5.2.4. Results and Discussions
To answer the experimental question, the CSV files generated by the Java application were analyzed.
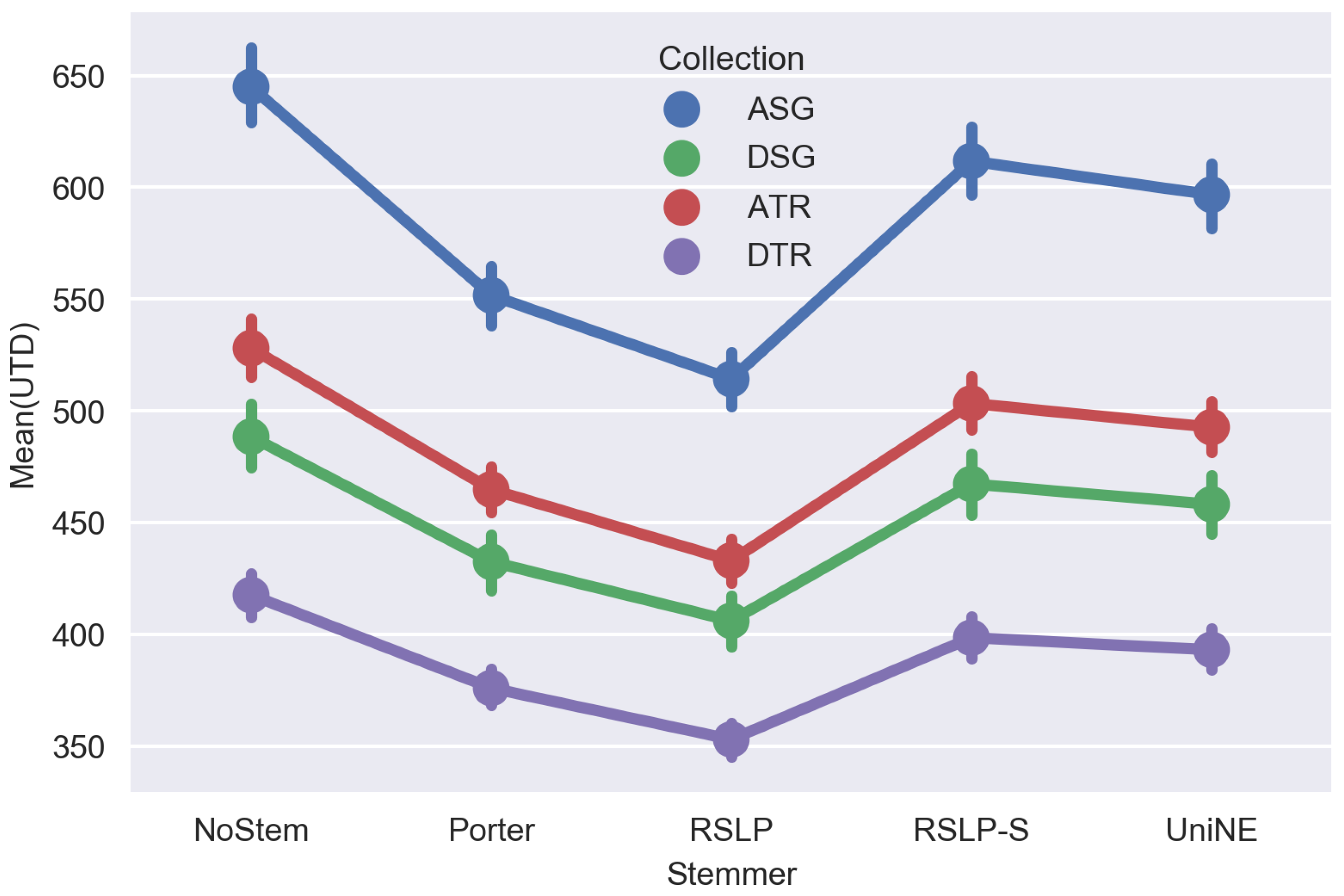
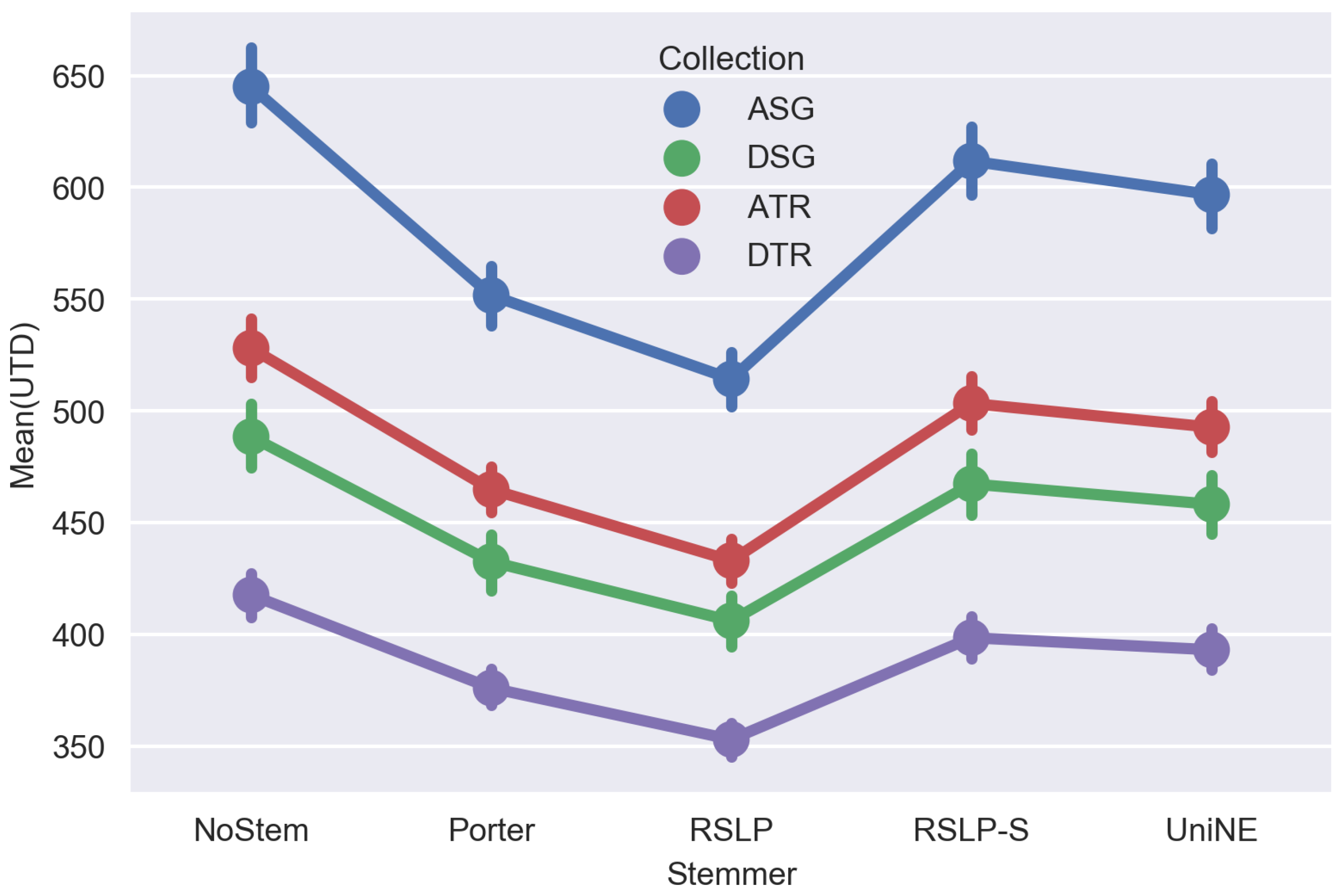
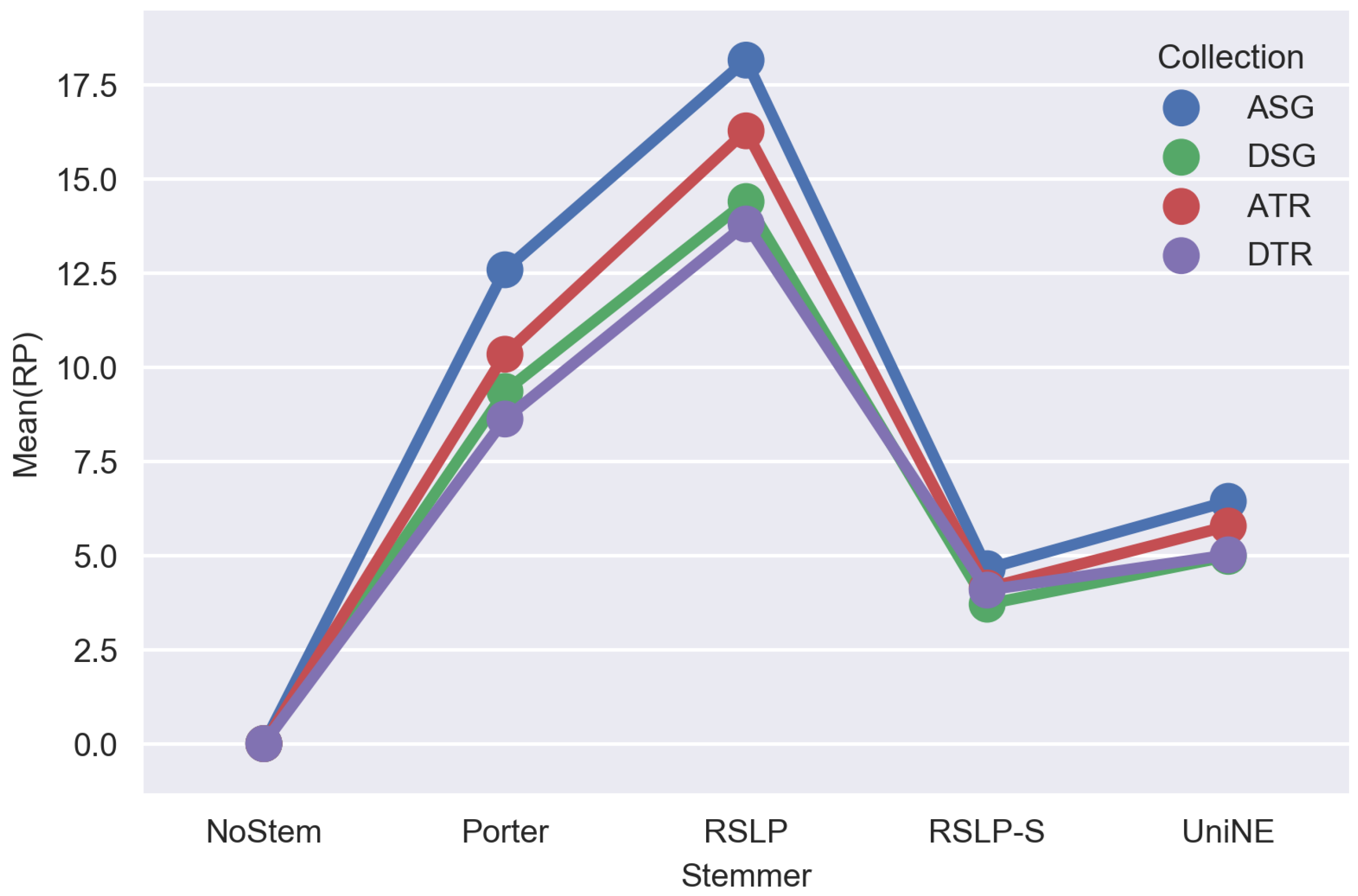
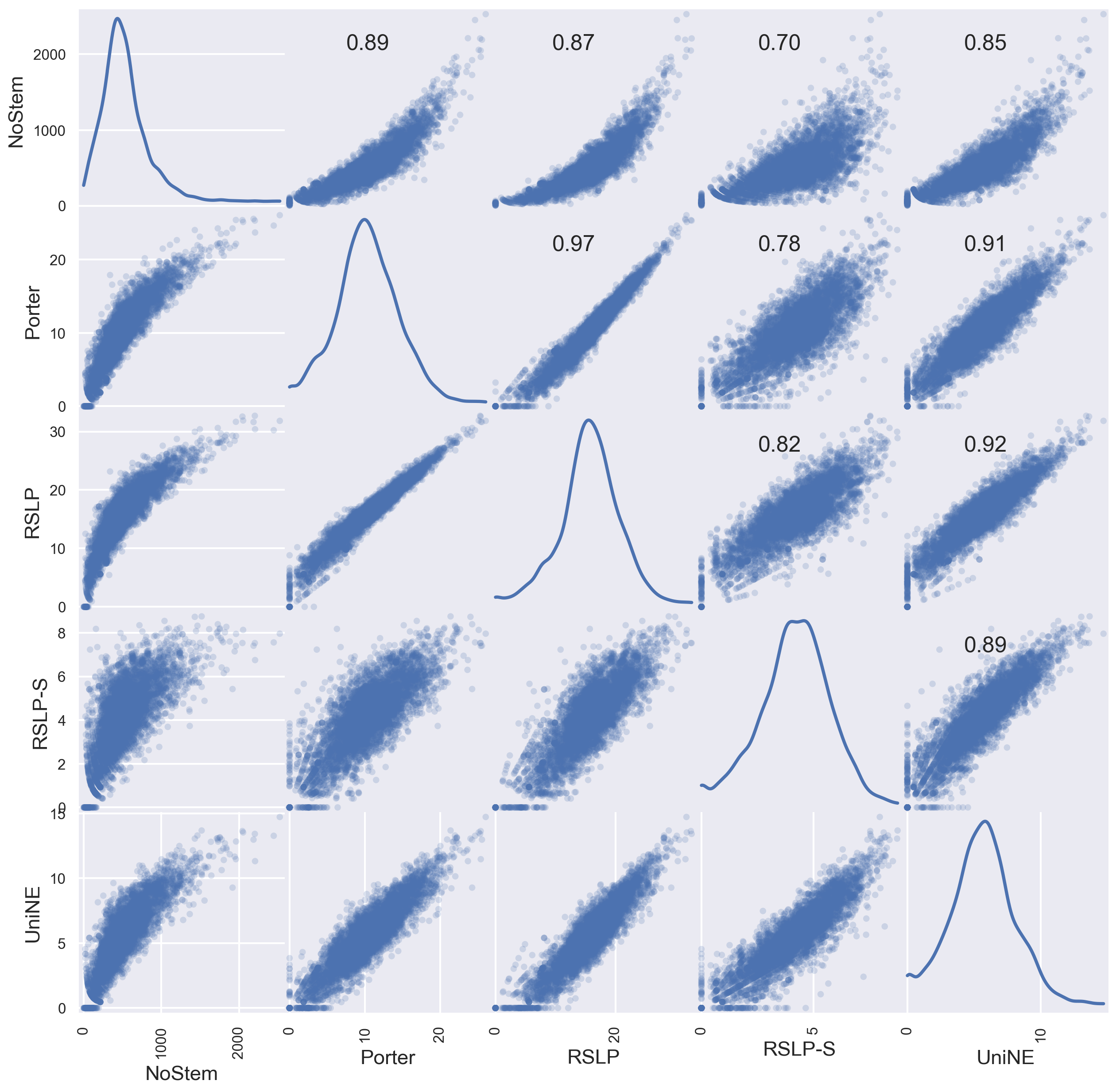
Table 10 shows the metrics obtained after applying the stemming algorithms on the judicial database. Thus, we can visualize the effectiveness of algorithms grouped by metric and collection. In addition, the
% column shows the percentage difference between the treatment and the control group, and the
|d| column displays the Cohen’s d index with its respective confidence interval.
Looking at
Table 10, the use of radicalization seems to have a positive impact only in the judgments of Special Courts (ATR), with the algorithms RSLP-S and UniNE causing an increase of the metrics when compared with the control group (NoStem). However, we need to analyze this data in the light of statistics to find evidence to corroborate, or not, the apparent differences described. For this, we adopted a confidence level of 95% (
) for the whole experiment. To improve understanding, we separated the analysis by collection, facilitating the visualization of the impact of dimensionality reduction on the metrics studied.
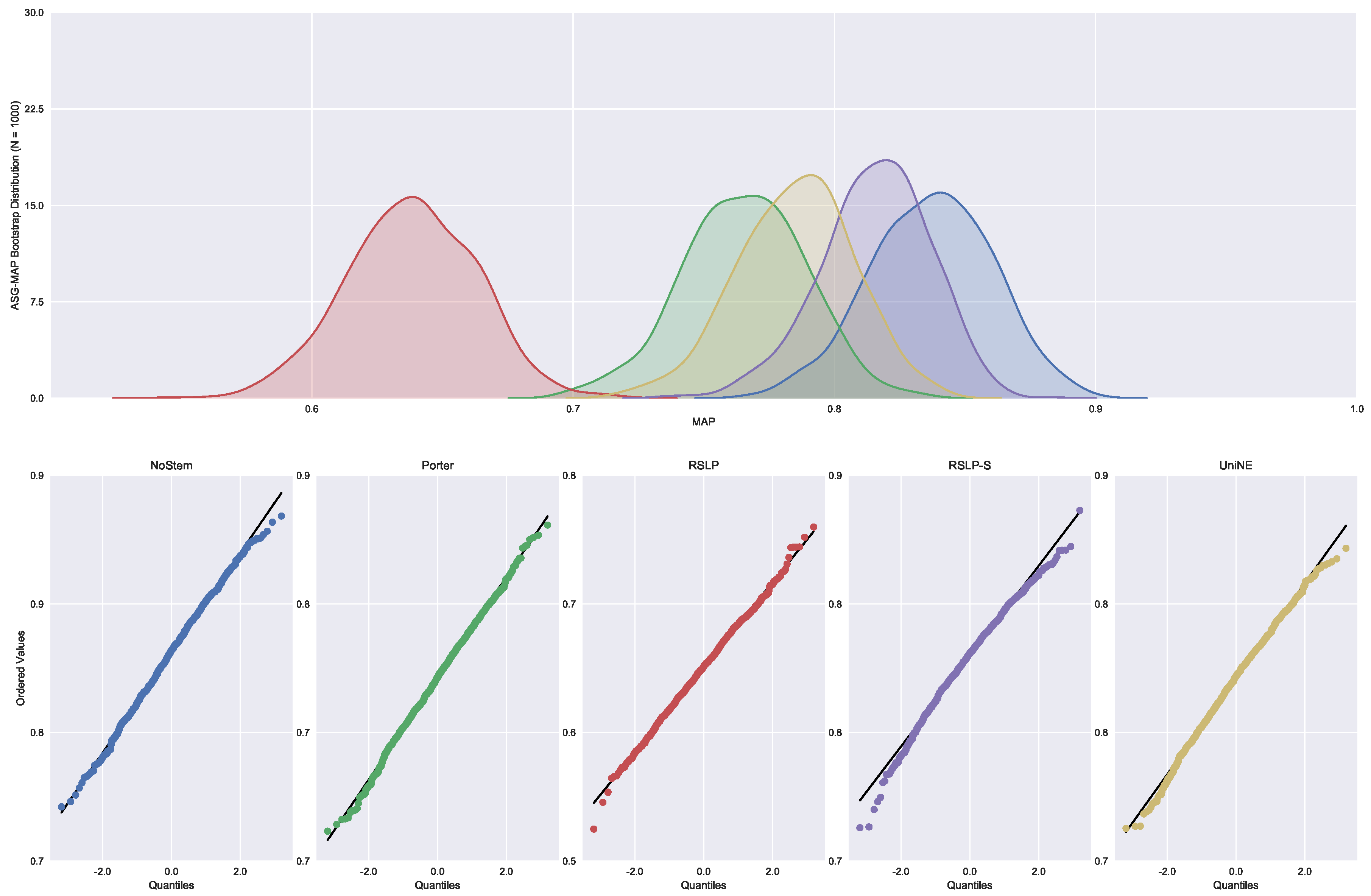
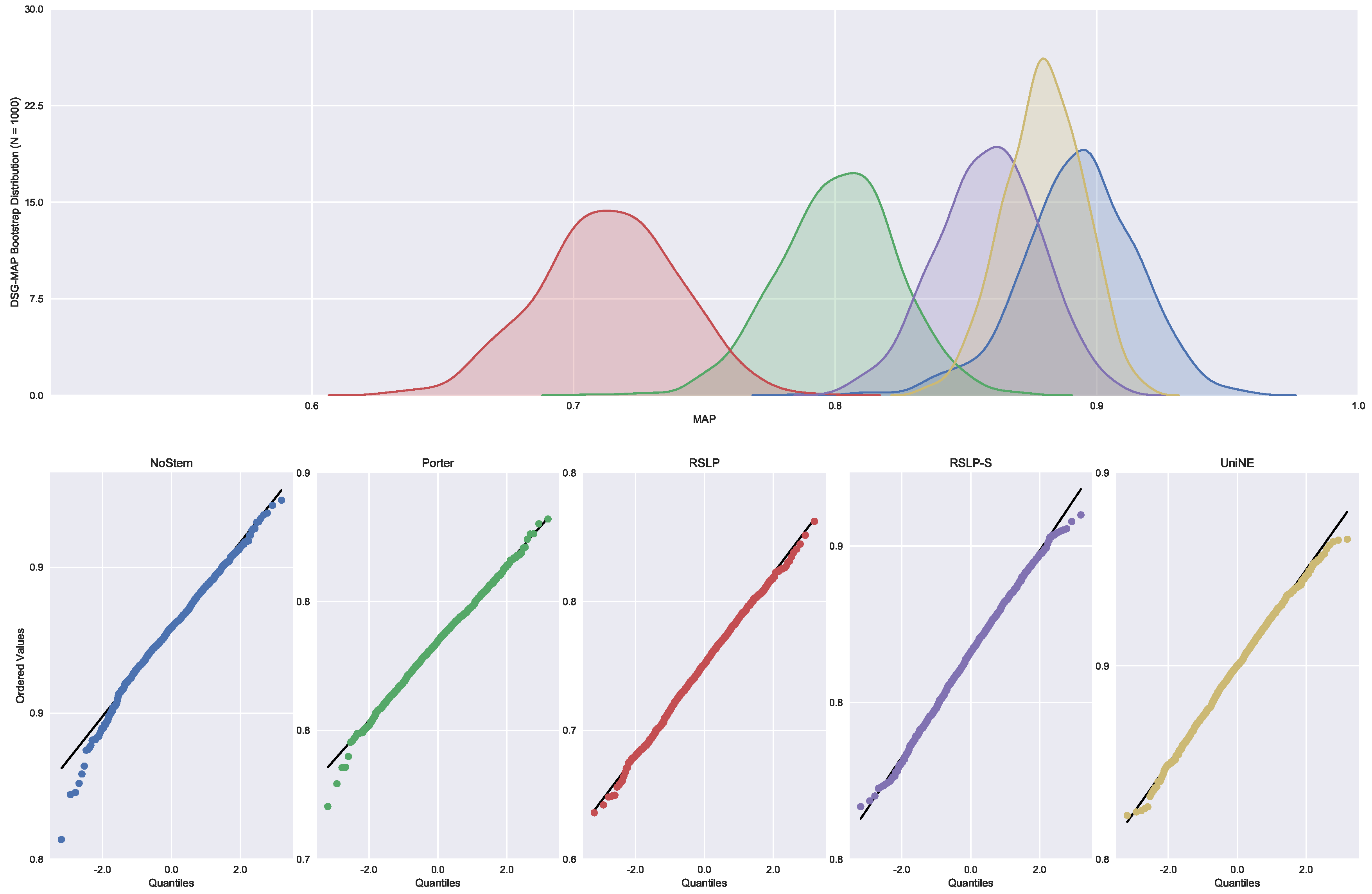
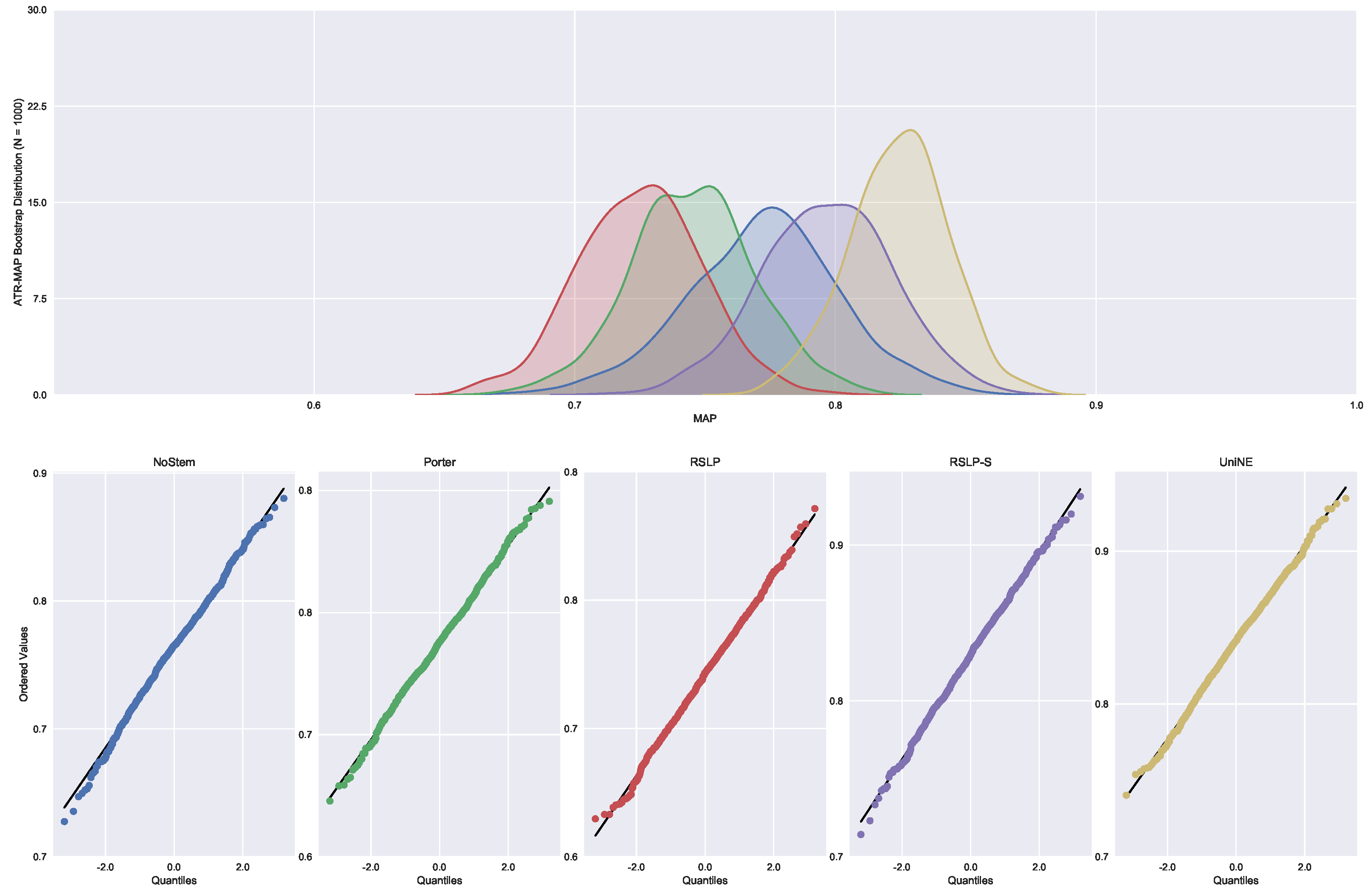
Judgments of Appeals Court (ASG). We started by analyzing the normality with respect to MAP metric. Looking at the graphs,
Figure 5, the five treatments seem to have a normal distribution, since they present most of the values around the mean (a bell curve shape). In addition, the probability graphs at the bottom of the same figure show that almost all points lie on the line, expected behaviour for a Normal distribution.
However, the hypothesis of data normality was rejected, since the Shapiro–Wilk test presented a p-value of less than 0.001 for the RSLP-S treatment, below, therefore, the significance level adopted for this experiment. We then conducted the Levene test to validate the null hypothesis of homoscedasticity (equality of variances) between the groups. However, this hypothesis was rejected (p-value < 0.001).
As not all treatments had a Normal distribution and there was heteroscedasticity, we conducted the Kruskal–Wallis test to validate Hypothesis 1, equality of MAP between treatments (). Once conducted, the test showed evidence of difference between the algorithms (p-value < 0.001).
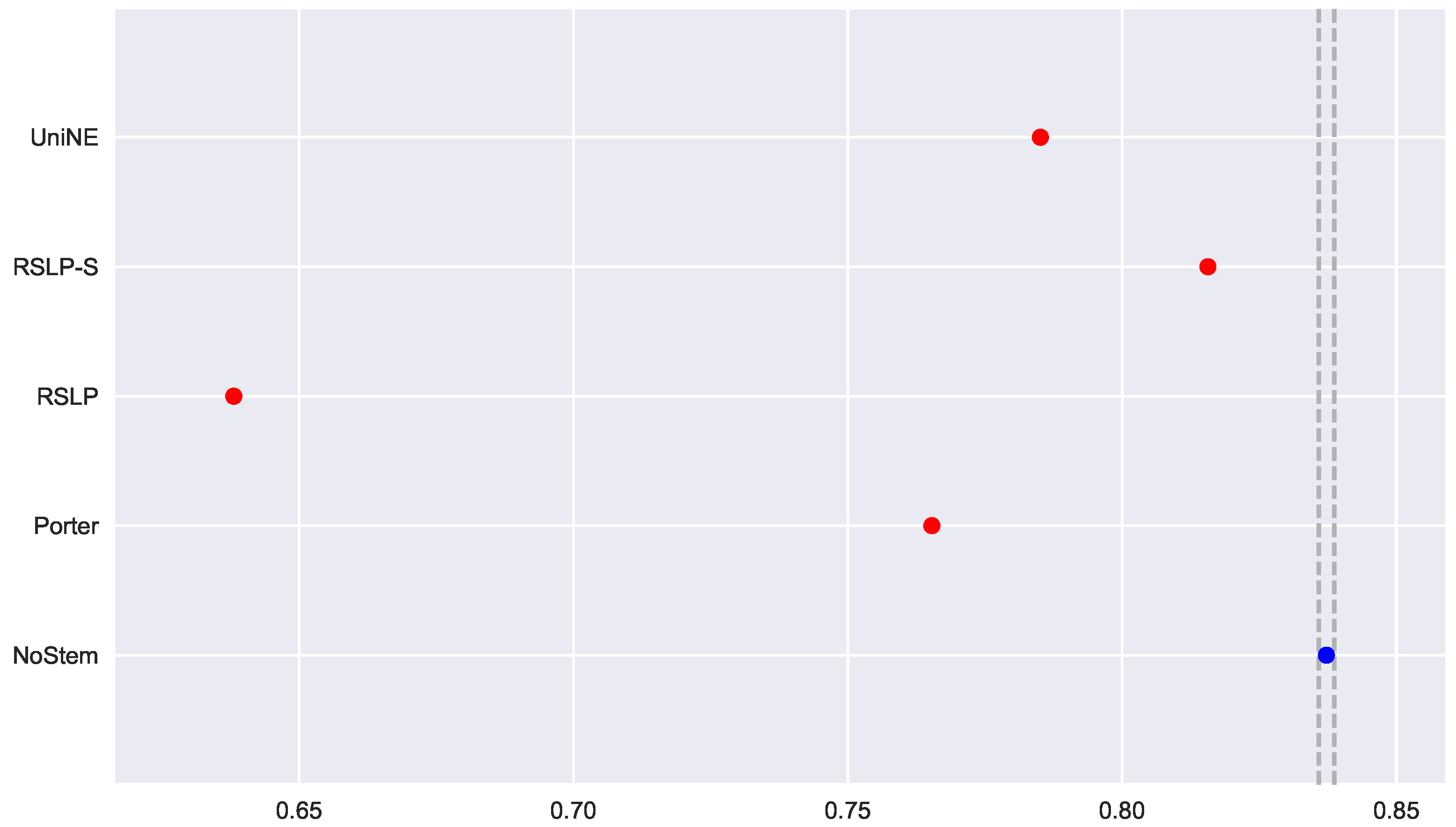
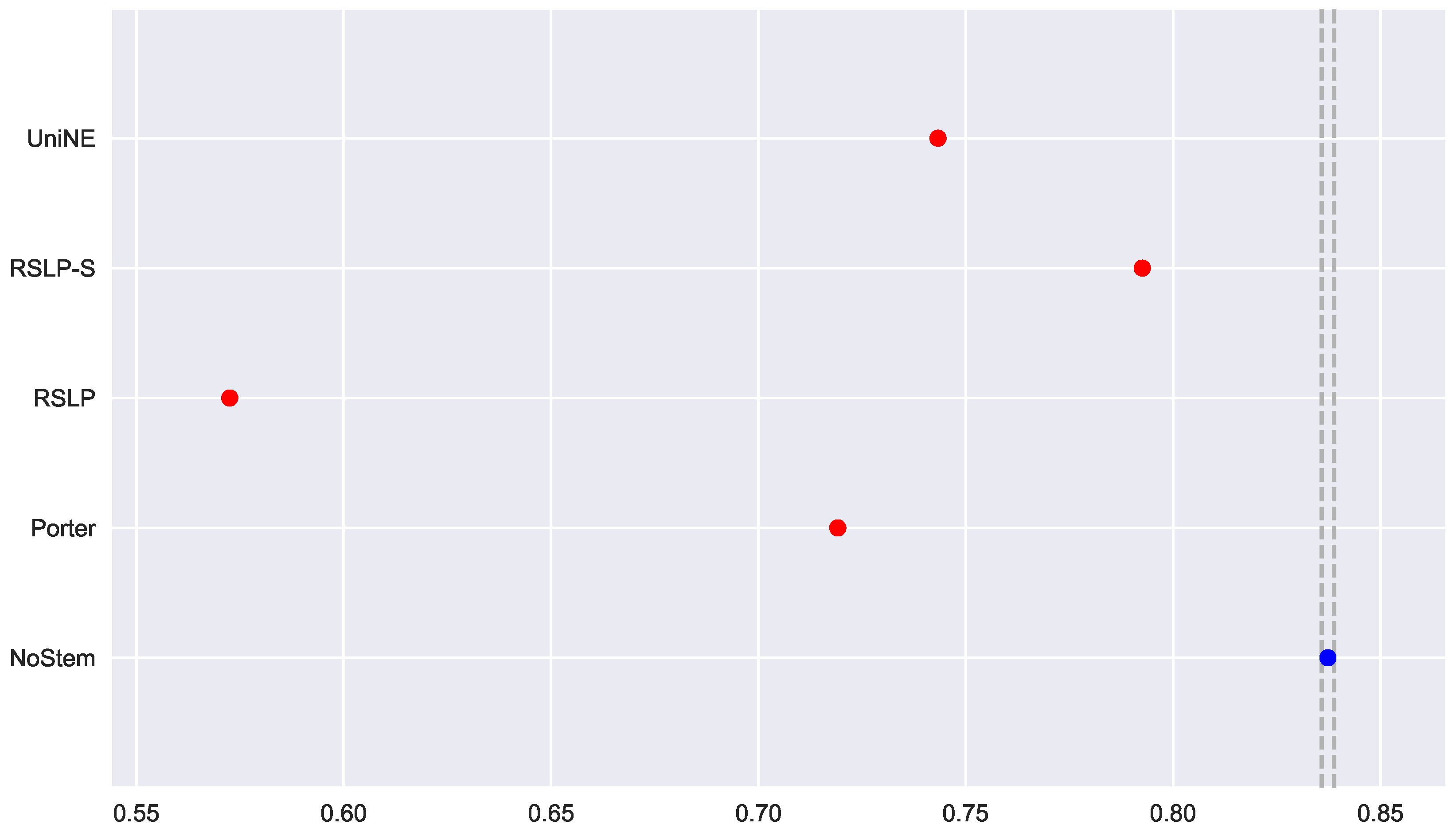
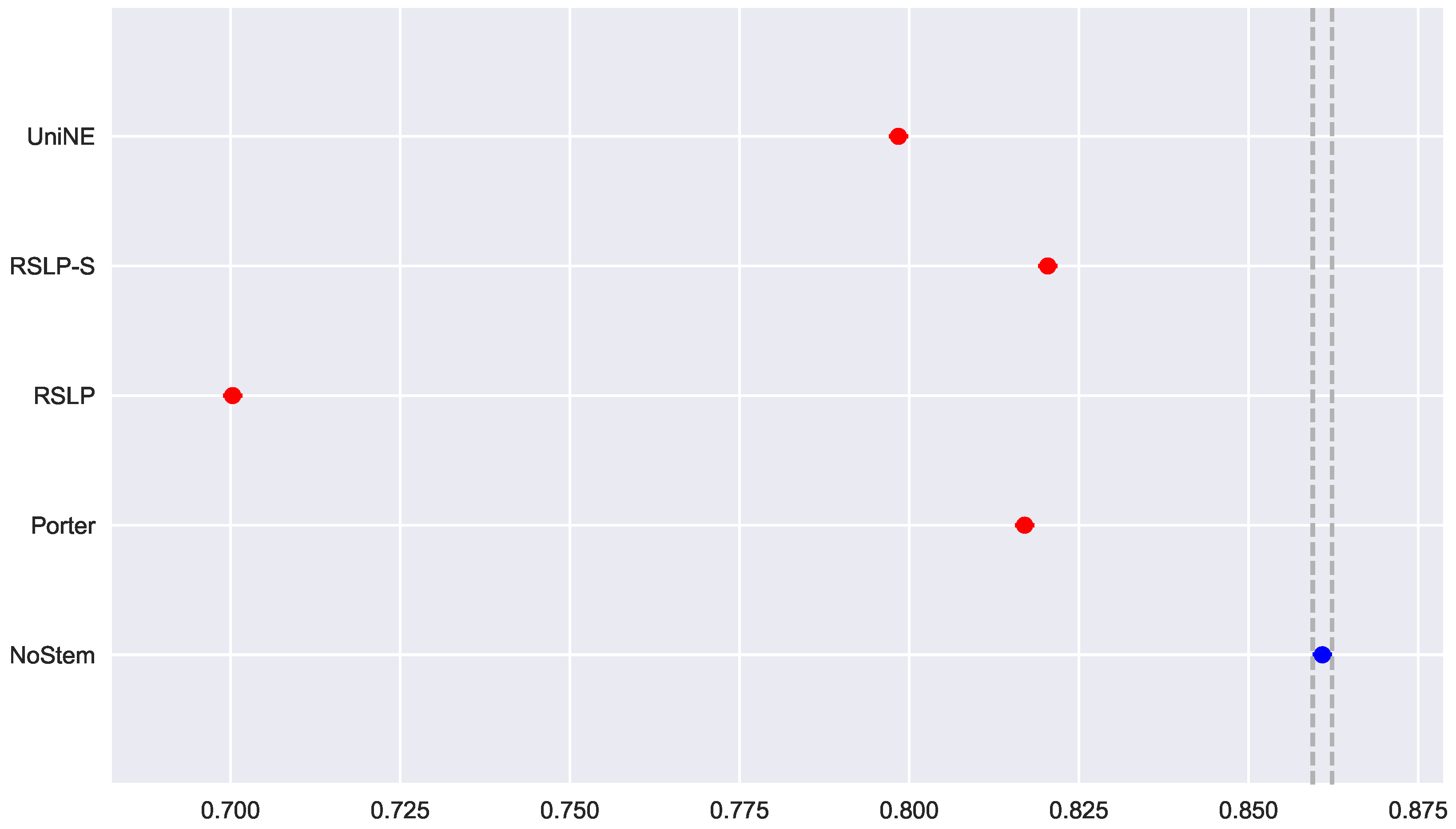
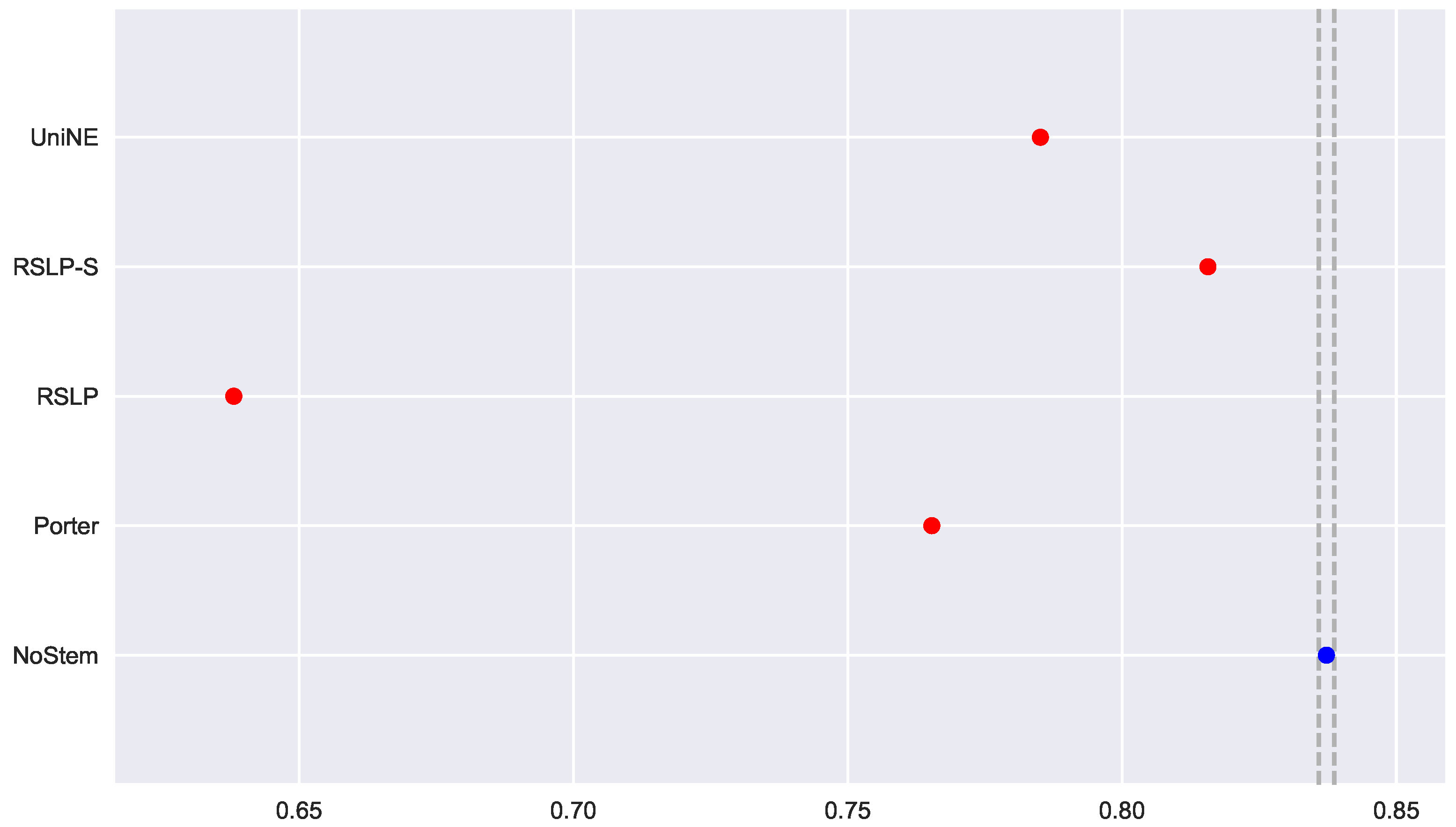
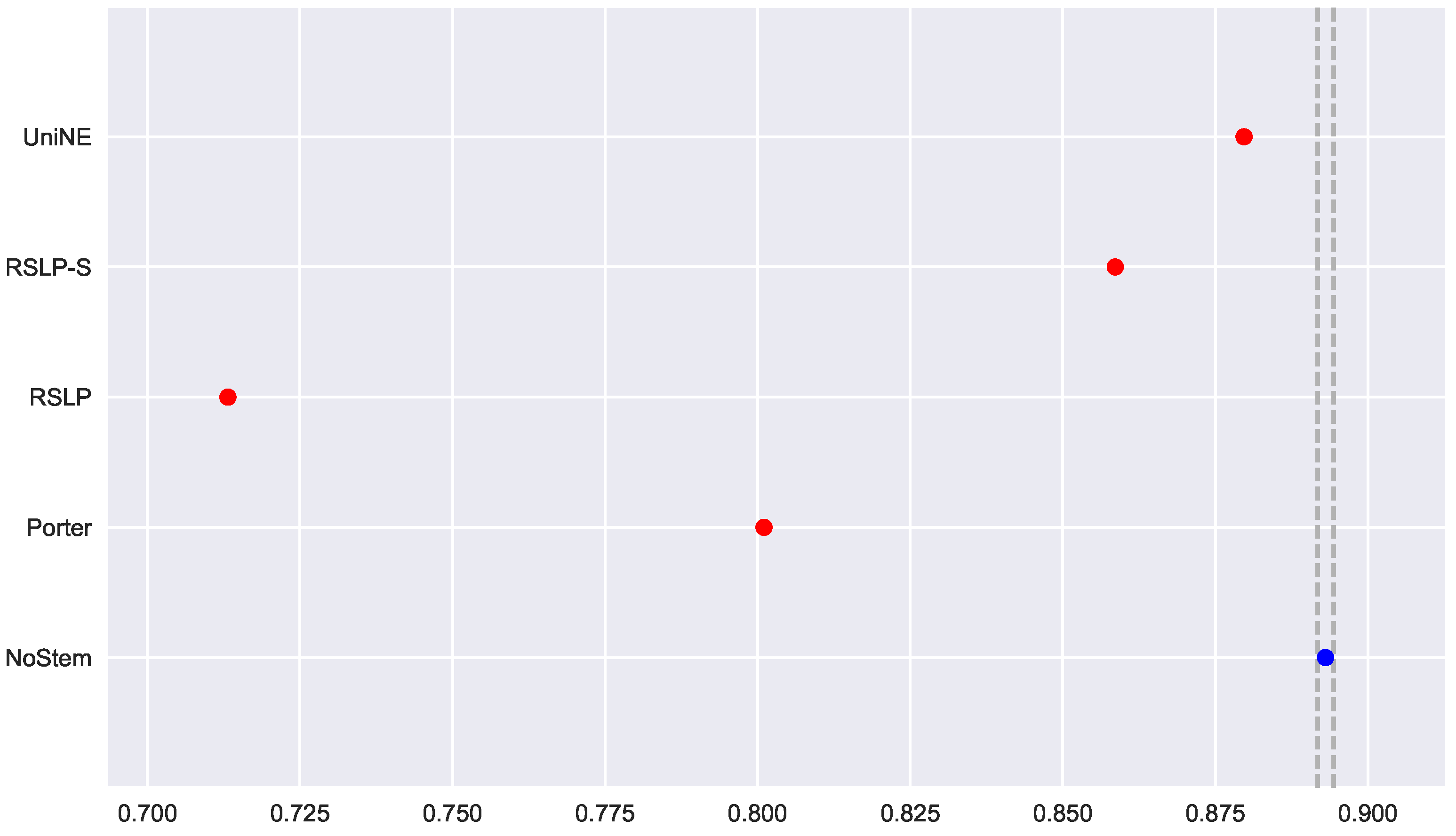
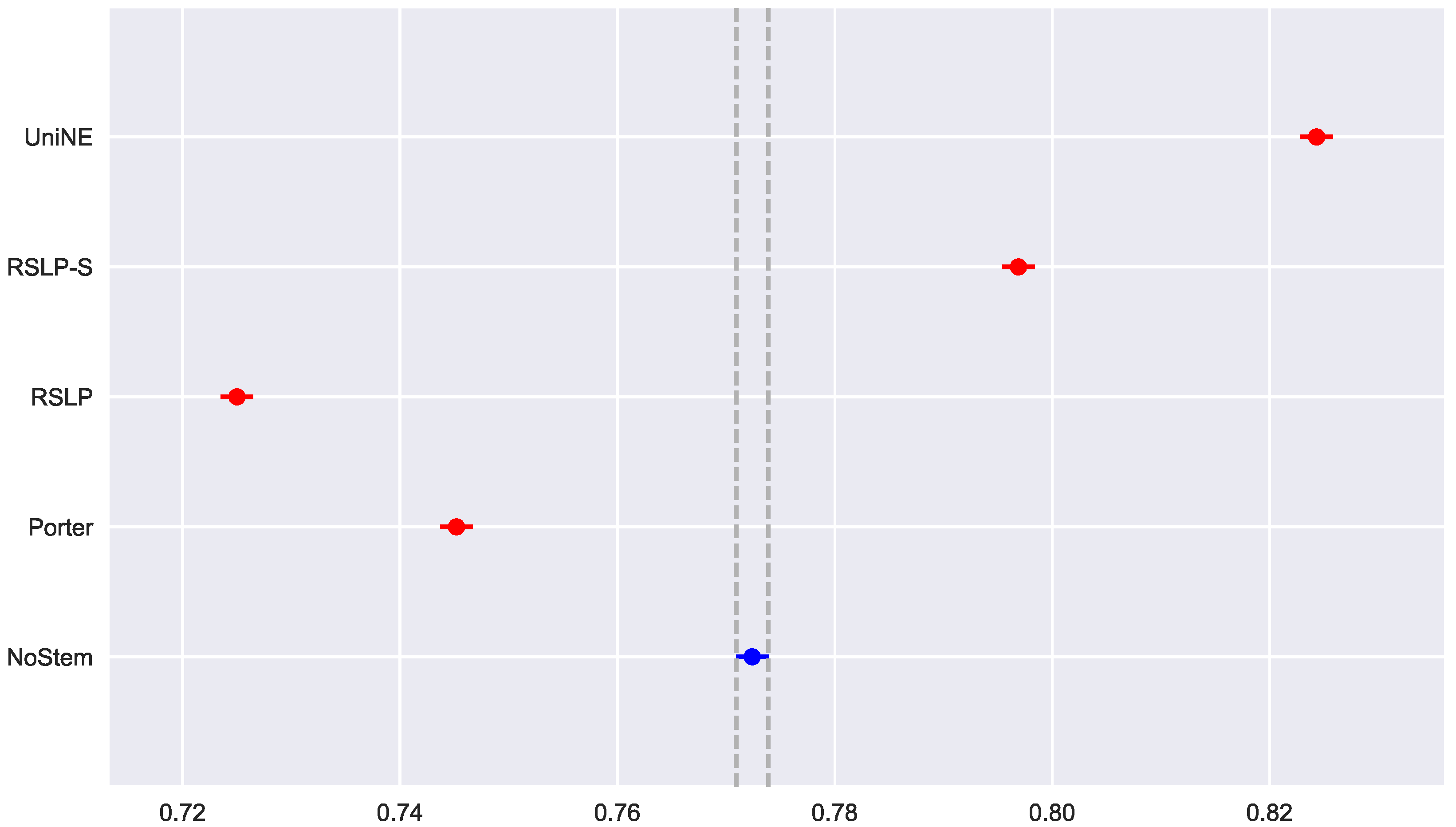
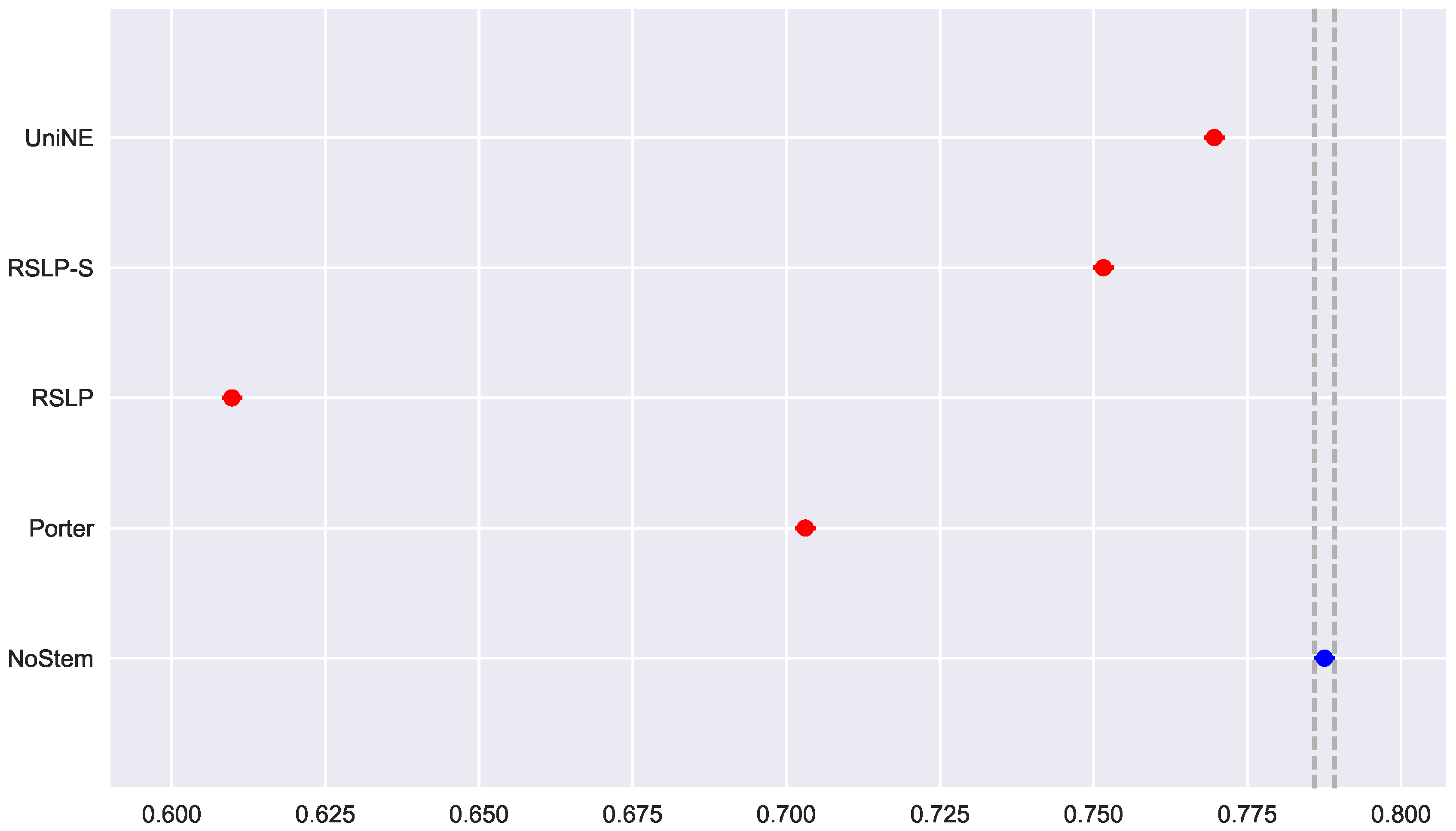
To visualize these differences, we construct
Figure 6 and conduct a post hoc analysis with Mann–Whitney tests, applying the Benferroni correction (
). In the figure, the blue dot highlights the control group and the vertical lines represent the confidence interval. Thus, both the graph and the tests conducted showed a decrease in effectiveness of the jurisprudential information retrieval with respect to MAP.
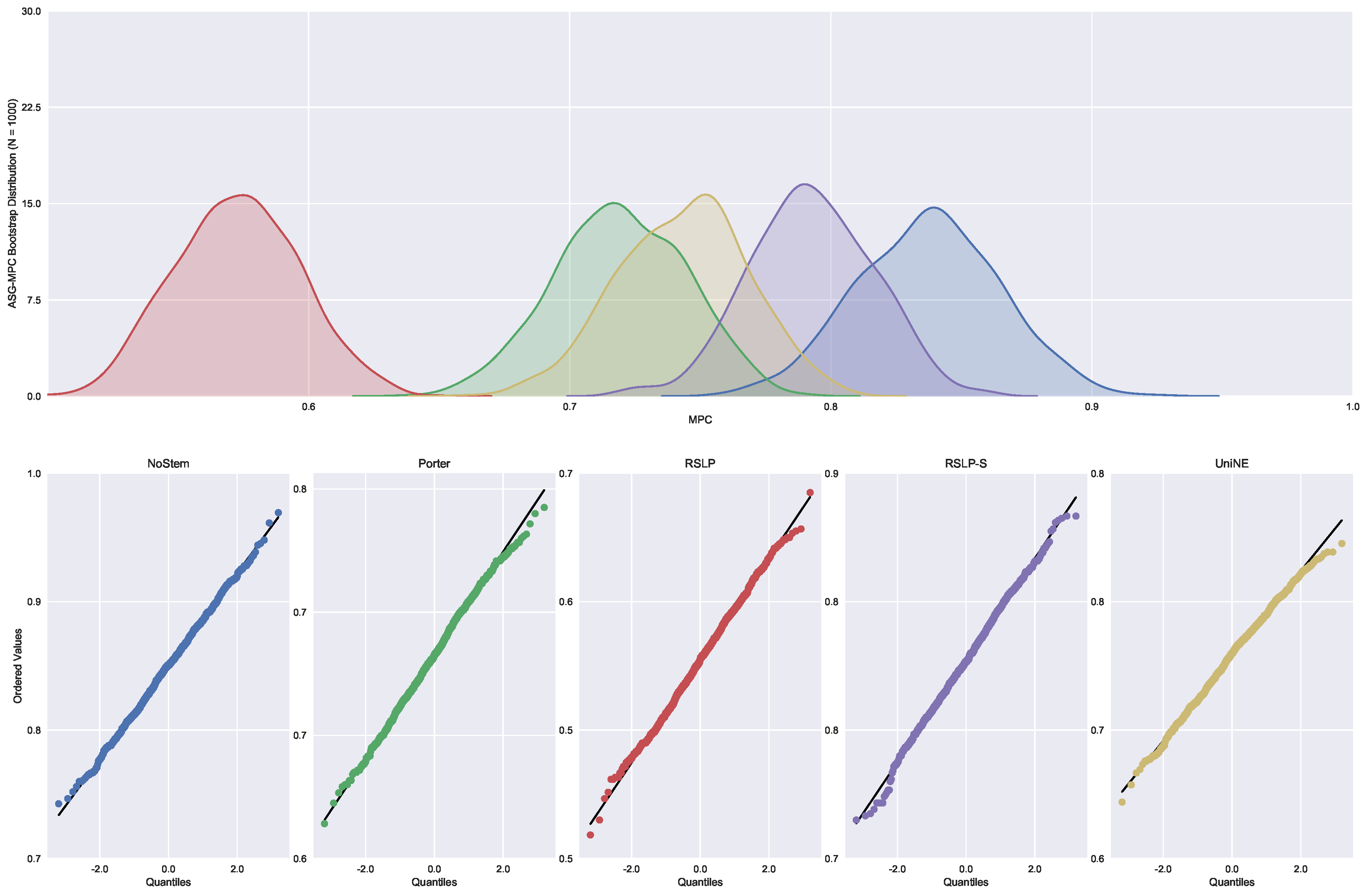
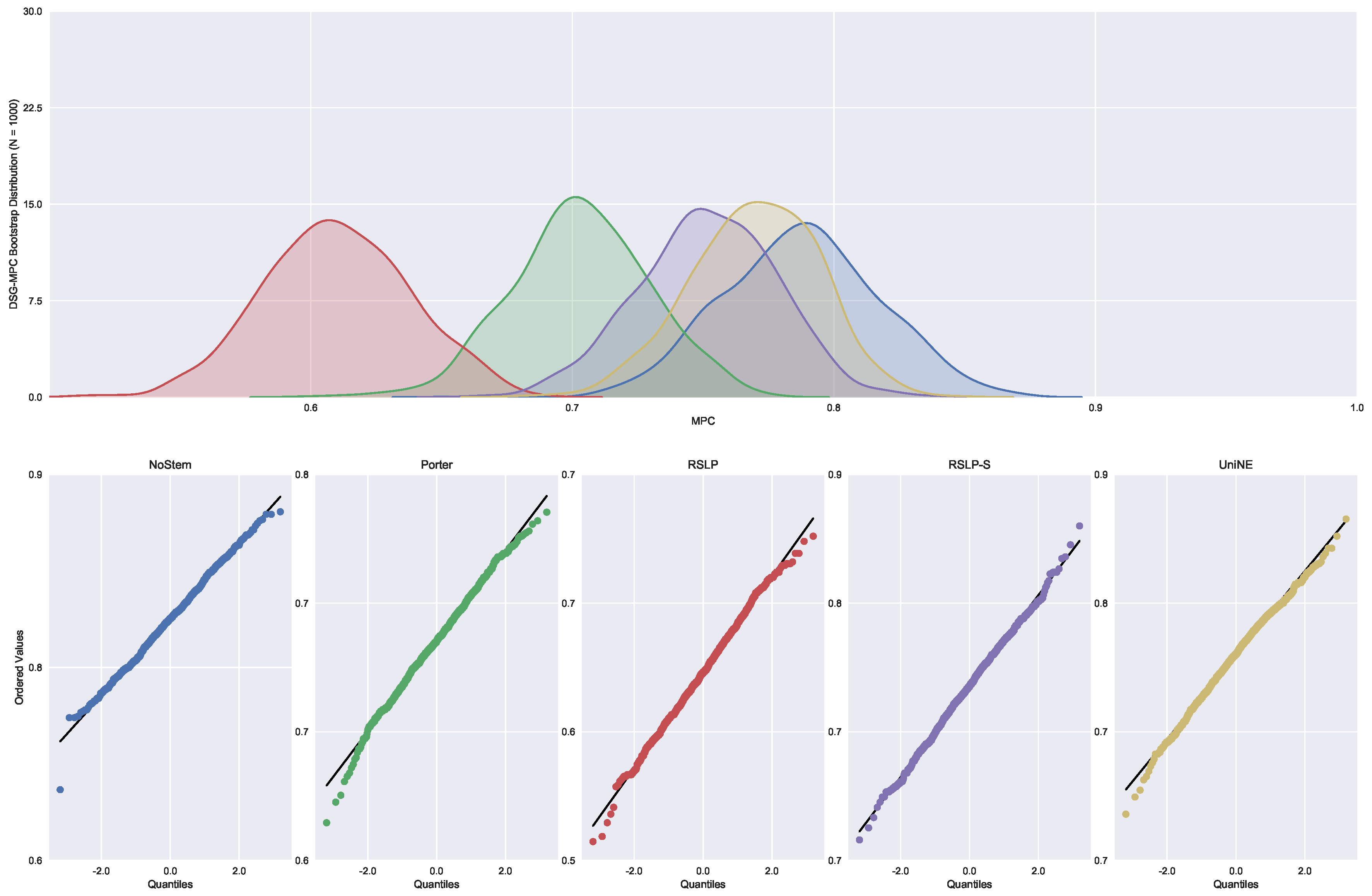
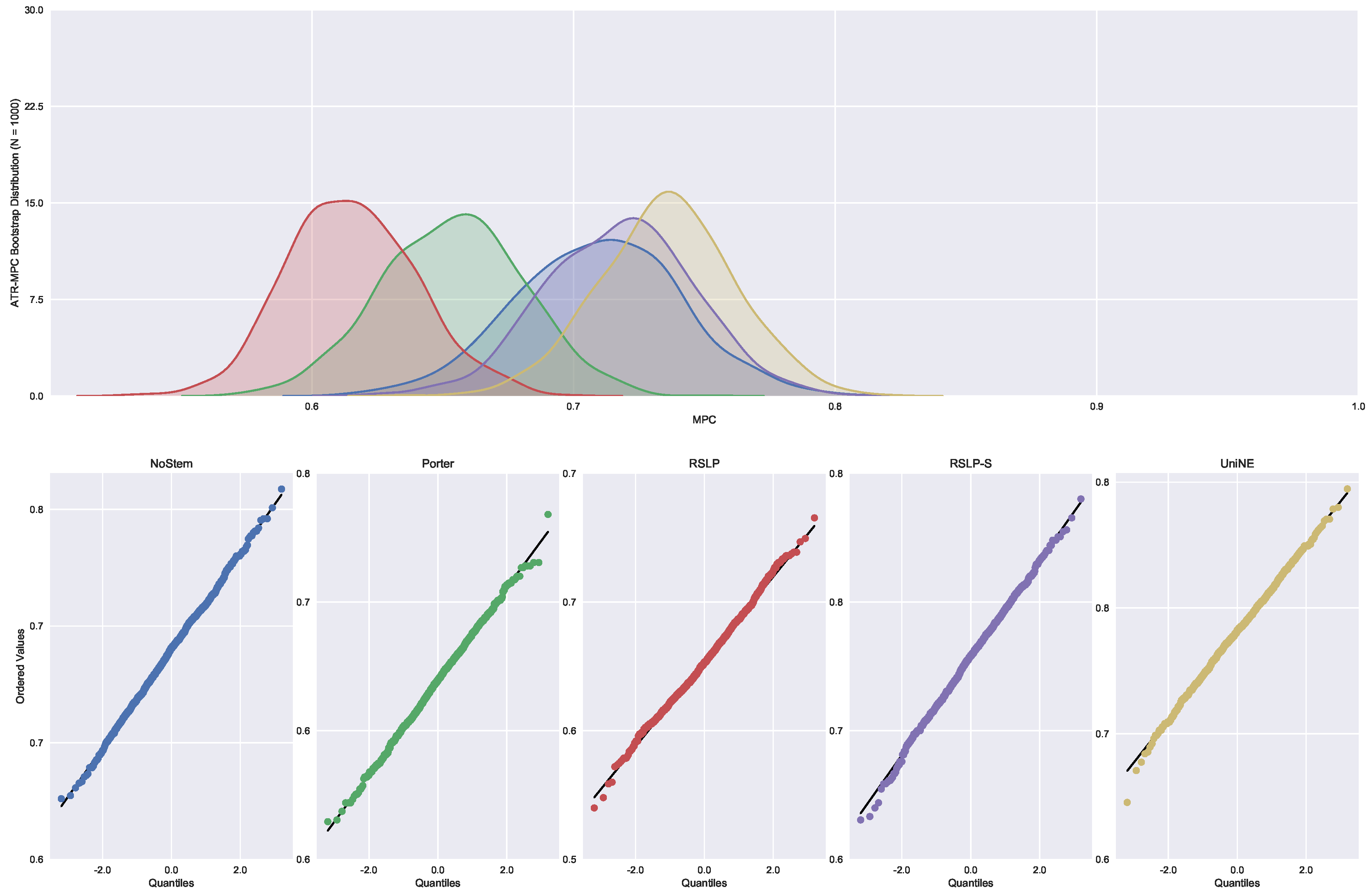
Continuing the analysis of the metrics, we checked the assumption of data normality regarding the MPC. In this case, we can see in
Figure 7 that the distributions appear normal and the execution of the Shapiro-Wilk test did not reject this hypothesis, except for the UniNE algorithm, because it was below the level of significance (
p-value = 0.027). The Levene test showed heteroscedasticity of the data (
p-value < 0.001) and the Kruskal–Wallis test refuted the hypothesis of MPC equality among the groups (
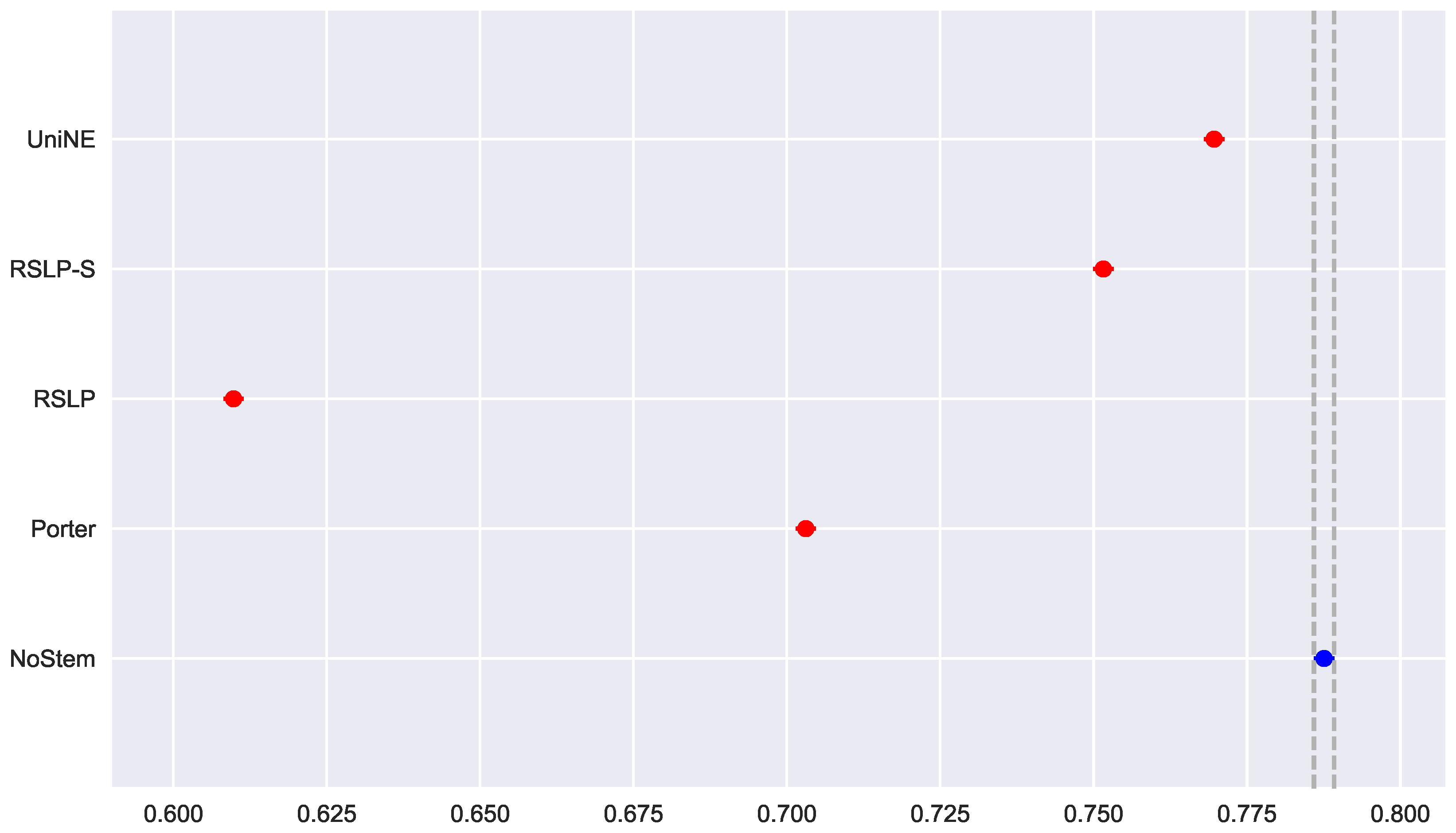
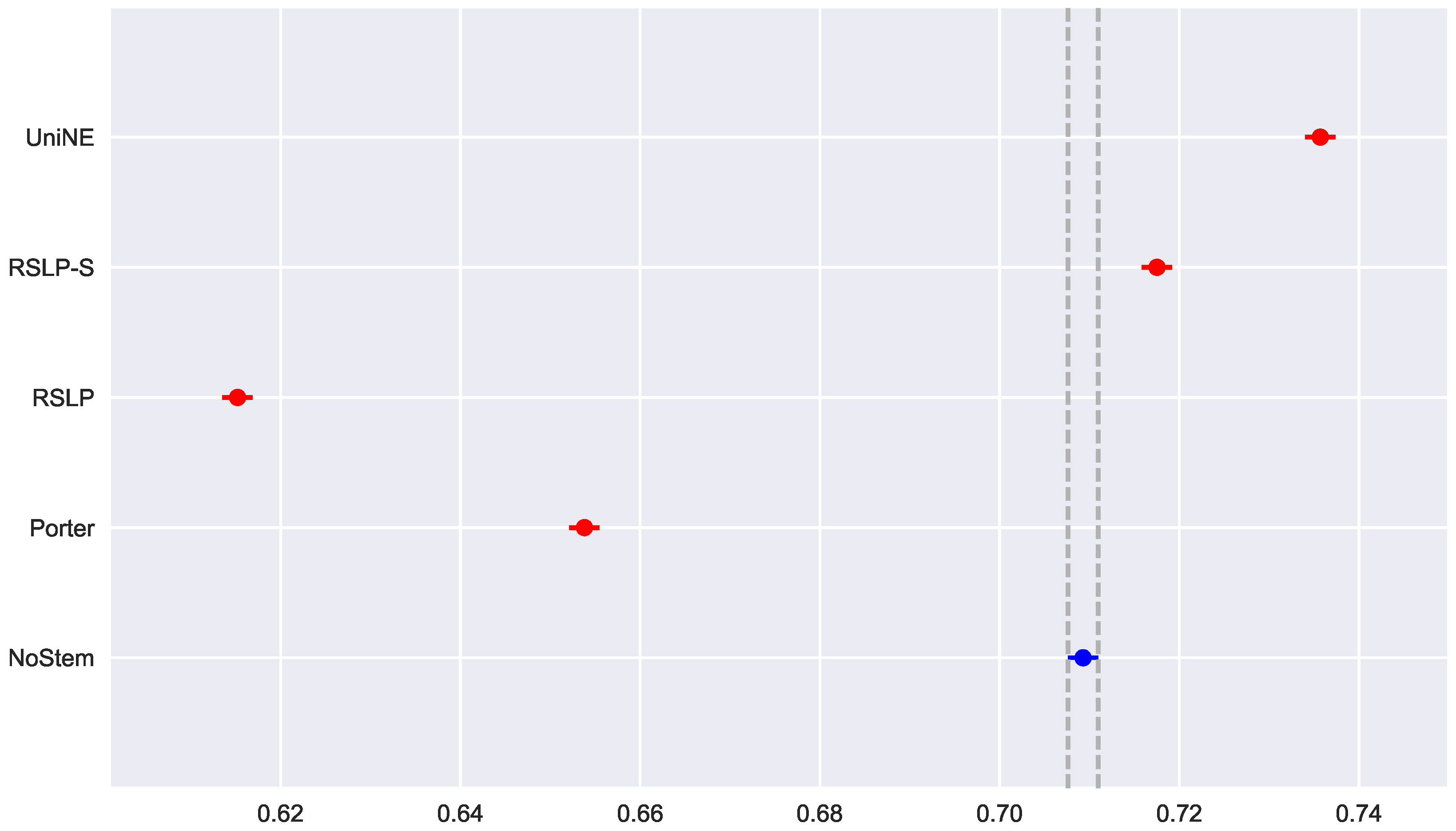
). After visual analysis of the metric for each treatment (
Figure 8) and study of the statistical significance of these differences using the Mann–Whitney test, with all comparisons having
p-value below 0.001, we arrived to the conclusion that MPC, as well as MAP, was negatively affected by the use of radicalization.
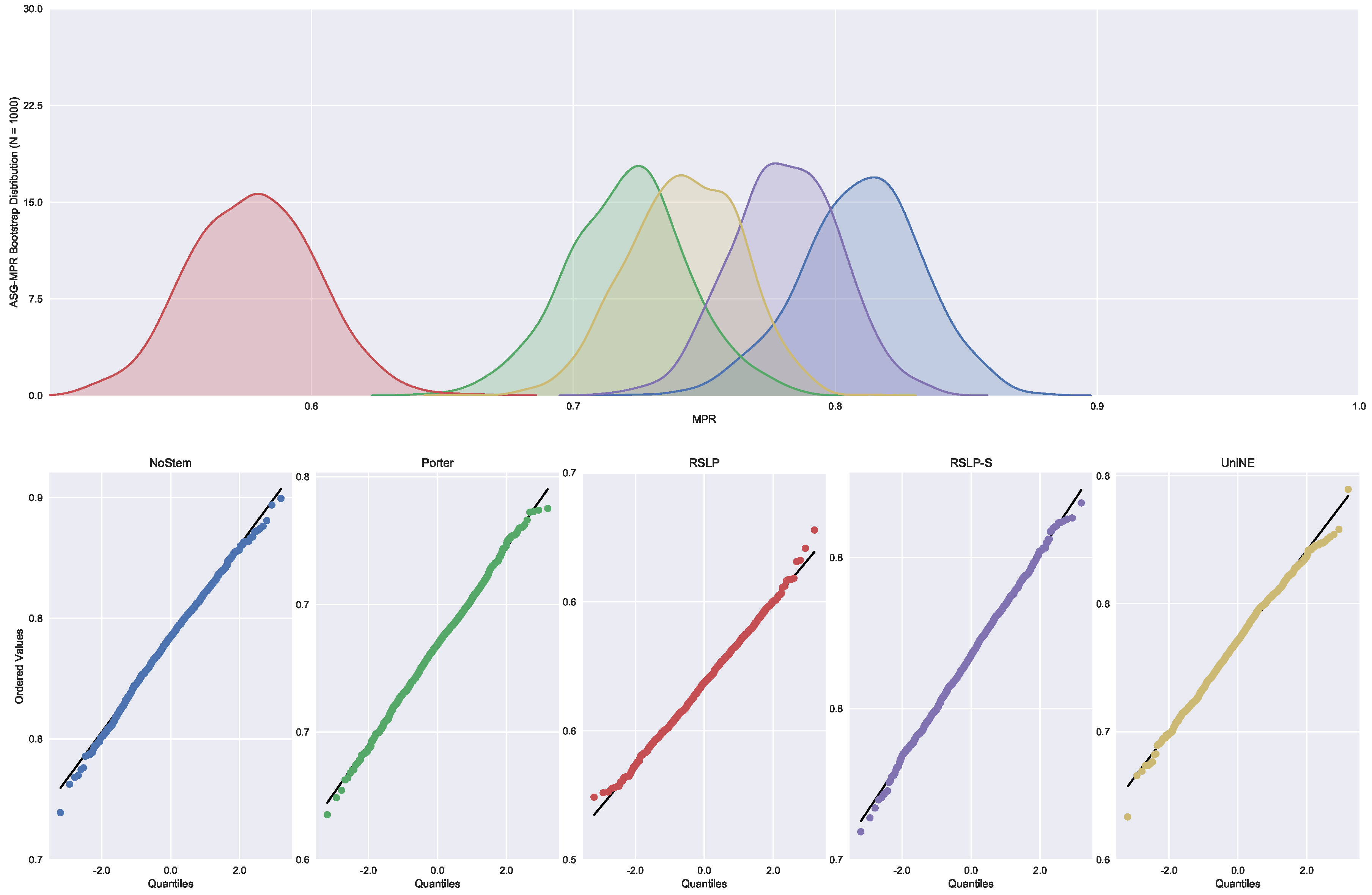
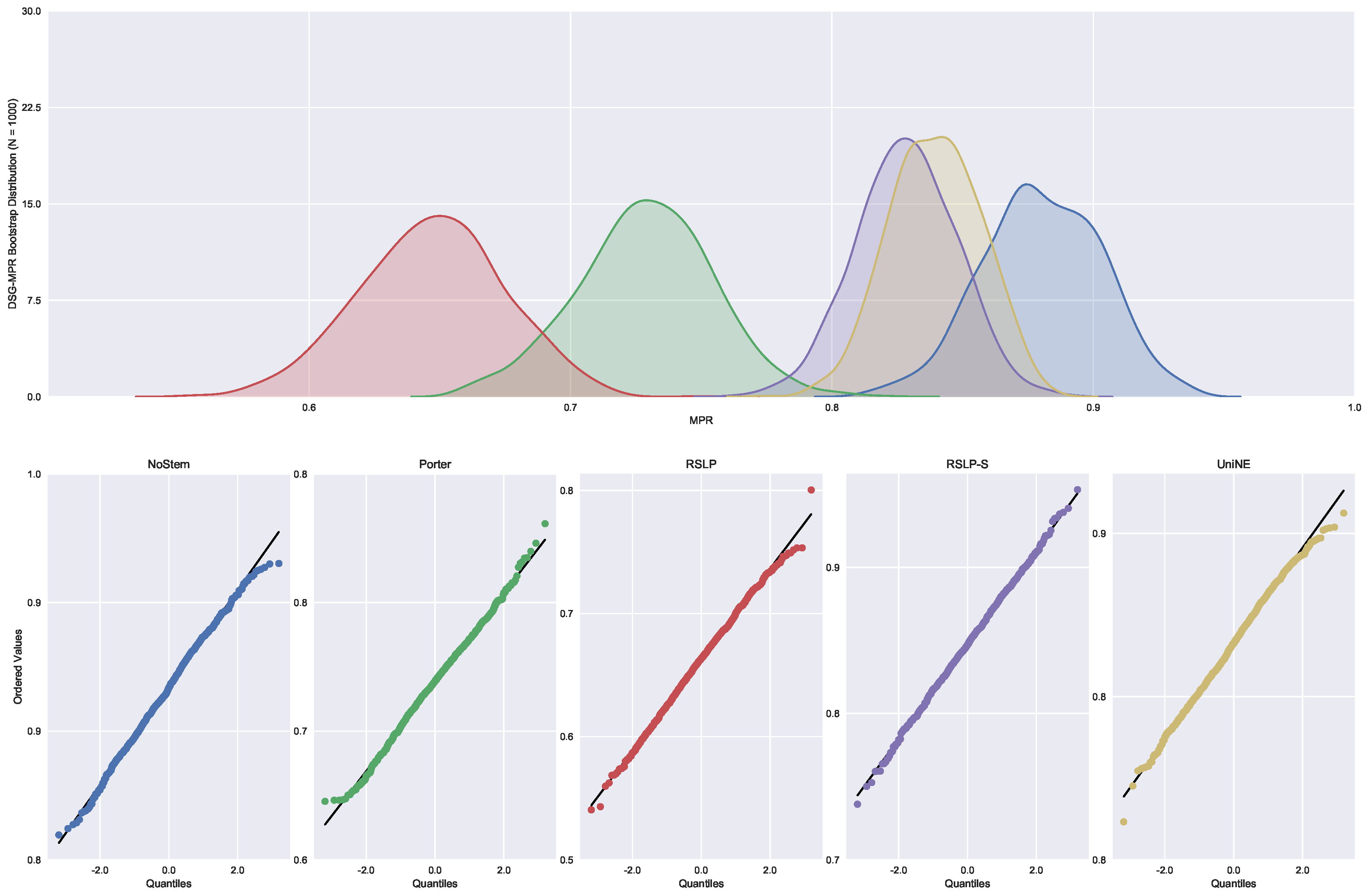
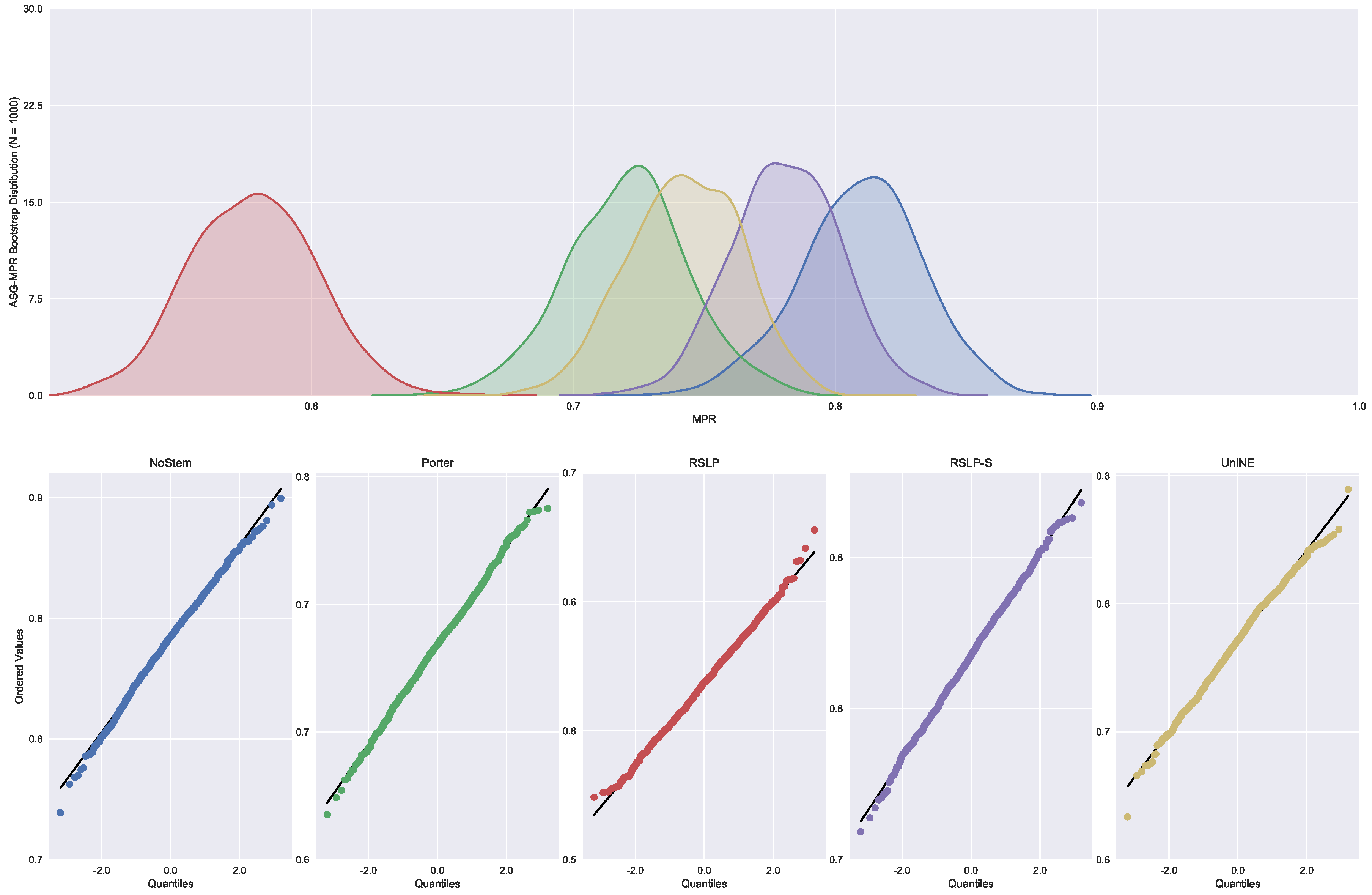
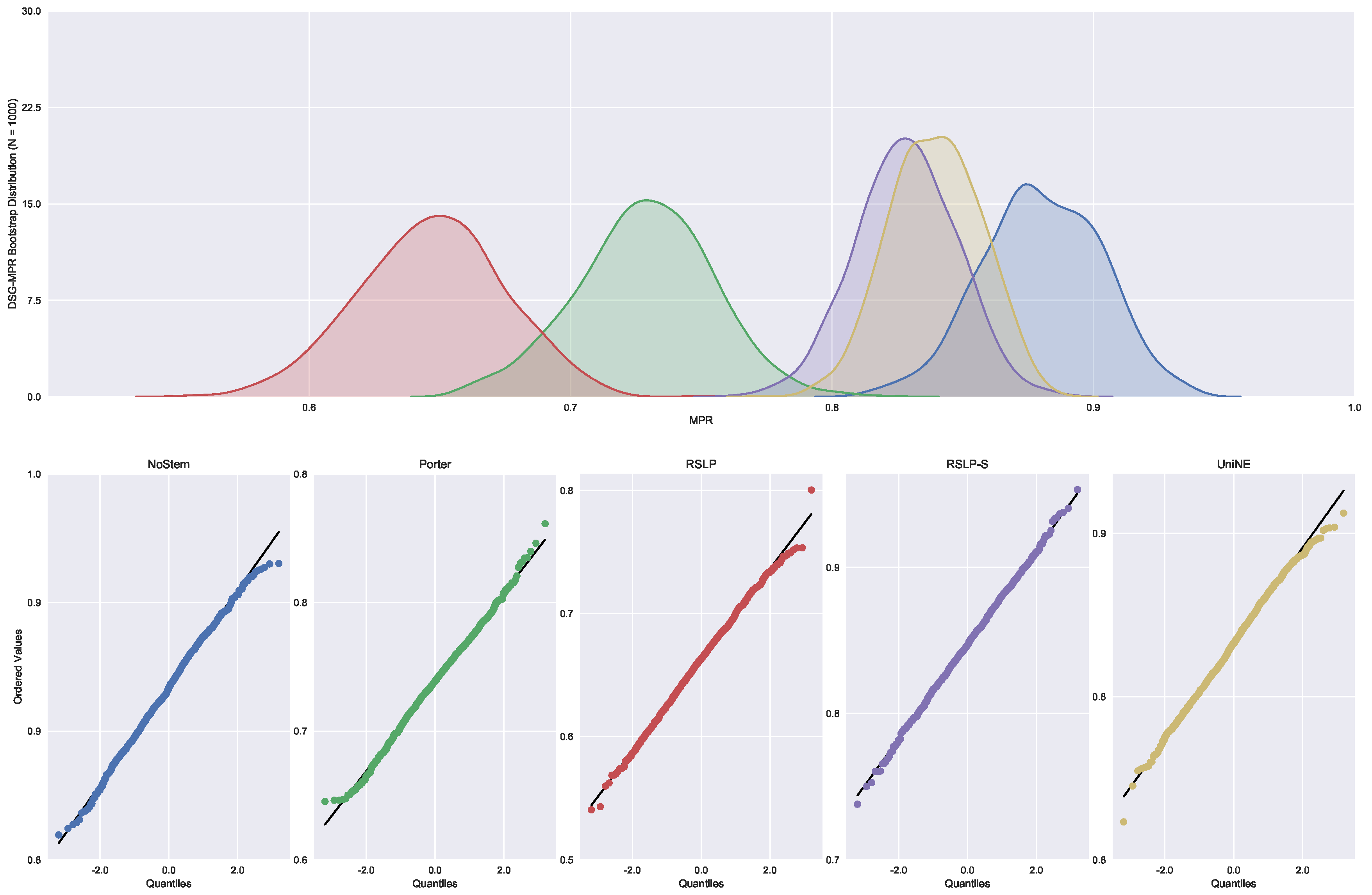
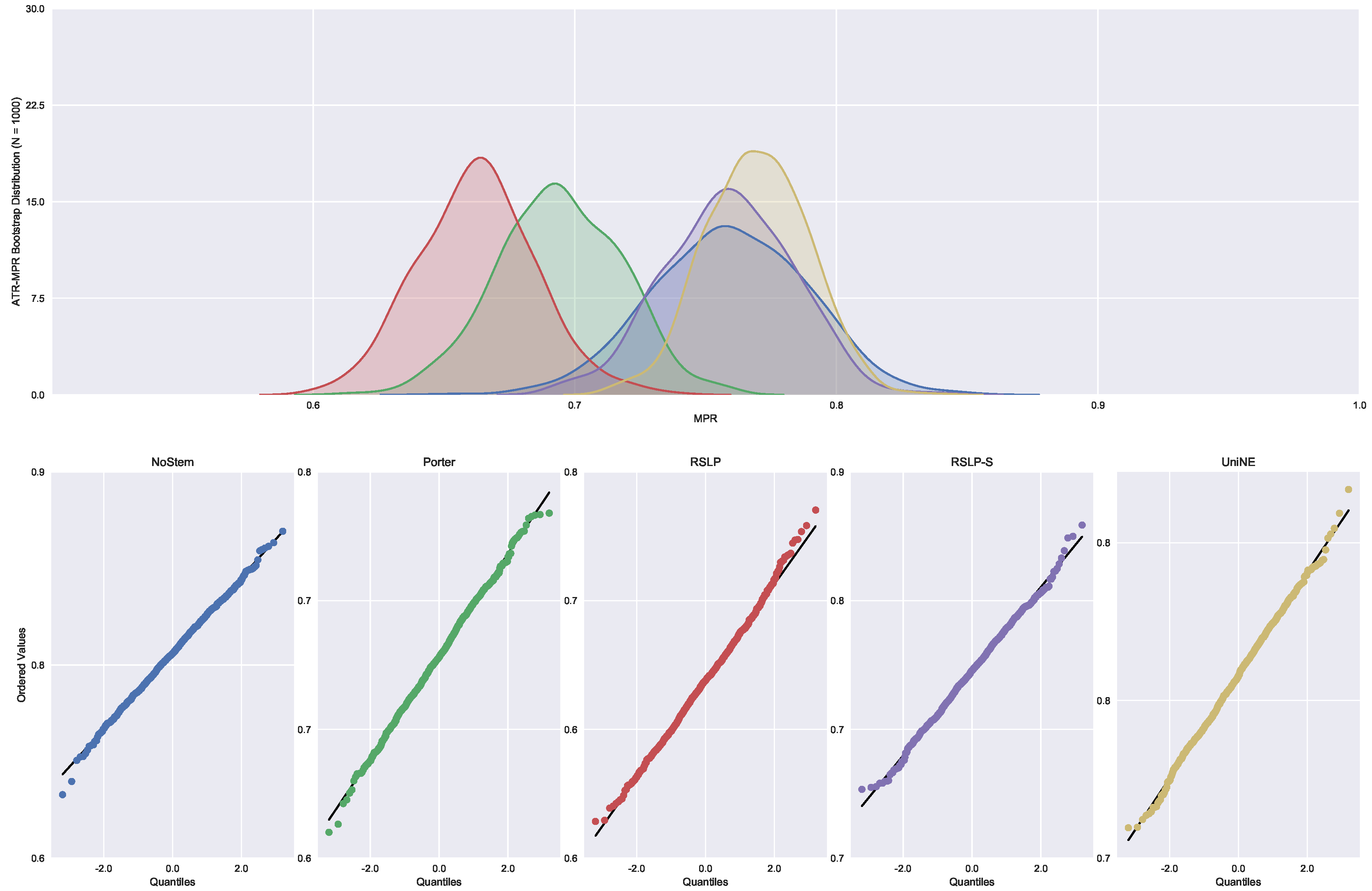
Finally, the data distribution of MRP (
Figure 9) behaved in a manner analogous to that of MPC, with the same deviation of normality from the UniNE algorithm detected by the Shapiro–Wilk test (
p-value < 0.001) and heteroscedasticity found by the Levene test (
p-value < 0.001). As in the other two metrics, the Kruskal–Wallis test refuted the MRP equality between the algorithms (
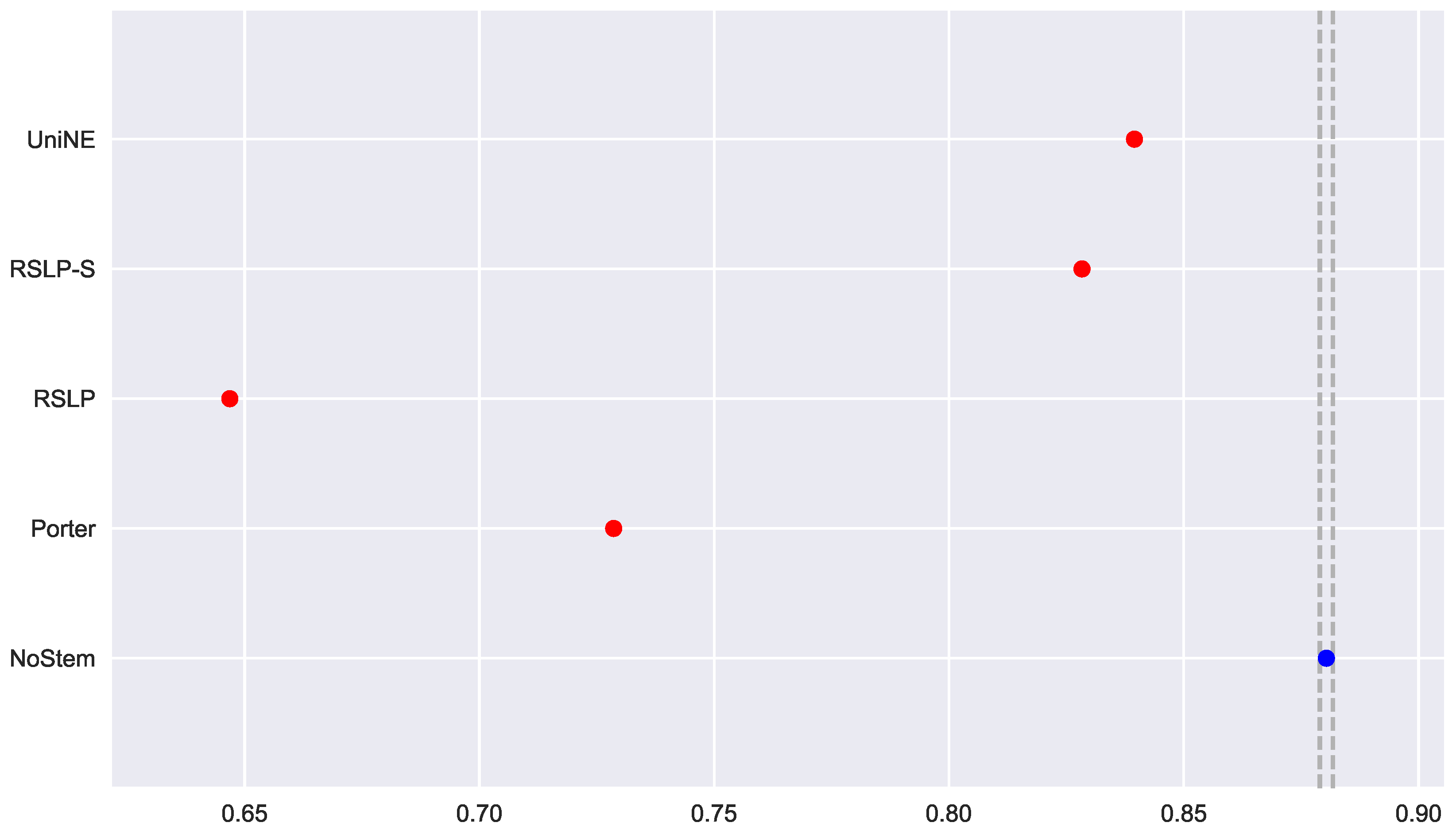
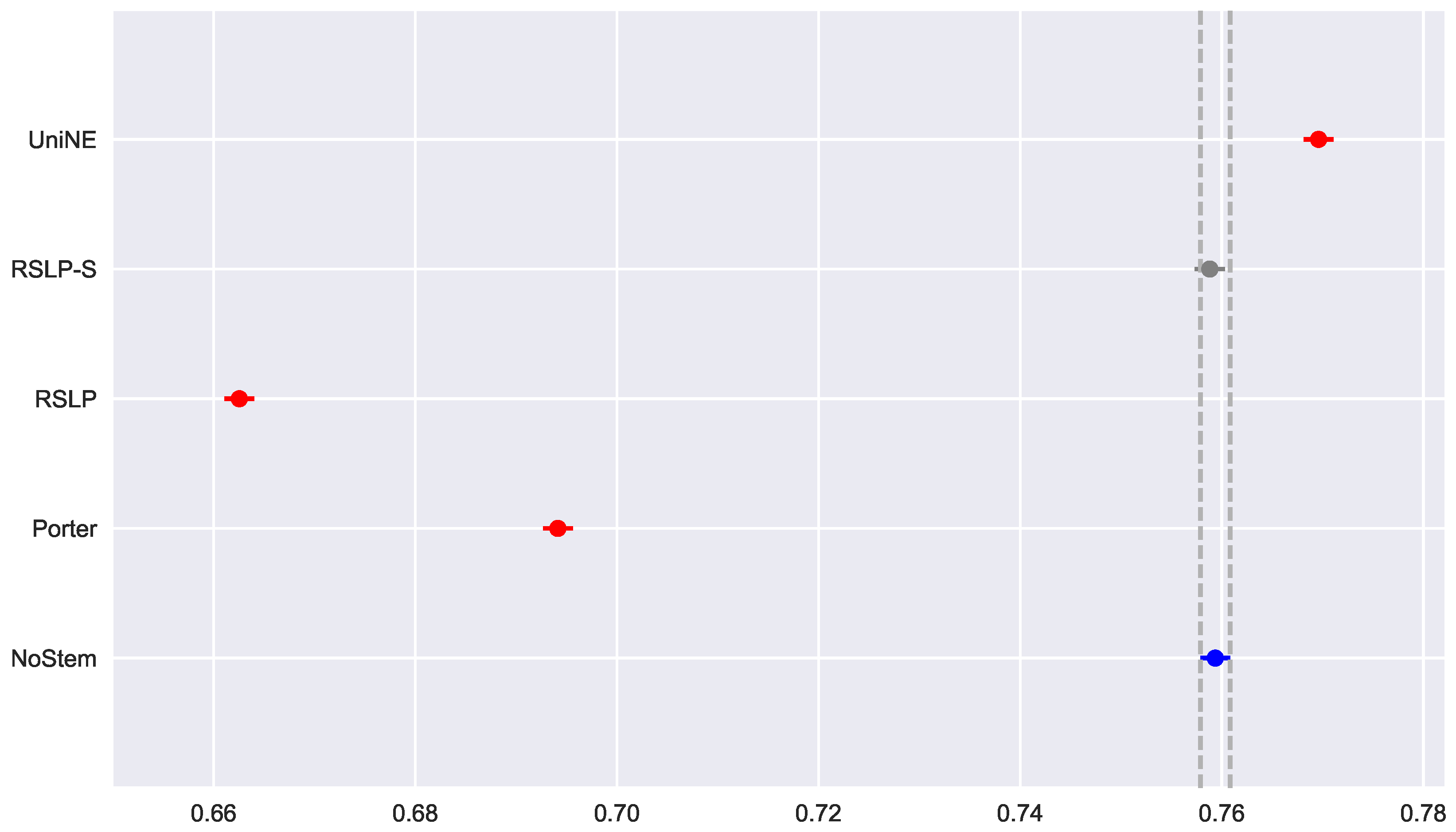
) and the post hoc analysis with Mann–Whitney showed that the difference among the treatments , illustrated by
Figure 10, and the control group was statistically significant (
p-value < 0.001).
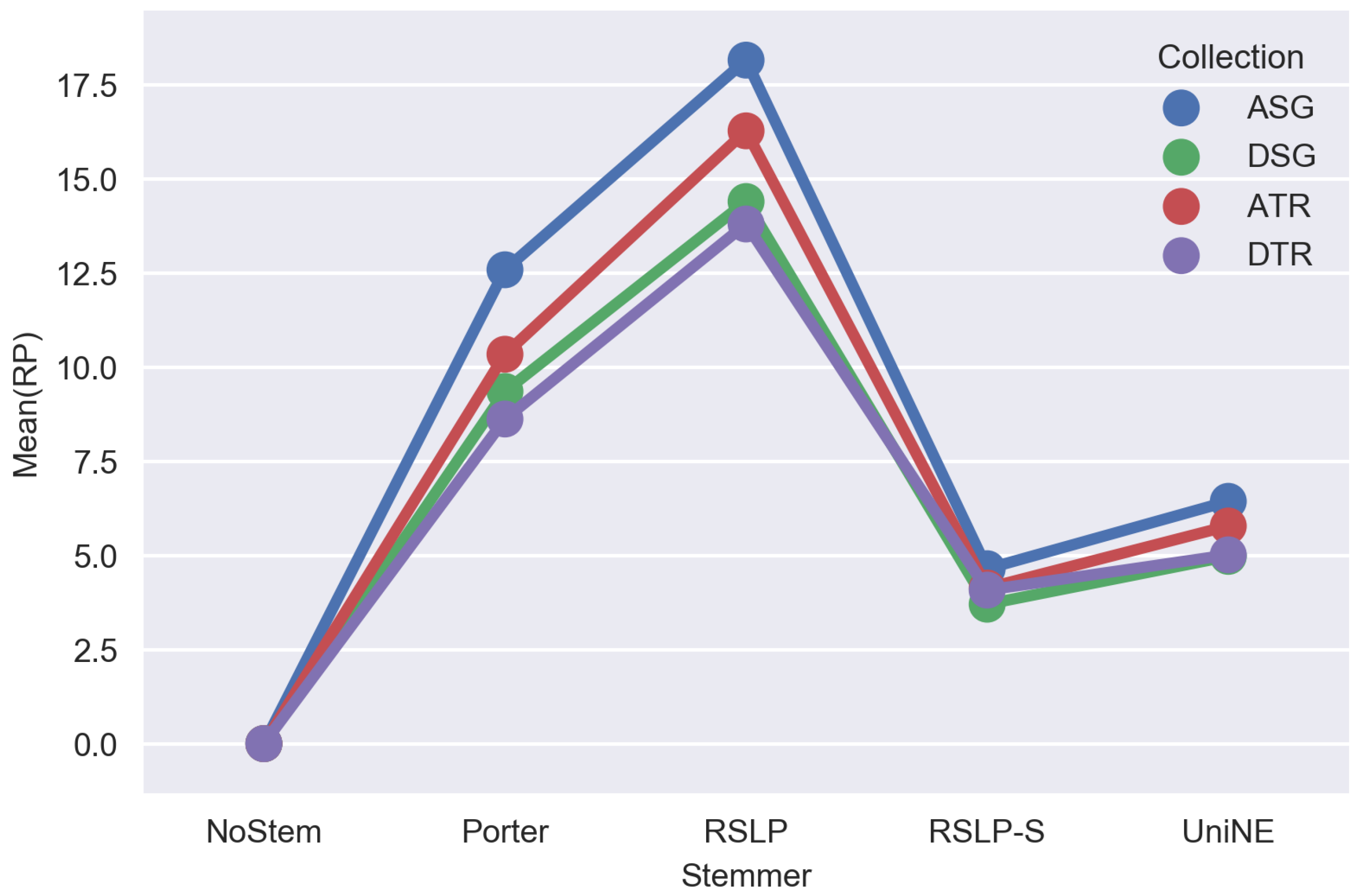
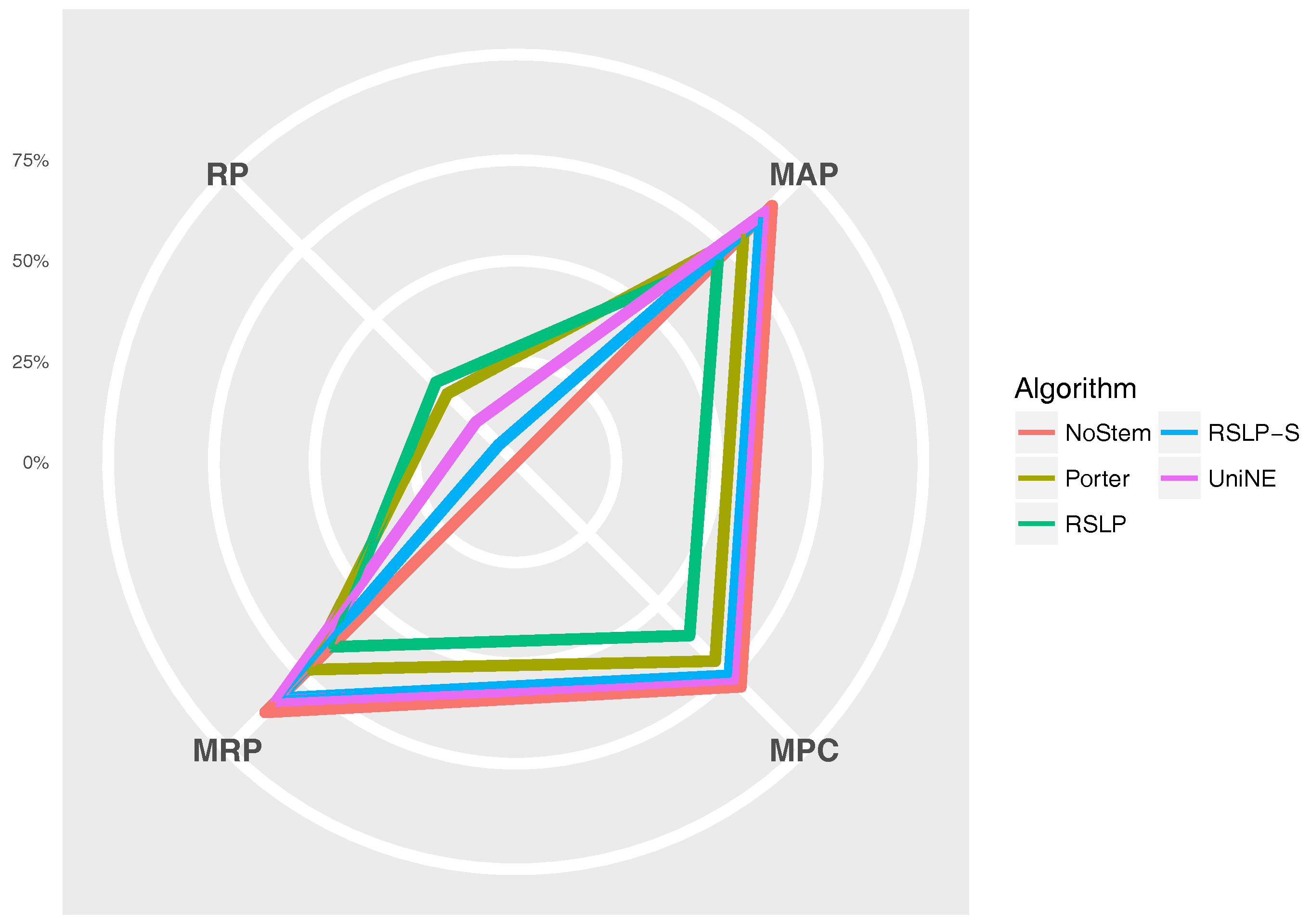
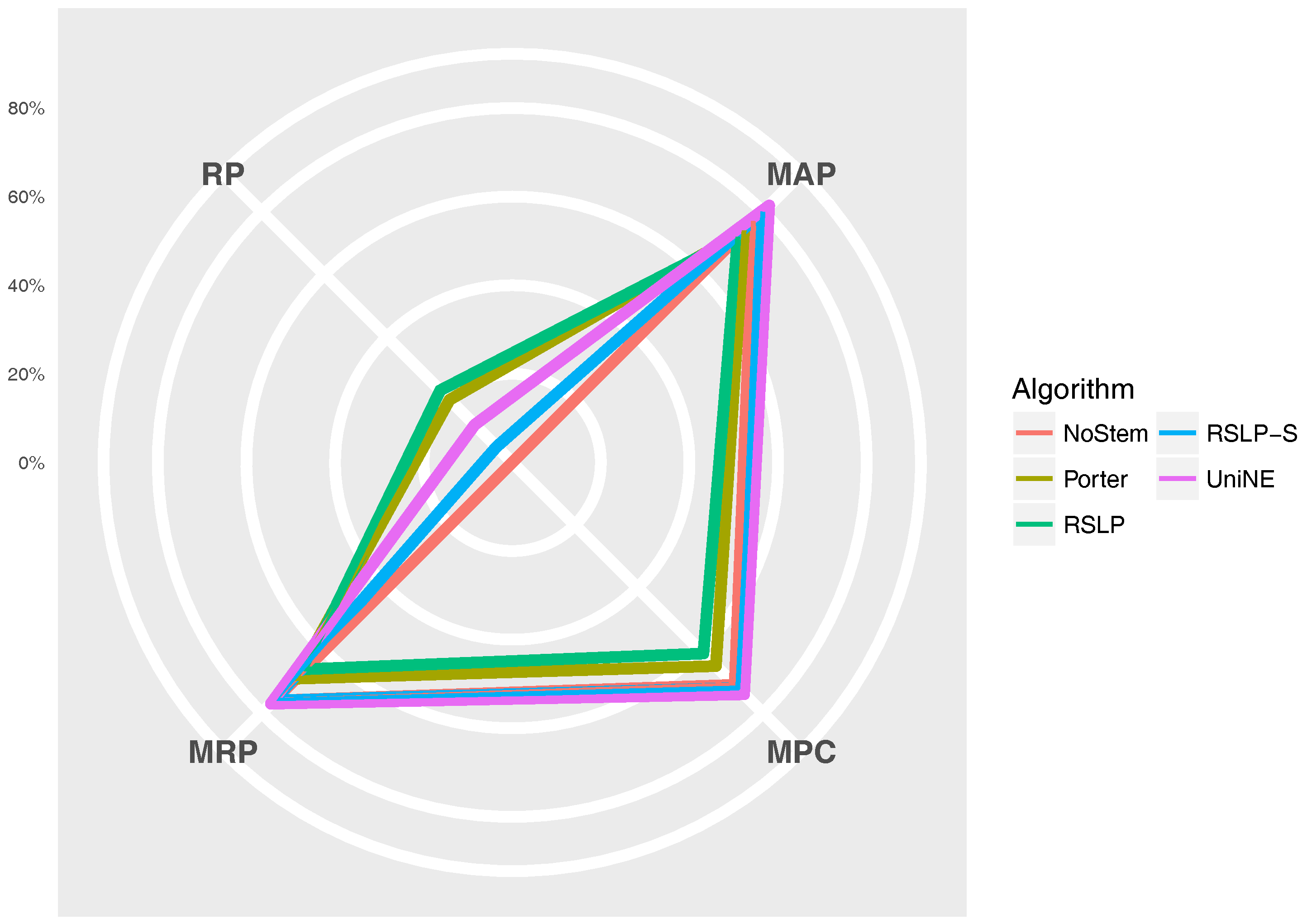
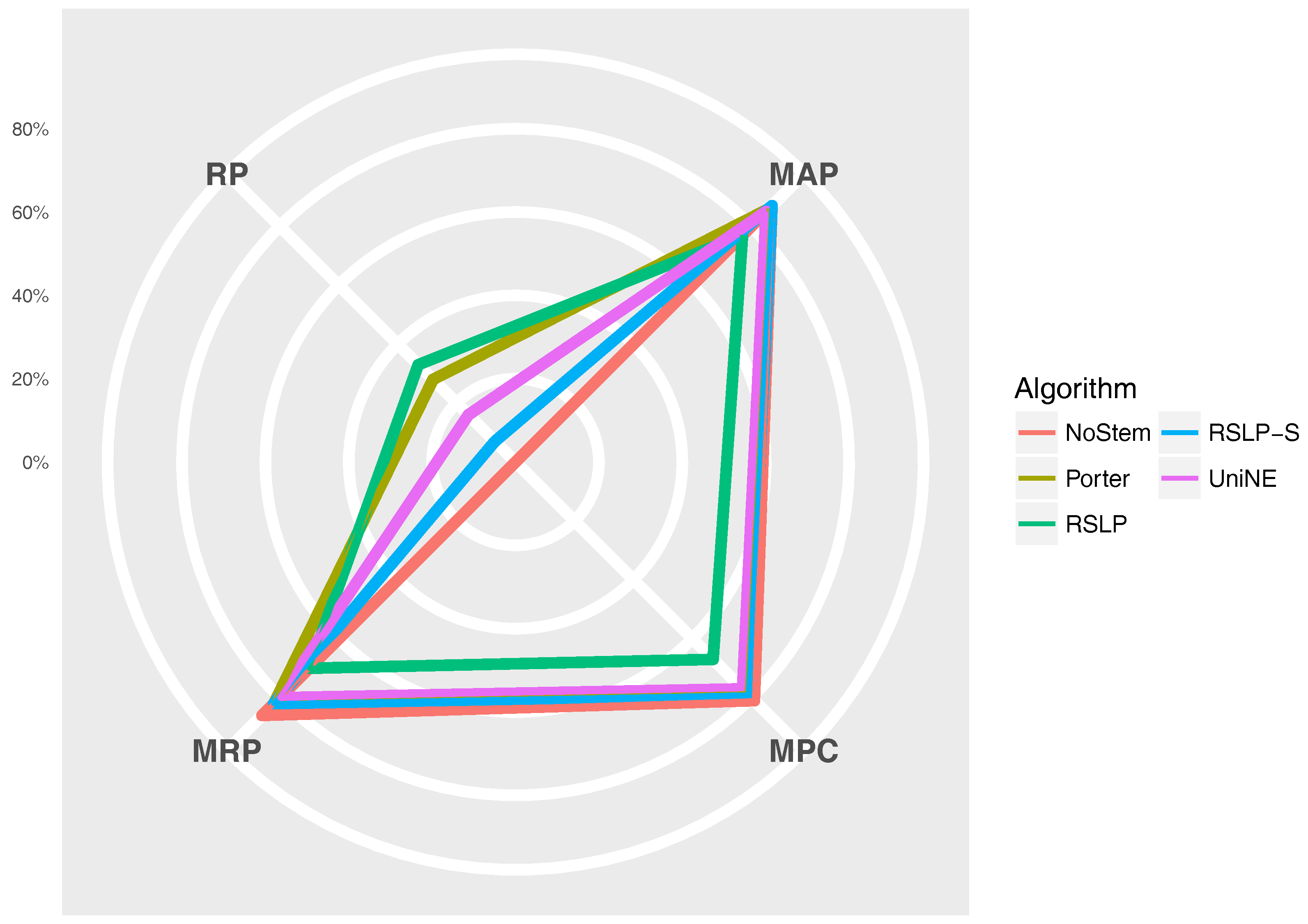
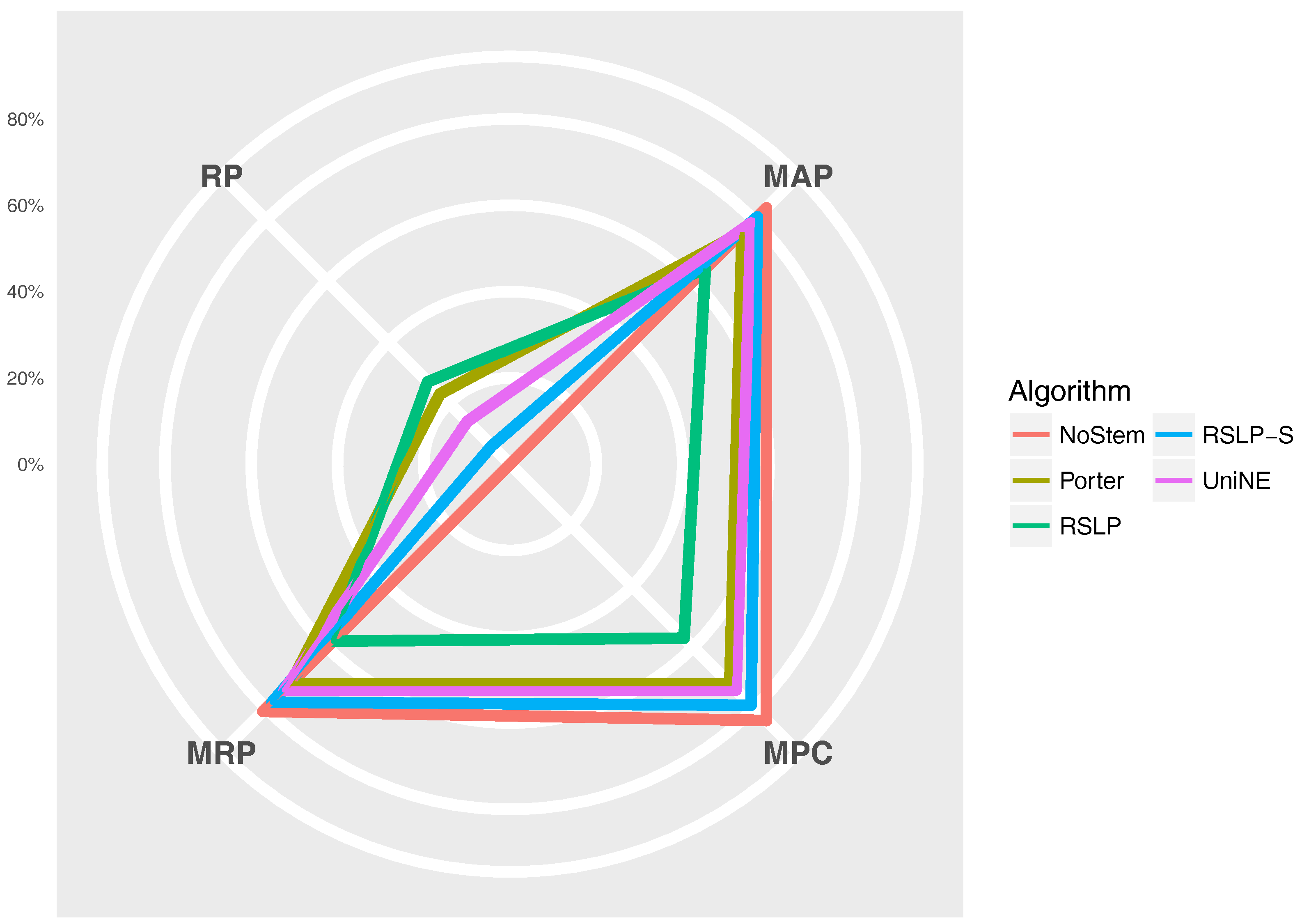
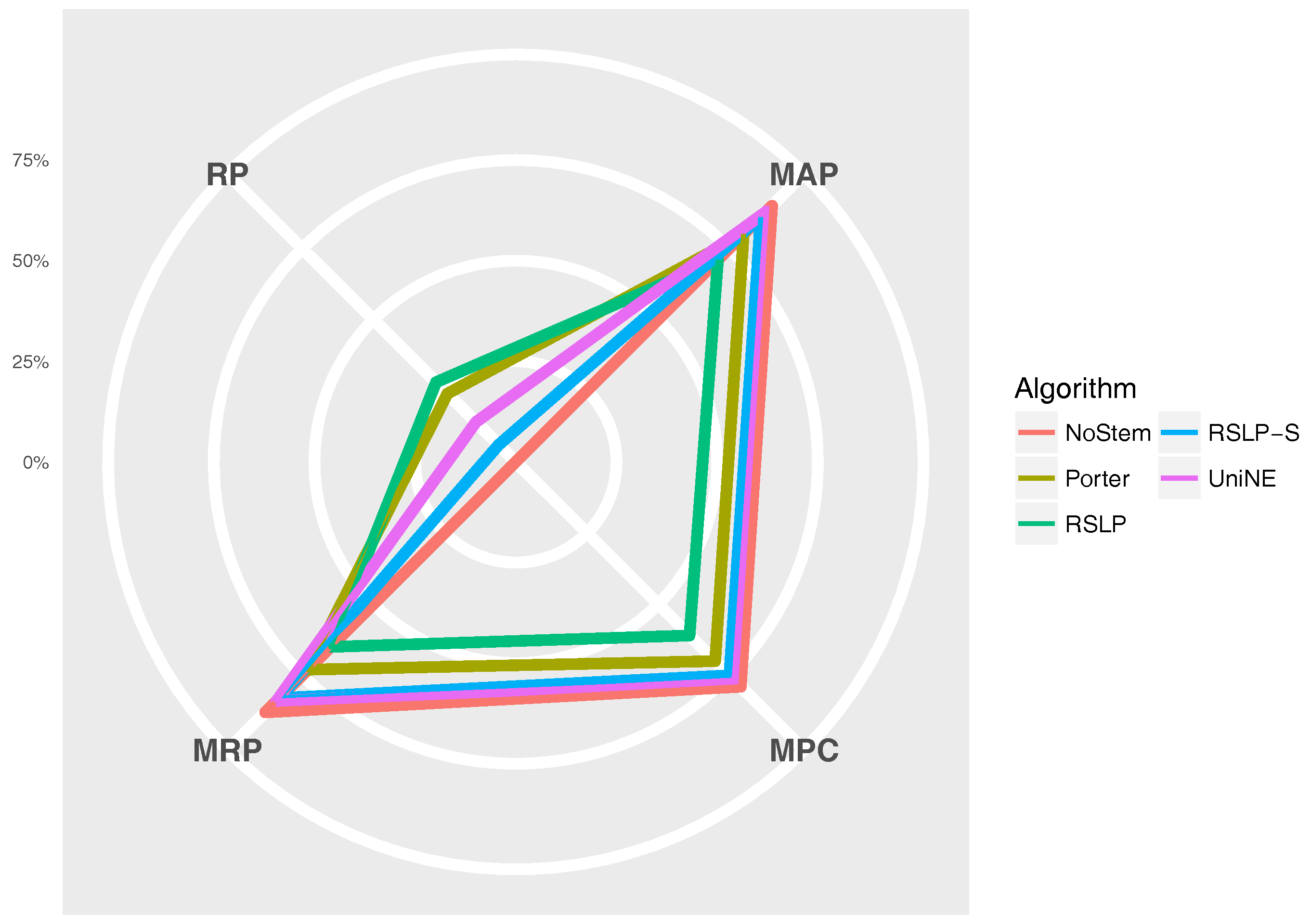
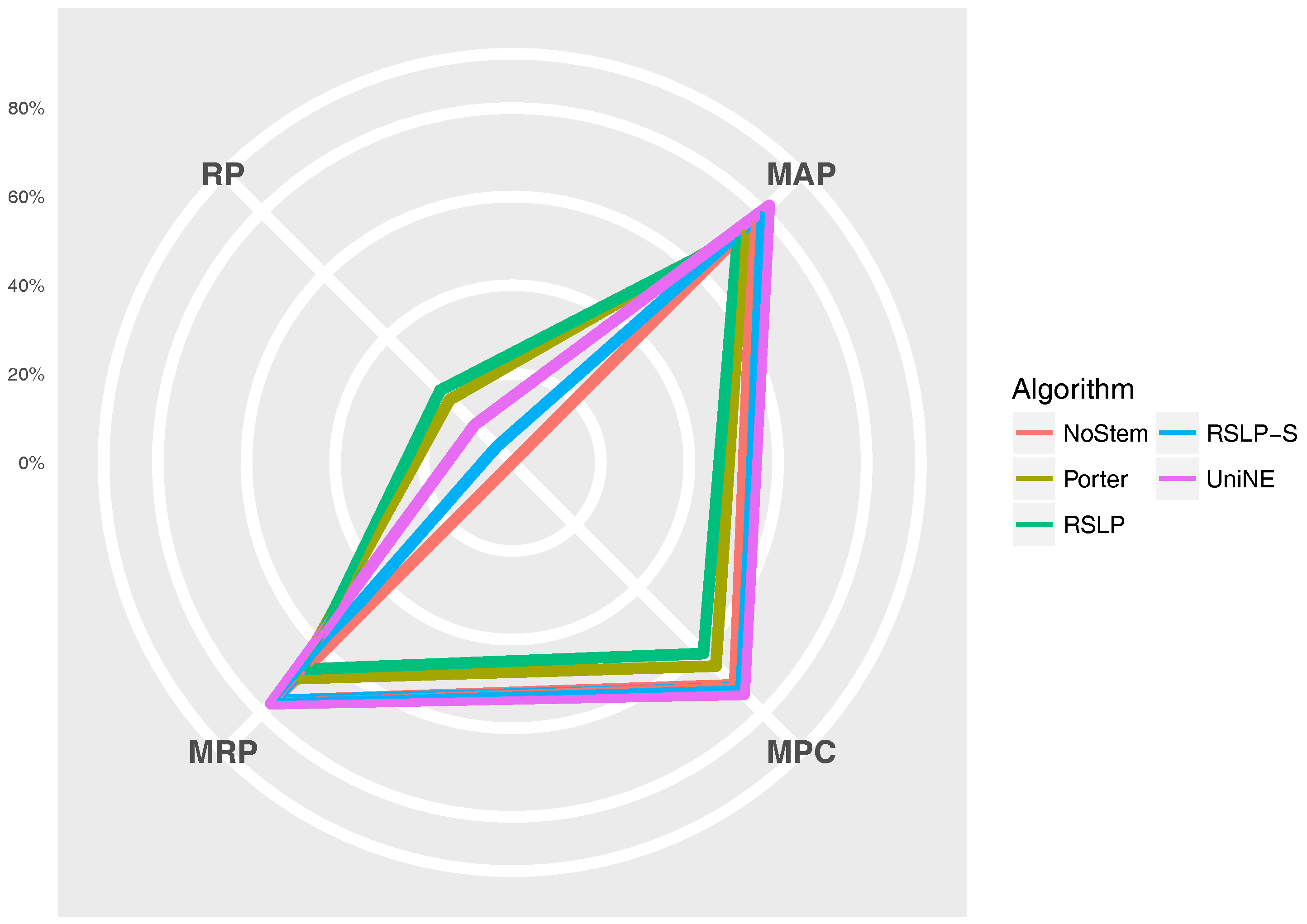
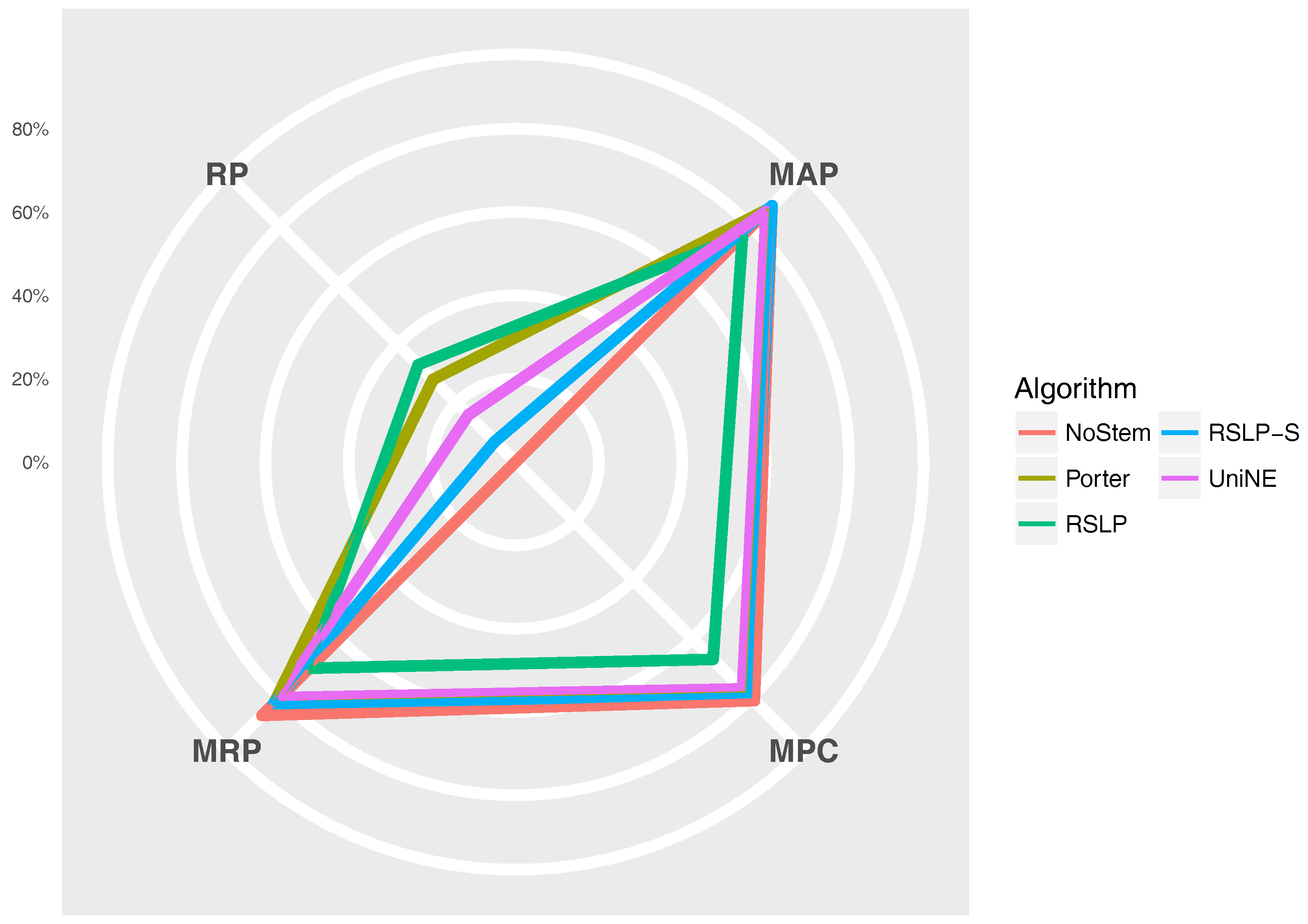
The
Figure 11 radius shows the percentage value of the RP (dimensionality reduction), MAP, MPC and MRP metrics. Thus, we can see, for example, that, although the RSLP algorithm reduces the dimensionality of the data to a greater degree, it stands out in relation to the others due to the decrease in the efficiency of the jurisprudential information retrieval.
Monocratic decisions of Appeals Court (DSG). In this and the next two subsections, we will describe the results found in a more direct way, considering that we use the same analysis process described by the previous topic.
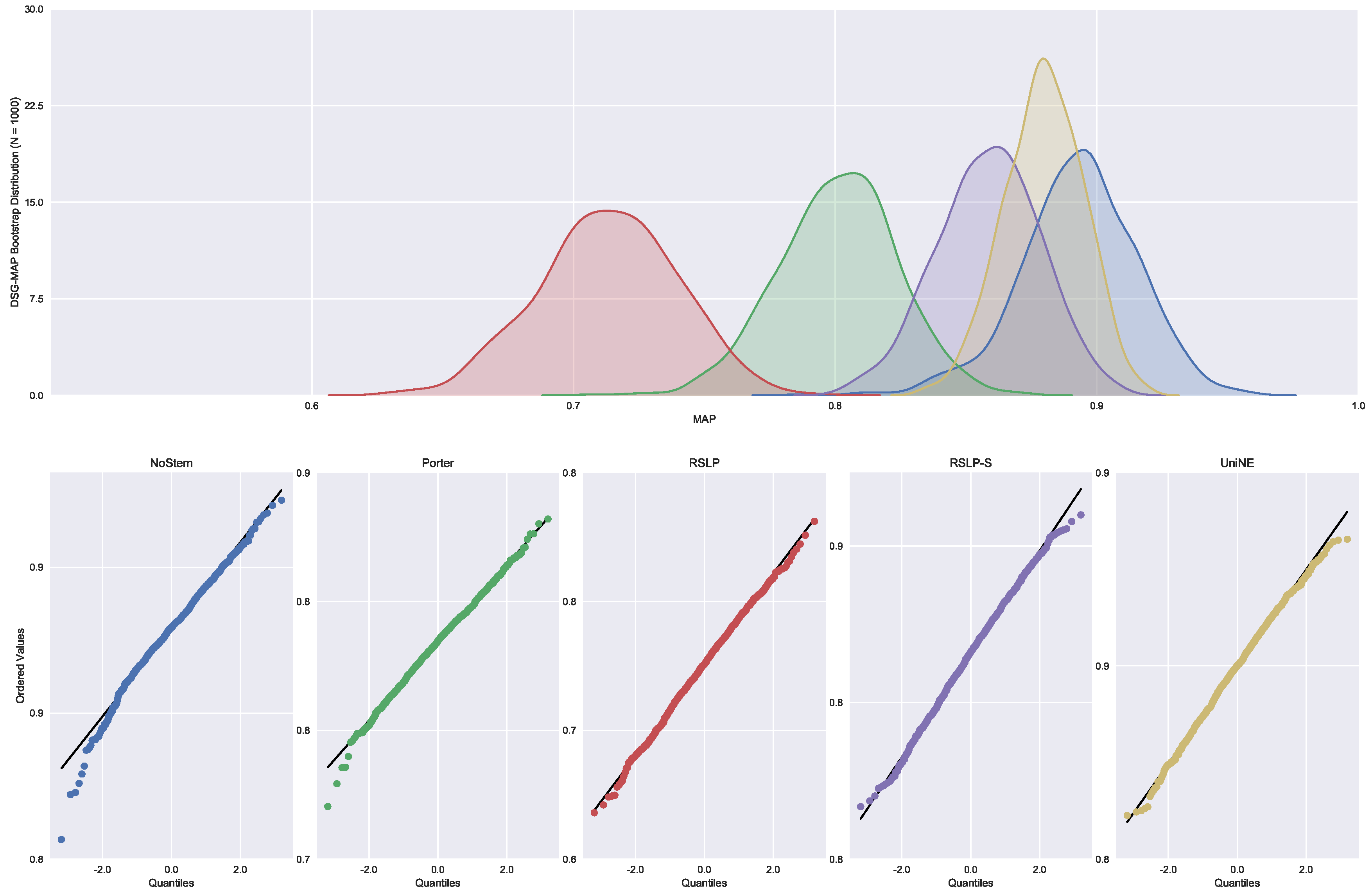
With regard to the distribution of the distribution of MAP data (
Figure 12), the Shapiro–Wilk test refuted the normality hypothesis of the NoStem (
p-value < 0.001) and Porter (
p-value = 0.049) algorithms. Then, the Levene test refuted the hypothesis of homoscedasticity among the groups (
p-value < 0.001) and the MAP equality, hypothesis
, was rejected by the Kruskal–Wallis test with
p-value less than 0.001. The differences illustrated by
Figure 13 were statistically significant (
p-value < 0.001) through a post hoc analysis with the Mann–Whitney test.
On the other hand, the normality premise of MPC (
Figure 14) was violated by the Porter and UniNE algorithms, with
p-values equals to 0.017 and 0.006, respectively. In addition, we confirmed the heteroskedasticity of the data and the significance of the differences between the treatments (
Figure 15), refuting the hypothesis
, since the tests found a
p-value less than 0.001.
Although the normality of the MRP (
Figure 16) was evidenced by the Shapiro–Wilk tests, with all treatments presenting
p-value higher than the level of significance adopted by the experiment, the Levene test refuted the hypothesis of homoscedasticity of the data. With this, we again chose to use the non-parametric Kruskal–Wallis test to verify the hypothesis of MRP equality among groups (
). This hypothesis was rejected (
p-value < 0.001) and the Mann–Whitney test evidenced the difference between radicalization and control group (
Figure 17). Finally, we can visualize the multiple variables involved in the experiment through
Figure 18.
Judgments of Special Courts (ATR). According to
Table 10, this collection was the only one of the four studied in which radicalization caused an increase of the three metrics. Thus, we will analyze whether this difference in relation to the control group was statistically significant.
The control group did not present data normality (
p-value = 0.045) with respect to MAP (
Figure 19) and the homoscedasticity hypothesis was rejected (
p-value < 0.001). Following the process, conduction of the Kruskal–Wallis test showed that there was a difference among the studied groups (
p-value < 0.001), that is, the hypothesis
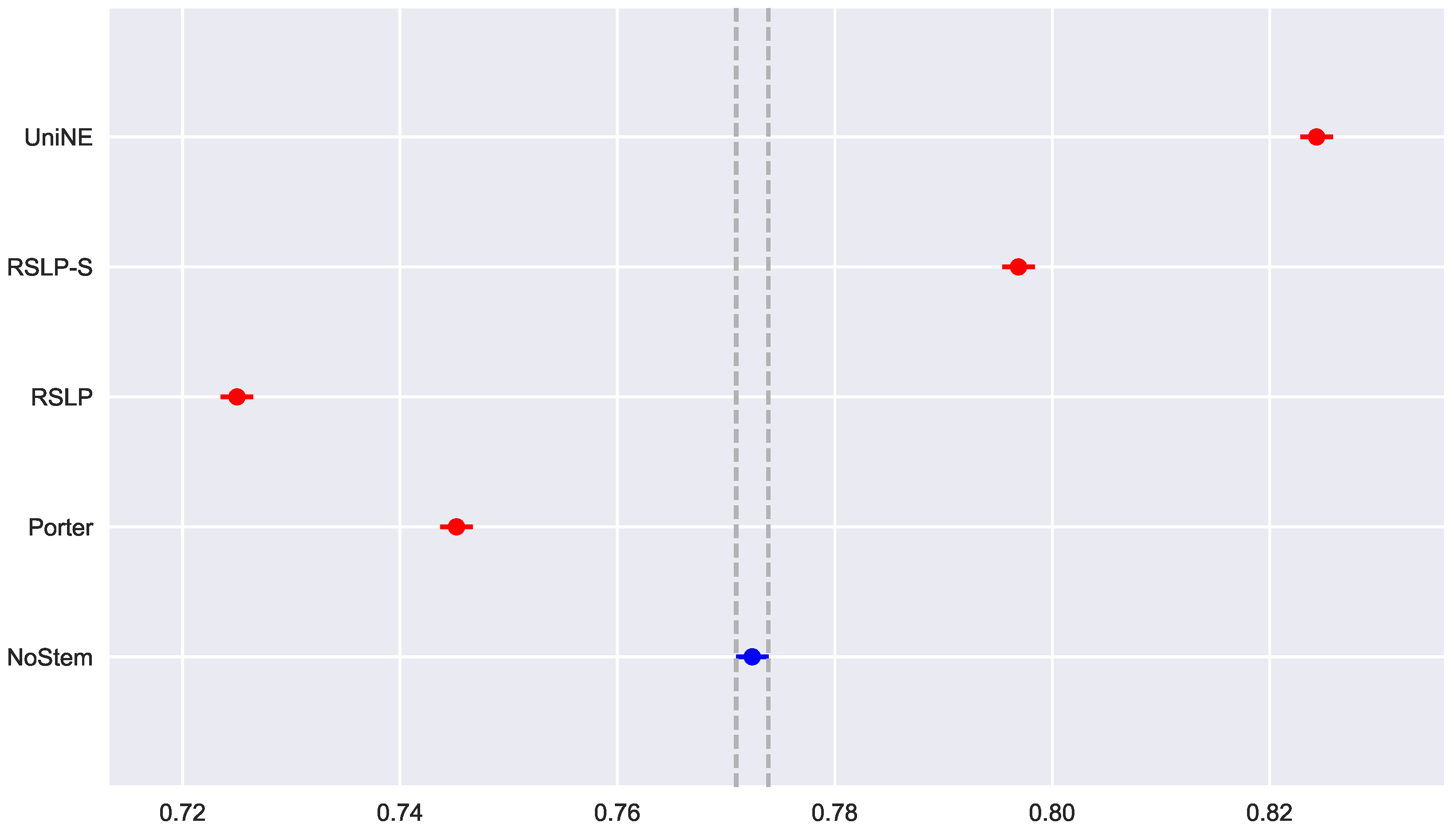
was rejected. Post hoc analysis showed that the RSLP-S and UniNE algorithms (
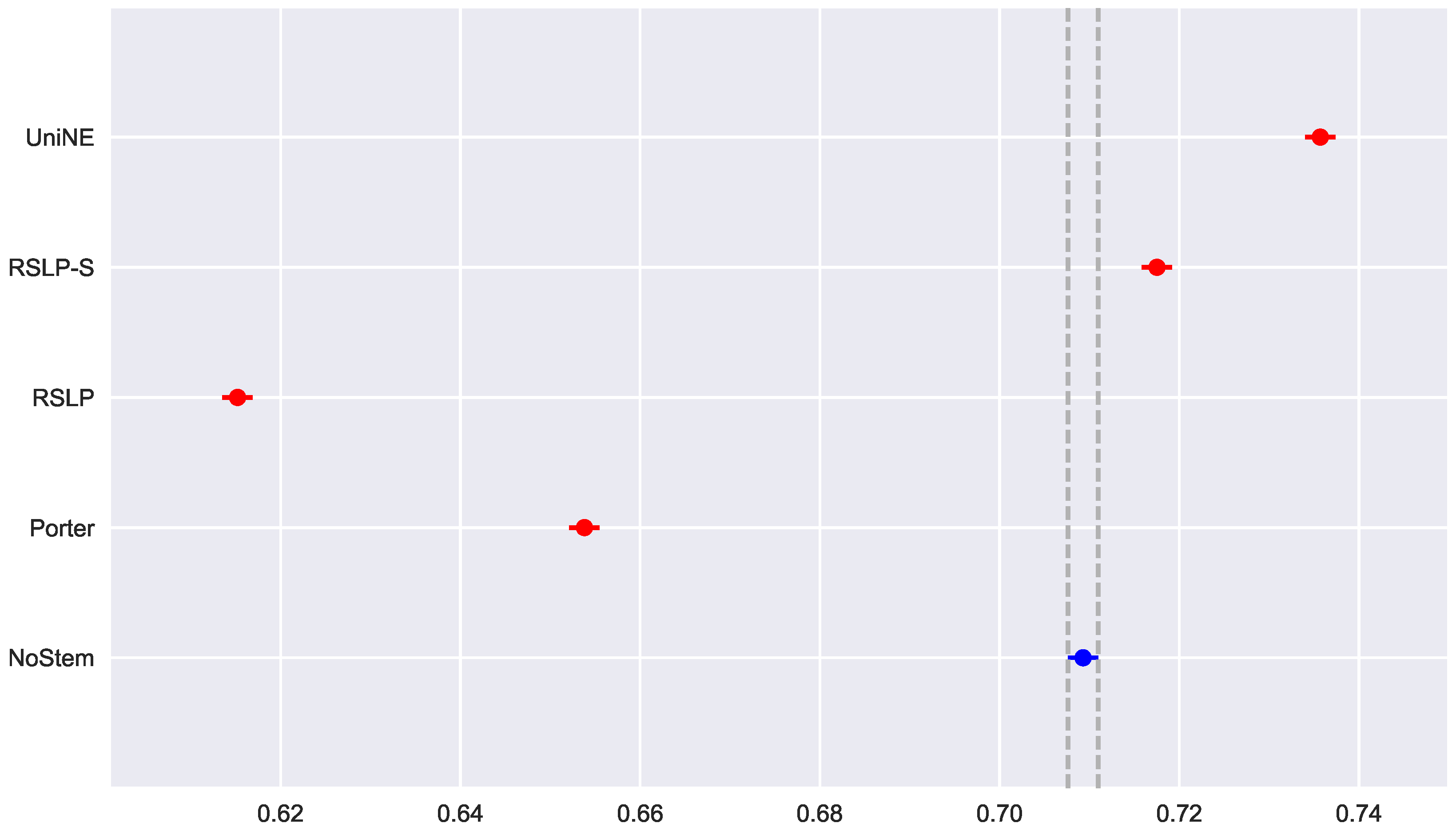
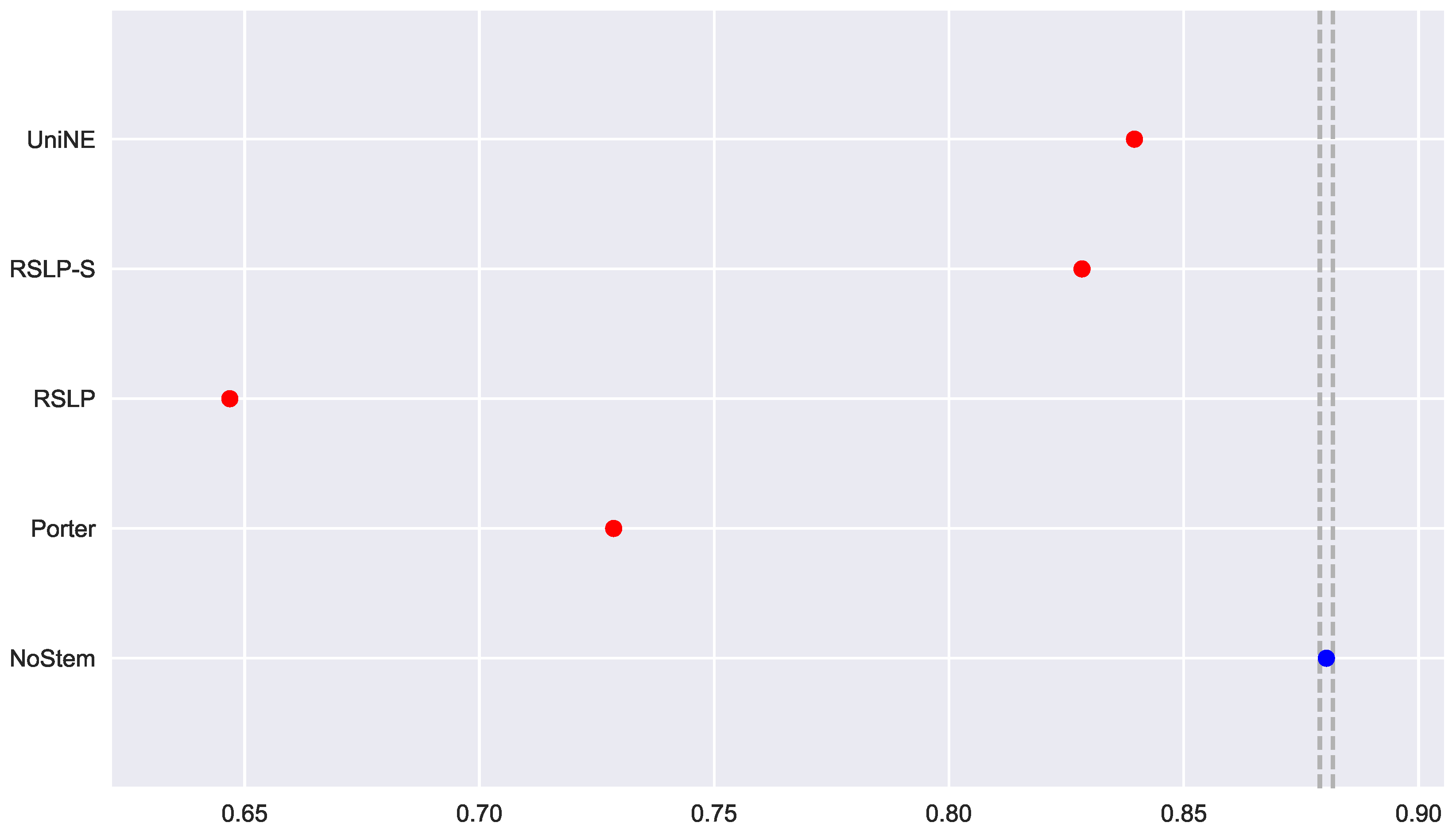
Figure 20) showed a significant improvement of MAP.
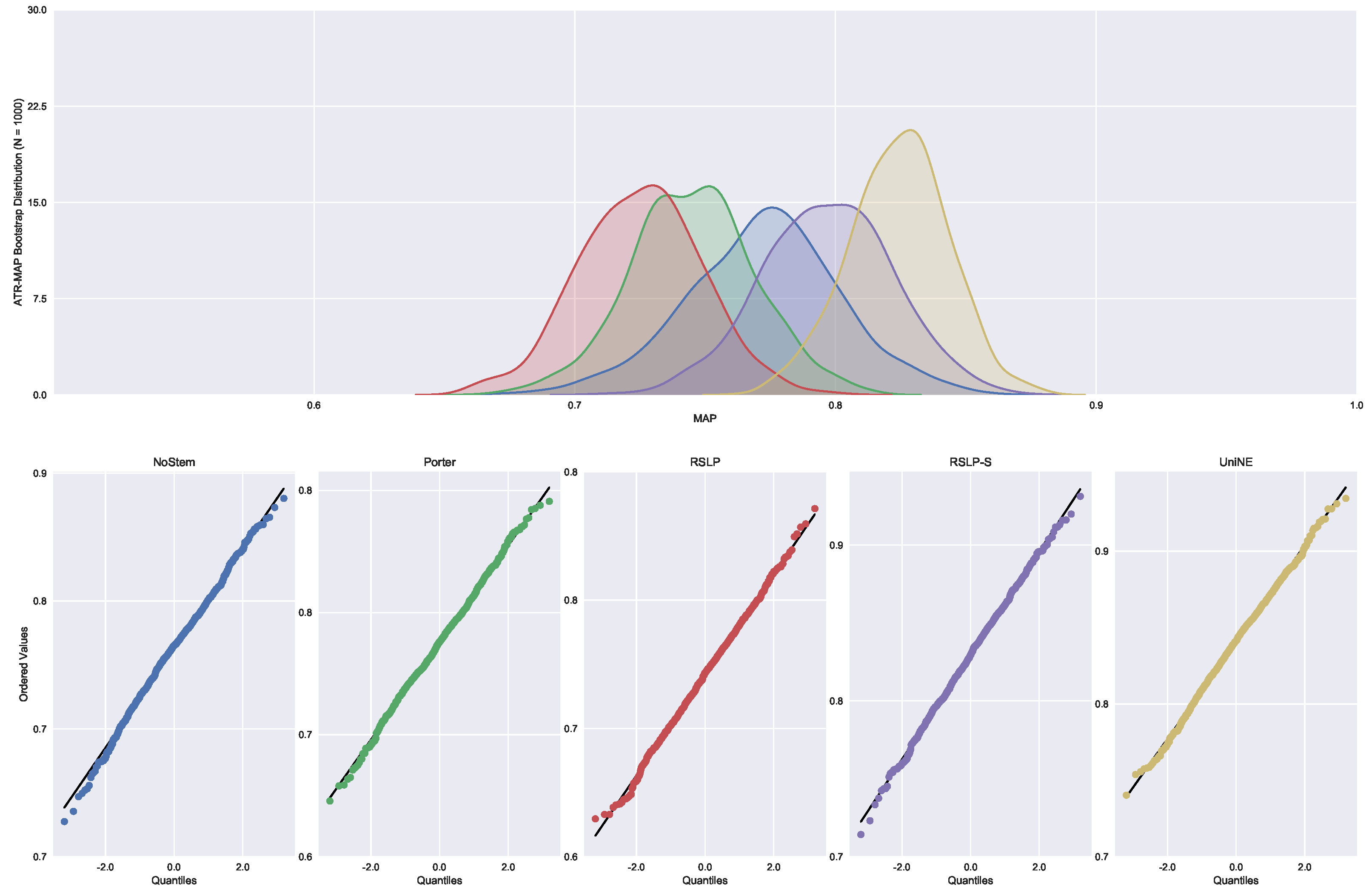
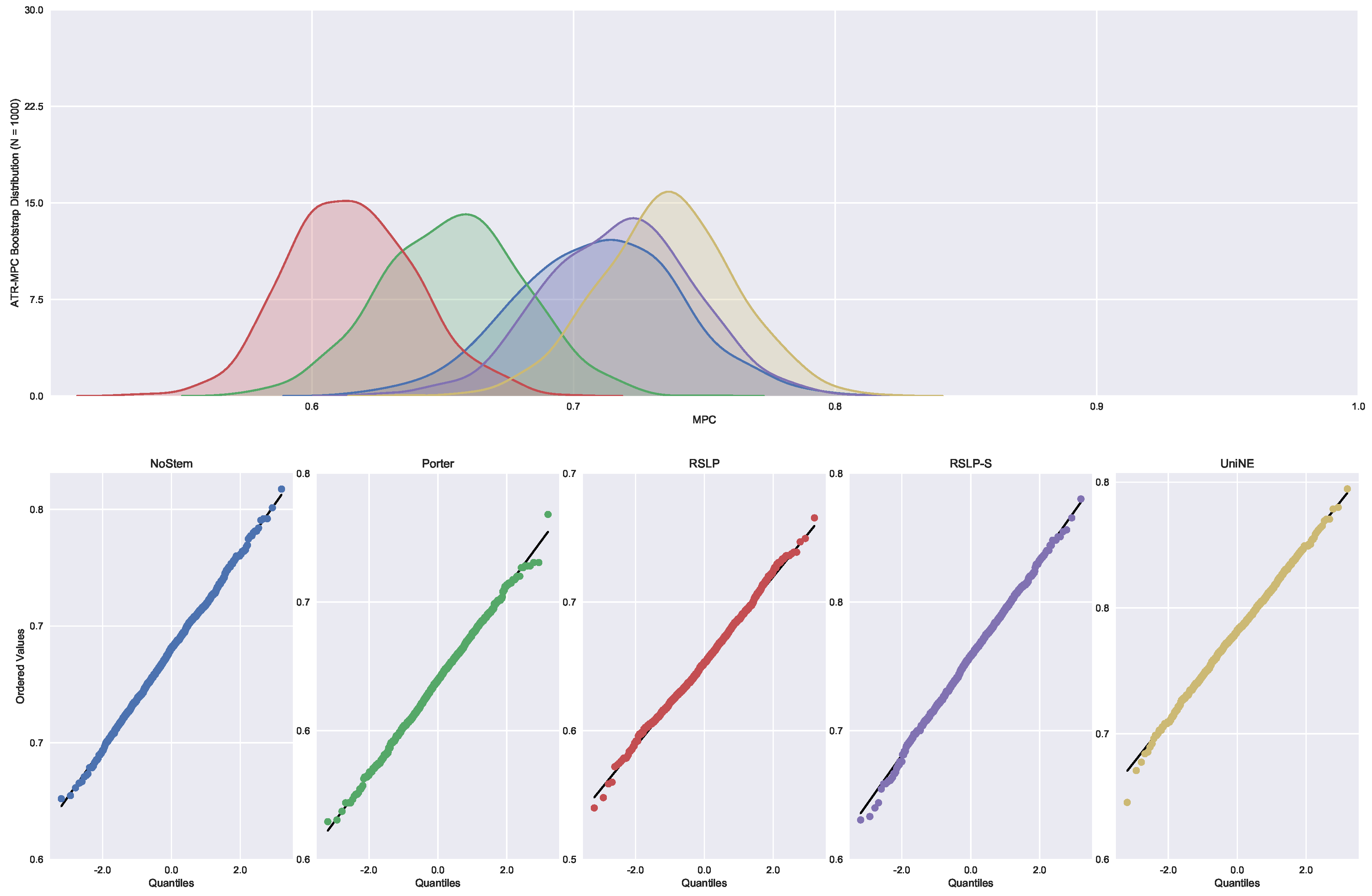
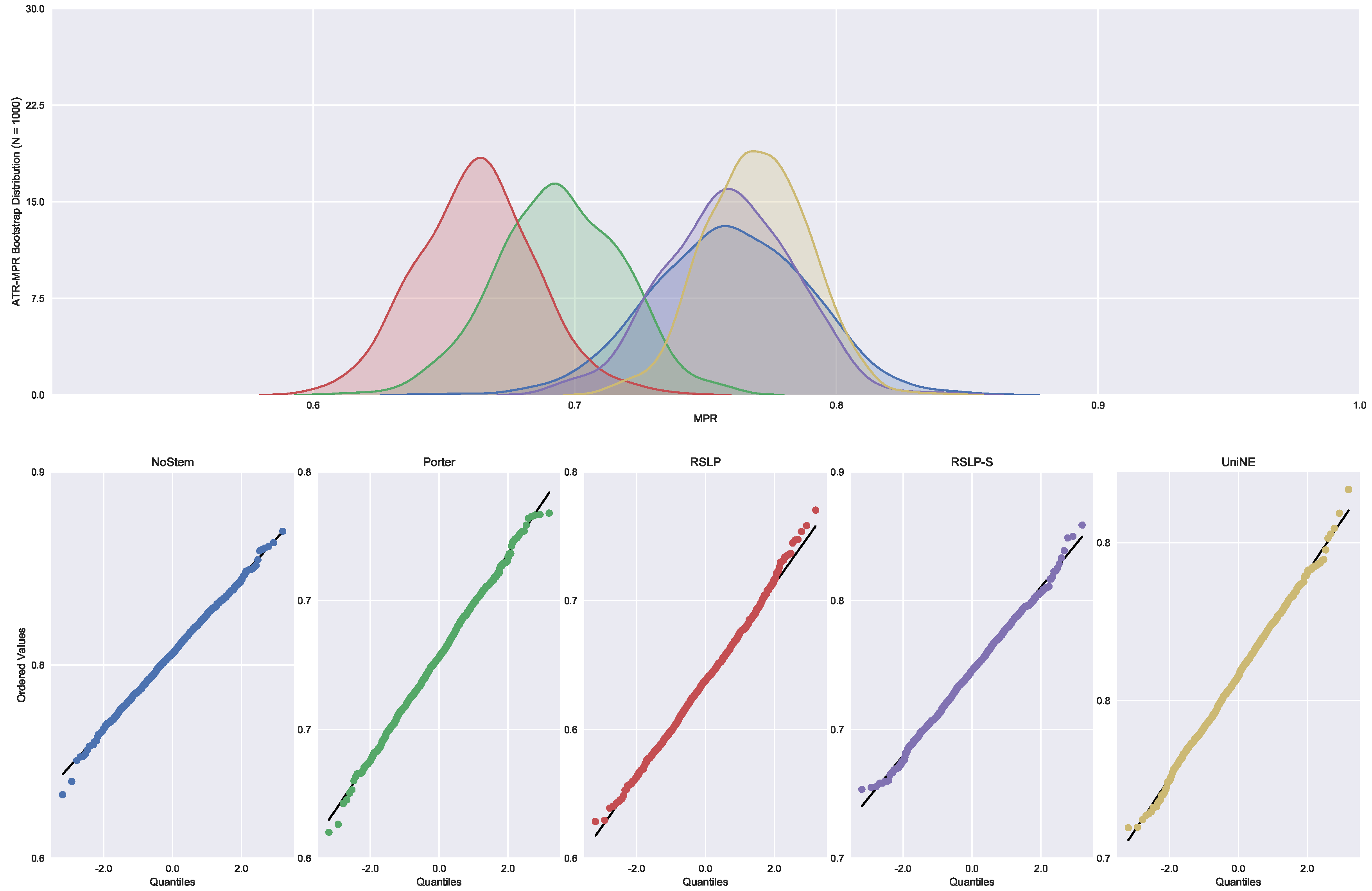
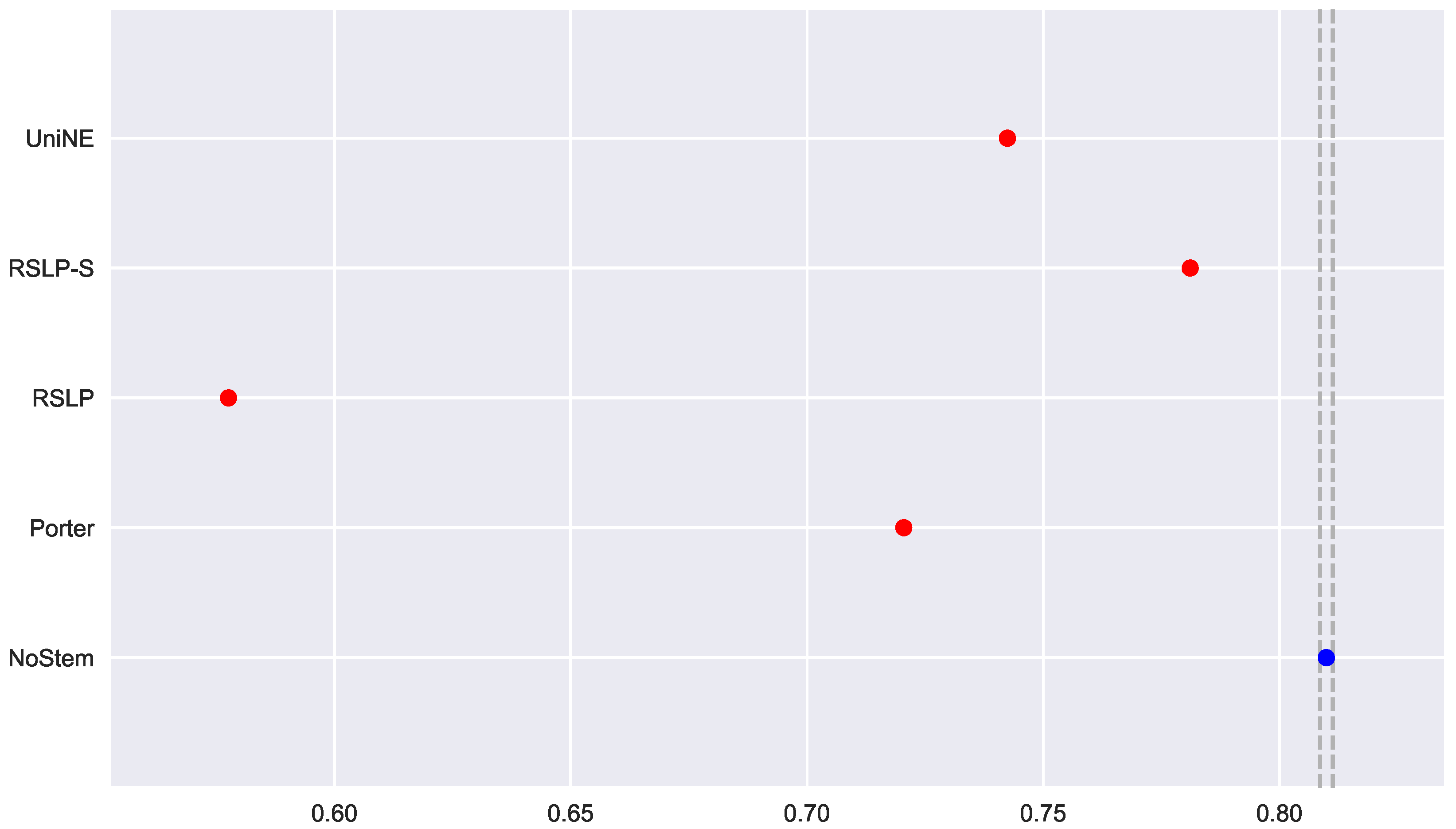
In addition to an improvement in MAP, these two algorithms also caused an improvement in the MPC of the ATR jurisprudence information retrieval. For this analysis, we conducted the Shapiro–Wilk test on the bootstrap data distribution (
Figure 21) and tested the homoskedasticity of the data. Although all groups were normal, there were heteroscedasticity of the treatments. Thus, we reject the hypothesis
, MPC equality among groups, with the Kruskal–Wallis test (
p-value < 0.001) and validate the significance of this difference, illustrated by
Figure 22 with Mann–Whitney.
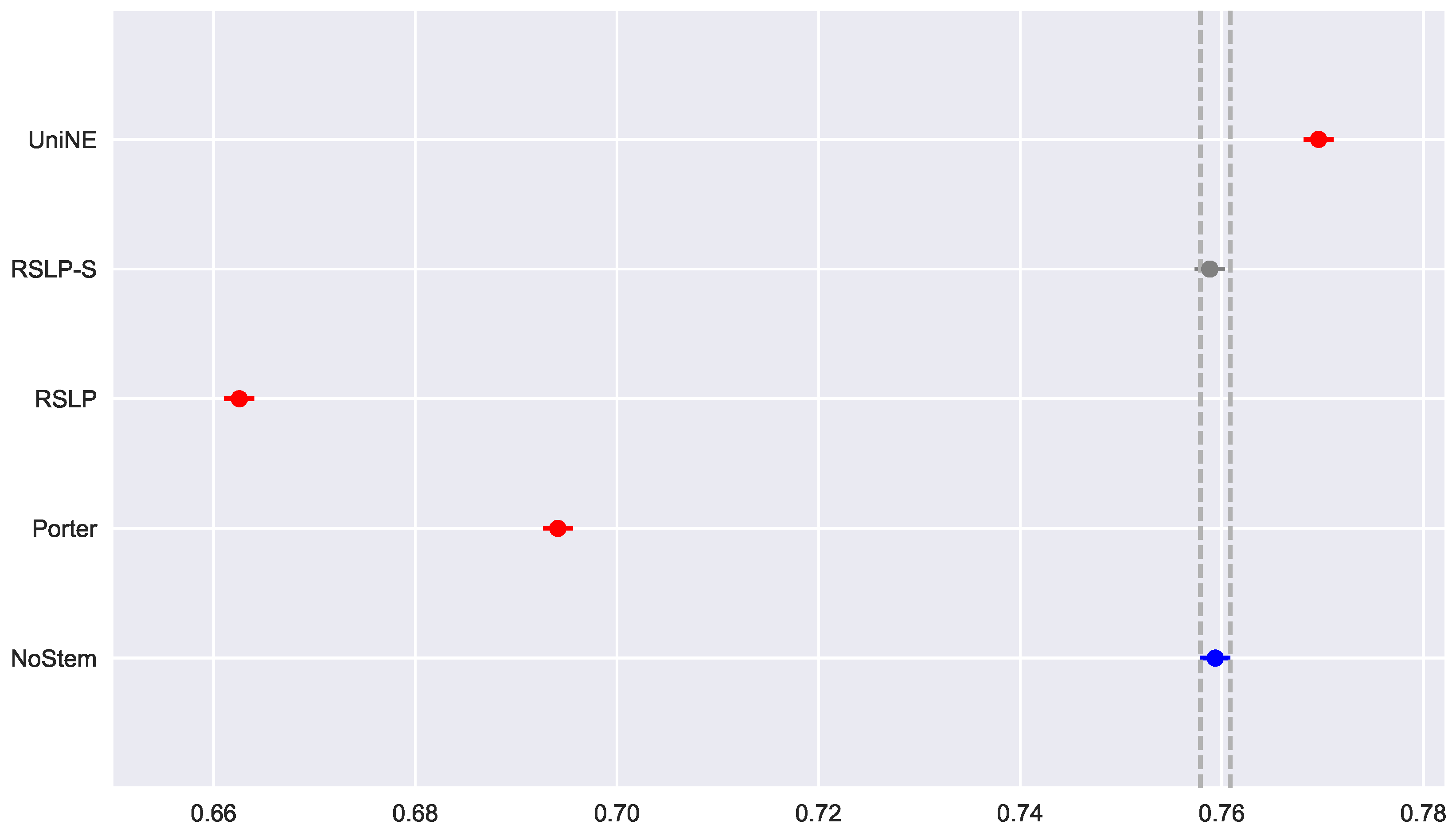
Similar to the previous metric, all treatments followed a Normal distribution and there was heteroscedasticity of the MRP data (
Figure 23). However, according to post hoc analysis, only the UniNE algorithm caused an improvement of this metric (
Figure 24), thus rejecting the hypothesis of MRP equality among the treatments (
). However, as
Figure 25 shows, the RSLP-S algorithm presented a greater dimensionality reduction than the control group, so even though they have the same MRP, it becomes a more advantageous option in storage efficiency.
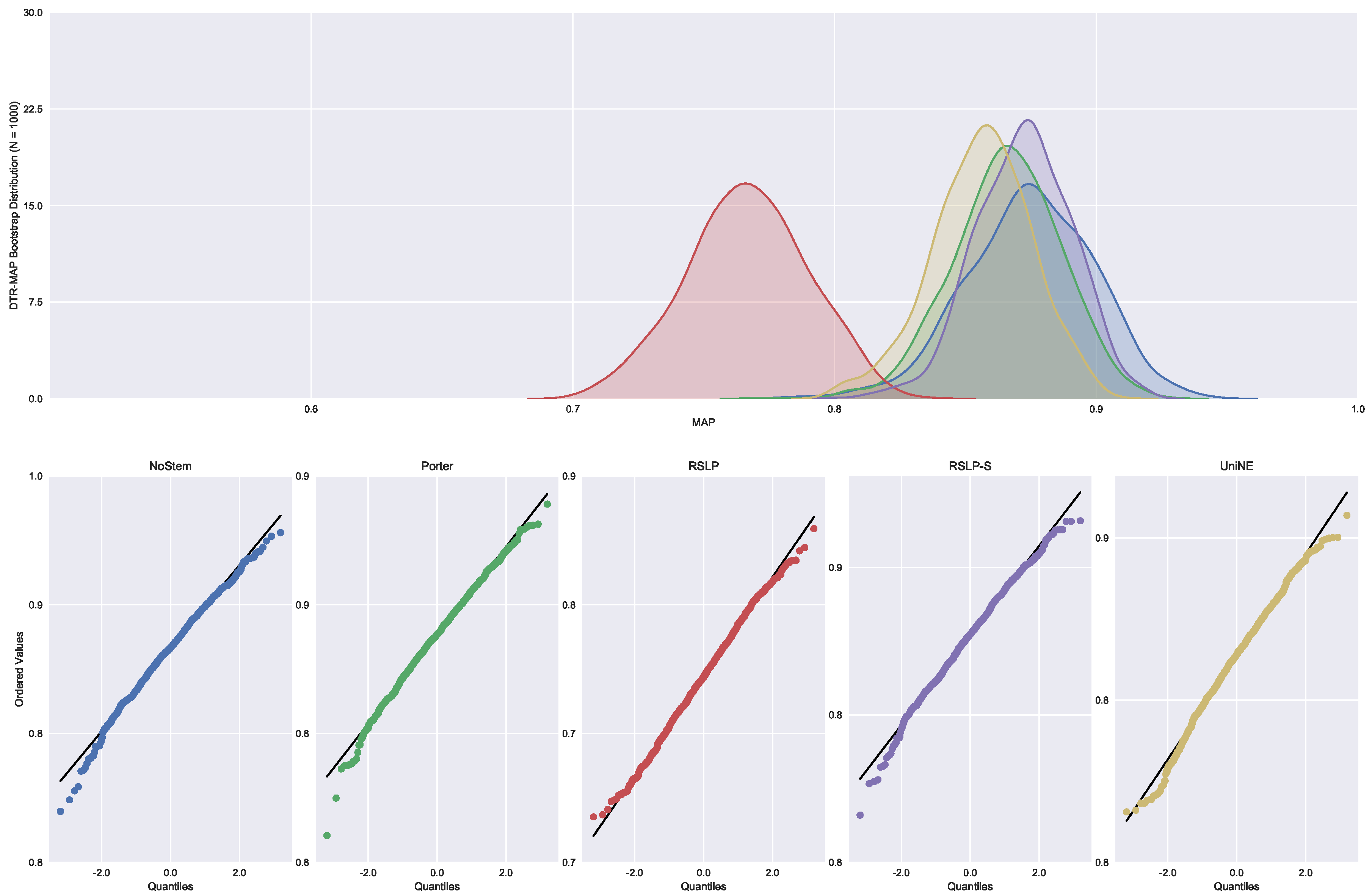
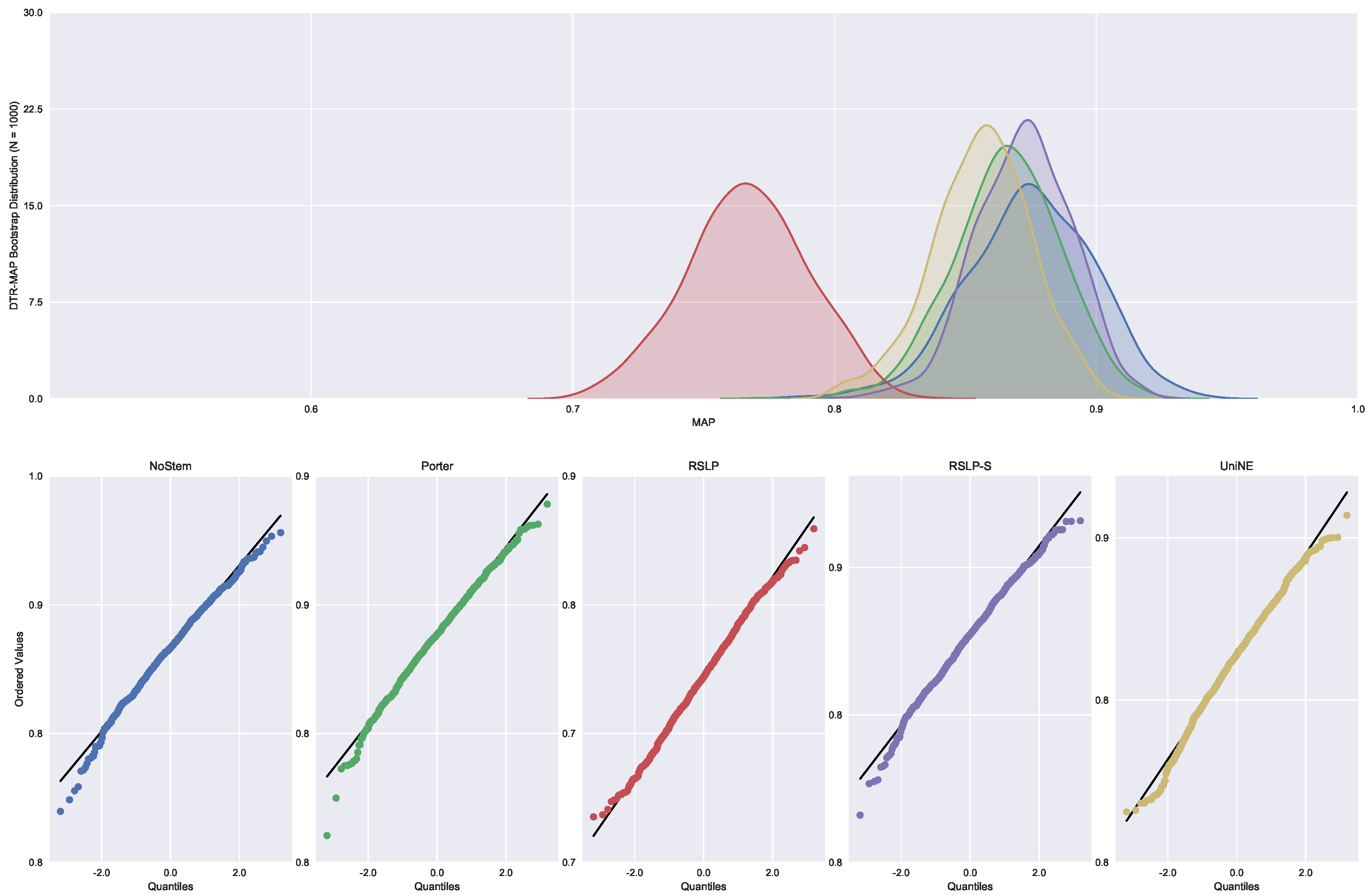
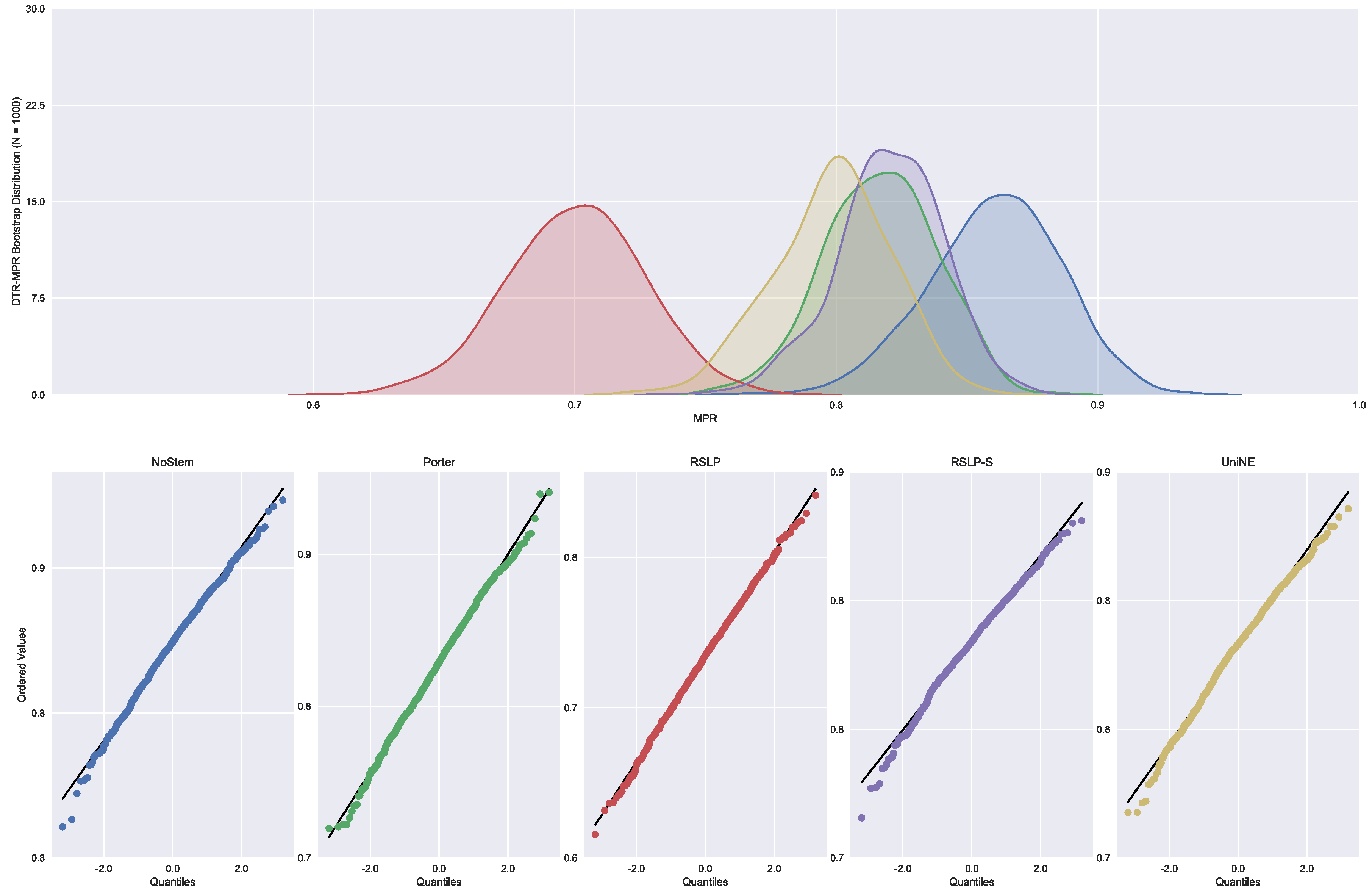
Monocratic decisions of Special Courts (DTR). In this collection, the MAP normality distribution (
Figure 26) was rejected for the NoStem (
p-value < 0.001), Porter (
p-value = 0.001), RSLP-S (
p-value = 0.002) and UniNE (
p-value < 0.001).
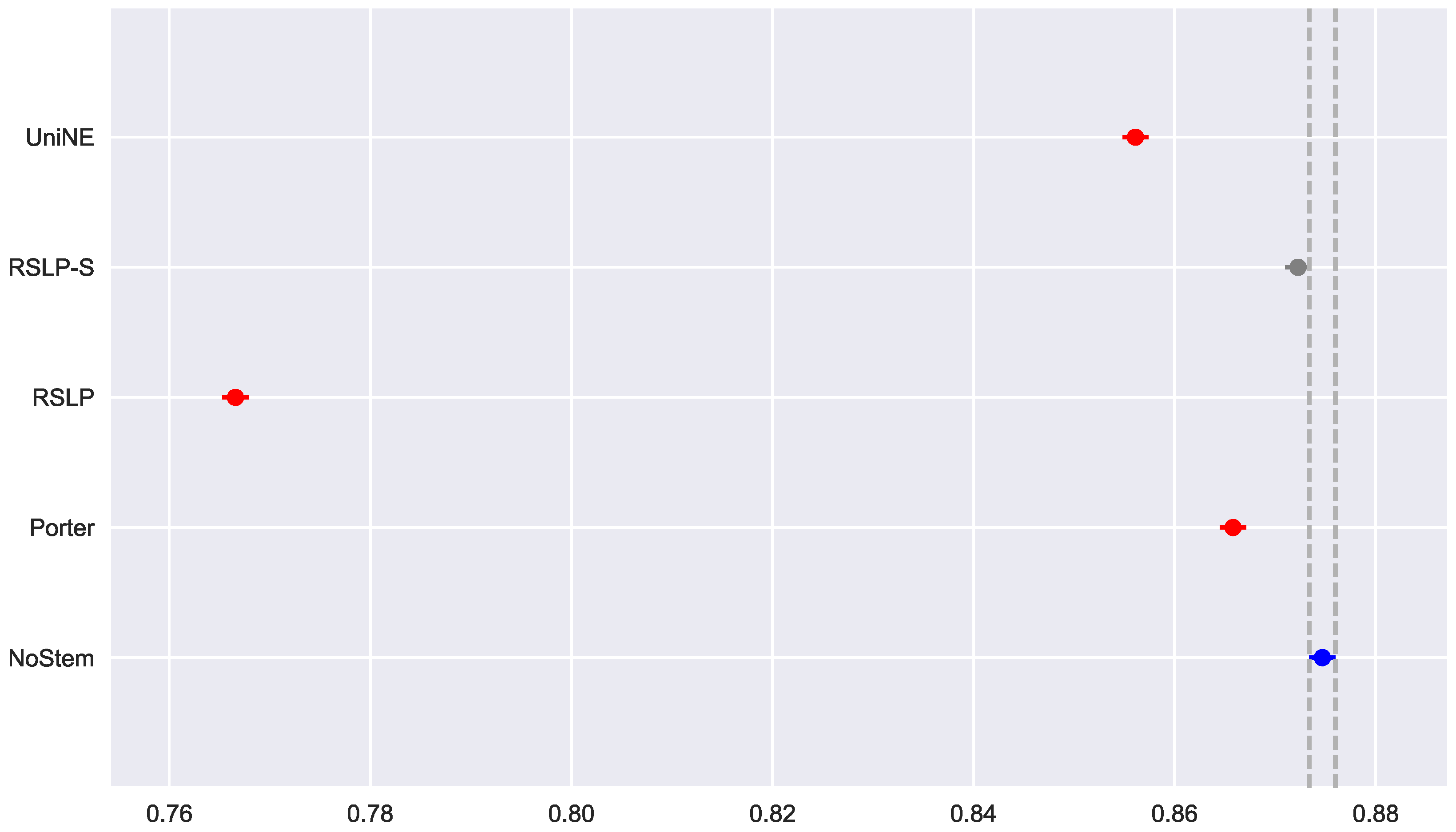
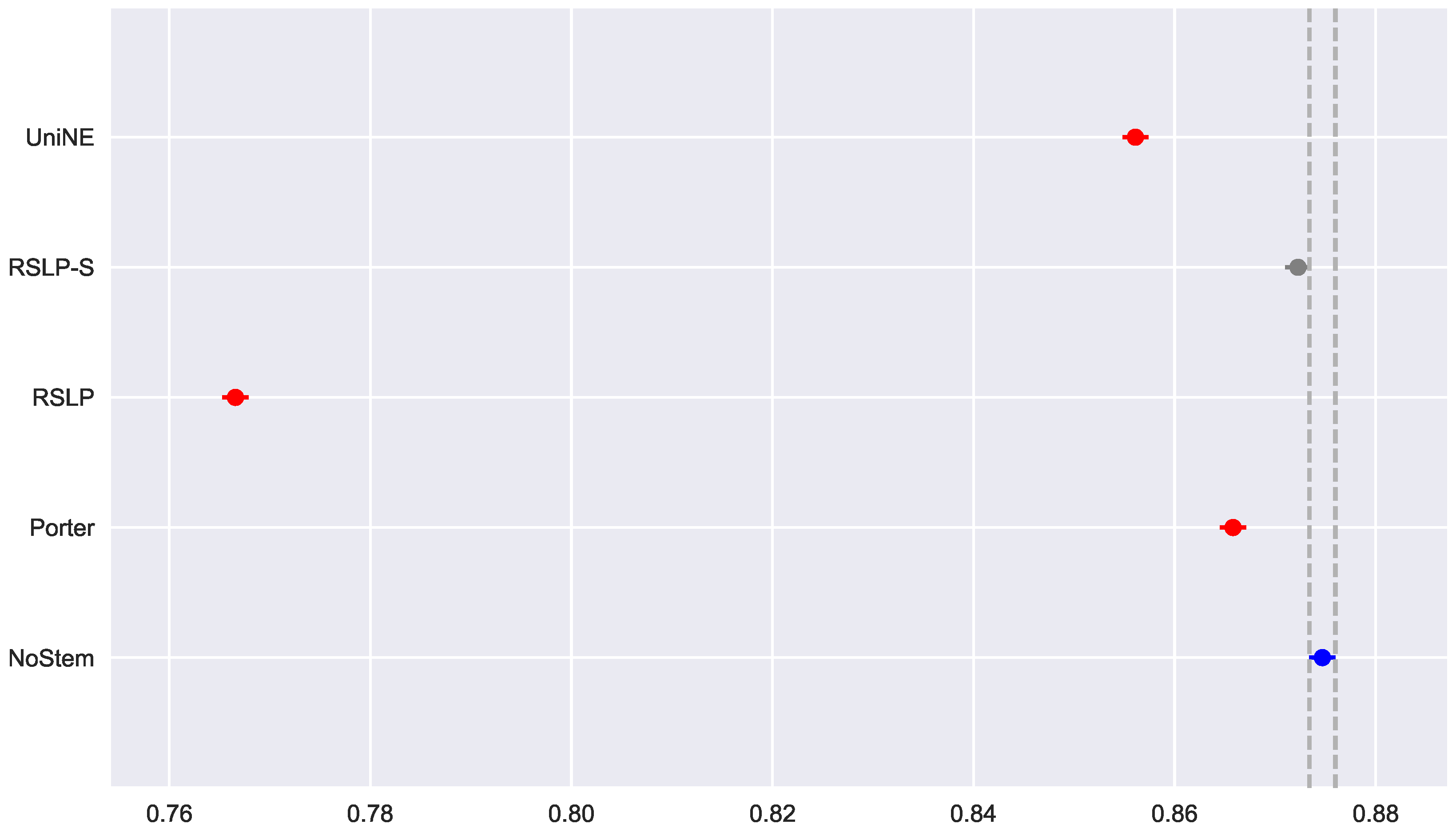
After rejecting the homoscedasticity of the data, we tested the hypothesis of MAP equality among treatments (
). Having been refuted by the Kruskal–Wallis test, we conducted a post hoc analysis with the Mann–Whitney test. The difference among the treatments and the control group, shown by
Figure 27, was statistically significant, however, the RSLP-S algorithm presented a
p-value equals to 0.02, very close to the significance level of the experiment.
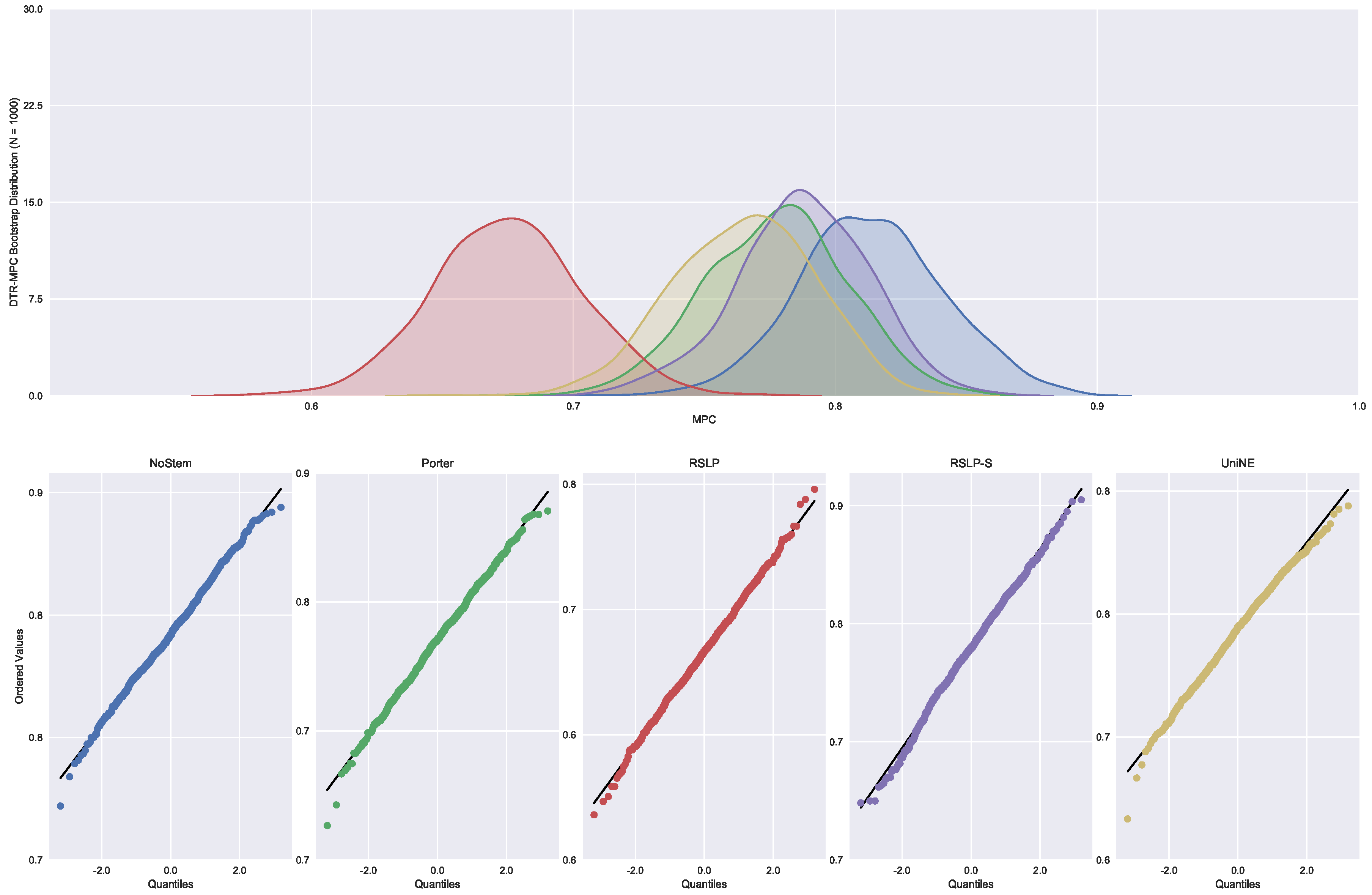
Then, the normality premise of the MPC,
Figure 28, was violated by the RSLP-S and UniNE algorithms, with
p-values equals to 0.021 and 0.016, respectively. In addition, we confirmed the heteroscedasticity of the data and the significance of the differences between the treatments (
Figure 29), refuting the hypothesis
, since the tests found a
p-value less than 0.001.
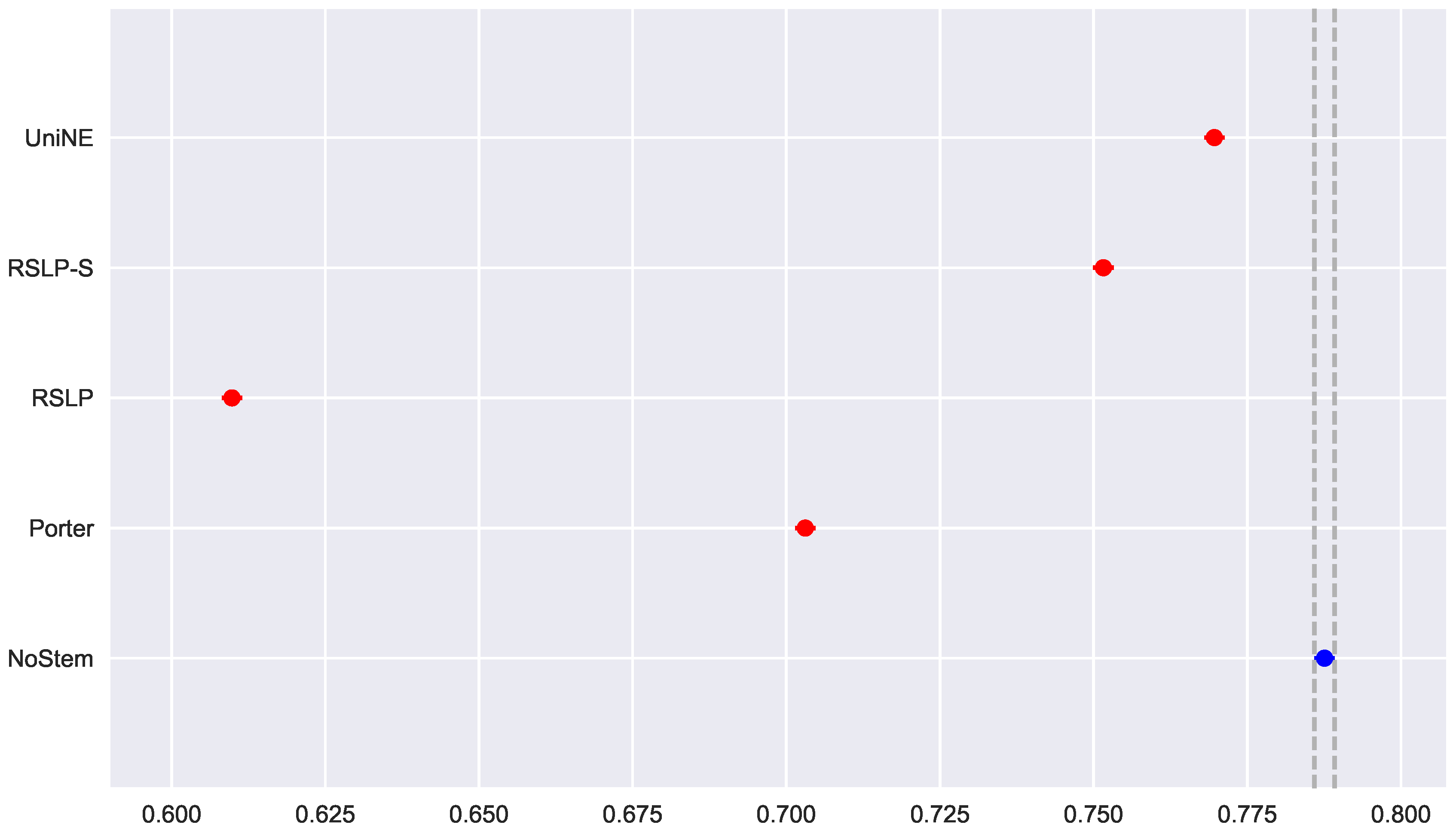
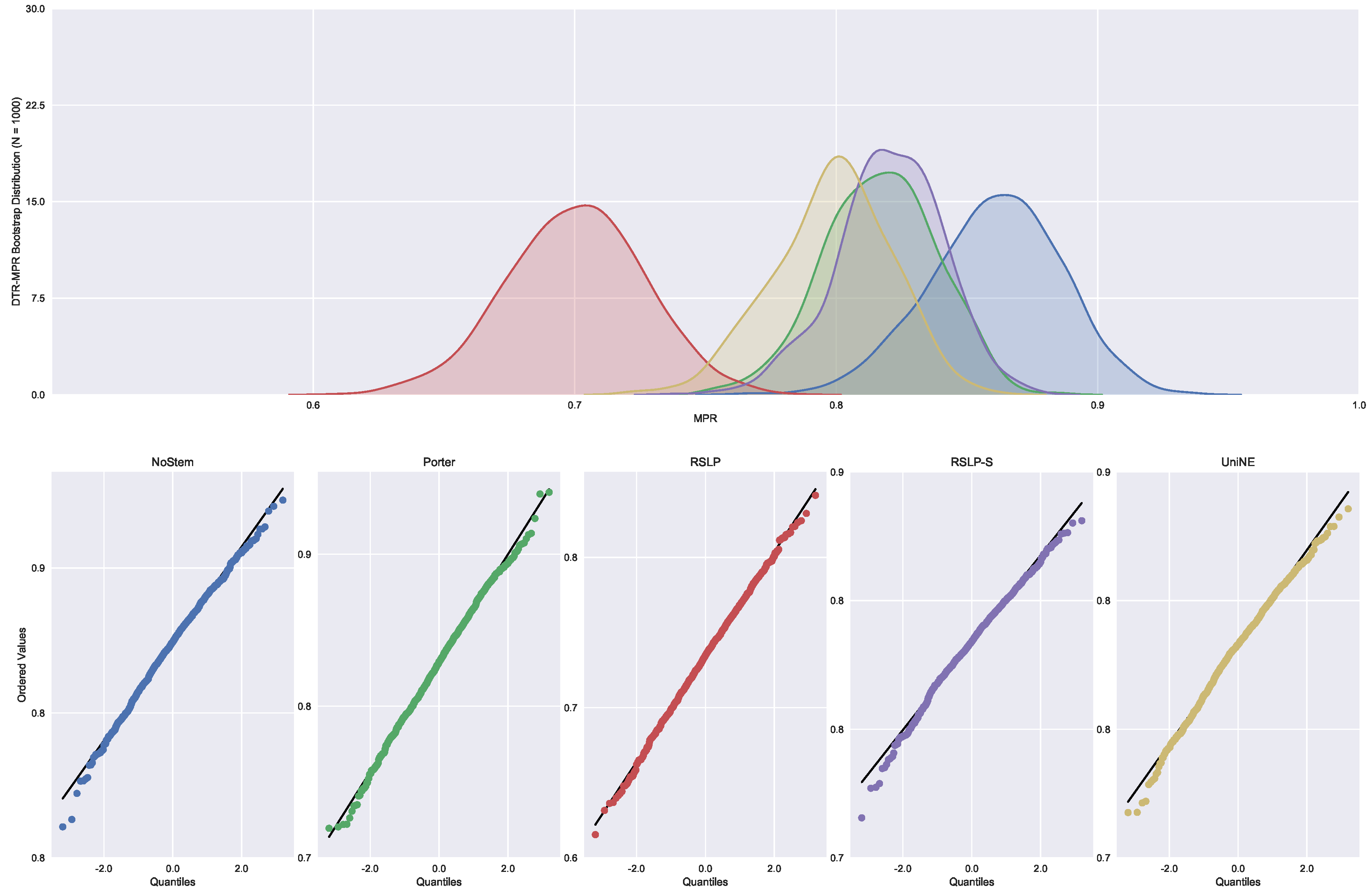
Lastly, the analysis of the MRP metric (
Figure 30) showed that the algorithms NoStem (
p-value = 0.01), RSLP-S (
p-value < 0.001) and UniNE (
p-value = 0.001) do not adhere to the Normal distribution. As in the other metrics, the Levene test showed heteroscedasticity among the groups. In this scenario, we found non-equality of MRP among the treatments using the Kruskal–Wallis test, and the Mann–Whitney tests showed a statistically significant difference, with a
p-value lower than 0.001, among all treatments and the control group (
Figure 31). Through
Figure 32, we can see that the RSLP-S and UniNE algorithms present MAP, MPC and MRP very close to those of the control group. Thus, the data analyst can make the choice for one of these algorithms and benefit from the dimensionality reduction.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}