A Survey on Information Diffusion in Online Social Networks: Models and Methods

Abstract
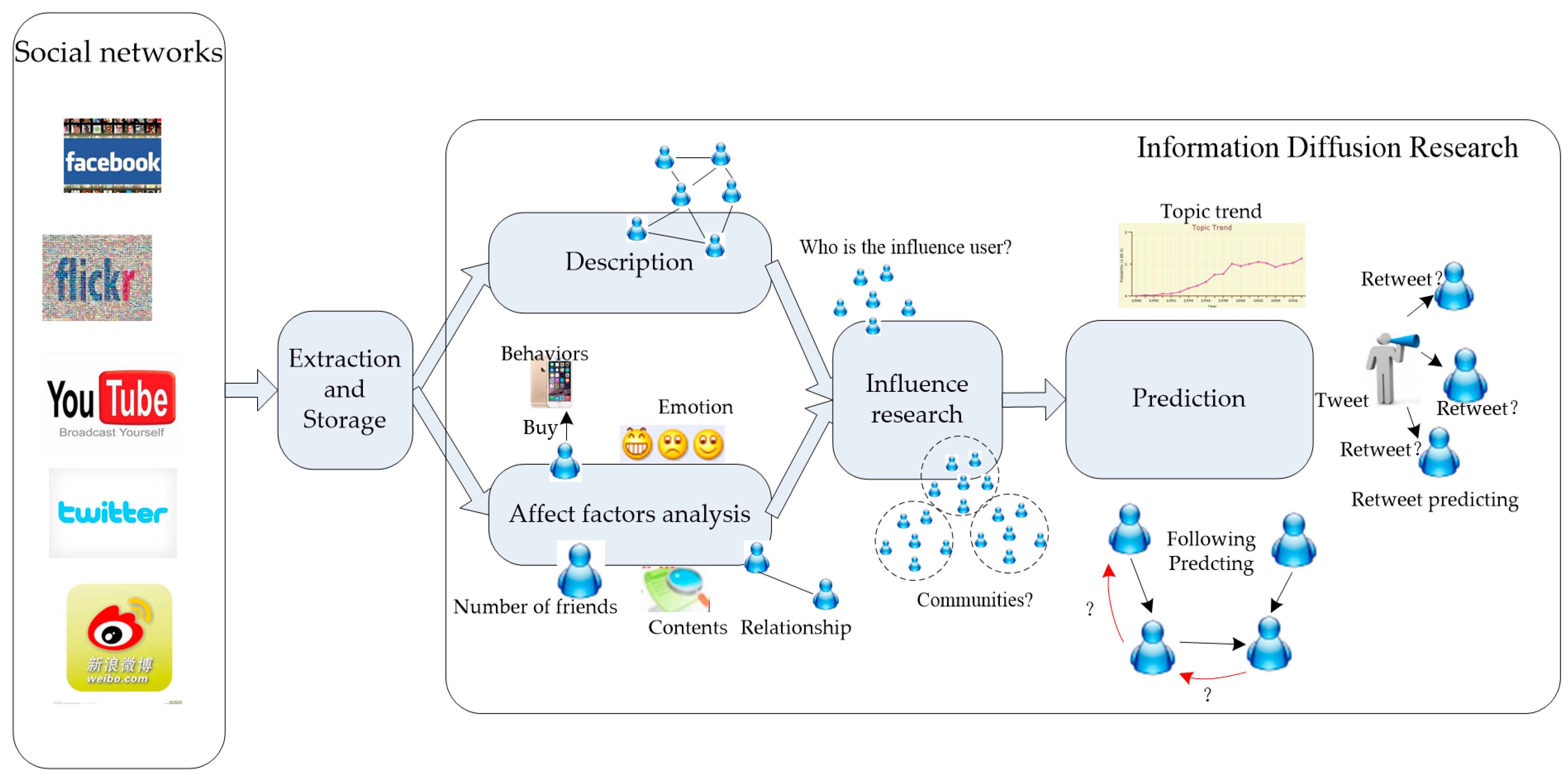
:1. Introduction
2. Explanatory Models
2.1. Aims of the Explanatory Models
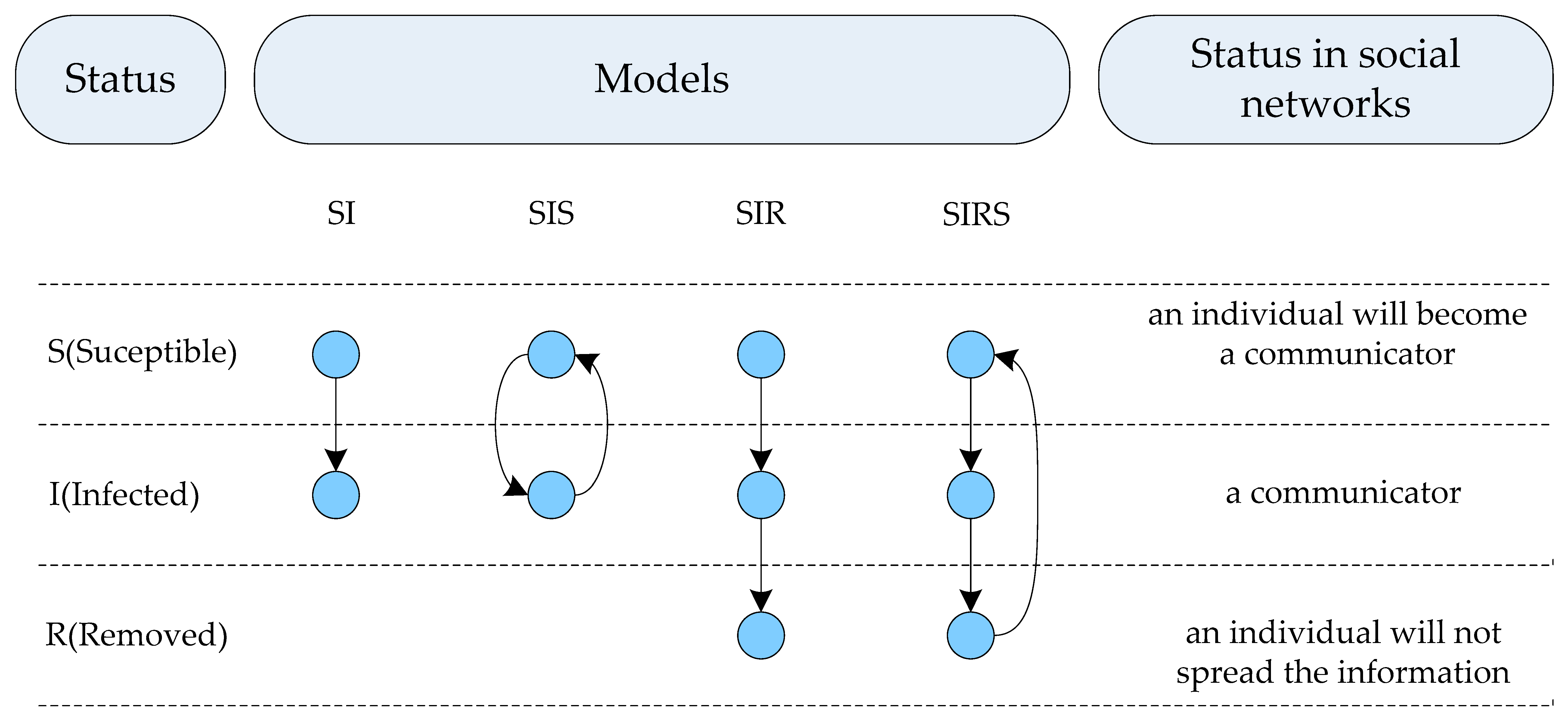
2.2. The Basic Epidemics Model
2.2.1. The SI Model
2.2.2. The SIS Model
2.2.3. The SIR Model
2.2.4. The SIRS Model
2.2.5. Epidemic Models in Social Networks
2.3. Influence Models in Social Networks
2.3.1. Individual Influence
2.3.2. Community Influence
2.3.3. Influence Maximization
3. Predictive Models
3.1. Aims of Predictive Models
3.2. Independent Cascade Model (ICM)
3.3. Linear Threshold Model (LTM)
3.4. Game Theory Model (GTM)
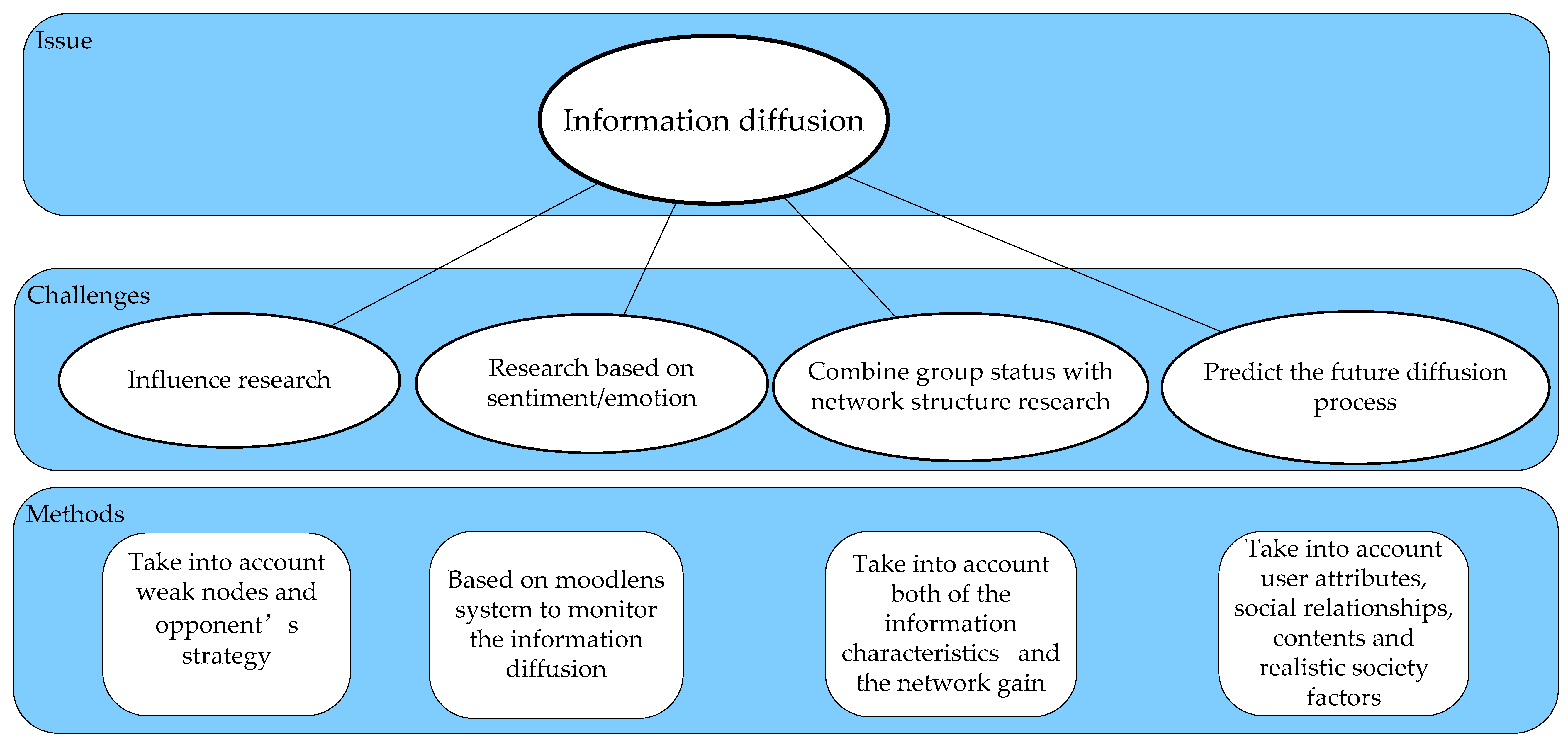
4. Future Challenges
4.1. Influence Analysis
4.2. Information Diffusion Based on Sentiment/Emotion
4.3. Combine Group Status with Network Structure Research
4.4. Prediction of Information Diffusion
5. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Barnes, J.A. Class and committees in a Norwegian island parish, human relations. Hum. Relat. 1954, 7, 39–58. [Google Scholar] [CrossRef]
- Christakis, N.A.; Fowler, J.H. The spread of obesity in a large social network over 32 years. N. Engl. J. Med. 2007, 357, 370–379. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wu, Y. How behaviors spread in dynamic social networks. Comput. Math. Organ. Theory 2012, 18, 419–444. [Google Scholar] [CrossRef]
- Fallahpour, R.; Chakouvari, S.; Askari, H. Analytical solutions for rumor spreading dynamical model in a social network. Nonlinear Eng. 2015, 4, 23–29. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Y.; Wang, K. An analysis of rumor propagation based on propagation force. Physica A 2015, 443, 469–474. [Google Scholar] [CrossRef]
- Li, D.; Ma, J.; Tian, Z.; Zhu, H. An evolutionary game for the diffusion of rumor in complex networks. Physica A 2015, 433, 51–58. [Google Scholar] [CrossRef]
- Lönnqvist, J.E.; Deters, F.G.E. Facebook friends, subjective well-being, social support, and personality. Comput. Hum. Behav. 2016, 55, 113–120. [Google Scholar] [CrossRef]
- Dong, Y.H.; Chen, H.; Qian, W.N.; Zhou, A.Y. Micro-blog social moods and Chinese stock market: The influence of emotional valence and arousal on Shanghai composite index volume. Int. J. Embed. Syst. 2015, 7, 148–155. [Google Scholar] [CrossRef]
- Cui, Q.; Qiu, Z.; Liu, W.; Hu, Z. Complex dynamics of an sir epidemic model with nonlinear saturate incidence and recovery rate. Entropy 2017, 19, 305. [Google Scholar] [CrossRef]
- Guo, J.; Zhang, P.; Fang, B.X.; Zhou, C.; Cao, Y.; Guo, L. Personalized key propogating users mining based on LT model. Chin. J. Comput. 2014, 37, 809–818. [Google Scholar]
- Binxing, F. Online Social Network Analysis; Publishing House of Electronics Industry: Beijing, China, 2014. [Google Scholar]
- Guille, A.; Hacid, H.; Favre, C.; Zighed, D. Information diffusion in online social networks: A survey. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 31–36. [Google Scholar]
- Li, D.; Xu, Z.M.; Li, S.; Liu, T.; Wang, X.W. A survey on information diffusion in online social networks. Chin. J. Comput. 2014, 254, 31–36. [Google Scholar]
- Wani, M.; Ahmad, M. Information diffusion modelling and social network parameters (A survey). In Proceedings of the International Conference on Advances in Computers, Communication and Electronic Engineering, Kashmir, India, 16–18 March 2015; pp. 245–249. [Google Scholar]
- Kumaran, P.; Chitrakala, S. A survey on influence spreader identification in online social network. In Proceedings of the International Conference on Information Communication and Embedded Systems, Chennal, India, 25–26 February 2016; pp. 1–7. [Google Scholar]
- Dey, K.; Kaushik, S.; Subramaniam, L.V. Literature survey on interplay of topics, information diffusion and connections on social networks. arXiv, 2017; arXiv:1706.00921. [Google Scholar]
- Han, X.; Niu, L. On charactering of information propagation in online social networks. J. Netw. 2013, 8, 124–132. [Google Scholar]
- Ou, C.; Jin, X.; Wang, Y.; Cheng, X. Modelling heterogeneous information spreading abilities of social network ties. Simul. Model. Pract. Theory 2017, 75, 67–76. [Google Scholar] [CrossRef]
- Pastorsatorras, R. Epidemic spreading in scale-free networks. Phys. Rev. Lett. 2001, 86, 3200–3203. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J. The structure and function of complex networks. Soc. Ind. Appl. Math. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Newman, M.E. Threshold effects for two pathogens spreading on a network. Phys. Rev. Lett. 2005, 95, 108701. [Google Scholar] [CrossRef] [PubMed]
- Gross, T.; D’Lima, C.J.; Blasius, B. Epidemic dynamics on an adaptive network. Phys. Rev. Lett. 2006, 96, 208701. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Yan, E.W.; Song, M. Microblog information diffusion: Simulation based on sir model. J. Beijing Univ. Posts Telecommun. 2014, 16, 28–33. [Google Scholar]
- Jin, Y.; Wang, W.; Xiao, S. An sirs model with a nonlinear incidence rate. Chaos Solitons Fractals 2007, 34, 1482–1497. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, Z.K. Information spreading on dynamic social networks. Commun. Nonlinear Sci. Numer. Simul. 2012, 19, 896–904. [Google Scholar] [CrossRef]
- Wang, C.; Yang, X.Y.; Xu, K.; Ma, J.F. Seir-based model for the information spreading over SNS. Tien Tzu Hsueh Pao/Acta Electron. Sin. 2014, 42, 2325–2330. [Google Scholar]
- Xu, R.; Li, H.; Xing, C. Research on information dissemination model for social networking services. Int. J. Comput. Sci. Appl. 2013, 2, 1–6. [Google Scholar]
- Ding, X.J. Research on propagation model of public opinion topics based on SCIR in microblogging. Comput. Eng. Appl. 2015, 51, 20–26. [Google Scholar]
- John, C.; Joshua, S.A. Epidemiological modeling of online social network dynamics. arXiv, 2014; arXiv:1401.4208. [Google Scholar]
- Feng, L.; Hu, Y.; Li, B.; Stanley, H.E.; Havlin, S.; Braunstein, L.A. Competing for attention in social media under information overload conditions. PLoS ONE 2015, 10, e0126090. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Lin, Z.; Jin, Y.; Cheng, S.; Yang, T. Esis: Emotion-based spreader–ignorant–stifler model for information diffusion. Knowl.-Based Syst. 2015, 81, 46–55. [Google Scholar] [CrossRef]
- Qu, B.; Hanjalic, A.; Wang, H. Heterogeneous recovery rates against sis epidemics in directed networks. In Proceedings of the International Conference on Network Games, Control and Optimization, Trento, Italia, 29–31 October 2014. [Google Scholar]
- Lu, D.; Yang, S.; Zhang, J.; Wang, H.; Li, D. Resilience of epidemics for sis model on networks. Chaos 2017, 27, 083105. [Google Scholar] [CrossRef] [PubMed]
- Wasserman, S.; Faust, K. Social network analysis methods and applications. Struct. Anal. Soc. Sci. 1994, 91, 219–220. [Google Scholar]
- Li, H.; Cui, J.; Ma, J. Social influence study in online networks: A three-level review. J. Comput. Sci. Technol. 2015, 30, 184–199. [Google Scholar] [CrossRef]
- Fan, X.H.; Zhao, J.; Fang, B.X.; Li, Y.X. Influence diffusion probability model and utilizing it to identify network opinion leader. Chin. J. Comput. 2013, 36, 360–367. [Google Scholar] [CrossRef]
- Wu, X.D.; Li, Y.; Li, L. Influence analysisi of online social networks. Chin. J. Comput. 2014, 37, 735–752. [Google Scholar]
- Wang, C.X.; Guan, X.H.; Qin, T.; Zhou, Y.D. Modelling on opinion leader’s influence in microblog message propagation and its application. J. Softw. 2015, 26, 1473–1485. [Google Scholar]
- Chen, B.; Tang, X.; Yu, L.; Liu, Y. Identifying method for opinion leaders in social network based on competency model. J. Commun. 2014, 35, 12–22. [Google Scholar]
- Mao, J.X.; Liu, Y.Q.; Zhang, M.; Ma, S.P. Social influence analysis for micro-blog user based on user behavior. Chin. J. Comput. 2014, 37, 791–800. [Google Scholar]
- Wu, X.; Zhang, H.; Zhao, X.; Li, B.; Yang, C. Mining algorithm of microblogging opinion leaders based on user-behavior network. Appl. Res. Comput. 2015, 32, 2678–2683. [Google Scholar]
- Ullah, F.; Lee, S. Identification of influential nodes based on temporal-aware modeling of multi-hop neighbor interactions for influence spread maximization. Physica A 2017, 486, 968–985. [Google Scholar] [CrossRef]
- Sheikhahmadi, A.; Nematbakhsh, M.A.; Zareie, A. Identification of influential users by neighbors in online social networks. Physica A 2017, 486, 517–534. [Google Scholar] [CrossRef]
- Yang, T.; Jin, R.; Chi, Y.; Zhu, S. Combining Link and Content for Community Detection; Springer: New York, NY, USA, 2014; pp. 190–201. [Google Scholar]
- Zhou, Y.; Cheng, H.; Yu, J.X. Clustering large attributed graphs: An efficient incremental approach. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 689–698. [Google Scholar]
- Ruan, Y.; Fuhry, D.; Parthasarathy, S. Efficient community detection in large networks using content and links. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2012; pp. 1089–1098. [Google Scholar]
- Yang, J.; Mcauley, J.; Leskovec, J. Community detection in networks with node attributes. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining Workshops, Dallas, TX, USA, 7–10 December 2013; pp. 1151–1156. [Google Scholar]
- Yang, B.; Manandhar, S. Community discovery using social links and author-based sentiment topics. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Beijing, China, 17–20 August 2014; pp. 580–587. [Google Scholar]
- Peng, C.; Kolda, T.G.; Pinar, A. Accelerating community detection by using K-core subgraphs. arXiv, 2014; arXiv:11403.2226. [Google Scholar]
- Gurini, D.F.; Gasparetti, F.; Micarelli, A.; Sansonetti, G. Analysis of sentiment communities in online networks. In Proceedings of the International Workshop on Social Personalisation & Search Co-Located with the ACM SIGIR Conference, Santiago, Chile, 9–13 August 2015; pp. 1–3. [Google Scholar]
- Ullah, F.; Lee, S. Community clustering based on trust modeling weighted by user interests in online social networks. Chaos Solitons Fractals 2017, 103, 194–204. [Google Scholar] [CrossRef]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the spread of influence through a social network. In Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 137–146. [Google Scholar]
- Jung, K.; Heo, W.; Chen, W. Irie: Scalable and robust influence maximization in social networks. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 918–923. [Google Scholar]
- Kim, J.; Kim, S.K.; Yu, H. Scalable and parallelizable processing of influence maximization for large-scale social networks? In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering, Brisbane, Australia, 8–12 April 2013; pp. 266–277. [Google Scholar]
- Borgs, C.; Brautbar, M.; Chayes, J.; Lucier, B. Maximizing social influence in nearly optimal time. arXiv, 2012; arXiv:1212.0884. [Google Scholar]
- Tang, Y.; Xiao, X.; Shi, Y. Influence maximization: Near-optimal time complexity meets practical efficiency. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 75–86. [Google Scholar]
- Wang, Y.; Huang, W.J.; Zong, L.; Wang, T.J.; Yang, D.Q. Influence maximization with limit cost in social network. Sci. China Inf. Sci. 2013, 56, 1–14. [Google Scholar] [CrossRef]
- Lei, S.; Maniu, S.; Mo, L.; Cheng, R.; Senellart, P. Online influence maximization. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 645–654. [Google Scholar]
- Lin, S.C.; Lin, S.D.; Chen, M.S. A learning-based framework to handle multi-round multi-party influence maximization on social networks. In Proceedings of the 21st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 695–704. [Google Scholar]
- Horel, T.; Singer, Y. Scalable methods for adaptively seeding a social network. In Proceedings of the 24th International World Wide Web Conference (WWW2015), Florence, Italy, 18–22 May 2015; pp. 1–14. [Google Scholar]
- Hui, L.I.; Shen, B.; Cui, J.; Ma, J. Ugc-driven social influence study in online micro-blogging sites. China Commun. 2014, 11, 141–151. [Google Scholar]
- Li, H.; Bhowmick, S.S.; Sun, A.; Cui, J. Conformity-aware influence maximization in online social networks. VLDB J. 2014, 24, 117–141. [Google Scholar] [CrossRef]
- Li, H.; Bhowmick, S.S.; Cui, J.; Gao, Y.; Ma, J. Getreal: Towards realistic selection of influence maximization strategies in competitive networks. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015; pp. 1525–1537. [Google Scholar]
- Morone, F.; Makse, H.A. Influence maximization in complex networks through optimal percolation. Nature 2015, 524, 65–68. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Wang, Y.; Yang, S. Efficient influence maximization in social networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Paris, France, 28 June–1 July 2009; pp. 199–208. [Google Scholar]
- Saito, K.; Nakano, R.; Kimura, M. Prediction of information diffusion probabilities for independent cascade model. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Zagreb, Croatia, 3–5 September 2008; pp. 67–75. [Google Scholar]
- Wang, C.; Chen, W.; Wang, Y. Scalable influence maximization for independent cascade model in large-scale social networks. Data Min. Knowl. Discov. 2012, 25, 545–576. [Google Scholar] [CrossRef]
- Arora, A.; Galhotra, S.; Virinchi, S.; Roy, S. Asim: A scalable algorithm for influence maximization under the independent cascade model. In Proceedings of the 24th ACM International Conference on World Wide Web Companion, Florence, Italy, 18–22 May 2015; pp. 35–36. [Google Scholar]
- Barbieri, N.; Bonchi, F.; Manco, G. Topic-aware social influence propagation models. Knowl. Inf. Syst. 2012, 37, 555–584. [Google Scholar] [CrossRef]
- Kim, J.; Lee, W.; Yu, H. Ct-ic: Continuously activated and time-restricted independent cascade model for viral marketing. Knowl.-Based Syst. 2012, 62, 960–965. [Google Scholar] [CrossRef]
- Zhu, T.; Wang, B.; Wu, B.; Zhu, C. Maximizing the spread of influence ranking in social networks. Inf. Sci. 2014, 278, 535–544. [Google Scholar] [CrossRef]
- Chen, W.; Yuan, Y.; Zhang, L. Scalable influence maximization in social networks under the linear threshold model. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 88–97. [Google Scholar]
- Lagnier, C.; Denoyer, L.; Gaussier, E.; Gallinari, P. Predicting Information Diffusion in Social Networks Using Content and User’s Profiles; Springer: Berlin, Germany, 2013; pp. 74–85. [Google Scholar]
- Chen, H.; Wang, Y.T. Threshold-based heuristic algorithm for influence maximization. J. Comput. Res. Dev. 2012, 49, 2181–2188. [Google Scholar]
- Camerer, C.F. Behavioral game theory experiment in strategic interaction. J. Socio-Econom. 2003, 32, 135–146. [Google Scholar]
- Hang, Q.F.; Zhu, J.M.; Song, B.; Zhang, N. Game model of information transmission in social networks. J. Chin. Comput. Syst. 2014, 35, 473–477. [Google Scholar]
- Wang, Y.; Yu, J.; Qu, W.; Shen, H.; Cheng, X.; Lin, C. Everlutionary game model and analysis methods network group behavior. Chin. J. Comput. 2015, 38, 282–300. [Google Scholar]
- Liu, D.; Wang, Y.; Jia, Y.; Li, J.; Yu, Z. From strangers to neighbors: Link prediction in microblogs using social distance game. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014. [Google Scholar]
- Hu, Z.; Yao, J.; Cui, B.; Xing, E. Community level diffusion extraction. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD’15), Melbourne, Australia, 31 May–4 June 2015; pp. 1555–1569. [Google Scholar]
- Zhao, J.; Dong, L.; Wu, J.; Xu, K. Moodlens: An emoticon-based sentiment analysis system for Chinese tweets. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1528–1531. [Google Scholar]
- Fan, R.; Zhao, J.; Chen, Y.; Xu, K. Anger is more influential than joy: Sentiment correlation in Weibo. PLoS ONE 2014, 9, e110184. [Google Scholar] [CrossRef] [PubMed]
- Kramer, A.D.; Guillory, J.E.; Hancock, J.T. Experimental evidence of massive-scale emotional contagion through social networks. Proc. Natl. Acad. Sci. USA 2014, 111, 8788–8790. [Google Scholar] [CrossRef] [PubMed]
- Chua, F.C.T.; Lauw, H.W.; Lim, E.P. Generative models for item adoptions using social correlation. IEEE Trans. Knowl. Data Eng. 2013, 25, 2036–2048. [Google Scholar] [CrossRef]
- Lee, J.R.; Chung, C.W. A new correlation-based information diffusion prediction. In Proceedings of the 23rd International Conference on World Wide Web Companion, Seoul, Korea, 7–11 April 2014; pp. 346–351. [Google Scholar]
- Cao, J.X.; Wu, J.L.; Shi, W.; Liu, B.; Zheng, X.; Luo, J.Z. Sina microblog information diffusion analysis and prediction. Chin. J. Comput. 2014, 37, 779–790. [Google Scholar]
- Zhao, Q.; Erdogdu, M.A.; He, H.Y.; Rajaraman, A.; Leskovec, J. Seismic: A self-exciting point process model for predicting tweet popularity. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1513–1522. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scalable Model | Method | Consider the User’s Different Behaviors | Expression of the Diffusion Process | Dynamic Infected Rate and Recovery Rate | Performance Metrics | Applications |
|---|---|---|---|---|---|---|
| SEIR [26] | add Exposed node | - |  | - | distribution of nodes density | detect the affect factors: login frequency and number of friends |
| S-SEIR [27] | information value is considered | √ |  δ = user behavior | - | distribution of S, E, I, and R | simulate the diffusion process |
| SCIR [28] | add Contacted node | - |  | - | distribution of I and R | represent the regularity of online topic spreading |
| irSIR [29] | add Infection Recovery dynamics | - |  v = an infectious recovery rate | √ | degree of fitting with real data | describe OSN abandonment |
| FSIR [30] | consider the behavior of the neighbors | √ |  = node degree | √ | degree of fitting with real data | detect the affect factors: information numbers and friends numbers |
| ESIS [31] | consider the information weight with emotion | - |  = the probability of I to S; = the strength of edge e from i to j | √ | degree of fitting with real data | detect the affect factors: propagation probability and transmission intensity |
| Researcher | Network Structure | User Interactions | User Attributes | Method | Quantitative Criterion | Applications | |
|---|---|---|---|---|---|---|---|
| User behaviors | Other features | ||||||
| Chenxu [38] | √ | - | - | - | social network analysis | out-degree | identify opinion leaders and prediction |
| Bo [39] | - | √ | √ | centrality | competency | activists, centrality and intermediary | identify opinion leaders and influence maximization |
| Jiaxin [40] | √ | - | √ | access time | social network analysis | capability of diffusion | influence predicting |
| Xianhui [41] | √ | √ | √ | topic and weight | page-rank | coverage and coreratio | mining topic opinion leader |
| Ullah [42] | √ | √ | √ | neighbors-of-neighbors | social network analysis | activists | identify influential nodes |
| Model | Links | Attributes or Contents | Sentiment | Method | Quantitative Criterion |
|---|---|---|---|---|---|
| PCL-DC [44] | √ | √ | - | probability | - |
| SA-Cluster-Inc [45] | √ | prolific and topic | - | cluster | density and entropy function |
| CODICIL [46] | √ | stemmed words, title and context, tags | - | cluster | quality function |
| sentiment-topic based [48] | √ | user, text | √ | probability | sentiment-topic similarity |
| SVO [50] | √ | interests | √ | cluster | homophily |
| interest and trust based [51] | √ | interest, trust | - | both | quality function |
| Model | Find Seeds | Techniques for Choosing Seed Nodes | Data/Model Driven | Multi-Round | Multi Innovations/Items/Information | Application |
|---|---|---|---|---|---|---|
| OIM [58] | √ | explore-exploit, heuristic | model | √ | - | individual influence maximization |
| Adaptively Seeding [60] | √ | friendship paradox | data | - | - | |
| CASINO [62] | √ | conformity aware is mentioned | data | √ | - | |
| Optimal percolation [64] | √ | the important of weak nodes | data | - | - | |
| STORM [59] | √ | maximization the total gain | data | √ | √ | competitive influence maximization |
| GETREAL [63] | √ | game theory | model | - | √ |
| Model | Basic Model | Research Views | Application | ||
|---|---|---|---|---|---|
| IC | LT | GT | |||
| EM [66] | √ | - | - | the likelihood for information diffusion episodes | prediction of propagation probability |
| ASIM [68] | √ | - | - | combine running-time with memory-consumption | influence maximization |
| TIC, TLT [69] | √ | √ | - | Topic-aware | prediction of topic distribution |
| DRUC [73] | - | √ | - | information content and user profile | find affect factors |
| Heuristic and Greedy [74] | - | √ | - | influence of nodes and the node’s activation threshold | select the greatest influence nodes |
| Microscopic [76] | - | - | √ | relationship and cost | prediction of the information spread |
| Evolutionary game [77] | - | - | √ | individual information behavior in micro level | prediction of information diffusion in dynamic network |
| Game Coalitional [78] | - | - | √ | structure of social network and interactive features | relationships prediction |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Wang, X.; Gao, K.; Zhang, S. A Survey on Information Diffusion in Online Social Networks: Models and Methods. Information 2017, 8, 118. https://doi.org/10.3390/info8040118
Li M, Wang X, Gao K, Zhang S. A Survey on Information Diffusion in Online Social Networks: Models and Methods. Information. 2017; 8(4):118. https://doi.org/10.3390/info8040118
Chicago/Turabian StyleLi, Mei, Xiang Wang, Kai Gao, and Shanshan Zhang. 2017. "A Survey on Information Diffusion in Online Social Networks: Models and Methods" Information 8, no. 4: 118. https://doi.org/10.3390/info8040118
APA StyleLi, M., Wang, X., Gao, K., & Zhang, S. (2017). A Survey on Information Diffusion in Online Social Networks: Models and Methods. Information, 8(4), 118. https://doi.org/10.3390/info8040118