
Improving QoS Management Using Associative Memory and Event-Driven Transaction History


Abstract
1. Introduction
2. Related Works
3. Background and Reference Scenario
3.1. Distributed Software Applications
3.2. Distributed Environment
3.2.1. Configurations
3.3. Quality of Service Manager
- (i)
- Metrics (SLIs) defined in the SLA and their related constraints, such as SLOs, represent the QoS constraints, which represent the ultimate goal of the manager.
- (ii)
- A Time Series Database (TSDB), where the metrics’ runtime values are collected, stored, and indexed by time.
- (iii)
- A Multi-Dimensional Vector (MDV) that summarizes the expected behavior of each component in terms of QoS metrics values, given specific workloads and hardware configurations as described in Section 3.2.1. This data structure significantly influences the SLADE management capabilities because each entry represents a suitable target for its control actions.
- (iv)
- A set of Resource Provider Configurations (RPCs) that relates the resource provider, the hardware configuration, and the set of actions that can be executed on a specific provider to deploy a component with that hardware configuration.
4. Proposed Approach
4.1. Associative Memory
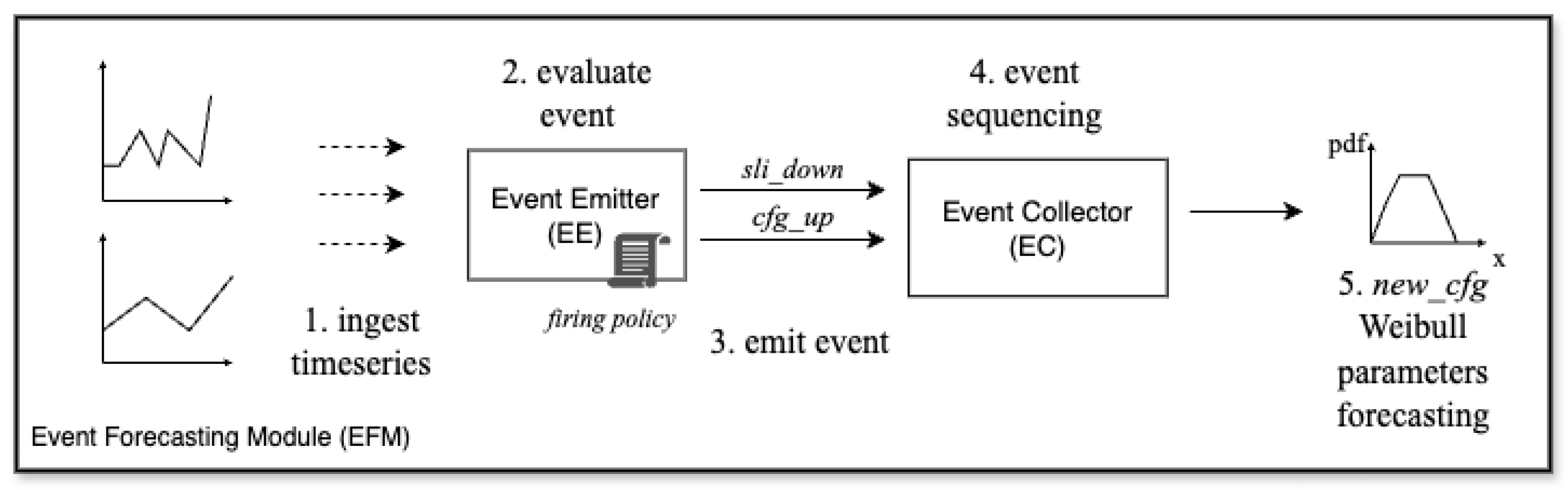
4.2. Event Forecasting Module
5. Implementation Overview
5.1. Associative Memory
- Each load level becomes a row of a matrix.
- Each range of metric values becomes a column of the matrix.
- The observed hardware configuration for that load and that range of associated metric values becomes the matrix entry.
- The higher the percentage of “known conditions”, the greater the speedup obtained using the cache. This ranges from a 23% improvement for the cache on configuration 5/8—20% (5 workloads, 8 hardware configurations, and 20% known conditions) to 188% (almost 2×) for the cache on configuration 10/12—80%.
- The higher the number of workload ranges and hardware configurations, the greater the impact of the cache.
5.2. Event Prediction
- In the analysis phase, the values are used to enable SLADE to operate in a proactive mode. Since a cfg_up event occurs as a result of either a rapid workload increase or a degradation of the SLI, a rising probability of a cfg_up event can be interpreted as a signal of one of these preliminary conditions, allowing the system to take action to avoid an SLI violation. This is particularly useful when the error budget is low.
- In the planning phase, the values are used in conjunction with the current hardware configuration. If the probability of a cfg_up event is high and at least one component is already in the highest-performing class, SLADE will interpret this as an indication that a new, better hardware configuration is needed and will trigger the incremental learning process.
Event Forecasting Module Implementation Design
6. Conclusions and Future Direction
- Implementing the system using the “Structural Machine” model introduced in [37]. In particular, it is planned to map the functionalities offered by the autopoietic manager with those of the component that interfaces SLADE directly with resource providers and to use the classification algorithm to trigger the resource allocation procedure.
- Exploring different solutions to exploit better the information obtained from the event-based transaction system. In this context, the aim is to improve time-to-event prediction using more events and, at the same time, extend the set of predicted events to increase the capabilities of the Analysis phase of MAPE in anticipating possible unfavorable scenarios.
- Adopt, in the planning phase, the use of N single-class classifiers [38] instead of a single classifier for N classes to better manage the issue of the finite number of classes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Di Stefano, A.; Di Stefano, A.; Morana, G. Improving QoS through network isolation in PaaS. Future Gener. Comput. Syst. 2022, 131, 91–105. [Google Scholar] [CrossRef]
- Fowler, M.; Lewis, J. Microservices. 2014. Available online: https://martinfowler.com/articles/microservices.html (accessed on 1 July 2024).
- Buyya, R.; Yeo, C.S.; Venugopal, S.; Broberg, J.; Brandic, I. Cloud computing and emerging IT platforms: Vision, hype, and reality for delivering computing as the 5th utility. Future Gener. Comput. Syst. 2009, 25, 599–616. [Google Scholar] [CrossRef]
- Kephart, J.; Chess, D. The vision of autonomic computing. Computer 2003, 36, 41–50. [Google Scholar] [CrossRef]
- Iglesia, D.G.D.L.; Weyns, D. Mape-k formal templates to rigorously design behaviors for self-adaptive systems. ACM Trans. Auton. Adapt. Syst. 2015, 10, 1–31. [Google Scholar] [CrossRef]
- Halima, R.B.; Hachicha, M.; Jemal, A.; Kacem, A.H. Mape-k patterns for self-adaptation in cyber-physical systems. J. Supercomput. 2022, 79, 4917–4943. [Google Scholar] [CrossRef]
- Mikkilineni, R.; Kelly, W.P.; Crawley, G. Digital Genome and Self-Regulating Distributed Software Applications with Associative Memory and Event-Driven History. Computers 2024, 13, 220. [Google Scholar] [CrossRef]
- Zhao, L. Event Prediction in the Big Data Era: A Systematic Survey. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Martinsson, E. WTTE-RNN: Weibull Time to Event Recurrent Neural Network. Master’s Thesis, Chalmers University of Technology, Gothenburg, Sweden, 2016. [Google Scholar]
- Mikkilineni, R.; Kelly, W.P. Machine Intelligence with Associative Memory and Event-Driven Transaction History. Preprints, 2024; in press. [Google Scholar] [CrossRef]
- Nadeem, S.; Amin, N.u.; Zaman, S.K.u.; Khan, M.A.; Ahmad, Z.; Iqbal, J.; Khan, A.; Algarni, A.D.; Elmannai, H. Runtime Management of Service Level Agreements through Proactive Resource Provisioning for a Cloud Environment. Electronics 2023, 12, 296. [Google Scholar] [CrossRef]
- Singh, S.; Chana, I. Cloud resource provisioning: Survey, status and future research directions. Knowl. Inf. Syst. 2016, 49, 1005–1069. [Google Scholar] [CrossRef]
- Gill, S.S.; Chana, I. A Survey on Resource Scheduling in Cloud Computing: Issues and Challenges. J. Grid Comput. 2016, 14, 217–264. [Google Scholar] [CrossRef]
- Gill, S.S.; Buyya, R. Resource Provisioning Based Scheduling Framework for Execution of Heterogeneous and Clustered Workloads in Clouds: From Fundamental to Autonomic Offering. J. Grid Comput. 2019, 17, 385–417. [Google Scholar] [CrossRef]
- Gmach, D.; Rolia, J.; Cherkasova, L.; Kemper, A. Workload Analysis and Demand Prediction of Enterprise Data Center Applications. In Proceedings of the 2007 IEEE 10th International Symposium on Workload Characterization, Boston, MA, USA, 27–29 September 2007; pp. 171–180. [Google Scholar] [CrossRef]
- Di, S.; Kondo, D.; Cirne, W. Host load prediction in a Google compute cloud with a Bayesian model. In Proceedings of the SC’12: International Conference on High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 24–29 June 2012; pp. 1–11. [Google Scholar] [CrossRef]
- Khan, A.; Yan, X.; Tao, S.; Anerousis, N. Workload characterization and prediction in the cloud: A multiple time series approach. In Proceedings of the 2012 IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012; pp. 1287–1294. [Google Scholar] [CrossRef]
- Padala, P.; Zhu, X.; Uysal, M.; Wang, Z.; Singhal, S.; Merchant, A.; Salem, K. Adaptive control of virtualized resources in utility computing environments. In Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems, Lisbon, Portugal, 21–23 March 2007; Volume 41, pp. 289–302. [Google Scholar] [CrossRef]
- Garcis, A.; Blanquer, I.; García, V. SLA-driven dynamic cloud resource management. Future Gener. Comput. Syst. 2014, 31, 1–11. [Google Scholar] [CrossRef]
- Bulej, L.; Bureš, T.; Filandr, A.; Hnětynka, P.; Hnětynková, I.; Pacovský, J.; Sandor, G.; Gerostathopoulos, I. Managing latency in edge–cloud environment. J. Syst. Softw. 2021, 172, 110872. [Google Scholar] [CrossRef]
- Khalyeyev, D.; Bureš, T.; Hnětynka, P. Towards a Reference Component Model of Edge-Cloud Continuum. In Proceedings of the 2023 IEEE 20th International Conference on Software Architecture Companion (ICSA-C), L’Aquila, Italy, 13–17 March 2023; pp. 91–95. [Google Scholar] [CrossRef]
- Kubernetes, Production-Grade Container Orchestration. Available online: https://kubernetes.io/ (accessed on 1 July 2024).
- ks, S.; Jaisankar, N. An automated resource management framework for minimizing SLA violations and negotiation in collaborative cloud. Int. J. Cogn. Comput. Eng. 2020, 1, 27–35. [Google Scholar] [CrossRef]
- Di Modica, G.; Di Stefano, A.; Morana, G.; Tomarchio, O. On the Cost of the Management of user Applications in a Multicloud Environment. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud (FiCloud), Istanbul, Turkey, 26–28 August 2019; pp. 175–181. [Google Scholar] [CrossRef]
- Mikkilineni, R. Mark Burgin’s Legacy: The General Theory of Information, the Digital Genome, and the Future of Machine Intelligence. Philosophies 2023, 8, 107. [Google Scholar] [CrossRef]
- Mikkilineni, R. A New Class of Autopoietic and Cognitive Machines. Information 2022, 13, 24. [Google Scholar] [CrossRef]
- Auer, F.; Lenarduzzi, V.; Felderer, M.; Taibi, D. From monolithic systems to Microservices: An assessment framework. Inf. Softw. Technol. 2021, 137, 106600. [Google Scholar] [CrossRef]
- Villamizar, M.; Garcés, O.; Castro, H.; Verano, M.; Salamanca, L.; Casallas, R.; Gil, S. Evaluating the monolithic and the microservice architecture pattern to deploy web applications in the cloud. In Proceedings of the 2015 10th Computing Colombian Conference (10CCC), Bogotá, Colombia, 21–25 September 2015; pp. 583–590. [Google Scholar] [CrossRef]
- Felter, W.; Ferreira, A.; Rajamony, R.; Rubio, J. An updated performance comparison of virtual machines and Linux containers. In Proceedings of the 2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Philadelphia, PA, USA, 29–31 March 2015; pp. 171–172. [Google Scholar] [CrossRef]
- Tapia, F.; Mora, M.A.; Fuertes, W.; Aules, H.; Flores, E.; Toulkeridis, T. From Monolithic Systems to Microservices: A Comparative Study of Performance. Appl. Sci. 2020, 10, 5797. [Google Scholar] [CrossRef]
- Di Stefano, A.; Gollo, M.; Morana, G. Forthcoming. An SLA-driven, AI-based QoS Manager for Controlling Application Performance on Edge Cloud Continuum. In Proceedings of the 2024 IEEE International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Reggio Emilia, Italy, 26–29 June 2024. [Google Scholar]
- Rabenstein, B.; Volz, J. Prometheus: A Next-Generation Monitoring System (Talk); SoundCloud Ltd.: Dublin, Ireland, 2015. [Google Scholar]
- Red Hat, Inc. Ansible. Available online: https://ansible.com (accessed on 1 July 2024).
- HashiCorp, Inc. Terraform. Available online: https://terraform.io (accessed on 1 July 2024).
- Chaudhary, A.; Kolhe, S.; Kamal, R. An improved random forest classifier for multi-class classification. Inf. Process. Agric. 2016, 3, 215–222. [Google Scholar] [CrossRef]
- Shyalika, C.; Wickramarachchi, R.; Sheth, A. A Comprehensive Survey on Rare Event Prediction. arXiv 2023, arXiv:2309.11356. [Google Scholar]
- Mikkilineni, R. The Science of Information Processing Structures and the Design of a New Class of Distributed Computing Structures. Proceedings 2022, 81, 53. [Google Scholar] [CrossRef]
- Désir, C.; Bernard, S.; Petitjean, C.; Heutte, L. A New Random Forest Method for One-Class Classification. In Structural, Syntactic, and Statistical Pattern Recognition; Gimel’farb, G., Hancock, E., Imiya, A., Kuijper, A., Kudo, M., Omachi, S., Windeatt, T., Yamada, K., Eds.; Elsevier: Berlin/Heidelberg, Germany, 2012; pp. 282–290. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Configuration | CPU | Memory | Replicas | Thread Pool Size | Cache Size | Monetary Cost | Alt Name |
|---|---|---|---|---|---|---|---|
| cfg_small_aws_eu | 2 | 2048 MB | 5 | 10 | 512 MB | $50 | 0 |
| cfg_small_gcp_eu | 2 | 2048 MB | 5 | 10 | 512 MB | $40 | 1 |
| cfg_small_gcp_us | 2 | 2048 MB | 5 | 10 | 512 MB | $40 | 2 |
| Global Config ID | Global Alt Name | Component 1 Alt Name | Component 2 Alt Name | Component 3 Alt Name | Component 4 Alt Name | Total Cost |
|---|---|---|---|---|---|---|
| 1 | 0000 | 0 | 0 | 0 | 0 | $160 |
| 2 | 0001 | 0 | 0 | 0 | 1 | $180 |
| … | … | … | … | … | … | … |
| 80 | 2221 | 2 | 2 | 2 | 1 | $300 |
| 81 | 2222 | 2 | 2 | 2 | 2 | $350 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Stefano, A.; Gollo, M.; Morana, G. Improving QoS Management Using Associative Memory and Event-Driven Transaction History. Information 2024, 15, 569. https://doi.org/10.3390/info15090569
Di Stefano A, Gollo M, Morana G. Improving QoS Management Using Associative Memory and Event-Driven Transaction History. Information. 2024; 15(9):569. https://doi.org/10.3390/info15090569
Chicago/Turabian StyleDi Stefano, Antonella, Massimo Gollo, and Giovanni Morana. 2024. "Improving QoS Management Using Associative Memory and Event-Driven Transaction History" Information 15, no. 9: 569. https://doi.org/10.3390/info15090569
APA StyleDi Stefano, A., Gollo, M., & Morana, G. (2024). Improving QoS Management Using Associative Memory and Event-Driven Transaction History. Information, 15(9), 569. https://doi.org/10.3390/info15090569