
Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions


Abstract
1. Introduction
Survey Methodology
- (1)
- List and describe the DL and CNN techniques and network types;
- (2)
- Present the problems of CNN and provide alternative solutions;
- (3)
- List and explain CNN architectures;
- (4)
- Evaluate the applications of CNN.
2. Convolutional Neural Network (CNN or ConvNet)
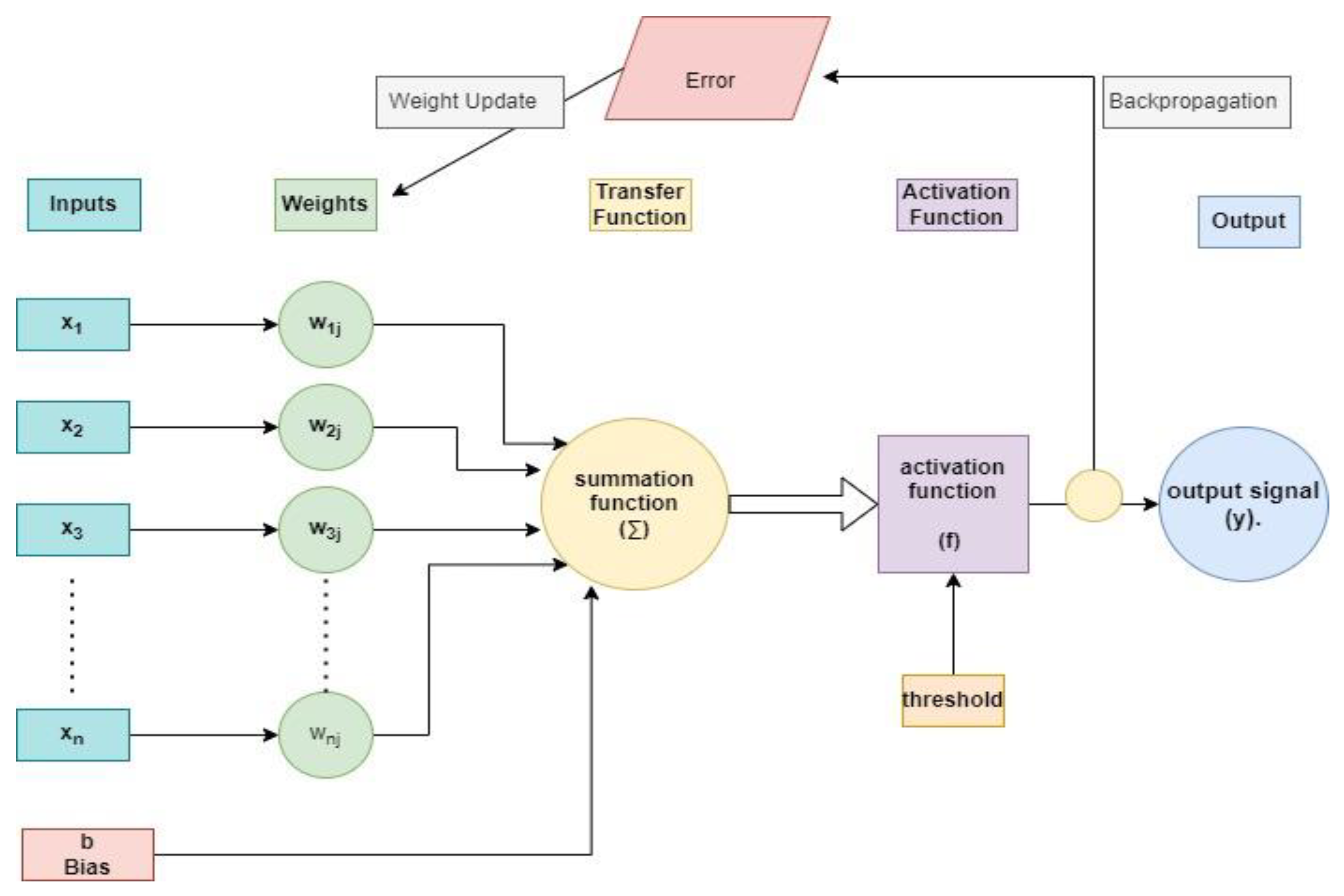
2.1. CNN Fundamentals
- Convolutional;
- Pooling;
- Function of Activation;
- Fully Connected.
2.1.1. Input Image
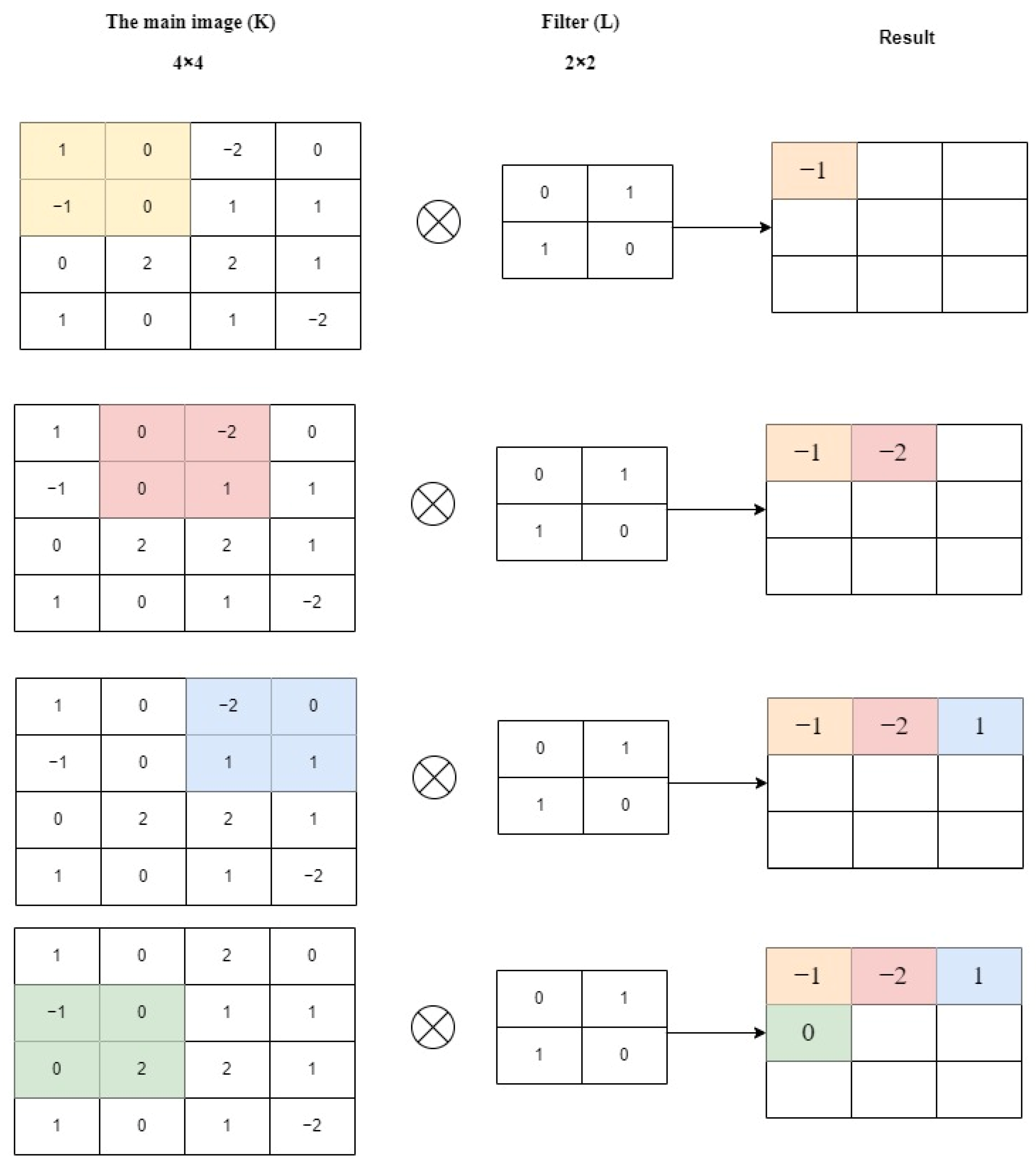
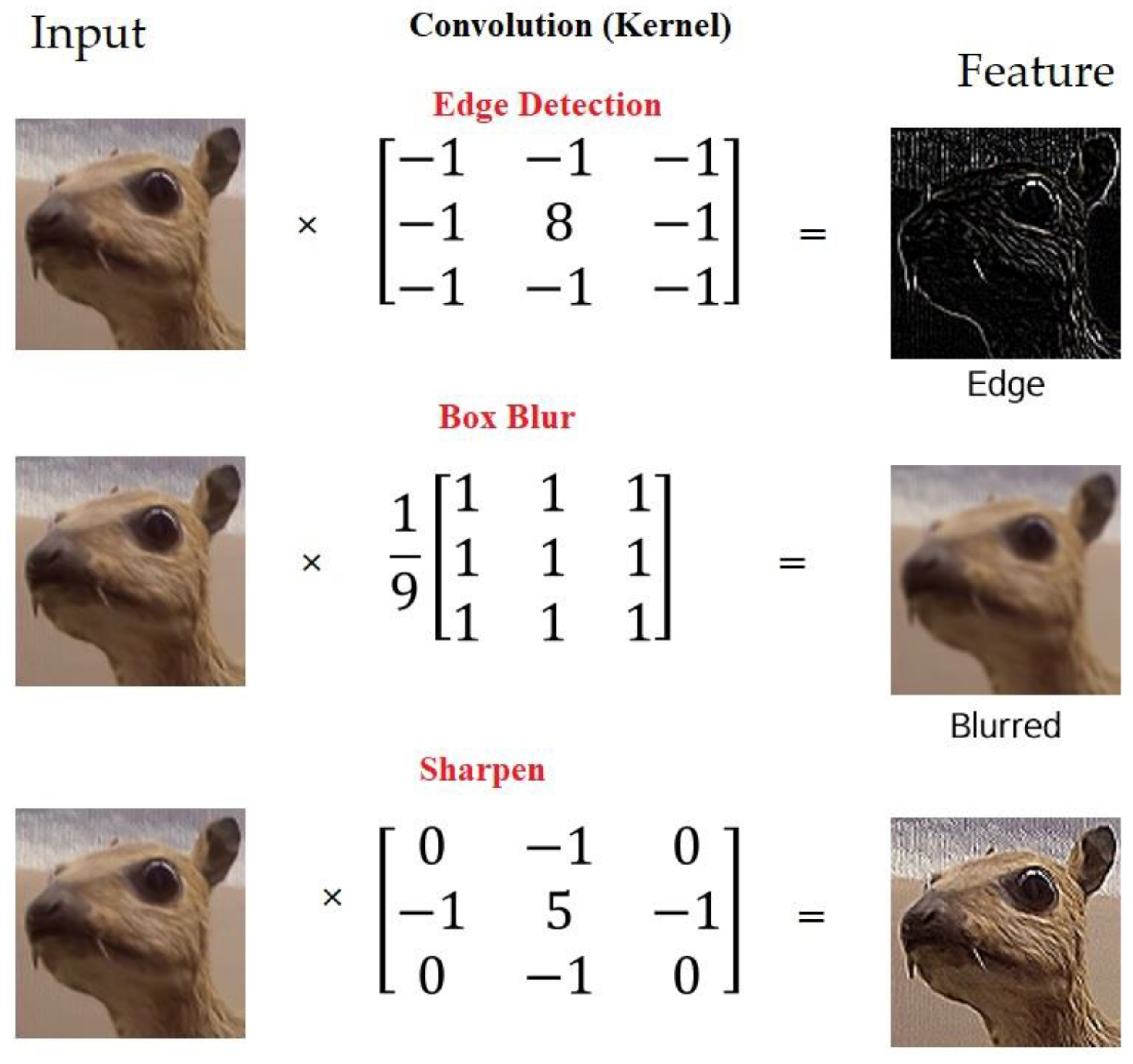
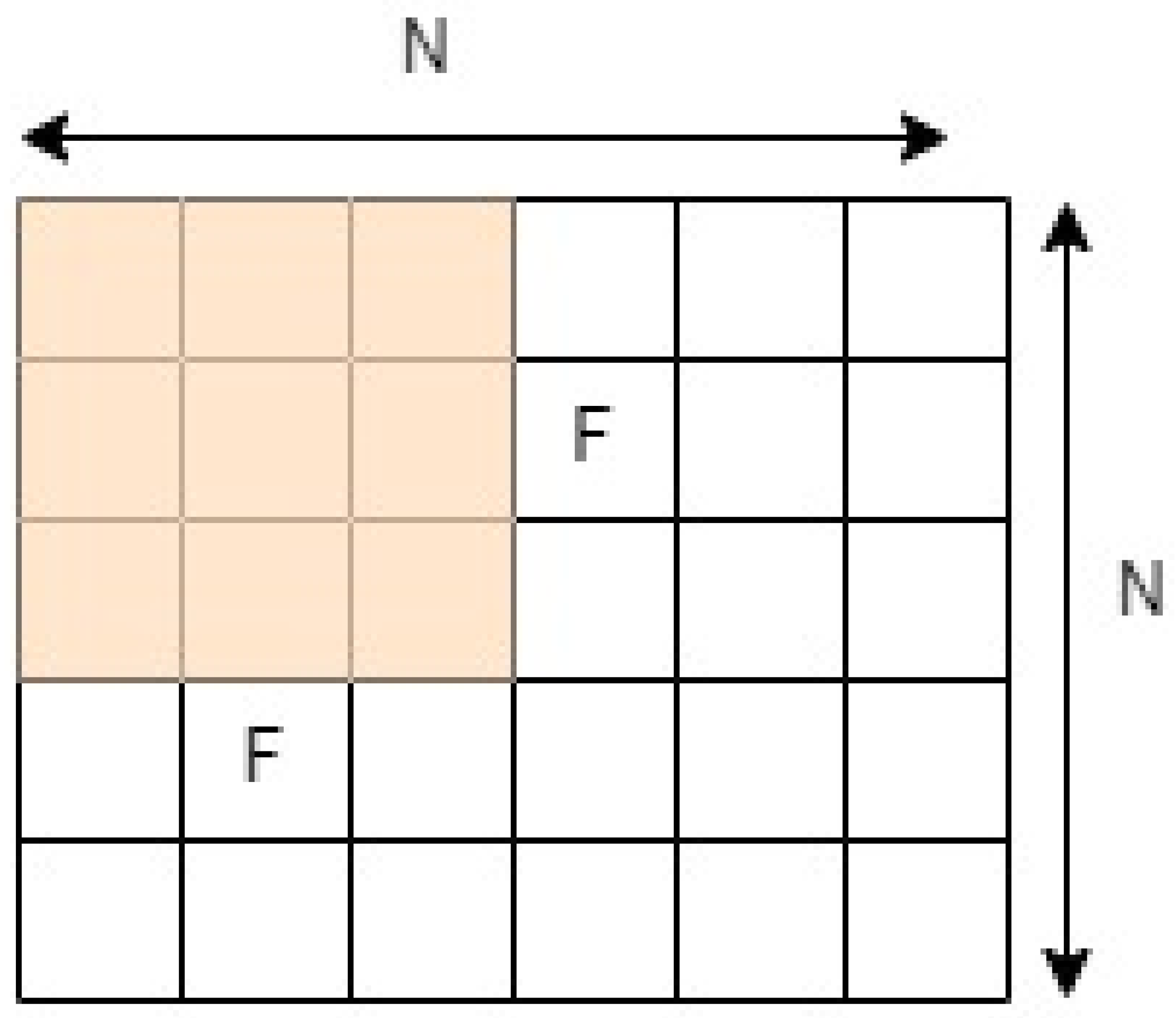
2.1.2. Convolutional Layer
2.1.3. Pooling
2.1.4. Non-Linearity (Function of Activation)
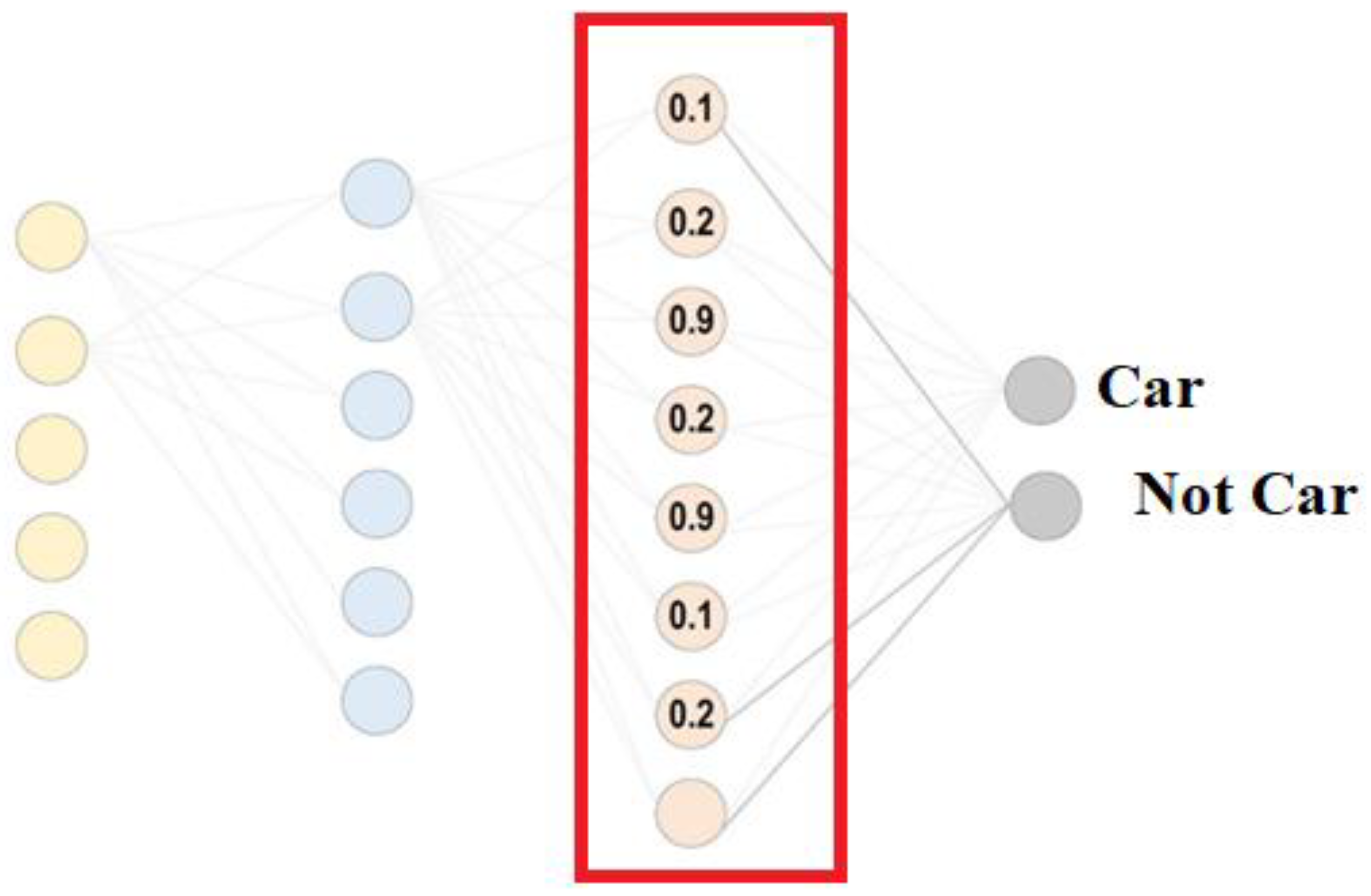
2.1.5. Fully Connected Layer
- –
- To rephrase, in a completely connected layer, all of the neurons communicate with their counterparts in the layer below. It is a classifier used by CNN.
- –
- Being a feed-forward ANN, it performs similarly to a regular multi-layer perceptron network. Input to the FC layer comes from the last pooling or convolutional layer.
- –
- This is a vector input created by increasing the thickness of the feature maps [24].
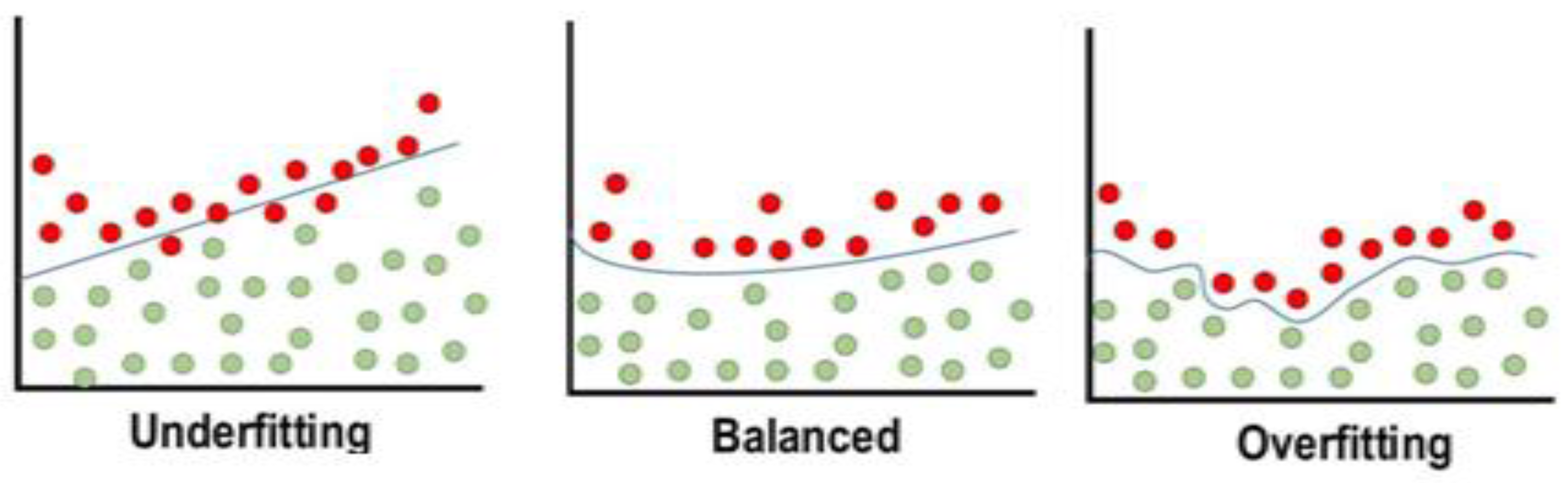
3. Regularization of CNN
- It stops the disappearing gradient issue before it starts.
- It has the ability to effectively manage bad weight initialization.
- It significantly reduces the amount of time needed for network convergence (which will be very helpful for large datasets).
- It has difficulty reducing training dependence on various hyperparameters.
- Over-fitting is less likely because it only slightly affects regularization [35].
4. Popular CNN Architecture
Several CNN Architectures
5. Different Types of CNN Architectures
5.1. Classification
5.2. Detection
5.3. Segmentation
5.4. Popular Applications
6. Future Directions
7. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications, and Research Directions. SN Comput. Sci. 2021, 2, 1–21. [Google Scholar] [CrossRef]
- Du, K.-L.; Swamy, M.N.S. Fundamentals of Machine Learning. Neural Netw. Stat. Learn. 2019, 21–63. [Google Scholar] [CrossRef]
- ZZhao, Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Indrakumari, R.; Poongodi, T.; Singh, K. Introduction to Deep Learning. EAI/Springer Innov. Commun. Comput. 2021, 1–22. [Google Scholar] [CrossRef]
- AI vs Machine Learning vs Deep Learning|Edureka. Available online: https://www.edureka.co/blog/ai-vs-machine-learning-vs-deep-learning/ (accessed on 11 August 2022).
- Cintra, R.J.; Duffner, S.; Garcia, C.; Leite, A. Low-complexity approximate convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5981–5992. [Google Scholar] [CrossRef]
- Rusk, N. Deep learning. Nat. Methods 2017, 13, 35. [Google Scholar] [CrossRef]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 34, 249–270. [Google Scholar] [CrossRef]
- Mishra, R.K.; Reddy, G.Y.S.; Pathak, H. The Understanding of Deep Learning: A Comprehensive Review. Math. Probl. Eng. 2021, 2021, 1–5. [Google Scholar] [CrossRef]
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep Learning Applications in Medical Image Analysis. IEEE Access 2017, 6, 9375–9379. [Google Scholar] [CrossRef]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies, and applications to object detection. Prog. Artif. Intell. 2019, 9, 85–112. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Introduction to Convolutional Neural Networks (CNNs)|The Most Popular Deep Learning architecture|by Louis Bouchard|What is Artificial Intelligence|Medium. Available online: https://medium.com/what-is-artificial-intelligence/introduction-to-convolutional-neural-networks-cnns-the-most-popular-deep-learning-architecture-b938f62f133f (accessed on 8 August 2022).
- Koushik, J. Understanding Convolutional Neural Networks. May 2016. Available online: http://arxiv.org/abs/1605.09081 (accessed on 13 August 2022).
- Bezdan, T.; Džakula, N.B. Convolutional Neural Network Layers and Architectures. In International Scientific Conference on Information Technology and Data Related Research; Singidunum University: Belgrade, Serbia, 2019; pp. 445–451. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, J.; Chen, X.; Zhang, D. How to fully exploit the abilities of aerial image detectors. In Proceedings of the IEEE International Conference on Computer Vision Workshops 2019, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Rodriguez, R.; Gonzalez, C.I.; Martinez, G.E.; Melin, P. An Improved Convolutional Neural Network Based on a Parameter Modification of the Convolution Layer. In Fuzzy Logic Hybrid Extensions of Neural and Optimization Algorithms: Theory and Applications; Springer: Cham, Switzerland, 2021; pp. 125–147. [Google Scholar] [CrossRef]
- Batmaz, Z.; Yurekli, A.; Bilge, A.; Kaleli, C. A review on deep learning for recommender systems: Challenges and remedies. Artif. Intell. Rev. 2019, 52, 137. [Google Scholar] [CrossRef]
- Fang, X. Understanding deep learning via back-tracking and deconvolution. J. Big Data 2017, 4, 40. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 83. [Google Scholar] [CrossRef] [PubMed]
- Du, K.L.; Swamy, M.N.S. Neural networks and statistical learning, second edition. In Neural Networks and Statistical Learning, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–988. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, M.; Chen, T.; Sun, Z.; Ma, Y.; Yu, B. Recent advances in convolutional neural network acceleration. Neurocomputing 2019, 323, 37–51. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN variants for computer vision: History, architecture, application, challenges and future scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Prakash, K.B.; Kannan, R.; Alexander, S.A.; Kanagachidambaresan, G.R. Advanced Deep Learning for Engineers and Scientists: A Practical Approach; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Hsieh, M.-R.; Lin, Y.-L.; Hsu, W. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE International Conference on Computer Vision 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8311–8320. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. Foveabox: Beyond anchor-based object detector. arXiv 2019, arXiv:1904.0379729. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q. Dropblock: A regularization method for convolutional networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Dutchess County, NY, USA; pp. 10727–10737.
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? In Advances in Neural Information Processing Systems 2019; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2019; pp. 4696–4705. [Google Scholar]
- Dollár, K.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6569–6578. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head r-cnn: In defense of twostage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Swapna, M.; Sharma, D.Y.K.; Prasad, D.B. CNN Architectures: Alex Net, Le Net, VGG, Google Net, Res Net. Int. J. Recent Technol. Eng. 2020, 8, 953–959. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.; Yeh, I.-H.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W. CSPNet: A new backbone that can enhance learning capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE International Conference on Computer Vision 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6023–6032. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. Cornernet-lite: Efficient keypoint based object detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic segmentation of aerial images with shuffling convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Pailla, D. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Terrail, J.D.; Jurie, F. On the use of deep neural networks for the detection of small vehicles in ortho-images. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP 2017), Beijing, China, 17–20 September 2017; pp. 4212–4216. [Google Scholar]
- Shen, J.; Shafiq, M.O. Deep Learning Convolutional Neural Networks with Dropout—A Parallel Approach. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA 2018, Orlando, FL, USA, 17–20 December 2018; pp. 572–577. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Adem, K. Impact of activation functions and number of layers on detection of exudates using circular Hough transform and convolutional neural networks. Expert. Syst. Appl. 2022, 203, 117583. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Zhang, Z. Improved Adam Optimizer for Deep Neural Networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018. [Google Scholar] [CrossRef]
- Coelho, I.M.; Coelho, V.N.; Luz, E.J.D.S.; Ochi, L.S.; Guimarães, F.G.; Rios, E. A GPU deep learning metaheuristic based model for time series forecasting. Appl. Energy 2017, 201, 412–418. [Google Scholar] [CrossRef]
- Huh, J.-H.; Seo, Y.-S. Understanding edge computing: Engineering evolution with artificial intelligence. IEEE Access 2019, 7, 164229–164245. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture Name | Layers | Main Contribution | Highlights | Strength | Gaps |
|---|---|---|---|---|---|
| LeNet LeNet-5 [1998] | 7 (5 Convolution + 2 FC) | First popular CNN architecture | Rapidly deployable and effective at resolving small-scale image recognition issues |
| Inadequate scaling to varied image classes; Filter sizes that are too large; Weak feature extraction |
| AlexNet [2012] | 8 (5 Convolution + 3 Fully Connected) | More depth and breadth than the LeNet-Employs Relu, dropout, and overlap Pooling-NVIDIA GTX 580 GPUs Makes use of Dropout and ReLU | AlexNet is comparable to LeNet-5, except it is more complex, has more filters per layer and employs stacked convolutional layers. |
| Neurons in the first and second layers that are dormant
|
| ZfNet [2014] | 8 | Conceptualization of middle levels |
| Further processing of information is necessary for visualization. | |
| VGG [2014] | 16–19 (13–16 convolution + 3 FC | -Homogeneous structure—Small kernel size. -Enhanced depth, reduced filter size | The accuracy of a model is improved by employing small convolutional filters with dimensions of 3 3 in each layer. |
| Implementation of computationally costly fully linked layers |
| GoogLeNet [2015] | 22 Convolution layers, 9 Inception modules | -Presented the block concept-Separated the transform and merge notions Increased depth, the block concept, a different filter size, and the concatenation concept | A deeper and broader architecture with various receptive field sizes and a number of extremely small convolutions. |
| Due to diverse topologies, parameter modification is arduous and time-consuming.
|
| Inception-V3 [2015] | 42 Convolution layers, 10 Inception modules 48 | -Resolves the representational bottleneck issue—Change large-size filters to tiny-size filters -Employs a tiny filter size and improved feature representation | Enhances the efficiency of a network. The application of Batch Normalization expedites the training process. Inception-building elements are employed effectively to go deeper. | Utilized asymmetric filters and bottleneck layer to decrease the computational expense of deep designs |
|
| ResNet [2016] | 50 in ResNet-50, 101 in ResNet-101, 152 in ResNet-152 | -Identity mapping based on links—Long-term retention of knowledge. Overfitting-resistant due to symmetry mapping-based skip connections | A unique design that features “skip connections” and extensive batch normalization. | Reduces the error rate of deeper networks; introduces the concept of residual learning; mitigates the vanishing gradient problem |
|
| DenseNet DenseNet-121 [2017] | 117 Convolution layers, 3 Transition layers, and 1 Classification layer | -Information transmission between layers Blocks of layers; layers that are interconnected. | All layers are intimately connected to one another in a feed-forward fashion. It mitigates the problem of vanishing gradients and requires few parameters. |
| Significant rise in parameters as a result of an increase in the number of feature-maps per layer |
| Models | Types of CNN | Advantages | Limitations |
|---|---|---|---|
| Fast R-CNN [2015] | Object detection Two-stage framework | The properties of CNN are calculated in a single loop, making the detection of objects 25 times faster than the RCNN approach (an average of 20 s is required to study a picture). | Using an external candidate region generator slows down the detection procedure. |
| Faster R-CNN [2015] | Object detection Two-stage framework | The RPN approach enables near-real-time object detection, around 0.12 s per image. | Despite the algorithm’s effectiveness, it is too slow to be used in applications requiring real-time, such as driverless vehicles. |
| Mask R-CNN [2017] | Object detection Two-stage framework | When segmenting the objects in an image, the location of the objects becomes more exact. | Its execution time is longer than that of the Faster-RCNN approach; hence, it cannot be implemented in real-time applications. |
| YOLO [2015] | Object detection One-stage framework | The efficiency of object localization enables its usage in real-time applications. | The technique has trouble accurately detecting little items. |
| SSD [2016] | Object detection One-stage framework | YOLO and Faster R-CNN advantages are balanced with high detection speed and high object detection rate. | Compared to the Fast-RCNN and Faster-RCNN algorithms, the object detection accuracy is less precise. |
| FCN [2014] | Semantic segmentation | Obtaining a complete convolutional layer (without connected layer). | Poor precision of feature maps and significant GPU utilization. |
| UNet [2015] | Semantic segmentation | The structure has fewer parameters and is basically like the letter U. Appropriate for object detection in limited medical image samples. | It is difficult to acquire uniform sub-sampling and up-sampling standards. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taye, M.M. Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions. Computation 2023, 11, 52. https://doi.org/10.3390/computation11030052
Taye MM. Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions. Computation. 2023; 11(3):52. https://doi.org/10.3390/computation11030052
Chicago/Turabian StyleTaye, Mohammad Mustafa. 2023. "Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions" Computation 11, no. 3: 52. https://doi.org/10.3390/computation11030052
APA StyleTaye, M. M. (2023). Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions. Computation, 11(3), 52. https://doi.org/10.3390/computation11030052