First Steps towards Data-Driven Adversarial Deduplication

 ,
,
Abstract
:1. Introduction and Motivation
2. Deduplication Leveraging Text-Based Features
- Procure information from online discussions in forums and marketplaces; this is an ongoing effort that is generally carried out in a semi-automatic manner by specialists [6].
- Prepare the data by performing several cleaning processes (see below).
- Train one or more machine learning classifiers to recognize posts written by each user. For this step, we assume that posts made under different user names correspond to different users—we come back to this assumption when analyzing the results yielded in the testing phase. Note that another option is to train a single multi-class classifier that discriminates among all users. We decided to train one classifier per user for two main reasons: (a) large numbers of users (classes, in that case) are more difficult to manage, and the resulting classifier would be less flexible—by training one classifier per user it is possible to incorporate features that only apply to certain users; (b) perhaps most importantly, we would like to be flexible with respect to the incorporation of new users, which would cause the single classifier to be retrained with each addition.
- Apply the classifiers to pairs of new posts by users X and Y; if either X’s classifier states that a post written by Y was written by X, or vice versa, then we generate a deduplication hypothesis.
- The set of deduplication hypotheses are sent to human analysts for further treatment.
| 2-grams | 3-grams | |
| software | so, of, ft, tw, wa, ar, re | sof, oft, ftw, twa, war, are |
| sofware | so, of, fw, wa, ar, re | sof, ofw, fwa, war, are |
| softwarez | so, of, ft, tw, wa, ar, re, ez | sof, oft, ftw, twa, war, are, rez |
| sophwarez | so, op, ph, hw, wa, ar, re, ez | sop, oph, phw, hwa, war, are, rez |
3. Empirical Evaluation
- Dataset: posts table, which contains posts users table, which contains 128 users.
- Data cleaning and preparation: We removed HTML tags from posts using the BeautifulSoup tool (https://www.crummy.com/software/BeautifulSoup), removed URLs, extra spaces, and strings that contained a combination of letters and numbers. Finally, we discarded posts that either contained less than 140 characters (i.e., anything shorter than the maximum length of an SMS message or tweet before the expansion) or any of the following strings “quote from:”, “quote:”, “wrote:”, “originally posted by”, “re:”, or “begin pgp message”. This yielded “clean” posts corresponding to 54 users.
- Feature generation: We used the well-known TF-IDF (term frequency-inverse document frequency) technique to produce vectors of features based on n-grams, which essentially consists of assigning weights to features in such a way that they increase proportionally to the number of times they occur in a document, and also takes into account the number of times the feature occurs in the whole corpus.
- Classifiers: Different standard machine learning approaches were implemented with a standard Python library (http://scikit-learn.org/stable):
- -
- Decision Trees
- -
- Logistic Regression
- -
- Multinomial Bayesian Networks
- -
- Random Forests
- -
- Support Vector Machines, with both linear and radial basis function (rbf) kernels
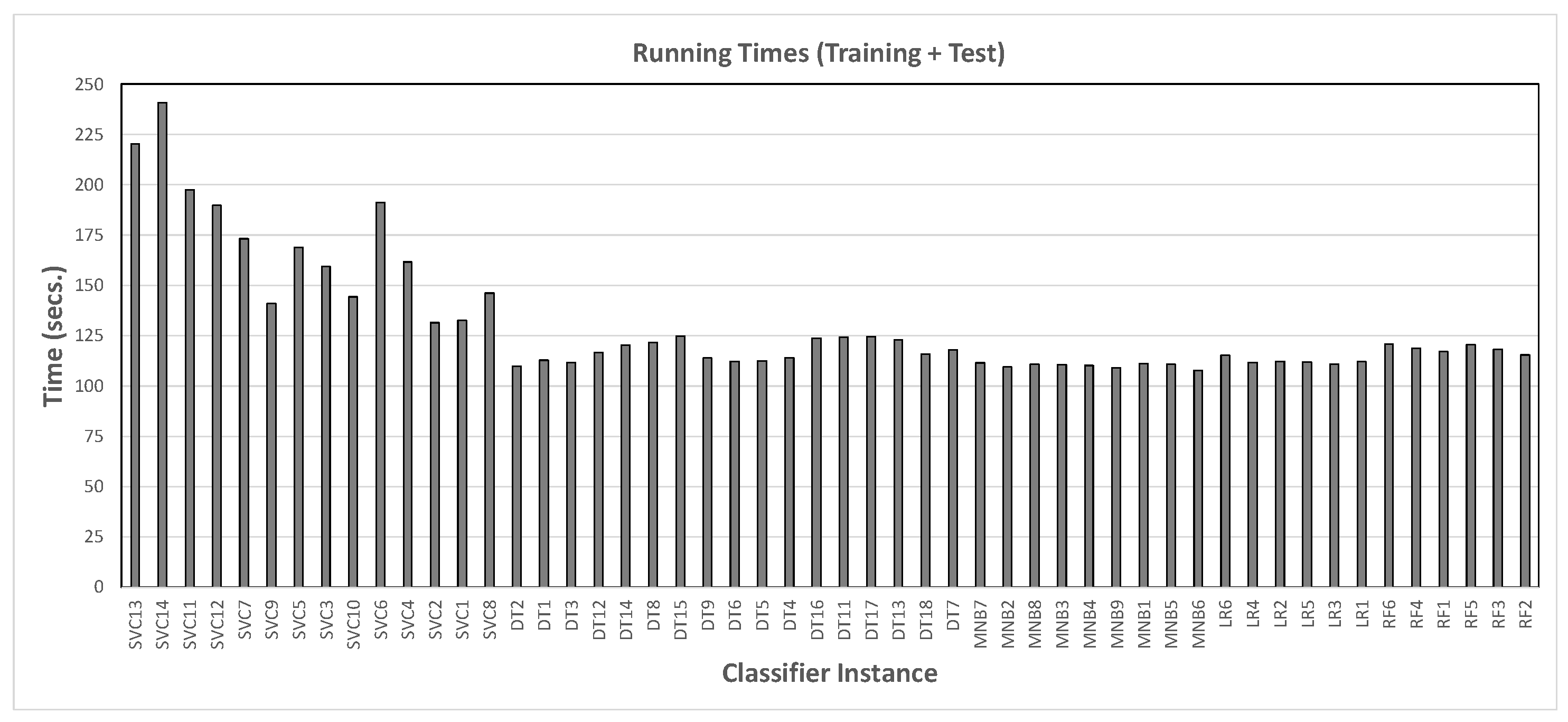
- Hyperparameters: We explored different values of two main hyperparameters: max_df and n_gram range. The former is a bound on the frequency with which a feature occurs in a post (essentially, as frequency increases the information content of a feature becomes lower), while the latter determines the length of the substrings into which the text is split. This yielded a set of 52 classifier instances (cf. Table 2).For some classifier instances, we also applied a bound on the number of features taken into account by the classifier (max_features). This space was explored manually by testing the effect of different settings on performance and running time (more features yield better performance, up to a certain point). The final selection yielded the following:
- -
- DT2 is DT1 with max_features = 2500
- -
- DT3 is DT1 with max_features = 2000
- -
- DT9 is DT8 with max_features = 3000
- -
- DT5 has max_features = 3000
- -
- DT6 has max_features = 2000
- -
- DT18 is DT17 with max_features = 5000
- -
- MNB6 is MNB5 with max_features = 3000
This set of classifier instances was generated by means of manual exploration of the hyperparameters, looking for the combinations that had the most potential to yield high values for precision and recall.
3.1. Empirical Evaluation Phase 1: Broad Evaluation of Different Classifiers and Hyperparameter Settings
- Choose 10 users at random.
- Training phase: For each user , train a classifier using between 200 and 500 sample posts written by them (positive examples, actual number of posts depended on availability) and the same number of posts written under other screen names (presumed negative examples).
- Testing phase: For each user, take 20 test posts that were not used to train any of the classifiers and query each resulting classifier. This yields a confusion matrix M where each row corresponds to a user and each column to a classifier. contains the number of posts classified by classifier as corresponding to user . Note that a perfect confusion matrix in this case should have a value of 20 along the diagonal, and values of zero in all other cells. Table 3 shows an actual instance of such a matrix.
- In order to evaluate the performance of each classifier, we make use of the following notions:
- -
- True positives(tp): A test post written by user is classified correctly by classifier ; the number of true positives for is found at position .
- -
- False positives(fp): A test post written by user is classified incorrectly by a classifier ; the number of false positives for can be found by calculating .
- -
- True negatives(tn): A test post written by user is classified correctly by a classifier ; the number of true negatives for each classifier is simply .
- -
- False negatives(fn): A test post written by user is classified incorrectly by classifier ; the number of false negatives for is calculated as .
Based on the confusion matrix M and the above calculations, we can then derive:andwhich are standard metrics used to evaluate classifier performance. Finally, the harmonic mean of these two values, known as the F1 measure, is typically used as a good way to compare the performance of a set of classifiers.
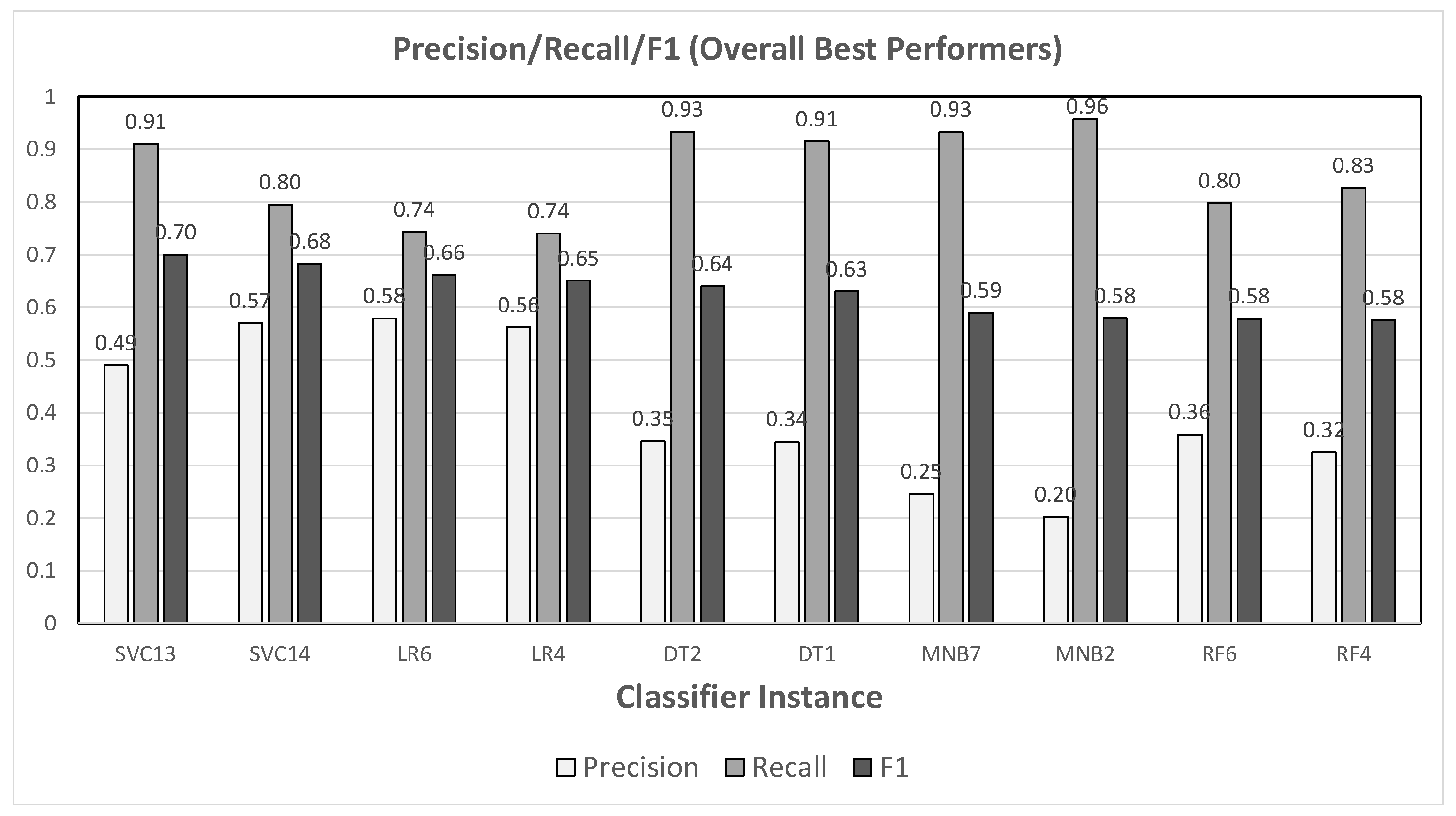
3.2. Results for Phase 1
3.3. Empirical Evaluation Phase 2: Seeding Known Duplicates
- SVC13
- LR6
- E1 = {SVC13, SVC14, LR6, LR4}
- E2 = {SVC13, SVC14, LR6}
- E3 = {SVC13, SVC14, LR4}
- E4 = {SVC13, LR4, LR6}
- E5 = {SVC14, LR4, LR6}
- For a pair of users that is known (or, rather, assumed) to be different:
- -
- True negative: classifier says no
- -
- False positive: classifier says yes
True positives and false negatives are impossible in this case. - For a pair of users that is known to correspond to a duplicate:
- -
- True positive: classifier says yes
- -
- False negative: classifier says no
True negatives and false positives are impossible in this case.
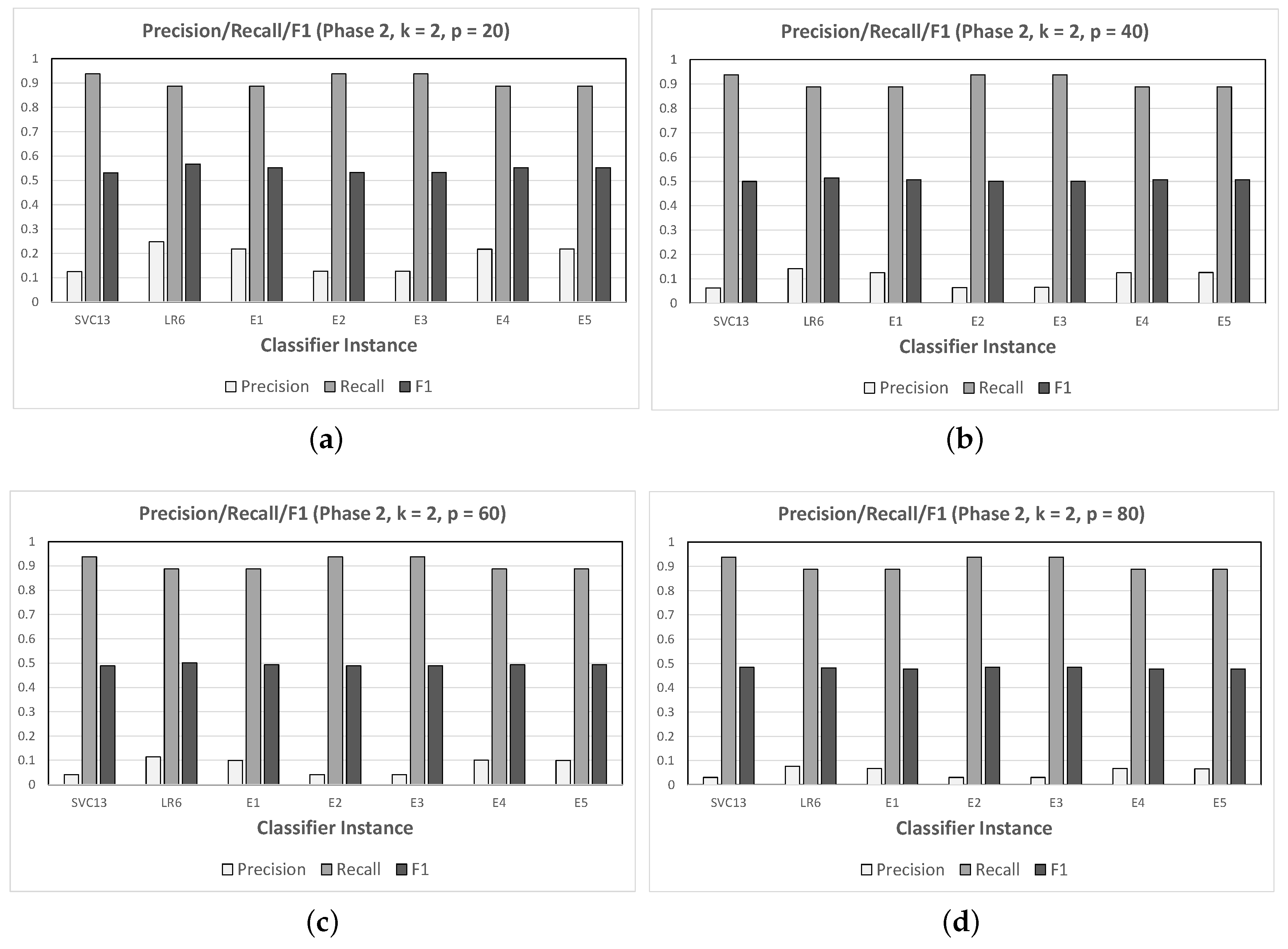
3.4. Results for Phase 2
- For :
- -
- SVC13: 1452 (%)
- -
- LR6: 451 (%)
- -
- E1: 605 (%)
- -
- E2: 1444 (%)
- -
- E3: 1445 (%)
- -
- E4: 609 (%)
- -
- E5: 599 (%)
- For :
- -
- SVC13: 1425 (%)
- -
- LR6: 140 (%)
- -
- E1: 204 (%)
- -
- E2: 1396 (%)
- -
- E3: 1396 (%)
- -
- E4: 203 (%)
- -
- E5: 207 (%)
- Posts by user 353596:“lol i have that pasted to the front door of my officebut if we really want to get technical here…these are all "cheap" translations of binary. i will type up a full explanation from home tonight. i also dug up and old piece of software that i have that is wonderful for quick lookups. i will post that as well.”“well "%path%" is the variable name. "path" is a term. it is always more important to learns terms and concepts rather than syntax that is specific to an environment.but yeah”“didn^t mean to burst your bubble about the script. i also saw some of the samples but none of them conviced me that the user thought they were really talking to a human being. most were prolly playing along like i do there are some msn ones also… anyone has visited they didn^t sign up for the forums. but that^s ok they can lurk for a while: whatsup:”
- Posts by user 352820:“there are a few newish tools for but the issues with bt in the first place was poor implementation on behalf of the manufacturers, most of which were fixed.”“well if talking about power friendly then a hd in lan enclosure would be best. you could build something that would consume less power but it would be more expensive, unless you are looking for and upwards.”“the only good way to work in computer security straight is to be a "black hat" then at some point (arrested a few to many times, you get a wife/family) you decide you can’t do it any more. the other way is to go into sysadmin and at some point, once you have experience going into nothing but security, u”, i see way to many people about trying to sell themselves as pen-testers and security consultants and know fuck all, don’t be one of those people.”
4. Related Work
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Elmagarmid, A.K.; Ipeirotis, P.G.; Verykios, V.S. Duplicate Record Detection: A Survey. IEEE Trans. Knowl. Data Eng. 2007, 19, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Bleiholder, J.; Naumann, F. Data Fusion. ACM Comput. Surv. 2009, 41, 1–41. [Google Scholar] [CrossRef]
- Nunes, E.; Diab, A.; Gunn, A.T.; Marin, E.; Mishra, V.; Paliath, V.; Robertson, J.; Shakarian, J.; Thart, A.; Shakarian, P. Darknet and deepnet mining for proactive cybersecurity threat intelligence. arXiv, 2016; arXiv:1607.08583. [Google Scholar] [Green Version]
- NIST. National Vulnerability Database. Available online: https://nvd.nist.gov/ (accessed on 24 July 2018).
- CVE. Common Vulnerabilities and Exposures: The Standard for Information Security Vulnerability Names. Available online: http://cve.mitre.org/ (accessed on 24 July 2018).
- Shakarian, J.; Gunn, A.T.; Shakarian, P. Exploring Malicious Hacker Forums. In Cyber Deception, Building the Scientific Foundation; Springer: Cham, Switzerland, 2016; pp. 261–284. [Google Scholar]
- Getoor, L.; Machanavajjhala, A. Entity Resolution: Theory, Practice and Open Challenges. Proc. VLDB Endow. 2012, 5, 2018–2019. [Google Scholar] [CrossRef]
- Bhattacharya, I.; Getoor, L. Collective Entity Resolution in Relational Data. ACM Trans. Knowl. Discov. Data 2007, 1, 5. [Google Scholar] [CrossRef]
- Whang, S.E.; Menestrina, D.; Koutrika, G.; Theobald, M.; Garcia-Molina, H. Entity Resolution with Iterative Blocking. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of data, Providence, RI, USA, 29 June–2 July 2009. [Google Scholar]
- Bhattacharya, I.; Getoor, L. Query-time entity resolution. J. Artif. Intell. Res. 2007, 30, 621–657. [Google Scholar] [CrossRef]
- Bahmani, Z.; Bertossi, L.E.; Vasiloglou, N. ERBlox: Combining matching dependencies with machine learning for entity resolution. Int. J. Approx. Reason. 2017, 83, 118–141. [Google Scholar] [CrossRef]
- Fan, W. Dependencies Revisited for Improving Data Quality. In Proceedings of the Twenty-Seventh ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Vancouver, BC, Canada, 9–12 June 2008; pp. 159–170. [Google Scholar]
- Fan, W.; Jia, X.; Li, J.; Ma, S. Reasoning About Record Matching Rules. Proc. VLDB Endow. 2009, 2, 407–418. [Google Scholar] [CrossRef]
- Bertossi, L.E.; Kolahi, S.; Lakshmanan, L.V.S. Data Cleaning and Query Answering with Matching Dependencies and Matching Functions. Theory Comput. Syst. 2013, 52, 441–482. [Google Scholar] [CrossRef]
- Rao, J.R.; Rohatgi, P. Can pseudonymity really guarantee privacy? In Proceedings of the 9th USENIX Security Symposium, Denver, CO, USA, 14–17 August 2000; pp. 85–96. [Google Scholar]
- Novak, J.; Raghavan, P.; Tomkins, A. Anti-aliasing on the web. In Proceedings of the 13th International Conference on World Wide Web, Manhattan, NY, USA, 17–22 May 2004; pp. 30–39. [Google Scholar]
- Brennan, M.; Afroz, S.; Greenstadt, R. Adversarial stylometry: Circumventing authorship recognition to preserve privacy and anonymity. ACM Trans. Inf. Syst. Secur. 2012, 15, 12. [Google Scholar] [CrossRef]
- Swain, S.; Mishra, G.; Sindhu, C. Recent approaches on authorship attribution techniques: An overview. In Proceedings of the 2017 International Conference of Electronics, Communication and Aerospace Technology, Tamil Nadu, India, 20–22 April 2017; pp. 557–566. [Google Scholar]
- Abbasi, A.; Chen, H. Writeprints: A stylometric approach to identity-level identification and similarity detection in cyberspace. ACM Trans. Inf. Syst. 2008, 26, 7. [Google Scholar] [CrossRef]
- Narayanan, A.; Paskov, H.; Gong, N.Z.; Bethencourt, J.; Stefanov, E.; Shin, E.C.R.; Song, D. On the feasibility of internet-scale author identification. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 300–314. [Google Scholar]
- Johansson, F.; Kaati, L.; Shrestha, A. Detecting multiple aliases in social media. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara Falls, ON, Canada, 25–28 August 2013; pp. 1004–1011. [Google Scholar]
- Orebaugh, A.; Allnutt, J. Classification of instant messaging communications for forensics analysis. Int. J. Forensic Comput. Sci. 2009, 1, 22–28. [Google Scholar] [CrossRef]
- Rocha, A.; Scheirer, W.J.; Forstall, C.W.; Cavalcante, T.; Theophilo, A.; Shen, B.; Carvalho, A.R.B.; Stamatatos, E. Authorship Attribution for Social Media Forensics. IEEE Trans. Inf. Forensics Secur. 2017, 12, 5–33. [Google Scholar] [CrossRef]
- Tsikerdekis, M.; Zeadally, S. Multiple account identity deception detection in social media using nonverbal behavior. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1311–1321. [Google Scholar] [CrossRef]
- Ho, T.N.; Ng, W.K. Application of Stylometry to DarkWeb Forum User Identification. In Proceedings of the International Conference on Information and Communications Security, Singapore, 29 November–2 December 2016. [Google Scholar]
- Zheng, X.; Lai, Y.M.; Chow, K.P.; Hui, L.C.; Yiu, S.M. Sockpuppet detection in online discussion forums. In Proceedings of the Seventh International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Dalian, China, 14–16 October 2011; pp. 374–377. [Google Scholar]
- Kumar, S.; Cheng, J.; Leskovec, J.; Subrahmanian, V. An army of me: Sockpuppets in online discussion communities. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 857–866. [Google Scholar]
- Yamak, Z.; Saunier, J.; Vercouter, L. SocksCatch: Automatic detection and grouping of sockpuppets in social media. Knowl.-Based Syst. 2018, 149, 124–142. [Google Scholar] [CrossRef]
- Spitters, M.; Klaver, F.; Koot, G.; van Staalduinen, M. Authorship analysis on dark marketplace forums. In Proceedings of the European Intelligence and Security Informatics Conference, Manchester, UK, 7–9 September 2015; pp. 1–8. [Google Scholar]
- Marin, E.; Diab, A.; Shakarian, P. Product offerings in malicious hacker markets. In Proceedings of the IEEE Intelligence and Security Informatics 2016 Conference, Tucson, Arizona, USA, 27–30 September 2016; pp. 187–189. [Google Scholar]
- Nunes, E.; Shakarian, P.; Simari, G.I. At-risk system identification via analysis of discussions on the darkweb. In Proceedings of the APWG Symposium on Electronic Crime Research, San Diego, CA, USA, 15–17 May 2018; pp. 1–12. [Google Scholar]
- Tavabi, N.; Goyal, P.; Almukaynizi, M.; Shakarian, P.; Lerman, K. DarkEmbed: Exploit Prediction with Neural Language Models. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Users n | Number of Possible Pairs |
|---|---|
| 50 | 1225 |
| 100 | 4950 |
| 150 | 11,175 |
| 200 | 19,900 |
| 500 | 124,750 |
| 1000 | 499,500 |
| 2000 | 1,999,000 |
| 5000 | 12,497,500 |
| 10,000 | 49,995,000 |
| ID | Classifier Type | max_df | n-grams |
|---|---|---|---|
| SVC1 | SVM–linear kernel | 0.02 | [3,3] |
| SVC2 | SVM–linear kernel | 0.03 | [3,3] |
| SVC3 | SVM–linear kernel | 0.02 | [4,4] |
| SVC4 | SVM–linear kernel | 0.01 | [4,4] |
| SVC5 | SVM–linear kernel | 0.03 | [5,5] |
| SVC6 | SVM–linear kernel | 0.03 | [3,4] |
| SVC7 | SVM–linear kernel | 0.06 | [3,4] |
| SVC8 | SVM–rbf kernel | 0.01 | [3,3] |
| SVC9 | SVM–rbf kernel | 0.05 | [3,3] |
| SVC10 | SVM–rbf kernel | 0.03 | [3,3] |
| SVC11 | SVM–rbf kernel | 0.05 | [4,4] |
| SVC12 | SVM–rbf kernel | 0.08 | [4,4] |
| SVC13 | SVM–rbf kernel | 0.05 | [5,5] |
| SVC14 | SVM–rbf kernel | 0.03 | [5,5] |
| DT1 | Decision Tree | 0.05 | [3,3] |
| DT2 | Decision Tree | 0.05 | [3,3] |
| DT3 | Decision Tree | 0.05 | [3,3] |
| DT4 | Decision Tree | 0.02 | [3,3] |
| DT5 | Decision Tree | 0.03 | [3,3] |
| DT6 | Decision Tree | 0.03 | [3,3] |
| DT7 | Decision Tree | 0.009 | [3,3] |
| DT8 | Decision Tree | 0.03 | [4,4] |
| DT9 | Decision Tree | 0.03 | [4,4] |
| DT11 | Decision Tree | 0.02 | [4,4] |
| DT12 | Decision Tree | 0.05 | [4,4] |
| DT13 | Decision Tree | 0.01 | [4,4] |
| DT14 | Decision Tree | 0.05 | [5,5] |
| DT15 | Decision Tree | 0.03 | [5,5] |
| DT16 | Decision Tree | 0.02 | [5,5] |
| DT17 | Decision Tree | 0.01 | [5,5] |
| DT18 | Decision Tree | 0.01 | [5,5] |
| MNB1 | Multinomial Bayesian Network | 0.02 | [3,3] |
| MNB2 | Multinomial Bayesian Network | 0.01 | [3,3] |
| MNB3 | Multinomial Bayesian Network | 0.008 | [3,3] |
| MNB4 | Multinomial Bayesian Network | 0.007 | [3,3] |
| MNB5 | Multinomial Bayesian Network | 0.005 | [3,3] |
| MNB6 | Multinomial Bayesian Network | 0.005 | [3,3] |
| MNB7 | Multinomial Bayesian Network | 0.005 | [4,4] |
| MNB8 | Multinomial Bayesian Network | 0.005 | [4,4] |
| MNB9 | Multinomial Bayesian Network | 0.003 | [5,5] |
| LR1 | Logistic Regression | 0.03 | [3,3] |
| LR2 | Logistic Regression | 0.02 | [3,3] |
| LR3 | Logistic Regression | 0.03 | [4,4] |
| LR4 | Logistic Regression | 0.01 | [4,4] |
| LR5 | Logistic Regression | 0.03 | [5,5] |
| LR6 | Logistic Regression | 0.01 | [5,5] |
| RF1 | Random Forest | 0.03 | [3,3] |
| RF2 | Random Forest | 0.02 | [3,3] |
| RF3 | Random Forest | 0.03 | [4,4] |
| RF4 | Random Forest | 0.02 | [4,4] |
| RF5 | Random Forest | 0.03 | [5,5] |
| RF6 | Random Forest | 0.02 | [5,5] |
| 352792 | 20307 | 117723 | 43315 | 161133 | 282143 | 353596 | 352809 | 13585 | 146319 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 19 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | |
| 7 | 17 | 6 | 5 | 9 | 9 | 2 | 3 | 2 | 9 | |
| 5 | 5 | 19 | 6 | 4 | 3 | 4 | 6 | 1 | 9 | |
| 9 | 2 | 1 | 17 | 2 | 0 | 2 | 6 | 1 | 8 | |
| 5 | 4 | 4 | 7 | 17 | 2 | 5 | 0 | 0 | 13 | |
| 4 | 9 | 9 | 8 | 2 | 14 | 4 | 4 | 0 | 9 | |
| 12 | 7 | 11 | 16 | 8 | 3 | 17 | 8 | 6 | 14 | |
| 3 | 6 | 4 | 8 | 4 | 3 | 8 | 10 | 0 | 9 | |
| 1 | 2 | 9 | 4 | 4 | 7 | 9 | 2 | 17 | 9 | |
| 12 | 5 | 7 | 10 | 10 | 4 | 9 | 5 | 1 | 17 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paredes, J.N.; Simari, G.I.; Martinez, M.V.; Falappa, M.A. First Steps towards Data-Driven Adversarial Deduplication. Information 2018, 9, 189. https://doi.org/10.3390/info9080189
Paredes JN, Simari GI, Martinez MV, Falappa MA. First Steps towards Data-Driven Adversarial Deduplication. Information. 2018; 9(8):189. https://doi.org/10.3390/info9080189
Chicago/Turabian StyleParedes, Jose N., Gerardo I. Simari, Maria Vanina Martinez, and Marcelo A. Falappa. 2018. "First Steps towards Data-Driven Adversarial Deduplication" Information 9, no. 8: 189. https://doi.org/10.3390/info9080189
APA StyleParedes, J. N., Simari, G. I., Martinez, M. V., & Falappa, M. A. (2018). First Steps towards Data-Driven Adversarial Deduplication. Information, 9(8), 189. https://doi.org/10.3390/info9080189