Whether this analysis is carried out at the level of standardized or unstandardized parameters, is regulated by the way the dependent variable is entered into the analysis. Entering RT or cognitive performance from best to worst performance bands as absolute values will yield an analysis on the level of unstandardized estimates. In contrast, when RT or performance is z-standardized within each performance band, the analysis is performed on the level of standardized estimates. For convenience and ease of interpretation, we recommend that the measure for g is z-standardized in both the analysis with unstandardized and standardized estimates prior to the analysis.
1.3.1. New WPA Approaches with Unstandardized Estimates
Sequential Regression. The sequential regression approach is basically an extension of the traditional worst performance analysis. In a first step mean or median performance PF of each participant
i within each performance band
B is predicted by general intelligence
g:
This yields different unstandardized regression weights
for each performance band
B, representing the relationship of PF with
g within each performance band. The intercept of these regressions
in contrast represents the performance of a person with
, therefore
g should be centered prior to this step [
28].
In a second step the unstandardized regression weights
across performance bands
B are predicted by the number of performance band
B (i.e., the consecutive number of performance bands: 1 for the first and best performance band, 2 for the next best, and so on). This represents the moderation of the relationship between
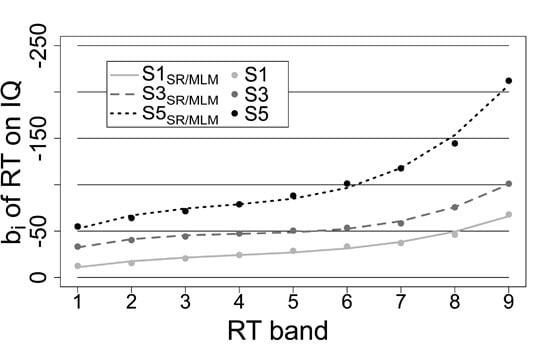
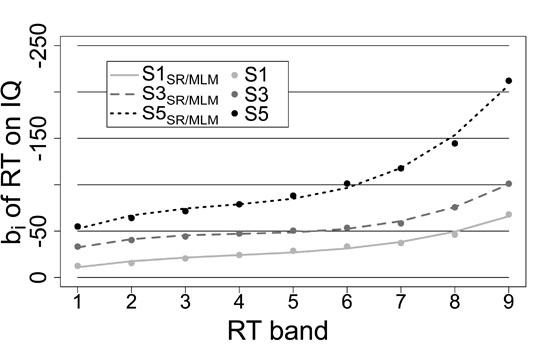
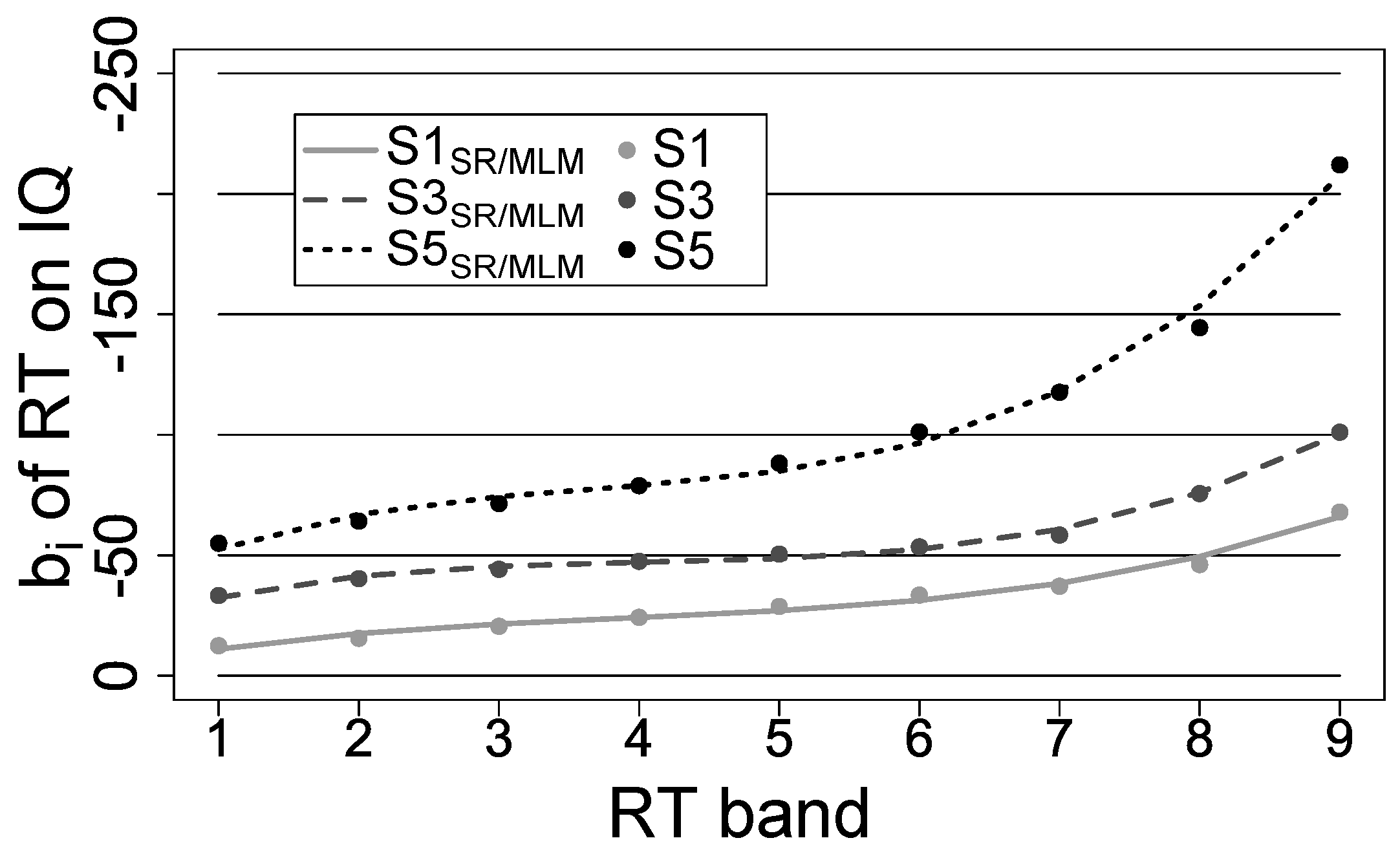
g and performance by performance bands. To approximate the increases of unstandardized regression weights across performance bands adequately it may be reasonable to implement non-linear parameters within this regression. In correspondence to the shape of increases of mean RT across performance bands (see Equation (
4) in the section of the Multi-level approach), we implemented a polynomial function of third order. Not only does this function approximate the increases in unstandardized regression weights reasonably well (
, see
Figure 1, p. 12), but it also implements the moderation of the RT–
g relationship by all performance band variables that describe the shape of increases in mean RT across performance bands (Equation (
4)). This solution suited the present data very well. Beyond that, this may still be a good description for the WPR in performance measures that show normal distribution at the intra-individual level in general due to their characteristic shape of increases of mean performance across performance bands. Therefore, the second regression was specified as follows:
For this second regression, there are two parameters that quantify the significance and magnitude of the WPR. The variance explained by the regression (i.e., ) represents in how far the unstandardized regression weights increase across performance bands and thus the significance of the WPR. As a high only indicates how consistent the increases in unstandardized regression weights across RT bands are, an additional measure is needed to quantify the magnitude of the WPR.
The shape and magnitude of the increases across performance bands are determined by the size of the slope parameters within the regression (
,
)
2. The intercept (
) of the regression represents the regression weight within the centred performance band (i.e.,
). As the interpretation of the three slope parameters within this regression is rather complex, we propose a difference between
in the worst performance (WP) percentile and in the best performance (BP) percentile in reference to mean performance (
) as a measure for the effect size (ES) of the WPR:
This effect size basically corresponds to the effect size Cohen’s q comparing the correlation between best performance and g to the correlation between worst performance and g. It quantifies the magnitude of increase in unstandardized regression weights as percentage of mean performance in the respective task (for an example see p. 12). Still, it is a simplification with respect to the full shape of the increases in unstandardized regression weights across performance bands. As it does only reflect the absolute difference between best and worst performance bands, it does not represent the non-linear shape of increases between best and worst performance bands. Thus, increases in unstandardized regression weights should always be plotted by performance bands, so that the shape of increases can be evaluated as well. Nevertheless, the proposed effect size may be a good heuristic to evaluate in how far increases in unstandardized regression weights are larger in one task or condition compared to another.
Altogether, the sequential regression approach quantifies the WPR by predicting the magnitude of the relationship between g and performance across performance bands by band number. This provides a set of regression parameters that can be tested for statistical significance on the one hand, and an estimate for the consistency of increases across percentiles on the other hand.
Mutli-level moderation. The multi-level approach is essentially equal to the sequential regression approach, except it estimates all parameters of the sequential regression approach within one step. Accounting for the data structure of performance bands nested in participants, the multi-level approach combines Equations (
1) and (
2) by entering Equation (
2) into Equation (
1).
In addition, the intercept varies across performance bands for obvious reasons. The mean performance within each performance band evidently decreases with ascending performance bands. Specifically performance in the first band will be best or fastest, whereas performance in the last band will be worst or slowest. Therefore the intercept
from Equation (
1) should be able to change across performance bands as well.
Similar to the increase of unstandardized regression weights across performance bands, the intercept does not increase linearly across performance bands either. In fact, a linear increase of intercepts across performance bands would correspond to an equal distribution of performance at the intra-individual level. Usually we would assume intra-individual performance to be normally distributed, or in case of reaction times right-skewed (e.g., ex-Gaussian or Wald distributed). The intercepts within these distributions usually show non-linear increases across performance bands. These increases are again quite well approximated by a polynomial function of third order. For this,
from Equation (
1) will be predicted by percentile:
Entering this equation into Equation (
1) together with Equation (
2) yields a prediction of the performance PF in each performance band
B for participants
i:
The term in the first line represents Equation (
2) and the term in the second line represents Equation (
4). Note that now performance within performance bands
is the dependent variable and that all regression parameters are summarized within one Equation.
As multi-level modeling (MLM) allows to separate effects on level 1 (within a person) and level 2 (between people), we may additionally implement random effects for predictors on level 1. This means that the level 1 parameters (i.e., regression weights of performance bands) may vary across level 2 units (i.e., participants). Specifically, this reflects inter-individual differences in the increases of mean RT across performance bands that basically correspond to inter-individual differences in the intra-individual distribution of performance or RTs. This seemed reasonable to us and therefore the whole Equation (
4) was estimated with random effects
3. This results in a MLM equation with correct notation of:
The performance PF in each performance band
B of each participant
i is composed of a random intercept (
) and random effects of performance band (
). This first line of Equation (
6) essentially is Equation (
4) . Additionally,
is predicted by a fixed effect of
g (
), representing the relationship of
and
g for
and cross level interactions between
g and
B (
), representing the increases of the relationship between
and
g across performance bands. This second line of Equation (
6) basically represents Equation (
2), with the difference that the interactions between performance band
B and
g are explicitly stated in Equation (
6).
This Equation of the MLM allows to estimate the interaction between performance band and
g on the relation between
g and performance across performance bands. However, because the dependent variable within this approach is the performance within each performance band
B, the overall explained variance
of this regression does not refer to the same explained variance as in the second step of the sequential regression approach. In contrast, this approach treats the unstandardized regression weights between
g and performance across performance bands as estimates, whereas the sequential regression approach enters these coefficients as manifest variables. Consequently, the sequential regression approach will underestimate the standard errors of coefficients in the second step and thus overestimates their statistical significance [
22]. In this sense, the MLM approach results in more accurate estimates of the standard errors from a statistical perspective, because it does not underestimate the standard errors of the respective coefficients. Hence, the MLM approach judges the significance of coefficients more accurately than the sequential regression approach.
The interpretation of the results of the MLM approach is arguably more complex. There is no direct measure for the effect size of the WPR, because unlike the
in the second step of the sequential regression approach, the
of the MLM approach does not refer to the consistency of the increases of unstandardized regression weighs across performance bands. Instead it refers to the variance explained in the performance (
) across performance bands. Still, the effect size introduced in Equation (
3) can be computed in the MLM approach as well. For this, the unstandardized regression weight
predicting PF by
g across performance bands
B can be estimated with
to
:
To calculate the effect size as stated in Equation (
3) the regression weights for the best and worst performance bands can be estimated. The mean performance can be estimated with the fixed slope (
), when the performance band variable was centered. With these variables, the proposed effect size can then be calculated.
1.3.2. New WPA Approaches for Standardized Regression Weights
To implement these two WPA approaches on the level of standardized regression weights, the performance within each performance band has to be z-standardized on the inter-individual standard deviation (SD) of the respective performance band. Although we thereby lose information on the absolute increases in performance across performance bands (e.g., increasing RTs from best to worst performance bands) the covariance structure between performance across performance bands and g remains the same only that it is now controlled for increasing variances from best to worst performance. Furthermore, it is necessary that g is z-standardized for the analyses on the level of standardized estimates. However, we recommend to do that for both the analyses on the level of unstandardized and standardized estimates.
Sequential Regression. For the sequential regression approach with standardized estimates only the first step differs considerably from analysing unstandardized estimates. Specifically, we no longer predict the absolute performance PF of each participant
i within each performance band
B, but the
z-standardized performance
within each performance band
B by general intelligence
g:
This results in standardized regression weights
for each performance band quantifying the standardized relationship (i.e., correlation) between performance in each performance band with
g. Please note that there is no longer any intercept for this regression, because the intercept is always zero when using
z-standardized measures. The standardized regression weights across performance bands
can again be predicted by the number of performance band in a second step that implements the moderation of the relationship between performance PF and
g by performance band:
According to the common assumption that correlations increase linearly from best to worst performance [
3], we implemented only a linear increases in standardized regression weights across performance bands.
4 Nevertheless, it is possible to implement non-linear increases in this approach as well. For this, additional regression weights specifying quadratic or cubic trends can be entered into Equation (
9), just like in Equation (
2).
Comparable to the sequential regression approach on the level of standardized regression weights, there are two parameters that quantify the significance of the WPR. On the one hand, the of this regression quantifies the consistency of increases in performance bands. On the other hand, the regression weight quantifies the size of increases across performance bands. The intercept quantifies the standardized relation for the centered performance band.
To quantify the magnitude of the WPR on the level of standardized estimates it is best to compute the effect size Cohen’s
q from Equation (
9). To do so, we calculate the estimated standardized regression weight for the best performance band
and the estimated standardized regression weight for the worst performance band
. These can then be transformed into
Z-values with a Fisher
Z-transformation and the difference between
and
yields Cohen’s
q [
12].
Multi-level moderation. Again, the Multi-level approach is essentially equal to the sequential regression approach apart from the fact that it estimates both steps of the sequential regression approach in one step. For this, Equation (
9) is entered into Equation (
8), resulting in:
In contrast to the MLM approach on the level of unstandardized regression weights, it is not necessary to estimate a fixed effect of the increases in performance across performance bands (see Equation (
4)), because the
z-standardization of performance in each performance band resulted in a mean performance of zero within each performance band. However, a random effect for this effect can still be estimated. This effect reflects that there may not be full differential stability in performance across performance bands. For example, one person can show above average performance in best performance bands and only average performance in worst performance bands, whereas for another person the position in comparison to other participants stays the same across performance bands. This results in a full MLM equation with correct notation of:
with the fixed effect
this results in:
Within this approach represents the relationship between performance and g in the centred performance band and represents the linear increase in this relationship across performance bands. The random effect represents the variance in the relative position across performance bands for participants. In detail, this variance would be zero, if performance across performance bands is perfectly correlated.
As in the sequential regression approach, the increase in standardized regression weights can be computed with
and
. Thus we can estimate the relationship between performance and
g in the best and worst performance band and estimate the effect size Cohen’s
q as difference between these two estimates on the level of
Z-scores. Specifically, the estimated standardized regression weight within each performance band
B can be estimated via:
Once more, the MLM approach treats the standardized regression weights across performance bands as estimated, whereas the sequential regression approach treats them as manifest. Thus the MLM approach is generally, for unstandardized and standardized estimates, the statistically more sound approach because it will lead to less attenuated standard errors of increases in regression weights and thus does not inflate α-error probability of these increases.





{kind=link}
{kind=link}