
A Two-Stage Joint Model for Domain-Specific Entity Detection and Linking Leveraging an Unlabeled Corpus

Abstract
:1. Introduction
- (1)
- The textual context is not well utilized. In the pipeline architecture, textual context is used in entity detection models to determine mention boundaries and infer mention types. However, the labeled data are often insufficient to train such entity detection models in specific domains, so the bag of words representation, which neglects the syntax and word orders, is adopted in some joint models [7,9,10].
- (2)
- The existing evaluation methods of entity coherence are not applicable for DSEDL. In general EDL tasks [11,12,13,14], semantic relatedness between entities is estimated relying on the massive hyperlinks in Wikipedia. However, this does not perform well in DSEDL because associations between entities are sparse in many DSKBs.
- (3)
- Generally, only entity coherence within the input document is considered. Nevertheless, co-occurring entities can be very few in short input texts, and in this case, the inner-document coherence is not discriminative.
- (1)
- A two-stage joint (TSJ) model is proposed for the DSEDL task, shedding light on the problems of data imbalance and computational complexity.
- (2)
- Several critical features are generated effectively by leveraging the unlabeled domain corpus. Specifically:
- (a)
- An LSTM-based [15] model is proposed to infer types of mentions, by exploiting the textual context. More importantly, a novel method is presented to automatically annotate training data for this model.
- (b)
- A corpus-based topical coherence measurement is given. To be specific, a pre-trained EDL model is used to tag the unlabeled data, then topical coherence is evaluated based on entity co-occurring relationships in the pseudo-labeled corpus.
- (c)
- The cross-document entity coherence is explored to solve the entity sparsity problem in short texts. Documents used here are selected from the pseudo-labeled corpus by a retrieval-based method.
2. Related Work
2.1. Pipeline Architecture for Entity Detection and Linking
2.2. Joint Models for Entity Detection and Linking
2.3. Feature Representation
3. Method
3.1. Two Stage Joint Model
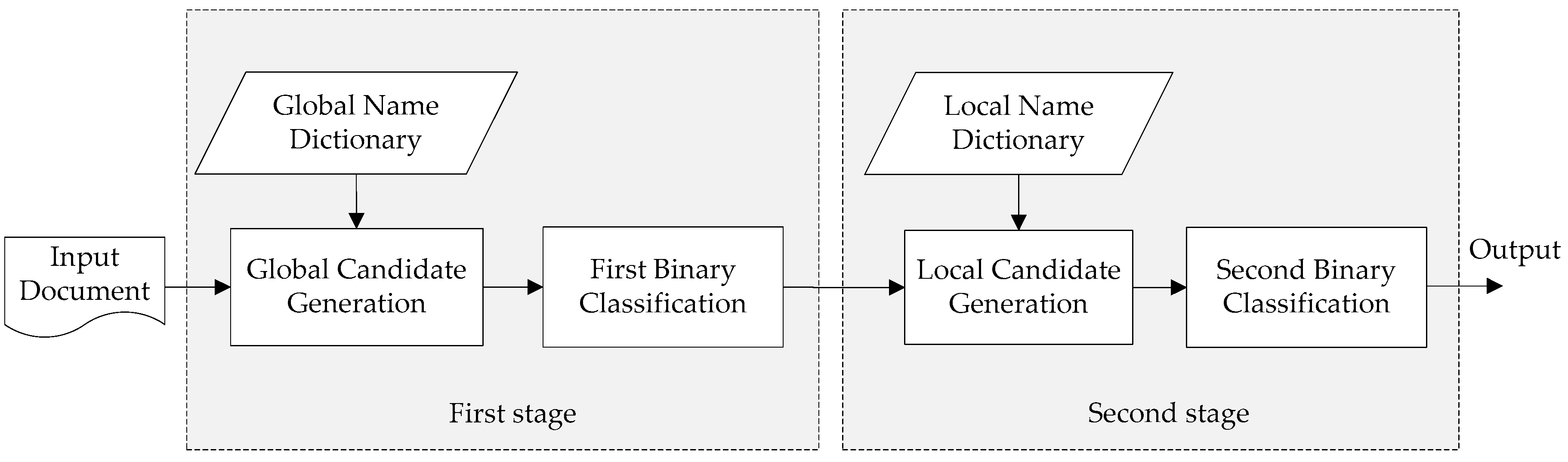
3.1.1. Framework
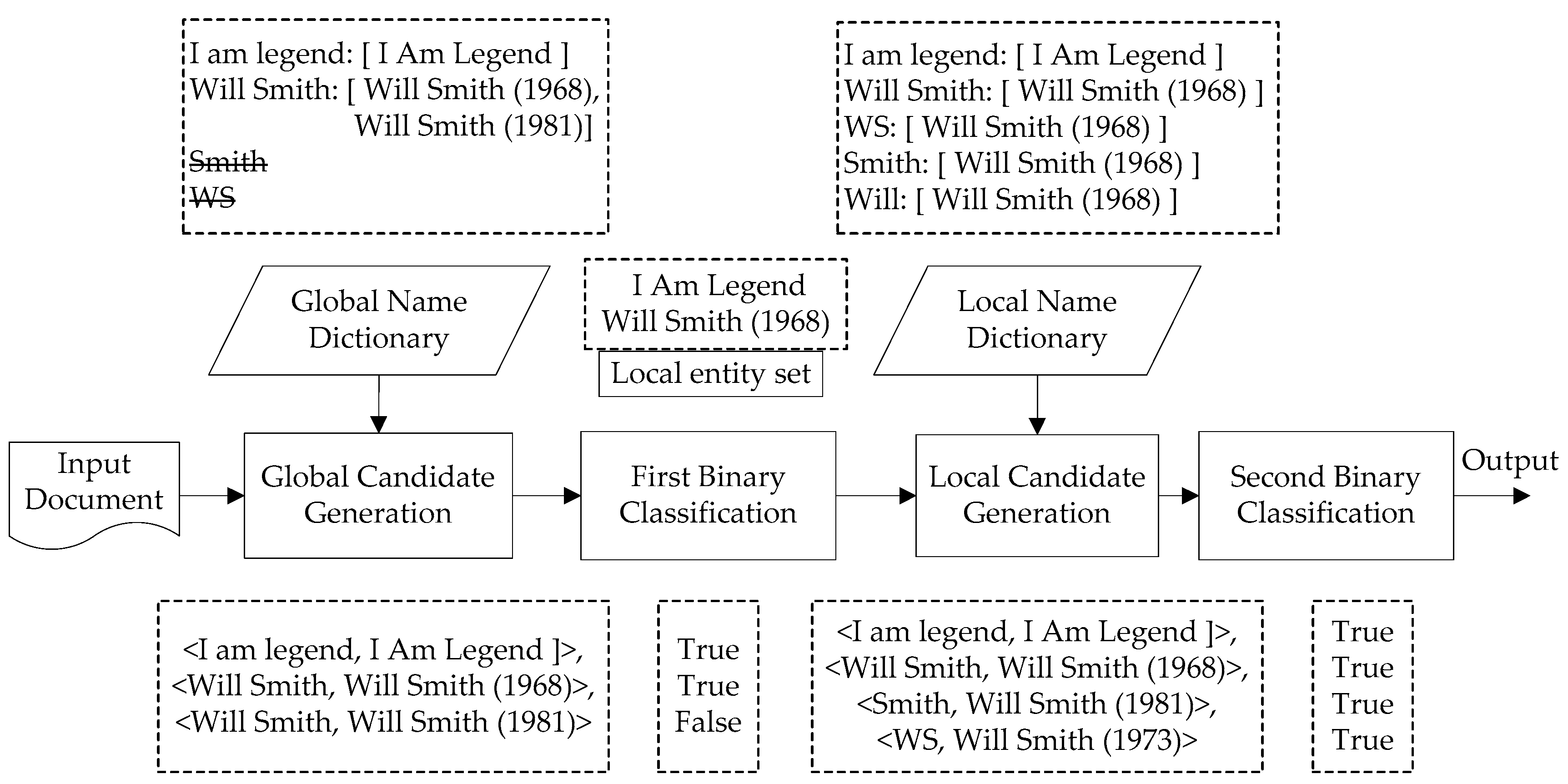
3.1.2. Name Dictionary Construction
- (1)
- Entities that are linked to in the first stage. That is, if an <n-gram, entity> candidate pair is labeled as positive by the first binary classifier, then this entity is added into the local entity set. The entities Will Smith and I am legend in Figure 2 are examples.
- (2)
- Entities that frequently appear in the extension document set. Here, the extension document set is a collection of documents that are selected from the pseudo-labeled corpus and have similar topics as the input text (see Section 3.2.4 for details). For an entity , if its document frequency exceeds the threshold , then it is included in the local entity set.
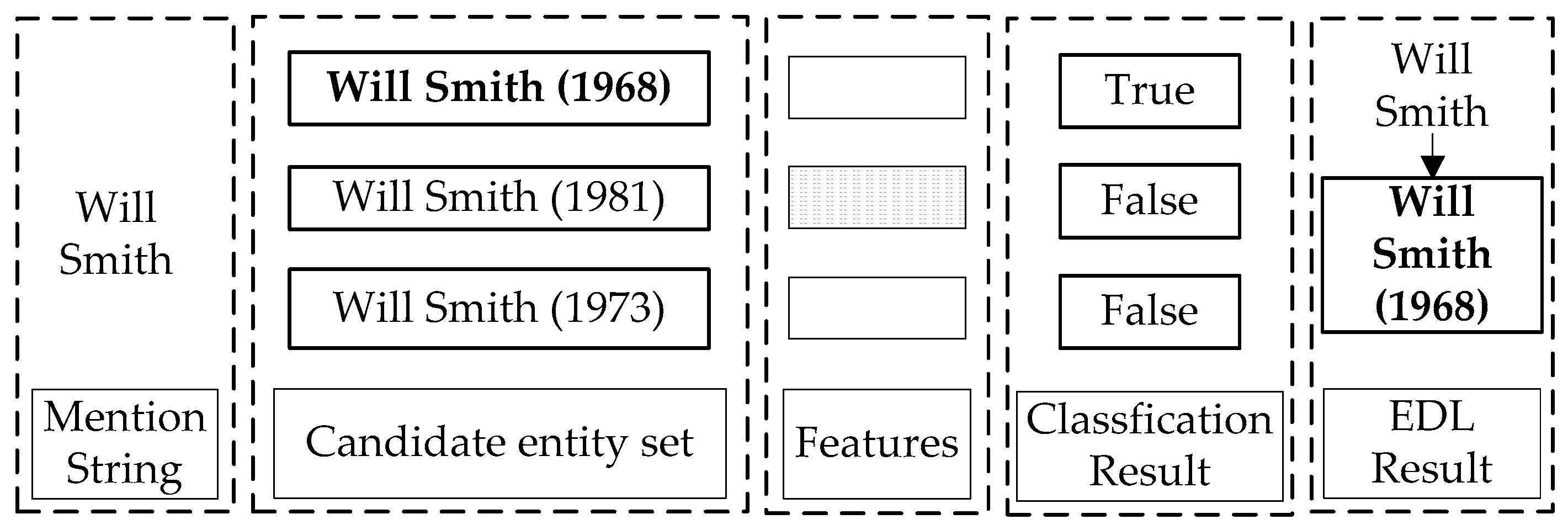
3.1.3. Candidate Generation
| Algorithm 1. Candidate generation algorithm. |
| Input: text , name dictionary Output: set of candidate pairs |
| Initialize , , ; while : , : while : ; if : if : = { for each ; else: if : ; ; else: ; break; end end return ; |
3.1.4. Binary Classification
3.2. Feature Representation Leveraging an Unlabeled Corpora
3.2.1. Features’ Overview
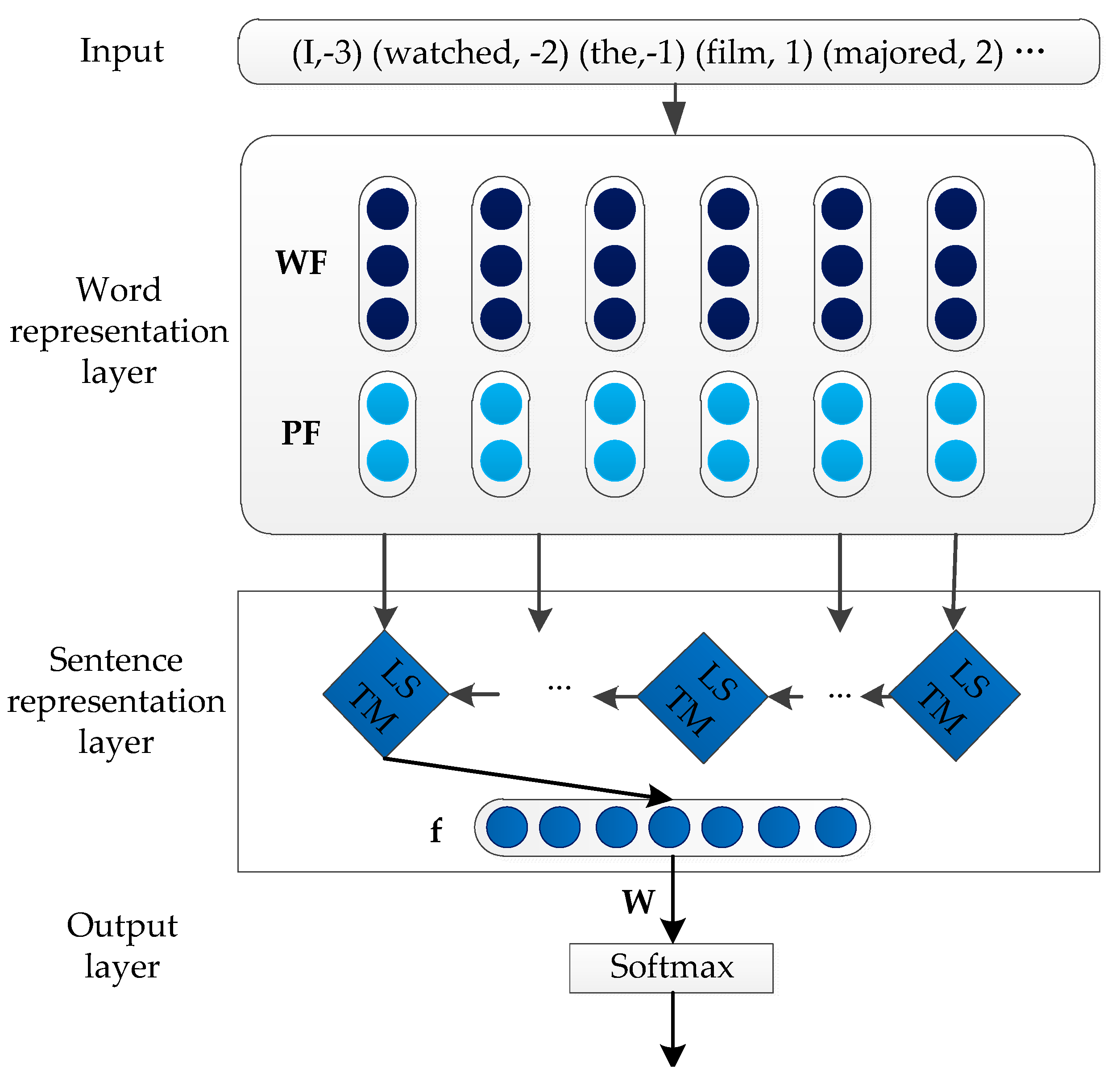
3.2.2. Mention Type
- (1)
- Word representation layer:
- (2)
- Sentence representation layer:
- (3)
- Output layer:
3.2.3. Corpus-Based Inner-Document Entity Coherence
- (1)
- Coherence between the candidate entity and all of the contextual words:
- (2)
- Coherence between candidate entities:
- (3)
- Distance-weighted coherence between entities:
3.2.4. Topical Coherence between Entities across Documents
- (1)
- Mention-entity linking rate:
- (2)
- Entity linked frequency:
- (3)
- Coherence between entities across documents:
4. Experiments
4.1. Dataset Preparation
- (1)
- The benchmark dataset:
- (2)
- The unlabeled corpus:
4.2. Evaluation Metrics
- (1)
- Entity detection evaluation:
- (2)
- Entity linking accuracy:
- (3)
- Overall evaluation:
4.3. Experimental Setup
- (1)
- The threshold in the local name dictionary:
- (2)
- The binary classification model of TSJ:
- (3)
- The LSTM-based model:
4.4. Experimental Results
4.4.1. Performance of the Proposed Method
- –
- Baseline (Base 1): only one joint model based on the binary classification, using the basic feature set. Partial names and abbreviation names are included in the name dictionary to cover the ambiguous mentions.
- –
- The first stage of the TSJ model (FTSJ): The difference between Base 1 and FTSJ lies in that abbreviated names and ambiguous partial names that have more than 15 candidate entities are excluded from the name dictionary.
- –
- The basic TSJ model (TSJ): the proposed two-stage architecture utilizing the basic feature set.
- –
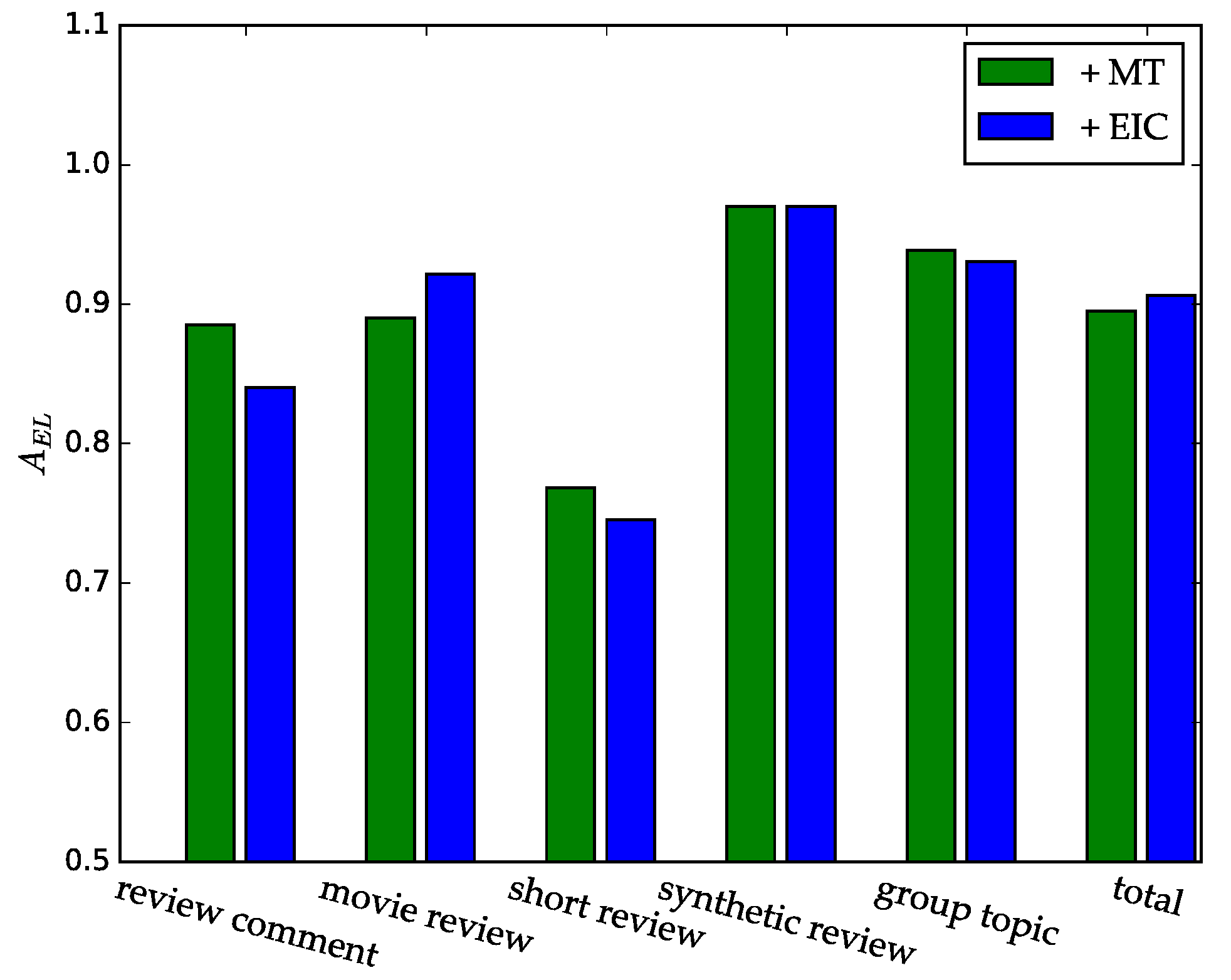
- + Mention type (+ MT): using the TSJ model and adding mention type features generated by the LSTM-based model to the feature set.
- –
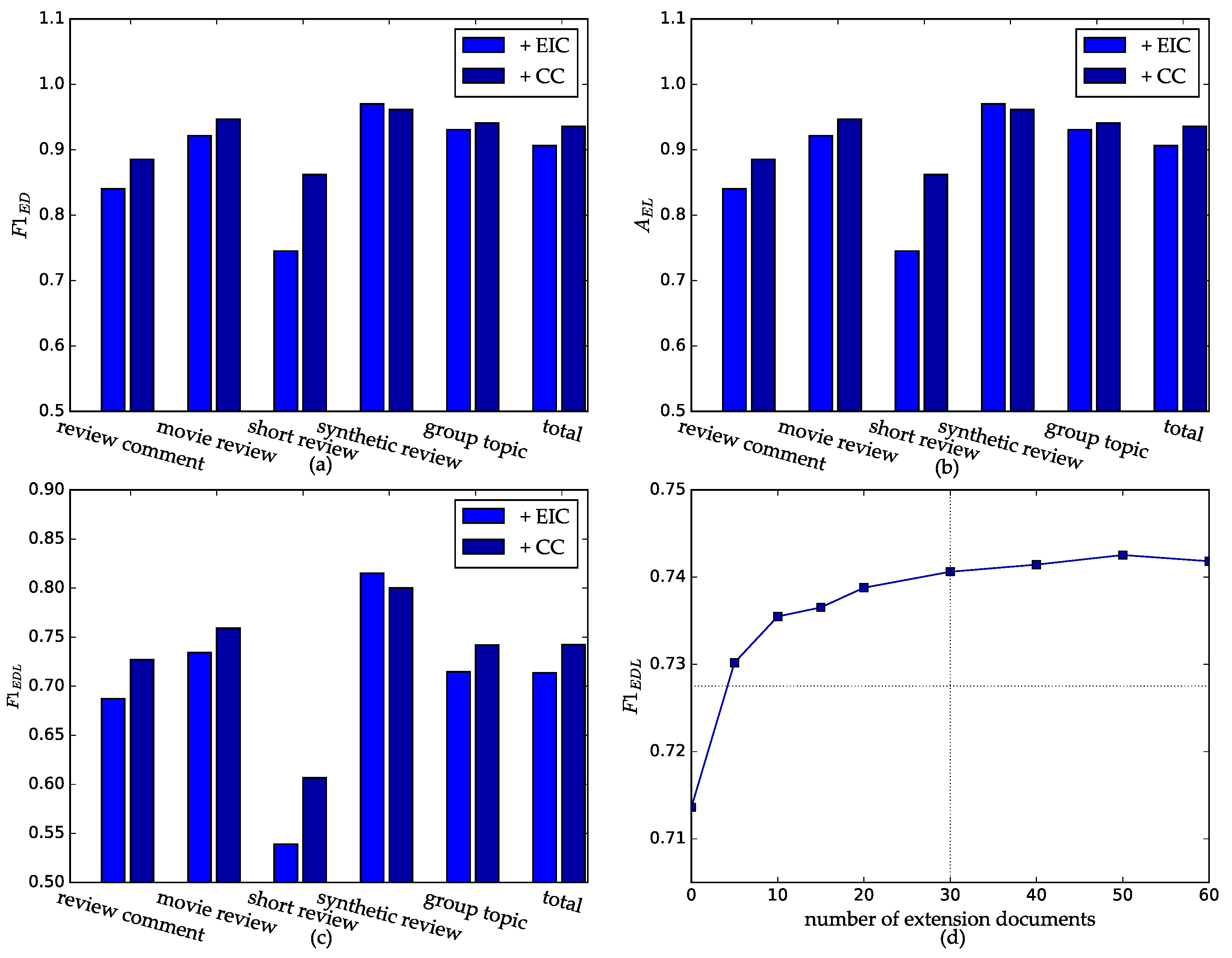
- + Extra inner-document topical coherence (+ EIC): on the basis of +MT, adding the corpus-based topical coherence features, namely , and introduced in Section 3.2.3.
- –
- + Cross-document coherence (+ CC): on the basis of +EIC, incorporating topical coherence across extension documents, namely , and introduced in Section 3.2.4.
- (1)
- The TSJ model:
- (2)
- The mention type features:
- (3)
- Corpus-based inner-document entity coherence:
- (4)
- Cross-document coherence:
4.4.2. Comparison with Other Methods
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
- 1.
- Features about the mention:
- (1)
- Mention length: The number of characters in the mention string.
- (2)
- Is title: Whether the first letter of the mention string is capitalized.
- (3)
- All capital: Whether all letters of the mention string are capitalized.
- (4)
- Term frequency: Frequency of the mention string in the text.
- (5)
- Document frequency: Document frequency of the mention string in the corpora.
- (6)
- : The number of the candidate entities.
- 2.
- Features about the candidate entity:
- (1)
- Entity type: The type of the entity, for example, The Twilight Saga: Breaking Dawn–Part 1 is a movie, and Barack Hussein Obama is a person. The type information is represented by the one-hot encoding.
- (2)
- Entity popularity: Entity popularity provides a prior possibility of the current entity. Traditionally, entity popularity is evaluated by hyperlinks and statistics, such as page views of the entity page within Wikipedia. The representation of entity popularity in a specific domain depends on the available data. For example, in the movie domain, the popularity of movies can be measured by the number of rating on Douban or IMDB, and the popularity of artists can be evaluated by the number of fans, while in the e-commerce domain, the popularity of products can be estimated by their sales and page views.
- 3.
- Textual context similarity:Textual context similarity measures the textual similarity between the description of the candidate entity and the context of the mention. Textual information of the mention and the entity is converted to vectors based on the bag of words model, and the dot-product of these two vectors is used to calculate the similarity [1]. Text associated with the entity can be extracted from the description page and textual attributes of the entity.
- 4.
- DSKB-based entity coherence:Entities mentioned within a passage are usually about the same or related topics. In DSEDL tasks, coherence between entities is evaluated based on the relationships recorded in the DSKB, and this DSKB-based coherence is also used in our method.
- (1)
- Topic coherence between mapping entities:
- (2)
- Coherence between mapping entities after a basic binary classification:
- (3)
- Topic coherence between mapping entities based on two-jump relationships:
References
- Shen, W.; Wang, J.; Han, J. Entity linking with a knowledge base: Issues, techniques, and solutions. IEEE Trans. Knowl. Data Eng. 2015, 27, 443–460. [Google Scholar] [CrossRef]
- Gottipati, S.; Jiang, J. Linking entities to a knowledge base with query expansion. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 804–813. [Google Scholar]
- Han, X.; Sun, L. A generative entity-mention model for linking entities with knowledge base. In Proceedings of the Meeting of the Association for Computational Linguistics, Oregon, Portland, 19–24 June 2011; Volume 1, pp. 945–954. [Google Scholar]
- Han, X.; Sun, L. An entity-topic model for entity linking. In Proceedings of the Empirical Methods in Natural Language Processing, Jeju Island, Korea, 12–14 July 2012; pp. 105–115. [Google Scholar]
- Zhang, W.; Sim, Y.C.; Su, J.; Tan, C.L. Entity linking with effective acronym expansion, instance selection and topic modeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Barcelona, Spain, 19–22 July 2011; pp. 1909–1914. [Google Scholar]
- Zhang, W.; Su, J.; Tan, C.L.; Wang, W.T. Entity linking leveraging: Automatically generated annotation. In Proceedings of the International Conference on Computational Linguistics, Beijing China, 23–27 August 2010; pp. 1290–1298. [Google Scholar]
- Zhang, J.; Li, J.; Li, X.; Shi, Y.; Li, J.; Wang, Z. Domain-specific Entity Linking via Fake Named Entity Detection. In Proceedings of the Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; pp. 101–116. [Google Scholar]
- Li, Y.; Tan, S.; Sun, H.; Han, J.; Roth, D.; Yan, X. Entity disambiguation with linkless knowledge bases. In Proceedings of the International World Wide Web Conferences, Montreal, Canada, 11–15 April 2016; pp. 1261–1270. [Google Scholar]
- Guo, S.; Chang, M.; Kiciman, E. To link or not to link? A study on end-to-end tweet entity linking. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Atlanta, GA, USA, 9–14 June 2013; pp. 1020–1030. [Google Scholar]
- Sil, A.; Yates, A. Re-ranking for joint named-entity recognition and linking. In Proceedings of the Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2369–2374. [Google Scholar]
- Han, X.; Sun, L.; Zhao, J. Collective entity linking in web text: A graph-based method. In Proceedings of the International Acm Sigir Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 765–774. [Google Scholar]
- Ratinov, L.; Roth, D.; Downey, D.; Anderson, M.R. Local and global algorithms for disambiguation to wikipedia. In Proceedings of the Meeting of the Association for Computational Linguistics, Oregon, Portland, 19–24 June 2011; pp. 1375–1384. [Google Scholar]
- Shen, W.; Wang, J.; Luo, P.; Wang, M. Linden: Linking named entities with knowledge base via semantic knowledge. In Proceedings of the International World Wide Web Conferences, Lyon, France, 16–20 April 2012; pp. 449–458. [Google Scholar]
- Liu, X.; Li, Y.; Wu, H.; Zhou, M.; Wei, F.; Lu, Y. Entity linking for tweets. In Proceedings of the Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 April 2013; pp. 1304–1311. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhou, G.; Su, J. Named entity recognition using an hmm-based chunk tagger. In Proceedings of the Meeting of the Association for Computational Linguistics, Philadelphia, Pennsylvania, 7–12 July 2002; pp. 473–480. [Google Scholar]
- Mccallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Edmonton, Canada, 27 May–1 June 2003; pp. 188–191. [Google Scholar]
- Bender, O.; Och, F.J.; Ney, H. Maximum entropy models for named entity recognition. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Edmonton, Canada, 27 May–1 June 2003; pp. 148–151. [Google Scholar]
- Hammerton, J. Named entity recognition with long short-term memory. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Edmonton, Canada, 27 May–1 June 2003; pp. 172–175. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar]
- Gattani, A.; Lamba, D.S.; Garera, N.; Tiwari, M.; Chai, X.; Das, S.; Subramaniam, S.; Rajaraman, A.; Harinarayan, V.; Doan, A. Entity extraction, linking, classification, and tagging for social media: A wikipedia-based approach. In Proceedings of the Very Large Data Base, Trento, Italy, 26–31 August 2013; Volume 6, pp. 1126–1137. [Google Scholar]
- Varma, V.; Bharat, V.; Kovelamudi, S.; Bysani, P.; Gsk, S.; Kiran, K.N.; Reddy, K.; Kumar, K.; Maganti, N. IIIt hyderabad at TAC 2009. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 16–17 November 2009; pp. 620–622. [Google Scholar]
- Pilz, A.; Paas, G. From names to entities using thematic context distance. In Proceedings of the Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 857–866. [Google Scholar]
- Pasca, R.B.; Marius. Using encyclopedic knowledge for named entity disambiguation. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 9–16. [Google Scholar]
- Zhang, W.; Yan, C.; Su, S.J. Nus-i2r: Learning a combined system for entity linking. In Proceedings of the Text Analysis Conference, Gaithersburg, MD, USA, 15–16 November 2010; Available online: https://tac.nist.gov/publications/2010/participant.papers/NUSchime.proceedings.pdf (accessed on 22 May 2017).
- Chen, Z.; Ji, H. Collaborative ranking: A case study on entity linking. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 771–781. [Google Scholar]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Furstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust disambiguation of named entities in text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- Shen, W.; Wang, J.; Luo, P.; Wang, M. Linking named entities in tweets with knowledge base via user interest modeling. Proceedings of 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 68–76. [Google Scholar]
- Zwicklbauer, S.; Seifert, C.; Granitzer, M. Robust and collective entity disambiguation through semantic embeddings. In Proceedings of the International Acm Sigir Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 425–434. [Google Scholar]
- Demartini, G.; Difallah, D.E.; Cudremauroux, P. Zencrowd: Leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 469–478. [Google Scholar]
- Zhang, J.; Li, J. Graph-based jointly modeling entity detection and linking in domain-specific area. In Knowledge Graph and Semantic Computing: Semantic, Knowledge, and Linked Big Data, Proceedings of the CCKS 2016: Chinese Conference on Knowledge Graph and Semantic Computing, Beijing, China, 19–22 September 2016; Chen, H., Ji, H., Sun, L., Wang, H., Qian, T., Ruan, T., Eds.; Springer Singapore: Singapore, 2016; pp. 146–159. [Google Scholar]
- Li, Y.; Wang, C.; Han, F.; Han, J.; Roth, D.; Yan, X. Mining evidences for named entity disambiguation. Proceedings of 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1070–1078. [Google Scholar]
- Yang, T.; Zhang, F.; Li, X.; Jia, Q.; Wang, C. Domain-specific entity discovery and linking task. In Knowledge Graph and Semantic Computing: Semantic, Knowledge, and Linked Big Data, Proceedings of the CCKS 2016: Chinese Conference on Knowledge Graph and Semantic Computing, Beijing, China, 19–22 September 2016; Chen, H., Ji, H., Sun, L., Wang, H., Qian, T., Ruan, T., Eds.; Springer Singapore: Singapore, 2016; pp. 214–218. [Google Scholar]
- Guo, Y.; Qin, B.; Liu, T.; Li, S. Microblog entity linking by leveraging extra posts. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 863–868. [Google Scholar]
- Williams, R.J.; Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Milne, D.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 509–518. [Google Scholar]
- Milne, D.; Witten, I.H. An open-source toolkit for mining wikipedia. Artif. Intell. 2013, 194, 222–239. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, H.; Chen, Q.; Hu, J.; Zhang, G.; Huang, D.; Tang, B. Icrc-dsedl: A film named entity discovery and linking system based on knowledge bases. In Knowledge Graph and Semantic Computing: Semantic, Knowledge, and Linked Big Data, Proceedings of the CCKS 2016: Chinese Conference on Knowledge Graph and Semantic Computing, Beijing, China, 19–22 September 2016; Chen, H., Ji, H., Sun, L., Wang, H., Qian, T., Ruan, T., Eds.; Springer Singapore: Singapore, 2016; pp. 205–213. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Descriptions | |
|---|---|---|
| Context independent | Mention string | Textual and statistical characteristics of the mention string |
| Entity | Entity popularity and entity type | |
| Context-dependent | Textual context similarity | Textual similarity between context of mentions and descriptions of entities |
| Mention type ( Section 3.2.2) | The probability of the mention being a certain type of entity | |
| DSKB-based entity coherence | Topical coherence between entities within the input document based on the link structures of the DSKB | |
| Corpus-based inner-document entity coherence ( Section 3.2.3) | Topical coherence between entities within the input document based on the pseudo-labeled corpus | |
| Topical coherence across documents ( Section 3.2.4) | Entity coherence across similar documents | |
| Other | Length of the input document | |
| Document Category | Train/Test | ||||
|---|---|---|---|---|---|
| Movie review | 225 | 150/75 | 2781 | 4085 | 18.16 |
| Short review | 480 | 320/160 | 72 | 814 | 1.70 |
| Comments of movie review | 299 | 200/99 | 129 | 478 | 1.60 |
| Group topic | 298 | 199/99 | 429 | 1801 | 6.04 |
| Synthetic review | 7 | 5/2 | 5460 | 713 | 101.86 |
| Total | 1309 | 874/435 | 661 | 7891 | 6.03 |
| Hyper Parameter | Word Embedding Dim. | Position Embedding Dim. | Sentence Feature Dim. | Meaningful Pre-defined Types |
|---|---|---|---|---|
| Value |
| Positive Samples for Movie Type | Positive Samples for Artist Type | Negative Samples |
|---|---|---|
| 1,839,893 | 1,359,595 | 5,172,380 |
| Configuration | Entity Detection | Entity Linking | Overall EDL | ||||
|---|---|---|---|---|---|---|---|
| Base | 77.01 | 64.94 | 70.46 | 88.67 | 68.29 | 57.58 | 62.48 |
| FTSJ | 80.57 | 65.29 | 72.13 | 89.96 | 72.48 | 58.64 | 64.89 |
| TSJ | 83.64 | 68.74 | 75.46 | 91.03 | 76.13 | 62.57 | 68.69 |
| + MT | 85.64 | 72.87 | 78.74 | 89.48 | 76.63 | 65.21 | 70.46 |
| + EIC | 85.74 | 72.80 | 78.74 | 90.63 | 77.71 | 65.98 | 71.36 |
| + CC | 87.05 | 73.37 | 79.63 | 93.26 | 81.18 | 68.43 | 74.26 |
| Method & Stage | Positive | Negative | Total | Positive/Negative |
|---|---|---|---|---|
| Baseline | 7666 | 789,378 | 797,044 | 1/102 |
| FTSJ | 6848 | 95,988 | 102,834 | 1/25 |
| TSJ | 5833 | 1938 | 7771 | 3/1 |
| Method | Entity Detection | Entity Linking | Overall EDL | ||||
|---|---|---|---|---|---|---|---|
| Ensemble joint EDL model | 79.33 | 81.30 | 80.30 | 93.45 | 74.13 | 75.98 | 75.43 |
| TSJ model | 87.05 | 73.37 | 79.63 | 93.26 | 81.18 | 68.43 | 74.26 |
| Joint EDL model | 76.85 | 79.21 | 78.01 | 92.41 | 71.02 | 73.18 | 72.08 |
| Pipeline model | 82.10 | 73.98 | 77.83 | 86.53 | 71.04 | 64.01 | 67.35 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Zhang, W.; Huang, T.; Liang, X.; Fu, K. A Two-Stage Joint Model for Domain-Specific Entity Detection and Linking Leveraging an Unlabeled Corpus. Information 2017, 8, 59. https://doi.org/10.3390/info8020059
Zhang H, Zhang W, Huang T, Liang X, Fu K. A Two-Stage Joint Model for Domain-Specific Entity Detection and Linking Leveraging an Unlabeled Corpus. Information. 2017; 8(2):59. https://doi.org/10.3390/info8020059
Chicago/Turabian StyleZhang, Hongzhi, Weili Zhang, Tinglei Huang, Xiao Liang, and Kun Fu. 2017. "A Two-Stage Joint Model for Domain-Specific Entity Detection and Linking Leveraging an Unlabeled Corpus" Information 8, no. 2: 59. https://doi.org/10.3390/info8020059
APA StyleZhang, H., Zhang, W., Huang, T., Liang, X., & Fu, K. (2017). A Two-Stage Joint Model for Domain-Specific Entity Detection and Linking Leveraging an Unlabeled Corpus. Information, 8(2), 59. https://doi.org/10.3390/info8020059