
A Deep Learning Model for Detecting Fake Medical Images to Mitigate Financial Insurance Fraud
 , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
- We have fine-tuned several CNN and transformer-based models to evaluate the performance of the deep learning models for fake medical cancer detection through images.
- We have considered the stable diffusion techniques to generate the fake medical images and to assess the model performance for the identification of these images.
- A detailed histogram analysis was performed to understand distribution changes.
- A user study was performed to compare human perception and deep learning models for detecting fake medical images.
2. Literature Review
Research Gap
- Fake Malignant Skin Cancer Dataset Preparation using Stable Diffusion-Based Mode;
- Dataset Preprocessing;
- Feature Analysis using Histogram;
- Training and Evaluation of ViT Model (Global Feature Extraction);
- Training and Evaluating CNN models with and without ImageNet (Weights).
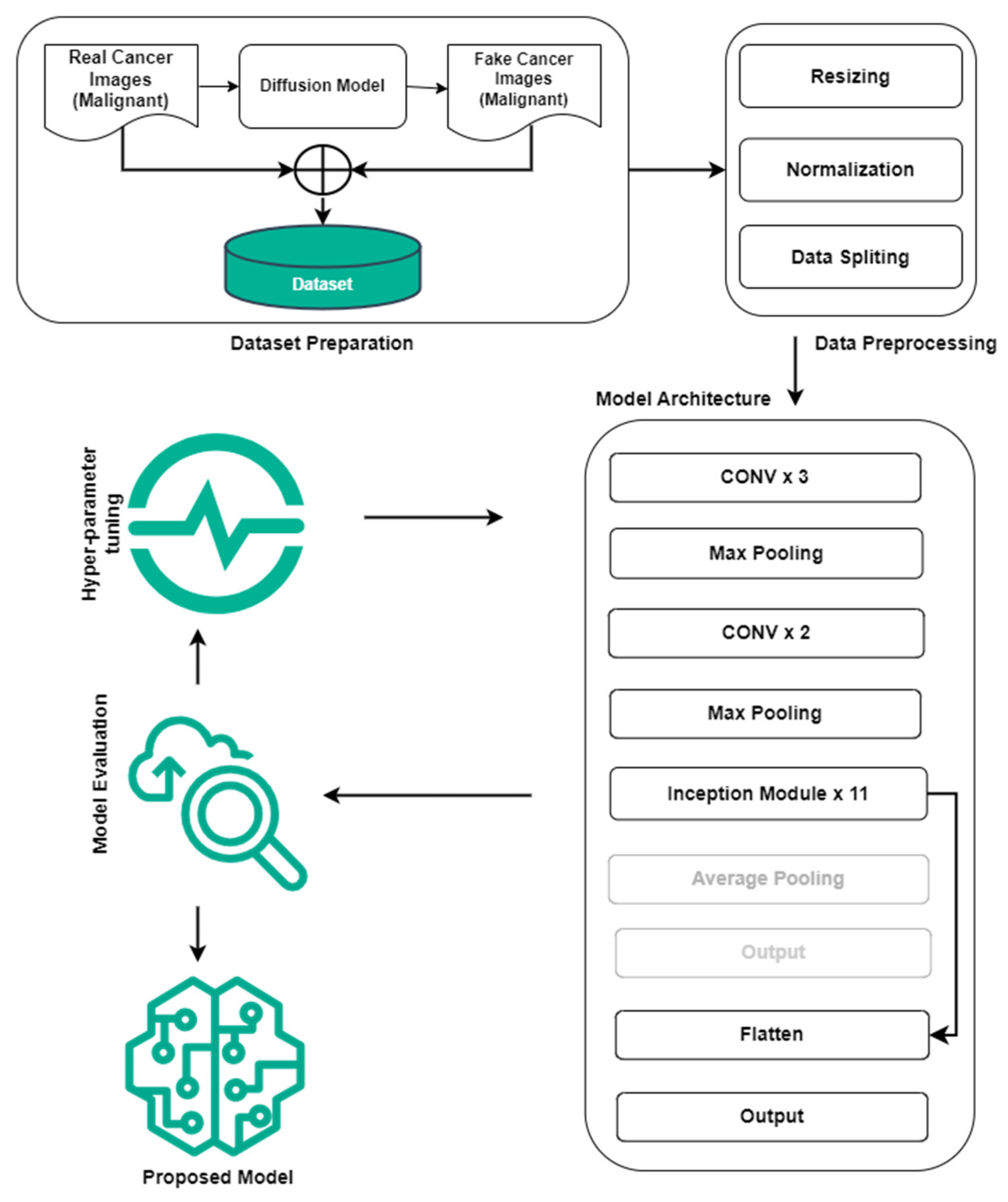
3. Methodology
3.1. Dataset
- Number of Inference Steps: This parameter determines the number of inference steps or iterations the diffusion model needs to complete to produce the final image. With each inference step, the image is further refined, bringing out more details and better quality. Higher-quality findings are usually obtained by increasing the number of inference stages, which also increases computing time. In our situation, effective images are generated for inference steps of 5.
- Image Guidance Scale: This parameter regulates how strongly the diffusion model receives image guidance. The influence of the starting image (if provided) on the generating process is referred to as image guidance. A greater value for “image_guidance_scale” increases the effect of the original image, which could result in generated images that preserve more aspects of the input image. We have set it to 1 in this study, and the influence of the original image remains at its initial level.
3.2. ViT Network Architecture
3.3. CNN-Based Pretrained Models
4. Results and Discussion
4.1. Evaluation Measures
4.2. Hardware Specifications
4.3. Experimental Results and Discussion
4.4. Practical Implications
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Label | Image | Label |
|---|---|---|---|
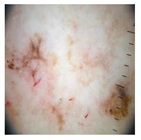 | Real |  | Fake |
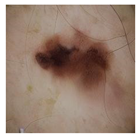 | Fake |  | Real |
 | Real |  | Fake |
 | Fake |  | Real |
 | Real |  | Fake |
 | Fake |  | Real |
 | Real |  | Fake |
 | Real | 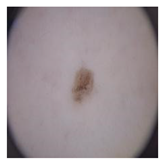 | Fake |
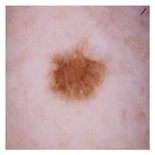 | Real |  | Fake |
 | Real |  | Fake |
| Image | Label | Image | Label |
|---|---|---|---|
 | Real |  | Fake |
 | Fake |  | Real |
 | Real |  | Fake |
 | Fake |  | Real |
 | Fake |  | Real |
References
- Brenner, D.J.; Hall, E.J. Computed Tomography—An Increasing Source of Radiation Exposure. N. Engl. J. Med. 2007, 357, 2277–2284. [Google Scholar] [CrossRef] [PubMed]
- McLean, I.D.; Martensen, J. Specialized Imaging. In Clinical Imaging: With Skeletal, Chest, & Abdominal Pattern Differentials, 3rd ed.; Mosby: Maryland Heights, MO, USA, 2014; pp. 44–78. [Google Scholar] [CrossRef]
- Strickland, N.H. Current topic: PACS (picture archiving and communication systems): Filmless radiology. Arch. Dis. Child. 2000, 83, 82–86. [Google Scholar] [CrossRef] [PubMed]
- Mejía-Granda, C.M.; Fernández-Alemán, J.L.; Carrillo-De-Gea, J.M.; García-Berná, J.A. Security vulnerabilities in healthcare: An analysis of medical devices and software. Med. Biol. Eng. Comput. 2023, 62, 257–273. [Google Scholar] [CrossRef]
- Christiaan, B. McAfee Researchers Find Poor Security Exposes Medical Data to Cybercriminals|McAfee Blog. Available online: https://www.mcafee.com/blogs/other-blogs/mcafee-labs/mcafee-researchers-find-poor-security-exposes-medical-data-to-cybercriminals/ (accessed on 28 April 2024).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Sci. Robot 2014, 3, 2672–2680. [Google Scholar] [CrossRef]
- Patel, Y.; Tanwar, S.; Gupta, R.; Bhattacharya, P.; Davidson, I.E.; Nyameko, R.; Aluvala, S.; Vimal, V. Deepfake Generation and Detection: Case Study and Challenges. IEEE Access 2023, 11, 143296–143323. [Google Scholar] [CrossRef]
- Passos, L.A.; Jodas, D.; Costa, K.A.P.; Júnior, L.A.S.; Rodrigues, D.; Del Ser, J.; Camacho, D.; Papa, J.P. A review of deep learning-based approaches for deepfake content detection. Expert Syst. 2024, 41, e13570. [Google Scholar] [CrossRef]
- Media Forensics. Available online: https://www.darpa.mil/program/media-forensics (accessed on 11 July 2023).
- Radiation Risk from Medical Imaging—Harvard Health. Available online: https://www.health.harvard.edu/cancer/radiation-risk-from-medical-imaging (accessed on 28 April 2024).
- Wang, X.; Wang, H.; Niu, S.; Zhang, J. Detection and localization of image forgeries using improved mask regional convolutional neural network. Math. Biosci. Eng. 2019, 16, 4581–4593. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10674–10685. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef]
- Mirsky, Y.; Mahler, T.; Shelef, I.; Elovici, Y. {CT-GAN}: Malicious Tampering of 3D Medical Imagery using Deep Learning. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- Liao, F.; Liang, M.; Li, Z.; Hu, X.; Song, S. Evaluate the malignancy of pulmonary nodules using the 3D deep leaky noisy-or network. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3484–3495. [Google Scholar] [CrossRef]
- Birajdar, G.; Mankar, V. Digital image forgery detection using passive techniques: A survey. Digit. Investig. 2013, 10, 226–245. [Google Scholar] [CrossRef]
- Singh, P.; Devi, K.J.; Thakkar, H.K.; Kotecha, K. Region-based hybrid medical image watermarking scheme for robust and secured transmission in IoMT. IEEE Access 2022, 10, 8974–8993. [Google Scholar] [CrossRef]
- Savaridass, M.P.; Deepika, R.; Aarnika, R.; Maniraj, V.; Gokilanandhi, P.; Kowsika, K. Digital watermarking for medical images using DWT and SVD technique. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1084, 012034. [Google Scholar] [CrossRef]
- Mohammed, A.; Jebur, B.A.; Younus, K.M. Hybrid DCT-SVD based digital watermarking scheme with chaotic encryption for medical images. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1152, 012025. [Google Scholar] [CrossRef]
- Thakur, T.; Singh, K.; Yadav, A. Blind approach for digital image forgery detection. Int. J. Comput. Appl. 2018, 179, 34–42. [Google Scholar] [CrossRef]
- Sharafudeen, M.; Chandra, S.S.V. Medical Deepfake Detection using 3-Dimensional Neural Learning. In Proceedings of the Artificial Neural Networks in Pattern Recognition: 10th IAPR TC3 Workshop, ANNPR 2022, Dubai, United Arab Emirates, 24–26 November 2022; Lecture Notes in Computer Science. Volume 13739, pp. 169–180. [Google Scholar] [CrossRef]
- Sharafudeen, M.; Chandra, S.S.V. Leveraging Vision Attention Transformers for Detection of Artificially Synthesized Dermoscopic Lesion Deepfakes Using Derm-CGAN. Diagnostics 2023, 13, 825. [Google Scholar] [CrossRef]
- Albahli, S.; Nawaz, M. MedNet: Medical deepfakes detection using an improved deep learning approach. Multimed. Tools Appl. 2024, 83, 48357–48375. [Google Scholar] [CrossRef]
- Amiri, E.; Mosallanejad, A.; Sheikhahmadi, A. The Optimal Model for Copy-Move Forgery Detection in Medical Images. J. Med Signals Sens. 2024, 14, 5. [Google Scholar] [CrossRef]
- High Resolution Images Create a Pseudo-Pulmonary Embolism (PE) Type Appearance—Chest Case Studies—CTisus CT Scanning. Available online: https://www.ctisus.com/teachingfiles/cases/chest/285194 (accessed on 10 August 2024).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Lecture Notes in Computer Science. pp. 740–755. [Google Scholar] [CrossRef]
- Wen, B.; Zhu, Y.; Subramanian, R.; Ng, T.-T.; Shen, X.; Winkler, S. COVERAGE—A novel database for copy-move forgery detection. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 161–165. [Google Scholar]
- Hsu, Y.; Chang, S. Detecting image splicing using geometry invariants and camera characteristics consistency. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; Available online: https://ieeexplore.ieee.org/abstract/document/4036658/ (accessed on 4 May 2024).
- Armato, S.G.; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.R.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef]
- SIPI Image Database. Available online: https://sipi.usc.edu/database/ (accessed on 4 May 2024).
- Kaggle: Your Machine Learning and Data Science Community. Available online: https://www.kaggle.com/ (accessed on 4 May 2024).
- Medical Images Home. Available online: http://www.onlinemedicalimages.com/index.php/en/ (accessed on 4 May 2024).
- The STARE Project. Available online: http://cecas.clemson.edu/~ahoover/stare/ (accessed on 4 May 2024).
- Tagare, H.D.; Jaffe, C.C.; Duncan, J. Medical image databases: A content-based retrieval approach. J. Am. Med. Inform. Assoc. 1997, 4, 184–198. [Google Scholar] [CrossRef]
- Budhiraja, R.; Kumar, M.; Das, M.; Bafila, A.S.; Singh, S. MeDiFakeD: Medical Deepfake Detection using Convolutional Reservoir Networks. In Proceedings of the 2022 IEEE Global Conference on Computing, Power and Communication Technologies (GlobConPT), New Delhi, India, 23–25 September 2022. [Google Scholar]
- The Lung Image Database Consortium image collection (LIDC-IDRI)|IEEE DataPort. Available online: https://ieee-dataport.org/documents/lung-image-database-consortium-image-collection-lidc-idri (accessed on 6 May 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A survey of visual transformers. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 7478–7498. [Google Scholar] [CrossRef]
- Skin Cancer: Malignant vs. Benign. Available online: https://www.kaggle.com/datasets/fanconic/skin-cancer-malignant-vs-benign (accessed on 6 May 2024).
- Javed, R.; Rahim, M.S.M.; Saba, T.; Fati, S.M.; Rehman, A.; Tariq, U. Statistical Histogram Decision Based Contrast Categorization of Skin Lesion Datasets Dermoscopic Images. Comput. Mater. Contin. 2021, 67, 2337–2352. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 10691–10700. Available online: https://arxiv.org/abs/1905.11946v5 (accessed on 10 May 2024).
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 10096–10106. Available online: https://arxiv.org/abs/2104.00298v3 (accessed on 10 August 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science. Volume 9908, pp. 630–645. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/abs/1409.1556v6 (accessed on 12 July 2023).
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2735–2745. [Google Scholar] [CrossRef]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Google Colaboratory. Available online: https://colab.google/ (accessed on 9 September 2023).
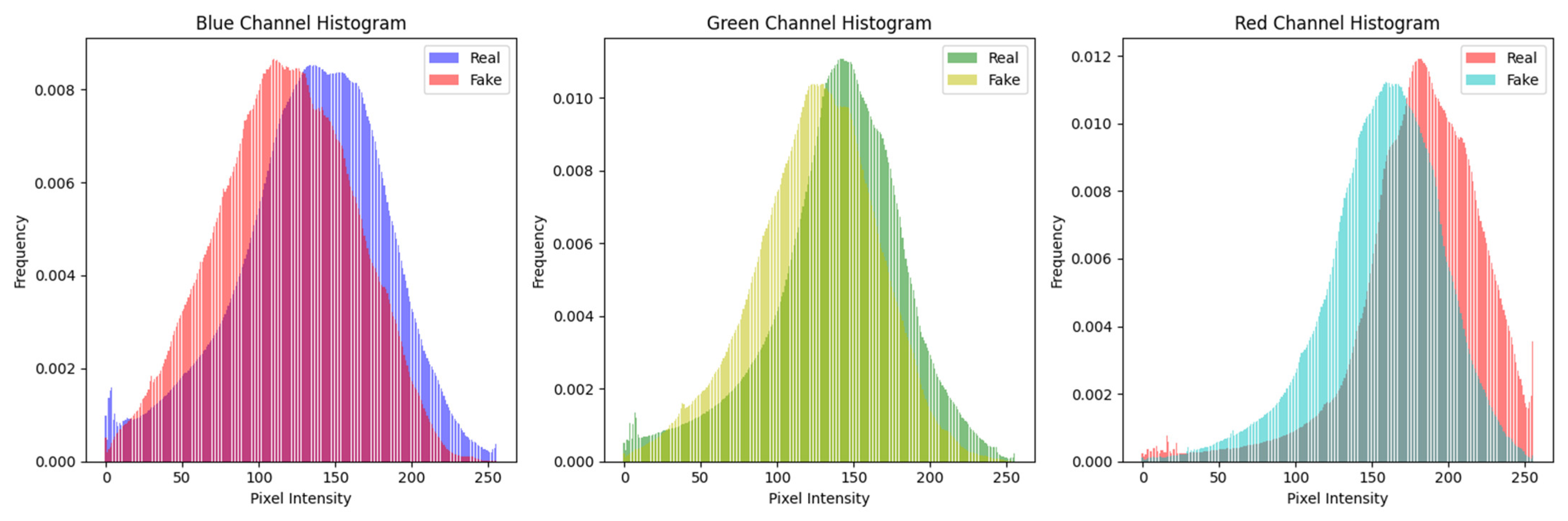
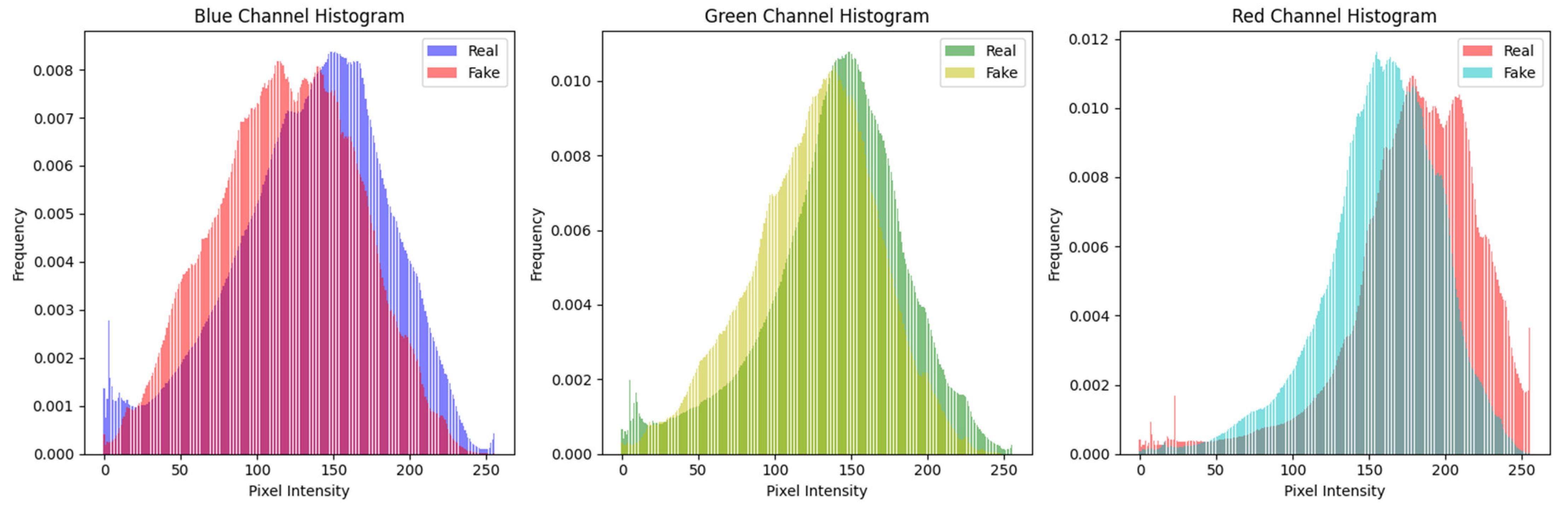







| Study | Dataset Description | Model | Results |
|---|---|---|---|
| Wang et al., 2019 [11] | (1) Synthetic dataset using the images from COCO [26] (2) Coverage Database [27] (3) Columbia Dataset [28] | Mask RCNN +Sobel Filter | (1) Average Precision (AP) COCO Synthetic Images = 0.769 (2) Coverage AP = 0.936 (3) Columbia AP = 0.978 |
| Frid-Adar et al., 2018 [13] | GAN is used to increase the Liver Lesions dataset to improve the performance of the CNN model for medical imaging | GAN and CNN | (1) Sensitivity with GAN Augmentation = 85.7% (2) Sensitivity with Classic Augmentation = 78.6% |
| Mirsky et al., 2019 [14] | 888 Scans (LIDC-IDRI Dataset [29] | CT-GAN framework | _ |
| Singh et al., 2022 [17] | Cover Images from OPENi (https://openi.nlm.nih.gov/, accessed on 4 May 2024), USC-SIPI [30], Kaggle [31,32] STARE [33] | Hybrid Domain Watermarking Techniques | Accuracy >= 97% |
| Savaridass et al., 2021 [18] | Medical Image Database [34] | Hybrid Watermarking (Discrete Wavelet Transform -DVT and Singular Value Decomposition-SVD) | Normalized Coefficient > 0.97 |
| Mohammed et al., 2021 [19] | Medical and Watermark Images | Discrete Cosine Transform (DCT) and SVD | Peak Signal to Noise Ratio (PSNR) = 59.98 decibels |
| Thakur et al., 2018 [20] | - | Passive Method, Speed-Up Robust Features–SURF and SVM | - |
| Sharafudeen et al., 2023 [21] | Dermoscopy Images (Real + CGANs Generated Images) | ML Models and Pretrained Deep Learning Models | Accuracy = 91.57% |
| Sharafudeen et.al., 2023 [22] | Dermoscopy Images (Real + CGANs Generated Images) | Vision Transformer | Accuracy = 97.18% |
| Albahli et al., 2023 [23] | CT-GAN Dataset (Lung CT-Scan) | EfficientNetV2-B4 | Accuracy = 85.49% |
| Amiri et al., 2024 [24] | Chest Case Study [25] | Discrete Cosine and Wavelet Transform, Equilibrium Optimization Algorithm | Precision = 90.07% |
| Budhiraja et al., 2022 [35] | Lung Image Database Consortium Image Collection (LIDC-IDRI) [36], CT-GAN Dataset [14] | Based on Convolutional Reservoir Networks (CoRN) | - |
| Sr. # | Real Malignant | Diffusion-Based Fake Malignant |
|---|---|---|
| 1 | 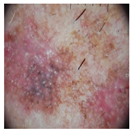 |  |
| 2 |  |  |
| 3 |  |  |
| Model | Layers | Hidden Size | Parameters |
|---|---|---|---|
| ViT Base | 12 | 768 | 86 M |
| ViT Large | 24 | 1024 | 307 M |
| ViT Huge | 32 | 1280 | 632 M |
| Model | Layers (Approx) | Parameters (Approx) |
|---|---|---|
| MobileNetV2 | 53 | 3.4 M |
| EfficientNetB0 | 214 | 5 M |
| Xception | 71 | 22 M |
| InceptionV3 | 159 | 23 M |
| EfficientNetV2B0 | 88 | 7.8 M |
| ResNet152V2 | 152 | 60.2 M |
| VGG19 | 19 | 143.67 M |
| ConvNeXt Base | 170 | 89 M |
| CoAtNetT | 118 | 14 M |
| ResNeSt | 50 | 28 M |
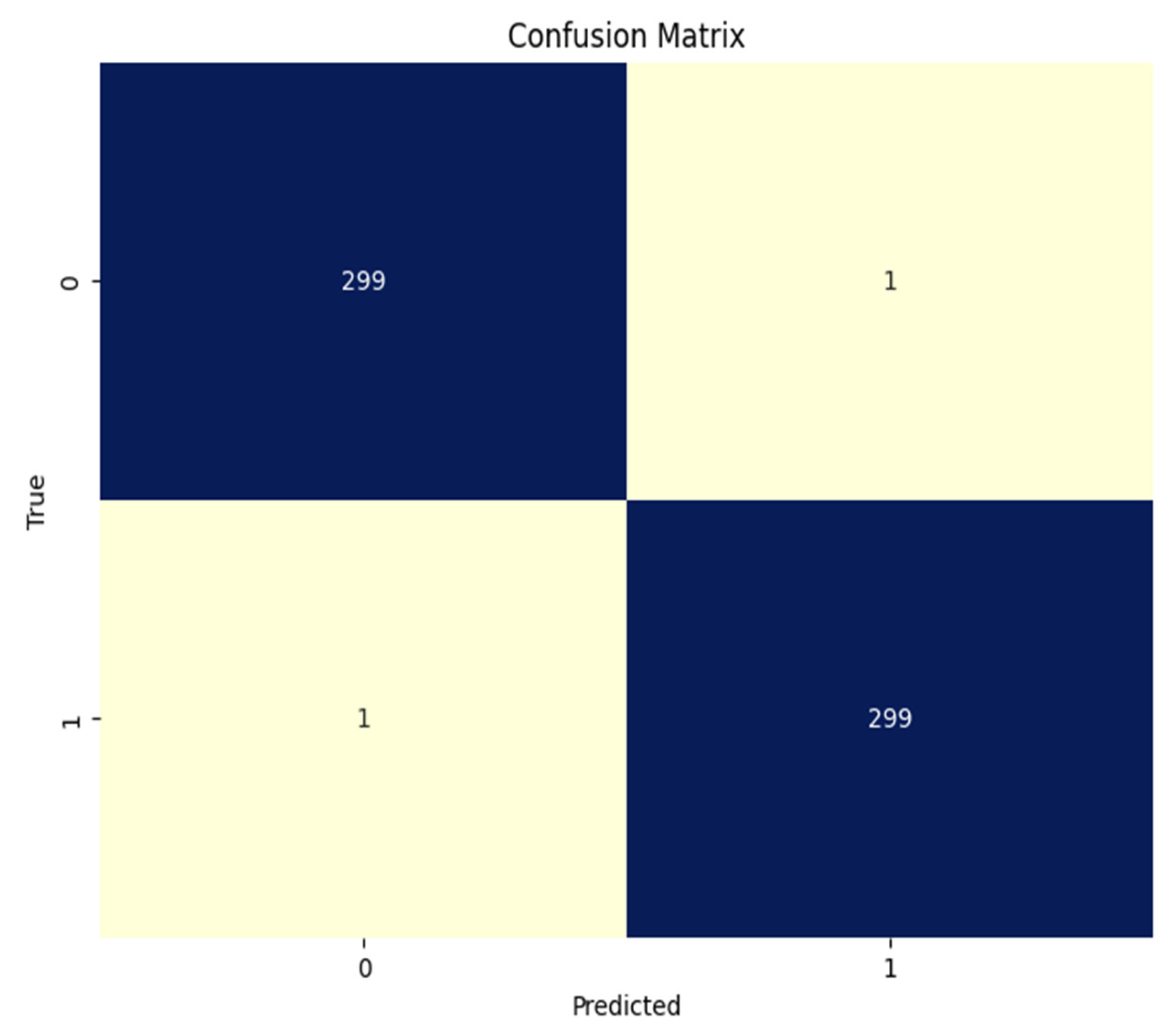
| Precision | Recall | F1 | Support | |
|---|---|---|---|---|
| 1/Real Malignant | 0.9966 | 0.9966 | 0.9966 | 300 |
| 0/Fake Malignant | 0.9966 | 0.9966 | 0.9966 | 300 |
| Macro Average | 0.9966 | 0.9966 | 0.9966 | 600 |
| Weighted Average | 0.9966 | 0.9966 | 0.9966 | 600 |
| Overall Accuracy = 0.9966 (99.66%) | ||||
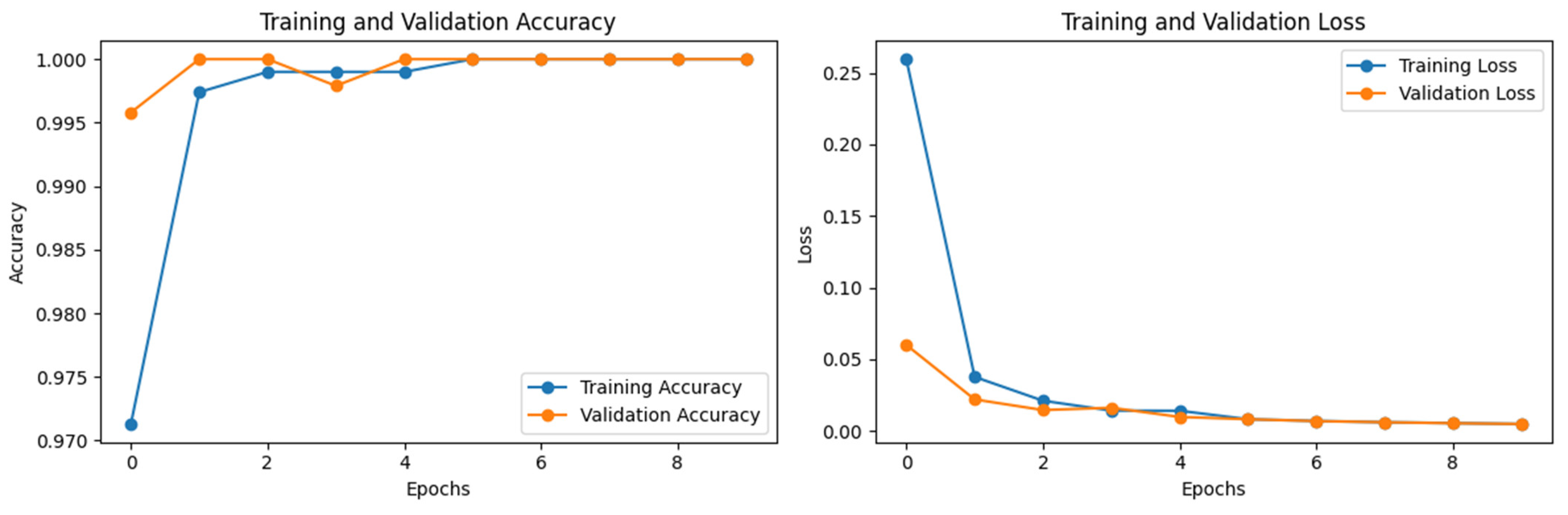
| Model | Trainable | Train Accuracy | Train Loss | Val Accuracy | Val Loss | Test Accuracy | Test Loss |
|---|---|---|---|---|---|---|---|
| InceptionV3 | False | 1.0000 | 0.0022 | 0.9457 | 0.1762 | 0.9449 | 0.1579 |
| InceptionV3 | True | 0.9995 | 0.0017 | 0.9979 | 0.0062 | 0.9966 | 0.0081 |
| MobileNetV2 | False | 1.0000 | 0.0005 | 0.9916 | 0.0578 | 0.9816 | 0.1127 |
| MobileNetV2 | True | 0.9937 | 0.0237 | 0.5115 | 42.97 | 0.5233 | 42.15 |
| EfficientNetB0 | False | 0.5085 | 0.702 | 0.4990 | 0.6229 | 0.500 | 0.6932 |
| EfficientNetB0 | True | 0.9927 | 0.0289 | 0.5010 | 7.6743 | 0.500 | 7.8245 |
| Xception | False | 0.9995 | 0.0056 | 0.9666 | 0.1318 | 0.9499 | 0.1564 |
| Xception | True | 1.0000 | 0.0017 | 0.9979 | 0.0023 | 0.9950 | 0.0110 |
| EfficientNetV2B0 | False | 0.5070 | 0.6987 | 0.5010 | 0.7052 | 0.5000 | 0.7057 |
| EfficientNetV2B0 | True | 0.9951 | 0.0139 | 0.9979 | 0.0140 | 0.9900 | 0.0247 |
| ResNet152V2 | False | 0.9991 | 0.0279 | 0.9520 | 0.1397 | 0.9466 | 0.1792 |
| ResNet152V2 | True | 1.0000 | 0.0014 | 0.9958 | 0.0272 | 0.9933 | 0.02231 |
| VGG19 | False | 0.4997 | 0.7710 | 0.5010 | 0.7697 | 0.5000 | 0.7704 |
| VGG19 | True | 0.9969 | 0.0111 | 0.9812 | 0.0499 | 0.9816 | 0.0717 |
| ConvextNet Base | False | 0.6187 | 0.6199 | 0.6180 | 0.6188 | 0.6349 | 0.6226 |
| ConvextNet Base | True | 1.0000 | 0.0041 | 0.9582 | 0.1328 | 0.9549 | 0.1775 |
| CoAtNetT | False | 0.4997 | 0.6942 | 0.5010 | 0.6939 | 0.5000 | 0.6940 |
| CoAtNetT | True | 0.5023 | 0.7130 | 0.4990 | 0.7168 | 0.5000 | 0.7011 |
| ResNest | False | 0.5003 | 0.7383 | 0.4990 | 0.7391 | 0.5000 | 0.7384 |
| ResNest | True | 0.9065 | 0.4698 | 0.9081 | 0.4671 | 0.8849 | 0.4821 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arshed, M.A.; Mumtaz, S.; Gherghina, Ș.C.; Urooj, N.; Ahmed, S.; Dewi, C. A Deep Learning Model for Detecting Fake Medical Images to Mitigate Financial Insurance Fraud. Computation 2024, 12, 173. https://doi.org/10.3390/computation12090173
Arshed MA, Mumtaz S, Gherghina ȘC, Urooj N, Ahmed S, Dewi C. A Deep Learning Model for Detecting Fake Medical Images to Mitigate Financial Insurance Fraud. Computation. 2024; 12(9):173. https://doi.org/10.3390/computation12090173
Chicago/Turabian StyleArshed, Muhammad Asad, Shahzad Mumtaz, Ștefan Cristian Gherghina, Neelam Urooj, Saeed Ahmed, and Christine Dewi. 2024. "A Deep Learning Model for Detecting Fake Medical Images to Mitigate Financial Insurance Fraud" Computation 12, no. 9: 173. https://doi.org/10.3390/computation12090173