuracy on the autumn 2022 exam and 100% on the spring 2021 exam. When tested on 30 unique questions not available online, GPT-4.o maintained a 96% accuracy rate. Furthermore, GPT-4.o consistently outperformed medical students across six state exams, with a statistically significant mean score of 95.54% compared with the students’ 72.15%. The study demonstrates that GPT-4.o outperforms both its predecessor, GPT-3.5, and a cohort of medical students, indicating its potential as a powerful tool in medical education and assessment. This improvement highlights the rapid evolution of LLMs and suggests that AI could play an increasingly important role in supporting and enhancing medical training, potentially offering supplementary resources for students and professionals. However, further research is needed to assess the limitations and practical applications of such AI systems in real-world medical practice.
1. Introduction
The environment and tools used for academic education and research have significantly changed in the past decades. Before the invention of textbooks as an educational tool, lectures were virtually the only option to gather knowledge from an expert. For some decades, students can principally decide by themselves whether or not they will visit a given lecture or learn the study material on their own. Nowadays, the use of textbooks is still very common; however, traditional textbooks are often used in conjunction with other resources, such as podcasts or videos. In parallel, the way students prepare assays significantly changed. While previously, different textbooks in libraries were screened for relevant information, nowadays, online resources such as Google, Bing, or Yandex are available. In addition, different AI tools are continuously developed, which principally can facilitate initial exploration of the literature in a domain in which someone is marginally familiar, for example, iris.ai, scite.ai, or jenni.ai.
In the past year, a new artificial intelligence (AI) model called ChatGPT garnered significant attention due to its ability to perform a diverse array of natural language-based tasks. GPT, which stands for Generative Pre-training Transformer, is a large language model (LLM) developed by OpenAI that uses the Transformer architecture and Reinforcement Learning from Human Feedback approach. The previous class of AI models has primarily been Deep Learning models, which are designed to learn and recognize data patterns. In contrast, the LLM AI algorithm can, if properly trained on sufficiently large amounts of text data, predict the likelihood of a given sequence of words based on the context of the words that come before it, a mechanism called “autoregressive”. These technologies offer a range of opportunities, such as the development of lifelike simulations, digital patients, tailored feedback systems, advanced evaluation techniques, and the ability to overcome language barriers [1]. Thus, the utilization of AI and generative language models holds immense potential in augmenting medical education. Others, however, argue that AI in general and, in particular, LLMs might be a challenge for academic teaching and integrity in the future [2,3,4].
OpenAI, the company behind ChatGPT, was founded in 2015. The first LLM, GPT-1, was introduced in June 2018 and consisted of 117 million pre-trained parameters. Its successor, GPT-2, already comprised 1.5 billion parameters and was released to the public by the end of 2019. In June 2020, GPT-3 followed, having been trained with more than 175 billion parameters, thus being over 100 times larger than GPT-1 and over 10 times larger than GPT-2. GPT-3 was the first model capable of handling comprehensive language tasks such as writing emails, generating code, or translating texts. On 30 November 2022, the company released an improved version, GPT-3.5, or ChatGPT. GPT-4, launched on 14 March 2023, is the latest and most advanced model in the GPT series, representing a significant leap forward. For example, unlike GPT 4.o, GPT-3.5 had no internet connection and, therefore, could not respond to queries on current topics. While the specifics of the GPT4 training data and architecture are not officially announced, they certainly build upon the strengths of GPT-3 and overcome some of its limitations.
In Germany, a regularly structured degree course in medicine takes six years and three months. It is completed by a final state exam (Staatsexamen), with which one obtains a license to practice as a physician (called approbation). The application procedure for a degree course in medicine is highly competitive and complicated due to the complex selection process via Hochschulstart. Medical studies and training in Germany are regulated under federal regulations on medical registration. There are currently three state exams the students have to pass during their studies: the first state exam, also called the M1 exam or formerly “Physikum”, which takes place after the second year; the second state exam, also called the M2 exam, which takes place after the fifth year; and the third state exam, also called the M3 exam, which takes place after the sixth year. The M1 exam consists of an oral and a written examination. The written part is conducted nationwide on two consecutive days and includes 600 multiple-choice questions from all preclinical subjects. The oral exams take place in anatomy, biochemistry, and physiology.
Previous studies have primarily assessed LLM performance in medical contexts using questions from simulated medical exams and open-source datasets [5,6,7,8]. More recent research has evaluated the performance of LLMs in actual examination settings [9,10,11]. In March 2023, OpenAI published a technical report on GPT-4 [12]. This report presents data on GPT-4’s performance in a variety of exams designed for humans. Of note, there was no specific pre-training for these exams. In these tests, GPT-4 performed remarkably well, frequently surpassing the scores of most human participants, and showed a significant improvement compared with the performance of GPT-3.5.
The primary objective of the current article was to assess the performance of GPT-3.5 on official medical board examinations. To this end, test questions from two previous state-wide exams were provided to GPT-3.5, and the percentage of correctly or wrongly answered questions was evaluated. The secondary objective was to evaluate the improvement of GPT technology by comparing the performance of GPT-3.5 and GPT-4o. Finally, we systematically compared the performance of GPT-4.o with that of a large cohort of medical students.
2. Materials and Methods
2.1. General Information and Applied Large Language Models
The study utilized an observational, cross-sectional design to evaluate the performance of GPT 3.5 and GPT-4.0 on 436 questions from M1 medical state exams (subject anatomy) from spring 2021 to autumn 2023. Each question was manually inputted into either GPT-3.5 or GPT-4.o (see below for more detailed information). GPT is a sophisticated language model created by OpenAI, headquartered in San Francisco, CA. It utilizes self-attention mechanisms and an extensive corpus of training data to generate natural language responses to textual input within a conversational context. Unlike other chatbots or conversational systems that have the ability to access external sources of information (such as conducting internet searches or accessing databases) to provide tailored responses to user inquiries, GPT-3.5 was a self-contained model that could not browse the internet. This means that all responses were generated in real-time, solely based on the abstract relationships between words, also known as “tokens”, in the neural network. Initially, this study used GPT-3.5, but additional experiments were conducted approximately 12 months later with GPT-4, which had since gained access to online information. Questions were directed to freely accessible and publicly available versions of GPT-3.5 and to the premium ChatGPT-4.o plus version, accessed through the Firefox web browser. No incognito mode was used.
2.2. Input Source
First, medical state exam (M1 exam, formerly called “Physikum”) multiple-choice questions were obtained from the Thieme examen online website. In contrast to other studies [13], multiple-choice questions (five options: A, B, C, D, or E) were provided to the LLM in German language but were translated to prepare this manuscript using GPT-4o. None of the questions had multiple valid answers.
In the first set of experiments, we assessed the performance of GPT-3.5 on official medical board examinations. To this end, anatomical gross macroscopy test questions from the autumn exam 2022 and the spring exam 2021 were obtained from the Thieme examen online website. Responses were categorized as either correct or incorrect. To investigate the reproducibility of the results, we repeated the experiment the next day using the same exam questions. For the spring 2021 exam questions, GPT-3.5 was re-challenged for the wrong answers by asking the question, “Are you sure?”, and the responses were categorized as follows: correct = after the re-challenge a correct answer was given; no change = after the re-challenge again a wrong answer was given; wrong = while the LLM apologizes for the wrong answer, again a wrong answer was given after the re-challenge. The described evaluations were performed between February and May 2023. Questions related to or including anatomical images or drawings were excluded.
In a second set of experiments, we aimed to compare the performance of GPT-3.5 versus GPT-4.o. To this end, the same questions as in the first part of this study were provided to the more advanced GPT-4.o version in June 2024. Responses were categorized as either correct or incorrect, and their frequencies were statistically compared. Beyond, we aimed to analyze in this part of the study if the potentially improved performance of GPT-4.o might be due to the fact that medical state exam questions are online and can, thus, be used as a template to answer the questions. To rule this out, 30 randomly chosen questions from previous anatomical exams at the university center Rostock were used as an input source for GPT-4o. Responses were categorized as either correct or incorrect.
In a third set of experiments, we aimed to evaluate the performance of GPT-4.o in comparison to medical students. To this end, anatomical gross macroscopy, microscopy, and embryology test questions were obtained from six different exams from the Thieme examen online website (id est; spring 2021–2023 and autumn 2021–2023), and the performance of GPT-4.0 was compared with the results of medical students (retrieved from the data repository of https://www.impp.de/pruefungen/medizin/l%C3%B6sungen-und-ergebnisse.html (accessed on 1 August 2024)). The total number of valid questions in this last part of the study was 344. Again, questions related to or including anatomical images or drawings were excluded, and responses were categorized as either correct or incorrect.
2.3. Analyses
Objective 1: To assess the performance of GPT-3.5 on official medical board examinations, gross anatomical questions from two exams (autumn 2022 and spring 2021) were included. Numbers of correct and incorrect answers, as well as numbers of unanswered questions, were recorded. Based on this information, we calculated the percentage of each categorical score. Reproducibility was defined as the agreement between the answers of the first and second rounds, provided by GPT-3.5, regardless of whether the provided/suggested answer was initially correct or incorrect.
Objective 2: To evaluate the improvement of GPT technology by comparing the performance of GPT-3.5 and GPT-4o. Gross anatomical questions from two exams (autumn 2022 and spring 2021) were included. Numbers of correct and incorrect answers from the first rounds were recorded for both GPT versions and statistically compared using Fisher’s exact test (two-sided).
Objective 3: To assess whether GPT-4.o performs superior to medical students. Gross anatomical, histological, and embryology questions from six exams (spring 2021–2023 and autumn 2021–2023) were included. Numbers of correct and incorrect answers were recorded for both GPT versions and statistically compared using a Mann–Whitney test.
All statistical analyses have been performed using Prism 9.2.0 (GraphPad Software Inc., San Diego, CA, USA). No outliers were excluded from the analyses. p-values of ≤0.05 were considered statistically significant.
3. Results
In the first set of experiments, 56 test questions from the autumn exam in 2022 were obtained from the Thieme examen online website (see Figure 1 and Table 1). Of those 56 questions, 11 were related to anatomical images and were, thus, excluded from any further analyses (highlighted by a star in Table 1).
In the first round, GPT-3.5 correctly answered 27 of the remaining 45 exam questions, which equals 60%. The suggested answer from GPT-3.5 was wrong in 14 cases. In another 4 cases, no answer was provided at all. To investigate the reproducibility of this result, we repeated the experiment the next day using the same exam questions (see second-round columns in Table 1). In the second round, GPT-3.5 correctly answered 29 of the 45 exam questions, which equals ~64%. The suggested answer from GPT-3.5 was wrong in 13 cases. In another 3 cases, no answer was provided at all. In most cases, those questions that were answered correctly in the first round were also correctly answered in the second round. On the other hand, those questions that were answered wrong in the first round were also wrongly answered in the second round. However, in some cases, false answers in the first round were correct in the second round and vice versa (highlighted in red in Table 1).
The spectrum of how GPT-3.5 responded to the given exam questions varied somehow. In some cases, a brief answer without any explanations was provided. For example, the provided answer for question #19 was “The greater curvature of the stomach is supplied primarily by the left gastric artery, so answer (B) is correct”. In other instances, GPT-3.5 provided more detailed explanations of why the given answer should be the correct one. For example, the provided answer for question #43 was “According to the rule of nines, which is used in first aid for a quick estimate of the affected skin surface in the case of burns, the body is divided into nine regions, each of which is assigned a certain percentage of the total skin surface. The ventral surface of the left leg corresponds to about 9% of the total skin surface. If this area were completely scalded, about 9% of the total skin surface would be affected. So the correct answer is (B) 9%”. Of note, this particular question was answered falsely in the first round but correctly in the second (see Table 1). Interestingly, in some cases, GPT-3.5 did not provide the correct multiple-choice item but correctly described which answer should be the correct one. In some cases, no conclusive answer was provided at all.
In order to reproduce the obtained results, 49 test questions from the M1 spring exam in 2021 were obtained from the Thieme examen online website. Of those 49 questions, 2 questions were related to anatomical images and were, thus, excluded from the analyses (highlighted by a star in Table 2). In the first round, GPT-3.5 correctly answered 25 of the remaining 47 exam questions, which equals ~53%. The suggested answer from GPT-3.5 was wrong in 19 cases. In another 3 cases, no answer was provided at all. To investigate the reproducibility of this result, we again repeated the experiment using the very same exam questions. In the second round, GPT-3.5 correctly answered 27 of the 47 exam questions, which equals ~57%. The suggested answer from GPT-3.5 was wrong in 18 cases. In another 2 cases, no answer was provided at all. Again, in most cases, those questions that were answered correctly in the first round were also correctly answered in the second round. On the other hand, those questions that were answered wrong in the first round were also wrongly answered in the second round. However, in some cases, false answers in the first round were correct in the second round and vice versa (highlighted in red in Table 2).
In the second round of the spring 2021 exam, no answers were provided for questions #9 (related to the course of the N. medianus) and #44 (related to the symptom “acromegaly”). Since the response for question #9 was “None of the statements is usually true”, next, we re-challenged GPT-3.5 by asking the question, “sure that none of the statements are true”. In contrast to the first response, the next response was correct. In particular, GPT-3.5 stated, “I’m sorry, I accidentally misunderstood your previous question. In fact, one of the statements about the course of the median nerve is correct. The median nerve runs between the heads of the pronator teres”. The response for question #44 was “Given the symptoms, the mass is most likely to be in the area of the pituitary stalk, which connects the hypothalamus and adenohypophysis. Tongue enlargement may be caused by compression of the mass on the hypoglossal nerves, while visual field limitations may be due to optic nerve compression. However, accurate localization of the mass requires imaging”. We, again, re-challenged GPT-3.5 by asking the following question: “what is the correct answer”. After this re-challenge, GPT-3.5 provided the correct answer.
In the next step, we decided to re-challenge GPT-3.5 for the 18 questions that were not correctly answered in the second round of the M1 spring exam 2021 (see Table 2) by simply asking the question “Are you sure?”. As demonstrated in Table 2, in eleven cases, GPT-3.5 persisted on the initially provided answer (highlighted by “no change” in Table 2); in four cases, the LLM apologized for the wrong answer but, again, provided a wrong answer (highlighted by “wrong” in Table 2), and in another four cases the LLM apologized for the wrong answer and provided a correct answer (highlighted by “correct” in Table 2).
So far, we have been able to demonstrate that GPT-3.5 is able to “understand” anatomical multiple-choice questions from medical exams and can provide, in a sufficient number of cases, correct answers. LLMs continuously develop. When starting this study in 2023, GPT-3.5 was available and, thus, used. In May 2024, GPT-4o was released by OpenAi. To analyze the performance of this advanced LLM, we challenged GPT-4o with the 45 test questions from the M1 autumn 2022 exam and the 47 test questions from the M1 spring 2021 exam. Surprisingly, GPT-4o greatly improved its performance with just three wrong answers in the autumn 2022 exam and zero wrong answers in the spring 2021 exam, respectively (see Figure 2). Statistical comparison using Fisher’s exact test rejected the null hypothesis (p = 0.0011 for the autumn 2022 exam and p < 0.0001 for the spring 2021 exam), demonstrating that GPT-4.o outperforms GPT-3.5 in this selection of anatomical medical state exam questions.
Allowing LLMs to access the internet can significantly expand their functionality by enabling them to retrieve up-to-date information, verify facts, and respond to queries that require real-time data. The better performance of GPT-4o versus GPT-3.5 in this study might be due to the fact that medical state exam questions are online and can, thus, potentially be used as a template to answer the questions. We, thus, decided in the next step to investigate the performance of GPT-4o in answering 30 randomly chosen multiple-choice questions from previous anatomical exams at the university center Rostock. Since these questions were prepared by our lecturers, they cannot be found by LLMs in any online repository. Of note, GPT-4o correctly answered 29 of the 30 exam questions, which equals a ~96% test performance.
Finally, we performed a systematic comparison of the performance of GPT-4o versus that of a large cohort of medical students by using entire anatomical questions from six distinct M1 state exams (spring 2011 to autumn 2023). As demonstrated in Figure 3, the GPT-4o outperformed medical students across all six medical examinations. Statistical comparison between GPT-4o and medical students’ test performance revealed that this difference is highly significant (GPT-4o mean 95.54 ± SEM 1.004 versus medical students mean 72.15 ± SEM1.673; p < 0.01).
4. Discussion
ChatGPT, an AI-powered chatbot developed by OpenAI, is currently creating a buzz across various academic and non-academic sectors. Its most promising feature is to respond to questions in a human-like manner. Due to its growing popularity and emerging use, it is crucial to conduct a critical assessment of the potential effects of GPT on research and teaching. In this study, we analyzed the areas of robustness and limitations of GPT’s responses to anatomical multiple-choice questions of the first medical state exam in Germany.
In university education, various examination methods are used, including term papers, oral exams, or multiple-choice tests. The use of LLMs in scientific writing, such as for preparing term papers, is already critically discussed in the literature [14,15,16,17] and represents an explicit limitation of such an assessment format in the future. Comparably, online exams, currently offered by many universities and in various formats, are at risk when students use LLMs [3,18]. Empirical research shows a significant increase in academic dishonesty in online environments [19,20]. For in-person multiple-choice exams, the risk of students using LLMs to cheat may initially appear minimal. However, with the rapid advancement of technologies, it is conceivable that optical systems, like smart glasses, could be developed to recognize text and, when connected to LLMs, assist in answering multiple-choice questions. To mitigate this risk, exam questions should be designed in ways that LLMs cannot easily handle. For instance, LLMs still struggle with logical reasoning [9,21], so questions requiring critical thinking rather than simple fact recall may eventually be safely used. Future research has to show the rules on how to prepare such kinds of questions.
Despite these reservations, some authors argue that the growing use of LLMs can also drive the evolution of university curricula [22]. For example, instead of traditional term papers, students could be tasked in the future to evaluate AI-generated content, learning to assess and refine its responses critically. Additionally, LLMs offer several potential benefits in academia, such as assisting non-native speakers by translating content and providing explanations in different languages, facilitating literature research, and supporting the preparation of multiple-choice exam questions, for example, by verifying the accuracy of possible answers.
Recent studies have shown that several LLMs are highly capable of answering medical exam questions from various specialties, different countries, and varying levels of difficulty. A summary of studies published in 2024 is shown in Table 3.
The general outcome of this literature research is that (i) different GPT versions are capable of answering medical exam questions of various disciplines, (ii) the effectiveness of LLMs in answering multiple-choice question assessments varies depending on the type of data input, (iii) the newer GPT-4 versions outperform GPT-3 versions, and (iv) the GPT-4 versions outperform in most cases other LLMs such as Bard or Bing.
Previous research showed that the effectiveness of generative pre-trained transformer (GPT) models in answering multiple-choice question assessments varies depending on the type of data input [21,86,87]. In one study, it was shown that the inclusion of code snippets makes multiple-choice questions more challenging for the GPT models, likely due to a combination of the models being somewhat more limited in handling computer programs compared with natural language and the inherent difficulty of the questions with code [86]. Another study nicely demonstrated that the feasibility of LLMs in providing accurate answers to multiple-choice questions related to feasibility issues is low [21].
Indeed, when ChatGPT was released more than a year ago, a number of studies were initiated addressing the performance of GPT in the context of academic examinations. For example, a study from the University of Minnesota Law School let GPT-3.5 take four final exams and compare the results to human students. Researchers found that GPT-3.5 could pass each exam but was not a great student [88]. In the context of medical exams or health issues, soon after its release, GPT3 has been tested in various disciplines, including hand surgery [89], questions related to pancreatic cancer and its surgical care [90], or basic life support and advanced cardiac life support [91]. Cai and colleagues investigated the ability of generative AI models to answer ophthalmology board-style questions [92]. They evaluated three LLMs with chat interfaces, Bing Chat (Microsoft) and GPT 3.5 and 4.o (OpenAI), and found that GPT-4.o and Bing Chat performed comparably to humans. Beyond, it was shown that ChatGPT-4.o outperformed ChatGPT 3.5, a finding that is in line with our results and results of other groups [8,9,12,87,93,94,95,96,97]. For example, a study using American Pharmacist Licensure Examination MC-questions as an input source for LLMs demonstrated a higher test performance of GPT-4 versus GPT-3 [87]. In another study, GPT-3.5 did not pass Polish medical examinations, whereas the GPT-4 models demonstrated the capability to pass the majority of the exams evaluated [96].
During our studies, we observed that re-feeding GPT-3.5 with a given query does not necessarily lead to the same answer. In a study by van Dis and colleagues [98], the authors asked ChatGPT the question, “how many patients with depression experience relapse after treatment”. As stated in that manuscript, ChatGPT generated an overly general text arguing that treatment effects are typically long-lasting. The authors criticized that ChatGPT did not provide accurate and detailed answers. More precisely, the authors stated that “numerous high-quality studies show … the risk of relapse ranges from 29% to 51% in the first year after treatment completion”. When we repeated the same query, ChatGPT generated a more sophisticated answer, stating that “According to research, approximately 50% of individuals who have experienced a single episode of depression are likely to experience a recurrence of the condition within five years”. Obviously, the underlying AI technology was able to learn from other textual input and, thus, can adopt its textual output. In line with our findings, the authors demonstrated that repeating the same query can generate a more detailed and accurate answer. Furthermore, in line with other reports, GPT-3.5 occasionally made unfaithful reasoning, i.e., the derived conclusion does not follow the previously generated reasoning chain. While chain-of-thought may imitate human reasoning processes, the fundamental nature of LLMs remains that of black-box probabilistic models, lacking a mechanism to guarantee the faithfulness of reasoning.
5. Conclusions
With the release of ChatGPT in 2022, it has become increasingly clear that this form of AI technology will significantly impact the way academic teaching will be organized and tested. Both serious concerns and great advantages and support can potentially be expected from such kinds of technologies [98]. Of note, one limitation of previous GPT versions was that it was trained on data up to September 2021. However, there are now versions available with online access. Beyond, future studies have to show the accuracy of different LLMs such as, for example, Google Bard, BioMedLM (formerly known as PubMed GPT), or Med-PaLM, the latter being the first AI system to surpass the pass mark on the U.S. Medical License Exam (USMLE)-style questions. While AI opens up new possibilities in various fields, including medicine, it also brings challenges that necessitate a thorough expert assessment. For any exams, testers should try to come up with questions that cannot be correctly answered by any of them in our days available LLMs. Limitations of the LLMs in logical reasoning might be a versatile option to construct appropriate multiple-choice exam questions in the future [4,99].
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Karabacak, M.; Ozkara, B.B.; Margetis, K.; Wintermark, M.; Bisdas, S. The Advent of Generative Language Models in Medical Education. JMIR Med. Educ. 2023, 9, e48163. [Google Scholar] [CrossRef]
- Currie, G.M. Academic integrity and artificial intelligence: Is ChatGPT hype, hero or heresy? Semin. Nucl. Med. 2023, 53, 719–730. [Google Scholar] [CrossRef] [PubMed]
- Susnjak, T.; McIntosh, T.R. ChatGPT: The End of Online Exam Integrity? Educ. Sci. 2024, 14, 656. [Google Scholar] [CrossRef]
- Stribling, D.; Xia, Y.; Amer, M.K.; Graim, K.S.; Mulligan, C.J.; Renne, R. The Model Student: GPT-4 Performance on Graduate Biomedical Science Exams. Sci. Rep. 2024, 14, 5670. [Google Scholar] [CrossRef] [PubMed]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Kanjee, Z.; Crowe, B.; Rodman, A. Accuracy of a Generative Artificial Intelligence Model in a Complex Diagnostic Challenge. JAMA 2023, 330, 78–80. [Google Scholar] [CrossRef]
- Hoch, C.C.; Wollenberg, B.; Lüers, J.C.; Knoedler, S.; Knoedler, L.; Frank, K.; Cotofana, S.; Alfertshofer, M. ChatGPT’s quiz skills in different otolaryngology subspecialties: An analysis of 2576 single-choice and multiple-choice board certification preparation questions. Eur. Arch. Oto-Rhino-Laryngol. 2023, 280, 4271–4278. [Google Scholar] [CrossRef]
- Giannos, P. Evaluating the limits of AI in medical specialisation: ChatGPT’s performance on the UK Neurology Specialty Certificate Examination. BMJ Neurol. Open 2023, 5, e000451. [Google Scholar] [CrossRef]
- Huang, R.S.T.; Lu, K.J.Q.; Meaney, C.; Kemppainen, J.; Punnett, A.; Leung, F.-H. Assessment of Resident and AI Chatbot Performance on the University of Toronto Family Medicine Residency Progress Test: Comparative Study. JMIR Med. Educ. 2023, 9, e50514. [Google Scholar] [CrossRef]
- Jang, D.; Yun, T.R.; Lee, C.Y.; Kwon, Y.K.; Kim, C.E. GPT-4 can pass the Korean National Licensing Examination for Korean Medicine Doctors. PLoS Digit. Health 2023, 2, e0000416. [Google Scholar] [CrossRef]
- Lin, S.Y.; Chan, P.K.; Hsu, W.H.; Kao, C.H. Exploring the proficiency of ChatGPT-4: An evaluation of its performance in the Taiwan advanced medical licensing examination. Digit. Health 2024, 10. [Google Scholar] [CrossRef] [PubMed]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Leoni Aleman, F.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Uriel, K.; Eran, C.; Eliya, S.; Jonathan, S.; Adam, F.; Eli, M.; Beki, S.; Ido, W. GPT versus resident physicians—A benchmark based on official board scores. NEJM AI 2024, 1, 5. [Google Scholar] [CrossRef]
- Stokel-Walker, C. AI bot ChatGPT writes smart essays—Should professors worry? Nature 2022. [Google Scholar] [CrossRef]
- Biswas, S. ChatGPT and the Future of Medical Writing. Radiology 2023, 307, e223312. [Google Scholar] [CrossRef]
- Gordijn, B.; Have, H.T. ChatGPT: Evolution or revolution? Med. Health Care Philos. 2023, 26, 1–2. [Google Scholar] [CrossRef]
- Stokel-Walker, C.; Van Noorden, R. What ChatGPT and generative AI mean for science. Nature 2023, 614, 214–216. [Google Scholar] [CrossRef]
- Buchmann, E.; Thor, A. Online Exams in the Era of ChatGPT. In Proceedings of the 21. Fachtagung Bildungstechnologien (DELFI), Aachen, Germany, 11–13 September 2023; Available online: https://dl.gi.de/handle/20.500.12116/42240 (accessed on 1 August 2024). [CrossRef]
- Malik, A.A.; Hassan, M.; Rizwan, M.; Mushtaque, I.; Lak, T.A.; Hussain, M. Impact of academic cheating and perceived online learning effectiveness on academic performance during the COVID-19 pandemic among Pakistani students. Front. Psychol. 2023, 14, 1124095. [Google Scholar] [CrossRef]
- Newton, P.M.; Essex, K. How Common is Cheating in Online Exams and did it Increase During the COVID-19 Pandemic? A Systematic Review. J. Acad. Ethics 2024, 22, 323–343. [Google Scholar] [CrossRef]
- Gupta, H.; Varshney, N.; Mishra, S.; Pal, K.K.; Sawant, S.A.; Scaria, K.; Goyal, S.; Baral, C. “John is 50 years old, can his son be 65?” Evaluating NLP Models’ Understanding of Feasibility. arXiv 2022, arXiv:2210.07471. [Google Scholar] [CrossRef]
- Ahmed, Y. Utilization of ChatGPT in Medical Education: Applications and Implications for Curriculum Enhancement. Acta Inform. Medica 2023, 31, 300–305. [Google Scholar] [CrossRef]
- Rodrigues Alessi, M.; Gomes, H.A.; Lopes de Castro, M.; Terumy Okamoto, C. Performance of ChatGPT in Solving Questions From the Progress Test (Brazilian National Medical Exam): A Potential Artificial Intelligence Tool in Medical Practice. Cureus 2024, 16, e64924. [Google Scholar] [CrossRef]
- Ebel, S.; Ehrengut, C.; Denecke, T.; Gößmann, H.; Beeskow, A.B. GPT-4o’s competency in answering the simulated written European Board of Interventional Radiology exam compared to a medical student and experts in Germany and its ability to generate exam items on interventional radiology: A descriptive study. J. Educ. Eval. Health Prof. 2024, 21, 21. [Google Scholar] [CrossRef]
- Al-Naser, Y.; Halka, F.; Ng, B.; Mountford, D.; Sharma, S.; Niure, K.; Yong-Hing, C.; Khosa, F.; Van der Pol, C. Evaluating Artificial Intelligence Competency in Education: Performance of ChatGPT-4 in the American Registry of Radiologic Technologists (ARRT) Radiography Certification Exam. Acad. Radiol. 2024, in press. [Google Scholar] [CrossRef]
- Hsieh, C.H.; Hsieh, H.Y.; Lin, H.P. Evaluating the performance of ChatGPT-3.5 and ChatGPT-4 on the Taiwan plastic surgery board examination. Heliyon 2024, 10, e34851. [Google Scholar] [CrossRef]
- Sadeq, M.A.; Ghorab, R.M.F.; Ashry, M.H.; Abozaid, A.M.; Banihani, H.A.; Salem, M.; Aisheh, M.T.A.; Abuzahra, S.; Mourid, M.R.; Assker, M.M.; et al. AI chatbots show promise but limitations on UK medical exam questions: A comparative performance study. Sci. Rep. 2024, 14, 18859. [Google Scholar] [CrossRef]
- Ming, S.; Guo, Q.; Cheng, W.; Lei, B. Influence of Model Evolution and System Roles on ChatGPT’s Performance in Chinese Medical Licensing Exams: Comparative Study. JMIR Med. Educ. 2024, 10, e52784. [Google Scholar] [CrossRef] [PubMed]
- Terwilliger, E.; Bcharah, G.; Bcharah, H.; Bcharah, E.; Richardson, C.; Scheffler, P. Advancing Medical Education: Performance of Generative Artificial Intelligence Models on Otolaryngology Board Preparation Questions with Image Analysis Insights. Cureus 2024, 16, e64204. [Google Scholar] [CrossRef] [PubMed]
- Nicikowski, J.; Szczepański, M.; Miedziaszczyk, M.; Kudliński, B. The potential of ChatGPT in medicine: An example analysis of nephrology specialty exams in Poland. Clin. Kidney J. 2024, 17, sfae193. [Google Scholar] [CrossRef]
- Chow, R.; Hasan, S.; Zheng, A.; Gao, C.; Valdes, G.; Yu, F.; Chhabra, A.; Raman, S.; Choi, J.I.; Lin, H.; et al. The Accuracy of Artificial Intelligence ChatGPT in Oncology Exam Questions. J. Am. Coll. Radiol. JACR 2024, in press. [Google Scholar] [CrossRef]
- Vij, O.; Calver, H.; Myall, N.; Dey, M.; Kouranloo, K. Evaluating the competency of ChatGPT in MRCP Part 1 and a systematic literature review of its capabilities in postgraduate medical assessments. PLoS ONE 2024, 19, e0307372. [Google Scholar] [CrossRef] [PubMed]
- Schoch, J.; Schmelz, H.U.; Strauch, A.; Borgmann, H.; Nestler, T. Performance of ChatGPT-3.5 and ChatGPT-4 on the European Board of Urology (EBU) exams: A comparative analysis. World J. Urol. 2024, 42, 445. [Google Scholar] [CrossRef] [PubMed]
- Menekşeoğlu, A.K.; İş, E.E. Comparative performance of artificial ıntelligence models in physical medicine and rehabilitation board-level questions. Rev. Da Assoc. Medica Bras. (1992) 2024, 70, e20240241. [Google Scholar] [CrossRef]
- Cherif, H.; Moussa, C.; Missaoui, A.M.; Salouage, I.; Mokaddem, S.; Dhahri, B. Appraisal of ChatGPT’s Aptitude for Medical Education: Comparative Analysis with Third-Year Medical Students in a Pulmonology Examination. JMIR Med. Educ. 2024, 10, e52818. [Google Scholar] [CrossRef]
- Sparks, C.A.; Kraeutler, M.J.; Chester, G.A.; Contrada, E.V.; Zhu, E.; Fasulo, S.M.; Scillia, A.J. Inadequate Performance of ChatGPT on Orthopedic Board-Style Written Exams. Cureus 2024, 16, e62643. [Google Scholar] [CrossRef] [PubMed]
- Zheng, C.; Ye, H.; Guo, J.; Yang, J.; Fei, P.; Yuan, Y.; Huang, D.; Huang, Y.; Peng, J.; Xie, X.; et al. Development and evaluation of a large language model of ophthalmology in Chinese. Br. J. Ophthalmol. 2024, in press. [Google Scholar] [CrossRef] [PubMed]
- Shang, L.; Li, R.; Xue, M.; Guo, Q.; Hou, Y. Evaluating the application of ChatGPT in China’s residency training education: An exploratory study. Med. Teach. 2024, in press. [Google Scholar] [CrossRef]
- Soulage, C.O.; Van Coppenolle, F.; Guebre-Egziabher, F. The conversational AI “ChatGPT” outperforms medical students on a physiology university examination. Adv. Physiol. Educ. 2024, in press. [Google Scholar] [CrossRef]
- Yudovich, M.S.; Makarova, E.; Hague, C.M.; Raman, J.D. Performance of GPT-3.5 and GPT-4 on standardized urology knowledge assessment items in the United States: A descriptive study. J. Educ. Eval. Health Prof. 2024, 21, 17. [Google Scholar] [CrossRef]
- Patel, E.A.; Fleischer, L.; Filip, P.; Eggerstedt, M.; Hutz, M.; Michaelides, E.; Batra, P.S.; Tajudeen, B.A. Comparative Performance of ChatGPT 3.5 and GPT4 on Rhinology Standardized Board Examination Questions. OTO Open 2024, 8, e164. [Google Scholar] [CrossRef]
- Borna, S.; Gomez-Cabello, C.A.; Pressman, S.M.; Haider, S.A.; Forte, A.J. Comparative Analysis of Large Language Models in Emergency Plastic Surgery Decision-Making: The Role of Physical Exam Data. J. Pers. Med. 2024, 14, 612. [Google Scholar] [CrossRef] [PubMed]
- Han, Y.; Choudhry, H.S.; Simon, M.E.; Katt, B.M. ChatGPT’s Performance on the Hand Surgery Self-Assessment Exam: A Critical Analysis. J. Hand Surg. Glob. Online 2024, 6, 200–205. [Google Scholar] [CrossRef]
- Touma, N.J.; Caterini, J.; Liblk, K. Performance of artificial intelligence on a simulated Canadian urology board exam: Is CHATGPT ready for primetime? Can. Urol. Assoc. J. 2024, 18. [Google Scholar] [CrossRef] [PubMed]
- Suwała, S.; Szulc, P.; Guzowski, C.; Kamińska, B.; Dorobiała, J.; Wojciechowska, K.; Berska, M.; Kubicka, O.; Kosturkiewicz, O.; Kosztulska, B.; et al. ChatGPT-3.5 passes Poland’s medical final examination-Is it possible for ChatGPT to become a doctor in Poland? SAGE Open Med. 2024, 12, 20503121241257777. [Google Scholar] [CrossRef] [PubMed]
- Alessandri-Bonetti, M.; Liu, H.Y.; Donovan, J.M.; Ziembicki, J.A.; Egro, F.M. A Comparative Analysis of ChatGPT, ChatGPT-4, and Google Bard Performances at the Advanced Burn Life Support Exam. J. Burn Care Res. 2024, 45, 945–948. [Google Scholar] [CrossRef]
- Duggan, R.; Tsuruda, K.M. ChatGPT performance on radiation technologist and therapist entry to practice exams. J. Med. Imaging Radiat. Sci. 2024, 55, 101426. [Google Scholar] [CrossRef]
- Takagi, S.; Koda, M.; Watari, T. The Performance of ChatGPT-4V in Interpreting Images and Tables in the Japanese Medical Licensing Exam. JMIR Med. Educ. 2024, 10, e54283. [Google Scholar] [CrossRef]
- Canillas Del Rey, F.; Canillas Arias, M. Exploring the potential of Artificial Intelligence in Traumatology: Conversational answers to specific questions. Rev. Esp. De Cir. Ortop. Y Traumatol. 2024, in press. [Google Scholar] [CrossRef]
- Powers, A.Y.; McCandless, M.G.; Taussky, P.; Vega, R.A.; Shutran, M.S.; Moses, Z.B. Educational Limitations of ChatGPT in Neurosurgery Board Preparation. Cureus 2024, 16, e58639. [Google Scholar] [CrossRef]
- D’Anna, G.; Van Cauter, S.; Thurnher, M.; Van Goethem, J.; Haller, S. Can large language models pass official high-grade exams of the European Society of Neuroradiology courses? A direct comparison between OpenAI chatGPT 3.5, OpenAI GPT4 and Google Bard. Neuroradiology 2024, 66, 1245–1250. [Google Scholar] [CrossRef]
- Alexandrou, M.; Mahtani, A.U.; Rempakos, A.; Mutlu, D.; Al Ogaili, A.; Gill, G.S.; Sharma, A.; Prasad, A.; Mastrodemos, O.C.; Sandoval, Y.; et al. Performance of ChatGPT on ACC/SCAI Interventional Cardiology Certification Simulation Exam. JACC Cardiovasc. Interv. 2024, 17, 1292–1293. [Google Scholar] [CrossRef]
- Rojas, M.; Rojas, M.; Burgess, V.; Toro-Pérez, J.; Salehi, S. Exploring the Performance of ChatGPT Versions 3.5, 4, and 4 with Vision in the Chilean Medical Licensing Examination: Observational Study. JMIR Med. Educ. 2024, 10, e55048. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.C.; Kurapati, S.S.; Younessi, D.N.; Scott, I.U.; Gong, D.A. Ethical and Professional Decision-Making Capabilities of Artificial Intelligence Chatbots: Evaluating ChatGPT’s Professional Competencies in Medicine. Med. Sci. Educ. 2024, 34, 331–333. [Google Scholar] [CrossRef]
- Shieh, A.; Tran, B.; He, G.; Kumar, M.; Freed, J.A.; Majety, P. Assessing ChatGPT 4.0’s test performance and clinical diagnostic accuracy on USMLE STEP 2 CK and clinical case reports. Sci. Rep. 2024, 14, 9330. [Google Scholar] [CrossRef] [PubMed]
- Taesotikul, S.; Singhan, W.; Taesotikul, T. ChatGPT vs pharmacy students in the pharmacotherapy time-limit test: A comparative study in Thailand. Curr. Pharm. Teach. Learn. 2024, 16, 404–410. [Google Scholar] [CrossRef] [PubMed]
- van Nuland, M.; Erdogan, A.; Aςar, C.; Contrucci, R.; Hilbrants, S.; Maanach, L.; Egberts, T.; van der Linden, P.D. Performance of ChatGPT on Factual Knowledge Questions Regarding Clinical Pharmacy. J. Clin. Pharmacol. 2024, 64, 1095–1100. [Google Scholar] [CrossRef]
- Vaishya, R.; Iyengar, K.P.; Patralekh, M.K.; Botchu, R.; Shirodkar, K.; Jain, V.K.; Vaish, A.; Scarlat, M.M. Effectiveness of AI-powered Chatbots in responding to orthopaedic postgraduate exam questions-an observational study. Int. Orthop. 2024, 48, 1963–1969. [Google Scholar] [CrossRef] [PubMed]
- Abbas, A.; Rehman, M.S.; Rehman, S.S. Comparing the Performance of Popular Large Language Models on the National Board of Medical Examiners Sample Questions. Cureus 2024, 16, e55991. [Google Scholar] [CrossRef]
- Cabañuz, C.; García-García, M. ChatGPT is an above-average student at the Faculty of Medicine of the University of Zaragoza and an excellent collaborator in the development of teaching materials. Rev. Esp. Patol. 2024, 57, 91–96. [Google Scholar] [CrossRef]
- Fiedler, B.; Azua, E.N.; Phillips, T.; Ahmed, A.S. ChatGPT performance on the American Shoulder and Elbow Surgeons maintenance of certification exam. J. Shoulder Elb. Surg. 2024, 33, 1888–1893. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Cheungpasitporn, W.; Cornell, L.D. Performance of GPT-4 Vision on kidney pathology exam questions. Am. J. Clin. Pathol. 2024, 162, 220–226. [Google Scholar] [CrossRef]
- Ghanem, D.; Nassar, J.E.; El Bachour, J.; Hanna, T. ChatGPT Earns American Board Certification in Hand Surgery. Hand Surg. Rehabil. 2024, 43, 101688. [Google Scholar] [CrossRef] [PubMed]
- Noda, M.; Ueno, T.; Koshu, R.; Takaso, Y.; Shimada, M.D.; Saito, C.; Sugimoto, H.; Fushiki, H.; Ito, M.; Nomura, A.; et al. Performance of GPT-4V in Answering the Japanese Otolaryngology Board Certification Examination Questions: Evaluation Study. JMIR Med. Educ. 2024, 10, e57054. [Google Scholar] [CrossRef]
- Le, M.; Davis, M. ChatGPT Yields a Passing Score on a Pediatric Board Preparatory Exam but Raises Red Flags. Glob. Pediatr. Health 2024, 11, 2333794x241240327. [Google Scholar] [CrossRef]
- Stengel, F.C.; Stienen, M.N.; Ivanov, M.; Gandía-González, M.L.; Raffa, G.; Ganau, M.; Whitfield, P.; Motov, S. Can AI pass the written European Board Examination in Neurological Surgery?-Ethical and practical issues. Brain Spine 2024, 4, 102765. [Google Scholar] [CrossRef]
- Garabet, R.; Mackey, B.P.; Cross, J.; Weingarten, M. ChatGPT-4 Performance on USMLE Step 1 Style Questions and Its Implications for Medical Education: A Comparative Study Across Systems and Disciplines. Med. Sci. Educ. 2024, 34, 145–152. [Google Scholar] [CrossRef] [PubMed]
- Gravina, A.G.; Pellegrino, R.; Palladino, G.; Imperio, G.; Ventura, A.; Federico, A. Charting new AI education in gastroenterology: Cross-sectional evaluation of ChatGPT and perplexity AI in medical residency exam. Dig. Liver Dis. 2024, 56, 1304–1311. [Google Scholar] [CrossRef] [PubMed]
- Nakao, T.; Miki, S.; Nakamura, Y.; Kikuchi, T.; Nomura, Y.; Hanaoka, S.; Yoshikawa, T.; Abe, O. Capability of GPT-4V(ision) in the Japanese National Medical Licensing Examination: Evaluation Study. JMIR Med. Educ. 2024, 10, e54393. [Google Scholar] [CrossRef]
- Ozeri, D.J.; Cohen, A.; Bacharach, N.; Ukashi, O.; Oppenheim, A. Performance of ChatGPT in Israeli Hebrew Internal Medicine National Residency Exam. Isr. Med. Assoc. J. IMAJ 2024, 26, 86–88. [Google Scholar]
- Su, M.C.; Lin, L.E.; Lin, L.H.; Chen, Y.C. Assessing question characteristic influences on ChatGPT’s performance and response-explanation consistency: Insights from Taiwan’s Nursing Licensing Exam. Int. J. Nurs. Stud. 2024, 153, 104717. [Google Scholar] [CrossRef]
- Valdez, D.; Bunnell, A.; Lim, S.Y.; Sadowski, P.; Shepherd, J.A. Performance of Progressive Generations of GPT on an Exam Designed for Certifying Physicians as Certified Clinical Densitometrists. J. Clin. Densitom. 2024, 27, 101480. [Google Scholar] [CrossRef] [PubMed]
- Farhat, F.; Chaudhry, B.M.; Nadeem, M.; Sohail, S.S.; Madsen, D. Evaluating Large Language Models for the National Premedical Exam in India: Comparative Analysis of GPT-3.5, GPT-4, and Bard. JMIR Med. Educ. 2024, 10, e51523. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.H.; Hsiao, H.J.; Yeh, P.C.; Wu, K.C.; Kao, C.H. Performance of ChatGPT on Stage 1 of the Taiwanese medical licensing exam. Digit. Health 2024, 10, 20552076241233144. [Google Scholar] [CrossRef]
- Zong, H.; Li, J.; Wu, E.; Wu, R.; Lu, J.; Shen, B. Performance of ChatGPT on Chinese national medical licensing examinations: A five-year examination evaluation study for physicians, pharmacists and nurses. BMC Med. Educ. 2024, 24, 143. [Google Scholar] [CrossRef]
- Morreel, S.; Verhoeven, V.; Mathysen, D. Microsoft Bing outperforms five other generative artificial intelligence chatbots in the Antwerp University multiple choice medical license exam. PLoS Digit. Health 2024, 3, e0000349. [Google Scholar] [CrossRef]
- Meyer, A.; Riese, J.; Streichert, T. Comparison of the Performance of GPT-3.5 and GPT-4 with That of Medical Students on the Written German Medical Licensing Examination: Observational Study. JMIR Med. Educ. 2024, 10, e50965. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, Y.; Nakata, T.; Aiga, K.; Etani, T.; Muramatsu, R.; Katagiri, S.; Kawai, H.; Higashino, F.; Enomoto, M.; Noda, M.; et al. Performance of Generative Pretrained Transformer on the National Medical Licensing Examination in Japan. PLoS Digit. Health 2024, 3, e0000433. [Google Scholar] [CrossRef]
- Herrmann-Werner, A.; Festl-Wietek, T.; Holderried, F.; Herschbach, L.; Griewatz, J.; Masters, K.; Zipfel, S.; Mahling, M. Assessing ChatGPT’s Mastery of Bloom’s Taxonomy Using Psychosomatic Medicine Exam Questions: Mixed-Methods Study. J. Med. Internet Res. 2024, 26, e52113. [Google Scholar] [CrossRef]
- Long, C.; Lowe, K.; Zhang, J.; Santos, A.D.; Alanazi, A.; O’Brien, D.; Wright, E.D.; Cote, D. A Novel Evaluation Model for Assessing ChatGPT on Otolaryngology-Head and Neck Surgery Certification Examinations: Performance Study. JMIR Med. Educ. 2024, 10, e49970. [Google Scholar] [CrossRef]
- Kollitsch, L.; Eredics, K.; Marszalek, M.; Rauchenwald, M.; Brookman-May, S.D.; Burger, M.; Körner-Riffard, K.; May, M. How does artificial intelligence master urological board examinations? A comparative analysis of different Large Language Models’ accuracy and reliability in the 2022 In-Service Assessment of the European Board of Urology. World J. Urol. 2024, 42, 20. [Google Scholar] [CrossRef]
- Ting, Y.T.; Hsieh, T.C.; Wang, Y.F.; Kuo, Y.C.; Chen, Y.J.; Chan, P.K.; Kao, C.H. Performance of ChatGPT incorporated chain-of-thought method in bilingual nuclear medicine physician board examinations. Digit. Health 2024, 10, 20552076231224074. [Google Scholar] [CrossRef] [PubMed]
- Shemer, A.; Cohen, M.; Altarescu, A.; Atar-Vardi, M.; Hecht, I.; Dubinsky-Pertzov, B.; Shoshany, N.; Zmujack, S.; Or, L.; Einan-Lifshitz, A.; et al. Diagnostic capabilities of ChatGPT in ophthalmology. Graefes Arch. Clin. Exp. Ophthalmol. 2024, 262, 2345–2352. [Google Scholar] [CrossRef] [PubMed]
- Sahin, M.C.; Sozer, A.; Kuzucu, P.; Turkmen, T.; Sahin, M.B.; Sozer, E.; Tufek, O.Y.; Nernekli, K.; Emmez, H.; Celtikci, E. Beyond human in neurosurgical exams: ChatGPT’s success in the Turkish neurosurgical society proficiency board exams. Comput. Biol. Med. 2024, 169, 107807. [Google Scholar] [CrossRef]
- Tsoutsanis, P.; Tsoutsanis, A. Evaluation of Large language model performance on the Multi-Specialty Recruitment Assessment (MSRA) exam. Comput. Biol. Med. 2024, 168, 107794. [Google Scholar] [CrossRef]
- Savelka, J.; Agarwal, A.; Bogart, C.; Sakr, M. Large Language Models (GPT) Struggle to Answer Multiple-Choice Questions about Code. arXiv 2023, arXiv:2303.08033. [Google Scholar] [CrossRef]
- Angel, M.; Patel, A.; Alachkar, A.; Baldi, P. Clinical Knowledge and Reasoning Abilities of AI Large Language Models in Pharmacy: A Comparative Study on the NAPLEX Exam. BioRxiv 2023. [Google Scholar] [CrossRef]
- Choi, J.; Hickman, K.; Monahan, A.; Schwarcz, D. ChatGPT Goes to Law School. J. Leg. Educ. 2023. Available online: https://ssrn.com/abstract=4335905 (accessed on 1 August 2024). [CrossRef]
- Traoré, S.Y.; Goetsch, T.; Muller, B.; Dabbagh, A.; Liverneaux, P.A. Is ChatGPT able to pass the first part of the European Board of Hand Surgery diploma examination? Hand Surg. Rehabil. 2023, 42, 362–364. [Google Scholar] [CrossRef] [PubMed]
- Moazzam, Z.; Cloyd, J.; Lima, H.A.; Pawlik, T.M. Quality of ChatGPT Responses to Questions Related to Pancreatic Cancer and its Surgical Care. Ann. Surg. Oncol. 2023, 30, 6284–6286. [Google Scholar] [CrossRef]
- Zhu, L.; Mou, W.; Yang, T.; Chen, R. ChatGPT can pass the AHA exams: Open-ended questions outperform multiple-choice format. Resuscitation 2023, 188, 109783. [Google Scholar] [CrossRef]
- Cai, L.Z.; Shaheen, A.; Jin, A.; Fukui, R.; Yi, J.S.; Yannuzzi, N.; Alabiad, C. Performance of Generative Large Language Models on Ophthalmology Board Style Questions. Am. J. Ophthalmol. 2023, 254, 141–149. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Lei, L.; Wu, L.; Sun, R.; Huang, Y.; Long, C.; Liu, X.; Lei, X.; Tang, J.; Huang, M. SafetyBench: Evaluating the Safety of Large Language Models with Multiple Choice Questions. arXiv 2023, arXiv:2309.07045. [Google Scholar] [CrossRef]
- Yue, S.; Song, S.; Cheng, X.; Hu, H. Do Large Language Models Understand Conversational Implicature—A case study with a chinese sitcom. arXiv 2024, arXiv:2404.19509. [Google Scholar] [CrossRef]
- Shetty, M.; Ettlinger, M.; Lynch, M. GPT-4, an artificial intelligence large language model, exhibits high levels of accuracy on dermatology specialty certificate exam questions. medRxiv 2023. [Google Scholar] [CrossRef]
- Jakub Pokrywka, J.K.E.G.n. GPT-4 passes most of the 297 written Polish Board Certification Examinations. arXiv 2024, arXiv:2405.01589. [Google Scholar]
- Guerra, G.A.; Hofmann, H.; Sobhani, S.; Hofmann, G.; Gomez, D.; Soroudi, D.; Hopkins, B.S.; Dallas, J.; Pangal, D.J.; Cheok, S.; et al. GPT-4 Artificial Intelligence Model Outperforms ChatGPT, Medical Students, and Neurosurgery Residents on Neurosurgery Written Board-Like Questions. World Neurosurg. 2023, 179, e160–e165. [Google Scholar] [CrossRef]
- van Dis, E.A.M.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five priorities for research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef]
- Hua, C. Reinforcement Learning and Feedback Control. In Reinforcement Learning Aided Performance Optimization of Feedback Control Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 27–57. [Google Scholar] [CrossRef]
Figure 1.
Illustration of test performance. The left side summarizes results from the Autumn 2022 exam, while the right side shows results from the Spring 2021 exam. For more details, refer to Table 1.
Figure 1.
Illustration of test performance. The left side summarizes results from the Autumn 2022 exam, while the right side shows results from the Spring 2021 exam. For more details, refer to Table 1.
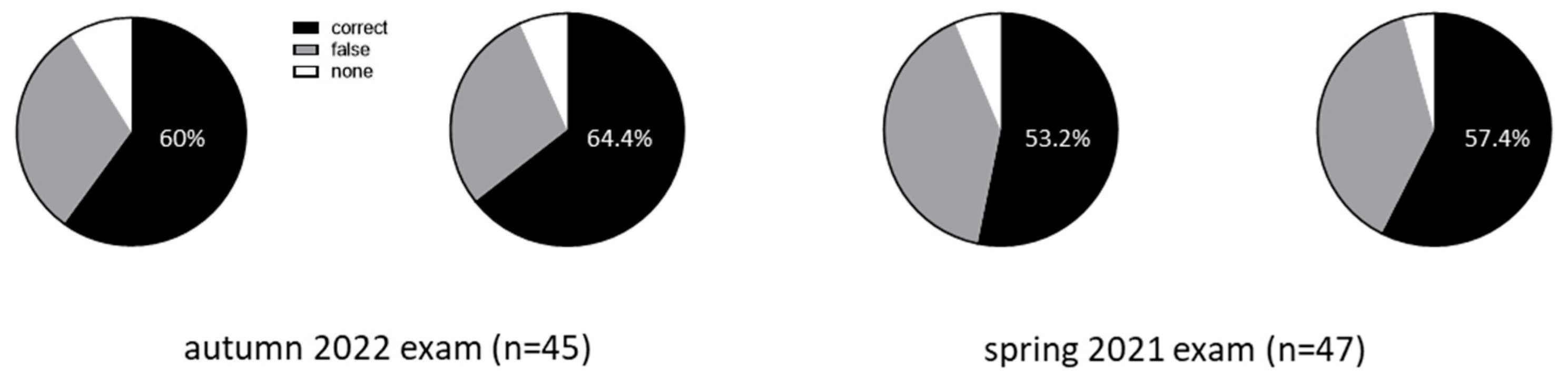
Figure 2.
Illustration of comparative test performance of GPT-3.5 versus GPT-4.o. The left side summarizes results from the autumn 2022 exam, while the right side shows results from the spring 2021 exam. Statistical comparison using Fisher’s exact test rejected the null hypothesis.
Figure 2.
Illustration of comparative test performance of GPT-3.5 versus GPT-4.o. The left side summarizes results from the autumn 2022 exam, while the right side shows results from the spring 2021 exam. Statistical comparison using Fisher’s exact test rejected the null hypothesis.

Figure 3.
Illustration of GPT-4.o versus medical students’ test performance in six anatomy M1 medical state exams (spring 2021 to autumn 2023). The two bars on the right side show mean performance. Note the significantly better performance of the LLM GPT-4.o compared with the broad medical student cohort; ** p ≤ 0.01.
Figure 3.
Illustration of GPT-4.o versus medical students’ test performance in six anatomy M1 medical state exams (spring 2021 to autumn 2023). The two bars on the right side show mean performance. Note the significantly better performance of the LLM GPT-4.o compared with the broad medical student cohort; ** p ≤ 0.01.


{kind=link}
{kind=link}
{kind=link}
Table 1.
This table demonstrates the results of the M1 autumn exam in 2022 (formerly called physikum). Stars (*) in the row “image” indicate questions that were not further processed because they contained relevant images or schematic drawings. The exam was provided to GPT-3.5 in duplicate, which is indicated by “1st round” and “2nd round”, respectively. The crosses indicate whether GPT-3.5 provided a correct, false, or no answer (see respective columns). Red crosses indicate inconcistent answers.
Table 1.
This table demonstrates the results of the M1 autumn exam in 2022 (formerly called physikum). Stars (*) in the row “image” indicate questions that were not further processed because they contained relevant images or schematic drawings. The exam was provided to GPT-3.5 in duplicate, which is indicated by “1st round” and “2nd round”, respectively. The crosses indicate whether GPT-3.5 provided a correct, false, or no answer (see respective columns). Red crosses indicate inconcistent answers.
| Autumn Exam in 2022 | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st Round | 2nd Round | ||||||||
| Index | Image | Topic | Correct | False | No Answer | Correct | False | No Answer | |
| 1 | penis | x | x | ||||||
| 2 | A vertebralis | x | x | ||||||
| 3 | cerebellum | x | x | ||||||
| 4 | * | ||||||||
| 5 | uterus | x | x | ||||||
| 6 | neuroanatomy of the optic tract | x | x | ||||||
| 7 | intestines | x | x | ||||||
| 8 | respiratory system | x | x | ||||||
| 9 | segmental innervation | x | x | ||||||
| 10 | * | ||||||||
| 11 | caecum | x | x | ||||||
| 12 | lymphatics | x | x | ||||||
| 13 | stomach | x | x | ||||||
| 14 | * | ||||||||
| 15 | inguinal region | x | x | ||||||
| 16 | coronary blood vessel | x | x | ||||||
| 17 | * | ||||||||
| 18 | face | x | x | ||||||
| 19 | intestines | x | x | ||||||
| 20 | * | ||||||||
| 21 | nose | x | x | ||||||
| 22 | thorax | x | x | ||||||
| 23 | Bursa omentalis | x | x | ||||||
| 24 | eye | x | x | ||||||
| 25 | neuroanatomy of the optic tract | x | x | ||||||
| 26 | neuroanatomy of the trigeminal nerve | x | x | ||||||
| 27 | * | ||||||||
| 28 | neuroanatomy of machanosensation | x | x | ||||||
| 29 | acromioclavicular joint | x | x | ||||||
| 30 | eye bulb movement | x | x | ||||||
| 31 | larynx | x | x | ||||||
| 32 | neuroanatomy of the trigeminal nerve | x | x | ||||||
| 33 | hand and wrist anatomy | x | x | ||||||
| 34 | lymphatics | x | x | ||||||
| 35 | brain stem nuclei | x | x | ||||||
| 36 | neuroanatomy of the cortex | x | x | ||||||
| 37 | * | ||||||||
| 38 | bile duct | x | x | ||||||
| 39 | tympanic | x | x | ||||||
| 40 | neck and throat | x | x | ||||||
| 41 | continence organs | x | x | ||||||
| 42 | * | ||||||||
| 43 | superficial anatomy | x | x | ||||||
| 44 | * | ||||||||
| 45 | lymphatics | x | x | ||||||
| 46 | neuroanatomy of the spinal cord | x | x | ||||||
| 47 | * | ||||||||
| 48 | * | ||||||||
| 49 | hand and wrist anatomy | x | x | ||||||
| 50 | eyeball | x | x | ||||||
| 51 | ankle joint and foot | x | x | ||||||
| 52 | knee joint | x | x | ||||||
| 53 | abdominal wall | x | x | ||||||
| 54 | neuroanatomy of the n facialis | x | x | ||||||
| 55 | hip joint | x | x | ||||||
| 56 | inguinal region | x | x | ||||||
Table 2.
This table demonstrates the results of the M1 spring exam in 2021 (formerly called physikum). Stars (*) in the row “image” indicate questions that were not further processed because they contained relevant images or schematic drawings. The exam was provided to GPT-3.5 in duplicate, which is indicated by “1st round” and “2nd round”, respectively. The crosses indicate whether GPT-3.5 provided correct, wrong, or no answer (see respective columns). Red crosses indicate inconcistent answers. In the column “re-challenge”, it is indicated whether GPT-3.5 provided an alternative answer in case simply asking the question, “Are you sure?” for all questions falsely answered in the 2nd round.
Table 2.
This table demonstrates the results of the M1 spring exam in 2021 (formerly called physikum). Stars (*) in the row “image” indicate questions that were not further processed because they contained relevant images or schematic drawings. The exam was provided to GPT-3.5 in duplicate, which is indicated by “1st round” and “2nd round”, respectively. The crosses indicate whether GPT-3.5 provided correct, wrong, or no answer (see respective columns). Red crosses indicate inconcistent answers. In the column “re-challenge”, it is indicated whether GPT-3.5 provided an alternative answer in case simply asking the question, “Are you sure?” for all questions falsely answered in the 2nd round.
| Spring Exam in 2021 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1st Round | 2nd Round | |||||||||
| Index | Image | Topic | Correct | False | No Answer | Correct | False | No Answer | Re-Challenge | |
| 1 | nose | x | x | wrong | ||||||
| 2 | vegetativum | x | x | |||||||
| 3 | reflexes | x | x | |||||||
| 4 | hand and wrist | x | x | |||||||
| 5 | * | |||||||||
| 6 | hand and wrist | x | x | correct | ||||||
| 7 | segental innervation | x | x | |||||||
| 8 | hand and wrist | x | x | |||||||
| 9 | N medianus | x | x | |||||||
| 10 | ankle joint and foot | x | x | |||||||
| 11 | ankle joint and foot | x | x | |||||||
| 12 | joints | x | x | no change | ||||||
| 13 | hip joint | x | x | correct | ||||||
| 14 | hip joint | x | x | |||||||
| 15 | N obturatorius | x | x | no change | ||||||
| 16 | hip joint | x | x | |||||||
| 17 | gluteal region | x | x | |||||||
| 18 | pelvis | x | x | no change | ||||||
| 19 | inguinal region | x | x | |||||||
| 20 | scrotum | x | x | |||||||
| 21 | lymphatics | x | x | no change | ||||||
| 22 | pelvis | x | x | |||||||
| 23 | abdomen | x | x | |||||||
| 24 | aorta | x | x | |||||||
| 25 | heart | x | x | |||||||
| 26 | heart | x | x | |||||||
| 27 | lymphatics | x | x | |||||||
| 28 | abdomen | x | x | |||||||
| 29 | abdomen | x | x | no change | ||||||
| 30 | abdomen | x | x | no change | ||||||
| 31 | abdomen | x | x | |||||||
| 32 | continence organs | x | x | wrong | ||||||
| 33 | adrenals | x | x | wrong | ||||||
| 34 | neck and throat | x | x | wrong | ||||||
| 35 | neck and throat | x | x | no change | ||||||
| 36 | neck and throat | x | x | no change | ||||||
| 37 | neck and throat | x | x | no change | ||||||
| 38 | vegetativum | x | x | |||||||
| 39 | head | x | x | |||||||
| 40 | CNS | x | x | |||||||
| 41 | CNS | x | x | |||||||
| 42 | CNS | x | x | correct | ||||||
| 43 | endocrinum | x | x | |||||||
| 44 | optic tract | x | x | |||||||
| 45 | eye | x | x | correct | ||||||
| 46 | eye | x | x | |||||||
| 47 | eye | x | x | no change | ||||||
| 48 | * | |||||||||
| 49 | vestibular | x | x | |||||||
Table 3.
Literature review of studies investigating the performance of LLMs, particularly GPT, on medical exam questions. Studies published in 2024 until the final publication of this paper have been included. Literature research was conducted in https://pubmed.ncbi.nlm.nih.gov/ using the search terms “ChatGPT AND medical exam”. Review articles were excluded. The term “ChatGPT” is just given in case no information regarding the specific LLM version was provided in the respective manuscript.
Table 3.
Literature review of studies investigating the performance of LLMs, particularly GPT, on medical exam questions. Studies published in 2024 until the final publication of this paper have been included. Literature research was conducted in https://pubmed.ncbi.nlm.nih.gov/ using the search terms “ChatGPT AND medical exam”. Review articles were excluded. The term “ChatGPT” is just given in case no information regarding the specific LLM version was provided in the respective manuscript.
| Citation | Study Resources | Applied LLM | Main Outcome(s) |
|---|---|---|---|
| [23] | Progress Test of the Brazilian National Medical Exam | GPT-3.5 | GPT-3.5 outperformed humans |
| [24] | European Board of Interventional Radiology exam | GPT-4.o | GPT-3.5 outperformed students and consultants; lower accuracy than certificate holders |
| [25] | American Registry of Radiologic Technologists Radiography Certification Exam | GPT-4 | Higher accuracy on text-based compared to image-based questions; performance varied by domain |
| [26] | Taiwan plastic surgery board exam | GPT3.5 and GPT-4 | ChatGPT-4 outperformed ChatGPT-3.5; ChatGPT-4 passed five out of eight yearly exams |
| [27] | U.K. medical board exam | Various | All LLMs scored higher on multiple-choice vs. true/false or “choose N” questions; best performance of GPT-4.o |
| [28] | Chinese Medical Licensing exam | GPT3.5 and GPT-4 | ChatGPT-4 outperformed ChatGPT-3.5; GPT-4.0 surpassed the accuracy threshold in 14 of 15 subspecialties |
| [29] | U.S. otolaryngology board exam (preparation tool BoardVitals) | ChatGPT, GPT-4, and Google Bard | GPT-4 outperformed ChatGPT and Bard |
| [30] | Polish nephrology speciality exam | GPT3.5 and GPT-4 | ChatGPT-4 outperformed ChatGPT-3.5; outperformed humans |
| [31] | U.S. national radiation oncology in-service examination | GPT3.5 and GPT-4.o | ChatGPT-4 outperformed ChatGPT-3.5; difference in performance by question category |
| [32] | Member of Royal College of Physicians Part 1 exam | GPT3.5 and GPT-4 | ChatGPT-4 outperformed ChatGPT-3.5; both versions above the historical pass mark for MRCP Part 1 |
| [33] | European Board of Urology exam | GPT3.5 and GPT-4 | ChatGPT-4 outperformed ChatGPT-3.5; performance varied by domain; GPT-4 passed all exams |
| [34] | American Board of Physical Medicine and Rehabilitation exam | GPT-3.5, GPT-4, and Google Bard | GPT-4 outperformed ChatGPT and Bard |
| [35] | Local pulmonology exam with third-year medical students | GPT-3.5 | Performance varied by domain and question type; performance closely mirrors that of an average medical student |
| [36] | Orthopedic Board-Style Written Exam | GPT-3.5 | Performs below a threshold likely to pass the American Board of Orthopedic Surgery (ABOS) Part I written exam |
| [37] | Chinese ophthalmology-related exam | own developed LLM (MOPH) | Good performance |
| [38] | Chinese residency final exam | GPT-3.5 | Potential for personalized Chinese medical education |
| [39] | French local physiology university exam | GPT-3.5 | Outperformed humans |
| [40] | American urology board exam | GPT-3.5 and GPT-4 | GPT-4 outperformed ChatGPT-3.5; performance relatively poor |
| [41] | Otolaryngology (Rhinology) Standardized Board Exam | GPT-3.5 and GPT-4 | GPT-4 outperformed ChatGPT-3.5 and residents |
| [42] | Vignettes covering emergency conditions in plastic surgery | GPT-4 and Gemini | GPT-4 outperformed Gemini; AI might support clinical decision-making |
| [43] | American Society for Surgery of the Hand exam | GPT-3.5 | Poor performance; performance varied by question type |
| [44] | Urology Canadian board exam | GPT-4 | GPT-4 underperformed compared to residents |
| [45] | Polish Medical Final exam | GPT-3.5 | GPT-3.5 underperformed compared to humans; passed 8 out of 11 exams |
| [46] | Advanced Burn Life Support exam | GPT-3.5, GPT-4, Bard | GPT-4 outperformed Bard; high accuracy of GPT-3.5 and GPT-4 |
| [47] | Canadian Association of Medical Radiation Technologists exam | GPT-4 | Passed exams; bad performance on critical thinking questions |
| [48] | Japanese Medical Licensing exam | GPT-4 | Passed exams; performance comparable to humans; performance varied by question type |
| [49] | Spanish orthopedic Surgery and Traumatology exam | GPT-3.5, Bard, Perplexity | GPT-3.5 outperformed Bard and Perplexity; |
| [50] | American Board of Neurological Surgery | ChatGPT | ChatGPT underperformed compared to humans |
| [51] | European Society of Neuroradiology exam | GPT-3.5, GPT-4, Bard | GPT-4 outperformed GPT-3.5 and Bard |
| [52] | Interventional cardiology exam | GPT-4 | GPT-4 underperformed compared to humans; passed the exam |
| [53] | Examen Único Nacional de Conocimientos de Medicina min Chile | GPT-3.5, GPT-4, GPT-4V | All versions passed the exam; GPT-4 and GPT-4V outperformed GPT-3.5 |
| [54] | AAMC PREview® exam | GPT-3.5, GPT-4 | GPT-4 outperformed GPT-3.5; both versions outperformed humans |
| [55] | United States Medical Licensing Exam (USMLE) Step 2 | GPT-3.5, GPT-4 | GPT-4 outperformed GPT-3.5; correctly listed differential diagnoses from case reports |
| [56] | Thai local 4th year pharmacy exam | GPT-3.5 | GPT-3.5 underperformed compared to humans |
| [57] | Dutch Clinical pharmacy exam (retrieved by parate kennis database) | GPT-4 | GPT-4 outperformed pharmacists |
| [58] | Postgraduate orthopaedic qualifying exam | GPT-3.5, GPT-4, Bard | Bard outperformed GPT-3.5 and GPT-4 |
| [59] | National Board of Medical Exam | GPT-4, GPT-3.5, Claude, Bard | GPT-4 outperformed GPT-3.5, Claude, and Bard |
| [60] | Anatomopathological Diagnostic and Therapeutic Procedures | ChatGPT | GPT-4 outperformed humans |
| [61] | American Shoulder and Elbow Surgeons Maintenance of Certification exam | GPT-3.5, GPT-4 | GPT-4 underperformed compared to humans; performance varied by question type |
| [62] | nephrology fellows exam | GLT-4V | GPT-4V underperformed compared to humans; performance varied by question type |
| [63] | American Society for Surgery of the Hand Self-Assessment exam | GPT-4 | GPT-4 underperformed compared to humans |
| [64] | Japanese Otolaryngology Board Certification exam | GPT-4V | Accuracy rate increased after translation to English; performance varied by question type |
| [65] | Pediatric Board Preparatory exam | GPT-3.5, GPT-4 | GPT-4 outperformed GPT-3.5, limitations with complex questions |
| [66] | European Board exam in Neurological Surgery | GPT-3.5, Bing, Bard | Bard outperformed GPT-3.5, Bing, and humans; performance varied by question type |
| [67] | United States Medical Licensing Exam STEP 1-style questions | GPT-4 | Passed exam |
| [68] | Italian gastroenterology-related national residency admission exam | GPT-3.5, Perplexity | GPT-3.5 outperformed Perplexity |
| [69] | Japanese National Medical Licensing exam | GPT-4V | 68% accuracy; input of images does not further improve performance |
| [11] | Taiwan advanced medical licensing exam | GPT-4 | Passed exams; chain-of-thought prompt increased performance |
| [70] | Israeli Hebrew Internal Medicine National Residency exam | GPT-3.5 | Suboptimal performance (~37%) |
| [71] | Taiwan Nursing Licensing exam | GPT-4 | Passed exam; performance varied by domain |
| [72] | International Society for Clinical Densitometry exam | GPT-3, GPT-4 | GPT-4 outperformed GPT-3; GPT-4 passed exam |
| [73] | Indian National Eligibility cum Entrance Test | GPT-3.5, GPT-4, Bard | GPT-4 outperformed GPT-3.5 and Bard, GPT-4, and GPT-3.5 passed the exam |
| [74] | Taiwanese Stage 1 of Senior Professional and Technical Exam for Medical Doctors | GPT-4 | Passed exam; performance varied by domain |
| [75] | Chinese national medical licensing exam | GPT-3.5 | Does not pass the exams; performance varied by domain and question type |
| [76] | Local Belgium medical licensing exam of University of Antwerp | GPT-3.5, GPT-4, Bard, Bing, Claude instant, Claude+ | All LLMs passed the exam; Bing and GPT-4 outperformed the other LLMs and humans |
| [77] | Medical licensing exam | GPT.3-5, GPT-4 | GPT-4 outperformed GPT-3.5 and humans |
| [78] | Japanese National Medical Licensing Examination | GPT.3-5, GPT-4 | GPT-4 outperformed GPT-3.5; optimization of prompts increases performance |
| [79] | Psychosomatic medicine | GPT-4 | Passed exam |
| [80] | Otolaryngology-head and neck surgery certification exam | GPT-4 | Passed exam |
| [81] | European Board of Urology (EBU) In-Service Assessment exam | GPT-3.5, GPT-4, Bing | GPT-4 and Bing outperformed GPT-3.5 |
| [82] | Taiwanese Nuclear Medicine Specialty Exam | GPT-4 | Passed exam; increased performance when adding chain-of-thoughts method |
| [83] | Medical cases in ophthalmology | GPT-3.5 | GPT-3.5 underperformed compared to residents |
| [84] | Turkish Neurosurgical Society Proficiency Board exam | GPT-4 | GPT-4 outperformed humans |
| [85] | Multi-Specialty Recruitment Assessment from PassMedicine | GPT-3.5, Llama2, Bard, Bing | Bing outperformed all other LLMs and humans |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kipp, M. From GPT-3.5 to GPT-4.o: A Leap in AI’s Medical Exam Performance. Information 2024, 15, 543. https://doi.org/10.3390/info15090543
AMA Style
Kipp M. From GPT-3.5 to GPT-4.o: A Leap in AI’s Medical Exam Performance. Information. 2024; 15(9):543. https://doi.org/10.3390/info15090543
Chicago/Turabian StyleKipp, Markus. 2024. "From GPT-3.5 to GPT-4.o: A Leap in AI’s Medical Exam Performance" Information 15, no. 9: 543. https://doi.org/10.3390/info15090543
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.