
A Quick Method for Predicting Reflectance Spectra of Nanophotonic Devices via Artificial Neural Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
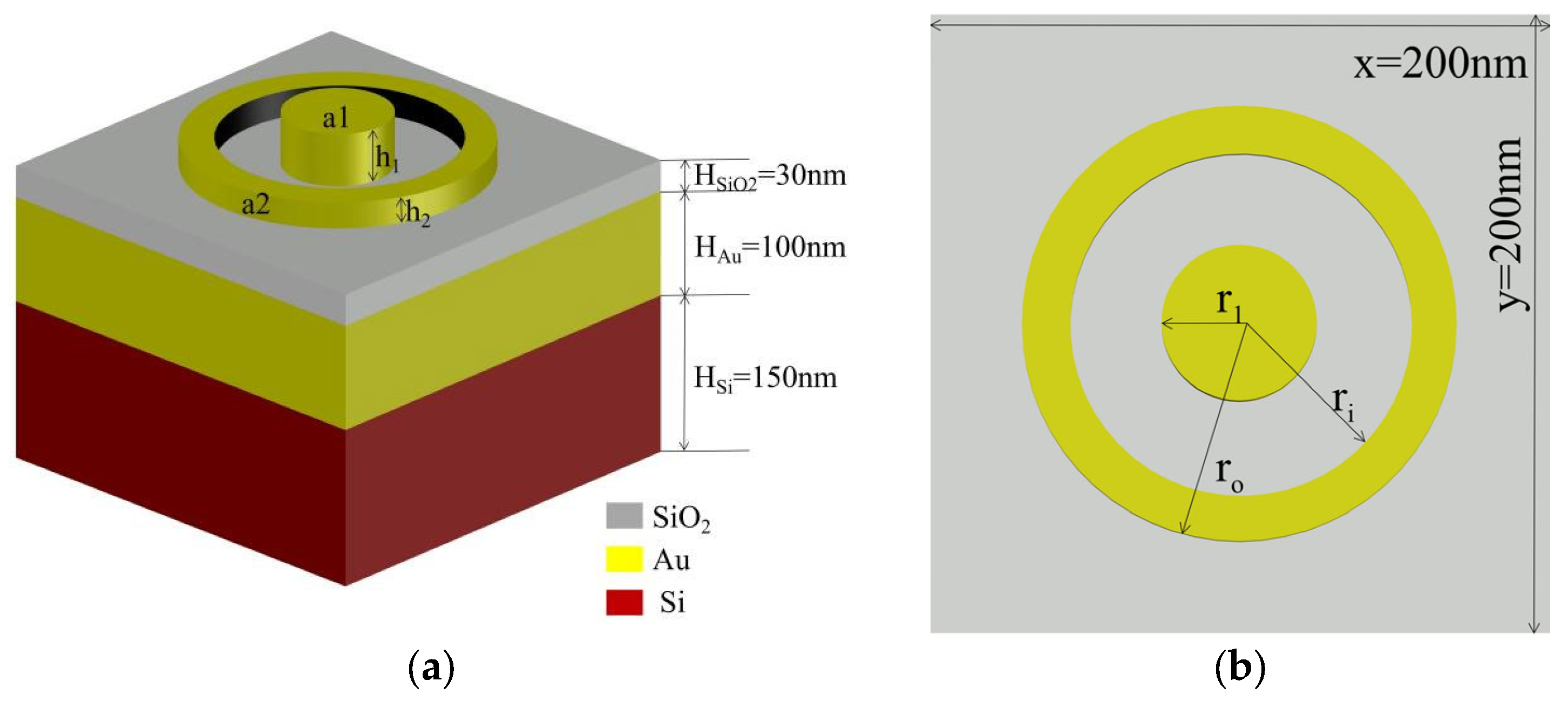
2.1. Nanophotonic Device Model
2.2. Artificial Neural Network
2.3. Training Process
2.4. Artificial Neural Network Structure
3. Results
3.1. Testing of the Test Set
3.2. Testing Outside the Data Set
3.3. Model’s Application Potential
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, C.C.; Yuan, H.Y.; Zhang, H.Y.; Zhao, W.; Zhang, N.E.; Zheng, Y.J.; Elshahat, S.; Liu, Y.C. On-chip topological nanophotonic devices. Chip 2022, 1, 100025. [Google Scholar] [CrossRef]
- Mohanty, A.; Li, Q.; Tadayon, M.A.; Roberts, S.P.; Bhatt, G.R.; Shim, E.; Ji, X.; Cardenas, J.; Miller, S.A.; Kepecs, A.; et al. Reconfigurable nanophotonic silicon probes for sub-millisecond deep-brain optical stimulation. Nat. Biomed. Eng. 2020, 4, 223–231. [Google Scholar] [CrossRef] [PubMed]
- Altug, H.; Oh, S.-H.; Maier, S.A.; Homola, J. Advances and applications of nanophotonic biosensors. Nat. Nanotechnol. 2022, 17, 5–16. [Google Scholar] [CrossRef]
- Li, S.; Miao, P.; Zhang, Y.; Wu, J.; Zhang, B.; Du, Y.; Han, X.; Sun, J.; Xu, P. Recent advances in plasmonic nanostructures for enhanced photocatalysis and electrocatalysis. Adv. Mater. 2021, 33, 2000086. [Google Scholar] [CrossRef] [PubMed]
- Anker, J.N.; Hall, W.P.; Lyandres, O.; Shah, N.C.; Zhao, J.; van Duyne, R.P. Biosensing with plasmonic nanosensors. Nat. Mater. 2008, 7, 442–453. [Google Scholar] [CrossRef]
- Fan, X.; White, I.M.; Shopova, S.I.; Zhu, H.; Suter, J.D.; Sun, Y. Sensitive optical biosensors for unlabeled targets: A review. Anal. Chim. Acta 2008, 620, 8–26. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Xue, W.; Cui, W.; Li, C.; Li, Z.; Pu, L.; Feng, J.; Xiao, X.; Wang, X.; Li, A.G. Tunable Fano resonance and enhanced sensing in a simple Au/TiO2 hybrid metasurface. Nanomaterials 2020, 10, 687. [Google Scholar] [CrossRef]
- Zhang, J.; Fang, Z.; Lin, J.; Zhou, J.; Wang, M.; Wu, R.; Gao, R.; Cheng, Y. Fabrication of crystalline microresonators of high quality factors with a controllable wedge angle on lithium niobate on insulator. Nanomaterials 2019, 9, 1218. [Google Scholar] [CrossRef] [PubMed]
- Abdollahramezani, S.; Hemmatyar, O.; Taghinejad, M.; Taghinejad, H.; Kiarashinejad, Y.; Zandehshahvar, M.; Fan, T.; Deshmukh, S.; Eftekhar, A.A.; Cai, W.; et al. Dynamic hybrid metasurfaces. Nano Lett. 2021, 21, 1238–1245. [Google Scholar] [CrossRef] [PubMed]
- Abdulhalim, I. Simplified optical scatterometry for periodic nanoarrays in the near-quasi-static limit. Appl. Opt. 2007, 46, 2219–2228. [Google Scholar] [CrossRef] [PubMed]
- Oskooi, A.F.; Roundy, D.; Ibanescu, M.; Bermel, P.; Joannopoulos, J.; Johnson, S.G. MEEP: A flexible free-software package for electromagnetic simulations by the FDTD method. Comput. Phys. Commun. 2010, 181, 687–702. [Google Scholar] [CrossRef]
- Multiphysics C; v. 5.6; COMSOL AB: Stockholm, Sweden, 2020; Available online: www.comsol.com (accessed on 12 May 2023).
- Côté, D. Using machine learning in communication networks. J. Opt. Commun. Netw. 2018, 10, D100–D109. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends® Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Abdollahramezani, S.; Hemmatyar, O.; Taghinejad, H.; Krasnok, A.; Kiarashinejad, Y.; Zandehshahvar, M.; Alù, A.; Adibi, A. Tunable nanophotonics enabled by chalcogenide phase-change materials. Nanophotonics 2020, 9, 1189–1241. [Google Scholar] [CrossRef]
- Abdollahramezani, S.; Hemmatyar, O.; Taghinejad, M.; Taghinejad, H.; Krasnok, A.; Eftekhar, A.A.; Teichrib, C.; Deshmukh, S.; El-Sayed, M.A.; Pop, E.; et al. Electrically driven reprogrammable phase-change metasurface reaching 80% efficiency. Nat. Commun. 2022, 13, 1696. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Barbastathis, G.; Ozcan, A.; Situ, G. On the use of deep learning for computational imaging. Optica 2019, 6, 921–943. [Google Scholar] [CrossRef]
- Peurifoy, J.; Shen, Y.; Jing, L.; Yang, Y.; Cano-Renteria, F.; DeLacy, B.G.; Joannopoulos, J.D.; Tegmark, M.; Soljačić, M. Nanophotonic particle simulation and inverse design using artificial neural networks. Sci. Adv. 2018, 4, eaar4206. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Shu, J.; Gu, W.; Gao, L. Deep neural network for plasmonic sensor modeling. Opt. Mater. Express 2019, 9, 3857–3862. [Google Scholar] [CrossRef]
- Malkiel, I.; Mrejen, M.; Nagler, A.; Arieli, U.; Wolf, L.; Suchowski, H. Plasmonic nanostructure design and characterization via deep learning. Light Sci. Appl. 2018, 7, 60. [Google Scholar] [CrossRef] [PubMed]
- Chugh, S.; Ghosh, S.; Gulistan, A.; Rahman, B.M.A. Machine learning regression approach to the nanophotonic waveguide analyses. J. Light. Technol. 2019, 37, 6080–6089. [Google Scholar] [CrossRef]
- An, S.; Fowler, C.; Zheng, B.; Shalaginov, M.Y.; Tang, H.; Li, H.; Zhou, L.; Ding, J.; Agarwal, A.M.; Rivero-Baleine, C.; et al. A deep learning approach for objective-driven all-dielectric metasurface design. ACS Photonics 2019, 6, 3196–3207. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, D.; Rodrigues, S.P.; Lee, K.-T.; Cai, W. A generative model for the inverse design of metamaterials. Bull. Am. Phys. Soc. 2019, 64, S21.005. [Google Scholar]
- Kojima, K.; Koike-Akino, T.; Tang, Y.; Wang, Y. Inverse design for integrated photonics using deep neural network. In Integrated Photonics Research, Silicon and Nanophotonics; Optica Publishing Group: Washington, DC, USA, 2021; p. IF3A-6. [Google Scholar]
- Tahersima, M.H.; Kojima, K.; Koike-Akino, T.; Jha, D.; Wang, B.; Lin, C.; Parsons, K. Deep neural network inverse design of integrated photonic power splitters. Sci. Rep. 2019, 9, 1368. [Google Scholar] [CrossRef]
- Wu, Q.; Li, X.; Jiang, L.; Xu, X.; Fang, D.; Zhang, J.; Song, C.; Yu, Z.; Wang, L.; Gao, L. Deep neural network for designing near-and far-field properties in plasmonic antennas. Opt. Mater. Express 2021, 11, 1907–1917. [Google Scholar] [CrossRef]
- Kallioniemi, I.; Saarinen, J.; Oja, E. Optical scatterometry of subwavelength diffraction gratings: Neural-network approach. Appl. Opt. 1998, 37, 5830–5835. [Google Scholar] [CrossRef] [PubMed]
- Pasha, D.; Abuleil, M.J.; August, I.Y.; Abdulhalim, I. Faster Multispectral Imager Based on Thin Liquid Crystal Modulator and 3D Neural Network Lattice. Laser Photonics Rev. 2023, 17, 2200913. [Google Scholar] [CrossRef]
- Balin, I.; Garmider, V.; Long, Y.; Abdulhalim, I. Training artificial neural network for optimization of nanostructured VO2-based smart window performance. Opt. Express 2019, 27, A1030–A1040. [Google Scholar] [CrossRef] [PubMed]
- So, S.; Badloe, T.; Noh, J.; Bravo-Abad, J.; Rho, J. Deep learning enabled inverse design in nanophotonics. Nanophotonics 2020, 9, 1041–1057. [Google Scholar] [CrossRef]
- Park, J.; Kim, S.; Nam, D.W.; Chung, H.; Park, C.Y.; Jang, M.S. Free-form optimization of nanophotonic devices: From classical methods to deep learning. Nanophotonics 2022, 11, 1809–1845. [Google Scholar] [CrossRef]
- Yao, Z.; Xia, X.; Hou, Y.; Zhang, P.; Zhai, X.; Chen, Y. Metasurface-enhanced optical lever sensitivity for atomic force microscopy. Nanotechnology 2019, 30, 365501. [Google Scholar] [CrossRef]
- Gui, S.; Shi, M.; Li, Z.; Wu, H.; Ren, Q.; Zhao, J. A Deep-Learning-Based Method for Optical Transmission Link Assessment Applied to Optical Clock Comparisons. Photonics 2023, 10, 920. [Google Scholar] [CrossRef]
- Aldahdooh, A.; Hamidouche, W.; Fezza, S.A.; Déforges, O. Adversarial example detection for DNN models: A review and experimental comparison. Artif. Intell. Rev. 2022, 55, 4403–4462. [Google Scholar] [CrossRef]
- Fumo, D. A gentle introduction to neural networks series-part 1. Towards Data Sci. 2017, 14–20. [Google Scholar]
- Charu, C.A. Neural Networks and Deep Learning: A Textbook; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Zhang, B.; Wang, G.; Gao, Y. A Quick Method for Predicting Reflectance Spectra of Nanophotonic Devices via Artificial Neural Network. Nanomaterials 2023, 13, 2839. https://doi.org/10.3390/nano13212839
Wang R, Zhang B, Wang G, Gao Y. A Quick Method for Predicting Reflectance Spectra of Nanophotonic Devices via Artificial Neural Network. Nanomaterials. 2023; 13(21):2839. https://doi.org/10.3390/nano13212839
Chicago/Turabian StyleWang, Rui, Baicheng Zhang, Guan Wang, and Yachen Gao. 2023. "A Quick Method for Predicting Reflectance Spectra of Nanophotonic Devices via Artificial Neural Network" Nanomaterials 13, no. 21: 2839. https://doi.org/10.3390/nano13212839
APA StyleWang, R., Zhang, B., Wang, G., & Gao, Y. (2023). A Quick Method for Predicting Reflectance Spectra of Nanophotonic Devices via Artificial Neural Network. Nanomaterials, 13(21), 2839. https://doi.org/10.3390/nano13212839