Evaluating User Behaviour in a Cooperative Environment


 ,
, 

Abstract
:1. Introduction
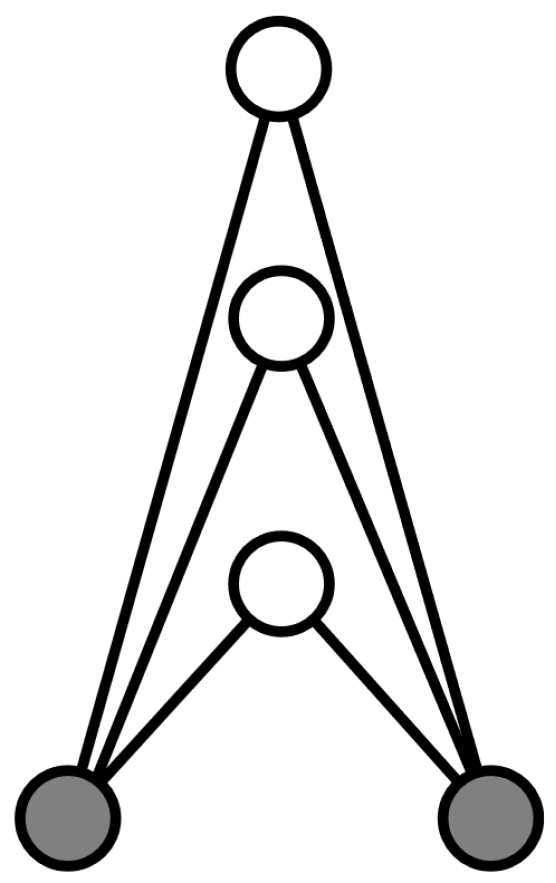
- Global Nonconformity (GNC): in many settings where a user observe the rankings ofothers, it has been shown in literature that this will influence its rank causing his/her own rankings to conform with others;
- Local Nonconformity (LNC): these parameters model the case of a user i ranking a user j that is influenced only by users ranked above j;
- Deference Aversion (DA): this parameter is the most intriguing in our context. The above-mentioned parameters deal with the mutual adjustment among raters regarding their relative assessments of third parties. In our framework, however, higher rankings are associated with positive evaluation (thus higher rewards), such that being ranked below others is aversive. Thus, if user l ranks j above i and i ranks l above j, i is ranking herself below l. As a consequence, deference aversion may lead i to resist ranking l above j.
2. Data Preparation
2.1. Dealing with Incomplete and Inconsistent Data
2.2. Enriching the Data: Data Posting
- stores the information of the profile from, whose compatibility level with some profile inis at least.
- stores the combinations name-value taken fromand the decision to add this couple to the profile from, represented by means ofattribute: 0 (not add) 1 (add).
- auxiliary relation that stores the comments for users with compatibility level greater than.
- stores the decision to suggest the commentto the user, represented by means ofattribute: 0 (not suggest) and 1 (suggest).
3. ERGM Sampling
3.1. Metropolis–Hastings
| Algorithm 1 MH Sampling. |
| Require:N output samples; B: number of samples for burn-in; |
| Ensure: a sequence of k network resource providers |
|
| Algorithm 2 Algorithm for Best Search sampling. |
| Require: A set of searches to be performed y, a rank matrix X, the probability array p, an integer , an integer |
| Ensure: a sequence of k sampled nodes |
| the current coalition of users, the probability of the current coalition of user, the generated coalition, the probability of the generated coalition, the set of generated coalition (that does not contain duplicated elements). |
|
- the fact that users formed a coalition, and
- the probability that the user in worked on y.
3.2. Using Clustering
4. Experimental Evaluation
4.1. Setup
4.2. Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Big Data. Nature 2008. Available online: https://www.nature.com/collections/wwymlhxvfs (accessed on 30 November 2018).
- Borkar, V.R.; Carey, M.J.; Li, C. Inside “Big Data Management”: Ogres, Onions, or Parfaits? In International Conference on Extending Database Technology; Rundensteiner, E.A., Markl, V., Manolescu, I., Amer-Yahia, S., Naumann, F., Ari, I., Eds.; ACM: New York, NY, USA, 2012; pp. 3–14. [Google Scholar]
- Lohr, S. The Age of Big Data. 2012. Available online: nytimes.com (accessed on 30 November 2018).
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The Next Frontier for Innovation, Competition, And Productivity; McKinsey Global Institute: New York, NY, USA, 2011. [Google Scholar]
- Agrawal, D.; Bernstein, P.; Bertino, E.; Davidson, S.; Dayal, U.; Franklin, M.; Gehrke, J.; Haas, L.; Halevy, A.; Han, J.; et al. Challenges and Opportunities With Big Data—A Community White Paper Developed by Leading Researchers across The United States; ACM: New York, NY, USA, 2012. [Google Scholar]
- Data, Data Everywhere. The Economist. 25 February 2010. Available online: https://www.emc.com/collateral/analyst-reports/ar-the-economist-data-data-everywhere.pdf (accessed on 30 November 2018).
- Cassavia, N.; Flesca, S.; Ianni, M.; Masciari, E.; Pulice, C. Distributed computing by leveraging and rewarding idling user resources from P2P networks. J. Parallel Distrib. Comput. 2018, 122, 81–94. [Google Scholar] [CrossRef]
- Almgren, K.; Lee, J. An empirical comparison of influence measurements for social network analysis. Soc. Netw. Anal. Min. 2016, 6, 52:1–52:18. [Google Scholar] [CrossRef]
- Rodríguez, H.; Macías, J.; Montalván, N.; Garzozi, R. Influence of Social Networks from Cellphones to Choose Restaurants, Salinas—2016. In Proceedings of International Conference on Information Theoretic Security (ICITS 2018); Springer: Cham, Switzerland, 2018; pp. 992–1003. [Google Scholar]
- Cassavia, N.; Masciari, E.; Pulice, C.; Saccà, D. Discovering User Behavioral Features to Enhance Information Search on Big Data. TiiS 2017, 7, 7:1–7:33. [Google Scholar] [CrossRef]
- Almgren, K.; Lee, J. Applying an influence measurement framework to large social network. J. Netw. Technol. 2016, 7, 7. [Google Scholar]
- Kempe, D.; Kleinberg, J.M.; Tardos, É. Maximizing the Spread of Influence Through a Social Network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 137–146. [Google Scholar]
- Lou, V.Y.; Bhagat, S.; Lakshmanan, L.V.S.; Vaswani, S. Modeling Non-Progressive Phenomena for Influence Propagation; CoRR: Leawood, KS, USA, 2014. [Google Scholar]
- Brown, L.D. Fundamentals of Statistical Exponential Families with Applications in Statistical Decision Theory. Available online: https://ci.nii.ac.jp/naid/10000043684/ (accessed on 30 November 2018).
- Krivitsky, P.N.; Butts, C.T. Exponential-family random graph models for rank-order relational data. Sociol. Methodol. 2017. [Google Scholar] [CrossRef]
- Zhang, C.J.; Chen, L.; Tong, Y.; Liu, Z. Cleaning uncertain data with a noisy crowd. In Proceedings of the 31st IEEE International Conference on Data Engineering (ICDE), Seoul, Korea, 13–17 April 2015; pp. 6–17. [Google Scholar]
- Budak, C.; Agrawal, D.; El Abbadi, A. Limiting the spread of misinformation in social networks. In Proceedings of the 20th International Conference on World Wide Web (WWW’11), Hyderabad, India, 28 March–1 April 2011; pp. 665–674. [Google Scholar]
- Chomicki, J.; Marcinkowski, J. Minimal-change integrity maintenance using tuple deletions. Inf. Comput. 2005, 197, 90–121. [Google Scholar] [CrossRef]
- Wijsen, J. A Survey of the Data Complexity of Consistent Query Answering under Key Constraints. In Proceedings of the International Symposium on Foundations of Information and Knowledge Systems (FoIKS), Bordeaux, France, 3–7 March 2014; pp. 62–78. [Google Scholar]
- Arenas, M.; Bertossi, L.E.; Chomicki, J. Consistent Query Answers in Inconsistent Databases. In Proceedings of the Eighteenth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS’99), Philadelphia, PA, USA, 31 May–3 June 1999; pp. 68–79. [Google Scholar]
- Lembo, D.; Lenzerini, M.; Rosati, R.; Ruzzi, M.; Savo, D.F. Inconsistency-Tolerant Semantics for Description Logics; Hitzler, P., Lukasiewicz, T., Eds.; Web Reasoning and Rule Systems, RR 2010, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6333. [Google Scholar]
- Lembo, D.; Lenzerini, M.; Rosati, R.; Ruzzi, M.; Savo, D.F. Query Rewriting for Inconsistent DL-Lite Ontologies; Rudolph, S., Gutierrez, C., Eds.; Web Reasoning and Rule Systems, RR 2011; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6902, pp. 155–169. [Google Scholar]
- Lembo, D.; Lenzerini, M.; Rosati, R.; Ruzzi, M.; Savo, D.F. Inconsistency-tolerant query answering in ontology-based data access. J. Web Semant. 2015, 33, 3–29. [Google Scholar] [CrossRef]
- Bienvenu, M. First-Order Expressibility Results for Queries over Inconsistent DL-Lite Knowledge Bases. In Proceedings of the 24th International Workshop on Description Logics (DL 2011), Barcelona, Spain, 13–16 July 2011. [Google Scholar]
- Bienvenu, M. On the Complexity of Consistent Query Answering in the Presence of Simple Ontologies. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence (AAAI’12), Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Rosati, R. On the Complexity of Dealing with Inconsistency in Description Logic Ontologies. In Proceedings of the Twenty-SeconD International Joint Conference on Artificial Intelligence—Volume Two (IJCAI’11), Barcelona, Spain, 16–22 July 2011; pp. 1057–1062. [Google Scholar]
- Bienvenu, M.; Rosati, R. Tractable Approximations of Consistent Query Answering for Robust Ontology-based Data Access. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence (IJCAI’3), Beijing, China, 3–9 August 2013; pp. 775–781. [Google Scholar]
- Lukasiewicz, T.; Martinez, M.V.; Simari, G.I. Inconsistency-Tolerant Query Rewriting for Linear Datalog+/−. In Proceedings of the Second international conference on Datalog in Academia and Industry (Datalog 2.0’12), Vienna, Austria, 11–13 September 2012; pp. 123–134. [Google Scholar]
- Lukasiewicz, T.; Martinez, M.V.; Simari, G.I. Complexity of Inconsistency-Tolerant Query Answering in Datalog+/−. In Proceedings of the OTM 2013 Conferences: Confederated International Conferences: CoopIS, DOA-Trusted Cloud, and ODBASE 2013, Graz, Austria, 9–13 September 2013; pp. 488–500. [Google Scholar]
- Lukasiewicz, T.; Martinez, M.V.; Pieris, A.; Simari, G.I. From Classical to Consistent Query Answering under Existential Rules. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 1546–1552. [Google Scholar]
- Lukasiewicz, T.; Martinez, M.V.; Simari, G.I. Inconsistency Handling in Datalog+/− Ontologies. In Proceedings of the 20th European Conference on Artificial Intelligence (ECAI 2012), Montpellier, France, 27–31 August 2012; pp. 558–563. [Google Scholar]
- Bienvenu, M.; Bourgaux, C.; Goasdoué, F. Querying Inconsistent Description Logic Knowledge Bases under Preferred Repair Semantics. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence (AAAI’14), Québec City, QC, Canada, 27–31 July 2014; pp. 996–1002. [Google Scholar]
- Furfaro, F.; Greco, S.; Molinaro, C. A three-valued semantics for querying and repairing inconsistent databases. Ann. Math. Artif. Intell. 2007, 51, 167–193. [Google Scholar] [CrossRef]
- Bohannon, P.; Flaster, M.; Fan, W.; Rastogi, R. A Cost-Based Model and Effective Heuristic for Repairing Constraints by Value Modification. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data (SIGMOD’05), Baltimore, MD, USA, 14–16 June 2005; pp. 143–154. [Google Scholar]
- Bertossi, L.E.; Bravo, L.; Franconi, E.; Lopatenko, A. The complexity and approximation of fixing numerical attributes in databases under integrity constraints. Inf. Syst. 2008, 33, 407–434. [Google Scholar] [CrossRef]
- Greco, S.; Molinaro, C. Approximate Probabilistic Query Answering over Inconsistent Databases; Li, Q., Spaccapietra, S., Yu, E., Olivé, A., Eds.; i Conceptual Modeling—ER 2008, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5231, pp. 311–325. [Google Scholar]
- Greco, S.; Molinaro, C. Probabilistic query answering over inconsistent databases. Ann. Math. Artif. Intell. 2012, 64, 185–207. [Google Scholar] [CrossRef]
- Flesca, S.; Furfaro, F.; Parisi, F. Querying and repairing inconsistent numerical databases. ACM Trans. Database Syst. 2010, 35, 14:1–14:50. [Google Scholar] [CrossRef]
- Greco, S.; Molinaro, C.; Trubitsyna, I. Computing Approximate Query Answers over Inconsistent Knowledge Bases. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI 2018), Stockholm, Sweden, 13–19 July 2018; pp. 1838–1846. [Google Scholar] [CrossRef]
- Martinez, M.V.; Parisi, F.; Pugliese, A.; Simari, G.I.; Subrahmanian, V.S. Policy-based inconsistency management in relational databases. Int. J. Approx. Reason. 2014, 55, 501–528. [Google Scholar] [CrossRef]
- Guagliardo, P.; Libkin, L. Making SQL Queries Correct on Incomplete Databases: A Feasibility Study. In Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems (PODS’16), San Francisco, CA, USA, 26 June–1 July 2016; pp. 211–223. [Google Scholar]
- Libkin, L. How to Define Certain Answers. In Proceedings of the International Joint Conferences on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, 25–31 July 2015; pp. 4282–4288. [Google Scholar]
- Libkin, L. Certain answers as objects and knowledge. Artif. Intell. 2016, 232, 1–19. [Google Scholar] [CrossRef]
- Greco, S.; Molinaro, C.; Trubitsyna, I. Computing Approximate Certain Answers over Incomplete Databases. In Proceedings of the 11th Alberto Mendelzon International Workshop on Foundations of Data Management and the Web, Montevideo, Uruguay, 7–9 June 2017. [Google Scholar]
- Andritsos, P.; Fuxman, A.; Miller, R.J. Clean Answers over Dirty Databases: A Probabilistic Approach. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 30. [Google Scholar]
- Calautti, M.; Libkin, L.; Pieris, A. An Operational Approach to Consistent Query Answering. In Proceedings of the 37th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, Houston, TX, USA, 10–15 June 2018; pp. 239–251. [Google Scholar] [CrossRef]
- Fagin, R.; Kolaitis, P.G.; Miller, R.J.; Popa, L. Data exchange: Semantics and query answering. Theor. Comput. Sci. 2005, 336, 89–124. [Google Scholar] [CrossRef]
- Deutsch, A.; Nash, A.; Remmel, J.B. The chase revisited. In Proceedings of the Twenty-Seventh ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems (PODS 2008), Vancouver, BC, Canada, 9–11 June 2008; pp. 149–158. [Google Scholar] [CrossRef]
- Greco, S.; Spezzano, F.; Trubitsyna, I. Checking Chase Termination: Cyclicity Analysis and Rewriting Techniques. IEEE Trans. Knowl. Data Eng. 2015, 27, 621–635. [Google Scholar] [CrossRef]
- Calautti, M.; Greco, S.; Molinaro, C.; Trubitsyna, I. Exploiting Equality Generating Dependencies in Checking Chase Termination. PVLDB 2016, 9, 396–407. [Google Scholar] [CrossRef]
- Cassavia, N.; Masciari, E.; Pulice, C.; Saccà, D. Discovering User Behavioral Features to Enhance Information Search on Big Data. TiiS 2017, 7, 7:1–7:33. [Google Scholar] [CrossRef]
- Saccà, D.; Serra, E.; Guzzo, A. Count Constraints and the Inverse OLAP Problem: Definition, Complexity and a Step toward Aggregate Data Exchange; Lukasiewicz, T., Sali, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2012; Volume 7153, pp. 352–369. [Google Scholar]
- Borodin, A.; Filmus, Y.; Oren, J. Threshold Models for Competitive Influence in Social Networks. In Proceedings of the 6th International Conference on Internet and Network Economics (WINE’10), Stanford, CA, USA, 13–17 December 2010; pp. 539–550. [Google Scholar]
- Chen, W.; Wang, Y.; Yang, S. Efficient Influence Maximization in Social Networks. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’09), Paris, France, 28 June–1 July 2009; pp. 199–208. [Google Scholar]
- Du, N.; Song, L.; Gomez-Rodriguez, M.; Zha, H. Scalable Influence Estimation in Continuous-Time Diffusion Networks; NIPS: London, UK, 2013; pp. 3147–3155. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. (Eds.) Data Clustering: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Greco, S.; Masciari, E.; Pontieri, L. Combining inductive and deductive tools for data analysis. AI Commun. 2001, 14, 69–82. [Google Scholar]
- Masciari, E.; Mazzeo, G.M.; Zaniolo, C. Analysing microarray expression data through effective clustering. Inf. Sci. 2014, 262, 32–45. [Google Scholar] [CrossRef]
- Mazzeo, G.M.; Masciari, E.; Zaniolo, C. A fast and accurate algorithm for unsupervised clustering around centroids. Inf. Sci. 2017, 400, 63–90. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 | |||
| 8 | |||
| 9 | |||
| 10 | |||
| 11 | |||
| 12 | |||
| 13 | |||
| 14 | |||
| 15 | |||
| 16 |
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 | |||
| 8 | |||
| 9 | |||
| 10 | |||
| 11 | |||
| 12 | |||
| 13 | |||
| 14 | |||
| 15 | |||
| 16 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazzi, E.; Cassavia, N.; Chiggiato, D.; Masciari, E.; Saccà, D.; Spada, A.; Trubitsyna, I. Evaluating User Behaviour in a Cooperative Environment. Information 2018, 9, 303. https://doi.org/10.3390/info9120303
Bazzi E, Cassavia N, Chiggiato D, Masciari E, Saccà D, Spada A, Trubitsyna I. Evaluating User Behaviour in a Cooperative Environment. Information. 2018; 9(12):303. https://doi.org/10.3390/info9120303
Chicago/Turabian StyleBazzi, Enrico, Nunziato Cassavia, Davide Chiggiato, Elio Masciari, Domenico Saccà, Alessandra Spada, and Irina Trubitsyna. 2018. "Evaluating User Behaviour in a Cooperative Environment" Information 9, no. 12: 303. https://doi.org/10.3390/info9120303
APA StyleBazzi, E., Cassavia, N., Chiggiato, D., Masciari, E., Saccà, D., Spada, A., & Trubitsyna, I. (2018). Evaluating User Behaviour in a Cooperative Environment. Information, 9(12), 303. https://doi.org/10.3390/info9120303