How Specific Abilities Might Throw ‘g’ a Curve: An Idea on How to Capitalize on the Predictive Validity of Specific Cognitive Abilities


Abstract
:1. Introduction
1.1. Critique on the g-Factor and Its Use as Single Predictor of Performance
1.2. Considering the Criterion—Specific Ability Relations
1.3. Considering the Predictor—Ability Differentiation Hypothesis
1.4. Curvilinear Relations
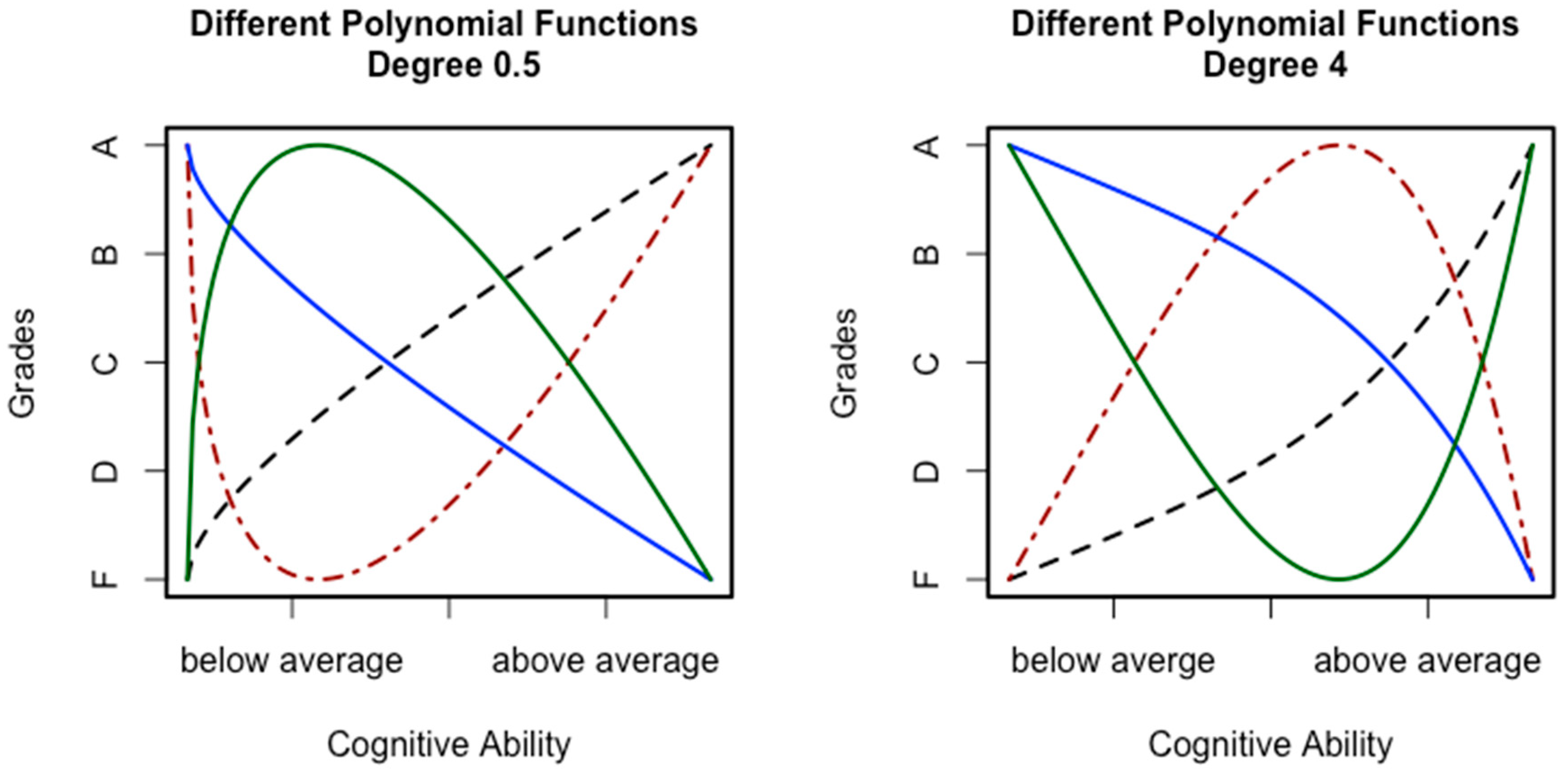
1.5. Modeling Curvilinear Effects
1.6. Summary and Aims of the Study
2. Methods
2.1. Sample, Measures, and Procedure
2.2. Statistical Analyses
3. Results
3.1. Multiple Linear Regressions
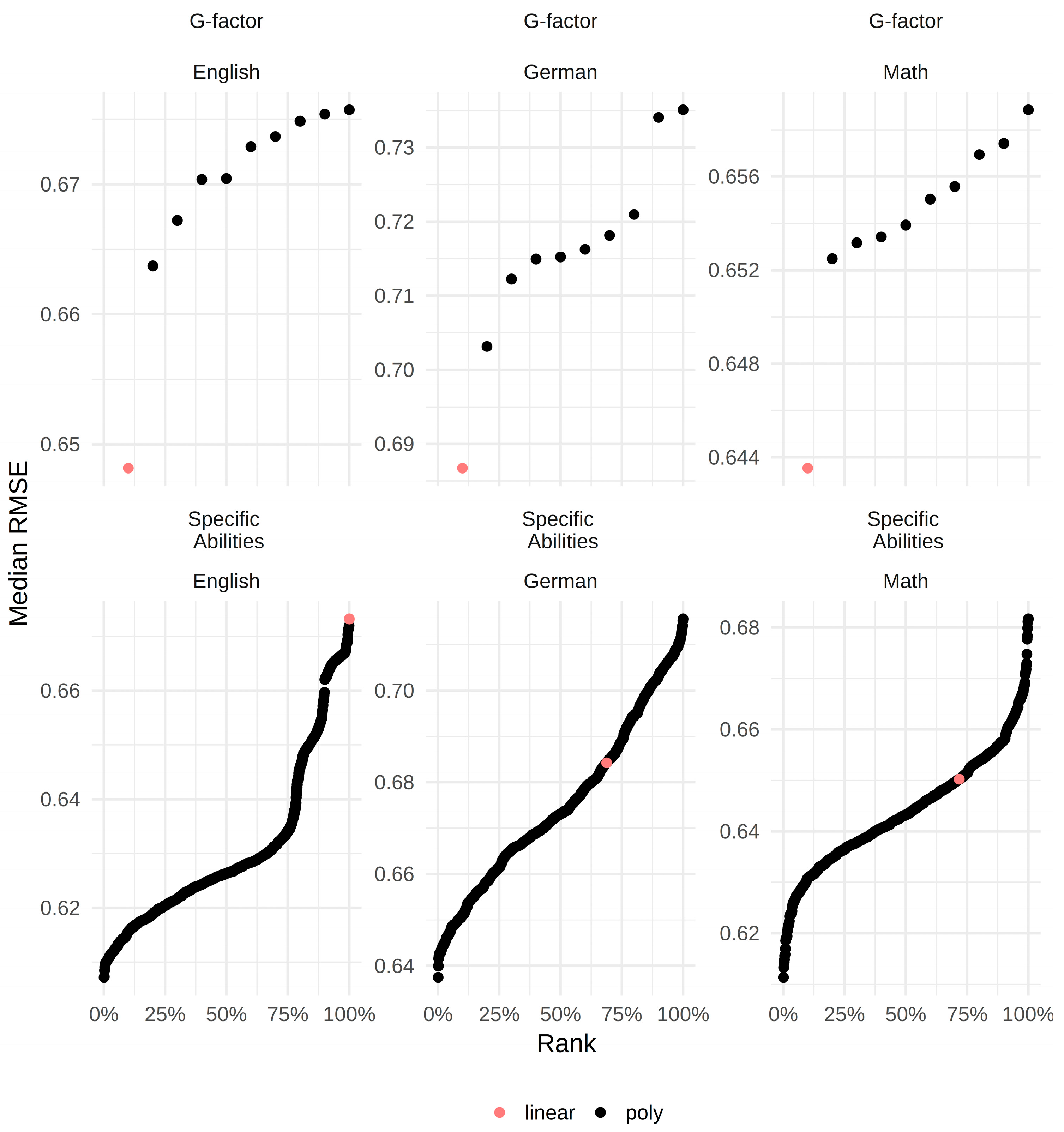
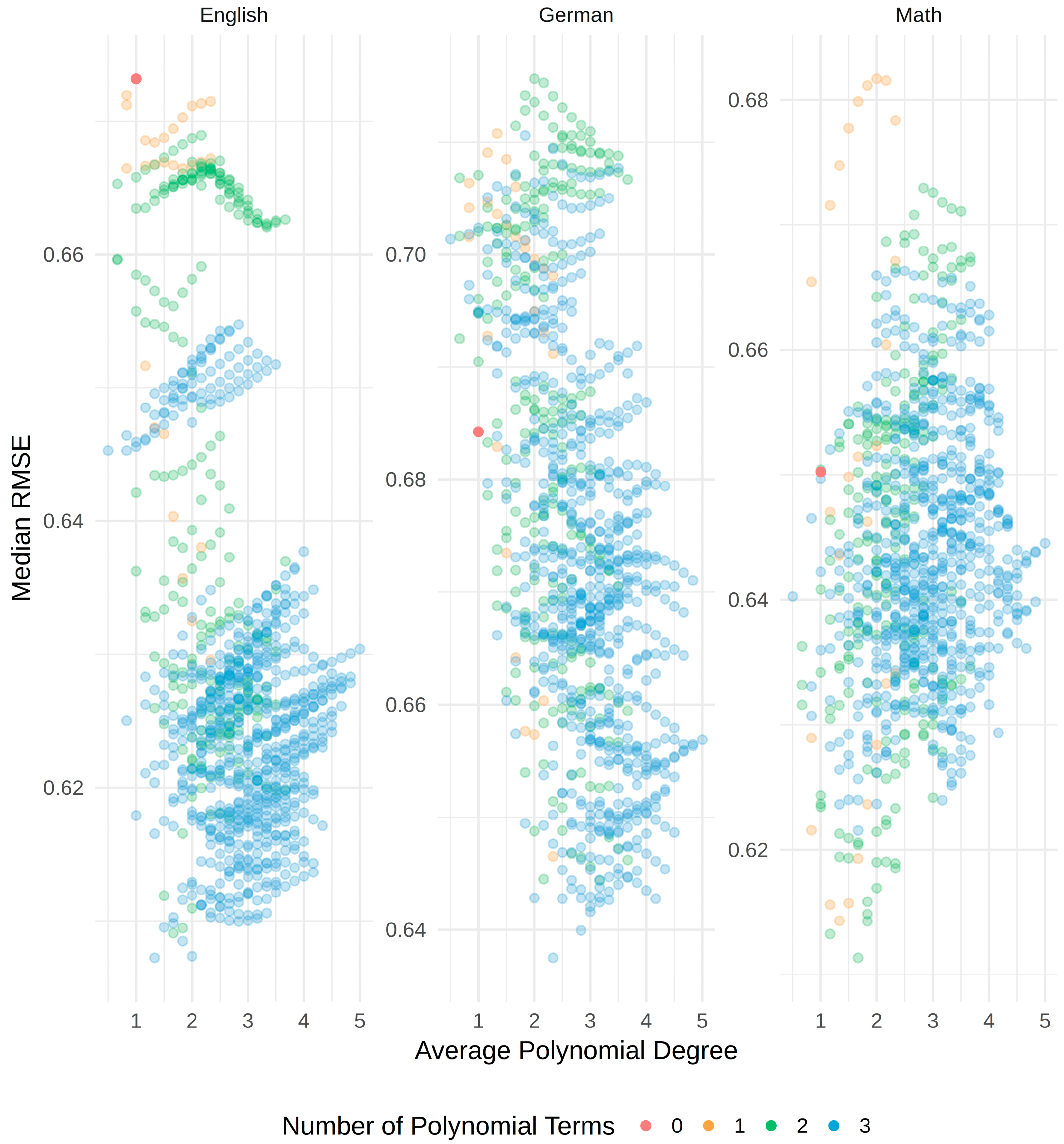
3.2. Selecting the Best Fitting Model
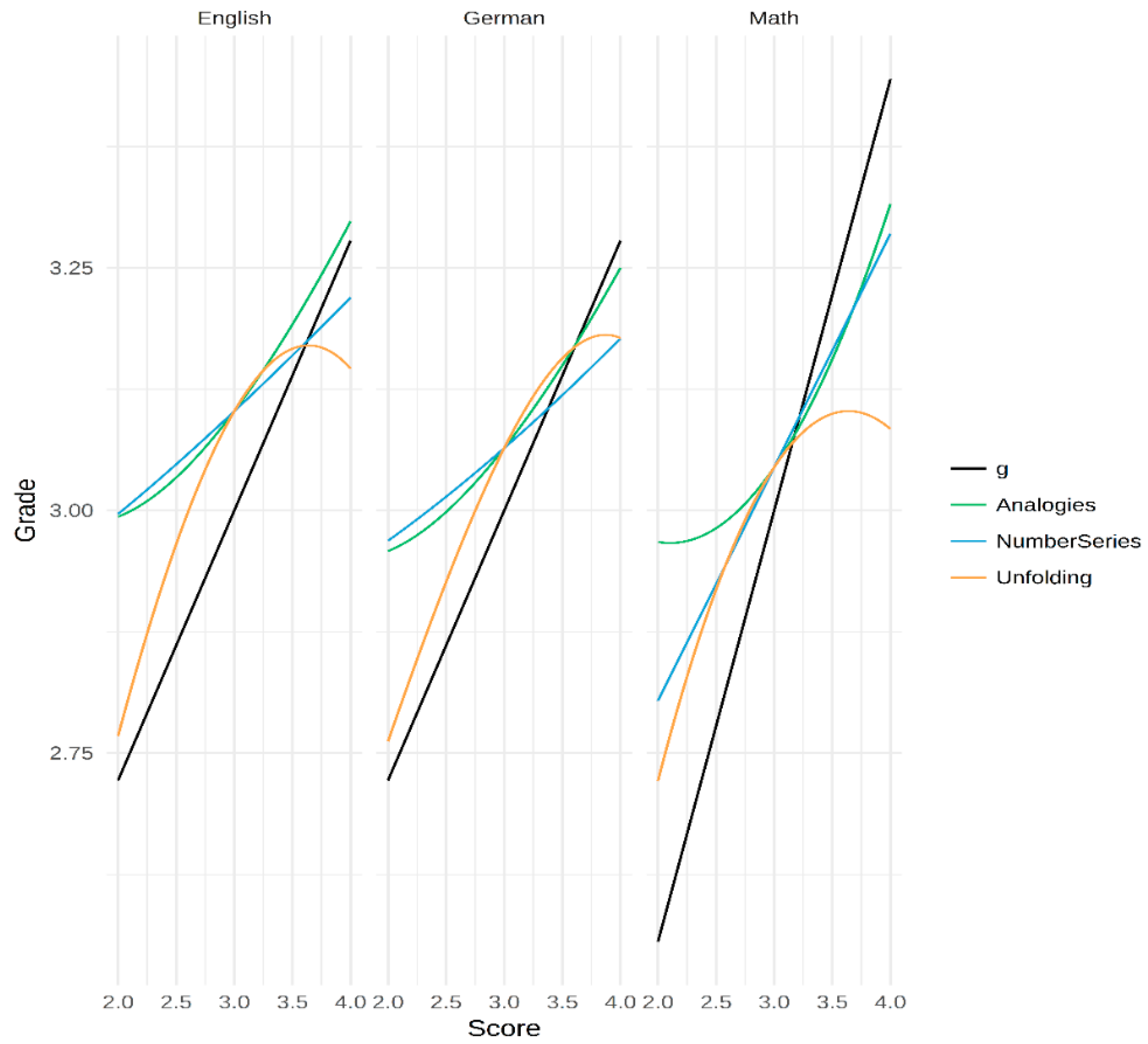
3.3. Exploring the Nature of the Curvilinear Relations
4. Discussion
4.1. Specific Abilities and Scholastic Performance
4.2. Machine Learning
4.3. Limitations and Outlook
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Fleming, J. Who will succeed in college? When the sat predicts black students’ performance. Rev. Higher Educ. 2002, 25, 281–296. [Google Scholar] [CrossRef]
- Hoffman, J.L.; Lowitzki, K.E. Predicting college success with high school grades and test scores: Limitations for minority students. Rev. Higher Educ. 2005, 28, 455–474. [Google Scholar] [CrossRef]
- Adams, S.J. Educational attainment and health: Evidence from a sample of older adults. Educ. Econ. 2002, 10, 97–109. [Google Scholar] [CrossRef]
- French, M.T.; Homer, J.F.; Popovici, I.; Robins, P.K. What you do in high school matters: High school gpa, educational attainment, and labor market earnings as a young adult. East. Econ. J. 2015, 41, 370–386. [Google Scholar] [CrossRef]
- Poropat, A.E. A meta-analysis of the five-factor model of personality and academic performance. Psychol. Bull. 2009, 135, 322–338. [Google Scholar] [CrossRef] [PubMed]
- Di Fabio, A.; Busoni, L. Fluid intelligence, personality traits and scholastic success: Empirical evidence in a sample of italian high school students. Personal. Individ. Differ. 2007, 43, 2095–2104. [Google Scholar] [CrossRef]
- Zhang, J.; Ziegler, M. How do the big five influence scholastic performance? A big five-narrow traits model or a double mediation model. Learn. Individ. Differ. 2016, 50, 93–102. [Google Scholar] [CrossRef]
- Ziegler, M.; Knogler, M.; Bühner, M. Conscientiousness, achievement striving, and intelligence as performance predictors in a sample of german psychology students: Always a linear relationship? Learn. Individ. Differ. 2009, 19, 288–292. [Google Scholar] [CrossRef]
- Kuncel, N.R.; Hezlett, S.A.; Ones, D.S. Academic performance, career potential, creativity, and job performance: Can one construct predict them all? J. Personal. Soc. Psychol. 2004, 86, 148–161. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, F.L.; Hunter, J.E. General mental ability in the world of work: Occupational attainment and job performance. J. Personal. Soc. Psychol. 2004, 86, 162–173. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, F.L.; Hunter, J.E. The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychol. Bull. 1998, 124, 262–274. [Google Scholar] [CrossRef]
- Gottfredson, L.S. Why g matters: The complexity of everyday life. Intelligence 1997, 24, 79–132. [Google Scholar] [CrossRef] [Green Version]
- Gottfredson, L.S.; Deary, I.J. Intelligence predicts health and longevity, but why? Curr. Direct. Psychol. Sci. 2004, 13, 1–14. [Google Scholar] [CrossRef]
- Coyle, T.R. Relations among general intelligence (g), aptitude tests, and GPA: Linear effects dominate. Intelligence 2015, 53, 16–22. [Google Scholar] [CrossRef]
- Neisser, U.; Boodoo, G.; Bouchard, T.J.; Boykin, A.W.; Brody, N.; Ceci, S.J.; Halpern, D.F.; Loehlin, J.C.; Perloff, R.; Sternberg, R.J.; et al. Intelligence: Knowns and unknowns. Am. Psychol. 1996, 51, 77–101. [Google Scholar] [CrossRef]
- Roth, B.; Becker, N.; Romeyke, S.; Schäfer, S.; Domnick, F.; Spinath, F.M. Intelligence and school grades: A meta-analysis. Intelligence 2015, 53, 118–137. [Google Scholar] [CrossRef]
- Cucina, J.M.; Peyton, S.T.; Su, C.; Byle, K.A. Role of mental abilities and mental tests in explaining high-school grades. Intelligence 2016, 54, 90–104. [Google Scholar] [CrossRef]
- McGrew, K.S. CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research. Intelligence 2009, 37, 1–10. [Google Scholar] [CrossRef]
- Schneider, W.J.; McGrew, K. The cattell-horn-carroll model of intelligence. In Contemporary Intellectual Assessment: Theories, Tests, and Issues; Flanagan, D.P., Harrison, P.L., Eds.; Guilford Press: New York, NY, USA, 2012; pp. 99–144. [Google Scholar]
- Román, F.J.; Abad, F.J.; Escorial, S.; Burgaleta, M.; Martínez, K.; Álvarez-Linera, J.; Quiroga, M.Á.; Karama, S.; Haier, R.J.; Colom, R. Reversed hierarchy in the brain for general and specific cognitive abilities: A morphometric analysis. Hum. Brain Map. 2014, 35, 3805–3818. [Google Scholar] [CrossRef] [PubMed]
- Steinmayr, R.; Spinath, B. Predicting school achievement from motivation and personality. Z. Padagogische Psychol. 2007, 21, 207–216. [Google Scholar] [CrossRef]
- Steinmayr, R.; Spinath, B. The importance of motivation as a predictor of school achievement. Learn. Individ. Differ. 2009, 19, 80–90. [Google Scholar] [CrossRef]
- Steinmayr, R.; Ziegler, M.; Träuble, B. Do intelligence and sustained attention interact in predicting academic achievement? Learn. Individ. Differ. 2010, 20, 14–18. [Google Scholar] [CrossRef]
- Zhang, J.; Ziegler, M. Interaction effects between openness and fluid intelligence predicting scholastic performance. J. Intell. 2015, 3, 91–110. [Google Scholar] [CrossRef]
- Brogden, H.E.; Taylor, E.K. The theory and classification of criterion bias. Educ. Psychol. Meas. 1950, 10, 159–183. [Google Scholar] [CrossRef]
- Spearman, C. The Abilities of Man; Macmillan: London, UK, 1927. [Google Scholar]
- Deary, I.J.; Pagliari, C. The strength of g at different levels of ability: Have detterman and daniel rediscovered spearman’s “law of diminishing returns”? Intelligence 1991, 15, 247–250. [Google Scholar] [CrossRef]
- Kovacs, K.; Conway, A.R.A. Process overlap theory: A unified account of the general factor of intelligence. Psychol. Inq. 2016, 27, 151–177. [Google Scholar] [CrossRef]
- Ackerman, P.L. Process overlap and g do not adequately account for a general factor of intelligence. Psychol. Inq. 2016, 27, 178–180. [Google Scholar] [CrossRef]
- Stankov, L. Overemphasized “g”. J. Intell. 2017, 5, 33. [Google Scholar] [CrossRef]
- Schneider, W.J.; Newman, D.A. Intelligence is multidimensional: Theoretical review and implications of specific cognitive abilities. Hum. Resour. Manag. Rev. 2015, 25, 12–27. [Google Scholar] [CrossRef]
- Ackerman, P.L.; Beier, M.E.; Boyle, M.O. Working memory and intelligence: The same or different constructs? Psychol. Bull. 2005, 131, 30–60. [Google Scholar] [CrossRef] [PubMed]
- MacCann, C.; Joseph, D.L.; Newman, D.A.; Roberts, R.D. Emotional intelligence is a second-stratum factor of intelligence: Evidence from hierarchical and bifactor models. Emotion 2014, 14, 358–374. [Google Scholar] [CrossRef] [PubMed]
- Reeve, C.L.; Meyer, R.D.; Bonaccio, S. Intelligence-personality associations reconsidered: The importance of distinguishing between general and narrow dimensions of intelligence. Intelligence 2006, 34, 387–402. [Google Scholar] [CrossRef]
- Brunner, M.; Süß, H.M. Analyzing the reliability of multidimensional measures: An example from intelligence research. Educ. Psychol. Meas. 2005, 65, 227–240. [Google Scholar] [CrossRef]
- Gignac, G.E.; Kretzschmar, A. Evaluating dimensional distinctness with correlated-factor models: Limitations and suggestions. Intelligence 2017, 62, 138–147. [Google Scholar] [CrossRef]
- Ziegler, M.; Dietl, E.; Danay, E.; Vogel, M.; Bühner, M. Predicting training success with general mental ability, specific ability tests, and (un) structured interviews: A meta analysis with unique samples. Int. J. Select. Assess. 2011, 19, 170–182. [Google Scholar] [CrossRef]
- Ziegler, M.; Brunner, M. Test standards and psychometric modeling. In Psychosocial Skills and School Systems in the 21st Century; Lipnevich, A.A., Preckel, F., Roberts, R., Eds.; Springer: Göttingen, Germany, 2016; pp. 29–55. [Google Scholar]
- Wittmann, W.W. Multivariate reliability theory: Principles of symmetry and successful validation strategies. In Handbook of Multivariate Experimental Psychology. Perspectives on Individual Differences; Nesselroade, J.R., Cattell, R.B., Eds.; Plenum Press: New York, NY, USA, 1988; Volume 2, p. 966. [Google Scholar]
- Coyle, T.R.; Snyder, A.C.; Richmond, M.C.; Little, M. Sat non-g residuals predict course specific gpas: Support for investment theory. Intelligence 2015, 51, 57–66. [Google Scholar] [CrossRef]
- Lang, J.W.; Kersting, M.; Hülsheger, U.R.; Lang, J. General mental ability, narrower cognitive abilities, and job performance: The perspective of the nested-factors model of cognitive abilities. Pers. Psychol. 2010, 63, 595–640. [Google Scholar] [CrossRef]
- Spinath, B.; Eckert, C.; Steinmayr, R. Gender differences in school success: What are the roles of students’ intelligence, personality and motivation? Educ. Res. 2014, 56, 230–243. [Google Scholar] [CrossRef]
- Carpenter, P.A.; Just, M.A.; Shell, P. What one intelligence test measures: A theoretical account of the processing in the raven progressive matrices test. Psychol. Rev. 1990, 97, 404–431. [Google Scholar] [CrossRef] [PubMed]
- Deary, I.J.; Strand, S.; Smith, P.; Fernandes, C. Intelligence and educational achievement. Intelligence 2007, 35, 13–21. [Google Scholar] [CrossRef]
- Greiff, S.; Heene, M. Why psychological assessment needs to start worrying about model fit. Eur. J. Psychol. Assess. 2017, 33, 313–317. [Google Scholar] [CrossRef]
- Heene, M.; Hilbert, S.; Draxler, C.; Ziegler, M.; Bühner, M. Masking misfit in confirmatory factor analysis by increasing unique variances: A cautionary note on the usefulness of cutoff values of fit indices. Psychol. Methods 2011, 16, 319–336. [Google Scholar] [CrossRef] [PubMed]
- Ziegler, M.; Danay, E.; Heene, M.; Asendorpf, J.; Bühner, M. Openness, fluid intelligence, and crystallized intelligence: Toward an integrative model. J. Res. Personal. 2012, 46, 173–183. [Google Scholar] [CrossRef]
- Tucker-Drob, E.M. Differentiation of cognitive abilities across the life span. Dev. Psychol. 2009, 45, 1097–1118. [Google Scholar] [CrossRef] [PubMed]
- Molenaar, D.; Dolan, C.V.; Wicherts, J.M.; van der Maas, H.L.J. Modeling differentiation of cognitive abilities within the higher-order factor model using moderated factor analysis. Intelligence 2010, 38, 611–624. [Google Scholar] [CrossRef]
- Detterman, D.K.; Daniel, M.H. Correlations of mental tests with each other and with cognitive variables are highest for low IQ groups. Intelligence 1989, 13, 349–359. [Google Scholar] [CrossRef]
- Deary, I.J.; Egan, V.; Gibson, G.J.; Austin, E.J.; Brand, C.R.; Kellaghan, T. Intelligence and the differentiation hypothesis. Intelligence 1996, 23, 105–132. [Google Scholar] [CrossRef]
- Blum, D.; Holling, H. Spearman’s law of diminishing returns. A meta-analysis. Intelligence 2017, 65, 60–66. [Google Scholar] [CrossRef]
- Cortina, J.M. Interaction, nonlinearity, and multicollinearity: Implications for multiple regression. J. Manag. 1993, 19, 915–922. [Google Scholar] [CrossRef]
- Yerkes, R.M.; Dodson, J.D. The relation of strength of stimulus to rapidity of habit-formation. J. Comp. Neurol. Psychol. 1908, 18, 459–482. [Google Scholar] [CrossRef]
- Antonakis, J.; House, R.J.; Simonton, D.K. Can super smart leaders suffer from too much of a good thing? The curvilinear effect of intelligence on perceived leadership behavior. J. Appl. Psychol. 2017, 102, 1003–1021. [Google Scholar] [CrossRef] [PubMed]
- Wonderlic. Wonderlic Personnel & Scholastic Level Exam: User’s Manual; Wonderlic Personnel Test, Inc.: Libertyville, IL, USA, 2002. [Google Scholar]
- Ganzach, Y.; Gotlibobski, C.; Greenberg, D.; Pazy, A. General mental ability and pay: Nonlinear effects. Intelligence 2013, 41, 631–637. [Google Scholar] [CrossRef]
- Tett, R.P.; Burnett, D.D. A personality trait-based interactionist model of job performance. J. Appl. Psychol. 2003, 88, 500–517. [Google Scholar] [CrossRef] [PubMed]
- Ziegler, M.; Bensch, D.; Maaß, U.; Schult, V.; Vogel, M.; Bühner, M. Big five facets as predictor of job training performance: The role of specific job demands. Learn. Individ. Differ. 2014, 29, 1–7. [Google Scholar] [CrossRef]
- Gardner, R.G.; Harris, T.B.; Li, N.; Kirkman, B.L.; Mathieu, J.E. Understanding “it depends” in organizational research. Organ. Res. Methods 2017, 20, 610–638. [Google Scholar] [CrossRef]
- McClelland, G.H.; Judd, C.M. Statistical difficulties of detecting interactions and moderator effects. Psychol. Bull. 1993, 114, 376–390. [Google Scholar] [CrossRef] [PubMed]
- Siemsen, E.; Roth, A.; Oliveira, P. Common method bias in regression models with linear, quadratic, and interaction effects. Organ. Res. Methods 2009, 13, 456–476. [Google Scholar] [CrossRef]
- Lantz, B. Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Simonsohn, U. Two-Lines: A Valid Alternative to the Invalid Testing of u-Shaped Relationships with Quadratic Regressions. Available online: https://ssrn.com/abstract=3021690 or http://dx.doi.org/10.2139/ssrn.3021690 (accessed on 21 March 2018).
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Bleidorn, W.; Hopwood, C.J. Using machine learning to advance personality assessment and theory. Personal. Soc. Psychol. Rev. 2018. [Google Scholar] [CrossRef] [PubMed]
- Yarkoni, T.; Westfall, J. Choosing prediction over explanation in psychology: Lessons from machine learning. Perspect. Psychol. Sci. 2017, 12, 1–23. [Google Scholar] [CrossRef] [PubMed]
- Sauer, S.; Buettner, R.; Heidenreich, T.; Lemke, J.; Berg, C.; Kurz, C. Mindful machine learning. Eur. J. Psychol. Assess. 2018, 34, 6–13. [Google Scholar] [CrossRef]
- Kersting, M.; Althoff, K.; Jäger, A.O. Wilde-Intelligenz-Test 2: Wit-2 [Wilde-Intelligence-Test 2: Wit 2]; Hogrefe, Verlag für Psychologie: Göttingen, Germany, 2008. [Google Scholar]
- Cumming, G. The new statistics: Why and how. Psychol. Sci. 2014, 25, 7–29. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- RStudio. Rstudio: Integrated Development Environment for R (Version 1.1.419); Rstudio: Boston, MA, USA, 2012. [Google Scholar]
- Revelle, W. Psych: Procedures for Psychological, Psychometric, and Personality Research; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Behrendt, S. Lm.Beta: Add Standardized Regression Coefficients to Lm-Objects. R Package Version 1.5-1; R Foundation for Statistical Computing: Vienna, Austria, 2014; Available online: http://CRAN.R-project.org/package=lm.beta (accessed on 18 July 2018).
- Xie, Y.H. Knitr: A General-Purpose Package for Dynamic Report Generation in R. R Package Version 1.17; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Stanley, D. Apatables: Create American Psychological Association (APA) Style Tables. R Package Version 1.5.1; R Foundation for Statistical Computing: Vienna, Austria, 2017; Available online: https://CRAN.R-project.org/package=apaTables (accessed on 18 July 2018).
- Kuhn, M. Caret: Classification and Regression Training. R Package Version 6.0-77; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Wickham, H. Tidyverse: Easily Install and Load’Tidyverse’Packages. R Package Version; R Foundation for Statistical Computing: Vienna, Austria, 2017; Volume 1. [Google Scholar]
- Wickham, H.; Hester, J.; Francois, R. Readr: Read Rectangular Text Data. R Package Version 1.1.1; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Dalal, D.K.; Zickar, M.J. Some common myths about centering predictor variables in moderated multiple regression and polynomial regression. Organ. Res. Methods 2011, 15, 339–362. [Google Scholar] [CrossRef]
- Gignac, G.E.; Szodorai, E.T. Effect size guidelines for individual differences researchers. Personal. Individ. Differ. 2016, 102, 74–78. [Google Scholar] [CrossRef]
- Bosco, F.A.; Aguinis, H.; Singh, K.; Field, J.G.; Pierce, C.A. Correlational effect size benchmarks. J. Appl. Psychol. 2015, 100, 431–449. [Google Scholar] [CrossRef] [PubMed]
- Lindqvist, E.; Vestman, R. The labor market returns to cognitive and noncognitive ability: Evidence from the Swedish enlistment. Am. Econ. J. Appl. Econ. 2011, 3, 101–128. [Google Scholar] [CrossRef]
- Schipolowski, S.; Wilhelm, O.; Schroeders, U. On the nature of crystallized intelligence: The relationship between verbal ability and factual knowledge. Intelligence 2014, 46, 156–168. [Google Scholar] [CrossRef]
- Ziegler, M.; Danay, E.; Schölmerich, F.; Bühner, M. Predicting academic success with the big 5 rated from different points of view: Self-rated, other rated and faked. Eur. J. Personal. 2010, 24, 341–355. [Google Scholar] [CrossRef]
- Park, G.; Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Kosinski, M.; Stillwell, D.J.; Ungar, L.H.; Seligman, M.E.P. Automatic personality assessment through social media language. J. Personal. Soc. Psychol. 2014, 108, 934–952. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Gong, T.; Kosinski, M.; Stillwell, D.; Davidson, R.L. Building a profile of subjective well-being for social media users. PLoS ONE 2017, 12, e0187278. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Kosinski, M. Deep neural networks are more accurate than humans at detecting sexual orientation from facial images. J. Personal. Soc. Psychol. 2018, 114, 246–257. [Google Scholar] [CrossRef] [PubMed]
| 1 | The OSF link to this paper is: https://osf.io/g69ke/?view_only=9e35c20578904c37a418a7d03218dbff. Here, you can find the R code for these analyses, the data set, as well as further analyses mentioned. |
| 2 | The OSF link to this paper is: https://osf.io/g69ke/?view_only=9e35c20578904c37a418a7d03218dbff. Here, you can find the R code for these analyses, the data set, as well as further analyses mentioned. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. Age | 16.03 | 1.49 | |||||||||||
| 2. Unfolding | 9.31 | 4.26 | 0.12 | ||||||||||
| [−0.01, 0.25] | |||||||||||||
| 3. Unfolding scaled | 3.00 | 1.00 | 0.12 | 1.00 ** | |||||||||
| [−0.01, 0.25] | [1.00, 1.00] | ||||||||||||
| 4. Analogies | 8.21 | 3.80 | 0.31 ** | 0.33 ** | 0.33 ** | ||||||||
| [0.19, 0.43] | [0.21, 0.44] | [0.21, 0.44] | |||||||||||
| 5. Analogies scaled | 3.00 | 1.00 | 0.31 ** | 0.33 ** | 0.33 ** | 1.00 ** | |||||||
| [0.19, 0.43] | [0.21, 0.44] | [0.21, 0.44] | [1.00, 1.00] | ||||||||||
| 6. Number Series | 8.26 | 4.01 | 0.21 ** | 0.39 ** | 0.39 ** | 0.39 ** | 0.39 ** | ||||||
| [0.08, 0.33] | [0.27, 0.50] | [0.27, 0.50] | [0.27, 0.50] | [0.27, 0.50] | |||||||||
| 7. Number Series scaled | 3.00 | 1.00 | 0.21 ** | 0.39 ** | 0.39 ** | 0.39 ** | 0.39 ** | 10.00 ** | |||||
| [0.08, 0.33] | [0.27, 0.50] | [0.27, 0.50] | [0.27, 0.50] | [0.27, 0.50] | [1.00, 1.00] | ||||||||
| 8. Factor Score (g) | −0.00 | 0.81 | 0.28 ** | 0.71 ** | 0.71 ** | 0.72 ** | 0.72 ** | 0.85 ** | 0.85 ** | ||||
| [0.15, 0.39] | [0.64, 0.77] | [0.64, 0.77] | [0.64, 0.77] | [0.64, 0.77] | [0.80, 0.88] | [0.80, 0.88] | |||||||
| 9. Factor Score (g) scaled | 3.00 | 1.00 | 0.28 ** | 0.71 ** | 0.71 ** | 0.72 ** | 0.72 ** | 0.85 ** | 0.85 ** | 1.00 ** | |||
| [0.15, 0.39] | [0.64, 0.77] | [0.64, 0.77] | [0.64, 0.77] | [0.64, 0.77] | [0.80, 0.88] | [0.80, 0.88] | [1.00, 1.00] | ||||||
| 10. Grade German | 3.91 | 0.94 | 0.23 ** | 0.22 ** | 0.22 ** | 0.24 ** | 0.24 ** | 0.19 ** | 0.19 ** | 0.28 ** | 0.28 ** | ||
| [0.10, 0.35] | [0.09, 0.34] | [0.09, 0.34] | [0.11, 0.36] | [0.11, 0.36] | [0.06, 0.32] | [0.06, 0.32] | [0.15, 0.40] | [0.15, 0.40] | |||||
| 11. Grade English | 3.74 | 0.94 | 0.19 ** | 0.13 | 0.13 | 0.27 ** | 0.27 ** | 0.22 ** | 0.22 ** | 0.27 ** | 0.27 ** | 0.54 ** | |
| [0.06, 0.32] | [−0.00, 0.26] | [−0.00, 0.26] | [0.15, 0.39] | [0.15, 0.39] | [0.09, 0.34] | [0.09, 0.34] | [0.14, 0.39] | [0.14, 0.39] | [0.44, 0.63] | ||||
| 12. Grade Sports | 5.05 | 0.72 | −0.01 | −0.01 | −0.01 | 0.10 | 0.10 | 0.03 | 0.03 | 0.05 | 0.05 | 0.16 * | 0.11 |
| [−0.15, 0.12] | [−0.14, 0.13] | [−0.14, 0.13] | [−0.04, 0.22] | [−0.04, 0.22] | [−0.11, 0.16] | [−0.11, 0.16] | [−0.09, 0.18] | [−0.09, 0.18] | [0.02, 0.28] | [−0.02, 0.24] |
| Subject | Predictor | b | b 95% CI [LL, UL] | β | β 95% CI [LL, UL] | r | R2 | Adj. R2 |
|---|---|---|---|---|---|---|---|---|
| Math | ||||||||
| Factor Score (g) | 0.44 ** | [0.32, 0.56] | 0.44 | [0.32, 0.56] | 0.44 ** | |||
| R2 = 0.198 ** | 0.194 | |||||||
| 95% CI [0.11, 0.29] | ||||||||
| German | ||||||||
| Factor Score (g) | 0.28 ** | [0.15, 0.41] | 0.28 | [0.15, 0.41] | 0.28 ** | |||
| R2 = 0.077 ** | 0.073 | |||||||
| 95% CI [0.02, 0.15] | ||||||||
| English | ||||||||
| Factor Score (g) | 0.27 ** | [0.14, 0.40] | 0.27 | [0.14, 0.40] | 0.27 ** | |||
| R2 = 0.074 ** | 0.070 | |||||||
| 95% CI [0.02, 0.15] | ||||||||
| Sports | ||||||||
| Factor Score (g) | 0.05 | [−0.09, 0.18] | 0.05 | [−0.09, 0.18] | 0.05 | |||
| R2 = 0.002 | −0.002 | |||||||
| 95% CI [0.00, 0.03] |
| Subject | Predictor | b | b 95% CI [LL, UL] | β | β 95% CI [LL, UL] | sr2 | sr2 95% CI [LL, UL] | r | R2 | Adj. R2 |
|---|---|---|---|---|---|---|---|---|---|---|
| Math | ||||||||||
| Unfolding | 0.15 * | [0.02, 0.28] | 0.15 | [0.02, 0.28] | 0.02 | [−0.01, 0.05] | 0.31 ** | |||
| Analogies | 0.22 ** | [0.08, 0.35] | 0.22 | [0.08, 0.35] | 0.04 | [−0.01, 0.08] | 0.35 ** | |||
| Number Series | 0.22 ** | [0.08, 0.35] | 0.22 | [0.08, 0.35] | 0.04 | [−0.01, 0.08] | 0.36 ** | |||
| R2 = 0.200 ** | 0.189 | |||||||||
| 95% CI [0.11, 0.28] | ||||||||||
| German | ||||||||||
| Unfolding | 0.14 | [−0.01, 0.28] | 0.14 | [−0.01, 0.28] | 0.01 | [−0.02, 0.05] | 0.22 ** | |||
| Analogies | 0.16 * | [0.02, 0.31] | 0.16 | [0.02, 0.31] | 0.02 | [−0.02, 0.06] | 0.24 ** | |||
| Number Series | 0.08 | [−0.07, 0.22] | 0.08 | [−0.07, 0.22] | 0.00 | [−0.01, 0.02] | 0.19 ** | |||
| R2 = 0.083 ** | 0.071 | |||||||||
| 95% CI [0.02, 0.15] | ||||||||||
| English | ||||||||||
| Unfolding | 0.01 | [−0.14, 0.15] | 0.01 | [−0.14, 0.15] | 0.00 | [−0.00, 0.00] | 0.13 | |||
| Analogies | 0.22 ** | [0.08, 0.36] | 0.22 | [0.08, 0.36] | 0.04 | [−0.01, 0.09] | 0.27 ** | |||
| Number Series | 0.13 | [−0.01, 0.28] | 0.13 | [−0.01, 0.28] | 0.01 | [−0.02, 0.04] | 0.22 ** | |||
| R2 = 0.089 ** | 0.077 | |||||||||
| 95% CI [0.02, 0.16] | ||||||||||
| Sports | ||||||||||
| Unfolding | −0.04 | [−0.19, 0.11] | −0.04 | [−0.19, 0.11] | 0.00 | [−0.01, 0.01] | −0.01 | |||
| Analogies | 0.11 | [−0.04, 0.26] | 0.11 | [−0.04, 0.26] | 0.01 | [−0.02, 0.04] | 0.10 | |||
| Number Series | −0.00 | [−0.15, 0.15] | −0.00 | [−0.15, 0.15] | 0.00 | [−0.00, 0.00] | 0.03 | |||
| R2 = 0.011 | −0.003 | |||||||||
| 95% CI [<0.01, 0.04] |
| Predictor | Criterion | Degree | Adjusted R2 | RMSE | ||
| g-factor | ||||||
| Math | 1 | 0.194 | 0.644 | |||
| German | 1 | 0.073 | 0.687 | |||
| English | 1 | 0.070 | 0.648 | |||
| Specific Ability Test Scores | Unfolding | Analogies | Number Series | |||
| Math | 2 | 2 | 1 | 0.220 | 0.611 | |
| German | 3 | 0.5 | 0.5 | 0.083 | 0.637 | |
| English | 5 | 0.5 | 1.5 | 0.091 | 0.607 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ziegler, M.; Peikert, A. How Specific Abilities Might Throw ‘g’ a Curve: An Idea on How to Capitalize on the Predictive Validity of Specific Cognitive Abilities. J. Intell. 2018, 6, 41. https://doi.org/10.3390/jintelligence6030041
Ziegler M, Peikert A. How Specific Abilities Might Throw ‘g’ a Curve: An Idea on How to Capitalize on the Predictive Validity of Specific Cognitive Abilities. Journal of Intelligence. 2018; 6(3):41. https://doi.org/10.3390/jintelligence6030041
Chicago/Turabian StyleZiegler, Matthias, and Aaron Peikert. 2018. "How Specific Abilities Might Throw ‘g’ a Curve: An Idea on How to Capitalize on the Predictive Validity of Specific Cognitive Abilities" Journal of Intelligence 6, no. 3: 41. https://doi.org/10.3390/jintelligence6030041
APA StyleZiegler, M., & Peikert, A. (2018). How Specific Abilities Might Throw ‘g’ a Curve: An Idea on How to Capitalize on the Predictive Validity of Specific Cognitive Abilities. Journal of Intelligence, 6(3), 41. https://doi.org/10.3390/jintelligence6030041