Gender and Accuracy in Decoding Affect Cues: A Meta-Analysis


Abstract
:1. Introduction
Past Meta-Analyses
2. Method
2.1. Definition of Key Concepts
2.1.1. Gender
2.1.2. Accuracy
2.1.3. Test
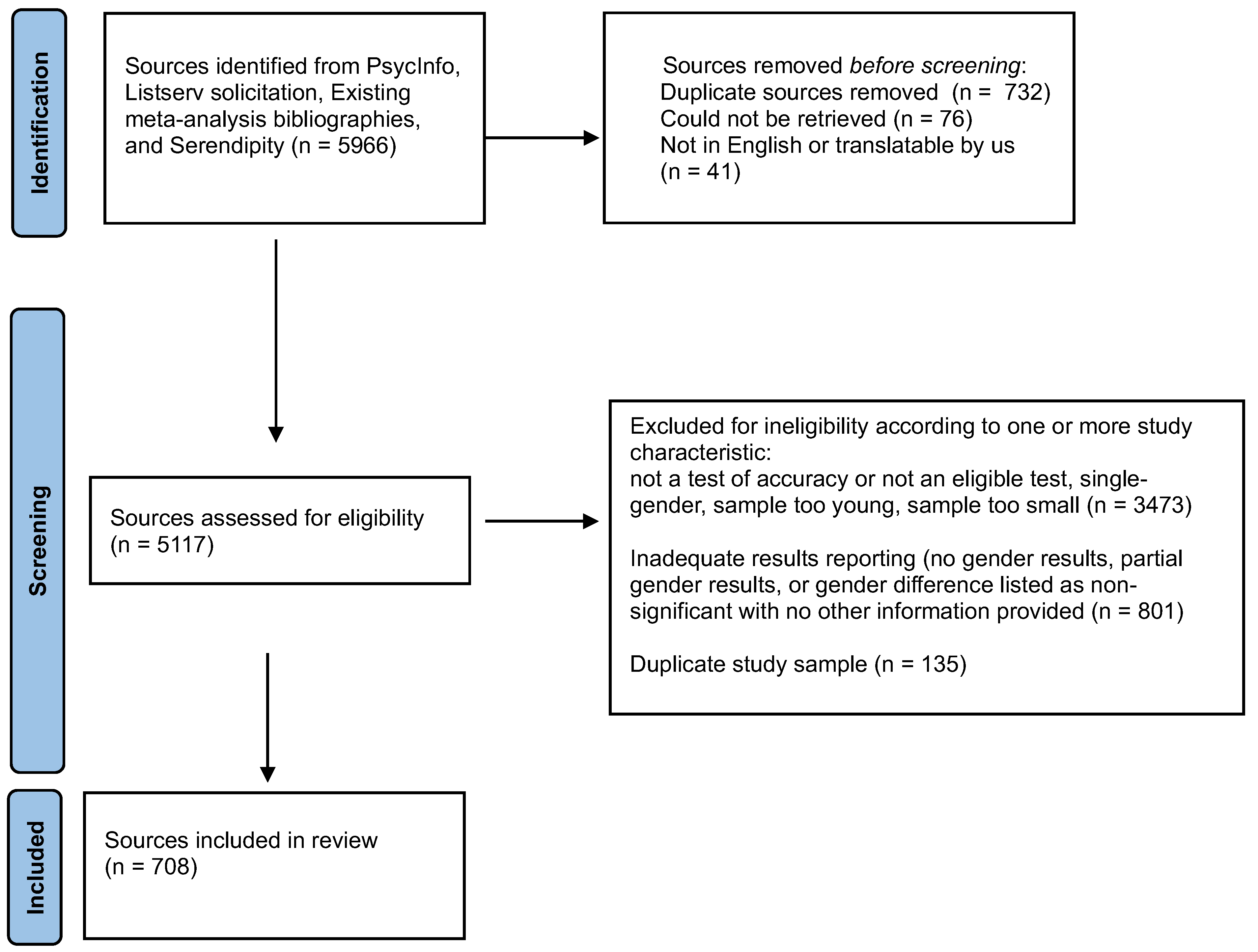
2.2. Search
2.3. Inclusion Criteria for Perceivers
2.4. Inclusion Criteria for Test Characteristics
2.5. Exclusions Not Mentioned Above
2.6. Reliability of Search Procedure
2.7. Flow Chart of Screening
2.8. Database Characteristics
2.8.1. Study Characteristics
2.8.2. Perceiver Characteristics
2.8.3. Test Characteristics
2.9. Reliability of Study Coding and Effect Size Coding
2.10. Effect Size Coding and Statistical Analysis
3. Results
3.1. Overall Gender Difference
3.2. Sample Characteristics (Level 2 Moderators)
3.2.1. Participant Health Status
3.2.2. Study Location
3.2.3. Participant Age
3.2.4. Participant Race
3.2.5. First Author Gender
3.2.6. Year
3.3. Test Characteristics (Level 1 Moderators)
3.3.1. Number of Items
3.3.2. Cue Channels
3.3.3. Specific Tests
3.3.4. Stimulus Presentation Mode
3.3.5. Stimulus Creation Mode
3.3.6. Target Gender
3.3.7. Target Age
3.3.8. Target Race/Ethnicity
3.3.9. Authors’ Analysis Model
3.4. Publication Bias
3.4.1. Publication Status
3.4.2. Other Publication Bias Procedures
4. Discussion
Origins of the Gender Difference
5. Limitations
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Test | Stimulus | Cue | Cue |
|---|---|---|---|
| Creation Mode | Channels | Content | |
| Pictures of Facial Affect (POFA; (Ekman and Friesen 1976)) | Posed | Face | Basic emotions (usually 6) |
| Diagnostic Analysis of Nonverbal Accuracy-Adult Faces (DANVA; (Nowicki and Duke 1994)) | Posed | Face | 4 basic emotions |
| Japanese and Caucasian Facial Expressions of Emotion (JACFEE; (Biehl et al. 1997)) | Posed | Face | 7 basic emotions |
| Penn Emotion Identification Test (ER40; (Gur et al. 2012)) | Posed | Face | 4 basic emotions |
| Reading the Mind in the Eyes Test (RMET; (Baron-Cohen et al. 2001)) | Unknown | Eye region | 36 affective states |
| Profile of Nonverbal Sensitivity (PONS; (Rosenthal et al. 1979)) | Posed | Video with face, body, and masked voice (alone and in all combinations) | 20 affective scenarios |
| The Awareness of Social Inference Test-Emotion Evaluation Test (TASIT-EET; (McDonald et al. 2006)) | Posed | Full video with masked voice | 6 basic emotions |
| Geneva Emotion Recognition Test (GERT; (Schlegel et al. 2014)) | Posed | Full video with masked voice | 14 emotions |
| 1 | Because comparison of cue channels is complicated when many different tests are involved, we performed analysis of results for one test (PONS) that has single- and multiple-cue modalities, using published data from the test’s development monograph (norm group of N = 480; Table 3.3 in Rosenthal et al. 1979). The 20 face-only items and the 40 voice-only items showed much smaller effects than did the full 220-item test—rs of 0.12, 0.10, and 0.24, respectively. The full test has face, body, full figure, and two methods of masking the verbal content of the voice items, all singly presented or in combination. However, body-only (20 items) showed a big gender effect (d = 0.24). So, for that large sample, the single channels did not necessarily show a smaller gender difference than combined channels. Also, Table 7.1 in Rosenthal et al. (1979), which summarizes 23 samples of participants, showed the same mixed picture, where the female advantage was not consistently bigger for combined-cue channels than for single-cue channels. We also looked at results for the PONS test in the current meta-analytic database. There are 51 PONS results, 16 involving single channels (face only, body only, or voice) and 35 involving multiple channels. The difference in the gender effect between single- and multiple-cue channels is significant, F(1, 49) = 5.02, p = .03 (M r for single channels = 0.10, M r for multiple channels = 0.18). However, for these 51 studies, the correlation between effect size and the number of items was 0.39, p < .004. When the number of items is controlled for, the difference disappears (F < 1, p = .52). For the PONS, therefore, the issue of whether single channels produce smaller effects than multiple channels is ambiguous. |
References
- Acland, Erinn L., Joanna Peplak, Anjali Suri, and Tina Malti. 2023. Emotion recognition links to reactive and proactive aggression across childhood: A multi-study design. Development and Psychopathology 36: 1122–33. [Google Scholar] [CrossRef] [PubMed]
- Alkire, Armand A., Mary E. Collum, and Jaques Kaswan. 1968. Information exchange and accuracy of verbal communication under social power conditions. Journal of Personality and Social Psychology 9: 301–8. [Google Scholar] [CrossRef] [PubMed]
- Aloe, Ariel M., Emily E. Tanner-Smith, Betsy J. Becker, and David B. Wilson. 2016. Campbell Methods Policy Note on Synthesizing Bivariate and Partial Effect Sizes (Version 1.1, updated December 2016). Philadelphia: The Campbell Collaboration. [Google Scholar] [CrossRef]
- American Psychological Association. 2022. Gender. Available online: https://apastyle.apa.org/style-grammar-guidelines/bias-free-language/gender (accessed on 14 August 2024).
- Baron-Cohen, Simon, Sally Wheelwright, Jacqueline Hill, Yogini Raste, and Ian Plumb. 2001. The “Reading the Mind in the Eyes” Test Revised Version: A study with normal adults, and adults with Asperger syndrome or high-functioning autism. Journal of Child Psychology and Psychiatry 42: 241–51. [Google Scholar] [CrossRef]
- Baron-Cohen, Simon, Daniel C. Bowen, Rosemary J. Holt, Carrie Allison, Bonnie Auyeung, Michael V. Lombardo, Paula Smith, and Meng-Chuan Lai. 2015. The “Reading the Mind in the Eyes” Test: Complete absence of typical sex difference in ~400 men and women with autism. PLoS ONE 10: e0136521. [Google Scholar] [CrossRef]
- Biehl, Michael, David Matsumoto, Paul Ekman, Valerie Hearn, Karl Heider, Tsutomu Kudoh, and Veronica Ton. 1997. Matsumoto and Ekman’s Japanese and Caucasian Facial Expressions of Emotion (JACFEE): Reliability data and cross-national differences. Journal of Nonverbal Behavior 21: 3–21. [Google Scholar] [CrossRef]
- Briton, Nancy J., and Judith A. Hall. 1995. Beliefs about female and male nonverbal communication. Sex Roles 32: 79–90. [Google Scholar] [CrossRef]
- Byron, Kristin. 2007. Male and female managers’ ability to read emotions: Relationships with supervisor’s performance ratings and subordinates’ satisfaction ratings. Journal of Occupational and Organizational Psychology 80: 713–33. [Google Scholar] [CrossRef]
- Byron, Kristin, Sophia Terranova, and Stephen Nowicki. 2007. Nonverbal emotion recognition and salespersons: Linking ability to perceived and actual success. Journal of Applied Social Psychology 37: 2600–19. [Google Scholar] [CrossRef]
- Cotter, Jack, Kiri Granger, Rosa Backx, Matthew Hobbs, Chung Yen Looi, and Jennifer H. Barnett. 2018. Social cognitive dysfunction as a clinical marker: A systematic review of meta-analyses across 30 clinical conditions. Neuroscience & Biobehavioral Reviews 84: 92–99. [Google Scholar] [CrossRef]
- Cvencek, Dario, Andrew N. Meltzoff, and Anthony G. Greenwald. 2011. Math-gender stereotypes in elementary school children. Child Development 82: 766–79. [Google Scholar] [CrossRef]
- Del Giudice, Marco, Tom Booth, and Paul Irwing. 2012. The distance between Mars and Venus: Measuring global sex differences in personality. PLoS ONE 7: e29265. [Google Scholar] [CrossRef] [PubMed]
- Eagly, Alice H., and Linda L. Carli. 1981. Sex of researchers and sex-typed communications as determinants of sex differences in influenceability: A meta-analysis of social influence studies. Psychological Bulletin 90: 1–20. [Google Scholar] [CrossRef]
- Eagly, Alice H., and Wendy Wood. 1999. The origins of sex differences in human behavior: Evolved dispositions versus social roles. American Psychologist 54: 408–23. [Google Scholar] [CrossRef]
- Eagly, Alice H., and William Revelle. 2022. Understanding the magnitude of psychological differences between women and men requires seeing the forest and the trees. Perspectives on Psychological Science 17: 1339–58. [Google Scholar] [CrossRef]
- Ekman, Paul, and Wallace V. Friesen. 1976. Pictures of Facial Affect. Palo Alto: Consulting Psychologists Press. [Google Scholar]
- Ekman, Paul, Wallace V. Friesen, Maureen O’Sullivan, Anthony Chan, Irene Diacoyanni-Tarlatzis, Karl Heider, Rainer Krause, William Ayhan LeCompte, Tom Pitcairn, Pio E. Ricci-Bitti, and et al. 1987. Universals and cultural differences in the judgments of facial expressions of emotion. Journal of Personality and Social Psychology 53: 712–17. [Google Scholar] [CrossRef]
- Elfenbein, Hillary Anger, and Carolyn MacCann. 2017. A closer look at ability emotional intelligence (EI): What are its component parts, and how do they relate to each other? Social and Personality Psychology Compass 11: e12324. [Google Scholar] [CrossRef]
- Elfenbein, Hillary Anger, Maw Der Foo, Judith White, Hwee Hoon Tan, and Voon Chuan Aik. 2007. Reading your counterpart: The benefit of emotion recognition accuracy for effectiveness in negotiation. Journal of Nonverbal Behavior 31: 205–23. [Google Scholar] [CrossRef]
- Fiori, Marina, Shagini Udayar, and Ashley Vesely Maillefer. 2022. Emotion information processing as a new component of emotional intelligence: Theoretical framework and empirical evidence. European Journal of Personality 36: 245–64. [Google Scholar] [CrossRef]
- Funder, David C., and Monica J. Harris. 1986. On the several facets of personality assessment: The case of social acuity. Journal of Personality 54: 528–50. [Google Scholar] [CrossRef]
- Gates, Georgina S. 1923. An experimental study of the growth of social perception. Journal of Educational Psychology 14: 449–61. [Google Scholar] [CrossRef]
- Geary, David C. 2019. Evolutionary perspective on sex differences in the expression of neurological diseases. Progress in Neurobiology 176: 33–53. [Google Scholar] [CrossRef] [PubMed]
- Geary, David C. 2021. Now you see them, and now you don’t: An evolutionarily informed model of environmental influences on human sex differences. Neuroscience & Biobehavioral Reviews 125: 26–32. [Google Scholar] [CrossRef]
- Giofrè, David, Katie Allen, Enrico Toffalini, and Sara Caviola. 2022. The impasse on gender differences in intelligence: A meta-analysis on WISC batteries. Educational Psychology Review 34: 2543–68. [Google Scholar] [CrossRef]
- Greenberg, David M., Varun Warrier, Ahmad Abu-Akel, Carrie Allison, Krzysztof Z. Gajos, Katharina Reinecke, P. Jason Rentfrow, Marcin A. Radecki, and Simon Baron-Cohen. 2022. Sex and age differences in “theory of mind” across 57 countries using the English version of the “Reading the Mind in the Eyes” Test. Proceedings of the National Academy of Sciences 120: e2022385119. [Google Scholar] [CrossRef]
- Gur, Ruben C., Jan Richard, Monica E. Calkins, Rosetta Chiavacci, John A. Hansen, Warren B. Bilker, James Loughead, John J. Connolly, Haijun Qiu, Frank D. Mentch, and et al. 2012. Age group and sex differences in performance on a computerized neurocognitive battery in children age 8−21. Neuropsychology 26: 251–65. [Google Scholar] [CrossRef] [PubMed]
- Hall, Judith A. 1978. Gender effects in decoding nonverbal cues. Psychological Bulletin 85: 845–57. [Google Scholar] [CrossRef]
- Hall, Judith A. 1984. Nonverbal Sex Differences: Communication Accuracy and Expressive Style. Baltimore: The Johns Hopkins University Press. [Google Scholar]
- Hall, Judith A. 2006. How big are nonverbal sex differences? The case of smiling and nonverbal sensitivity. In Sex Differences and Similarities in Communication, 2nd ed. Edited by Kathryn Dindia and Daniel J. Canary. Mahwah: Lawrence Erlbaum Associates Publishers, pp. 59–81. [Google Scholar]
- Hall, Judith A., and David Miller. 2025. Meta-analysis. In Handbook of Research Methods in Social and Personality Psychology, 3rd ed. Edited by Harry T. Reis, Tessa West and Charles M. Judd. Cambridge: Cambridge University Press. [Google Scholar]
- Hall, Judith A., Sarah D. Gunnery, and Terrence G. Horgan. 2016. Gender differences in interpersonal accuracy. In The Social Psychology of Perceiving Others Accurately. Edited by Judith A. Hall, Marianne Schmid Mast and Tessa V. West. Cambridge: Cambridge University Press, pp. 309–27. [Google Scholar] [CrossRef]
- Hall, Judith A., Susan A. Andrzejewski, and Jennelle E. Yopchick. 2009. Psychosocial correlates of interpersonal sensitivity: A meta-analysis. Journal of Nonverbal Behavior 33: 149–80. [Google Scholar] [CrossRef]
- Halpern, Diane F., and Mary L. LaMay. 2000. The smarter sex: A critical review of sex differences in intelligence. Educational Psychology Review 12: 229–46. [Google Scholar] [CrossRef]
- Halpern, Diane F., Carli A. Straight, and Clayton L. Stephenson. 2011. Beliefs about cognitive gender differences: Accurate for direction, underestimated for size. Sex Roles 64: 336–47. [Google Scholar] [CrossRef]
- Hampel, Vera, Mary Hausfeld, and Jochen I. Menges. 2024. Is dealing with emotions a women’s skill? A meta-analysis of gender and emotional intelligence. Academy of Management Proceedings 2024: 19297. [Google Scholar] [CrossRef]
- Hampson, Elizabeth, Paul Istasy, Sawayra Owais, Jessica A. Chow, Belal Howidi, and Sarah J. Ouellette. 2021. Sex differences in the recognition of children’s emotional expressions: A test of the fitness threat hypothesis. Evolutionary Psychological Science 7: 45–60. [Google Scholar] [CrossRef]
- Haselton, Martie G., and David M. Buss. 2000. Error management theory: A new perspective on biases in cross-sex mind reading. Journal of Personality and Social Psychology 78: 81–91. [Google Scholar] [CrossRef]
- Herman, Jody L., Andrew R. Flores, and Kathryn K. O’Neill. 2022. How Many Adults and Youth Identify as Transgender in the United States? Los Angeles: The Williams Institute, UCLA School of Law. [Google Scholar]
- Hodges, Sara D., and Murat Kezer. 2021. It is hard to read minds without words: Cues to use to achieve empathic accuracy. Journal of Intelligence 9: 27. [Google Scholar] [CrossRef] [PubMed]
- Hoffmann, Holger, Henrik Kessler, Tobias Eppel, Stefanie Rukavina, and Harald C. Traue. 2010. Expression intensity, gender and facial emotion recognition: Women recognize only subtle facial emotions better than men. Acta Psychologica 135: 278–83. [Google Scholar] [CrossRef]
- Hyde, Janet S., and Marcia C. Linn. 1988. Gender differences in verbal ability: A meta-analysis. Psychological Bulletin 104: 53–69. [Google Scholar] [CrossRef]
- Hyde, Janet S., Elizabeth Fennema, and Susan J. Lamon. 1990. Gender differences in mathematics performance: A meta-analysis. Psychological Bulletin 107: 139–55. [Google Scholar] [CrossRef] [PubMed]
- Ickes, William, Linda Stinson, Victor Bissonnette, and Stella Garcia. 1990. Naturalistic social cognition: Empathic accuracy in mixed-sex dyads. Journal of Personality and Social Psychology 59: 730–42. [Google Scholar] [CrossRef]
- Ickes, William, Paul R. Gesn, and Tiffany Graham. 2000. Gender differences in empathic accuracy: Differential ability or differential motivation? Personal Relationships 7: 95–109. [Google Scholar] [CrossRef]
- Jardine, Brittany B., Sarah Vannier, and Daniel Voyer. 2022. Emotional intelligence and romantic relationship satisfaction: A systematic review and meta-analysis. Personality and Individual Differences 196: 111713. [Google Scholar] [CrossRef]
- Joseph, Dana L., and Daniel A. Newman. 2010. Emotional intelligence: An integrative meta-analysis and cascading model. Journal of Applied Psychology 95: 54–78. [Google Scholar] [CrossRef]
- Kirkland, Rena, Eric Peterson, Crystal Baker, Stephanie Miller, and Steven Pulos. 2013. Meta-analysis reveals adult female superiority in “Reading the Mind in the Eyes” Test. North American Journal of Psychology 15: 121–46. [Google Scholar]
- Kret, Mariska E., and Beatrice De Gelder. 2012. A review on sex differences in processing emotional signals. Neuropsychologia 50: 1211–21. [Google Scholar] [CrossRef] [PubMed]
- Kurkul, Wen W. 2007. Nonverbal communication in one-to-one music performance instruction. Psychology of Music 35: 327–62. [Google Scholar] [CrossRef]
- LaFrance, Marianne, and Nancy M. Henley. 1994. On oppressing hypotheses: Or differences in nonverbal sensitivity revisited. In Power/Gender: Social Relations in Theory and Practice. Edited by H. Lorraine Radtke and Henderikus J. Stam. Thousand Oaks: Sage, pp. 287–311. [Google Scholar]
- Longman, R. Stewart, Donald H. Saklofske, and Tak S. Fung. 2007. WAIS-III percentile scores by education and sex for U.S. and Canadian populations. Assessment 14: 426–32. [Google Scholar] [CrossRef]
- MacCann, Carolyn, Yasemin Erbas, Egon Dejonckheere, Amirali Minbashian, Peter Kuppens, and Kirill Fayn. 2020. Emotional intelligence relates to emotions, emotion dynamics, and emotion complexity: A meta-analysis and experience sampling study. European Journal of Psychological Assessment 36: 460–70. [Google Scholar] [CrossRef]
- Maeda, Yukiko, and So Yoon Yoon. 2013. A meta-analysis on gender differences in mental rotation ability measured by the Purdue Spatial Visualization Tests: Visualization of Rotations (PSVT:R). Educational Psychology Review 25: 69–94. [Google Scholar] [CrossRef]
- Mayer, John D., David R. Caruso, and Peter Salovey. 2016. The ability model of emotional intelligence: Principles and updates. Emotion Review 8: 290–300. [Google Scholar] [CrossRef]
- McClure, Erin B. 2000. A meta-analytic review of sex differences in facial expression processing and their development in infants, children, and adolescents. Psychological Bulletin 126: 424–53. [Google Scholar] [CrossRef]
- McDonald, Skye, Cristina Bornhofen, David Shum, Esther Long, Clare Saunders, and Kerryn Neulinger. 2006. Reliability and validity of The Awareness of Social Inference Test (TASIT): A clinical test of social perception. Disability and Rehabilitation 28: 1529–42. [Google Scholar] [CrossRef]
- Merten, Jörg. 2005. Culture, gender and the recognition of the basic emotions. Psychologia 48: 306–16. [Google Scholar] [CrossRef]
- Monroy, Maria, Alan S. Cowen, and Dacher Keltner. 2022. Intersectionality in emotion signaling and recognition: The influence of gender, ethnicity, and social class. Emotion 22: 1980–88. [Google Scholar] [CrossRef]
- Nowicki, Stephen, and Marshall P. Duke. 1994. Individual differences in the nonverbal communication of affect: The diagnostic analysis of nonverbal accuracy scale. Journal of Nonverbal Behavior 18: 9–35. [Google Scholar] [CrossRef]
- Ogawa, Kazumi, and Judith A. Hall. 2022. Development of the Test of Nonverbal Cue Knowledge-II (TONCK-II). Journal of Nonverbal Behavior 46: 569–92. [Google Scholar] [CrossRef]
- Page, Matthew J., Joanne E. McKenzie, Patrick M. Bossuyt, Isabelle Boutron, Tammy C. Hoffmann, Cynthia D. Mulrow, Larissa Shamseer, Jennifer M. Tetzlaff, Elie A. Akl, Sue E. Brennan, and et al. 2021. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. The BMJ 372: 1–9. [Google Scholar] [CrossRef]
- Petersen, Jennifer. 2018. Gender difference in verbal performance: A meta-analysis of United States state performance assessments. Educational Psychology Review 30: 1269–81. [Google Scholar] [CrossRef]
- Petrides, K V., Adrian Furnham, and G. Neil Martin. 2004. Estimates of emotional and psychometric intelligence: Evidence for gender-based stereotypes. The Journal of Social Psychology 144: 149–162. [Google Scholar] [CrossRef]
- Pustejovsky, James E., and Melissa A. Rodgers. 2019. Testing for funnel plot asymmetry of standardized mean differences. Research Synthesis Methods 10: 57–71. [Google Scholar] [CrossRef]
- Richard, F. Dan, Charles F. Bond, and Juli J. Stokes-Zoota. 2003. One hundred years of social psychology quantitatively described. Review of General Psychology 7: 331–63. [Google Scholar] [CrossRef]
- Rodgers, Melissa A., and James E. Pustejovsky. 2021. Evaluating meta-analytic methods to detect selective reporting in the presence of dependent effect sizes. Psychological Methods 26: 141–60. [Google Scholar] [CrossRef]
- Roivainen, Eka. 2011. Gender differences in processing speed: A review of recent research. Learning and Individual Differences 21: 145–49. [Google Scholar] [CrossRef]
- Rosenthal, Robert, Dane Archer, Judith A. Hall, M. Robin DiMatteo, and Peter L. Rogers. 1979. Sensitivity to Nonverbal Communication: The Pons Test. Baltimore: The Johns Hopkins University Press. [Google Scholar] [CrossRef]
- Sasson, Noah J., Amy E. Pinkham, Jan Richard, Paul Hughett, Raquel E. Gur, and Ruben C. Gur. 2010. Controlling for response biases clarifies sex and age differences in facial affect recognition. Journal of Nonverbal Behavior 34: 207–21. [Google Scholar] [CrossRef]
- Schlegel, Katja. 2020. Inter- and intrapersonal downsides of accurately perceiving others’ emotions. In Social Intelligence and Nonverbal Communication. Edited by Robert J. Sternberg and Aleksandra Kostić. Berlin/Heidelberg: Springer, pp. 359–95. [Google Scholar] [CrossRef]
- Schlegel, Katja. 2021. The effects of emotion recognition training on interpersonal effectiveness. Basic and Applied Social Psychology 43: 141–53. [Google Scholar] [CrossRef]
- Schlegel, Katja, and Marcello Mortillaro. 2019. The Geneva Emotional Competence Test (GECo): An ability measure of workplace emotional intelligence. Journal of Applied Psychology 104: 559–80. [Google Scholar] [CrossRef]
- Schlegel, Katja, Didier Grandjean, and Klaus R. Scherer. 2014. Introducing the Geneva Emotion Recognition Test: An example of Rasch-based test development. Psychological Assessment 26: 666–72. [Google Scholar] [CrossRef]
- Schlegel, Katja, Ishabel M. Vicaria, Derek M. Isaacowitz, and Judith A. Hall. 2017. Effectiveness of a short audiovisual emotion recognition training program in adults. Motivation and Emotion 41: 646–60. [Google Scholar] [CrossRef]
- Schlegel, Katja, Johnny R. J. Fontaine, and Klaus R. Scherer. 2019. The nomological network of emotion recognition ability: Evidence from the Geneva Emotion Recognition Test. European Journal of Psychological Assessment 35: 352–63. [Google Scholar] [CrossRef]
- Schlegel, Katja, Monica de Jong, and Smaranda Boros. 2024. Conflict management 101: How emotional intelligence can make or break a manager. International Journal of Conflict Management 36: 145–65. [Google Scholar] [CrossRef]
- Schmid Mast, Marianne, and Judith A. Hall. 2018. The impact of interpersonal accuracy on behavioral outcomes. Current Directions in Psychological Science 27: 309–14. [Google Scholar] [CrossRef]
- Thompson, Ashley E., and Daniel Voyer. 2014. Sex differences in the ability to recognise non-verbal displays of emotion: A meta-analysis. Cognition and Emotion 28: 1164–95. [Google Scholar] [CrossRef]
- Viechtbauer, Wolfgang. 2010. Conducting meta-analyses in R with the metafor package. Journal of Statistical Software 36: 1–48. [Google Scholar] [CrossRef]
- Wang, Yihan, Qian Luo, Yuanmeng Zhang, and Ke Zhao. 2024. Synchrony or asynchrony: Development of facial expression recognition from childhood to adolescence based on large-scale evidence. Frontiers in Psychology 15: 1379652. [Google Scholar] [CrossRef] [PubMed]
- Wood, Wendy, and Alice H. Eagly. 2002. A cross-cultural analysis of the behavior of women and men: Implications for the origins of sex differences. Psychological Bulletin 128: 699–727. [Google Scholar] [CrossRef] [PubMed]
- Zaki, Jamil, Niall Bolger, and Kevin Ochsner. 2008. It takes two: The interpersonal nature of empathic accuracy. Psychological Science 19: 399–404. [Google Scholar] [CrossRef]
- Zell, Ethan, Zlatan Krizan, and Sabrina R. Teeter. 2015. Evaluating gender similarities and differences using metasynthesis. American Psychologist 70: 10–20. [Google Scholar] [CrossRef] [PubMed]

| Study | M Effect Size a (Number of Effects) | Percentage Showing Female Advantage b | Instruments | Moderators |
|---|---|---|---|---|
| Hall (1978) | 0.20 (46) | 84% | Assorted | Cue channels, perceiver age, publication year, sample size, target age, target gender |
| Rosenthal et al. (1979) | 0.20 (133) | 80% | PONS c | None |
| Hall (1984) | 0.25 (18) | 81% | Assorted | Cue channels, first author gender |
| McClure (2000) | 0.09 (60) | n/r | Assorted | First author gender, instrument or measurement technique, perceiver age, publication status, target age |
| Kirkland et al. (2013) | 0.09 (42) | n/r | RMET d | Language of test, perceiver country, publication status, researcher group |
| Thompson and Voyer (2014) | 0.14 (404) | n/r | Assorted | Cue channels, emotion, emotion type, instrument, measurement, target age, target gender, perceiver age, presentation method, posed/spontaneous, publication year |
| Hall et al. (2016) | 0.22 (37) | 92% | Assorted | Cue channels |
| Variable | Description |
|---|---|
| Study moderator variables | |
| Participant health | Nonclinical (83.6%); clinical: psychosis (6.4%); physical illness/disability/injury (2.6%); cognitive impairment (2.4%); affective disorders (2.2%); neurodevelopmental disorders (1.4%); other (1.5%) |
| Location (k = 1003) | United States (36.9%); non-Anglophone Europe (29.1%); United Kingdom and Ireland (9.4%); East and Southeast Asia (5.9%); Australia and New Zealand (5.8%); diverse countries (4.5%); Canada (2.8%); Central and South America and Mexico (2.7%); Middle East (1.6%); other locations (1.4%) |
| Participant age (k = 888) | M = 30.55 (SD = 14.87), Md = 27, range = 8–87 |
| Participant age group (k = 1007) | 8–12 (6.4%); 13–17 (5.8%); 18–27 (43.1%); 28 and up or combination of this and preceding category (44.8%) |
| Participant race (k = 376) | White (62.8%); East or Southeast Asian (16.2%); mix of two or more of races (<60% of a named group: 16.0%); African-American (2.7%); other (2.4%) |
| First author gender (k = 991) | Male (43.7%); female (56.3%) |
| Year of publication | M = 2014, Md = 2018, range = 1931–2023 |
| Other descriptives | |
| Study origin | PsycInfo search (85.9%); bibliographies (9.5%); serendipity and unpublished from listserves (4.7%) |
| Search terms | Emotion recognition (46.2%); Reading the Mind in the Eyes Test (25.4%); other tests and categories (28.4%) |
| Type of source | Results were in article, chapter, or book (47.4%); results were from article and sent by its author on request (46.9%); thesis or dissertation, meta-analysis, or unpublished from listserves (5.8%) |
| N of male participants (k = 989) | M = 399.15, Md = 48, range = 15–142,694 |
| N of female participants (k = 989) | M = 442.85, Md = 61, range = 15–148,923 |
| Total N of participants | M = 828.52, Md = 110, range = 30–291,617, grand total N = 837,637 |
| Variable | Description |
|---|---|
| Number of items (k = 1114) | M = 50.98 (SD = 51.95), Md = 36, range = 4–399 |
| Cue channel (k = 1187) | Face only (43.2%); eyes only (31.8%); voice only (content masked or no verbal content) (7.0%); full video, masked voice (6.0%); full video, unmasked voice (5.5%); multichannel total (multiple separately tested cue channels combined in total score) (5.2%); other (1.3%) |
| Test (k = 1187) | Reading the Mind in the Eyes (RMET, 30.5%); Pictures of Facial Affect (POFA, 9.3%); Penn Emotion Recognition Test (ER40, 4.5%); Profile of Nonverbal Sensitivity (PONS, 4.3%); Diagnostic Analysis of Nonverbal Accuracy-Adult Faces (DANVA-AF, 3.8%); Geneva Emotion Recognition Test (GERT, 2.9%); combination of two or more tests (2.9%); Japanese and Caucasian Facial Expressions of Emotion (JACFEE, 2.0%); The Awareness of Social Inference Test (TASIT, 1.9%); others (37.9%) |
| Stimulus presentation mode (k = 1091) | Static or photographs morphed to simulate movement (80.8%); film or video (19.2%) [item not coded for voice-only tests] |
| Stimulus creation mode (k = 806) | Posed (87.2%); spontaneous (12.8%) |
| Target gender (k = 1117) | Male (2.3%); female (8.1%); both (89.6%) |
| Target age (k = 1169) | Children (2.2%); adults (96.8%); both (0.9%) |
| Target race/ethnicity (k = 983) | White (78.0%); mixture (<80% of any named group, 17.7%); East Asian (3.4%); other (0.9%) |
| Moderator | k | r | SE | CI.LB | CI.UB | r Controlling for Health Status |
|---|---|---|---|---|---|---|
| Participant health status a | ||||||
| Nonclinical | 984 | 0.13 *** | 0.004 | 0.121 | 0.137 | |
| Cognitively impaired | 27 | 0.04 | 0.031 | −0.026 | 0.098 | |
| Physical illness or condition | 32 | 0.11 *** | 0.026 | 0.056 | 0.158 | |
| Neurodevelopmental disorder | 16 | 0.06 | 0.038 | −0.017 | 0.133 | |
| Psychosis | 86 | 0.04 * | 0.016 | 0.008 | 0.073 | |
| Affective disorder | 25 | 0.04 | 0.029 | −0.012 | 0.103 | |
| Other mental/behavioral diagnoses | 12 | 0.08 * | 0.040 | 0.003 | 0.159 | |
| Study location b | ||||||
| USA | 462 | 0.13 *** | 0.006 | 0.120 | 0.145 | 0.14 *** |
| Non-Anglophone Europe | 325 | 0.12 *** | 0.008 | 0.102 | 0.132 | 0.13 *** |
| Australia and New Zealand | 68 | 0.12 *** | 0.018 | 0.085 | 0.157 | 0.14 *** |
| Diverse countries | 54 | 0.11 *** | 0.017 | 0.081 | 0.147 | 0.14 *** |
| UK and Ireland | 106 | 0.09 *** | 0.014 | 0.064 | 0.118 | 0.10 *** |
| East and Southeast Asia | 71 | 0.10 *** | 0.017 | 0.068 | 0.133 | 0.12 *** |
| Canada | 33 | 0.09 *** | 0.025 | 0.040 | 0.138 | 0.09 *** |
| Central and South America, Mexico | 28 | 0.09 *** | 0.023 | 0.045 | 0.136 | 0.09 *** |
| Middle East | 17 | 0.11 ** | 0.034 | 0.041 | 0.174 | 0.12 *** |
| Participant mean age | ||||||
| 8–12 years | 77 | 0.09 *** | 0.015 | 0.058 | 0.116 | 0.09 *** |
| 13–17 years | 67 | 0.18 *** | 0.015 | 0.151 | 0.209 | 0.19 *** |
| 18–27 years | 516 | 0.14 *** | 0.006 | 0.128 | 0.152 | 0.14 *** |
| >28 years or mix of 18–27 and >28 | 524 | 0.10 *** | 0.006 | 0.084 | 0.106 | 0.11 *** |
| Sample race c | ||||||
| White | 297 | 0.13 *** | 0.008 | 0.118 | 0.148 | 0.14 *** |
| East and Southeast Asian | 79 | 0.10 *** | 0.016 | 0.069 | 0.131 | 0.11 *** |
| African American in USA | 12 | 0.10 * | 0.045 | 0.010 | 0.187 | 0.12 ** |
| Mixture (no ethnic group compromised >60% of sample) | 73 | 0.08 *** | 0.015 | 0.054 | 0.114 | 0.09 *** |
| First author gender | ||||||
| Male | 483 | 0.11 *** | 0.006 | 0.100 | 0.124 | 0.12 *** |
| Female | 681 | 0.12 *** | 0.006 | 0.114 | 0.135 | 0.14 *** |
| Publication status | ||||||
| Published article | 514 | 0.13 *** | 0.006 | 0.123 | 0.145 | 0.14 *** |
| Result sent by author on our request (only from 2015 onward) | 584 | 0.10 *** | 0.006 | 0.085 | 0.109 | 0.11 *** |
| Master’s thesis or dissertation | 42 | 0.14 *** | 0.021 | 0.100 | 0.184 | 0.15 *** |
| Unpublished | 20 | 0.15 *** | 0.036 | 0.075 | 0.215 | 0.15 *** |
| Chapter or book | 15 | 0.19 *** | 0.034 | 0.119 | 0.252 | 0.18 *** |
| Effect size sent on request of Kirkland et al. (2013) | 13 | 0.09 * | 0.038 | 0.011 | 0.160 | 0.09 * |
| Moderator | k | r | SE | CI.LB | CI.UB | r Controlling for Health Status |
|---|---|---|---|---|---|---|
| Cue channel a | ||||||
| Face | 513 | 0.12 *** | 0.006 | 0.105 | 0.127 | 0.16 *** |
| Masked voice | 81 | 0.13 *** | 0.014 | 0.105 | 0.158 | 0.13 *** |
| Body and hands | 14 | 0.10 *** | 0.030 | 0.041 | 0.159 | 0.14 *** |
| Full video with unmasked voice | 65 | 0.12 *** | 0.016 | 0.085 | 0.148 | 0.11 *** |
| Eyes | 378 | 0.12 *** | 0.006 | 0.102 | 0.127 | 0.12 *** |
| Full video with masked voice | 71 | 0.13 *** | 0.013 | 0.105 | 0.156 | 0.12 *** |
| Multichannel total | 62 | 0.15 *** | 0.015 | 0.120 | 0.180 | 0.14 *** |
| Specific tests a | ||||||
| Reading the Mind in the Eyes (RMET) | 362 | 0.11 *** | 0.006 | 0.099 | 0.124 | 0.12 *** |
| The Awareness of Social Inference Test (TASIT) | 23 | 0.14 *** | 0.023 | 0.093 | 0.182 | 0.15 *** |
| Diagnostic Analysis of Nonverbal Accuracy (DANVA), adult faces | 45 | 0.15 *** | 0.017 | 0.115 | 0.180 | 0.15 *** |
| ER40 (from Penn Computerized Neurocognitive Battery) | 54 | 0.07 *** | 0.016 | 0.041 | 0.101 | 0.09 *** |
| Pictures of Facial Affect (POFA), includes Brief Affect Recognition Task (BART) | 110 | 0.14 *** | 0.013 | 0.113 | 0.165 | 0.16 *** |
| Geneva Emotion Recognition Test (GERT) | 34 | 0.16 *** | 0.018 | 0.126 | 0.198 | 0.17 *** |
| Combination of two or more tests | 34 | 0.15 *** | 0.019 | 0.108 | 0.184 | 0.16 *** |
| Japanese and Caucasian Facial Expressions of Emotion (JACFEE) | 24 | 0.09 ** | 0.028 | 0.034 | 0.144 | 0.10 *** |
| PONS | 51 | 0.16 *** | 0.018 | 0.130 | 0.200 | 0.17 *** |
| Other tests | 451 | 0.12 *** | 0.006 | 0.104 | 0.128 | 0.13 *** |
| Stimulus presentation mode | ||||||
| Static | 881 | 0.12 *** | 0.004 | 0.107 | 0.124 | 0.13 *** |
| Dynamic | 210 | 0.14 *** | 0.009 | 0.118 | 0.152 | 0.14 *** |
| Stimulus creation mode | ||||||
| Spontaneous | 103 | 0.12 *** | 0.005 | 0.112 | 0.133 | 0.14 *** |
| Posed | 703 | 0.12 *** | 0.013 | 0.091 | 0.141 | 0.12 *** |
| Target gender | ||||||
| Male only | 26 | 0.08 ** | 0.024 | 0.031 | 0.124 | 0.10 *** |
| Female only | 90 | 0.13 *** | 0.014 | 0.108 | 0.161 | 0.14 *** |
| Male and female | 1001 | 0.12 *** | 0.004 | 0.108 | 0.125 | 0.13 *** |
| Target age | ||||||
| Child | 26 | 0.14 *** | 0.025 | 0.093 | 0.193 | 0.15 *** |
| Adult | 1132 | 0.12 *** | 0.004 | 0.109 | 0.125 | 0.13 *** |
| Child and adult | 11 | 0.15 ** | 0.047 | 0.060 | 0.243 | 0.15 *** |
| Target race/ethnicity | ||||||
| White | 767 | 0.12 *** | 0.004 | 0.113 | 0.130 | 0.13 *** |
| East Asian | 33 | 0.12 *** | 0.021 | 0.078 | 0.159 | 0.13 *** |
| Multiple ethnicities | 174 | 0.10 *** | 0.009 | 0.078 | 0.113 | 0.11 *** |
| Authors’ analysis model | ||||||
| No covariates | 1104 | 0.11 *** | 0.004 | 0.105 | 0.121 | 0.12 *** |
| With covariates | 67 | 0.21 *** | 0.016 | 0.176 | 0.237 | 0.21 *** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hall, J.A.; Gunnery, S.D.; Schlegel, K. Gender and Accuracy in Decoding Affect Cues: A Meta-Analysis. J. Intell. 2025, 13, 38. https://doi.org/10.3390/jintelligence13030038
Hall JA, Gunnery SD, Schlegel K. Gender and Accuracy in Decoding Affect Cues: A Meta-Analysis. Journal of Intelligence. 2025; 13(3):38. https://doi.org/10.3390/jintelligence13030038
Chicago/Turabian StyleHall, Judith A., Sarah D. Gunnery, and Katja Schlegel. 2025. "Gender and Accuracy in Decoding Affect Cues: A Meta-Analysis" Journal of Intelligence 13, no. 3: 38. https://doi.org/10.3390/jintelligence13030038
APA StyleHall, J. A., Gunnery, S. D., & Schlegel, K. (2025). Gender and Accuracy in Decoding Affect Cues: A Meta-Analysis. Journal of Intelligence, 13(3), 38. https://doi.org/10.3390/jintelligence13030038