Abstract
Classic video compression methods usually suffer from long encode time and requires large memories, making it hard to deploy on edge devices; thus, video compressive sensing, which requires less resources during encoding, is receiving more attention. We propose a robust mixed-rate ROI-aware video compressive sensing algorithm for transmission line surveillance video compression. The proposed method compresses foreground targets and background frames separately and uses reversible neural network to reconstruct original frames. The result on transmission line surveillance video data shows that the proposed compressive sensing method can achieve 26.47, 34.71 PSNR and 0.6839, 0.9320 SSIM higher than existing methods on 1.5% and 15% measurement rates, and the proposed ROI extraction net can precisely retrieve regions under high noise levels. This research not only demonstrates the potential for a more efficient video compression technique in resource-constrained environments, but also lays a foundation for future advancements in video compressive sensing techniques and their applications in various real-time surveillance systems.
1. Introduction
With the development of intelligent power grid systems in recent years, edge surveillance devices have come to produce large amounts of video data, bringing stress on data transmission and storage. A classic video compression solution like H.264/AVC using complex encoders requires dedicated hardware to compress raw video data, and thus is not suitable for edge applications where calculation and storage resources are limited. The Nyquist sampling theory states that sampling frequency should be two times the original signal frequency to fully recover original signals during reconstruction. Candès et al. [1] proved that if the original signal is sparse, we can fully recover original signals below the Nyquist frequency limit, allowing us to sample and compress at the same time. In transmission line edge surveillance application, the sampling, storage and transmission costs of surveillance video data are high; therefore, compressive sensing is helpful to reduce data sampling and storage costs.
Classic compressive sensing approaches use fixed sensing matrices to compress and iterative optimization solvers to reconstruct, which are slow and heavyweight. Deep learning-based compressive sensing methods use learnable sensing matrices [2,3] or end-to-end reconstruction networks [4], significantly improving reconstruction speed and quality. Other approaches leverage autoencoders [5] and generative models [6] to enhance compression and reconstruction performance.
Existing methods which compress each video frame equally are not suitable for transmission line surveillance scenes. Transmission line surveillance video is usually captured by fixed-position cameras, and video frames remain unchanged most of the time and for most of the area. Compressing all regions of the video frame equally is inefficient for surveillance purposes [7]. Meanwhile, analog cameras produce noisy and corrupted video data in real scenes, making it difficult to compress and reconstruct video data [8]. Current methods use heavyweight networks to achieve high-quality reconstruction results, but high training costs and memory consumption make it difficult to deploy deep networks on edge computing devices [9].
There are still two problems that need to be solved: (1) The existing method of equally compressing each video frame is not suitable for transmission line monitoring scenarios. Uniformly compressing all areas of the video frame is detrimental to the efficiency of monitoring videos. (2) A high-quality reconstruction network requires large memory to train. In order to solve the existing problems, we propose a dual-scale dual-sampling rate compressed sensing algorithm for transmission line surveillance videos. The main contributions are as follows:
- We propose a dual-scale video-frame compressive sensing method based on dilated convolution. When the size of the sampling matrix is fixed, dilated convolution is used to extract image features of different scales and achieve compressed sampling at both large and small scales, which helps to improve the quality of video frame reconstruction.
- We propose a memory-efficient video frame compressed sensing reconstruction algorithm. Compared with existing methods, the proposed compressed sensing reconstruction algorithm based on reversible neural network can be trained under limited memory.
- We propose an ROI extraction method based on compressed representation, which can quickly extract an ROI area of the original image size on compressed representation under high noise level. Compared with existing methods, the proposed method more accurately extracts the ROI area, thus improving the compression sampling ratio.
2. Related Work
Video compressive sensing can be divided into two categories: temporal video compressive sensing and spatial video compressive sensing.
Temporal video compressive sensing is inspired by video snapshot compressive imaging. This type of video compressive sensing algorithm compresses several video frames into a single measurement, and usually test on high-speed video datasets. GAP-TV [10] uses iteration-based methods to reconstruct video frames under total variation restraint. PnP-FFDNet [11] proposes a Plug-and-Play reconstruction framework, adding deep denoising in each iteration to improve reconstruction quality. Different from iterative methods, non-iterative methods use deep neural networks to accelerate reconstruction. BIRNAT [12] uses convolution and recurrent neural networks to reconstruct. Wu et al. used a 3D convolution network to capture temporal features [13], while STFormer [14] designed a spatial–temporal transformer architecture to capture the correlation in both spatial and temporal features. Temporal video compressive sensing models work well on videos captured with high-speed cameras, which are thus not suitable for low-speed surveillance videos.
Spatial video compressive sensing usually treat video frames as an image sequence, using image compressive sensing techniques to compress videos. To better capture the temporal features between frames, Zhao et al. proposed a video compressive sensing reconstruction algorithm [15] using intra-frame correlations to optimize frame reconstruction quality. However, iteration-based algorithms usually need a lot of time and resources to reconstruct the original frame. ReconNet [16] is the first to use a full convolution network to implement an end-to-end compressive sensing reconstruction algorithm, which achieves higher quality in less time. ReconNet uses fixed random Gaussian matrix as a sensing matrix, which is not efficient to model unique properties of various data. Xie et al. proposed an adaptive compressive sensing algorithm [17]. Combined with the above techniques, Xu et al. proposed a real-time end-to-end video compressive sensing framework [18] that divides video frame groups into key frames and non-key frames and separately compresses them, then uses a synthesis network to jointly reconstruct video frames. Most spatial video compressive sensing algorithms treat video frames equally, which is not efficient to utilize a unique sparsity of surveillance video. People are usually interested in changing regions and moving objects in surveillance videos, while frames in surveillance videos remain unchanged most of the time, so equally compressing unchanged frames along with changing frames is inefficient. Yang et al. proposed a surveillance decomposition method based on compressive sensing [19]. The method learned a low-rank representation of nearly static background, then decomposed the video to extract sparse foreground. A DNN-based parallel video compression network was proposed in 2020 [20], using a mixture of Gaussian model as background model to model background and extract changing area as foreground. The compression process follows a classic video compression scheme, which includes motion compensation, frame interpolation and entropy coding. Du et al. proposed an ROI-aware video compressive sensing-scheme MRVCS [21], separately compressing foreground and background to achieve higher reconstruction quality under a comparably low measurement rate. Foreground extraction is based on compressed representation, which is faster than extracting on input frames.
3. Proposed Method
3.1. Overview
Before video compression, we need to identify the dynamic and static regions within the video. The former is referred to as the Region of Interest (ROI), while the latter is the background region. The ROI contains rich detailed information compared to the background; so, to improve compression efficiency, we adopt a mixed compression method.
An overview of the proposed surveillance video compression and reconstruction method is shown in Figure 1. At the compression stage, the proposed method first uses the proposed ROI extraction method based on compressed representation to extract the changing area, and then uses high sampling rate to compress the ROI area of the frame to obtain a high-sampling-rate compression representation. The static background area is compressed under low sampling rate to obtain a low-sampling-rate compression representation, and then the compressed representations of the two sampling rates are mixed according to the extracted changing area map to obtain the final compressed representation. At the reconstruction stage, the compressed representations of high and low sampling rates are separated according to the changing area map and reconstructed using high- and low-sampling-rate reversible reconstruction networks, respectively, to obtain the reconstructed changing area image and the reconstructed background image. Finally, the two images are spliced and synthesized to obtain the final reconstructed frame of the current video frame.
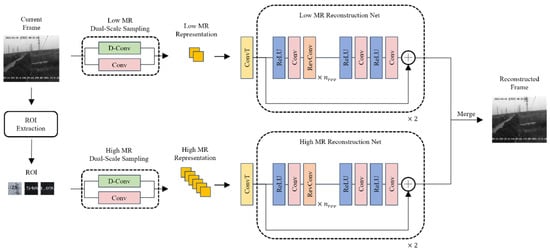
Figure 1.
Compression and reconstruction overall flow chart.
During video compression, we apply low-sampling-rate compression to the reference frame (usually the first frame) to obtain a baseline low-sampling-rate representation. Next, we perform the same low-sampling-rate compression on the current frame to generate its low-sampling-rate representation. By comparing the low-sampling-rate representations of the current frame and the reference frame, we calculate the differences between them. A change threshold is set to identify pixel regions with significant differences, which may indicate motion or scene changes. The results of the difference calculation are compared against the change threshold to determine which areas constitute the Region of Interest (ROI). These areas are marked for high-quality processing. We then analyze the pixel connectivity to merge adjacent areas of change and form a complete ROI. Edge detection algorithms are applied within the ROI to further enhance edge clarity, ensuring important details are not overlooked. Morphological operations, such as dilation and erosion, are performed on the extracted ROI to remove noise and optimize the region’s shape. At frame reconstruction, we reconstruct low- and high-measurement-rate representations and concatenate reconstruction results as the final reconstruction of the current frame.
3.2. Dual-Scale Compressive Sampling Based on Dilated Convolution
In single-rate compressive sensing, the formula of compressive sensing is shown below:
where is the sensing matrix, is the input frame and is the compressed representation of the input frame.
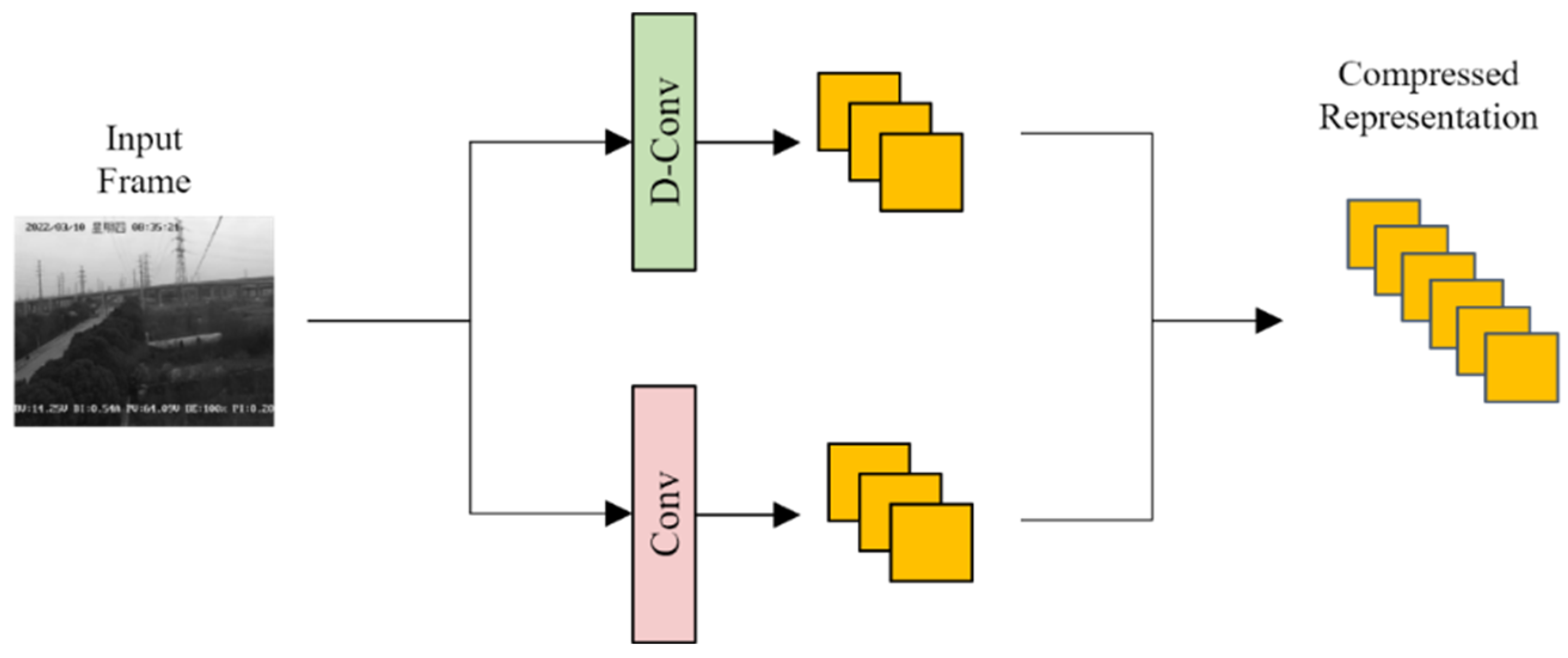
In order to train the sensing matrix to compress video frames, the proposed compressive sensing method uses a convolutional neural network to implement compressive sampling on the input video frame. After convolution, we treat the output feature maps as a compressed representation of the input video frame, as shown in Figure 2.
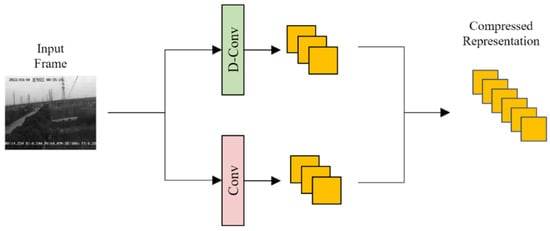
Figure 2.
Overview of single-rate video-frame compressive sensing procedure.
The proposed compressive sampling network adopts a dual-stream framework. For the input video frame to be compressed, dilated convolution and ordinary convolution are used to generate large-scale and small-scale compressed representations, respectively. The large-scale and small-scale compressed representations are then processed according to the depth dimension of the feature map. Splicing is performed to obtain the final dual-scale compressed representation. The dilated convolution is a special convolution technique that expands the receptive field by introducing a dilation coefficient in the convolution kernel without increasing the computational complexity. The dilated convolution is implemented by inserting holes between the elements of the convolution kernel, which can effectively capture information of different scales. This convolution method can strike a balance between different compression rates, achieve efficient compression while retaining important details in the video frame, and control the sampling density of the video frame. Therefore, in our experiments, by combining the structure of dilated convolution and ordinary convolution, the performance of the model in video compression and reconstruction tasks is significantly improved.
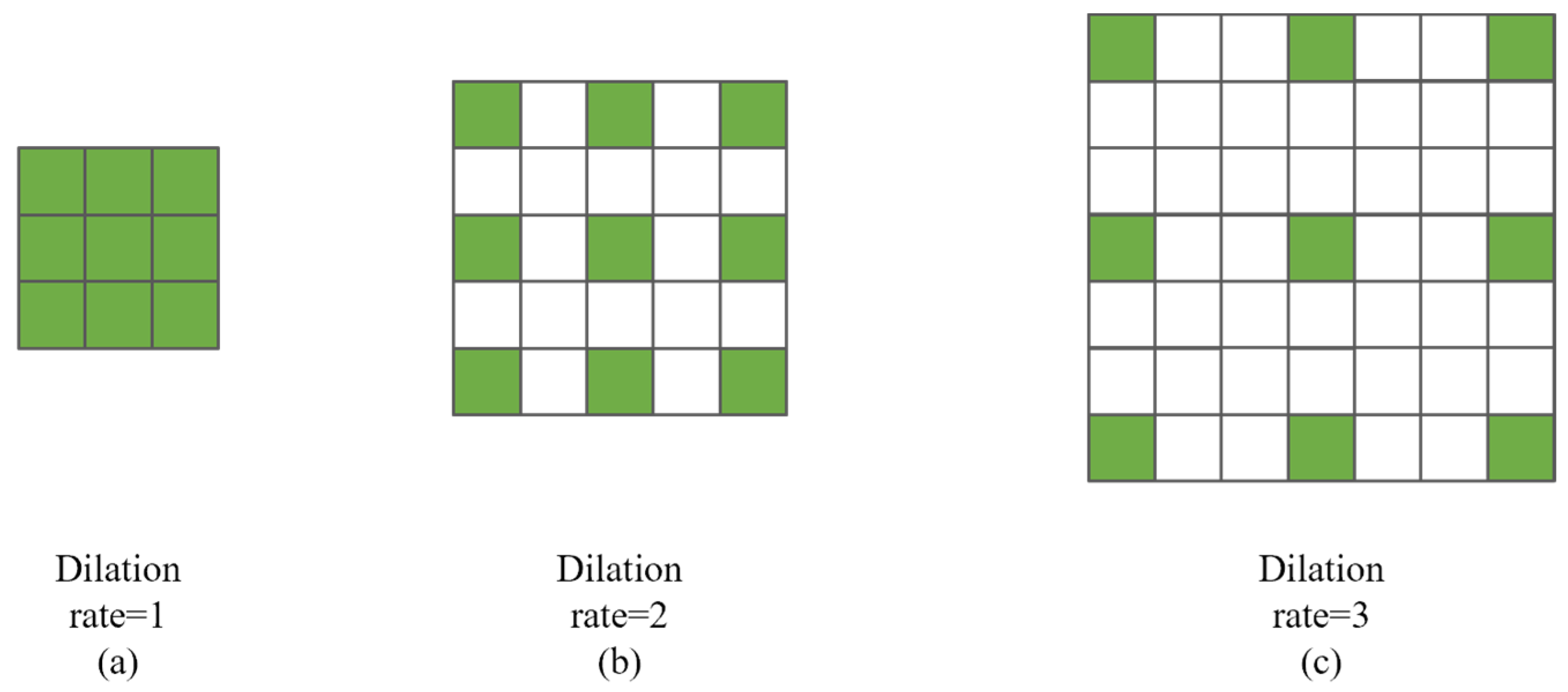
Ordinary convolution can be regarded as a dilated convolution with an expansion coefficient of 1, as shown in Figure 3a. When the expansion coefficient is 2, the distance between each trainable element of the convolution kernel is 1, as shown in Figure 3b; when the expansion coefficient is 3, the distance between each trainable element of the convolution kernel is 2, as shown in Figure 3c. During inference, elements in all positions of the convolution kernel participate in the operation. During training, only elements in green positions are updated, and elements in white positions are always constant, 0.
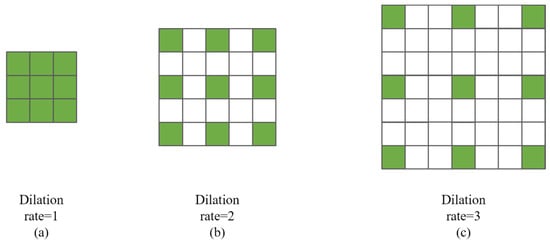
Figure 3.
Trainable weight setting of dilated convolution kernel under different dilation rates.
When compressing and sampling video frames, the convolution kernel size is fixed, the dilated convolution operation is used to generate a large-scale compressed representation, the ordinary convolution operation generates a small-scale compressed representation, and finally, the two-scale compressed representations are spliced to obtain the final compressed representation. The dual-scale compressed sampling is shown in the following formula:
where is the dilated convolution operation, is the convolution operation, and is the matrix concatenate operation.
The setting of the proposed dual-scale compressive sampling network is shown in Table 1.

Table 1.
Convolutional network settings in video-frame compressive sensing.
3.3. Video Frame Reconstruction Network Based on Reversible Neural Network
We propose a two-stage network to reconstruct the compressed representation. For each measurement rate, we train the compressed sensing reconstruction network separately. It should be noted that the measurement rate in compressed sensing usually refers to the ratio of the actual sampled data volume to the original data volume. The measurement rate determines the degree of information retention during the compression process. The higher the measurement rate, the more information is retained, and the lower the measurement rate, the more information is compressed. Unlike the sampling rate, the measurement rate pays more attention to the proportion of data compression and is a relative indicator used in compressed sensing. The sampling rate is an absolute indicator used when the signal is discretized, emphasizing the speed or density of sampling.
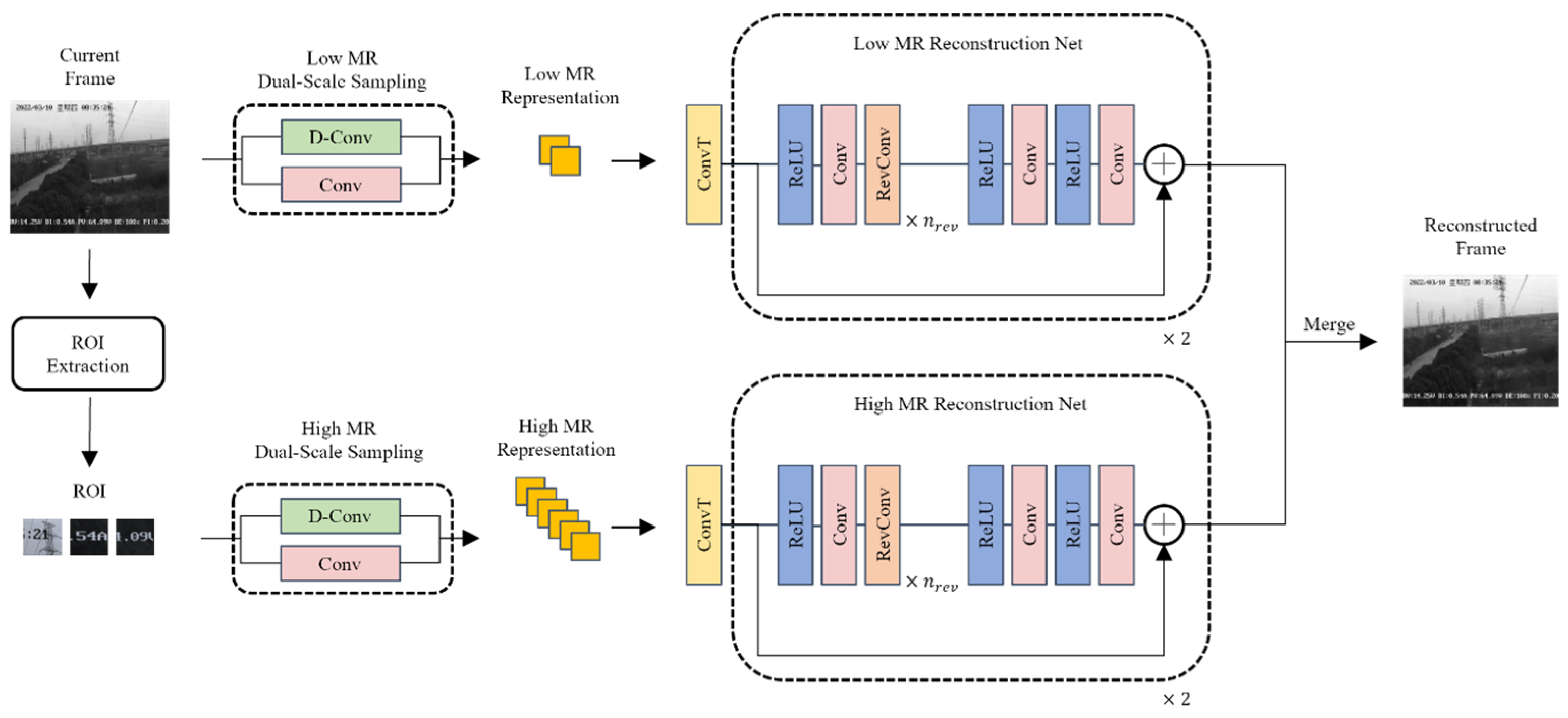
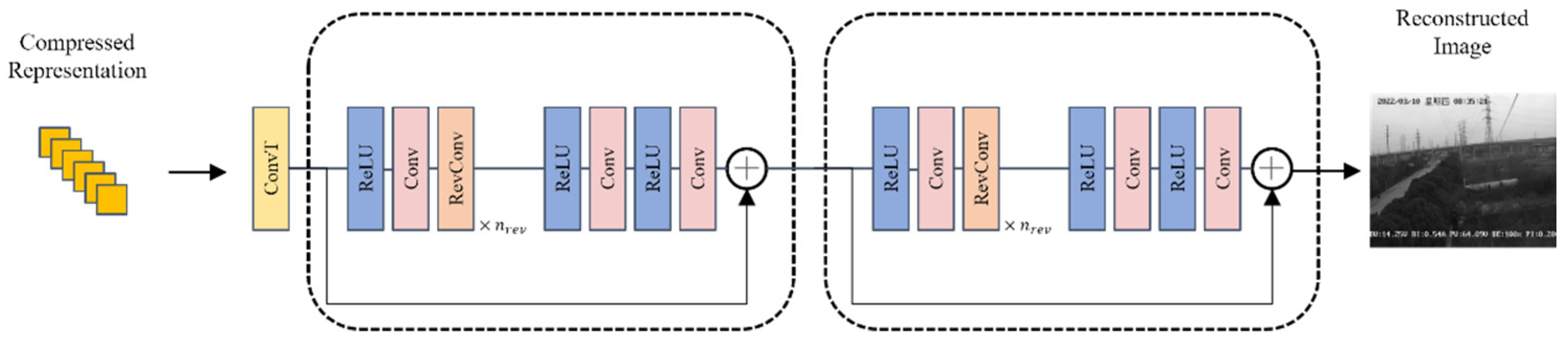
The reconstruction network architecture we propose is shown in Figure 4.
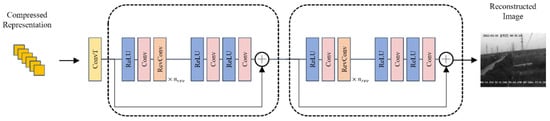
Figure 4.
Overview of proposed video frame reconstruction algorithm.
Proposed reconstruction method first using transposed convolution to make coarse reconstruction of compressed representation, then using a two-stage reversible reconstruction network for reconstruction. The two stages of the reconstruction network share the same architecture. The overall process of the proposed reconstruction network is shown below:
Gomez et al. proposed reversible residual network [22] by specially designing a reversible block architecture, so that a non-invertible operation such as residual link can be used in a reversible network. Inspired by their work, we designed a residual reversible convolution block for each stage. The forward process of a reversible convolution block is defined as follows:
During backward propagation, the input can be calculated by output , thereby reducing the overall memory requirements during training. The reverse process is defined as follows:
where and represent convolution, is the input, and is the output. Reversible convolution blocks can be stacked a certain number of times to achieve better reconstruction results [23]. Based on experimental results, this paper determined that stacking 17 reversible convolution blocks can control the computational complexity while ensuring the reconstruction quality. The network of each stage is shown below. Stage 1 and stage 2 share the same network architecture, and the settings of the reconstruction network are shown below Table 2.
Table 2.
Reconstruction network settings.
3.4. ROI Extraction Based on Compressive Sensing
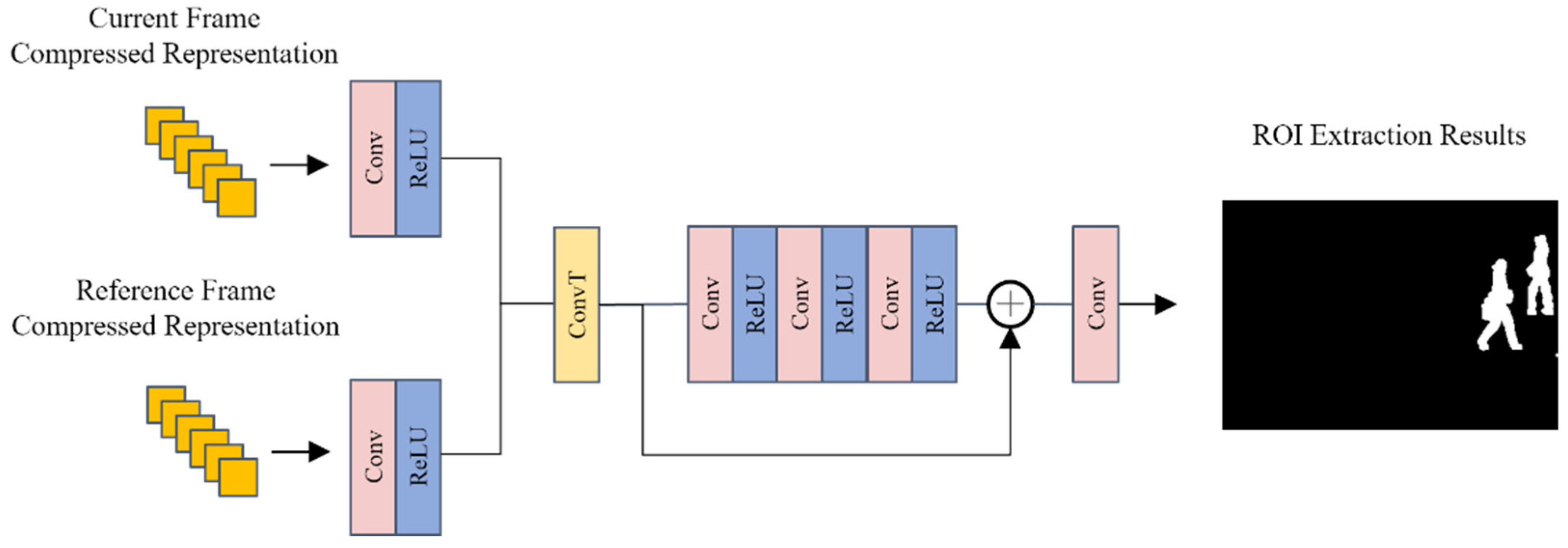
Existing ROI extraction methods based on compressive sensing are limited by the scale of compressed representation and cannot accurately extract hotspot areas and moving targets. Therefore, this paper proposes a compressed sensing changing area extraction algorithm based on twin networks, which obtains the same size as the original image in terms of compressed representation. The same applies to the moving area chart. The overview of the ROI extraction algorithm is shown in Figure 5.
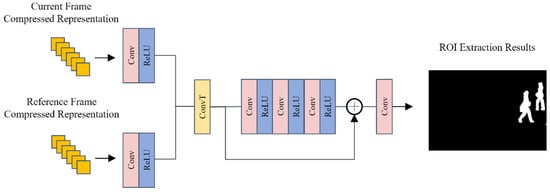
Figure 5.
Overview of proposed ROI extraction method.
The proposed method uses Siamese architecture, which inputs the current frame and the reference frame. During extraction, the proposed method first extracts features on a compressed representation of the current frame and the reference frame, then the extracted features are spliced and upsampled using transposed convolution. Then, using residual network to refine the intermediate feature, the output is processed through convolution to obtain the final ROI area extraction result. Settings of the proposed ROI extraction are shown in the following Table 3.
Table 3.
ROI extraction network settings.
3.5. Method Adaptation Across Multiple Scenarios
Adjusting the ROI extraction and compression strategies according to the characteristics of the video is crucial for the effectiveness of video compressive sensing algorithms. Continuously maintaining the advantages of video compressive sensing algorithms across different types of videos and surveillance environments presents significant challenges. Our algorithm can adapt to different video types by simply adjusting parameters or the model structure, thus minimizing unnecessary costs caused by environmental changes and differences in video modalities.
For videos with high object motion speeds, the detection capabilities for moving objects can be enhanced by increasing the frame-to-frame differential analysis. More sophisticated motion detection algorithms, such as optical flow methods, can be employed to accurately track moving objects. By increasing the temporal sensitivity of ROI extraction and utilizing our proposed dual-stream framework for compressive sampling, the network can identify and process frequently changing and static regions without compromising information retention. Finally, encoding parameters are automatically adjusted based on the content dynamics to ensure the quality of compression in dynamic areas.
For videos in low-variation scenes, ROI extraction can be simplified to periodic checks or using a lower frequency of frame differencing. This reduces computational resource consumption. Since the content changes are minimal, the compressive sampling network can safely increase the compression rate, reducing data storage and transmission requirements. Regular full-frame updates are inserted to prevent cumulative errors from long-term compression, thus ensuring video quality.
For videos with low light, image enhancement techniques such as histogram equalization or local contrast enhancement can be applied before compression to improve image quality and reduce compression errors. Noise suppression algorithms are introduced into our foundational framework to reduce the impact of noise in low-light videos, preventing noise from being mistakenly identified as critical information during compression. These modifications to the compressive sensing model not only enhance the reconstruction capabilities for areas with low contrast but also ensure that important details are not lost.
Our robust mixed-rate ROI-aware video compressive sensing is designed modularly, making ROI extraction and compression modules configurable to dynamically adjust parameters based on video characteristics. These technical adjustments significantly enhance the performance and adaptability of the compressive sensing algorithm across various video types and environmental conditions, ensuring effective video monitoring even on resource-constrained devices.
4. Results
4.1. Experiment Settings
In this section, we use a private dataset which contains surveillance color video collected from 17 different locations, with each video recorded over 30 min. The video frame shape is 576 × 704 × 3. We randomly pick 80% for training and 20% for testing. For deep models, we train 500 epochs on GTX 4080Ti with the batch size set to 4. The model is optimized by Adam, initial learning rate is set to 10−4 and at 100 epochs. The experiments are trained on Intel Core i7-12700K and 1 NVIDIA RTX 3090 GPU. The RAM size is 128GiB. The system platform is Ubuntu 22.04. Codes run on PyTorch 1.12.1 and Python 3.9.
4.2. Experiment Metrics
4.2.1. Reconstruction Quality
We use peak signal/noise ratio (PSNR) and structural similarity (SSIM) to quantize our reconstruction quality. PSNR is defined below:
where is the maximum value of pixel, which is 255 in this paper. MSE represents mean square error between the original image and reconstructed image.
SSIM is defined below:
4.2.2. ROI Extraction Accuracy
We use precision and recall, which are commonly used in the field of object detection as metrices. The precision is calculated as follows:
The recall is calculated as follows:
The F1-Score is calculated as follows:
where is the number of pixels predicted to be foreground and actually foreground, is the number of pixels predicted to be foreground but are actually background; is the number of pixels predicted to be background but are actually foreground.
4.3. Experiment Results
4.3.1. Video Frame Reconstruction Quality
The proposed method mixes high and low measurement rates when compressing video frames. We train and test reconstruction models where the measurement rate is set to 15% and 1%. We compare the proposed method (dual-scale dual-rate video compressive sensing, D2VCS) with a none-deep method such as singular-value decomposition (SVD), discrete cosine transform (DCT) and deep method MRVCS. Figure 6 shows the visualization of reconstruction quality under low and high measurement rates. The results are shown in Table 4 and Table 5.

Figure 6.
Visualization of reconstruction quality under low and high measurement rates.
Table 4.
PSNR and SSIM under 15% measurement rate.
Table 5.
PSNR and SSIM under 1.5% measurement rate.
The results shows that deep compressive sensing methods are superior than classic compression algorithms for image, and the proposed method gains better reconstruction quality by only using one stage of reconstruction compared to the three stages of reconstruction by the model MRVCS. In addition to PSNR and SSIM, deep models show better performance under low measurement rates. Table 1 shows that the proposed method achieves 0.40 dB, 1.67 dB improvement in PSNR and 0.0006, 0.0175 improvement in SSIM at stages 1 and 2 compared with the second best results (MRVCS) under a 15% measurement rate. Table 2 shows that the proposed method achieves 0.81 dB, 1.25 dB improvement in PSNR and 0.003, 0.0106 improvement in SSIM at stages 1 and 2 compared with the second best results (MRVCS method) under a 1% measurement rate on the transmission line surveillance video dataset.
4.3.2. Ablation Study of Proposed Dual-Scale Sampling
In order to prove the effectiveness of the dual-scale sampling module, we replaced the single-scale compressed sampling in MRVCS with the dual-scale compressed sampling network in D2VCS. This swap was conducted under both high and low measurement rates while keeping the number of trainable weights constant. The results of the reconstruction quality are shown in Table 6 and Table 7. The comparison results show that the proposed dual-scale sampling can improve the quality of video frame reconstruction.
Table 6.
PSNR and SSIM under 15% measurement rate.
Table 7.
PSNR and SSIM under 1.5% measurement rate.
4.3.3. Changing Detection and Extraction on Compressed Representation
In real surveillance video applications, people pay more attention to active targets in surveillance videos. However, the existing ROI-region video-compressed sensing methods do not quantify the extraction accuracy of active foregrounds, and the extraction accuracy is greatly affected by noise. Therefore, the hotspot area extraction results of this model and the classic statistical model-based methods MoG and KDE [24] and the same type of method, MRVCS, were all tested on the public CD.Net pedestrian dataset [25]. The visual results of the hotspot area extraction are shown in Figure 7.

Figure 7.
Visualization of ROI extraction results under different noise levels. (a) , (b) , (c) .
We add Gaussian noise with a mean value of 0 and a variance of 0.5 to the original image to synthesize noisy image. The formula of generating noisy image is shown below:
where is the Gaussian noise intensity parameter, is the normalized original image, and is the image containing noise.
Experimental results show that compared with the classic ROI-region extraction method based on statistical models, the ROI-region extraction method based on compressed representation extracts faster and can accurately extract regions in high-noise scenes. Compared with similar methods, the method proposed in this paper can more accurately extract the ROI area of the original image size. The quantification of ROI area extraction accuracy is shown in Table 8, Table 9 and Table 10.
Table 8.
ROI extraction quality when .
Table 9.
ROI extraction quality when .
Table 10.
ROI extraction quality when .
The ROI extraction method of MRVCS can only extract small-sized ROI areas and cannot extract original-sized ROI areas. Therefore, although the recall rate is superior among the four methods, the F1-Score is the lowest among the four methods. The proposed ROI extraction network has a suboptimal recall rate compared to the hotspot area extraction method of MRVCS. The F1-Score is optimal at each noise level, but it can extract changing areas more precisely, thereby increasing the effective sampling ratio and reducing the proportion of invalid samples in static areas.
At the same time, we also compare the ROI extraction time of different algorithms on the pedestrian dataset. The quantitative results are shown in Table 11.
Table 11.
ROI extraction time per frame.
4.4. Experiment on Real Surveillance Video Dataset
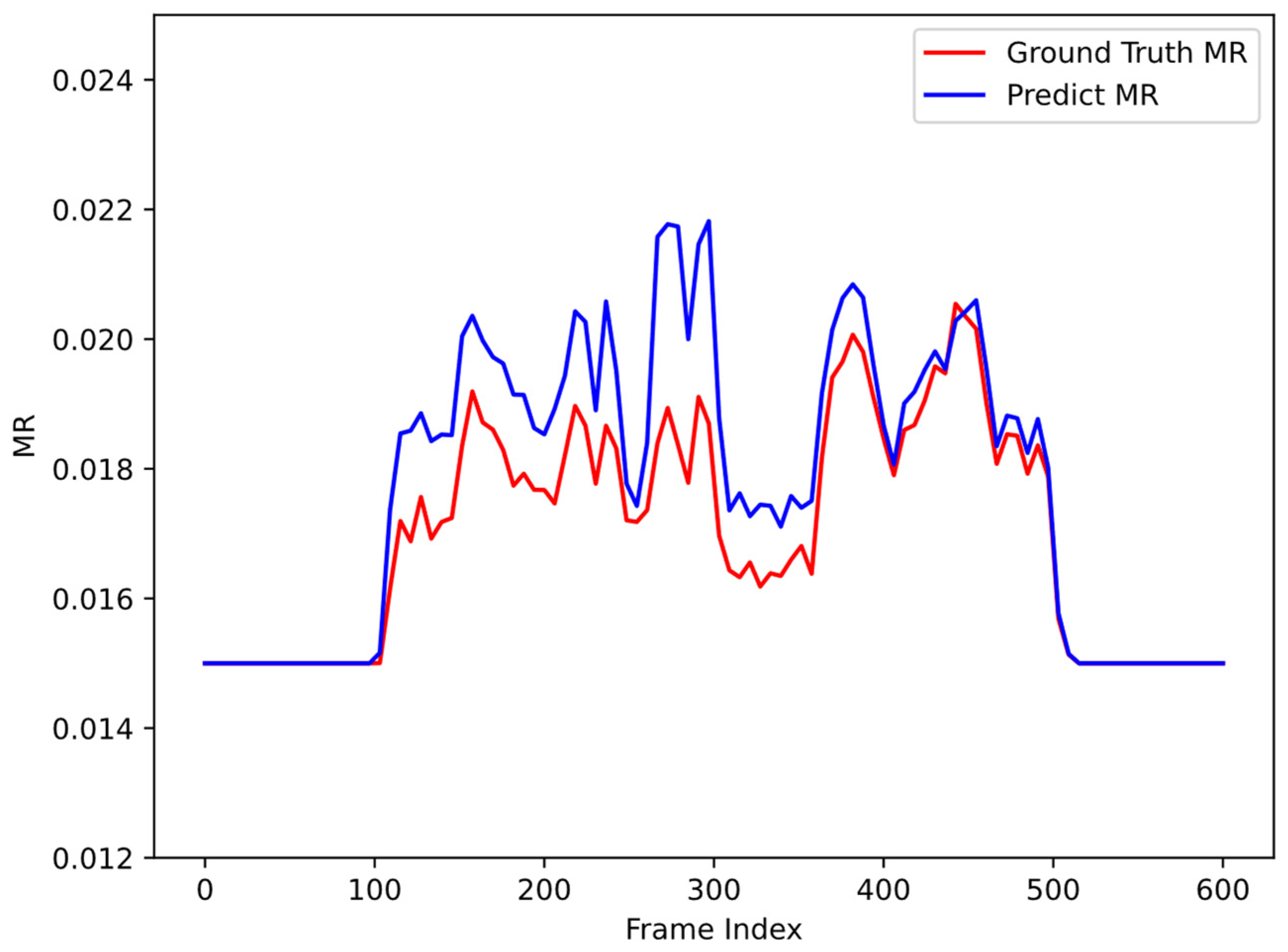
We conducted a compression test of mixed sampling rates on the pedestrian dataset. The red line is the theoretical sampling rate, which is obtained by dividing the number of pixels in the ROI area by the total number of pixels in the image. The blue line is the predicted sampling rate during compression using this algorithm; the prediction sampling rate is calculated as follows:
where Worig and are, respectively, the width and height of the original image; is the extracted ROI matrix; is the value of the pixel at the position; the value of the foreground position is 1; the pixel value at the background position is 0; and and are the low sampling rate and high sampling rate, respectively. The values of the measurement rate are set to 1.5% and 15%, respectively. As can be seen from Figure 8, the sampling rate change trend predicted by the algorithm in this article is similar to the theoretical sampling rate.
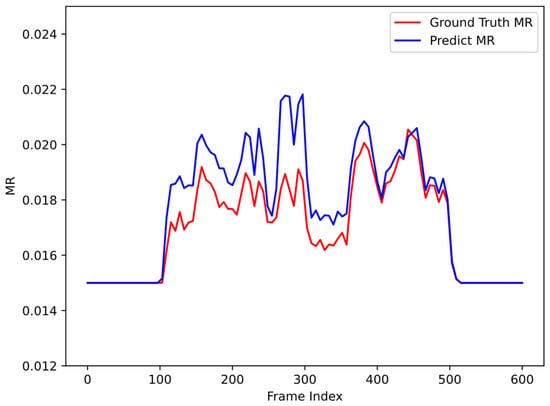
Figure 8.
Comparison of predicted MR and ground truth MR on pedestrian dataset.
We further test the measurement rate and reconstruction quality of the proposed methods on real surveillance videos. The test results are shown in the Table 12.
Table 12.
Measurement rate and reconstruction quality on real surveillance dataset.
4.5. Training Memory Consumption
We tested the training memory consumption on the proposed method with MRVCS, and the result is shown in Table 13.
Table 13.
Training memory consumption.
Proposed reconstruction network effectively reduces the training memory consumption through the reversible neural network and can train larger and deeper reconstruction networks at the edge to improve the reconstruction quality.
5. Conclusions
We propose a robust mixed-rate compressed sensing method for transmission line surveillance videos, using a convolutional network to achieve trainable compressed sampling. Compared with the compressed sampling of a pure convolutional network, the dual-scale compressed sampling network based on dilated convolution has better performance. The reconstruction quality is effectively improved under the same parameter scale; in the reconstruction stage, reversible blocks are used to build a deep reconstruction network to reduce memory consumption. The experimental results show that compared with the same type of mixed-sampling-rate video-compressed sensing method, this method has better reconstruction quality and is similar to deeper networks that can be trained to provide better reconstruction quality with less training memory consumption. Our proposed ROI extraction method based on compressive sensing can quickly and accurately extract ROI in noisy input. The results show that the extraction accuracy and F1-Score of the proposed method on synthetic noise pedestrian datasets are higher than existing methods.
However, despite these advancements, our study has certain limitations, including its primary testing on synthetic noise datasets, which may affect generalizability to real-world environments. The method’s computational complexity, despite reduced memory usage, remains high, and its performance is highly dependent on precise parameter tuning. Despite these challenges, this research significantly advances video surveillance and compressed sensing, offering enhanced video compression and scalability for real-time applications.
Author Contributions
Conceptualization, L.G., S.H., Q.L. and Z.F.; data curation, T.Z.; formal analysis, L.G.; funding acquisition, S.H. and Z.F.; investigation, T.Z.; methodology, L.G., Q.L., Z.F., Z.M. and S.H.; project administration, Z.M., S.H., T.Z., Q.L. and Z.F.; resources, Z.M. and S.H.; software, L.G.; supervision, S.H.; validation, T.Z. and S.H.; visualization, T.Z.; writing—original draft, L.G., Q.L., Z.F., Z.M. and S.H.; writing—review and editing, Q.L., Z.F. and S.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Research on Cloud Edge Collaborative Intelligent Image Analysis Technology Based on Artificial Intelligence Platform (No. J2023003).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
I would first like to thank Jiangsu Provincial Electric Power Corporation for providing the experimental environment and necessary equipment and conditions for this research. In addition, I could not have completed this dissertation without the support of my friends, who provided stimulating discussions as well as happy distractions to rest my mind outside of my research.
Conflicts of Interest
Authors Lisha Gao, Zhoujun Ma, Shuo Han, Tiancheng Zhao were employed by the Company Nanjing Power Supply Branch, State Grid Jiangsu Electric Power Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Candès, E.J.; Romberg, J.K.; Tao, T. Stable Signal Recovery from Incomplete and Inaccurate Measurements. Comm. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar] [CrossRef]
- Iliadis, M.; Spinoulas, L.; Katsaggelos, A.K. DeepBinaryMask: Learning a Binary Mask for Video Compressive Sensing. Digit. Signal Process. 2020, 96, 102591. [Google Scholar] [CrossRef]
- Adler, A.; Elad, M.; Hel-Or, Y. Compressed Learning: A Deep Neural Network Approach. IEEE Trans. Signal Process. 2017, 65, 5687–5699. [Google Scholar]
- Iliadis, M.; Spinoulas, L.; Katsaggelos, A.K. Deep Fully-Connected Networks for Video Compressive Sensing. Digit. Signal Process. 2018, 72, 9–18. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 52–59. [Google Scholar]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A.G. Compressed Sensing Using Generative Models. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 537–546. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-Local Recurrent Network for Image Restoration. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, ON, Canada, 2–8 December 2018; pp. 1673–1682. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yuan, X. Generalized Alternating Projection Based Total Variation Minimization for Compressive Sensing. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2539–2543. [Google Scholar]
- Yuan, X.; Liu, Y.; Suo, J.; Dai, Q. Plug-and-Play Algorithms for Large-Scale Snapshot Compressive Imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1444–1454. [Google Scholar]
- Cheng, Z.; Lu, R.; Wang, Z.; Zhang, H.; Chen, B.; Meng, Z.; Yuan, X. BIRNAT: Bidirectional Recurrent Neural Networks with Adversarial Training for Video Snapshot Compressive Imaging. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 258–275. [Google Scholar]
- Z, W.; Zhang, J.; Mou, C. Dense Deep Unfolding Network with 3D-CNN Prior for Snapshot Compressive Imaging. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4872–4881. [Google Scholar]
- Wang, L.; Cao, M.; Zhong, Y.; Yuan, X. Spatial-Temporal Transformer for Video Snapshot Compressive Imaging. arXiv 2022, arXiv:2209.01578. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Ma, S.; Zhang, J.; Xiong, R.; Gao, W. Video Compressive Sensing Reconstruction via Reweighted Residual Sparsity. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1182–1195. [Google Scholar] [CrossRef]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. ReconNet: Non-Iterative Reconstruction of Images from Compressively Sensed Measurements. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 449–458. [Google Scholar]
- Xie, X.; Wang, Y.; Shi, G.; Wang, C.; Du, J.; Han, X. Adaptive Measurement Network for CS Image Reconstruction. In Proceedings of the Computer Vision: Second CCF Chinese Conference, CCCV 2017, Tianjin, China, 11–14 October 2017; Proceedings, Part II. Springer: Singapore, 2017; pp. 407–417. [Google Scholar]
- Xu, K.; Ren, F. CSVideoNet: A Real-Time End-to-End Learning Framework for High-Frame-Rate Video Compressive Sensing. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1680–1688. [Google Scholar]
- Yang, F.; Jiang, H.; Shen, Z.; Deng, W.; Metaxas, D. Adaptive Low Rank and Sparse Decomposition of Video Using Compressive Sensing. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 1016–1020. [Google Scholar]
- Wu, L.; Huang, K.; Shen, H.; Gao, L. Foreground-Background Parallel Compression with Residual Encoding for Surveillance Video. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2711–2724. [Google Scholar] [CrossRef]
- Du, J.; Xie, X.; Shi, G. Multi-Rate Video Compressive Sensing for Fixed Scene Measurement. In Proceedings of the The 5th International Conference on Video and Image Processing, Hayward, CA, USA, 22–25 December 2021; ACM: New York, NY, USA, 2021; pp. 177–183. [Google Scholar]
- Gomez, A.N.; Ren, M.; Urtasun, R.; Grosse, R.B. The Reversible Residual Network: Backpropagation Without Storing Activations. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Jacobsen, J.H.; Smeulders, A.W.; Oyallon, E. i-revnet: Deep Invertible Networks. arXiv 2018, arXiv:1802.07088. [Google Scholar]
- Goyette, N.; Jodoin, P.-M.; Porikli, F.; Konrad, J.; Ishwar, P. Changedetection.net: A New Change Detection Benchmark Dataset. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–8. [Google Scholar]
- Elgammal, A.; Harwood, D.; Davis, L. Non-Parametric Model for Background Subtraction. In Proceedings of the Computer Vision—ECCV 2000: 6th European Conference on Computer Vision, Dublin, Ireland, 26 June–1 July 2000; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2000; pp. 751–767. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).