Linking Open Descriptions of Social Events (LODSE): A New Ontology for Social Event Classification



Abstract
:1. Introduction
- Concert: U2 at O2 London Arena;
- Tags: music, rock, alternative rock, post-punk.
- A new ontology named LODSE, which deals effectively with social events;
- A new improved approach for social event classification;
- The proposed LODSE ontology increments the percentage of correctly classified events as well as the execution time.
2. Related Work
3. The LODSE Ontology for Social Events
- Individuals—the basic objects;
- Classes—sets, collections or types of objects;
- Attributes—properties, characteristics, or parameters that objects may have to share;
- Relationships—between objects.
3.1. The LODE Ontology
- What is happening?
- Where is it happening?
- When is it happening?
- Who is involved?
3.2. The Domain and Scope of LODSE Ontology
- What event is it?
- What is the name of the event?
- Who is the artist?
- Who is the organizer?
- Where will the event occur?
- What time is the event?
- What kind of event is it?
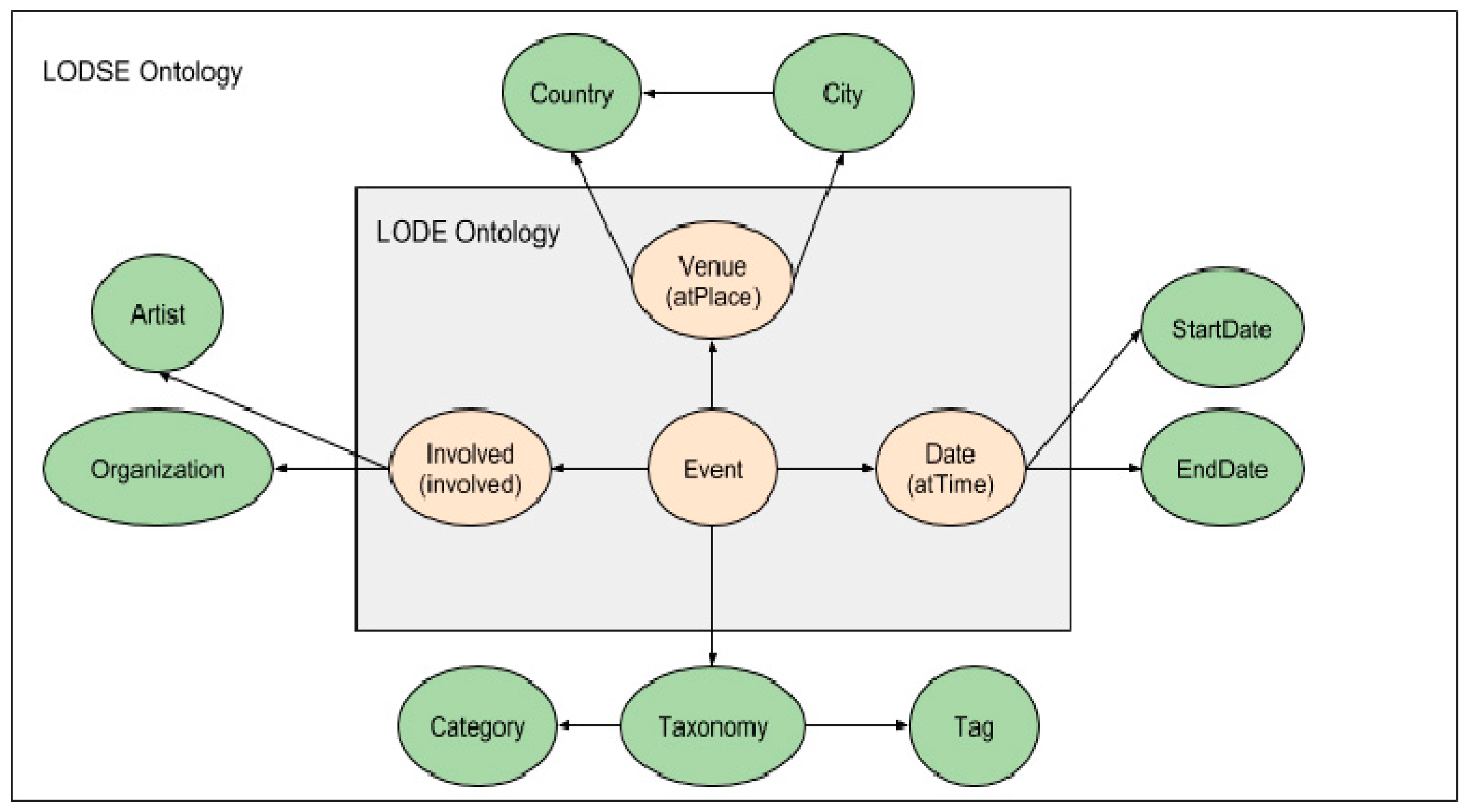
3.3. The Classes and the Class Hierarchy
- Event—a class that describes an event and answers the questions “What event is it?” and “What is the name of the event?”;
- Involved—a class that describes who is involved in the event and answers the questions “Who is the artist?” and “Who is the organizer?”;
- ○
- Artist—a subclass describing the artist of the event;
- ○
- Organization—a subclass describing the organizer of the event;
- Date—a class that represents the date of the event and answers the question “What time is the event?”;
- ○
- startDate—a subclass representing the start date of the event;
- ○
- endDate—a subclass representing the end date of the event;
- Venue—a class that describes the place where the event will take place and answers the question “Where will the event occur?”;
- ○
- City—a subclass describing the city where the event will take place;
- ○
- Country—a subclass describing the country where the event will take place;
- Taxonomy—a class that represents the categorization of an event and answers the question “What kind of event is it?”
- ○
- Tag—a subclass representing the event tag;
- ○
- Category—a subclass representing the category of the event.
- Event—Date: All events occur on a certain date. The event can have a start and also an end date;
- Event—Venue: All events take place at a particular venue. This venue is located in a city/country and the city belongs to a country;
- Event—Involved: Every event has someone involved. Depending on the type of the event the entities that may be involved are the artists or the event organizers;
- Event—Taxonomy: The event belongs to a certain taxonomy; this is, the event is classified or with a pre-defined category or with a tag.
3.4. The Properties of Classes and Their Facets
4. Experimental Setup
4.1. The Hardware
- Machine_1—Processor 1.4GHz Intel Core i5, 8GB RAM DD3;
- Machine_2—Intel Xeon Processor 2.39GHz, 40GB RAM.
4.2. The Data Mining Software
4.3. The Random Forest Algorithm
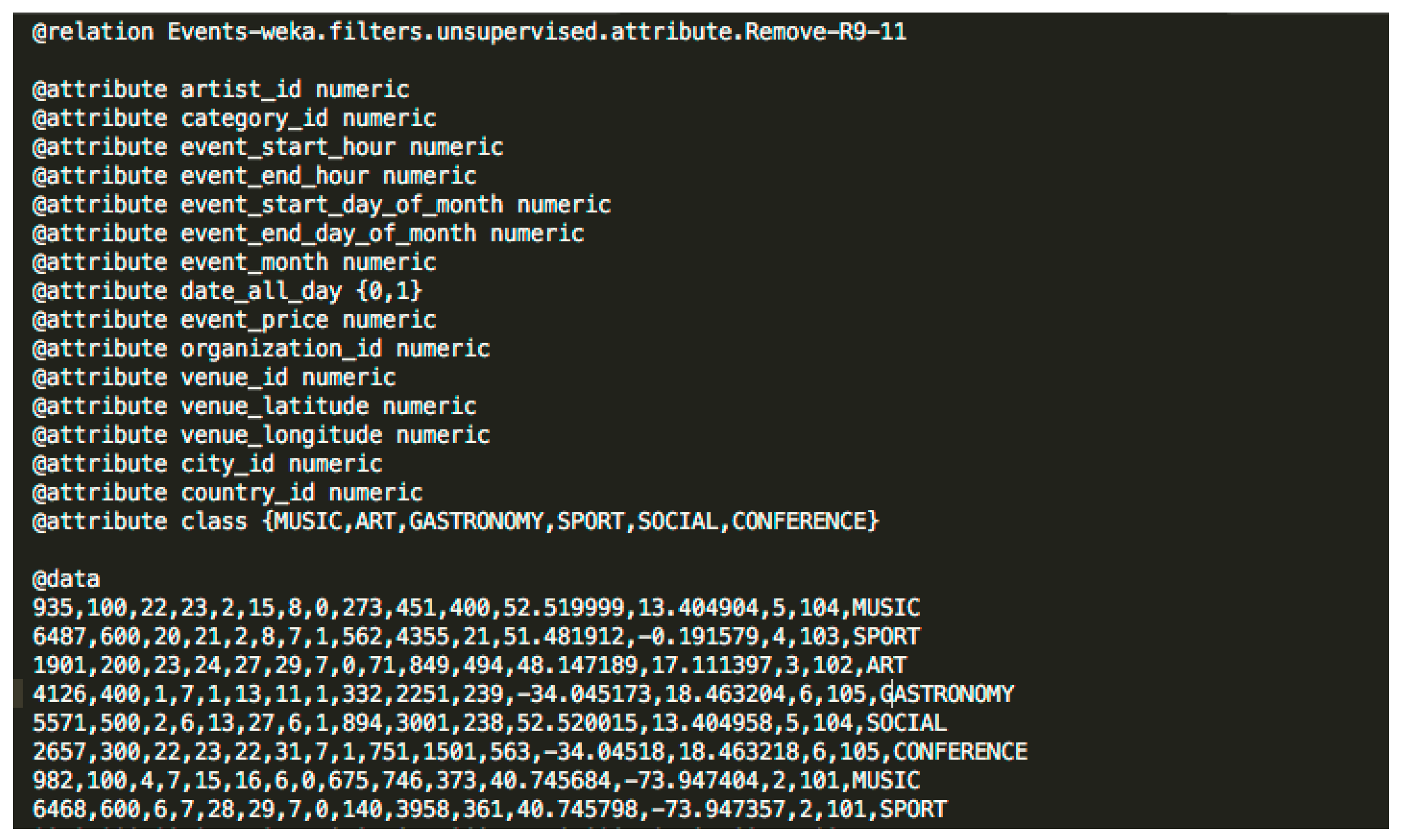
4.4. The Datasets
5. Experimental Evaluation Results
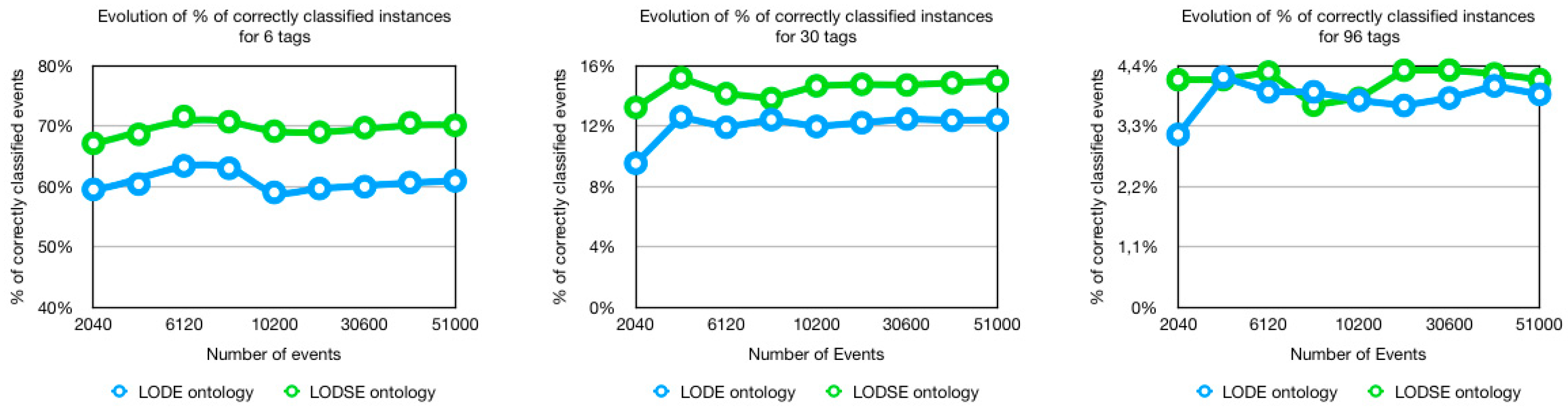
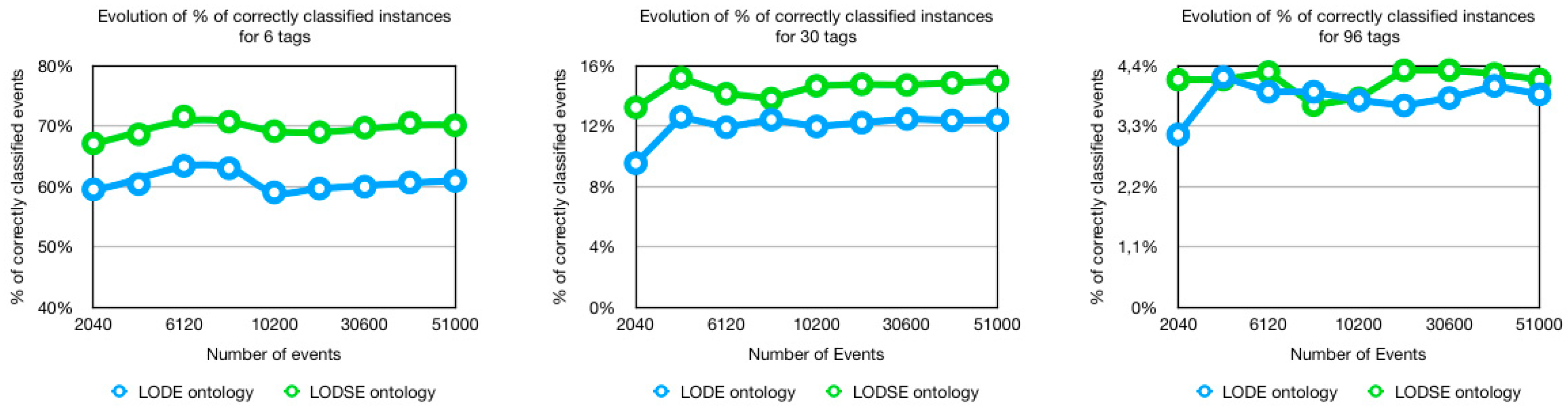
5.1. Percentage of Correctly Classified Instances
- 12.78% more correctly classified events when the number of tags was 6;
- 17.31% more correctly classified events when the number of tags was 30;
- 7.12% more correctly classified events when the number of tags was 96.
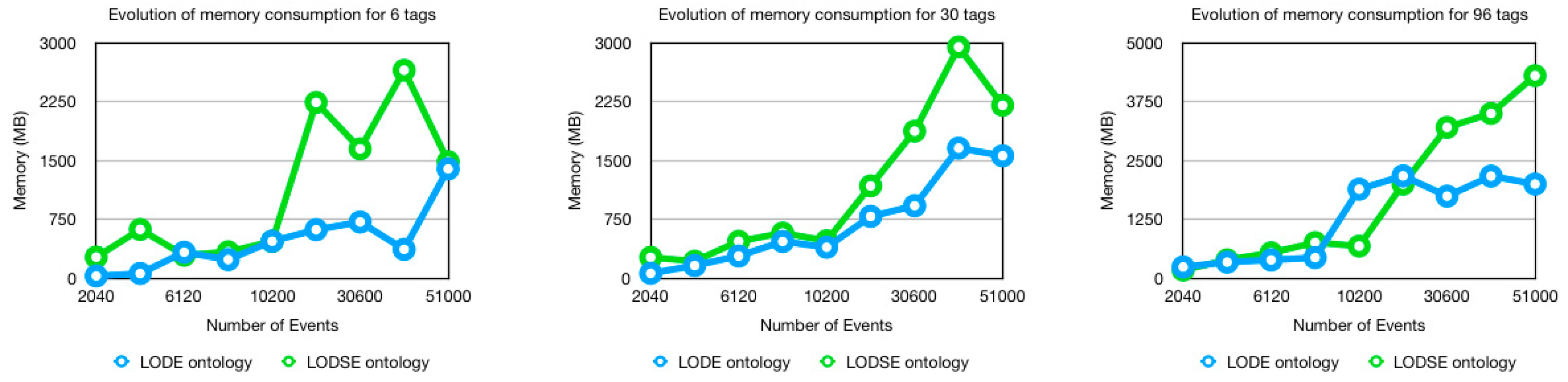
5.2. Memory Consumption
- 46.34% more memory than the LODE ontology when the number of tags was 6;
- 37.20% more memory than the LODE ontology when the number of tags was 30;
- 0.44% less memory than the LODE ontology when the number of tags was 96.
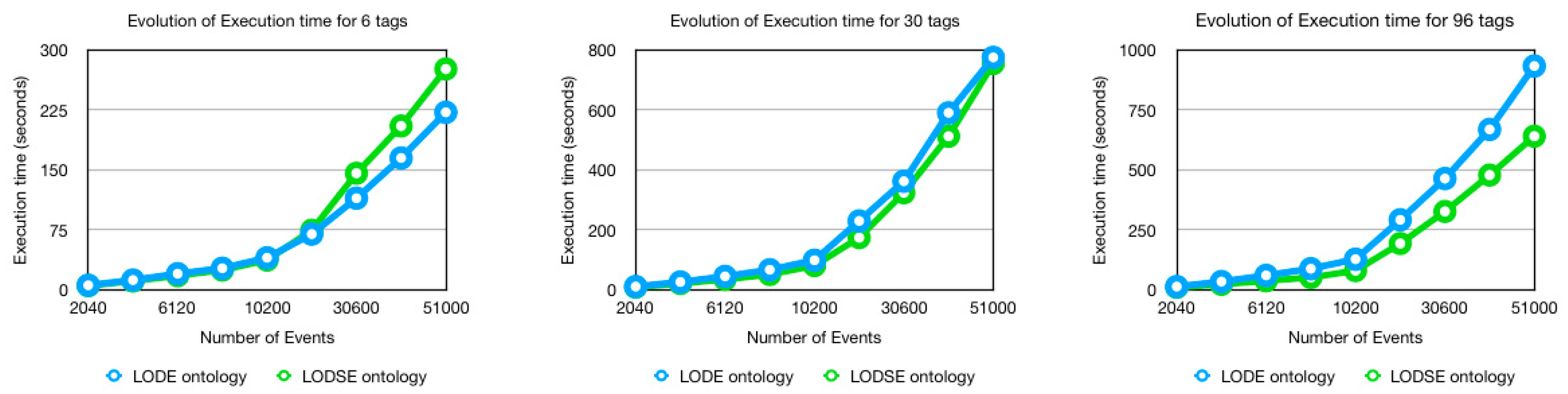
5.3. Execution Time
- 1.64% more time when the number of tags is 6;
- 7.05% less time when the number of tags is 30;
- 12.28% less time when the number of tags is 96.
5.4. Discussion of The Results
6. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Shaw, R.; Troncy, R.; Hardman, L. LODE: Linking open descriptions of events. In Asian Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2009; pp. 153–167. [Google Scholar]
- Troncy, R.; Fialho, A.; Hardman, L.; Saathoff, C. Experiencing Events through User-Generated Media. Available online: https://www.researchgate.net/profile/Raphael_Troncy/publication/228346078_Experiencing_Events_through_User-Generated_Media/links/09e41506c69fe5ad92000000/Experiencing-Events-through-User-Generated-Media.pdf (accessed on 8 May 2018).
- Barrigas, H.; Barrigas, D.; Barata, M.; Bernardino, J.; Furtado, P. Scalability of Facebook Architecture. In New Contributions in Information Systems and Technologies; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Nguyen, D.; Le, T. Recommendation system for Facebook public events based on probabilistic classification and re-ranking. In Proceedings of the Eighth International Conference on Knowledge and Systems Engineering, Hanoi, Vietnam, 6–8 October 2016; pp. 133–138. [Google Scholar]
- Girolami, M.; Chessa, S.; Caruso, A. On Service Discovery in Mobile Social Networks: Survey and Perspectives. Available online: https://www.sciencedirect.com/science/article/pii/S1389128615001991 (accessed on 8 May 2018).
- Zeppelzauer, M.; Schopfhauser, D. Multimodal classification of events in social media. Image Vis. Comput. 2016, 53, 45–56. [Google Scholar] [CrossRef] [Green Version]
- Shaw, R.; Troncy, R. LODE: An Ontology for Linking Open Descriptions of Events. Available online: http://linkedevents.org/ontology/ (accessed on 8 May 2018).
- Dong, T.; Liang, C.; Xu, H. Social media and internet public events. Telemat. Inf. 2017, 34, 726–739. [Google Scholar] [CrossRef]
- Panagiotou, N.; Katakis, I.; Gunopulos, D. Detecting events in online social networks: Definitions trends and challenges. In Solving Large Scale Learning Tasks. Challenges and Algorithms; Springer International Publishing: Cham, Switzerland, 2016; pp. 42–44. [Google Scholar]
- Sutanto, T.; Nayak, R. ADMRG @ MediaEval 2013 Social Event Detection. Available online: https://eprints.qut.edu.au/63821/1/ADMRG-QUT_MediaEval_SED_2013.pdf (accessed on 28 June 2018).
- Benson, E.; Haghighi, A.; Barzilay, R. Event discovery in social media feeds. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 389–398. [Google Scholar]
- Gupta, I.; Gautam, K.; Chandramouli, K. Vit @ MediaEval 2013 social event detection task: Semantic structuring of complementary information for clustering events. In Proceedings of the MediaEval Workshop, Barcelona, Spain, 18–19 October 2013. [Google Scholar]
- Nowak, S.; Lukashevich, H. Multilabel classification evaluation using ontology information. In Proceedings of the ESWC Workshop on Inductive Reasoning and Machine Learning on the Semantic Web, Heraklion, Crete, Greece, 1 June 2009. [Google Scholar]
- Guarino, N. Formal ontology and information systems. In Formal Ontology in Information Systems: Proceedings of the First International Conference (FOIS’98), June 6–8, Trento, Italy; IOS press: Amsterdam, The Netherlands, 1998; pp. 3–15. [Google Scholar]
- Noy, N.F.; Mcguinness, D. Ontology Development 101: A Guide to Creating Your First Ontology. Available online: http://www.corais.org/sites/default/files/ontology_development_101_aguide_to_creating_your_first_ontology.pdf (accessed on 28 June 2018).
- Grüninger, M.; Fox, M.S. Methodology for the Design and Evaluation of Ontologies. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.44.8723 (accessed on 28 June 2018).
- Uschold, M.; Gruninger, M. Ontologies principles methods and applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef]
- Weka 3: Data Mining Software in Java. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 28 June 2018).
- Russell, I.; Markov, Z. An introduction to the Weka data mining system. In Proceedings of the 11th Annual SIGCSE Conference on Innovation and technology in Computer Science Education, Bologna, Italy, 26–28 June 2006. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? Lect. Notes Comput. Sci. 2012, 7376, 154–168. [Google Scholar]
- Rodrigues, M.A.; Silva, R.R.; Bernardino, J. An event search platform using machine learning. In Proceedings of the International Conference on Software Engineering and Knowledge Engineering (SEKE 2017), Pittsburgh, PA, USA, 5–7 July 2017; Available online: https://ksiresearchorg.ipage.com/seke/seke17paper/seke17paper_159.pdf (accessed on 28 June 2018).
- Breiman, L. Random forests. Mach. Learn. 2011, 45, 5–32. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Properties | Facets |
|---|---|---|
| Event | eventID | number |
| eventName | string | |
| eventDescription | string | |
| eventPrice | number | |
| eventURL | string | |
| eventDateCreated | date | |
| eventDateModified | date | |
| Involved | involvedName | string |
| involvedDescription | string | |
| involvedOfficialWebsite | string | |
| Artist | artistID | number |
| organizationID | number | |
| Date StartDate EndDate | date | date |
| time | date | |
| allDay | boolean | |
| Venue | venueID | number |
| venueName | string | |
| venueDescription | string | |
| venueLatitude | number | |
| venueLongitude | number | |
| venueCapacity | number | |
| venuePostalCode | string | |
| City | cityID | number |
| Country | countryID | number |
| Taxonomy | name | string |
| Category | categoryID | number |
| Tag | tagID | number |
| Attributes | Type |
|---|---|
| artist_id | numeric |
| event_start_hour | numeric |
| event_end_day_of_month | numeric |
| event_maybe_count | numeric |
| event_interested_count | numeric |
| event_attendind_count | numeric |
| venue_id | numeric |
| venue_longitude | numeric |
| Attributes | Type |
|---|---|
| artist_id | numeric |
| category_id | numeric |
| event_start_hour | numeric |
| event_end_hour | Numeric |
| event_start_day_of_month | numeric |
| event_end_day_of_month | numeric |
| event_month | numeric |
| date_all_day | boolean |
| event_price | numeric |
| organization_id | numeric |
| venue_id | numeric |
| venue_latitude | numeric |
| venue_longitude | numeric |
| city_id | numeric |
| country_id | numeric |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodrigues, M.; Rocha Silva, R.; Bernardino, J. Linking Open Descriptions of Social Events (LODSE): A New Ontology for Social Event Classification. Information 2018, 9, 164. https://doi.org/10.3390/info9070164
Rodrigues M, Rocha Silva R, Bernardino J. Linking Open Descriptions of Social Events (LODSE): A New Ontology for Social Event Classification. Information. 2018; 9(7):164. https://doi.org/10.3390/info9070164
Chicago/Turabian StyleRodrigues, Marcelo, Rodrigo Rocha Silva, and Jorge Bernardino. 2018. "Linking Open Descriptions of Social Events (LODSE): A New Ontology for Social Event Classification" Information 9, no. 7: 164. https://doi.org/10.3390/info9070164
APA StyleRodrigues, M., Rocha Silva, R., & Bernardino, J. (2018). Linking Open Descriptions of Social Events (LODSE): A New Ontology for Social Event Classification. Information, 9(7), 164. https://doi.org/10.3390/info9070164