An Improved Genetic Algorithm with a New Initialization Mechanism Based on Regression Techniques

 ,
,  ,
, 
Abstract
:
1. Introduction
2. Background
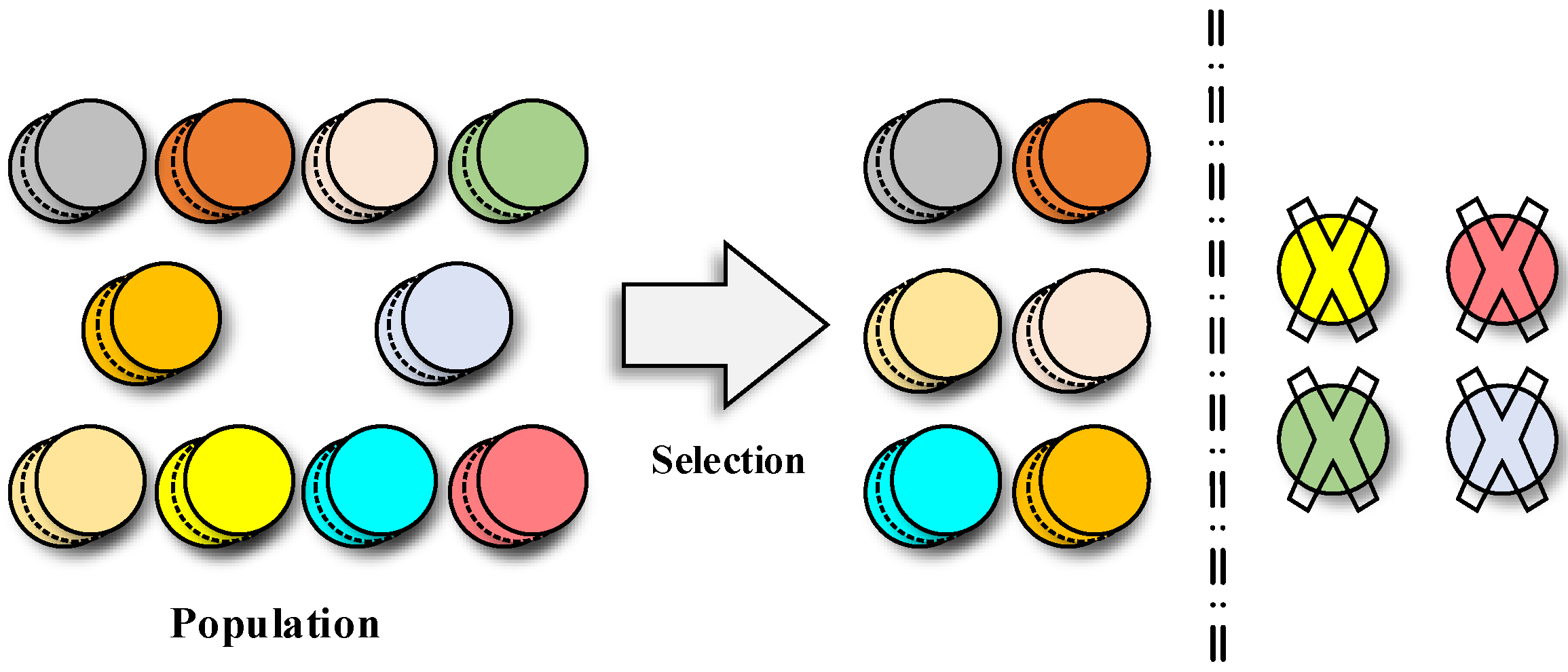
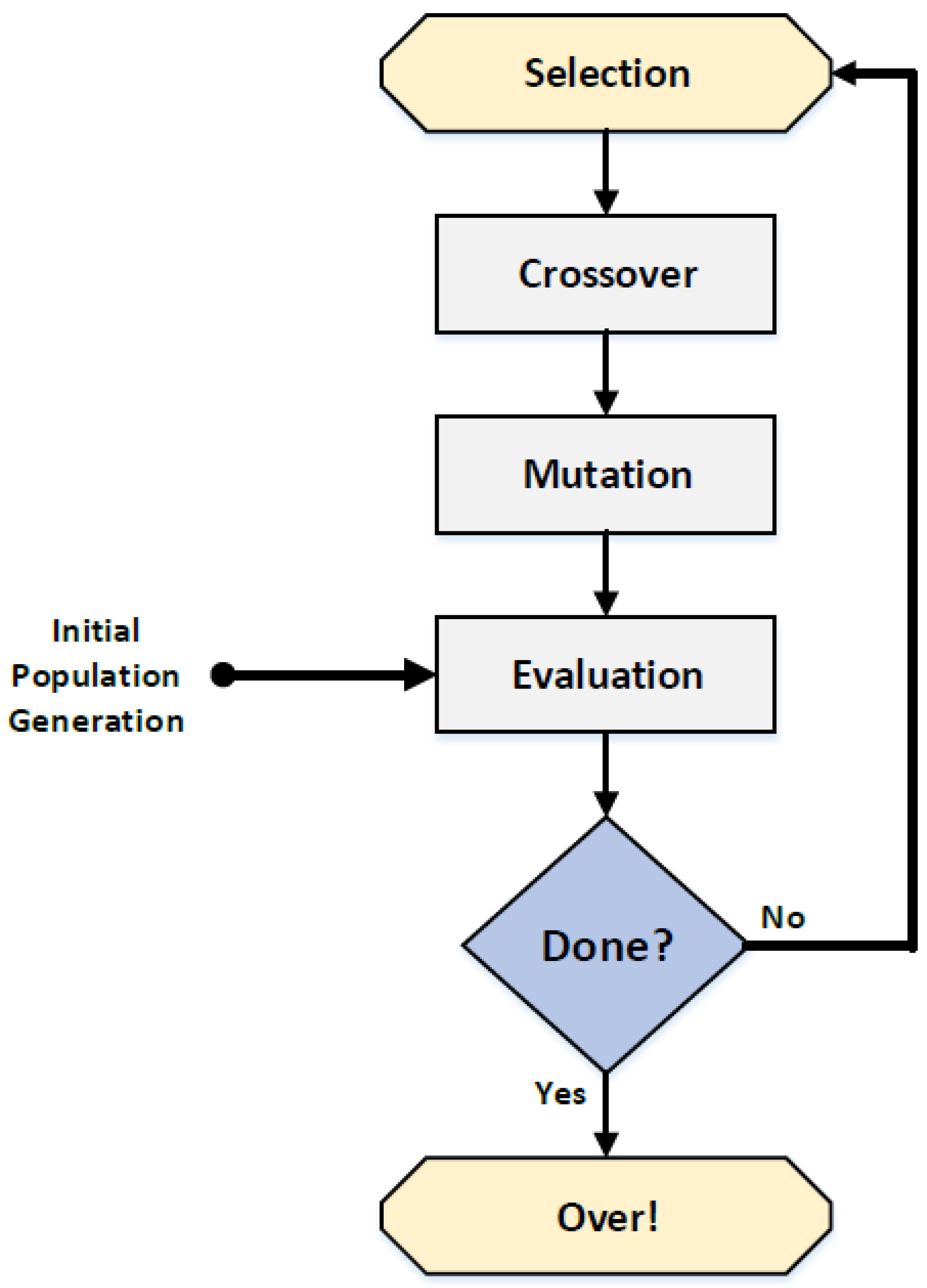
2.1. Basic Principles of Genetic Algorithms
- Binary encoding: all individuals are represented as series of bits 0 or 1; each bit represents a gene in the chromosome. For example, the Knapsack problem uses binary encoding:
Chromosome A 111100101100111011101101 Chromosome B 111111100010110001011111 Binary encoding example - Permutation encoding: every single individual is represented as a string of numbers that represents a position in a sequence. For example, ordering problems and traveling salesman problem (TSP) use the Permutation encoding technique:
Chromosome A 1 3 5 6 2 4 7 8 9 Chromosome B 6 5 8 7 2 2 1 3 9 Permutation encoding example - Value encoding: the individual in this type of encoding is implemented as a string of some values. These values can be any character or real number. For example, the process of determining weights for neural network uses value encoding technique:
Chromosome A 1.2324 5.3243 0.4556 2.3293 2.4545 Chromosome B ACDJEIFJDHDIERJFFDDFLFEGT Chromosome C (back), (back), (right), (forward), (left) Value encoding example - Tree encoding: All chromosomes are structured as a tree of some objects (i.e., commands in programming language):
Chromosome A Chromosome B ![Information 09 00167 i001]()
![Information 09 00167 i002]()
( + x ( / 5 y ) ) ( do_until step wall )


- Reaching the peak level of generations.
- Improving fitness still below the threshold value.
2.2. Solving Travelling Salesman Problem (TSP) with GA
- Symmetric traveling salesman problem: The distance or cost between any two city nodes is equal for both directions (undirected graph), i.e., the distance from node1 to node2 and the distance from node2 to node1 are alike. Therefore, the expected solutions here will be (n − 1)!.
- Asymmetric traveling salesman problem: The distance or cost between any two city nodes is not equal for both directions (directed graph), i.e., the distance from node1 to node2 is not the same from the distance from node2 to node1. Thus, the expected solutions will be (n − 1)!/2.
- Multi traveling salesman problem: More than one salesperson involved in the problem of finding optimal route.
- Binary representation: a bit string is used to implement each city for example, 4-bit string is used to represent each city of 6 cities TSP, i.e., strings: a tour 1-3-6-5-2-4 is implemented: (00010011 0110 0101 0010 0100).
- Path representation: where there is a natural representation for the path [45], for example: a path 1-3-7-6-5-2-4 is represented: (1 3 7 6 5 2 4).
- Adjacency representation: The destination city that is linked to the source may become the source for an upcoming tour.
- Ordinal representation: The path from one city to another is implemented as an array of cities. The path i, in the list, is a number ranging from 1 to ().
2.3. Population Seeding Techniques
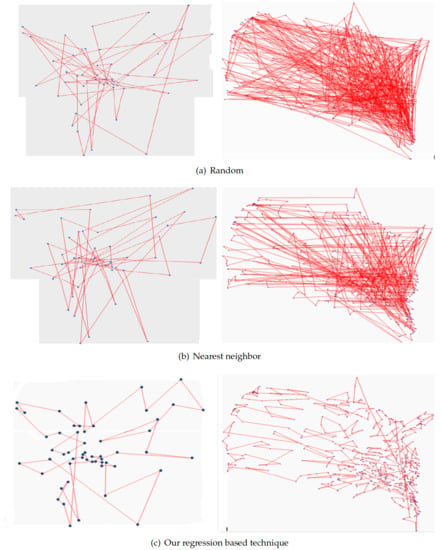
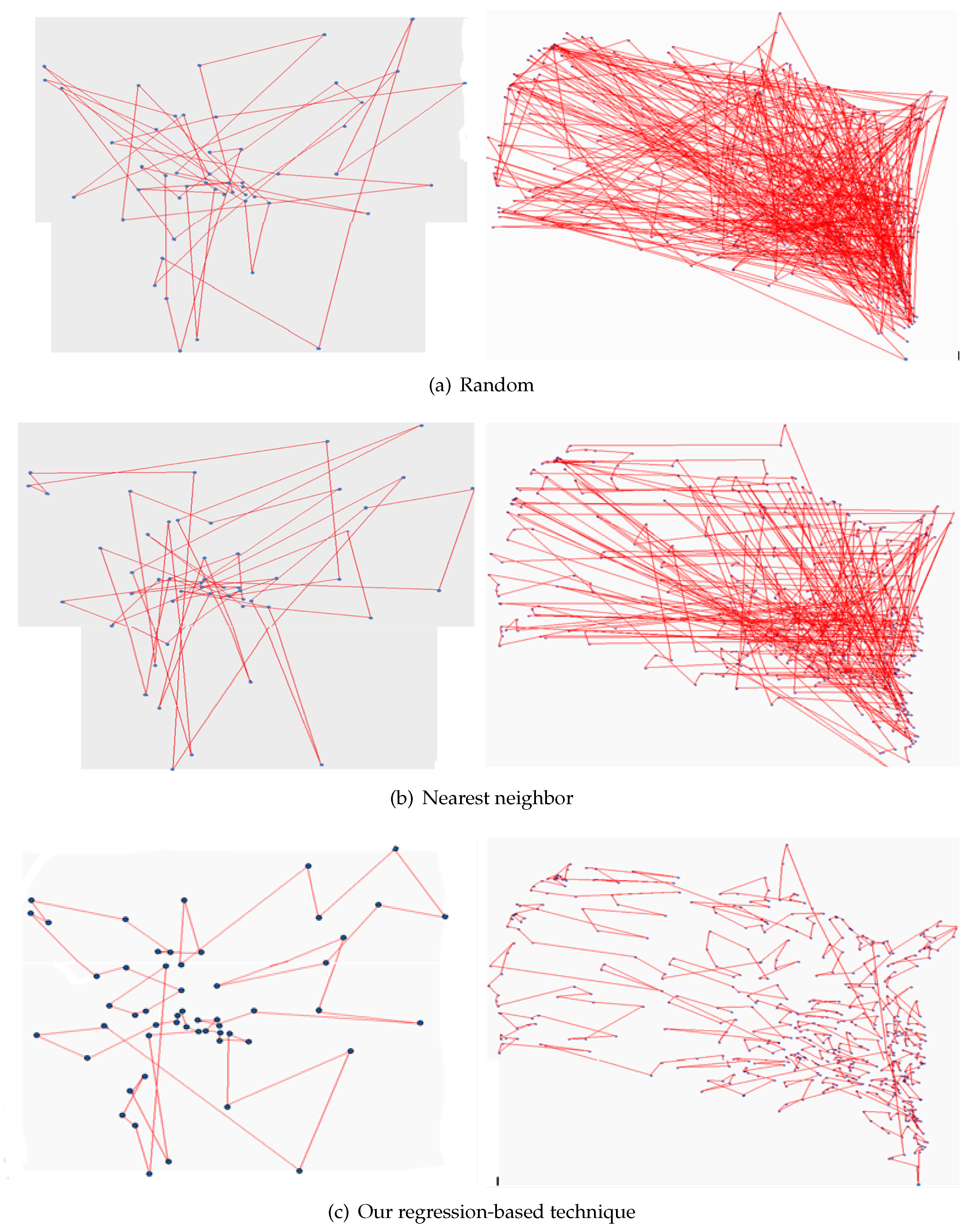
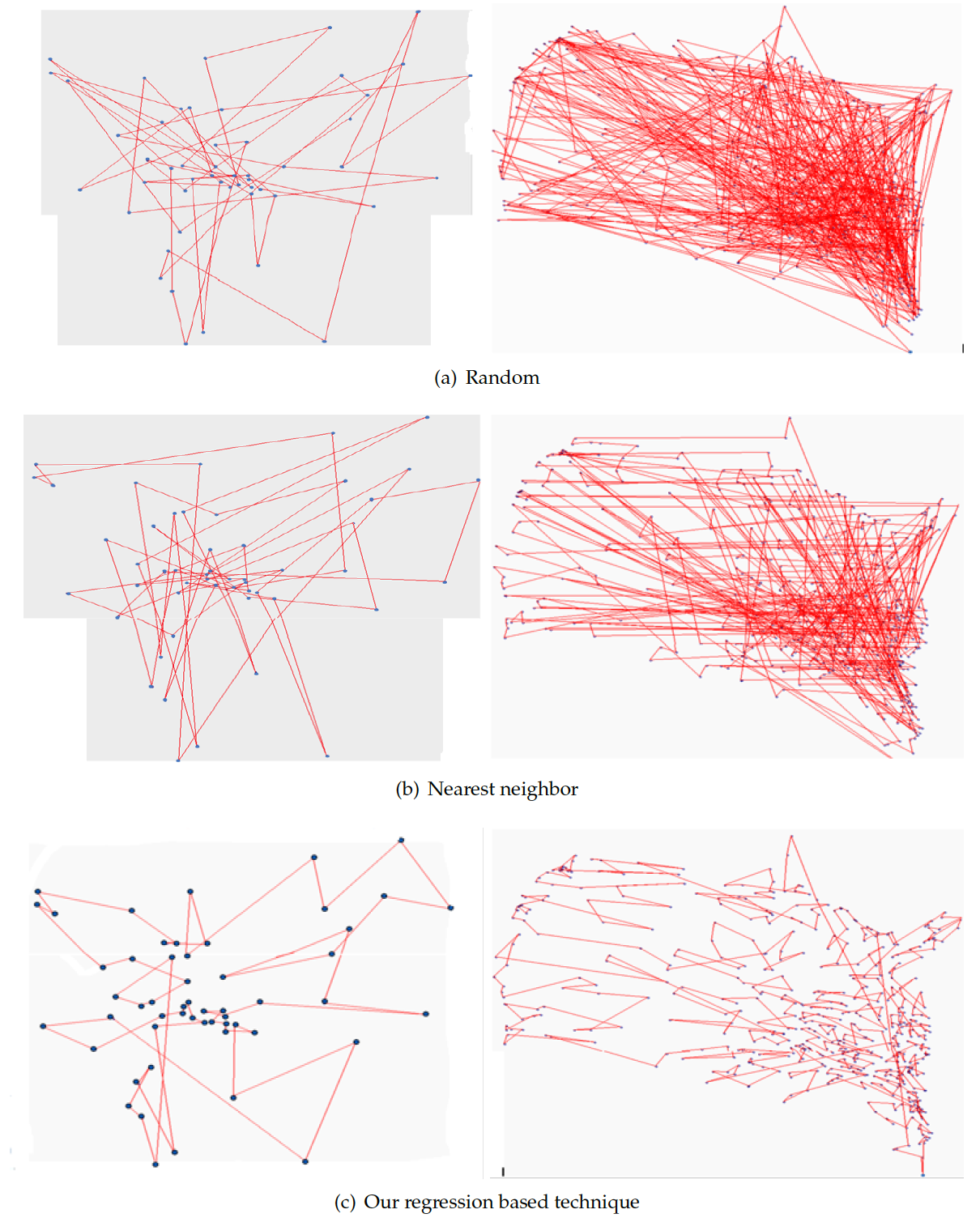
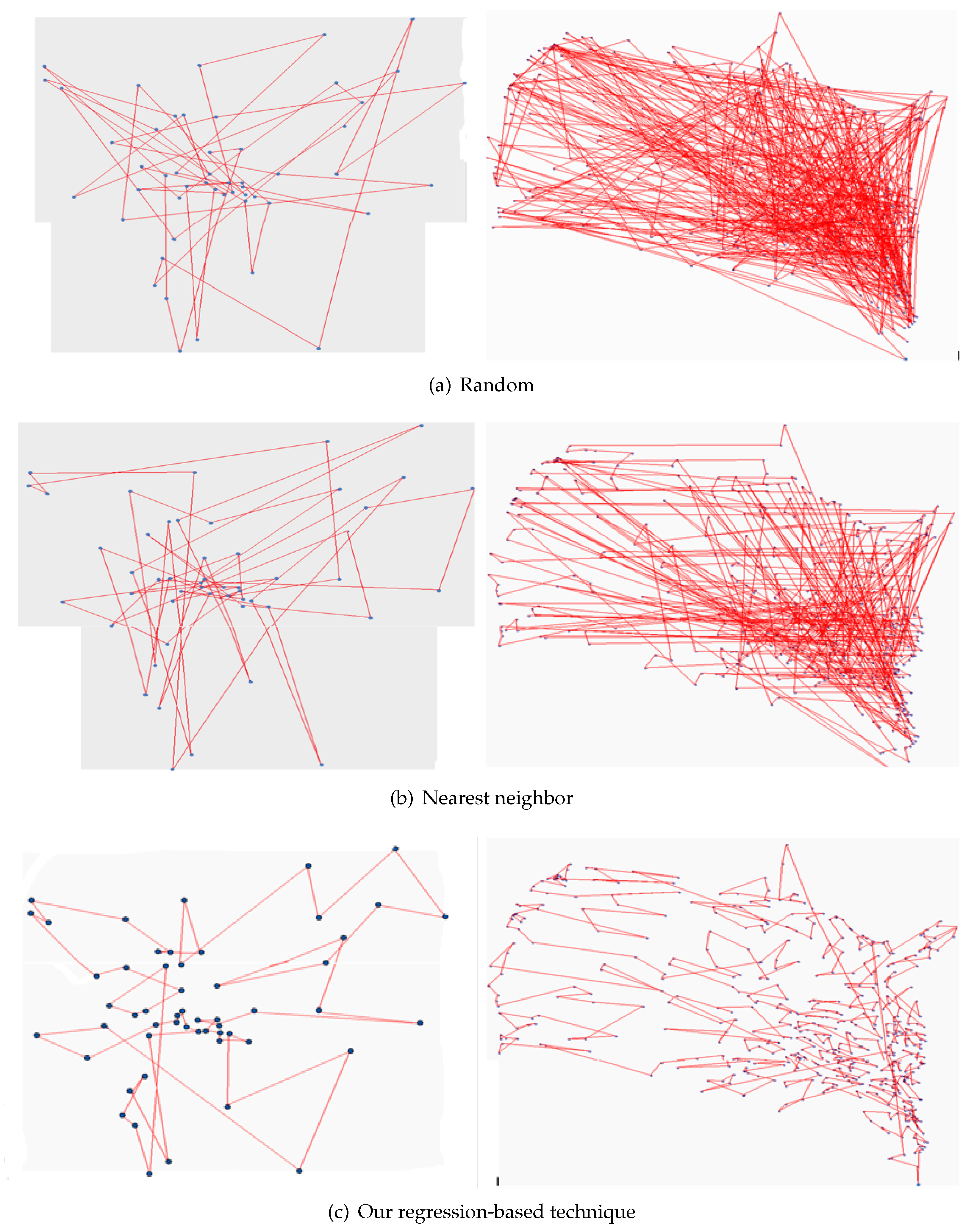
- Random Initialization: Random initial population seeding technique is the simplest and the most common technique that generates the initial population to GA. This technique is preferred when the prior information about the problem or the optimal solution is trivial. The sentence ‘generate an initial population’ related to the process of generating the initial population by using random initialization technique. In TSP, the random initialization technique selects the cities of the initial solutions randomly. During the individual generation, the random initialization technique generates a random number between 1 and n. If the current individual is already contains the generated number, then it generates a new number. Otherwise, the generated number is added to the current individuals. The Operation is repeated until the desired individual size (n) is reached. There are many random initial population methods aim to generate a random numbers such as the uniform random sequence, Sobol random, and quasi random [2,48].
- Nearest Neighbor: The nearest neighbor (NN) is considered as one of the most common initial population seeding technique. NN may still good alternative to random initial population technique in order to generate an initial population solutions that are used in solving TSP with GAs [49,50,51,52,53]. In the case of NN technique, the generation of each individual starts by selecting random city as the starting city and then the nearest city to be added as the new starting city. Iteratively, NN adds the nearest city to the current city that was not added to the individual until the individual includes all the cities in the problem space. The generated individuals from the NN population seeding can improve the evolving search process in the next generations as they were created from a city nearest to the current city [52].
- Selective Initialization: Yang [54] presented a selective initial population technique based on the K-nearest neighbor (KNN) sub graph. The KNN builds a graph contains all cities such as and , based on the distance matrix. Where is one of the KNN cities of or is one of the KNN cities of . The selective initial population technique grants the higher priority to the KNN sub graph edges. Firstly, from the city c, the next city will be randomly selected from c’s KNN list, but if all cities of c in KNN list are selected, then the next city is randomly selected from unvisited cities.
- Gene Bank: Wei et al. [55] proposed a greedy GA that depends on Gene Bank (GB) to generate the initial population to GA. GB technique aims to generate a high quality initial population solution. The GB is created based on the distance between cities by gathering the permutation of N cities. The initial population solutions that are generated from the GB are greater than the average fitness. In the case of solving TSP with N cities, the GB is constructed from c closer cities to city I, where c is the gene size less than or equal . Each gene of the first city, I, is randomly chosen. Then, the closest unvisited city j from the i-th row is selected and from the j-th row the closest unvisited city k is selected. On the other hand, if all j-th row cities are visited, then the next city is randomly chosen from unvisited cities list.
- Sorted Population: Yugay et al. [28] proposed a sorted initial population technique to modify and improve GA based on the principle of the better offspring’s which are generated from the best parents. SP technique generates a large number of initial population solutions and sorts the min ascending order based on their fitness value in case of TSP-short distance. Finally, some of initial populations that have bad fitness are eliminated. The probability of finding a good solution in the population is very high when the initial population is very large. So, the sorted initial population technique is more likely to find a favorable initial population solution.
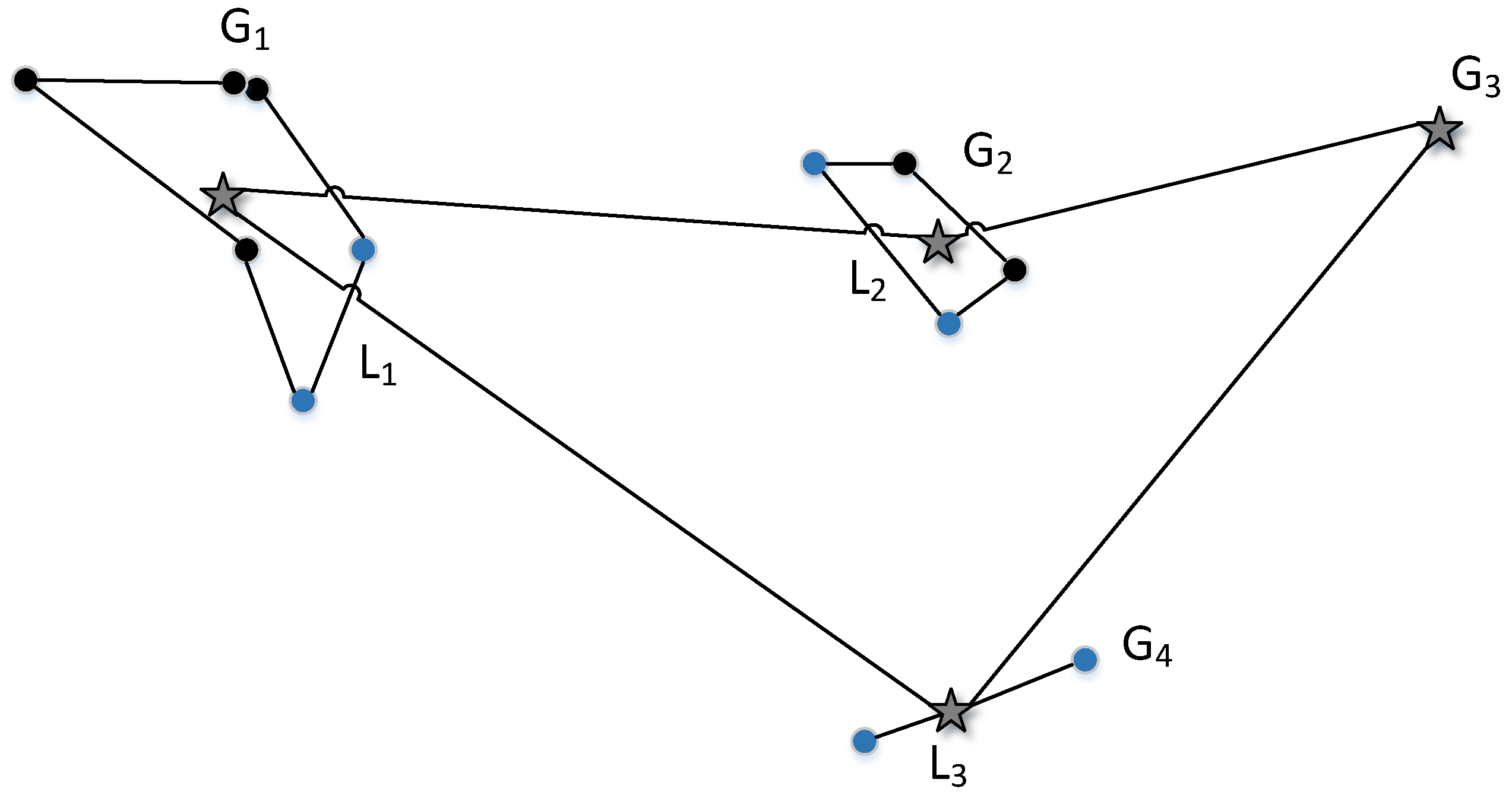
- K-means Initial Population: Deng et al. [33] introduced a new initial population technique to improve the performance of GA by using k-means algorithm for solving TSP. The proposed strategy used the k-means clustering to split a large-scale of TSP into small groups k, where and N = number of cities. Next, KIP applies GA to find the local optimal path for each groups and a global optimal path that connects each local optimal solution, see Figure 6. K-means based initial population technique was compared with two initializations, random and gene bank initialization techniques. The results showed that this particular initialization technique is more efficient to improve GA.
- Knowledge Based Initialization: Li et al. [56] proposed a knowledge based initialization technique to elevate the performance of GA in solving TSP. The main idea of KI based on generating initial population without path crossover, see Figure 7. However, when the number of involved nodes is large; it is too difficult to delete the crossover path without triggering another path. KI uses a heuristic method based on coordinate the transformation and the polar angle along with learned knowledge to create the initial population. The main idea is to split the plane into disjoint sectors; by increasing the polar angle to choose the cities that does not cause path crossover. Knowledge based initial population technique was compared to four other initializations: random, NN, gene bank, and Vari-begin with Vari-diversity techniques. The results showed that knowledge based nitialization technique is better than other techniques on the improvement of GA.
- Ordered Distance Vector Population Seeding: Paul et al. [7,57] disclosed an initial population seeding techniques that have a property of randomness and individual diversity based on the ordered distance vector (ODV). Three different initial population seeding techniques have been lunched based on ODV, namely ODV-EV, ODV-VE, and ODV-VV.The best adjacent (BA) number plays an important role in the individual diversity of the population. It assumes that any city in the optimal solution is connected to city , where is one of nearest BA number of cities to . In addition, Indevlen is the number represents the number of cities in each individual. In ODV techniques, the ordered distance matrix (ODM) size is created by using the value of BA and the given problem distance matrix. The techniques of generating the initial population using the ODM can be represented as follows:
- –
- ODV-EV. In ODV-EV technique, each individual in the populations begins with same city. A random number (BAi) is generated within the (BA) before inserting each city into each individual. The podv-ev that is generated using the ODV-EV technique can be represented as:where —an individual in the , o—individuals total number in the population , n—problem size. Each individual first city is remained same, i.e., .
- –
- ODV-VE. In ODV-VE technique, each individual is assigned a random number (BAi) which is generated within the BA; and the same random number (BAi) is used to adjust each city in the individual. After that, the BA number of individuals, in the population begins with the same initial city number. The ODV-VE technique can be represented as:where (BA) is the number of individuals and the first city is the same, i.e., , , and so on.
- –
- ODV-VV. In ODV-VV technique, a new random number (BAi) between 1 and BA is generated before inserting any city to any individual. The starting city for each individual is randomly selected. The generated initial population seeding from ODV-VV is efficient and has good individual diversity. The ODV-VV technique can be represented as:
- Insertion Population Seeding: The process of the insertion initial population seeding (In) technique starts with a partial path that contains several randomly selected cities. Then, iteratively inserts the nearest city to any city in the partial path. Finally, adds the edge to the lowest cost position at the path [58].
- Solomon Heuristic Seeding: Solomon Heuristic is a modification of the heuristic that was proposed for the vehicle routing problem with time windows by Solomon [59]. It starts with a partial path contains two cities that are randomly selected. Next, it calculates the inserting cost at any possible positions on the path for each city that is not inserted in the path. Finally, inserts the city into the path at the optimal position cost.
- Selection techniques such as Rank-based selection, Tournament selection, and Roulette Wheel selection.
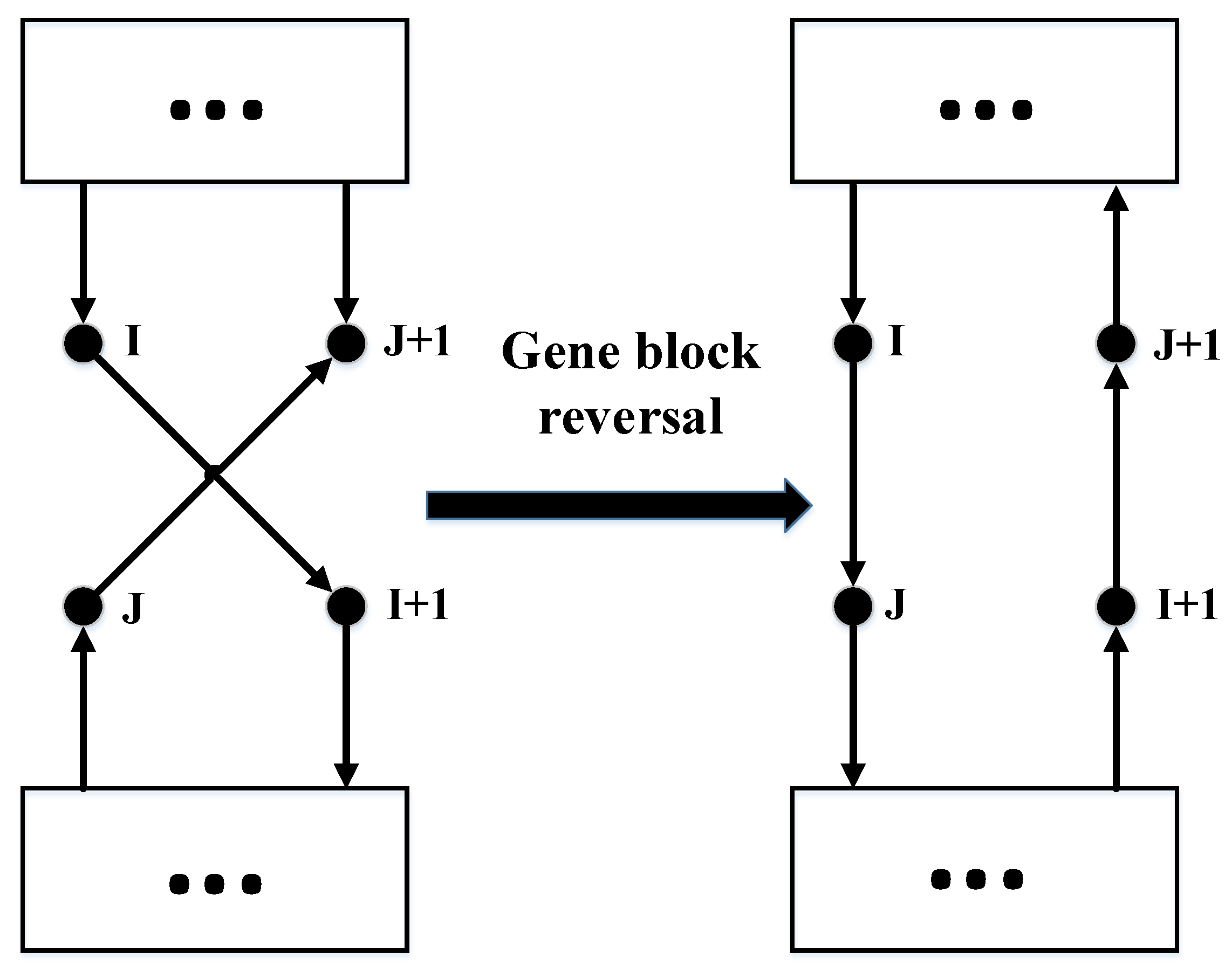
- Crossover: handled single-point crossover, two point crossover, and uniform crossover.
- Different Population Size.
- Crossover Rate: The rate of crossover operator used in each experiment.
- Mutation Rate: Aims to find the best operator to their technique to be used in the experiments.
- The larger population size, the higher efficiency in the search space.
- The moderate population size ranged from (12–4000).
- The increasing or decreasing of crossover rate leads to lose some solutions, where the range of crossover rate from (–1) and the range of mutation rate from (–1).
- Finding the best initial population is critical to find the optimal or near-optimal solution.
- The need of population diversity to avoid GA early convergence problem.
- Avoid falling in the local optimal solution problem:
- (a)
- Decrease the GA search time that are consumed for finding an optimal or near-optimal solution.
- (b)
- Decrease the numbers of generations that are needed to obtain the optimal or near-optimal solution.
3. Proposed Initialization Technique Based on Linear Regression
- (1)
- start with dividing the large-scale TSP into four small sub-problems using regression line and the perpendicular line, and classify the points into four categories. Each category is divided into four new categories recursively by using the regression line and the perpendicular line. The process carries on until having the target category that contains a small number of instances (x,y) points. Maximum four cities or (x,y) points assigned to each category that are considered as initial population for TSP sub-problem. The process ends up when the local optimal solution is obtained for each category.
- (2)
- Rebuild the initial populations seeding by reconnecting all local optimal solutions together. Finally, mutate the initial population N times to obtain N solutions, where N is the population size.
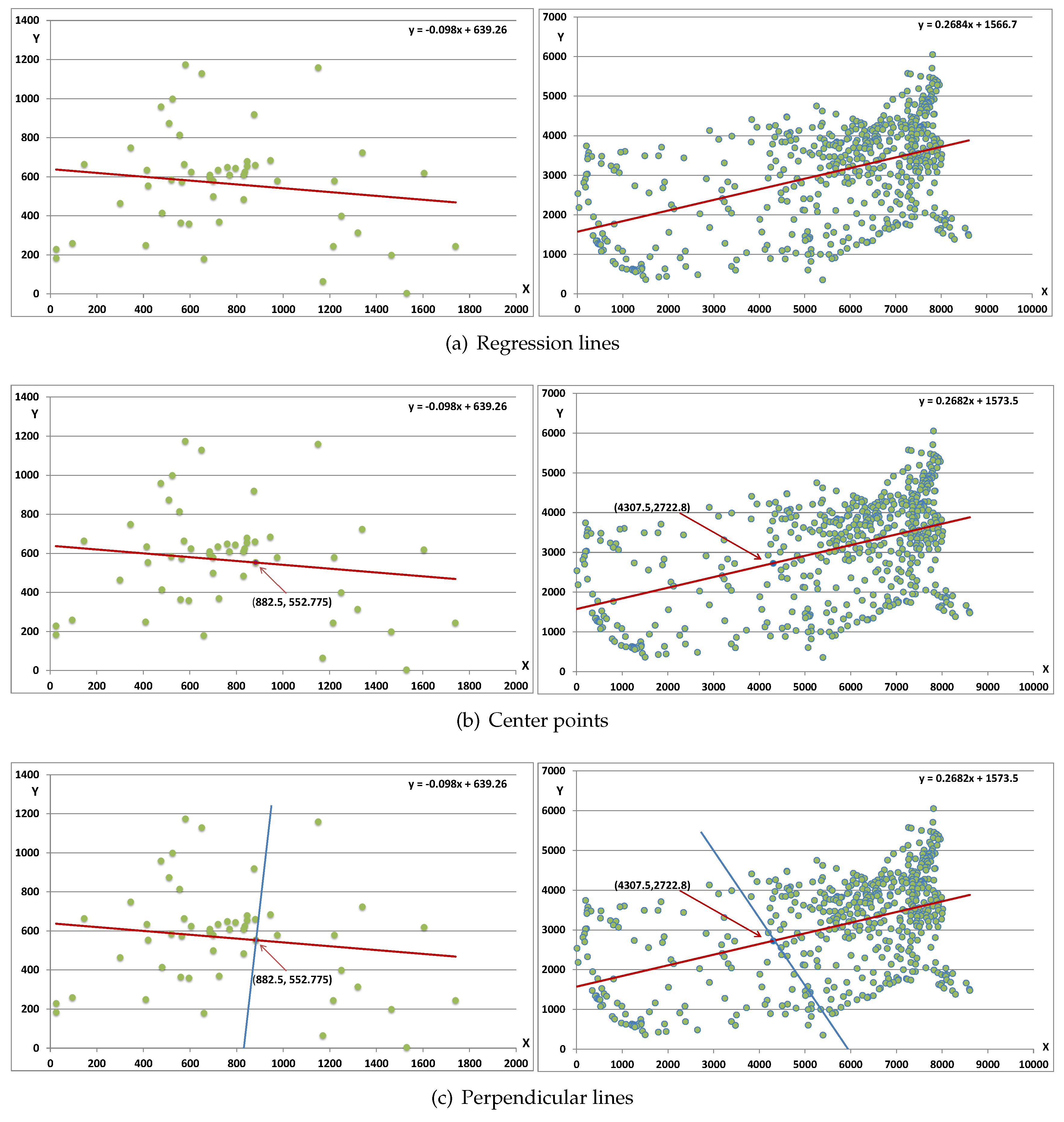
- Step 1: Find the regression line equation () that divide the points into two sections. To compute the regression line for berlin52 ( cities), we note that , , , , so that we see the constants the y-intercept, the slope of the line, see Equation (5). Thus, the regression line equation is given by . Similarly for att532 ( cities), we note that , , , , so that we see the constants the y-intercept, the slope of the line. Thus, the regression line equation is given by . See Figure 9a that shows these regression lines graphically.
- Step 2: Find the center points (x,y) of the regression lines. For berlin52 the center point (, ) is calculated from the end points (25, ), (1740, ), for and att532 the center point (, ) is calculated from the end points (8605, ), (10, ). See Figure 9b that shows these center points.
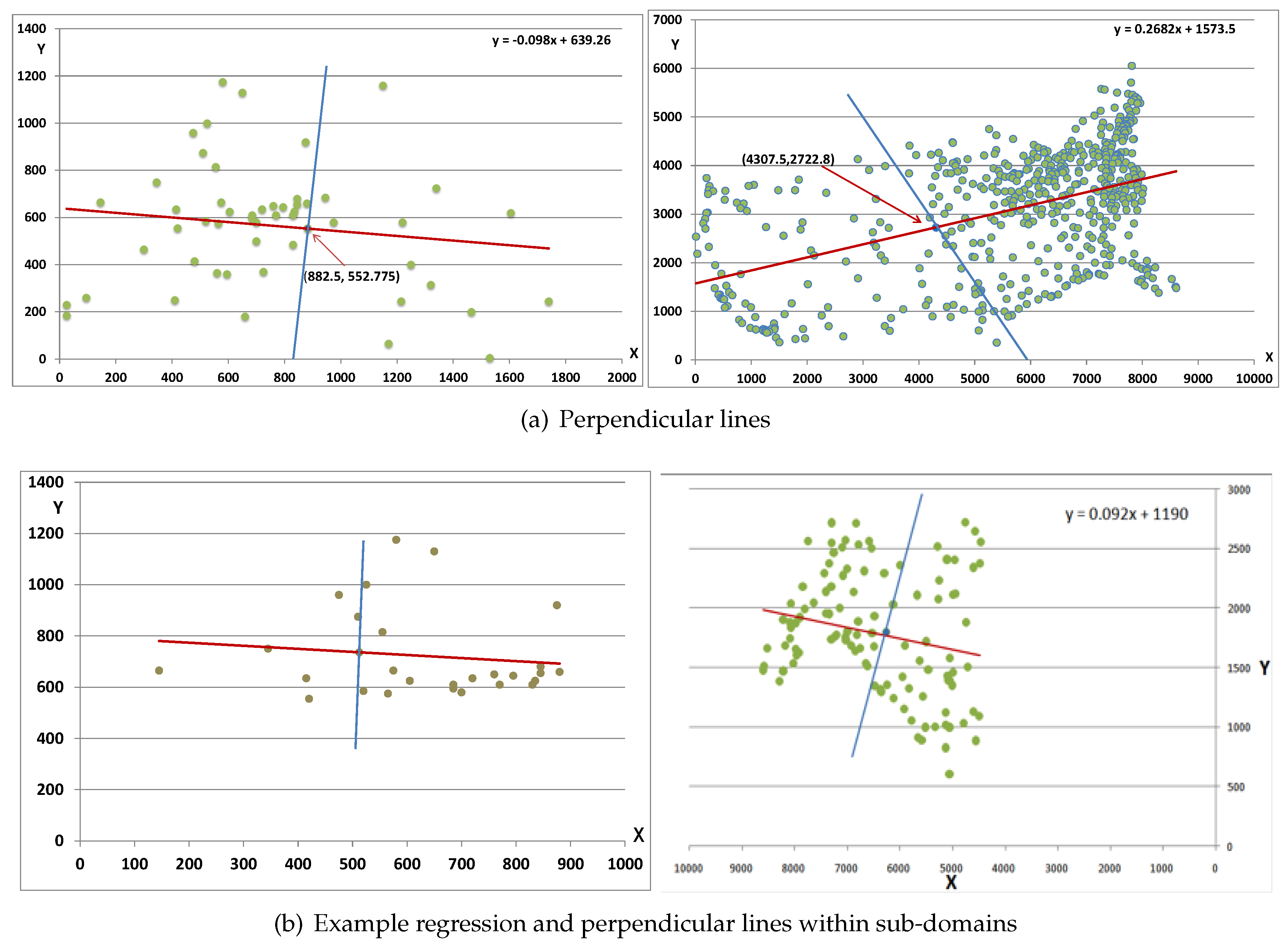
- Step 3: Find the perpendicular line equation that intersects the regression line at the center point. Note that the regression line slope is b, then the perpendicular line slope . The perpendicular line equation can then be obtained by using the line slope and the intersection point with the regression line (center point). See Figure 9c that shows these perpendicular lines.
- Step 4: Shift the center point to the origin point, and then allocate the regression line and the perpendicular line on the (x, y) axis. Next, classify the points into four categories A, B, C, and D, see Figure 10a.
- Step 5: Recursively, compute the regression and perpendicular lines (Steps 1 to 4) four times for each category A, B, C, and D, see Figure 10b for examples.
- Step 6: Terminate the recursive computation if the number of points (cities) less than or equal to four.
- Step 7: Select a random city to be the starting city, and then add the nearest city as new starting city until having all cities connected in the category of the local path. The group in each category is connected with the nearest group in other categories until all groups are connected in a global path.
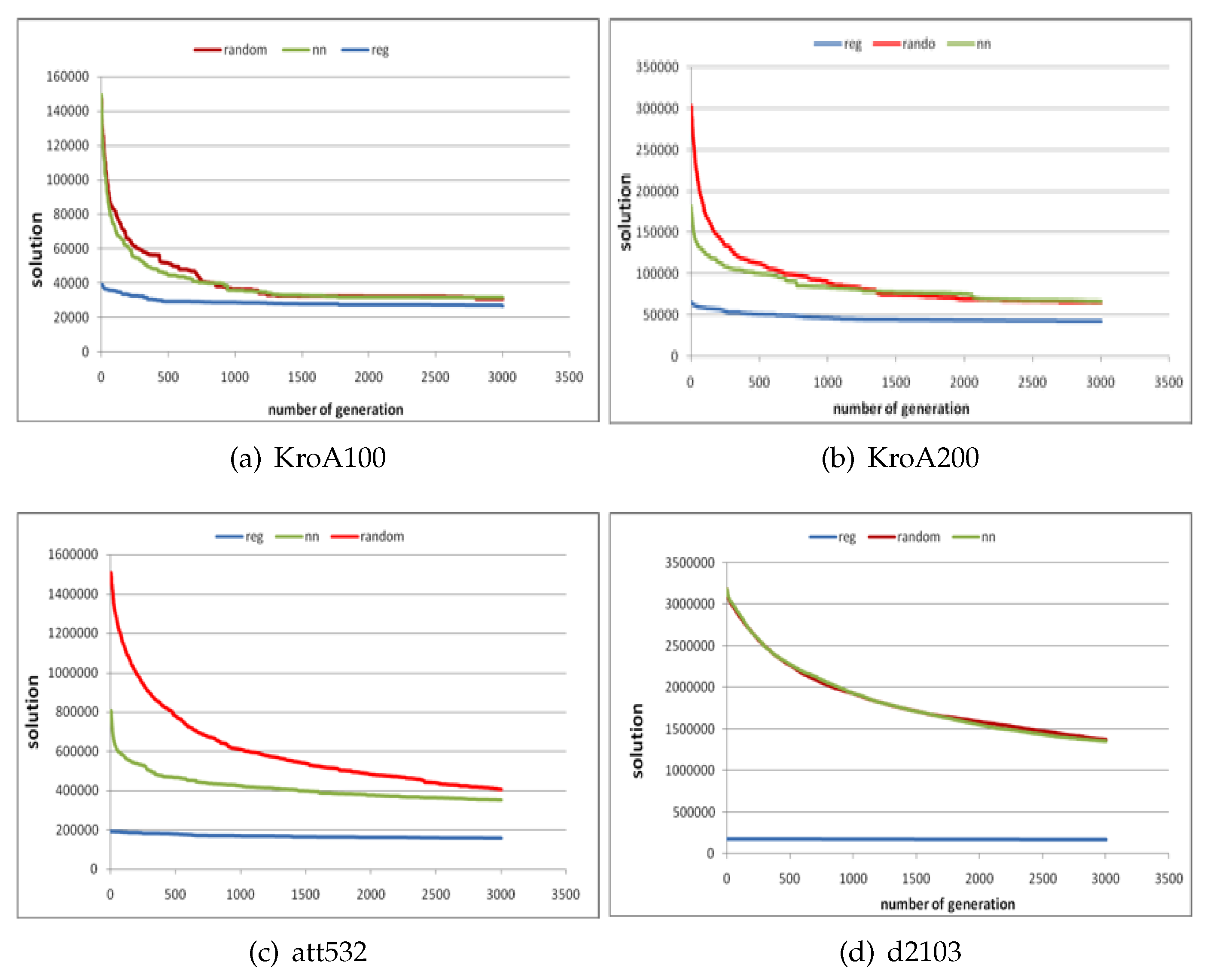
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Assessment Criteria
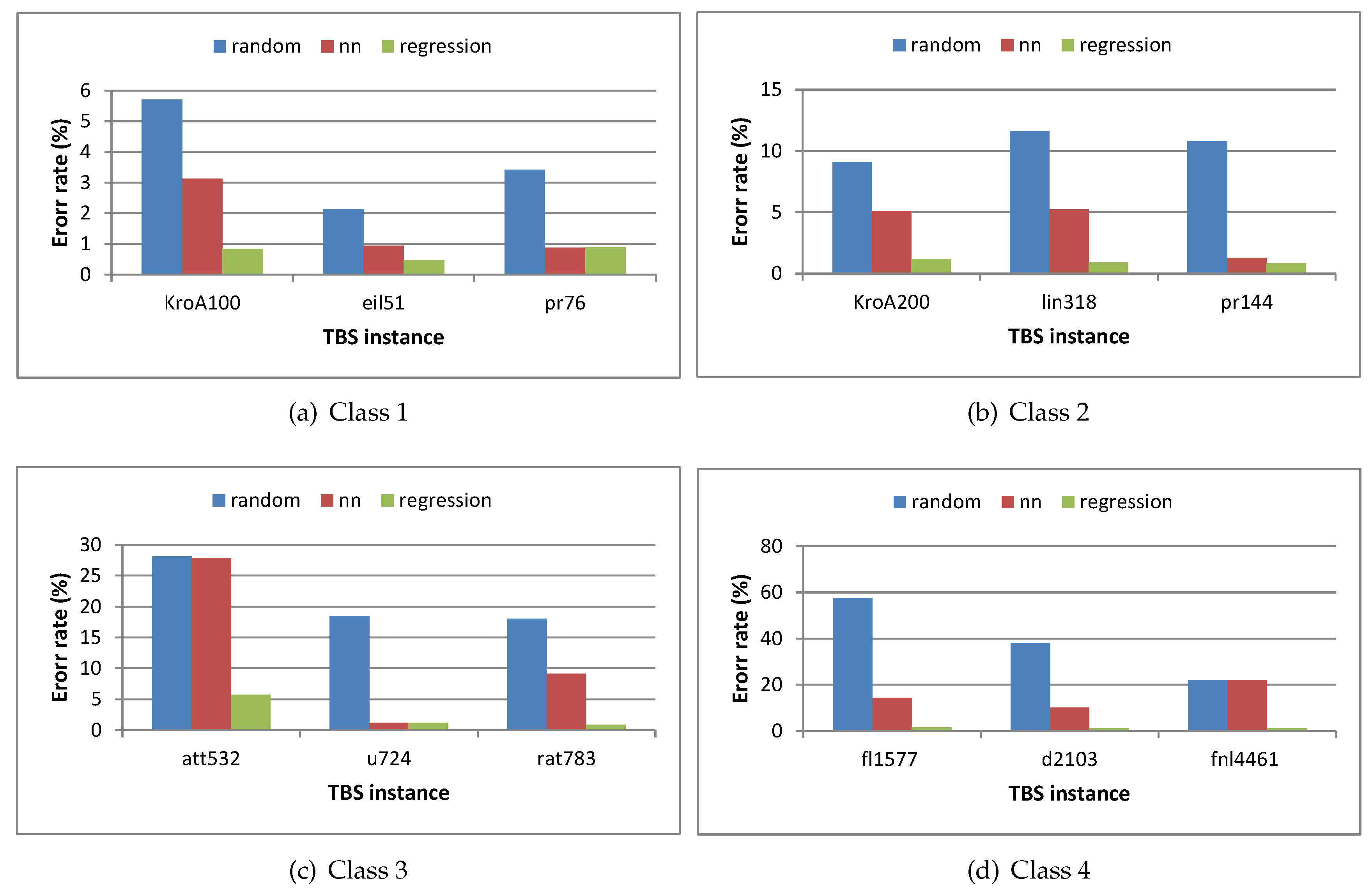
- Error Rate is the percentage of the difference between the known optimal solution and the fitness value of the solution for the problem [52,70,71]. It can be represented as:The error rate can be classified into two types based on the fitness values in the population. First, individuals with high error rate due to the initial population with worst fitness value. Second, individuals with low error rate due to the initial population with worst fitness [32].
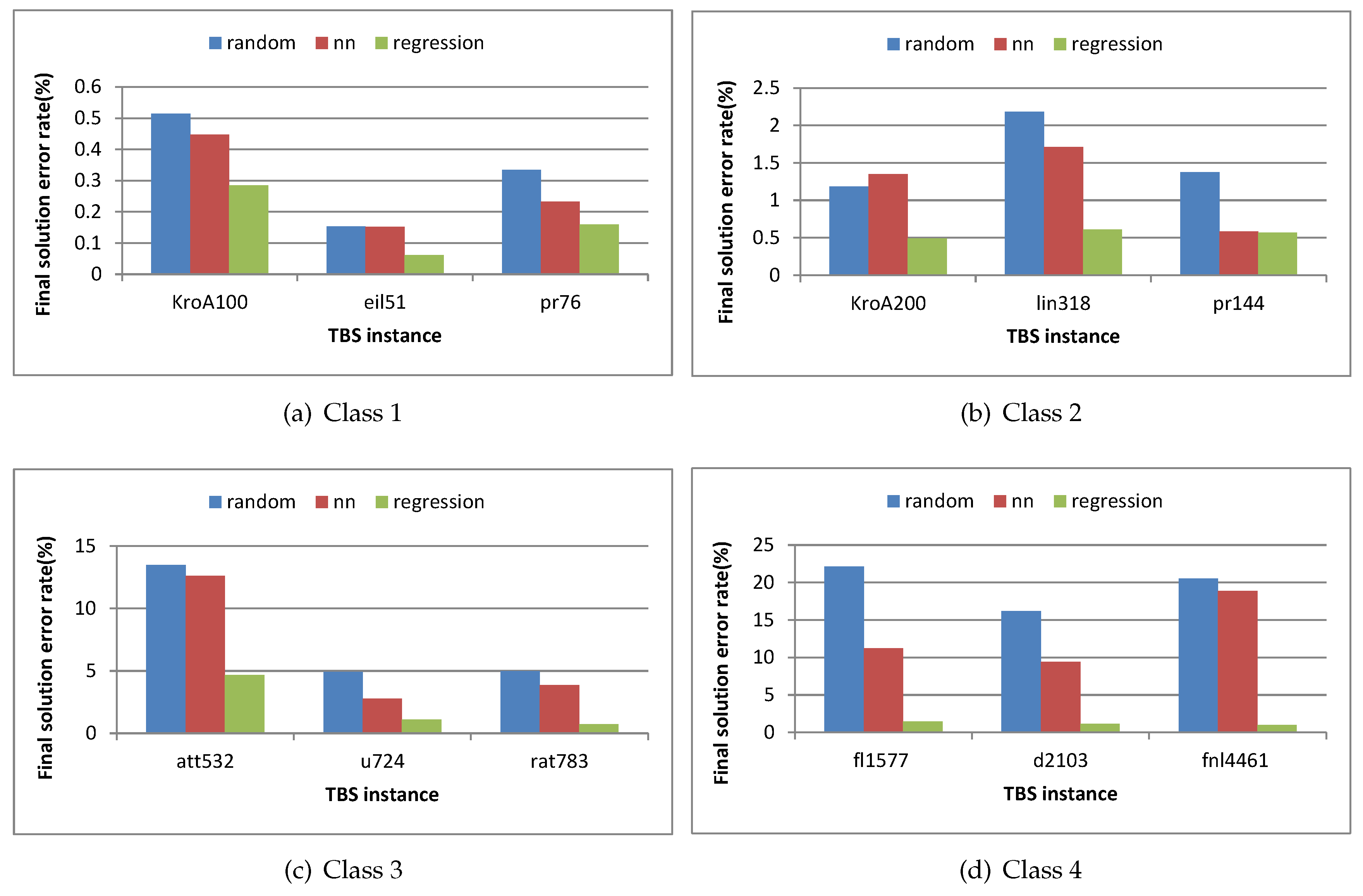
- Final Solution Error Rate refers to the difference between the known optimal solution and the final solution that is resulted when applying the GAs on TSP instances using one of initial population technique. It can be represented as:This factor measures the quality of the generated population by finding the effect of applying initial population technique on Gas performance to obtain a solution near to optimal one.
- ANOVA: A one-way analysis of variance (ANOVA) is used as one of statistical analysis techniques that test if one or more groups mean are significantly different from each other. Specifically, the ANOVA statistical analysis tests the null hypothesis:where, = group mean and k = the number of groups. The one-way ANOVA test is performed with critical value (the value that must be exceeded to reject the null hypothesis (H0)). H0 is accepted if the sig value is greater than the critical value () which equals () in this work. Otherwise, the H0 should be rejected and H1 should be accepted. That means there are two groups at least are different from each other. The one-way ANOVA cannot determine which specific groups were statistically different from each other. Therefore, to determine the different groups, a post hoc test such Duncan’s multiple range test, and least significant difference (LSD) test are used.
- Duncan’s multiple range test (DMRT): This is considered as one of the most important statistical analysis tests that is used to find group differences after rejecting the null hypothesis. It is called post hoc or multiple comparison tests [72]. The Duncan’s multiple range tests compares all pairs of groups mean. It computes the numeric boundaries that allow classifying the difference between any two techniques range [73]. If there is a significant difference between the population means, DMRT will have a high probability of declaring the difference. For this reasons, the Duncan’s test has being the most popular test among researchers. The DMRT was implemented in this work for classifying the study groups (random, nearest neighbor, and regression) into homogenous group. The classified groups and sig value show if there is a significant difference between groups or not. Pairs of means resulting from a group comparison study with more than two groups are significantly different from each other with level of significance (). However, DMRT produces information about the significant difference between groups without differentiates their mean.
- Least significant difference (LSD): This is one of post-hoc test developed by Ronald Fisher in 1935. In general, the (LSD) is a method used to calculate and compare groups mean after rejecting the ANOVA null hypothesis (H0) of equal means using the ANOVA F-test [72]. Rejecting H0 means there are at least two means different from each other, but if the ANOVA F-test fails to reject the H0, there will be no need to apply LSD as it will incorrectly propose a significant differences between groups mean. LSD computes the minimum significant variance between two means, and to declare any significant difference larger than the LSD.
4.3. Experimental Results and Discussion
5. Conclusions
- Performance analysis of the regression-based technique with different GA operators such as different population size, mutation rate, and number of generations that may lead to improve the GA performance by finding optimal parameters.
- Analysis of new performance evaluation criteria including, computational time and distinct solutions need to be compared to old or new initial population techniques.
- Applying the proposed technique on different NP problems (e.g., Knapsack and job scheduling problem), as this paper evaluated the proposed technique on TSP only.
Author Contributions
Funding
Conflicts of Interest
References
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Katayama, K.; Sakamoto, H.; Narihisa, H. The efficiency of hybrid mutation genetic algorithm for the travelling salesman problem. Math. Comput. Model. 2000, 31, 197–203. [Google Scholar] [CrossRef]
- Mustafa, W. Optimization of production systems using genetic algorithms. Int. J. Comput. Intell. Appl. 2003, 3, 233–248. [Google Scholar] [CrossRef]
- Zhong, J.; Hu, X.; Zhang, J.; Gu, M. Comparison of performance between different selection strategies on simple genetic algorithms. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005. [Google Scholar]
- Louis, S.J.; Tang, R. Interactive genetic algorithms for the traveling salesman problem. In Proceedings of the 1st Annual Conference on Genetic and Evolutionary Computation, Orlando, FL, USA, 13–17 July 1999; Volume 1. [Google Scholar]
- Man, K.-F.; Tang, K.-S.; Kwong, S. Genetic algorithms: Concepts and applications in engineering design. IEEE Trans. Ind. Electron. 1996, 43, 519–534. [Google Scholar] [CrossRef]
- Paul, P.V.; Dhavachelvan, P.; Baskaran, R. A novel population initialization technique for genetic algorithm. In Proceedings of the 2013 International Conference on Circuits, Power and Computing Technologies (ICCPCT), Nagercoil, India, 20–21 March 2013. [Google Scholar]
- Hassanat, A.B.; Alkafaween, E.; Al-Nawaiseh, N.A.; Abbadi, M.A.; Alkasassbeh, M.; Alhasanat, M.B. Enhancing genetic algorithms using multi mutations: Experimental results on the travelling salesman problem. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 785. [Google Scholar]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization, and Machine Learning; Addison-Wesley: Reading, MA, USA, 1989. [Google Scholar]
- Tsang, P.W.; Au, A.T.S. A genetic algorithm for projective invariant object recognition. In Proceedings of the Digital Processing Applications (TENCON ’96), Perth, Australia, 29 November 1996. [Google Scholar]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Benkhellat, Z.; Belmehdi, A. Genetic algorithms in speech recognition systems. In Proceedings of the International Conference on Industrial Engineering and Operations Management, Istanbul, Turkey, 3–6 July 2012. [Google Scholar]
- Gupta, D.; Ghafir, S. An overview of methods maintaining diversity in genetic algorithms. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 56–60. [Google Scholar]
- Srivastava, P.R.; Kim, T.-H. Application of genetic algorithm in software testing. Int. J. Softw. Eng. Appl. 2009, 3, 87–96. [Google Scholar]
- Zhou, X.; Fang, M.; Ma, H. Genetic algorithm with an improved initial population technique for automatic clustering of low-dimensional data. Information 2018, 9, 101. [Google Scholar] [CrossRef]
- Wang, Y.; Lu, J. Optimization of China crude oil transportation network with genetic ant colony algorithm. Information 2015, 6, 467–480. [Google Scholar] [CrossRef]
- Gang, L.; Zhang, M.; Zhao, X.; Wang, S. Improved genetic algorithm optimization for forward vehicle detection problems. Information 2015, 6, 339–360. [Google Scholar] [CrossRef]
- Cimino, M.G.C.A.; Gigliola, V. An interval-valued approach to business process simulation based on genetic algorithms and the BPMN. Information 2014, 5, 319–356. [Google Scholar] [CrossRef]
- Aliakbarpour, H.; Prasath, V.B.; Dias, J. On optimal multi-sensor network configuration for 3D registration. J. Sens. Actuator Netw. 2015, 4, 293–314, Special issue on 3D Wireless Sensor Network. [Google Scholar] [CrossRef]
- Ayala, H.V.H.; dos Santos Coelho, L. Tuning of PID controller based on a multiobjective genetic algorithm applied to a robotic manipulator. Expert Syst. Appl. 2012, 39, 8968–8974. [Google Scholar] [CrossRef]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Berlin, Germany, 2003; Volume 53. [Google Scholar]
- Abu-Qdari, S.A. An Improved GA with Initial Population Technique for the Travelling Salesman Problem. Master’s Thesis, Mutah University, Maw tah, Jordan, 2017. [Google Scholar]
- Alkafaween, E. Novel Methods for Enhancing the Performance of Genetic Algorithms, Master’s Thesis, Mutah University, Mawtah, Jordan, 2015. [Google Scholar]
- Maaranen, H.; Miettinen, K.; Makela, M.M. Quasi-random initial population for genetic algorithms. Comput. Math. Appl. 2004, 47, 1885–1895. [Google Scholar] [CrossRef]
- Maaranen, H.; Miettinen, K.; Penttinen, A. On initial populations of a genetic algorithm for continuous optimization problems. J. Glob. Optim. 2007, 37, 405–436. [Google Scholar] [CrossRef]
- Pullan, W. Adapting the genetic algorithm to the travelling salesman problem. In Proceedings of the 2003 Congress on Evolutionary Computation (CEC ’03), Canberra, Australia, 8–12 December 2003. [Google Scholar]
- Hue, X. Genetic Algorithms for Optimization: Background and Applications; Edinburgh Parallel Computing Centre: Edinburgh, UK, 1997; Volume 10. [Google Scholar]
- Yugay, O.; Kim, I.; Kim, B.; Ko, F.I.S. Hybrid genetic algorithm for solving traveling salesman problem with sorted population. In Proceedings of the Third International Conference on Convergence and Hybrid Information Technology (ICCIT), Busan, Korea, 11–13 November 2008. [Google Scholar]
- Laporte, G. The traveling salesman problem: An overview of exact and approximate algorithms. Eur. J. Oper. Res. 1992, 59, 231–247. [Google Scholar] [CrossRef]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M.A. A novel population initialization method for accelerating evolutionary algorithms. Comput. Math. Appl. 2007, 53, 1605–1614. [Google Scholar] [CrossRef]
- Li, X.; Xiao, N.; Claramunt, C.; Lin, H. Initialization strategies to enhancing the performance of genetic algorithms for the p-median problem. Comput. Ind. Eng. 2011, 61, 1024–1034. [Google Scholar] [CrossRef]
- Albayrak, M.; Allahverdi, N. Development a new mutation operator to solve the traveling salesman problem by aid of genetic algorithms. Expert Syst. Appl. 2011, 38, 1313–1320. [Google Scholar] [CrossRef]
- Deng, Y.; Liu, Y.; Zhou, D. An improved genetic algorithm with initial population strategy for symmetric TSP. Math. Probl. Eng. 2015, 2015. [Google Scholar] [CrossRef]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer Science and Business Media: Berlin, Germany, 2013. [Google Scholar]
- Sivanandam, S.N.; Deepa, S.N. Introduction to Genetic Algorithms; Springer: Berlin, Germany, 2007. [Google Scholar]
- Lurgi, M.; Robertson, D. Evolution in ecological agent systems. Int. J. Bio-Inspir. Comput. 2011, 3, 331–345. [Google Scholar] [CrossRef]
- Akerkar, R.; Sajja, P.S. Genetic Algorithms and Evolutionary Computing. In Intelligent Techniques for Data Science; Springer: Berlin, Germany, 2016; pp. 157–184. [Google Scholar]
- Back, T.; Schwefel, H.-P. An overview of evolutionary algorithms for parameter optimization. Evol. Comput. 1993, 1, 1–23. [Google Scholar] [CrossRef]
- Shukla, P.K.; Tripathi, S.P. A Review on the interpretability-accuracy trade-off in evolutionary multi-objective fuzzy systems (EMOFS). Information 2012, 3, 256–277. [Google Scholar] [CrossRef]
- Hassanat, A.B.; Alkafaween, E.A. On enhancing genetic algorithms using new crossovers. Int. J. Comput. Appl. Technol. 2017, 55, 202–212. [Google Scholar] [CrossRef]
- Shukla, A.; Pandey, H.M.; Mehrotra, D. Comparative review of selection techniques in genetic algorithm. In Proceedings of the 2015 International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), Noida, India, 25–27 Febuary 2015. [Google Scholar]
- Kaya, Y.; Uyar, M. A novel crossover operator for genetic algorithms: Ring crossover. arXiv, 2011; arXiv:1105.0355. [Google Scholar]
- Korejo, I.; Yang, S.; Brohi, K.; Khuhro, Z.U. Multi-population methods with adaptive mutation for multi-modal optimization problems. Int. J. Soft Comput. Artif. Intell. Appl. (IJSCAI) 2013, 2. [Google Scholar] [CrossRef]
- Rao, A.; Hedge, S.K. Literature survey on travelling salesman problem using genetic algorithms. Int. J. Adv. Res. Edu. Technol. (IJARET) 2015, 2, 42. [Google Scholar]
- Mohebifar, A. New binary representation in genetic algorithms for solvingTSP by mapping permutations to a list of ordered numbers. WSEAS Trans. Comput. Res. 2006, 1, 114–118. [Google Scholar]
- Abdoun, O.; Abouchabaka, J.; Tajani, C. Analyzing the performance of mutation operators to solve the travelling salesman problem. arXiv, 2012; arXiv:1203.3099. [Google Scholar]
- Homaifar, A.; Guan, S.; Liepins, G.E. A new approach on the traveling salesman problem by genetic algorithms. In Proceedings of the 5th International Conference on Genetic Algorithms, Urbana-Champaign, IL, USA, 15 June 1993. [Google Scholar]
- Qu, L.; Sun, R. A synergetic approach to genetic algorithms for solving traveling salesman problem. Inf. Sci. 1999, 117, 267–283. [Google Scholar] [CrossRef]
- Kaur, D.; Murugappan, M.M. Performance enhancement in solving traveling salesman problem using hybrid genetic algorithm. In Proceedings of the NAFIPS 2008—2008 Annual Meeting of the North American Fuzzy Information Processing Society, New York City, NY, USA, 19–22 May 2008. [Google Scholar]
- Liao, X.-P. An orthogonal genetic algorithm with total flowtime minimization for the no-wait flow shop problem. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009. [Google Scholar]
- Lu, T.; Zhu, J. A genetic algorithm for finding a path subject to two constraints. Appl. Soft Comput. 2013, 13, 891–898. [Google Scholar] [CrossRef]
- Ray, S.S.; Bandyopadhyay, S.; Pal, S.K. Genetic operators for combinatorial optimization in TSP and microarray gene ordering. Appl. Intell. 2007, 26, 183–195. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Tsai, C.-W. A new approach for solving large traveling salesman problem using evolutionary ant rules. In Proceedings of the 2002 International Joint Conference on Neural Networks, IJCNN’02 (Cat. No.02CH37290), Honolulu, HI, USA, 12–17 May 2002. [Google Scholar]
- Yang, R. Solving large travelling salesman problems with small populations. In Proceedings of the Second International Conference on Genetic Algorithms in Engineering Systems, Glasgow, UK, 2–4 September 1997; pp. 157–162. [Google Scholar]
- Wei, Y.; Hu, Y.; Gu, K. Parallel search strategies for TSPs using a greedy genetic algorithm. In Proceedings of the Third International Conference on Natural Computation (ICNC 2007), Haikou, China, 24–27 August 2007. [Google Scholar]
- Li, C.; Chu, X.; Chen, Y.; Xing, L. A knowledge-based technique for initializing a genetic algorithm. J. Intell. Fuzzy Syst. 2016, 31, 1145–1152. [Google Scholar] [CrossRef]
- Paul, P.V.; Ramalingam, A.; Baskaran, R.; Dhavachelvan, P.; Vivekanandan, K.; Subramanian, R.; Venkatachalapathy, V.S.K. Performance analyses on population seeding techniques for genetic algorithms. Int. J. Eng. Technol. (IJET) 2013, 5, 2993–3000. [Google Scholar]
- Osaba, E.; Diaz, F. Comparison of a memetic algorithm and a tabu search algorithm for the traveling salesman problem. In Proceedings of the 2012 Federated Conference on Computer Science and Information Systems (FedCSIS), Wroclaw, Poland, 9–12 September 2012. [Google Scholar]
- Solomon, M.M. Algorithms for the vehicle routing and scheduling problems with time window constraints. Oper. Res. 1987, 35, 254–265. [Google Scholar] [CrossRef]
- Raja, P.V.; Bhaskaran, V.M. Improving the Performance of Genetic Algorithm by reducing the population size. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 86–91. [Google Scholar]
- Chiroma, H.; Abdulkareem, S.; Abubakar, A.; Zeki, A.; Gital, A.Y.U.; Usman, M.J. Correlation Study of Genetic Algorithm Operators: Crossover and Mutation Probabilities. In Proceedings of the International Symposium on Mathematical Sciences and Computing Research 2013 (iSMSC 2013), Perak, Malaysia, 6–7 December 2013; pp. 39–43. [Google Scholar]
- Shanmugam, M.; Basha, M.S.S.; Paul, P.V.; Dhavachelvan, P.; Baskaran, R. Performance assessment over heuristic population seeding techniques of genetic algorithm: Benchmark analyses on traveling salesman problems. Int. J. Appl. Eng. Res. (IJAER) 2013, 8, 1171–1184. [Google Scholar]
- Paul, P.V.; Moganarangan, N.; Kumar, S.S.; Raju, R.; Vengattaraman, T.; Dhavachelvan, P. Performance analyses over population seeding techniques of the permutation-coded genetic algorithm: An empirical study based on traveling salesman problems. Appl. Soft Comput. 2015, 32, 383–402. [Google Scholar] [CrossRef]
- Osaba, E.; Carballedo, R.; Diaz, F.; Onieva, E.; Lopez, P.; Perallos, A. On the influence of using initialization functions on genetic algorithms solving combinatorial optimization problems: A first study on the TSP. In Proceedings of the IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS), Linz, Austria, 2–4 June 2014. [Google Scholar]
- Chen, Y.; Fan, Z.-P.; Ma, J.; Zeng, S. A hybrid grouping genetic algorithm for reviewer group construction problem. Expert Syst. Appl. 2011, 38, 2401–2411. [Google Scholar] [CrossRef]
- Eiben, A.E.; Hinterding, R.; Michalewicz, Z. Parameter control in evolutionary algorithms. IEEE Trans. Evol. Comput. 1999, 3, 124–141. [Google Scholar] [CrossRef] [Green Version]
- Pedersen, D. Coarse-Grained Parallel Genetic Algorithms: Three Implementations and Their Analysis. Master’s Thesis, Kate Gleason College, Rochester, NY, USA, 5 January 1998. [Google Scholar]
- Sharma, A.; Mehta, A. Review paper of various selection methods in genetic algorithm. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1476–1479. [Google Scholar]
- Davis, L. Applying adaptive algorithms to epistatic domains. IJCAI 1985, 85, 162–164. [Google Scholar]
- Banzhaf, W. The “molecular” traveling salesman. Biol. Cybern. 1990, 64, 7–14. [Google Scholar] [CrossRef]
- Jayalakshmi, G.A.; Sathiamoorthy, S.; Rajaram, R. A hybrid genetic algorithm—A new approach to solve traveling salesman problem. Int. J. Comput. Eng. Sci. 2001, 2, 339–355. [Google Scholar] [CrossRef]
- Shaffer, J.P. A semi-Bayesian study of Duncan’s Bayesian multiple comparison procedure. J. Stat. Plan. Inference 1999, 82, 197–213. [Google Scholar] [CrossRef]
- Brown, A.M. A new software for carrying out one-way ANOVA post hoc tests. Comput. Methods Progr. Biomed. 2005, 79, 89–95. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
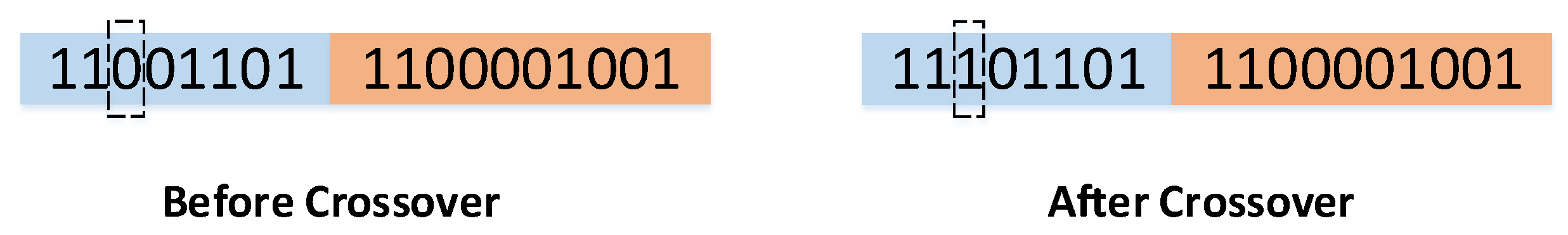{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
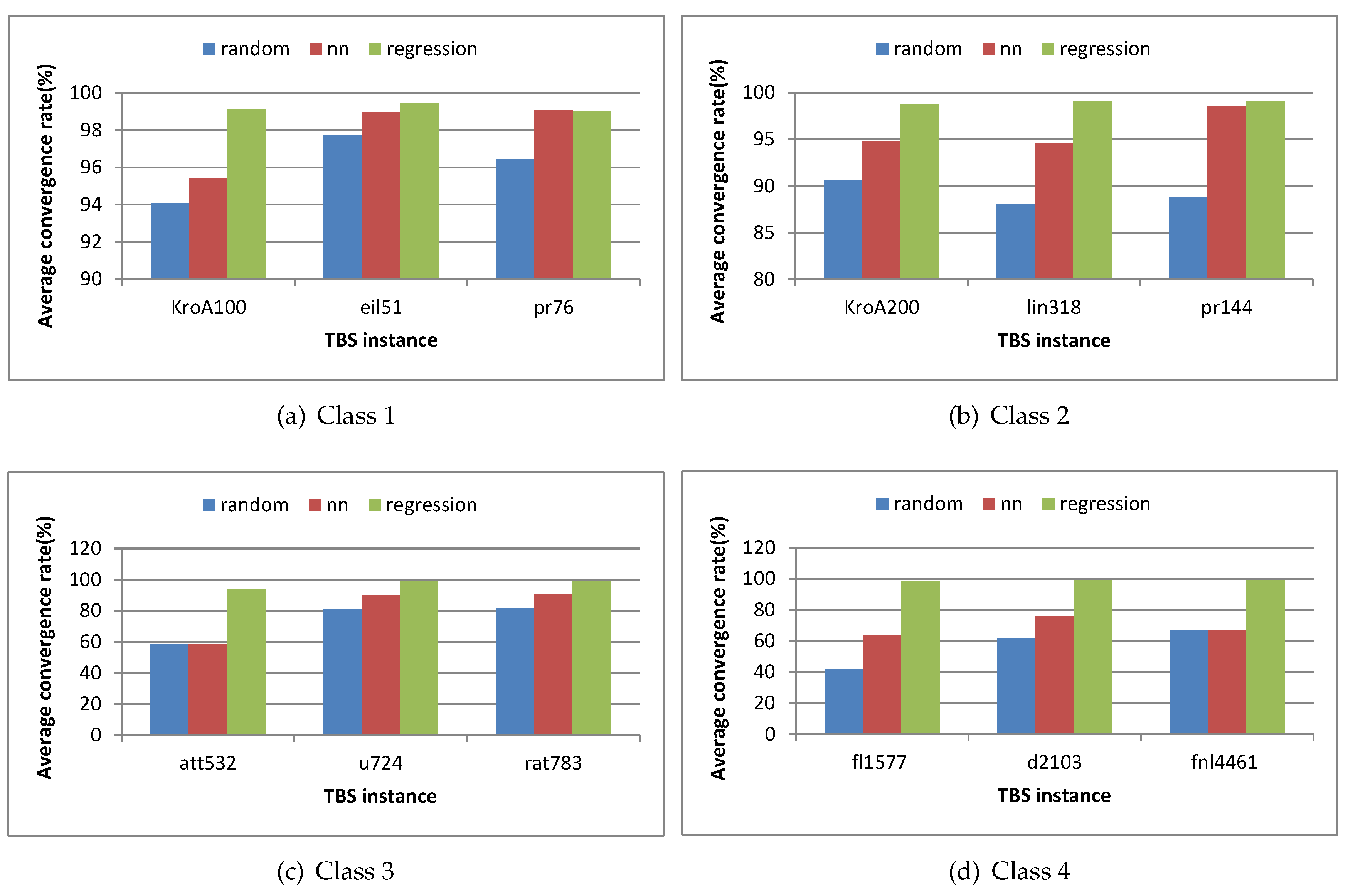{kind=link}
{kind=link}
{kind=link}
| No | Parameter | Value/Technique |
|---|---|---|
| 1 | Population Size | 100 |
| 2 | Generation Limit | 3000 |
| 3 | Initialization Technique | Random, NN, and regression |
| 4 | Crossover Method | one-point modified crossover |
| 5 | Crossover Probability | 0.82 |
| 6 | Mutation Method | Exchange mutation |
| 7 | Mutation Probability | 0.1 |
| 8 | Selection | Roulette wheel |
| 9 | Termination Condition | Generation limit |
| No | Class | Instance Size | Instances |
|---|---|---|---|
| 1 | Class 1 | Size ≤ 100 | KroA100, pr76, eil51 |
| 2 | Class 2 | 100 < Size ≤ 500 | KroA200, pr144, lin318 |
| 3 | Class 3 | 500 < Size ≤ 1000 | att532, rat783, u724 |
| 4 | Class 4 | 1000 < Size ≤ 5000 | fl1577, fnl4461, d2103 |
| Si/no | Class | Problem | Optimal Solution | Random | NN | Regression | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | Worst | Time | Best | Worst | Time | Best | Worst | Time | ||||
| 1 | Class 1 | KroA100 | 21282 | 5.707593 | 6.1524763 | 2 | 3.119679 | 6.0301663 | 3 | 0.834367 | 0.930646 | 33 |
| 2 | eil51 | 426 | 2.129108 | 2.4389671 | 1 | 0.943662 | 1.1197183 | 1 | 0.467136 | 0.615023 | 20 | |
| 3 | pr76 | 108159 | 3.412661 | 3.7008293 | 1 | 0.873483 | 1.0330994 | 2 | 0.881794 | 1.043667 | 29 | |
| 4 | Class 2 | KroA200 | 29368 | 9.112061 | 9.7429856 | 5 | 5.112435 | 5.259398 | 3 | 1.190207 | 1.318646 | 66 |
| 5 | lin318 | 42029 | 11.64106 | 12.197197 | 6 | 5.216184 | 5.6842656 | 5 | 0.916153 | 0.958077 | 115 | |
| 6 | pr144 | 58537 | 10.81328 | 11.651656 | 3 | 1.265268 | 1.5631652 | 2 | 0.848421 | 0.90172 | 56 | |
| 7 | Class 3 | att532 | 27686 | 28.14841 | 54.836199 | 17 | 27.91581 | 54.879 | 12 | 5.753486 | 6.145778 | 292 |
| 8 | u724 | 41910 | 18.48289 | 19.108304 | 20 | 1.159127 | 19.011644 | 19 | 1.159127 | 1.2157 | 217 | |
| 9 | rat783 | 8806 | 18.01306 | 18.654781 | 21 | 9.135703 | 9.4115376 | 23 | 0.872473 | 0.90427 | 230 | |
| 10 | Class 4 | fl1577 | 22249 | 57.4638 | 58.642726 | 56 | 14.26936 | 58.611398 | 66 | 1.532114 | 1.587802 | 483 |
| 11 | d2103 | 80450 | 38.15525 | 38.674779 | 5 | 10.16072 | 38.595165 | 100 | 1.162884 | 1.202722 | 642 | |
| 12 | fnl4461 | 182566 | 22.101 | 43.99948 | 6 | 22.06794 | 43.880471 | 408 | 1.018339 | 1.03906 | 1516 | |
| N | Mean | Standard Deviation | Std. Error | 95% Confidence Interval for Mean | Minimum | Maximum | ||
|---|---|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | |||||||
| Random | 12 | 18.7650 | 16.13439 | 4.65760 | 8.5137 | 29.0163 | 2.13 | 57.46 |
| NN | 12 | 8.4366 | 8.89413 | 2.56751 | 2.7856 | 14.0877 | 0.87 | 27.92 |
| Regression | 12 | 1.3864 | 1.39959 | 0.40403 | 0.4971 | 2.2756 | 0.47 | 5.75 |
| Total | 36 | 9.5293 | 12.63646 | 2.10608 | 5.2538 | 13.8049 | 0.47 | 57.46 |
| Sum of Squares | df | Mean Square | F | Sig. | |
|---|---|---|---|---|---|
| Between Groups | 1833.595 | 2 | 916.798 | 8.057 | 0.001 |
| Within Groups | 3755.212 | 33 | 113.794 | ||
| Total | 5588.807 | 35 |
| Technique | N | Subset for | |
|---|---|---|---|
| 1 | 2 | ||
| Random | 12 | 18.7650 | |
| NN | 12 | 8.4366 | |
| Regression | 12 | 1.3864 | |
| Sig. | 0.115 | 1.000 | |
| Technique | Technique | Mean Difference | Std. Error | Sig. | 95% Confidence Interval | |
|---|---|---|---|---|---|---|
| (I) | (J) | (I–J) | Lower Bound | Upper Bound | ||
| Random | NN | 10.32840 * | 4.35496 | 0.024 | 1.4682 | 19.1886 |
| Regression | 17.37864 * | 4.35496 | 0.000 | 8.5184 | 26.2389 | |
| NN | Random | −10.32840 * | 4.35496 | 0.024 | −19.1886 | −1.4682 |
| Regression | 7.05024 | 4.35496 | 0.115 | −1.8100 | 15.9105 | |
| Regression | Random | −17.37864 * | 4.35496 | 0.000 | −26.2389 | −8.5184 |
| NN | −7.05024 | 4.35496 | 0.115 | −15.9105 | 1.8100 | |
| Si/no | Class | Problem | Optimal Solution | Population Seeding Techniques | ||
|---|---|---|---|---|---|---|
| Random | NN | Regression | ||||
| 1 | Class 1 | KroA100 | 21282 | 94.0699652 | 95.425078 | 99.117494 |
| 2 | eil51 | 426 | 97.7159624 | 98.96831 | 99.45892 | |
| 3 | pr76 | 108159 | 96.4432548 | 99.046709 | 99.037269 | |
| 4 | Class 2 | KroA200 | 29368 | 90.5724768 | 94.814083 | 98.745573 |
| 5 | lin318 | 42029 | 88.0808727 | 94.549775 | 99.062885 | |
| 6 | pr144 | 58537 | 88.7675316 | 98.585783 | 99.12493 | |
| 7 | Class 3 | att532 | 27686 | 58.5076934 | 58.602597 | 94.050368 |
| 8 | u724 | 41910 | 81.2044023 | 89.914615 | 98.812586 | |
| 9 | rat783 | 8806 | 81.6660799 | 90.72638 | 99.111628 | |
| 10 | Class 4 | fl1577 | 22249 | 41.9467392 | 63.559621 | 98.440042 |
| 11 | d2103 | 80450 | 61.5849845 | 75.622057 | 98.817197 | |
| 12 | fnl4461 | 182566 | 66.9497579 | 67.025796 | 98.971301 | |
| Technique | N | Mean | Standard Deviation | Standard Error | 95% Confidence Interval for Mean | Min. | Max. | |
|---|---|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | |||||||
| Random | 12 | 78.9591 | 17.70148 | 5.10998 | 67.7122 | 90.2061 | 41.95 | 97.72 |
| NN | 12 | 85.5701 | 15.05677 | 4.34652 | 76.0035 | 95.1367 | 58.60 | 99.05 |
| Regression | 12 | 98.5625 | 1.44309 | 0.41658 | 97.6456 | 99.4794 | 94.05 | 99.46 |
| Total | 36 | 87.6972 | 15.44635 | 2.57439 | 82.4709 | 92.9235 | 41.95 | 99.46 |
| Sum of Squares | df | Mean Square | F | Sig. | |
|---|---|---|---|---|---|
| Between Groups | 2387.201 | 2 | 1193.601 | 6.605 | 0.004 |
| Within Groups | 5963.442 | 33 | 180.710 | ||
| Total | 8350.643 | 35 |
| Technique | N | Subset for | |
|---|---|---|---|
| 1 | 2 | ||
| Random | 12 | 78.9591 | |
| NN | 12 | 85.5701 | |
| Regression | 12 | 98.5625 | |
| Sig. | 0.237 | 1.000 | |
| Technique | Technique | Mean Difference | Standard | Sig. | 95% Confidence Interval | |
|---|---|---|---|---|---|---|
| (I) | (J) | (I–J) | Error | Lower Bound | Upper Bound | |
| Random | NN | −6.61092 | 5.48802 | 0.237 | −17.7764 | 4.5545 |
| Regression | −19.60337 * | 5.48802 | 0.001 | −30.7688 | −8.4379 | |
| NN | Random | 6.61092 | 5.48802 | 0.237 | −4.5545 | 17.7764 |
| Regression | −12.99245 * | 5.48802 | 0.024 | −24.1579 | −1.8270 | |
| Regression | Random | 19.60337 * | 5.48802 | 0.001 | 8.4379 | 30.7688 |
| NN | 12.99245 * | 5.48802 | 0.024 | 1.8270 | 24.1579 | |
| Si/no | Class | Problem | Optimal Solution | Population Seeding Techniques | ||
|---|---|---|---|---|---|---|
| Random | NN | Regression | ||||
| 1 | Class 1 | KroA100 | 21282 | 0.514533409 | 0.447488488 | 0.28387839 |
| 2 | eil51 | 426 | 0.153051643 | 0.151760563 | 0.06220657 | |
| 3 | pr76 | 108159 | 0.334713246 | 0.232944092 | 0.15975739 | |
| 4 | Class 2 | KroA200 | 29368 | 1.183575661 | 1.349473917 | 0.48822868 |
| 5 | lin318 | 42029 | 2.184444074 | 1.712403341 | 0.61007043 | |
| 6 | pr144 | 58537 | 1.376344876 | 0.585363958 | 0.57191264 | |
| 7 | Class 3 | att532 | 27686 | 13.47315972 | 12.60865419 | 4.67371415 |
| 8 | u724 | 41910 | 4.942157003 | 2.795419948 | 1.12181937 | |
| 9 | rat783 | 8806 | 4.982392687 | 3.87176357 | 0.74465705 | |
| 10 | Class 4 | fl1577 | 22249 | 22.10749022 | 11.21874017 | 1.46520743 |
| 11 | d2103 | 80450 | 16.16575637 | 9.38666128 | 1.14121193 | |
| 12 | fnl4461 | 182566 | 20.54833978 | 18.85593922 | 1.01935355 | |
| Technique | N | Mean | Standard Deviation | Standard Error | 95% Confidence Interval for Mean | Min. | Max. | |
|---|---|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | |||||||
| Random | 12 | 7.3305 | 8.34874 | 2.41007 | 2.0260 | 12.6350 | 0.15 | 22.11 |
| NN | 12 | 0.9808 | 1.23616 | 0.35685 | 0.1954 | 1.7663 | 0.06 | 4.67 |
| Regression | 12 | 0.1791 | 0.28387 | 0.08194 | −0.0012 | 0.3595 | 0.02 | 1.02 |
| Total | 36 | 2.8302 | 5.73914 | 0.95652 | 0.8883 | 4.7720 | 0.02 | 22.11 |
| Sum of Squares | df | Mean Square | F | Sig. | |
|---|---|---|---|---|---|
| Between Groups | 368.411 | 2 | 184.205 | 7.749 | 0.002 |
| Within Groups | 784.411 | 33 | 23.770 | ||
| Total | 1152.821 | 35 |
| Technique | N | Subset for | |
|---|---|---|---|
| 1 | 2 | ||
| Random | 12 | 7.3305 | |
| NN | 12 | 0.9808 | |
| Regression | 12 | 0.1791 | |
| Sig. | 0.690 | 1.000 | |
| Technique | Technique | Mean Difference | Standard | Sig. | 95% Confidence Interval | |
|---|---|---|---|---|---|---|
| (I) | (J) | (I–J) | Error | Lower Bound | Upper Bound | |
| Random | NN | 6.34965 * | 1.99039 | 0.003 | 2.3002 | 10.3991 |
| Regression | 7.15136 * | 1.99039 | 0.001 | 3.1019 | 11.2008 | |
| NN | Random | −6.34965 * | 1.99039 | 0.003 | −10.3991 | −2.3002 |
| Regression | 0.80171 | 1.99039 | 0.690 | −3.2478 | 4.8512 | |
| Regression | Random | −7.15136 * | 1.99039 | 0.001 | −11.2008 | −3.1019 |
| NN | −0.80171 | 1.99039 | 0.690 | −4.8512 | 3.2478 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassanat, A.B.; Prasath, V.B.S.; Abbadi, M.A.; Abu-Qdari, S.A.; Faris, H. An Improved Genetic Algorithm with a New Initialization Mechanism Based on Regression Techniques. Information 2018, 9, 167. https://doi.org/10.3390/info9070167
Hassanat AB, Prasath VBS, Abbadi MA, Abu-Qdari SA, Faris H. An Improved Genetic Algorithm with a New Initialization Mechanism Based on Regression Techniques. Information. 2018; 9(7):167. https://doi.org/10.3390/info9070167
Chicago/Turabian StyleHassanat, Ahmad B., V. B. Surya Prasath, Mohammed Ali Abbadi, Salam Amer Abu-Qdari, and Hossam Faris. 2018. "An Improved Genetic Algorithm with a New Initialization Mechanism Based on Regression Techniques" Information 9, no. 7: 167. https://doi.org/10.3390/info9070167
APA StyleHassanat, A. B., Prasath, V. B. S., Abbadi, M. A., Abu-Qdari, S. A., & Faris, H. (2018). An Improved Genetic Algorithm with a New Initialization Mechanism Based on Regression Techniques. Information, 9(7), 167. https://doi.org/10.3390/info9070167