1. Introduction
Access to accurate information in the modern era is a major challenge that organizations have to face. For example, a police officer must know whether he has the right to apply the law when a new situation arises. The social worker must have accurate information about the applicant. The doctor wants to know all the information about the patient who could be treated in any hospital and with any diagnosis.
The aforementioned situations and many other situations require quick access to either a single common source of information, or to a data collection system from various sources. The main problem is that each of the sources of information usually allows obtaining specific information stored in it and this, as a result, entails a loss of understanding of the requested object as a whole. The latter leads to the fact that the information obtained does not reflect the full content of the object. Therefore, it is important to create systems for the automatic collection of data from databases of various types and structures.
Relational databases are the most common forms of data storage. In addition to these databases, there are NoSQL and NewSQL databases. These new forms of databases today are used by more and more companies, including such large ones as Google or Amazon [
1]. Chen et al. [
2] describe fifteen categories of NoSQL databases and some principles and examples for choosing a suitable NoSQL database for different industries. Diogo et al. [
3] analyze and compare the consistency model implementation on five popular NoSQL databases: Redis, Cassandra, MongoDB, Neo4j, and OrientDB.
The problem of combining information is not only that data is collected from databases of various types. Even if the databases are of the same type, the databases can have a different structure. When combining information, it is necessary to analyze the structure of the new database for the combined information. In this part, there is again a problem: the lack of a NoSQL database formalized apparatus for determining the number and composition of collections, in contrast to relational databases with methodologies based on relational algebra and functional dependencies. Each database administrator analyzes the structure and composition of the future database based on their experience and recommendations of leading experts.
The aim of our research was to find a method that allows creating the optimal collection structure with embedded documents with an orientation to future database queries. We have created such a method. Our research has shown that this method can also be used to transform databases such as a family of columns and even relational databases. The purpose of this article is to familiarize readers with this method and demonstrate its work on document databases, as these databases are very often used in practice and well described in a large number of publications, for example, [
4,
5,
6,
7].
We propose a new formalized method for constructing a NoSQL document database, taking into account the structure of queries planned for execution to the database. This method consists of steps and rules that allow creating a database structure that will speed up database queries and make the database smaller by storing fewer duplicates.
The method has two key properties: it takes into account the structure of queries and the relationship between database objects. The first property allows not to use “join” operations in database queries. The second property, due to the organization of embedded documents, reduces the number of duplicate data in the database, and makes the database smaller. The method can be used when creating new databases or restructuring existing document databases, as well as when converting relational databases to document databases.
The article is structured as follows. The second section provides an overview of related work, shows the diversity of existing solutions and their focus. In the third section, based on the analysis of existing solutions, it shows the relevance of the task of finding a formalized method for converting data from one format to another, taking into account the structure of queries. The fourth section provides a methodology for transforming the data structure depending on the initial state of the database, the fifth section describes a method for converting data from one format to another, taking into account the structure of queries and relationships between objects. The sixth section presents the results of testing the method. In conclusion, the research results are summarized and the eighth section contains the main directions for continuing research.
2. Related Work
Database consolidation is an important task in many areas of database applications, such as heterogeneous database integration, e-commerce, data warehousing, or semantic query processing. A lot of research has been and is being done in the world today by individual scientists as well as research organizations and, as a result, various solutions are offered for this problem. Among the known results in the field of database consolidation are the systems SemInt [
8,
9], Learning Source Descriptions (LSD) in [
10,
11], Semantic Knowledge Articulation Tool (SKAT) [
12], TranScm [
13], Palopoli in [
14], ARTEMIS [
15,
16], and Mediator environment for Multiple Information Sources (MOMIS) [
17,
18]. However, all of these systems focus on consolidating relational databases and do not solve the problem of integrating a relational database with NoSQL or NewSQL. In our research, we created a method that can be used to consolidate relational databases and NoSQL with the resulting NoSQL database.
It should be noted that many studies over the past thirty years have been devoted to the problems of transforming a relational database schema [
19,
20]. No matter how the scheme of the relational database has been improved, it has its limitations, which contributed to the development of other forms of databases, such as key-value and their varieties [
4,
5,
6,
7] or graph databases [
21].
The integration of relational databases and NoSQL is a new problem that is relevant to the urgency of the solution and studied little today.
Chickerur [
22] proposed a way to transfer relational databases to MongoDB by converting tables to CSV files and import the converted files using the built-in MongoDB command. He also compared the performance of MySQL and MongoDB using queries to add, update, and delete data from an airline database. Performance tests showed that MongoDB performs queries well on large amounts of data. However, this method only directly translates tables into collections without regard to the relationships between tables. MongoDB performs worse queries on a set of collections. Our method differs in that it takes into account the structure of database queries.
Hanine et al. [
23] developed an approach to transferring data from relational databases to MongoDB, which consists of three stages: extracting data from the source database, converting data, and transferring the converted data to the target database. Unfortunately, this approach does not solve the problem of the dependence of query performance on database schemas and relationships between objects. In our approach, we take into account the relationships and show that query performance increases from this.
Li et al. [
24] proposed a model for converting a relational schema into a NoSQL database schema based on a data structure and data queries. This model has a three-phase structure: a description of the structure of the relational database and the requirements for data queries; query-oriented data modeling for NoSQL database; a query-oriented description of the NoSQL database schema. In this model, there is no allowance for dependencies between database objects during the transition from a relational database to a NoSQL database. The new NoSQL database structure is based only on metadata about objects and queries. The method described in [
25] is also based on information about queries. In our approach, we show how relationships between objects affect the structure of a document with embedded documents.
Zhao et al. [
26] proposed an approach to data migration from a relational database to a NoSQL database based on relational algebra methods. In this study, the authors propose adapting the theory and methods of relational algebra to the development of the MongoDB database schema. For the same purposes, we use set theory, which allows us to construct formalized rules for translating a relational database into a MongoDB database.
Alotaibi et al. [
27] propose six rules for translating a relational database into a NoSQL database of three types (Column-Based, Document-Based, and Graph-Based). Moreover, in all three types, NoSQL database subspecies are considered. Each rule is associated with the type of relationship between the tables (1-1, 1-M, M-M) or with a special operation carried out in one of the tables (for example, aggregation). This article demonstrates how easy it is to translate a relational database into NoSQL if it is possible to ignore the structure of the queries. The problem is that NoSQL databases are query-specific. Those queries that refer to several tables in the relational database will work very slowly in the NoSQL database, if there was a direct translation of the relational database into NoSQL. The main problem is the lack of NoSQL databases of the operations of join data sets (collections, tables, families, etc.). The authors solve this problem by creating a single collection in the NoSQL database. This is not a good solution: combine all the tables into one collection. This leads to an increase in data volume and a memory problem. At the end of our article, we show, based on the results of testing, that our approach based on building a certain number of collections is better than the approach based on creating a single collection.
Celesti et al. [
28] accelerate queries that use operations «join» at the application level. They implement their approach also in MongoDB. Their approach is good because it allows saving data models. This approach will not be very good in case of data consolidation, when the same data will appear in different models in one way or another and, as a result, during consolidation, structure modification will still be necessary. We solve this problem in our approach. When consolidating to an existing database of another database, objects and new object attributes appear in the current database. Therefore, database queries in the previous form cannot be performed or are executed for a very long time. The method proposed by us allows restructuring the database schema so that all queries are executed quickly.
One possible solution is the NoSQLayer software module, which can consist of two modules [
29,
30]: a data transfer module that identifies and analyzes the NoSQL database schema and converts it into a relational database schema, and a data mapping module that allows users to create queries in SQL, selecting data from the NoSQL database. This program is not intended for data migration and many queries work more slowly than if there were direct access to the NoSQL database in the built-in query language [
31]. In our approach, we optimize the database query processing using the internal query language.
Feng et al. [
32] developed an approach to transforming UML class diagrams into a Cassandra database schema. This approach does not provide for optimizing the NoSQL schema for executing queries. Currently, we tested and proved that the query structure when creating a collection affects performance in the MongoDB database, and we are currently testing our approach on Cassandra.
Kartinis et al. [
33] provided a technology that allows translating relational database systems into document-oriented databases. This technology consists of two stages: description of the data of the existing relational database and transfer to the NoSQL database. This technology does not provide for optimizing the NoSQL schema for queries. Our method takes into account the relationships between tables to create embedded documents and reduce the size of the database.
According to [
34], relations in a document-oriented database model can be represented in the form of embedded documents and relationships between these documents. However, firstly, embedded documents can be used for a limited amount of data, and secondly, it remains a problem to determine the form of embedding. The studies described in [
34] confirm this. A positive characteristic of our method is not only its ability to make decisions about the need to use embedded documents, but, very importantly, the definition of the form of embedded documents and the place where they should be embedded.
Gu et al. [
35] applied the traditional rules of normalizing the relational database schema theory (normal form theorems: second and third normal forms (2NF, 3NF) and the Boyce–Codd normal form (BCNF)) to develop the MongoDB schema. For example, if there is a functional relationship between two attributes, then both data attributes are converted to a single data item in MongoDB. The same principle applies to partial and transitive dependencies. Testing showed that, as a result of applying this approach, it is possible to actually increase query performance for related database objects. However, testing was carried out on a small scheme. The approach does not take into account relationships “Many to Many”, primary keys and foreign keys. In this article, we show how relationships of this type between objects can be taken into account.
Thus, the analysis of works in the field of optimizing the structure of NoSQL databases, in particular, document databases, showed that there are many different approaches to translating databases, but there is no integrated approach that would simultaneously take into account the types of relationships between objects and the structure of queries to objects databases and would allow building such a number of collections and such an internal structure that queries to select data from a document database are executed as quickly as possible.
In this article, examples of tests of the proposed method used MongoDB databases of various structures and sizes.
MongoDB is a database that is used very often in various subject areas. In the literature, there are many good methodologies for its application for various practical problems. For example, Wang et al. [
36] describe the sharding technology of MongoDB and the new approach to managing large-scale remote sensing data; Marrara et al. [
37] describe a method for constructing blind queries to JSON document stores using MongoDB as an example; the method for processing queries in the space-time range based on the index using the example of a large database MongoDB is described by Qian et al. [
38]. Many works are devoted to describing the application of the MongoDB system in various subject areas: to create a prototype of a three-dimensional cadastral system and three-dimensional visualization [
39]; predicting the consumed heat capacity of buildings [
40], to control groundwater flow and contaminant transport [
41], in a personalized healthcare monitoring system [
42] and, of course, IoT applications [
43].
3. Formulation of the Problem
Transferring data between different data sources is a necessary step for many data mining tasks. However, the differences between the storage methods in the two relational and non-relational (NoSQL) forms pose many problems in the areas of data translation, transformation, and consolidation. One of these problems is matching NoSQL collections to relational database tables. For translation, transformation, and consolidation of various types of databases, it is also necessary to take into account the lack of structure in some databases and the features of the query language.
For relational databases, there are methods for creating relationships based on declared functional dependencies between attributes. For NoSQL and NewSQL databases, such formalized methods do not exist, only recommendations. For example, when converting a relational database into a document database, the database administrator has little benefit from knowing the relational database schema. He needs to consider many options for the form of a document database in order to choose the best one.
In this case, the following options for formatting are possible (the list is not complete):
To each table in a relational database to assign a separate collection of documents in MongoDB;
From all tables in the relational database to make one collection of documents in MongoDB, by applying the join operation to the tables;
To create such a set of document collections in MongoDB, so that they most fully fit the queries being executed.
These three options can be effective with one database design and not be effective with another database. In our article [
25], we presented a method based on set theory, which allows determining which of the three options will be effective. In this article, we show how it is possible to make the selected collection structure even more effective if you create collections with attached documents. At the same time, the choice of the number of collections and the determination of the contents of the collections (with embedded documents or without embedded documents) is based on such parameters as: attributes of objects in the database, structure of queries to the database and types of relationships between database objects.
4. The Methodology for Determining Collections in a Document Database
In the method of creating collections without embedded documents, the new MongoDB database is created on the basis of the existing relational database. We have shown that the use of a formalized set-based approach helps to find the optimal collection of collections in MongoDB based on information about the executed queries to the database.
If the new MongoDB database is not created from a relational database then it is necessary to use information about the attributes of objects that are planned to be stored in the database; apply relational algebra methods to these attributes and create a database schema that satisfies the normal form.
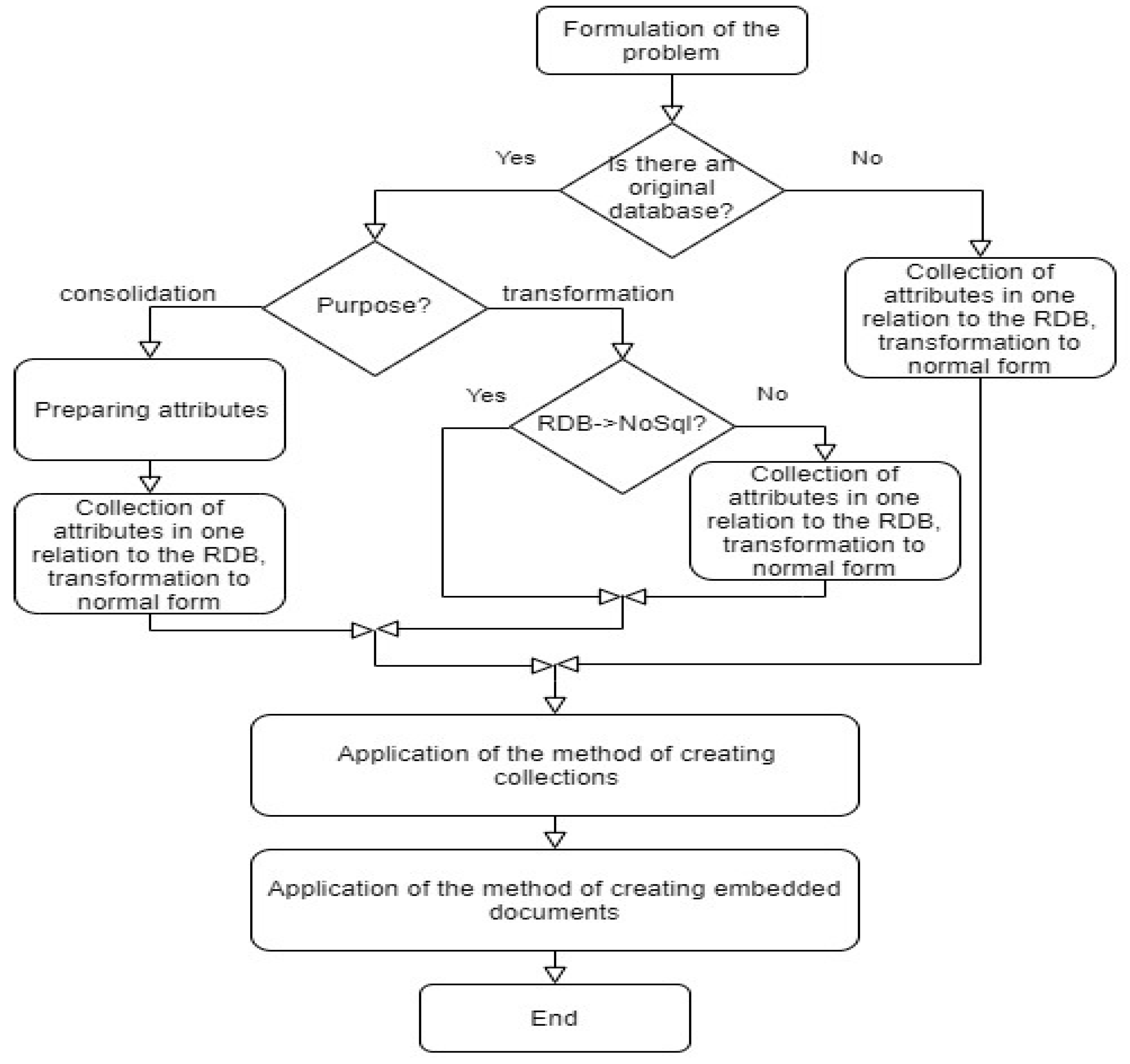
The methodology for preparing input data for applying the method of searching for the optimal form of a document database is shown in
Figure 1.
Figure 1 shows that if the final result should be a document database, then for optimal performance of query execution it is necessary to apply our two methods sequentially to the set of attributes of database objects:
These two methods are applicable when translating a relational database into a document database, consolidation of a relational database with a document database, document database restructuring, and creating a new document database.
To determine the need to create embedded documents, it is better if the scheme is initially reduced to normal form using relational algebra. This will allow compromising between query performance and the minimum amount of memory for storing data.
To determine the structure of embedded documents, it is necessary to have information about the relationships between objects. One way to obtain this information is to search for functional dependencies between the attributes of objects, then construct a relational database schema and bring the schema to normal form using the relational algebra [
44]. At the same time, the data remain in the same form; only the schemes are studied. Therefore, this process is not time-consuming and does not affect data. The relational database schema is intended in this case to describe the relationships between objects in order to understand which documents should be embedded.
5. Methods for Determining the Structure of Embedded Documents in the Database
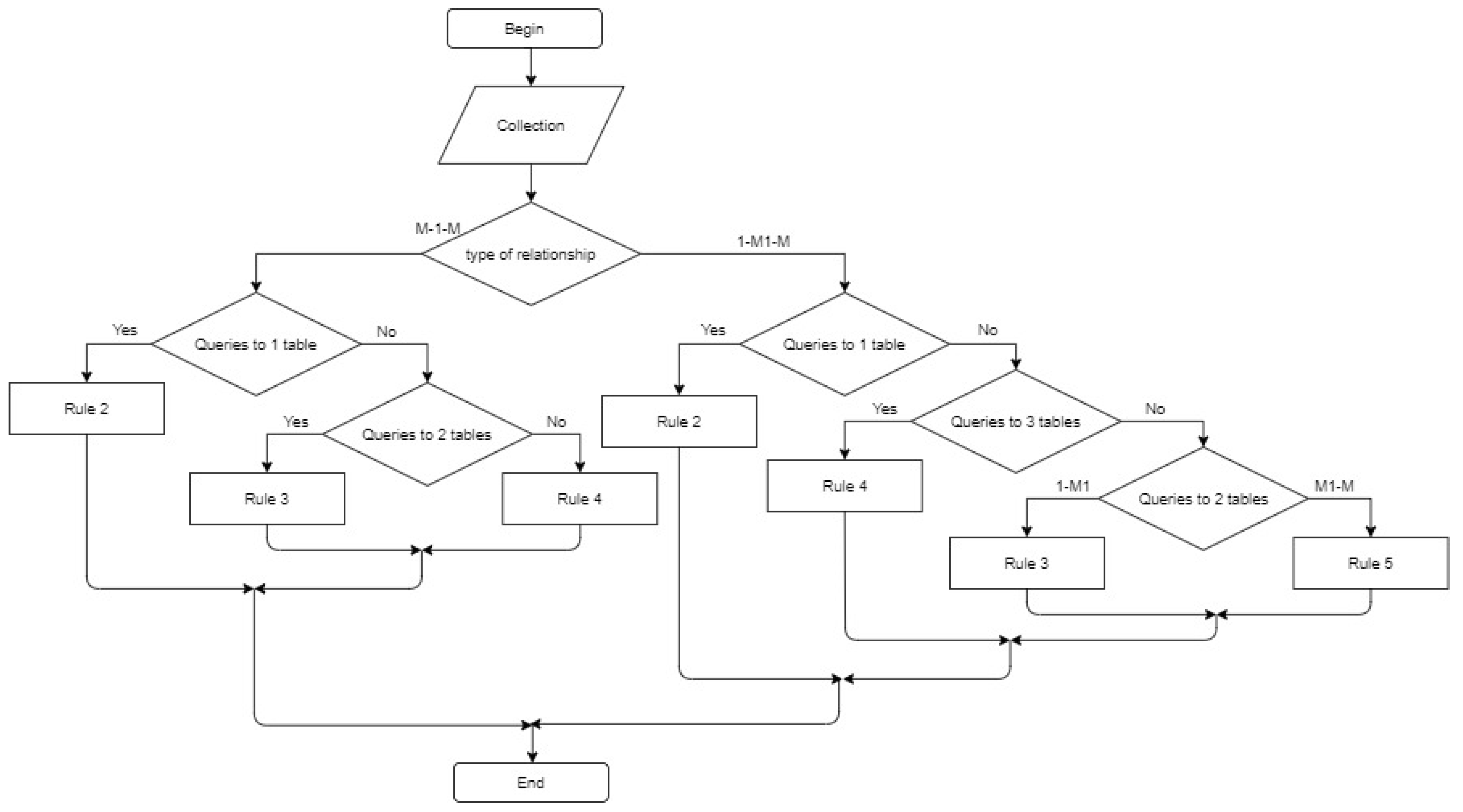
The method for determining the number and order of embedded documents is based on the type of relationships between tables in the relational model. Depending on the type of link, it is necessary to apply a specific rule to create a document in the collection.
The first step in applying this method as shown in
Figure 1 it is necessary to collect all the attributes that are in the document database into one collection (an analog of many fields of one table). Then, convert the schema of this table to normal form (preferably BCNF). The input to the search for the structure and number of collections in the document database is a set of these tables.
Below we consider the main types of relationships (one-to-one «», one-to-many «», many-to-many «») for two tables and three tables. The rules for the three tables are based on the rules for two tables. The rules for a model of more than three tables will be based on the rules for two and three tables, so it makes no sense to consider them.
We show that when applying the method for determining the number of collections from [
25], embedded documents can only exist when there is a
relationship between tables whose attributes are included in the collection. Therefore, for two tables, only one rule is deduced.
When determining the form of embedded documents based on three tables, the sequence of relationships between the tables and the number of primary and secondary tables is important.
5.1. Defining Embedded Documents for Two Tables
This subsection presents the rules for determining the form of embedded documents for document database collections consisting of documents compiled on the basis of a two-table relational database schema. At the beginning, the necessary information on input data is given, on the basis of which a decision is made on the need and form of embedded documents, then the rules and an explanation of these rules are given.
Input data:
Queries in the sets
and
are queries only for data selection, i.e., in terms of SQL, queries of the form “select ... from … where ...”. These queries can have multi-level subqueries, there can be operations of aggregation, grouping, sorting. In them, in terms of SQL, there can also be operations of joining, intersecting, and subtracting tables, since the method [
25] was previously applied. Under database queries are not considered database queries to delete, modify, and insert data.
Output data: Collection .
Rule 1. An embedded document should consist of attributes of the set:
and the new structure of the
collection has the form:
where
and
are the names of the new keys for the embedded documents.
Explanation. The principle of creating embedded documents: to group those attributes that are in the queries executed simultaneously to two tables. These attributes are the set . However, the remaining attributes from table , which are in the collection , are obviously those attributes that are included only in queries to table , i.e., these are attributes from the sets . Among the sets there may be sets that contain the attributes . To separate them from the embedded document is to complicate the query. Therefore, they must be subtracted from the sets . Thus, the set , these are the attributes from the -th query , which are only in queries to the table and at the same time contain attributes from queries if . In total, such attributes will be . These attributes must be added to the embedded document along with the attributes .
If attributes from the set in the collection that are not included in the embedded document are left in the main document, this means increasing the amount of data in the collection. Therefore, they must be collected in a separate subdocument. These attributes can be included in the queries of the set along with other attributes that are included in the first embedded document. These attributes are set: .
Thus: the attributes from (1) will be included in the embedded document.
Note 1. If , then the new collection structure will have the form: . It is this option that is often implemented when translating tables of a relational database with relationships in MongoDB according to the principle: all tables must be assigned one collection.
Note 2. Above, only the relation of tables of type 1-M was considered. If the relational database schema initially satisfied the normal form of BCNF, 3NF, or 4NF, then there can be no other relationships between tables and . If for some reason, such as the denormalization of the relational database schema, this relationship exists, then:
There can be no embedded documents for relationship between tables of the database of type , due to the correspondence to each record from table of a single record from table .
For an relationship, embedded documents are built on the same principle as for relationship.
5.2. Defining Embedded Documents for Three Tables Not Interconnected Sequentially
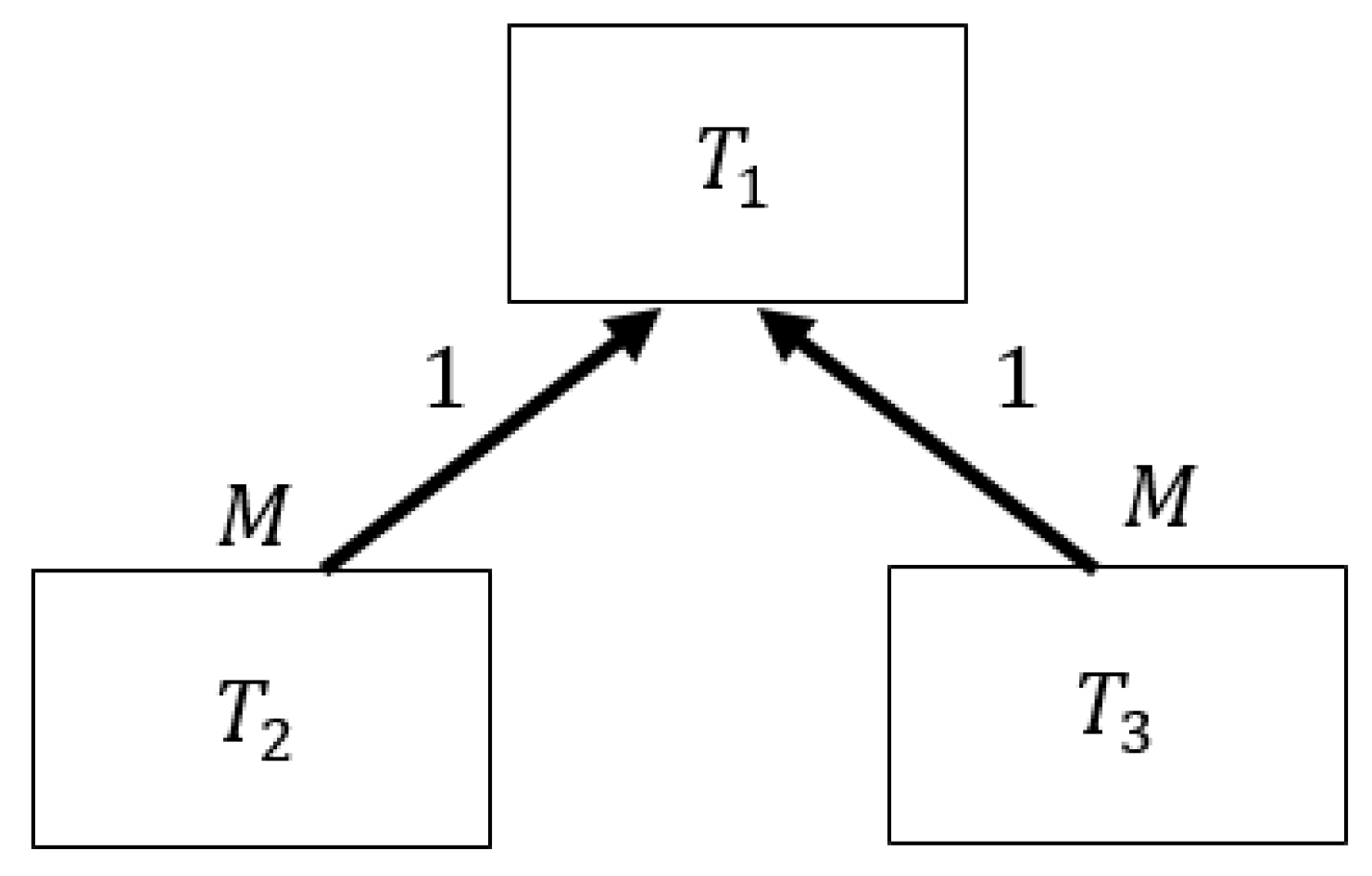
This subsection presents the rules for determining the form of embedded documents for document database collections based on a three-table relational database schema. In this database schema, one table is the main table, and two other tables are associated with this table.
Input data:
Three tables of the relational model, on the basis of which the non-relational document database schema is built:
,
, and
:
where
is the
-th field of the
-th table,
is the number of fields in relation to
, is the number of fields in the table
, and
is the number of fields in the table
.
By the method of defining collections in a document database, a collection has been obtained:
Tables
,
, and
have relationships of type
:
or more schematically in
Figure 2.
In the tables the keys belonging to this collection are defined:
Output data: Collection .
Rule 2. If
is the query that refers only to the attributes of one table, for Example
, then from
Section 5.1, it follows that there cannot be embedded documents in this collection.
Rule 3. If
is the query that refers to the attributes of two tables
,
or
,
, then in
Section 5.1, it is shown that the new structure of the collection
will have the form (1).
Rule 4. If
is the database query that refers to the attributes of all three tables
,
, and
, then the new structure of the collection
will have the form:
where
are the names of new keys for embedded documents; attributes
—these are all attributes of the table
included in queries of type
for the collection
; attributes
are all attributes of the table
included in queries of type
to the collection
,
is the number of queries of type
,
is the set of attributes that are not included in
of all the attributes of table
included in the collection
,
is the set of attributes that are not included in
of all the attributes of table
included in the collection
.
5.3. Defining Embedded Documents for Three Tables Interconnected Sequentially
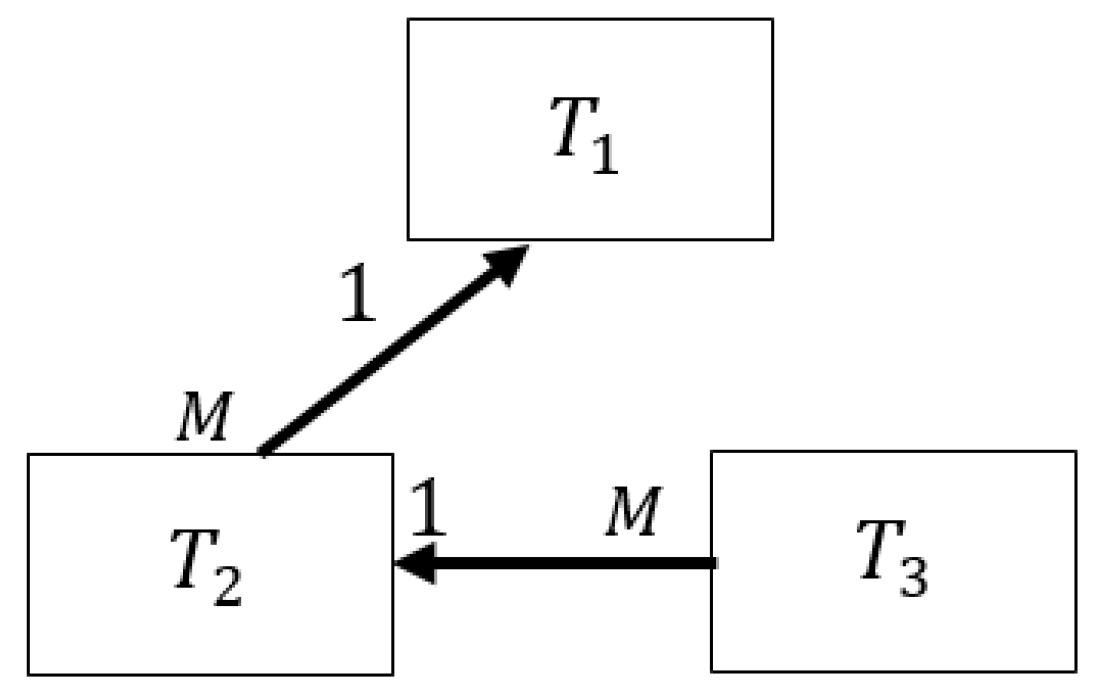
This section presents the rules for determining the form of embedded documents for document database collections based on a three-table relational database schema. Unlike the previous section in this database schema, the tables are connected in series: the first table is the main one in conjunction with the second table, the second table is the main one in conjunction with the third table.
Input data:
Three tables of the relational model, on the basis of which the non-relational document database schema is built:
,
, and
:
where
is the
-th field of the
-th table,
is the number of fields in relation to
, is the number of fields in the table
, and
is the number of fields in the table
.
By the method of defining collections in a document database, a collection has been obtained:
Tables
,
, and
have relationships of type
:
or more schematically in
Figure 3.
In the tables the keys belonging to this collection are defined:
Output data: Collection .
Consider the possible query options for the collection :
is the database query that refers only to the attributes of one table, for example, .
This case is considered in
Section 5.1 when defining embedded documents for a collection constructed from the attributes of two tables and it is shown that there cannot be embedded documents in this collection.
—a query that refers to the attributes of two tables , , or , .
This case is considered in
Section 5.1 when defining embedded documents for a collection built from the attributes of two tables and it is shown that the new structure of the collection
will take the form according to Rule 1.
—a query that refers to the attributes of all three tables , and .
This case is a generalization of Case B from two tables to three tables. In this case, the new structure of the collection will have the form:
Rule 5.
where
are the names of new keys for embedded documents; attributes
—these are all attributes of the table
included in queries of type
for the collection
; attributes
are all attributes of the table
included in queries of type
to the collection
,
is the number of queries of type
,
is the set of attributes that are not included in
of all the attributes of table
included in the collection
, and
is the set of attributes that are not included in
of all the attributes of table
included in the collection
.
—a query that refers to the attributes of two tables and .
Because database query to the attributes of tables and can be performed only through the attributes of the table , then this case as a result reduces to Case C).
Note 3. If the collection is created for more than three tables, then the form of embedded documents is determined according to Rules 1–5.
The scheme for applying the rules for the three tables is given in
Appendix A.
6. Testing the Effectiveness of the Methodology for Determining the Structure of Embedded Documents in a Document Database
To test the effectiveness of the developed methodology for determining the structure of embedded documents in document databases, we performed queries to databases filled with the same attribute values, but having different collection structures: with and without embedded documents.
Testing was carried out on a personal computer: Intel (R) Core (TM) i7-8700 CPU @ 3.20GHz, with Windows operating system, MySQL Community Server Version 8.0.17, MongoDB Community Server v. 4.0.5.
During the experiments, all additional functions, such as cache, indexes, and multi-threading, were disabled. The used data is synthetic. Each database query is executed 25 times. The difference in the execution time of each of 25 times for one query varied within e = 0.01 ms (for example: t1 = 0.3526 ms, t2 = 0.3401 ms, etc.). The execution time of each database query, given in all tables below, is the average execution time of a given query 25 times.
Below are three examples from the testing.
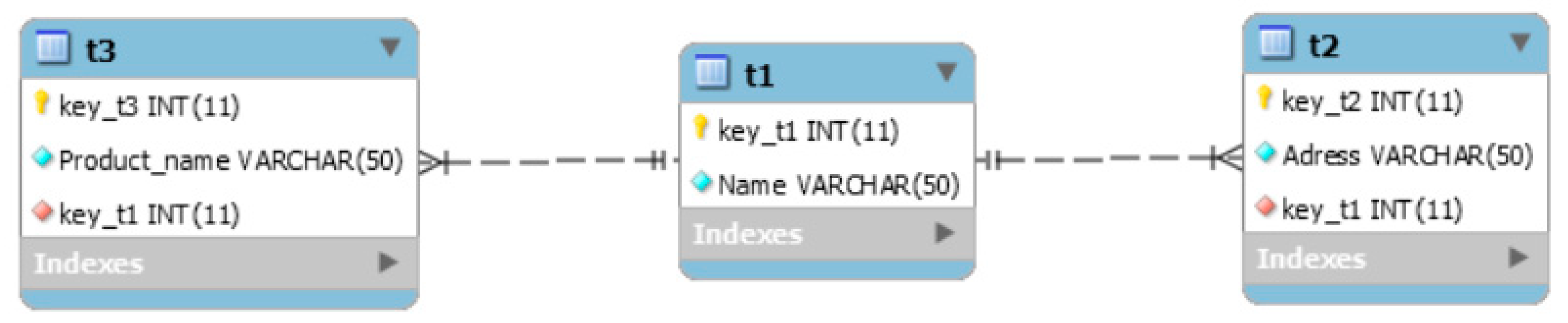
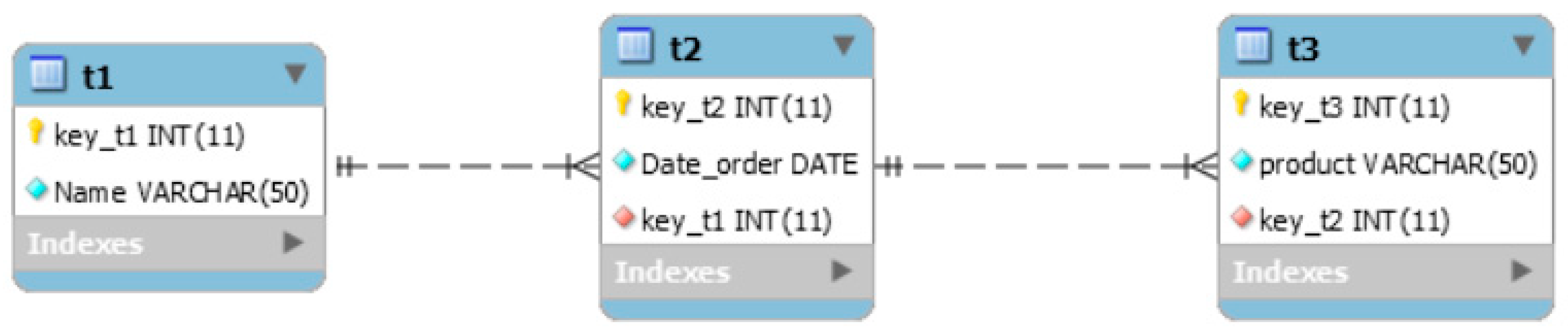
Example 1. To establish relationships between objects in the MongoDB database, it was built a schema of a relational database consisting of three tables, one of which is the main and two associated with it (
Figure 4). Data volume: main table
—10,000 records, related tables:
—100,000 records,
—100,000 records.
The database schema shown in
Figure 4 has two MongoDB databases in accordance with it:
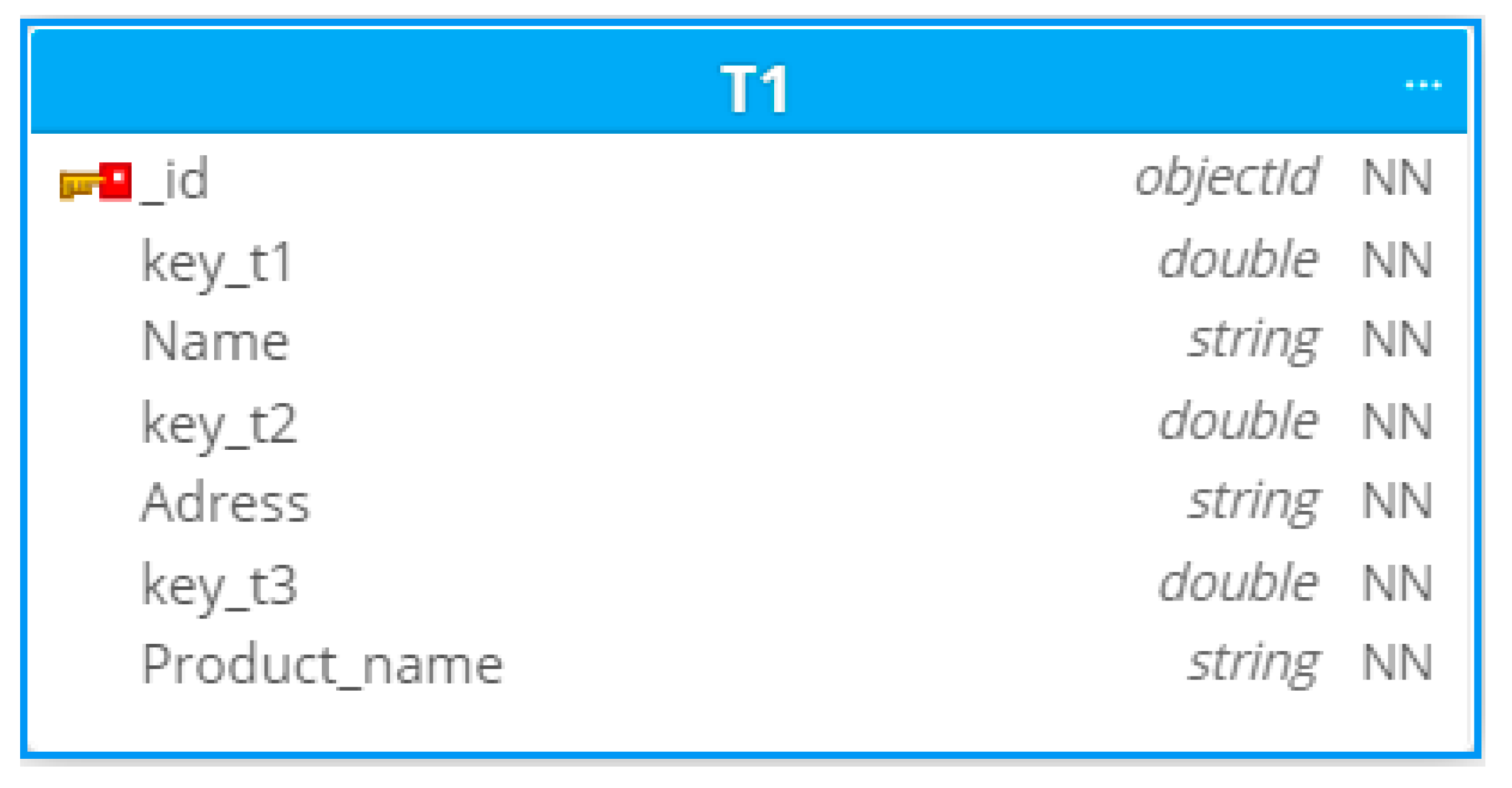
- (1).
A database consisting of one collection
, including all fields of tables
,
and
. A fragment of this collection is shown in
Figure 5.
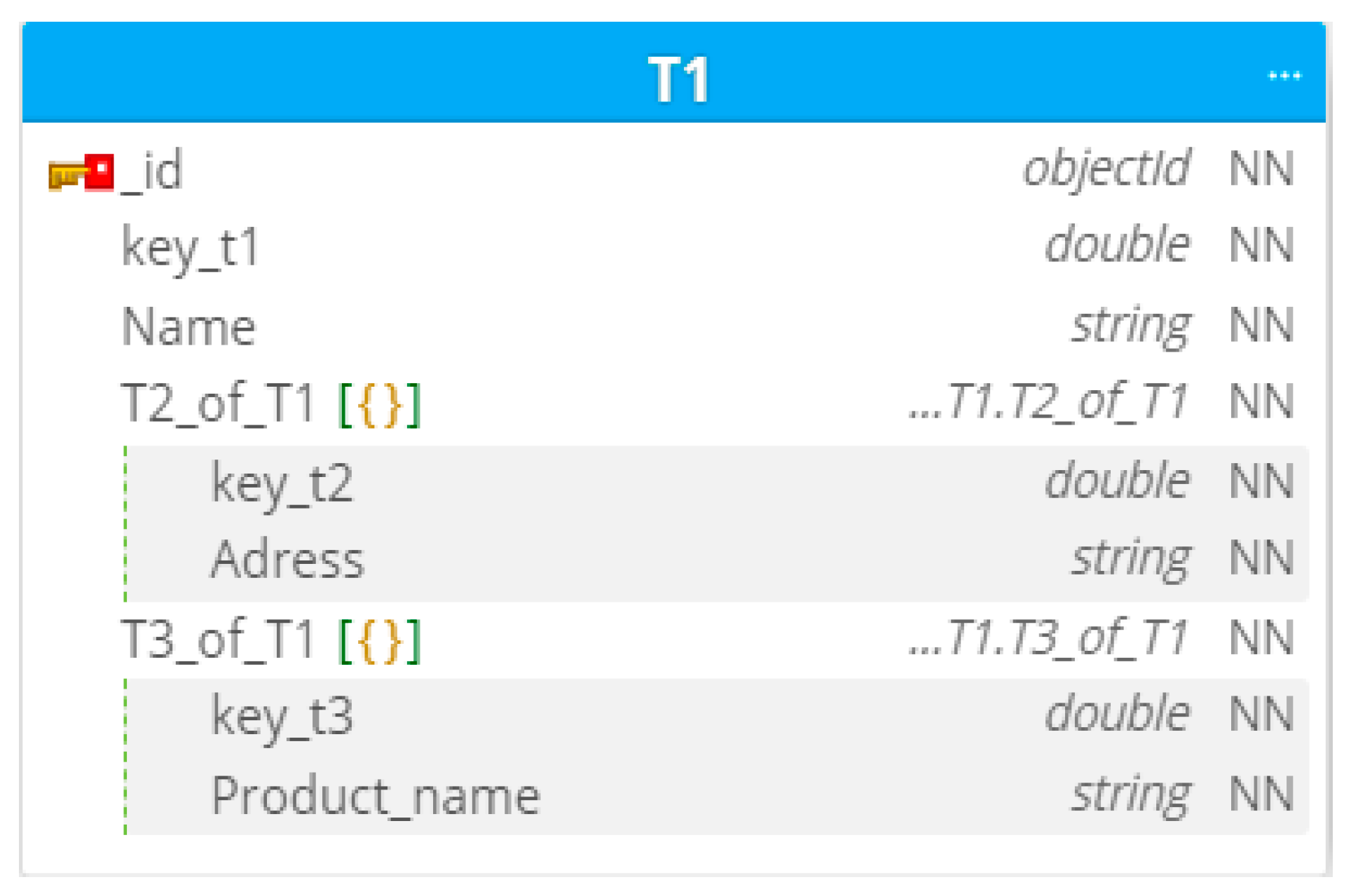
- (2).
The database, built in accordance with the Rules 1–4 described in
Section 5. The new structure of the collection
’ will have the form:
The structure of this collection is shown in
Figure 6.
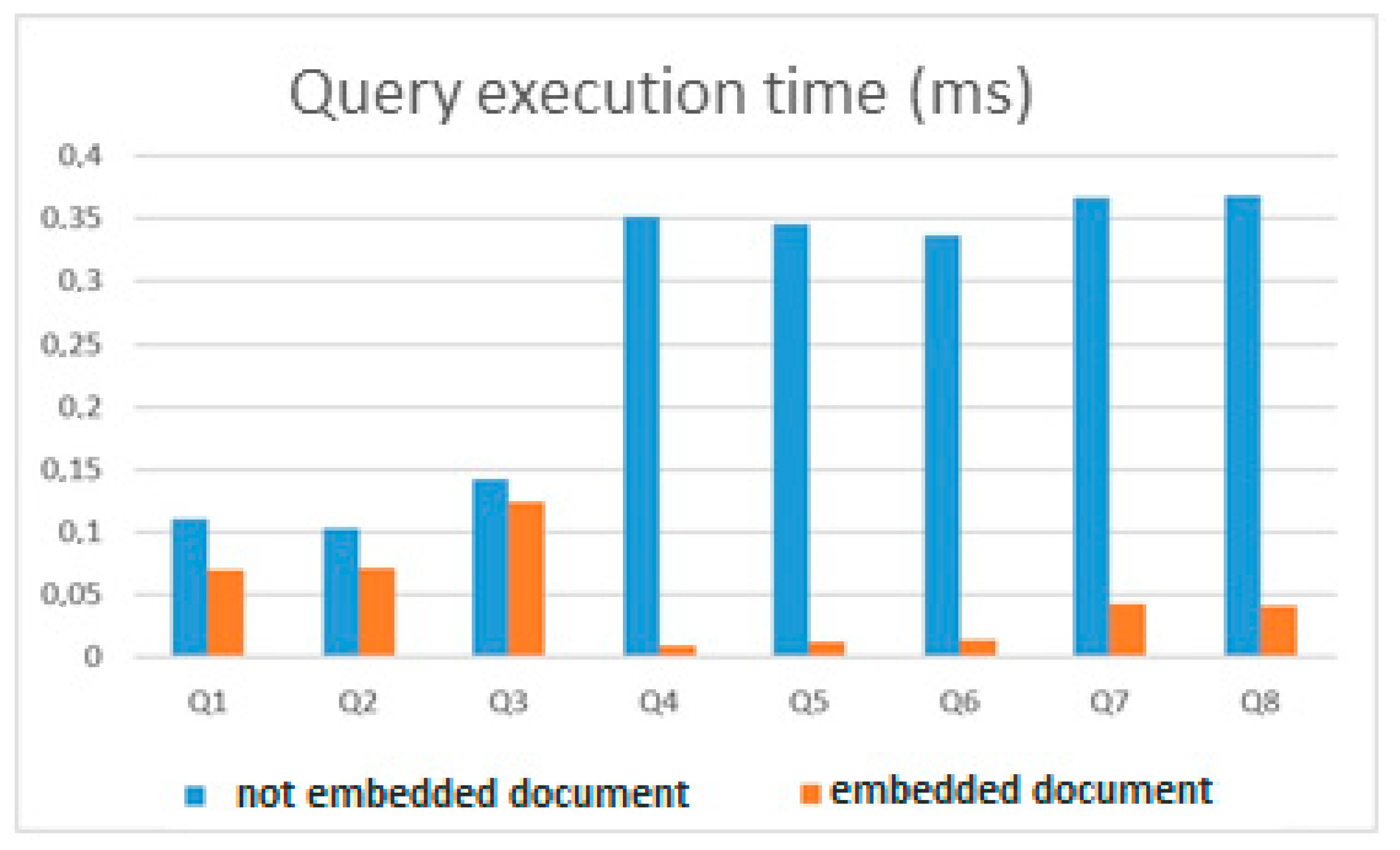
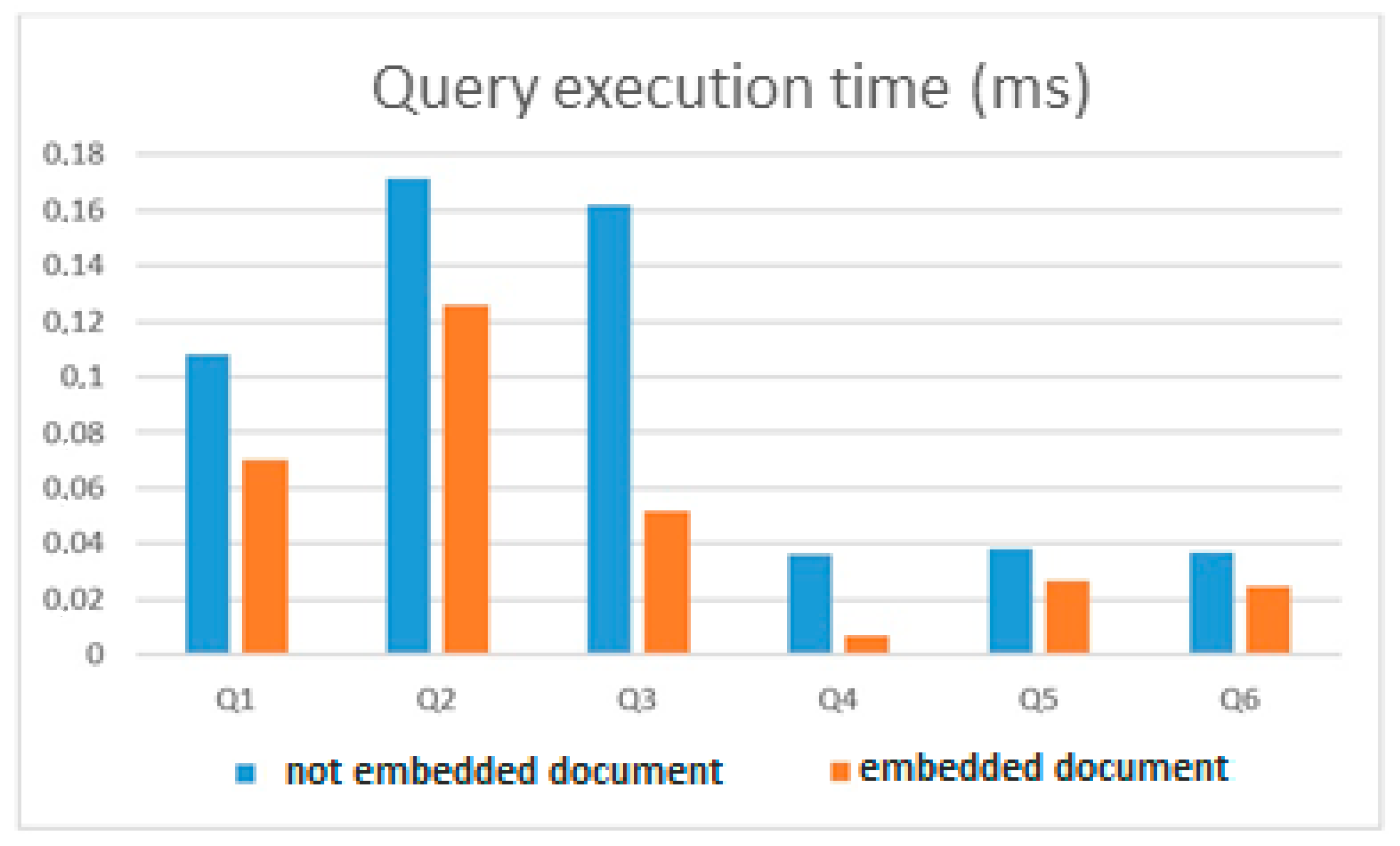
To test these two variants of the MongoDB database, eight queries were executed, differing in their structure. The average value of the query execution time is presented in
Table 1 and in
Figure 7.
Example 2. To establish relationships between objects in the MongoDB database, it was built a schema of a relational database consisting of three tables connected in series (
Figure 8). Data volume: main table
—10,000 records,
—60,000 records,
—100,000 records. The volume of
in this example is less than in Example 1. This is because
in Example 1 was a secondary table, but in this example,
is a secondary table for
and the main for
. Therefore, the data volume in it should be more than in
and less than in
.
Let two MongoDB databases be set in accordance with the database schema shown in
Figure 8:
- (1).
A database consisting of one collection
, composed of all the fields of tables
,
, and
. A fragment of this collection is shown in
Figure 8.
- (2).
The database, built in accordance with Rules 1–4 described in
Section 5. The new structure of the collection
’ will have the form:
The structure of this collection is shown in
Figure 9.
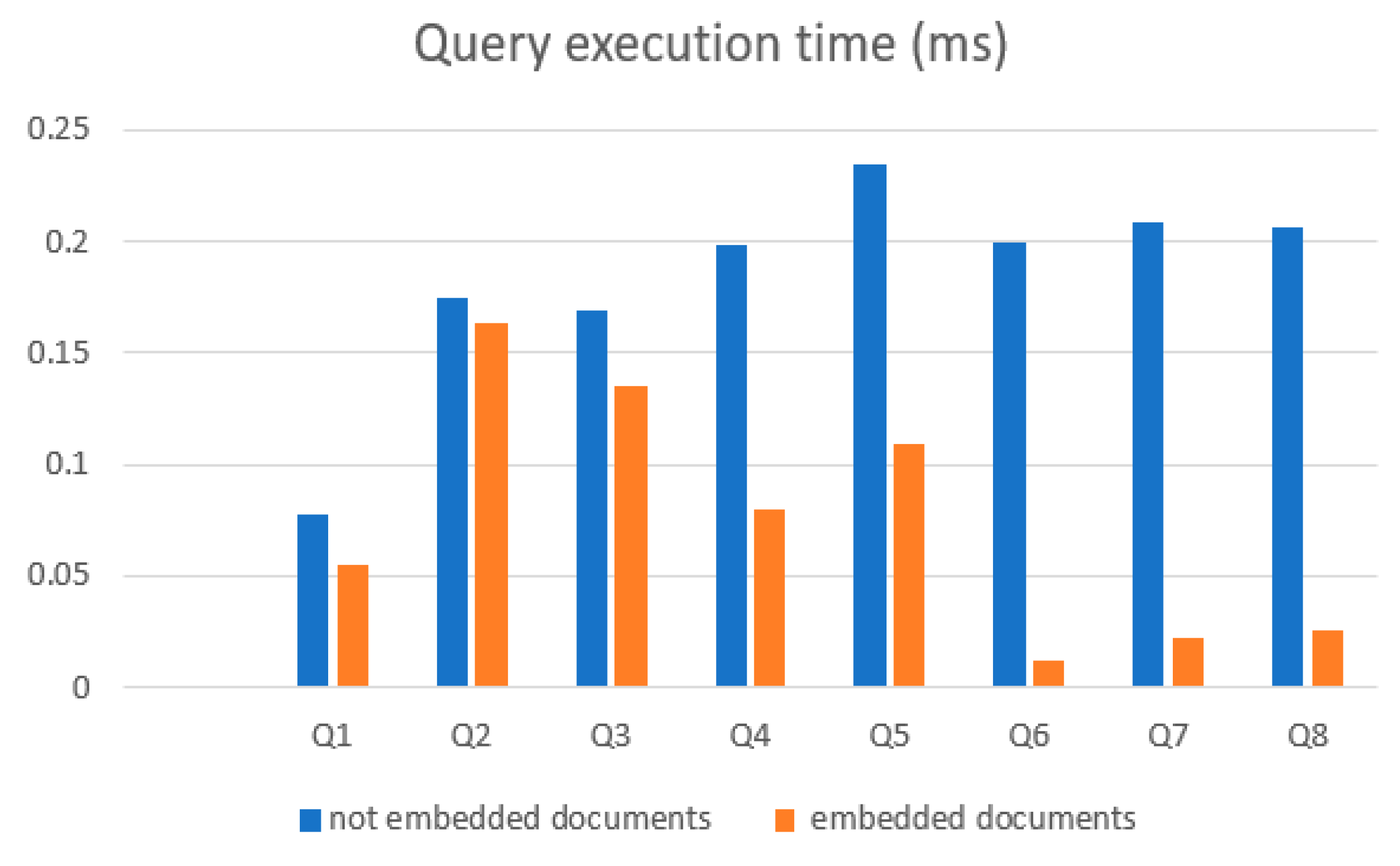
To test these two variants of the MongoDB database, six queries were executed, differing in their structure. The average value of the query execution time is presented in
Table 2 and in
Figure 10.
Example 3. To establish relationships between objects in the MongoDB database, it was built a schema of a relational database consisting of four tables. Two tables are the main and two tables are secondary (
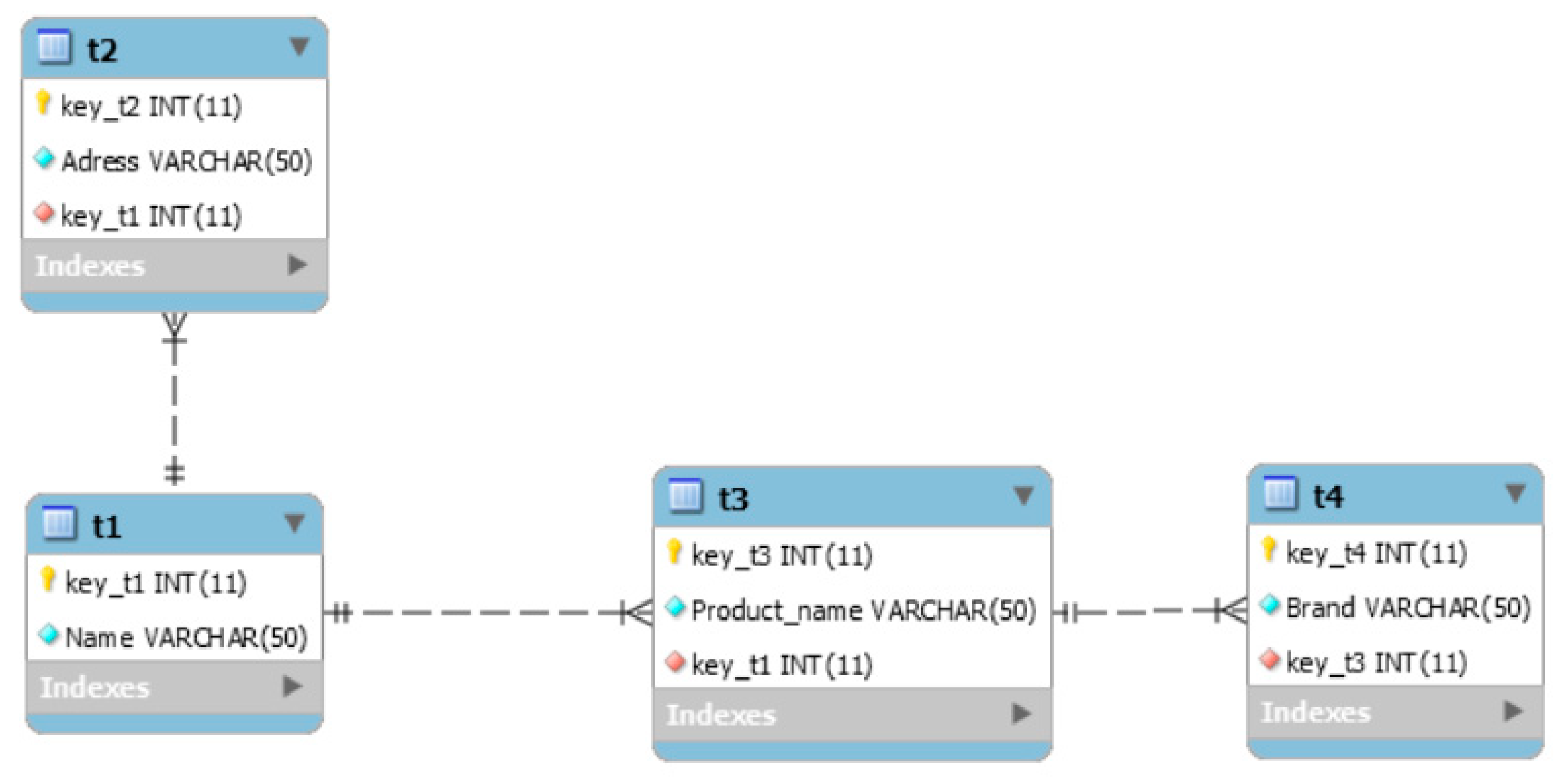
Figure 11). Data volume: T1—15,000 records, T2—50,000 records, T3—110,000 records, and T4—200,000 records.
Let two MongoDB databases be set in accordance with the database schema shown in
Figure 8:
- (1).
A database consisting of one collection
, composed of all the fields of tables
,
,
and
. A fragment of this collection is shown in
Figure 8.
- (2).
The database, built in accordance with Rules 1–4 described in
Section 5. The new structure of the collection
’ will have the form:
The structure of this collection is shown in
Figure 12.
To test these two variants of the MongoDB database, eight queries were executed, differing in their structure. The average value of the query execution time is presented in
Table 3 and in
Figure 13. Examples of queries are given in
Appendix B.
We have tested the method on databases of various contents and structure. In this article, we have demonstrated three of the most revealing examples that can be schematically represented as follows (
Table 4):
For databases whose documents contain attributes of more than two tables, many other options for embedded documents are possible. The method described above allows uniquely determining the form of embedding documents.
The diagrams in
Figure 8,
Figure 10, and
Figure 13 show that depending on the structure of the queries, the speedup of the query execution in the database created by the proposed method (this is a database with embedded documents in the figures) can be from 10% to 70%, but all queries with embedded documents were faster. This can be explained by the fact that the volume of the collection when using embedded documents is much smaller than in the case of building a collection without embedded documents. For example, in Example 1, when transferring data from a MySQL database to MongoDB, a new collection with embedded documents consisted of 20,000 documents and had a volume of ≈20 MB, and a collection without embedded documents consisted of 100,770 documents and had a volume of ≈138 MB. Therefore, it is very important to evaluate in which collections documents should be embedded and in which not. These examples show the effectiveness of the application of the methodology and rules for constructing collections described in
Section 4 and
Section 5, taking into account the relationships between the objects in the database and the structure of the queries that are executed to them.
7. Conclusions
As a result of the research, a formalized method based on set theory was developed that allows automating the process of building a document database for a given set of properties of objects and the relationships between them. Information on the structure of database queries allows determining the number and composition of collections for the MongoDB database so that it is possible not to perform “join” operations in database queries. Taking into account the relationships between objects allows assessing the need to create embedded documents, their number and composition.
For example, let two tables be obtained from the results of constructing a relational schema based on database attributes. Let each table have five attributes. Then, it is possible to create one collection of nine attributes (taking into account the relationship of the tables). It is possible to create two collections of four and five attributes. It is possible to create three collections of three attributes. It is possible to create four collections of two and three attributes. There are other options. It is possible to create collections with embedded documents, or without embedded documents. In total, we get more than 10 options. Which to choose? It all depends on what queries will be performed most often on tables and how tables are related. This is what our method does. The method unambiguously answers these questions: how many and which collections.
We thoroughly tested our method on document databases of various structures with different relationships between tables. In each test, we measured the average query execution time. We showed some of these measurements in
Section 6. Having analyzed all the measurements of query execution time, we conclude that organizing a database using the method proposed in this article allows us to speed up query execution by 10–50% compared with other forms of database organization. The percentage of increasing the speed of query execution depends on two parameters: the initial database schema (before applying the method described in this article to this schema) and the structure of the query.
This method can be used when translating a database from relational format to MongoDB format, to define collections in a new MongoDB database, and when consolidating databases of various structures.
In general, the proposed method can be applied to:
Creating an effective structure of a new document database;
Data translation from a relational database to a document database;
Data translation from an arbitrary database into a document database;
Database consolidation.
There are other possibilities for applying this method, such as creating temporary collections, etc.
It should also be noted that the data is transferred to the new structure last, and this is usually done using software modules or using the tuple algebra, which is partially described in [
44].
8. Further Research
As shown in the examples, the method works well for all queries. However, for some queries, the method works better, while for others it is worse. For example, it can be seen from
Appendix B that Q3 and Q6 queries are performed on tables T1, T2, and T3. The query Q3 in the new form of the database does not work much better than in the previous one. The query Q6 in the new form is much faster than in the previous one. We have not yet found an explanation for this fact. This is the subject of our further research.
The main problem in document databases was that there was no formalized method that would unequivocally give an answer to the administrator about the optimal form and structure of documents taking into account database queries. Among NoSQL databases, there are databases of the type of a column family, which are also used to store related data and are also oriented to specific database queries. Therefore, for these databases, the decision on the optimal organization of column families is also important. At the moment, we are conducting research on the adaptation of the proposed method to the databases of the column family (using Casandra as an example).
When restructuring the database, the next step after defining a new database structure for the database administrator is to rewrite the queries from the old form to the new form (if these queries are in stored procedures or scripts). To speed up the process of converting a database from one form to another, we have created an approach to the automatic conversion of queries. The input for the query conversion method is information about the form and structure of the document, which is output by the method described in this article. We are currently testing this method.
One way to improve query performance is to create indexes. When changing the form of organization of the database, the use of indexes to the previous attributes may not give their initial effectiveness. Therefore, it is necessary to conduct research to supplement the method (presented in this article) with information about indexes. This we plan to do in a future study.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















