

Center-Guided Network with Dynamic Attention for Transmission Tower Detection


Abstract
:1. Introduction
- We design a novel center-guided network that focuses on TT detection in aerial images.
- We introduce a two-stage detection head with SIoU loss, which improves the quality of bounding boxes.
- The experimental results on a public dataset demonstrate that the proposed CGDA performs well in detecting TTs.
2. Related Works
2.1. Object Detection Based Deep Learning
2.2. Transmission Tower Detection
3. Methods
3.1. Overall Framework
3.2. Dynamic Attention
3.3. Two-Stage Detection Head
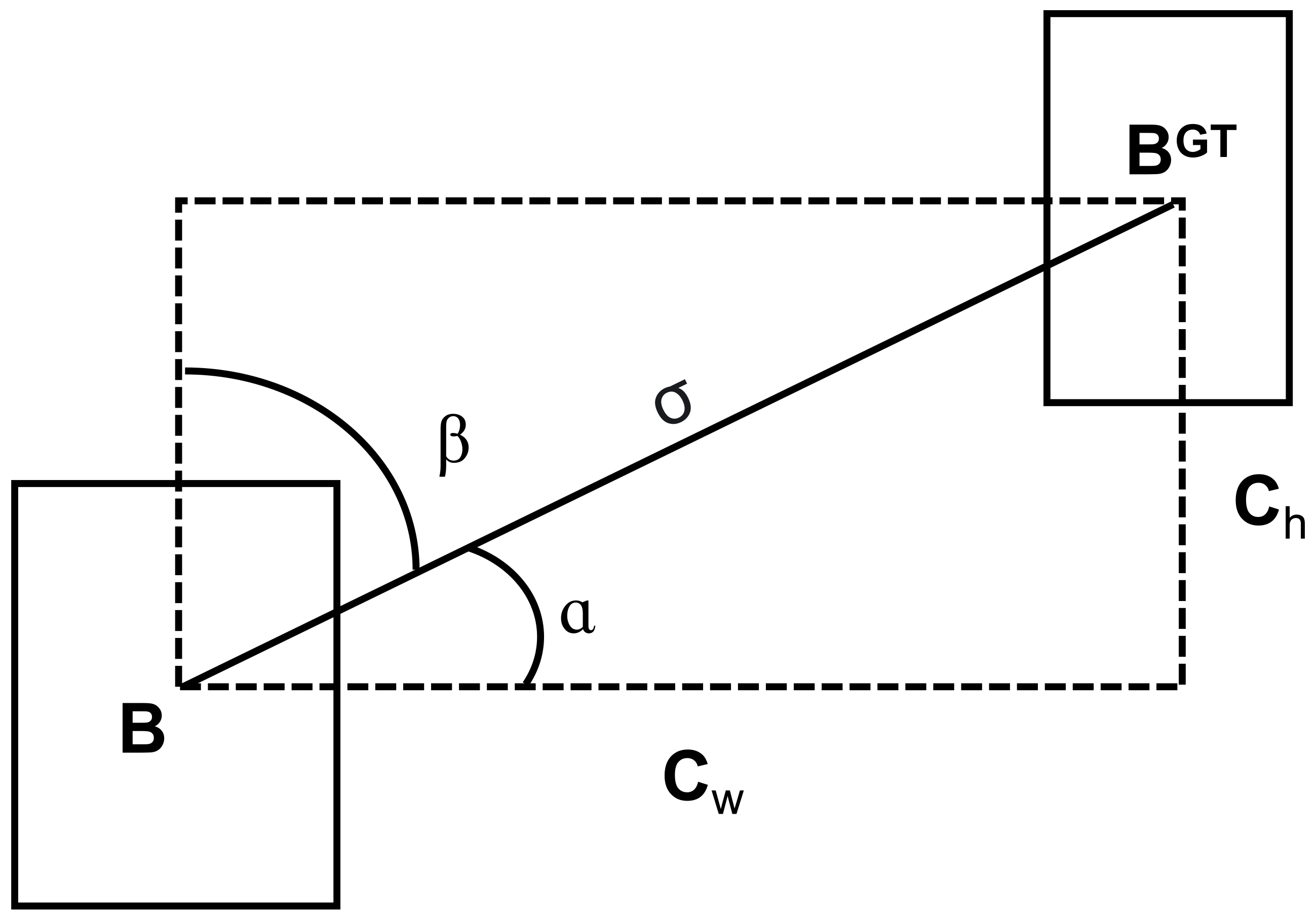
3.4. Loss Function
4. Results and Discussion
4.1. Dataset and Evaluation Protocol
4.2. Implementation Details
4.3. Experimental Results
4.4. Ablation Study
4.5. Failure Case Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hosseini, M.M.; Umunnakwe, A.; Parvania, M.; Tasdizen, T. Intelligent Damage Classification and Estimation in Power Distribution Poles Using Unmanned Aerial Vehicles and Convolutional Neural Networks. IEEE Trans. Smart Grid 2020, 11, 3325–3333. [Google Scholar] [CrossRef]
- Lim, G.J.; Kim, S.; Cho, J.; Gong, Y.; Khodaei, A. Multi-UAV Pre-Positioning and Routing for Power Network Damage Assessment. IEEE Trans. Smart Grid 2016, 9, 3643–3651. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, Z.; Wang, Y. Bidirection-Fusion-YOLOv3: An Improved Method for Insulator Defect Detection Using UAV Image. IEEE Trans. Instrum. Meas. 2022, 71, 3521408. [Google Scholar] [CrossRef]
- Chen, C.; Yang, B.; Song, S.; Peng, X.; Huang, R. Automatic Clearance Anomaly Detection for Transmission Line Corridors Utilizing UAV-Borne LIDAR Data. Remote Sens. 2018, 10, 613. [Google Scholar] [CrossRef]
- Zhuo, X.; Koch, T.; Kurz, F.; Fraundorfer, F.; Reinartz, P. Automatic UAV Image Geo-Registration by Matching UAV Images to Georeferenced Image Data. Remote Sens. 2017, 9, 376. [Google Scholar] [CrossRef]
- Tilawat, J.; Theera-Umpon, N.; Auephanwiriyakul, S. Automatic Detection of Electricity Pylons in Aerial Video Sequences. In Proceedings of the 2010 International Conference on Electronics and Information Engineering, Kyoto, Japan, 1–3 August 2010; Volume 1, pp. V1-342–V1-346. [Google Scholar]
- Qiao, S.; Sun, Y.; Zhang, H. Deep Learning Based Electric Pylon Detection in Remote Sensing Images. Remote Sens. 2020, 12, 1857. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Manninen, H.; Ramlal, C.J.; Singh, A.; Kilter, J.; Landsberg, M. Multi-Stage Deep Learning Networks for Automated Assessment of Electricity Transmission Infrastructure Using Fly-by Images. Electr. Power Syst. Res. 2022, 209, 107948. [Google Scholar] [CrossRef]
- Peterlevitz, A.J.; Chinelatto, M.A.; Menezes, A.G.; Motta, C.A.M.; Pereira, G.A.B.; Lopes, G.L.; Souza, G.D.M.; Rodrigues, J.; Godoy, L.C.; Koller, M.A.F.F.; et al. Sim-to-Real Transfer for Object Detection in Aerial Inspections of Transmission Towers. IEEE Access Pract. Innov. Open Solut. 2023, 11, 110312–110327. [Google Scholar] [CrossRef]
- Zhu, G.; Zhang, W.; Wang, M.; Wang, J.; Fang, X. Corner Guided Instance Segmentation Network for Power Lines and Transmission Towers Detection. Expert Syst. Appl. 2023, 234, 121087. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Liu, C.; Hogan, A.; Chaurasia, A.; Diaconu, L.; Ingham, F.; Colmagro, A.; Ye, H.; et al. Ultralytics/Yolov5: V4. 0-Nn. SiLU () Activations, Weights & Biases Logging, PyTorch Hub Integration. Zenodo. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 16 April 2025).
- Aboah, A.; Wang, B.; Bagci, U.; Adu-Gyamfi, Y. Real-Time Multi-Class Helmet Violation Detection Using Few-Shot Data Sampling Technique and Yolov8. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5350–5358. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Jocher, G.; Qiu, J. Ultralytics YOLO11. 2024. Available online: https://www.ultralytics.com/ (accessed on 16 April 2025).
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. Centripetalnet: Pursuing High-Quality Keypoint Pairs for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10519–10528. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Sampedro, C.; Martinez, C.; Chauhan, A.; Campoy, P. A Supervised Approach to Electric Tower Detection and Classification for Power Line Inspection. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 1970–1977. [Google Scholar]
- Tian, G.; Meng, S.; Bai, X.; Zhi, Y.; Ou, W.; Fei, X.; Tan, Y. Electric Tower Target Identification Based on High-Resolution SAR Image and Deep Learning. J. Phys. Conf. Ser. 2020, 1453, 012117. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads With Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7373–7382. [Google Scholar]
- Gevorgyan, Z. SIoU Loss: More Powerful Learning for Bounding Box Regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Abdelfattah, R.; Wang, X.; Wang, S. TTPLA: An Aerial-Image Dataset for Detection and Segmentation of Transmission Towers and Power Lines. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open Mmlab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Tower-Lattice | Tower-Tucohy | Tower-Wooden |
|---|---|---|---|
| Faster RCNN [8] | 59.4 | 54.5 | 24.1 |
| FCOS [18] | 62.8 | 60.8 | 31.9 |
| ATTS [28] | 59.5 | 56.9 | 28.9 |
| YOLOx [17] | 40.0 | 32.5 | 10.9 |
| YOLOv5 [22] | 33.1 | 23.7 | 5.5 |
| YOLOv6 [24] | 52.9 | 47.9 | 24.2 |
| YOLOv8 [23] | 62.0 | 55.2 | 28.9 |
| YOLOv11 [25] | 67.2 | 64.1 | 28.5 |
| YOLOv12 [26] | 64.6 | 63.7 | 30.0 |
| CenterNet [12] | 57.3 | 51.7 | 28.5 |
| CenterNet (Swin) [29] | 64.3 | 57.3 | 31.2 |
| CornerNet [19] | 48.8 | 43.9 | 15.7 |
| RTMDet [42] | 58.3 | 55.1 | 29.3 |
| CentripetalNet [27] | 56.1 | 47.8 | 20.2 |
| CGDA (ours) | 65.5 | 62.9 | 39.0 |
| Method | APavg | AP50% | AP75% | P | R | F1-Score |
|---|---|---|---|---|---|---|
| Faster RCNN [8] | 46.0 | 66.2 | 50.6 | 68.8 | 64.4 | 66.5 |
| FCOS [18] | 51.8 | 71.1 | 51.1 | 75.8 | 62.4 | 68.5 |
| ATTS [28] | 48.4 | 68.6 | 52.8 | 68.7 | 67.8 | 68.3 |
| YOLOx [17] | 27.8 | 53.5 | 26.3 | 63.7 | 52.3 | 57.4 |
| YOLOv5 [22] | 20.7 | 39.5 | 19.3 | 74.6 | 29.6 | 42.4 |
| YOLOv6 [24] | 41.7 | 62.3 | 44.9 | 68.6 | 63.7 | 66.1 |
| YOLOv8 [23] | 48.7 | 67.0 | 53.2 | 74.2 | 66.0 | 69.8 |
| YOLOv11 [25] | 53.3 | 70.2 | 57.1 | 72.7 | 67.5 | 70.0 |
| YOLOv12 [26] | 52.8 | 69.4 | 58.2 | 75.1 | 65.6 | 70.0 |
| CenterNet [12] | 45.9 | 69.0 | 49.7 | 65.9 | 60.4 | 63.0 |
| CenterNet (Swin) [29] | 51.0 | 70.2 | 56.8 | 71.2 | 70.3 | 70.7 |
| CornerNet [19] | 36.2 | 43.9 | 36.2 | 40.2 | 47.1 | 43.4 |
| RTMDet [42] | 47.6 | 69.8 | 52.4 | 67.3 | 62.0 | 49.4 |
| CentripetalNet [27] | 41.4 | 52.1 | 42.3 | 71.5 | 43.8 | 54.3 |
| CGDA (ours) | 55.8 | 72.9 | 58.4 | 69.3 | 74.2 | 71.7 |
| Method | Training Time (h) | Params (M) | Inference Time (ms) |
|---|---|---|---|
| Faster RCNN [8] | 3.4 | 41.4 | 45.7 |
| FCOS [18] | 2.6 | 32.1 | 51.0 |
| ATTS [28] | 2.5 | 32.1 | 50.9 |
| YOLOx [17] | 1.8 | 8.9 | 11.9 |
| YOLOv5 [22] | 1.2 | 7.0 | 8.6 |
| YOLOv6 [24] | 2.0 | 18.5 | 24.7 |
| YOLOv8 [23] | 1.6 | 11.1 | 9.7 |
| YOLOv11 [25] | 1.4 | 9.4 | 9.9 |
| YOLOv12 [26] | 2.4 | 9.3 | 12.4 |
| CenterNet [12] | 1.9 | 29.2 | 30.4 |
| CenterNet (Swin) [29] | 2.5 | 35.6 | 59.2 |
| CornerNet [19] | 11.7 | 201 | 232.6 |
| RTMDet [42] | 1.2 | 8.9 | 20.8 |
| CentripetalNet [27] | 14.7 | 206 | 285.7 |
| CGDA (ours) | 3.6 | 34.1 | 48.1 |
| Method | 1st APavg | 2nd APavg | 3rd APavg | Mean Value | t-Value | p-Value |
|---|---|---|---|---|---|---|
| CenterNet | 45.92 | 45.26 | 46.66 | 45.94 | −36.83 | 7.37 × 10−4 |
| CGDA | 55.41 | 55.63 | 56.34 | 55.79 |
| Loss Type | APavg | AP50% | AP75% |
|---|---|---|---|
| IoU | 48.1 | 69.1 | 51.8 |
| GIoU | 52.6 | 75.3 | 55.3 |
| DIoU | 53.1 | 72.0 | 56.3 |
| CIoU | 52.7 | 74.1 | 58.1 |
| EIoU | 52.5 | 71.5 | 56.3 |
| SIoU | 53.9 | 71.3 | 59.3 |
| APavg | AP50% | AP75% | |
|---|---|---|---|
| 1 | 54.7 | 72.5 | 60.4 |
| 2 | 53.7 | 72.2 | 56.8 |
| 4 | 53.2 | 70.7 | 57.2 |
| 6 | 55.8 | 72.9 | 58.4 |
| 8 | 55.3 | 73.4 | 56.9 |
| 10 | 54.6 | 71.3 | 59.8 |
| Two-Stage Detection Head | Dynamic Attention | SIoU Loss | APavg | AP50% | AP75% |
|---|---|---|---|---|---|
| 45.9 | 59.0 | 49.7 | |||
| ✓ | 48.1 | 69.1 | 51.8 | ||
| ✓ | 49.2 | 65.0 | 52.2 | ||
| ✓ | ✓ | 53.9 | 71.3 | 59.3 | |
| ✓ | ✓ | 52.3 | 72.5 | 56.8 | |
| ✓ | ✓ | ✓ | 55.8 | 72.9 | 58.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Liang, Z.; Yang, J.; Lyu, C.; Xu, Y. Center-Guided Network with Dynamic Attention for Transmission Tower Detection. Information 2025, 16, 331. https://doi.org/10.3390/info16040331
Li X, Liang Z, Yang J, Lyu C, Xu Y. Center-Guided Network with Dynamic Attention for Transmission Tower Detection. Information. 2025; 16(4):331. https://doi.org/10.3390/info16040331
Chicago/Turabian StyleLi, Xiaobin, Zhuwei Liang, Jingbin Yang, Chuanlong Lyu, and Yuge Xu. 2025. "Center-Guided Network with Dynamic Attention for Transmission Tower Detection" Information 16, no. 4: 331. https://doi.org/10.3390/info16040331
APA StyleLi, X., Liang, Z., Yang, J., Lyu, C., & Xu, Y. (2025). Center-Guided Network with Dynamic Attention for Transmission Tower Detection. Information, 16(4), 331. https://doi.org/10.3390/info16040331