Towards Aiding Decision-Making in Social Networks by Using Sentiment and Stress Combined Analysis



Abstract
:1. Introduction
2. Materials and Methods
2.1. Presentation Agent
2.2. Sentiment Analyzer Agent
- Aspect-based Sentiment Analysis: The kind of Sentiment Analysis chosen for the system was aspect-based. This type of Sentiment Analysis, as explained in the previous section, performs an analysis based on concrete aspects found in the sentences of texts, creating the model as an aspect set with associated polarities and later using it to perform the classification on text messages. We used an annotated dataset with polarities assigned to short written messages (tweets), extracted from diverse variated topics (e.g., politics) for training the model. This dataset is extracted from the TASS (Taller de Análisis de Sentimientos) experimental evaluation workshop [18,19].
- Aspect extraction: We selected a frequency-based method for performing the aspect extraction, where we create aspects as the terms found in the training corpora, which are unigrams. We select then the terms or aspects with a higher frequency of appearance in the corpora to constitute the aspect set.
- Sentiment classification: Since we have an annotated corpora of data with sentences labeled with a polarity, we classified the aspects of the aspect set using those labels, assigning to them a polarity as the one with a major appearance on the training labeled corpora (the corpora assigns polarities to sentences, so we took those polarities as associated with the terms appearing in the sentence), which means that we use a Bayesian classifier.
- Sentence classification: For using the model, we perform a classification of short written texts as follows: All the possible n-grams of the message are compared with each aspect of the aspect set, and, if an aspect is found, we store that information. Finally, when all the aspects of the aspect set are compared, we determine the sentiment of the message as the most predominant polarity found from the previous exploration—either positive, negative or neutral.
2.3. Stress Analyzer Agent
2.4. Combination Analyzer Agent
2.5. Advisor Agent
2.6. Persistence Agent
2.7. Design of the Experiment
- Podemos (A political corpora made of messages related to the politic party ’Podemos’). This is a very large corpora (about 1.9 millions of tweets).
- Star Wars (A leisure corpora about the famous franchise of films Star Wars, which gathers tweets of people from all around the world). It is a very large corpora (about 12 millions of tweets), but only a small part of it is messages in Spanish, and we need them to be in that language because the aspect sets of the Analyzers are in Spanish only.
- Calculate its combined value using both the sentiment and stress value in the way we explained in the Section 2.4.
- Calculate the mode of the sentiment polarities in the replies of that tweet.
- Calculate the mode of the stress levels found in the replies of the tweet.
- Calculate the combined value of the replies using both modes previously calculated.
2.7.1. Metrics of the Experimentation
- For Sentiment Analysis, percentage of concordance sentiment (PCsen):tweetsConc = Amount of tweets with the same emotional polarity than the mode in its replies. tweetsTotal = Amount of total tweets with replies analyzed:
- For Stress Analysis, percentage of concordance stress (PCstr):tweetsConc = Amount of tweets with the same stress levels than the mode in its replies. tweetsTotal = Amount of total tweets with replies analyzed:
- For the Combined Analysis, percentage of concordance combined (PCcomb):tweetsConc = Amount of tweets with the same value, combining emotional polarity and stress levels than the one calculated with the mode of the sentimental polarities and stress levels in its replies.tweetsTotal = Amount of total tweets with replies analyzed:
- Recall for the Sentiment Analyzer (RecallSA):NegativeTweetsDetected = amount of tweets considered negative that the analyzer detected.NegativeTweets = Amount of tweets considered negative in the corpora:
- Recall for the Stress Analyzer (RecallStr):NegativeTweetsDetected = amount of tweets considered negative that the analyzer detected (which in this case is associated with the stress level considered negative).NegativeTweets = Amount of tweets considered negative in the corpora (again it is associated with the stress level considered negative):
- Recall for the Combined Analyzer (RecallCombined):NegativeTweetsDetected = amount of tweets considered negative that the analyzer detected.NegativeTweets = Amount of tweets considered negative in the corpora:
2.7.2. Plan of the Experiments
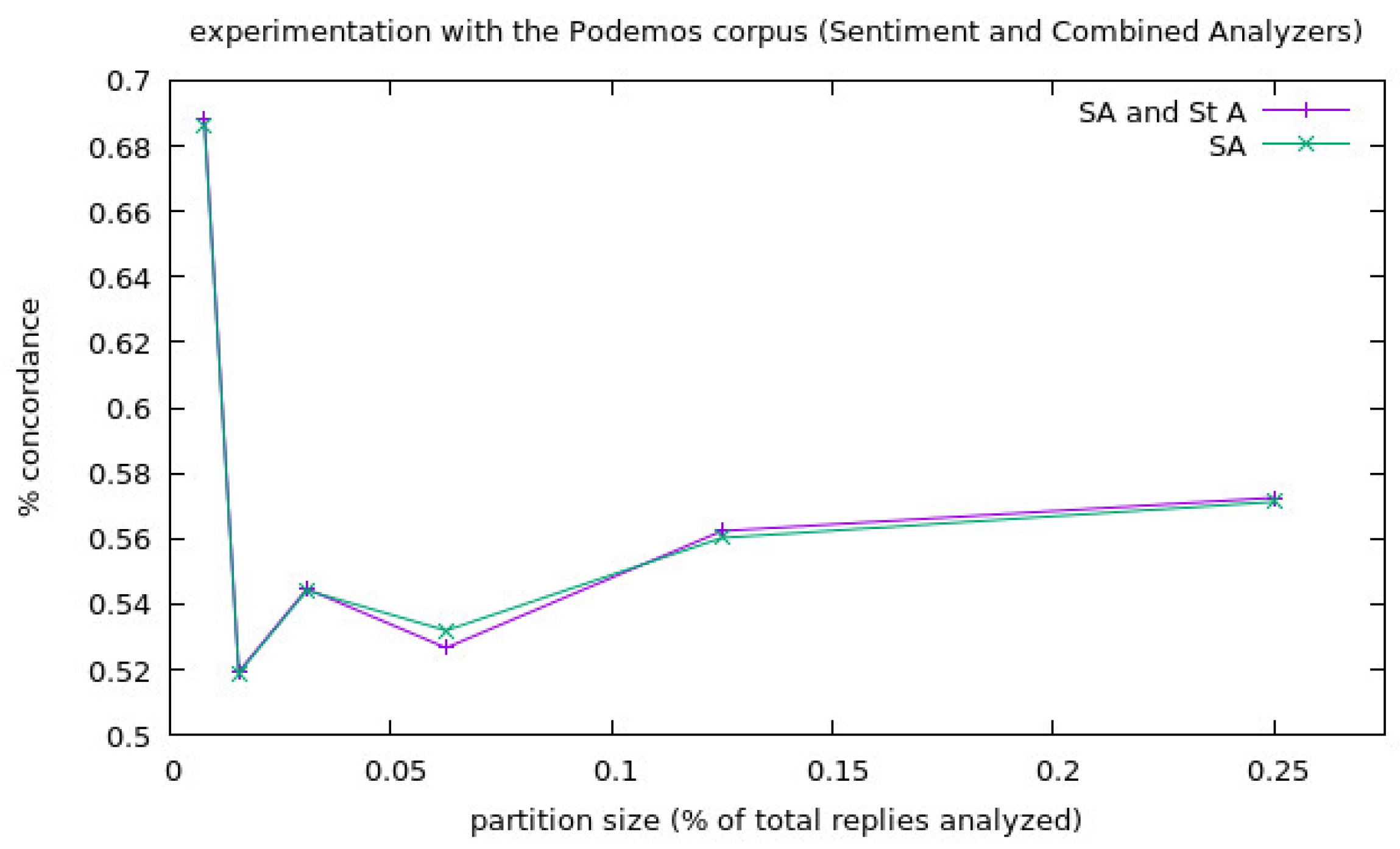
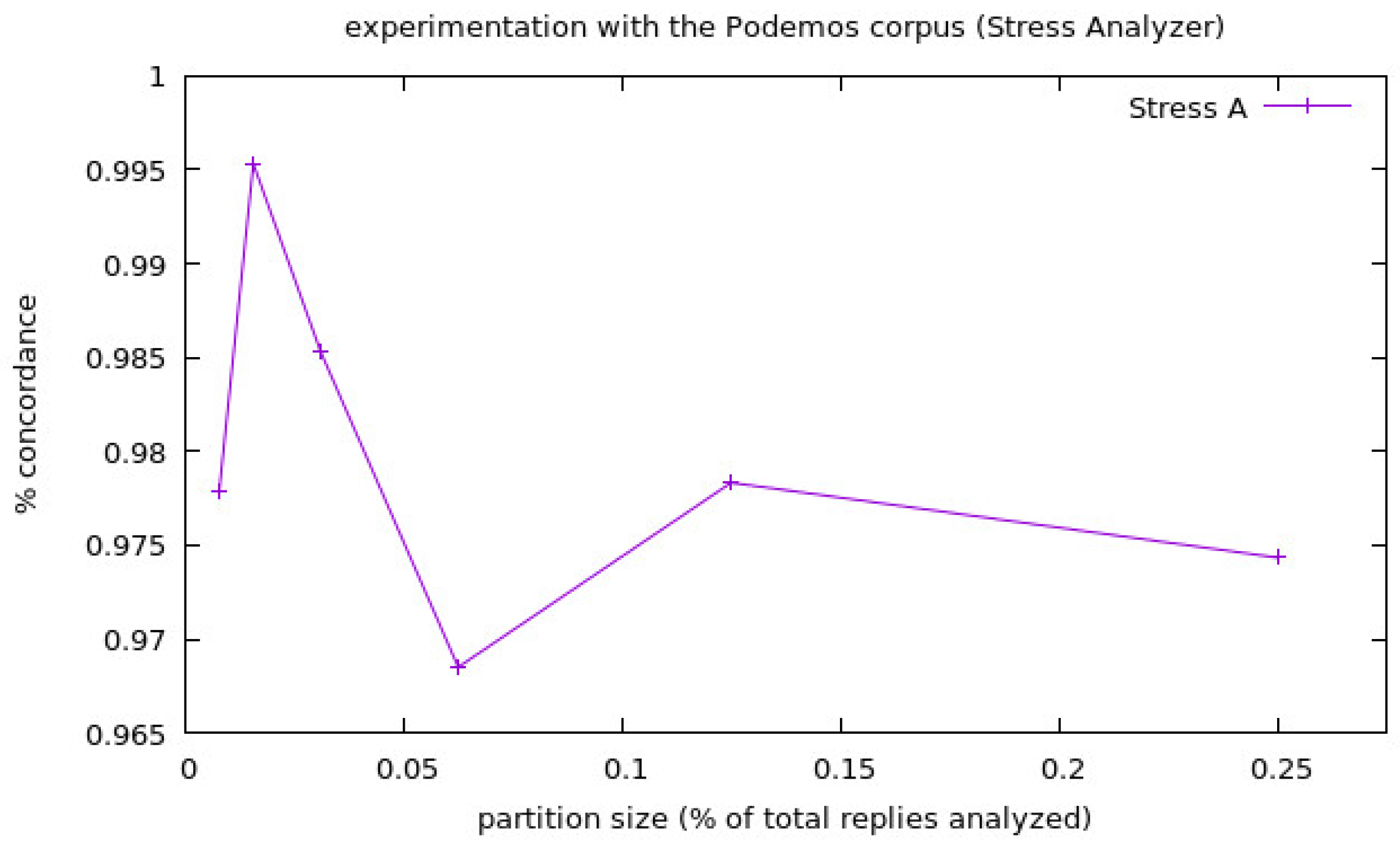
- Experimentation with the corpora Podemos: We prepared an experimentation with the corpora Podemos in the following way: We partitioned this corpora and, since it is a very large corpora, we decided to make six different partition sizes, doing four different experiments for each partition size. This was done in this way because the largest partition size was 1/4 of the corpora replies, and the maximum amount of parts that we could perform without using a tweet more than one time was four. We performed each experiment using the three different analyzers. The first partition is 1/128 of the total replies of the corpora for each experiment (around 1700 replies); the second partition is 1/64 of the replies; in this same way, the following four partitions are of 1/32, 1/16, 1/8 and 1/4 of the total replies, and the final results of the experimentation can be seen in Table 1.
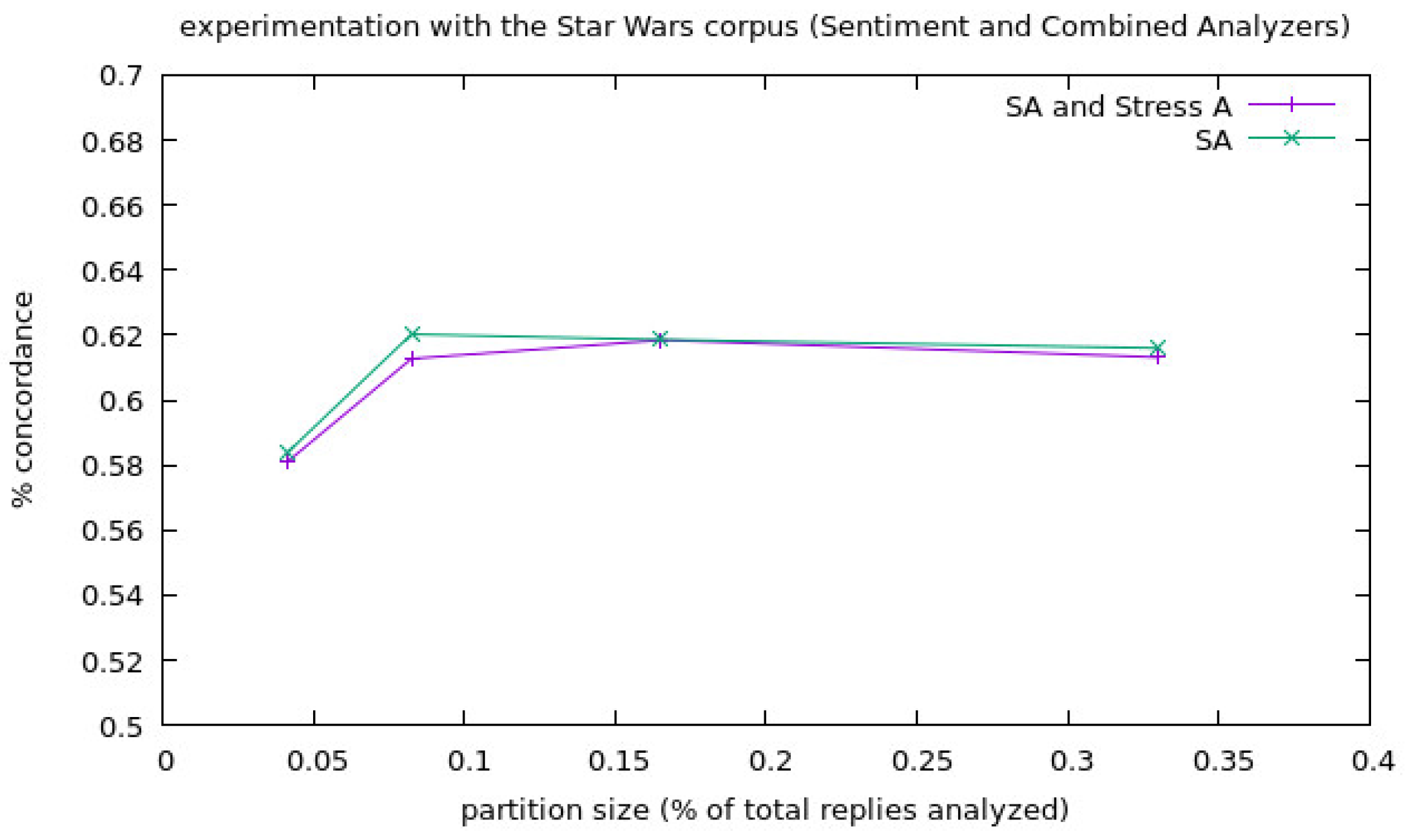
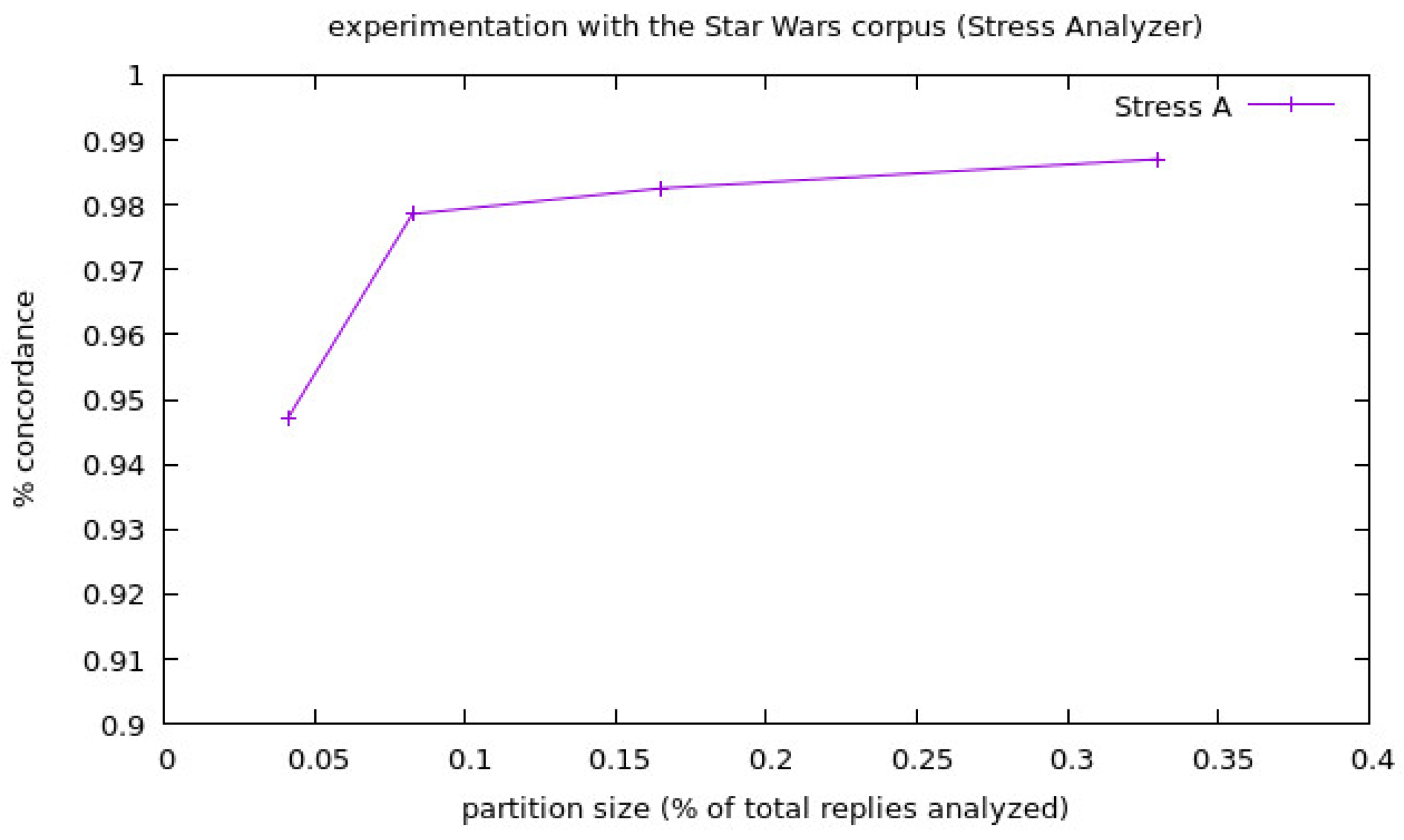
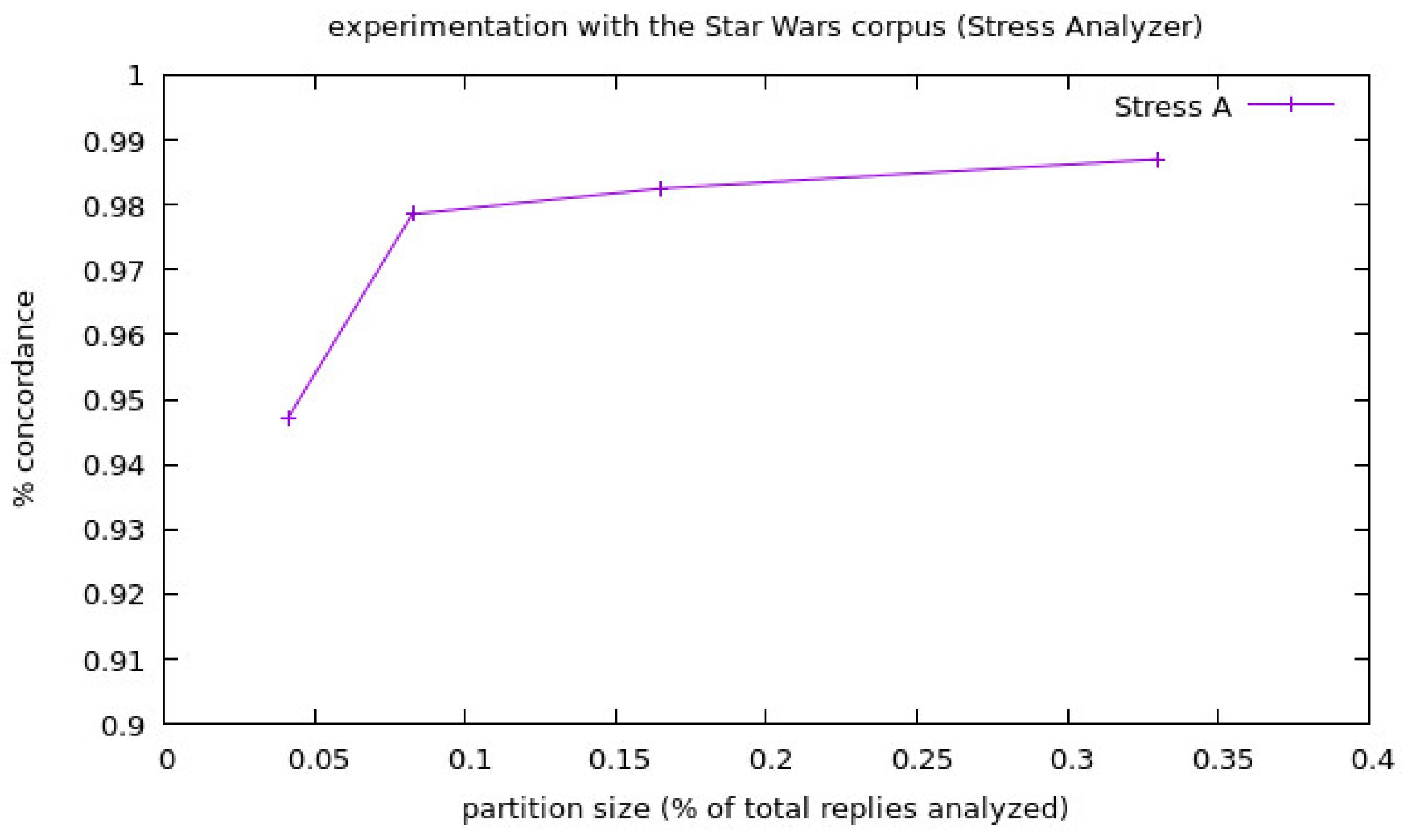
- Experimentation with the corpora Star Wars: we prepared the experimentation for the Star Wars corpora as shown in the following: we made partitions of the corpora with four different partition sizes and with three different experiments for each one, and we performed the partitions in this way because even when the corpora is a large corpora, the amount of tweets in Spanish is not high, resulting in a modest amount of replies in Spanish (22,543 replies). Remember that, since the aspect sets of the Analyzers are built with aspects in Spanish, we can only analyze Spanish tweets with them. Again, the maximum amount of different experiments that could be performed with the biggest partition size, without using data in more than one different experiment, was used for all the partition sizes (in this case 3). For each experiment, we used the three analyzers, and the number of replies for each partition size were 1/3, 1/6, 1/12 and 1/24 of the total replies of the corpora. The final results of this experimentation are shown in Table 2.
- SA and Stress A: Sentiment Analysis combined with Stress Analysis.
- SA: Only Sentiment Analysis.
- Stress A: Only Stress Analysis.
3. Results
Results of the Experimentation
4. Discussion
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Vanderhoven, E.; Schellens, T.; Vanderlinde, R.; Valcke, M. Developing educational materials about risks on social network sites: A design based research approach. Educ. Technol. Res. Dev. 2016, 64, 459–480. [Google Scholar] [CrossRef] [Green Version]
- Vanderhoven, E.; Schellens, T.; Valcke, M. Educating Teens about the Risks on Social Network Sites. An intervention study in Secondary Education. Comunicar 2014, 22, 123–131. [Google Scholar] [CrossRef]
- Christofides, E.; Muise, A.; Desmarais, S. Risky Disclosures on Facebook: The Effect of Having a Bad Experience on Online Behavior. J. Adolesc. Res. 2012, 27, 714–731. [Google Scholar] [CrossRef]
- George, J.M.; Dane, E. Affect, emotion, and decision-making. Organ. Behav. Hum. Dec. Process. 2016, 136, 47–55. [Google Scholar] [CrossRef]
- Ciccarelli, M.; Griffiths, M.D.; Nigro, G.; Cosenza, M. Decision making, cognitive distortions and emotional distress: A comparison between pathological gamblers and healthy controls. J. Behav. Ther. Exp. Psychiatry 2017, 54, 204–210. [Google Scholar] [CrossRef] [PubMed]
- Thelwall, M. TensiStrength: Stress and relaxation magnitude detection for social media texts. Inf. Process. Manag. 2017, 53, 106–121. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining. Ser. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Feldman, R. Techniques and Applications for Sentiment Analysis. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Schouten, K.; Frasincar, F. Survey on Aspect-Level Sentiment Analysis. IEEE Trans. Knowl. Data Eng. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Jakob, N.; Gurevych, I. Extracting opinion targets in a singleand cross-domain setting with conditional random fields. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 1035–1045. [Google Scholar]
- Hu, M.; Liu, B. Mining opinion features in customer reviews. In Proceedings of the 19th National Conference on Artifical Intelligence, San Jose, CA, USA, 25–29 July 2004; pp. 755–760. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Rincon, J.A.; de la Prieta, F.; Zanardini, D.; Julian, V.; Carrascosa, C. Influencing over people with a social emotional model. Neurocomputing 2017, 231, 47–54. [Google Scholar] [CrossRef]
- Gao, W.; Yoshinaga, N.; Kaji, N.; Kitsuregawa, M. Modeling user leniency and product popularity for sentiment classification. In Proceedings of the IJCNLP, Nagoya, Japan, 14–18 October 2013. [Google Scholar]
- Seroussi, Y.; Zukerman, I.; Bohnert, F. Collaborative inference of sentiments from texts, User Model. In Proceedings of the 18th International Conference on User Modeling, Adaptation and Personalization; Springer: New York, NY, USA, 2010; pp. 195–206. [Google Scholar]
- Nakamura, H.; Mise, S.; Mine, T. Personalized Recommendation for Public Transportation Using User Context. In Proceedings of the 5th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Kumamoto, Japan, 10–14 July 2016; pp. 224–229. [Google Scholar]
- Gregori, M.E.; Cámara, J.P.; Bada, G.A. A Jabber-based Multi-agent System Platform. In Proceedings of the Fifth International Joint Conference on Autonomous Agents and Multiagent Systems, Hakodate, Japan, 8–12 May 2006; pp. 1282–1284. [Google Scholar]
- Villena-Román, J.; Lana-Serrano, S.; Martínez-Cámara, E.; González-Cristóbal, J.C. TASS—Workshop on Sentiment Analysis at SEPLN. Procesamiento del Lenguaje Natural 2013, 50, 37–44. [Google Scholar]
- Villena-Román, J.; García-Morera, J.; Lana-Serrano, S.; González-Cristóbal, J.C. TASS 2013—A Second Step in Reputation Analysis in Spanish. Procesamiento del Lenguaje Natural 2014, 52, 37–44. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partition Size | Experiment | PCsen | PCstr | PCcomb |
|---|---|---|---|---|
| 2/128 of replies | 1 | 0.5975 | 0.9752 | 0.5944 |
| 2 | 0.5594 | 0.9752 | 0.5644 | |
| 3 | 0.5881 | 0.9611 | 0.5943 | |
| 4 | 1.0 | 1.0 | 1.0 | |
| 2/64 of replies | 1 | 0.5789 | 1.0 | 0.5789 |
| 2 | 0.4583 | 1.0 | 0.4583 | |
| 3 | 0.5680 | 0.9813 | 0.5697 | |
| 4 | 0.4706 | 1.0 | 0.4706 | |
| 2/32 of replies | 1 | 0.5 | 0.9833 | 0.5 |
| 2 | 0.5682 | 1.0 | 0.5682 | |
| 3 | 0.5261 | 0.9799 | 0.5281 | |
| 4 | 0.5824 | 0.9780 | 0.5824 | |
| 2/16 of replies | 1 | 0.5132 | 0.9737 | 0.5 |
| 2 | 0.5156 | 0.9778 | 0.52 | |
| 3 | 0.5616 | 0.9726 | 0.5616 | |
| 4 | 0.5375 | 0.95 | 0.525 | |
| 2/8 of replies | 1 | 0.5508 | 0.9786 | 0.5508 |
| 2 | 0.5546 | 0.9738 | 0.5611 | |
| 3 | 0.5493 | 0.983 | 0.5511 | |
| 4 | 0.5864 | 0.978 | 0.5864 | |
| 2/4 of replies | 1 | 0.5591 | 0.9694 | 0.5577 |
| 2 | 0.5948 | 0.9752 | 0.6020 | |
| 3 | 0.5638 | 0.9741 | 0.5618 | |
| 4 | 0.5674 | 0.9787 | 0.5686 |
| Partition Size | Experiment | PCsen | PCstr | PCcomb |
|---|---|---|---|---|
| 1/3 of replies | 1 | 0.6107 | 0.9905 | 0.6069 |
| 2 | 0.6 | 1.0 | 0.6 | |
| 3 | 0.6373 | 0.9707 | 0.6327 | |
| 1/6 of replies | 1 | 0.6075 | 0.9791 | 0.6045 |
| 2 | 0.6209 | 0.9783 | 0.6137 | |
| 3 | 0.6275 | 0.9902 | 0.6373 | |
| 1/12 of replies | 1 | 0.6075 | 0.9794 | 0.6075 |
| 2 | 0.6391 | 0.9699 | 0.6165 | |
| 3 | 0.6142 | 0.9864 | 0.6142 | |
| 1/24 of replies | 1 | 0.6061 | 0.9865 | 0.6044 |
| 2 | 0.52 | 0.98 | 0.5133 | |
| 3 | 0.625 | 0.875 | 0.625 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguado, G.; Julian, V.; Garcia-Fornes, A. Towards Aiding Decision-Making in Social Networks by Using Sentiment and Stress Combined Analysis. Information 2018, 9, 107. https://doi.org/10.3390/info9050107
Aguado G, Julian V, Garcia-Fornes A. Towards Aiding Decision-Making in Social Networks by Using Sentiment and Stress Combined Analysis. Information. 2018; 9(5):107. https://doi.org/10.3390/info9050107
Chicago/Turabian StyleAguado, Guillem, Vicente Julian, and Ana Garcia-Fornes. 2018. "Towards Aiding Decision-Making in Social Networks by Using Sentiment and Stress Combined Analysis" Information 9, no. 5: 107. https://doi.org/10.3390/info9050107
APA StyleAguado, G., Julian, V., & Garcia-Fornes, A. (2018). Towards Aiding Decision-Making in Social Networks by Using Sentiment and Stress Combined Analysis. Information, 9(5), 107. https://doi.org/10.3390/info9050107