A Recent Development of a Network Approach to Assessment Data: Latent Space Item Response Modeling for Intelligence Studies


Abstract
1. Introduction
2. Latent Space Item Response Model
2.1. Model
2.2. Inference
3. Empirical Illustrations
3.1. Data Description
- Items 1–8: Pre-Operational
- Items 9–16: Primary
- Items 17–24: Concrete
- Items 25–32: Abstract
- Items 33–40: Formal
- Items 41–48: Systematic
- Items 49–56: Metasystematic
3.2. Main Analysis
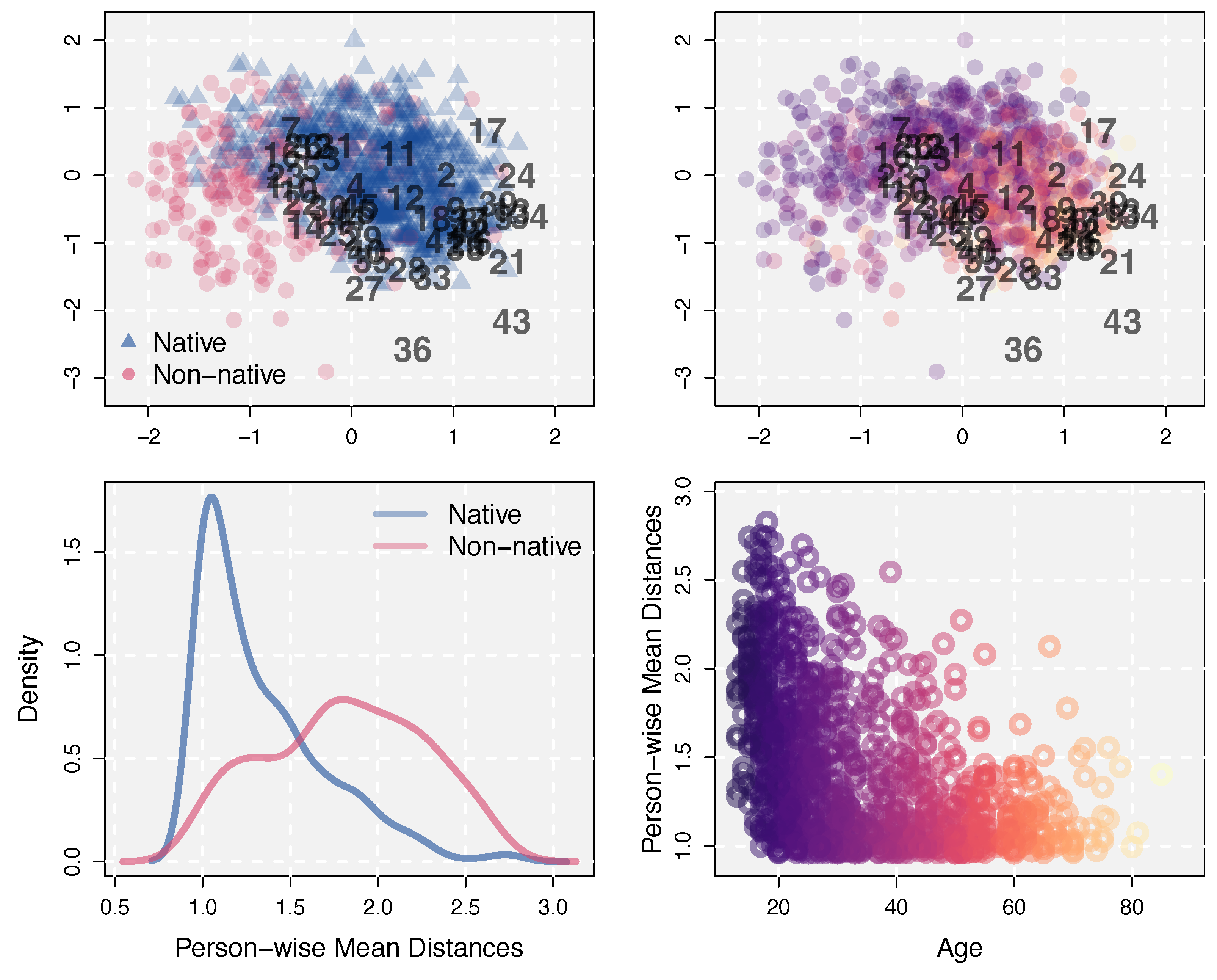
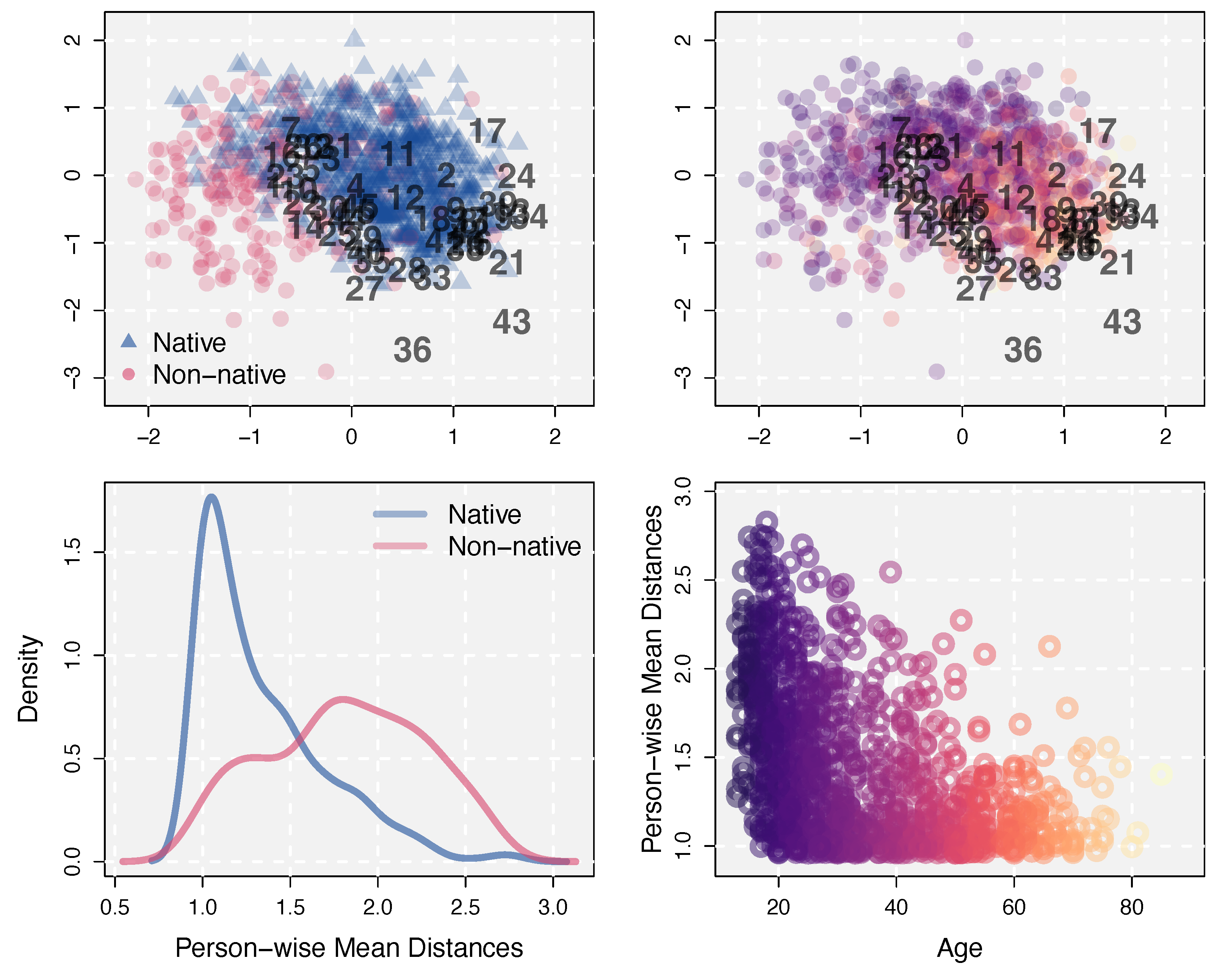
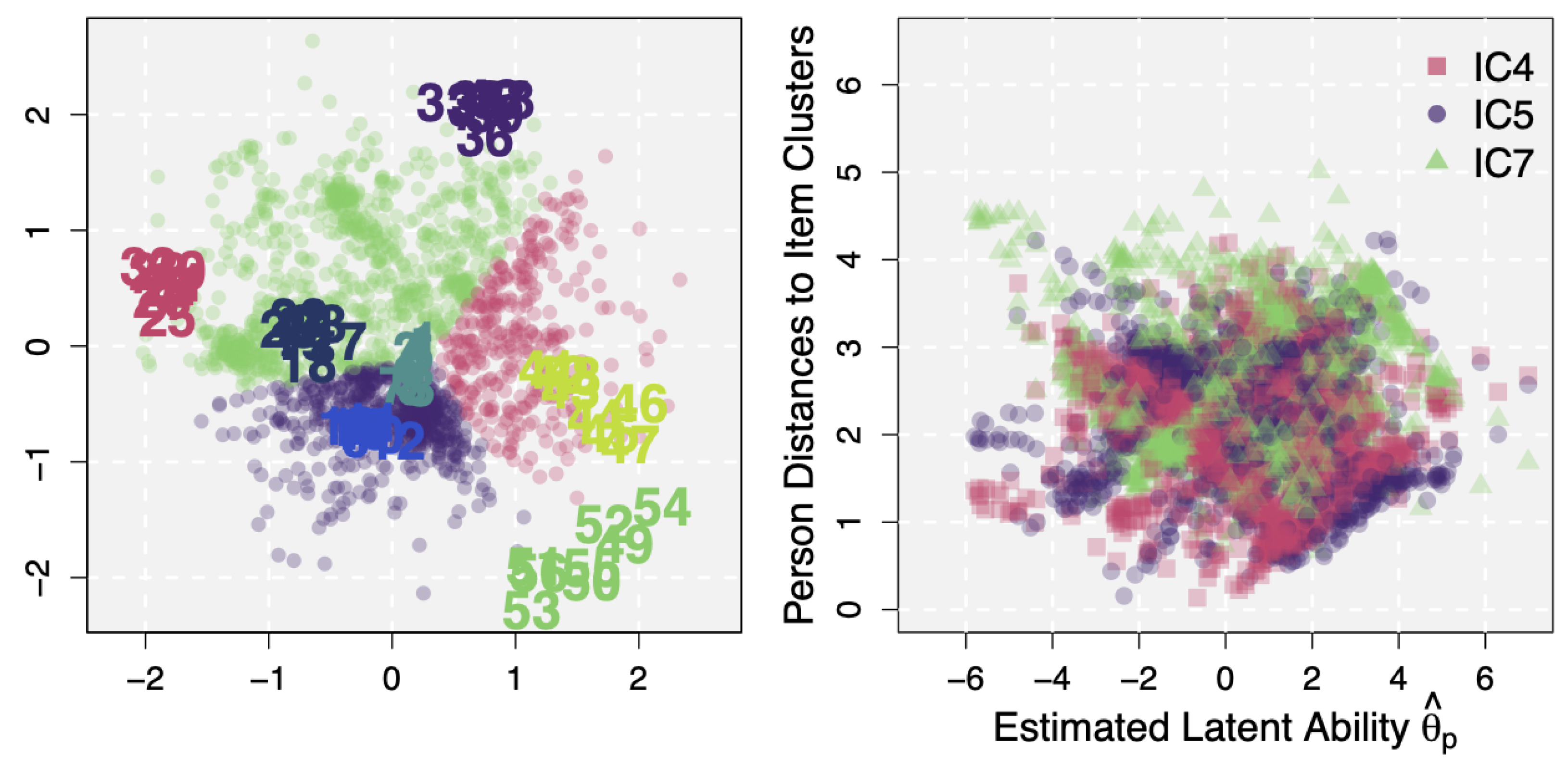
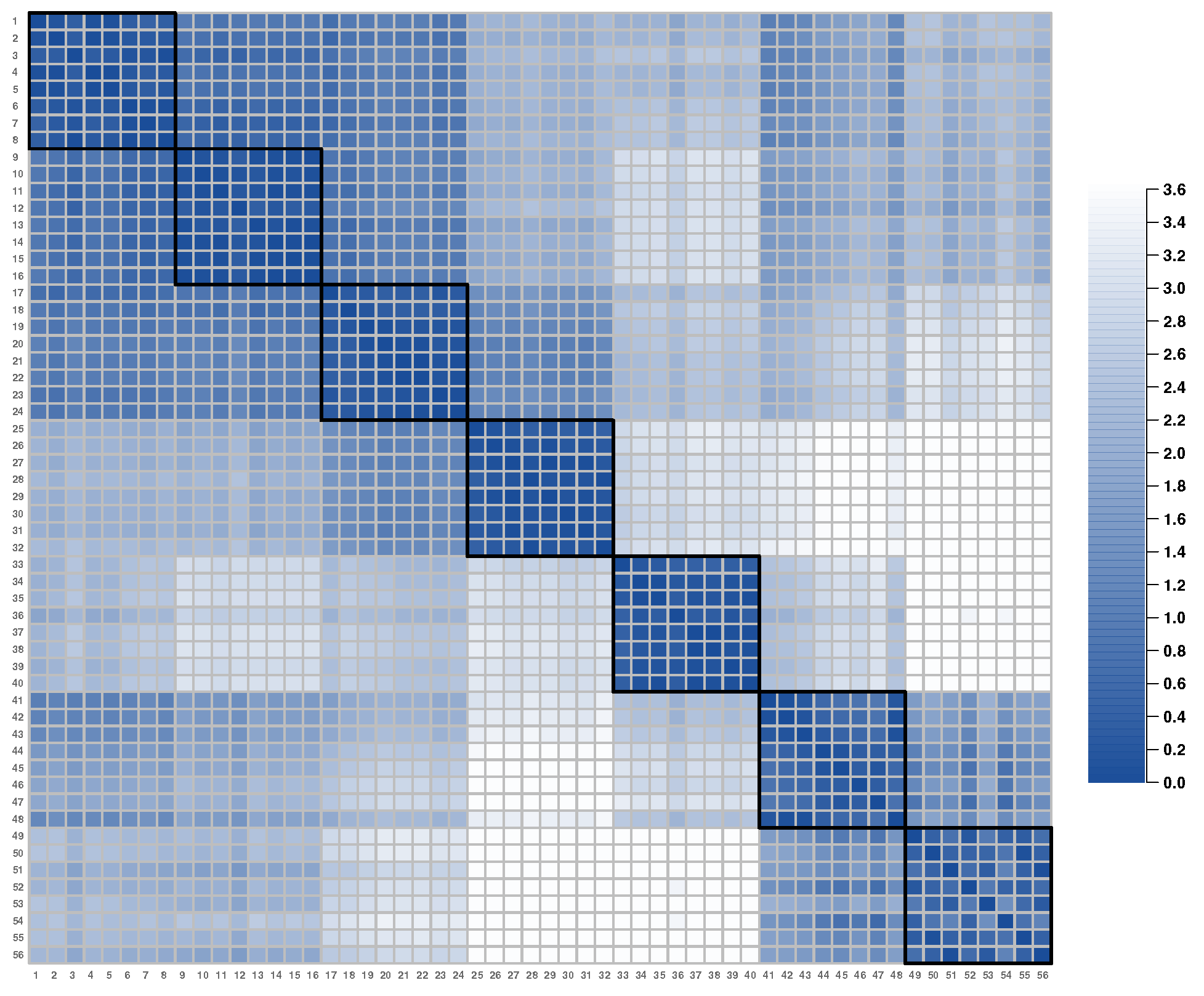
3.2.1. Positions in the Estimated Latent Space
- Item 36: fulminant doohickey ligature epistle letter
- Item 43: fugacious vapid fractious querulous extemporaneous
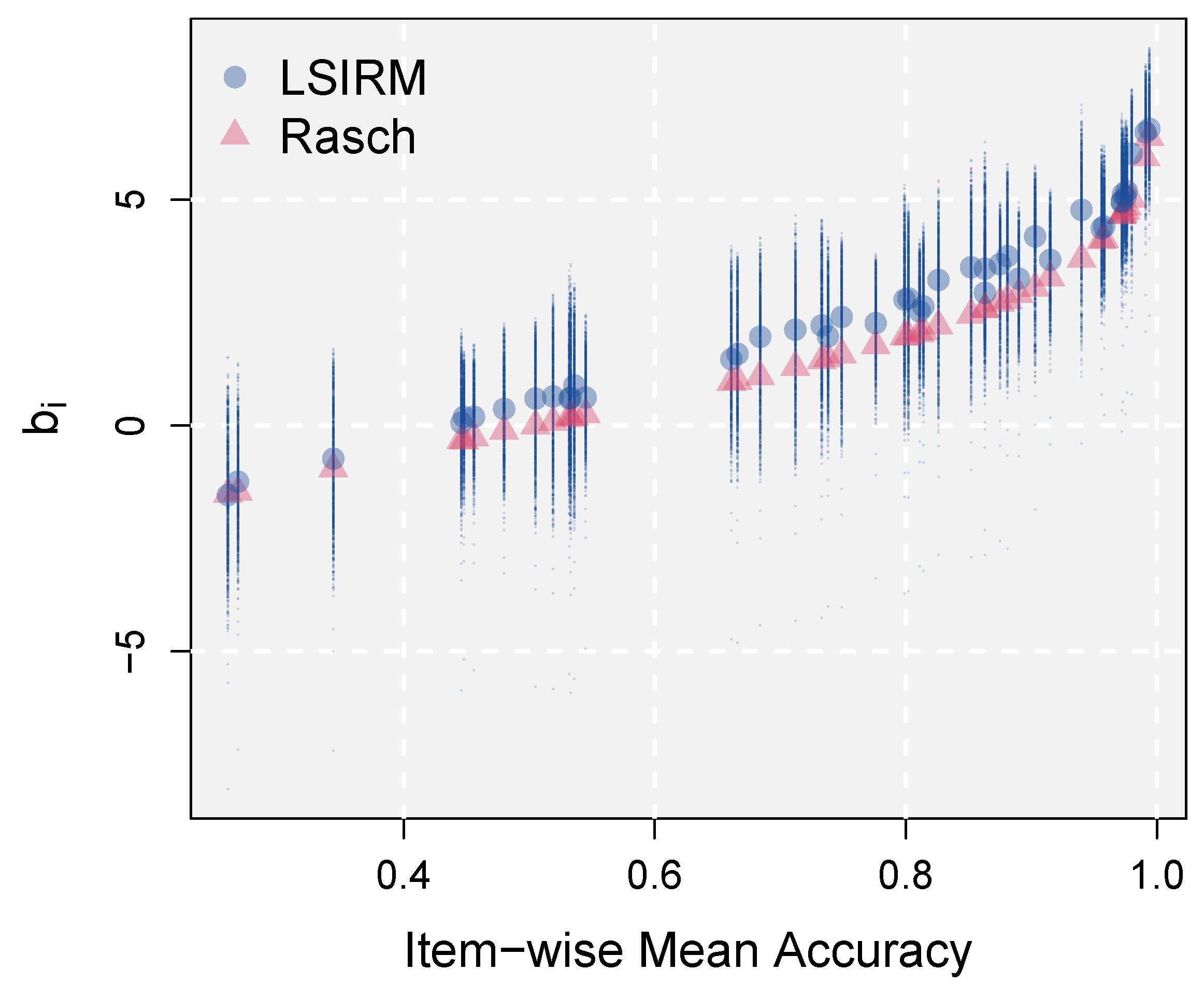
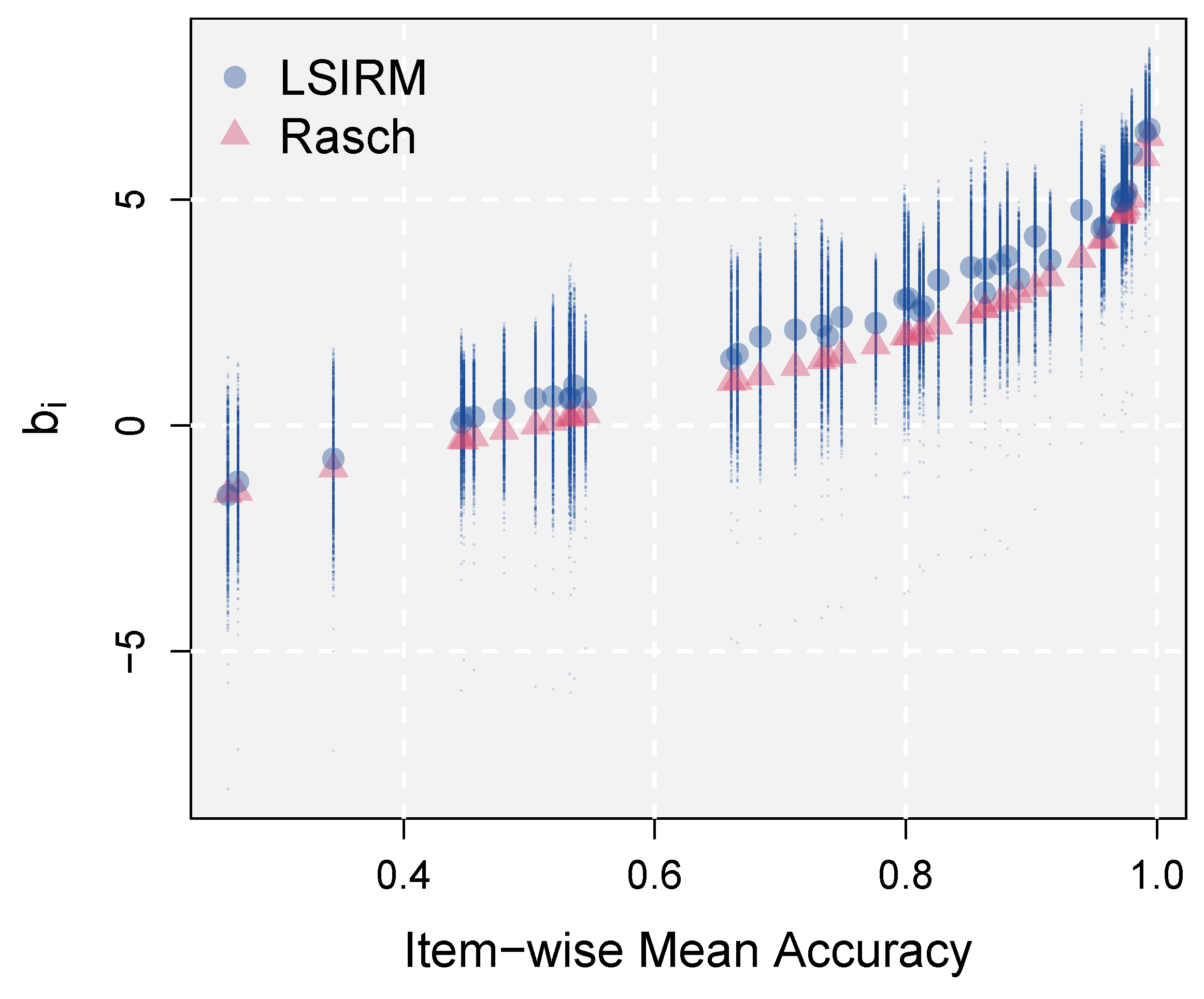
3.2.2. Varying Item Difficulties across Persons
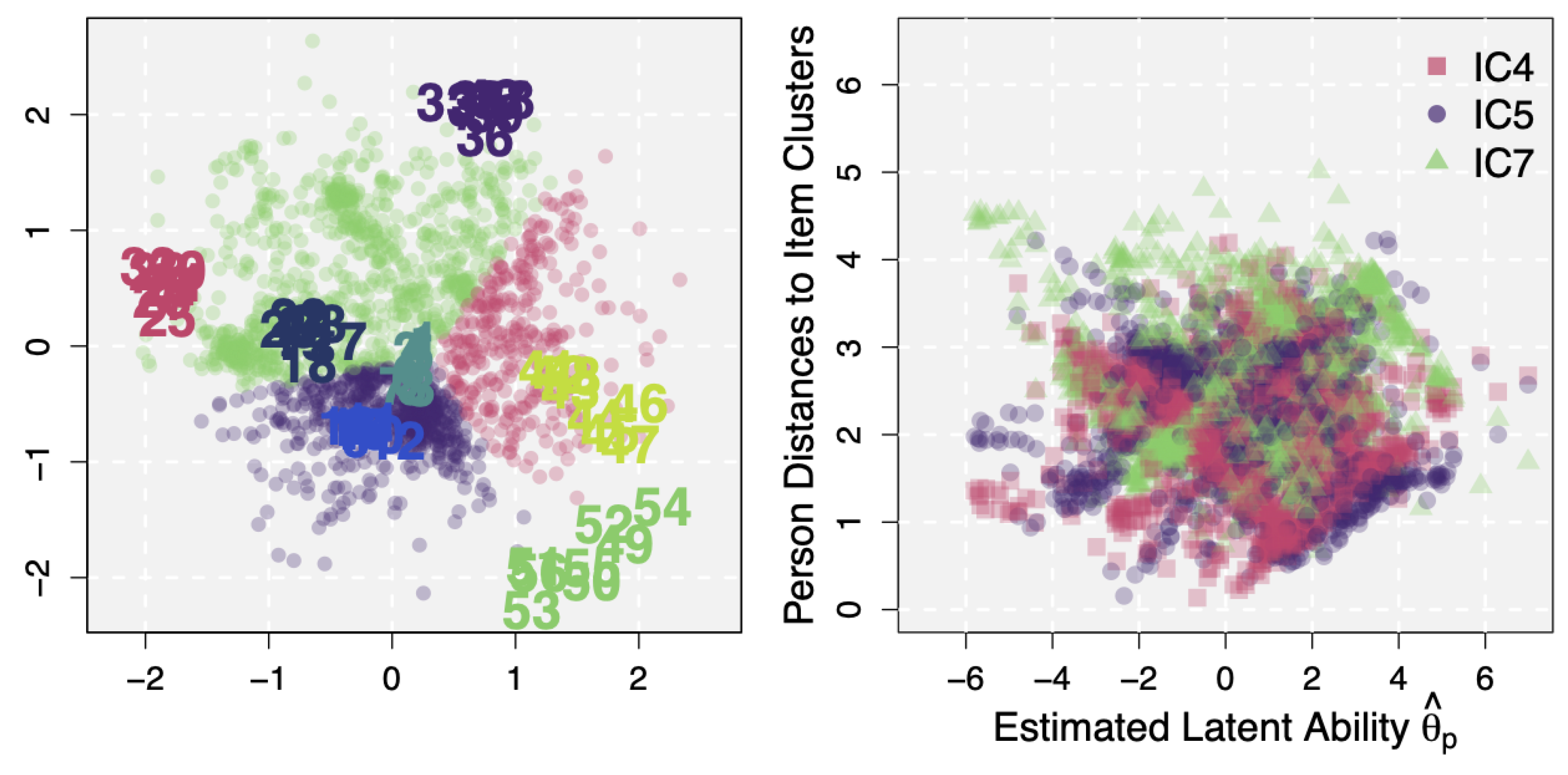
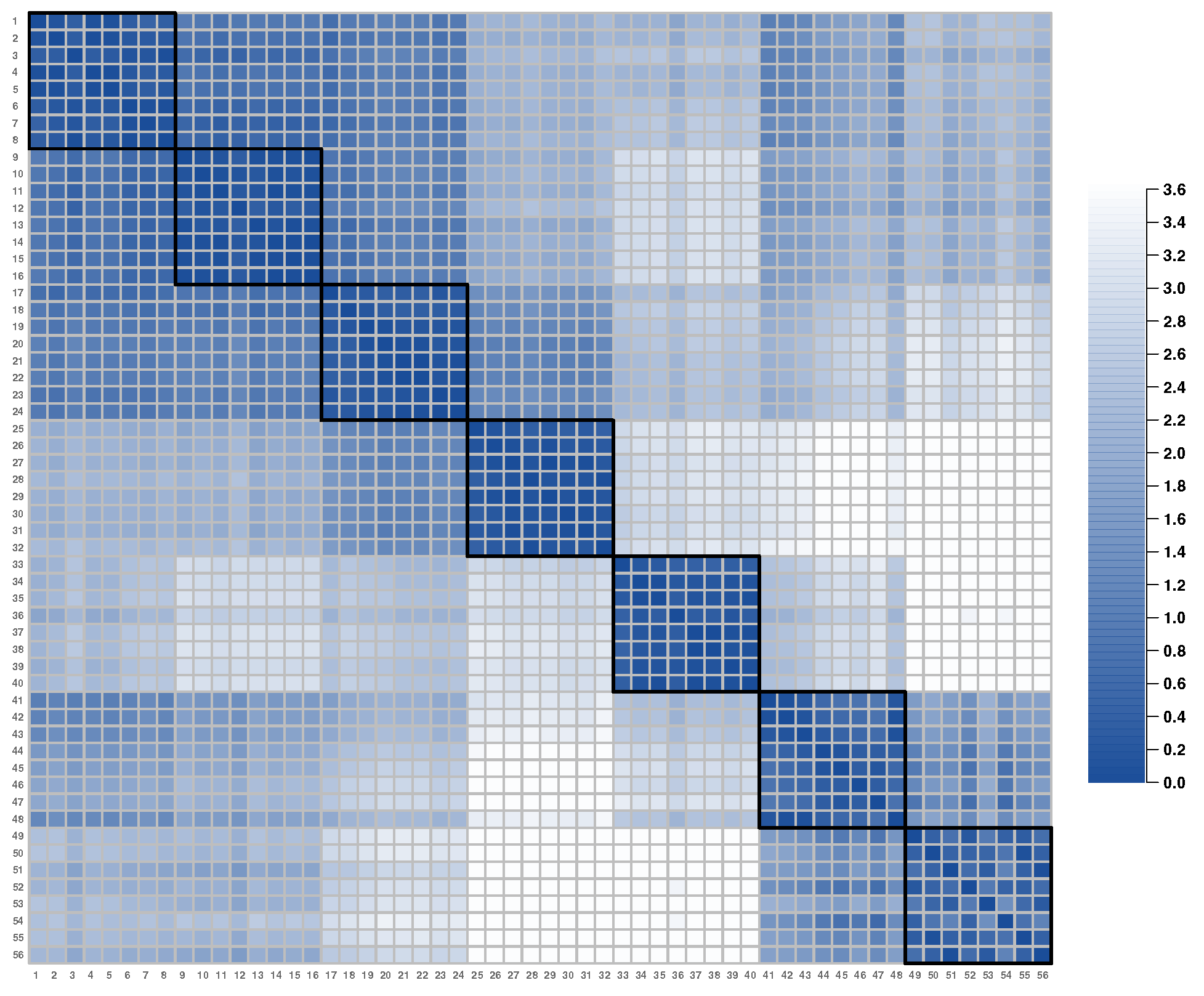
3.2.3. Studying Additional Item Information and Latent Structure: Unspecified Factors as a Data Source of Conditional Dependence
3.2.4. Person-Item Interactions from Conditional Dependence and Generation of Personalized Feedback
4. Discussion
4.1. Summary
4.2. Advantages of the LSIRM
4.3. Related Modeling Approaches
4.4. Conclusion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CD | Conditional Dependence |
| CFA | Confirmatory Factor Analysis |
| CI | Conditional Independence |
| DIF | Differential Item Functioning |
| EGA | Exploratory Graph Analysis |
| HMC | Hamiltonian Monte Carlo |
| IRDT | Inductive Reasoning Developmental Test |
| IRT | Item Response Theory |
| LR | Likelihood Ratio |
| LSDIRT | Latent Space Diffusion Item Response Theory Model |
| LSIRM | Latent Space Item Response Model |
| RT | Response Time |
| SD | Standard Deviation |
| VIQT | Vocabulary-based Intelligence Quotient Test |
| 2PLM | Two-Parameter Logistic IRT Model |
References
- Binet, Alred, and Théodore Simon. 1948. The development of the binet-simon scale, 1905–1908. In Readings in the History of Psychology. Edited by Wayne Dennis. Norwalk: Appleton-Century-Crofts, pp. 412–24. [Google Scholar]
- Bolsinova, Maria, and Dylan Molenaar. 2018. Modeling nonlinear conditional dependence between response time and accuracy. Frontiers in Psychology 9: 370012. [Google Scholar] [CrossRef] [PubMed]
- Bolsinova, Maria, Jesper Tijmstra, and Dylan Molenaar. 2017a. Response moderation models for conditional dependence between response time and response accuracy. British Journal of Mathematical and Statistical Psychology 70: 257–79. [Google Scholar] [CrossRef] [PubMed]
- Bolsinova, Maria, Jesper Tijmstra, Dylan Molenaar, and Paul De Boeck. 2017b. Conditional dependence between response time and accuracy: An overview of its possible sources and directions for distinguishing between them. Frontiers in Psychology 8: 202. [Google Scholar] [CrossRef] [PubMed]
- Bolsinova, Maria, Paul De Boeck, and Jesper Tijmstra. 2017c. Modelling conditional dependence between response and accuracy. Psychometrika 82: 1126–48. [Google Scholar] [CrossRef] [PubMed]
- Borg, Ingwer, and Patrick J. F. Gorenen. 2005. Modern Multidimensional Scaling: Theory and Applications, 2nd ed. New York: Springer. [Google Scholar]
- De Boeck, Paul, Haiqin Chen, and Mark Davison. 2017. Spontaneous and imposed speed of cognitive test responses. British Journal of Mathematical and Statistical Psychology 70: 225–37. [Google Scholar] [CrossRef] [PubMed]
- Epskamp, Sacha, Gunter Maris, Lourens J. Waldorp, and Denny Borsboom. 2018. Network psychometrics. In The Wiley Handbook of Psychometric Testing: A Multidisciplinary Reference on Survey, Scale and Test Development. Edited by Paul Irwing, Tom Booth and David J. Hughes. Hoboken: Wiley, pp. 953–86. [Google Scholar]
- Friel, Nial, Riccardo Rastelli, Jason Wyse, and Adrian E. Raftery. 2016. Interlocking directorates in irish companies using a latent space model for bipartite networks. Proceedings of the National Academy of Sciences 113: 6629–34. [Google Scholar] [CrossRef]
- Gelman, Andrew. 1996. Inference and monitoring convergence. In Markov Chain Monte Carlo in Practice. Edited by Walter R. Gilks, Sylvia Richardson and David J. Spiegelhalter. Boca Raton: CRC Press, pp. 131–43. [Google Scholar]
- Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis, 3rd ed. Boca Raton: CRC Press. [Google Scholar]
- Go, Dongyoung, Jina Park, Junyong Park, Minjeong Jeon, and Ick Hoon Jin. 2022. lsirm12pl: An r package for latent space item response modeling. arXiv arXiv:2205.06989. [Google Scholar]
- Goldhammer, Frank, Johannes Naumann, and Samuel Greiff. 2015. More is not always better: The relation between item response and item response time in raven’s matrices. Journal of Intelligence 3: 21–40. [Google Scholar] [CrossRef]
- Goldhammer, Frank, Johannes Naumann, Annette Stelter, Krisztina Tóth, Heiko Rölke, and Eckhard Klieme. 2014. The time on task effect in reading and problem solving is moderated by task difficulty and skill: Insights from a computer-based large-scale assessment. Journal of Educational Psychology 106: 608–26. [Google Scholar] [CrossRef]
- Golino, Hudson F., and Sacha Epskamp. 2017. Exploratory graph analysis: A new approach for estimating the number of dimensions in psychological research. PLoS ONE 12: E0174035. [Google Scholar] [CrossRef]
- Gower, John C. 1975. Generalized procrustes analysis. Psychometrika 40: 33–51. [Google Scholar] [CrossRef]
- Handcock, Mark S., Adrian E. Raftery, and Jeremy M. Tantrum. 2007. Model-based clustering for social networks. Journal of the Royal Statistical Society: Series A (Statistics in Society) 170: 301–54. [Google Scholar] [CrossRef]
- Ho, Eric, and Minjeong Jeon. 2023. Interaction map: A visualization tool for personalized learning based on assessment data. Psych 5: 1140–55. [Google Scholar] [CrossRef]
- Hoff, Peter D., Adrian E. Raftery, and Mark S. Handcock. 2002. Latent space approaches to social network analysis. Journal of the American Statistical Association 97: 1090–8. [Google Scholar] [CrossRef]
- Ishwaran, Hemant, and J. Sunil Rao. 2005. Spike and slab variable selection: Frequentist and Bayesian strategies. The Annals of Statistics 33: 730–73. [Google Scholar] [CrossRef]
- Jeon, Minjeong, Ick Hoon Jin, Michael Schweinberger, and Samuel Baugh. 2021. Mapping unobserved item–respondent interactions: A latent space item response model with interaction map. Psychometrika 86: 378–403. [Google Scholar] [CrossRef] [PubMed]
- Kang, Inhan, Minjeong Jeon, and Ivailo Partchev. 2023. A latent space diffusion item response theory model to explore conditional dependence between responses and response times. Psychometrika 88: 830–64. [Google Scholar] [CrossRef] [PubMed]
- Kang, Inhan, Paul De Boeck, and Ivalio Partchev. 2022a. A randomness perspective on intelligence processes. Intelligence 91: 101632. [Google Scholar] [CrossRef]
- Kang, Inhan, Paul De Boeck, and Roger Ratcliff. 2022b. Modeling conditional dependence of response accuracy and response time with the diffusion item response theory model. Psychometrika 87: 725–48. [Google Scholar] [CrossRef]
- Luo, Jinwen, Ludovica De Carolis, Biao Zeng, and Minjeong Jeon. 2023. Bayesian estimation of latent space item response models with JAGS, Stan, and NIMBLE in R. Psych 5: 396–415. [Google Scholar] [CrossRef]
- Magis, David, Sébastien Béland, Francis Tuerlinckx, and Paul De Boeck. 2010. A general framework and an R package for the detection of dichotomous differential item functioning. Behavioral Research Methods 42: 847–62. [Google Scholar] [CrossRef] [PubMed]
- Marsman, Maarten, Denny Borsboom, Joost Kruis, Sacha Epskamp, Riet van Bork, Lourens J. Waldorp, Han L. J. van der Maas, and Gunter Maris. 2018. An introduction to network psychometrics: Relating ising network models to item response theory models. Multivariate Behavioral Research 53: 15–35. [Google Scholar] [CrossRef] [PubMed]
- Meng, Xiang-Bin, Jian Tao, and Hua-Hua Chang. 2015. A conditional joint modeling approach for locally dependent item responses and response times. Journal of Educational Measurement 52: 1–27. [Google Scholar] [CrossRef]
- Mitchell, Toby J., and John J. Beauchamp. 1988. Bayesian variable selection in linear regression. Journal of the American Statistical Association 83: 1023–32. [Google Scholar] [CrossRef]
- Molenaar, Dylan. 2021. A flexible moderated factor analysis approach to test for measurement invariance across a continuous variable. Psychological Methods 26: 660–79. [Google Scholar] [CrossRef] [PubMed]
- Partchev, Ivailo, and Paul De Boeck. 2012. Can fast and slow intelligence be differentiated? Intelligence 40: 23–32. [Google Scholar] [CrossRef]
- Rasch, Georg. 1961. On general laws and meaning of measurement in psychology. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 4: Contributions to Biology and Problems of Medicine. Edited by Jerzy Neyman. Oakland, Berkeley and Los Angeles: University of California Press, pp. 321–33. [Google Scholar]
- Roberts, James S., and James E. Laughlin. 1996. A unidimensional item response model for unfolding responses from a graded disagree-agree response scale. Applied Psychological Measurement 20: 231–55. [Google Scholar] [CrossRef]
- Roberts, James S., John R. Donoghue, and James E. Laughlin. 2000. A general item response theory model for unfolding unidimensional polytomous responses. Applied Psychological Measurement 24: 3–32. [Google Scholar] [CrossRef]
- Smith, Anna L., Dena M. Asta, and Catherine A. Calder. 2019. The Geometry of Continuous Latent Space Models for Network Data. Statistical Science 34: 428–53. [Google Scholar] [CrossRef]
- Spearman, Charles. 1904. “General intelligence”, objectively determined and measured. The American Journal of Psychology 15: 201–92. [Google Scholar] [CrossRef]
- Stan Development Team. 2024. Stan Modeling Language User’s Guide and Reference Manual Version 2.34. Available online: https://mc-stan.org/users/documentation/ (accessed on 27 March 2024).
- Thissen, David, Lynne Steinberg, and Howard Wainer. 1993. Detection of differential item functioning using the parameters of item response models. In Differential Item Functioning. Edited by Paul W. Holland and Howard Wainer. Mahwah: Lawrence Erlbaum Associates, Inc., pp. 67–113. [Google Scholar]
- van der Linden, Wim J. 2007. A hierarchical framework for modeling speed and accuracy on test items. Psychometrika 72: 287–308. [Google Scholar] [CrossRef]
- van der Linden, Win J., and Cees A. W. Glas. 2010. Statistical tests of conditional independence between responses and/or response times on test items. Psychometrika 75: 120–39. [Google Scholar] [CrossRef]
- van der Maas, Han L. J., Conor V. Dolan, Raoul P. P. P. Grasman, Jelte M. Wicherts, Hilde M. Huizenga, and Maartje E. J. Raijmakers. 2006. A dynamical model of general intelligence: The positive manifold of intelligence by mutualism. Psychological Review 113: 842–61. [Google Scholar] [CrossRef] [PubMed]
- van Rijn, Peter W., and Usama S. Ali. 2017. A comparison of item response models for accuracy and speed of item responses with applications to adaptive testing. British Journal of Mathematical and Statistical Psychology 70: 317–45. [Google Scholar] [CrossRef]
- Wang, Chun, and Gongjun Xu. 2015. A mixture hierarchical model for response times and response accuracy. British Journal of Mathematical and Statistical Psychology 68: 456–77. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IC | Item Positions | Item Distances | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | Mean | |||
| 1 | 0.168 | −0.174 | - | 0.673 | 0.902 | 2.116 | 2.316 | 1.476 | 2.178 | 1.601 |
| 2 | −0.207 | −0.733 | - | 0.977 | 2.054 | 2.960 | 1.840 | 2.094 | 1.766 | |
| 3 | −0.685 | 0.120 | - | 1.214 | 2.422 | 2.373 | 2.988 | 1.813 | ||
| 4 | −1.828 | 0.529 | - | 3.008 | 3.584 | 4.143 | 2.686 | |||
| 5 | 0.758 | 2.065 | - | 2.677 | 3.989 | 2.895 | ||||
| 6 | 1.613 | −0.471 | - | 1.370 | 2.220 | |||||
| 7 | 1.570 | −1.840 | - | 2.794 | ||||||
| Person | Ability | Positions | Person-Wise Mean Distances to Item Clusters | Acc | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||
| 64 | 1.043 | −1.227 | 0.656 | 1.622 | 1.723 | 0.762 | 0.615 | 2.434 | 3.055 | 3.749 | 0.571 |
| 1359 | 1.155 | −1.285 | 1.016 | 1.877 | 2.054 | 1.078 | 0.730 | 2.296 | 3.257 | 4.038 | 0.571 |
| 1653 | 1.227 | 1.015 | −1.775 | 1.812 | 1.607 | 2.546 | 3.660 | 3.849 | 1.435 | 0.559 | 0.411 |
| 1655 | 1.060 | 1.424 | −0.976 | 1.491 | 1.650 | 2.377 | 3.584 | 3.113 | 0.539 | 0.877 | 0.446 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, I.; Jeon, M. A Recent Development of a Network Approach to Assessment Data: Latent Space Item Response Modeling for Intelligence Studies. J. Intell. 2024, 12, 38. https://doi.org/10.3390/jintelligence12040038
Kang I, Jeon M. A Recent Development of a Network Approach to Assessment Data: Latent Space Item Response Modeling for Intelligence Studies. Journal of Intelligence. 2024; 12(4):38. https://doi.org/10.3390/jintelligence12040038
Chicago/Turabian StyleKang, Inhan, and Minjeong Jeon. 2024. "A Recent Development of a Network Approach to Assessment Data: Latent Space Item Response Modeling for Intelligence Studies" Journal of Intelligence 12, no. 4: 38. https://doi.org/10.3390/jintelligence12040038
APA StyleKang, I., & Jeon, M. (2024). A Recent Development of a Network Approach to Assessment Data: Latent Space Item Response Modeling for Intelligence Studies. Journal of Intelligence, 12(4), 38. https://doi.org/10.3390/jintelligence12040038