

High-Performance Mobility Simulation: Implementation of a Parallel Distributed Message-Passing Algorithm for MATSim †

Abstract
1. Introduction
1.1. Motivation
1.2. Aim of the Study
- We develop a prototype implementation that scales on HPC clusters. The implementation is fully compatible with MATSim’s input and output format, allowing the use of existing and calibrated simulation scenarios for testing. The prototype implementation is available as an open-source GitHub repository (https://github.com/matsim-vsp/parallel_qsim_rust, accessed on 4 February 2025) and release v0.2.0, used in this study, is captured as a Zenodo repository [10].
- We benchmark the prototype on the HRN@ZIB HPC cluster, capable of scaling to more than one thousand processes, using an open-source, real-world simulation scenario. Similar to the source code, all input, and output files are available under an open-access license in a Zenodo repository to enable reproducibility [11].
- Based on the executed benchmarks, we show that the distributed algorithm is latency bound even on high-performance communication hardware, and that balancing the computational load becomes less of a problem for large numbers of computing processes at the cost of computational efficiency. Additionally, we can show that the time dedicated to inter process communication depends on the maximum number of neighbors any process has.
1.3. Related Work
2. Methodology
2.1. Traffic Flow Simulation
2.1.1. Link Management
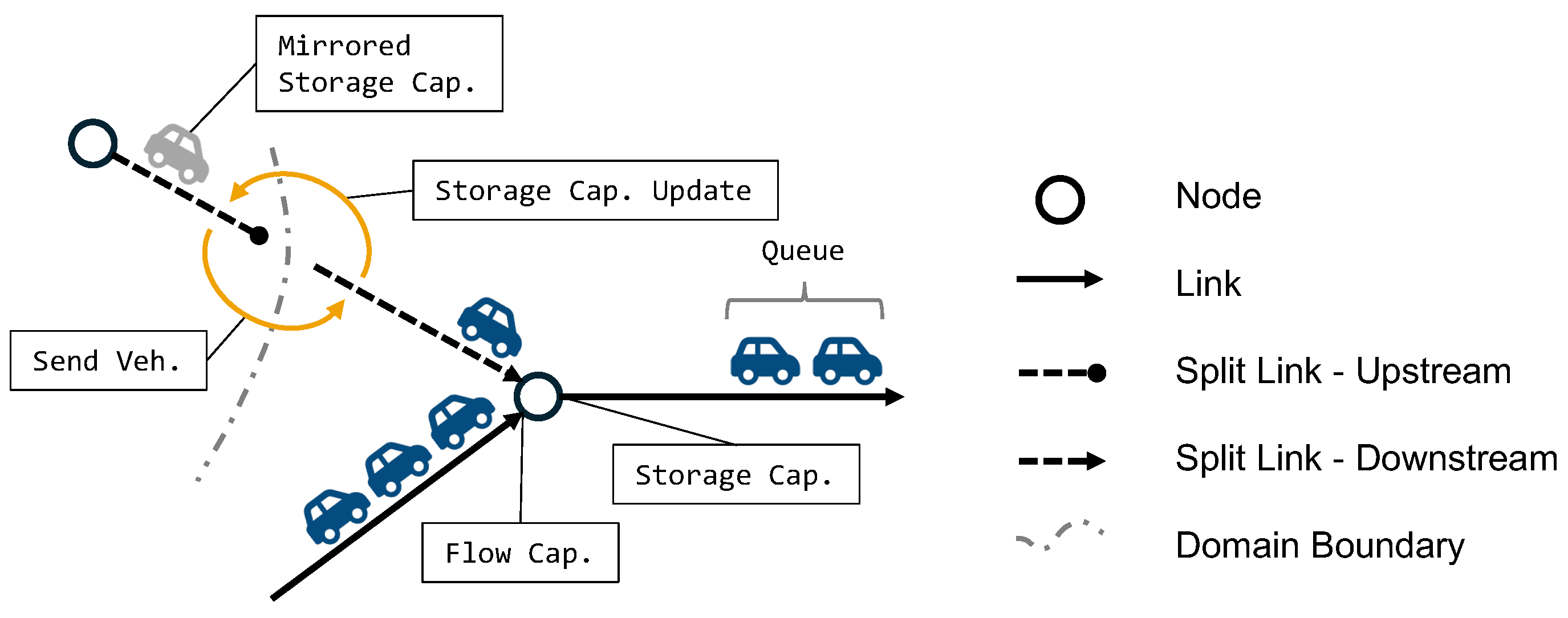
- Entering the link: Vehicles can enter a link only if sufficient storage capacity is available. The storage capacity of a link is determined by its length and number of lanes. For example, assuming one car occupies 7.5 m, a 30 m one lane link has a capacity of 4 cars. Figure 1 illustrates this constraint at the start of the link.
- Traversing the link: Vehicles traversing the link are managed using a queue. In the example of Figure 1 two vehicles are managed in the queue of the link on the right. The prototype implements a FIFO (First In First Out) queue so that vehicles leave in the same order as they have entered a link. The earliest exit time by which a vehicle can exit a link under free flow conditions is determined by the freespeed of the link (one can consider this to be the street’s speed limit), and the vehicle’s maximum velocity. Vehicles stay in the queue at least until the simulation reaches the calculated earliest exit time. The FIFO characteristics also mean, that if a vehicle is blocked by another vehicle, it cannot leave the link upon its earliest exit time, but has to wait until all other vehicles in front of it have left the link. One reason for a vehicle blocking other vehicles behind it can be a lower maximum velocity. Faster vehicles have to queue behind that vehicle.
- Leaving the link: The vehicle at the head of the queue may leave the link if the simulation has progressed to its earliest exit time. To actually leave the link, a second condition, sufficient flow capacity, must be met. The flow capacity determines how many vehicles can traverse a link within a given time period. On a residential road, for example, the flow capacity can be assumed to be 600 vehicles per hour. This translates to one vehicle every six seconds. With the help of Figure 1 we can explain how this constraint is enforced. We assume that all three vehicles queued on the link on the left have the same earliest exit time, while the link has a capacity of 600 vehicles per hour. When the simulation reaches the earliest exit time of the vehicles, the first vehicle would be able to leave the link immediately—given that the next link has sufficient storage capacity. The second vehicle would also be able to leave, given its earliest exit time. However, as the first vehicle has consumed one unit of flow capacity, the second vehicle has to wait another six seconds before enough flow capacity has accumulated on the link, for it to exit. Figure 1 illustrates that the flow capacity constraint is enforced at the end of the link by pointing the label to the end of the incoming link.
2.1.2. Intersection Update
- In the QSim, links are split into two segments: a queue and a buffer. Vehicles entering a link from an intersection are first placed in the queue, similar to our approach. However, when a vehicle becomes eligible to exit the link (based on its exit time), given sufficient flow capacity, it is placed into the buffer of the link. During the intersection update, only vehicles in a link’s buffer are considered for crossing the intersection. This separation of queue and buffer is primarily necessary in QSim due to its use of data structures shared between concurrent threads. By splitting the link into these two parts, QSim allows independent operations at the upstream and downstream ends of a link in parallelized executions. In contrast, our prototype relies on a message-passing approach, ensuring that each process operates on its data in isolation. This eliminates the need for an additional buffer data structure, as the flow capacity constraint is enforced directly within the queue.
- Because links in the prototype implementation only manage a single queue data structure, the flow capacity constraint is enforced during the intersection update. In contrast, the QSim enforces this constraint when vehicles are moved from the queue to the buffer of a link.
- The QSim calculates the available storage capacity based on the vehicles present in the queue. Since the intersection update in the QSim only operates on vehicles in the link’s buffer, changes to the storage capacity are propagated to the upstream end of the link in the next time step. In the prototype implementation, which operates on a single queue data structure, this behavior is emulated using a bookkeeping mechanism. This mechanism releases storage capacity for vehicles leaving a link only after the intersection update for all nodes within a network partition is completed.
- Another key distinction is how vehicles are handled upon entering and exiting traffic. In our implementation, vehicles are added to the end of the queue when they enter traffic, and they fully traverse the last link of their route before being removed during the intersection update. This approach allows the termination of vehicles to be handled as part of the intersection update, as previously described. In contrast, MATSim’s QSim inserts and removes vehicles between the queue and the buffer.
| Listing 1. Intersection Update. |
 |
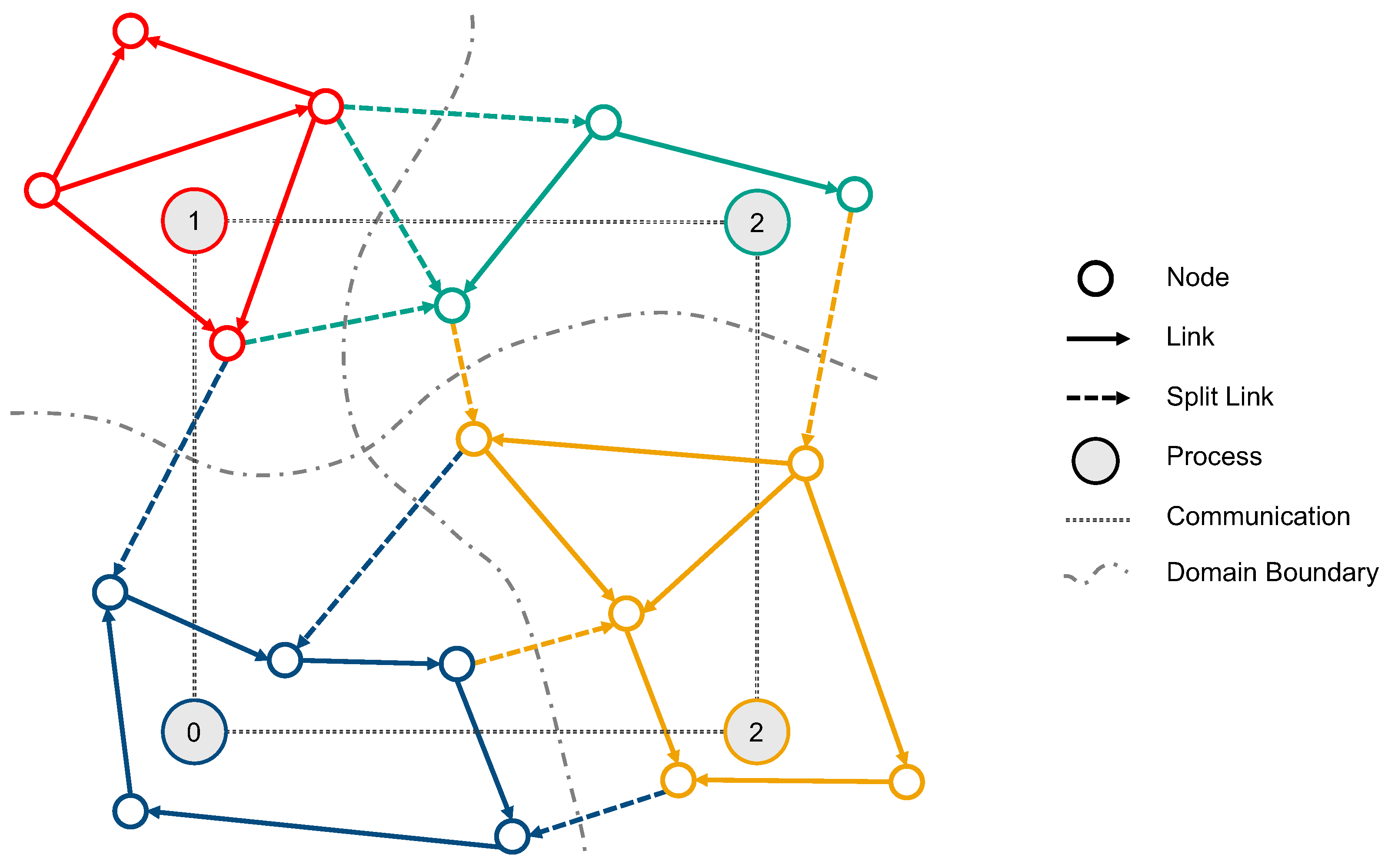
2.2. Domain Decomposition
2.3. Simulation Loop
- Finish activities: Synthetic persons performing activities are stored in a priority queue, ordered by the end time of their activities. Those who have reached the end time of an activity are removed from the queue and start the next plan element, which involves either a teleportation leg or a leg performed on the simulated network.
- Teleport: Synthetic persons finishing a teleportation leg start the next activity by being placed into the activity queue (see [28] (Chapters 12.3.1, 12.3.2) for the concept of teleported legs).
- Move nodes: This step corresponds to the intersection update explained in Section 2.1 and involves iterating over all nodes of the network partition, moving vehicles that have reached the end of a link onto the next link in the vehicle’s route. In the case of a vehicle reaching the end of its route, the vehicle is removed from the simulated network and the next plan element of the synthetic person is started by placing it into the activity queue.
- Move links: The movement of vehicles on the network is constrained by the flow and storage capacities of links. During the move links step, the bookkeeping of these capacities is updated for the next time step. This step also includes collecting all vehicles and capacity updates that must be sent to another process.
- Send and receive The collected vehicles and capacity updates are passed to a message broker, which coordinates the message exchange with other processes. This step involves communicating the collected information to the corresponding processes, as well as awaiting and receiving incoming messages (see Section 2.4). Received vehicles and capacity updates from other processes are applied to the simulated network in this step.
| Listing 2. Main simulation loop. |
 |
2.4. Inter Process Communication
- Send: Corresponding to lines 4–6 this step involves serializing messages into the wire format and issuing a non-blocking ISend call to the underlying MPI implementation for each neighbor process.
- Receive: On line 12 a blocking Recv call to the underlying MPI implementation is issued and the process awaits messages from any other process. This step is the rendezvous point for neighbors, as faster processes must wait for slower processes to send messages, before they can be received. Additionally, this step involves the time to transmit messages over the communication hardware.
- Handle: On lines 13–14, received messages are deserialized from wire format back into a message data structure and pushed into the result list.
| Listing 3. Inter process communication. |
 |
3. Results
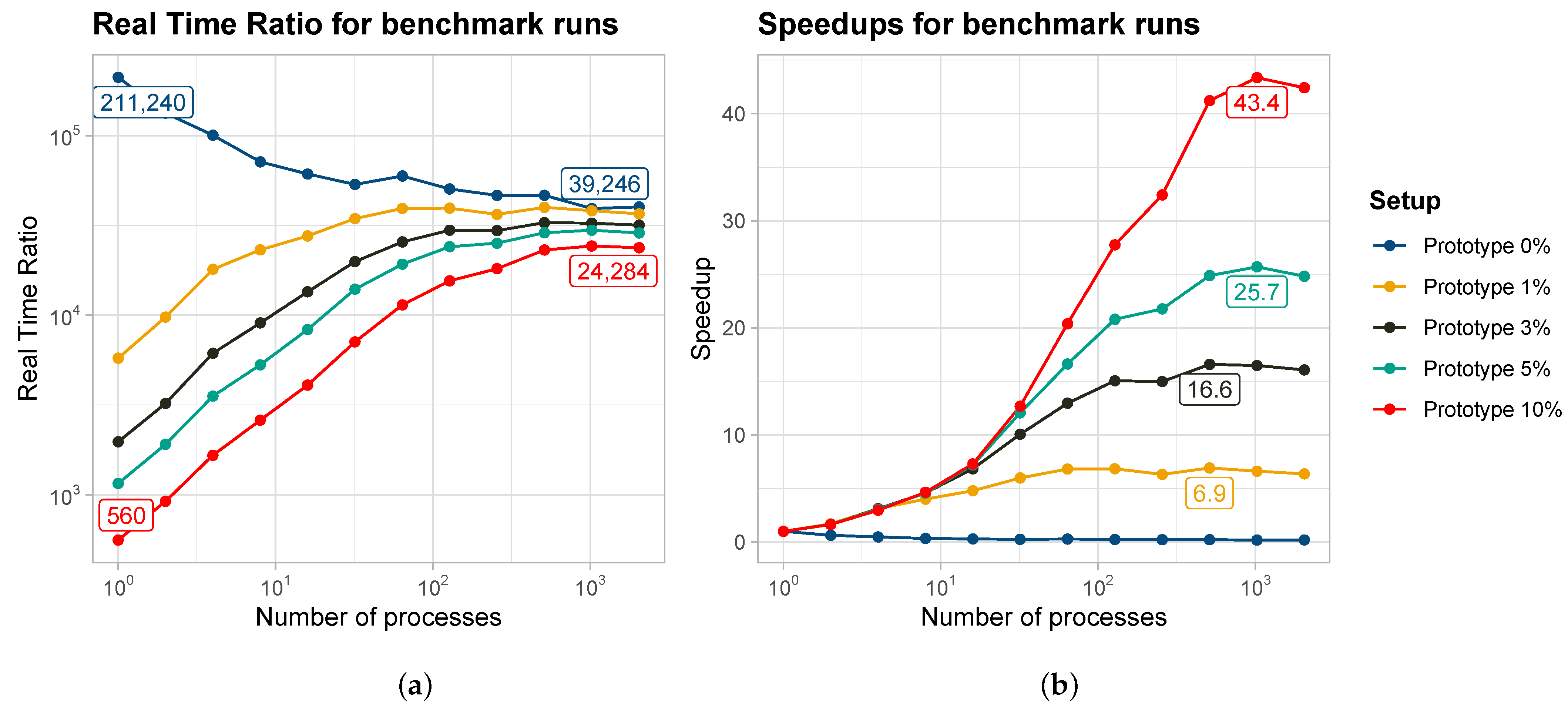
3.1. Overall Performance
3.2. Latency as a Limiting Factor
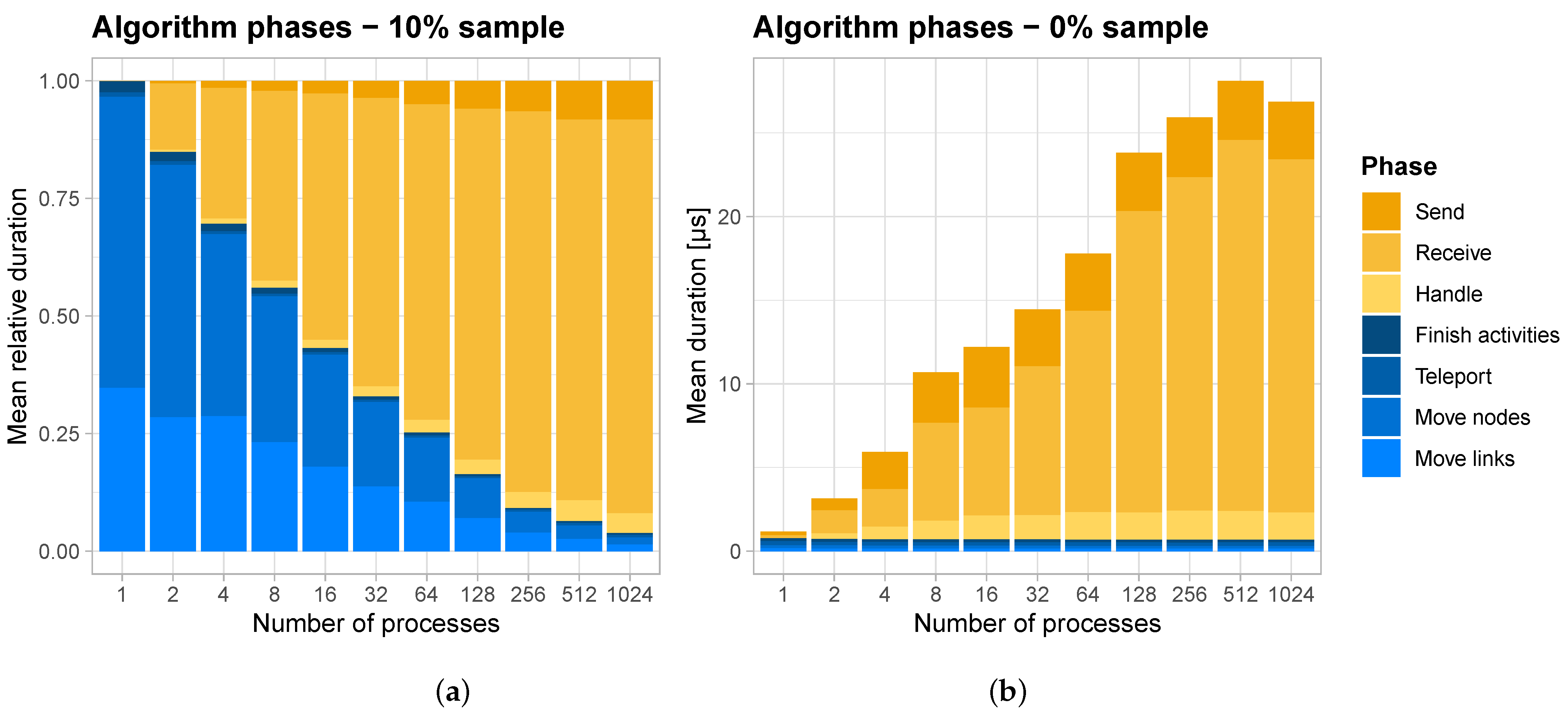
3.3. Load Balancing as a Limiting Factor
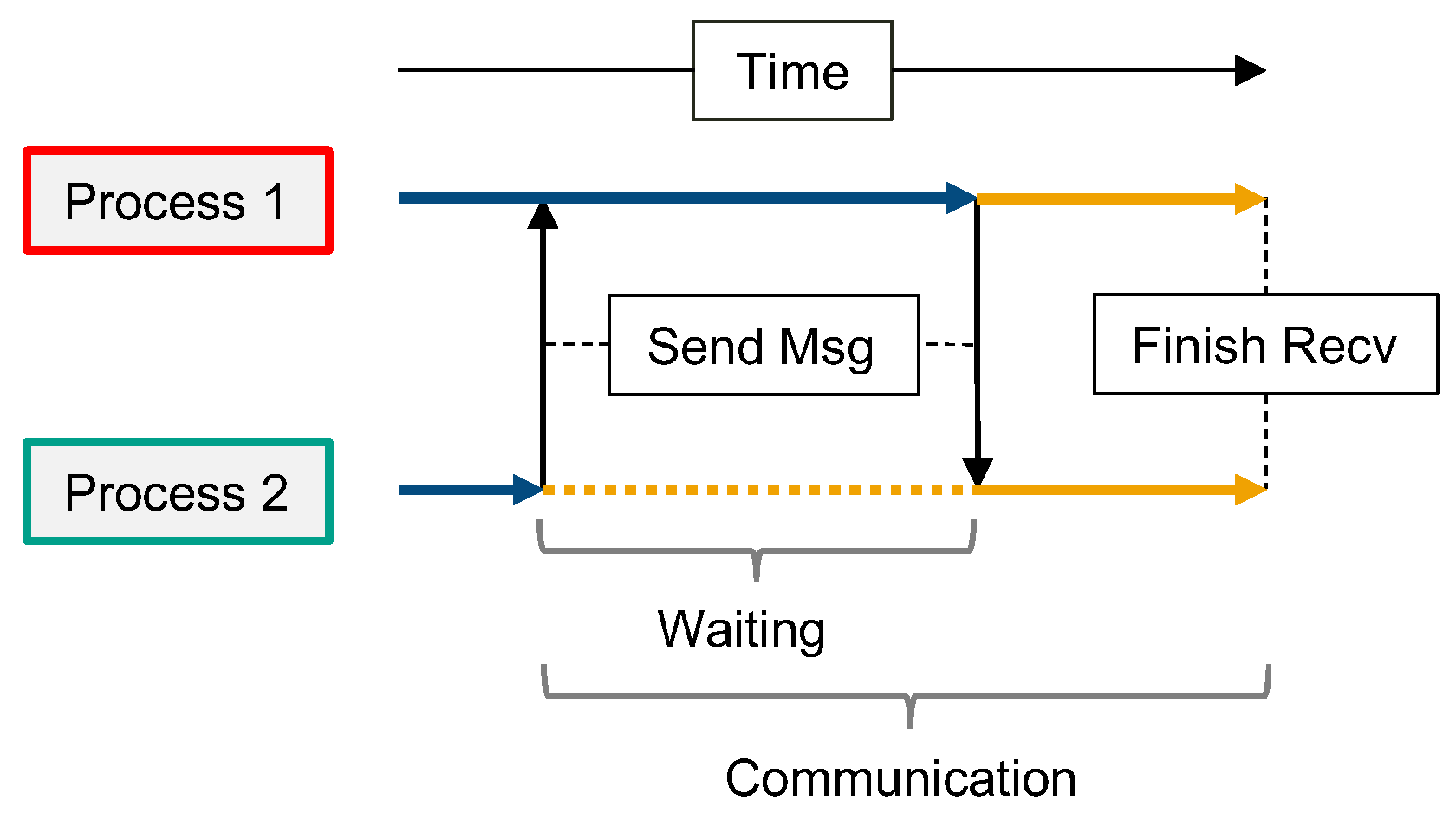
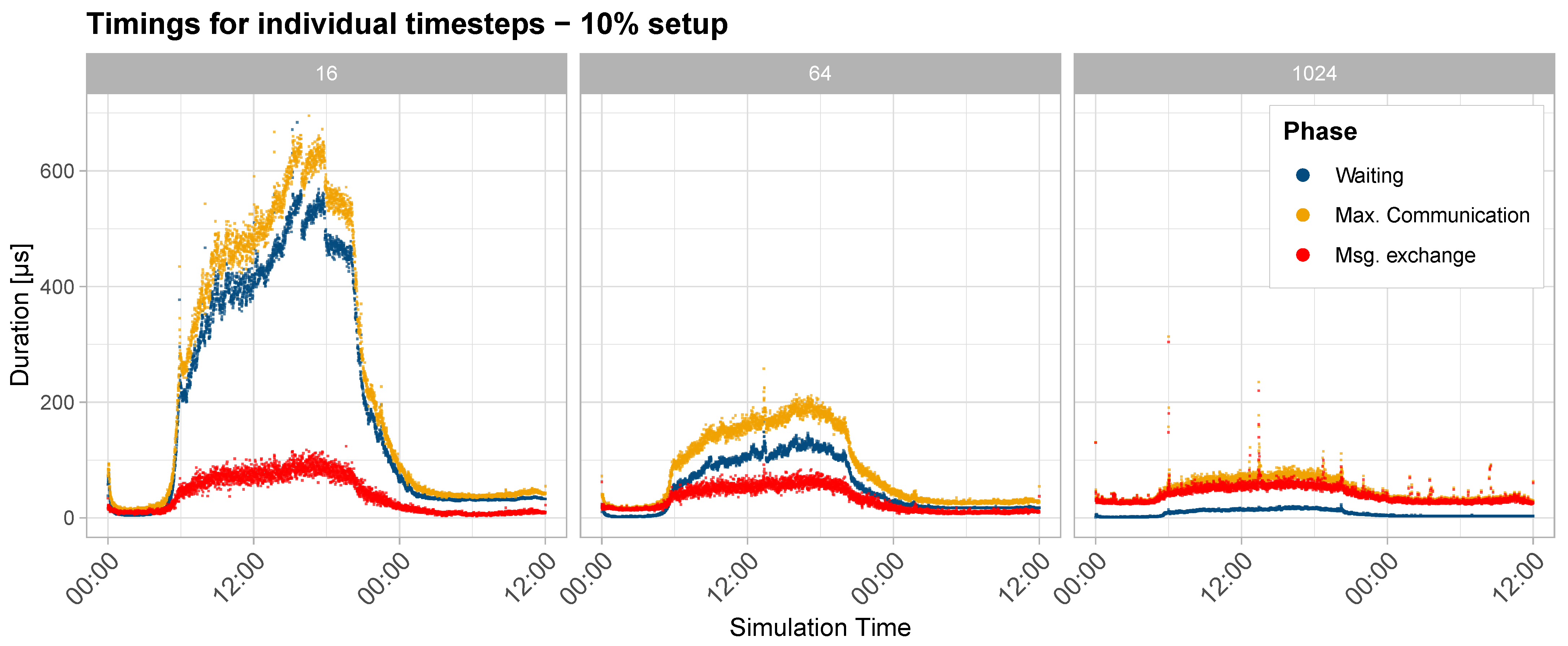
- Wait time: To measure load imbalances, we use the difference between the fastest and slowest processes during a simulation time step. In Figure 3 the time spent computing a time step in the simulation is indicated by blue arrows. Figure 3 illustrates how faster processes must wait for slower processes to finish the simulation computation before adjacent processes can exchange messages. Large waiting times indicate unbalanced computational loads, while small waiting times suggest that each process handles a similar amount of work.
- Maximum communication time: Also shown in Figure 3 is the maximum time any process spends in the communication phase. This includes the waiting time and the time to transmit messages over the communication hardware.
- Message exchange time: The message exchange time cannot be measured directly in our application, as waiting for other process and transmitting messages occur in a single MPI Recv call. However, we can derive the time spent exchanging messages by subtracting the wait time of one simulation time step from the maximum communication time any process experienced. This duration corresponds to the straight yellow part of the arrows depicted in Figure 3.
3.4. Performance Model
- Large Scenario: For a simulation with 10 times more computational load (blue line), the computation on a single process is 10 times slower than the 10% scenario. However, a similar RTR can be achieved when increasing the number of processes 10-fold beyond the maximum number of processes used for the 10% scenario.
- Future Communication Hardware: Assuming a future 10-fold improvement in communication hardware latency (yellow line), the application scales effectively across more processes. Faster hardware reduces the communication bottleneck, delaying the point where performance converges.
- Ethernet Communication Hardware: Running the application on slower, standard Ethernet hardware (gray line) has a negative impact on performance. Assuming a latency of 10 µs per message exchange on a Gigabit Ethernet connection, the achievable RTR is significantly reduced. The model also predicts an earlier convergence in performance improvements, effectively limiting the scalability of the simulation.
- Fewer Neighbors: If the maximum number of neighbors approaches the average assumed in our previous work (green line), the RTR improves significantly.
4. Discussion
4.1. Prototype Implementation
4.2. Performance Model
4.3. Hardware Impacts
4.4. Possible Performance Improvements
4.4.1. Reducing Necessary Communication
- As indicated in by the analysis of the 0% setup, the communication time is primarily determined by the process with the largest number of neighbors. In our test runs involving large numbers of processes, the maximum number of neighboring domains reached up to 22, while the average remained around 6. By optimizing domain decomposition to reduce the maximum number of neighbors, we could decrease the number of exchanged messages, thereby reducing communication times. The objective of this optimization is to bring the maximum number of neighbors closer to the average value.
- The current architecture requires synchronization of neighbor processes at every simulated time step. Turek [29] introduce a desynchronized traffic simulation, which shows linear scalability due to larger synchronization intervals. Instead of communicating instant updates of vehicles entering or leaving links, the synchronization interval in our approach could be increased by accounting for the time vehicles travel across links, as well as backwards travelling holes as suggested by Charypar et al. [30].
- The synchronization between processes could be shifted from a conservative to an optimistic approach. In a simulation using an optimistic synchronization strategy, each process executes the traffic simulation independently, without explicitly waiting for synchronization messages. If a conflicting message is received from another process, the receiving process rolls back its simulation to the point where the message can be correctly applied. This approach reduces the need for synchronization messages at every time step. Chan et al. [19] present promising results using this approach, as discussed further in Section 4.5.
4.4.2. Improving Necessary Communication
- Currently, our point-to-point communication involves three MPI-calls: ISend, MProbe, and MRecv, necessitating two network requests per message exchange. By adopting non-blocking counterparts for MProbe and MRecv, we could alleviate the constraints on the order of execution, though the total number of network requests would remain unchanged.
- Transitioning to a higher level of abstraction for inter-process communication could also be beneficial. MPI v3 introduces collective communication primitives for distributed graph topologies. This could be particularly effective using the neighbor_alltoallv function.
- Utilizing distributed graph topologies can optimize the physical locality of adjacent simulation domains, particularly for very large simulation setups. In many large HPC clusters, network topologies are arranged in a tree structure. This arrangement can result in neighbor partitions being placed on nodes located at opposite ends of the network tree. Consequently, messages must traverse multiple interconnects, leading to increased communication times. By leveraging MPI v3’s graph topology features, partitions can be mapped to computing nodes that are physically closer to each other. This placement reduces the number of interconnects that messages need to cross, thereby improving inter-process communication times and overall runtime efficiency.
- MPI 3’s one-sided communication infrastructure allows asynchronous access to memory sections of remote processes through MPI windows, reducing the synchronization required for data exchange. However, this method requires careful management of memory offsets, making it more complex to implement.
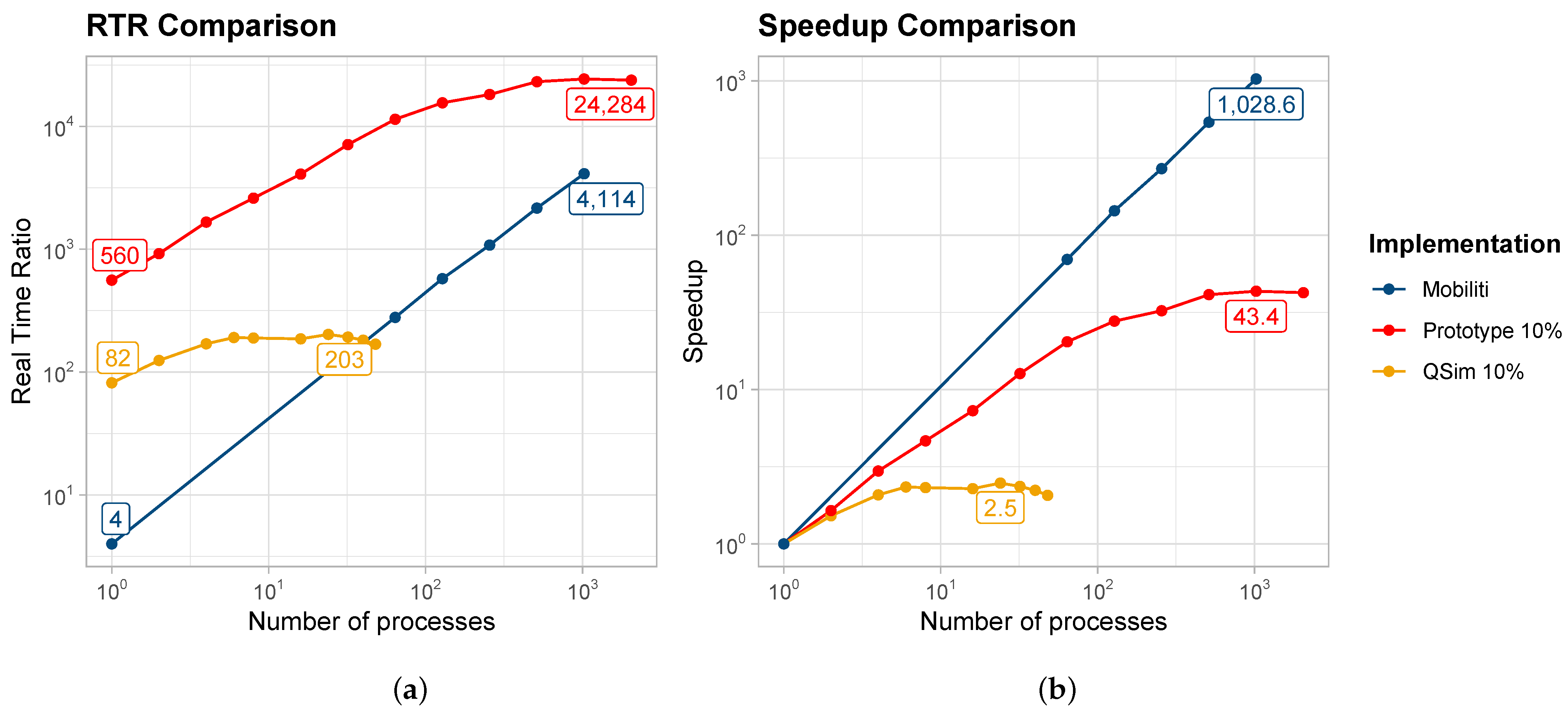
4.5. Comparison with Other Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CERN | European Organization for Nuclear Research |
| CPU | Central Processing Unit |
| FIFO | First In First Out |
| GPU | Graphics Processing Unit |
| HPC | High-Performance Computing |
| JVM | Java Virtual Machine |
| MATSim | Multi-Agent Transport Simulation |
| mobsim | mobility simulation |
| MPI | Message Passing Interface |
| pt | public transit |
| RTR | Real-Time Ratio |
| SIMD | Single Instruction Multiple Data |
References
- Desa, U.N. World Urbanization Prospects 2018: Highlights; Technical report; United Nations: New York, NY, USA, 2018. [Google Scholar]
- Aleko, D.R.; Djahel, S. An efficient Adaptive Traffic Light Control System for urban road traffic congestion reduction in smart cities. Information 2020, 11, 119. [Google Scholar] [CrossRef]
- Xiong, C.; Zhu, Z.; He, X.; Chen, X.; Zhu, S.; Mahapatra, S.; Chang, G.L.; Zhang, L. Developing a 24-hour large-scale microscopic traffic simulation model for the before-and-after study of a new tolled freeway in the Washington, DC–Baltimore region. J. Transp. Eng. 2015, 141, 05015001. [Google Scholar] [CrossRef]
- Perumalla, K.; Bremer, M.; Brown, K.; Chan, C. Computer Science Research Needs for Parallel Discrete Event Simulation (PDES); Technical Report LLNL-TR-840193; U.S. Department of Energy: Germantown, MD, USA, 2022.
- Leiserson, C.E.; Thompson, N.C.; Emer, J.S.; Kuszmaul, B.C.; Lampson, B.W.; Sanchez, D.; Schardl, T.B. There’s plenty of room at the Top: What will drive computer performance after Moore’s law? Science 2020, 368, aam9744. [Google Scholar] [CrossRef] [PubMed]
- Horni, A.; Nagel, K.; Axhausen, K.W. The Multi-Agent Transport Simulation Matsim; Ubiquity Press: London, UK, 2016. [Google Scholar] [CrossRef]
- Dobler, C.; Axhausen, K.W. Design and Implementation of a Parallel Queue-Based Traffic Flow Simulation; IVT: Zürich, Switzerland, 2011. [Google Scholar] [CrossRef]
- Graur, D.; Bruno, R.; Bischoff, J.; Rieser, M.; Scherr, W.; Hoefler, T.; Alonso, G. Hermes: Enabling efficient large-scale simulation in MATSim. Procedia Comput. Sci. 2021, 184, 635–641. [Google Scholar] [CrossRef]
- Cetin, N.; Burri, A.; Nagel, K. A large-scale agent-based traffic microsimulation based on queue model. In Proceedings of the Swiss Transport Research Conference (STRC), Monte Verita, Switzerland, 19–21 March 2003. [Google Scholar]
- Laudan, J.; Heinrich, P. Parallel QSim Rust v0.2.0; Zenodo: Genève, Switzerland, 2024. [Google Scholar] [CrossRef]
- Laudan, J. Rust QSim Simulation Experiment; Zenodo: Genève, Switzerland, 2024. [Google Scholar] [CrossRef]
- Laudan, J.; Heinrich, P.; Nagel, K. High-performance simulations for urban planning: Implementing parallel distributed multi-agent systems in MATSim. In Proceedings of the 2024 23rd International Symposium on Parallel and Distributed Computing (ISPDC), Chur, Switzerland, 8–10 July 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Strippgen, D. Investigating the Technical Possibilities of Real-Time Interaction with Simulations of Mobile Intelligent Particles. Ph.D. Thesis, Technische Universität Berlin, Berlin, Germany, 2009. [Google Scholar] [CrossRef]
- Wan, L.; Yin, G.; Wang, J.; Ben-Dor, G.; Ogulenko, A.; Huang, Z. PATRIC: A high performance parallel urban transport simulation framework based on traffic clustering. Simul. Model. Pract. Theory 2023, 126, 102775. [Google Scholar] [CrossRef]
- Gong, Z.; Tang, W.; Bennett, D.A.; Thill, J.C. Parallel agent-based simulation of individual-level spatial interactions within a multicore computing environment. Int. J. Geogr. Inf. Sci. 2013, 27, 1152–1170. [Google Scholar] [CrossRef]
- OpenMP Architecture Review Board. OpenMP Application Programming Interface; OpenMP Architecture Review Board: Atlanta, GA, USA, 2023. [Google Scholar]
- Qu, Y.; Zhou, X. Large-scale dynamic transportation network simulation: A space-time-event parallel computing approach. Transp. Res. Part C Emerg. Technol. 2017, 75, 1–16. [Google Scholar] [CrossRef]
- Bragard, Q.; Ventresque, A.; Murphy, L. Self-Balancing Decentralized Distributed Platform for Urban Traffic Simulation. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1190–1197. [Google Scholar] [CrossRef]
- Chan, C.; Wang, B.; Bachan, J.; Macfarlane, J. Mobiliti: Scalable Transportation Simulation Using High-Performance Parallel Computing. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 634–641. [Google Scholar] [CrossRef]
- Xiao, J.; Andelfinger, P.; Eckhoff, D.; Cai, W.; Knoll, A. A Survey on Agent-based Simulation Using Hardware Accelerators. ACM Comput. Surv. 2019, 51, 1–35. [Google Scholar] [CrossRef]
- Zhou, H.; Dorsman, J.L.; Snelder, M.; Romph, E.d.; Mandjes, M. GPU-based Parallel Computing for Activity-based Travel Demand Models. Procedia Comput. Sci. 2019, 151, 726–732. [Google Scholar] [CrossRef]
- Saprykin, A.; Chokani, N.; Abhari, R.S. GEMSim: A GPU-accelerated multi-modal mobility simulator for large-scale scenarios. Simul. Model. Pract. Theory 2019, 94, 199–214. [Google Scholar] [CrossRef]
- Saprykin, A.; Chokani, N.; Abhari, R.S. Accelerating agent-based demand-responsive transport simulations with GPUs. Future Gener. Comput. Syst. 2022, 131, 43–58. [Google Scholar] [CrossRef]
- Message Passing Interface Forum. MPI: A Message-Passing Interface Standard Version 4.1. November 2023. Available online: https://www.mpi-forum.org/docs/mpi-4.1/mpi41-report.pdf (accessed on 6 February 2024).
- Vega-Gisbert, O.; Roman, J.E.; Squyres, J.M. Design and implementation of Java bindings in Open MPI. Parallel Comput. 2016, 59, 1–20. [Google Scholar] [CrossRef]
- Gabriel, E.; Fagg, G.E.; Bosilca, G.; Angskun, T.; Dongarra, J.J.; Squyres, J.M.; Sahay, V.; Kambadur, P.; Barrett, B.; Lumsdaine, A.; et al. Open MPI: Goals, Concept, and Design of a Next Generation MPI Implementation. In Proceedings of the Recent Advances in Parallel Virtual Machine and Message Passing Interface, Budapest, Hungary, 19–22 September 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 97–104. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. Multilevelk-way Partitioning Scheme for Irregular Graphs. J. Parallel Distrib. Comput. 1998, 48, 96–129. [Google Scholar] [CrossRef]
- Horni, A.; Nagel, K.; Axhausen, K. MATSim User Guide; Technische Universität Berlin: Berlin, Germany, 2024. [Google Scholar]
- Turek, W. Erlang-based desynchronized urban traffic simulation for high-performance computing systems. Future Gener. Comput. Syst. 2018, 79, 645–652. [Google Scholar] [CrossRef]
- Charypar, D.; Axhausen, K.W.; Nagel, K. Event-Driven Queue-Based Traffic Flow Microsimulation. Transp. Res. Rec. 2007, 2003, 35–40. [Google Scholar] [CrossRef]
- Ghosh, S.; Halappanavar, M.; Kalyanaraman, A.; Khan, A.; Gebremedhin, A.H. Exploring MPI Communication Models for Graph Applications Using Graph Matching as a Case Study. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 761–770. [Google Scholar] [CrossRef]
- Gropp, W.; Hoefler, T.; Thakur, R.; Lusk, E. Using Advanced MPI: Modern Features of the Message-Passing Interface; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Lastovetsky, A.; Manumachu, R.R. Energy-efficient parallel computing: Challenges to scaling. Information 2023, 14, 248. [Google Scholar] [CrossRef]
- Karypis, G.; Kumar, V. Multilevel Algorithms for Multi-Constraint Graph Partitioning. In Proceedings of the SC ’98: Proceedings of the 1998 ACM/IEEE Conference on Supercomputing, Orlando, FL, USA, 7–13 November 1998; p. 28. [Google Scholar] [CrossRef]
- Krakowski, F.; Ruhland, F.; Schöttner, M. Infinileap: Modern High-Performance Networking for Distributed Java Applications based on RDMA. In Proceedings of the 2021 IEEE 27th International Conference on Parallel and Distributed Systems (ICPADS), Beijing, China, 14–16 December 2021; pp. 652–659. [Google Scholar] [CrossRef]
- Ruhland, F.; Krakowski, F.; Schöttner, M. hadroNIO: Accelerating Java NIO via UCX. In Proceedings of the 2021 20th International Symposium on Parallel and Distributed Computing (ISPDC), Cluj-Napoca, Romania, 28–30 July 2021; pp. 25–32. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processes | Average Number of Neighbors | Maximum Number of Neighbors | Duration in µs by Average Number of Neighbors | Duration in µs by Maximum Number of Neighbors |
|---|---|---|---|---|
| 2 | 1.00 | 1.0 | 1.4 | 1.4 |
| 4 | 2.50 | 3.0 | 0.9 | 0.7 |
| 8 | 4.25 | 6.0 | 1.4 | 1.0 |
| 16 | 5.25 | 7.0 | 1.2 | 0.9 |
| 32 | 5.25 | 9.0 | 1.7 | 1.0 |
| 64 | 5.78 | 12.0 | 2.1 | 1.0 |
| 128 | 6.06 | 19.0 | 3.0 | 0.9 |
| 256 | 6.29 | 19.0 | 3.2 | 1.0 |
| 512 | 6.07 | 22.0 | 3.7 | 1.0 |
| 1024 | 5.77 | 21.0 | 3.7 | 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laudan, J.; Heinrich, P.; Nagel, K. High-Performance Mobility Simulation: Implementation of a Parallel Distributed Message-Passing Algorithm for MATSim. Information 2025, 16, 116. https://doi.org/10.3390/info16020116
Laudan J, Heinrich P, Nagel K. High-Performance Mobility Simulation: Implementation of a Parallel Distributed Message-Passing Algorithm for MATSim. Information. 2025; 16(2):116. https://doi.org/10.3390/info16020116
Chicago/Turabian StyleLaudan, Janek, Paul Heinrich, and Kai Nagel. 2025. "High-Performance Mobility Simulation: Implementation of a Parallel Distributed Message-Passing Algorithm for MATSim" Information 16, no. 2: 116. https://doi.org/10.3390/info16020116
APA StyleLaudan, J., Heinrich, P., & Nagel, K. (2025). High-Performance Mobility Simulation: Implementation of a Parallel Distributed Message-Passing Algorithm for MATSim. Information, 16(2), 116. https://doi.org/10.3390/info16020116