Entity Attribute Value Style Modeling Approach for Archetype Based Data


Abstract
:1. Introduction
- Sparseness: Among the vast dimensions (attributes) of healthcare domain, only few are active for a patient [1]. For example, a patient with fever might not undergo any blood test, and thus, the corresponding attributes will contain null (sparse) values.
- Frequent Evolution: With time, medical knowledge evolves. This results in new diagnosis parameters for providing more accurate decisions. For example, a few years back, four-dimensional (4D) ultrasound technology had been introduced that assisted in a better understanding of the fetus. This requires changes in existing database schema (and thus, changes in corresponding healthcare application) for accommodating the new knowledge in terms of attributes/parameters to be recorded and presented to the user on demand.
- Quick Data Access: Data extraction can be for a specific patient or for a population. When patient data or population is extracted, target data can be characterized as rows and columns of a relational model, respectively. Extracting patient data instantly is highly demanded in healthcare domain as it can lead to life loss. Whereas, population queries need not be answered in real time [1]. But, irrespective of the type of query, faster data access is always appreciable.
- Faster data retrieval: Besides the extensive adaptability of EAV in the healthcare domain, EAV lacks search efficiency. For data extraction, an exhaustive scan of EAV tables is required, which adds a delay in processing the output. Thus, this research paper proposes an entity attribute value style modeling approach for standardized Electronic Health Record (EHR) databases. The new storage model proposed is termed as Two Dimensional Entity Attribute Value Model (2D EAV) that extends the EAV to provide faster accessibility for patient-specific and population queries in comparison to EAV. 2D EAV uses a mixture of the EAV model and the NSM of RDBMS to produce a generic storage system that stores only non-sparse data and can accommodate new knowledge with a better access speed.
- Complex ad-hoc query support: EAV database is complemented with metadata to store all schema related details. EAV model represents the physical structure (i.e., how data is actually stored on disk) and the metadata associated with it depicts the logical structure (i.e., how data is visible to end users). However, in the healthcare domain, end users (such as, doctors, nurses, patients, and pharmacists) need not require any knowledge about the physical and/or logical structure of data. Moreover, every user is not aware of SQL. Even if a user is aware of SQL, the query corresponding to EAV will be highly complex and error-prone [1]. Thus, a Graphical User Interface (GUI) must be provided to the medical domain user for accessing Electronic Health Records (EHRs) that are stored in the database of a healthcare application. Current research provides a GUI corresponding to 2D EAV storage system. The GUI generates the SQL query corresponding to ad-hoc queries on fly, such as query that is constructed by desktop resident query tools, to extract the desired information without any prior knowledge about the underlying schema (2D EAV in our case) provided to the proposed GUI as an input.
1.1. Related Studeis
- NoSQL systems have been introduced to overcome limitations of Relational Database Management Systems (RDBMS) (See the next following Section 1.1.1).
- In the healthcare domain, dual model approach opens a new path for handling data to make a stable system that can capture future knowledge without making changes in the existing application (See the next following Section 1.1.2).
- Various storage approaches over existing RDBMS are suggested to make the system compatible with future evolution and/or to avoid sparseness (see the next following Section 1.1.3).
1.1.1. Why Not Nosql?
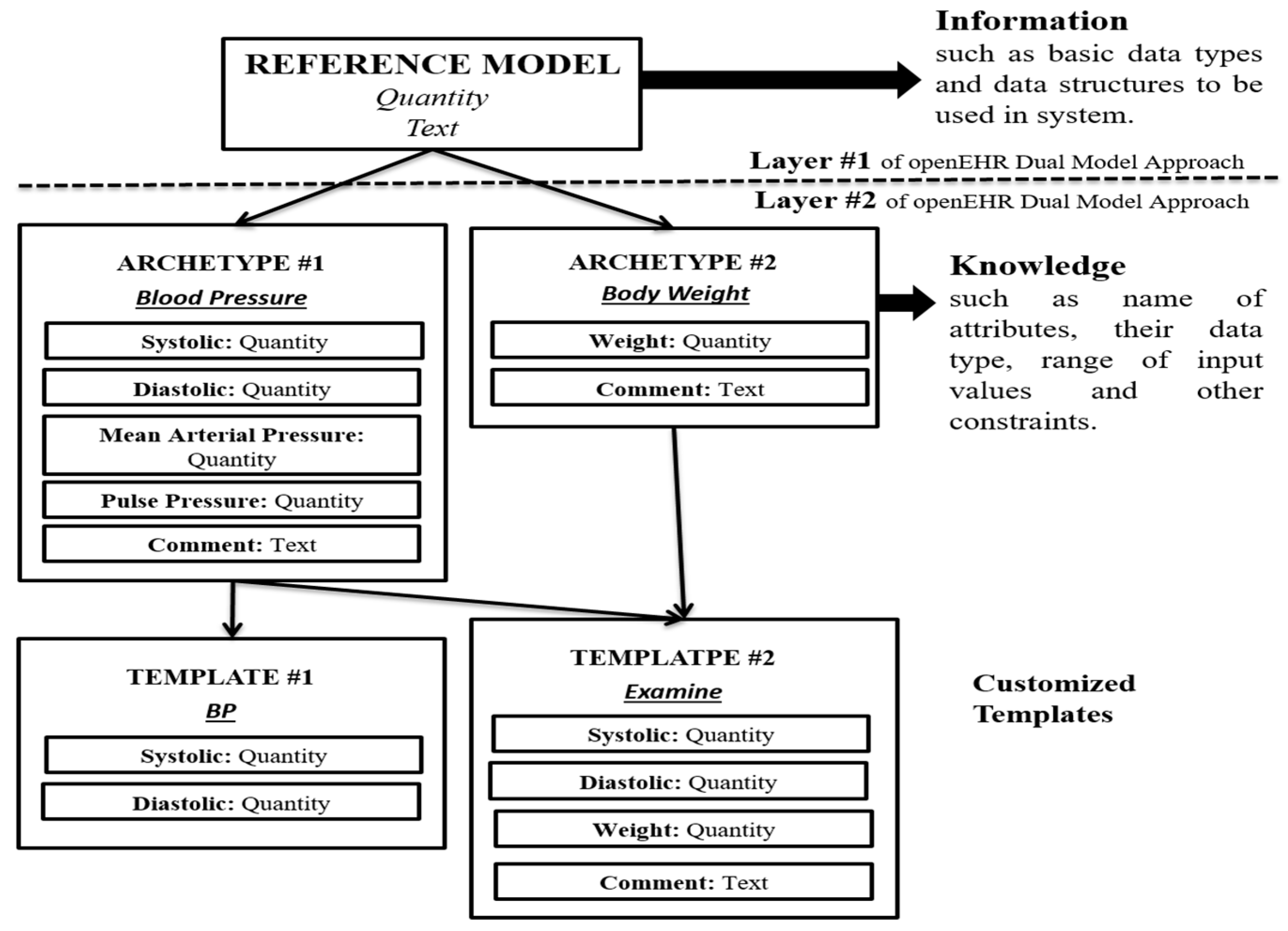
1.1.2. Storage of openEHR Standard Based Data
1.1.3. Storage Approaches in RDBMS for Sparse Dataset
- ‘Sparse Column’ functionality is not applicable to many data types that are quite common nowadays, such as ‘String’, ‘Timestamp’, and ‘Geometry’, etc.
- No constraints can be applied to ‘Sparse Columns’.
- No data compression is possible for ‘Sparse Columns’.
- Copying data from one machine to another will result in a loss of the ‘Sparse Column’ functionality.
1.1.4. Performing Analytical Operations
1.2. Objective of This Research
2. Method
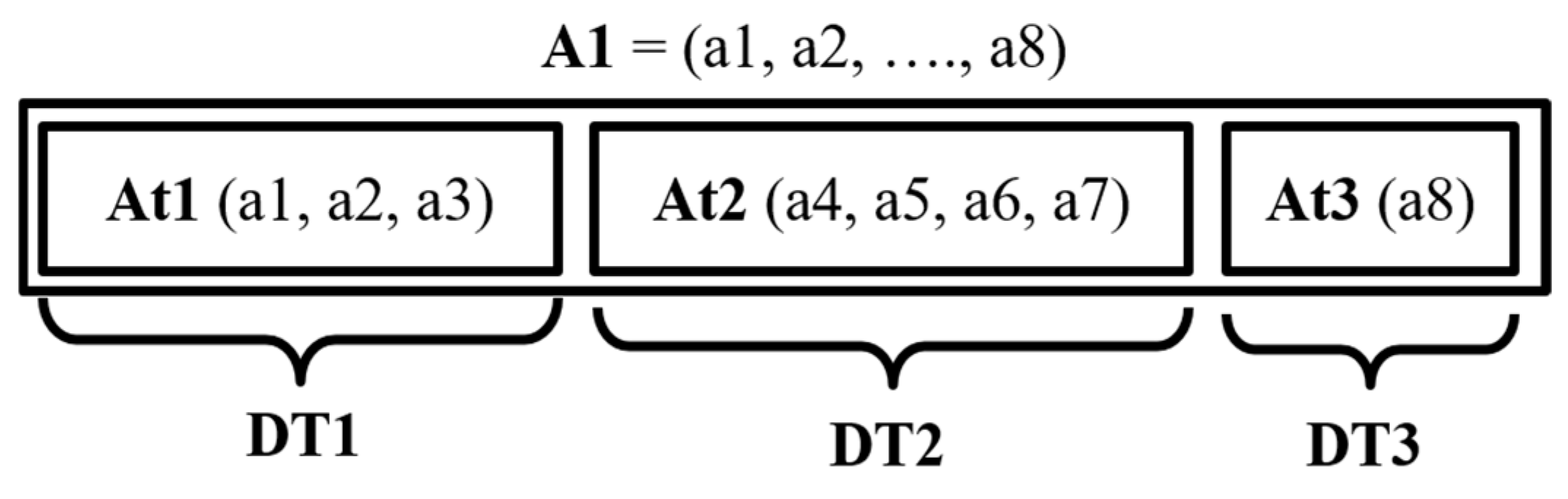
2.1. Design and Implementation of 2D EAV
- At1 = {a1, a2, a3}
- At2 = {a4, a5, a6, a7}
- At3 = {a8}
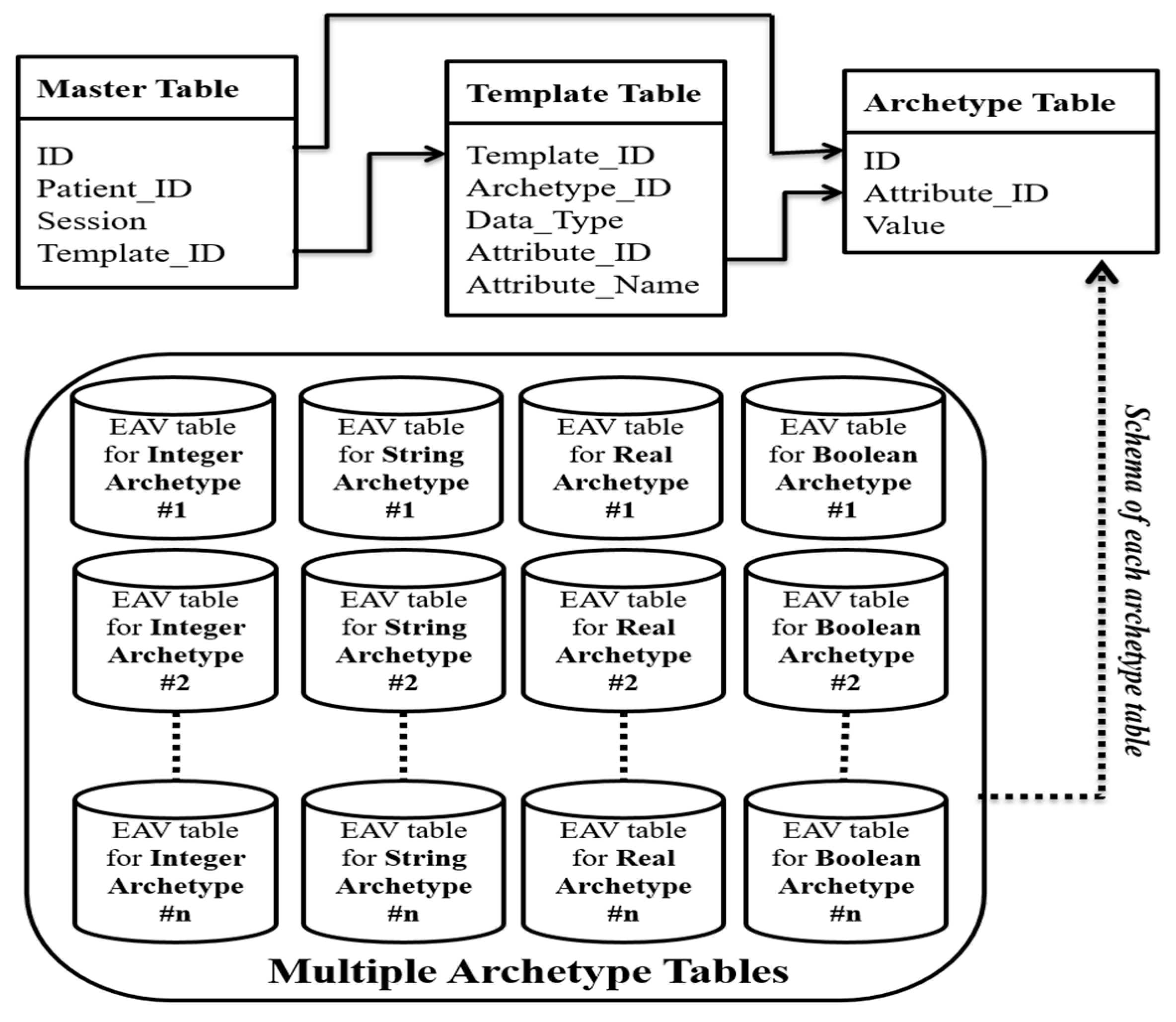
- Master Table: The Master table is designed with the aim of uniquely identifying a patient’s admittance to the hospital. The Master table follows the relational approach, since it stores data that contains no null values and have a fixed schema. ID column is the primary key of the Master table that stores auto-generated sequential numbers to identify each entry in the Master table uniquely. Patient_ID is unique for a particular patient, but it cannot serve as a candidate key in a Master table since a patient can have multiple admittances to a hospital, and thus, many entries in the Master table. Session is recorded to support a temporal behavior of standardized EHRs. Each entry in the Session column consists of a date (using ddmmyyyy format) followed by time (hhmm), at which the underlying data is stored in the database. Template_ID reserves the ID of the template through which the data is stored in the database.
- Template Table: Every organization customizes their template as per their needs using Template Designer [65]. To identify each template uniquely, the Template_ID is maintained as it is. The Template table follows the EAV approach. However, the ‘Attribute’ column (of the EAV model) is defined using two columns (Archetype_ID and Data_Type) in the Template table to account for the fact that the EAV storage model is divided into two dimensions (archetype and data type). Each archetype constitutes of a set of attributes. To identify the particular attribute that belongs to a defined template, Attribute_ID is used. Attribute_Name specifies the name of the attribute corresponding to Attribute_ID.
- For each data type (of elements) in an archetype, we construct one EAV table (known as Archetype table). If a new version of an archetype is released with some new data type, a new table can be accommodated in the existing architecture; otherwise, existing tables can capture newer version elements.
- Basic data items represented by the archetype basic data type are mapped to the corresponding equivalent data type of the underlying RDBMS. Single-valued and Multi-valued attributes can be easily captured in the same Archetype table since, one row of Archetype table corresponds to one data entry.
- In case of a multi-valued attribute, a combination of ID, Attribute_ID, and Value defines the primary key for the underlying Archetype tables. Otherwise, the combination of ID, Attribute_ID serves as the primary key for the various Archetype table.
- ID is the primary key in Master table (metadata of 2D EAV). ID column in each Archetype table is declared as the foreign key that refers to ID column of Master table.
- Use of ID enables unique identification of each data instance. For rapid access, ID column of each Archetype table is indexed.
- An archetype can inherit knowledge from existing archetypes (as inheritance in Templates). This type of inheritance is maintained through a special attribute type, termed as Archetype slot. Archetype slot is supported in 2D EAV through metadata, i.e., Template table. A template derives knowledge from archetypes. A detail of archetypes participating in a template is stored in ‘Template’ table. All of the archetype slots are viewed as embedded within the same archetype. Thus, all of the details are stored within ‘Template’ table.
- Collection data items (such as CLUSTER, ITEM_TREE, ITEM_LIST) [36] are considered to be embedded within the archetype. Collection data items are flattened to store corresponding data. Thus, Archetype tables storing data can also hold collection data items (viewed as flattened).
- Aggregation relationship is supported in 2D EAV through metadata, i.e., template table. A template derives knowledge from archetypes. A detail of archetypes participating in a template is stored in ‘Template’ table. All the relationships of participating archetypes to other archetypes are viewed as embedded within the same template. Thus, all details are stored within ‘Template’ table.
- Each Archetype table is termed as a concatenated string of archetype name, an underscore and the underlying data type.
- openEHR defines a semantic path for each attribute within an archetype. This path provides a mechanism to uniquely identify an attribute within an archetype. In 2D EAV, each attribute of an archetype is mapped to a unique code through a manually designed mapping table. The use of attribute codes in place of long semantic paths help in achieving a better readability and saving storage space. Set of codes can be replicated for some other archetype. The use of replicated codes does not create any problem since the codes are unique within an archetype, and 2D EAV uses the combination of Archetype_ID and Attribute_ID to identify an element.
2.2. Evaluation of Performance
- ➢
- The total number of entries in the Relational table, Tr = R × Atot.
- ➢
- The total number of entries in the Archetype table, Ta = 3 × (R × Ann − R) (as there are three entries corresponding to each non-null entry except the Patient_ID).
- ➢
- The total number of entries in the Master table, Tm = R × 4 (four entries corresponding to one row of the relational table).
- ➢
- The total number of entries in the Template table is negligible, since the number of templates used is much smaller.
- So, Tr >Tm + Ta
- R × Atot > R × 4 + 3 × (R × Ann − R)
- Atot > 4 + 3 × (Ann − 1)
- Atot > 3 × Ann − 1
- Atot > 3 × Ann (neglecting −1 since 3 × Ann >> 1)
2.3. Environment
- (1)
- 2D EAV: Our experiment version of 2D EAV is built on the top of PostgreSQL version 9.5, and our installation preserves the default configuration parameters. The query builder has been implanted using Java SE Development Kit 8. For 2D EAV, one Master table, one Template table, and 10 Archetype tables have been constructed. Among the 10 Archetypes tables, 2 tables (one real for QUANTITY and one string for TEXT) per archetype are included. Basic archetype data types can be mapped to SQL data types using the mapping rules suggested by Wang et al. [9].
- (2)
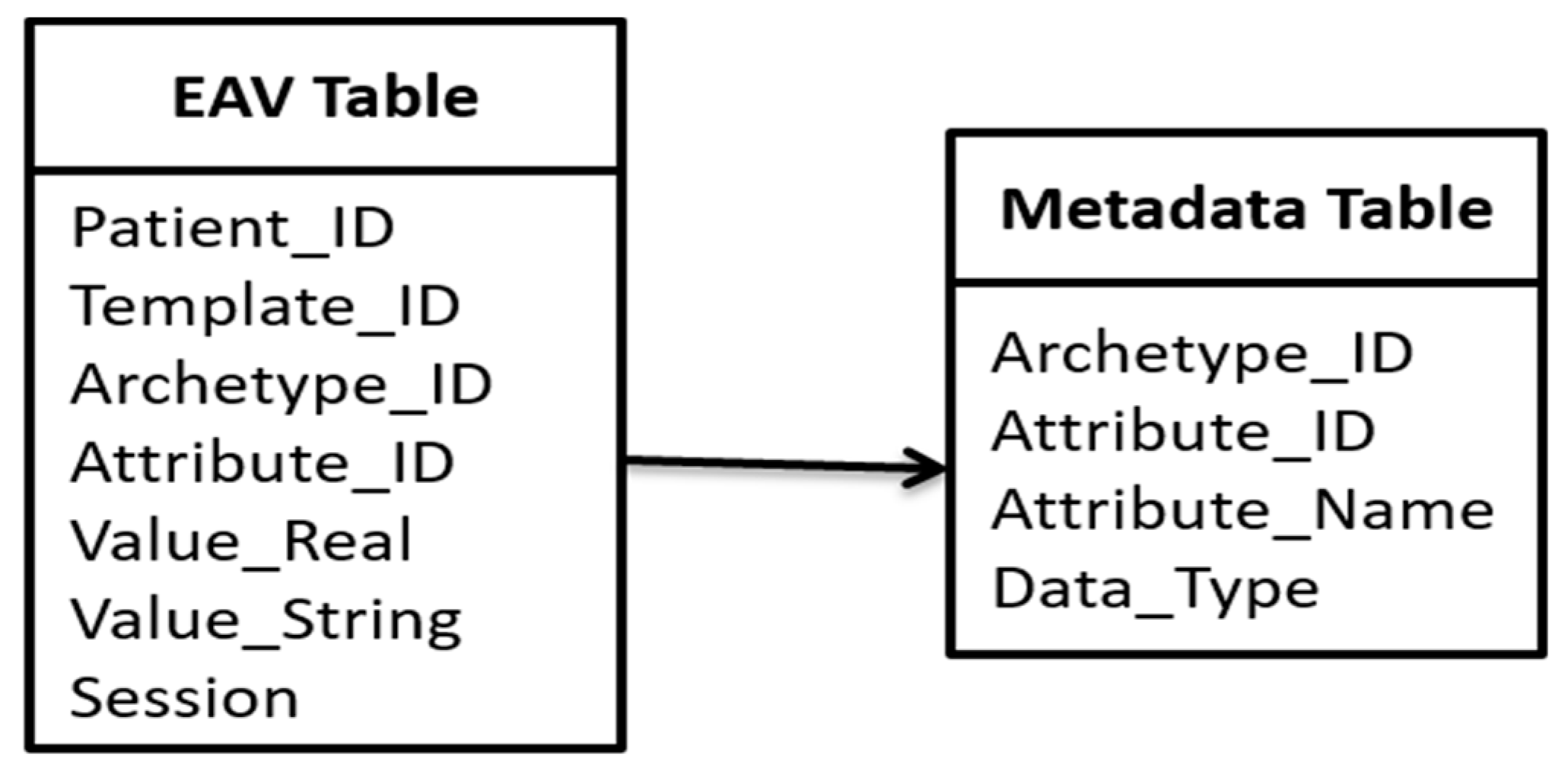
- EAV: The standard EAV model has been extended for experiments to accommodate heterogeneity (through columns ‘Value_Real’, and ‘Value_String’), temporal behavior (through column ‘Session’) and support for template-centric queries (through columns ‘Template_ID’, and Archetype_ID). Thus, one EAV table is constituted by six columns (Patient_ID, Template_ID, Archetype_ID, Attribute_ID, Value_Real, Value_String, and Session). For query support of EAV, one metadata table (See Appendix D) consists of four columns (Archetype_ID, Attribute_ID, Attribute_Name, and Data_Type). Indexes are defined on Patient_ID Template_ID, and Archetype_ID columns (for the EAV table), and on Archetype_ID column (for the metadata table) for faster execution of queries. EAV system is built also built on the top of PostgreSQL version 9.5.
- (3)
- MongoDB: The most popular NoSQL database system as per db ranking system is MongoDB [71]. It provides same flexibility as EAV. Hundreds of well-known production systems uses MongoDB [72]. It is a document oriented NoSQL database that inherently store data as key-value pairs (key being the combination of Entity and Attribute). Thus, we choose MonogoDB to evaluate the performance of proposed approach i.e., 2D EAV. The default configuration parameters of MongoDB has been preserved during experimentation.
3. Result
3.1. Efficiency of Storage
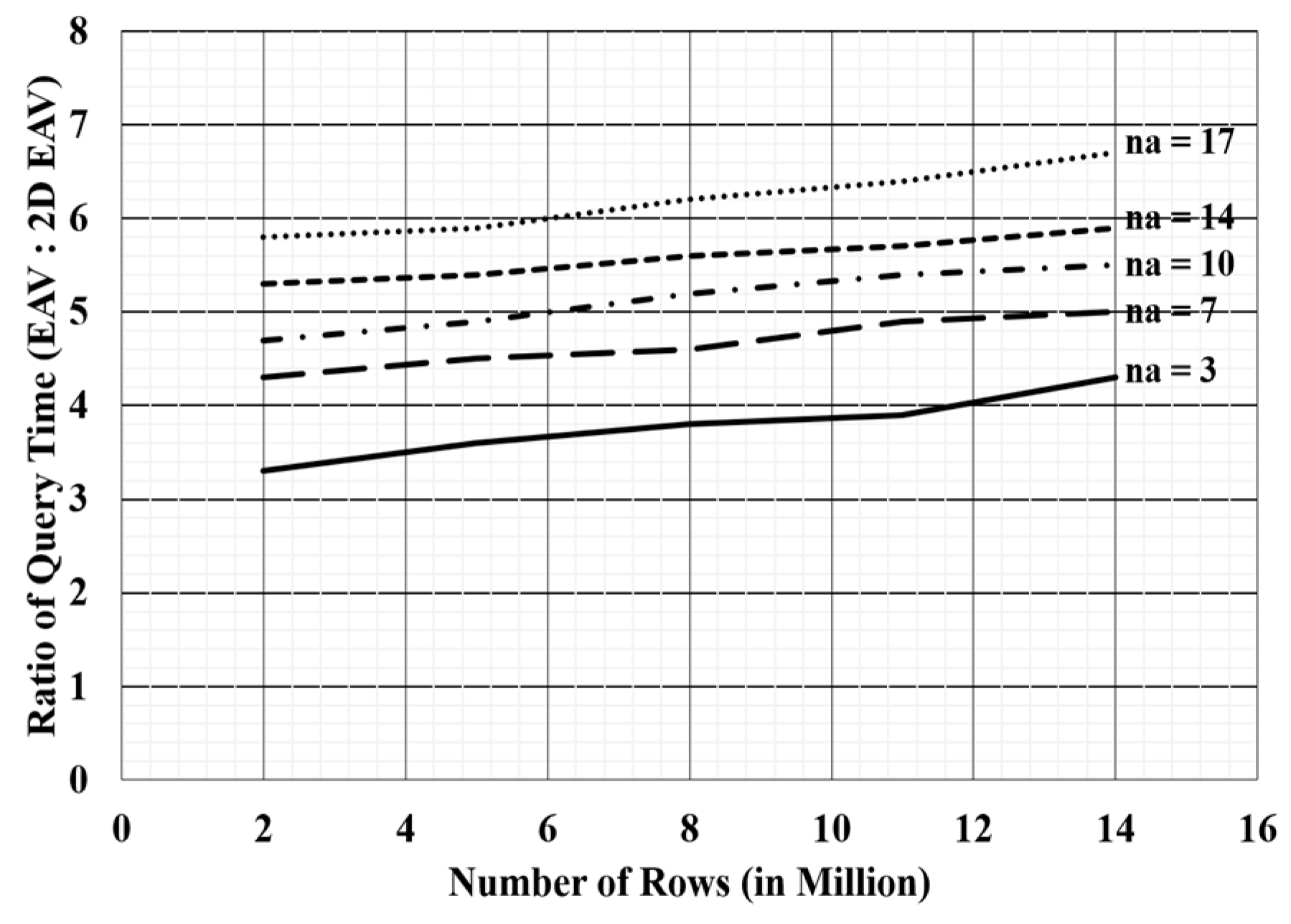
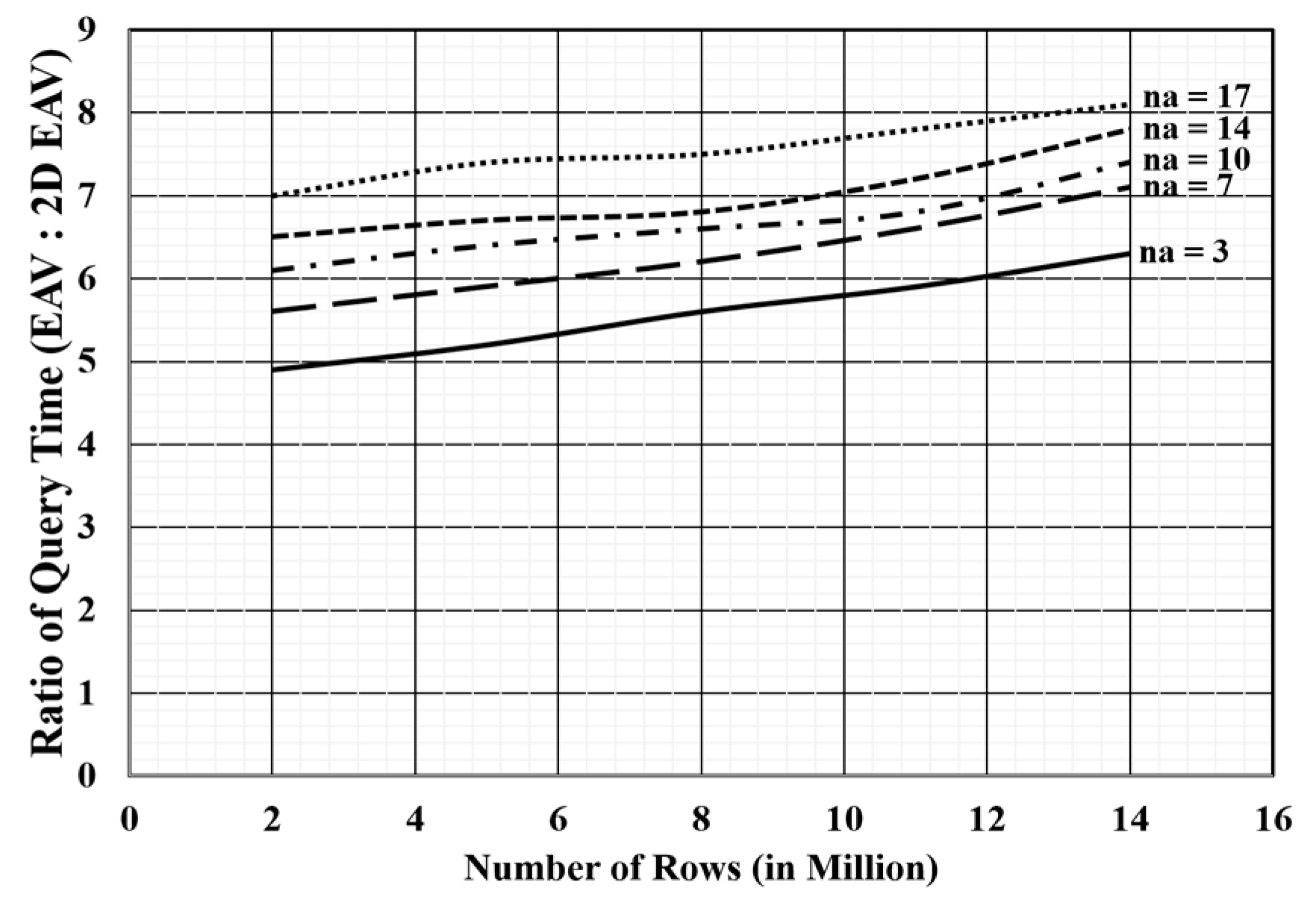
3.2. Performance
4. Discussion
4.1. Advantages of 2D EAV
- Faster Data Retrieval: 2D EAV stores data in various partitions and provides metadata to communicate with these partitions flawlessly. This restricts the search space of desired data to a few partitions, and thus, improves the speed of data retrieval.
- Adaptability to Other Domains: In this paper, we highlight the use of 2D EAV specifically for EHRs; however, an example process of creating an archetype for a subject schedule and for hotels is discussed in [73]. Once the archetype system is ready, 2D EAV can be easily adopted for the underlying domain by simply renaming the ‘patient_id’ as ‘entity_id’. All other semantics of 2D EAV will remain unchanged for the desired domain. We have mainly focused on standardized EHRs due to the availability of archetypes for the healthcare domain, and the need for generic storage for EHRs.
4.2. Comparison with Other Studies
- ARM: ARM maps each archetype to a relational table and 2D EAV maps each archetype to a distinct EAV table that is further categorized based on data type. Loss of stability (since, schema is not built using RM) in 2D EAV is compensated with the generic behavior of capturing any future evolution without modifying the existing system. ARM requires prior knowledge of identification attributes and frequently enquired data items for building indexing support. ARM also requires building a separate table for supporting multiple occurrences of collection data structures. 2D EAV in contrast to ARM requires no prior knowledge of data items. It does not construct separate tables for multiple occurrences of collection data structure.
- Node+Path (using BLOB): In 2D EAV, unique archetype and attribute names are coded to identify various hierarchies, rather using BLOB. Thus, it requires reduced storage and provides faster data access.
- EAV: In contrast to EAV, 2D EAV is focused on improving the access speed of standardized EHRs, rather than dealing with a complex query structure. It overcomes complex query difficulties through an efficient user interface.
4.3. Limitations
- Managing Inter-relationship: The inter-relationship among the tables is stored in Template table of 2D EAV. It helps in managing this complexity. Template table defines the set of attributes corresponding to each template, and thus, inter-related archetypes. For instance, there are ‘m’ hospitals that are involved in the information system; each having their own customized templates and a template on an average constitutes ‘n’ attributes. Thus, template table will contain ‘m × n’ rows. If a new template is introduced into the existing system with ‘z’ attributes, then ‘z’ rows are added to existing ‘m × n’ rows of template table giving a total of ‘m × n + z’ rows. In contrast to ARM approach, 2D EAV handles the introduction of a new table by simply inserting some rows in the metadata table, eliminating the need of manually defining the inter-relationship of existing archetypes with a newly introduced archetype.
- Data Accessibility Cost: EHRs are extracted for either clinical purpose or research purpose. A clinical activity normally involves the extraction of patient specific data to provide care services. Query interface of 2D EAV produces output in the form of EAV table. The results obtained are visually more appropriate for doctors due to document-like view of medical records. Thus, resultant records (following EAV) need not be self-JOINed to be presented in accordance with a relational approach. When EHRs are used for research objectives (such as finding the effect of some drug or growth rate of any disease, etc.), epidemiological queries are involved for the extraction of records. Such queries need not be answered in real time [1], and thus, a delay in data is acceptable. However, 2D EAV access data more quickly than EAV.
5. Conclusions
Author Contributions
Conflicts of Interest
Appendix A
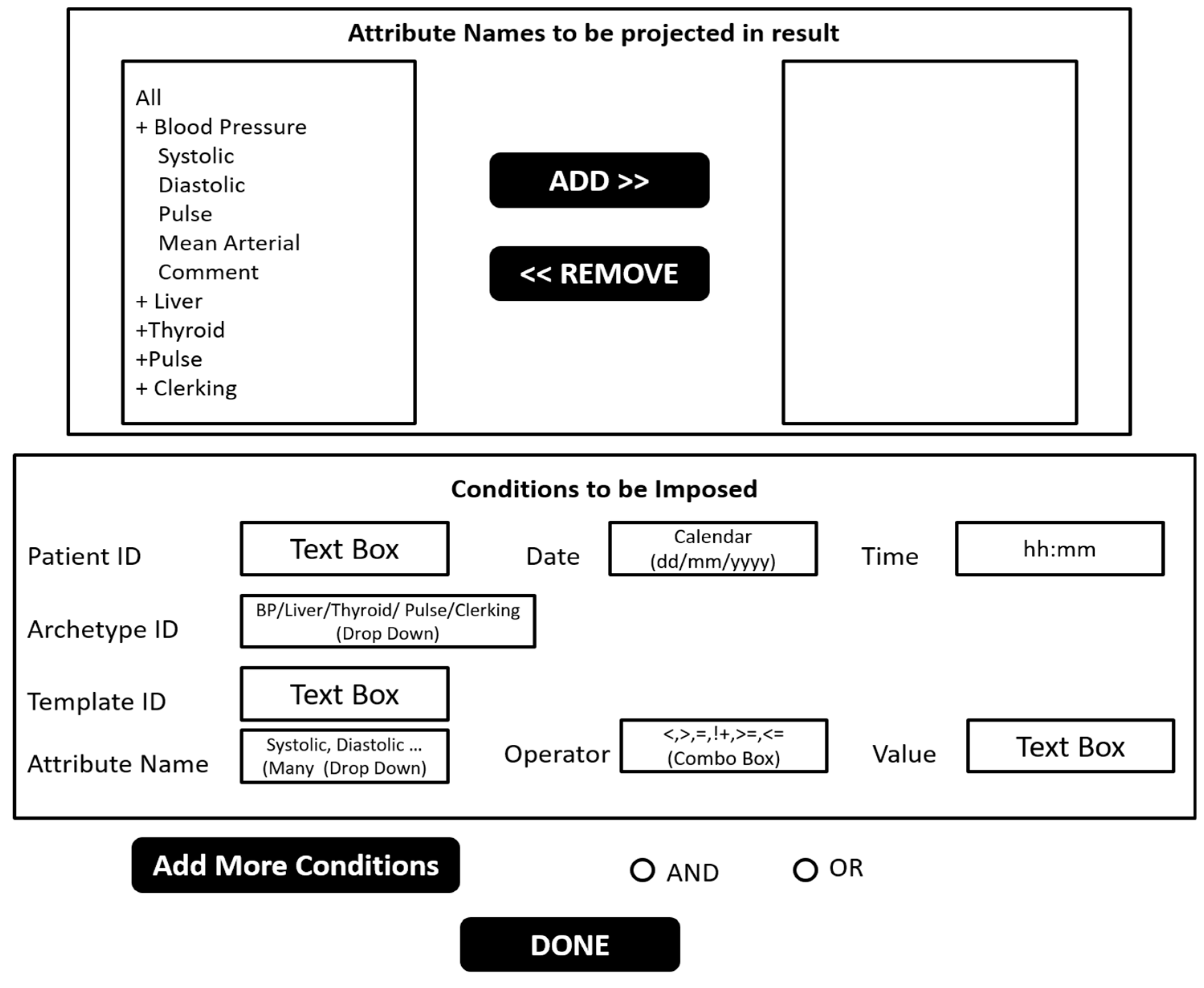
| Algorithm A1 |
| Input: Master Table (M), Template Table (T), set of Archetype Tables (A), Patient_ID (P), Session (S), set of Attribute_Name (N) to be projected, Condition (Attribute Name: AN, Operator: OP and Value: V), Archetype_ID (I) and Template_ID (TI) |
| Output: EAV table containing enquired data (Tout). |
| //TEMPI, TEMPTI, TEMPAT, TEMPAR, TEMPTI and TEMPF are temporary tables. Two Variables NameT and AI for storing name of table and Attribute_ID for AN |
|
| FUNCTION IDS |
| Input: Patient_ID (P), Session (S) and Template_ID (TI) |
| Output: List of ID (TEMPI) to be in output and List of Template_ID (TEMPTI). |
| if (P != NULL) then |
| if (S != NULL) then |
| if (TI != NULL) then |
| foreach record r є M do |
| if (r.Patient_ID == P) && (r.Session == S) && (r.Template_ID == TI) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else foreach record r є M do |
| if (r.Patient_ID == P) && (r.Session == S) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else if (TI != NULL) then |
| foreach record r є M do |
| if (r.Patient_ID == P) && (r.Template_ID == TI) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else foreach record r є M do |
| if (r.Patient_ID == P) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else if (S != NULL) then |
| if (TI != NULL) then |
| foreach record r є M do |
| if (r.Session == S) && (r.Template_ID == TI) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else foreach record r є M do |
| if (r.Session == S) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else if (TI != NULL) then |
| foreach record r є M do |
| if (r.Template_ID == TI) then |
| APPEND r.ID to TEMPI and r.Template_ID to TEMPTI; |
| else TEMPI =NULL and TEMPTI =NULL; |
| FUNCTION ARCHTAB |
| Input: List of ID (TEMPI) and List of Template ID (TEMPTI). |
| Output: List of archetype tables containing desired data (TEMPF), Attribute_ID corresponding to attribute in condition part (AI). |
| foreach record q є T do |
| if (q.Attribute_Name IN N) then |
| APPEND CONCAT(q.Archetype_ID, “_”, q.data_Type) to TEMPAT; |
| if (q.Archetype_ID == I) then |
| APPEND CONCAT(q.Archetype_ID, “_”, q.data_Type) to TEMPAR; |
| if (q.Template_ID є TEMPTI) then |
| APPEND CONCAT(q.Archetype_ID, “_”, q.data_Type) to TEMPT; |
| if (q.Attribute_Name ==AN) then |
| NameT = CONCAT(q.Archetype_ID, “_”, q.data_Type) ; |
| AI = Attribute_ID; |
| if (TEMPAT != NULL) then |
| if (TEMPAR != NULL) then |
| if (TEMPT!= NULL) then |
| TEMPF = INTERSECTION(TEMPAT, TEMPAR, TEMPT); |
| else TEMPF = INTERSECTION (TEMPAT , TEMPAR); |
| else if (TEMPT!= NULL) then |
| TEMPF = INTERSECTION (TEMPAT, TEMPT); |
| else TEMPF = TEMPAT ; |
| else if (TEMPAR != NULL) then |
| if (TEMPT!= NULL) then |
| TEMPF = INTERSECTION (TEMPAR, TEMPT); |
| else TEMPF = TEMPAR; |
| else if (TEMPT!= NULL) then |
| TEMPF = TEMPT; |
| else TEMPF = NULL; |
| FUNCTION EXTRACT Input: List of ID (TEMPI) and List of archetype tables (TEMPF), Attribute_ID (AI) Output: EAV table containing enquired data (Tout). if (TEMPI == NULL) then foreach record u of table name stored in NameT do if (u.Attribute_ID = AI) && (u.Value OP V) then APPEND u.ID to TEMPI; if (TEMPI != NULL) then if (TEMPF != NULL) then foreach table X whose name lies IN TEMPF foreach record s є X do if (s.ID IN TEMPI ) && (s.Attribute_ID IN N) then APPEND s to Tout; else foreach table X whose name lies IN TEMPF do foreach record s є X do if (s.ID IN TEMPI ) then APPEND s to Tout; else if (TEMPF != NULL) then foreach table X whose name lies IN TEMPF foreach record s є X do if (s.Attribute_ID IN N) then APPEND s to Tout; else foreach table X whose name lies IN TEMPF foreach record s є X do APPEND s to Tout; |
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Field | Field Data Type | SQL Type |
|---|---|---|---|
| CodePhrase | codeString | String | NVARCHAR |
| DvBoolean | Value | Boolean | INTEGER |
| DvCodedText | definingCode | CodePhrase | # |
| DvCount | magnitude | Integer | INTEGER |
| DvDateTime | Value | String | NVARCHAR |
| DvEHRURI | Value | URI | NVARCHAR |
| DvIdentifier | Id | String | NVARCHAR |
| DvMultimedia | uri | DvURI | # |
| DvProportion | precision | Integer | INTEGER |
| DvQuantity | magnitude | Double | FLOAT |
| Units | String | NVARCHAR | |
| DvText | Value | String | NVARCHAR |
| DvURI | Value | URI | NVARCHAR |
| GenricID | Value | String | NVARCHAR |
| Name | String | NVARCHAR | |
| Link | Target | DvEHRURI | # |
- Entity Integrity: Every record stored in the 2D EAV database is uniquely identified by a combination of ID and Attribute_ID. In other words, the ID and Attribute_ID columns in Archetype Tables compose a PRIMARY KEY. A primary attribute can never be NULL, since 2D EAV is built for storing non-null values.
- Domain Integrity: 2D EAV is defined for archetype based system. Domain constraints are well defined in archetypes. Any data entered in the system conforms to the semantics of constraints specified in AM and RM.
- Referential Integrity: References are made from the Master table to the various Archetype tables, where the ID column serves as the primary key.
Appendix C. Archetypes Used in Data Collection
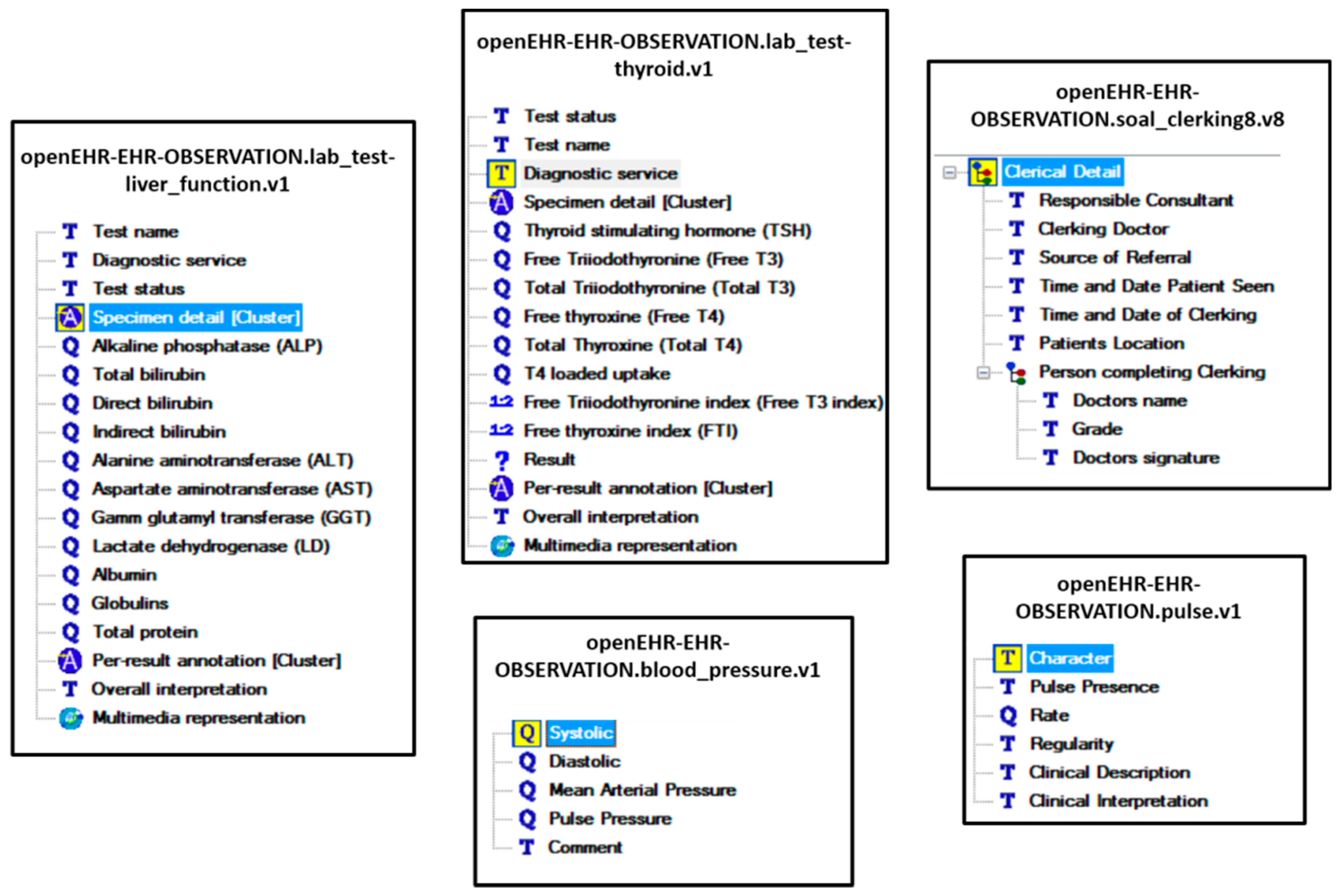
- Four TEXT attributes, eleven QUANTITY attributes, one MULTIMEDIA attribute, and two CLUSTERS are present in openEHR openEHR-EHRs-OBSERVATION.lab_test-liver_function.v1archetype.
- Four TEXT attributes, six QUANTITY attributes, one MULTIMEDIA attribute, and two CLUSTERS are present in openEHR-EHRs-OBSERVATION.lab_test-thyroid.v1 archetype.
- One TEXT attribute, and four QUANTITY attributes are present in openEHR-EHRs-OBSERVATION.blood_pressure.v1 archetype.
- Five TEXT attributes, and one QUANTITY attribute is present in openEHR-EHRs-OBSERVATION.pulse.v1 archetype.
- Six TEXT attributes, and one COMPOSITION attribute (containing 3 TEXT attributes) is present in openEHR-EHRs-OBSERVATION.soap_clerking8.v8 archetype.

Appendix D. Modified EAV for Experimentation

Appendix E
| Type | # | Query Description |
|---|---|---|
| Patient-centric | Q1 | List records of patient with Patient_ID 1004 |
| Q2 | List records of patient with Patient_ID 924 | |
| Q3 | List records of patient with Patient_ID 14306 | |
| Q4 | List records of patient with Patient_ID 14 | |
| Q5 | List records of patient with Patient_ID 5126 | |
| Attribute-centric | Q6 | List all stored values of systolic pressure |
| Q7 | List all stored values of diastolic pressure | |
| Q8 | List all stored values of Total Thyroxine | |
| Q9 | List all stored values of T4 loaded uptake | |
| Q10 | List all stored values of Albumin | |
| Archetype-centric | Q11 | List all blood pressure archetype records |
| Q12 | List all liver archetype records | |
| Q13 | List all thyroid archetype records | |
| Q14 | List all liver and thyroid archetype records | |
| Q15 | List all blood pressure and liver archetype records | |
| Template-centric | Q16 | List all records having Template_ID 18 |
| Q17 | List all records having Template_ID 25 | |
| Q18 | List all records having Template_ID 1 | |
| Q19 | List all records having Template_ID 13 | |
| Q20 | List all records having Template_ID 8 | |
| Hybrid (Patient + Attribute) | Q21 | List Thyroid stimulating hormone of the patient with Patient_ID 927 |
| Q22 | List Systolic pressure of the patient with Patient_ID 15003 | |
| Q23 | List Diastolic pressure of the patient with Patient_ID 14969 | |
| Q24 | List Alkaline Phosphatase of the patient with Patient_ID 5 | |
| Q25 | List Test Name of the patient with Patient_ID 556 | |
| Hybrid (Patient + Archetype + Template) | Q26 | List all Blood Pressure archetype records of the patient with Patient_ID 14987 and Template 25 |
| Q27 | List all Blood Pressure archetype records of the patient with Patient_ID 15384 and Template 25 | |
| Q28 | List all Thyroid archetype records of the patient with Patient_ID 6209 and Template 10 | |
| Q29 | List all Liver archetype records of the patient with Patient_ID 590 and Template 1 | |
| Q30 | List all Liver archetype records of the patient with Patient_ID 561 and Template 3 | |
| Hybrid (Patient + Attribute + Archetype+ Template) | Q31 | List the Alkaline Phosphatase for Template_ID 1, Archetype Liver and Patient_ID 606 |
| Q32 | List the Globulins for Template_ID 3, Archetype Liver and Patient_ID 432 | |
| Q33 | List the Result for Template_ID 17, Archetype Thyroid and Patient_ID 11833 | |
| Q34 | List the Comment for Template_ID 25, Archetype Blood Pressure and Patient_ID 14938 | |
| Q35 | List the Comment for Template_ID 25, Archetype Blood Pressure and Patient_ID 15008 | |
| Hybrid (2 Same) | Q36 | List the systolic pressure of patients with diastolic pressure >90 |
| Q37 | List the systolic and diastolic pressure of patients with comment as Hypotension | |
| Q38 | List records belonging to Blood Pressure archetype or Liver archetype | |
| Q39 | List records belonging to Template_ID 1 or Template_ID 3 | |
| Q40 | List records of patients with Patient_ID > 14942 and Patient _ID < 15293 |
Appendix F. Sample Query Set for Experiment
| Query No. | MongoDB | EAV | 2D EAV |
|---|---|---|---|
| Q1 | db.mycol.find({“Patient_ID” :1004}) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV WHERE Patient_ID = 1004; | SELECT Thyroid_Text.ATTRIBUTE_ID, Thyroid_Text.VALUE FROM Thyroid_Text WHERE Thyroid_Text.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Patient_ID = 1004) UNION SELECT Thyroid_Numeric.ATTRIBUTE_ID CAST (Thyroid_Numeric.VALUEAS character(8)) FROM Thyroid_Numeric WHERE Thyroid_Numeric.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Patient_ID = 1004); |
| Q6 | db.mycol.find({}, {“Systolic” :1}) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV, Metadata WHERE Attribute_ID = Metadata.Attribute_ID AND Metadata.Attribute_Name = ‘Systolic’; | SELECT BP_Numeric.PATIENT_ID, BP_Numeric.ATTRIBUTE_ID, BP_Numeric.VALUE FROM BP_Numeric WHERE BP_Numeric.ATTRIBUTE_ID IN (SELECT TemplateTable.Attribute_ID FROM TemplateTable WHERE TemplateTable.Attribute_Name = ‘Systolic’); |
| Q11 | db.mycol.find({“TestName”: “BP”}, {“Systolic” :1, “Diastolic” :1, “MeanArterial” :1, “PulsePressure”:1, “Comment”:1 }) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV WHERE Archetype_ID = ‘BP’; | SELECT BP_Numeric.PATIENT_ID, BP_Numeric.ATTRIBUTE_ID, BP_Numeric.VALUE FROM BP_Numeric UNION SELECT BP_Text.PATIENT_ID, BP_Text.ATTRIBUTE_ID, BP_Text.VALUE FROM BP_Text; |
| Q16 | db.mycol.find({TestName :“‘Thyroid’”}, {“ Patient_ID” :1, “Result” :1 }) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV WHERE Template_ID = 18; | SELECT Thyroid_Text.PATIENT_ID, Thyroid_Text.ATTRIBUTE_ID, Thyroid_Text.VALUE FROM Thyroid_Text WHERE Thyroid_Text.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Template_ID = ‘18′); |
| Q21 | db.mycol.find({“Patient_ID” : 927}, {“Patient_ID” :1, “ThyroidStimulaingHormone” :1 }) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV, Metadata WHERE Attribute_ID = Metadata.Attribute_ID AND Patient_ID = 927 AND Metadata.Attribute_Name = ‘Thyroid stimulaing hormone’; | SELECT Thyroid_Numeric.PATIENT_ID, Thyroid_Numeric.ATTRIBUTE_ID, Thyroid_Numeric.VALUE FROM Thyroid_Numeric WHERE Thyroid_Numeric.ATTRIBUTE_ID IN (SELECT TemplateTable.Attribute_ID FROM TemplateTable WHERE TemplateTable.Attribute_Name = ‘Thyroid stimulating hormone’) AND Thyroid_Numeric.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Patient_ID = 927); |
| Q26 | db.mycol.find({“TestName”: “BP”, “Patient_ID” : 14987}, {“Patient_ID”:1, “Systolic” :1, “Diastolic” :1, “Comment”:1 }) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV WHERE Archetype_ID = ‘BP’ AND Patient_ID = 14987 AND Template_ID = 25; | SELECT BP_Numeric.PATIENT_ID, BP_Numeric.ATTRIBUTE_ID, BP_Numeric.VALUE FROM BP_Numeric WHERE BP_Numeric.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Patient_ID = 14987 AND MasterTable.Template_ID = ‘25′) UNION SELECT BP_Text.PATIENT_ID, BP_Text.ATTRIBUTE_ID, BP_Text.VALUE FROM BP_Text WHERE BP_Text.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Patient_ID = 14987 AND MasterTable.Template_ID = ‘25′); |
| Q31 | db.mycol.find({“TestName”: “Liver”, “Patient_ID” : 606}, {“AlkalinePhosphatase”:1}) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV, Metadata WHERE Attribute_ID = Metadata.Attribute_ID AND Archetype_ID = ‘Liver’ AND Patient_ID = 601 AND Template_ID = 1 AND Metadata.Attribute_Name = ‘Alkaline Phosphatase’; | SELECT Liver_Numeric.PATIENT_ID, Liver_Numeric.ATTRIBUTE_ID, Liver_Numeric.VALUE FROM Liver_Numeric WHERE Liver_Numeric.PATIENT_ID IN (SELECT MasterTable.ID FROM MasterTable WHERE MasterTable.Patient_ID = 601 AND MasterTable.Template_ID = ‘1′) AND Liver_Numeric.ATTRIBUTE_ID IN (SELECT TemplateTable.Attribute_ID FROM TemplateTable WHERE TemplateTable.Attribute_Name = ‘Alkaline Phosphatase’); |
| Q36 | db.mycol.find({“Diastolic”:{$gt:90}}, {“Systolic” :1}) | SELECT Patient_ID, Attribute_ID, Value_Real, Value_String FROM EAV, Metadata WHERE Patient_ID IN (SELECT Patient_ID FROM EAV, Metadata WHERE Attribute_ID = Metadata.Attribute_ID AND Metadata.Attribute_Name = ‘Diastolic’ AND Value_Real > 90.00) AND Attribute_ID = Metadata.Attribute_ID AND Metadata.Attribute_Name = ‘Systolic’; | SELECT BP_Numeric.PATIENT_ID, BP_Numeric.ATTRIBUTE_ID, BP_Numeric.VALUE FROM BP_Numeric WHERE BP_Numeric.PATIENT_ID IN (SELECT BP_Numeric.PATIENT_ID FROM BP_Numeric WHERE BP_Numeric.ATTRIBUTE_ID IN (SELECT TemplateTable.Attribute_ID FROM TemplateTable WHERE TemplateTable.Attribute_Name = ‘Diastolic’) AND BP_Numeric.VALUE > 90) AND BP_Numeric.ATTRIBUTE_ID IN (SELECT TemplateTable.Attribute_ID FROM TemplateTable WHERE TemplateTable.Attribute_Name = ‘Systolic’); |
References
- Dinu, V.; Nadkarni, P. Guidelines for the effective use of entity–attribute–value modeling for biomedical databases. Int. J. Med. Inform. 2007, 76, 769–779. [Google Scholar] [CrossRef] [PubMed]
- Ramakrishnan, R.; Gehrke, J. Database Management Systems; McGraw Hill: New York, NY, USA, 2000. [Google Scholar]
- Agrawal, R.; Somani, A.; Xu, Y. Storage and Querying of E-Commerce Data; VLDB: Roma, Italy, 2001; Volume 1, pp. 149–158. [Google Scholar]
- Chu, E.; Beckmann, J.; Naughton, J. The case for a wide-table approach to manage sparse relational data sets. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 821–832. [Google Scholar]
- Beckmann, J.L.; Halverson, A.; Krishnamurthy, R.; Naughton, J.F. Extending RDBMSs to support sparse datasets using an interpreted attribute storage format. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 58. [Google Scholar]
- Copeland, G.P.; Khoshafian, S.N. A decomposition storage model. ACM SIGMOD Rec. 1985, 14, 268–279. [Google Scholar] [CrossRef]
- Freire, S.M.; Sundvall, E.; Karlsson, D.; Lambrix, P. Performance of xml databases for epidemiological queries in archetype-based ehrs. In Proceedings of the Scandinavian Conference on Health Informatics 2012, Linköping, Sweden, 2–3 October 2012; Linköping University Electronic Press: Linköping, Sweden, 2012. No. 070. pp. 51–57. [Google Scholar]
- Node+Path Persistence. Available online: https://openehr.atlassian.net/wiki/pages/viewpage.action?pageId=6553626 (accessed on 18 February 2016).
- Wang, L.; Min, L.; Wang, R.; Lu, X.; Duan, H. Archetype relational mapping-a practical openEHR persistence solution. BMC Med. Inform. Decis. Mak. 2015, 15, 88. [Google Scholar] [CrossRef] [PubMed]
- Corwin, J.; Silberschatz, A.; Miller, P.L.; Marenco, L. Dynamic tables: An architecture for managing evolving, heterogeneous biomedical data in relational database management systems. J. Am. Med. Inform. Assoc. 2007, 14, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Luo, G.; Frey, L.J. Efficient execution methods of pivoting for bulk extraction of Entity-Attribute-Value-modeled data. IEEE J. Biomed. Health Inform. 2016, 20, 644–654. [Google Scholar] [CrossRef] [PubMed]
- Duftschmid, G.; Wrba, T.; Rinner, C. Extraction of standardized archetyped data from Electronic Health Record Systems based on the Entity-Attribute-Value Model. Int. J. Med. Inform. 2010, 79, 585–597. [Google Scholar] [CrossRef] [PubMed]
- Johnson, S. Generic data modeling for clinical repositories. J. Am. Med. Inform. Assoc. 1996, 3, 328–339. [Google Scholar] [CrossRef] [PubMed]
- Abadi, D.J.; Marcus, A.; Madden, S.R.; Hollenbach, K. SW-Store: A vertically partitioned DBMS for Semantic Web data management. VLDB J. 2009, 18, 385–406. [Google Scholar] [CrossRef]
- Stead, W.; Hammond, W.; Straube, M. A chartless record—Is it adequate? J. Med. Syst. 1983, 7, 103–109. [Google Scholar] [CrossRef] [PubMed]
- Warner, H.; Olmsted, C.; Rutherford, B. HELP—A program for medical decision making. Comput. Biomed. Res. 1972, 5, 65–74. [Google Scholar] [CrossRef]
- Pryor, T. The HELP medical record system. MD Comput. 1988, 5, 22–33. [Google Scholar] [PubMed]
- Huff, S.M.; Haug, D.J.; Stevens, L.E.; Dupont, C.C.; Pryor, T.A. HELP the next generation: A new clientserver architecture. In Proceedings of the 18th Symposium on Computer Applications in Medical Care, Washington, DC, USA, 5–9 November 1994; IEEE Computer Press: Los Alamitos, CA, USA, 1994; pp. 271–275. [Google Scholar]
- Nadkarni, P.M.; Brandt, C.; Frawley, S.; Sayward, F.G.; Einbinder, R.; Zelterman, D.; Schacter, L.; Miller, P.L. Managing attribute-value clinical trials data using the ACT/DB client—Server database system. J. Am. Med. Inform. Assoc. 1998, 5, 139–151. [Google Scholar] [CrossRef] [PubMed]
- Brandt, C.; Nadkarni, P.; Marenco, L.; Karras, B.T.; Lu, C.; Schacter, L.; Fisk, J.M.; Miller, P.L. Reengineering a database for clinical trials management: Lessons for system architects. Control. Clin. Trials 2000, 21, 440–461. [Google Scholar] [CrossRef]
- Nadkarni, P.M.; Marenco, L.; Chen, R.; Skoufos, E.; Shepherd, G.; Miller, P. Organization of Heterogeneous Scientific Data Using the EAV/CR Representation. J. Am. Med. Inform. Assoc. 1999, 6, 478–493. [Google Scholar] [CrossRef] [PubMed]
- Shepherd, G.M.; Healy, M.D.; Singer, M.S.; Peterson, B.E.; Mirsky, J.S.; Wright, L.; Smith, J.E.; Nadkarni, P.M.; Miller, P.L. Senselab: A project in multidisciplinary, multilevel sensory integration. In Neuroinformatics: An Overview of the Human Brain Project; Koslow, S.H., Huerta, M.F., Eds.; Lawrence Erlbaum Associates, Inc.: Mahwah, NJ, USA, 1997; pp. 21–56. [Google Scholar]
- Marenco, L.; Nadkarni, P.; Skoufos, E.; Shepherd, G.; Miller, P. Neuronal database integration: The Senselab EAV data model. In Proceedings of the AMIA Symposium, Washington, DC, USA, 6–10 November 1999; pp. 102–106. [Google Scholar]
- Oracle Health Sciences Clintrial|Oracle. Available online: http://www.oracle.com/us/industries/life-sciences/health-sciences-clintrial-363570.html (accessed on 10 August 2016).
- Oracle Clinical—Overview|Oracle. Available online: http://www.oracle.com/us/products/applications/health-sciences/e-clinical/clinical/index.html (accessed on 14 August 2016).
- Oracle Designer Product Information. Available online: http://www.oracle.com/technetwork/developer-tools/designer/overview/index-082236.html (accessed on 14 August 2016).
- Kalido—Home. Available online: http://kalido.com/ (accessed on 14 August 2016).
- Evans, R.S.; Lloyd, J.F.; Pierce, L.A. Clinical use of an enterprise data warehouse. In Proceedings of the AMIA Annual Symposium Proceedings, Chicago, IL, USA, 3–7 November 2012; Volume 2012, p. 189. [Google Scholar]
- Entity–Attribute–Value Model—Wikipedia. Available online: https://en.wikipedia.org/wiki/Entity%E2%80%93attribute%E2%80%93value_model (accessed on 12 September 2017).
- Paraiso-Medina, S.; Perez-Rey, D.; Bucur, A.; Claerhout, B.; Alonso-Calvo, R. Semantic normalization and query abstraction based on SNOMED-CT and HL7: Supporting multicentric clinical Trials. IEEE J. Biomed. Health Inform. 2015, 19, 1061–1067. [Google Scholar] [CrossRef] [PubMed]
- OpenEHR Community. Available online: http://www.openehr.org/ (accessed on 10 October 2016).
- CEN—European Committee for Standardization: Standards. Available online: http://www.cen.eu/CEN/Sectors/TechnicalCommitteesWorkshops/CENTechnicalCommittees/Pages/Standards.aspx?param=6232&title=CEN/TC+251 (accessed on 11 July 2016).
- ISO 13606-1. Health Informatics: Electronic Health Record Communication. Part 1: RM, 1st ed.; International Organization for Standardization (ISO): Geneva, Switzerland, 2008. [Google Scholar]
- ISO 13606-2. Health Informatics: Electronic Health Record Communication. Part 2: Archetype Interchange Specification, 1st ed.; International Organization for Standardization (ISO): Geneva, Switzerland, 2008. [Google Scholar]
- HL7. Health Level 7. Available online: www.hl7.org (accessed on 23 October 2013).
- Beale, T.; Heard, S. The openEHR architecture: Architecture/overview. In openEHR Release 1.0.2; openEHR Foundation: London, UK, 2008. [Google Scholar]
- Grimson, J.; Grimson, W.; Berry, D.; Stephens, G.; Felton, E.; Kalra, D.; Toussaint, P.; Weier, O.W. A CORBA-based integration of distributed electronic healthcare records using the synapses approach. IEEE Trans. Inf. Technol. Biomed. 1998, 2, 124–138. [Google Scholar] [CrossRef] [PubMed]
- Kobayashi, S.; Kimura, E.; Ishihara, K. Archetype model-driven development framework for EHR web system. Healthc. Inform. Res. 2013, 19, 271–277. [Google Scholar] [CrossRef] [PubMed]
- Trigo, J.D.; Kohl, C.D.; Eguzkiza, A.; Martinez-Espronceda, M.; Alesanco, A.; Serrano, L.; Garcia, J.; Knaup, P. On the seamless, harmonized use of ISO/IEEE11073 and openEHR. IEEE J. Biomed. Health Inform. 2014, 18, 872–884. [Google Scholar] [CrossRef] [PubMed]
- Sachdeva, S.; Bhalla, S. Semantic interoperability in standardized electronic health record databases. J. Data Inf. Qual. (JDIQ) 2012, 3. [Google Scholar] [CrossRef]
- CKM. Clinical Knowledge Manager. Available online: http://www.openehr.org/knowledge/ (accessed on 12 December 2016).
- International Health Terminology Standards Development Organisation. Systematized Nomenclature of Medicine-Clinical Terms (SNOMED CT). Available online: http://www.ihtsdo.org/snomed-ct/ (accessed on 14 September 2016).
- Nadkarni, P. Clinical Research Computing: A Practitioner’s Handbook; Academic Press: Cambridge, MA, USA, 2016; Chapter 3. [Google Scholar]
- Tahara, D.; Diamond, T.; Abadi, D.J. Sinew: A SQL system for multi-structured data. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 22–27 June 2014; pp. 815–826. [Google Scholar]
- Pavlo, A.; Aslett, M. What’s Really New with NewSQL? ACM SIGMOD Rec. 2016, 45, 45–55. [Google Scholar] [CrossRef]
- Cui, B.; Zhao, J.; Yang, D. Exploring correlated subspaces for efficient query processing in sparse databases. IEEE Trans. Knowl. Data Eng. 2010, 22, 219–233. [Google Scholar] [CrossRef]
- Use Sparse Columns|Microsoft Docs. Available online: https://docs.microsoft.com/en-us/sql/relational-databases/tables/use-sparse-columns (accessed on 24 September 2017).
- Abadi, D.J. Column Stores for Wide and Sparse Data; CIDR: Asilomar, CA, USA, January 2007; pp. 292–297. [Google Scholar]
- Larson, P.A.; Clinciu, C.; Fraser, C.; Hanson, E.N.; Mokhtar, M.; Nowakiewicz, M.; Papadimos, V.; Price, S.L.; Rangarajan, S.; Rusanu, R.; et al. Enhancements to SQL server column stores. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1159–1168. [Google Scholar]
- Ailamaki, A.; DeWitt, D.J.; Hill, M.D.; Skounakis, M. Weaving Relations for Cache Performance. In Proceedings of the 27th International Conference on Very Large Data Bases, Rome, Italy, 11–14 September 2001; Volume 1, pp. 169–180. [Google Scholar]
- Ramamurthy, R.; DeWitt, D.J.; Su, Q. A case for fractured mirrors. VLDB J. 2003, 12, 89–101. [Google Scholar] [CrossRef]
- Grund, M.; Krüger, J.; Plattner, H.; Zeier, A.; Cudre-Mauroux, P.; Madden, S. HYRISE: A main memory hybrid storage engine. Proc. VLDB Endow. 2010, 4, 105–116. [Google Scholar] [CrossRef]
- Pinnecke, M.; Broneske, D.; Durand, G.C.; Saake, G. Are Databases Fit for Hybrid Workloads on GPUs? A Storage Engine’s Perspective. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 1599–1606. [Google Scholar]
- Bornhoevd, C.; Werner, H. Dynamic Database Schemas for Highly Irregularly Structured or Heterogeneous Data. U.S. Patent 8,352,510, 8 January 2013. [Google Scholar]
- Baumgartner, C.; Plant, C.; Railing, K.; Kriegel, H.P.; Kroger, P. Subspace selection for clustering high-dimensional data. In Proceedings of the Fourth IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004; pp. 11–18. [Google Scholar]
- Zhang, D.; Chee, Y.M.; Mondal, A.; Tung, A.K.; Kitsuregawa, M. Keyword search in spatial databases: Towards searching by document. In Proceedings of the IEEE 25th International Conference on Data Engineering (ICDE’09), Shanghai, China, 29 March–2 April 2009; pp. 688–699. [Google Scholar]
- Abadi, D.J.; Myers, D.S.; DeWitt, D.J.; Madden, S.R. Materialization strategies in a column-oriented DBMS. In Proceedings of the IEEE 23rd International Conference on Data Engineering (ICDE 2007), Istanbul, Turkey, 15–20 April 2007; pp. 466–475. [Google Scholar]
- Murphy, S.N.; Weber, G.; Mendis, M.; Gainer, V.; Chueh, H.C.; Churchill, S.; Kohane, I. Serving the enterprise and beyond with informatics for integrating biology and the bedside (i2b2). J. Am. Med. Inform. Assoc. 2010, 17, 124–130. [Google Scholar] [CrossRef] [PubMed]
- Deshmukh, V.G.; Meystre, S.M.; Mitchell, J.A. Evaluating the informatics for integrating biology and the bedside system for clinical research. BMC Med. Res. Methodol. 2009, 9, 70. [Google Scholar] [CrossRef] [PubMed]
- Haarbrandt, B.; Tute, E.; Marschollek, M. Automated population of an i2b2 clinical data warehouse from an openEHR-based data repository. J. Biomed. Inform. 2016, 63, 277–294. [Google Scholar] [CrossRef] [PubMed]
- Ramachandran, R.; Nair, D.P.; Jasmi, J. A horizontal fragmentation method based on data semantics. In Proceedings of the 2016 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Chennai, India, 15–17 December 2016; pp. 1–5. [Google Scholar]
- OpenEHR—Wikipedia. Available online: https://en.wikipedia.org/wiki/OpenEHR (accessed on 10 December 2016).
- Ocean Informatics. Available online: https://code4health.org/_attachment/modellingintro/2015_11_Modelling_Intro.pdf (accessed on 10 December 2016).
- Poll Results—Top 10 Archetypes for Use in an Emergency—Health Information Model—openEHR Wiki. Available online: https://openehr.atlassian.net/wiki/display/healthmod/Poll+Results+Top+10+archetypes+for+use+in+an+Emergency (accessed on 10 December 2016).
- openEHR-Modelling Tools. Available online: http://www.openehr.org/downloads/modellingtools (accessed on 10 December 2016).
- Batra, S.; Sachdeva, S.; Mehndiratta, P.; Parashar, H.J. Mining standardized semantic interoperable electronic healthcare records. In Biomedical Informatics and Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 179–193. [Google Scholar]
- CNET Networks, Inc. CNET Product Directory. Available online: http://shopper.cnet.com/4296-3000_9-0-0-0.html (accessed on 12 September 2016).
- UCI Machine Learning Repository: Liver Disorders Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Liver+Disorders (accessed on 12 September 2016).
- UCI Machine Learning Repository: Thyroid Disease Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/Thyroid+Disease (accessed on 12 September 2016).
- The Facts about High Blood Pressure—American Heart Association. Available online: http://www.heart.org/HEARTORG/Conditions/HighBloodPressure/GettheFactsAboutHighBloodPressure/The-Facts-About-High-Blood-Pressure_UCM_002050_Article.jsp#.WSpqPGiGPIU (accessed on 12 September 2016).
- DB-Engines Ranking—Popularity Ranking of Database Management Systems. Available online: http://db-engines.com/en/ranking (accessed on 15 November 2017).
- Our Customers|MongoDB. Available online: https://www.mongodb.com/who-uses-mongodb (accessed on 15 November 2017).
- Beale, T.; Heard, S. The openEHR Archetype Model—Archetype Definition Language ADL 1.4. In openEHR Release 1.0.2; openEHR Foundation: London, UK, 2008. [Google Scholar]








| Persistence Approach | Modeling Level | Advantage | Limitation |
|---|---|---|---|
| Object Relational Model (ORM) [7] | Reference Model | Simple process of creating tables for classes defined in RM. Also, stable in nature since, RM is stable. | Deep hierarchy present in openEHR RM structure complicates the ORM scenario. |
| XML, JSON, & Node+Path (using BLOB) [8] | Reference Model | BLOB is used to denote the hierarchy in form of path. | Complicated paths that consume more space as well as cause delay in data access. |
| Archetype Relational Mapping (ARM) [9] | Archetype | One relational table is created corresponding to one archetype. | Schema evolution requires efforts from schema designer to modify schema and thus, changes in application code. |
| S.No. | Storage Variant | Load Time (Milliseconds) | Size (MB) |
|---|---|---|---|
| 1 | EAV | 6462 | 98.6 |
| 2 | MongoDB | 60,000 | 28.5 |
| 3 | 2D EAV | 5800 | 63.2 |
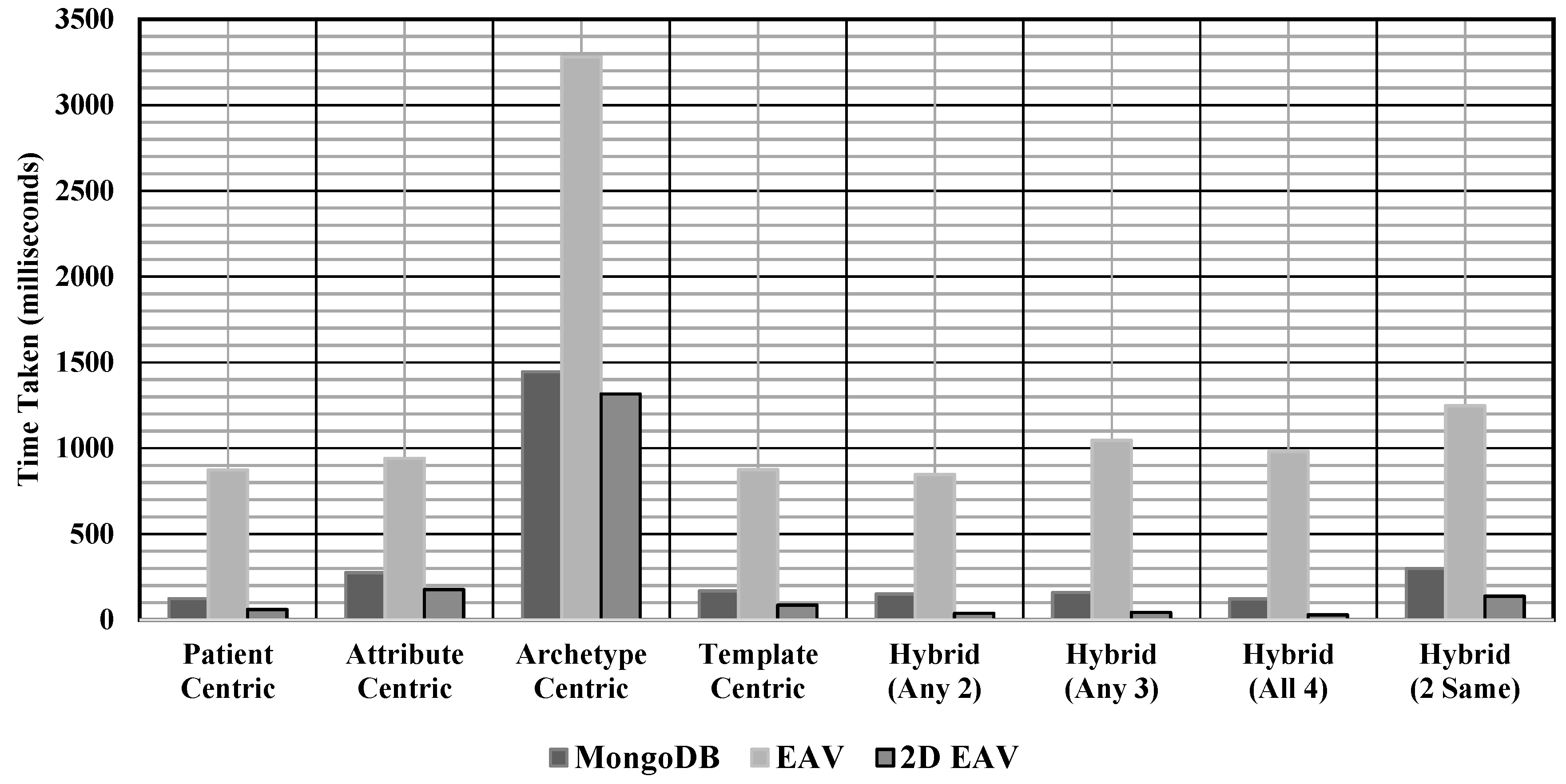
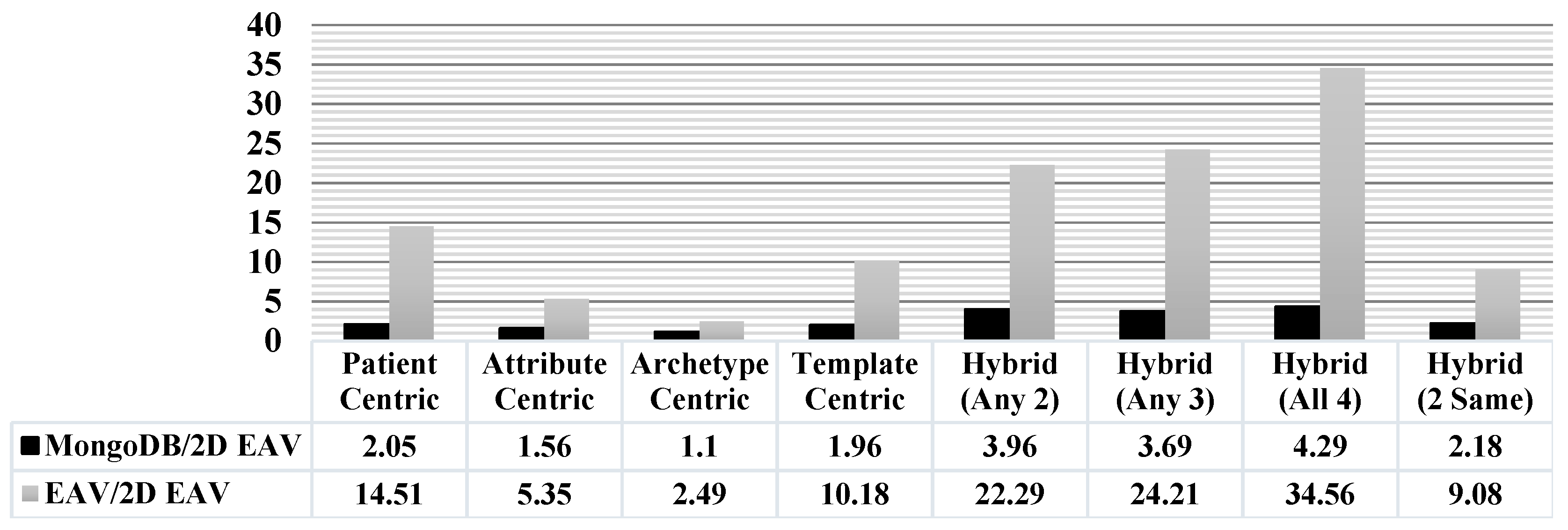
| S.No. | Query Category | Data Access Time (Milliseconds) | ||
|---|---|---|---|---|
| EAV | MongoDB | 2D EAV | ||
| 1 | Patient Centric | 873.8 | 123.6 | 60.2 |
| 2 | Attribute Centric | 941.4 | 274.2 | 176 |
| 3 | Archetype Centric | 3280 | 1446 | 1315.8 |
| 4 | Template Centric | 875.2 | 168.4 | 86 |
| 5 | Hybrid (Any 2) | 847 | 150.4 | 38 |
| 6 | Hybrid (Any 3) | 1045.8 | 159.4 | 43.2 |
| 7 | Hybrid (All 4) | 981.6 | 121.8 | 28.4 |
| 8 | Hybrid (2 Same) | 1013.6 | 299.8 | 137.4 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Batra, S.; Sachdeva, S.; Bhalla, S. Entity Attribute Value Style Modeling Approach for Archetype Based Data. Information 2018, 9, 2. https://doi.org/10.3390/info9010002
Batra S, Sachdeva S, Bhalla S. Entity Attribute Value Style Modeling Approach for Archetype Based Data. Information. 2018; 9(1):2. https://doi.org/10.3390/info9010002
Chicago/Turabian StyleBatra, Shivani, Shelly Sachdeva, and Subhash Bhalla. 2018. "Entity Attribute Value Style Modeling Approach for Archetype Based Data" Information 9, no. 1: 2. https://doi.org/10.3390/info9010002
APA StyleBatra, S., Sachdeva, S., & Bhalla, S. (2018). Entity Attribute Value Style Modeling Approach for Archetype Based Data. Information, 9(1), 2. https://doi.org/10.3390/info9010002