

Detecting Potential Investors in Crypto Assets: Insights from Machine Learning Models and Explainable AI

Abstract
:
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Gathering the Data
- The first set included a general and a control question. The general question inquired whether the respondent invests and, if yes, where the control question assessed their familiarity with the concept of crypto assets.
- The second set focused on demographic data such as gender, age (condition: 18 years or older), monthly net income, and level of education.
- The third set included statements that respondents answered using a 5-point Likert scale (1—strongly disagree, 5—strongly agree). In this part, we explored perceptions of financial literacy, understanding of crypto-assets, perceptions of regulatory security, and benefits and risks of crypto assets. We were also interested in the impact of the social environment on attitudes towards crypto markets.
- The fourth strand is aimed at examining the likelihood of future investment in crypto assets. We used a sliding scale question where respondents rated how likely they were to invest in the next year (0 = definitely no, 100 = definitely yes).
3.2. Database
3.3. Modeling
4. Results
5. Conclusions
5.1. Key Findings
5.2. Implications
5.3. Future Research and Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2009. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 8 January 2025).
- Seoyouung, K.; Atulya, S.; Daljeet, V. Crypto-Assets Unencrypted. J. Invest. Manag. Forthcom. 2018, p. abs/3117859. Available online: https://ssrn.com/abstract=3117859 (accessed on 8 January 2025).
- Koehler, S.; Dhameliya, N.; Patel, B.; Anumandla, S.K.R. AI-Enhanced Cryptocurrency Trading Algorithm for Optimal Investment Strategies. Asian Account. Audit. Adv. 2018, 9, 101–114. [Google Scholar]
- Leahy, E. AI-Powered Bitcoin Trading: Developing an Investment Strategy with Artificial Intelligence; John Wiley & Sons: Hoboken, NJ, USA, 2024. [Google Scholar]
- Babaei, G.; Giudici, P.; Raffinetti, E. Explainable artificial intelligence for crypto asset allocation. Financ. Res. Lett. 2022, 47, 102941. [Google Scholar] [CrossRef]
- Kahneman, D.; Tversky, A. Prospect Theory: An Analysis of Decision under Risk. In Handbook of the Fundamentals of Financial Decision Making; World Scientific Handbook in Financial Economics Series; World Scientific: Singapore, 2013; pp. 99–127. [Google Scholar]
- Ajzen, I. The theory of planned behavior. Organ. Behav. Hum. Decis. Process. 1991, 50, 179–211. [Google Scholar] [CrossRef]
- Pilatin, A.; Dilek, Ö. Investor intention, investor behavior and crypto assets in the framework of decomposed theory of planned behavior. Curr. Psychol. 2024, 43, 1309–1324. [Google Scholar] [CrossRef]
- Mittal, S.K. Behavior biases and investment decision: Theoretical and research framework. Qual. Res. Financ. Mark. 2022, 14, 213–228. [Google Scholar] [CrossRef]
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. Manag. Inf. Syst. 1989, 13, 319–339. [Google Scholar] [CrossRef]
- Almeida, J.; Gonçalves, T.C. A systematic literature review of investor behavior in the cryptocurrency markets. J. Behav. Exp. Financ. 2023, 37, 100785. [Google Scholar] [CrossRef]
- Ante, L.; Fiedler, I.; Von Meduna, M.; Steinmetz, F. Individual Cryptocurrency Investors: Evidence from a Population Survey. Int. J. Innov. Technol. Manag. 2022, 19, 2250008. [Google Scholar] [CrossRef]
- Colombo, J.A.; Yarovaya, L. Are crypto and non-crypto investors alike? Evidence from a comprehensive survey in Brazil. Technol. Soc. 2024, 76, 102468. [Google Scholar] [CrossRef]
- Jin, S.V. “Technopian but lonely investors?”: Comparison between investors and non-investors of blockchain technologies, cryptocurrencies, and non-fungible tokens (NFTs) in Artificial Intelligence-Driven FinTech and decentralized finance (DeFi). Telemat. Inform. Rep. 2024, 14, 100128. [Google Scholar] [CrossRef]
- Tzavaras, C. Investor Demographics and their Impact on the Intention to Invest in Cryptocurrencies: An Empirical Analysis of Crypto Investors and Non-Crypto Investors. Utrecht University. 2023. Available online: https://studenttheses.uu.nl/bitstream/handle/20.500.12932/45007/Tzavaras%2CC._5437393.pdf?sequence=1&isAllowed=y (accessed on 24 March 2025).
- Caelen, O. A Bayesian interpretation of the confusion matrix. Ann. Math. Artif. Intell. 2017, 81, 429–450. [Google Scholar] [CrossRef]
- Muschelli, J. ROC and AUC with a Binary Predictor: A Potentially Misleading Metric. J. Classif. 2020, 37, 696–708. [Google Scholar] [CrossRef] [PubMed]
- Webb, G.I. Naïve Bayes. In Encyclopedia of Machine Learning and Data Mining; Springer: Berlin/Heidelberg, Germany, 2017; Available online: https://www.researchgate.net/profile/Geoffrey-Webb/publication/306313918_Naive_Bayes/links/5cab15724585157bd32a75b6/Naive-Bayes.pdf (accessed on 24 March 2025).
- Pérez, A.; Larrañaga, P.; Inza, I. Bayesian classifiers based on kernel density estimation: Flexible classifiers. Int. J. Approx. Reason. 2009, 50, 341–362. [Google Scholar] [CrossRef]
- John, G.H.; Langley, P. Estimating Continuous Distributions in Bayesian Classifiers. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Bellevue, WA, USA, 11–15 July 2013; pp. 338–345. [Google Scholar]
- Suthaharan, S. Support Vector Machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Boston, MA, USA, 2016; pp. 207–235. [Google Scholar]
- Wu, J.; Yang, H. Linear Regression-Based Efficient SVM Learning for Large-Scale Classification. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2357–2369. [Google Scholar] [CrossRef] [PubMed]
- Angelov, P.P.; Soares, E.A.; Jiang, R.; Arnold, N.I.; Atkinson, P.M. Explainable artificial intelligence: An analytical review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11. [Google Scholar] [CrossRef]
- Mane, D.; Magar, A.; Khode, O.; Koli, S.; Bhat, K.; Korade, P. Unlocking Machine Learning Model Decisions: A Comparative Analysis of LIME and SHAP for Enhanced Interpretability. J. Electr. Syst. 2024, 20, 598–613. [Google Scholar] [CrossRef]
- Parr, T.; Wilson, J.D. Partial dependence through stratification. Mach. Learn. Appl. 2021, 6, 100146. [Google Scholar] [CrossRef]
- Greenwell, B.M. pdp: An R Package for Constructing Partial Dependence Plots. R J. 2017, 9, 421–436. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Type of Variable | Stock of Value | Notes |
|---|---|---|---|
| Prob_cat—likelihood of investing in crypto assets in the future (dependent) | Categorical | 1, 2, 3 | 0—No, 1—Yes |
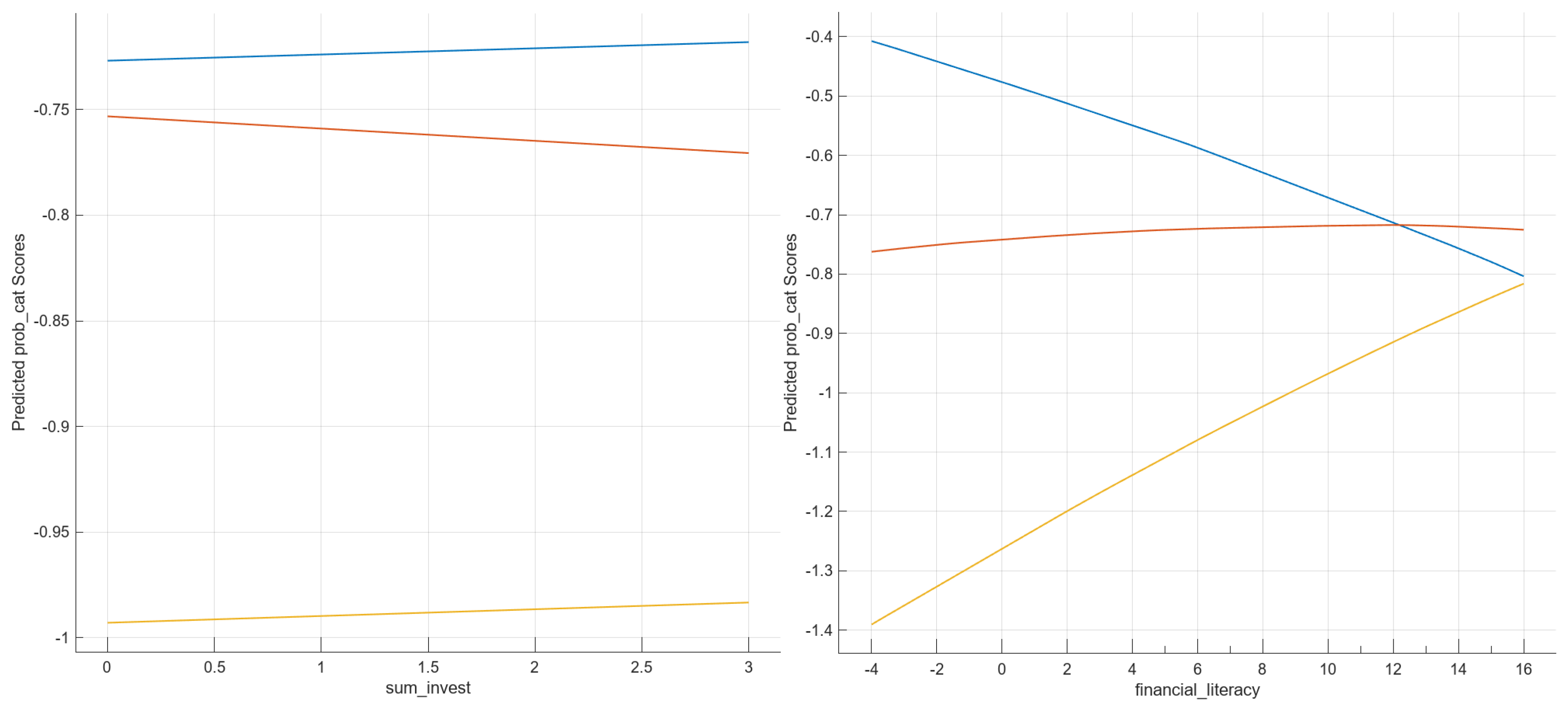
| Sum_invest—number of different investments | Numerical, discrete | 0–7 | |
| Financial_literacy—perception of financial literacy | Numerical, discrete | −4–16 | |
| Social_env—attitude of the social environment towards the crypto market | Numerical, discrete | −5–20 | |
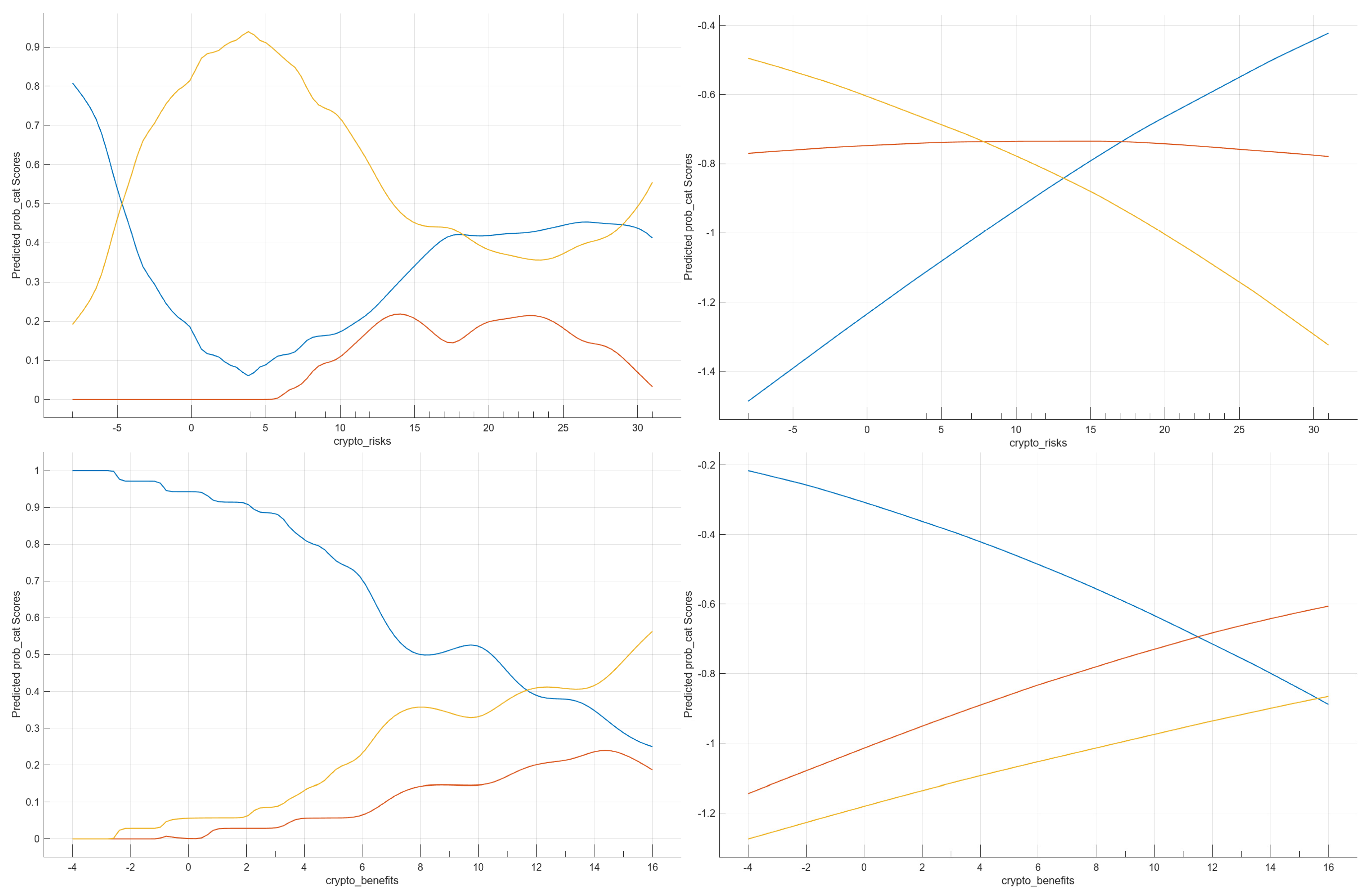
| Crypto_benefits—perceived benefits of crypto assets | Numerical, discrete | −4–16 | |
| Crypto_risks—perceived risks of crypto assets | Numerical, discrete | −8–32 | |
| Crypto_understanding—perceived understanding of crypto assets | Numerical, discrete | −6–24 | |
| Regulatory_safety—perception of regulatory safety | Numerical, discrete | −4–16 | |
| Gender | Binary | 0, 1 | 0—No, 1—Yes |
| Edu_primary—primary school | Binary | 0, 1 | 0—No, 1—Yes |
| Edu_high—high school | Binary | 0, 1 | 0—No, 1—Yes |
| Edu_col—college | Binary | 0, 1 | 0—No, 1—Yes |
| Edu_more—diploma, masters, PhD | Binary | 0, 1 | 0—No, 1—Yes |
| Inc1000—monthly income is less than EUR 1000 | Binary | 0, 1 | 0—No, 1—Yes |
| Inc2000—monthly income is more than EUR 2000 | Binary | 0, 1 | 0—No, 1—Yes |
| Birth_year—year of birth | Numerical, discrete | 1956–2004 |
| Model | Accuracy | Weighted Total Costs | |||
|---|---|---|---|---|---|
| Type | Sub-Type | Hyperparameters | Validation (%) | Test (%) | |
| Tree | Fine Tree | Max. Numb. of Splits: 100, Split Crit.: Gini’s Diversity Index | 59.29 | 60.00 | 71 |
| Medium Tree | Max. Numb. of Splits: 20, Split Crit.: Gini’s Diversity Index | 58.57 | 60.00 | 72 | |
| Coarse Tree | Max. Numb. of Splits: 4, Split Crit.: Gini’s Diversity Index | 67.86 | 71.43 | 55 | |
| Naïve Bayes | Gaussian Naïve Bayes | Distribution for Numeric/Categorical Predictors: Kernel/MVMN | 69.29 | 82.86 | 49 |
| Kernel Naïve Bayes | Distribution for Numeric/Categorical Predictors: Kernel/MVMN, Type: Gaussian, Support: Unbounded, Standardized Data | 72.14 | 71.43 | 49 | |
| Regression Analysis | Efficient Logistic Reg. | Learner: Logistic Regression, Regularization strength (Lambda): Auto, Beta Tolerance: 0.0001, Multiclass Coding: One-vs-One | 67.86 | 68.57 | 56 |
| Support Vector Machines (SVMs) | Linear SVM | Kernel Scale: Automatic, Box constraint level: 1, Multiclass Method: One-vs-One, Standardized Data | 70.00 | 77.14 | 50 |
| Quadratic SVM | Kernel scale: Automatic, Box constraint level: 1, Multiclass Method: One-vs-One, Standardized Data | 66.43 | 68.57 | 58 | |
| Cubic SVM | Kernel scale: Automatic, Box constraint level: 1, Multiclass Method: One-vs-One, Standardized Data | 65.00 | 74.29 | 58 | |
| Fine Gaussian SVM | Kernel function: Cubic, Kernel scale: 0.97, Box constraint level: 1, Multiclass Method: One-vs-One, Standardized Data | 47.86 | 48.57 | 91 | |
| Medium Gaussian SVM | Kernel scale: 3.9, Box constraint level: 1, Multiclass Method: One-vs-One, Standardized Data | 67.14 | 77.14 | 54 | |
| Coarse Gaussian SVM | Kernel scale: 15, Box constraint level: 1, Multiclass Method: One-vs-One, Standardized data | 65.00 | 71.43 | 59 | |
| Efficient Linear SVM | Learner: SVM, Regularization strength (Lambda): Auto, Beta Tolerance: 0.0001, Multiclass Coding: One-vs-One | 71.43 | 74.29 | 49 | |
| Ensemble Methods | Boosted Trees | Ensemble method: AdaBoost, Max. numb. of splits: 20, Numb. of learners: 30, Learning rate: 0.1 | 64.29 | 71.43 | 60 |
| Bagged Trees | Ensemble method: Bag, Max. numb. of splits: 139, Numb. of learners: 30 | 69.29 | 74.29 | 52 | |
| RUSBoosted Trees | Ensemble method: RUBoost, Max. numb. of splits: 20, Max. numb. of learners: 30, Learning rate: 0.1 | 65.71 | 77.14 | 56 | |
| Neural Networks | Narrow Neural Network | Numb. of full connected layers: 1, First layer size: 10, Activation: ReLU, Iteration limit: 1000, Regularization strength (Lambda): 0, Standardized data | 61.43 | 71.43 | 64 |
| Medium Neural Network | Numb. of full connected layers: 1, First layer size: 25, Activation: ReLU, Iteration limit: 1000, Regularization strength (Lambda): 0, Standardized data | 65.00 | 77.14 | 57 | |
| Wide Neural Network | Numb. of full connected layers: 1, First layer size: 100, Activation: ReLU, Iteration limit: 1000, Regularization strength (Lambda): 0, Standardized data | 66.43 | 62.86 | 60 | |
| Bilayered Neural Network | Numb. of full connected layers: 2, First layer size: 10, Second layer size: 10, Activation: ReLU, Iteration limit: 1000, Regularization strength (Lambda): 0, Standardized data | 67.14 | 74.29 | 55 | |
| Trilayered Neural Network | Numb. of full connected layers: 3, First layer size: 10, Second layer size: 10, Third layer size: 10, Activation: ReLU, Iteration limit: 1000, Regularization strength (Lambda): 0, Standardized data | 62.14 | 71.43 | 63 | |
| Kernel | SVM Kernel | Numb. Of expansion dimensions: Auto, Regularization strength (Lambda): Auto, Kernel scale: Auto, Multiclass method: One-vs-One, Iteration limit: 1000 | 66.43 | 74.29 | 56 |
| Logistic Regression Kernel | Numb. Of expansion dimensions: Auto, Regularization strength (Lambda): Auto, Kernel scale: Auto, Multiclass method: One-vs-One, Iteration limit: 1000 | 63.57 | 77.14 | 59 | |
| Kernel Naïve Bayes | Efficient Linear SVM | ||||||
| True/Predicted | 1 | 2 | 3 | 1 | 2 | 3 | |
| Validation Set | 1 | 76.7% | 33.3% | 9.4% | 72.5% | 16.7% | 13.2% |
| 2 | 18.3% | 48.1% | 11.3% | 20.3% | 55.6% | 11.3% | |
| 3 | 5% | 18.5% | 79.2% | 7.2% | 27.8% | 75.5% | |
| Test Set | 1 | 73.3% | 66.7% | 7.1% | 76.5% | 40% | 7.7% |
| 2 | 26.7% | 33.3% | 7.1% | 23.5% | 40% | 7.7% | |
| 3 | / | / | 85.7% | / | 20% | 84.6% | |
| Kernel Naïve Bayes | Efficient Linear SVM | ||||||
| Predicted Class | 1 | 2 | 3 | 1 | 2 | 3 | |
| Validation Set | PPV | 76.7% | 48.1% | 79.2% | 72.5% | 55.6% | 75.5% |
| FDR | 23.3% | 51.9% | 20.8% | 27.5% | 44.4% | 24.5% | |
| Test Set | PPV | 73.3% | 33.3% | 85.7% | 76.5% | 40% | 84.6% |
| FDR | 26.7% | 66.7% | 14.3% | 23.5% | 60% | 15.4% | |
| Kernel Naïve Bayes | Efficient Linear SVM | ||||||
|---|---|---|---|---|---|---|---|
| Predictor | Predictor Value | Class 1 | Class 2 | Class 3 | Class 1 | Class 2 | Class 3 |
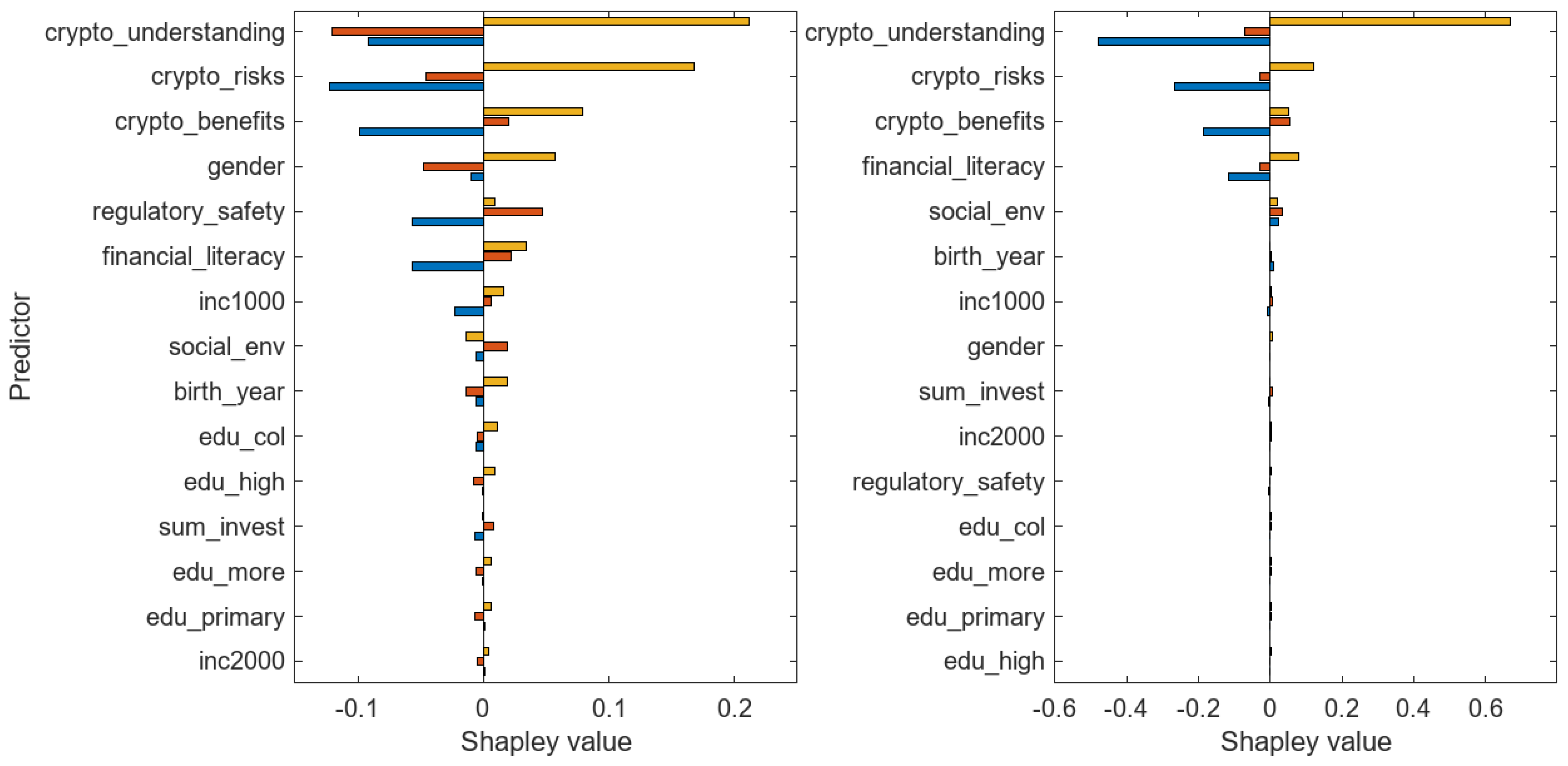
| crypto_understanding | 19 | −0.0914 | −0.1204 | 0.2117 | −0.4788 | −0.0701 | 0.6687 |
| crypto_risks | 12 | −0.1223 | −0.0454 | 0.1677 | −0.4788 | −0.0701 | 0.6687 |
| crypto_benefits | 15 | −0.0987 | 0.0198 | 0.0789 | −0.1876 | 0.0550 | 0.0494 |
| gender | 1 | −0.0096 | −0.0479 | 0.0574 | −0.0012 | −0.0030 | 0.0059 |
| financial_literacy | 15 | −0.0563 | 0.0221 | 0.0342 | −0.1178 | −0.0293 | 0.0795 |
| birth_year | 1999 | −0.0054 | −0.0137 | 0.0191 | 0.0105 | 0.0035 | −0.0029 |
| inc1000 | 1 | −0.0226 | 0.0063 | 0.0163 | −0.0069 | 0.0069 | 0.0014 |
| social_env | 10 | −0.0055 | 0.0193 | −0.0139 | 0.0241 | 0.0338 | 0.0184 |
| edu_col | 1 | −0.0060 | −0.0050 | 0.0110 | −0.0027 | 0.0009 | 0.0033 |
| regulatory_safety | 10 | −0.0568 | 0.0473 | 0.0095 | −0.0036 | −0.0002 | 0.0035 |
| edu_high | 0 | −0.0010 | −0.0079 | 0.0089 | −0.0006 | 0.0004 | 0.0029 |
| edu_more | 0 | −0.0010 | −0.0056 | 0.0066 | −0.0020 | 0.0021 | 0.0024 |
| edu_primary | 0 | 0.0007 | −0.0064 | 0.0057 | −0.0012 | 0.0017 | 0.0023 |
| inc2000 | 0 | 0.0006 | −0.0046 | 0.0039 | −0.0024 | 0.0030 | 0.0021 |
| sum_invest | 0 | −0.0070 | 0.0081 | −0.0011 | −0.0040 | 0.0050 | 0.0003 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jagrič, T.; Luetić, D.; Mumel, D.; Herman, A. Detecting Potential Investors in Crypto Assets: Insights from Machine Learning Models and Explainable AI. Information 2025, 16, 269. https://doi.org/10.3390/info16040269
Jagrič T, Luetić D, Mumel D, Herman A. Detecting Potential Investors in Crypto Assets: Insights from Machine Learning Models and Explainable AI. Information. 2025; 16(4):269. https://doi.org/10.3390/info16040269
Chicago/Turabian StyleJagrič, Timotej, Davor Luetić, Damijan Mumel, and Aljaž Herman. 2025. "Detecting Potential Investors in Crypto Assets: Insights from Machine Learning Models and Explainable AI" Information 16, no. 4: 269. https://doi.org/10.3390/info16040269
APA StyleJagrič, T., Luetić, D., Mumel, D., & Herman, A. (2025). Detecting Potential Investors in Crypto Assets: Insights from Machine Learning Models and Explainable AI. Information, 16(4), 269. https://doi.org/10.3390/info16040269