Efficient Public Key Encryption with Disjunctive Keywords Search Using the New Keywords Conversion Method


Abstract
:1. Introduction
- (1)
- A new method for converting the index and query keywords into a vector space model is proposed. The dimension of the vectors generated by the proposed method is more small than that generated by the previous methods. Moreover, our scheme is based on an equation of degree n with one unknown. The coefficients of this equation is composed of the index keyword set, while the roots of this equation is composed of the query keyword set. The coefficients and roots create the attribute vectors and predicate vectors, respectively. Thus, our method can easily be combined with other techniques, such as IPE scheme and composite bilinear order groups. By combining the new approach with an efficient IPE scheme, we propose a more efficient IPE-based PEDK scheme with a better time and space complexity (We denote this PEDK scheme by PEDK-1).
- (2)
- We also demonstrate that a construction of PEDK does not rely on IPE. Applying techniques of dual system encryption and composite order group, a new PEDK scheme without IPE, denoted by PEDK-2, is given. We show that this scheme can largely reduce the complexity of index building and key generation compared with our former proposal.
2. Preliminaries
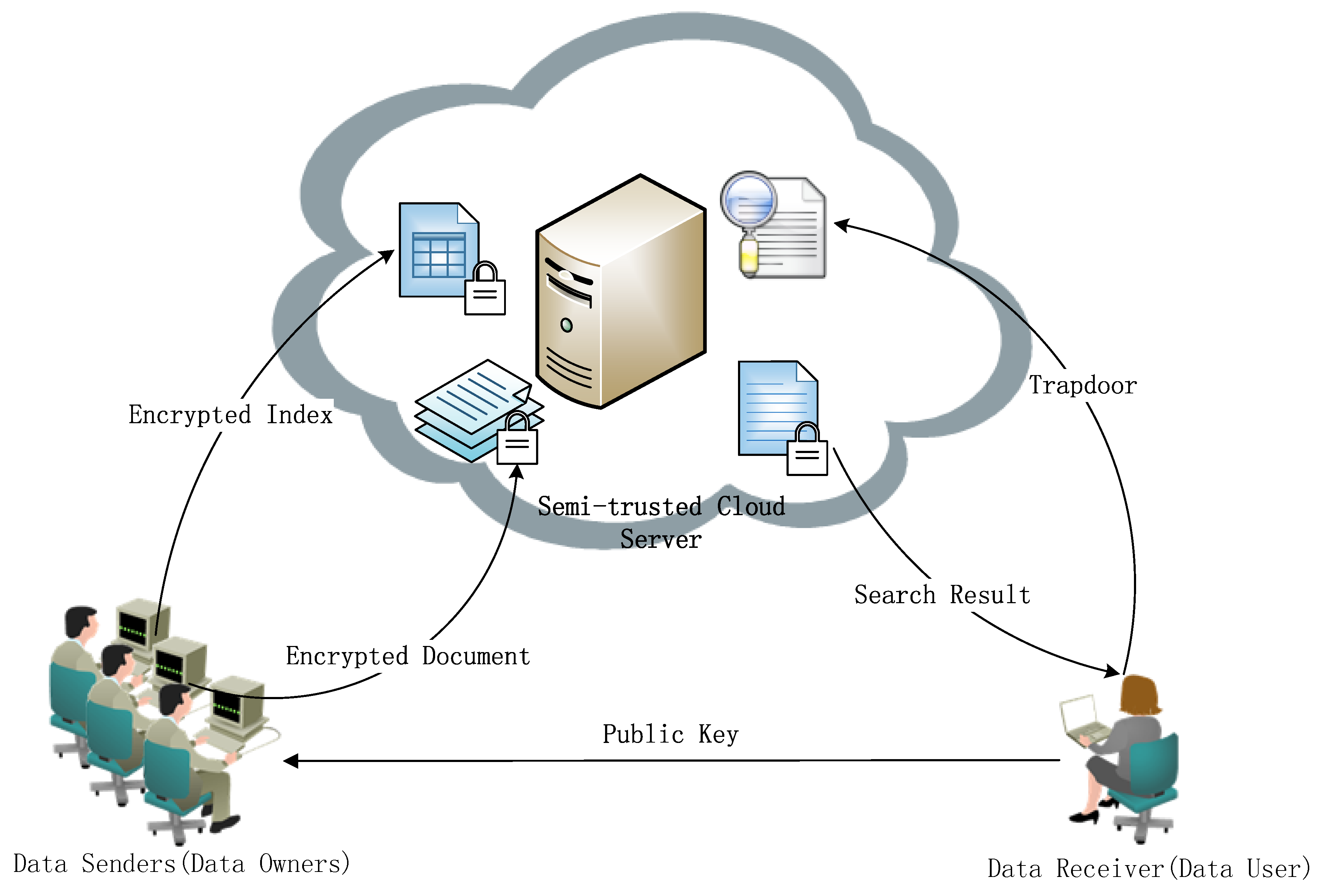
2.1. Model of PEDK
- (1)
- KeyGen(γ): The algorithm takes a security parameter γ as input, and outputs a key pair , where “pk” and “sk” represent public key and secret key, respectively.
- (2)
- IndexBuild(pk,W): By taking advantage of “pk” and a keyword set , the sender applies the algorithm to create an encrypted index .
- (3)
- Trapdoor(sk,Q): By utilizing the keyword query and “sk”, the receiver adopts this algorithm to generate a trapdoor , where .
- (4)
- Test(pk, , ): The server executes this algorithm to test whether the encrypted index and the trapdoor contain at least one same keyword. It takes , and “pk” as input. If , then it outputs 1; otherwise, 0 .
2.2. Security Definition of PEDK
- (1)
- Setup: The challenger C performs the KeyGen() algorithm to generate and . Then, C sends to the attacker A.
- (2)
- Phase 1: The attacker A can adaptively ask C for any trapdoor of query Q he wants.
- (3)
- Challenge: A randomly chooses two keyword sets and , and gives them to C. Suppose that are the keyword sets which are queried to construct trapdoors in phase 1, where t is the number of trapdoors queried in phase 1, there is a restriction in which and for each . Then, C picks a random bit , and creates . After that, A sends to A.
- (4)
- Phase 2: Under the restriction mentioned above, A can continue to issue any query Q he wants. C responds the corresponding trapdoor.
- (5)
- Response: A outputs . If , then A wins the game.
2.3. Composite Order Bilinear Groups and Complexity Assumption
- Bilinear: ,where and ;
- Non-degenerate: is a generator of if g is a generator of G;
- Computable: For any , an efficient algorithm must exist to compute .
3. Proposed PEDK Schemes
3.1. Conversion Method
- (1)
- For the keyword set , constructing a function:According to the coefficient of the , a vector can be obtained.
- (2)
- For each keyword in the keyword set Q, we construct , and output a vector set .
3.2. PEDK-1
- -
- KeyGen: it runs to generate a key pair , and then sets and .
- -
- IndexBuild: For the keyword set W, it uses the Equation (2) to create an vector . After this, it outputs as the index of W. Note that it sets the to 1.
- -
- Trapdoor: For the query Q, it generates a group of vectors . By applying to each vector, it creates a trapdoor , where and .
- -
- Test: Given and , it runs for each . If there is at least one such that outputs 1, then it outputs 1. Otherwise, it outputs 0.
3.3. PEDK-2
- -
- KeyGen: Randomly selecting a bilinear group G of order (where ,,, are distinct primes), , and and where , pk is published as:The secret key is where is a generator of .
- -
- IndexBuild: Given a keyword set , the algorithm uses the Equation (2) to create an vector . Choosing random elements , for the vector , the encryption algorithm creates the index as:where and .
- -
- Trapdoor: Given a keyword set where , the trapdoor generation algorithm chooses and generates random elements where , and by using and raising it to the random exponents modulo N. Then, it chooses random elements and two random orthogonal vector bases , and in which whenever and for all where is a random elements in . Suppose that and where , it computes:where . The trapdoor of keyword set Q is :
- -
- Test: After receiving a trapdoor and a secure index , the algorithm works as follows:
- (a)
- The algorithm computes for each .
- (b)
- Choosing a counter k, and setting .
- (c)
- If , then go to step d), otherwise the algorithm computes: . If , then the algorithm outputs 1 and ends. Otherwise, it sets and goes to the step c).
- (d)
- The algorithm outputs 0 and ends.
4. Security Analysis
4.1. Security of PEDK-1
4.2. Security of PEDK-2
- This game is the original security game.
- Suppose that the keyword set is one of the challenge keyword sets. We construct an n-degree polynomial . This game is identical to the real game except that the attacker is not allowed to obtain a trapdoor in which the corresponding keyword set does not contain any keyword w which satisfies . This restriction will be kept throughout the following games.
- For each , we define identical to except that A is given the semi-functional index. Moreover, the first k trapdoors are semi-functional and the rest are normal. In , the trapdoors sent to A are normal, but the index is semi-functional. In , both trapdoor and index are in the semi-functional form.
- Letting the keyword set be one of the challenge keyword sets, we construct an n-degree polynomial mentioned above. Compared with , the index in this game is a semi-functional encryption of a challenge vector that its first k elements are random and the rest of the elements are , where .
5. Performance Evaluation
5.1. Theoretical Analysis
5.2. Experimental Results
- (1)
- Figure 3a–c show that the execution time of key generation, index building and trapdoor generation is linear with in PEDK-1, while in PEDK-2. Since the PEDK-1 scheme is based on the dual pairing vector space DPVS, the PEDK-2 has a better performance in the key generation, index building and trapdoor generation phase; and
- (2)
- Figure 3d indicate that the running time of testing in PEDK-1 and PEDK-2 is linear with , and the time cost in PEDK-2 is nearly four times more than that in PEDK-1 since the pairing operations in a composite group are more time-consuming than that in a prime one.
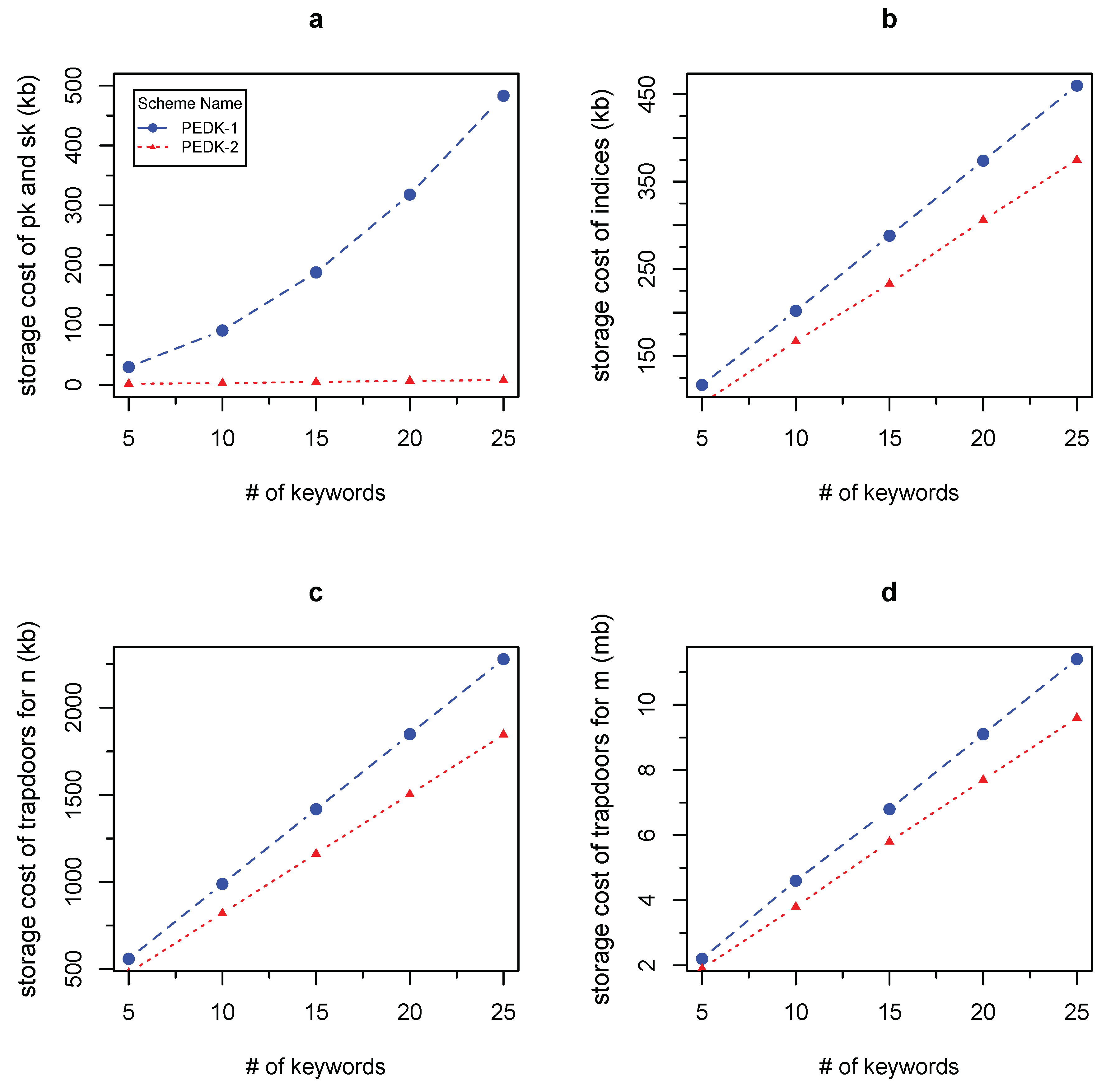
- (1)
- Figure 5a–c show the impact of n on the storage size of keys (pk and sk), indices and trapdoors. Figure 5a verifies that the storage size of keys is linear with in PEDK-1, while in PEDK-2. Given a fixed parameter m, Figure 5b,c show that the storage size of indices and trapdoors is linear with , and PEDK-2 needs less space overhead than PEDK-1 since PEDK-2 needs less group elements in the index and trapdoor.
- (2)
- Because the parameter m only affects the phases of trapdoor and test, we only present Figure 5d to show the impact of m on the storage size of trapdoors. Given a fixed parameter n, both the trapdoor size in PEDK-1 and that in PEDK-2 are linear with . Due to owning less elements in the trapdoor, the space consumption in PEDK-2 is still less than that in PEDK-1.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| PECK | Public key encryption with conjunctive keyword search |
| PEDK | Public key encryption with disjunctive keyword search |
| PECDK | Public key encryption with conjunctive and disjunctive keyword search |
| IPE | Inner product encryption |
| SE | Searchable encryption |
| SSE | Searchable symmetric key encryption |
| SPE | Searchable public key encryption |
| PK | Public key |
| SK | Secret key |
| DPVS | Dual pairing vector space |
| XYNU | Xinyang normal university |
Appendix A
- Case 1: divides b,
- Case 2: can not divide b and can divide b,
- Case 3: and .
References
- Park, D.J.; Kim, K.; Lee, P.J. Public Key Encryption with Conjunctive Field Keyword Search. In Proceedings of the 5th International Workshop, WISA 2004, Jeju Island, Korea, 23–25 August 2004; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2004; Volume 3325, pp. 73–86. [Google Scholar]
- Hwang, Y.H.; Lee, P.J. Public Key Encryption with Conjunctive Keyword Search and Its Extension to a Multi-user System. In Proceedings of the First International Conference, Tokyo, Japan, 2–4 July 2007; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2007; Volume 4575, pp. 2–22. [Google Scholar]
- Boneh, D.; Waters, B. Conjunctive, Subset, and Range Queries on Encrypted Data. In Proceedings of the 4th Theory of Cryptography Conference, TCC 2007, Amsterdam, The Netherlands, 21–24 February 2007; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2007; Volume 4392, pp. 535–554. [Google Scholar]
- Katz, J.; Sahai, A.; Waters, B. Predicate encryption supporting disjunctions, polynomial equations, and inner products. J. Cryptol. 2013, 26, 191–224. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, S. POSTER: Efficient Method for Disjunctive and Conjunctive Keyword Search over Encrypted Data. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1535–1537. [Google Scholar]
- Song, D.; Wagner, D.; Perrig, A. Practical Techniques for Searching on Encrypted Data. In Proceedings of the IEEE Symposium on Research in Security and Privacy 2000, Berkeley, CA, USA, 14–17 May 2000; IEEE Computer Society Press: Los Alamitos, CA, USA, 2000; pp. 44–55. [Google Scholar]
- Goh, E.J. Secure indexes. IACR Cryptol. ePrint Arch. 2003, 2003, 216. [Google Scholar]
- Li, J.; Lin, X.; Zhang, Y.; Han, J. KSF-OABE: Outsourced attribute-based encryption with keyword search function for cloud storage. IEEE Trans. Ser. Comput. 2017, 10, 715–725. [Google Scholar] [CrossRef]
- Li, J.; Shi, Y.; Zhang, Y. Searchable Ciphertext-Policy Attribute-Based Encryption with Revocation in Cloud Storage. Int. J. Commun. Syst. 2017, 30, e2942. [Google Scholar] [CrossRef]
- Cash, D.; Jarecki, S.; Jutla, C.; Krawczyk, H.; Roşu, M.C.; Steiner, M. Highly-Scalable Searchable Symmetric Encryption with Support for Boolean Queries. In Proceedings of the 33rd Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2013; pp. 353–373. [Google Scholar]
- Cash, D.; Jaeger, J.; Jarecki, S.; Jutla, C.S.; Krawczyk, H.; Rosu, M.C.; Steiner, M. Dynamic Searchable Encryption in Very-Large Databases: Data Structures and Implementation. Netw. Distrib. Syst. Secur. Symp. 2014, 14, 23–26. [Google Scholar]
- Boldyreva, A.; Chenette, N.; Lee, Y.; O’neill, A. Order-Preserving Symmetric Encryption. In Proceedings of the 28th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cologne, Germany, 26–30 April 2009; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2009; pp. 224–241. [Google Scholar]
- Zerr, S.; Olmedilla, D.; Nejdl, W.; Siberski, W. Zerber+R:top-k retrieval from a confidential index. In Proceedings of the 12th International Conference on Extending Database Technology: Advances in Database Technology, Saint Petersburg, Russia, 24–26 March 2009; pp. 439–449. [Google Scholar]
- Wang, C.; Cao, N.; Ren, K.; Lou, W. Enabling Secure and Efficient Ranked Keyword Search over Outsourced Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1467–1479. [Google Scholar] [CrossRef]
- Fu, Z.; Sun, X.; Liu, Q.; Zhou, L.; Shu, J. Achieving Efficient Cloud Search Services: Multi-Keyword Ranked Search over Encrypted Cloud Data Supporting Parallel Computing. IEICE Trans. Commun. 2015, 98, 190–200. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Sun, X.; Wang, Q. A Secure and Dynamic Multi-Keyword Ranked Search Scheme over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 340–352. [Google Scholar] [CrossRef]
- Boneh, D.; Di Crescenzo, G.; Ostrovsky, R.; Persiano, G. Public Key Encryption with Keyword Search. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2004; Volume 3027, pp. 506–522. [Google Scholar]
- Dan, B.; Franklin, M. Identity-Based Encryption from the Weil Pairing. In Society for Industrial and Applied Mathematics; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Abdalla, M.; Bellare, M.; Catalano, D.; Kiltz, E.; Kohno, T.; Lange, T.; Malone-Lee, J.; Neven, G.; Paillier, P.; Shi, H. Searchable Encryption Revisited: Consistency Properties, Relation to Anonymous IBE, and Extensions. In Proceedings of the 25th Annual International Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2005; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; Volume 3621, pp. 205–222. [Google Scholar]
- Li, J.; Yao, W.; Zhang, Y.; Qian, H.; Han, J. Flexible and fine-grained attribute-based data storage in cloud computing. IEEE Trans. Ser. Comput. 2017, 10, 785–796. [Google Scholar] [CrossRef]
- Lewko, A.; Okamoto, T.; Sahai, A.; Takashima, K.; Waters, B. Fully secure functional encryption: Attribute-based encryption and (hierarchical) inner product encryption. In Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, France, 30 May–3 June 2010; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2010; Volume 6110, pp. 62–91. [Google Scholar]
- Okamoto, T.; Takashima, K. Achieving short ciphertexts or short secret-keys for adaptively secure general inner-product encryption. Des. Codes Cryptogr. 2015, 77, 138–159. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, F. An efficient public key encryption with conjunctive-subset keyword search. J. Netw. Comput. Appl. 2011, 34, 262–267. [Google Scholar] [CrossRef]
- Song, C.; Liu, X.; Yan, Y. Efficient Public Key Encryption with Field-Free Conjunctive Keywords Search. In Proceedings of the 6th International Conference, INTRUST 2014, Beijing, China, 16–17 December 2014; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2014; pp. 394–406. [Google Scholar]
- Wang, B.; Hou, Y.; Li, M.; Wang, H.; Li, H. Scalable multidimensional range search over encrypted cloud data with tree-based index. In Proceedings of the ACM Symposium on Information, Computer and Communications Security, Kyoto, Japan, 4–6 June 2014; pp. 111–122. [Google Scholar]
- Ding, M.; Gao, F.; Jin, Z.; Zhang, H. An efficient Public Key Encryption with Conjunctive Keyword Search scheme based on pairings. In Proceedings of the 2012 3rd IEEE International Conference on Network Infrastructure and Digital Content, Beijing, China, 21–23 September 2013; pp. 526–530. [Google Scholar]
- Hwang, M.S.; Hsu, S.T.; Lee, C.C. A New Public Key Encryption with Conjunctive Field Keyword Search Scheme. Inf. Technol. Control. 2014, 43, 277–288. [Google Scholar] [CrossRef]
- Miao, Y.; Ma, J.; Liu, X.; Zhang, J.; Liu, Z. VKSE-MO: Verifiable keyword search over encrypted data in multi-owner settings. Inf. Sci. 2017, 60, 122105. [Google Scholar] [CrossRef]
- Xu, P.; Wu, Q.; Wang, W.; Susilo, W.; Domingo-Ferrer, J.; Jin, H. Generating Searchable Public-Key Ciphertexts With Hidden Structures for Fast Keyword Search. IEEE Trans. Inf. Forensics Secur. 2017, 10, 1993–2006. [Google Scholar]
- Xu, P.; He, S.; Wang, W.; Susilo, W.; Jin, H. Lightweight Searchable Public-key Encryption for Cloud-assisted Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2017, 14, 3712–3723. [Google Scholar] [CrossRef]
- Zhu, H.; Mei, Z.; Wu, B.; Li, H.; Cui, Z. Fuzzy Keyword Search and Access Control over Ciphertexts in Cloud Computing. In Proceedings of the 22nd Australasian Conference, ACISP 2017, Auckland, New Zealand, 3–5 July 2017; Lecture Notes in Computer Science. Springer: Cham, Germany, 2017; pp. 248–265. [Google Scholar]
- Boneh, D.; Goh, E.; Nissim, K. Evaluating 2-dnf formulas on ciphertexts. In Proceedings of the Second Theory of Cryptography Conference, TCC 2005, Cambridge, MA, USA, 10–12 February 2005; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2005; Volume 3378, pp. 325–342. [Google Scholar]
- Bellare, M.; Waters, B.; Yilek, S. Identity-based encryption secure against selective opening attack. In Proceedings of the 8th Theory of Cryptography Conference, TCC 2011, Providence, RI, USA, 28–30 March 2011; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Waters, B. Dual system encryption: Realizing fully secure IBE and HIBE under simple assumptions. In Proceedings of the 29th Annual International Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 2009; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2009; Volume 5677, pp. 619–636. [Google Scholar]
- Caro, A.D. The Java Pairing Based Cryptography Library (JPBC). 2013, pp. 2–24. Available online: http://gas.dia.unisa.it/projects/jpbc/ (accessed on 4 December 2013).
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2017; pp. 1480–1489. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Ref. | Query Condition | Additional Security Measures | Fast Search |
|---|---|---|---|---|
| Standard SPE | [23] | Conjunctive keyword search | - | - |
| [24] | Conjunctive keyword search | - | - | |
| [22] | Disjunctive keyword search | - | - | |
| [3] | Range, conjunctive keywords, subset search | - | - | |
| [5] | Conjunctive and disjunctive keyword search | - | - | |
| [25] | Range search | - | - | |
| Special SPE | [26] | Conjunctive keyword search | Verifiable | - |
| [27] | Conjunctive keyword search | Verifiable | - | |
| [28] | Single keyword search | Verifiable and Access control | - | |
| [29] | Single keyword search | - | Yes | |
| [30] | Single keyword search | - | Yes | |
| [31] | Fuzzy keyword search | Access control | - |
| PEDK-0 | PECDK | PEDK-1 | PEDK-2 | |
|---|---|---|---|---|
| Key Generation | ||||
| Index Building | ||||
| Trapdoor Generation | ||||
| Testing |
| PEDK-0 | PECDK | PEDK-1 | PEDK-2 | |
|---|---|---|---|---|
| PK size | ||||
| SK size | ||||
| Trapdoor size | ||||
| Index size |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Li, Y.; Wang, Y. Efficient Public Key Encryption with Disjunctive Keywords Search Using the New Keywords Conversion Method. Information 2018, 9, 272. https://doi.org/10.3390/info9110272
Zhang Y, Li Y, Wang Y. Efficient Public Key Encryption with Disjunctive Keywords Search Using the New Keywords Conversion Method. Information. 2018; 9(11):272. https://doi.org/10.3390/info9110272
Chicago/Turabian StyleZhang, Yu, Yin Li, and Yifan Wang. 2018. "Efficient Public Key Encryption with Disjunctive Keywords Search Using the New Keywords Conversion Method" Information 9, no. 11: 272. https://doi.org/10.3390/info9110272
APA StyleZhang, Y., Li, Y., & Wang, Y. (2018). Efficient Public Key Encryption with Disjunctive Keywords Search Using the New Keywords Conversion Method. Information, 9(11), 272. https://doi.org/10.3390/info9110272