Visual Saliency Based Just Noticeable Difference Estimation in DWT Domain


Abstract
:1. Introduction
2. Related Work
2.1. Wavelet Transform
2.2. JND Estimations
2.3. Visual Saliency Model
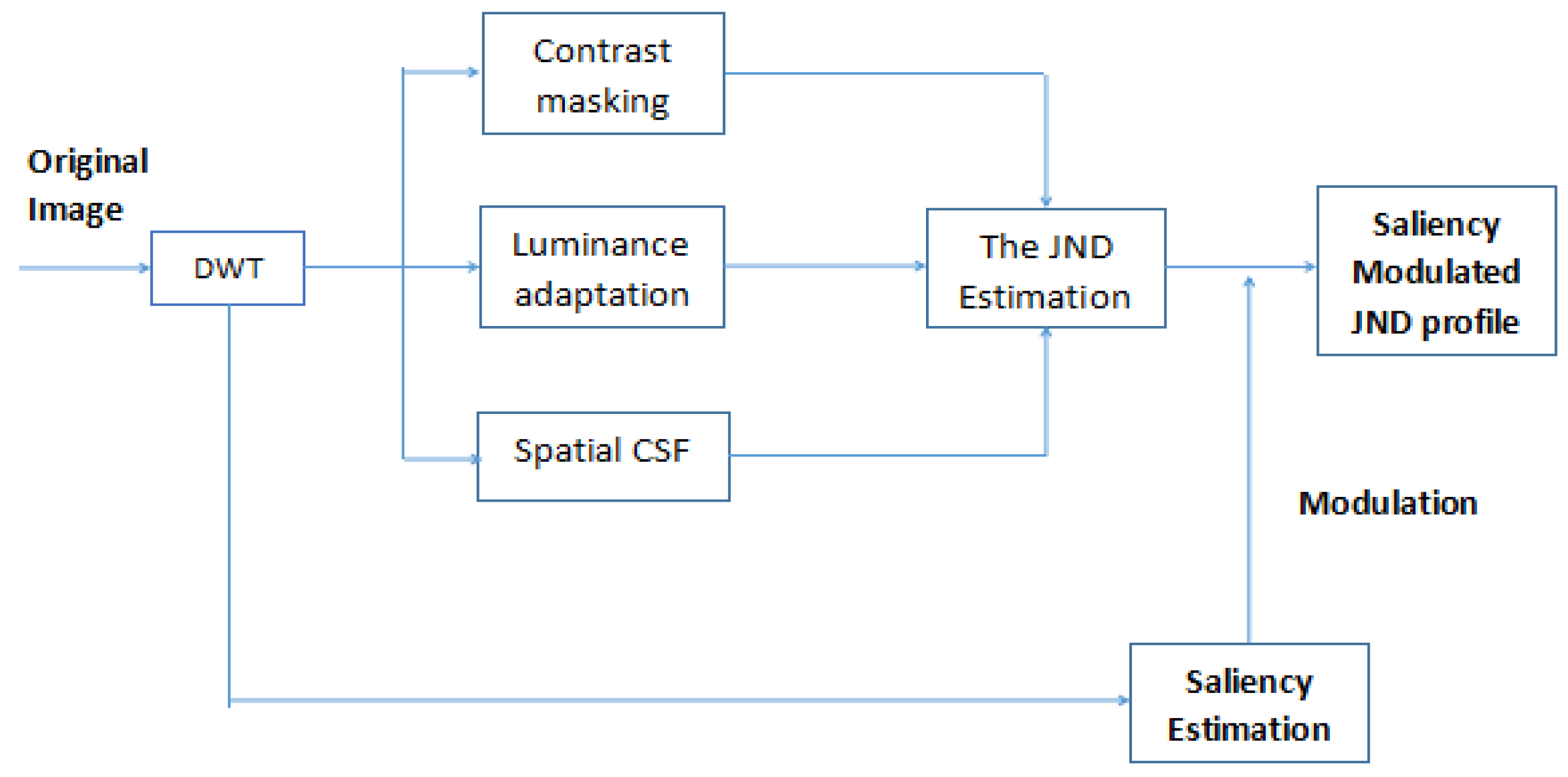
3. Proposed Model
3.1. Overall JND Modeling
3.1.1. Complete JND Estimation
3.1.2. Spatial CSF
3.1.3. Luminance Masking
3.1.4. Contrast Masking
3.2. Saliency Estimation
3.3. Saliency Modulated JND Profile
3.4. Setting the Parameters of the SJND Model
4. Experimental Results and Performance Analysis
4.1. Evaluating Saliency Estimation
4.2. Evaluating Saliency Modulated JND Profile
4.2.1. The Objective Experiment
4.2.2. The PSNR
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xiao, L.; Wei, Z.H.; Wu, H.-Z. A digital watermarking in wavelet domain utilizing huma visual masking. J. China Inst. Commun. 2002, 23, 100–106. [Google Scholar]
- Watson, A.B.; Yang, G.Y.; Solomon, J.A.; Villasenor, J. Visibility of wavelet quantization noise. IEEE Trans. Image Process. 1997, 6, 1164–1175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Wang, H.; Wang, L.; Hu, X.; Tu, Q.; Men, A. Perceptual video coding based on saliency and Just Noticeable Distortion for H.265/HEVC. In Proceedings of the 2014 International Symposium on Wireless Personal Multimedia Communications (WPMC), Sydney, Australia, 7–10 September 2014; pp. 106–111. [Google Scholar]
- Wang, C.; Zhang, T.; Wan, W.; Han, X.; Xu, M. A Novel STDM Watermarking Using Visual Saliency-Based JND Model. Information 2017, 8, 103. [Google Scholar] [CrossRef]
- Lu, Z.; Lin, W.; Yang, X.; Ong, E.; Yao, S. Modeling visual attention’s modulatory aftereffects on visual sensitivity and quality evaluation. IEEE Trans. Image Process. 2005, 14, 1928–1942. [Google Scholar] [PubMed]
- Niu, Y.; Kyan, M.; Ma, L.; Beghdadi, A.; Krishnan, S. Visual saliency’s modulatory effect on just noticeable distortion profile and its application in image watermarking. Signal Process. Image Commun. 2013, 28, 917–928. [Google Scholar] [CrossRef]
- Hadizadeh, H. A saliency-modulated just-noticeable-distortion model with nonlinear saliency modulation functions. Pattern Recogn. Lett. 2016, 84, 49–55. [Google Scholar] [CrossRef]
- Daubechies, I. Orthonormal Bases of Compactly Supported Wavelets II. Variations on a Theme. SIAM J. Math. Anal. 1993, 24, 499–519. [Google Scholar] [CrossRef]
- Chou, C.H.; Li, Y.C. A perceptual tuned subband image coder based on the Measure of just-noticeable-distortion profile. IEEE Trans. Circuits Syst. Video Technol. 1996, 5, 467–476. [Google Scholar] [CrossRef]
- Chin, Y.J.; Berger, T. A Software-Only Videocodec Using Pixelwise Conditional Differential Replenishment and Perceptual Enhancements; IEEE Press: Piscataway, NJ, USA, 1999. [Google Scholar]
- Yang, X.; Lin, W.; Lu, Z.; Ong, E.; Yao, S. Motion-compensated residue preprocessing in video coding based on just-noticeable-distortion profile. IEEE Trans. Circuits Syst. Video Technol. 2005, 15, 742–752. [Google Scholar] [CrossRef]
- Safranek, R.J.; Johnston, J.D. A perceptually tuned sub-band image coder with image dependent quantization and post-quantization data compression. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Glasgow, UK, 23–26 May 1989; Volume 3, pp. 1945–1948. [Google Scholar]
- Ahumada, A.J. Luminance-model-based DCT quantization for color image compression. In SPIE 1666, Human Vision, Visual Processing, and Digital Display III; International Society for Optics and Photonics: San Diego, CA, USA, 1992; pp. 365–374. [Google Scholar]
- Watson, A.B. DCTune: A Technique for Visual Optimization of DCT Quantization Matrices for Individual Images. In Proceedings of the 9th Computing in Aerospace Conference, San Diego, CA, USA, 19 October 1993; pp. 946–949. [Google Scholar]
- Tong, H.H.Y.; Venetsanopoulos, A.N. A perceptual model for JPEG applications based on block classification, texture masking, and luminance masking. In Proceedings of the 1998 International Conference on Image Processing, ICIP98 (Cat. No. 98CB36269), Chicago, IL, USA, 4–7 October 1998; Volume 3, pp. 428–432. [Google Scholar]
- Bae, S.H.; Kim, M. A Novel DCT-Based JND Model for Luminance Adaptation Effect in DCT Frequency. IEEE Signal Process. Lett. 2013, 20, 893–896. [Google Scholar]
- Xu, L.; Li, H.; Zeng, L.; Ngan, K.N. Saliency detection using joint spatial-color constraint and multi-scale segmentation. J. Vis. Commun. Image Represent. 2013, 24, 465–476. [Google Scholar] [CrossRef]
- Fang, Y.; Chen, Z.; Lin, W.; Lin, C.-W. Saliency detection in the compressed domain for adaptive image retargeting. IEEE Trans. Image Process. 2012, 21, 3888–3901. [Google Scholar] [CrossRef] [PubMed]
- Tian, Q.; Sebe, N.; Lew, M.S.; Loupias, E.; Huang, T.S. Image retrieval using wavelet-based salient points. J. Electron. Imaging 2003, 10, 835–849. [Google Scholar]
- Zeng, W.; Yang, M.; Cui, Z.; Al-Kabbany, A. An improved saliency detection using wavelet transform. In Proceedings of the 2015 IEEE International Conference on Communication Software and Networks (ICCSN), Chengdu, China, 6–7 June 2015. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Detection Based on Multiscale Deep CNN Features; IEEE Press: Piscataway, NJ, USA, 2016. [Google Scholar]
- Wang, Q.; Zheng, W.; Piramuthu, R. GraB: Visual Saliency via Novel Graph Model and Background Priors. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 535–543. [Google Scholar]
- Cui, L.; Li, W. Adaptive multiwavelet-based watermarking through JPW masking. IEEE Trans. Image Process. 2011, 20, 1047–1060. [Google Scholar] [PubMed]
- Mannos, J.; Sakrison, D.J. The Effects of a Visual Fidelity Criterion on the Encoding of Images; IEEE Press: Piscataway, NJ, USA, 1974. [Google Scholar]
- Xie, G.; Shen, H. Toward improved wavelet-based watermarking using the pixel-wise masking model. In Proceedings of the IEEE International Conference on Image Processing, Genova, Italy, 11–14 September 2005; p. I-689-92. [Google Scholar]
- Liu, Z.; Karam, L.J.; Watson, A.B. JPEG2000 encoding with perceptual distortion control. In Proceedings of the 2003 International Conference on Image Processing (Cat. No. 03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 1, p. I-637-40. [Google Scholar]
- Teo, P.C.; Heeger, D.J. Perceptual image distortion. In Proceedings of the 1st International Conference onImage Processing, Austin, TX, USA, 13–16 November 1994; Volume 2179, pp. 127–141. [Google Scholar]
- Hontsch, I.; Karam, L.J. Adaptive image coding with perceptual distortion control. IEEE Trans. Image Process. 2002, 11, 213–222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Shen, Y.; Li, H. VSI: A visual saliency-induced index for perceptual image quality assessment. IEEE Trans. Image Process. 2014, 23, 4270–4281. [Google Scholar] [CrossRef] [PubMed]
- Scharfenberger, C.; Jain, A.; Wong, A.; Fieguth, P. Image saliency detection via multi-scale statistical non-redundancy modeling. In Proceedings of the 2014 IEEE International Conference onImage Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4294–4298. [Google Scholar]
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 353–367. [Google Scholar] [PubMed]
- Zebbiche, K.; Khelifi, F. Efficient wavelet-based perceptual watermark masking for robust fingerprint image watermarking. IET Image Process. 2014, 8, 23–32. [Google Scholar] [CrossRef]
- Liu, K.C. Wavelet-based watermarking for color images through visual masking. AEUE Int. J. Electron. Commun. 2010, 64, 112–124. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Number | Unmodulated | Modulated | p-Value |
|---|---|---|---|
| A1 | 14 | 36 | 0.0019 |
| A2 | 15 | 35 | 0.0047 |
| A3 | 20 | 30 | 0.1573 |
| A4 | 13 | 37 | 0.0007 |
| A5 | 10 | 40 | 0.0001 |
| A6 | 8 | 42 | 0.0001 |
| A7 | 17 | 33 | 0.0237 |
| A8 | 12 | 38 | 0.0002 |
| A9 | 10 | 40 | 0.0001 |
| A10 | 15 | 35 | 0.0047 |
| B1 | 11 | 39 | 0.0001 |
| B2 | 14 | 36 | 0.0019 |
| B3 | 28 | 22 | 0.3961 |
| B4 | 9 | 41 | 0.0001 |
| B5 | 16 | 34 | 0.0109 |
| B6 | 12 | 38 | 0.0002 |
| B7 | 14 | 36 | 0.0019 |
| B8 | 11 | 39 | 0.0001 |
| B9 | 15 | 35 | 0.0047 |
| B10 | 13 | 37 | 0.0007 |
| Total | 277 | 723 | 0.0001 |
| Image Number | Unmodulated | Modulated | p-Value |
|---|---|---|---|
| A1 | 10 | 40 | 0.0001 |
| A2 | 13 | 37 | 0.0006 |
| A3 | 20 | 30 | 0.1573 |
| A4 | 15 | 35 | 0.0047 |
| A5 | 11 | 39 | 0.0001 |
| A6 | 14 | 36 | 0.0002 |
| A7 | 26 | 24 | 0.7773 |
| A8 | 16 | 34 | 0.0002 |
| A9 | 9 | 41 | 0.0001 |
| A10 | 11 | 39 | 0.0001 |
| B1 | 14 | 36 | 0.0019 |
| B2 | 17 | 33 | 0.0237 |
| B3 | 15 | 35 | 0.0047 |
| B4 | 30 | 20 | 0.1573 |
| B5 | 16 | 34 | 0.0109 |
| B6 | 14 | 36 | 0.0002 |
| B7 | 16 | 34 | 0.0109 |
| B8 | 12 | 38 | 0.0002 |
| B9 | 10 | 40 | 0.0001 |
| B10 | 8 | 42 | 0.0001 |
| Total | 297 | 703 | 0.0001 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Han, X.; Wan, W.; Li, J.; Sun, J.; Xu, M. Visual Saliency Based Just Noticeable Difference Estimation in DWT Domain. Information 2018, 9, 178. https://doi.org/10.3390/info9070178
Wang C, Han X, Wan W, Li J, Sun J, Xu M. Visual Saliency Based Just Noticeable Difference Estimation in DWT Domain. Information. 2018; 9(7):178. https://doi.org/10.3390/info9070178
Chicago/Turabian StyleWang, Chunxing, Xiaoyue Han, Wenbo Wan, Jing Li, Jiande Sun, and Meiling Xu. 2018. "Visual Saliency Based Just Noticeable Difference Estimation in DWT Domain" Information 9, no. 7: 178. https://doi.org/10.3390/info9070178
APA StyleWang, C., Han, X., Wan, W., Li, J., Sun, J., & Xu, M. (2018). Visual Saliency Based Just Noticeable Difference Estimation in DWT Domain. Information, 9(7), 178. https://doi.org/10.3390/info9070178