
Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs



Abstract
:1. Introduction
2. Related Work
3. POI Recommendation with Weighted Ranking Criterion
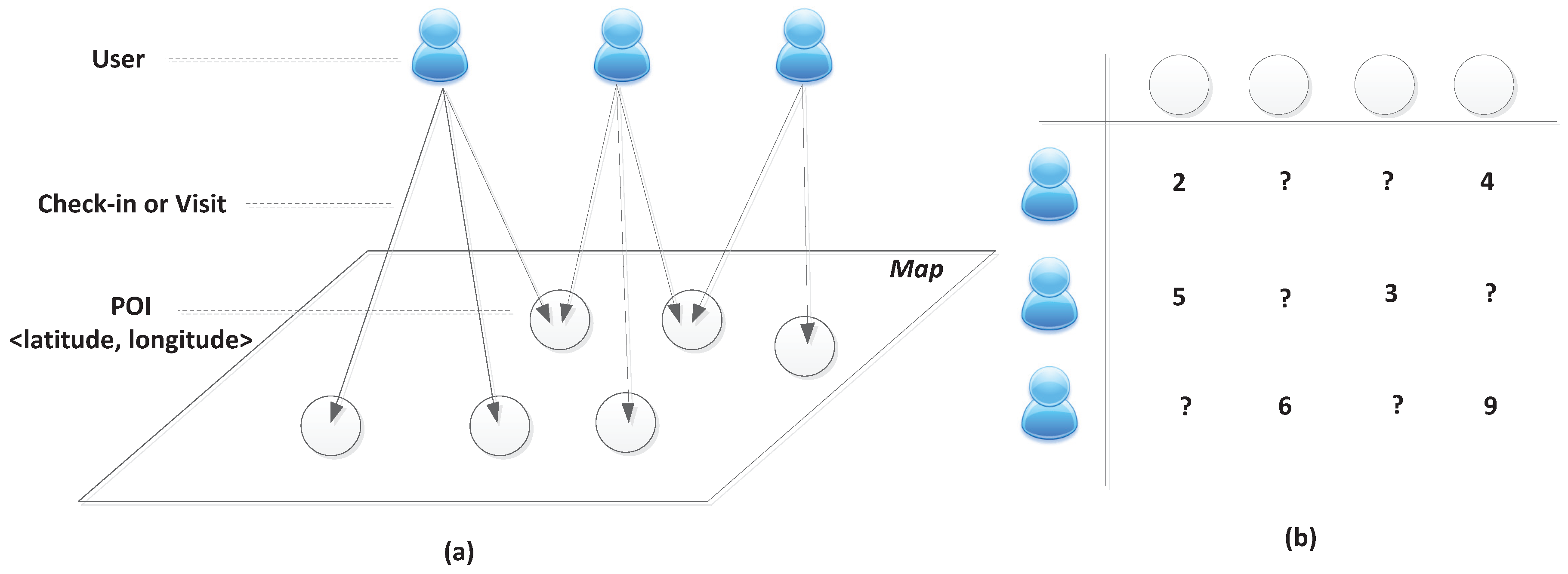
3.1. Problem Description
3.2. Bayesian Personalized Ranking Criterion
3.3. Frequency-Based Weighted Ranking Criterion
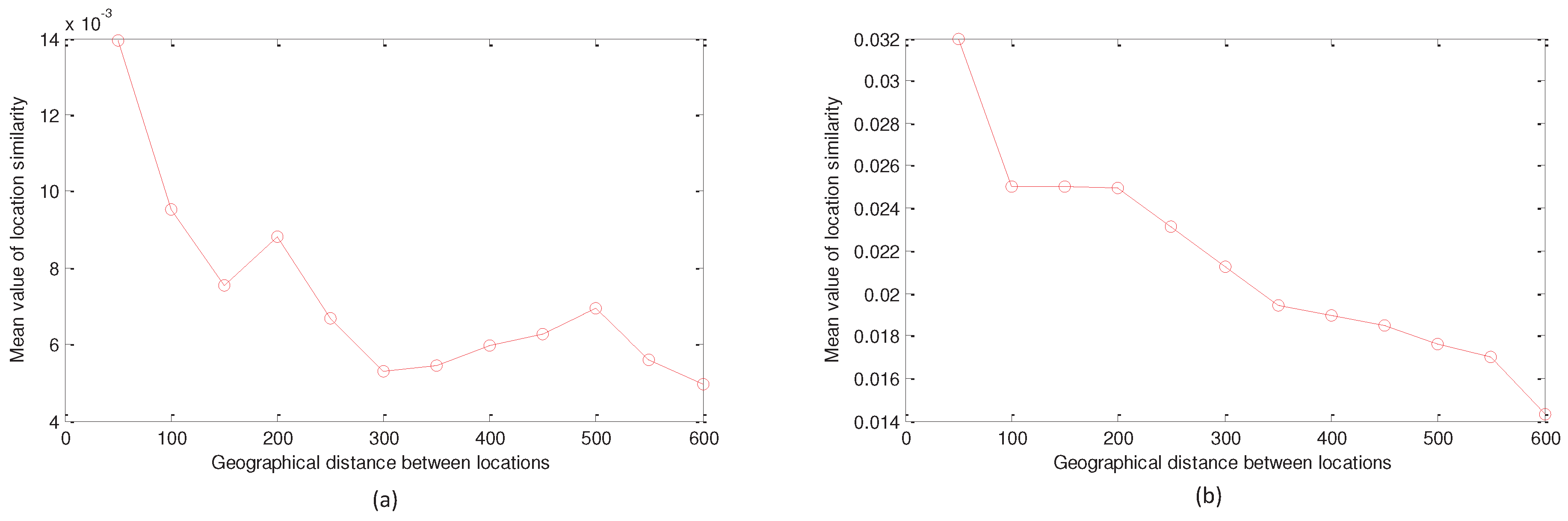
3.4. Geographically-Based Weighted Ranking Criterion
3.5. Fused Weighted Ranking Criterion
| Algorithm 1: Learning procedure of WBPR-FD. | |
| 1 | Input: |
| 2 | The check-in frequency matrix R, weight factors w and d, parameter α |
| learning rate η, regularization parameter and | |
| 3 | Output: |
| 4 | U, V |
| 5 | initialize U and V |
| 6 | repeat |
| 7 | draw from |
| 8 | |
| 9 | Update , the u-th row of U according to Equation (9); |
| 10 | Update , the i-th row of V according to Equation (10); |
| 11 | Update , the j-th row of V according to Equation (11); |
| 12 | Compute the objective function WBPR-FD(t) in step t according to Equation (8); |
| 13 | until WBPR-FD(t)-WBPR-FD() (tolerate error); |
| 14 | return U and V; |
3.6. Complexity Analysis
4. Data Analysis and Experiments
4.1. Datasets
4.2. Empirical Data Analysis
4.3. Evaluation Metrics
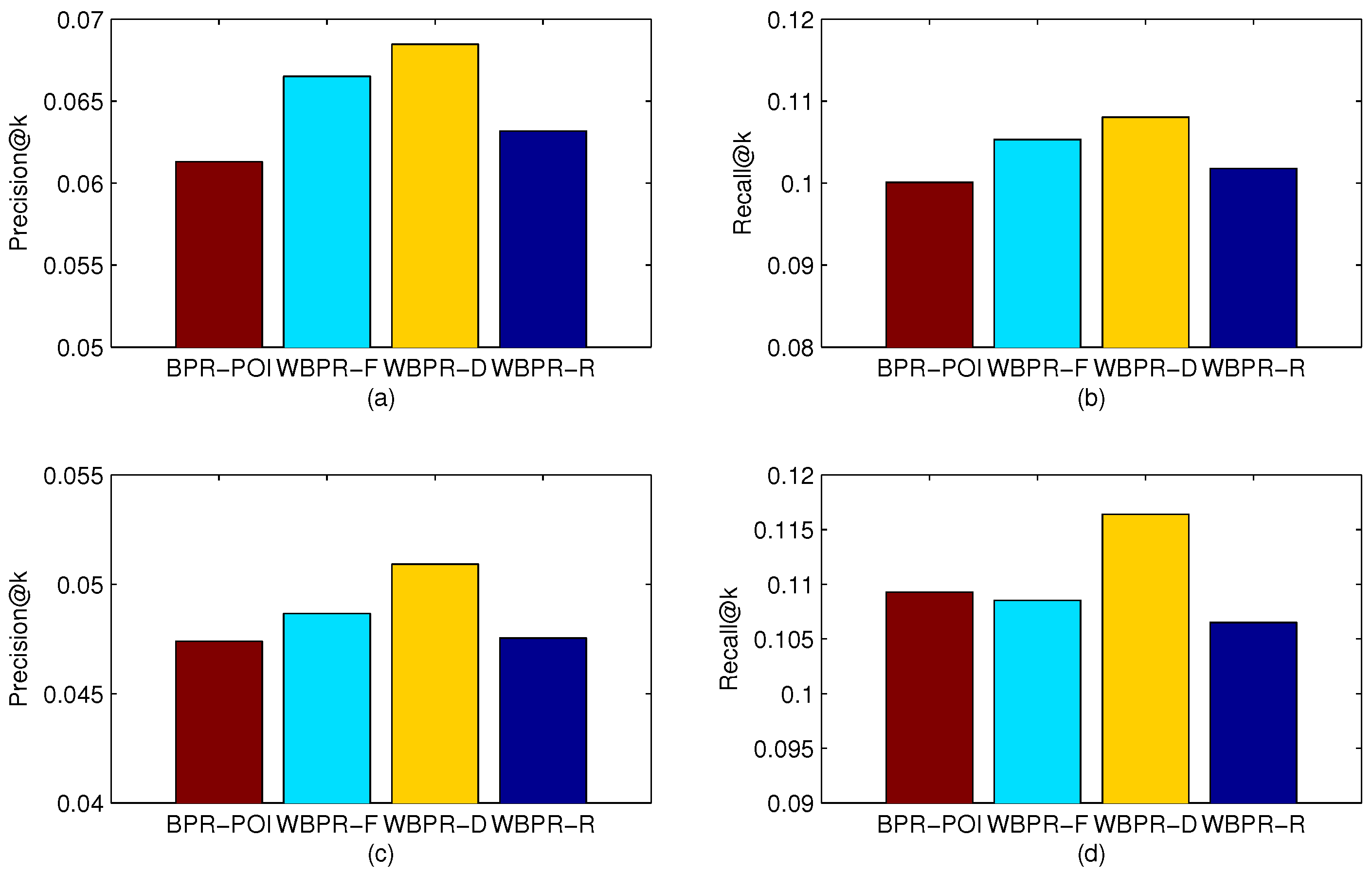
4.4. Performance Comparison
4.5. Impact of Parameters
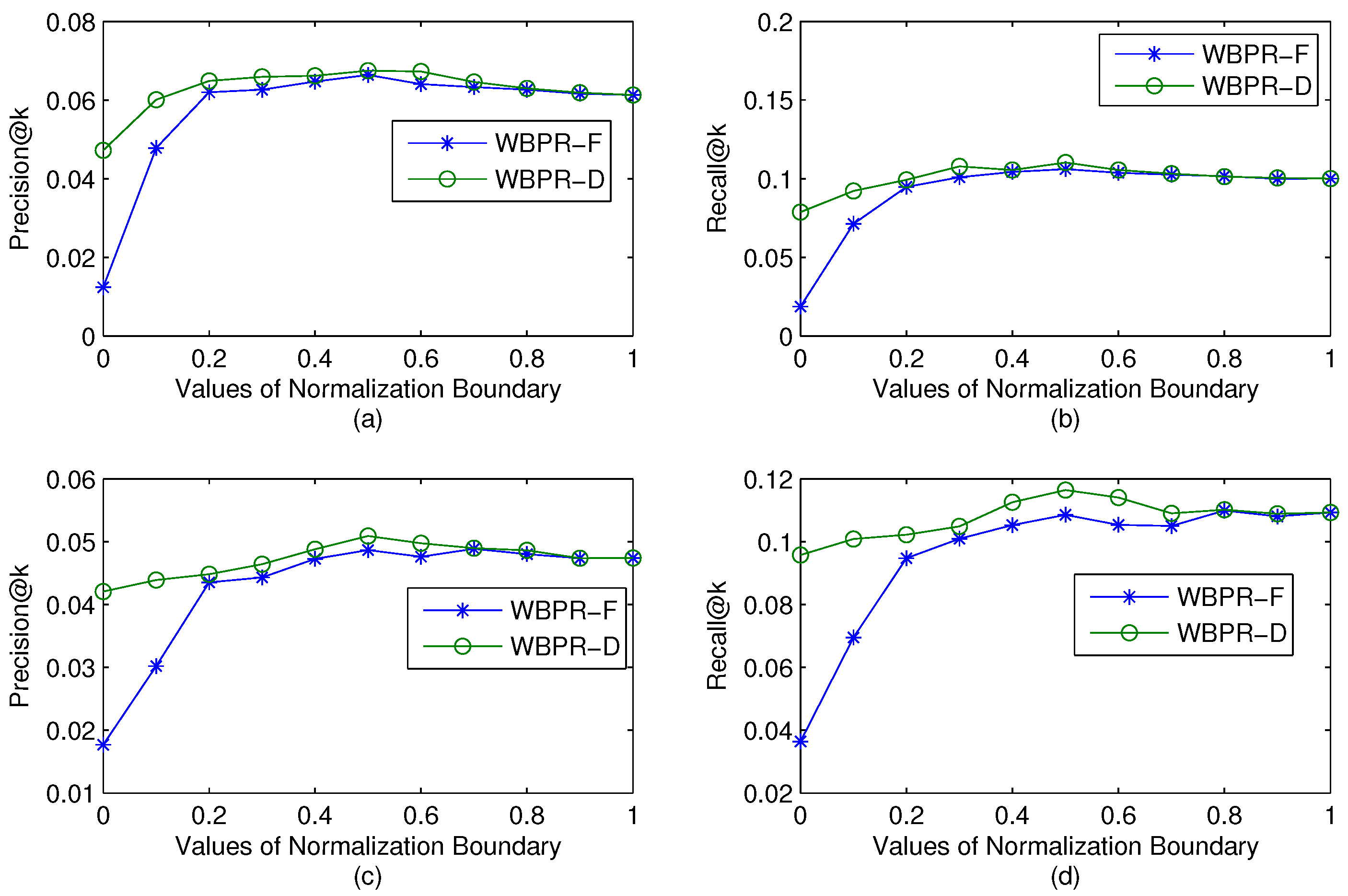
4.5.1. Impact of the Normalization Boundary of the Weight Factors
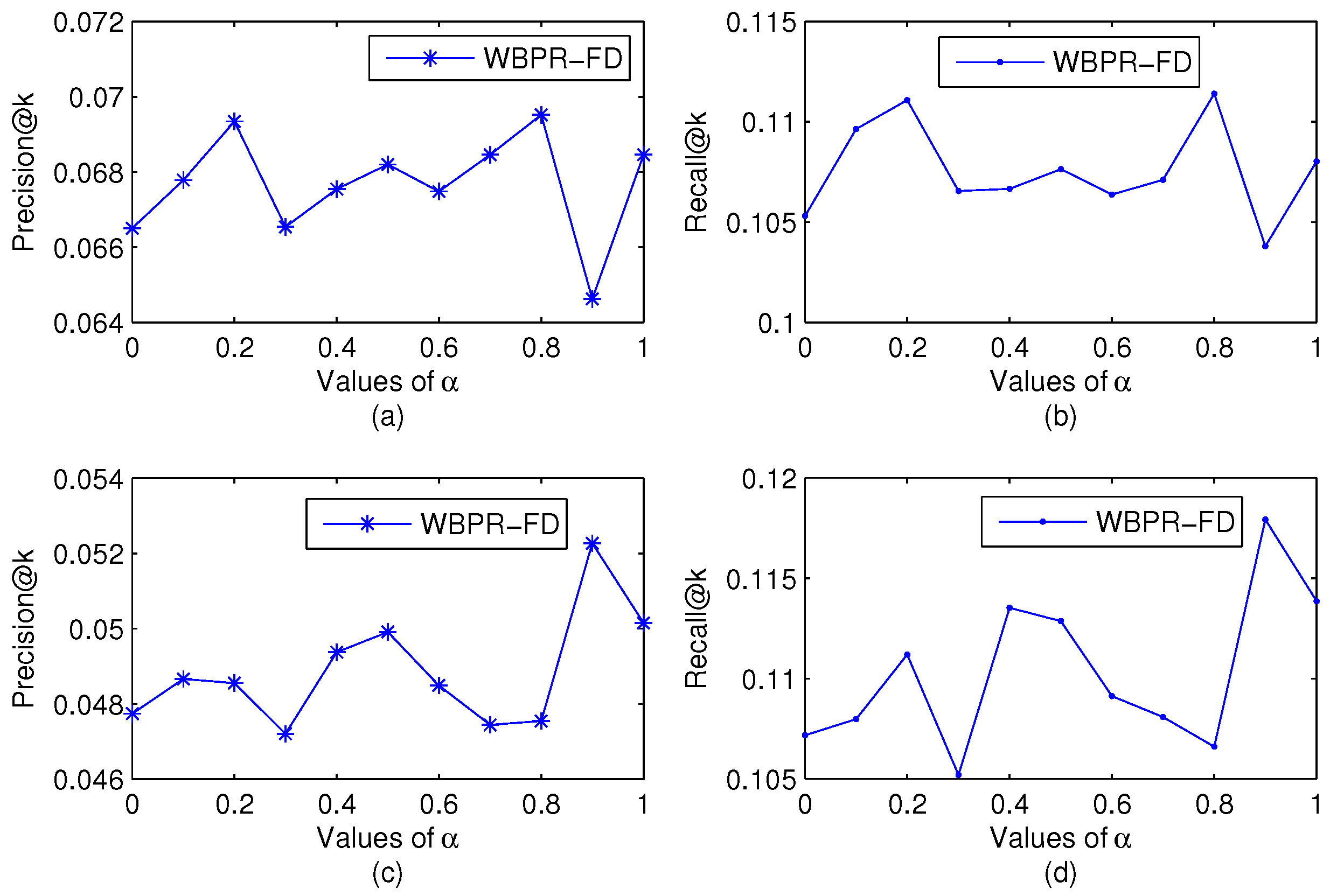
4.5.2. Impact of Parameter α
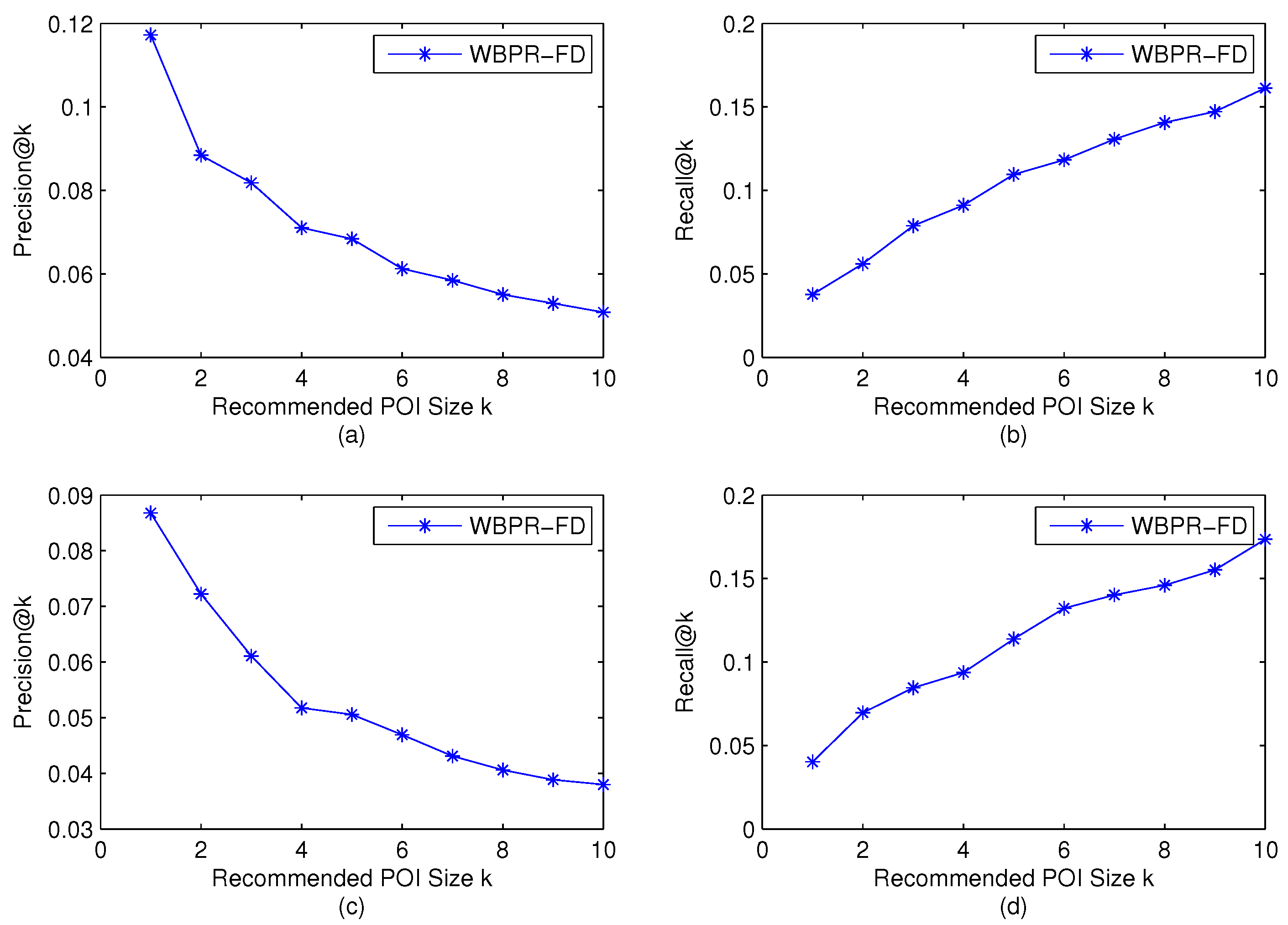
4.6. Impact of Recommended POI Sizes
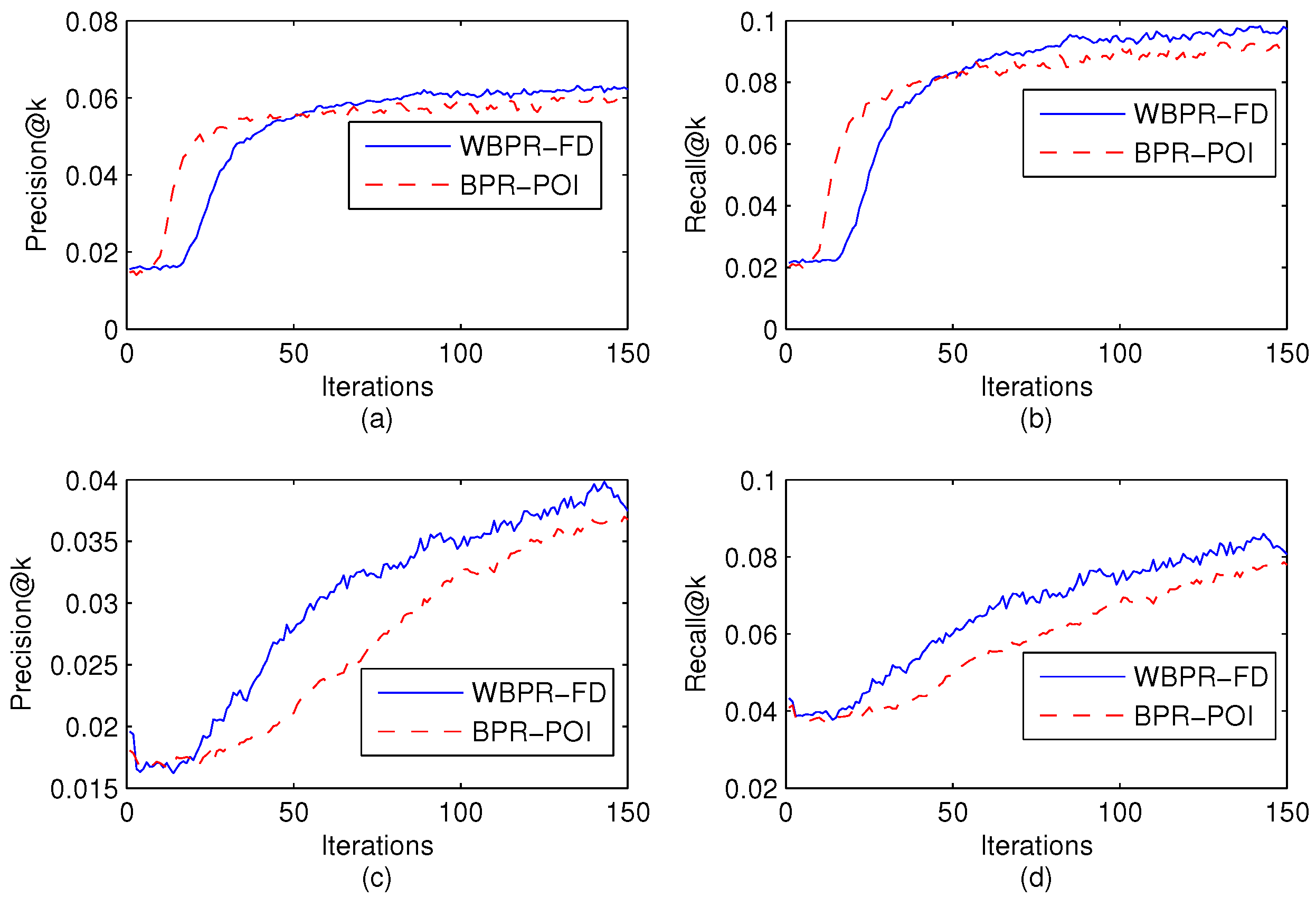
4.7. Convergence Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 831–840.
- Li, X.; Cong, G.; Li, X.L.; Pham, T.A.N.; Krishnaswamy, S. Rank-GeoFM: A ranking based geographical factorization method for point of interest recommendation. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 433–442.
- Ying, H.; Chen, L.; Xiong, Y.; Wu, J. PGRank: Personalized Geographical Ranking for Point-of-Interest Recommendation. In Proceedings of the 25th International Conference Companion on World Wide Web. International World Wide Web Conferences Steering Committee, Montreal, QC, Canada, 11–15 April 2016; pp. 137–138.
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 325–334.
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. Fused Matrix Factorization with Geographical and Social Influence in Location-Based Social Networks. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 12, pp. 17–23.
- Zhang, J.D.; Chow, C.Y. iGSLR: personalized geo-social location recommendation: A kernel density estimation approach. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013; pp. 334–343.
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning geographical preferences for point-of-interest recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051.
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461.
- Zheng, V.W.; Zheng, Y.; Xie, X.; Yang, Q. Towards mobile intelligence: Learning from GPS history data for collaborative recommendation. Artif. Intell. 2012, 184, 17–37. [Google Scholar] [CrossRef]
- Cho, S.B. Exploiting machine learning techniques for location recognition and prediction with smartphone logs. Neurocomputing 2016, 176, 98–106. [Google Scholar] [CrossRef]
- Yin, H.; Cui, B.; Chen, L.; Hu, Z.; Zhang, C. Modeling location-based user rating profiles for personalized recommendation. ACM Trans. Knowl. Discov. Data 2015, 9, 19. [Google Scholar] [CrossRef]
- Gao, H.; Tang, J.; Liu, H. Personalized location recommendation on location-based social networks. In Proceedings of the 8th ACM Conference on Recommender Systems, Silicon Valley, CA, USA, 6–10 October 2014; pp. 399–400.
- Yin, H.; Cui, B.; Huang, Z.; Wang, W.; Wu, X.; Zhou, X. Joint modeling of users’ interests and mobility patterns for point-of-interest recommendation. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 819–822.
- Cheng, C.; Yang, H.; King, I.; Lyu, M.R. A Unified Point-of-Interest Recommendation Framework in Location-Based Social Networks. ACM Trans. Intell. Syst. Technol. 2016, 8, 10. [Google Scholar] [CrossRef]
- Zhao, S.; Zhao, T.; Yang, H.; Lyu, M.R.; King, I. STELLAR: Spatial-Temporal Latent Ranking for Successive Point-of-Interest Recommendation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016.
- Ye, M.; Yin, P.; Lee, W.C. Location recommendation for location-based social networks. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 458–461.
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 363–372.
- Zhang, J.D.; Chow, C.Y.; Li, Y. iGeoRec: A personalized and efficient geographical location recommendation framework. IEEE Trans. Serv. Comput. 2015, 8, 701–714. [Google Scholar] [CrossRef]
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Content-Aware Point of Interest Recommendation on Location-Based Social Networks. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 1721–1727.
- Griesner, J.B.; Abdessalem, T.; Naacke, H. POI Recommendation: Towards Fused Matrix Factorization with Geographical and Temporal Influences. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 301–304.
- Gao, H.; Tang, J.; Hu, X.; Liu, H. Exploring temporal effects for location recommendation on location-based social networks. In Proceedings of the 7th ACM conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 93–100.
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940.
- Karatzoglou, A.; Baltrunas, L.; Shi, Y. Learning to rank for recommender systems. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 493–494.
- Normalization (statistics). Available online: https://en.wikipedia.org/wiki/Normalization_(statistics) (accessed on 4 February 2017).
- Haversine formula. Available online: https://en.wikipedia.org/wiki/Haversine_formula (accessed on 4 February 2017).
- Gowalla. Available online: https://snap.stanford.edu/data/loc-gowalla.html (accessed on 4 February 2017).
- Brightkite. Available online: https://snap.stanford.edu/data/loc-brightkite.html (accessed on 4 February 2017).
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090.
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 43–52.
- Weimer, M.; Karatzoglou, A.; Le, Q.V.; Smola, A. Maximum margin matrix factorization for collaborative ranking. Available online: http://www.markusweimer.com/files/pub/2007/2007-NIPS.pdf (accessed on 4 February 2017).
- Guo, L.; Ma, J.; Chen, Z.; Zhong, H. Learning to recommend with social contextual information from implicit feedback. Soft Comput. 2015, 19, 1351–1362. [Google Scholar] [CrossRef]
- Pan, R.; Zhou, Y.; Cao, B.; Liu, N.N.; Lukose, R.; Scholz, M.; Yang, Q. One-class collaborative filtering. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 502–511.
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Gowalla | Brightkite |
|---|---|---|
| number of users | 32,134 | 11,142 |
| number of POIs | 8867 | 4369 |
| number of check-ins | 575,323 | 100,069 |
| Min. number of POIs per user | 5 | 3 |
| Min. number of check-ins per POI | 1 | 1 |
| Check-in sparsity | 99.838 | 99.833 |
| Metric | Dataset | Random | MostPopular | WRMF | GeoMF | BPR-POI | WBPR-F | WBPR-D | WBPR-FD |
|---|---|---|---|---|---|---|---|---|---|
| Gowalla | 0.00046 | 0.01562 | 0.0500 | 0.0602 | 0.0613 | 0.0665 | 0.06846 | 0.06952 | |
| Brightkite | 0.00058 | 0.01811 | 0.04828 | 0.04987 | 0.04739 | 0.04866 | 0.05091 | 0.05227 | |
| Gowalla | 0.00055 | 0.02236 | 0.0667 | 0.1004 | 0.1001 | 0.10531 | 0.10803 | 0.11140 | |
| Brightkite | 0.00104 | 0.04146 | 0.10484 | 0.10943 | 0.10929 | 0.10852 | 0.1164 | 0.11794 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, L.; Jiang, H.; Wang, X.; Liu, F. Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs. Information 2017, 8, 20. https://doi.org/10.3390/info8010020
Guo L, Jiang H, Wang X, Liu F. Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs. Information. 2017; 8(1):20. https://doi.org/10.3390/info8010020
Chicago/Turabian StyleGuo, Lei, Haoran Jiang, Xinhua Wang, and Fangai Liu. 2017. "Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs" Information 8, no. 1: 20. https://doi.org/10.3390/info8010020
APA StyleGuo, L., Jiang, H., Wang, X., & Liu, F. (2017). Learning to Recommend Point-of-Interest with the Weighted Bayesian Personalized Ranking Method in LBSNs. Information, 8(1), 20. https://doi.org/10.3390/info8010020