

A Centralized Approach to the Logging Mechanisms of Distributed Complex ERP Applications


Abstract
1. Introduction
- Web server level: the infrastructure that supports the entire application.
- Database level: the operations performed for managing the persistent data of the application.
- Business logic levels: the completeness of the computing operations performed to provide the application’s facilities.
- Application presentation level: the components that sustain and offer functionalities to the user accessible interfaces.
- The date it was issued
- The part of the application that produced it
- A significant description [6].
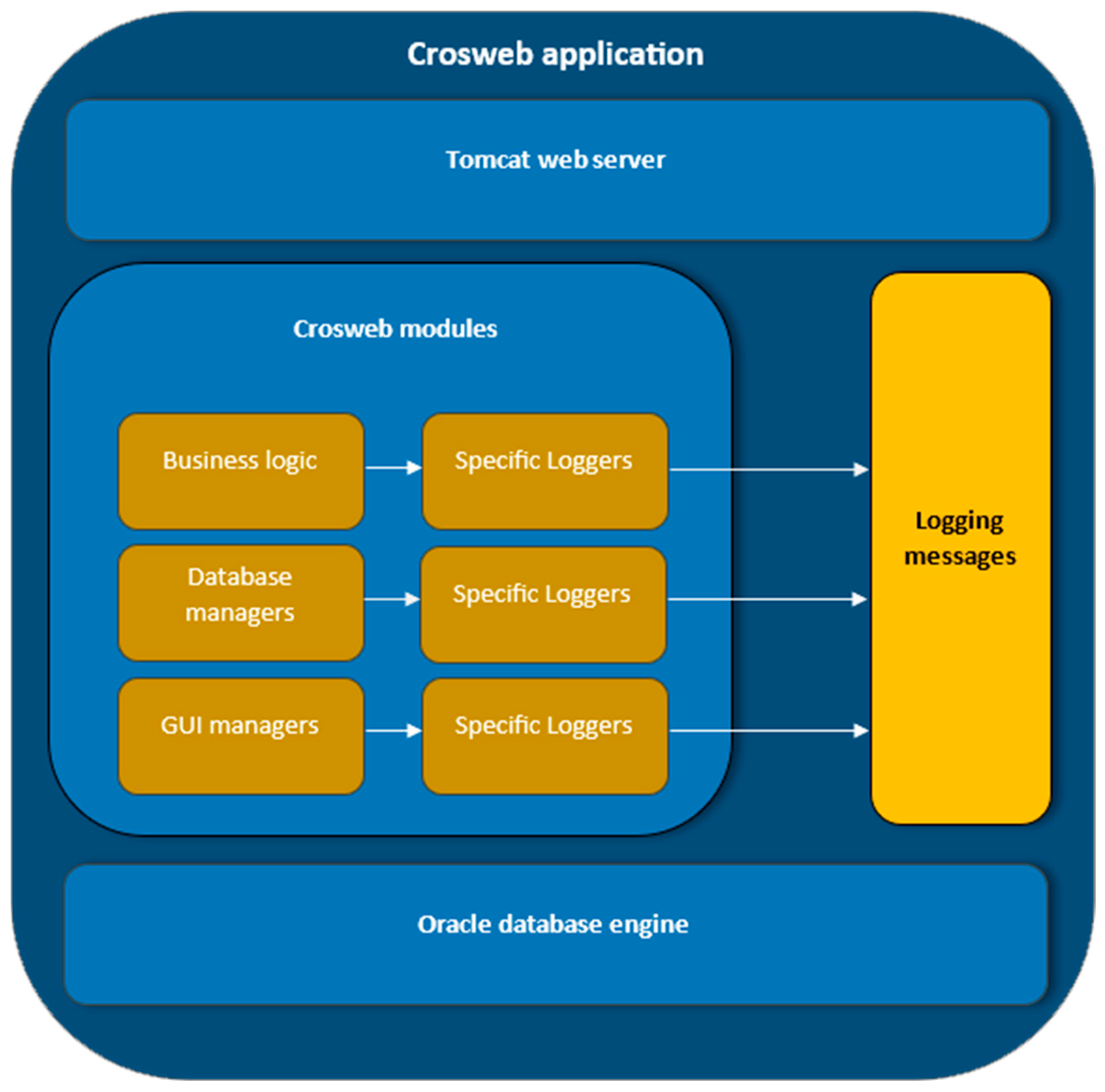
2. The Crosweb Context
- Business logic implementation files: written in Java, define the data processing specific to each functioning situation.
- Database communication files: written in Java and by the JDBC [21] bridge can launch database interrogations and receive and interpret the obtained results.
- Graphical User Interface (GUI) managers:
- ○
- Layout files: written in Java and contain page elements’ components defined by descriptor attributes.
- ○
- ○
- Resource files: Multimedia content (images, etc.) are associated with each developed page.
- ○
- Component manager files: written in Java, control the functionality and behavior of the developed web components (menus, buttons, charts, tables, etc.).
- ○
- Page manager files: written in Java and are responsible for assembling all the components embedded in a certain page. They also interpret the roles associated with each user.
- ○
- Renderer files: written in Java and are specialized in web content production. They deliver browser displayable content based on the entire infra-structure mentioned above.
3. Crosweb Logging Mechanisms
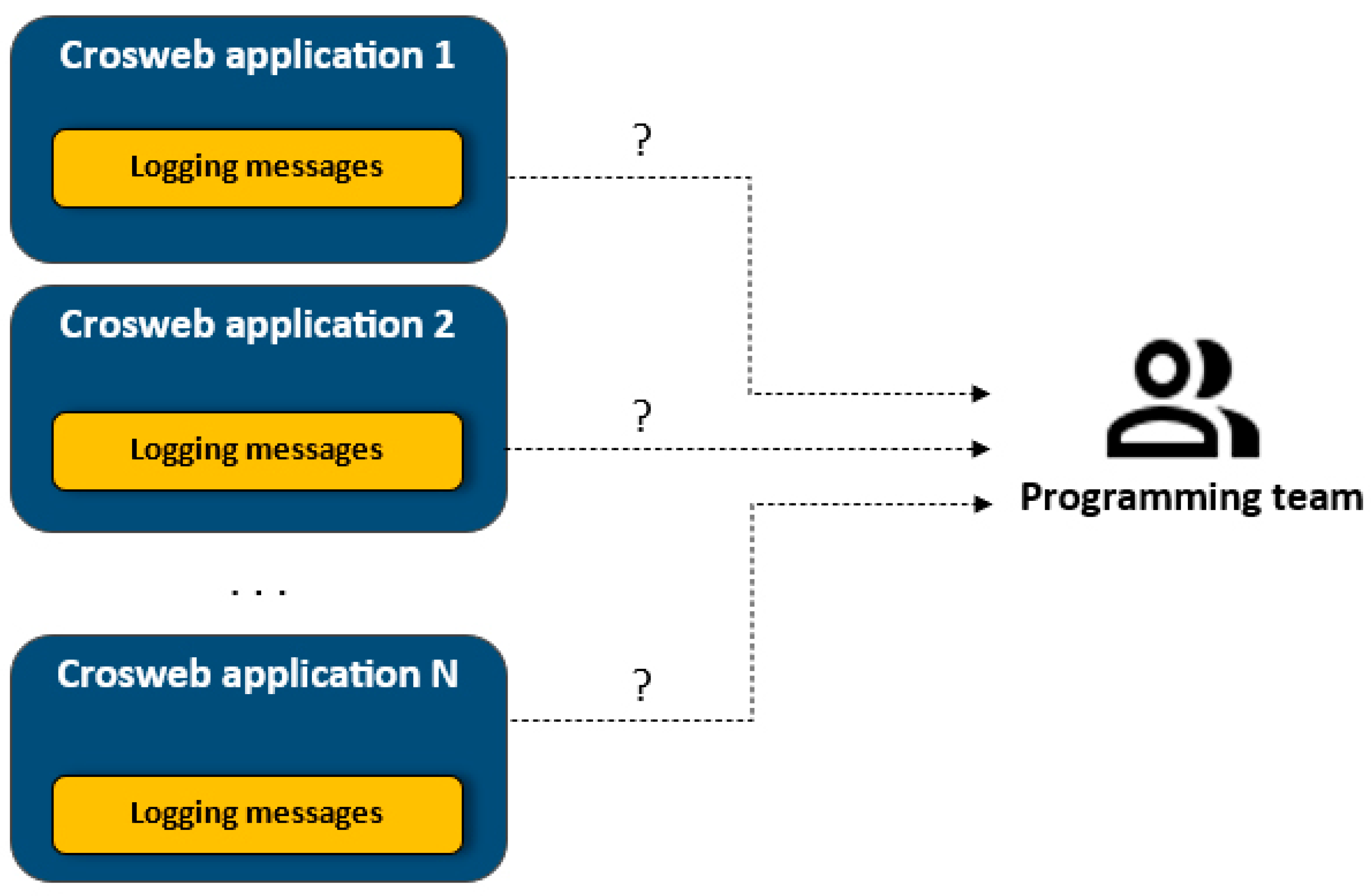
3.1. Initial Implementation of Logging Mechanisms
- Specific instances of Logger type [28] created in each Java source code that is capable of launching logging messages.
- Direct calls to specific logging methods (debug(), error(), warn(), etc.) or to the generic method log() [25]. Both method categories receive as parameter the message to be re-ported in logging, the second one’s functioning being controlled in addition by the log level.
- Seeing the actual logging messages.
- Determining the installed Crosweb application version.
- Determining the underlying installed software infrastructure (Tomcat and Oracle versions).
- Trying to replicate the scenario that led to the reported problems.
- Fixing the determined issues.
- Deploying the fixed codes on the machines that signaled the problems.
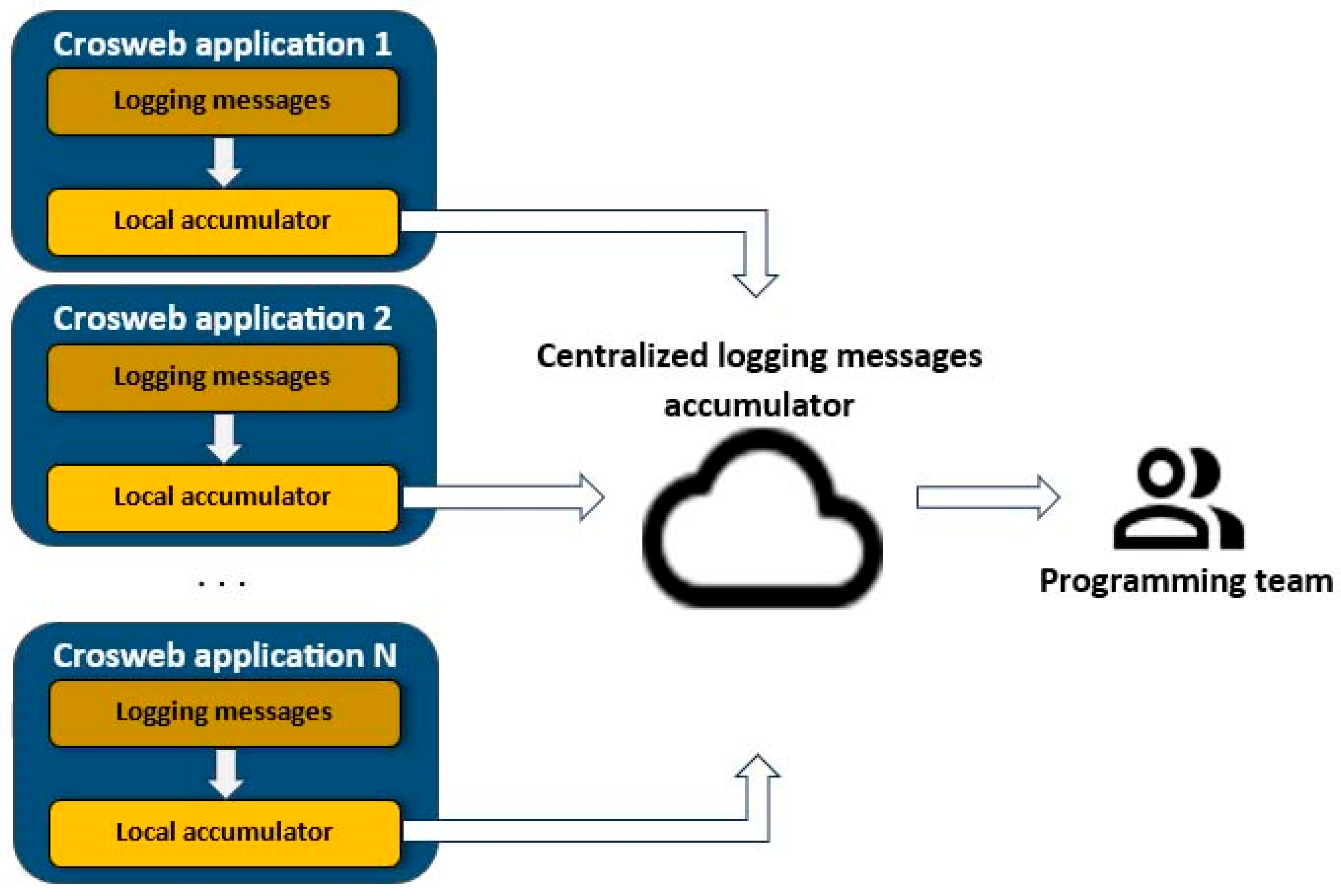
3.2. The Centralized Logging Mechanisms
3.2.1. The Structure of Logging Messages
- Payload (actual reported data).
- Overhead (additional identifiers).
- log_client_id: the identifier of the Crosweb registered client currently using the application.
- log_node_id: the Crosweb node that signals the message.
- log_level: the message error level (INFO, WARNING, DEBUG, etc.).
- log_class: the Java class containing the code that signaled the error.
- log_module_name: the Crosweb module that signals the problem.
- log_action_name: the action (if any) that led to the reported problem.
- log_date: the date the logging message was reported.
- log_user_id: the identifier of the Crosweb registered user (if existent).
- log_session_id: the Crosweb session identifier (if existent).
- log_session_created_at: the timestamp the session was created (if the session exists).
- log_layer: the Crosweb layer from which the error was launched.
- log_package: the Crosweb package from which the error was launched.
- log_component: the Crosweb component from which the error was launched.
- log_line: the line number in the Java source code that signaled the error.
- log_context_id: the internal Crosweb context identifier (if existent).
- log_context_page: the Crosweb web page that was running when the error was reported (if existent).
- log_request_id: the Crosweb web page request identifier (if existent).
- log_request_type: the Crosweb request type (if existent).
- log_message: the actual error message explaining its nature.
- Independent of the number of parameters and the order in which they are specified.
- Elastic enough to allow the omission of some parameters that may not have values in certain contexts.
- Universal enough to be processed in various technologies and programming languages (can be created, transmitted, and disassembled in Java, JavaScript, etc.).
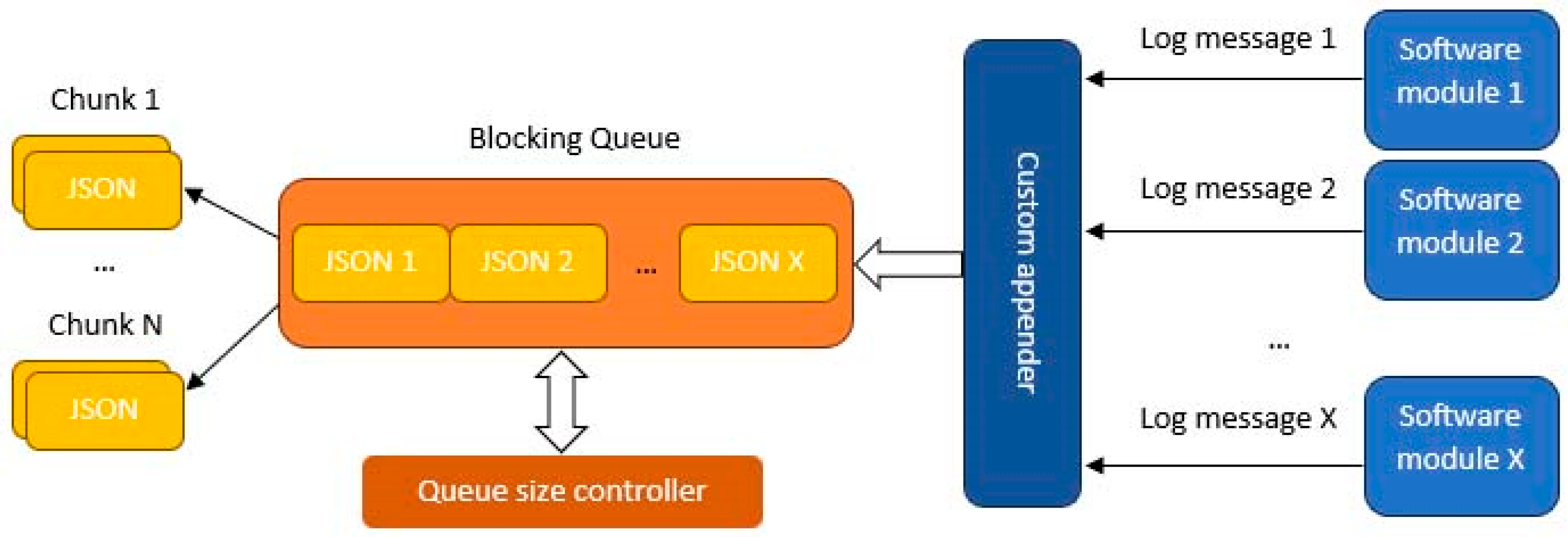
3.2.2. Local Logging Messages Accumulators
Custom Appender Configuration
| <?xml version=“1.0” encoding=“UTF-8” ?> <Configuration strict=“true” monitorInterval=“5” packages=“crosweb.helpers”> <Appenders> <LogMessagesAppender name=“logMessagesAppender”> <PatternLayout pattern=“%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} – %msg%n”/> </LogMessagesAppender> <!-- … other appenders … --> </Appenders> <Loggers> <!-- modules that trigger the appender --> <Logger name=“cros.package1” additivity=“false” level=“info”> <AppenderRef ref=“logMessagesAppender”/> </Logger> <!-- … other modules --> <Logger name=“cros.packageN” additivity=“false” level=“info”> <AppenderRef ref=“logMessagesAppender”/> </Logger> </Loggers> </Configuration> |
| //logger declaration private static final Logger logger = LoggerManager.framework(SessionFilter.class); //setting logging parameters ThreadContext.put(“parameter_name”, “parameter value”); //logger triggering logger.debug(“Call performed with session “ + session.getId() + “ at “ + servletPath); |
Custom Appender Functionality
- Add new singular entries to its own internal repository, in a thread-safe manner.
- Extract chunks of data from the repository, in a thread-safe manner.
- Monitor its capacity and handle the edge case scenarios (empty or full).
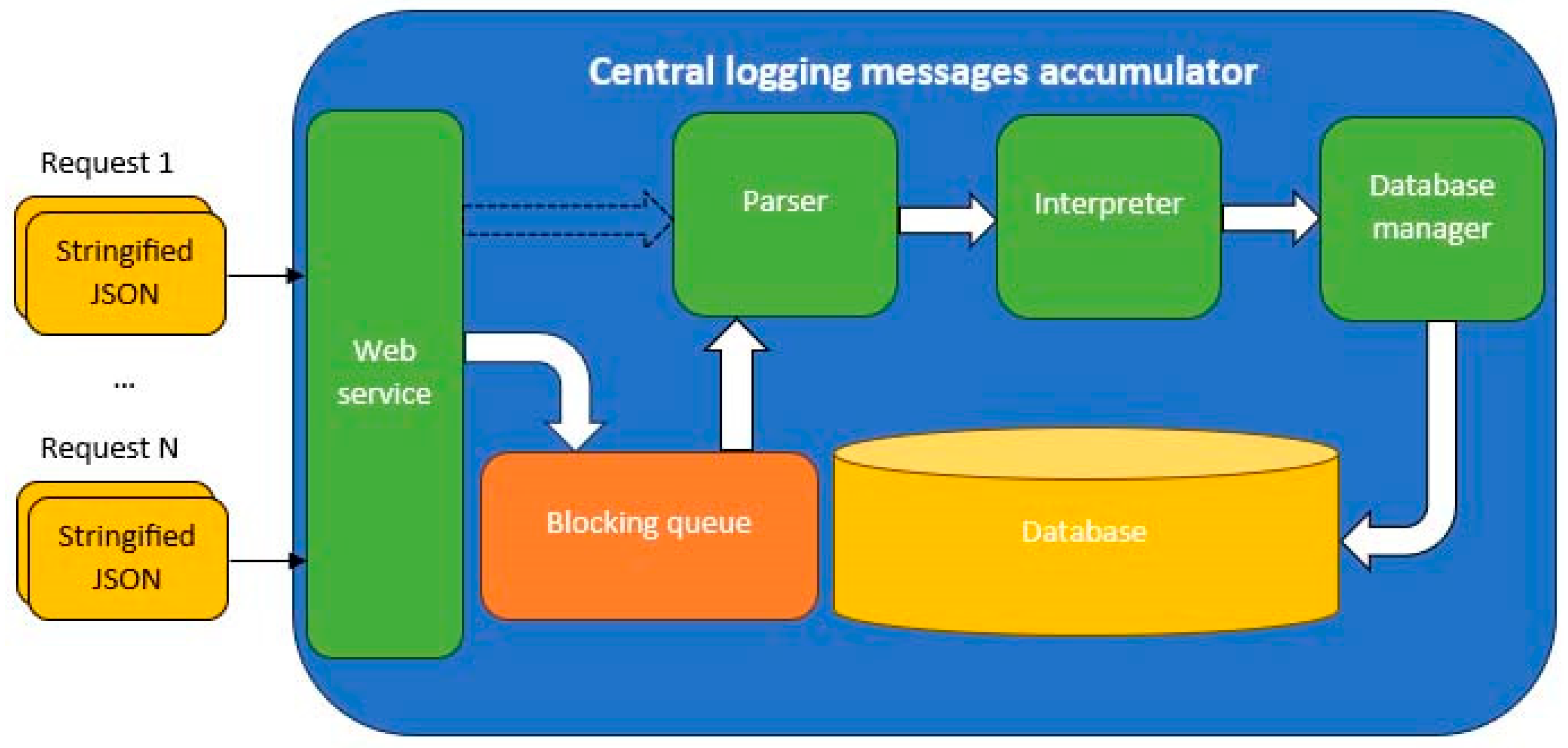
3.2.3. The Central Logging Messages Accumulator
- Queue extraction.
- Parsing.
- Interpretation.
- Database insertion.
- LogJSONInterpreter—a class specialized in interpreting the JSON stringified data.
- LogQueueConsumer—a consumer thread-type class that digests the data stored in the queue.
3.2.4. The Centralized Logging Messages Displayer
- Form a global view about the health of all the Crosweb deployments.
- Deliver the required information for fixing the eventual abnormal situations that may occur.
- By date.
- By logging message type (ERROR, DEBUG, etc.).
- By Crosweb client identifier.
- By module name.
- By request type.
- By Crosweb package.
- By Crosweb component.
- An abbreviated initial view containing the main characteristics of the logged data. This view is the default one.
- An extended view containing all the database-stored fields related to the logged data. This view is presented only if requested by the programmer who analyzes the logs.
- “viewed”
- “obsolete”
- “in progress”
- “solved”.
4. Results
- C1—Global measurement: considering the effectiveness of solutioning the reported errors that occurred in the ERP solutions developed using the Crosweb platform.
- C2—Metrics measurement: analyzing specific measures that reflect the effort made by the platform to manage successfully the logging messages
4.1. C1—Global Measurement
4.2. C1—Metrics Measurement
- RAM Memory usage for storing the logging messages queues: an average of 500 messages/queue, each message having an average of 1000 characters: 500 Kbytes (round up from 488.28 Kbytes).
- Time intervals elapsed for delivering the stringified JSON objects representing the logged messages: less than 1ms added with the network ping time.
- Database storage capacity used for an average of 500 users/h/Crosweb ERP, 1000 logging messages/h: 500 Mbytes/h. This produces an average of 4 Gbytes/work day (assuming there are roughly 8 working hours/day). In a month with an average of 20 working days, approximately 800 Gbytes will be consumed for storing the logged data.
5. Discussion
6. Conclusions
6.1. Achievements
6.2. Further Directions
- Preserving only the latest logging information. The data older than a predefined time threshold can be automatically overridden.
- Selecting the logging messages severity that need to benefit of the centralized logging mechanisms. Usually, only the occurred errors need a quick solution, and these kinds of situations occur very rarely in the deployed ERP products; they are more common in the development and testing phases.
6.3. Final Words
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Distributed Applications. Available online: https://www.techtarget.com/searchitoperations/definition/distributed-applications-distributed-apps (accessed on 1 March 2024).
- Software Versioning Best Practices. Available online: https://cpl.thalesgroup.com/software-monetization/software-versioning-basics (accessed on 15 January 2024).
- How Can You Effectively Handle API Versioning and Maintenance in Large-Scale Projects. Available online: https://www.linkedin.com/advice/0/how-can-you-effectively-handle-api-versioning-maintenance-asxwf (accessed on 15 January 2024).
- Generating Log Messages from Your Code. Available online: https://developer.apple.com/documentation/os/logging/generating_log_messages_from_your_code (accessed on 13 February 2024).
- Logging Levels. Available online: https://www.xcitium.com/knowledge-base/logging-levels/ (accessed on 13 February 2025).
- Formatting Log Messages. Available online: https://docs.gigaspaces.com/latest/admin/logging-formatting-messages.html (accessed on 3 February 2024).
- Windows Logging Guide: The Basics. Available online: https://www.crowdstrike.com/guides/windows-logging/ (accessed on 20 February 2024).
- View Log Messages in Console on Mac. Available online: https://support.apple.com/guide/console/log-messages-cnsl1012/mac (accessed on 20 February 2024).
- Java Logging Overview. Available online: https://docs.oracle.com/en/java/javase/11/core/java-logging-overview.html#GUID-B83B652C-17EA-48D9-93D2-563AE1FF8EDA (accessed on 21 February 2024).
- Getting Started Quickly with C++ Logging. Available online: https://www.sentinelone.com/blog/getting-started-quickly-cplusplus-logging/ (accessed on 21 February 2024).
- (Python) Logging Howto. Available online: https://docs.python.org/3/howto/logging.html (accessed on 21 February 2024).
- Console: Log() Static Method. Available online: https://developer.mozilla.org/en-US/docs/Web/API/console/log_static (accessed on 11 February 2024).
- How to Log Messages to Different Files. Available online: https://symfony.com/doc/current/logging/channels_handlers.html (accessed on 11 February 2024).
- Guidelines for Creating a Logging Database. Available online: https://www.ibm.com/docs/en/cognos-analytics/11.1.0?topic=messages-guidelines-creating-logging-database (accessed on 11 February 2024).
- Elastic Stack. Available online: https://www.elastic.co/elastic-stack (accessed on 14 February 2025).
- Splunk. Available online: https://www.fortinet.com/resources/cyberglossary/what-is-splunk#:~:text=Splunk%20is%20a%20big%20data,management%2C%20compliance%2C%20and%20security (accessed on 22 January 2025).
- Fluentd. Available online: https://www.fluentd.org/ (accessed on 2 February 2025).
- Database|Oracle. Available online: https://www.oracle.com/database/ (accessed on 26 February 2024).
- Java|Oracle. Available online: https://www.java.com/en/ (accessed on 15 January 2024).
- Apache Tomcat. Available online: https://tomcat.apache.org/ (accessed on 29 January 2024).
- Java JDBC API. Available online: https://docs.oracle.com/javase/8/docs/technotes/guides/jdbc/ (accessed on 20 February 2024).
- CSS: Cascading Style Sheets. Available online: https://developer.mozilla.org/en-US/docs/Web/CSS (accessed on 30 January 2024).
- JavaScript|MDN. Available online: https://developer.mozilla.org/en-US/docs/Web/JavaScript (accessed on 30 January 2024).
- Apache Logging Services Log4j. Available online: https://logging.apache.org/log4j/2.x/ (accessed on 10 January 2024).
- Apache Maven Project. Available online: https://maven.apache.org/ (accessed on 11 January 2024).
- Configuring Log4j 2. Available online: https://logging.apache.org/log4j/2.x/manual/configuration.html (accessed on 20 February 2024).
- Log4j 2 Architecture. Available online: https://logging.apache.org/log4j/2.x/manual/architecture.html (accessed on 13 February 2024).
- Logger Class (Java SE 21 & JDK 21). Available online: https://docs.oracle.com/en/java/javase/21/docs/api/java.logging/java/util/logging/Logger.html (accessed on 2 February 2024).
- Log4j 2 Appenders. Available online: https://logging.apache.org/log4j/2.x/manual/appenders.html (accessed on 2 February 2024).
- JSON. Available online: https://www.json.org/json-en.html (accessed on 23 February 2024).
- ArrayBlockingQueue Class. Available online: https://docs.oracle.com/en/java/javase/21/docs/api/java.base/java/util/concurrent/ArrayBlockingQueue.html (accessed on 21 February 2024).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LogMessagesAppender Class | |
|---|---|
| Class header | class LogMessagesAppender extends AbstractAppender //variables for ensuring the synchronicity private final ReadWriteLock readWriteLock private final Lock readLock //thread that sends the accumulated data LogMessagesSender log_messages_sender; //other helper variables |
| Class attributes | |
| Class methods | //constructor protected LogMessagesAppender(String name, Filter filter, Layout<? extends Serializable> layout, final boolean ignoreExceptions); //appender start method (overridden) public void start(); //append method (populate and store the JSON representation of the current logging message) public void append(LogEvent event); //method that triggers the log_messages_sender public void processJSONObject(String JSON_object); |
| Initial Queue Capacity | Queue Increase Percentage | Queue Cloning Duration |
|---|---|---|
| 500 items | 20% | 1–5 ms |
| 1000 items | 20% | 1–7 ms |
| 2000 items | 20% | 2–9 ms |
| 10,000 items | 20% | 5–12 ms |
| 100,000 items | 20% | 10–15 ms |
| 500,000 items | 20% | 10–15 ms |
| Consumer Thread Step | Raw Messages Processed/Cycle | Time Required for Processing 1 Raw Message | Total Time Required | Exceeding Time |
|---|---|---|---|---|
| 500 | 416.66 | 1 ms | 416.66 ms | 83.33 ms |
| 1000 | 833.33 | 1 ms | 833.33 ms | 166.66 ms |
| 2000 | 1666.66 | 1 ms | 1666.66 ms | 333.33 ms |
| LogServlet Class | |
|---|---|
| Class header | class LogServlet extends HttpServlet //the logging queue BlockingQueue<Map<String, Map<String, String>>> queue; //queue capacity int queue_size; //the consumer process LogQueueConsumer consumer; |
| Class attributes | |
| Class methods | //constructor public LogServlet(); //requests servicing method (overridden) @Override protected void doService(HttpServletRequest request, HttpServletResponse response, JSONObject authorizationPayload) throws HttpException, DataException, IOException //request parsing method public Vector parseRequest(HttpServletRequest request); //queue appending method public void appendToQueue(LogJSONInterpreter json_interpreter); |
| Error Localization | Avg. Error Solving Time (Before Centralized Logging) [min.] | Avg. Error Solving Time (After Centralized Logging) [min] | Improvement [%] |
|---|---|---|---|
| Web interface | 60 | 40 | 33.33% |
| Database | 45 | 25 | 44.44% |
| Software module (Java code) | 120 | 100 | 16.66% |
| Infrastructure | 180 | 160 | 11.11% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strilețchi, C.; Pop, P.G.; Gavrilă, C. A Centralized Approach to the Logging Mechanisms of Distributed Complex ERP Applications. Information 2025, 16, 216. https://doi.org/10.3390/info16030216
Strilețchi C, Pop PG, Gavrilă C. A Centralized Approach to the Logging Mechanisms of Distributed Complex ERP Applications. Information. 2025; 16(3):216. https://doi.org/10.3390/info16030216
Chicago/Turabian StyleStrilețchi, Cosmin, Petre G. Pop, and Christian Gavrilă. 2025. "A Centralized Approach to the Logging Mechanisms of Distributed Complex ERP Applications" Information 16, no. 3: 216. https://doi.org/10.3390/info16030216
APA StyleStrilețchi, C., Pop, P. G., & Gavrilă, C. (2025). A Centralized Approach to the Logging Mechanisms of Distributed Complex ERP Applications. Information, 16(3), 216. https://doi.org/10.3390/info16030216