
The Weights Reset Technique for Deep Neural Networks Implicit Regularization




Abstract
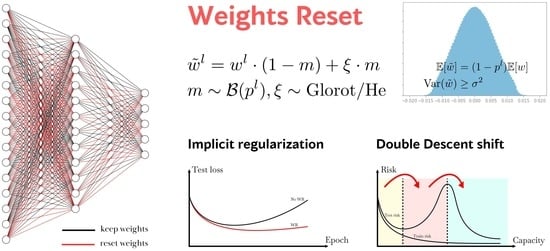
1. Introduction
- L1/L2 regularization. Originally, the idea of regularization was proposed by Tikhonov (it is known as Tikhonov regularization [1]), and was developed for the solution of ill-posed problems. It is effective as a method of estimating the coefficients of multiple-regression models in scenarios where the input variables are highly correlated which commonly occurs in models with large numbers of parameters (Ridge regression). Later the idea of regularization, particularly L1/L2 regularization, was applied to the solution of machine learning problems.
- The concept of weight decay, which involves adding a penalty term to the error function to discourage large weights. It was first proposed in the context of neural networks in [2]. While this is not an implicit regularization method, it serves as a useful benchmark for later methods.
- The trade-off between model complexity and generalization performance, which is an important theme in regularization. In [3], Lecun et al. proposed a technique called “optimal brain damage” that involves pruning the weights in a neural network to improve its generalization performance. It can be considered as a form of regularization since it reduces the number of parameters in the model and can help prevent overfitting.
- Early stopping. Prechelt in [4] provided an analysis of the effectiveness of early stopping for neural network training, including an exploration of the optimal stopping point based on a validation set. Caruana in [5] explored the effects of early stopping on different optimization algorithms for neural networks, and provided a detailed analysis of the trade-off between overfitting and underfitting.
- Dropout is a regularization technique proposed by Srivastava et al. in [6]. It involves randomly dropping out some of the neurons in a layer during training, which has the effect of preventing the network from overreliance on any one feature. Dropout is an implicit regularization technique because it introduces noise into the training process, which has a regularizing effect.
- Batch normalization is a technique proposed by Ioffe and Szegedy in [7] that normalizes the inputs to each layer to have zero mean and unit variance. This has the effect of stabilizing the distribution of activations and gradients, which makes training more robust to hyperparameter choices and reduces the need for explicit regularization.
- Data augmentation is a technique that involves generating new training examples by applying random transformations to the existing examples. This has the effect of increasing the size of the training set and making the model more robust to variations in the input. One of the earliest papers to introduce data augmentation in the context of image classification using neural networks was [8].
- Implicit bias of optimization algorithms. The concept of implicit bias of optimization algorithms was introduced in [9]. This paper showed that the choice of an optimization algorithm can have a significant impact on the generalization performance of a neural network, even when the data are linearly separable. Specifically, the authors showed that gradient descent with weight decay implicitly imposes a bias towards solutions that have smaller L2 norm, which can explain the generalization performance of neural networks trained with this algorithm. The paper also introduced a framework for analyzing the implicit bias of optimization algorithms on different classes of data.
2. Materials and Methods
3. Results
3.1. Evaluation of Various Weights Reset Configurations
3.2. Comparison of Weights Reset with Other Regularization Techniques
3.3. Effects of the Weights Reset Method Illustrated on Loss Surfaces and Different Training Trajectories
3.4. Analysis of the Distribution of the Weights
3.5. Estimation of Weights Mean and Variance
3.6. Experimental Analysis with Models of Various Capacities
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tikhonov, A.; Arsenin, V. Solution of Ill-Posed Problems; Winston & Sons: Washington, DC, USA, 1977; p. 258. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning representations by back-propagating errors. Nature 1986, 322, 533–536. [Google Scholar] [CrossRef]
- LeCun, Y.; Denker, J.; Solla, S. Optimal Brain Damage. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1989; Touretzky, D., Ed.; Morgan-Kaufmann: Burlington, MA, USA, 1989; Volume 2. [Google Scholar]
- Prechelt, L. Early Stopping-But When? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar] [CrossRef]
- Caruana, R.; Lawrence, S.; Giles, L. Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping. In Proceedings of the Advances in Neural Information Processing Systems 13—Proceedings of the 2000 14th AAnnual Conference on Neural Information Processing Systems, NIPS 2000, Denver, CO, USA, 27 November–2 December 2000. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, JMLR.org, ICML’15, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Soudry, D.; Hoffer, E.; Srebro, N. The Implicit Bias of Gradient Descent on Separable Data. J. Mach. Learn. Res. 2017, 19, 2822–2878. [Google Scholar]
- Razin, N.; Cohen, N. Implicit Regularization in Deep Learning May Not Be Explainable by Norms. In Proceedings of the 34th International Conference on Neural Information Processing Systems NIPS’20, Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Zhang, L.; Xu, Z.Q.J.; Luo, T.; Zhang, Y. Limitation of characterizing implicit regularization by data-independent functions. arXiv 2022, arXiv:2201.12198. [Google Scholar]
- Behdin, K.; Mazumder, R. Sharpness-Aware Minimization: An Implicit Regularization Perspective. arXiv 2023, arXiv:2302.11836. [Google Scholar]
- Gulcehre, C.; Srinivasan, S.; Sygnowski, J.; Ostrovski, G.; Farajtabar, M.; Hoffman, M.; Pascanu, R.; Doucet, A. An Empirical Study of Implicit Regularization in Deep Offline RL. arXiv 2022, arXiv:2207.02099. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canade, 2009. [Google Scholar]
- Li, F.F.; Andreeto, M.; Ranzato, M.; Perona, P. Caltech 101. CaltechDATA 2022. [Google Scholar] [CrossRef]
- Howard, J. Imagewang. Available online: https://github.com/fastai/imagenette/ (accessed on 27 July 2023).
- Belkin, M.; Hsu, D.; Ma, S.; Mandal, S. Reconciling modern machine-learning practice and the classical bias–variance trade-off. Proc. Natl. Acad. Sci. USA 2019, 116, 15849–15854. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Grigoriy, P. Weights Reset Implicit Regularization. Available online: https://github.com/amcircle/weights-reset/ (accessed on 27 July 2023).
- TensorFlow Datasets. A Collection of Ready-to-Use Datasets. Available online: https://www.tensorflow.org/datasets (accessed on 27 July 2023).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 27 July 2023).
- Keras. 2015. Available online: https://keras.io (accessed on 27 July 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Li, H.; Xu, Z.; Taylor, G.; Studer, C.; Goldstein, T. Visualizing the Loss Landscape of Neural Nets. arXiv 2018, arXiv:1712.09913. [Google Scholar]
- Nakkiran, P.; Kaplun, G.; Bansal, Y.; Yang, T.; Barak, B.; Sutskever, I. Deep Double Descent: Where Bigger Models and More Data Hurt. arXiv 2019, arXiv:1912.02292. [Google Scholar] [CrossRef]
- Advani, M.S.; Saxe, A.M. High-dimensional dynamics of generalization error in neural networks. arXiv 2017, arXiv:1710.03667. [Google Scholar] [CrossRef] [PubMed]
- Geiger, M.; Spigler, S.; d’Ascoli, S.; Sagun, L.; Baity-Jesi, M.; Biroli, G.; Wyart, M. Jamming transition as a paradigm to understand the loss landscape of deep neural networks. Phys. Rev. E 2019, 100, 012115. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Layer Description |
|---|---|
| conv2d | Conv2D(32, 5, strides=2, padding=‘same’, activation=‘relu’, kernel_initializer=‘he_normal’) |
| conv2d_1 | Conv2D(64, 3, strides=2, padding=‘same’, activation=‘relu’, kernel_initializer=‘he_normal’) |
| conv2d_2 | Conv2D(128, 3, strides=2, padding=‘same’, activation=‘relu’, kernel_initializer=‘he_normal’) |
| conv2d_3 | Conv2D(256, 3, strides=2, padding=‘same’, activation=‘relu’, kernel_initializer=‘he_normal’) |
| flatten | Flatten() |
| dense | Dense(512, activation=‘relu’, kernel_initializer=‘he_normal’) |
| dense_1 | Dense(num_classes, activation=‘softmax’, kernel_initializer=‘glorot_normal’) |
| Configuration Number | Resetting Rate Per Layer | |||
|---|---|---|---|---|
| Dense_1 | Dense | Conv2d_3 | Conv2d_2 | |
| 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 1.0 | 1.0 | 1.0 | 0.5 |
| 2 | 1.0 | 1.0 | 0.5 | 0.5 |
| 3 | 1.0 | 1.0 | 1.0 | 0.0 |
| 4 | 1.0 | 1.0 | 0.5 | 0.0 |
| 5 | 1.0 | 0.5 | 0.5 | 0.0 |
| 6 | 1.0 | 1.0 | 0.0 | 0.0 |
| 7 | 1.0 | 0.5 | 0.0 | 0.0 |
| 8 | 0.5 | 0.5 | 0.0 | 0.0 |
| 9 | 1.0 | 0.0 | 0.0 | 0.0 |
| 10 | 0.5 | 0.0 | 0.0 | 0.0 |
| 11 | 0.0 | 0.0 | 0.0 | 0.0 |
| Configuration | Caltech-101 | CIFAR-100 | Imagenette | |||
|---|---|---|---|---|---|---|
| Train Loss | Test Loss | Train Loss | Test Loss | Train Loss | Test Loss | |
| Base model | 0.8367 | 2.8035 | 2.0674 | 2.7846 | 0.6384 | 1.2371 |
| Weights Reset for last dense layers with 1.0 rate | 0.5940 | 1.9010 | 1.9595 | 2.4300 | 0.1181 | 0.8676 |
| Dropout before dense_1 with 0.3 rate | 0.4209 | 2.7031 | 1.6716 | 2.6442 | 0.5044 | 1.2183 |
| Dropout before dense_1 with 0.5 rate | 0.6253 | 2.7438 | 1.5513 | 2.5744 | 0.4669 | 1.1713 |
| Dropout before dense_1 with 0.8 rate | 0.0117 | 2.4733 | 1.5762 | 2.5522 | 0.3444 | 1.0567 |
| Gaussian Dropout before dense_1 with 0.3 rate | 0.9503 | 2.7266 | 1.6395 | 2.6424 | 0.8118 | 1.2368 |
| Gaussian Dropout before dense_1 with 0.5 rate | 0.2304 | 2.6611 | 1.6331 | 2.5845 | 0.2959 | 1.1607 |
| Gaussian Dropout before dense_1 with 0.8 rate | 0.0010 | 2.2374 | 1.6096 | 2.5677 | 0.1871 | 1.0300 |
| Gaussian Noise before dense_1 with 0.001 standard deviation | 1.4134 | 2.9390 | 2.0551 | 2.7993 | 0.6859 | 1.2291 |
| Gaussian Noise before dense_1 with 0.01 standard deviation | 0.8953 | 2.9985 | 1.9171 | 2.7913 | 0.3998 | 1.2307 |
| Gaussian Noise before dense_1 with 0.1 standard deviation | 1.2585 | 3.0858 | 1.9524 | 2.7968 | 0.7066 | 1.2672 |
| L1+L2 regularization for last dense layers with 0.01 factor | 4.6247 | 4.6243 | 4.6051 | 4.6052 | 2.3020 | 2.3022 |
| L1+L2 regularization for last dense layers with 0.001 factor | 0.8166 | 2.7672 | 2.0337 | 2.6814 | 0.5991 | 1.1577 |
| Dropout before dense_1 with 0.2 rate and before dense with 0.3 rate | 0.2304 | 2.7733 | 1.2421 | 2.5074 | 0.5709. | 1.1715 |
| Dropout before dense_1 with 0.3 rate and before dense with 0.5 rate | 0.1588 | 2.6932 | 1.0989 | 2.3516 | 0.1955 | 1.1987 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Plusch, G.; Arsenyev-Obraztsov, S.; Kochueva, O. The Weights Reset Technique for Deep Neural Networks Implicit Regularization. Computation 2023, 11, 148. https://doi.org/10.3390/computation11080148
Plusch G, Arsenyev-Obraztsov S, Kochueva O. The Weights Reset Technique for Deep Neural Networks Implicit Regularization. Computation. 2023; 11(8):148. https://doi.org/10.3390/computation11080148
Chicago/Turabian StylePlusch, Grigoriy, Sergey Arsenyev-Obraztsov, and Olga Kochueva. 2023. "The Weights Reset Technique for Deep Neural Networks Implicit Regularization" Computation 11, no. 8: 148. https://doi.org/10.3390/computation11080148
APA StylePlusch, G., Arsenyev-Obraztsov, S., & Kochueva, O. (2023). The Weights Reset Technique for Deep Neural Networks Implicit Regularization. Computation, 11(8), 148. https://doi.org/10.3390/computation11080148